
[Pytorch] Pytorch 자주 사용하는 함수
지난번 포스트에서 Pytorch 에서 Tensor 를 생성하는 방법과 Tensor 연산 및 조작들을 정리했다. 이어서 이 포스트에서는 Pytorch 를 기반으로 자주 사용하는 함수를 정리해보자. 특히, BERT 를 시작으로 한 오늘날 파운데이션 모델의 발전은 pre-trained 된 모델을 fine-tuning 하는 활용력이 중요하게 되었다. 이에 따라 Pre-trained 모델을 사용하는 법도 정리해보자.
자주 사용하는 함수
- Pytorch 로 모델링을 하거나 post processing 을 할 때 자주 사용하게 되는 함수를 정리해보자.
- 이 포스트는 지속적으로 업데이트 할 예정이다.
Random Sampling
- Pytorch 는 초기화, 샘플링 등 다양한 곳에 활용될 수 있는 랜덤 함수를 제공한다.
- 대표적인 확률분포인 베르누이, 다항분포, 정규분포 등과 함께
torch.randn,torch.randperm,torch.poisson등이 있다. - 자세한 것은 공식문서를 참고하자.
torch.randn(2, 3)
# tensor([[ 0.3580, -1.8308, 1.1344],
# [ 1.2502, 0.3324, -1.9243]])
torch.randperm(4)
# tensor([2, 0, 3, 1])
rates = torch.rand(4, 4) * 5
torch.poisson(rates)
# tensor([[5., 4., 2., 3.],
# [2., 3., 2., 1.],
# [0., 1., 0., 0.],
# [1., 3., 7., 1.]])
expand 와 repeat
expand와repeat은 torch 에서 값을 반복시키는 대표적인 연산이다.- 먼저
expand는 특정 tensor 를 반복하여 생성하며 개수가 1 인 차원에만 적용하여 반복할 수 있다.
x = torch.tensor([[1], [2], [3]])
x.size()
# torch.Size([3, 1])
x.expand(3, 4)
# tensor([[1, 1, 1, 1],
# [2, 2, 2, 2],
# [3, 3, 3, 3]])
x.expand(-1, 4)
# tensor([[1, 1, 1, 1],
# [2, 2, 2, 2],
# [3, 3, 3, 3]])
- 위 코드를 살펴보면
torch.Size([3, 1])크기에서 1 에 해당하는 차원을 4 의 크기로 확대하면 기존에 가지고 있던 값이 복사된다. - 이는 차원의 개수가 1 인 곳에만 적용 가능하므로 크기를 늘릴 차원 크기만큼 숫자를 입력하고 변함이 없는 차원은
-1로 입력하면 쉽게 사용할 수 있다. - 아래와 같이 사용하면 여러 차원에도 적용할 수 있다.
y = torch.rand(3, 1, 1)
# tensor([[[0.4637]],
# [[0.5258]],
# [[0.2620]]])
y.expand(-1, 3, 4)
# tensor([[[0.4637, 0.4637, 0.4637, 0.4637],
# [0.4637, 0.4637, 0.4637, 0.4637],
# [0.4637, 0.4637, 0.4637, 0.4637]],
# [[0.5258, 0.5258, 0.5258, 0.5258],
# [0.5258, 0.5258, 0.5258, 0.5258],
# [0.5258, 0.5258, 0.5258, 0.5258]],
# [[0.2620, 0.2620, 0.2620, 0.2620],
# [0.2620, 0.2620, 0.2620, 0.2620],
# [0.2620, 0.2620, 0.2620, 0.2620]]])
- 이처럼
expand연산은 차원이 1 인 어떤 차원의 값을 원하는 크기만큼 같은 값으로 채우는 반면,repeat연산은 어떤 tensor 를 완전히 반복하여 값을 채운다. 아래 예제를 보자.
x = torch.rand(2, 3)
# tensor([[0.3420, 0.6117, 0.8471],
# [0.0250, 0.7804, 0.5909]])
# torch.Size([2, 3])
x.repeat(3, 2, 2)
# tensor([[[0.3420, 0.6117, 0.8471, 0.3420, 0.6117, 0.8471],
# [0.0250, 0.7804, 0.5909, 0.0250, 0.7804, 0.5909],
# [0.3420, 0.6117, 0.8471, 0.3420, 0.6117, 0.8471],
# [0.0250, 0.7804, 0.5909, 0.0250, 0.7804, 0.5909]],
# [[0.3420, 0.6117, 0.8471, 0.3420, 0.6117, 0.8471],
# [0.0250, 0.7804, 0.5909, 0.0250, 0.7804, 0.5909],
# [0.3420, 0.6117, 0.8471, 0.3420, 0.6117, 0.8471],
# [0.0250, 0.7804, 0.5909, 0.0250, 0.7804, 0.5909]],
# [[0.3420, 0.6117, 0.8471, 0.3420, 0.6117, 0.8471],
# [0.0250, 0.7804, 0.5909, 0.0250, 0.7804, 0.5909],
# [0.3420, 0.6117, 0.8471, 0.3420, 0.6117, 0.8471],
# [0.0250, 0.7804, 0.5909, 0.0250, 0.7804, 0.5909]]])
x.repeat(3, 2, 2).shape
# torch.Size([3, 4, 6])
- 위 코드를 살펴보면
xtensor 의 값이 repeat 한 크기 만큼 반복되는 것을 확인할 수 있다. - 즉 원래
xtensor 의torch.Size([2, 3])크기에.repeat(3, 2, 2)으로 반복하면(3, 2 X 2, 3 X 2) = (3, 4, 6)이 되는 것이다.
a = torch.tensor([1,2,3,4,5,6]).view(3,2,1)
print(a.size()) # torch.Size([3, 2, 1])
print(a.repeat(2, 3, 2, 5).size()) # torch.Size([2, 9, 4, 5])
- 위 예제를 보면
atensor 를.repeat(2,3,2,5)로 반복하면 각 차원의 rank 에 맞게 곱해지는 것을 확인할 수 있다. - 이처럼
expand와repeat은 기존의 tensor 를 이용하여 더 큰 크기의 tensor 를 만든다는 점에서 같지만 내부적인 동작 방식에 차이가 있다.expand의 경우 원본 tensor 를 참조하여 만들기 때문에(shallow copy) 원본 tensor 의 값이 변경되면expand의 값 또한 변경된다.- 반면
repeat은 깊은 복사(deep copy)로 만들어지기 때문에 원본 tensor 가 변경되더라도 값 변경이 발생하지 않는다.
a = torch.rand(1, 1, 3)
print(a)
# tensor([[[0.8415, 0.2347, 0.9298]]])
b = a.expand(4, -1, -1)
c = a.repeat(4, 1, 1)
print(b.shape) # torch.Size([4, 1, 3])
print(c.shape) # torch.Size([4, 1, 3])
a[0, 0, 0] = 0 # 원본 tensor 값 변경
print(a)
# tensor([[[0.0000, 0.2347, 0.9298]]])
print(b)
# tensor([[[0.0000, 0.2347, 0.9298]],
# [[0.0000, 0.2347, 0.9298]],
# [[0.0000, 0.2347, 0.9298]],
# [[0.0000, 0.2347, 0.9298]]])
print(c)
# tensor([[[0.8415, 0.2347, 0.9298]],
# [[0.8415, 0.2347, 0.9298]],
# [[0.8415, 0.2347, 0.9298]],
# [[0.8415, 0.2347, 0.9298]]])
Initialization
init.uniform(tensor, a, b)나init.normal(tensor, mean, std)함수를 사용하면uniform또는normal분포로 값이 초기화된 tensor 를 만들 수 있다.- 이 때 초기화되는 tensor 는 weight tensor 다. 또한 상수 형태의 초기화도 가능하다.
