
[Trouble Shooting] 유튜브 크롤링 및 Mac 터미널
사이드 프로젝트를 진행하면서 1차로 데이터를 수집하는 역할을 맡았다. 유튜브 검색을 통해 데이터를 수집하는데, 이 과정에서 겪었던 문제를 정리하고자 한다.
Webdriver Thread
- 크롤링에
Selenium을 활용했다. 이 때webdriver가 종종 무한 대기에 빠지는 경우가 있었다. selenium과 Chrome 의 버전이 호환이 안되는 문제였는데,selenium = "^4.24.0"버전부터는 따로Service()내에 Manager 를 포함시키지 않고 실행해도 문제가 없다고 한다.- 그럼에도 불구하고 확인되지 않는 원인으로 종종 무한 대기에 빠지는 것을 마냥 기다릴 순 없어서,
Threading으로 timeout 을 줘서 에러를 발생시키도록 했다.
def start_driver(user_agent, timeout=15):
"""
Selenium WebDriver 실행, 지정한 시간 내에 실행되지 않으면 TimeoutError 를 발생
Args:
args (argparse): config 얻기
timeout (int): 타임아웃 시간(초).
Returns:
webdriver: Selenium WebDriver 객체
Raises:
TimeoutError: 드라이버가 타임아웃 내에 실행되지 않으면 발생
"""
driver = None
error = None
user_agent = user_agent
def launch_driver():
nonlocal driver, error
try:
service = Service()
options = webdriver.ChromeOptions()
options.add_argument("user-agent=" + user_agent)
options.add_argument("headless")
options.add_argument("--mute-audio")
driver = webdriver.Chrome(service=service, options=options)
except WebDriverException as e:
error = e
# 스레드로 드라이버 실행
thread = threading.Thread(target=launch_driver)
thread.start()
thread.join(timeout)
if thread.is_alive():
# 타임아웃 발생 시 스레드를 중단하고 에러 발생
raise TimeoutError(f"WebDriver did not start within {timeout} seconds.")
if error:
# WebDriverException 발생 시 다시 던짐
raise error
return driver
launch_driver()함수를 통해서 driver 를 구동시키고, 이 때thread.join(timeout)을 이용해서timeout에 따라 driver 가 일정시간 내에 구동되지 않으면 에러를 발생시킨다.- 주의할 점은 Python 에서는 thread 를 강제 종료하는 기능을 제공하지 않기 때문에, 터미널 상에서
ps명령어 등을 통해 ChromeDriver 를 종료해주는 것이 자원 누수를 막는다.
작업 효율성
- 작업 효율성을 위해 데이터 수집 시 데이터 수집 결과 csv 파일을 읽고 새로운 데이터를 추가한 뒤 저장하는 것을 반복하게 했다.
- 기존 코드에서는 모든 데이터 크롤링이 끝나야 csv 파일이 만들어지게 되는데, 긴 시간 크롤링 하는 도중 수정할 부분이 있거나 오류가 발생했을 때 날리는 시간이 매우 아까웠다.
- 이에 따라
argparse를 통해 작업의 step 단위를 주어 작업이 재개되도록 했다. -
아래는 팀 github 에 작성한 README 다.
