
[Segmentation] 7. SegFormer
- Semantic Segmentation 연구 동향 (SegFormer)
- 최근 Semantic Segmentation 연구 동향
- 크게 두 가지이다.
- Classification task 에서 성능이 좋은 pretrained backbone 을 활용한다.
- Semantic Segmentation 에 적합한 모델을 설계한다.
- Vision Transformer
- Image Classification 에서 높은 성능을 달성했다. 이를 Seg 에 적용하려는 시도가 늘었다.
- ViT 와 CNN 의 차이는, CNN 은 입력 이미지가 들어왔을 때 layer 를 깊게 쌓음에 따라서 receptive field 를 넓히려는 시도를 한다. 따라서 깊은 layer 에서 receptive field 가 큰 모습을 보인다. 즉 receptive field 가 layer 의 depth 와 dependency 가 생기게 된다.
- 그로 인한 특징은 layer 를 deep 하게 쌓음으로써 얻는 이점에 대한 한계가 존재한다. 이러한 한계를 ViT 에서는 self attention 을 기반으로 해결했다고 생각할 수 있다. 즉 global 정보를 self attention 기법으로 추출한 것이다.
-
SETR
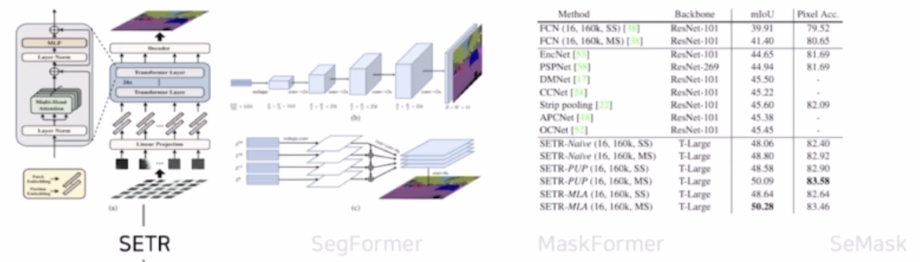
- Segmentation task 에 ViT 를 backbone 으로 적용한 대표적인 모델이다.
- ViT 와 같이 입력 이미지를 patch 로 나누고 patch 와 position 에 대한 embedding 을 수행한 다음 transformer 를 이용해서 segmentation 을 수행한다.
-
SegFormer
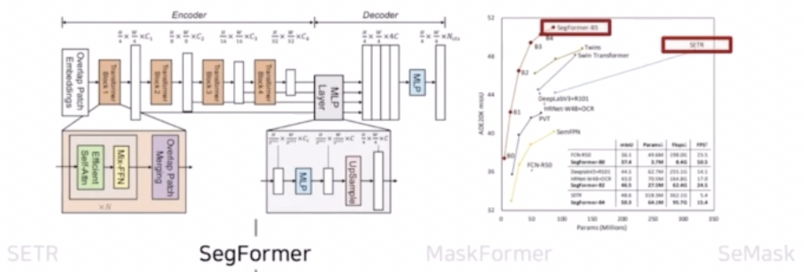
- 기존 ViT 를 backbone 으로 사용한 SETR 의 한계점인 low efficiency 와 real time 적용의 어려움을 극복한 단순하고 효율적인 모델이다.
- 실제 SETR 과 SegFormer 의 파라미터 수와 성능을 보면 SegFormer 가 파라미터 수가 훨씬 적음에도 불구하고 성능이 높다.
- 모델의 구조 자체도 심플한 형태를 가진다.
-
MaskFormer
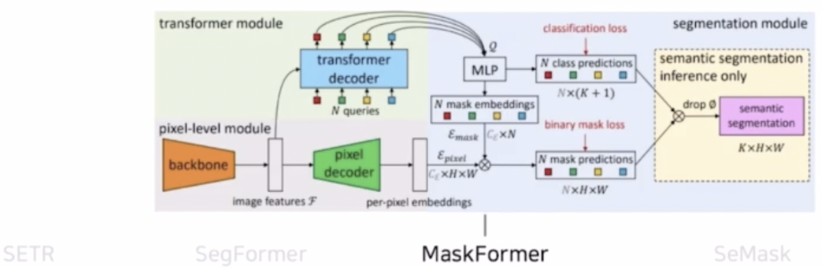
- transformer 를 사용하면서 기존 classification loss 에 binary mask loss 를 추가한 모델이다.
-
SeMask
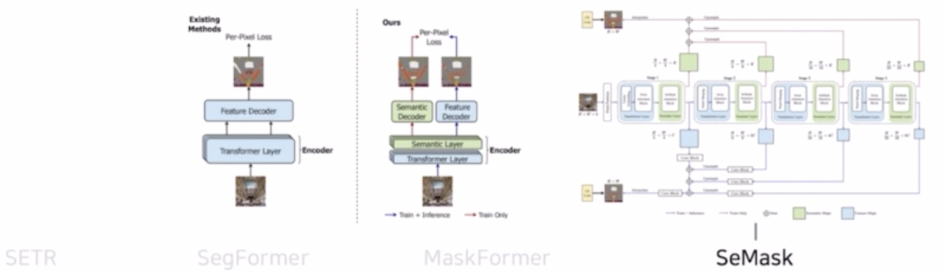
- pretrained 된 모델을 segmentation 에 많이 활용하고 있는데, 이 때 pretrained 된 모델을 바로 가져오는 것이 아니라 semantic layer 를 새로 추가해서 활용하는 것을 제안한 연구다.
- 즉 pretrained 된 hierarchical transformer backbone 에 semantic layer 를 추가한 모델이다.
- 크게 두 가지이다.
