
[Data Processing, Trouble Shooting] Pandas & Polars
Kaggle 대회 Jane Street Real-Time Market Data Forecasting 에 참여하면서 대용량 데이터를 다루는데 Pandas 보다 더 빠르면서 메모리 효율이 좋은 Polars 를 다루게 되었다.
이 기회에 Pandas 와 Polars 의 차이를 정리하고, Pandas 및 Polars 의 문법을 비교하며 정리하려 한다. Pandas 까지 다루는 이유는 아직 Polars 의 경우 scikit-learn 과 호환이 잘 안되기 때문에 Pandas 로 변환해줘야 하기 때문이다.
Parquet
- Pandas 와 Polars 에 대해 정리하기 전에, 위 대회에서 사용되는 데이터 포맷인
parquet에 대해 먼저 간단히 알아보자. - Pandas 보다 Polars 가 대용량 데이터에서 더 성능이 좋은 것처럼, Parquet 이 CSV 보다 메모리 효율적이다. 실제로 Parquet 은 작은 파일 사이즈와 낮은 I/O 사용을 목적으로 개발되었다.
- 파케이(parquet)란 데이터를 저장하는 방식 중 하나로 하둡 Ecosystem 에서 많이 사용되는 파일 포맷이다.
- 하둡 Ecosystem 은 하둡 프레임워크를 이루는 다양한 프로젝트들의 모임을 의미한다. 빅데이터 문제를 효율적으로 해결하기 위해 만들어진 서브 프로젝트들의 집합으로, 수집, 처리, 저장 등의 프로젝트가 포함된다.
- 이 때, 빅데이터를 처리하기 위해서는 많은 시간과 비용이 들어가기 때문에 빠르게 읽고, 저장에 있어 압축률이 좋아야 한다.
- 이러한 특징을 가진 파일 포맷으로는 Parquet, ORC, Avro(에이브로)가 있다.
- Parquet 와 ORC 는 열 기반으로 데이터를 저장하는 반면 Avro 는 행 기반 형식으로 데이터를 저장한다.
- 데이터베이스에는 행 기반으로 저장하는 방식(MySQL 등)과 열 기반(BigQuery 등)으로 저장하는 방식이 있다.
- 열 기반 데이터베이스는 읽기가 많은 분석 워크로드에 최적화 되어있다.
- 행 기반 데이터베이스는 쓰기가 많은 트랜잭션 워크로드에 최적화 되어있다.
- 이처럼 데이터를 저장하고 공유하기 위한 파일 포맷에도 행 기반의 CSV 가 있는 반면 열 기반의 Parquet 이 있다.
-
Parquet 는 프로그래밍 언어, 데이터 모델 혹은 데이터 처리 엔진과는 독립적으로 column 기반으로 데이터를 효율적으로 저장하여 처리 성능을 비약적으로 향상시킬 수 있다.
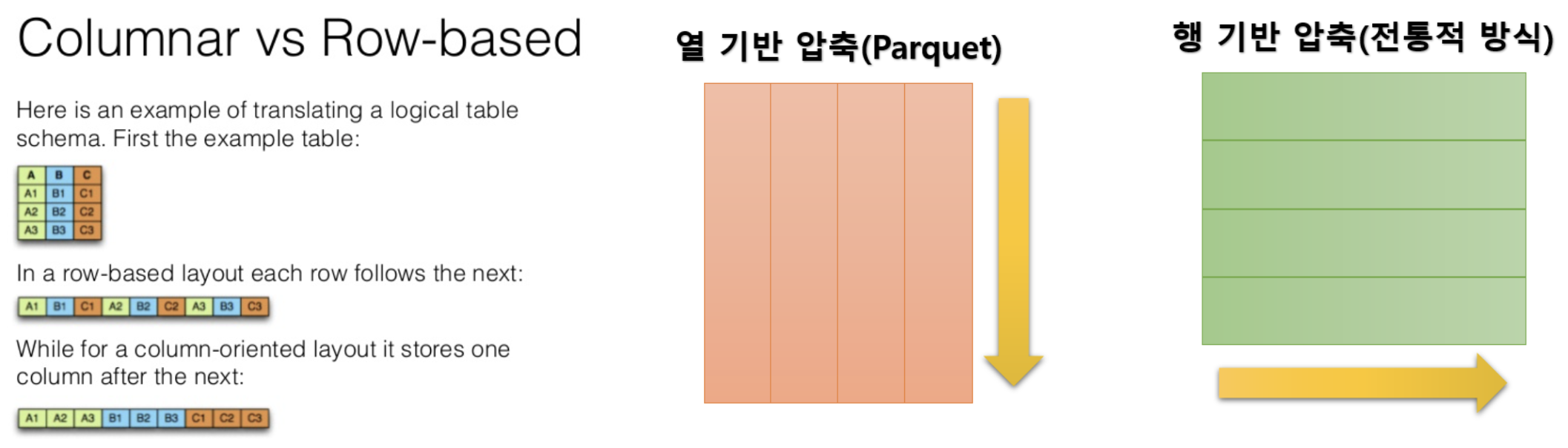
- 위 그림의 맨 왼쪽을 보면, 열 기반으로 저장되는 포맷에 대해 확인할 수 있다. 이렇게 열 기반으로 저장하게 되면 압축률이 좋다.
- 열(Column)기반의 저장이 압축률이 좋은 이유는, 같은 column 에는 유사한 데이터가 연속된 구조로 저장되어 있고 데이터가 균일해지기 때문이다.
- 특히 같은 문자열의 반복은 매우 작게 압축할 수 있다. 데이터의 종류에 따라 다르지만, column 기반 데이터베이스는 압축되지 않은 row 기반 데이터베이스와 비교하면 1/10 이하로 압축 가능하다.
- 데이터 분석에서는 종종 일부 column 만 집계 대상이 되기 때문에, 이렇게 column 기반으로 압축하면 필요한 feature(column) 만을 빠르게 읽고 집계할 수 있다.
- 따라서 column 을 기반으로 데이터를 처리하면 row 를 기반으로 압축했을 때에 비해 데이터의 압축률이 더 높고, 필요한 column 의 데이터만 읽어서 처리하는 것이 가능하기 때문에 데이터 처리에 들어가는 자원을 절약할 수 있다.
- 그렇다면 column 기반으로 저장하는 것이 좋다라고 생각할 수 있는데, MySQL 과 같이 row 기반 저장 방식의 데이터베이스는 매일 발생하는 대량의 트랜잭션을 지연 없이 처리하기 위해 데이터 추가를 효율적으로 할 수 있도록 한다. 즉 새로운 레코드를 추가할 경우 끝부분에 추가되기 때문에 고속으로 쓰기가 가능하다.
- 이처럼 Parquet 는 하둡 에코시스템 안에서 언제든지 사용 가능한 데이터 저장 포맷으로, Spark SQL 은 자동으로 기존의 데이터 스키마를 유지하는 Parquet 파일의 읽기와 쓰기를 지원한다.
- 유사한 파일 형식의 ORC 도 Parquet 와 마찬가지로 압축률이 높고 스키마를 가지고 있으며 처리속도가 빠르지만 ORC 는 Hive 에 최적화된 형식이고, Parquet 은 Spark 에 최적화된 형식이라고 볼 수 있다.
- 또한 Parquet 파일을 쓸 때 모든 column 은 호환성을 위해 자동으로
null을 허용하도록 변경된다.
장점
- Parquet 는 높은 압축률을 가지고, column 단위로 구성하면 데이터가 더 균일하므로 압축률이 높아진다. 즉 Parquet 는 열 단위로 압축을 수행하며 이로써 파일의 크기도 작아지기 때문에 용량을 덜 차지하게 된다.
- 또한 데이터 유형별로 유연한 압축 옵션과 확장 가능한 인코딩 스키마를 지원하도록 구촉되어 있다. column 에 동일한 데이터 타입이 저장되기 때문에 column 별로 적합한(데이터형에 유리한) 인코딩을 사용할 수 있다. 따라서 정수 및 문자열 데이터를 압축하는데 서로 다른 인코딩을 사용한다.
-
빅데이터를 분석하거나 쿼리를 실행할 때, 전체 column 중에서 일부 필요한 column 을 선택해서 가져오는 형식이므로 선택되지 않은 column 의 데이터에서는 I/O 가 발생하지 않게 된다. 이로써 스캔되는 데이터 양이 훨씬 적어진다.
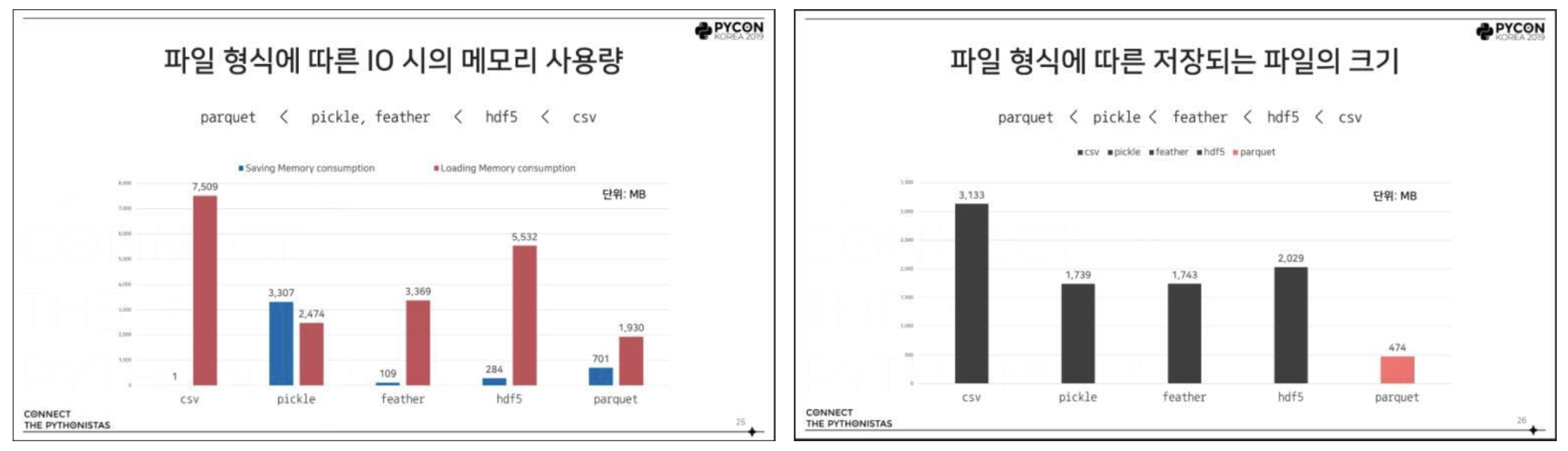
- 위 그림에서 왼쪽은 파일 형식에 따른 I/O 시 메모리 사용량과 파일의 크기를 비교한 파이콘 발표 자료다.
- 또한 오른쪽 그림은 Pandas 를 기준으로 측정된 지표이긴 하지만, 파일을 저장할 때 CSV 보다는 Parquet, HDF5 등의 형식을 사용하면 시간과 메모리를 절약할 수 있다.
