
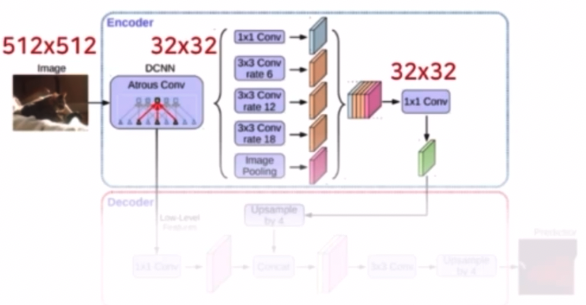
[Segmentation] 6. HRNet
- Semantic Segmentation 연구 동향 (HRNet)
- Deep High-Resolution Representation Learning for Visual Recognition (HRNetv2)
- HRNet 의 등장배경
- Image Classification Network 의 발전과 Segmentation 과 어떤 식으로 연관이 있을까?
- 딥러닝은 LeNet 을 기반으로 CNN 의 발전이 시작되었다.
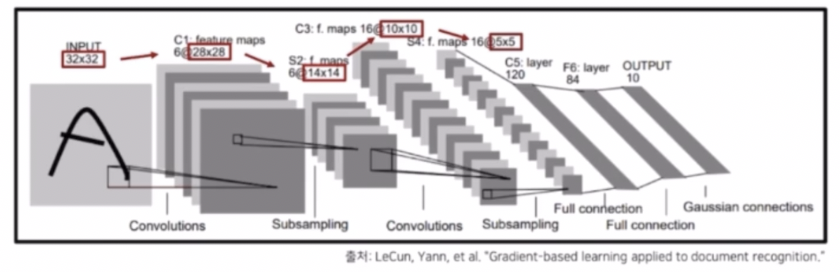
- 초창기 네트워크는 32x32 의 이미지를 받아서 conv, pooling 등의 연산으로 5x5 의 feature map 을 생성했다.
- AlexNet 은 224 x 224 라는 훨씬 큰 입력 이미지를 받아서 순차적으로 conv 와 pooling 등의 연산을 통해 저해상도의 feature map 을 뽑아서 최종 결과를 생성해냈다.
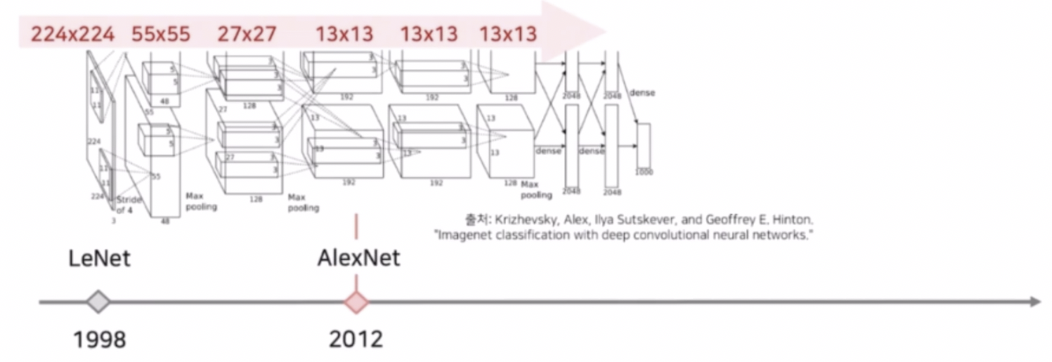
- VGGNet 은 3x3 conv 를 적극적으로 활용해서 좋은 성능을 거두었다. 이 때도 5개의 max pooling 을 통해서 224x224 를 7x7 까지 줄여서 feature map 을 추출하고 이후 dense layer 를 통과해서 최종 output 을 생성했다.
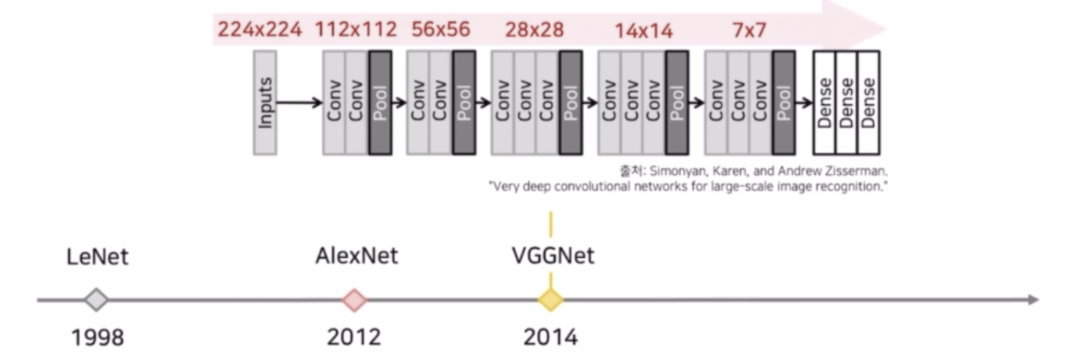
- skip connection 을 활용한 ResNet. 여기서는 max pooling 이외에도 conv 에 stride 2 를 적용해서 크기를 줄였다.
- 이후 EfficientNet 도 Resolution 크기를 224 에서 7 까지 줄이고 최종 결과를 생성했다.
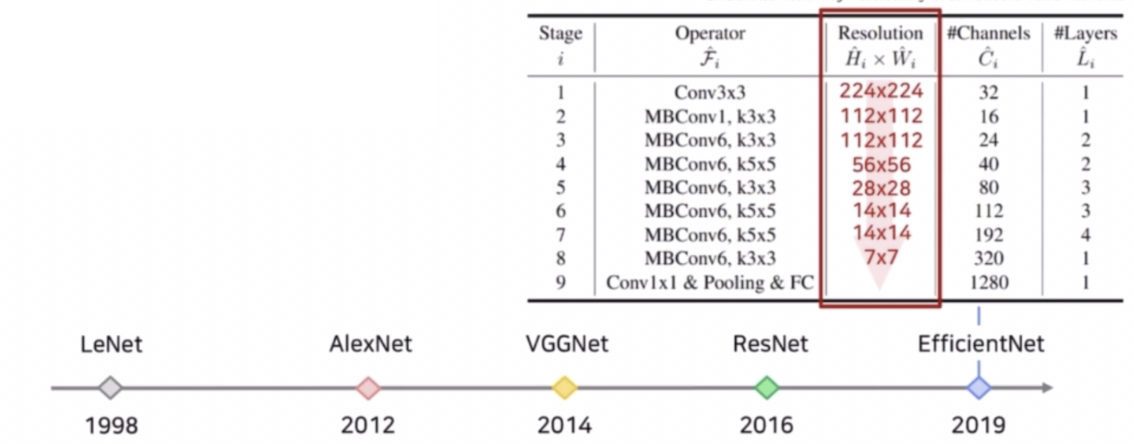
- 여기까지 정리하면, 이미지 분류를 위한 CNN 구조는 고해상도 입력을 점차 저해상도로 줄여나가는 LeNet 의 설계 방식을 사용했다.