-
SegFormer
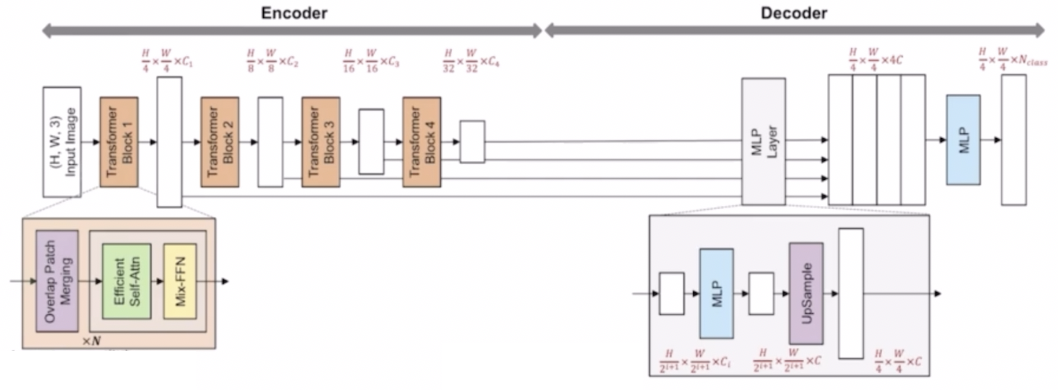
- ViT 를 활용한 SETR 의 한계점을 개선한 논문으로서 simple 하면서도 efficient 하다는 특징이 있다.
- segmentation task 에 맞게 encoder-decoder 구조이다.
- Encoder 의 가장 큰 특징은 multi-level feature map 을 추출했다는 것이다.
- Decoder 의 가장 큰 특징은 lightweight AII-MLP layer 를 구성했다는 특징이 있다.
- Encoder
- 고해상도(high-resolution) 특징과 저해상도(low-resolution) 특징을 같이 추출하고 유지한다.
- 입력 초기에는 high resolution 의 feature 를 그리고 layer 가 쌓아짐에 따라 low resolution 의 feature 를 추출한다.
- 다른 resolution 을 가지는 4개의 feature 를 모두 활용해서 MLP layer 에 입력으로 넣어준다.
- 4개의 feature 는 Hierarchical 한 multi level 의 feature map 을 구성한다. multi level feature map 은 HRNet 이나 DeepLab, UNet 에서도 살펴볼 수 있다.
- HRNet 은 입력이미지를 Stem 에서 1/4 만큼 줄이고 이 feature map 을 4개의 병렬 flow 로 활용했다. UNet 은 Encoder 에서 입력이미지를 conv 를 통과시키고 down sampling 을 통해서 1/2 씩 계속 감소시킨 다음, Encoder 의 feature 를 Decoder 에서 concatenate 하는 과정을 계속 거쳤다. DeepLab v3+ 는 Encoder 중간 부분에서 feature 가 나오고, 이를 활용해서 Decoder 에서 같이 결합해서 활용했다.
- SegFormer 에서도 multi level feature map, 즉 high resolution 부터 low resolution 까지 추출한 다음 활용했다.
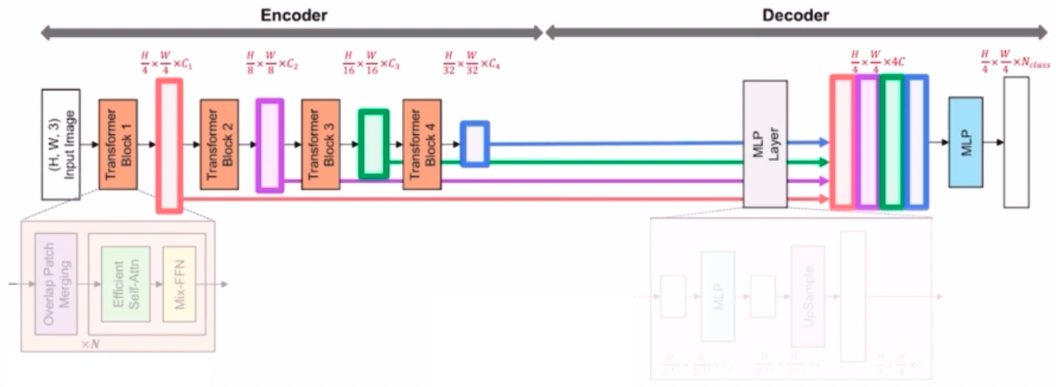
- SegFormer 의 Encoder 를 구성하고 있는 Transformer Block 에 대해 살펴보자.
- Transformer block 은 세가지 구성요소로 이루어져 있다.
- Overlap Patch Merging
- Efficient SA(self-attention)
- Mix-FFN
-
구성요소 1-1) Local Continuity 를 보존하기 위해 overlapping patch merging 을 도입했다.
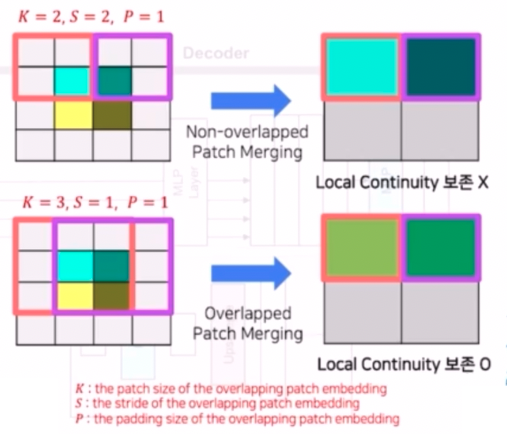
- 인접 픽셀의 값이 유사한 경우 image 는 local continuity 를 갖는다고 하며, semantic segmentation task 에서 유용하다. 즉 인접한 픽셀들 간에 연속성 및 공간적 정보가 이어진다는 것이다.
- 이 Overlapping Patch Merging 파트는 ViT 의 한계점 중 하나인 ViT 가 semantic segmentation task 에 적합하게 설계된 모델이 아니라는 점을 해결하기 위해 도입되었다.
- 기존의 ViT 는 입력 이미지를 16x16 의 patch 로 나눈 다음에, 서로 간의 patch 가 겹치는 영역이 안 생기도록 추출한다. 이를 non-overlapped 라고 표현한다.