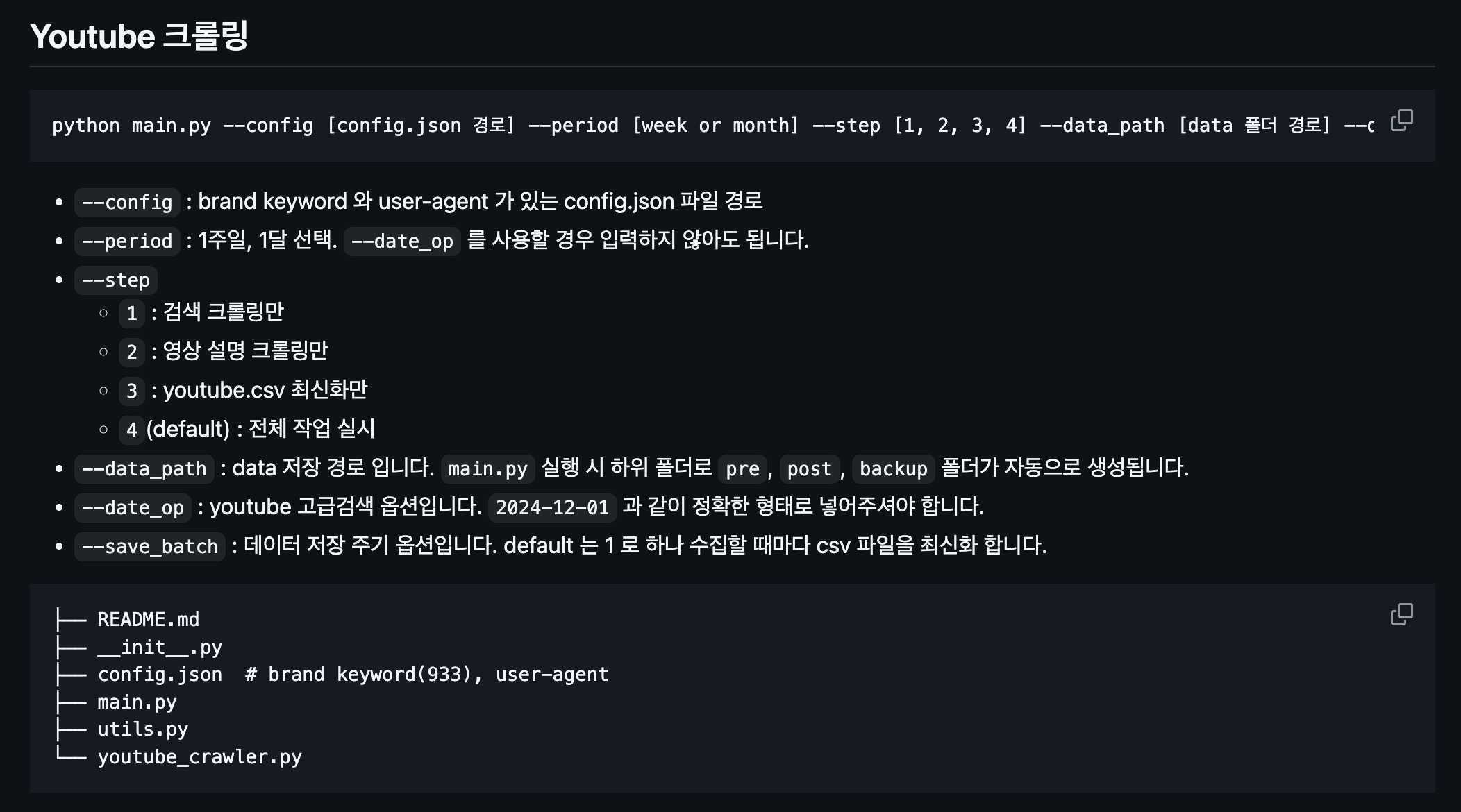
- 또한 작업 중지 후 재개할 때, 기존의 수집된 data 에서 이미 수집된 data 를 걸러내고, 작업이 끊긴 시점부터 진행하면 좋을 것 같아 아래와 같은 코드를 구현했다.