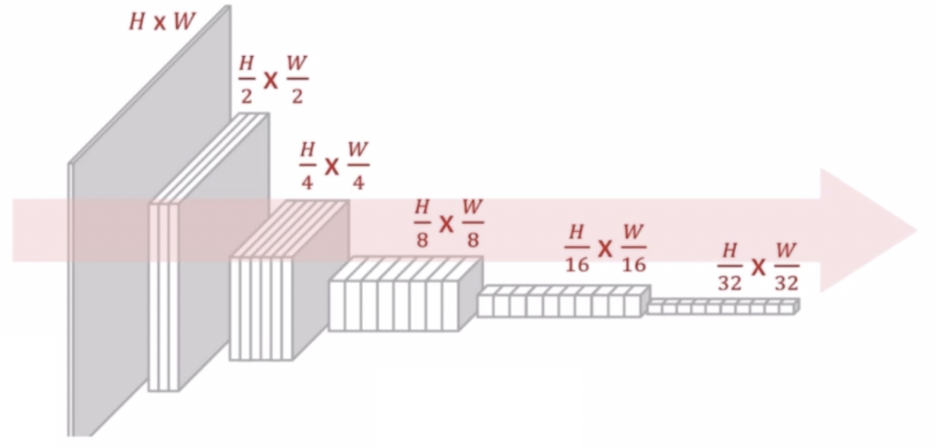
- 일반적으로 32 배만큼 크기를 줄이고 그 결과에 dense layer 를 적용해서 최종 결과를 냈다.
- 그리고 저해상도 high-level feature map 을 이용해서 Upsampling, Decoder 등으로 Segmentation 결과를 생성한다.
- 이 의미는, Image Classification 의 네트워크를 backbone 으로 가져와서 사용하고 마지막으로 생성된 high level feature 에 decoder 를 달거나 upsampling, transposed conv 를 달아서 최종 segmentation 을 수행한 것이다.
- 왜 Image Classification 모델이 해상도를 점점 줄여나갈까?
- 특정 물체를 분류하는데 많은 경우에 이미지 내 모든 특징이 필요하지 않다. CAM 이나 grad CAM 을 해보면 대부분의 CAM 은 가장 중요한 영역만을 추출한다. 그 이유는 class 를 분류하는데 객체의 모든 특징이 아니라 가장 대표적인 특징들만 중요하다는 것이다.
- 해상도를 줄여서 얻는 이점이 있다. 해상도가 줄어들어 효율적인 연산이 가능하며, 각 픽셀이 넓은 receptive field 를 갖게 된다. max pooling 에 의해서 이미지 크기를 줄이면, 계산량 측면에서 w 와 h 가 줄어서 연산량이 많이 감소한다. 픽셀 단위로 생각해보면 픽셀 하나가 보는 영역이 넓어지는 즉, receptive field 가 넓어진다.
- 중요한 특징만을 추출하여 과적합을 방지한다.
- Image Classification vs. Semantic Segmenation
- Segmentation 은 이미지 분류와 다르게 이미지 내 모든 픽셀에 대한 분류를 진행하기 때문에 더 많고 자세한 정보가 필요하다.
- 이미지 분류 모델은 공간적(spatial) 정보를 크게 고려하지 않지만, segmentation 의 경우 예측하려는 각 픽셀 주변의 context 를 잘 파악하기 위해 공간 상의 위치 정보가 중요하다.
- 중요 특징을 추출하기 위해 수행하는 pooling 등의 연산은 모든 픽셀에 대해 정확히 분류하기에 자세한 정보를 유지하지 못한다. 따라서 Segmentation 에서는 pooling 에 의해서 손실되는 정보들이 적어야 한다.
- 분류의 경우 모든 특징들이 필요가 없는데, segmentation 의 경우 픽셀마다의 모든 분류를 수행해야 한다. 따라서 더 많고 자세한 정보가 필요하기 때문에 높은 해상도를 유지하는 것이 좋다.
- 그렇기 때문에 이미지 분류 모델을 그대로 사용하여 얻은 저해상도 특징은 모든 픽셀에 대해 정확한 분류를 수행하기엔 부족한 정보를 가진다. 즉, 저해상도의 특징을 가지고 픽셀 단위의 probability map 을 생성하는 것은 픽셀 내에서 정확한 분류를 수행하기에는 어렵다.
- 따라서 대부분의 Segmentation 연구들은 해상도를 어느정도 높여서 자세한 정보를 유지한 이후에 segmentation 을 수행한다.
- 저해상도(low resolution) feature map 을 생성하고 다시 고해상도(high resolution)로 복원하는 방식의 기존 연구
- DeconvNet, SegNet, U-Net 등이 있다.
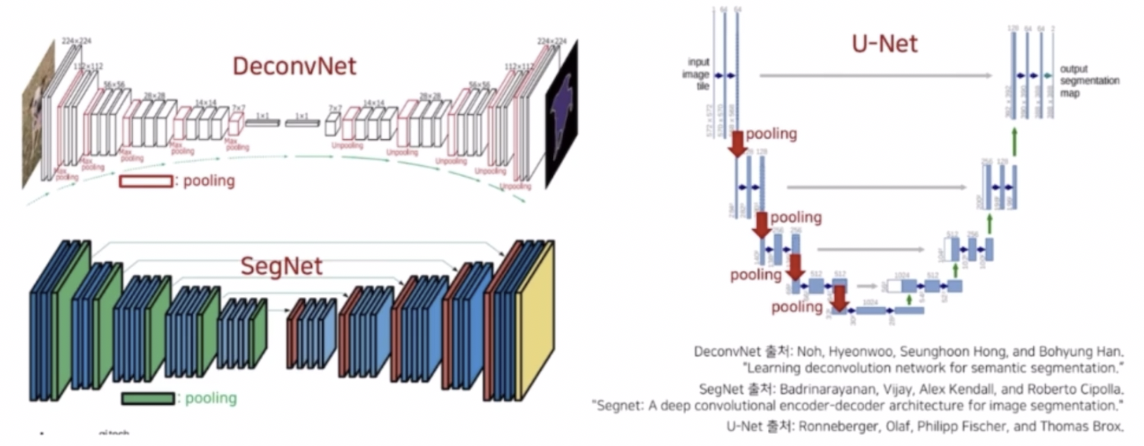
- 해당 모델들은 encoder-decoder 의 형태이다.