- 이처럼 Parquet 은 복잡한 데이터를 대량으로 다루는데 최적화되어 있다. 따라서 CSV 와 비교했을 때 스토리지를 줄여주고 쿼리 런타임도 대폭 줄어들게 된다.
- 해당 블로그에서는 Parquet 의 파일 구조를 설명하고 있다. 참고해보자.
- 참고로 Parquet 는 오픈소스 Apache 하둡 생태계의 일부로서 활발하게 개발 진행 중이며 사용자 및 개발자 커뮤니티에 의해 지속적으로 개선 및 유지 관리되고 있다. 또한 데이터를 오픈 포맷으로 저장하면 공급업체에 묶이지 않고 유연성 높일 수 있으며 많은 최신 고성능 DB 에서 사용하는 독점 파일 포맷과 비교 가능하다.
- 즉, 특정 DB 공급업체에 묶이지 않고도 동일한 데이터 레이크 아키텍처 내에서 AWS Athena, AWS Redshift, Qubole 과 같은 다양한 쿼리 엔진을 사용 가능하다.
Polars 란?
- Polars 는 Pandas 와 같은 기존의 데이터 처리 라이브러리가 가진 성능적 한계를 극복하기 위해 탄생했다.
Rust라는 프로그래밍 언어로 작성된 Polars 는 멀티스레딩과 병렬 처리를 지원하여, 대규모 데이터셋을 보다 빠르고 효율적으로 처리할 수 있도록 설계되었다.- 주요 목적은 데이터 과학자와 엔지니어들이 대용량 데이터를 다룰 때 직면하는 성능 문제를 해결하고, 메모리 사용을 최적화하며, 직관적이고 간결한 API를 통해 사용성을 높이는 것이다.
- 단일 머신의 자원을 최대한 활용할 수 있도록 병렬 처리와 벡터화 연산을 통해 column 기반 처리를 최적화하고, 캐싱도 효율적으로 관리하여 Vectorized Query Engine 라이브러리라고 불리기도 한다.
-
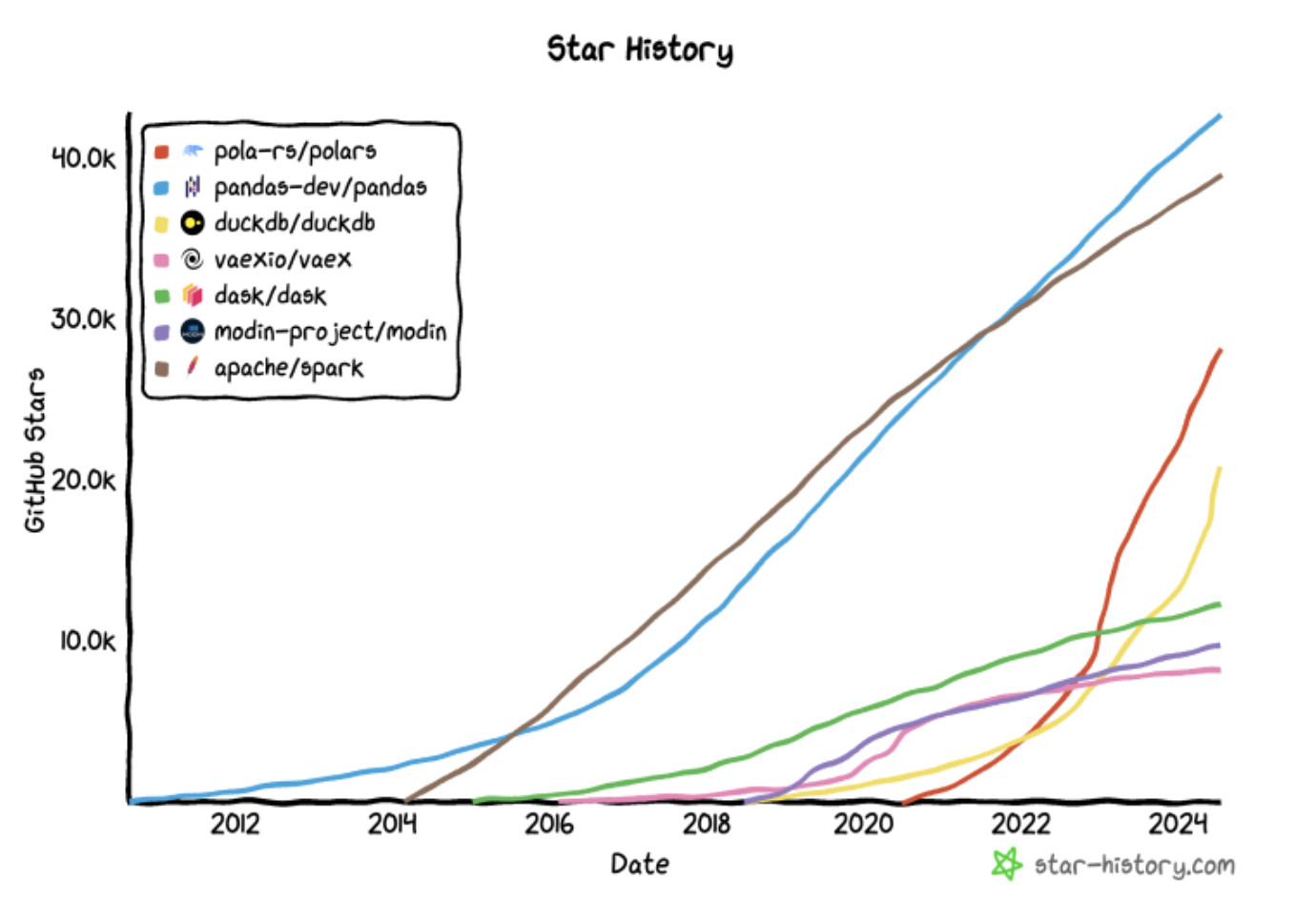
오픈소스라면 아무리 성능이 좋고 사용성이 뛰어나도 사용자가 적다면 금방 없어질 수도 있고 버전업이 더딜 수도 있다. 그러나 Polars 의 Github star 수를 보면 빠른 성장세를 보여주고 있다.
Pandas 의 단점
- Pandas 는 NumPy 와 Matplotlib 기반으로 이루어진 Data 분석용 라이브러리다. 자체적으로 Series 와 DataFrame 2 가지의 형식을 제공하면서 다양한 통계적인 연산 등을 제공한다.
- NumPy 기반의 혼합 Python Package 이며 일부 연산은 최적화를 위한 Cython 등으로 구현되어 있다.
- Pandas 는 정형 데이터를 다루는데 최적화 되어있다. 현재도 데이터 처리 라이브러리 중 가장 많이 사용되는 것은 Pandas 다.
-
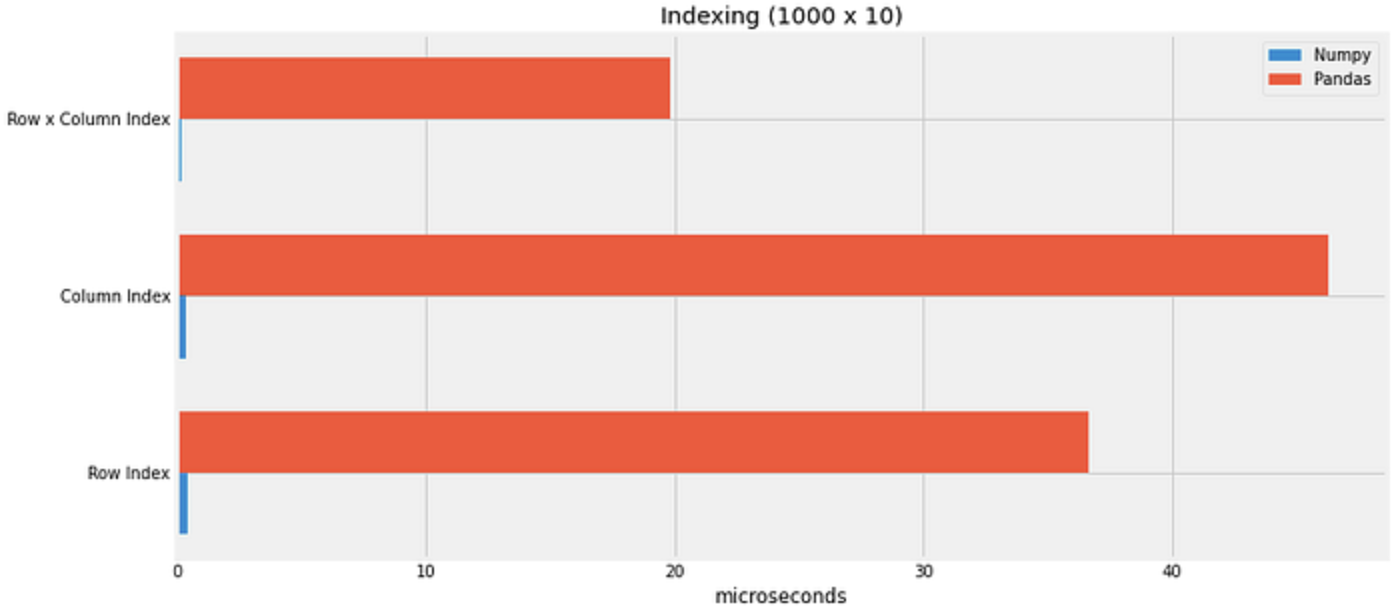
Pandas 의 단점은 “느리다”는 것이다. Pandas 가 NumPy를 기반으로 만들어졌다고 했는데 실제 NumPy 와 같은 연산을 했을 경우 다음과 같이 차이가 많이 난다.
- 그래서 왜 Pandas 는 느린걸까? 여러 곳에서 교차적으로 조사한 결과 다음과 같은 공통적인 이야기가 존재한다.
- NumPy array 에 추가적으로 Label, row, columns, index 와 그 외의 Metadata 가 필요하다.
- 기능이 많기 때문에 이러한 기능을 사용하기 위한 무결성과 유연성을 위하여 추가적인 작업, 변환이 필요하다.
- Python 으로 코드가 작성되어있다(GIL). 따라서 기본적으로 Single 코어에서 동작하고 인터프리터 언어로서 태생적으로 느린 코드 한계가 존재한다.
- 이러한 이유로 인하여 다른 언어 기반으로 만들어진 모듈에 비해 속도가 느릴 수 밖에 없는 한계가 존재한다.
- H20.ai 에서는 다양한 데이터 처리 라이브러리를 비교했다. 해당 링크를 보면 알 수 있지만, Pandas 의 경우 속도가 느리거나 Out of Memory 오류가 자주 생긴다.
Polars 의 장점
- Polars User Guide 에서 말하는 Polars 가 추구하는 Goal 은 다음과 같다.
- 시스템에서 사용할 수 있는 모든 코어 사용
- 쿼리 최적화를 통한 불필요한 작업 / 메모리 사용 줄이기
- 사용 가능한 RAM 보다 더 큰 Dataset 다루기
- 일관성 있고 예측 가능한 API
- 엄격한 Schema (쿼리 실행 전 데이터 유형을 알아야 한다.)
- 위의 Goal 들을 실현하기 위해 Polars 는 Pandas 와 아래 섹션들에 해당하는 특징을 가진다. 이것이 Polars 의 장점이 된다.
