
[Pytorch, Hardware] Pytorch 학습 관련 Tip
Pytorch 를 사용하다보면 다양한 기술들을 적용시킬 수 있는데, 이 중 알고 있으면 좋은 것이 학습 속도의 개선시키거나 안정적으로 학습할 수 있도록 하는 tip 들이다. 여기에는 굉장히 많은 사람들이 의견을 나누고 있지만, 개인적으로 Pytorch 의 공식문서와 Pytorch Blog 나 Pytorch Forum 등에서 얻을 수 있는 Tip 들이 가치있고 신뢰가 가는 정보라고 생각한다.
또한 추가적으로 참고할 만한 것은 Pytorch Lightning 이다. Pytorch Lightning 은 Pytorch에 대한 High-level 인터페이스를 제공하는 오픈소스 Python 라이브러리로서 코드의 추상화를 통해, 프레임워크를 넘어 하나의 코드 스타일로 자리 잡기 위해 탄생한 프로젝트다. Pytorch Lightning 의 공식문서에는 사용자의 수준에 따른 Skill 들을 정리해놨고 여기에도 정말 가치있는 정보들이 많다.
따라서 개인적으로 신뢰할 수 있는 소스에서 얻은 Pytorch 관련 Tip 들을 이 포스트에 끊임없이 업데이트해 나가고자 한다.
Pytorch import & Setting
- Pytorch 로 모델을 구현하고 학습을 시키기 위해서 import 해야 하는 대표적인 라이브러리들이다.
import torch
import torchvision
import torch.nn as nn # neural network 모음 (e.g. nn.Linear, nn.Conv2d, BatchNorm, Loss functions, Activation functions, ...)
import torch.optim as optim # Optimization algorithm 모음 (e.g. SGD, Adam, ...)
import torch.nn.functional as F # parameter 가 필요 없는 Function 모음
from torch.utils.data import Dataset, DataLoader # 데이터셋 관리 및 mini-batch 생성을 위한 함수 모음
import torchvision.datasets as datasets # 표준 데이터셋 모음 (e.g. MNIST, ImageNet, ...)
import torchvision.transforms as transforms # 데이터셋에 적용 할 수 있는 transform 관련 함수 모음
import torch.backends.cudnn as cudnn # cudnn 을 다루기 위한 값 모음
from torch.utils.tensorboard import SummaryWriter # tensorboard 에 logging 하기 위한 함수 모음
from torchsummary import summary # summary 를 통한 model 의 상태 및 현황을 확인 하기 위한 함수 모음
import torch.onnx # model 을 onnx 로 변환하기 위한 함수 모음
- 같은 학습 데이터로 학습하고, 동일한 테스트 데이터로 테스트함에도 매번 실행해보면 모델의 학습 parameter 와 테스트 결과가 동일하지 않은 경우가 많다.
- 이는 높은 수준의 재생산성(Reproducibility)을 요구하는 대회나 업무에 지장을 줄 수 있다. 따라서 아래의 코드는 Pytorch 를 사용할 때 최대한 Reproducibility 를 유지할 수 있는 방법이다.
- 이를 통해 각 학습과 실험에서 디버깅과 재현을 유용하게 할 수 있다.
def seed(seed=42):
random.seed(seed) # python random 모듈 seed 고정
np.random.seed(seed) # numpy 의 seed 고정
torch.manual_seed(seed) # pytorch 내부적으로 사용하는 seed 값 설정
torch.cuda.manual_seed_all(seed) # if use multi-GPU
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
torch.use_deterministic_algorithms(True) # Optional
os.environ["PYTHONHASHSEED"] = str(seed)
- 난수 생성기의
seed를 고정하면, 매번 프로그램을 실행할 때마다 생성되는 난수들의 수열을 같도록 할 수 있다. 따라서 Pytorch 와 관련 라이브러리에서 사용되는 난수 관련seed를 고정한다. - Pytorch Lightning 에선 Pytorch 와 관련된 난수 생성기의
seed를 고정하는 코드를 포함하고 있다. cudnn은 convolution 연산을 수행하는 과정에 벤치마킹을 통해서 지금 환경에 가장 적합한 알고리즘을 선정해 수행한다고 한다. 즉 이 과정에서 다른 알고리즘이 선정되면 연산의 결과값이 달라질 수 있는 것이다. 이에 따라torch.backends.cudnn.benchmark를False로 둔다.- 그러나 재사용성을 확보하는 것이 중요치 않다면,
torch.backends.cudnn.benchmark = True로 두어 autotuner 로서 성능 향상과 자동 최적화 라는 효과를 얻을 수 있다. - 이는 PyTorch 에서 CUDA Deep Neural Network 라이브러리(cuDNN)의 동작 방식을 최적화하는 데 사용되므로, 이 설정을 활성화하면 cuDNN 은 시작 시 여러 알고리즘을 벤치마킹하여 현재 하드웨어와 input 크기에 대해 가장 빠른 것을 선택한다. 특히 다음과 같은 경우에 유용하다.
- convolution 작업 최적화: 딥러닝 모델, 특히 CNN 에서는 convolution 연산이 주요 계산 부하를 차지한다. 이 때 해당 설정의 활성화는 이러한 convolution 연산을 더 빠르게 수행하기 위해 최적의 알고리즘을 찾는다. 실제로 NVIDIA cuDNN 은 CNN 을 위한 다양한 알고리즘을 지원하고 있다.
- 그러나 고정된 input 크기일 때만 효과적이고, input 크기가 동적으로 변하면 매번 최적화된 알고리즘을 찾게 되어 시간이 더 오래 걸릴 수도 있다. 또한 Batch size 와 input / output size 가 최소 64, 이상적으로는 256 으로 나뉘어지는 수로 선택하기를 권장한다.
- 그러나 재사용성을 확보하는 것이 중요치 않다면,
- 위처럼 CUDA 벤치마킹을 비활성화하면 애플리케이션이 실행될 때마다 CUDA 가 동일한 알고리즘을 선택하도록 보장하지만, 해당 알고리즘 자체는 비결정적일 수 있다.
- 이를 방지하기 위해
torch.use_deterministic_algorithms(True)또는torch.backends.cudnn.deterministic = True를 설정한다.torch.backends.cudnn.deterministic = True는 cudnn(GPU)를 이용한 연산을 Deterministic 한 알고리즘, 즉 방식이 결정되어 있는 연산만 사용하고 randomness 가 들어간 연산은 사용하지 않는다.torch.use_deterministic_algorithms(True)는 cuda 뿐 아니라 Pytorch 의 연산들도 deterministic 한 연산만 사용하게 할 수 있다.- 이 때 주의해야 할 점은 해당 공식문서에 보면 이 설정에 영향을 받는 연산들이 나와있는데, CNN 에서 자주 사용하는
nn.AdaptiveAvgPool2d나torch.nn.MaxUnpool2d등에서 Error 를 발생하게 된다.
- Python 의 자체 hashing 알고리즘은 random 요소가 있다. 이 hash 결과에 영향을 주는 random 요소가
PYTHONHASHSEED다. 이 또한 고정해주면 재사용성에 좋다. - 참고로
seed=42에서 42 는 머신러닝/딥러닝에서 random seed 에 일반적으로 쓰이는 숫자로, 그 기원은 더글라스 애덤스의 <은하수를 여행하는 히치하이커를 위한 안내서> 에 있다. (중요한 것은 아니지만 재밌는 사실)
def seed_worker(worker_id):
worker_seed = torch.initial_seed() % 2**32
numpy.random.seed(worker_seed)
random.seed(worker_seed)
g = torch.Generator()
g.manual_seed(0)
DataLoader(
train_dataset,
batch_size=batch_size,
num_workers=num_workers,
worker_init_fn=seed_worker,
generator=g,
)
DataLoader에서 Multiprocess 를 사용할 경우, 각 worker 에는base_seed + worker_id로 seed 가 설정된다고 한다. 이 때DataLoader에 영향을 주는 다른 라이브러리의 seed 는 이와 같지 않을 수 있다.- 따라서 위 코드처럼 worker 마다 seed 를 설정하는 함수를
DataLoader생성 시worker_init_fn에 넣어주는 것이 좋다. 또한base_seed를 생성하는generator도 seed 를 고정해주는 것이 좋다.