- DeconvNet 과 SegNet 은 encoder 에서 VGG16 을 backbone 으로 사용해서 총 5개의 max pooling 에 의해서 입력 resolution 을 1/32 만큼 줄였다. 그리고 저해상도를 고해상도로 복원하기 위해서 UnPooling 을 사용했다.
- U-Net 은 encoder 에서 4개의 max pooling 과 zero padding 을 적용하지 않은 conv 를 이용해서 입력 resolution 을 줄였다. 그리고 저해상도를 고해상도로 복원하기 위해서 transposed conv 를 이용했다.
- max pooling 에 의해서 정보 손실이 어느정도 발생하는데, 이를 잘 복원해주기 위해서 DeconvNet 과 SegNet 은 Unpooling 을 통해서 max pooling 시 잃어버린 공간적인 정보를 복원했다.
- UNet 은 같은 계층에 encoder 의 feature map 을 crop 한 다음 건네주는 skip connection 을 해서 이전 layer 의 정보를 효과적으로 활용했다.
- 그러나 이렇게 low resolution 을 만들고 고해상도로 복원하는 과정은 sparse 한 feature map 을 생성한다는 문제점이 있었다.
- 그래서 DeepLab 에서는 dilated conv 를 이용했다.
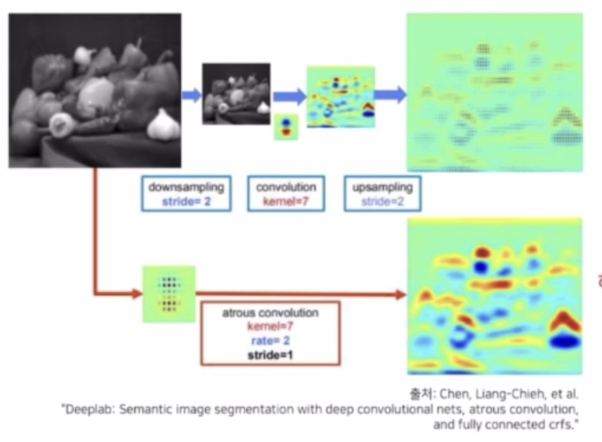
- 넓은 receptive field 를 갖기 위해 down sampling 후 conv 를 취하고 upsampling 이용한 결과 sparse 한 feature map 이 추출된다.
- 이러한 문제를 해결해주기 위해서 down sampling 과 up sampling 을 제거하고 conv 을 해상도를 적게 줄이면서 넓은 receptive field 를 갖도록 dilated conv 를 사용하면 dense 한 feature map 을 추출할 수 있다. 성능 또한 좋아진다.
- Dilated Conv 사용
- DilatedNet, DeepLab 이 있다.
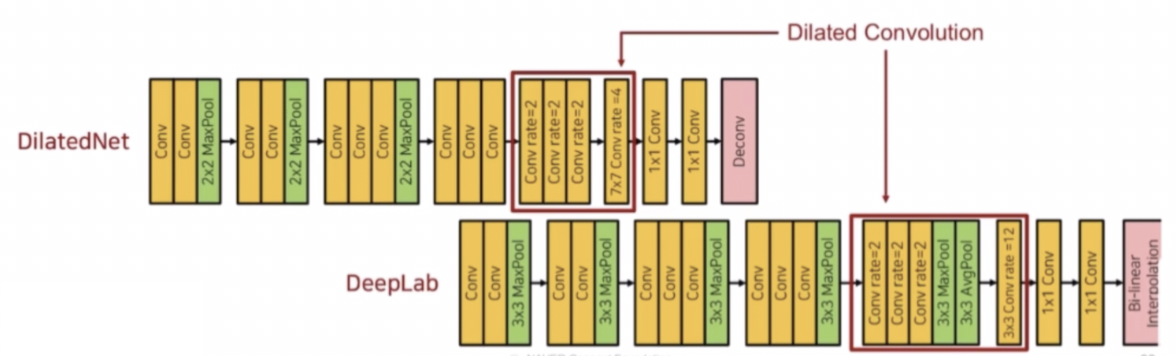
- DilatedNet 은 low resolution 이 아니라 medium resolution 의 정보를 고해상도로 복원하는 과정을 가진다.
- 왜 medium resolution 이냐면, DilatedNet 은 max pooling 을 일부 제거하고 입력 이미지의 크기를 1/8 만큼 줄였다.
- DeepLab 은 5개의 pooling 이 있지만, 중간의 pooling 은 max pooling 시 크기의 변동이 일어나지 않기 때문에 resolution 자체는 1/8 만큼만 줄어든다.
- 이렇게 1/8 만큼 줄어든 feature map 에 대해서 dilated conv 을 적용해서 receptive field 를 넓혔다.
- 이후 1/32 가 아니라 1/8 만큼 줄어든 medium resolution 을 가지고 DilatedNet 은 transposed conv 를 이용해서 고해상도로 복원하고, DeepLab 은 bilinear interpolation 을 통해서 고해상도로 복원한다.
- DeepLab v3+ 는 자세한 정보를 유지하기 위해 Xception 구조 내 max pooling 연산을 depthwise separable conv 로 변경했다.
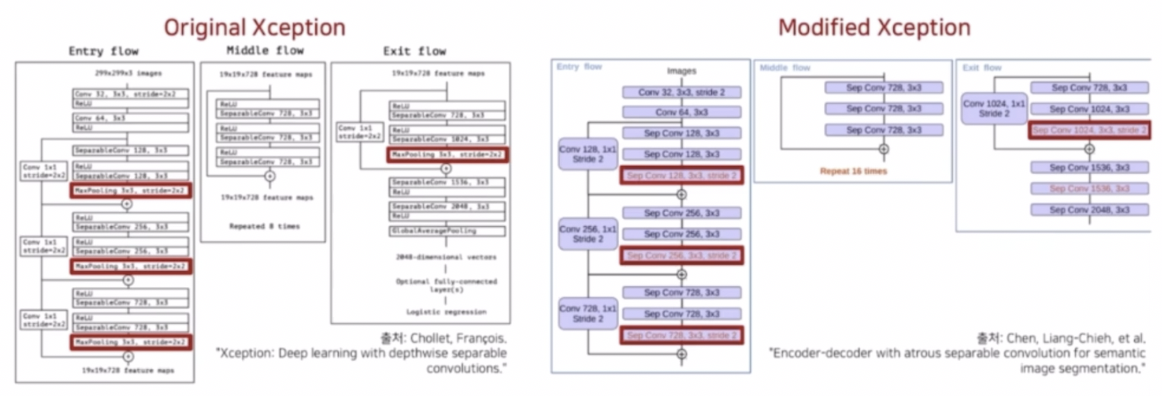
- DeepLab v3+ 는 encoder-decoder 구조의 장점과 dilated conv 의 장점을 모두 통합해서 사용했다. Xception 에서 Exit flow 에 stride 2 를 가지는 conv 를 제거해줌으로써 크기의 변동은 1/16 으로 만들어주고, 그 다음에 max pooling 연산을 depthwise separable conv 으로 바꿔서 정보를 좀 더 효율적으로 추출했다.