- 최근에는
init.uniform_이나init.normal_,init.kaiming_normal_등으로 inplace 하게 사용한다.
import torch.nn.init as init
x1 = init.uniform(torch.FloatTensor(3,4),a=0,b=9)
print(x1)
# tensor([[1.1068, 8.5250, 7.1036, 8.1112],
# [4.4030, 3.8945, 5.8992, 4.3647],
# [5.0161, 1.1555, 4.7554, 1.2162]])
x2 = init.normal(torch.FloatTensor(3,4),std=0.2)
print(x2)
# tensor([[-0.1206, -0.0202, -0.0681, -0.3214],
# [ 0.0651, 0.2593, -0.0066, -0.3084],
# [-0.1021, 0.2501, -0.0159, -0.0528]])
x3 = init.constant(torch.FloatTensor(3,4),3.1415)
print(x3)
# tensor([[3.1415, 3.1415, 3.1415, 3.1415],
# [3.1415, 3.1415, 3.1415, 3.1415],
# [3.1415, 3.1415, 3.1415, 3.1415]])
torchvision.models 사용
torchvision.models에서 제공되는 pre-trained 모델을 사용해야 하는 경우 아래와 같은 코드를 통해 모델을 다운받고 사용할 수 있다.- 이를 통해 다양한 데이터셋으로 학습된 다양한 모델들을 사용할 수 있다. torchvision 공식문서에서 확인할 수 있고, 아래 코드로도 확인할 수 있다.
import torchvision
import torchvision.models as models
models.list_models()
- 아래 코드는 ResNet 예시다.
deprecated된 것은 torchvision 이 버전업 되면서 옛 사용 방식에 해당한다.
from torchvision.models import resnet50, ResNet50_Weights
# Using pretrained weights:
resnet50(weights=ResNet50_Weights.IMAGENET1K_V1)
resnet50(weights="IMAGENET1K_V1")
resnet50(pretrained=True) # deprecated
resnet50(True) # deprecated
# Using no weights:
resnet50(weights=None)
resnet50()
resnet50(pretrained=False) # deprecated
resnet50(False) # deprecated
models.resnet50(weights="IMAGENET1K_V1")을 실행하면 모델이 어느 경로에 다운되는지 확인할 수 있다. 그 경로는 보통/Users/.cache/torch/hub/checkpoints/에 있다.- 이 경로에 있는
resnet50-0676ba61.pth파일이 바로 ImageNet 으로 pre-trained 된 모델이다. - 이를 인터넷이 되는 PC 에서 다운 받고 파일을 복사한 뒤 인터넷이 안되는 리눅스 PC 의
~/.cache/torch/hub/checkpoints에 복사한 파일을 붙여 넣고 사용할 수 있다.
opencv 와 tensor
- Computer Vision task 에서 이미지를 다룰 때 torch 와 함께 이미지 처리 라이브러리로
PIL이나opencv를 많이 사용한다. 이 중에서opencv로 이미지 tensor 를 다루는 법을 알아보자. - opencv 로 이미지를 읽으면
numpy.ndarray의 데이터가 되며, 이를tensor로 변환하는 과정은 아래와 같다.- 먼저 opencv 로 이미지를 읽으면 이미지를
(H, W, C)의 형태로 읽게 된다. 이는 Pytorch 에서 다루는 tensor 의(B, C, H, W)형태와 비교해보면 channel 인C의 위치가 다르다. - 또한 opencv 는 RGB 채널이 아닌 BRG 채널로 이미지를 읽기 때문에 이 순서를 바꿔준다.
- 학습 시 사용하는 이미지 tensor 값의 범위는 0 ~ 1 의 scale 로 normalize 하여 많이 사용한다.
- 먼저 opencv 로 이미지를 읽으면 이미지를
- 아래 코드의
load_image는 이미지를 opencv 로 읽어서 BGR 을 RGB 로 바꾼 뒤, 원하는 사이즈로 resize 한다. tensorify는(H, W, C)형태의 numpy 데이터를(B, C, H, W)의 tensor 로 변경한다. 또한 하나의 픽셀 최대값인 255 로 나눠주어 값의 범위는 0 ~ 1 로 변경된다. 따라서 tensor 의 크기는(1, C, H, W)가 된다.
load_images = lambda path, h, w: cv2.resize(cv2.cvtColor(cv2.imread(path, cv2.IMREAD_UNCHANGED), cv2.COLOR_BGR2RGB), ((w, h)))
tensorify = lambda x: torch.Tensor(x.transpose((2, 0, 1))).unsqueeze(0).float().div(255.0)
img_tensor = tensorify(load_images("img.png", 400, 300))
print(img_tensor.shape) # torch.Size([1, 3, 400, 300])
opencv를 이용하여 이미지 데이터를 입력 받고, 이를torch.Tensor타입 및(Batch, Channel, Height, Width)형태로 바꾸는 예시를 보자.- 하나의 컬러 이미지를 예시로
(1, 3, height, width)형태를 가진다.- 먼저 opencv 를 이용하여 이미지 데이터 읽는다.
- 이후 BGR 에서 RGB 채널로 바꿔준다.
- opencv 로 읽은
numpy.ndarray형태의 데이터를torch.Tensor형태로 바꿔준다. (H,W,C)의 차원을(C,H,W)로 바꿔준다.- 마지막으로 Batch 채널을 추가한다. 즉,
(Channel, Height, Width)에서unsqueeze를 통해 ` (Batch, Channel, Height, Width)` 로 바꾼다.
# ① opencv 를 이용하여 이미지 데이터 읽기
img = cv2.imread("image.png")
# ② (Optional) BGR → RGB
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# ③ Numpy → Tensor
img = torch.Tensor(img)
# ④ Dimension 변경
img = img.permute(2, 0, 1)
# ⑤ (Channel, Height, Width) → (Batch, Channel, Height, Width)
img = torch.unsqueeze(img, 0)
torch.argmax(input, dim, keepdim)
argmax는 말 그대로 arguments of max 의 의미다. 즉, 어떤 함수를 최대로 만드는 정의역의 점들, elements 혹은 매개변수를 말한다.- argmax 함수가 받는 argument 는 차례대로
input,dim,keepdim이다.input은 메서드에 입력되는 Tensor 다.dim은 어느 축을 기준으로 argmax 연산을 할 지 결정한다.keepdim은 argmax 연산의 기준 축을 생략할 지 그대로 둘 지를 결정한다. argmax 를 하면 각 축마다 값이 1개만 남게 되므로 필요 여부에 따라 남길 수도 있고 삭제할 수도 있다.
- Pytorch 를 이용하여 이미지 처리를 할 때, 주로 사용하는 방법은 아래와 같다.
# 1. input 이 (channel, height, width) 인 경우
torch.argmax(input, dim = 0, keepdim = True)
# 2. input이 (batch, channel, height, width) 인 경우
torch.argmax(input, dim = 1, keepdim = True)
- 일반적으로 이미지 처리를 할 때, 출력의
channel의 수만큼 클래스 label 을 가지고 있는 경우가 많다. 이 때, 가장 큰 값을 argmax 연산하여 가장 큰 index 를 구할 수 있다. - 예를 들어 segmentation task 의 경우 위 코드와 같은 형태가 그대로 사용될 수 있다. 1 번 케이스의 경우 batch 가 고려되지 않은 것이고 2 번 케이스의 경우 batch 가 고려된 것이다.
- segmentation 의 경우 이미지의 height, width 크기에 channel 의 수가 label 의 수와 동일하게 되어 있다. 그 중 가장 큰 값을 가지는 channel 이 그 픽셀의 label 이 된다.
- 따라서 argmax 를 취하면
channel은 1 로 되고 height 와 width 의 크기는 유지된다. - 아래 예제는 0번째 (channel), 1번째 (height), 2번째 (width) 방향으로 각각 argmarx 를 한 것이다. 또한
keepdim을 기본값인False로 둘 경우와True로 둘 경우를 구분하여 어떻게 shape 이 변화하는 지 살펴보자.
