
[Segmentation] 8. Semantic Segmentation 연구 동향
- Semantic Segmentation 연구 동향2
- WSSS (Weakly Supervised Semantic Segmentation)
- Segmentation 을 수행할 때 pixel label 이 없을 경우 image label 혹은 box label 과 같은 약한 label 로 segmentation 을 수행하는 task 이다.

- classification, localization, detection, segmentation 의 경우 클래스를 분류만 수행하는지, 위치까지 파악하는지, multi-object 에도 가능한지에 따라 나눌 수 있었다.
- 주목할 점은 이러한 task 들을 진행할 때 annotation 시간도 다르다.

- Segmentation 은 pixel 마다 annotation 을 달기 때문에 가장 많은 시간이 걸린다. 즉 pixel-leel labeling 이 image-level labeling 보다 78배나 오래 걸린다.
- 이렇게 labeling 에 시간이 오래걸리면 현실적으로 데이터를 구축해서 학습하는 과정이 매우 오래걸린다. 그렇다면 만드는 시간이 짧고 이미 많이 만들어진 image-level label 만 가지고 segmentation 을 할 수 있지 않을까 고민할 수 있다.
- 이를 위한 것이 바로 WSSS 이다.
- Weakly Supervision 은 테스트 시 요구하는 output 보다 더 간단한 annotation 을 가지고 학습하는 것을 의미한다.

- 즉 test 에서 픽셀 단위의 classification 을 수행하지만 학습 단계에서는 픽셀 단위의 annotation 이 아니라 이미지나 포인트, bbox, scribble 을 가지고 학습을 한 후 최종 inference 때에는 픽셀 단위 classification 결과를 얻게 만드는 것이다.
- 이 때 쉬운 annotation 일수록 segmentation 하는데 더 어렵다고 알려져 있다. 그렇다면 어떤 식으로 WSSS 를 수행할까?
- Naive approach
- 일반적으로는 분류 모델을 이용해서 pseudo labeling 을 만들고 이를 segmentation 모델로 다시 학습하는 방법이 있다.
- 가지고 있는 image level label 을 활용하여 분류 모델을 먼저 학습시킨다.
- 그 이후 분류 모델에서 CAM, Grad-CAM 혹은 attention 등을 이용해서 모델이 클래스를 구분할 때 어디를 바라보고 있는지에 대한 정보를 추출한다.
- 그러한 CAM 을 통해서 모델이 클래스를 구분할 때 어느 영역을 바라보고 있는지 추출한 pseudo mask 를 얻을 수 있다.
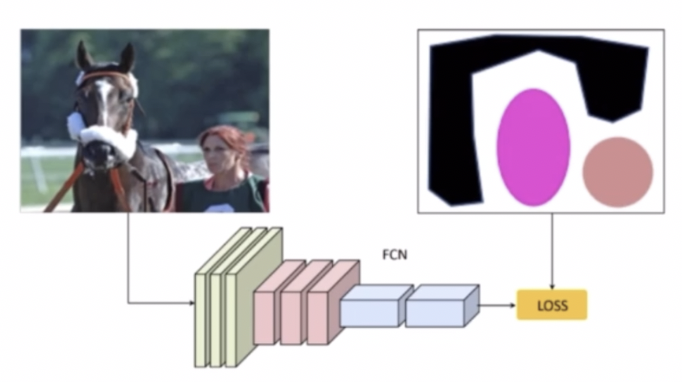
- 이렇게 얻은 pseudo mask 를 이용해서 segmentation 의 FCN 모델을 학습한다.
- 학습한 FCN 모델을 가지고 새로운 입력 이미지가 들어왔을 때 Segmentation 을 수행할 수 있다.
- 즉, Segmentation task 를 수행할 때 pixel-level label 이 없이 수행한 것이다.
- 정리하면, classification 모델을 가지고 image-level label 을 학습시켜 모델이 어느 영역을 바라보고 있는지에 대한 정보를 CAM 을 통해서 추출한다. 그렇게 얻은 CAM 에 대한 정보를 pseudo mask 로 활용해서 segmentation 모델을 학습시킨다. 그렇게 만든 segmentation 모델을 가지고 새로운 이미지가 들어왔을 때 inference 를 하는 것이다.
- 그러나 pseudo-mask 의 결과가 좋지 않다는 문제점이 있다. CAM 과 grad-CAM 을 보자.