- 또한 기존의 encoder-decoder 에서 max pooling 이나 stride 2 를 가지는 conv 가 down sampling 과정에서 잃어버린 정보를 복원해주는 것처럼 low level 의 feature 를 전달해주는 skip connection 도 활용했다.
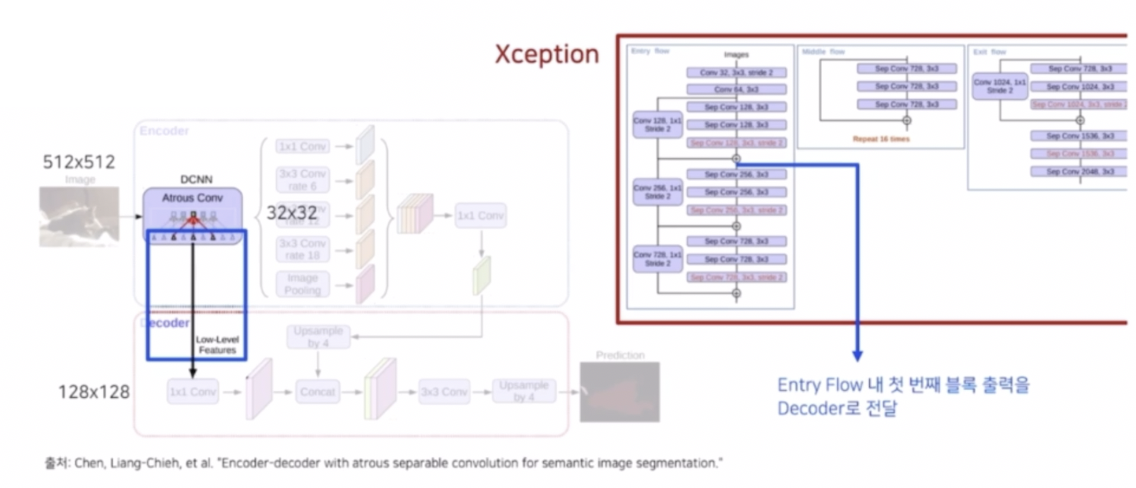
- 이렇게 본 이전의 모델을 정리하면 1) 여러번의 max pooling 연산을 통해서 저해상도(low-resolution)을 만든 다음에 이를 다시 키우는 구조와 2) Pooling 연산을 적용하긴 하지만 개수를 줄여서 medium resolution 을 만들고 dilated conv 를 적용하는 형태를 살펴볼 수 있다.
- 그러나, 위 모델들은 Classification 모델을 그대로 backbone 으로 활용하거나 약간의 변형을 주고 사용했는데, 이는 일반적으로 classification 을 목적으로 만들어진 네트워크이기 때문에 time complexity 가 높은 문제점이 있다.
- 그리고 classification 에서는 저해상도로 줄이는 구조의 장점으로 인풋 데이터를 저해상도로 만드는 구조를 가지고 있다. 이로 인해 Segmentation 에서 Upsampling 을 이용해 고해상도로 복원하여 feature map 을 생성하는데, 이는 공간 상에서 위치 정보의 민감도(position-sensitivity)가 낮다.
- 즉 high resolution 을 low, medium resolution 으로 낮춘 후에 다시 복원하는 문제점과 Classification 네트워크를 그대로 가져와서 사용하는 문제점을 해결하면서, 강력한 위치정보를 가지는 visual recognition 문제에 적합한 구조의 필요성이 생겼다.
- 이를 위해 저해상도/중해상도를 고해상도로 복원하는 것이 아닌, 고해상도 정보를 계속 유지하면서 그리고 이전에 만들어진 classification 네트워크를 그대로 가져오는 것이 아니라 Segmentation 같은 visual recognition task 에 적합한 backbone 을 만들 수 있다.
- 그것이 바로 HRNet(High Resolution Network) 의 시작이자 가장 핵심적인 부분이다.

- HRNet 은 High Resolution 특징을 유지하고 그 부분 외에도 medium resolution, low resolution 을 같이 유지하는 특징을 가진다.
- HRNet 은 주로 image classification 에서 사용되는 backbone 이 아닌, 위치 정보가 중요한 visual recognition 문제(segmentation, object detection, pose estimation 등)에 사용할 수 있는 새로운 backbone 이다!
- 이를 가지고 추가적인 기법을 붙인 연구들이 최근 SOTA 를 많이 달성하고 있다.
- HRNet 구조
-
핵심 구성요소 1) 전체 과정에서 고해상도(high resolution) 특징을 계속 유지한다.

- 이 때 high resolution 이 원본 이미지 크기를 그대로 유지한다는 것은 아니다.

- 다음과 같이 high resolution 은 1/4 만큼 줄인 크기를 의미한다. 이 때 크기를 줄이기 위해서 stride conv 2개를 이용해서 각각 1/2 씩 줄인다. 따라서 전체 구조에서 1/4 해상도를 그대로 유지한다.
- 왜 1/4 만큼 줄였는데 high resolution 이라고 표현하는 것일까?
- 기존의 Network 와 비교하면 해상도에 차이가 있다.
- UNet 의 경우 4개의 max pooling 과 padding 을 적용하지 않은 conv 를 통해서 해상도가 약 1/20 으로 감소했다.