CPU & GPU transfer
-
아래는 무어의 법칙을 나타내는 그림이다.
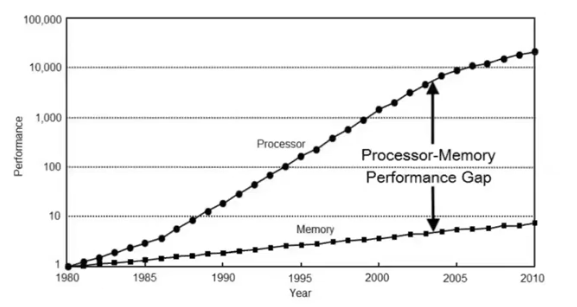
- 위 그림을 보면, 연산기의 속도는 exponential 하게 증가하고 있지만 그에 비해 메모리의 속도는 따라잡지 못하고 있다. 이런 문제점이 지금도 계속되고 있다.
- 연산 속도가 빨라지게 되면서 연산기는 메모리에서 데이터를 읽어 들일 때까지 할 일이 없이 가만히 있어야 하는 문제가 많이 발생한다. 이러한 이유로 상당수의 현대 workload 는 연산량이 아니라 메모리에 의해서 병목이 발생하는 경우가 흔하다.
- 따라서 대부분의 연산이 메모리에 의해 병목이 발생하는 memory-bound 이기 때문에, 데이터를 어떻게 이동시키는가가 최적화에서 매우 중요한 이슈가 된다.
- 이를 좀 더 구체적으로 보자. Computer Vision 분야에는 매우 많은 양의 데이터를 CPU 에서 GPU 로 transfer 해주어야 한다.
- 이 때 GPU A100 의 HBM(DRAM, 데이터를 기억하고 저장하는 역할을 수행)의 속도는 초속 2TB 정도인데, CPU 와 GPU 를 연결하는데 일반적으로 사용되는 PCI bus 의 경우 한쪽 방향은 초속 16GB 밖에 되지 않는다.
-
이는 양방향 합치면 초속 32GB 밖에 되지 않는 것이고, GPU DRAM 의 읽는 속도보다 훨씬 느리다.
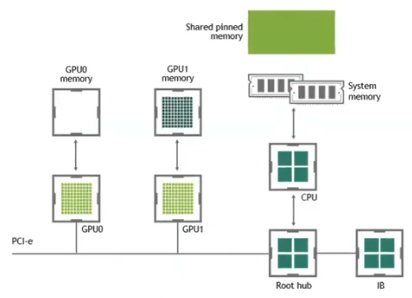
- 이 때문에 코드 내에서 CPU 와 GPU 사이의 데이터를 통신하는 것을 최소화하는 것이 중요하다.
- 이외의 다양한 병목에 대해서 해당 포스트에 잘 정리해두었다.
Asynchronous Techniques
-
CUDA 의 중요한 컨셉 중 하나는 Asynchronous Execution 이다.
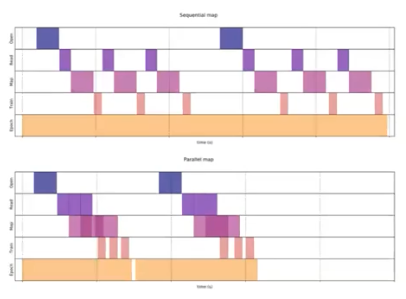
- CUDA GPU 를 device 라고 부르고, device 에 명령을 내리는 CPU 를 host 라고 부른다. CUDA 는 device 와 host 를 강제로 동기화하지 않는 이상 비동기적(asynchronous)으로 실행된다.
- 이 방식이 효율적이기 때문에, CUDA 뿐 아니라 많은 프로그램에서도 이러한 비동기적 방식을 최대한 활용하려고 노력하고 있다. 실제로 Pytorch 도 비동기성을 살리고자 노력하고 있다.
- 이 비동기성에서 제일 중요한 것이 바로 위 그림에서 아래에 위치한 것처럼 연산과 데이터 전송을 중첩시키는 것이다.
- CUDA 에서 CPU(host) 가 GPU 에게 명령을 보낼 때, CPU 는 명령이 끝날 때까지 기다려주지 않는다. 그 다음 자신의 일을 하러 넘어간다. 따라서 CPU 입장에서는 GPU 에게 일을 시키는 중에 자기 할 일을 하는 것이 효율적이다.
- 이러한 상황이 발생하는 가장 대표적인 경우가 데이터를 읽어 들여서 GPU 로 전송할 때다.
- 그림에서 위 부분은 naive 한 방식으로, CPU 가 파일을 열고 데이터를 읽고 GPU 에 전송하고 GPU 에서 연산을 한다. 이를 CPU 는 기다리면서 GPU 연산이 끝나면 다음 데이터를 읽는다.
- 이러한 방식은 너무 비효율적이다. CPU 가 파일을 열고 데이터를 읽는 도중 전송을 처리하고, 전송이 되자마자 GPU 에서 연산이 처리되면 훨씬 더 빠르게 작업이 진행된다.
-
Pytorch 에서는 CUDA 의 비동기성을 살리기 위해서 default 로 asynchronous 하게 함수를 호출한다.

- 위 그림처럼 Pytorch 의 경우 CPU 에서 명령을 내리면, GPU 에서 연산을 처리하는 동안 CPU 는 다음 명령을 내리고 미리 기다리고 있다가 처리가 되는 방식이다.
- 즉 CPU 에서 명령의 stream 을 내리면 GPU 는 그보다 더 오래 걸리기 때문에 GPU 가 일을 하지 않는 구간이 발생하지 않는다. 이런 방식을 통해서 보다 더 효율적으로 작업을 진행할 수 있다.
Things to Avoid
- 우리가 코드에서 잘못 사용하고 있는 것 중에는
.item()과.cpu()를 적용시키는 것이다. 이 두 함수를 호출하면 CPU 와 GPU 를 강제로 synchronize 를 시킨다. - 즉 CPU 가 GPU 의 일이 끝날 때까지 기다리도록 하는 명령어인 것이다. 이를 많이 쓰면 동기화를 계속 발생시키기 때문에 작업이 느려진다.
- Pytorch Lightning 에서도 CPU 와 GPU 사이에 데이터가 전송되는 과정을 피하라고 하면서 추천하는 메소드와 추천하지 않는 메소드를 구분하고 있다.
# BAD
.cpu()
.item()
.numpy()
print(tensor)
# GOOD
.detach() # computational graph 에서 분리(detach)된 새로운 tensor 를 반환
- BAD 에 해당하는 코드들은 데이터를 다시 CPU 에 올리는 역할을 한다. 학습을 위해 model parameter 와 input data 를 GPU 위에 올려놨는데, 굳이 다시 CPU 로 옮기는 것이 비효율적이라는 것이다.
- CPU 에서 GPU 로 데이터를 전송하는 것이 연산에 비해 훨씬 느린 작업이기도 하고, CPU 와 GPU 를 synchronize 시킴으로써 작업의 공백이 생긴다.