- CAM & Grad-CAM
-
CAM
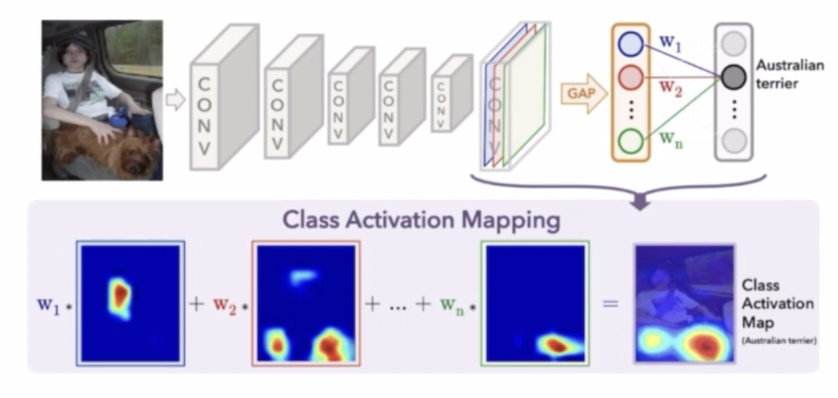
- CAM 은 Class Activation Mapping 으로 Classification 모델을 학습하면서 생성이 가능하다. 특정 클래스의 물체가 사진의 어떤 영역에 위치하고 있는지를 유추할 수 있는 기법이다.
- GAP 를 통과하기 전의 feature map 에 GAP 를 통과한 이후 weight 를 곱해주면 특정 클래스가 어느 영역에 위치하는지 활성화된 정보를 이용해서 유추할 수 있다.
- 이와 같이 CAM 의 활성화된 정보를 이용해서 pseudo label 로 활용한다.
-
feature map 의 의미
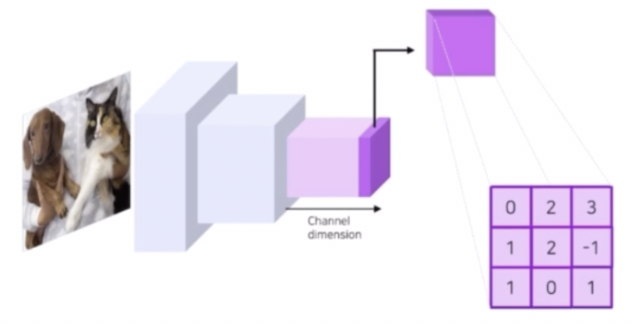
- 고양이, 강아지 분류 task 를 예를 들면, 모델은 학습 시에 고양이인지 강아지인지를 구분할 feature map 을 생성한다.
- 각 feature map 은 고양이인지 강아지인지 구분하기 위한 정보를 담고 있다.
- 또한 각 feature map 의 채널 별로 다른 정보를 담고 있다.
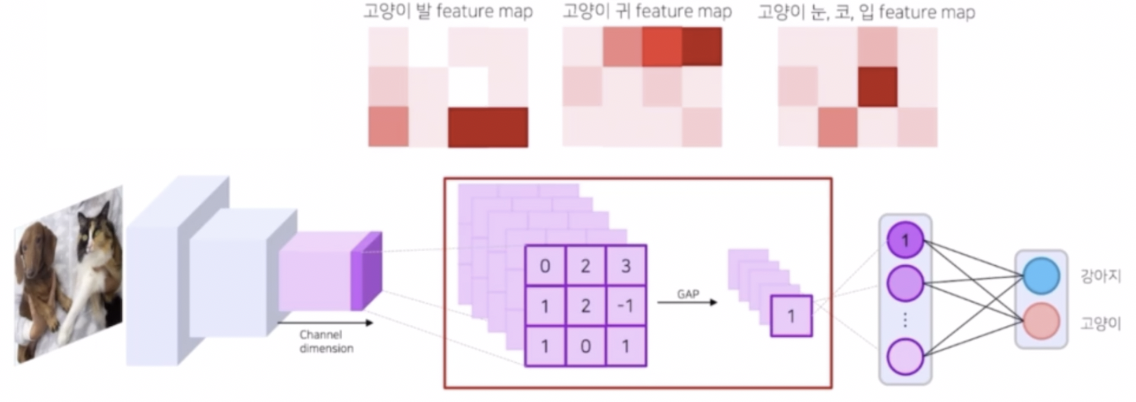
- feature map 이 n 개 정도 만들어졌다고 했을 때, 각 채널에 따라서 feature map 들은 서로 다른 정보를 담고 있다. 이후 이를 GAP(Global AVerage Pooling) 을 통과시켜서 각 채널별 feature map 을 대표하는 대표값을 뽑아낼 수 있다.
- fc layer 인 Classifier 는 GAP(혹은 flatten)되어 대표값으로 이루어진 feature vector의 각 원소에 class 별로 다른 weight 를 주어서 scoring 을 한다.
- 이렇게 fc layer 를 통과하게 되면 각 feature map 의 weight 가 얼마나 되는지를 얻을 수 있다. 이 weight 는 중요도로 표현될 수 있다.
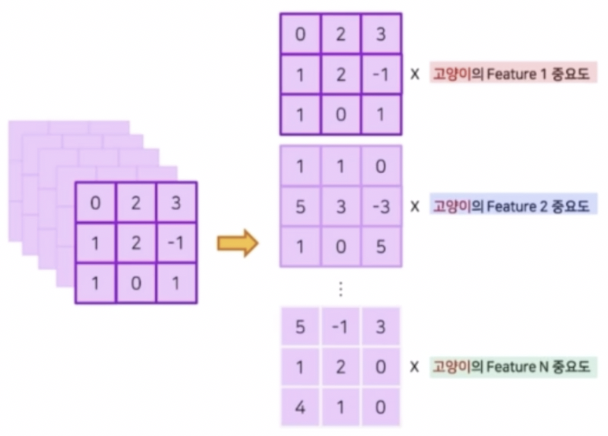
- weight 는 feature map 을 대표하는 대표값이 얼마나 중요한지에 대한 정보를 담고 있다. 이 중요도를 GAP 이전의 feature map 에 곱하면 feature map 자체가 얼마나 중요한지에 대한 정보가 생성될 수 있다.