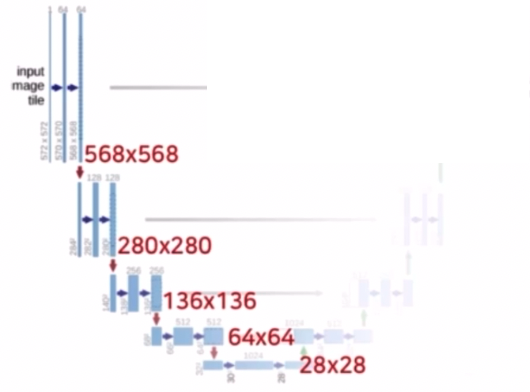
- DeepLab v3+ 의 경우 Xception backbone 을 거치면서 해상도가 1/16 으로 감소한다.
- 그에 비해 HRNet 의 경우에는 원본 이미지를 1/4 로 감소시켜 해상도를 유지하므로 다른 구조들에 비해 상대적으로 높은 해상도를 유지한다.
-
핵심 구성요소 2) 고해상도부터 저해상도까지 다양한 해상도를 갖는 feature를 병렬적으로 연산한다.
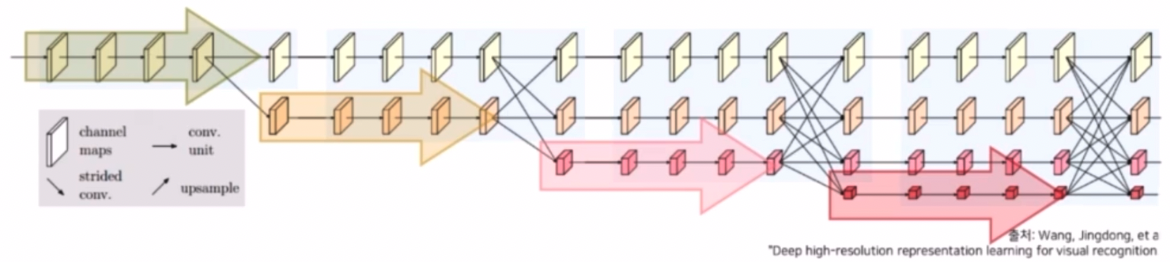
- 기존의 segmentation 모델들은 연산의 효율성, receptive field 를 넓이기 위해 이미지 크기를 줄여 왔다. HRNet 이 고해상도의 특징만 유지했다면 conv 들을 통과하면서 많은 연산량에 문제가 있었을 것이고 receptive field 가 작았을 것이다. 그래서 성능이 별로 좋지 않았을 것이다.
- 그러나 중해상도, 저해상도의 정보도 유지하면서 병렬적으로 연산하기 때문에 receptive field 의 문제 해결을 시도했다.
- 또한 고해상도는 채널을 작게하고, 저해상도는 채널을 크게 해서 차원적인 부분에서도 효율적인 연산을 고려했다.
-
Parallel Multi-Resolution Convolution Stream

- 고해상도 conv stream 을 시작으로 점차 해상도를 줄여 저해상도 stream 을 새롭게 생성한다.
- 새로운 stream 을 생성할 때 해상도는 이전 단계 해상도의 1/2 로 감소시킨다.
- 이 때 얻을 수 있는 장점은, 해상도를 줄여 넓은 receptive field 를 갖는 특징을 고해상도 특징과 함께 학습시킬 수 있다.
- 고해상도에서는 훨씬 위치에 민감하면서도 max pooling 등에 의해서 손실되기 이전의 정보들을 담고 있고, 저해상도 부분에서는 넓은 receptive field 를 바탕으로 좀 더 풍부한 semantic 한 정보를 담고 있다.
-
핵심 구성요소 3) 다중 해상도 정보를 반복적으로 융합한다.
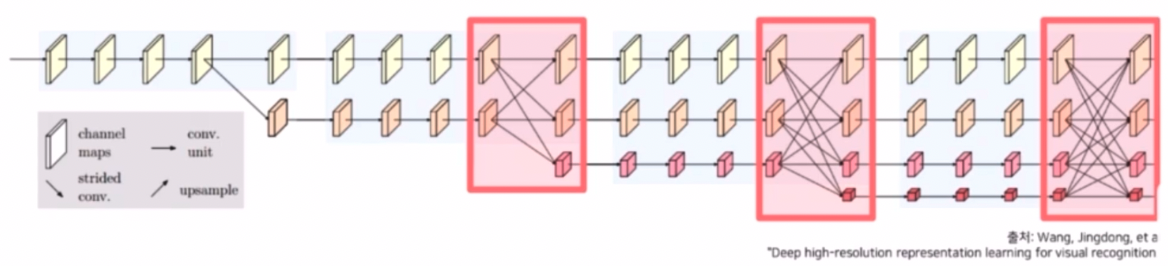
- 각각의 해상도가 갖는 정보를 다른 해상도 stream 에 전달하여 정보를 융합한다.
- 고해상도 특징은 공간 상의 높은 위치 정보 민감도(position-sensitivity)를 가진다. max pooling 등 연산을 진행하기 전이기 때문에 위치에 대한 민감한 정보들이 많이 줄어들지 않았기 때문이다.
- 저해상도 특징은 넓은 receptive field 로 인해서 상대적으로 풍부한 의미 정보(semantic information)를 가진다.
- 이런 위치에 민감한 정보와 semantic 정보를 결합시키면서 고해상도에서는 이전에 부족했던 넓은 receptive field 를 바탕으로 한 semantic한 정보를 담을 수 있고, 저해상도에서는 이전에 부족했던 position 에 민감한 정보를 고해상도로부터 전달 받아서 서로의 부족한 부분을 보완할 수 있다.
- 하지만 이 때 고해상도는 채널을 작게 하고 저해상도는 채널을 크게 해서 채널이 맞지 않는다. 또한 resolution 도 맞지 않기 때문에 이를 조절해주는 장치가 필요하다.
- Repeated Multi-Resolution Fusions
- 각각의 해상도가 갖는 정보를 다른 해상도 stream 에 전달하여 정보를 융합한다.
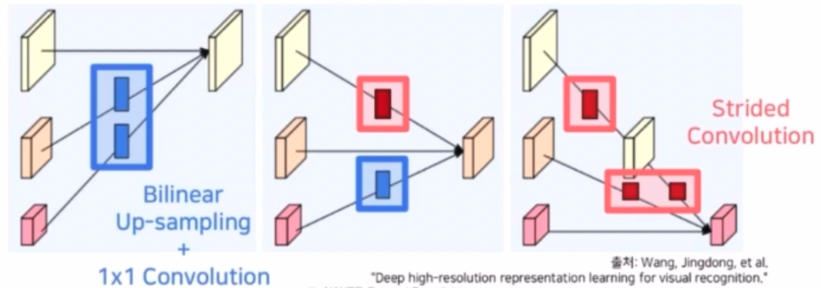
- 고해상도의 정보를 저해상도 stream 에 전달할 때에는 Stride conv 연산을 활용한다. 이는 정보 손실을 최소화하기 위해 pooling 대신 사용한다.