# (channel, height, width)
A = torch.randint(10, (3, 4, 2))
print(A)
# tensor([[[6, 4],
# [8, 0],
# [8, 4],
# [2, 4]],
# [[2, 8],
# [3, 6],
# [4, 7],
# [0, 9]],
# [[8, 0],
# [3, 9],
# [0, 5],
# [7, 3]]])
# 0번째 축(channel) 기준 argmax w/o keepdim
torch.argmax(A, dim=0)
# tensor([[2, 1],
# [0, 2],
# [0, 1],
# [2, 1]])
torch.argmax(A, dim=0).shape # torch.Size([4, 2])
# 0번째 축(channel) 기준 argmax w/ Keepdim
torch.argmax(A, dim=0, keepdim = True)
# tensor([[[2, 1],
# [0, 2],
# [0, 1],
# [2, 1]]])
torch.argmax(A, dim=0, keepdim = True).shape # torch.Size([1, 4, 2])
# 1번째 축(height) 기준 argmax w/o Keepdim
torch.argmax(A, dim=1)
# tensor([[2, 3],
# [2, 3],
# [0, 1]])
torch.argmax(A, dim=1).shape # torch.Size([3, 2])
# 1번째 축(height) 기준 argmax w/ Keepdim
torch.argmax(A, dim=1, keepdim = True)
# tensor([[[2, 3]],
# [[2, 3]],
# [[0, 1]]])
torch.argmax(A, dim=1, keepdim = True).shape # torch.Size([3, 1, 2])
# 2번째 축(width) 기준 argmax w/o Keepdim
torch.argmax(A, dim=2)
# tensor([[0, 0, 0, 1],
# [1, 1, 1, 1],
# [0, 1, 1, 0]])
torch.argmax(A, dim=2).shape # torch.Size([3, 4])
# 2번째 축(width) 기준 argmax w/ Keepdim
torch.argmax(A, dim=2, keepdim=True)
# tensor([[[0],
# [0],
# [0],
# [1]],
# [[1],
# [1],
# [1],
# [1]],
# [[0],
# [1],
# [1],
# [0]]])
torch.argmax(A, dim=2, keepdim=True).shape # torch.Size([3, 4, 1])
-
아래 그림을 보면 쉽게 이해할 수 있다.
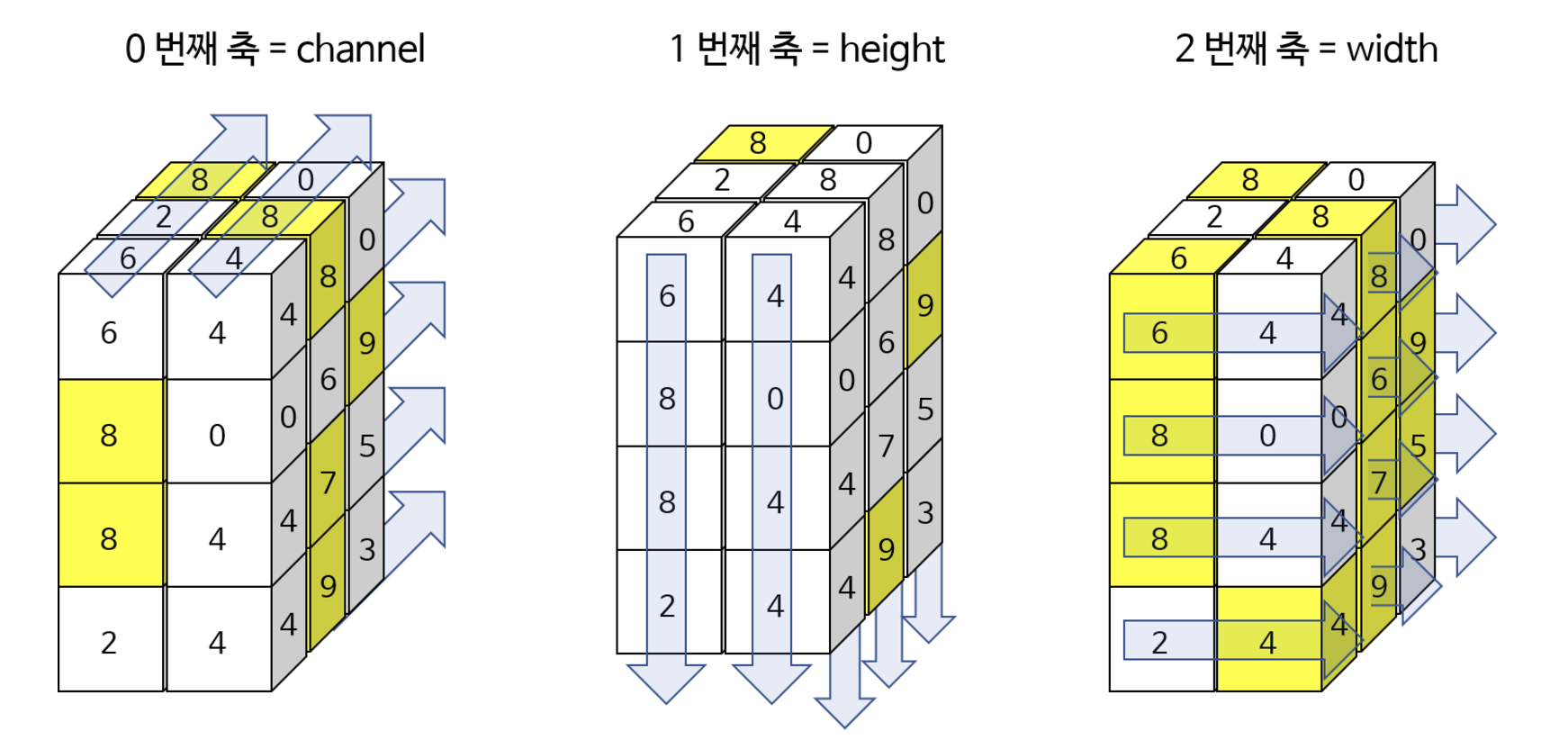
-
height 와 width 만 고려하면 더욱 간단해진다.
B = torch.rand(3, 2)
# tensor([[0.8425, 0.3970],
# [0.5268, 0.7384],
# [0.5639, 0.3080]])
torch.argmax(B, dim=0) # tensor([0, 1])
torch.argmax(B, dim=0, keepdim=True) # tensor([[0, 1]])
torch.argmax(B, dim=1) # tensor([0, 1, 0])
torch.argmax(B, dim=1, keepdim=True)
# tensor([[0],
# [1],
# [0]])
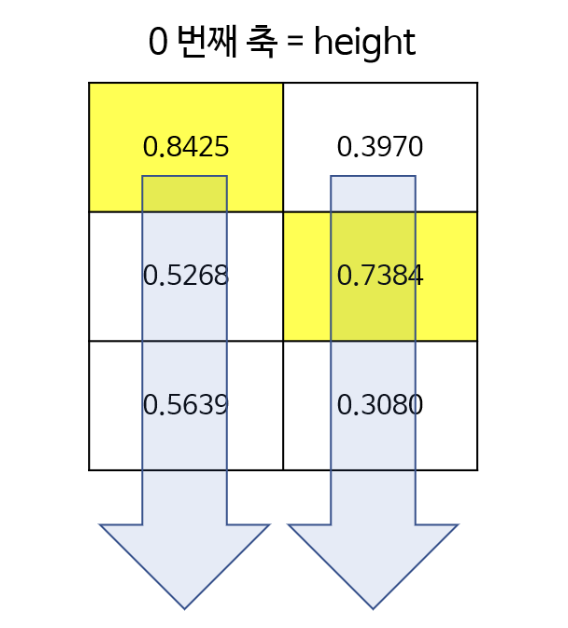
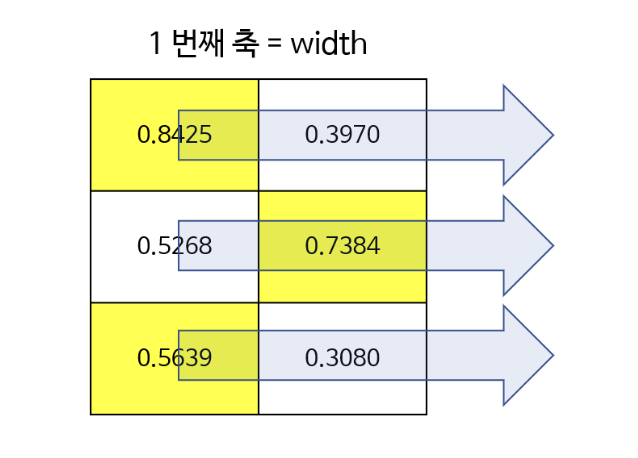
- 첫번째 그림은
dim=0으로 height 축이다. 따라서 각 열에서 세로 방향으로 최대값이 선택된다. - 두번째 그림은
dim=1으로 width 축이다. 따라서 각 행에서 가로 방향으로 최대값이 선택된다.
F.interpolate() / nn.Upsample()
- 보간은 두 점을 연결하는 방법을 의미한다. 여기서 말하는 연결은 궤적을 생성한다는 뜻이다. 보간이 필요한 이유는 정보를 압축한 것을 다시 복원하기 위함이다.
- 특징점이라 불리는 선의 모양 복원에 꼭 필요한 점을 취해서 저장하는데 이 과정을 sampling 이라 부른다. 일반적으로 sampling 은 일정 시간 주기로 선의 점을 취하는 방식을 사용하는데 녹음 기술에서 많이 쓴다.