1. Rust 기반
- Polars 의 이름을 보면 Pola + rs(rust)일 정도로 Rust 로 구현됐다는 것을 강조하고 있다.
- Rust 의 소유권 모델 덕분에 메모리 관리에 대한 오버헤드가 없으며, 안전한 동시성과 병렬 처리가 가능하다.
- 메모리 캐싱과 재사용성 또한 높다. 이러한 특징이 데이터 처리 성능을 극대화하는 데에 크게 기여한다.
- 이처럼 Polars 의 코어는 Rust 로 구현되어 있으며 이를 사용하기 위한 인터페이스로 Python, R, Javascript 를 지원한다고 이해할 수 있다. 인터페이스 역할을 하는 언어는 앞으로도 계속 추가 예정이라고 한다.
Rust에 대해서는 추후에 다뤄보자.
2. 멀티코어 병렬 처리 & Apache Arrow 기반
Pandas는 기본적으로 Python 을 기반으로 단일 스레드에서 동작한다. 그래서 여러 코어를 가진 컴퓨터라 할지라도 한 번에 한 가지만 처리한다. 이는 작은 데이터셋에서는 괜찮지만, 데이터가 많아지면 처리가 느려진다.Polars는 여기서 한 단계 더 나아가 멀티코어 병렬 처리를 지원한다. 여러 코어를 사용해 한 번에 여러 작업을 처리할 수 있어 데이터가 클수록 성능 차이가 극명하게 나타난다.- 추가적으로 최적화된 알고리즘을 이용하여 중복 복사를 최소화하고, 효율적인 캐시 메모리 사용, 병렬 시 경합을 최소화시켜 더욱 빠르게 동작할 수 있게 한다.
- 또한 Polars 는 프로그래밍 언어 독립적인 컬럼 기반(Columnar) 메모리 포맷인
Apache Arrow모델을 사용하여 메모리 상에서 column 구조로 데이터를 정의하고, 이를 기반으로 벡터화(vectorized) 연산과 SIMD(Single Instruction Multiple Data)를 사용한 CPU 최적화를 하여 성능을 높였다.- 이를 통해 zero-copy 데이터 공유가 가능하고 직렬화/역직렬화 효율이 매우 높아서 여러 코어나 프로세스가 작업할 때 데이터 교환 비용을 줄일 수 있다.
- 참고로 SIMD 란, 병렬 컴퓨팅의 한 종류로 하나의 명령어로 여러 개의 데이터를 동시에 계산하는 방식(GPU 등과 같은 벡터 프로세서에서 많이 사용되는 방식)이다.
- 이와 관련해서는 Arrow Columnar Format 을 확인해보자.
- 최근 Pandas(v2.0 이후)나 Dask, Ray 등의 오픈소스에서 Arrow 를 채택하고 있고 이를 위해
PyArrow라는 구현체를 사용하는데, Polars 에서는 이것도 Rust 로 개발된 구현체를 사용하여 내부에서 사용한다. - Arrow 를 사용하는 경우, ArrowTable 형태로 타 오픈소스와의 호환성을 어느 정도 유지하면서 데이터를 주고받을 수 있다(ex. Ray Dataset 과 Polars DataFrame).
3. Lazy execution 지원
- Pandas 는 데이터에 무언가를 하라고 명령하면 바로바로 실행하는 ‘즉시 실행(Eager execution)‘ 방식을 사용한다. 데이터 필터링이나 집계 등은 실행할 때마다 처리되어 결과를 바로 보여준다.
- 이는 큰 데이터에서 매번 실행할 때마다 시간이 많이 걸리고, 메모리도 그만큼 소모된다.
- Polars 는 ‘지연 실행(Lazy execution)‘ 방식을 사용한다. 즉, 여러 명령을 한 번에 묶어 최적화한 다음, 마지막에 한꺼번에 처리하는 방식이다.
- 쉽게 말해 Polars 의 Lazy API 는 즉시 연산을 수행하지 않고, Query Plan 이라고 하는 연산 계획을 수립한 후 최적의 시점에 연산을 실행하는 지연 평가(Lazy evaluation) 방식이다.
- 이를 통해 모든 작업을 최적화된 방식으로 한 번에 처리하기 때문에 속도가 훨씬 빠르고, 불필요한 중간 연산을 줄일 수 있다.
- 또한 필터링과 pushdown 등의 최적화 기술을 사용하여 필요한 데이터만 읽어와서 처리하기 때문에 메모리 소모와 연산 복잡도를 줄여 준다.
- 참고로 pushdown 이란, 쿼리 연산을 스토리지 계층으로 한 단계 내려서 데이터 로드 비용을 최소화하는 기술이다. pushdown 에 대한 정책과 구현은 솔루션이나 오픈소스마다 다르지만, 해당 개념은 최적화를 위해 대부분 채택하고 있다.
- Polars 에서는 아래 세 가지 pushdown 을 수행하여 최적화를 수행한다.
- Predicate pushdown(조건자 푸시다운): 필터를 적용해 요청한 데이터만 읽는 방식(filter pushdown 이라고도 함)
- Project pushdown: 필요한 열만 읽는 방식
- Slice pushdown: 필요한 슬라이스(일부 행)만 읽는 방식
- 자세한 최적화 정보는 Polars user guide 의 Optimizations 를 참고하자.
- 이러한 Lazy API 의 특징으로 Polars 는 Pandas 와 유사한 Series, DataFrame 과 더불어
LazyFrame을 지원한다. 이는 즉각적으로 연산을 하는 게 아니라 쿼리 플랜만 담아두고 있다가 값이 필요할 때, 즉 구체화(materialize)할 때collect()함수를 호출하여 연산하는 방식이다. - 정리하면, Polars 는 필요한 부분만 연산하는 Lazy 방식을 지원함으로써 필요한 부분은 빠르고, 필요하지 않은 부분은 무시하는 방식의 연산을 가능하게 해준다. 이를 통하여 메모리 효율적이면서, 빠르게 작업이 가능하다.
- 실제로 우아한 형제들에서 약 1.8GB 의 parquet 파일(70,765,275 rows * 26 columns)로 진행한 실험의 결과는 아래와 같다.
- Eager API: 메모리 소모(peak) 17.84GB, 실행 시간 9.07초
- Lazy API: 메모리 소모(peak) 5.9GB, 실행 시간 1.009초
- 같은 Polars 로 처리하지만 어떤 방식으로 처리했는지에 따라 엄청난 차이가 나는 것을 확인할 수 있다. 이와 같이 큰 차이가 나는 것은 Lazy 연산 시에 내부적으로 여러 최적화를 하기 때문이다.
4. 메모리 효율성 및 IO 기능
- Pandas 는 데이터가 메모리에 전부 올라가 있기 때문에, 데이터 크기가 커질수록 메모리 사용량도 크게 증가한다. 이로 인해 Out of Memory(OOM) 에러를 만날 때가 많다.
- 반면 Polars 는 필요할 때만 메모리를 사용하는 매우 효율적인 구조를 가지고 있다. 특히 Polars 의 Lazy API 를 사용하면, 필요하지 않은 중간 결과들을 메모리에 올리지 않고 최적화된 방식으로 처리해 메모리 사용량을 최소화할 수 있다.
- 로컬 파일, 클라우드 스토리지, 데이터베이스 등 다양한 데이터 스토리지 계층을 지원하고 성능 또한 매우 우수하다.
- 기본적으로 CSV, JSON, Parquet, Avro 등 다양한 포맷에 대한 읽기/쓰기를 지원하고 파일을 읽을 때도 별표(asterisk, *)와 같은 Globs Pattern 을 활용해서 여러 파일을 읽어올 수 있어서 매우 편리하다.
- 실무에서는 데이터베이스나 Trino 와 같은 쿼리 엔진에 쿼리를 제출하고 그 결과로
polars.DataFrame을 반환하는read_database()기능도 자주 사용하고 있다. read_*와 같은 함수 대신scan_*이라는 함수를 사용하게 되면 Lazy API 를 위한LazyFrame으로 반환되어 이를 활용하여 바로 Lazy 연산을 수행할 수 있다. 이렇게 되면 즉각적으로 모든 데이터를 메모리에 올리는 것이 아닌 최적화를 한 후 실제 연산을 수행하여 더 효율적으로 처리할 수 있다.- 실제로 우아한 형제들에서 710MB parquet file (7,373,092 rows * 64 columns) 로 읽기를 테스트해 본 IO 성능 실험은 아래와 같다.
- Polars 의
read_parquet: 4s 554ms - Pandas 의
read_parquet: 33s 916ms
- Polars 의
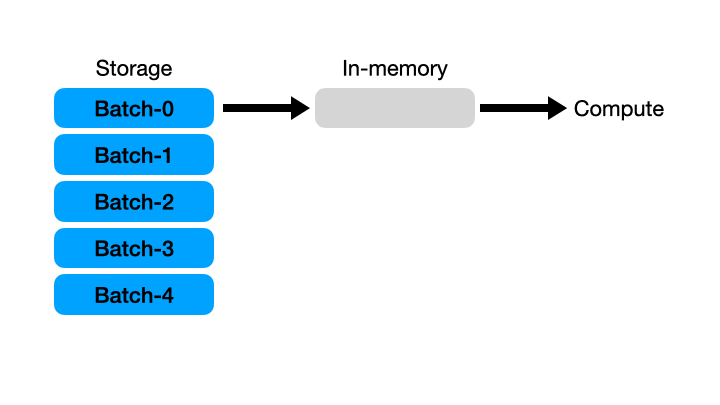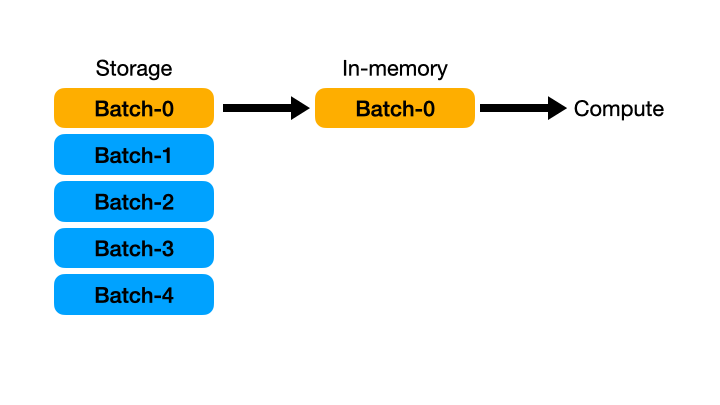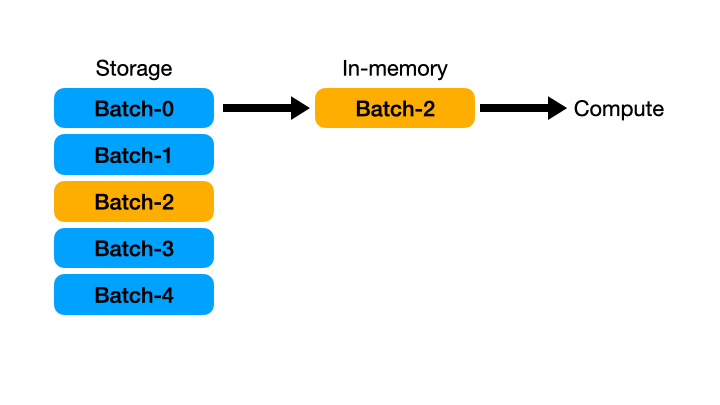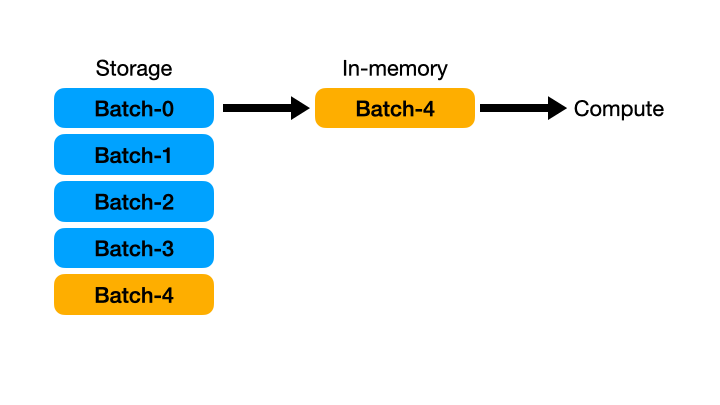
5. Out of core 방식(Streaming API)
- Polars 에서는
streaming이라는 기능을 활용해서 out of core 방식으로 연산을 수행할 수 있다. - 여기서 out of core 방식이란 external memory 알고리즘이라고도 하는데, 메모리에 담기 너무 큰 데이터를 처리할 때 디스크나 네트워크 등을 통해 일정 단위로 데이터를 가져와서 처리하는 방식을 말한다.