.cpu()는 GPU 메모리에 있는 tensor 를 CPU 메모리로 복사한다..item()은 tensor 내의 값을 python number 로 반환한다..numpy()는 tensor 를numpy.ndarray로 변환한다. 이 때 tensor 가 반드시 CPU 에 먼저 올라가 있어야한다.- 이러한 메서드들의 연산 자체는 느리지 않지만, GPU 를 사용하는 코드가 동기화되는 것이 주된 문제다.
- 즉, CUDA 연산이 비동기적으로 실행되다가 동기화 연산인
tensor.item()에서 타이밍이 누적되는 것이고, 이는 값을 가져와 CPU 로 전달하기 위해 GPU 계산이 완료될 때까지 기다려야 하기 때문이다.
- 따라서 불필요한 CPU 와 GPU 의 synchronization 을 피하자는 것이며, 여기에는
.cuda()나.to(device)도 포함될 수 있다. - 반대로 GOOD 에 해당하는
.detach()는 사용하는 것을 추천하고 있는데, 이는 아래 섹션에서 더 자세히 다룰 것이므로 간단하게만 보자..detach()는 모델이 학습하는 과정에서 back propagation 을 하기 위해 사용하는 computational graph 에서 tensor 를 분리시킨다.- 이를 통해 graph 의 history 를 끊어내어 GPU 메모리에 도움이 된다.
- 그렇다면 위 BAD 에 해당하는 코드를 아예 사용하면 안되는 것일까? 실제로 해당 코드들은 CLI 에 모델의 학습 현황이나 validation 결과를 monitoring 할 수 있도록 하는데 사용된다.
- 중요한 것은 이러한 동기화 연산이 진행되는 메서드를 사용하지 말라는 것이 아니고 사용을 너무 남발하지 말자는 의미다. mini-batch 마다 호출하는 것은 비효율적이며, 적정한 epoch 나 특정 조건 아래에서만 호출할 수 있도록 하자.
- 이 외에도 Wandb 나 tensorboard 와 같은 Experiment Management Tool 을 적극 활용할 수도 있다.
- 또한
.item()을 제외하고.cpu()와.numpy()를 사용하게 된다면.detach().cpu().numpy()의 순서로 사용하는 것이 가장 좋다.
Construct tensors
- Tensor 를 생성할 때도 CPU 와 GPU 사이에 데이터를 전송하는 것을 신경쓸 수 있다. 바로 GPU 에 곧장 데이터를 로드하는 방법이다.
# BAD
t = tensor.rand(2, 2).cuda()
# GOOD
t = tensor.rand(2, 2, device = torch.device('cuda'))
- BAD case 의 경우 CPU 에 tensor 를 생성한 후 GPU 로 전송하기 때문에 상대적으로 시간이 오래 걸린다.
- 따라서 앞으로는 tensor 를 생성할 때 arugment 에
device를 GPU 로 주어 tensor 가 GPU 위에 생성되도록 하자. - 그러나 만약 tensor 를 model 의 attribute 로 생성해야 한다면, 해당 Module 의 생성자
__init__에서 buffer 로 등록하는 것이 좋다고 한다.
# bad
self.t = torch.rand(2, 2, device=self.device)
# good
self.register_buffer("t", torch.rand(2, 2))
Data Pre-fetch
- 그러나 딥러닝을 학습시킬 때 데이터를 tensor 로 생성하는 것보다 mini-batch 로 돌아가면서 GPU 에 올리는 일이 일반적이다.
-
따라서 연산을 하는 도중에 그 다음 batch 의 데이터를 가지고 오는 것이 중요하다.
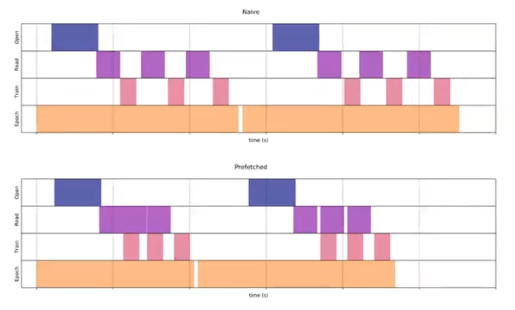
- 위 그림을 보면 위의 naive 한 방식보다 아래의 pre-fetch 된 것이 더 효율적임을 알 수 있다. 이를 코드로 작성하면 아래와 같다.
for i, (images, target) in enumerate(train_loader):
if args.gpu is not None:
images = images.cuda(args.gpu, non_blocking=True)
# images = images.to(args.gpu, non_blocking=True)
if torch.cuda.is_available():
target = target.cuda(args.gpu, non_blocking=True)
output = model(images)
loss = criterion(output, target)
- 즉 GPU 로 보낼 때
.cuda(device, non_blocking=True)또는.to(device, non_blocking=True)를 사용하는 것이다. 해당 옵션은 CPU 에서 GPU 로 데이터를 전달하는 매커니즘과 연관된 옵션이다. - 아래 DataLoader 부분에서 다루겠지만, host(CPU) 에서 GPU 로의 복사는 pin(page-lock) memory 에서 생성 될 때 훨씬 빠르다.
- 따라서 CPU 위의 tensor 및 스토리지는 pinned region 에 데이터를 넣은 상태로 객체의 복사본을 전달하는
pin_memory메서드를 사용한다. - 또한 tensor 및 스토리지를 고정하면 비동기(asynchronous) GPU 복사본을 사용할 수 있다. 비동기식으로 GPU 에 데이터 전달 기능을 추가하려면
non_blocking = Trueargument 를.to()또는.cuda()호출 시 전달하면 된다. - 이를 통해 Asynchronous 하게 데이터를 전송할 수 있고 보다 더 효율적으로 작업할 수 있다. 즉 위 그림처럼 GPU 연산 간격을 줄여 연산 속도 향상에 도움이 된다.
DataLoader
- Pytorch 를 이용하여 학습할 때, 우리는 데이터를 mini-batch 로 불러오기 위해
DataLoader를 사용한다. 이 때DataLoader의 argument 로 다양한 것들이 있다.
from torch.utils.data import DataLoader
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False,
drop_last=False, timeout=0, worker_init_fn=None, *, prefetch_factor=2, persistent_workers=False)
- 일반적으로
batch_size를 키우면 GPU 메모리를 최대한 활용하여 학습 시간을 단축하는데 큰 도움이 된다. 그러나batch_size가 클수록, 수렴이 느려질 수 있기 때문에 아래와 같은 방법을 사용해서 보완할 수 있다.- Tune learning rate, tune weight decay
- Add learning rate warm-ups & decay
- 이외에
Dataloader의 argument 중 Pytorch 학습 속도를 개선시키는데 도움이 되는 것은num_workers와pin_memory다.
num_workers
num_workers는 CPU 에서 GPU 로 데이터를 로드할 때 사용하는 프로세스의 개수를 뜻한다. 이를 통해 병렬적으로 데이터를 읽어들이는 것을 처리할 수 있다.- 컴퓨터에서 병목(bottle-neck) 현상이 발생하는 대표적인 구간이 바로 I/O(Input/Output) 연산이다.