- SegFormer 는 Overlapping Patch Merging 를 위 그림과 같이, 입력 이미지를 patch 로 나눌 때 patch 간 겹치는 부분이 있도록 생성한다. 이렇게 해주는 이유는 segmentation 의 mask 혹은 이미지를 생각했을 때, 인접한 픽셀들은 같은 클래스를 가지는 경우가 많다. 그래서 공간적으로 가까운 픽셀들이 같은 클래스에 속하는 경향이 있다.
- 기존의 ViT 는 patch 를 겹치는 영역없이 쪼갰기 때문에 보존하기 어렵지만, SegFormer 에서는 patch 를 overlap 되게 만들어 local continuity 를 보존했다. 즉 patch 마다 같이 반영되는 특징이 있어 local continuity 를 보존하는 것이다. 이에 따라 좀 더 segmentation task 에 알맞은 patch 를 만들 수 있다.
- 추가적으로 overlapping patch merging 파트는 conv 를 이용해서 patch 를 만든다. 이 때 conv 에 kernel size, stride, padding 을 주어 입력 이미지의 크기를 줄여주는 역할도 같이 수행하게 된다.
- 이를 Encoder 전체 과정에서 살펴보면, Encoder 에는 총 4개의 transformer block 이 있다.
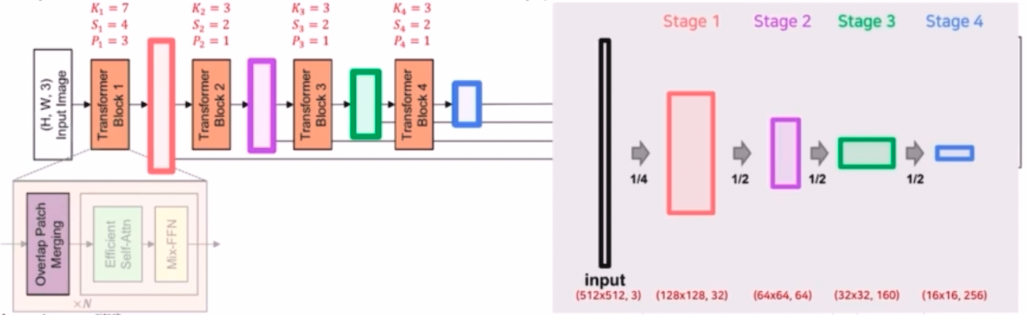
- 각 transformer block 은 3가지 구성요소를 가지는데, 그 중 overlap patch merging 은 파라미터를 초기에는 kernel size 7, stride 4, padding 3 을 가지고 나머지 transformer block 에서는 3, 2, 1 을 가진다.
- ViT 는 16x16 의 patch size 를 가졌다면, SegFormer 는 4x4 의 훨씬 작은 patch size 를 구성해서 좀 더 dense prediction task 인 segmentation 에 더 적합하게 설계를 했다.
- 또한 convolution 의 kernel size, stride, padding 을 조절해서 입력 이미지의 크기를 줄이는데, 첫번째 stage 에서는 1/4 만큼 줄이고, 그 외 나머지 stage 에서는 1/2 만큼 줄인다.
- 이렇게 줄인 feature 를 이용해서 high resolution 부터 low resolution 까지 다양한 hierarchical 한 feature 를 생성한 것이다.
- 구성요소 1-2) Efficient SA
- 기존 Encoder 의 SA layer 는 높은 계산 복잡도 $O(N^2)$ 를 가진다. $(N = H\times W)$
- 기존 attention 수식 $\text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^T}{\sqrt{d_{head}}}\right)V$ 을 보면 $Q$ 와 $K^T$ 를 곱하고 이를 scaling($\sqrt{d_{head}}$) 해준 다음에 softmax 이후에 $V$ 를 곱한다. 이 때 $QK^T$ 는 차원이 H, W, C 일 때 $O((H \times W)^2)$ 의 계산 복잡도를 가진다.
- 즉 입력 이미지의 크기가 커지면 커질수록, 즉 H 와 W 가 커질수록 계산 복잡도가 계속해서 증가한다.
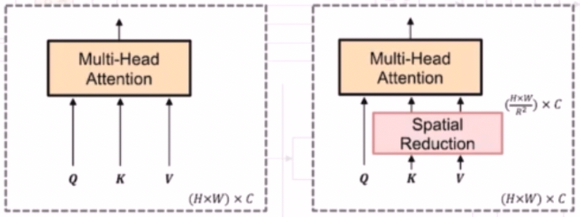
- 이러한 이유로 해당 논문에서는 pyramid vision transformer 라는 PVT 논문에서 제안한 spatial reduction 개념을 활용했다. 이를 통해 높은 계산 복잡도를 낮추려는 시도를 한 것이다.
- Spatial Reduction 을 해주는 Efficient SA 의 경우 $K$ 와 $V$ 에 spatial reduction 을 취해서 기존의 차원이 $H, W, C$ 라면 Reduction Ratio($R$) 의 제곱배 만큼으로 spatial part($H, W$) 를 나눠준다.
- 이렇게 Reduction Ratio($R$) 를 도입하여 $K, V$ 의 sequence length 를 줄여 효율적으로 attention 을 계산할 수 있다. 즉 입력 이미지의 $H, W$ 가 커지더라도 효율적으로 attention 을 계산할 수 있도록 하는 것이다.
