
[Segmentation] 5. Segmentation for competition
- Semantic Segmentation 대회에서 사용하는 방법들1
- SMP
- Segmentation model pytorch
- 실무나 대회 관점에서 smp 를 많이 활용한다.
- 많은 인코더와 디코더를 제공해준다. 따라서 모델 사용이 편하다.
- pretrained weight 를 제공한다.
- metric 과 loss 등이 다양하다.
- timm 의 encoder 도 제공해준다.
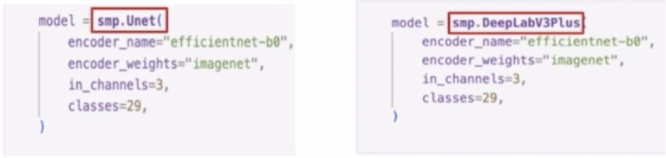
smp.아키텍처로 사용할 수 있다.- encoder
- name 부분에 내가 사용할 encoder 이름을 작성한다.
- weight 는 imagenet 뿐만 아니라 다른 pretrained weight 를 제공한다. 이 부분은 모델마다 확인이 필요하다.
- in_channels, classes 는 내가 가진 데이터셋에 맞게 넣어준다.
- smp.Unet 에 encoder 를 efficientnet 을 사용함으로써 EfficientUnet 을 사용할 수 있다.
- 유의미한 실험들
- 디버깅 모드: 실험 환경이 잘 설정되었는지 체크하기 위한 과정
- epoch 를 1~2 정도로 설정하여 loss 가 정상적으로 감소하는지 확인할 수 있다.
- 샘플링을 통해 데이터셋의 일부분을 추출해서 돌려볼 수도 있다.
- 전체 코드가 잘 돌아가면 원래 실험으로 진행할 수 있다.
- 시드 고정
- 시드: 컴퓨터의 난수를 생성하는 룰 정도로 이해하면 된다.
- 모델의 성능을 비교할 때 실험마다 성능이 달라지는 것을 방지하고 재생산해내기 위해 시드를 고정한다.
- torch 외 numpy, os 관련 시드 고정

- validation set 의 시드 고정

- 실험 기록
- 실험 결과 공유를 해주면 반복되는 실험을 줄일 수 있다.
- 다양한 툴들의 도움을 받을 수 있다. Notion, Google 스프레드 시트, 슬랙 등
- 실험은 한 번에 하나씩
- 실험을 할 때에는 하나의 조건만을 변경해가며 실험해야 한다.
- 여러 개의 실험 중 어떤 것이 모델의 좋은 영향을 끼쳤는지 구분이 안된다. 따라서 한가지 요인, 즉 한가지 독립변수만 두고 실험해야 한다.
- 이전 실험 조건에서 모델과 Augmentation 방법을 모두 변경하여 새로운 실험을 하면, 두 조건 중 어떤 조건이 성능 향상/하락에 영향을 주었는지 알기 어렵다.
- 팀원들 각각이 베이스라인을 만들고 마지막에 앙상블 하면 성능이 좋았다!
- Validation set 만들기
- Validation 이 중요한 이유는 1) 제출을 하지 않아도 모델의 성능을 평가할 수 있고, 2) Public 리더보드의 성능에 오버피팅 되지 않도록 도와준다.
- 제출횟수가 적기 때문에 제출하지 않고도 성능 비교를 할 수 있는 세팅이 필요하다. 이를 위해서 Validation 이 필요하다.
-
Hold out