- 이처럼 딥러닝에서 interpolation(보간법) 은 작은(압축된) feature 의 크기를 크게 키울 때 사용한다.
- 사용할 수 있는 대표적인 방법으로는
F.interpolate()와nn.Upsample()방법이 있다. 이는 Segmentation task 에서 자주 사용하게 된다. - 먼저, Pytorch 에서 제공하는
torch.nn.functional as F의interpolate가 어떻게 사용되는지 보자.
torch.nn.functional.interpolate(
input, # input tensor
size=None, # output spatial size 로 int 나 int 형 tuple(height, width) 이 입력으로 들어온다.
scale_factor=None, # spatial size 에 곱해지는 scale 값
mode='nearest', # 어떤 방법으로 upsampling 할 것인지를 나타낸다. 'nearest', 'linear', 'bilinear', 'bicubic', 'trilinear', 'area' 등이 있다.
align_corners=False, # interpolate 할 때, 가장자리를 어떻게 처리할 지 나타낸다.
)
F.interpolate함수에서 필수적으로 사용하는 것은input,size,mode이고 추가적으로align_corners를 사용한다.size는 interpolate 할 목표 output spatial size 다. 이 때, 입력해야 할 size 는 batch 와 channel 을 뺀 int 로 이루어진 tuple 이다.- 예를 들어 이미지의 경우 height 와 width 만 있기 때문에 (
new_height,new_width) 형태여야 한다. - Tensor 의 크기와 대응되도록 height, width 순서로 입력해야 한다.
- 중요한 것은 size 와 scale_factor 중 하나만 입력해야 한다.
- 예를 들어 이미지의 경우 height 와 width 만 있기 때문에 (
scale_factor는 spatial size 에 곱해져 intperpolate 할 목표 size 가 된다.mode는 upsampling 하는 방법으로nearest또는bilinear를 대표적으로 사용할 수 있다.nearest의 경우 주변 값을 실제 사용하는 것으로, 존재하는 실제 픽셀 값을 사용해야 하는 경우 사용할 수 있다. 예를 들어 input 의 feature 값이 정수인데 interpolate 한 output 의 값들도 정수가 되어야 한다면 nearest 를 사용하여 소수값이 생기지 않도록 할 수 있다.bilinear는 bilinear interpolation 방법을 이용한 것으로, 이미지와 같은 height, width 의 속성을 가지는 데이터에 적합한 interpolation 방법이다. height, width 로 구성된 2 차원 평면이므로 interpolation 할 때 사용되는 변수도 2개다. 이 방법은 단 방향의, 1 개의 변수를 이용하여 interpolation 하는 linear 보다 좀 더 나은 방법이다.
import torch
import torch.nn as nn
import torch.nn.functional as F
input = torch.arange(0, 16, dtype=torch.float32).reshape(1, 1, 4, 4)
# size : torch.Size([1, 1, 4, 4])
# value : tensor([[[[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.],
# [12., 13., 14., 15.]]]])
F.interpolate(input, scale_factor=2, mode='nearest')
# tensor([[[[ 0., 0., 1., 1., 2., 2., 3., 3.],
# [ 0., 0., 1., 1., 2., 2., 3., 3.],
# [ 4., 4., 5., 5., 6., 6., 7., 7.],
# [ 4., 4., 5., 5., 6., 6., 7., 7.],
# [ 8., 8., 9., 9., 10., 10., 11., 11.],
# [ 8., 8., 9., 9., 10., 10., 11., 11.],
# [12., 12., 13., 13., 14., 14., 15., 15.],
# [12., 12., 13., 13., 14., 14., 15., 15.]]]])
F.interpolate(input, scale_factor=0.8, mode='nearest')
# tensor([[[[ 0., 1., 2.],
# [ 4., 5., 6.],
# [ 8., 9., 10.]]]])
F.interpolate(input, size=(5, 3), mode='bilinear')
# tensor([[[[ 0.1667, 1.5000, 2.8333],
# [ 2.9667, 4.3000, 5.6333],
# [ 6.1667, 7.5000, 8.8333],
# [ 9.3667, 10.7000, 12.0333],
# [12.1667, 13.5000, 14.8333]]]])
align_corners를 이해하기 위해 아래 그림을 먼저 보자. 이는 source image 가 (4, 4) 크기일 때, target 은 (8, 8) 로 2 배 upsampling 하는 예제다.-
align_corners는 원래 이미지의 끝점(corner)를 resize 된 이미지의 corner 와 정렬할지 여부를 결정한다. 이 값은 보간 결과에 중요한 영향을 미친다.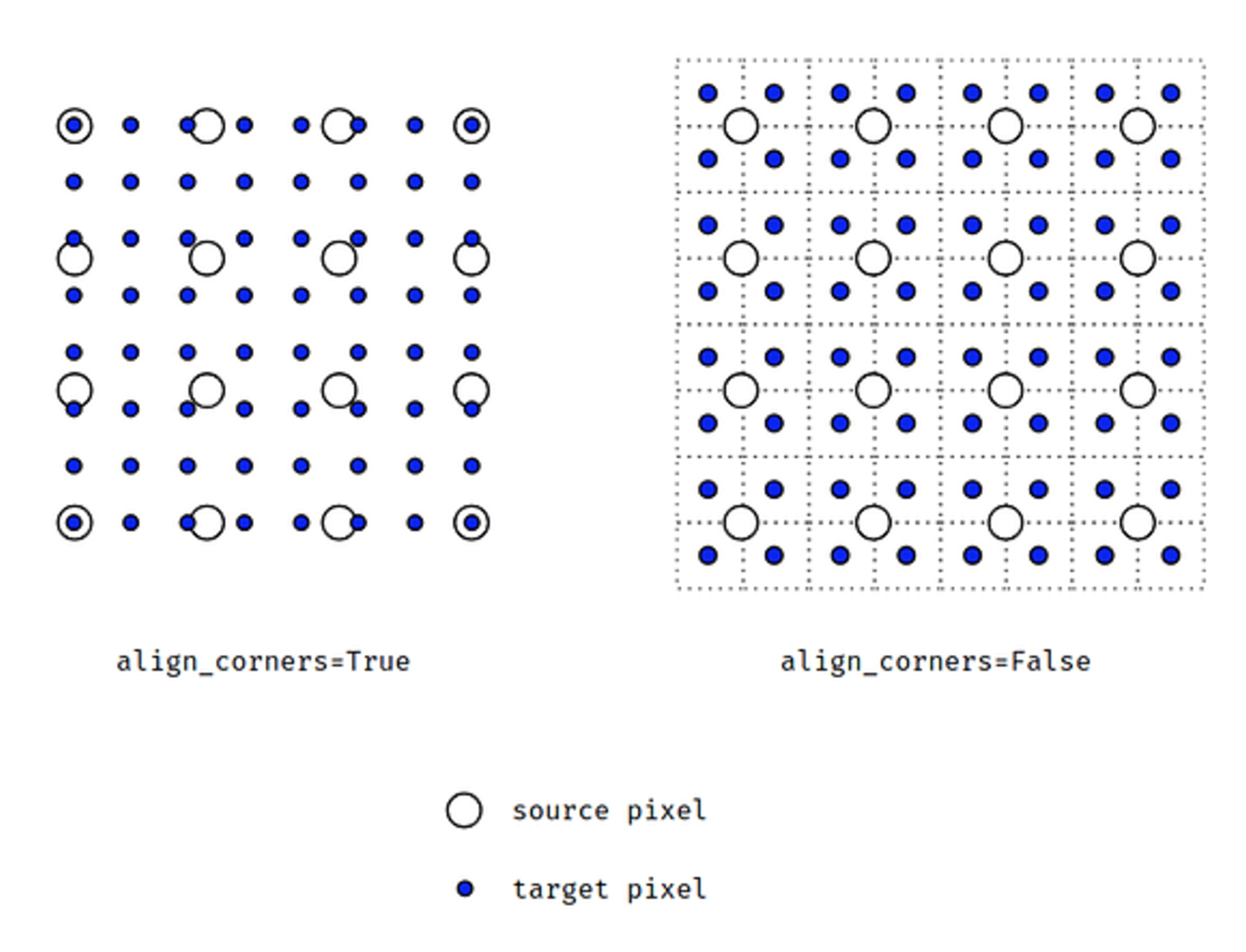
- 왼쪽 그림은
align_corners = True인 상태이고 오른쪽 그림이False인 상태다. align_corners=False의 그림 처럼 픽셀 영역으로 grid 를 그렸을 때, source 는 grid 의 교차점에 위치한 것을 전제로 한다.- 이 때,
align_corners=True면 target 또한 source grid 의 교차점에 값을 위치시키려고 하지만,align_corners=False이면 target 은 한 픽셀 영역을 가지려고 한다. - 따라서
align_corners=True인 상태라면 source 의 끝점과 target 의 끝점이 일치한 상태에서 interpolation 이 된다. 말 그대로 corner 기준으로 정렬이 맞춰진 것이다. - 반면
align_corners=False가 되면 corner 는 정렬되지 않지만 샘플링 간격이 더 균일하게 분포된다. 즉 위 오른쪽 그림처럼 source 의 픽셀들이 target 픽셀과 균일한 간격으로 구성된다. - segmentation 에서
align_corners = True로 두면 좀 더 성능이 좋다고 알려져 있다. 따라서 이 값은True로 두는 것을 권장한다. - 다만
ONNX로 변환해야 하는 경우 버전에 따라서 반드시align_corners = False로 두어야 하는 경우가 있으므로 이 점은 유의해야 한다.