- 즉 이 weight 를 GAP 이전의 feature map 에 곱함으로써 어떤 영역이 class 판단에 있어서 중요했는지 알 수 있다. 이 때 score 가 높은 영역이 중요한 영역이 된다.
- GAP 이전의 각 feature map 에 해당 weight 를 곱하고 summation 하면 클래스를 예측할 때 어떤 위치가 중요한지 얻을 수 있다. 이를 통해서 클래스의 위치를 판단할 수 있다.
- Grad-CAM
- CAM 은 마지막 layer 가 GAP 를 꼭 가져야 한다는 문제점이 있다. 이로 인해 일반적인 classification network 에 바로 적용하기 어렵다.
- 즉 GAP 바로 이전에 마지막 layer 에서만 CAM 을 얻을 수 있고 그 이전의 layer 들이 어떤 식으로 어디가 활성화되고 있는지에 대해서는 확인하기 어렵다는 한계점이 있다.
- 이러한 한계를 극복하기 위한 시도가 Grad-CAM 이다.
- Grad-CAM 에서는 특정 feature map 의 중요도를 GAP 에서의 weight 가 아니라 feature map 의 값이 변할 때 score 가 얼마나 변하는지 그 변화량 분의 변화량으로 파악한다.
- 즉 특정 feature map 에 변화가 있을 때, class score 에도 변화가 크게 일어난다면 중요도가 높은 feature 라고 생각할 수 있다.
- feature map 의 값이 변할 때 score 도 크게 변한다면, 즉 클래스 분류에서 영향을 많이 끼쳤다면 이 feature map 은 중요한 요소라고 생각할 수 있다. 반대로 feature 의 변화가 score 에 큰 변화가 없다면 중요도가 낮은 feature map 이라고 생각할 수 있다.
- feature map 변화량 / class score 변화량 = 기울기 = 미분값으로 중요도를 결정한다고 생각할 수 있다.
- feature map 에 곱해지는 weight 값은 k 번째 feature map 의 요소 하나하나가 바뀔 때 y score의 변화가 얼마나 일어나는지 변화량을 계산한 후, 모든 픽셀 요소에 대해서 이 변화량을 더해주고 평균 낸 값으로 계산할 수 있다.
- 즉 k 번째 feature map 의 특정 class 에 대한 중요도($w$) 는 $\frac{1}{N}\displaystyle\sum_{x, y}\frac{\partial y \; class}{\partial f_k(x, y)}$ 로 계산할 수 있다.
- 이렇게 하면 GAP 를 사용하지 않기 때문에, 어떠한 feature map 에 대해서도 변화량을 통해서 weight(중요도)를 계산할 수 있다. 이를 통해 새로운 backbone 에도 Grad-CAM 을 적용해서 CAM 결과를 추출해낼 수 있다.
- 이렇게 CAM 과 Grad-CAM 을 통해서 classification network 만을 이용해서 segme ntation 을 수행하기 위한 pseudo mask 를 생성하는 것이다.
- 이렇게 생성한 CAM 과 Grad-CAM 의 경우 WSSS task 에 바로 적용하기 어렵다.
-
CAM 의 결과가 sharp 하지 않다.

- sharp 하지 않다는 것은 object 의 모습을 반영하기 보다는 동글동글한 모양으로 생성된다는 것이다.
- 왜 이렇게 CAM 이 sharp 하지 않고 동글동글할까?
- 대표적인 이유는 입력이미지의 크기와 feature map 의 크기가 서로 다르기 때문이다.
- 원본 이미지를 conv 를 거치면서 resolution 이 줄어든 feature map 을 추출한다. 입력 이미지에 대해서 CAM 을 추출하기 위해 feature map 과 입력 이미지의 크기를 맞춰주는 작업이 필요하고 이 때 Upsampling 을 해줘야 한다. 즉, CAM 을 이미지와 동일한 크기로 만드는 Upsampling 과정에서 동글동글해진다고 생각할 수 있다.
- 따라서 WSSS 에서는 이렇게 sharp 하지 않은 CAM 의 결과가 좋지 않아, 관련 연구가 진행되고 있다.
-
CAM 을 Sharp 하게 만들어주기 위한 시도 중 하나는 boundary 를 정교하게 만들어서 이를 loss 에 포함시키는 방법이 있다.