# 이미 처리된 데이터 불러오기
if os.path.exists(results):
processed_df = pd.read_csv(results, encoding="utf-8")
processed = set(
processed_df[["keywords", "title", "link"]]
.apply(tuple, axis=1)
.tolist()
)
print(f"이미 처리된 URL 개수: {len(processed)}")
try:
for i in tqdm(range(len(df)), total=len(df), desc="크롤링 진행 중"):
row = df.iloc[i, :]
check = (
row["keywords"],
row["title"],
row["link"],
)
URL = row["link"]
# 이미 처리된 데이터는 건너뛰기
if check in processed:
continue
try:
작업 코드
except Exception as e:
print(f"URL {URL} 에서 에러 발생: {e}")
error_log.append((URL, e))
processed_df = pd.concat([processed_df, new_row], ignore_index=True)
processed.add(check)
if i % batch == 0:
processed_df.to_csv(results, index=False, encoding="utf-8")
time.sleep(random.uniform(1, 3))
finally:
driver.quit()
- 위 코드에서 수집된 데이터 csv 파일을 불러와서,
keywords, title, link를 기준으로 이미 수집된 데이터인지 아닌지를 판단한다. - 이후 데이터를 수집한 뒤
processed에 지속적으로 추가하여 중복 제거와 이후 작업 재개 시 작업이 끊긴 곳 부터 시작할 수 있도록 했다. batch의 경우 데이터 저장 주기다. docker 등에서 데이터 수집 자동화를 할 때, 리소스를 효율적으로 사용하기 위해서 일정 수 만큼 데이터가 수집되면 csv 파일을 업데이트 한다.
도움이 된 linux 명령어
- 작업을 진행하면서 많이 쓴 linux 명령어를 정리해보자.
ps
- Process Status 의 약어를 이름으로 사용한 ps 명령어를 사용하면 현재 구동 중인 프로세스 정보를 확인할 수 있다.
- 명령어와 함께 사용되는 주요 옵션들은 다음과 같다.
-e: 현재 사용자뿐만 아니라 다른 사용자들이 구동시킨 모든 프로세스를 보여준다. 즉,-e옵션이 없다면 ps 명령어는 현재 사용자(Shell)가 실행 중인 프로세스만 보여준다.-f: 보다 상세한 정보를 보여준다. (Full format)--f: 보다 더 상세한 정보를 보여준다. (Long format)
ps-efl명령어를 통해 출력되는 결과의 각 필드의 의미는 다음과 같다. 실행 환경마다 필드의 이름 혹은 출력 순서가 다를 수 있다.F: 프로세스 플래그4: used super-user privileges1: forked but didn’t exec5:4 & 1 플래그에 모두 해당하는 경우0: 어떤 플래그에도 해당하지 않는 경우
S: 프로세스의 현재 상태R: 실행 중 혹은 실행될 수 있는 상태S: 대기 상태 (약 20초 이상)I: 대기 상태 (약 20초 이하)T: 작업 제어에 의해 정지된 상태D: 디스크 관련 대기 상태P: 페이지 관련 대기 상태X: 메모리 확보를 위한 대기 상태>: 인위적으로 우선 순위가 높아진 상태Z: 좀비 프로세스
UID: 프로세스를 실행시킨 사용자 IDPID: 프로세스에 부여된 IDPPID: 프로세스의 부모 프로세스 ID (Parent Process ID)C: CPU 사용량(%)PRI: 프로세스 우선순위NI: 프로세스의 CPU 자원 사용 우선순위 (Nice)ADDR: 프로세스의 메모리 주소SZ: 가상 메모리 사용량STIME: 프로세스 시작 시간TTY: 프로세스가 실행된 터미널의 종류와 번호TIME: 프로세스에 의해 사용된 CPU 시간CMD: 실행된 프로세스의 이름 혹은 실행된 명령
ctrl + z 와 jobs
- 위 두 명령어와 아래의
fg, bg는 집에서 크롤링 하다가 카페에 가서 공부를 하며 크롤링을 재개할 수 있게 해준 명령어다. ctrl + z는 진행 중인 프로세스를 일시 정지한다. 다만 크롤링의 경우selenium을 쓸 때 driver 가 꺼져 작업을 재개하더라도 오류가 나는 경우가 있었다.- 따라서 작업을
ctrl + c로 완전 종료하고 다시 재개했을 때 작업이 끊긴 지점의 데이터부터 수집을 시작하는 것이 해결 방법이었다. - linux 의 shell 에서는 프로세스를 작업(job) 단위로 관리한다. 작업은 foreground 와 background 두 가지 방식으로 동작한다.