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
input = torch.arange(0, 16, dtype=torch.float32).reshape(1, 1, 4, 4)
# size : torch.Size([1, 1, 4, 4])
# value : tensor([[[[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.],
# [12., 13., 14., 15.]]]])
F.interpolate(input, scale_factor=2, mode='bilinear', align_corners=False)
# tensor([[[[ 0.0000, 0.2500, 0.7500, 1.2500, 1.7500, 2.2500, 2.7500, 3.0000],
# [ 1.0000, 1.2500, 1.7500, 2.2500, 2.7500, 3.2500, 3.7500, 4.0000],
# [ 3.0000, 3.2500, 3.7500, 4.2500, 4.7500, 5.2500, 5.7500, 6.0000],
# [ 5.0000, 5.2500, 5.7500, 6.2500, 6.7500, 7.2500, 7.7500, 8.0000],
# [ 7.0000, 7.2500, 7.7500, 8.2500, 8.7500, 9.2500, 9.7500, 10.0000],
# [ 9.0000, 9.2500, 9.7500, 10.2500, 10.7500, 11.2500, 11.7500, 12.0000],
# [11.0000, 11.2500, 11.7500, 12.2500, 12.7500, 13.2500, 13.7500, 14.0000],
# [12.0000, 12.2500, 12.7500, 13.2500, 13.7500, 14.2500, 14.7500, 15.0000]]]])
F.interpolate(input, scale_factor=2, mode='bilinear', align_corners=True)
# tensor([[[[ 0.0000, 0.4286, 0.8571, 1.2857, 1.7143, 2.1429, 2.5714, 3.0000],
# [ 1.7143, 2.1429, 2.5714, 3.0000, 3.4286, 3.8571, 4.2857, 4.7143],
# [ 3.4286, 3.8571, 4.2857, 4.7143, 5.1429, 5.5714, 6.0000, 6.4286],
# [ 5.1429, 5.5714, 6.0000, 6.4286, 6.8571, 7.2857, 7.7143, 8.1429],
# [ 6.8571, 7.2857, 7.7143, 8.1429, 8.5714, 9.0000, 9.4286, 9.8571],
# [ 8.5714, 9.0000, 9.4286, 9.8571, 10.2857, 10.7143, 11.1429, 11.5714],
# [10.2857, 10.7143, 11.1429, 11.5714, 12.0000, 12.4286, 12.8571, 13.2857],
# [12.0000, 12.4286, 12.8571, 13.2857, 13.7143, 14.1429, 14.5714, 15.0000]]]])
- 즉 정리하면 다음과 같다.
align_corners=True- 원래 이미지의 corner 픽셀 위치를 resize 된 이미지의 corner 픽셀 위치에 정확히 정렬한다.
- 샘플링 간격이 균일하지 않을 수 있다.
- 사용 시 선형 보간과 같이 스케일링 간의 상대적인 변화가 더 잘 유지된다.
- 이 설정은 보통 기하학적으로 의미 있는 크기 변경이 필요할 때 적합하다.
align_corners=False(기본값)- 픽셀 중심이 기준으로 사용된다. 원래 이미지와 resize 된 이미지의 corner 위치는 정렬되지 않는다.
- 샘플링 간격이 균일하게 유지된다.
- 일반적으로 픽셀 간 상대적 위치의 일관성을 더 중요하게 여기는 경우에 적합하다. CNN 기반 모델에서는 이 옵션이 더 자연스러운 결과를 주는 경우가 많다.
- 그 다음으로
nn.Upsample()을 보자. 이 방법 또한F.interpolate()와 거의 같다. F.interpolate()가 upsampling / downsampling 을 모두 할 수 있듯이nn.Upsample()또한 upsampling / downsampling 을 할 수 있지만 의미상 Upsample 의 목적으로만 사용하는 것이 좋다.- 먼저
Upsample메서드를 살펴보자.
torch.nn.Upsample(
size: Optional[Union[T, Tuple[T, ...]]] = None,
scale_factor: Optional[Union[T, Tuple[T, ...]]] = None,
mode: str = 'nearest',
align_corners: Optional[bool] = None
)
Upsample함수는 1D, 2D, 3D 데이터를 모두 입력으로 받을 수 있다. 단 여기서 Dimension 은 Batch 사이즈를 제외한 크기다.- 따라서 입력은
batch_size x channels x height x width의 크기를 가진다. 예를 들어 이미지 데이터의 경우 입력이 4차원이 된다. 32 batch size 의 (224, 224) 크기의 컬러 이미지라면(32, 3, 224, 224)가 된다. - 중요한 것은
Upsample에 어떤 방식으로 output 의 크기를 명시할 것인가이다. 이에 해당하는 것이size또는scale_factor에 해당한다.size는 특정 size 로 Upsampling 하는 방법으로, 정확한 size 를 정해주는 방법이다.- 반면
scale_factor는 현재 input 대비 몇 배를 Upsampling 해줄 지 정해주는 scale 값에 해당한다.
size와scale_factor중 어떤 것을 사용해도 상관없지만 중요한 것은 모호성을 줄이기 위해 둘 중 하나만을 사용하는 것이다.- 앞의 interpolate 와 동일하게 feature 를 크게 만들기 위한 방법(
mode)으로nearest,linear,bilinear,bicubic,trilinear가 있고 기본값은nearest다. - 아래는
Upsample을 이용한 예제로,F.interpolate()와 결과가 같다.
import torch
import torch.nn as nn
import torch.nn.functional as F
input = torch.arange(0, 16, dtype=torch.float32).reshape(1, 1, 4, 4)
# F.interpolate(input, scale_factor=2, mode='nearest')
m = nn.Upsample(scale_factor=2, mode = 'nearest')
m(input)
# F.interpolate(input, scale_factor=0.8, mode='nearest')
m = nn.Upsample(scale_factor=0.8, mode='nearest')
m(input)
# F.interpolate(input, scale_factor=2, mode='bilinear', align_corners=False)
m = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False)
m(input)
F.interpolate(input, size=(5, 3), mode='bilinear', align_corners=False)
m = nn.Upsample(size=(5, 3), mode='bilinear', align_corners=False)
m(input)
nn.AvgPool2d / nn.AdaptiveAvgPool2d
nn.AvgPool2d와nn.AdaptiveAvgPool2d모두 pooling layer에 사용된다. 그러나 사용 방식이 조금 다르다.AvgPool2d(kernel_size, stride, padding)에서는 pooling 작업에 대한 kernel 및 stride 크기를 정의해야 동작한다. 예를 들어kernel=3, stride=2, padding=0을 사용하는 AvgPool2d 는 5x5 tensor 를 3x3 tensor 로, 7x7 tensor 는 4x4 tensor 로 줄인다.- 반면
AdaptiveAvgPool2d(output_size)에서는 pooling 작업이 끝날 때 필요한 출력 크기를 입력한다. 예를 들어,output_size=(3,3)를 사용하는 AdaptiveAvgPool2d 는 5x5 및 7x7 tensor 모두를 3x3 tensor 로 줄인다. 이 기능은 입력 feature 의 크기에 변동이 있거나 CNN 에서 fc layer 를 사용하는 경우에 특히 유용하다.