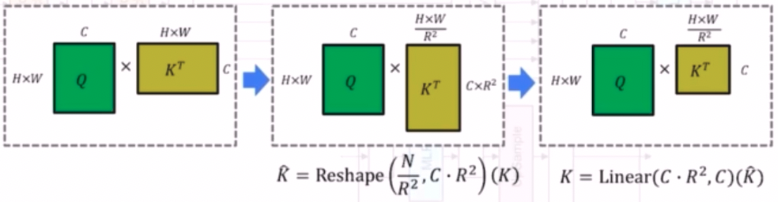
- Efficient SA 는 Reduction Ratio($R$)을 도입하여 $K^T$ 를 $R^2$ 만큼 으로 reshape 를 해준다. 그래서 기존의 $H \times W$, $C$ 가 $\frac{H \times W}{R^2}$, $C \cdot R^2$ 로 reshape 되고, 그 이후 Linear Projection 을 통해 $C \cdot R^2$ 를 C 만큼으로 줄인다.
- 이로 인해 원래 SA 의 계산복잡도인 $O(N^2)$ 를 $O(\frac{N^2}{R^2})$ 로 감소시키는 효과가 있다.
- Efficient SA 는 transformer block 1부터 4까지 모두 있고, $R$ 은 8, 4, 2, 1 로 입력이미지의 feature size 가 클 때에는 $R$ 도 크게 한다. feature map 의 크기가 작아짐에 따라 $R$ 의 크기도 줄이고 마지막 transformer block 은 $R$ 이 1로 efficient SA 를 적용하지 않았다.
- 구성요소 1-3) Mix-FFN
- 기존 ViT 같은 경우 location information 을 반영해주기 위해서 position embedding 을 활용한다. 그러나 ViT 의 positinal encoding 의 문제점은 train set 의 resolution 을 기반으로 학습된 PE(positional encoding)를 resolution 이 다른 test set 에 적용하는 경우 interpolation 으로 인해 성능이 저하된다.
- 즉, 논문에서는 test 와 train 의 resolution 이 다를 때, PE 는 train set 의 resolution 을 기반으로 학습되었기 때문에 interpolate 를 통해서 test set 의 resolution 을 맞춰줘야 하는 작업이 필요하고 이 경우 성능의 감소가 있다고 언급했다.

- 실제 논문 실험 결과를 보면 inference resolution 에서 1024 x 2048 로 변했을 때 mIoU 성능이 떨어짐을 확인할 수 있다.
- 추가로 저자는 Semantic Seg 에서는 positional encoding 과정이 필요없다고 주장한다. 따라서 PE 를 사용하는 대신에 Feed Forward(MLP) 와 3x3 conv 이 결합된 Mix-FFN 을 도입했다. 이 때 수식은 다음과 같다. $x_{out} = \text{MLP}\left( \text{GELU} \left( \text{Conv}{3 \times 3} \left( \text{MLP} (x{in}) \right) \right) \right) + x_{in}$
- 실제 Mix-FFN 의 결과는 inference resolution 이 달라도 성능 변화 폭이 크게 줄었다.
- Transformer block 은 세가지 구성요소로 이루어져 있다.
- Decoder
- SegFormer 의 Decoder 는 효율적이고 간단한 lightweight AII-MLP 구조를 가졌다. Decoder 는 MLP layer 로 구성되어 있다.
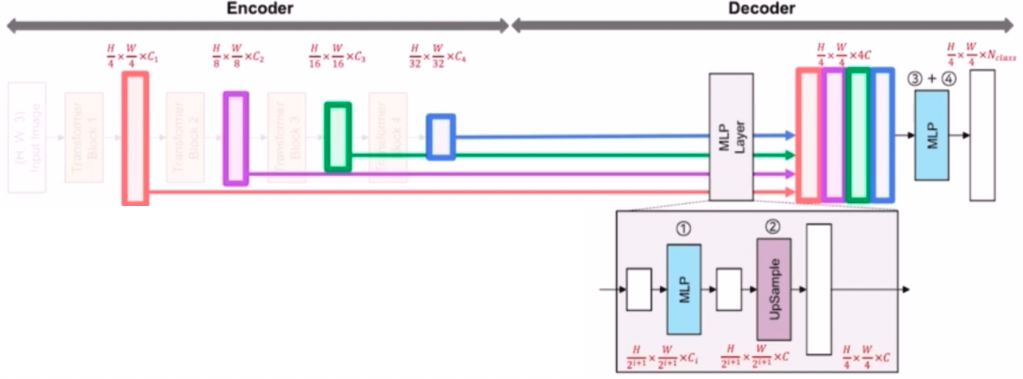
- Encoder 에서 추출된 multi-level feature 들을 입력으로 받는다.
- Decoder 의 MLP layer 는 multi-level feature 의 input 들이 들어왔을 때 먼저 MLP 를 통과시켜서 채널을 $C$ 로 통일시킨다.
- 그 이후 feature size 를 원본 이미지의 1/4 크기로 유지하기 위해서 Up sampling 을 한다.
- 이렇게 되면 최종적으로 MLP 로 채널을 맞추고 Upsampling 으로 크기를 맞춰서, resolution 은 원본 이미지의 1/4 크기, 채널은 $C$ 을 가진다.
- 이 MLP, Upsampling 과정을 4 개의 multi-level feature 에 대해 수행하고 이후 concatenate 를 시킨다. 이후 또 한번의 MLP 를 통해서 4배로 증가한 채널을 $C$ 로 변경해주고 $N_{class}$ 채널의 최종 segmentation mask 를 예측한다.
- SegFormer 세부 구조
- 논문과 코드 구현의 Architecture 차이가 있다. 바로 Encoder 의 transformer block 내 순서에 차이가 있다.