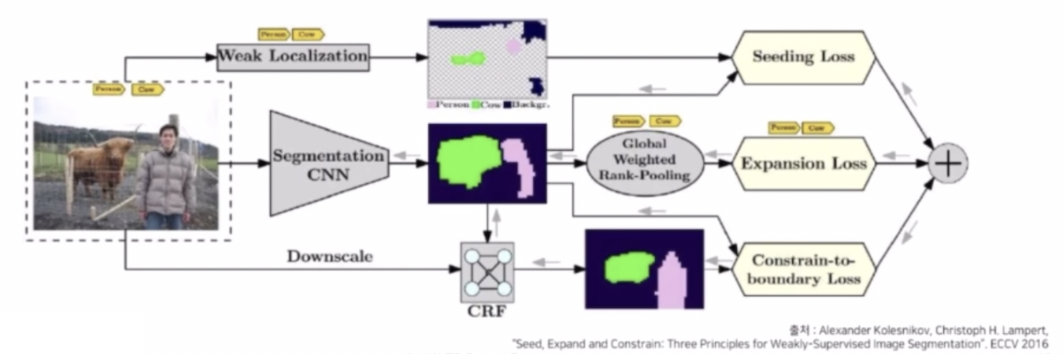
- Segmentaton 모델의 output 을 생성해내고 이를 CRF 를 통해서 물체의 형태를 정교하게 만들어준다.
- CRF 란 probability map 과 입력 이미지를 입력으로 받아서 색깔과 픽셀의 위치에 따라서 가장자리나 object 의 외곽 형태들을 디테일하게 만들어주는 후처리 기법이다.
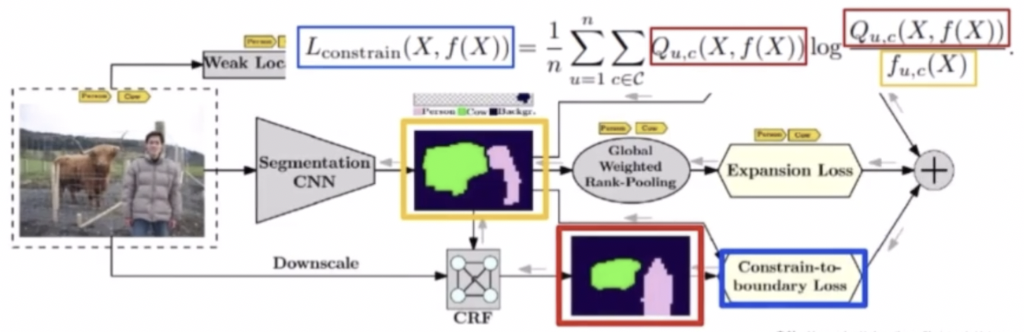
- Segmentation 결과에 CRF 를 통해서 정교하게 object 형상을 생성해내고, 이 Segmentation output 과 CRF output 이 같아지도록 KL divergence loss 를 적용해서 boundary 를 강화시키는 loss 를 사용할 수 있다. 이 부분이 바로 Constraint to boundary loss 이다.
-
그 외에 CAM 의 결과 자체를 sharp 하게 만들어주기 위해서 transfer learning 을 이용한 접근법도 있다.
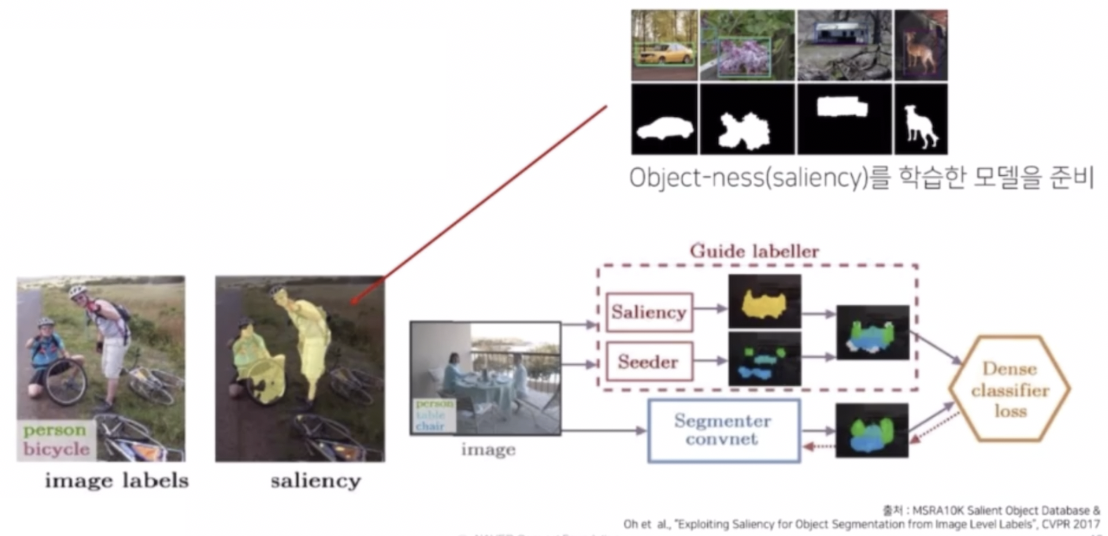
- Saliency 라고 부르는 일종의 object 를 바라볼 때 어디를 처음으로 보는지에 대한 정보를 활용한다.