- stride conv 를 통해 크기를 1/2 로 줄여가면서 해상도를 맞춘다. 또한 conv 에서 채널도 맞춰준다.
- 저해상도 정보를 고해상도 stream 에 전달할 때에는 크기를 맞춰줄 때는 Time complexity 를 고려하여 conv 대신에 Bilinear Upsampling 를 사용하고, 채널 수를 맞추기 위한 1x1 conv 연산을 사용한다.
-
마지막으로 이렇게 해서 만든 4개의 resolution 에 대한 feature map 을 가지고 해결하고자 하는 문제에 따라서 서로 다른 representation head 를 만든다. 즉 서로 다른 출력을 형성한다.
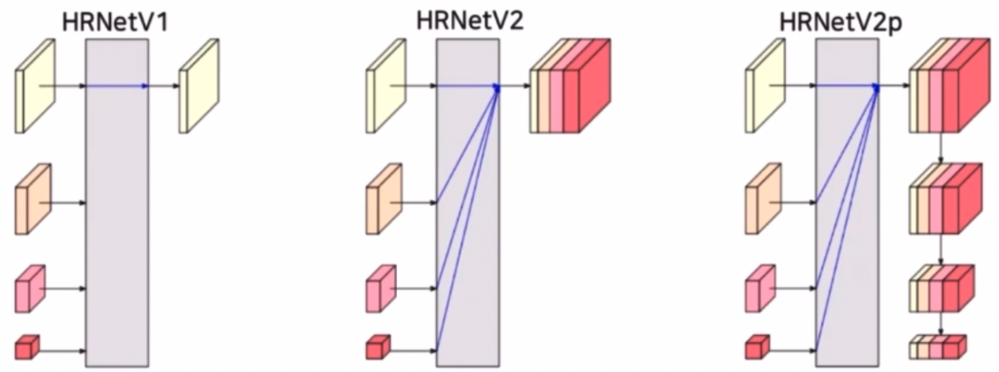
- HRNetV1
- 저해상도를 제외한 고해상도 특징만을 최종 출력으로 사용한다.
- Pose Estimation(Keypoint Detection) 문제에 활용한다.
- HRNetV2
- 고해상도 뿐만 아니라 중해상도, 저해상도 정보를 같이 활용한다.
- 저해상도 특징들을 bilinear upsampling 을 통해 고해상도 크기로 변환 후 모든 특징들을 concat 하여 출력한다.
- Semantic Segmentation 문제에 활용한다. HRNetV2 인 Representation Head 이후 Segmentation Head 를 통과시키는 것이다.
- HRNetV2p
- HRNetV2 의 결과에서 추가로 down sampling 한 결과를 출력한다.
- HRNetV2p 는 Faster-RCNN 등의 backbone 으로 사용되어 Object Detection 문에 활용된다.
- HRNetV1
-
-
HRNet 세부구조 및 구현
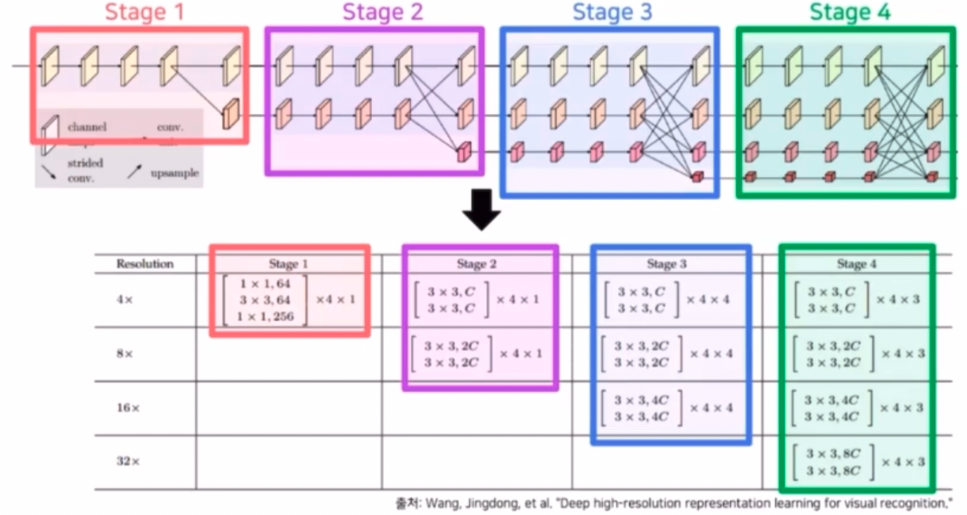
- ResNet 에서 본 것처럼 residual unit 으로 구성된 block 이 반복되는 형태를 가진다.
- 위 표에서 Resolution 은 그만큼 곱해야 원본이미지 크기가 됨을 의미한다. 가장 위(4x)가 high resolution 이다.
- 이 때 주목할 점은 채널이다. 위 이미지에서 $C$ 는 가장 높은 해상도 stream 의 채널 수다. 저해상도로 갈수록 채널 $C$ 가 2배씩 증가한다.
- 만약 $C$ 가 48 이라면 고해상도는 H, W, 48 이고 저해상도로 갈수록 H 와 W 는 1/2 씩, $C$ 는 2 씩 곱해진다.
- 이 때 가장 높은 해상도 stream 의 채널 수($C$)에 따라서 네트워크의 명칭이 정해진다. HRNetV2 는 Segmentation 에 사용되고, $C$ 에 따라 HRNetV2-W18, W32, W40 등으로 정해진다.
- 위에서 W 의 경우 resolution 의 W, H 가 아니라 채널 $C$ 를 의미한다.
- HRNetV2-W48 을 가지고 예시를 보자.
- 512 x 512 의 입력, $C$ 는 48이다.
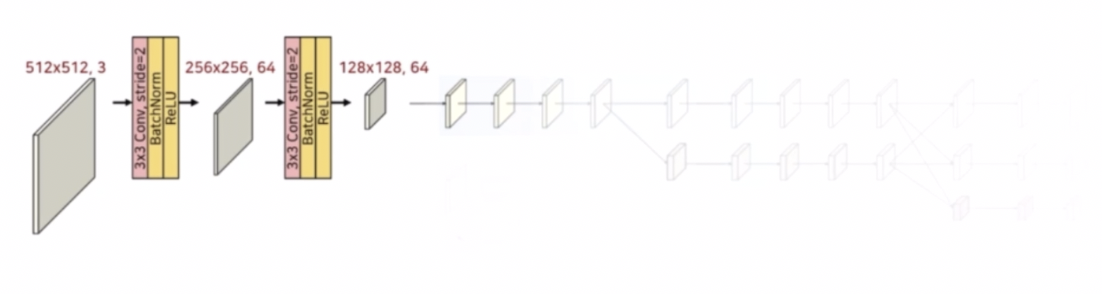
- Stem 부분에서는 stride conv 를 이용해서 크기를 각각 1/2 배씩 줄인다.