AvgPool2d는 공식 문서 에 feature size 의 계산이 잘 나와있다. 아래 공식을 보자.-
\[\begin{aligned} H_{\text{out}} &= \Bigl\lfloor \frac{H_{\text{in}} + 2 \times \text{padding[0]} - \text{kernel_size[0]}}{\text{stride[0]}} + 1 \Bigr\rfloor \\ W_{\text{out}} &= \Bigl\lfloor \frac{W_{\text{in}} + 2 \times \text{padding[1]} - \text{kernel_size[1]}}{\text{stride[1]}} + 1 \Bigr\rfloor \end{aligned}\]kernel_size와stride를 입력하여 Average Pooling 을 하면 아래와 같이 $(N, C, H_{\text{in}}, W_{\text{in}})$ 크기의 입력이 $(N, C, H_{\text{out}}, W_{\text{out}})$ 크기로 변경된다. - 여기서 핵심이 되는
kernel_size와stride크기는 직접 입력해주어야 하고,padding은 기본값이 0 이기 때문에 입력하지 않으면 0 이 된다.
# pool of square window of size=3, stride=2
m = nn.AvgPool2d(3, stride=2)
# pool of non-square window
m = nn.AvgPool2d((3, 2), stride=(2, 1))
input = torch.randn(20, 16, 50, 32)
output = m(input)
- 반면
nn.AdaptiveAvgPool2d는 kernel_size, stride, padding 을 입력하는 대신에output_size를 입력해준다. 그러면 위 식에 따라서 자동으로 kernel_size, stride, padding 이 결정되어 pooling 할 수 있다. - 즉, Average Pooling 을 할 때 출력 크기를 조절하기 상당히 쉬워진다.
# target output size of 5x7
m = nn.AdaptiveAvgPool2d((5,7))
input = torch.randn(1, 64, 8, 9)
output = m(input)
# torch.Size([1, 64, 5, 7])
# target output size of 7x7 (square)
m = nn.AdaptiveAvgPool2d(7)
input = torch.randn(1, 64, 10, 9)
output = m(input)
# torch.Size([1, 64, 7, 7])
# target output size of 10x7
m = nn.AdaptiveMaxPool2d((None, 7))
input = torch.randn(1, 64, 10, 9)
output = m(input)
# torch.Size([1, 64, 10, 7])
AdaptiveAvgPool2d가 동작되는 원리를 살펴보자.
input = torch.tensor([[[[1,2,3], [4,5,6], [7,8,9]]]], dtype=torch.float)
# torch.Size([1, 1, 3, 3])
# tensor([[[[1., 2., 3.],
# [4., 5., 6.],
# [7., 8., 9.]]]])
output = nn.AdaptiveAvgPool2d((2,2))(input)
# tensor([[[[3., 4.],
# [6., 7.]]]])
- 위 예제에서 출력 사이즈가 (3, 3) 에서 (2, 2) 로 고정되므로, kernel 의 크기는 (2, 2) 로 자동적으로 정해진다. 따라서 다음과 같이 계산된다.
tensor([[[[(1+2+4+5)/4., (2+3+5+6)/4.], = tensor([[[[3., 4.],
[(4+5+7+8)/4., (5+6+8+9)/4.]]]]) [6., 7.]]]])
torch.scatter
torch.scatter(input, dim, index, src, reduce)는 index 가 가리키는 위치에 특정 값을 대입하는 연산이다. scatter 가 ‘흩뿌리다’ 라는 의미를 가지듯 특정 index 에 특정 값을 대입하는 연산으로 값을 흩뿌린다고 생각하면 된다.- 여기에도 weight initialization 처럼
torch.scatter와torch.scatter_가 있다.torch.scatter는out-of-place버전으로 별도 메모리를 할당받아 추가로 데이터를 만드는 버전이다.torch.scatter_는inplace버전으로 기존의 데이터에 바로 적용되어 그대로 사용하는 방법이다.
- inplace 하게 동작되는
torch.scatter_는 아래와 같이 동작한다.
# Tensor.scatter_(dim, index, src, reduce=None) → Tensor
self[index[i][j][k]][j][k] = src[i][j][k] # if dim == 0
self[i][index[i][j][k]][k] = src[i][j][k] # if dim == 1
self[i][j][index[i][j][k]] = src[i][j][k] # if dim == 2
- 위 코드에서
self는inplace동작 기준으로 기존의 tensor 그대로를 의미한다.dim값에 따라 어떤 dimension 에src값이 대입되는 지 달라진다. - 사용되는 파라미터는 아래와 같다.
dim (int): index 가 적용될 dimension 이다.index (LongTensor):scatter할 값의 입력할 값인src와dim이 아닌 차원들의 수가 같도록 지정한다. 만약 index 가 비어있으면 변경되지 않는다.src (Tensor or float):dim방향의index로 실제 입력할 값이다.reduce (str, optional): 값을 넣지 않으면src값을 단순 대입하게 된다. 만약add를 사용하면 대입 대신에 덧셈이 적용되고multiply를 사용하면 곱셈이 적용된다.
src = torch.arange(1, 11).reshape((2, 5))
print(src)
# tensor([[ 1, 2, 3, 4, 5],
# [ 6, 7, 8, 9, 10]])
index = torch.tensor([[0, 1, 2, 0, 2]])
torch.zeros(3, 5, dtype=src.dtype).scatter_(0, index, src)
# tensor([[1, 0, 0, 4, 0],
# [0, 2, 0, 0, 0],
# [0, 0, 3, 0, 5]])
- 위 예제는
dim=0이므로 행 방향으로 (3, 5) size 의 zero tensor 에[1, 2, 3, 4, 5]가 각 index 의 행에 대입된 것을 볼 수 있다. gather때와 마찬가지로 index 를 나타내는 값 자체는 기준 되는 차원의 index bound 를 넘을 수 없다.- 위 예제에서
[6, 7, 8, 9 10]에 해당하는 index 는 지정되지 않았으므로 무시된다.
src = torch.arange(1, 11).reshape((2, 5))
print(src)
# tensor([[ 1, 2, 3, 4, 5],
# [ 6, 7, 8, 9, 10]])
index = torch.tensor([[0, 1, 2], [0, 1, 4]])
torch.zeros(3, 5, dtype=src.dtype).scatter_(1, index, src)
# tensor([[1, 2, 3, 0, 0],
# [6, 7, 0, 0, 8],
# [0, 0, 0, 0, 0]])
- 위 예제에서는
dim=1이므로 열 방향으로 (3, 5) size 의 zero tensor 에 연산된 것을 볼 수 있다. - 이와 같은
scatter연산은one hot을 만들 때 유용하게 사용할 수 있다.
load 와 save
- 모델을 학습하는 과정에서 validation 결과가 가장 좋거나 일정 epoch 가 지나면 checkpoint 로 모델을 저장한다. 이 때 모델을 저장하고 불러오는 방법에 대하여 다뤄보자.
save_checkpoint와load_checkpoint를 통해 모델을 어떻게 저장하고 불러오는 지 알 수 있다.- 먼저 이를 알기 위해서
state_dict에 대하여 이해해야 한다.state_dict은 dictionary 형태로 데이터를 쉽게 저장하거나 불러올 수 있게 해준다. state_dict에는 각 계층을 parameter Tensor 로 매핑한다. 이 때, 학습 가능한 parameter 를 가지는 layer(convolution layer, linear layer 등)들이 모델의state_dict에 항목을 가지게 된다.- optimizer 객체(torch.optim) 또한 optimizer 의 상태 뿐 아니라 사용된 hyper parameter 정보가 포함된 state_dict 을 가진다.
inference를 위해 모델을 저장할 때는 모델의 학습된 parameter 만 저장하며 이 때torch.save()함수를 이용한다.- Pytorch 에서는 모델을 저장할 때
.pt또는.pth확장자를 사용하는 것이 일반적인 규칙이며 아래 코드와 같이tar를 통한 압축 형태로*.pth.tar와 같이 많이 사용한다. - 이 이후에
inference용도로 사용하려면 모델을 load 하고model.eval()을 실행하여 dropout 및 batch normalization 이 evaluation 모드로 설정되도록 해야한다.
import torch
import torchvision
import torch.nn as nn # neural network modules
import torch.optim as optim # Optimization algorithms, SGD, Adam, etc.