- 해당 접근에서는 외부 데이터셋으로 saliency 에 대한 정보를 담아놓은 데이터셋을 기반으로 Saliency 모델 자체를 학습을 한다.
- Seeder 부분을 통해서 뽑아낸 CAM 의 결과와 Saliency 를 학습한 네트워크의 Saliency 를 특정한 룰 기반으로 합쳐서 좀 더 sharp 한 결과를 얻어낸 다음에 이를 pseudo mask 자체로 활용하는 접근이 있었다.
-
최신 연구 중 하나는 Self Supervised Learning 을 사용한 연구도 있다.
- CAM 결과가 입력 이미지의 size 에 따라서 다른 결과를 보이는 관찰을 했다. 입력 이미지의 사이즈가 작아질수록 CAM 의 결과가 더 sharp 하지 않게 만들어진다.
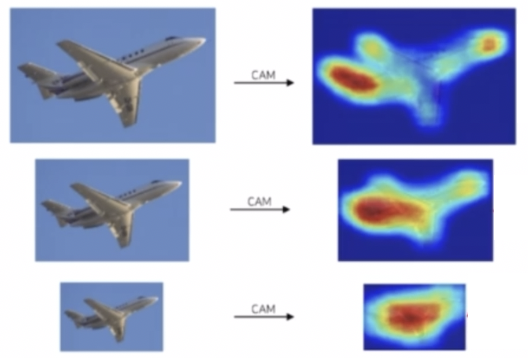
- 이에 따라 CAM 의 결과를 일관성 있게 만드는 loss 를 반영해줄 수 있다.
- 입력 이미지에 대해서 CAM 을 추출하고 down sampling 한 결과와 down sampling 을 수행하고 CAM 을 추출한 결과, 즉 2개의 CAM 의 결과가 모양이 같도록 L1 Loss 를 적용하는 것이다.
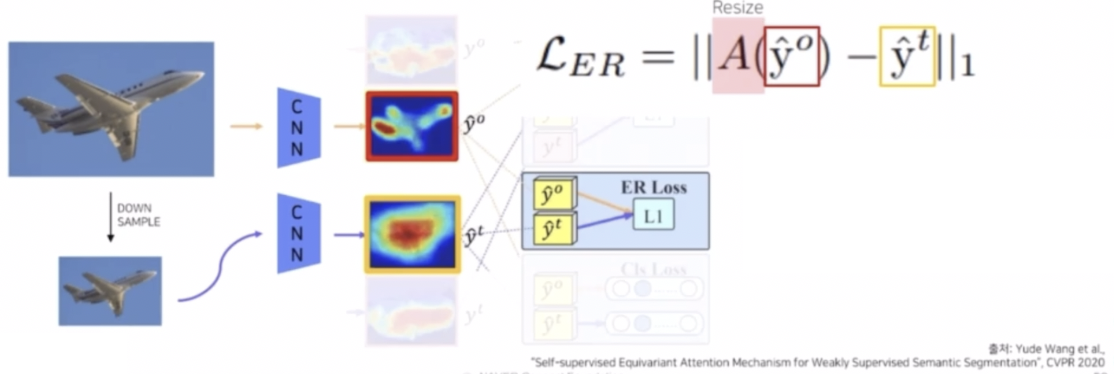
- 이를 ER Loss 라고 표현해서 원본 이미지의 CAM 을 통과하고 resize 한 결과와 down sampling 으로 크기를 줄인 다음에 CAM 을 뽑은 결과를 L1 Loss 를 통과시켜서 같은 모양을 가지도록 loss 를 반영하는 것이다.

-
- CAM 의 결과가 sharp 하지 않다는 특징 말고도 특징적인 영역에만 CAM 이 집중된다는 특징이 있다.
- CAM 은 classification 할 때 중요한 부분에만 집중되어 활성화된 모습을 확인할 수 있다.
- 왜 이런식으로 CAM 이 특징적인 부분에만 집중하는 것일까?
- 첫번째 이유는 분류 모델 자체의 loss 에 있다. 즉 Classification 을 통해 간접적으로 학습했기 때문이다.
- 분류 모델은 CAM 을 잘하기 위함이 아니라 물체가 어떤 클래스를 가지는지 잘 구분하기 위해 학습하기 때문에, CAM 이 물체와 같은 모양을 할 이유가 적다. 즉 CAM 이 object 전체를 포함할 이유가 적다.
- 두번째 이유는 분류를 잘하도록 다른 클래스임을 확실하게 알 수 있는 특징에 의존할 수 없다.
- 동물의 몸만 보는 경우보다 얼굴만 보는 경우가 구분하기 더 편하다.
- 마찬가지로 모델 또한 동일하게 몸과 얼굴 중에서 얼굴만 보는 경우가 더 구분하기 쉽고 인식하기 편하다.
-
세번째 이유는 같은 클래스의 물체 끼리 서로 다른 모습을 갖고 있기 때문에 공통적으로 보이는 특징에 의존한다.