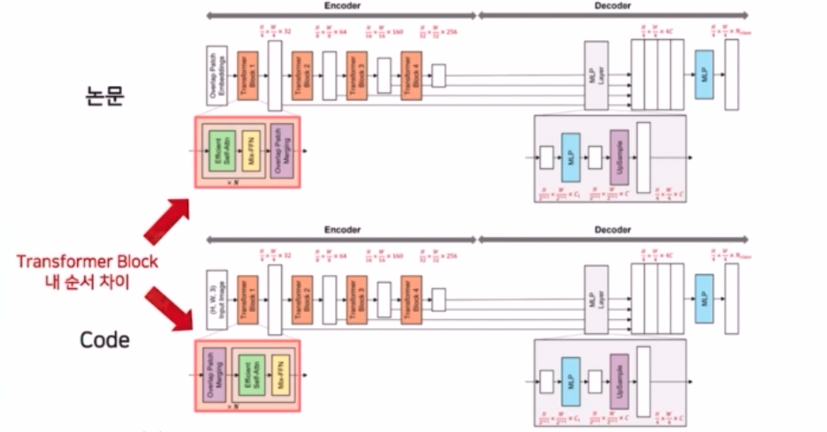
- 논문에서는 Overlap Patch Embedding 과정 이후 Efficient SA, Mix-FFN 그 이후 Overlap Patch Merging 과정을 거친다고 나왔다. 그러나 실제 구현체의 경우 입력 이미지가 들어왔을 때 Overlap Patch Merging 과정이 먼저 있고 Efficient SA 과 Mix-FFN 이 수행되는 순서이다.
- SegFormer 는 Encoder 파트를 Mix Transformer 라는 명칭으로 제안한다. 이 때 하이퍼 파라미터의 size 에 따라서 B0 부터 B5 까지를 표현한다.
- SegFormer-MiT-B0
-
Encoder
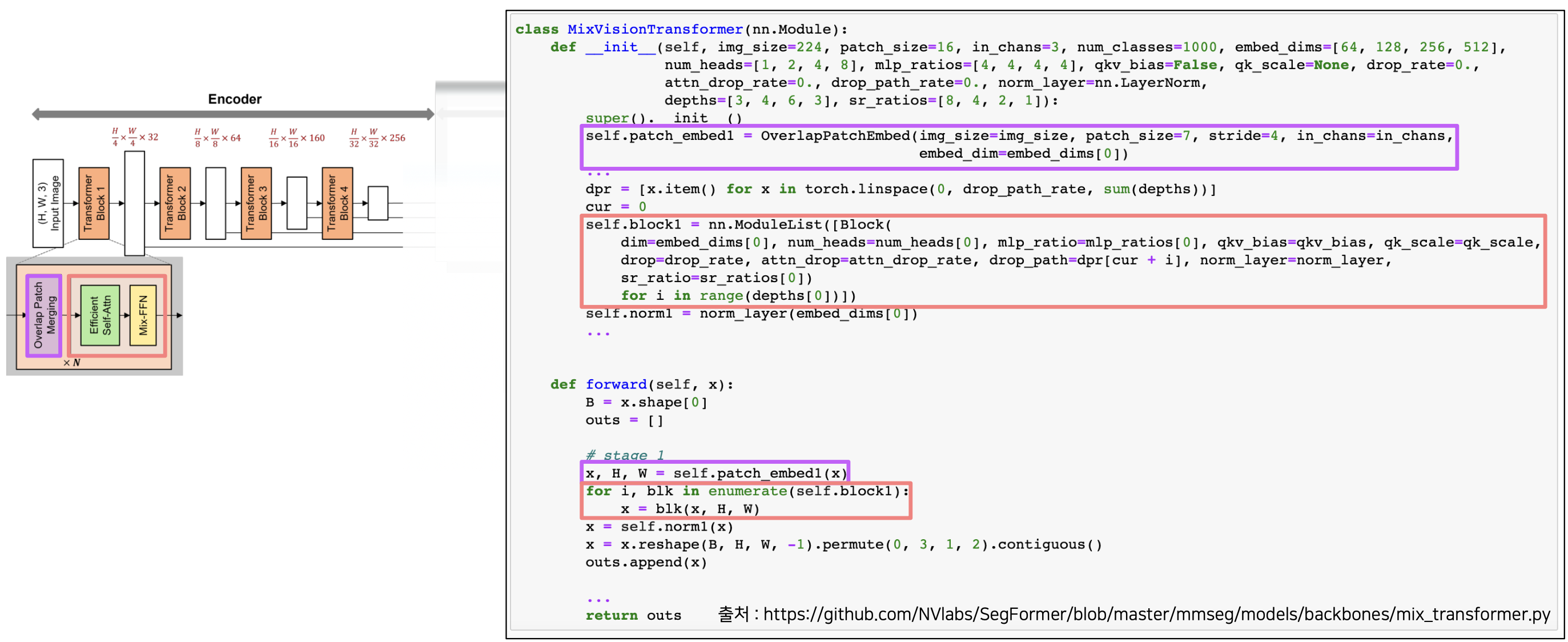
- tranasformer block 은 4개를 반복하고, 각각은 Overlap Patch Merging, Efficient SA, Mix-FFN 순서로 이루어진다.
- 하나의 transformer block 에서 Efficient SA 와 Mix-FFN 은 $N$ 만큼 반복한다.
-
Overlap Patch Embedding
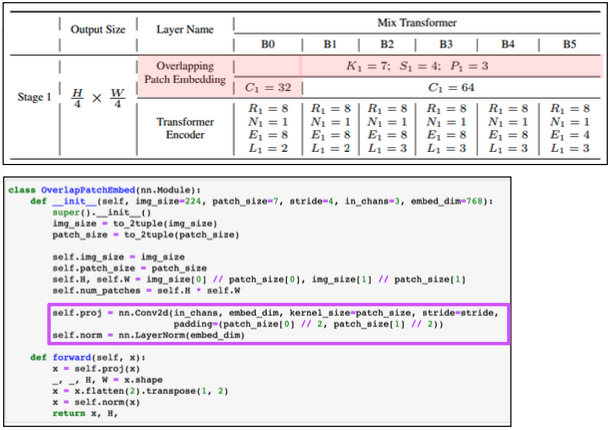
- conv 를 통해서 이루어진다.
- 입력 이미지가 512, 512, 3 이라면, 첫번째 transformer block 에서는 kernel size 7, stride 4, padding 3 을 주어서 입력이미지의 크기를 1/4 만큼 줄이게 된다. 이를 코드에서는
self.proj라고 표현한다. - 이후 flatten 과 layer norm 과정을 취해준다.