-
즉, 한 번에 모든 데이터를 메모리에 올리는 것이 아니라 일정 단위로 데이터를 자르고 그 조각을 가져와서 처리하고 이를 반복하는 것이다.
- 이 streaming 기능의 사용법은 매우 간단하다. 바로 Lazy API 를 사용할 때
collect()함수 내에서streaming=True옵션만 추가하면 된다. 즉, 일반적인 Lazy 연산으로 개발하고 마지막 구체화 시점에 streaming 옵션만 추가해 주면 된다. - 마찬가지로 우아한 형제들에서 용량의 총합이 8.8GB 인 다수의 parquet 파일을 가지고 테스트를 진행했다. 해당 테스트용 파일을 가지고 filtering 과 mean 집계 연산 등을 실행하면 Pandas 로는 OOM(out of memory) 으로 불가능하다. 또한 Polars 기본 연산으로도 수십 기가의 메모리를 소모한다.
- 그러나 streaming 기능을 이용하면 메모리 소모는 3.71 GB, 실행 시간은 6.835 초가 걸린다.
- Polars 의 발표 자료에서는 이 기능을 활용하면 200GB 정도의 데이터도 개인 노트북 환경에서 처리할 수 있다고 한다. 따라서 잘 활용한다면 매우 유용할 것이다.
- 추가적으로 Polars 의 성능에 대한 자료는 많지만 최근 업데이트된 벤치마킹 자료를 참고하면 도움이 될 것이다.
6. 사용 편의성
- Pandas 의 장점 중 하나는 매우 직관적인 API 다. 누구나 금방 익힐 수 있고, 데이터를 빠르게 처리할 수 있다. 그러나 큰 데이터에서 성능이 부족한 것은 분명한 단점이다.
- Polars 는 Pandas 와 매우 유사한 API 를 제공하면서도, 더 빠르고 강력한 성능을 보여준다. 또한 사용성 측면에서의 장점도 많다.
- Polars 의 Lazy API 의 사용
- 위에서 다룬 Lazy API 는 공식문서를 참고하면 금방 익숙해질 수 있으며, Pandas 보다 훨씬 더 복잡한 작업을 효율적으로 처리할 수 있다.
- SQL 과 비슷한 구조
- Polars 는 SQL 과 비슷한 표현식과 직관적인 문법을 가지고 있기 때문에 배우기 쉽고 가독성도 좋은 편이다.
- column 선택 시 편리함
- 데이터를 분석하거나 feature 엔지니어링을 할 때 원하는 column 을 선택해야 하는 경우가 많다.
- 그럴 때 column 이름을 리스트로 받아오거나 type 을 받아와서 필터링하기도 하는데 Polars 에서는 타입에 따라 선택할 수도 있고 정규식을 활용할 수도 있다.
- 학습이나 추론을 할 때 인코딩된 column 을 굉장히 자주 다루는데 아래 코드에서처럼 정규식으로 처리하면 매우 편리하다.
- 또한 테이블 생성을 위해 데이터 타입을 일괄 변경하거나, 정수형 혹은 숫자형 column 을 일괄 선택하는 기능도 사용하기 편하다.
- 시계열 연산
- Polars 는 시계열 지원이 좋은 편이다. 시간과 관련된 여러 타입을 지원하며, 리샘플링이나 시간 윈도우 기반 그룹화 등의 기능도 제공한다.
- 중간 보간법으로 Upsample 을 쉽게 할 수 있고,
group_by_dynamic함수로 고정 윈도우 연산이나 롤링 윈도우 연산이 가능하다. - 그리고 일치하는 키가 존재하지 않을 때 가장 가까운 값을 기준으로 join 하는 기능인
asof join도 지원해서 실무에서 자주 사용하고 있다. - 자세한 코드 예제는 아래에서 Pandas 와 비교하는 부분을 참고하자.
- SQL 직접 사용
- 최근 DuckDB 와 같은 도구에서 로컬 및 클라우드 스토리지 내 파일이나 DataFrame 객체에 직접 SQL 쿼리를 할 수 있도록 지원하는데, Polars 역시 비슷한 기능을 제공한다.
- Python 기반으로 연산하는게 익숙치 않다면 SQL 을 사용할 수도 있고, 이 기능을 사용하면 쿼리 최적화가 수행되기 때문에 성능을 높일 수도 있다.
실무 적용 예시
- 우아한 형제들에서는 이러한 Polars 를 실무에 도입하여 배달예상시간 학습 파이프라인 개선, 사용자 정의 함수 적용 개선, 준실시간 추론 파이프라인을 개선했다.
- 학습 파이프라인 개선
- 학습 파이프라인에 포함되어 있는 수천만 행의 학습 데이터(parquet 파일)를 가져와서 읽고 이를 전처리하는 부분을 Polars 로 변경한 결과, 기존에 사용하던 Dask 대비 실행시간은 80% 수준으로 단축하고 메모리는 40% 수준으로 감소시켰다고 한다.
- UDF 적용 개선
- Pandas 에서는
apply를 활용해 사용자 정의 함수(User Defined Function, UDF)를 행 단위로 수행할 수 있다. 물론 Polars 도 같은 기능을 지원한다. - 사용자 정의 함수를 적용하여 변환하는 부분을 Polars 로 변경하고 나서 성능 개선을 체감할 수 있었다고 한다. 물론 Polars 도 Python UDF 를 적용할 때는 자체 지원 함수를 사용할 때보다 성능이 현저하게 떨어지게 되고 이에 대한 경고 또한 공식 문서에 포함되어 있다.
- 왜냐하면 UDF 실행 때문에 Rust 코어의 장점이나 벡터화 연산의 장점을 많이 잃어버리기 때문이다. 그러나 Pandas 대비 훌륭한 실행시간 개선을 보여준다.
- 데이터 전처리를 할 때 위/경도 데이터를 가져와서 지구 공간 인덱스인 H3 index 로 변환하는 부분이 있는데, 이 부분을 Polars 코드로 변경했더니 기존 Pandas 로 24.3초 정도 걸리던 연산이 5.87초로 단축되었다. 거의 5배 가량 빨라진 것이다.
- 중요하고 많이 사용하는 UDF 의 경우 함수 자체를 Rust 로 개발하고 이를 Python 코드에서 호출해서 사용하면 성능을 더 높일 수 있다.
- Pandas 에서는
- 준실시간 추론 파이프라인 개선
- 배달의 민족에서는 고객에게 더 정확한 시간을 안내하기 위해 준실시간 추론을 하게 된다. 배달예상시간의 경우, 사용자가 지면을 조회하면서 여러 가게에 대한 시간을 확인하기 때문에 모든 케이스를 고려하여 미리 featyre 를 생성해 놓고 준실시간 추론 시점에 feature 를 가져와 메모리에 올리고 간단한 처리를 하여 모델에 넣게 된다. 그리고 이 모델의 추론 결과를 비즈니스 로직과 전시를 담당하는 쪽에 이벤트로 만들어 전달해야 한다.
- 이 과정에서도 Polars 를 적용하여 눈에 띄는 성능 효율화를 가져올 수 있었다고 한다.
- 구체적으로 수행한 작업은 파일 읽기, group_by 및 aggregation 작업, 이벤트 형태로 변환하기 위한 UDF 적용 작업이었는데, 매번 실행할 때마다 24GB 정도의 메모리를 소모하던 것을 대략 40% 이하로 줄여서 10GB 정도로 감소시켰다. 이를 통해 k8s pod 사이즈를 줄여서 비용 효율을 높일 수 있었다고 한다.
Pandas vs. Polars
- 이제 Pandas 와 Polars 에서 특정 기능들이 어떤 함수와 메서드로 이루어져 있는지 알아보고, 성능을 비교해보도록 하자. Pandas 와 Polars 의 각 버전은 아래와 같다.
polars = "^1.17.1"
pandas = "^2.2.3"
- 비교를 위해 사용할 데이터는 Kaggle 대회 Jane Street Real-Time Market Data Forecasting 에서 제공하는 학습 데이터 중
partition_id=9를 사용한다. 파일 형식은.parquet, 파일 크기는 1.64GB, 92 개의 column 과 6,274,576 개의 row 로 이루어져 있다. - 구체적으로 Pandas 와 Polars 의 Eager API(즉시 실행), Lazy API(지연 실행) 를 비교해보자.
IO
- 파일 입출력(IO)에 대해서 Pandas 와 Polars 모두 읽기는
read_, 쓰기는write_의 형식을 따른다. - 각 공식문서(pandas, polars)를 보면 CSV, Parquet, JSON, execl 등 파일 포맷에 대한 데이터 읽기/쓰기 기능을 제공한다. 참고로
.pkl과 같은 Pickle 파일은 Python 의 객체 직렬화 형식이기 때문에 Pandas 에서만 읽을 수 있다.
pandas
- pandas 는
.read_parquet을 이용하여 parquet 파일을 읽는다.
pandas.read_parquet(path, engine='auto', columns=None, storage_options=None,
use_nullable_dtypes=<no_default>, dtype_backend=<no_default>, filesystem=None, filters=None,
**kwargs)
path에는file://localhost/path/to/tables또는s3://bucket/partition_dir와 같이 URL 형태로도 가능하다. 이 때 필요한 정보들은storage_options에 주면 된다.engine에는auto, pyarrow, fastparquet가 가능하다. 기본값은auto이며 먼저pyarrow를 시도하고 이후에fastparquet을 시도한다. 이를 통해 ArrowTable 형태로 타 오픈소스와의 호환성을 어느 정도 유지하면서 데이터를 주고받을 수 있다(ex. Ray Dataset 과 Polars DataFrame).- 즉 pandas 는 주로 numpy 배열을 데이터 저장 및 처리를 위한 내부 구조로 사용하여 Arrow 를 직접 기반으로 하지 않지만, Arrow 를 활용할 수 있는 I/O 연산과 데이터 교환 기능을 제공하는 것이다.
columns에는 사용할 column 을 list 로 건네준다. 또한filters에는 데이터를 읽을 때(column, operation, val)의 형식으로 조건을 주면 필터링된 데이터를 읽게 된다.- 자세한 옵션은 공식문서를 참고하자.
import pandas as pd
pd_df = pd.read_parquet(path)
# CPU times: user 3.58 s, sys: 3.59 s, total: 7.17 s
# Wall time: 3.43 s
sys.getsizeof(pd_df) # 메모리 확인
# 2214925472
polars
- polars 의 Eager API 도 마찬가지로
.read_parquet을 이용하여 parquet 파일을 읽는다.