- 따라서 I/O 연산에 최대 사용할 수 있는 코어를 적당하게 나누어 주어서 병목 현상을 제거하는 것이 전체 학습 시간을 줄일 수 있는 데 도움이 된다.
num_workers = 0이 기본값으로 사용된다. 이 의미는 data loading 이 오직 main process 에서만 발생하도록 하는 synchronous 방법을 의미한다.num_workers > 0이 되도록 설정하면 asynchronous 하게 data loading 이 가능해지기 때문에, GPU 연산과 병렬적으로 data lodaing 이 가능하게 되어 병목 문제를 개선할 수 있다.-
따라서 이러한
num_workers는 특히 computer vision 과 같이 데이터 사이즈가 큰 영역에서 더 잘 활용할 수 있다.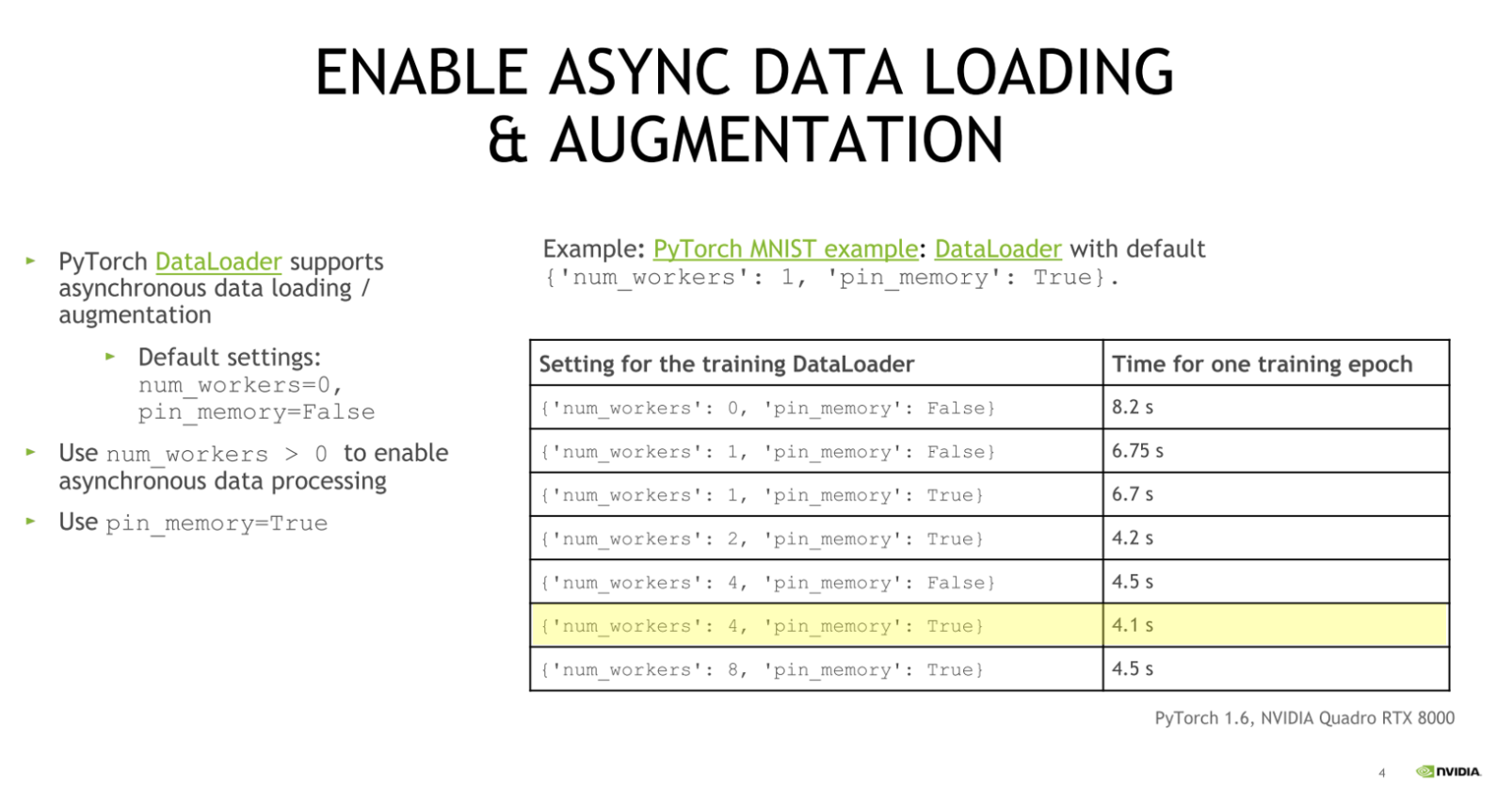
- 위 그림은 NVIDIA 의 conference 에서 발췌한 내용이며 기본값인
num_workers=0, pin_memory=False를num_workers > 0, pin_memory=True로 변경하면서 실험했을 때 성능 변화를 나타낸 것이다. - 이를 통해 NVIDIA 에서도
DataLoader의 argument 로num_workers > 0과 pin_memory=True를 사용하기를 추천하고 있다. - 그러나 가장 좋은 것은 본인이 실험하는 환경의 CPU 와 RAM 자원을 고려해서 결정하는 것이 가장 좋다.
- 그렇다면
num_workers는 많으면 많을수록 좋은 것일까? 이를 몇으로 설정해야 좋을까? - 그러나
DataLoader에서num_workers를 0 보다 큰 숫자로 설정했을 때 작동하지 않는 error 가 발생하는 경우가 있다. -
이 문제는
DataLoader의 원론적인 이슈가 아니라 Python 때문이다.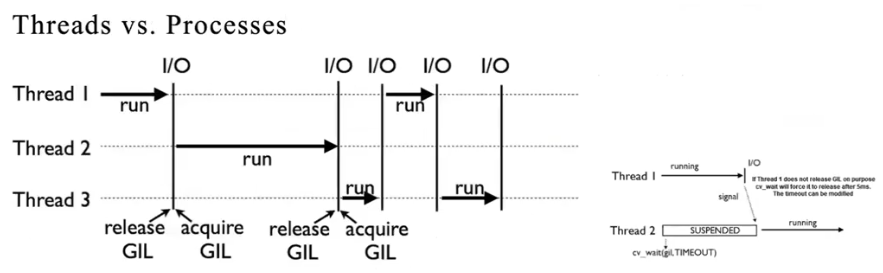 Python GIL
Python GIL - Python 은 GIL(Global Interprter Lock) 개념 때문에 병렬 처리를 잘 하지 못한다. 이에 따라 C 언어나 다른 프로그래밍 언어에서 하는 멀티쓰레딩을 진행할 수 없다.
- 따라서 서로 다른 프로세스를 만들어야 하는데, 서로 다른 프로세스는 메모리를 공유하지 않는다. 이 때문에 서로 다른 프로세스 사이에서 데이터를 전송하기 위해 메세지를 보내야 한다.
- Python 에서는 이 메세지를
pickle이라는 모듈로 압축을 해서 전송을 한다. 바로 이것이DataLoader에서num_workers숫자를 1 이상으로 했을 때Unpicleable object error가 발생하는 이유다. - 멀티 프로세싱을 하면서 pickling 을 통과해야 하는데, 이 pickling 을 통과할 수 없는 객체가 존재하기 때문이다.
- 이처럼 근본적으로 Python 의 문제이지, 멀티프로세싱 자체의 문제가 아니다. pickling 이 안되는 부분만 적당히 제거한다면 멀티프로세싱의 효과를 볼 수 있다.
pin_memory
DataLoader에서 GPU 학습에 중요한 또 다른 argument 는pin_memory=False다. 이는 말그대로 고정된 메모리를 뜻하며 default 값이False다.-
이를
True로 두면DataLoader가 Pinned Memory 로 데이터를 할당하게 되고 더 빠르게 데이터를 전송할 수 있다.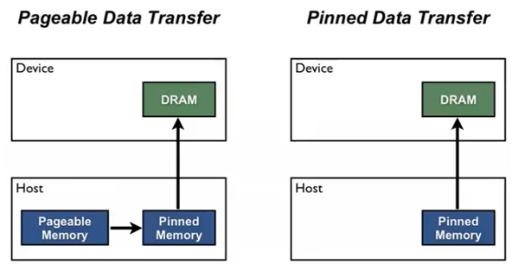 Host 는 CPU 이고 Device 는 GPU 다.