-
Efficient Self-Attention + Mix-FFN
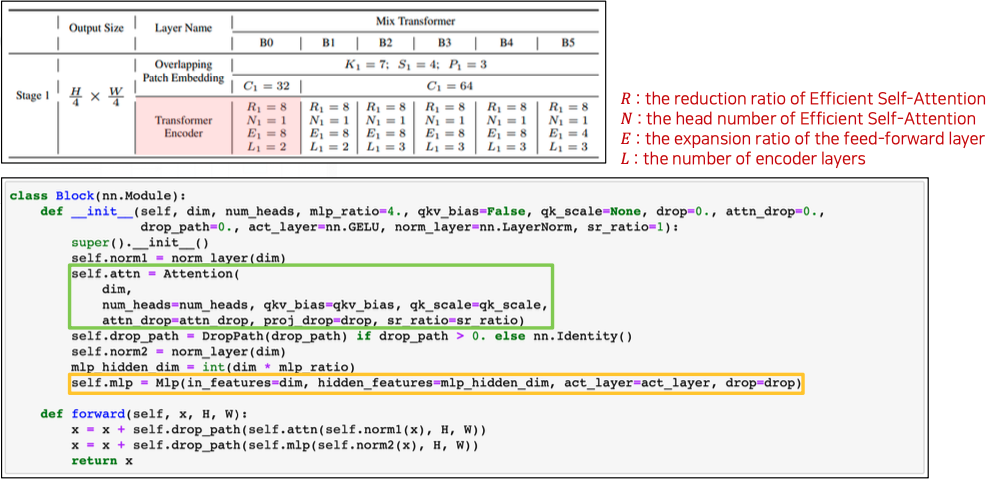
- Block 은 Efficient SA 와 Mix-FFN 으로 구성된다.
-
Efficient SA
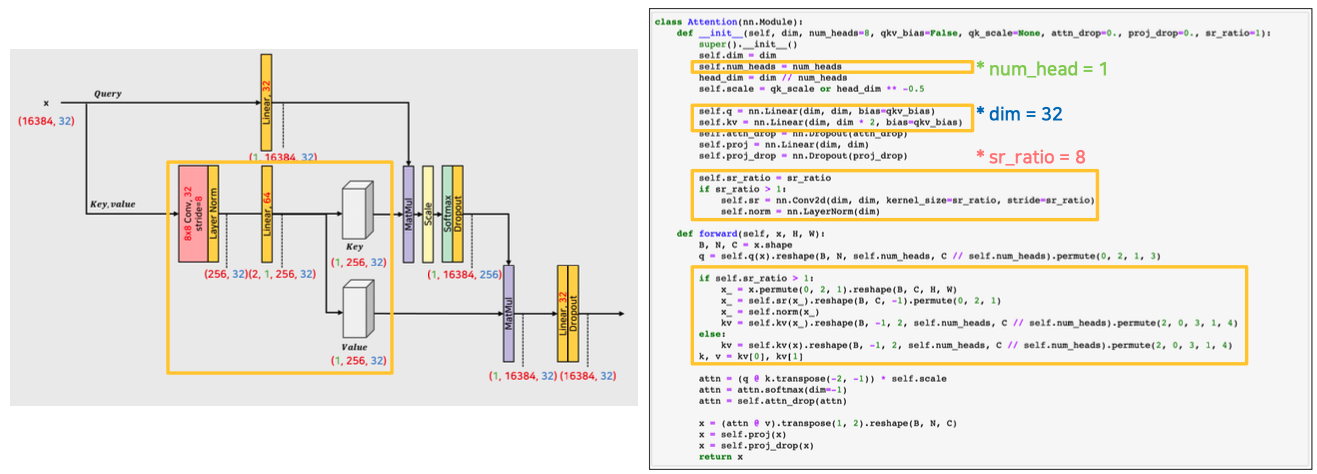
- $K$ 와 $V$ 에 대해서 Spatial Reduction 을 해준다.
- 이 때 conv 연산을 통해 spatial reduction 을 진행한다. 즉 $K^T$ 를 reshape 해서 ($\frac{H \times W}{R^2}, C \cdot R^2$) 으로 만들어주고 Linear Projection 을 통해서 $C \cdot R^2$ 을 $C$ 로 만들어주는 것을 conv 를 이용해서 연산하는 것이다.
- 먼저 입력을
permute와reshape으로 conv 연산이 가능하게 만들어준 뒤, Reduction Ratio($R$) 에 따라 입력의 크기를 줄이는 reshape 을 한다. 이후 reshape 된 것을 하나의 픽셀로 projection 을 해주는 과정을 진행하는데, 이 두 과정을 conv 를 이용해서 연산하는 것이다. - 자세히 보면 다음과 같다.
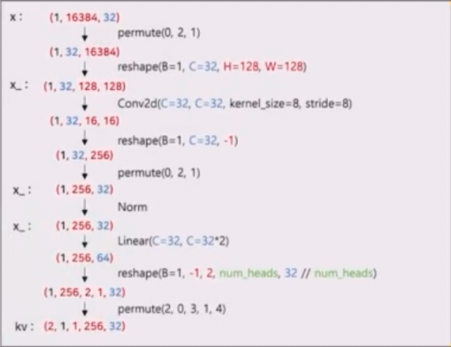
- 입력이 들어왔을 때 permute 와 reshape 으로 conv 연산이 가능하게 만들어준다. 이후 H, W 인 128, 128 를 conv 를 통해서 spatial reduction 을 해준다.
- 이후 다시 reshape 민 permute 과정을 거쳐서 normalization 후에 K 와 V 에 대해서 linear 연산을 통해 입력 채널을 바꿔준다.
- 그 이후 num_head 연산을 수행한다.