# polars (eager)
polars.read_parquet(source: FileSource, *,
columns: list[int] | list[str] | None = None,
n_rows: int | None = None,
row_index_name: str | None = None,
row_index_offset: int = 0,
parallel: ParallelStrategy = 'auto',
use_statistics: bool = True,
hive_partitioning: bool | None = None,
glob: bool = True,
schema: SchemaDict | None = None,
hive_schema: SchemaDict | None = None,
try_parse_hive_dates: bool = True,
rechunk: bool = False,
low_memory: bool = False,
storage_options: dict[str, Any] | None = None,
credential_provider: CredentialProviderFunction | Literal['auto'] | None = 'auto',
retries: int = 2,
use_pyarrow: bool = False,
pyarrow_options: dict[str, Any] | None = None,
memory_map: bool = True,
include_file_paths: str | None = None,
allow_missing_columns: bool = False) -> DataFrame[source]
- 위 함수를 보면 argument 가 pandas 보다 많다. 이중에 기억하면 좋은 것은
glob=True로 되어있어 위 polars 의 장점에서 본 것처럼 globs pattern 을 사용해서 파일을 읽어올 수 있다. 자세한 코드는 아래에서 보자. - 또한 pandas 와 마찬가지로 cloud 내에 있는 데이터를 읽어올 수 있으며, 이 때 필요한 정보는
storage_options에 dict 형태로 넣어주면 된다. - 이 외에 각 컬럼의 data type 을 특정할 수 있는
schema도 있다. 이에 대해서는 아래 data type 섹션에서 다룰 것이다. 이외에 자세한 argument 들은 공식문서를 참조하자.
import polars as pl
pl_df = pl.read_parquet(path)
# CPU times: user 2.77 s, sys: 1.47 s, total: 4.23 s
# Wall time: 1.22 s
sys.getsizeof(pl_df) # 메모리 확인
# 48
- 위 결과를 보면 pandas 보다 더 빠르게 데이터를 읽어오는 것을 확인할 수 있다. 이는 아래의 내부 구현 방식들에서 비롯된 이유들 때문이다.
- polars 는 Rust 언어로 작성되어 Rust 의 네이티브 성능 덕분에 파일 읽기/쓰기와 같은 IO 작업이 더 빠르게 수행된다. 반면 pandas 는 Python 으로 작성된 고수준 API로, C 와 Cython 확장을 사용하지만 Python 인터프리터의 오버헤드로 인해 IO 속도가 제한적이다.
- 위에서 살펴본 것처럼 polars 는 IO 작업에서 멀티스레딩을 적극 활용하여 CPU 코어를 병렬로 사용할 수 있다. 예를 들어, CSV 나 Parquet 파일을 읽을 때 파일을 여러 청크로 나눠 병렬로 처리한다. 반면에 pandas 는 기본적으로 단일 스레드에서 작업하기 때문에 큰 파일을 처리할 때 성능이 제한된다.
- polars 는 컬럼 지향(columnar) 데이터 처리 방식을 사용하여 파일의 특정 컬럼만 선택적으로 로드하거나, 로드 중에 즉시 최적화된 데이터 타입으로 변환할 수 있다. 이는 메모리 사용을 줄이고 불필요한 데이터를 로드하지 않기 때문에 IO 성능이 더 뛰어나다.
- polars 는 Rust 기반의 빠른 압축/해제 라이브러리를 사용해 GZIP, Parquet, Feather 등 다양한 형식의 파일을 매우 효율적으로 읽고 쓸 수 있다. 물론 pandas 도 압축된 파일들을 읽고 쓸 수 있지만, 특히 Parquet, Arrow 와 같은 컬럼 지향 포맷에 최적화가 잘 되어 있어 Pandas 보다 월등히 빠르다.
- polars 는 Zero-Copy 기술을 사용하여 데이터의 복사를 최소화한다. 예를 들어, Arrow 기반 포맷 파일(Parquet 등)을 읽을 때 데이터 복사를 하지 않고 그대로 사용할 수 있어 성능이 뛰어나다. 반면, pandas 는 데이터를 읽으면서 Python 객체로 변환해야 하기 때문에 오버헤드가 크다.
- 마지막으로 polars 는 Rust 컴파일러가 미리 최적화한 코드를 실행하여 파일 IO 와 관련된 많은 부분에서 CPU 캐시와 SIMD 명령어를 효과적으로 사용한다. 반면 pandas 는 런타임에 Python 해석기와 Cython 코드를 실행하기 때문에 최적화 수준이 제한된다.
- 다음으로 polars 의 Lazy API 인
.scan_parquet에 대해 알아보자.
# polars (lazy)
polars.scan_parquet(source: FileSource, *,
n_rows: int | None = None,
row_index_name: str | None = None,
row_index_offset: int = 0,
parallel: ParallelStrategy = 'auto',
use_statistics: bool = True,
hive_partitioning: bool | None = None,
glob: bool = True,
schema: SchemaDict | None = None,
hive_schema: SchemaDict | None = None,
try_parse_hive_dates: bool = True,
rechunk: bool = False,
low_memory: bool = False,
cache: bool = True,
storage_options: dict[str, Any] | None = None,
credential_provider: CredentialProviderFunction | Literal['auto'] | None = 'auto',
retries: int = 2,
include_file_paths: str | None = None,
allow_missing_columns: bool = False) -> LazyFrame[source]
- 위 출력값인
polars.LazyFrame은 즉각적으로 연산을 하는 게 아니라 쿼리 플랜만 담아두고 있다가 값이 필요할 때, 즉 구체화(materialize)할 때collect()함수를 호출하여 연산하는 방식이다. - 이러한 Eager API 와 Lazy API 의 차이는 실제 연산에 들어갔을 때 눈에 띄게 된다. 여기에
streaming기능을 사용하면 더 큰 데이터도 개인 랩톱 환경에서 처리할 수 있다.
pl_df_lz = pl.scan_parquet(path)
# CPU times: user 69 μs, sys: 3 μs, total: 72 μs
# Wall time: 75.1 μs
sys.getsizeof(pl_df_lz) # 메모리 확인
# 48
- 다음으로 polars 에서 globs pattern 을 이용하여 파일을 읽어보자. 이를 이용하면 아래 path 에서
part-0.parquet,part-1.parquet,part-100.parquet등을 한 번에 읽어올 수 있다.
pl_df_glob = pl.read_parquet("/Users/baekkwanghyun/Desktop/Bkkhyunn/bkkhyunn.github.io/practice/data/part-*.parquet")
# CPU times: user 2.99 s, sys: 1.26 s, total: 4.25 s
# Wall time: 1.39 s
- 한 가지 기억하면 써먹을 수 있는 것은, polars 는
read_database라는 함수를 통해query와uri를 건네주어 데이터베이스에서 직접 데이터를 가져올 수도 있다. 또한 아래와 같이 cloud storage 에서도 바로 데이터를 읽어올 수 있다.
# Cloud Storage 에서 데이터 읽어오기
df = pl.read_parquet("s3://bucket/*.parquet")
# read from DB
df = pl.read_database_uri(
query="SELECT * FROM foo",
uri="postgresql://username:password@server:port/database"
)
df = pl.read_database(
query="SELECT * FROM test_data",
connection=user_conn,
schema_overrides={"normalised_score": pl.UInt8},
)
- 읽기 이외에 쓰기에서도 pandas 보다 polars 가 더 빠르고 메모리 효율적으로 동작한다. 쓰기의 경우 pandas 에서는
to_확장자, polars 에서는.write_확장자형태의 함수를 이용하며, argument 로compression방식을 주어 gzip 형태로도 저장이 가능하다. - gzip 파일을 읽을 때는 위에서 사용한
read_parquet또는scan_parquet(polars Lazy API) 을 사용하면서 path 에gzip파일을 넣거나, polars 의 경우*.gzip과 같이 globs pattern 을 쓰면 파일의 압축 형식을 자동으로 처리하여 읽을 수 있다. - 마지막으로 polars 에서는 행 기반 포맷인 CSV 에 대해서도 two-pass 알고리즘을 이용해서 SIMD 연산을 증가시키고 성능을 올렸다고 한다. 또한 클라우드에 있는 데이터에 대한
scan성능도 올렸다고 하니, polars 의 기술 블로그를 참고해보자.
data type
- pandas 와 polars 뿐 아니라, 데이터 분석이나 ML 에서 데이터 타입은 중요하다. ML 모델이나 DL 모델에 데이터를 입력시키기 위해서는 int 나 float 과 같은 숫자형 데이터여야 하기 때문이다.
- 이 섹션에서 pandas 와 polars 가 다루는 데이터 타입과 데이터 타입의 변환, 생성 등을 알아보고 비교해보자.
pandas
- pandas 공식문서에 따르면, pandas 는 DataFrame 의 Series 나 개별 column 에 대해 Numpy array 와 데이터 타입(dtypes)을 사용한다.
- Numpy 는
float, int, bool, timedelta64[ns], datetime64[ns]타입을 지원하고, timezone-aware datetime 은 지원하지 않는다. - 아래와 같은 방법으로 pandas 의 데이터타입을 확인할 수 있다.
for dtype in dir(pd):
if dtype.endswith("Dtype"):
print(dtype[:-5], end=", ")
# Arrow, Boolean, Categorical, DatetimeTZ, Float32, Float64, Int16, Int32, Int64,
# Int8, Interval, Period, Sparse, String, UInt16, UInt32, UInt64, UInt8
- 위 공식문서에서 각 데이터 타입 별로 String Aliases 를 통해 데이터 타입을 확인하거나 변경할 수 있다.
- 또한
.dtypes또는.info()를 통해 각 column 이 어떤 데이터 타입으로 되어 있는지 확인할 수 있다.
pd_df.dtypes
# date_id int16
# time_id int16
# symbol_id int8
# weight float32
# feature_00 float32
# ...
# responder_4 float32
# responder_5 float32
# responder_6 float32
# responder_7 float32
# responder_8 float32
# Length: 92, dtype: object
.dtypes에서 맨 마지막 line 에 object 가 나오는 이유는,.dtypes의 결과가 Series 이고 해당 Series 가 object 데이터 타입을 가진다는 것이다.- 우리가 pandas 를 통해 데이터를 불러올 때 기본적으로 문자가 포함되어 있다면 object 자료형이 된다.