Host 는 CPU 이고 Device 는 GPU 다. - 일반적으로
torch.utils.data.DataLoader를 통하여 Host 에서 Device 로 데이터를 불러온다. - CPU 가 GPU 로 데이터를 전송하기 위해서 비동기적으로 전송하는 것을 기본으로 할 수 있는 것 같지만, 사실 그렇지 않다.
- CPU 는 OS 에서 페이징 기법을 통해 pageable memory 를 관리하는데 이는 가상 메모리를 관리하는 블록이다. 이 가상 메모리는 실제 메모리 블록에 대응되고 데이터의 메모리를 언제든지 다른 곳으로 옮길 수 있다.
- 따라서 위 그림의 왼쪽처럼, CPU 에서 GPU 에 데이터를 전달하기 위해서는 (i) pageable memory 에서 전달할 데이터들의 위치를 읽고, (ii) 전달할 데이터를 pinned memory 에 모아서 복사한 다음, (iii) pinned memory 영역에 있는 데이터를 GPU 로 전달한다.
- 그러나 CUDA Driver 입장에서는 OS 가 갑자기 데이터를 다른 곳으로 옮겨 버리면 데이터가 어디로 가 있는지 알 방법이 없다. 그렇기 때문에 Driver 가 항상 같은 위치에서 데이터를 읽을 수 있게 해주기 위해서 Pinned Memory 를 할당한다.
- 이러한 Pinned Memory 는 OS 에 의해서 페이징이 될 수 없는 메모리다. 따라서 Driver 는 Pinned Memory 로 데이터의 위치가 어디에 있는지 알 수 있기 때문에 데이터를 보고 연산으로 넘어갈 수 있다.
- 그렇지 않은
pin_memory=False의 경우 pagable memory 에서 pinned memory 로 복사하고 보내고를 반복해야 하기 때문에 느려지게 되고, Synchronous 한 데이터 전송을 하게 된다. - 따라서
pin_memory = True옵션은 pageable memory 의 과정을 줄여 CPU 에서 GPU 로 데이터를 효율적으로 전달할 수 있게 해준다. - 즉, pageable memory 에서 전달할 데이터들을 확인한 다음 pinned memory 영역에 옮기지 않고, CPU 메모리 영역에 GPU 로 옮길 데이터들을 바로 저장하는 방식이다. 따라서
DataLoader는 추가 연산 없이 이 pinned memory 영역에 있는 데이터들을 GPU 로 바로 옮길 수 있는 것이다. - 이런 연산 과정 때문에 pin_memory 를 사용하는 것을 page-locked memory 라고도 부른다. 이 연산 과정을 이해한다면 CPU 만을 이용하여 학습을 하는 경우 사용할 필요가 없다는 것을 알 수 있다.
- 이처럼
pin_memory = True로 설정하면 학습 중에 CPU 가 데이터를 GPU 로 전달하는 속도를 향상시키기 때문에, 이 옵션은 GPU 를 사용하여 학습할 때에는 항상 사용한다. - 그러나 주의할 점은 pinned(page-locked) memory 는 다른 작업에 의해 memory deallocation 되지 않기 때문에, 너무 많은 메모리를 점유하게 될 경우에 다른 데이터가 메모리에 못 올라오는 문제가 생길 수도 있다.
16-bit Precision
- 16-bit precision 은 32-bit 로 구성된 데이터를 16-bit 로 변환하여 사용하는 것이다. 이렇게 32-bit 데이터를 16-bit 로 변환하면 데이터가 차지하는 메모리 용량이 절반으로 줄 것이고, 모델 학습의 batch 사이즈를 두 배로 늘려 학습 속도를 더 빠르게 향상시킬 수가 있다.
- 또 C100, 2080Ti 와 같은 특정한 GPU 모델은 16-bit 계산에 특화되어 있다. 그래서 32-bit 계산을 시행할 때보다 16-bit 데이터를 계산할 때 속도가 3 배에서 많게는 8 배까지도 빨라질 수 있다고 한다. 이를 자세히 보자.
- NVIDIA 의 GPU 를 사용할 때,
FP32(32-bit Floating Point) 를 기본적인 데이터 타입으로 사용하고 있다. 이 때FP16을 기본 데이터 타입으로 바꿔 사용하면 모델이 가벼워져서 학습 시간을 단축할 수 있다. - AI 와 같은 HPC(High Performance Computing) 계열의 애플리케이션에선 높은 정밀도가 요구되는 연산이 필요하기 때문에 기본적으로
FP32혹은FP64연산을 사용한다. - V100 GPU 의 경우
FP32를 사용하면 14 TFLOPS(Tera Floating Operations per Second) 의 연산 속도를 가지는 반면,FP16을 사용하면 100 TFLOPS 의 연산 속도를 가지는 것을 확인할 수 있다. 실제 학습을 할 때에도 보통 2 ~ 3 배 정도 연산 속도가 빨라진다.
Mixed Precision Training
-
그러나 딥러닝에서 사용하는 weight 의 경우 매우 작은 값을 가지므로 단순히
FP16만을 사용하면 accuracy 성능에 문제가 발생할 수 있다.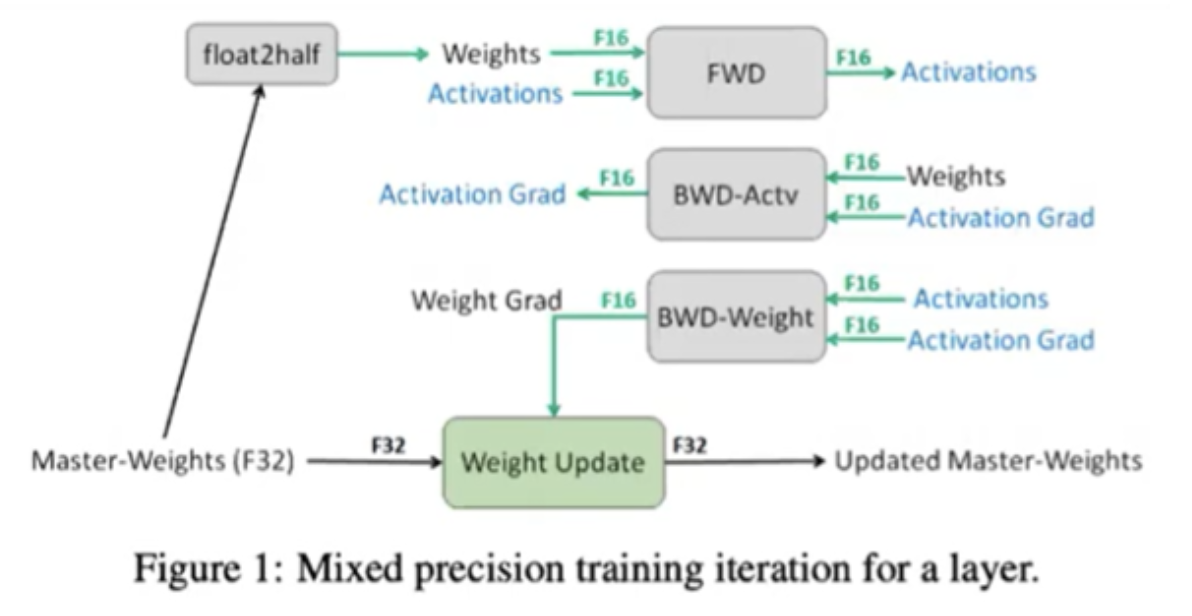
- 따라서 위 그림과 같이 Mixed Precision 이라는 방법을 이용하여
FP16과FP32를 섞어서 사용한다. Pytorch 는 AMP(Automatic Mixed Precision) 라는 패키지로 지원하고 있다.- AMP 는 해당 공식문서를 참고하자. MMDetection 이나 MMSegmentation 은 또한 AMP 를 지원하고 있다.