- Attention 은 Q, K, V 에 대해서 각각 linear 연산을 수행해준 뒤 행렬곱, softmax 및 scaling 을 취하는 부분이 있다. 위에서 linear, reshape, permute 가 같은 역할을 한다고 볼 수 있다.
- 참고할 점은 K 와 V 를 묶어서 한번에 수행해줬다는 점이다.
- 이처럼 K, V 를 spatial reduction 을 통해 축소를 수행하고, linear 연산을 수행하는데,
dim * 2인 이유는 K 와 V 를 묶어서 연산하기 때문이다. - 이후 K 와 V 로 나뉘게 된다.
-
Mix-FFN
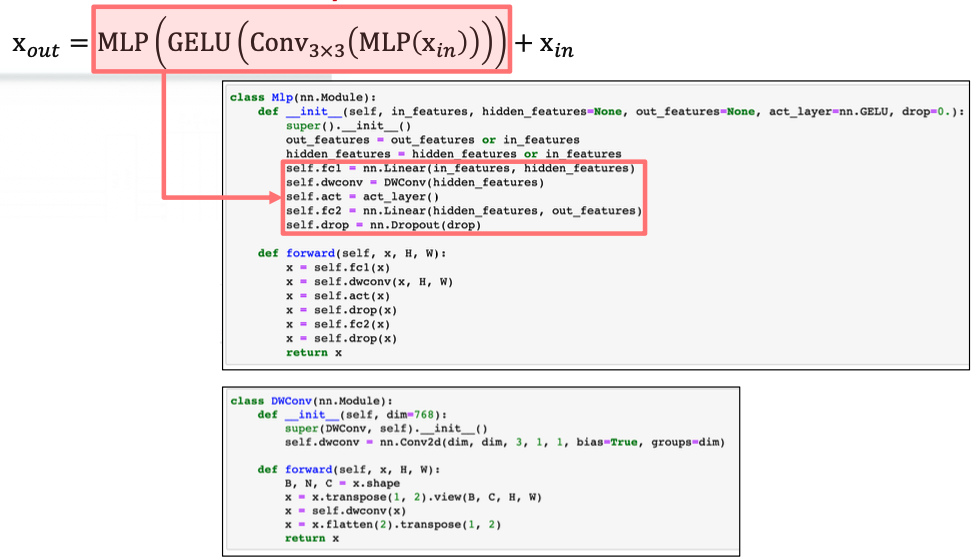
- 입력이 들어왔을 때 MLP, Conv, GELU, MLP 순서로 진행하고 다시 입력과 더해준다.
- Mix-FFN 에서 Conv 는 Depth-wise conv 를 이용한다.
- 이 과정들을 stage 1 부터 stage 4 까지 반복하면서 각 stage 의 결과를 저장하여 출력한다.
-
Decoder
- Decoder 에서는 각 stage 의 결과 4개를 받아서 MLP layer 를 통과시켜주고 concatenate 후 MLP 를 수행한다.
- MLP Layer 는 4개의 MLP 로 이루어져 있다.
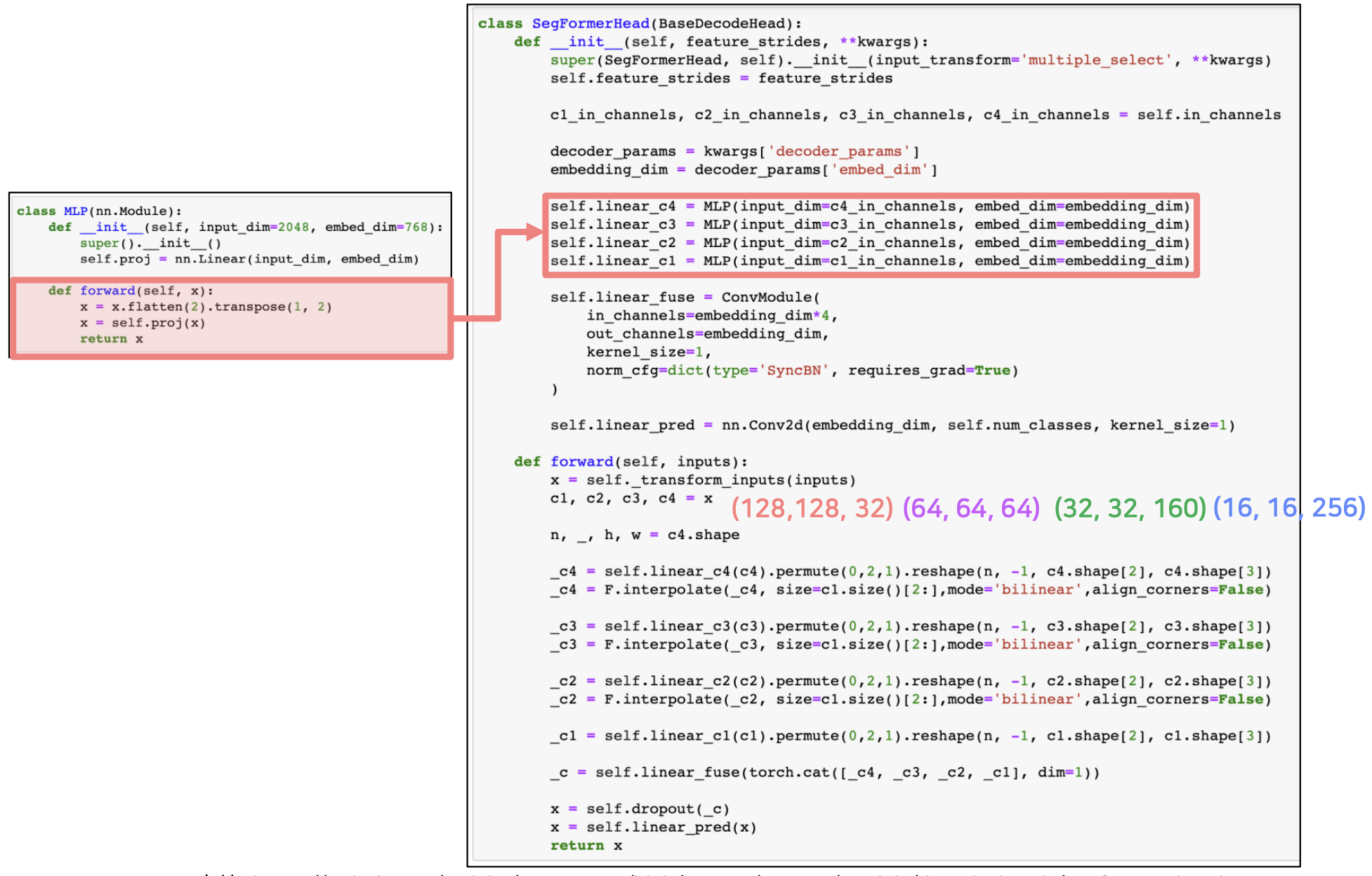
- 각 MLP 는 입력이 들어오면 flatten 후 linear 를 통해 projection 을 한다.