- pandas 에서 자주 보는 데이터 타입이 object 타입과 category 타입이다. 일반적인 문자열을 갖는 column 은 object 로 사용하고, 값이 종류가 제한적이거나 encoding 을 한다면 category 를 사용하게 된다.
- 만약 pandas 에서 DataFrame 을 생성할 때 각 column 의 데이터 타입을 명시해주지 않거나 여러 데이터 타입이 섞여 있다면 자동적으로 object 타입이 된다.
- pandas 에서는 string 을 저장할 때, string 을 포함한 python 객체들을 모두 포함하는
object데이터 타입과 오직 string 만 나타내는StringDtype이 있다.- 따라서 일반적으로 문자열은 object 타입이 되고, String 타입으로 사용하기 위해서는 사용자가 별도로 변경해야 한다.
.infer_objects()은 데이터 타입이 object 인 column 에 대해서 적당한 데이터 타입을 추론한다. 이 함수는 만들어진 DataFrame 에 데이터 타입을 명시하지 않았을 때 편리하게 사용할 수 있다.
- 정수 타입은 기본적으로
int64이고, 부동소수점 타입은 기본적으로float64다. 이는 32-bit 나 64-bit 의 운영체제와는 관계 없이 항상 기본값이다. 그러나 numpy 배열은 platform-dependent 하여 32-bit 운영체제에서는int32가 된다. - 추가적으로 pandas 는 기본적으로 numpy 의 upcasting rule 을 따른다.
- upcasting 은 더 작은 범위의 데이터 타입(ex. int32, float32)이 더 큰 범위의 데이터 타입(ex. float64)으로 자동 변환되는 것을 말한다. 이는 연산 중 데이터 타입의 일관성과 정확성을 유지하기 위해 수행된다.
- 예를 들어 정수(int)와 부동소수점(float) 간 연산은 float 로 변환되고, float32 와 float64 간 연산은 더 정밀한 float64 로 변환되는 것이다.
- 그러나 pandas 고유의 확장된 데이터 타입 때문에 일부 경우에는 다르게 동작할 수 있다. pandas 는 numpy 에 없는 확장 데이터 타입을 제공하며, 이는 upcasting 시 추가적인 동작을 초래할 수 있다. 예를 들어 Nullable Integer (Int32, Int64) 나 Categorical, Datetime with Timezone 이 이에 해당한다.
- 실제로 Nullable Integer 와 부동소수점의 연산은 float64 로 upcasting 된다.
- pandas 에서 데이터 타입을 변경할 때는
.astype()을 이용한다.- 기본적으로
.astype()을 통해 변환된 결과는 deep copy 를 반환한다. 만약 데이터 타입이 변경되지 않아도 복사본이 반환된다. 이를 변경하려면copy=False를 전달하면 된다. - astype 연산이 잘못된 경우에는 exception 이 발생한다.
- 기본적으로
- 이 외에 object 타입의 column 은
to_numeric(),to_datetime(),to_timedelta()로 데이터 타입을 바꿀 수 있다. - 이 때 argument 로
errors=coerce를 주면 에러를 발생시키는 것이 아니라 문제가 발생하는 데이터 포인트마다pd.NaT(datetime 이나 timedelta) 나np.nan(numeric) 으로 변경하고 그대로 데이터 타입을 변환한다.
pd_df["date_id"].astype(np.int32)
pd_df["feature_02"].astype(np.float64)
select_dtypes()은 인자로 데이터 타입을 주어 해당 데이터 타입을 가진 column 을 출력한다.select_dtypes()는 두 개의 argument 를 가지는데,include=[ ]와exclude=[ ]이다. 각 리스트 안에 포함시킬 데이터 타입이나 제외할 데이터 타입을 넣으면 된다.
pd_df.select_dtypes(include=["object"]) # 6274576 rows × 0 columns
pd_df.select_dtypes(exclude=["object"]) # 6274576 rows × 92 columns
- pandas 의 DataFrame 을 만들 때 아래와 같이 각 column 의 데이터 타입을 미리 지정해줄 수 있다.
d = {'col1': [1, 2], 'col2': [3, 4]}
df = pd.DataFrame(data=d, dtype=np.int8)
df.dtypes
# col1 int8
# col2 int8
# dtype: object
polars
- polars 는 Arrow 포맷과 Rust 기반 최적화를 바탕으로 numpy 및 pandas 와는 다른 접근 방식을 채택했다. polars 는 내부적으로 Arrow 데이터 타입을 기반으로 한다. Arrow 는 컬럼 지향(columnar) 데이터 형식으로, 성능과 메모리 효율성을 극대화하도록 설계된 오픈소스 프로젝트다.
- polars 의 데이터 타입은 Arrow 의 데이터 타입과 1:1로 매핑된다.
- Arrow 는 범용성과 효율성을 위해 설계되었으며, 다양한 프로그래밍 언어와 도구에서 호환 가능하다.
- polars 는 멀티스레딩과 SIMD(Vectorized Operations)를 활용하여 Arrow 데이터를 빠르게 처리한다.
- polars 는 데이터 정렬 방식을 Arrow Columnar Format 을 기반으로 한다. 이를 통해 Arrow 사양을 사용하는 다른 도구(Ray 또는 일부 pandas 등)와 데이터를 주고받을 때 거의 오버헤드 없이 처리할 수 있다.
- polars 공식문서에 따르면, polars 는 아래와 같은 총 18 개의 데이터 타입을 지원한다. 이는
__dir__을 통해서도 확인할 수 있다.Boolean: Boolean type that is bit-packed efficiently.Int8, Int16, Int32, and Int64: varying-precision integer types.UInt8, UInt16, UInt32, and UInt64: varying-precision unsigned integer types.Float32 and Float64: varying-precision float types.Decimal: 128-bit decimal type with optional precision and non-negative scale. This gives you fine-grained control over the precision of your floats.String: variable length UTF-8 encoded string data, typically human-readable.Binary: variable length, arbitrary raw binary data.Date: represents a calendar date.Time: represents a time of day.Datetime: represents a calendar date and time of day.Duration: represents a time duration.Array: homogeneous arbitrary dimension array with a fixed shape.List: homogeneous 1D container with variable length.Categorical: efficient encoding of string data where the categories are inferred at runtime.Enum: efficient ordered encoding of a set of predetermined string categories.Struct: composite product type that can store multiple fields.Object: wraps arbitrary Python objects.Null: represents null values.
- 위 데이터 타입들은 아래와 같이 분류된다.
- Numeric data type: 부호가 있는 정수(signed integers), 부호가 없는 정수(unsigned integers), 부동소수점 숫자(floating point numbers), 소수(Decimals)
- 중첩 데이터 타입(Nested data types): 리스트(lists), 구조체(structs), 배열(arrays)
- 시간 관련 데이터 타입(Temporal): 날짜(dates), 날짜와 시간(datetimes), 시간(times), 시간 차이(time deltas)
- 기타 데이터 타입(Miscellaneous): 문자열(strings), 이진 데이터(binary data), 불리언(Booleans), 범주형 데이터(categoricals), 열거형 데이터(enums), 객체(objects)
dir(pl.datatypes)
# 'Array', 'Binary', 'Boolean', 'Categorical', 'Date', 'Datetime', 'Decimal', 'Duration', 'Enum',
# 'Float32', 'Float64', 'Int16', 'Int32', 'Int64', 'Int8', 'IntegerType',
# 'List', 'Null', 'Object', 'String', 'Struct', 'Time',
# 'UInt16', 'UInt32', 'UInt64', 'UInt8', 'Utf8'
- 이러한 데이터 타입들에 대한 설명을 읽어보면 세세한 부분에서도 polars 가 효율성을 위해 개발된 것임을 알 수 있다.
- Boolean 타입 (
pl.Boolean) 은 효율적으로 비트 단위로 압축(bit-packed efficiently)된다.True(1)나False(0)를 나타내는데 단 하나의 비트만 필요하며, 1 바이트는 8비트로 구성되므로 polars 는 8 개의 Boolean 값을 저장하는 데 1바이트를 사용한다. - 따라서 polars 의 Series 에 $n$ 개의 Boolean 값이 있으면 polars 는 해당 Series 를 저장하는 데 $n/8$ 바이트를 사용한다.
- 또한 polars 가 밝힌 내용에 따르면, 결측값을 나타내는 polars 의
null값은 Python 의None과 같다.
s = pl.Series([1, None, 3, 4, 5, None])
print(s.count()) # 4
print(s.is_null().sum()) # 2
- 이 때 흥미로운 점은
is_null함수를 사용해 열(column)에서 어떤 값이 결측인지 확인하는 작업은 polars 에서 비용이 들지 않는다. - 이는 polars 가 Series 내에서 결측값 여부를 나타내는 유효성 마스크(validity mask)를 저장하기 때문이다. 이 유효성 마스크는 Boolean 값으로 구성되어 있으며, Series 의 항목 중 어떤 값이 결측인지 표시한다. 유효성 마스크는 Boolean 열과 동일한 방식으로 비트 단위로 압축(bit-packed)되어 저장되기 때문에 메모리 오버헤드가 최소화된다.
- polars 에는 Temporal Data Types 가 있는데, 여기에는
Date, Time, Datetime, Duration이 속한다. 특징적인 것은 pandas 와는 달리 polars 는 날짜 간의 차이를 나타내는Duration이 지원된다. 또한 timezone 을 지정해줄 수도 있다.
from datetime import datetime, timedelta, timezone
now = datetime.now()
datetimes = [
now,
now.replace(tzinfo=timezone(timedelta(hours=1))),
now.replace(tzinfo=timezone(timedelta(hours=-3))),
]
s = pl.Series(datetimes)
print(s) # All values are converted to UTC.
# shape: (3,)
# Series: '' [datetime[μs]]
# [
# 2024-11-22 19:14:25.468051
# 2024-11-22 18:14:25.468051
# 2024-11-22 22:14:25.468051
# ]
print(s.dt.convert_time_zone("Europe/Amsterdam"))
# shape: (3,)
# Series: '' [datetime[μs, Europe/Amsterdam]] # <-- new TZ shows in the data type
# [
# 2024-11-25 11:23:55.322912 CET # <-- times are adjusted to new TZ
# 2024-11-25 10:23:55.322912 CET
# 2024-11-25 14:23:55.322912 CET
# ]
bedtime = pl.Series([
datetime(2024, 11, 22, 23, 56),
datetime(2024, 11, 24, 0, 23),
datetime(2024, 11, 24, 23, 37),
])
wake_up = pl.Series([
datetime(2024, 11, 23, 7, 30),
datetime(2024, 11, 24, 7, 30),
datetime(2024, 11, 25, 8, 0),
])
sleep = wake_up - bedtime
print(sleep)
# shape: (3,)
# Series: '' [duration[μs]]
# [
# 7h 34m
# 7h 7m
# 8h 23m
# ]
- Decimal 데이터 타입은 소수점 아래 자릿수를 지정할 수 있다. 그러나 현재(24.11 기준)로서는 불안정한 기능이라고 한다.
dtype=pl.Decimal()으로 지정해줄 수 있으며, 두 개의 argument 가 들어간다. 첫번째 인수는 각 숫자의 최대 총 자릿수를 지정하며, 이를None으로 설정하면 polars 가 필요한 값을 추론한다. 두번째 인수로는 소수점 이하 자릿수를 설정한다. - polars 에서 범주형(categorical) 변수는 항상 문자열 데이터를 기반으로 파생된다. polars 에서 범주형 데이터를 처리할 때는 두 가지 유사한 데이터 타입을 제공한다. 바로
Enum과Categorical이다.- 각각에 대한 차이는 polars 의 공식문서를 참고하자.