- foreground : 작업이 종료되는 시점까지 다른 쉘 명령어를 수행할 수 없고 대기한다. 즉 다른 작업을 할 수 없다.
- background : 작업을 하는 동시에 다른 명령어들을 실행시킬 수 있다.
- 동시에 여러 명령어들을 실행시키는 것을 multi-tasking 이라고 하고, background 에서 명령어를 실행하기 위해서 뒤에
&를 붙여준다.
sleep 100&
- 또한
&로 background 에서 실행시키면 Mac 의 경우 해당 작업의PID가 나온다. 그리고 해당 작업이 완료되면 터미널에 아래와 같은 출력을 내뱉는다.
[2] + 33398 done sleep 100
jobs명령어는 현재 돌아가고 있는 background 프로세스 리스트를 모두 출력해준다. 이를 통해 background 에서 실행 중인 작업을 확인할 수 있다. 아래와 같이 결과가 나온다.
[1] - running sleep 50
[2] + running sleep 100
- 위
jobs의 출력에서[1], [2]가 jobs number 다. -, +는 무엇을 뜻할까? background 프로세스는 스택처럼 쌓이는데,+는 스택의 가장 위에 있다는 뜻이고-는 바로 그 다음 밑에 있다는 뜻이다.
fg %[jobs number] 와 bg %[jobs number]
bg는 foreground 프로세스를 background 로 바꿔주는 명령이다. 즉 foreground 를 후면 처리로 전환할 때 사용한다.- 전면 실행중인 명령에서
ctrl + z를 눌러 일시 정지한 후bg %[job number]명령을 하달하면, 후면 처리가 된다. - 만일 job 번호를 치지 않고 그냥
bg만 치면 jobs 목록에서+기호가 있는 job 번호가 우선 실행하게 된다. - 반면
fg는 background 를 전면 처리로 전환하는 명령어다. 마찬가지로fg %[job number]로 명령을 하달한다.
background 프로세스 일시정지
- background 로 실행시킨 프로세스를 일시 중지시키려면, 전면 처리 전환 기법과 함께 쓰면 된다.
&를 사용해 background 로 실행jobs명령을 사용해 job 번호(PID) 알아내고,fg명령어를 실행해 프로세스를 foreground 로 가져오기ctrl + z명령을 통해 foreground 에서 프로세스 일시중지
프로세스 유지 nohup
- nohup 은 no hang up 의 약자다.
- 일반적으로 시스템에서 로그아웃하면 로그아웃한 세션과 연관된 모든 프로세스에게 HUP 시그널(1)을 보내, 관련된 모든 프로세스는 자동으로 종료되지만
nohup을 사용하면 해당 시그널을 가로채 무시하기 때문에 로그아웃하더라도 프로세스를 계속 실행되게 된다. - 즉, 사용자가 로그아웃해도 실행 중인 프로세스를 background 로 유지시켜주는 명령어다.
nohup ./my_shellscript.sh
- 위와 같이 실행시키면 “nohup: appending output to
nohup.out” 메세지와 함께 해당 프로그램의 표준 출력이, nohup 을 실행시킨 경로에 nohup.out 으로 출력된다. - 만약 nohup.out 을 다른 파일에 쓰고 싶다면 아래 명령어를 사용하면 된다.
nohup ./my_shellscript.sh > nohup_script.out
nohup은 프로그램을 데몬의 형태로 실행시키는 것이기 때문에 로그아웃으로 세션이 종료되더라도 프로그램이 종료되지 않는다.- 그러나 background 의
&실행은 단지 프로그램을 사용자 눈에 보이지 않는 background 형태로 돌리고 있는 것이기 때문에 로그아웃으로 세션과 연결이 끊어지면 실행되고 있던 프로그램도 함께 종료된다. - 하지만 언젠가부터
&로 돌리더라도nohup과 동일하게 세션이 끊어져도 프로그램이 종료되지 않는 옵션이 디폴트로 적용되었기 때문에 두 명령어의 동작이 유사하게 보인다.
댓글 남기기