import torch.nn.functional as F # parameter 가 필요 없는 함수들
from torch.utils.data import DataLoader # dataset 관리와 mini batch 생성 관련
import torchvision.datasets as datasets # standard dataset 접근
import torchvision.transforms as transforms # dataset transformation 을 통한 augmentation
def save_checkpoint(state, filename="my_checkpoint.pth.tar"):
print("=> Saving checkpoint")
torch.save(state, filename)
def load_checkpoint(checkpoint, model, optimizer):
print("=> Loading checkpoint")
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
def main():
# Initialize network
model = torchvision.models.vgg16(pretrained=False)
optimizer = optim.Adam(model.parameters())
checkpoint = {
'state_dict' : model.state_dict(),
'optimizer': optimizer.state_dict(),
# 'epoch' : epoch,
# 'scheduler' : scheduler.state_dict(),
# 'lr' : lr,
# 'best_val', best_val
}
# Try save checkpoint
save_checkpoint(checkpoint)
# Try load checkpoint
load_checkpoint(torch.load("my_checkpoint.pth.tar"), model, optimizer)
# model.eval()
if __name__ == '__main__':
main()
model 의 parameter 확인
- 모델의 parameter 를 확인하는 방법은
model.parameters()를 통해 가능하다. - 단,
model.parameters()는 generator 타입이기 때문에 for 문과 같이 순회 또는next()를 이용하여 값에 접근할 수 있다.
# 바로 다음 값 1개 확인
next(model.parameters())
# for 문
for param in model.parameters():
print(param)
- 모델링 시 각 layer 에 name 을 지정했다면 더욱 쉽게 접근할 수 있다.
optimizer.state_dict()
- 위에서 모델과 함께 optimizer 의 state_dict 또한 같이 저장하는 것을 확인했다.
optimizer.state_dict()를 이용하면 현재 사용하고 있는 optimizer 의 상태 및 hyper parameter 를 저장할 수 있다.optimizer.state_dict()의 출력 결과는 dictionary 형태의state와 list 형태의param_groups가 있다.param_groups에는 사용된 optimizer 의 개수만큼 저장된다. 만약 1 개의 optimizer 를 사용했다면 list 의 원소 개수는 1 개다.
- 예를 들어 위 코드와 같이 현재 optimizer 의 상태는 checkpoint 에
'optimizer': optimizer.state_dict()로 저장된 상태라 가정해보자. - 이제 아래의 예제 코드는 현재 가장 많이 사용하는 optimizer 인
Adam을 이용했다.
model = torchvision.models.vgg16(pretrained=False)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
checkpoint = {
'state_dict' : model.state_dict(),
'optimizer': optimizer.state_dict(),
# 'epoch' : epoch,
# 'scheduler' : scheduler.state_dict(),
# 'lr' : lr,
# 'best_val', best_val
}
optimizer_checkpoint = checkpoint['optimizer']
print(optimizer_checkpoint.keys()) # dict_keys(['state', 'param_groups'])
optimizer_checkpoint_states = optimizer_checkpoint['state']
print(optimizer_checkpoint_state.keys()) # dict_keys([140610494128064, 140610158587976, 140610158588048, ... , ])
a_key = list(optimizer_checkpoint_states.keys())[0]
optimizer_checkpoint_state = optimizer_checkpoint_states[a_key]
print(optimizer_checkpoint_state.keys()) # dict_keys(['step', 'exp_avg', 'exp_avg_sq'])
optimizer_checkpoint_param_groups = optimizer_checkpoint['param_groups'] # list
optimizer_checkpoint_param_group = optimizer_checkpoint_param_groups[0]
print(optimizer_checkpoint_param_group.keys()) # dict_keys(['lr', 'betas', 'eps', 'weight_decay', 'amsgrad', 'initial_lr', 'params'])
- optimizer 로
Adam을 이용한optimizer.state_dict()의 계층 구조를 정리하면 아래와 같다.- state(dictionary): 현재 optimization state 를 저장하고 있다.
- step(int)
- exp_avg(torch.Tensor): exponential moving average of gradient values 로,
Adam에서 사용된다. - exp_avg_sq(torch.Tensor): exponential moving average of squared gradient values 로,
Adam에서 사용된다.
- param_groups(list): 모든 parameter_group 을 저장하고 있으며 각 parameter_group 은 최적화해야 하는 tensor 를 지정한다. 각 parameter_group 의 내용은 Adam 과 관련되어 있다. 이에 대해서는 추후 Adam 을 정리할 포스트에서 다룰 예정이다.
- index 0 parameters(dictionary)
- lr(float)
- betas(tuple)
- eps(float)
- weight_decay(float)
- amsgrad(bool)
- initial_lr(float)
- params(list): 모델에서 사용된 layer 의 id 를 나타낸다.
- id1(int)
- id2(int)
- …
- index 1 parameters(dictionary)
- …
- index 0 parameters(dictionary)
- state(dictionary): 현재 optimization state 를 저장하고 있다.
- 사전에 pre-traiend 된 weight 를 이용하여 학습을 재개할 때, model 의 parameter 와 더불어 optimizer 에 사용된 hyper parameter 와 각 optimizer 알고리즘에서 사용한 값들을 불러와서 학습이 중단된 위치에서 그대로 학습하도록 한다.
Pre-trained Model 사용
- 오늘날에는 파운데이션 모델 등 수많은 데이터를 가지고 미리 학습된(pre-trained) 모델을 가지고 fine-tuning 하거나 backbone network 로 활용한다. 이를 통해 원하는 모델을 만드는 시간을 매우 단축시킬 수 있다.
- 여기서 Pre-trained 된 모델을 사용하는 방법을 알아보자. 예시에서 사용하는 pre-trained model 에는 아래와 같은 정보로 모델이 저장되어 있다고 가정해보자.
checkpoint = {
'state_dict' : model.state_dict(),
'optimizer': optimizer.state_dict(),
'epoch' : epoch,
'scheduler' : scheduler.state_dict(),
'lr' : lr,
'best_val', best_val
}
- 위 6가지 정보는 모델의 학습을 계속 이어 나갈 때 꼭 필요한 정보들이다. 앞으로 학습할 때 모델을 저장한다면 위 정보들을 꼭 저장하자.
- 이러한 정보들을 저장한 checkpoint 를 불러올 때는 아래와 같은 방법으로 한다.
resume_file_path = "../path/to/the/.../pre_trained.pth"
checkpoint = torch.load(resume_file_path)
model.load_state_dict(checkpoint['state_dict'])
start_epoch = checkpoint['epoch']
optimizer.load_state_dict(checkpoint['optimizer'])
scheduler.load_state_dict(checkpoint['scheduler'])
best_val = checkpoint['best_val']
pre-trained model 수정
- 상황에 따라서는 학습된 모델을 그대로 사용하기 보다는 일부 layer 를 수정해야 하는 경우가 종종 있다.
- 이 때, 학습을 완료한 pre-trained weight 가 있다면 일부 layer 수정에 따라서 pre-trained weight 도 수정해야 한다.
- 이 경우 pre-trained weight 를 불러와서 필요 없는 layer 를 제거할 수 있는데, 이에 대해 정리해보자.
- 먼저
*.pth형태의 pre-trained weight 를 불러온다. 아래의weight_path는 pre-trained weight 파일이 저장된 경로다.
pretrained_weight = torch.load(weight_path)
- 위 코드를 실행하면
pretrained_weight에collections.OrderedDict타입으로 정보들이 저장된다. pretrained_weight의key는 layer 의 이름이고value는 layer의 weight 값이다.- 먼저 다음과 같이
key값을 탐색하여 필요 없는 layer 를 찾는다.
for i, key in enumerate(pretrained_weight.keys()):
print(f"{i}th, layer : {key}")
delete_layers = []
delete_layers.append("key value (layer name)")
for delete_layer in delete_layers:
del pretrained_weight[delete_layer]
- 필요 없는 layer 를 직접 제거하는 방법은 위처럼 for 문을 통하여 필요 없는 layer 의 목록을 직접 list 에 저장한 후
pretrained_weight에서 key 값(layer)을 제거한다. - 또 다른 방법으로 필요 없는 layer 의 시작 번호(0번 부터 시작)를 입력하면 그 이후의 모든 layer 를 제거하는 방법이 있다.
- 이 방법이 유용한 이유는 일반적으로 어떤 layer 를 삭제해야 한다면 그 layer 이후의 layer 또한 삭제가 필요한 경우가 많기 때문이다.