- 3x3 conv 에 stride 2 를 주고 BN 과 ReLU 를 통해서 크기를 1/2 배씩 줄이고 채널은 64로 맞춰준다.
-
이렇게 만든 128x128, 64 의 구조가 Stage 1 을 통과하게 된다.
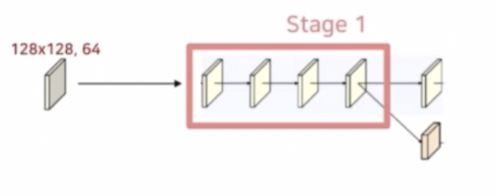
- Stage 1 에서는 1x1 conv → 3x3 conv → 1x1 conv 로 구성된 residual unit 이 4번만큼 반복된다.
- 이 때 입력 채널 64와 출력 채널 256 을 맞추기 위해 skip connection 에 1x1 conv 를 추가하여 residual 의 채널을 맞춰준다. 마지막 ReLU 는 identity 를 더해준 후에 통과시킨다.
- 그렇게 4번을 통과시킨 후, Strided Conv 로 새로운 하위 stream 을 생성한다.
- 이 단계부터 가장 높은 해상도 Stream 의 채널 수를 HRNetV2-W 의 $C$ 로 설정한다.
- 새로운 stream 의 해상도는 이전 단계 해상도의 1/2 로 감소하고 채널수는 2배 증가한다. 크기를 줄일 때는 max pooling 이 아니라 conv 의 stride 2 를 세팅해서 크기를 줄인다.
-
Stage 2
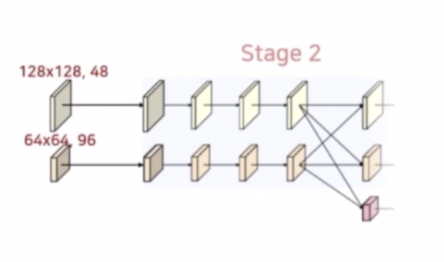
- Stage 2 부터는 고해상도와 중해상도가 각각 병렬적으로 학습되는 구조이다.
- 또한 기존의 residual unit 은 3개의 conv 을 적용했다면, 이번에는 unit 내에 3x3 conv 2개로 이루어져 있다. 그리고 각각 서로 다른 resolution 에서 진행된다.
- 각 stream 에 해당하는 해상도를 유지하기 위해 3x3 conv 를 사용하며, 채널 수(48, 96)를 유지한다. 이렇게 4번의 반복 연산을 진행한다.
- 이후 Stage 2 에서 Stage 3 으로 넘어가면서 마찬가지로 stride conv 를 통해 하위 stream 을 생성한다.
- 또한 bilinear upsampling 및 1x1 conv 로 상위 stream 을 생성한다.
- 새로운 stream 의 해상도는 이전 단계 해상도의 1/2 로 감소하고 채널 수는 2배 증가한다.
- 참고할 것은, 실제 그림에서는 고해상도에서 저해상도로, 중해상도에서 저해상도로 resolution 이 넘어가서 훈련되는 것처럼 보이지만 실제 official 코드는 바로 넘어가는 것이 아니라 고해상도에서 중해상도로, 중해상도에서 중해상도로 먼저 fusion 된 다음에 거기서 stride conv 를 통해서 하위 stream 이 생성된다.
- HRNet 저자의 언급에 따르면 각 해상도 정보가 다른 모든 해상도 정보를 집계한다는 관점에서는 두 구현 방법은 거의 동일하다고 한다.
- HRNet 논문에서는 중해상도에서 고해상도로 상위 stream 으로 흘러갈 때 bilinear upsampling 을 먼저 적용하고 1x1 conv 를 적용했다. 즉 해상도를 먼저 맞춰주고 그 다음에 채널을 맞춰준 것이다.
- 고해상도 stream 의 output 은 원래 고해상도와 중해상도에서 넘어온 feature 를 concat 이 아니라 sum 해서 만들어진다. 중해상도 stream 의 output 또한 마찬가지로 sum 을 이용한다. 이후 각 stream 마다 ReLU 를 취해준다.
- concat 을 하지 않고 sum 을 취한 이유는 concat 을 통해 채널이 2배 증가하는 것을 방지해준 것이다.
- 여기서도 한가지 이슈가 있는데, HRNet 논문에서는 bilinear upsampling 으로 해상도를 먼저 키우고 1x1 conv 로 채널을 맞춰준다고 했다. 그러나 official 코드에서는 1x1 conv 를 적용하고 bilinear upsampling 을 적용한 구조이다.
- 이 부분에 대해서 저자는 computational complexity 의 감소 효과가 있어서 1x1 conv 를 적용해서 채널을 줄이고 bilinear upsampling 을 했다고 언급했다.
- 고해상도 및 중해상도 stream 이 서로 fuse 된 후 중해상도 stream 에서 stride conv 를 이용해 3번째 저해상도 stream 을 생성한다. 이 때 마찬가지로 채널을 2배 늘리고 3x3 conv stride 2 를 통해 resolution 을 1/2 만큼 감소시킨다.
-
Stage 3
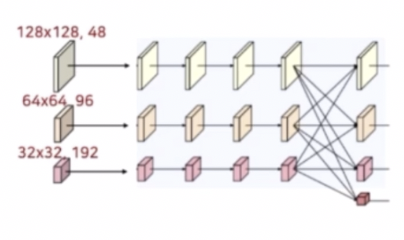
- Stage 3 는 Stage 2에서 사용한 block 을 채널 수만 변경하여 동일하게 사용한다. 반복되는 횟수 정도의 차이만 존재한다.