- AMP 에 대해서는 따로 포스트를 두어 더 자세하게 정리할 예정이다.
- 위 그림을 보면 Forward, Backward, Activation 등을 계산하여 gradient 를 구할 때는
FP16을 사용하고optimizer.step()을 이용하여 실제 weight update 가 발생할 때에는FP32를 사용하여 저장한다.FP32로 저장되는 weight 를 master weight 라고 한다. 이렇게 따로 저장하는 이유는FP16과FP32값 사이에 범위 차이가 발생하고, weight 의 경우 작은 값이기 때문에FP16으로는 성능에 영향을 미칠 수 있기 때문이다.- 따라서
FP16값이FP32값과 같은 precision 범위에서 계산이 될 수 있도록 별도 scaling factor를 따로 저장한다. 그리고 weight update 시 이 scaling factor 값을 계산 결과인FP16에 곱해주어FP32와 값의 범위가 유사해지도록 만들어 주는 방법을 사용한다.
scaler = torch.cuda.amp.GradScaler()
with torch.cuda.amp.autocast(enabled=use_fp16):
output = model(input)
loss = loss_fn(output, target)
if use_fp16:
scaler.scale(loss).backward()
if max_norm is not None:
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
scaler.step(optimizer)
scaler.update()
- 정리하면, 학습 과정에서 Pytorch tensor 의 default data type 인 32-bit floating point 를 16-bit 로 바꾸는 것이다. 그렇게 되면 parameter 의 크기가 가벼워지고 모델의 연산 속도가 빨라져 학습 시간을 단축할 수 있다.
- 그러나 성능 측면에서 감소가 발생할 수 있는데, 이를 위해 16-bit 를 32-bit 와 함께 사용하는 Mixed Precision Training 기법을 사용한다. 이 때 아래의 이점을 얻을 수 있다.
FP32으로만 학습할 때와 비슷한 정확도를 얻을 수 있다.- 필요한 메모리 사이즈가 감소한다.
- 학습 시간이 줄어든다.
- Tensor core 를 지원하는 V100 과 같은 GPU 는 mixed precision training 을 위한 하드웨어 가속을 제공하기 때문에 효과가 극대화될 수 있다. V100 기준으로 1.5 ~ 5 배 빨라진다.
- 참고로 FP16 precision 과는 관련이 없지만 Python 의
inttype 크기와 관련해서 흥미로운 사실이 있는데, Python 의 int type 은28 bytes라는 것이다.28 bytes = refcnt (8 bytes) + Type pointer (8 bytes) + PySize (8 bytes) + digits (4 bytes)- 여기서
refcnt는 Python GC 를 위한 참조 수,Type pointer는 Type 을 표현하기 위한 포인터다. Pysize, digits의 Array 구조 덕분에 큰 수에 대한 Overflow 걱정이 없다고 한다.- 자세한 사항은 해당 글에 잘 설명되어 있다.
Don’t accumulate history (cuda OOM)
- CUDA OOM 은 CUDA out of memory 의 약자로 GPU 를 활용해서 딥러닝을 할 때 숱하게 마주칠 수 있는 오류다.
- 이러한 오류가 발생했을 때 다양한 원인이 있고, 그에 맞는 다양한 해결책이 있다.
- batch size 를 줄이거나, 모델의 parameter 개수를 줄이거나 하는 방법도 있지만 여기서는 학습 알고리즘을 구현할 때 놓칠 수 있는 부분에 대해서 다뤄보자.
zero_grad()
- 일반적인 학습 알고리즘은 아래와 같다.
def train_loop(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
loss.backward()
optimizer.step()
optimizer.zero_grad()
if batch % 100 == 0:
loss, current = loss.item(), batch * batch_size + len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
loss.backward()는 각 layer 의 parameter 에 대하여 back propagation 을 통해 gradient 를 계산한다.optimizer.step()은 각 layer 의 parameter 와 같이 저장된 gradient 값을 이용하여 parameter 를 업데이트 한다. 이 명령어를 통해 parameter 가 업데이트되어 모델의 성능이 개선된다.optimizer.zero_grad()는 이전 step 에서 각 layer 별로 계산된 gradient 값을 모두 0 으로 초기화 하는 메서드다. 만약 0 으로 초기화 하지 않으면 이전 step 의 결과에 현재 step 의 gradient 가 누적으로 합해져서 계산된다.- 학습 중 gradient 가 누적되면 GPU 메모리 사용량이 증가한다. 따라서
optimizer.step()으로 weight 가 업데이트 됐다면 더 이상 필요하지 않으므로 gradient 를 해제하는 것이 메모리 사용량을 줄이는 방법이다. - 이처럼 누적을 피하기 위해서
.zero_grad()를 사용하고, 일반적으로DataLoader의 iteration 마다 실행한다. - 이 때, Pytorch 공식문서에
zero_grad를 검색하게 되면torch.nn.Module.zero_grad가 있고torch.optim.Optimizer.zero_grad가 있는데 일반적으로 후자를 사용한다. - 또한
optimizer.zero_grad(set_to_none=True)와 같이 argument 로set_to_none=True를 주는 것이 권장된다. - 이는 gradients 를 0 으로 설정하는 대신
None으로 설정한다. 이렇게 하면 일반적으로 메모리 사용량이 줄어들고 성능이 약간 개선될 수 있다고 한다. 그러나 아래와 같은 변화가 생길 수 있다.- 사용자가 gradient 에 접근하여 수동 연산을 수행하려 할 때,
None속성과 0 으로 가득 찬 Tensor 는 다르게 동작한다. zero_grad(set_to_none=True)후 backward pass 를 수행하면, gradient 를 받지 않은 파라미터의.grad는None임이 보장된다.torch.optim의 Optimizer 는 gradient 가 0 이거나None일 때 서로 다르게 동작한다.
- 사용자가 gradient 에 접근하여 수동 연산을 수행하려 할 때,
- 이 설정을 권장하는 이유는 아래와 같다.
- 모든 parameter 마다 메모리 내의 값을 변경하는 memset 을 실행하지 않는다.
- gradient 를 업데이트할 때
+=(read+write) 가 아닌=(write) 를 사용한다. 이는 0 도 read 를 한다는 의미다. - Pytorch 백엔드에서 더 효율적으로 gradient 를 0 으로 만든다. 즉 더 효율적으로
.zero_grad()를 실행한다.
Gradient Accumulation
- 앞서 언급했듯, CUDA out of memory 오류의 가장 일반적인 원인 중 하나는 너무 큰 batch-size 를 사용하는 것이다. 따라서 이 오류가 발생하면 먼저 batch-size 를 줄여보는 것이 일반적이다.
- 그러나 이 때 큰 batch-size 를 사용하면서 메모리가 부족하지 않도록 하는 gradient accumulation 기법을 사용할 수 있다.
- gradient accumulation 은 GPU 메모리가 큰 batch-size 로 인해 한 번의 iteration 에 모든 데이터를 동시에 처리할 수 없을 때 학습을 진행할 수 있게 하는 기법이다.
- 매 mini-batch 마다 모델 parameter 를 업데이트하는 대신, 여러 mini-batch 의 gradient 를 지정된 횟수만큼 누적한 후 한 번에 가중치를 update 한다.
- gradient accumulation 을 구현하면, 학습 loop 에서 매 backward pass 마다
optimizer.step()및optimizer.zero_grad()를 호출하는 것이 아니라, 미리 지정된 횟수(accumulation_steps)의 backward pass 마다 한 번 update 한다.
optimizer.zero_grad() # Explicitly zero the gradient buffers
for batch, (inputs, labels) in enumerate(dataloader):
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward() # Backward pass to calculate the gradient
if (batch + 1) % accumulation_steps == 0: # Wait for several backward passes
optimizer.step() # Now we can do an optimizer step
optimizer.zero_grad() # Reset gradients to zero
detach
- 학습 중 일부 epoch 를 진행하면 CUDA out of memory 에러가 발생하는 경우가 있다. 이 때 loss 계산 중에 이러한 에러가 발생할 수도 있다.