- 위 예제는 모두 타조의 모습이지만 어떤 사진은 얼굴만, 어떤 사진은 몸통만 나온다. 이렇게 같은 클래스여도 서로 다른 모습을 보이기 때문에 대체적으로 CAM 은 일반적인 얼굴과 부리 부분에 가장 집중할 수 밖에 없고 CAM 자체의 결과가 그렇게 나올 수밖에 없다.
- 즉 서로 다르게 생긴 와중에 비슷하게 생긴 부리에 집중해서 classification 을 수행하는 것이다.
- 이렇게 특징적인 부분에만 집중하는 것을 어떻게 해결할 수 있을까?
-
Adversarial Erasing (AE)
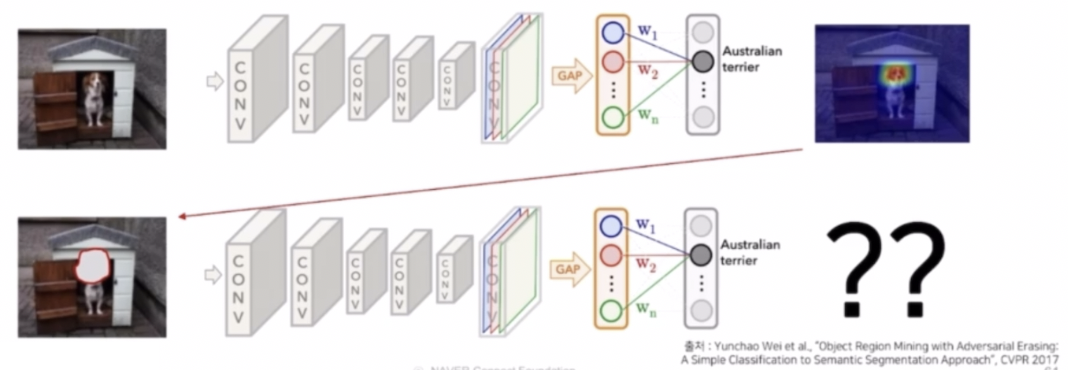
- CAM 이 가장 중요한 discriminate 한 영역만 추출한다면, 입력 이미지에서 해당 영역을 지우고 CAM 의 결과를 뽑는 것이다.
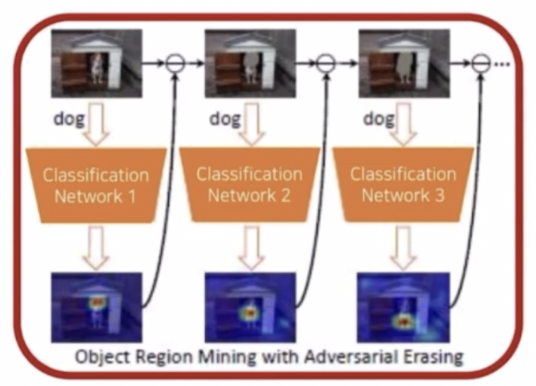
- 먼저 Classification Network 1을 통해서 입력이미지를 학습하고 CAM 을 추출한다.
- 그리고 CAM 의 결과 영역을 모델의 입력에서 제거한다. 이 때 단순 제거가 아닌 전체 학습 이미지의 평균으로 RGB 값을 대체한다.
- CAM 의 결과가 빨간색으로 중요한 영역, 노란색으로 덜 중요한 영역이 있는데 이러한 부분에 대해서는 threshold 값을 주어서 특정 값 이상의 부분만 제거를 진행한다.
- Classification Network 1 과 독립인 새로운 Classification Network 2 로 CAM 의 결과 영역이 제거된 이미지를 학습하고 CAM 결과를 생성한다.
- 똑같이 CAM 영역을 제거하고 새로운 Network 에 학습시켜 CAM 을 생성한다. 이 과정을 반복한다.
- 이후 지워진 CAM 영역들만 모으면 object 영역에 해당하는 최종 결과를 만들어낼 수 있다.

- Step 이 진행됨에 따라서 다른 영역에 CAM 이 생성됨을 확인할 수 있다.
- 한계점
- Output 별로 다른 모델을 학습해야하는 번거로움이 있다. 각 step 별로 독립인 network 를 가지고 CAM 의 결과를 추출하기 때문이다.
-
또한 각 클래스별로 필요한 step 이 다르다는 점이다.

- 예를 들어 말의 이미지는 특정 step 에서 충분한 pseudo-mask 를 얻었는데, 의자는 그 step 에서 불충분한 pseudo-mask 를 생성했음을 확인할 수 있다.
- 이렇게 object 마다 필요한 step 이 다르다는 문제점 때문에, 특정 클래스는 과도한 step 으로 인해 object 가 아닌 영역까지 mask 가 생기는 현상이 발생한다. 이를 over erasing 이라 표현한다.