- Enum 데이터 타입은 범주형 데이터를 처리할 때 사용해야 하는 권장 데이터 타입이다. Enum 데이터 타입은 시각적으로 출력될 때 문자열 값과 동일하게 보이지만, 내부적으로는 더 효율적으로 작동한다고 한다.
- 이는 polars 가 해당 Series 에 고정된 문자열 집합만이 유효한 값이라는 사실을 알고 있기 때문에, Enum 타입이 메모리를 더 적게 사용하고, Series 에서의 연산이 일반적으로 더 빠르며, Enum 타입에 포함되지 않는 값을 넣으려고 하면 오류가 발생한다.
- 또한, Enum 데이터 타입을 사용하면 범주(category)를 순서대로 다룰 수 있는 이점도 있다. 즉 학력 수준이라는 변수에서 “고졸” < “대졸” < “석사” < “박사” 과 같은 것이다.
- Categorical 데이터 타입은 Enum 과 달리 유효한 값을 사전에 지정할 필요가 없다. 대신 polars 가 자동으로 이러한 값을 추론한다.
- polars 는 일반적으로, Enum 을 실질적으로 사용할 수 없는 경우에만 Categorical 을 사용하는 것을 권장하고 있다.
- Enum 이든 Categorical 이든 상관없이
.cat네임스페이스와get_categories함수로 사용 중인 고유 카테고리 값을 추출할 수 있다.
- 마지막으로 polars 는 Object 데이터 타입을 통해 Series 에 임의의 Python 객체를 저장할 수 있다. Object 데이터 타입은 모든 데이터를 포괄할 수 있는 범용 타입(catch-all type)으로, 매우 일반적이기 때문에 polars 는 이 타입에서 임의의 객체를 처리하는 데 특화된 기능을 제공하지 않는다.
- Python 에서 제공하는 object 타입과 비슷한 방식으로 동작한다. 이를 이용하면 특정 데이터 타입이 필요하지 않을 때 유연하게 데이터를 다룰 수 있다.
- 그러나 Object 타입은 매우 일반적이기 때문에, 가능한 경우 더 구체적인 데이터 타입을 사용하는 것이 바람직하다.
- 부동소수점 Floating point 관련해서 polars 는 일반적으로 IEEE 754 부동소수점 표준을 따르지만 아래와 같은 예외가 있다.
- NaN 비교 규칙: NaN 은 다른 NaN 값과 동일한 값으로 간주된다. 또한 NaN 은 NaN 이 아닌 값보다 항상 크다고 간주된다.
- 0 및 NaN 부호(sign) 처리: 연산 결과에서 0 이나 NaN 의 부호에 대해 특정한 동작을 보장하지 않는다. NaN 값의 payload(부가 데이터)도 특정한 동작을 보장하지 않는다. 예를 들어, 정렬(sorting) 또는 그룹화(group by) 연산 중에 모든 0 은 +0 으로 통일되고, 모든 NaN 은 payload 가 없는 양수 NaN 으로 정규화(canonicalize)될 수 있다. 이는 효율적인 동등성 검사(equality checks)를 위해 수행된다.
- 정확성에 대한 한계: polars 는 부동소수점 연산에서 합리적으로 정확한 결과를 제공하려 하지만, 명시적으로 언급되지 않는 한 오차에 대해 보장하지 않는다. 일반적으로, 100% 정확한 결과를 제공하는 것은 비현실적으로 높은 비용을 요구하며, 64비트 부동소수점보다 훨씬 큰 내부 표현이 필요하다고 한다. 따라서 항상 어느 정도의 오차가 있을 수 있다.
- 자세한 데이터 타입에 대한 내용은 해당 polars 의 블로그 글을 참고하자.
- 위에서 살펴봤듯 만약 데이터의 특정 column 만 선택적으로 로드한다면, polars 는 columnar(컬럼 지향) 데이터 처리 방식을 사용하기 때문에 메모리 사용을 줄이고 IO 성능이 더욱 뛰어나다. 이 때 polars 는 데이터 로드 또는 DataFrame 생성 중에 즉시 최적화된 데이터 타입으로 변환할 수 있다.
- 이를 위해서
schema를 사용한다.schema는 열(column) 또는 시리즈(series)의 이름을 해당 열 또는 시리즈의 데이터 타입과 매핑한 것을 의미한다. - polars 는 데이터프레임이나 시리즈를 생성할 때 schema 를 자동으로 추론(infer)하지만, 필요하다면 이 추론 시스템을 재정의(override)할 수 있다. 이를 이용해서 데이터 로드 중 최적화된 데이터 타입으로 변환하는 것이다.
df = pl.DataFrame(
{
"name": ["Alice", "Ben", "Chloe", "Daniel"],
"age": [27, 39, 41, 43],
},
schema={"name": None, "age": pl.UInt8},
)
# shape: (4, 2)
# ┌────────┬─────┐
# │ name ┆ age │
# │ --- ┆ --- │
# │ str ┆ u8 │
# ╞════════╪═════╡
# │ Alice ┆ 27 │
# │ Ben ┆ 39 │
# │ Chloe ┆ 41 │
# │ Daniel ┆ 43 │
# └────────┴─────┘
- 위처럼 schema 가
None인 경우 특정 열에 대해 추론을 재정의하지 않은 것이고 polars 가 추론하게 된다. - 이 때 전체 스키마를 지정하려면
schema를, 일부만 재정의하려면schema_overrides를 사용하면 좋다. 즉schema_overrides는 추론을 재정의하고 싶지 않은 열을 생략할 수 있다.
df = pl.DataFrame(
{
"name": ["Alice", "Ben", "Chloe", "Daniel"],
"age": [27, 39, 41, 43],
},
schema_overrides={"age": pl.UInt8},
)
# shape: (4, 2)
# ┌────────┬─────┐
# │ name ┆ age │
# │ --- ┆ --- │
# │ str ┆ u8 │
# ╞════════╪═════╡
# │ Alice ┆ 27 │
# │ Ben ┆ 39 │
# │ Chloe ┆ 41 │
# │ Daniel ┆ 43 │
# └────────┴─────┘
- 물론 데이터를 폴더 혹은 cloud storage, DB 에서 읽을 때도
schemaargument 를 사용 가능하다. 이 때 기억해야 하는 점은 아래와 같다.read_확장자함수에서의 argument 인schema는 polars 의 schema 추론을 사용하지 않고 명시하는 것이다. 이 때 schema 에 전해주는 dict 에는 원본 데이터의 컬럼 순서와 같은 순서로column name : dtype의 형태로 주어져야 한다.- 또한 parquet 과 같이 schema 가 내장된 데이터의 경우, 해당 데이터가 가진 data type 과 같은 type 으로 구성된
schema를 건네주어야 한다. 즉 다른 data type 으로 바꾸는 것은 안된다. polars 에서는 실제로 parquet 파일을 읽을 때schema를 명시하는 것이 불안정하다고 말하니, 만약 data type 을 바꿀 필요가 있다면 내장된schema를 쓸 수 있도록 먼저 DataFrame 으로 읽고 이후에 바꾸도록 하자. - schema 를 내장한 파일 포맷은 parquet, Avro, ORC, Feather/Arrow IPC 등이 있다. 이러한 파일 포맷은 파일 내부에 각 컬럼의 데이터 타입과 이름을 저장한다. 따라서
schema_overrides는 지원되지 않는다. - polars 의
schema_overrides는 CSV 나 JSON 처럼 schema 가 내장되지 않은 데이터 파일에서 유용하다.
- 또한 DataFrame 에
.schema를 사용하면 각 컬럼 별 data type 을 알아낼 수 있다.
pl_df.schema
# Schema([('date_id', Int16),
# ('time_id', Int16),
# ('symbol_id', Int8),
# ('weight', Float32),
# ('feature_00', Float32),
# ...
- polars 에서 pandas 의
astype()처럼 data type 을 바꾸는 함수는.cast()다. 이 때 아래 코드와 같이 3 가지 방법으로 사용할 수 있다.
from datetime import date
df = pl.DataFrame(
{
"foo": [1, 2, 3],
"bar": [6.0, 7.0, 8.0],
"ham": [date(2020, 1, 2), date(2021, 3, 4), date(2022, 5, 6)],
}
)
# 각 컬럼 별 데이터 타입 변환
df.cast({"foo": pl.Float32, "bar": pl.UInt8})
# shape: (3, 3)
# ┌─────┬─────┬────────────┐
# │ foo ┆ bar ┆ ham │
# │ --- ┆ --- ┆ --- │
# │ f32 ┆ u8 ┆ date │
# ╞═════╪═════╪════════════╡
# │ 1.0 ┆ 6 ┆ 2020-01-02 │
# │ 2.0 ┆ 7 ┆ 2021-03-04 │
# │ 3.0 ┆ 8 ┆ 2022-05-06 │
# └─────┴─────┴────────────┘
# 데이터 타입 전체 변환
df.cast({pl.Date: pl.Datetime})
# shape: (3, 3)
# ┌─────┬─────┬─────────────────────┐
# │ foo ┆ bar ┆ ham │
# │ --- ┆ --- ┆ --- │
# │ i64 ┆ f64 ┆ datetime[μs] │
# ╞═════╪═════╪═════════════════════╡
# │ 1 ┆ 6.0 ┆ 2020-01-02 00:00:00 │
# │ 2 ┆ 7.0 ┆ 2021-03-04 00:00:00 │
# │ 3 ┆ 8.0 ┆ 2022-05-06 00:00:00 │
# └─────┴─────┴─────────────────────┘
# 데이터 프레임 전체 변환
df.cast(pl.String).to_dict(as_series=False)
# {'foo': ['1', '2', '3'],
# 'bar': ['6.0', '7.0', '8.0'],
# 'ham': ['2020-01-02', '2021-03-04', '2022-05-06']}
- 또한 pandas 의
select_dtypes()처럼 polars 에서 특정 data type 을 가진 column 을 가져오는 방법은df.select(pl.col(pl.String, pl.Int64, ...))와 같은 방법을 사용한다.
pl_df.select(pl.col(pl.Int16))
# shape: (6_274_576, 3)
# date_id time_id feature_11
# i16 i16 i16
# 1530 0 76
# 1530 0 76
# 1530 0 59
# 1530 0 11
# 1530 0 9
# … … …
# 1698 967 150
# 1698 967 195
# 1698 967 297
# 1698 967 214
# 1698 967 522
structures
- pandas 와 polars 의 데이터 구조에 대해 간단하게 알아보자.
pandas
- pandas 에는 익히 알고 있듯
pd.Series와pd.DataFrame이 있다. 두 데이터 구조의 가장 근본적인 차이는 column 개수에 있다. Series- pandas 에서 일종의 list 나 dict 처럼 사용된다.