- 전체 데이터를 8:2 로 분리해서 train, valid data 구성
- 80% train data 로 학습을 진행하고 20% valid data 로 검증하며 학습
- 이후 해당 모델로 inference 진행
- 장점은 빠른 속도로 모델에 대한 검증이 가능하다.
- 단점은 20%의 valid data 가 학습에 참여하지 못한다. 따라서 성능적 측면에서 떨어지게 된다. 또한 나머지 80% 데이터는 validation 검증이 되지 못해서 신뢰성도 좀 떨어지는 측면이 있다.
- 이런 Hold out 은 대회 데이터 사이즈가 커서 전부 검증하기 어렵거나 time series 와 같이 시간이 연속적이서 최근 데이터만 검증할 필요가 있는 경우 많이 사용한다.
- 성능이 떨어진다는 측면 때문에 vision 대회에서는 K-fold 를 많이 사용한다.
-
K-fold
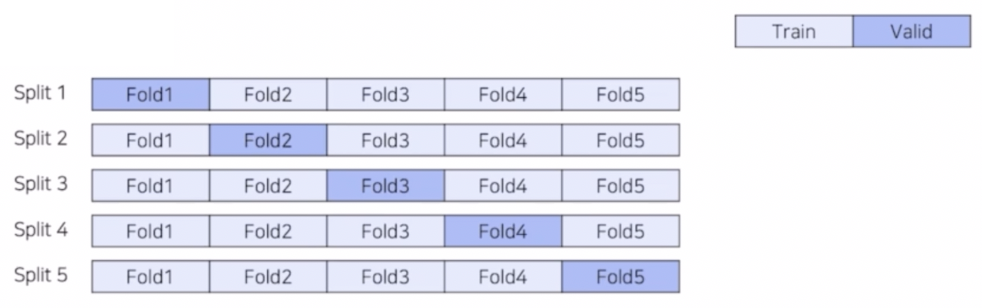
- 전체 데이터를 8:2 로 분리해서 train, valid 로 구성한다. 그러나 특정 validation 이 학습에 적용되지 못한다는 한계점을 극복하기 위해서 모든 validation part 는 검증과 동시에 학습에 참여할 수 있게 한다.
- 기존의 Hold out 과 동일하게 데이터를 나누었지만, split 개념을 도입해서 모든 데이터가 학습에 참여한다.
- Split 수 만큼 독립적인 모델을 학습하고 검증한다. 위 그림은 5 fold 이기 때문에 5개의 모델이 만들어진다.
- 독립적인 모델로 test 데이터에 대해 각각 inference 한 후, Ensemble 해준다.
- 장점은 모든 데이터셋이 학습에 참여하고, 모든 데이터셋 기반으로 검증하기 때문에 성능도 높고 신뢰성도 높다. 또한 앙상블의 효과로 대부분의 경우 모델의 성능이 향상된다.
- 단점은 Hold out 방식에 비해 k 배 만큼 시간이 소요되고, k 는 하이퍼 파라미터라는 점이다.
-
Stratified K-fold
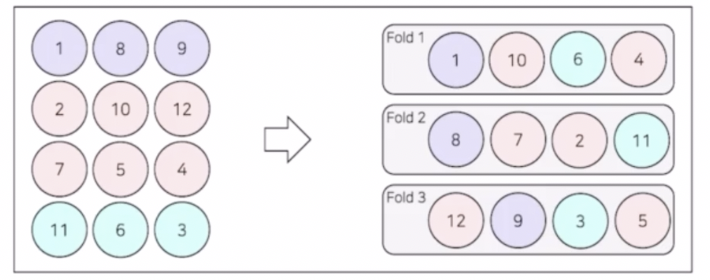
- 기존의 K fold 방식은 class distribution 을 고려하지 못한다. split 이 랜덤이기 때문이다.
- 이를 고려해서 fold 마다 class distribution 을 동일하게 split 한다. 각 fold 별로 클래스 비율이 맞게 나눠주는 것이다. 이를 통해 Class 가 imbalance 한 상황에서 사용하기 좋다.
-
Group K-fold
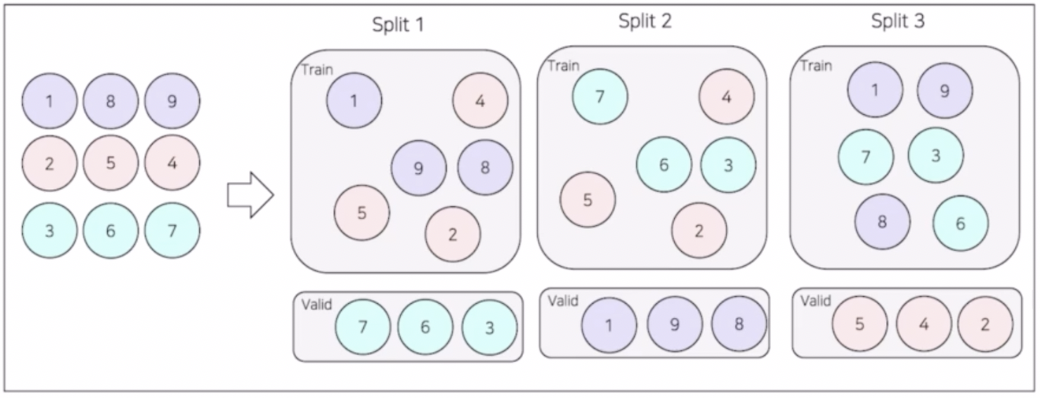
- 각각의 클래스보다는 각각의 그룹이 같은 fold 에 들어가도록 하는 방식이다.
- 이는 data Leakage 를 막기 위한 방법이다.
- 하나의 클래스에 속하는 데이터들은 어느정도 correlation 이 존재할 수 있다. 예를들어 위 이미지에서 한명의 환자에서 나온 데이터끼리 같은 클래스로 묶일 수 있다.
- 이 때 Stratified 로 split 을 하게 되면 train 에서 사용된 이미지와 validation 에서 사용된 이미지가 같은 클래스일 때 정답을 누설한 것처럼 될 수 있다. 왜냐하면 같은 환자에게서 나온 데이터로 학습하고 그 환자에게서 나온 데이터로 검증하기 때문이다.
- 이러면 실제 test 에서 validation 과 유사하게 나오지 않는 현상이 발생할 수 있다.
- 이를 없애기 위해서 train 과 validation 에 동일한 환자 데이터가 섞이지 않도록 나눠주는 방법이 Group K-fold 이다.
- 위 그림을 보면 각 split 마다 같은 환자의 데이터는 train / valid 로 나뉘지 않는다.
- 환자라는 그룹을 기반으로 같은 그룹에 있는 데이터는 train 혹은 valid 에 같이 속하도록 나눠준다.
-
Augmentation