- 우리는 학습 단계에서 가장 기본적으로 train 데이터셋과 validation 데이터셋에 대하여 Loss 를 구한다.
- train 데이터셋을 사용하는 경우 먼저 Loss 를 구하고, Loss 의
.backward()를 이용하여 back propagation 을 적용한다. - 반면 validation 과정에는 Loss 만 구하고 back propagation 은 적용하지 않는다. 이러한 차이점으로 인해 의도치 않게 CUDA out of memory 문제가 발생하곤 한다. 이를 자세히 보자.
- Pytorch 는 model, optimizer, loss 순서로 연결되어 있다. 즉 아래와 같다.
optimizer = optim.Adam(model.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
out = model(input)
loss = criterion(out, target)
loss.backward()
optimizer.step()
- 이 때,
loss.backward()를 하지 않으면 back propagation 을 하기 위한 computational graph 에 히스토리가 계속 쌓이게 된다. - 즉
loss.backward()연산을 하면 연결된 그래프에 back propagation 계산을 하게 되므로 히스토리가 쌓이지 않지만,loss.backward()를 하지 않고 사용하면 히스토리가 계속 쌓이게 되고 GPU 연산에도 영향을 주어 CUDA out of memory 문제가 발생한다. 즉 validation 과정에서 발생할 수 있다는 것이다. - 이 경우 loss 에
.detach()함수를 사용하여 그래프의 히스토리를 의도적으로 끊는 방법을 사용하여 메모리 문제를 피할 수 있다.
out = model(input)
criterion = nn.CrossEntropyLoss()
loss = criterion(out, target).detach()
- 위 예제에서는
.detach()로 loss 의 그래프가 끊어졌기 때문에backward()를 사용할 수 없다. 따라서 이 경우는backward()를 사용하지 않는 validation 에서 사용하면 GPU 메모리에 도움이 된다.
torch.cuda.empty_cache
- CUDA 할당 된 Tensor 를 GPU 메모리 상에서 완전히 해제하려면 먼저 변수를 제거하고 cache 를 비워야 실제 메모리에서 해제된다.
- 변수가 제거되어도 cache 를 남겨두는 이유는 동일한 목적으로 변수가 생성될 때, 빠르게 생성하기 위함이다.
- 만약 임시로 Tensor 를 만들었다가 제거해야 한다면 변수 제거 후 cache 를 비우면 메모리에서 완전 제거된다. 변수 제거는
del 변수명을 사용하고 cache 를 비울 때는torch.cuda.empty_cache()를 사용한다.
import torch
print(torch.cuda.memory_allocated())
# 0
print(torch.cuda.memory_reserved())
# 0
A = torch.rand(1000000000).cuda()
print(torch.cuda.memory_allocated())
# 4000000000
print(torch.cuda.memory_reserved())
# 4001366016
del A
print(torch.cuda.memory_allocated())
# 0
print(torch.cuda.memory_reserved())
# 4001366016
torch.cuda.empty_cache()
print(torch.cuda.memory_allocated())
# 0
print(torch.cuda.memory_reserved())
# 0
- 이처럼
torch.cuda.empty_cache()는 사용 되지 않는 GPU 상의 cache 를 정리해 memory 를 확보하지만, 마찬가지로 불필요하게 이 함수를 호출해서는 안된다. - GPU 의 메모리를 확보하기 위해 계속해서
torch.cuda.empty_cache()를 호출하게 되면 비동기적으로 움직이는 모든 GPU 가 동기화를 위해 기다리게 된다고 한다.
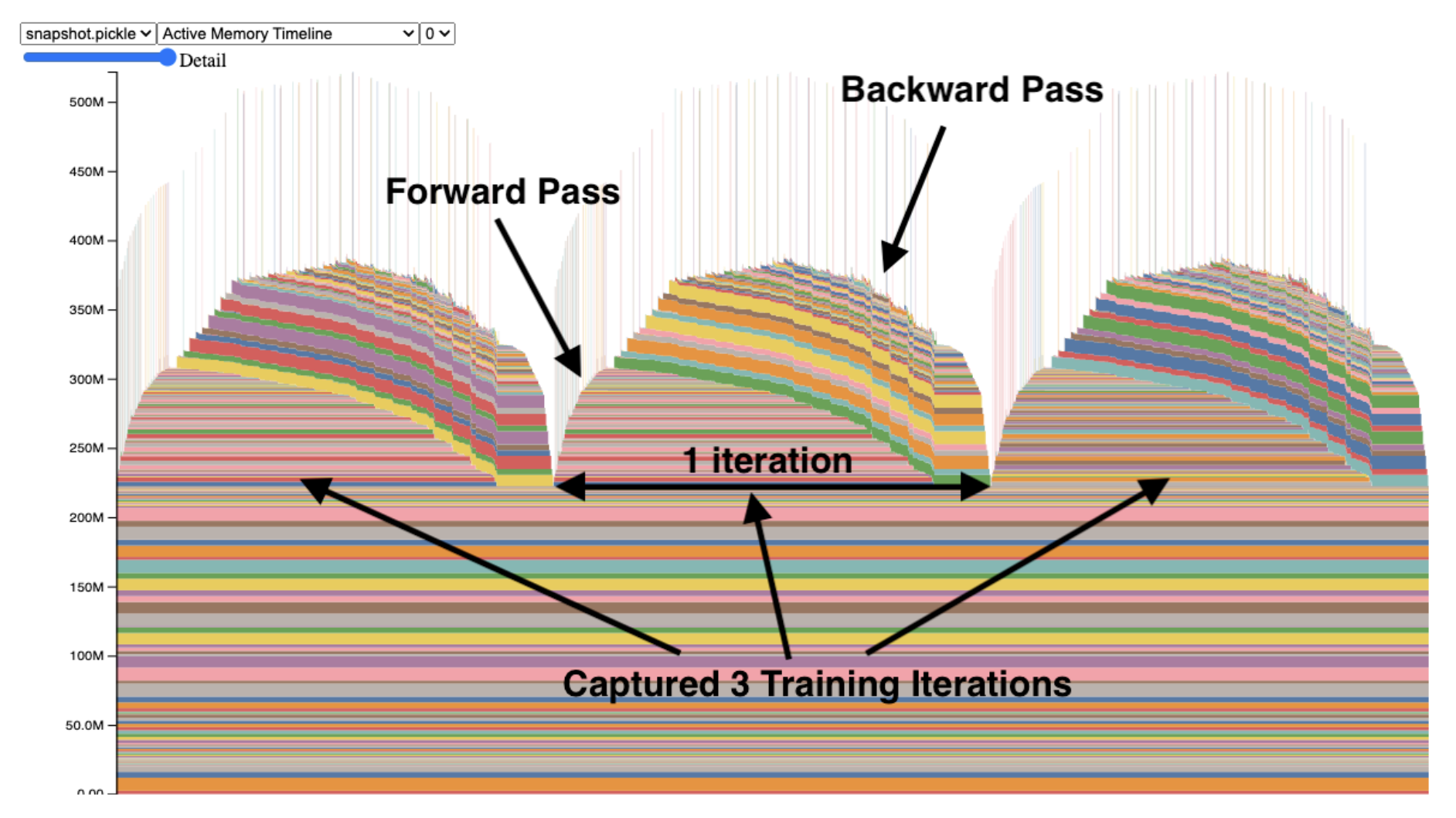
CUDA memory usage
- 해당 공식문서에는 GPU 메모리 사용에 대한 snapshot 을
pickle파일로 작성하는 법을 제공한다.