- 모든 유형의 데이터를 보유하는 1 차원 배열이다.
- 길이가
n일 때, 0 에서n-1의 index 로 값에 접근할 수 있다. 이 때, 하나의 index 에 하나의 값만 가진다.
DataFrameDataFrame은 2차원 배열 또는 행과 열이 있는 테이블과 같은 2차원 데이터 구조다. 이 때 서로 다른 데이터 타입을 column 으로 가질 수 있다.Series는 말그대로DataFrame의 단일 column 에 대한 데이터 구조다. 즉,DataFrame의 데이터가 실제로 메모리에는Series의 컬렉션으로 저장되는 것이다.
- 둘 다 매우 유사한 API 를 가지고 있지만
DataFrame메서드는 항상 둘 이상의 열이 있을 가능성을 충족한다는 것을 알 수 있다. - 물론
DataFrame에 다른Series(또는 이에 상응하는 객체)를 추가할 수 있으며 다른Series에Series를 추가하면DataFrame이 생성된다.
import pandas as pd
# series 생성
data = {'a':1, 'b':2, 'c':3}
pd.Series(data)
# a 1
# b 2
# c 3
# dtype: int64
# series 결합 dataframe
l1 = [1, 2, 3]
l2 = [100, 200, 300]
data1 = pd.Series(l1)
data2 = pd.Series(l2)
frame = {1 : data1, 2 : data2}
res = pd.DataFrame(frame)
print(res)
# 1 2
# 0 1 100
# 1 2 200
# 2 3 300
# dataframe 에 series 추가
l3 = [1000, 2000, 3000]
data3 = pd.Series(l3)
res[3] = data3
print(res)
# 1 2 3
# 0 1 100 1000
# 1 2 200 2000
# 2 3 300 3000
- 두 데이터 구조에 대한 자세한 옵션과 생성 방법은 pandas 공식문서를 확인해보자.
polars
- polars 에는 pandas 와 마찬가지로
pl.Series와pl.DataFrame이 있고, 추가적으로pl.LazyFrame이 존재한다. pl.Series는 1차원 동질적(homogeneous) 데이터 구조다. 여기서 homogeneous 이라는 것은 Series 내부의 모든 요소가 동일한 데이터 타입을 가진다는 것을 의미한다. 이는 pandas 도 마찬가지다.- Series 를 생성할 때 polars 는 제공된 값들을 기반으로 데이터 타입을 추론한다. 그러나 위에서 본 것처럼 추론 메커니즘을 무시하고 특정 데이터 타입을 지정할 수도 있다.
pl.DataFrame은 2차원 이질적(heterogeneous) 데이터 구조로, 고유한 이름을 가진 여러 Series 를 포함한다.- 데이터를 DataFrame 에 보관하면 polars API 를 사용하여 데이터를 조작하는 쿼리를 작성할 수 있다.
- 이를 위해 polars 가 제공하는 contexts 와 expressions 을 활용할 수 있다.
- 아래에서 list 를 value 로 하는 dict 을 사용하여 DataFrame 을 생성해보자.
import polars as pl
s = pl.Series("ints", [1, 2, 3, 4, 5])
print(s)
# shape: (5,)
# Series: 'ints' [i64]
# [
# 1
# 2
# 3
# 4
# 5
# ]
s1 = pl.Series("ints", [1, 2, 3, 4, 5])
s2 = pl.Series("uints", [1, 2, 3, 4, 5], dtype=pl.UInt64)
print(s1.dtype, s2.dtype) # Int64 UInt64
from datetime import date
df = pl.DataFrame(
{
"name": ["Alice Archer", "Ben Brown", "Chloe Cooper", "Daniel Donovan"],
"birthdate": [
date(1997, 1, 10),
date(1985, 2, 15),
date(1983, 3, 22),
date(1981, 4, 30),
],
"weight": [57.9, 72.5, 53.6, 83.1], # (kg)
"height": [1.56, 1.77, 1.65, 1.75], # (m)
}
)
print(df)
# shape: (4, 4)
# ┌────────────────┬────────────┬────────┬────────┐
# │ name ┆ birthdate ┆ weight ┆ height │
# │ --- ┆ --- ┆ --- ┆ --- │
# │ str ┆ date ┆ f64 ┆ f64 │
# ╞════════════════╪════════════╪════════╪════════╡
# │ Alice Archer ┆ 1997-01-10 ┆ 57.9 ┆ 1.56 │
# │ Ben Brown ┆ 1985-02-15 ┆ 72.5 ┆ 1.77 │
# │ Chloe Cooper ┆ 1983-03-22 ┆ 53.6 ┆ 1.65 │
# │ Daniel Donovan ┆ 1981-04-30 ┆ 83.1 ┆ 1.75 │
# └────────────────┴────────────┴────────┴────────┘
- 위에서 본 것처럼 polars 는 즉시 실행(Eager)과 지연 실행(Lazy) 두 가지 모드를 지원한다.
- 즉시 실행 모드에서는 쿼리가 바로 실행된다. 반면, 지연 실행 API 를 사용하면 쿼리는
collect명령이 호출될 때까지 쿼리가 실행되지 않는다. - 실행을 마지막 순간까지 미루는 것은 성능상 큰 이점을 제공할 수 있기 때문에 대부분의 경우 지연 실행 API 가 선호된다.
- 즉시 실행 모드에서는 쿼리가 바로 실행된다. 반면, 지연 실행 API 를 사용하면 쿼리는
- 예를 들어 Iris 데이터셋으로 두 모드의 실행 과정을 설명해보자.
- eager API 를 사용하면 먼저 1) Iris 데이터셋을 읽고, 2) 꽃받침 길이(sepal length)를 기준으로 데이터셋을 필터링하고, 3) 종(species)별로 꽃받침 너비(sepal width)의 평균 계산할 수 있다.
- 이 때 각 단계가 즉시 실행되며, 중간 결과를 반환한다. 그러나 이 방식은 데이터셋이 매우 크거나 주어진 메모리가 작을 때 비효율적일 수 있다. 즉 사용되지 않는 데이터를 읽거나 불필요한 작업을 수행할 가능성이 있다.
- Lazy API 를 사용하면, 모든 단계가 정의될 때까지 실행을 연기할 수 있다. 실행 전에 polars 의 쿼리 플래너(query planner)가 다양한 최적화를 수행한다.
- 대표적으로 아래와 같은 최적화가 진행된다.
- 조건(Predicate) 푸시다운: 데이터셋을 읽을 때 가능한 한 빨리 필터를 적용한다. 예를 들어, 꽃받침 길이가 5 보다 큰 행만 읽도록 최적화한다.
- 프로젝션(Projection) 푸시다운: 필요한 열만 선택해서 읽는다. 예를 들어, 꽃잎 길이(petal length)와 꽃잎 너비(petal width) 같은 불필요한 열을 읽지 않도록 최적화한다.
- 이러한 최적화의 이점은 메모리 및 CPU 의 부하를 크게 줄일 수 있고, 더 큰 데이터셋을 메모리에 적재하고 빠르게 처리할 수 있다.
- Lazy API 로 쿼리를 정의한 후,
collect를 호출하면 polars 가 정의된 쿼리들을 순차적으로 실행하도록 요청한다. - 또한 Lazy API 를 사용할 때,
explain함수를 사용하여 쿼리 계획(query plan)을 출력할 수 있다. 이 기능은 쿼리에 대해 어떤 최적화를 수행하는지 확인하고 싶을 때 유용하다. - 일반적으로 이러한 Lazy API 에 사용되는 데이터 구조가
pl.LazyFrame이다.
schema = pl.Schema(
{
"int_1": pl.Int16,
"int_2": pl.Int32,
"float_1": pl.Float64,
"float_2": pl.Float64,
"float_3": pl.Float64,
}
)
print(
pl.LazyFrame(schema=schema)
.select((pl.col(pl.Float64) * 1.1).name.suffix("*1.1"))
.explain()
)
# SELECT [[(col("float_1")) * (1.1)].alias("float_1*1.1"), [(col("float_2")) * (1.1)].alias("float_2*1.1"), [(col("float_3")) * (1.1)].alias("float_3*1.1")] FROM
# DF ["int_1", "int_2", "float_1", "float_2"]; PROJECT 3/5 COLUMNS
- 위 코드와 같이
pl.LazyFrame으로 데이터를 생성하지는 않고, Lazy API 의 특성상 크기가 매우 큰 데이터셋을scan_format을 이용하여pl.LazyFrame으로 읽은 뒤, 쿼리를 정의하고collect로 실행한다. - 추가적으로 polars 에서 새로운 column 을 만들때는
.with_columns()함수를 사용한다.
filtering & selection
- 위에서 본 것처럼 pandas 는 데이터를 read 할 때부터 filter 기능을 사용할 수 있고, 이후에 indexing, slicing, 조건문을 통해 직관적인 방법으로 필터링할 수 있다.
- polars 는
.filter()와.select()를 이용하는데, pandas 보다 효율적으로 동작한다. 아래에서 자세하게 비교해보자.
pandas
-
pandas 의 기본적인 indexing 은 아래와 같다.
Operation Syntax Result Select Column df[col]Series Select Row by label df.loc[label]Series Select Element by label, column df.loc[label, col]Element Select Row by integer location df.iloc[loc]Series Select Element by integer location on low, column df.iloc[loc, loc]Element Slice rows df[5:10]DataFrame Select rows by boolean vector df[bool_vec]DataFrame -
이를 코드로 확인해보자.
pd_df["date_id"]
# 0 1530
# 1 1530
# 2 1530
# 3 1530
# 4 1530
# ...
# 6274571 1698
# 6274572 1698
# 6274573 1698
# 6274574 1698
# 6274575 1698
# Name: date_id, Length: 6274576, dtype: int16
pd_df.loc[0]
# date_id 1530.000000
# time_id 0.000000
# symbol_id 0.000000
# weight 3.084694
# feature_00 1.153571
# ...
# responder_4 0.746552
# responder_5 0.552013
# responder_6 3.071231
# responder_7 0.914794
# responder_8 0.997124
# Name: 0, Length: 92, dtype: float32
pd_df.loc[0, 'date_id'] # np.int16(1530)
pd_df.iloc[0]
# date_id 1530.000000
# time_id 0.000000
# symbol_id 0.000000
# weight 3.084694
# feature_00 1.153571
# ...
# responder_4 0.746552
# responder_5 0.552013
# responder_6 3.071231
# responder_7 0.914794
# responder_8 0.997124
# Name: 0, Length: 92, dtype: float32
pd_df.iloc[0, 0] # np.int16(1530)
.loc과.iloc은 pandas 에서 filtering 과 selecting 을 할 때 가장 많이 사용하는 메서드다.- pandas 의 공식문서 중 Indexing and selecting data 에는 다양한 응용방식이 소개되어 있다.
polars
- 기본적인 indexing 은 아래와 같다.
aggregation operations
grouping operations
sorting
시계열 연산
SQL 사용
Reference
- https://butter-shower.tistory.com/245
- https://techblog.woowahan.com/18632/
- https://modulabs.co.kr/blog/polars
- https://qphone.tistory.com/4
- https://pola.rs/posts/understanding-polars-data-types
댓글 남기기