- 그러면 앞의 출력문을 통하여 제거해야 할 시작점의 index 를 이용하여 아래와 같이 삭제할 수 있다.
# [0, delete_start_number) 범위의 layer 만 남기고 나머지는 삭제
delete_start_number = 100
delete_layers = [key for i, key in enumerate(pretrained_weight.keys()) if i >= delete_start_number]
for delete_layer in delete_layers:
del pretrained_weight[delete_layer]
pre-trained model fine tuning
- pre-trained 모델을 이용하여 fine turing 하기 위해서는 선언된 모델의
requires_grad를False로 입력하면 된다. - 아래 코드는 임의의 모델을 이용하여 특정 layer 는 학습하고 특정 layer 는 학습하지 않도록 하는 코드다.
import torch
import torch.nn as nn
class CustomModel(nn.Module):
def __init__(self):
super(CustomModel, self).__init__()
self.freeze_layers = nn.Sequential(
# Defining a 2D convolution layer
nn.Conv2d(1, 4, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(4),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Defining another 2D convolution layer
nn.Conv2d(4, 4, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(4),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.non_freeze_layers = nn.Linear(4 * 7 * 7, 10)
# Defining the forward pass
def forward(self, x):
x = self.freeze_layers(x)
x = x.view(x.size(0), -1)
x = self.linear_layers(x)
return x
custom_model = CustomModel()
- 위 코드처럼 모델을 선언하면
freeze_layers와non_freeze_layers를 prefix 로 각 layer 에 접근할 수 있다. 각 layer 를 살펴보는 방법은 다음과 같다.
for name, param in custom_model.named_parameters():
print("name : ", name)
print("requires_grad : ", param.requires_grad)
print()
# name : freeze_layers.0.weight
# requires_grad : True
# name : freeze_layers.0.bias
# requires_grad : True
# name : freeze_layers.1.weight
# requires_grad : True
# name : freeze_layers.1.bias
# requires_grad : True
# name : freeze_layers.4.weight
# requires_grad : True
# name : freeze_layers.4.bias
# requires_grad : True
# name : freeze_layers.5.weight
# requires_grad : True
# name : freeze_layers.5.bias
# requires_grad : True
# name : non_freeze_layers.weight
# requires_grad : True
# name : non_freeze_layers.bias
# requires_grad : True
- 위 코드의 출력 결과에서 살펴볼 점은 첫번째로 각 parameter 의 name 과 requires_grad 값이다.
- 각 parameter 의 name 은 실제 모델에서 layer 를 선언할 때 사용한 변수명을 따른다.
- 따라서 fine tuning 시 freeze / non_freeze 대상을 구별하여 변수명을 선언하면 구현하는 데 도움이 된다.
requires_grad을 살펴보면 기본적으로 모델의 각 layer 를 선언할 때requires_grad=True로 설정되기 때문에 위 결과와 같이 모든 layer는requires_grad : True가 된다.
- 이 2가지 내용을 이용하여
freeze_layers로 시작하는 layer 는 학습하지 않도록requires_grad=False로 세팅할 수 있다.
non_freeze_prefix = "non_freeze"
for name, param in custom_model.named_parameters():
if name.startswith(non_freeze_prefix) == False:
param.requires_grad = False
for name, param in custom_model.named_parameters():
print("name : ", name)
print("requires_grad : ", param.requires_grad)
print()
# name : freeze_layers.0.weight
# requires_grad : False
# name : freeze_layers.0.bias
# requires_grad : False
# name : freeze_layers.1.weight
# requires_grad : False
# name : freeze_layers.1.bias
# requires_grad : False
# name : freeze_layers.4.weight
# requires_grad : False
# name : freeze_layers.4.bias
# requires_grad : False
# name : freeze_layers.5.weight
# requires_grad : False
# name : freeze_layers.5.bias
# requires_grad : False
# name : non_freeze_layers.weight
# requires_grad : True
# name : non_freeze_layers.bias
# requires_grad : True
- 위 코드의 결과를 살펴보면 마지막 2개의
non_freeze_layer에 해당하는 weight, bias 를 제외하고 모두requires_grad = False로 설정되어 있음을 알 수 있다. - 참고로 모델을 출력하면 아래와 같이 나오는데, convolution layer 와 batch normalization 을 제외하고는 parameter 가 없기 때문에 위와 같이
0, 1, 4, 5만 나오게 된다.
CustomModel(
(freeze_layers): Sequential(
(0): Conv2d(1, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(4, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(4, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): BatchNorm2d(4, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU(inplace=True)
(7): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(non_freeze_layers): Linear(in_features=196, out_features=10, bias=True)
)
checkpoint 값 변경 후 저장
- checkpoint 의 값을 변경 후 저장하는 방법에 대하여 알아보자. checkpoint 는 아래와 같은 구조로 저장되어 있다고 가정한다.
checkpoint = {
'state_dict' : model.state_dict(),
'optimizer': optimizer.state_dict(),
'epoch' : epoch,
'scheduler' : scheduler.state_dict(),
'lr' : lr,
'best_val', best_val
}
- 이 때, checkpoint 의 값을 변경 후 다시 저장하려면 아래와 같은 예시로 저장하면 된다.
resume_file_path1 = "../path/to/the/.../pre_trained1.pth"
resume_file_path2 = "../path/to/the/.../pre_trained2.pth"
checkpoint1 = torch.load(resume_file_path1)
checkpoint2 = torch.load(resume_file_path2)
checkpoint1['state_dict'] = checkpoint2['state_dict']
torch.save(state, filename)
일부 weight 만 업데이트
- 일반적으로 학습할 때를 제외하고는 모델의 weight 를 pre-trained weight 로 사용한다. 모델에 pre-trained weight 를 적용하기 위해서는 아래의 과정을 거친다.
- 먼저 모델 클래스를 이용하여
model객체를 생성한다. 아래 코드 예제에서는 객체명을model이라고 한다. - 이후 pre-trained weight 인 pickle 파일(p, pt, pth 확장자)을 불러온다. 불러온 데이터는 layer 의 이름을 key 값으로 하고 layer 의 weight 를 value 값으로 하는 dictionary 형태이며 일반적으로
collections내의OrderedDict타입이다(from collections import OrderedDict). 이 데이터를pretrained_dict라고 가정한다. pretrained_dict을 model 의 각 layer 에 적용하려면model.load_state_dict(pretrained_dict)을 사용한다. 그러면 각 layer 에 pretrained_dict 에 저장된 값이 덮어씌워지게 된다.
- 먼저 모델 클래스를 이용하여
- 만약 모든 weight 가 아닌 weight 일부를 변경하고 싶다면 어떻게 해야할까?
- 위 과정에서 모든 layer 별 이름이 key 값으로 정해지고 그 layer 의 weight 값이 value 값이 되는 것을 확인할 수 있다. 또한
model.load_state_dict(pretrained_dict)를 실행하려면 model 의 모든 layer 와 pre-train 데이터의 모든 key 에 해당하는 layer 가 1 대 1 대응이 되어야 성공적으로 수행된다. - 따라서 적용해야 할 model 의 전체 layer 의 key(이름), value(weight) 를 저장한 dictionary 와 업데이트 할 layer 에 해당하는 key, value 만 저장한 dictionary 를 2개 준비한다.
- 전체 layer:
model_dict = model.state_dict()을 통해 확인 가능하다. - 업데이트 할 layer: 업데이트 할 layer 만 key, value 값을 준비하며 key 는 실제 model 에서 사용하는 layer 의 key(이름)와 같아야 한다. 이 값을
update_dict라고 해보자.
- 전체 layer:
model_dict.update(update_dict)을 통하여 전체 dictionary 중 weight 를 업데이트 할 update_dict 의 값만 model_dict 에 덮어쓰기가 된다.- 이 방법을 통하여 부분적으로 weight 업데이트를 할 수 있다. 아래는 ResNet-50 을 이용하여 weight 를 부분적으로 업데이트 한 예제다.
import torch
model = torch.hub.load('pytorch/vision:v0.6.0', 'resnet50', pretrained=True)
model_dict = model.state_dict()
update_dict # update_dict is subset of model_dict
# 1. filter out unnecessary keys
filtered_update_dict = {k: v for k, v in update_dict.items() if k in model_dict}
# 2. overwrite entries in the existing state dict
model_dict.update(filtered_update_dict)
# 3. load the new state dict
model.load_state_dict(model_dict)
댓글 남기기