- 데이터 수 증가
- Generalization 강화
- 성능 향상
- Class imbalance 문제 해결
- 현실에서 볼 법한 상황을 만들어줌으로써 모델이 다양한 상황에서 학습이 잘 되도록 도와준다.
- Albumentation 라이브러리를 많이 사용한다. 내장된 기법 수가 많고 속도 측면에서 빠르다. 그리고 Pytorch 와 연동도 쉽다.
- 많은 Augmentation?
- 도메인에 맞는 Augmentation 기법이 필요하다.
- 번호판 인식에서 HorizontalFlip 을 제외한 Flip 이나 Rotate 는 실생활에서 보기 힘들다.
- 도메인과 관련된, 혹은 있을법한 상황을 만들어주는 것이 필요하다. 번호판 인식 task 에서 날씨 상황에 따라 성능이 달라진다. 비, 눈, 우박 등 특수한 기상상황에 대한 데이터가 부족하니 augmentation 으로 만들 수 있다.
- 그렇게 되면 다양한 상황에서도 일반화된 성능을 보여줄 수 있도록 모델에 대한 학습을 가능하게 만들어줄 수 있다.
- 많이 사용하는 Augmentation
-
Cutout
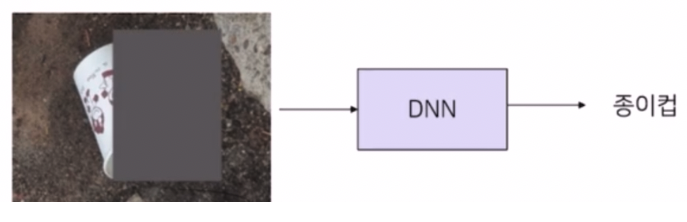
- 종이컵의 일부를 가리고 모델을 학습.
- 딥러닝 모델(DNN)은 모델의 전체 영역이 아니라 가리지 않은 영역만 보고 분류를 수행한다.
- 이렇게 될 경우, 모델은 종이컵의 전체 영역이 아니라 일부 영역 혹은 특정 정보가 제한된 상황에서 학습하기 때문에, 일부만 보고 분류할 수 있게 된다.
- 실제 Cutout 적용 시, 기존 모델 대비 전부 성능 향상이 있고 일반화 성능도 좋아진다.
- 그러나 Cutout 은 랜덤성이 심해서 객체의 일부 영역을 가려야 하는데 전체를 가리거나 거의 안 가리게 될 수 있다.