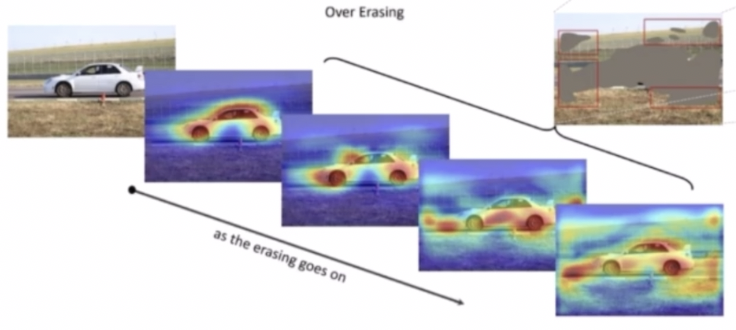
- 독립인 모델이 여러번 학습하는 문제와 over erasing 문제를 해결하기 위한 연구들이 후속적으로 나타나고 있다.
- Hide-and-Seek(HaS)
- 입력 이미지의 1 부분을 patch 단위로 random 하게 지워서 모델이 최대한 다양한 영역에서 특징을 뽑을 수 밖에 없도록 강제한다.
- 예를 들어 얼굴 영역이 지워진 경우에는 다리를 보고 강아지라는 것을 알게 되도록 학습시키는 것이다. 이렇게 되면 결과적으로 한 개의 네트워크로 Erasing 과 비슷한 효과가 생긴다.

- 입력 이미지를 (S, S) 의 크기를 가지는 패치로 나누고, 각 패치별로 확률을 0.5 로 해서 지울지 말지를 결정해준다. 그렇게 만든 이미지로 CNN 을 학습한다.
- 이 과정을 epoch 가 모두 진행될 때까지 계속해서 random 하게 지워지는 영역만 다르게 해서 학습한다.

- 그 결과, CAM 의 영역이 넓어진 것을 확인할 수 있다.
- 이런 식의 기법은 하나의 네트워크를 이용해서 결과를 얻었기 때문에, 여러 개의 네트워크가 필요하지 않고 여러 번 지우지 않기 때문에 over erasing 의 문제도 없다.
- 그러나 한가지 문제점은, random 하게 지워서 학습하는 것이 CAM 의 결과가 특징적인 부분만 집중하지 않는 non-discirminate 한 영역으로 확장될 것이라는 보장이 없다.
- 이에 다른 연구들은 하나의 네트워크만을 사용하는 것은 동일하게 하되 접근법은 조금 다르게 erasing 하는 방향으로 진행됐다.
-
ACoL (Adversarial Complementary Learning)
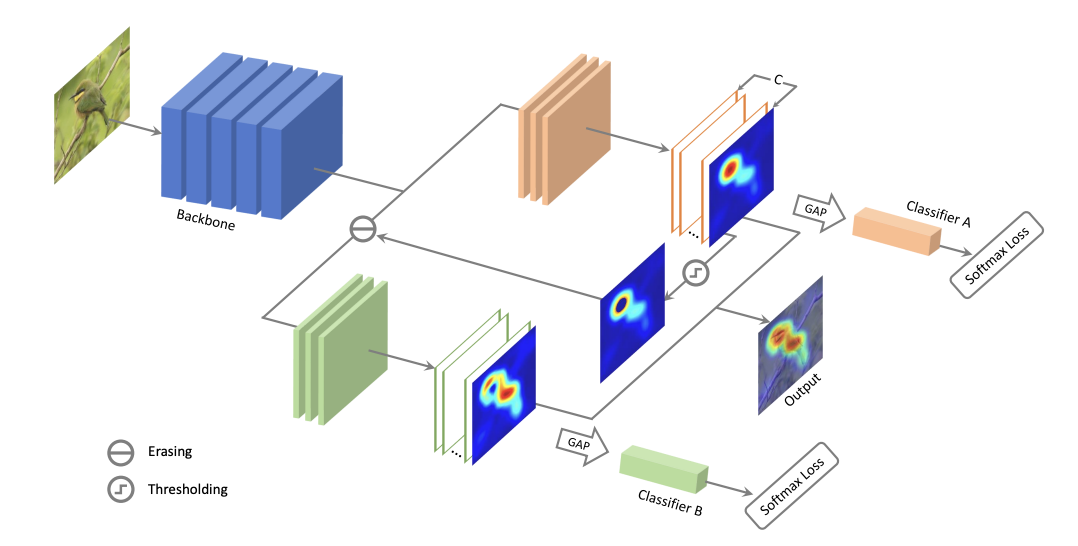
- 하나의 네트워크에서 2개의 classifier 를 이용해서 adversarial erasing 을 수행한다.
- 하나의 classifier 에서는 CAM 이 아니라 feature map으로 히트맵을 얻는다.
- 이후 생성한 히트맵에서 threshold 이상의 지울 영역을 구한 뒤 지우고, 삭제한 feature map 정보를 2번째 classifier 에 전달해서 히트맵을 다시 얻는다.
- 이후 2개의 히트맵을 결합시켜서 최종적인 결과를 생성해낸다.