- linear 연산은 채널을 $C$ 로 통일해준다.
- 그 이후 Upsampling 과정을 거친다. 이 때 linear 로 채널을 $C$ 로 맞춰준 후 바로 bilinear upsampling 를 적용해줄 수 없으니, 먼저 linear 결과에 permute + reshape 을 통해서 interpolation 연산이 가능한 형태로 만들어준다. 그 이후 bilinear upsampling 을 진행한다.
- 이렇게 linear 로 채널을 맞춰주고, bilinear upsampling 으로 크기를 맞춰준 후 각각의 결과물에 concat 을 진행한다.
- 이 후 1x1 conv 로 이루어진 linear_fuse 를 통해서 concat 으로 인한 채널 $4C$ 에서 $C$ 로 변화시켜준다.
- 전체적인 과정은 다음과 같다.
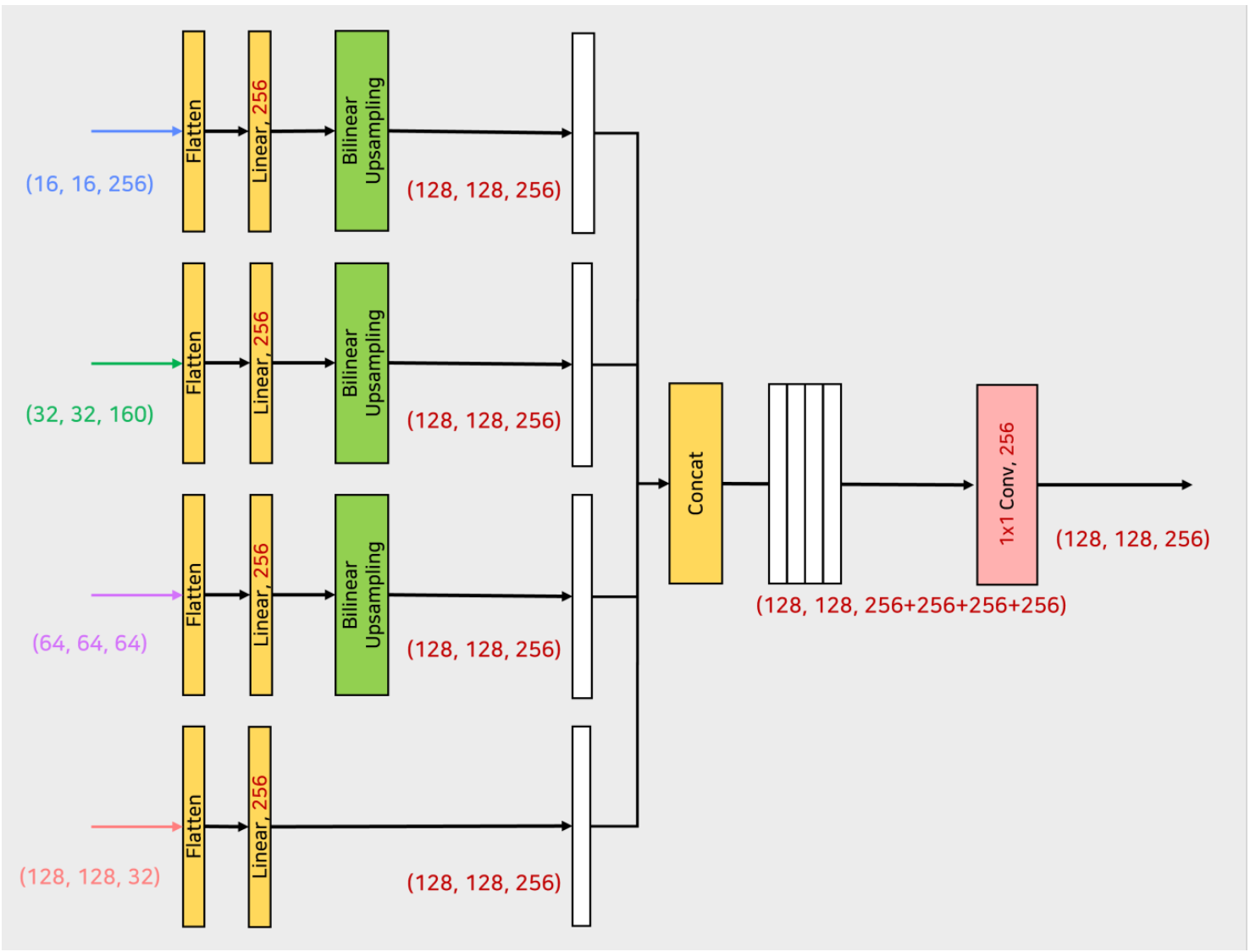
- 마지막으로 dropout 후 1x1 conv 를 통해서 원하는 num_class 만큼으로 pixel-wise prediction 을 수행한다.
-
- 최근 Semantic Segmentation 연구 동향
댓글 남기기