- 위 경우처럼 되면 모델이 학습을 못하거나 Cutout 을 적용하지 않은 결과가 된다.
- Albumentation 에서
CoarseDropout으로 구현한다.

- 하이퍼파라미터로 구멍의 개수, 높이, 너비의 범위를 결정할 수 있고, 실행 시 마다 다른 결과가 나온다.
- 따라서 Random 하게 Box 를 생성하기 때문에 이미지마다 성능의 편차가 존재한다.

- Gridmask
- Cutout 의 경우 객체의 중요 부분 혹은 Context information 을 삭제할 수 있다는 단점을 해결하기 위해, 규칙성있는 박스를 통해 Cutout 하는 기법이다.
- 입력 객체의 일부 영역을 가려서 모델의 학습을 통해 일반성을 높이는 컨셉은 동일하다. 그러나 Random 한 것이 아니라 규칙적으로 box 를 배치해서 Cutout 을 한다.

- GridMask 가 Cutout 대비 성능 개선 폭이 더 크다.
- Albumentation 에서는
GridDropout으로 사용한다.

- X, Y 방향으로 mask 의 개수, mask 의 크기, mask 의 시작점(random_offset)을 하이퍼파라미터로 결정할 수 있다.
-
Mixup
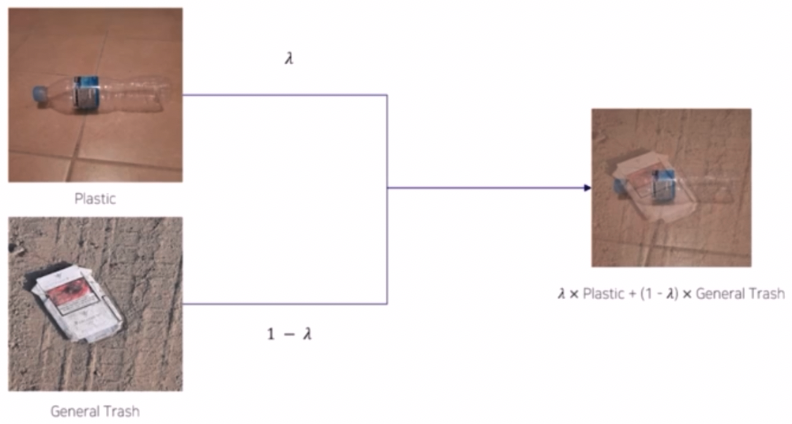
- 두 입력 이미지를 $\lambda$ 의 비율만큼 랜덤하게 섞어서 새로운 형태의 이미지를 만들어낸다.
- label 도 동일하게 $\lambda$ 의 비율을 적용해서 새롭게 만들어준다.
- 모델이 학습할 때 output 과 새롭게 만들어진 label 간의 차이를 비교해서 loss 를 계산하는 것이 Mixup 의 핵심이다.
- CutMix
- 많이 활용하고 있다.