- 첫번째 히트맵에서 검출된 영역은 두번째 히트맵에서 검출되지 않는다. 이 둘의 결과를 fuse 해서 더 넓은 mask 를 생성할 수 있다.
- 이러한 erasing 기법 이외에도 몇 가지 기법이 있다.
-
Dilated Conv 를 이용한 다양한 Receptive field 사용
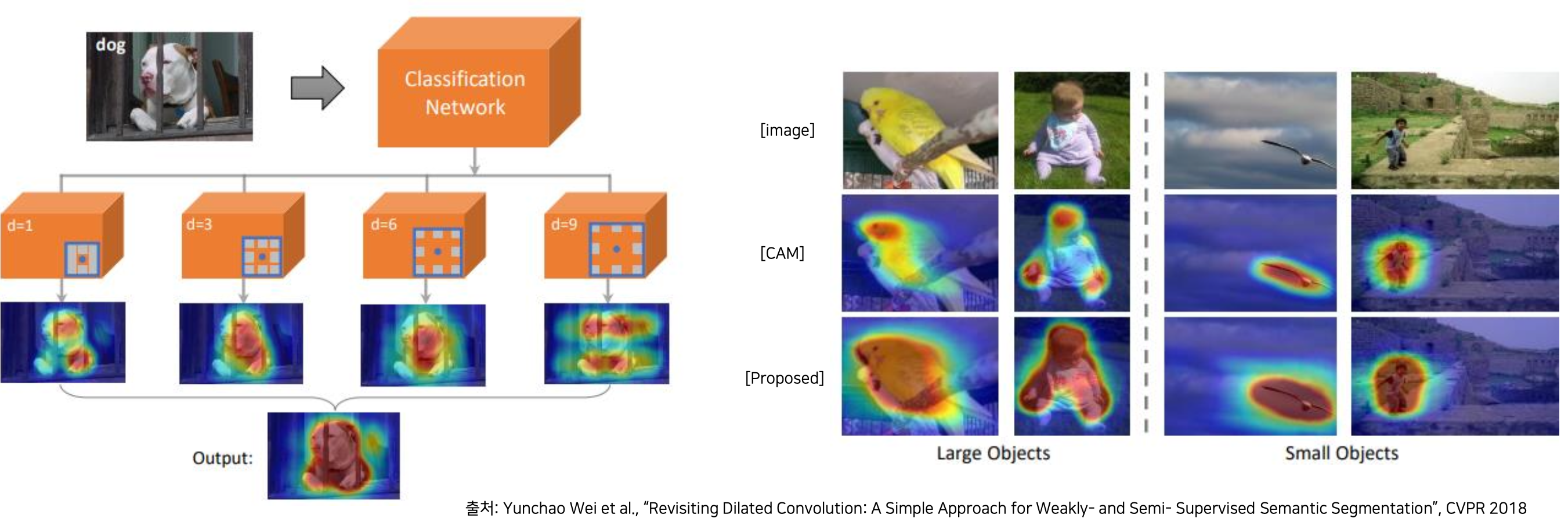
- dilated conv 비율에 따라서 receptive 가 넓어지는 특징을 이용해서, receptive field 를 다르게 하는 conv 를 여러개를 적용시켰다.
- 위 그림처럼 dilate 비율이 낮은 것은 CAM 의 결과가 좁게 나오고, dilate 비율이 커질수록 CAM 의 영역이 넓어진다. 이 결과들을 합쳤을 때 original CAM 결과에 대비해서 훨씬 좋게 나온다.
- receptive field 가 좁을수록 특징적인 영역은 좁아지게 되고, receptive field 가 넓을수록 특징적인 영역이 넓어지게 된다.
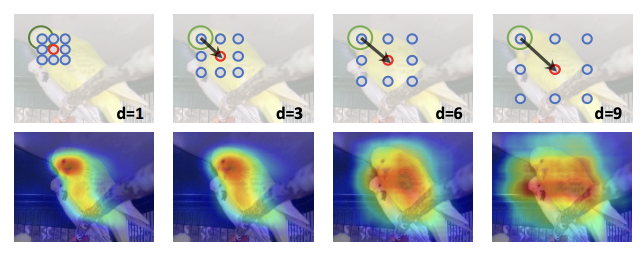
- receptive field 가 넓어짐에 따라서 object 가 아닌 영역에 대해서도 CAM 이 잡히는 경우가 많다. 이에 따라 receptive field 가 좁을 때 가중치를 더 크게 줘서 가중합을 통해서 최종적인 CAM 의 결과를 생성한다.
- 그 외에도 Augmentation 에서 본 Mixup 기법을 활용할 수 있다.
- Classifier 를 학습할 때 Mixup 을 사용해서 CAM 의 결과를 좋게한 연구도 있었다.
- 이러한 WSSS 는 Adversarial Erasing 을 이용한 방법 말고도 Sailency 혹은 Attention Mechanism 을 이용하거나 Pixel Affinity 를 이용한 방법 등 다양하게 발전되고 있다.
-
- WSSS (Weakly Supervised Semantic Segmentation)
댓글 남기기