# enable memory history, which will add tracebacks and event history to snapshots
torch.cuda.memory._record_memory_history()
run_your_code()
torch.cuda.memory._dump_snapshot("my_snapshot.pickle")
- 이후 Pytorch 에서 제공하는 시각화 URL 에 들어가서 이
pickle파일을 드래그하면 GPU 메모리의 사용량을 Timeline 에 따라 확인할 수 있다. -
또한 해당 Pytorch Blog 글 Understanding GPU Memory 1: Visualizing All Allocations over Time 은 이러한 기능을 통해 GPU Memory 에 대한 깊은 이해를 도울 정보를 제공한다.
DP & DDP
-
DP 는 DataParallel 의 준말로 간단하게 multi-threading 방식이다. 반면에 DDP 는 DistributedDataParallel 의 준말로 multi-processing 에 해당한다.
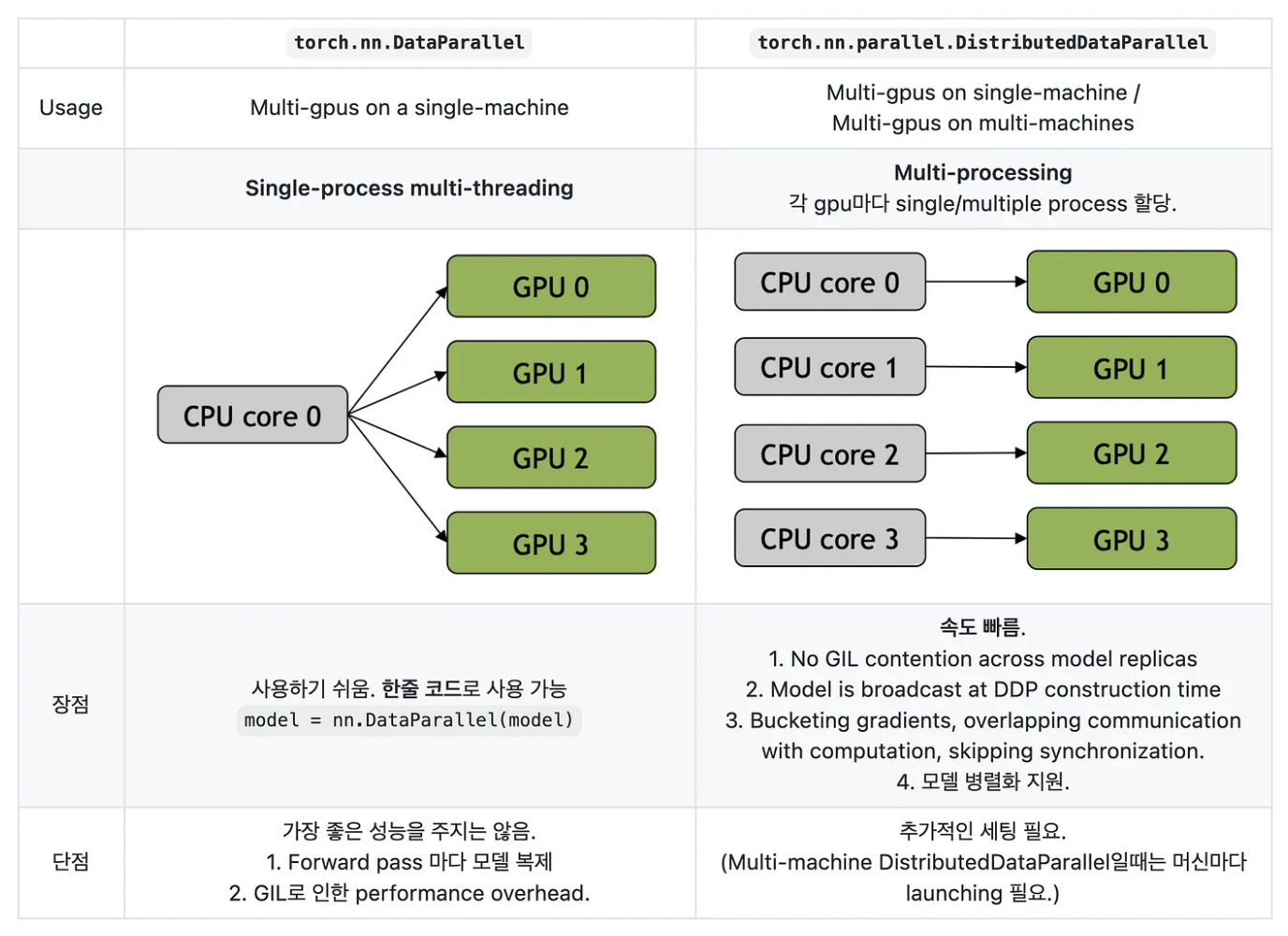
- Process 는 작업을 위해 실행되어야 할 명령어의 목록으로, process 를 실행하기 위해서는 memory 가 필요하다.
- 반면에 Thread 는 명령어 목록의 명령어 하나 하나를 실행하는 작업자다. 1 개의 process 에는 1 개 이상의 thread 가 있으며, 하나의 process 내에 있는 thread 들은 memory(자원)를 공유한다.
- Python 의 GIL(Global Interpreter Lock) 은 여러 개의 thread 가 동시에 실행되지 못하도록 막는 기능을 한다. 하나의 thread 에 모든 자원을 허락하고, 그 후에는 Lock 을 걸어 다른 thread 는 실행 불가하도록 하는 것이다.
- 이 때문에, Python 위에서 사용되는 Pytorch 에서는 DP 보단 DDP 방식이 더 빠르게 작동한다.
- 이러한 DP 와 DDP 에 대해서는 나중에 포스트를 따로 두어 더욱 자세히 정리할 예정이다.
model.eval() & torch.no_grad()
model.eval()은 모델 내부의 모든 layer 가 evaluation 모드 가 되게 한다. 따라서 Batch Normlization 이나 Dropout 이 작동하지 않고 gradient update 가 되지 않는다. 아래 예제를 보자.
drop = nn.Dropout(p=0.3)
x = torch.ones(1, 10)
# Train mode
drop.train()
print(drop(x)) # tensor([[1.4286, 1.4286, 0.0000, 1.4286, 0.0000, 1.4286, 1.4286, 0.0000, 1.4286, 1.4286]])
# Eval mode
drop.eval()
print(drop(x)) # tensor([[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]])
- 반면에
torch.no_grad()은 back propagation 이 발생하지 않게 한다. 즉 어떤 Tensor 가.no_grad()로 지정되면 autograd 엔진에게 이 정보를 알려주고 학습에서 제외된다. - 이를 통해 Backward pass 에 필요한 메모리를 절약할 수 있으므로 연산을 빠르게 할 수 있다. 그러나 동시에 Backward pass 를 할 수 없으므로 학습은 불가능하다.
x = torch.tensor([1], requires_grad=True)
with torch.no_grad():
y = x * 2
y.requires_grad # False
- 따라서 특정 layer 를 학습에서 제외하기 위해 back propagation 을 적용시키지 않으려면, 해당 layer 에
torch.no_grad()를 사용한다. - 그러나
model.eval()은 실제 inference 를 하기 전에 model 의 모든 layer 를 evaluation 모드로 변경하기 위해 사용한다. 특히 dropout 과 batch normalization 이 model 에 포함되어 있다면 반드시 사용해야 한다.
Reference
- https://lightning.ai/docs/pytorch/stable/advanced/speed.html
- https://gaussian37.github.io/dl-pytorch-snippets/
- https://medium.com/naver-shopping-dev/top-10-performance-tuning-practices-for-pytorch-e6c510152f76
댓글 남기기