- 두 가지 입력 이미지를 섞어주는 것은 동일하다. 그러나 단순하게 $\lambda$ 의 비율로 곱을 해서 합쳐주는 것이 아니라, 일부 영역은 이미지 1에서, 일부 영역은 이미지 2에서 가져온다.
- 이미지의 특정 부분을 잘라서 서로 교환하는 방식이다.
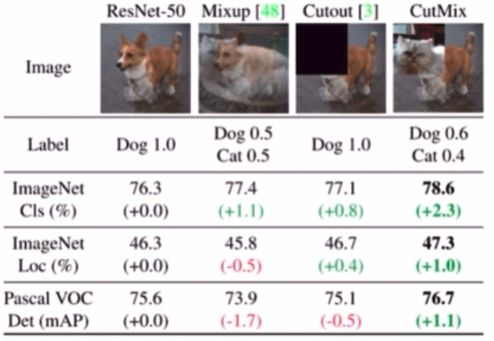
- CutMix 의 성능이 기존 모델 대비 성능 향상이 잘 된다.
- 먼저 기존의 이미지 크기 W, H 에서 얼마만큼 자를지 크기를 결정해준다. 이 때 하이퍼 파라미터로 cut_rat 을 정해준다.
- 자를 크기를 결정 후에 어느 영역을 자를지를 결정해준다.

- 랜덤하게 cx, cy 를 추출하고 영역을 잘라서 교환해준다.
np.clip은 자른 box 가 이미지의 바깥 부분으로 넘어가지 않게 방지해준다. - 마지막으로 input 이미지의 순서를 섞고, Permutation 을 통해서 어떤 이미지끼리 CutMix 할지를 결정한다.
- 이후 loss term 에 대한 계산을 해준다.
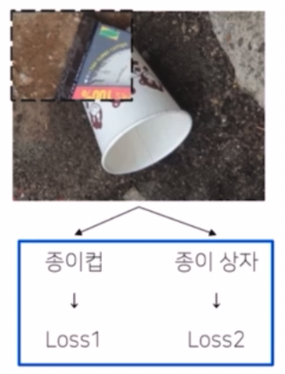
- 면적의 비율을 계산해서 loss 를 계산해준다. $\lambda$ 에 대한 계산을 전체 이미지에서 섞인 box 가 얼마만큼을 차지하는지에 대한 비율로 계산해준다.
- 원본은 $\lambda$ 만큼, CutMix 로 추가된 부분은 1-$\lambda$ 만큼으로 loss 를 계산해준다. 물론 loss 계산 시 비교되는 target 값은 사전에 원본용, CutMix 용으로 만들어둔다.
- 이렇게 코드를 짤 필요 없이, github 에 코드가 짜여진 것들이 많다.
-
SnapMix
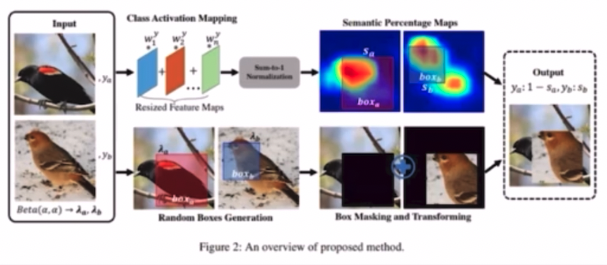
- CMA(Class Activation Map)을 이용해 이미지 및 라벨을 Mixing 하는 방법이다.
- 영역 크기만을 고려해 label 을 생성했던 CutMix 와 달리 영역의 의미적 중요도를 고려해서 label 을 생성한다.
- CropNonEmpytyMaskIfExists
- object 가 존재하는 부분을 중심으로 crop을 해서 해당 object 에 대해서 중점적으로 학습을 한다.
- object 가 존재하는 부분을 중심으로 crop 할 수 있다면 model 의 학습을 효율적으로 할 수 있다.