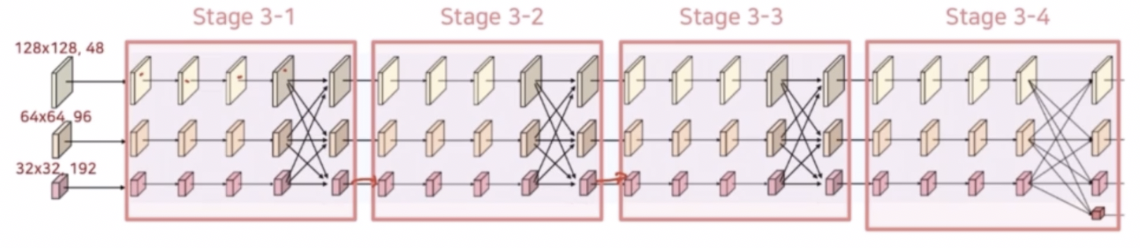
- 3x3 conv 2개를 가지는 residual unit 이 4번 반복되고 다중 해상도 stream 에 대해 fusion 을 수행한다.
- 이 residual unit 4번 반복 및 fusion 을 동일하게 4번을 반복한다.
- 마지막 4번째 반복(Stage 3-4) 후 새로운 해상도 stream 을 생성한다.
- 이 때 새로운 해상도 stream 은 Stage 2 의 fusion 과 동일하게 stride 2 conv 로 하위 stream 을 생성하고, bilinear upsampling 및 1x1 conv 로 상위 stream 을 생성한다.
- 마찬가지로 새로운 stream 의 해상도는 이전 단계 해상도의 1/2 만큼 줄어들고 채널 수는 2배 만큼 증가한다.
- fusion 에서 stream 을 두 단계 낮추는 경우, 첫번째 stride conv 는 채널 수를 그대로 유지하고 두번째 stride conv 에서 낮추는 stream 과 채널 수를 동일하게 맞춰준다(4배 한다). 반대로 stream 을 두 단계 높이는 경우 한 번의 bilinear upsampling 만으로 해상도 크기를 맞춰준다.
- Stream 을 한 단계 높이거나 낮추는 경우에는 stage 2 의 fusion 과 동일하게 한 번의 stride conv 또는 한 번의 bilinear upsampling 및 1x1 conv 를 수행한다.
- Stage 2 와 마찬가지로 공식 HRNet 구현 방법은 fusion 후 새로운 stream 을 생성한다.
-
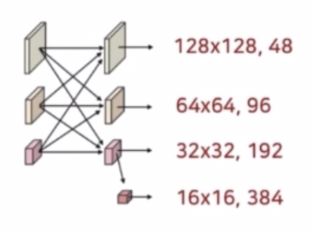
Stage 4
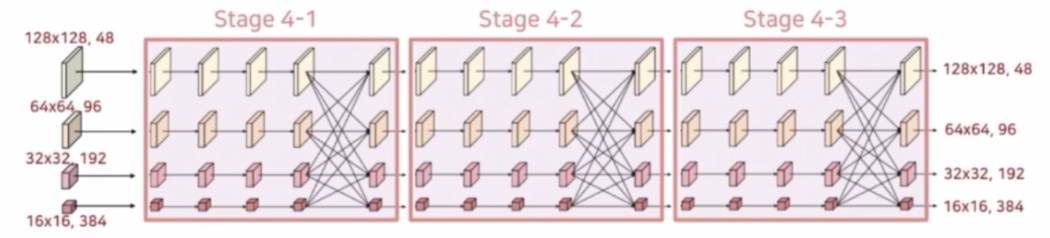
- 추가된 해상도 stream 및 반복횟수가 4에서 3으로 변한 것을 제외하면 Stage 3 와 전반적으로 동일하다. Stage 4 에서는 새로운 해상도 stream 이 추가되지 않는다.
-
Representation Head
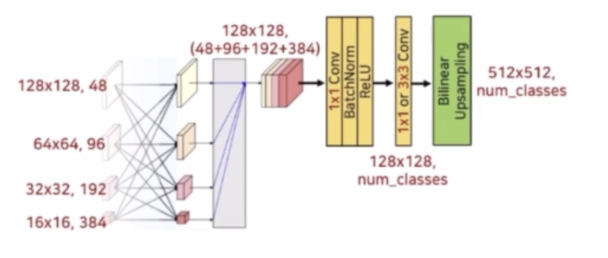
- Stage 4 까지 거친 결과를 Representation Head 를 통해서 통합해주는 과정을 거친다.
- 먼저 저해상도의 특징들은 해상도 크기가 맞지 않기 때문에 bilinear upsampling 과정을 통해서 고해상도 크기와 맞춰준다. 그 이후 concat 과정을 통해서 모든 feature 를 결합한다.
- 이렇게 고해상도부터 저해상도까지의 정보를 담고 있는 Representation 을 만든 다음에 이를 Segmentation Head 부분에 통과시킨다.
- Segmentation Head 의 구성은 1x1 conv, BN, ReLU 로 구성되어 있다. 그 이후 설정에 따라 1x1 또는 3x3 conv 연산을 통과시켜서 최종 예측할 class 수만큼을 채널로 가지는 Segmentation 결과를 생성한다.
- 이 때 생성된 Segmentation 결과는 원본 이미지 크기와 맞지 않기 때문에 bilinear upsampling 을 통해서 최종 출력을 생성한다.
- HRNet 실험 결과
- 모델 크기(#param.) 및 계산 복잡도(GFLOPs)에 따른 성능(mIoU) 비교이다.
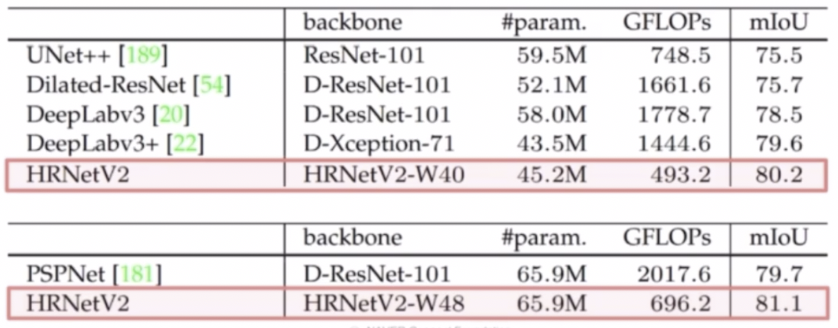
- 일반적인 classification network 를 backbone 으로 하는 모델들(UNet++, DeepLabv3, PSPNet)에 비해 성능적으로 매우 좋다. 또한 속도도 빨라졌다.
- 파라미터 수는 DeepLabv3 보다는 많지만 GFLOPs 가 더 빠르다.
- W40 에서 W48 로 $C$ 를 늘려주면 성능(mIoU)이 더 상승한다. 또한 파라미터 수는 늘었지만 GFLOPs 는 크게 증가하지 않는다.
댓글 남기기