- Albumentations 에 존재한다.
- Augmentation 을 적용해서 input 이 어떤 augmented output 으로 변화하는지 살펴보고, 하이퍼 파라미터 튜닝 과정을 거치면 좋다.
-
- 모델 파트 실험
- 다른 인코더, 디코더 아키텍처를 사용해볼 수 있다.
- PaperwithCodes 에서 리서치해보는 것이 좋다.
- 각종 하이퍼 파라미터를 손보기
-
Scheduler (Learning Rate)
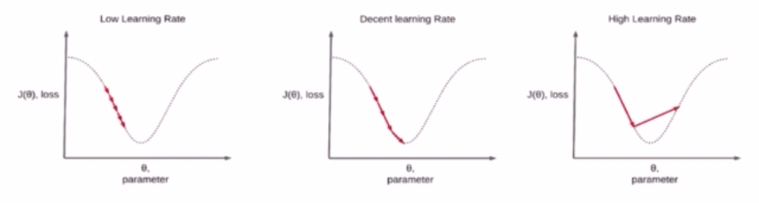
- Constant Learning Rate 는 문제점이 있다.
- lr rate 가 너무 작으면 학습 시간이 오래 소요되고, local minima 에 빠질 위험이 있다.
- 반면에 너무 크면 loss 가 발산하는 문제가 있다.
- 따라서 적절하게 모델을 수렴해줄 수 있는 lr rate 를 찾아야 한다.
- 이러한 lr rate 의 수렴을 도와주는 도구가 Learning Rate Scheduler 이다.
- Scheduler 는 학습 속도를 빠르게 해서 수렴을 하는데 도움을 주고, 높은 정확도를 가져서 성능을 개선시키기도 한다.
- 예를 들어 초반에 Scheduler 에 의해서 lr rate 를 초반에는 크게 하고 점점 decay 하여 더 빠르게 모델이 수렴하게 할 수 있다.
- Constant Learning Rate 는 문제점이 있다.
-
ConsineAnnealingLR
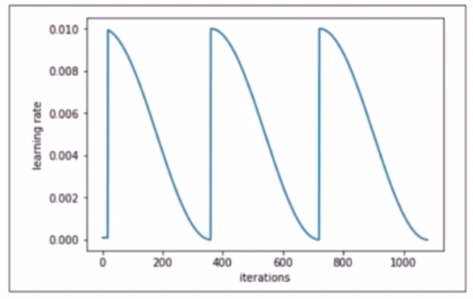
- lr rate 의 최대값과 최소값을 정해서 그 범위의 lr rate 를 consine 함수를 이용해서 스케줄링하는 방법이다.
- 최대값과 최소값 사이에서 lr rate 를 급격히 증가시켰다가 감소시키기 때문에 saddle point, 정체 구간을 빠르게 벗어나게 한다.
-
ReduceLROnPlateau
- 내가 설정한 metric의 성능이 향상되지 않을 때 lr rate 를 조절하는 방법이다.
- 다양한 하이퍼 파라미터를 가진다.
-
Gradual Warmup
- 학습을 시작할 때 매우 작은 lr rate 로 출발해서 특정 값에 도달할 때까지 lr rate 를 서서히 증가시키는 방법이다. 이후 감소시킨다.
- pretrained 된 weight 를 많이 가지고 오는데, 이를 높은 lr rate 로 학습하게 되면 기존에 사용하던 가중치가 깨지는 경우가 있다.
- 이 방식을 사용하면 weight 가 불안정한 초반에도 비교적으로 안정적인 학습을 수행할 수 있다.
- backbone 사용시에 weight 가 망가지는 것을 방지한다.
- Batch Size
- 일반적으로 batch size 가 크면 더 빨리 학습할 수 있고, 다양한 데이터셋에 대해서 학습하기 때문에 일반성이 더 좋아질 수 있다.
- 그러나 GPU 메모리에 의해서 조절의 한계점을 느끼기도 한다. 이를 해결하기 위한 도구들이 있다.
- Gradient Accumulation
- 모델의 weight 를 매 step 마다 업데이트 하지 않고, 일정 step 동안 gradient 를 누적한 다음 누적된 gradient 를 사용해서 weight 를 업데이트 하는 방법이다.
- 이는 batch size 를 키우는 장점이 있다.
- 실험을 통해서 적절한 batch size 를 확인해보자.
- Optimizer / Loss
- Adam, AdamW, AdamP, Radam
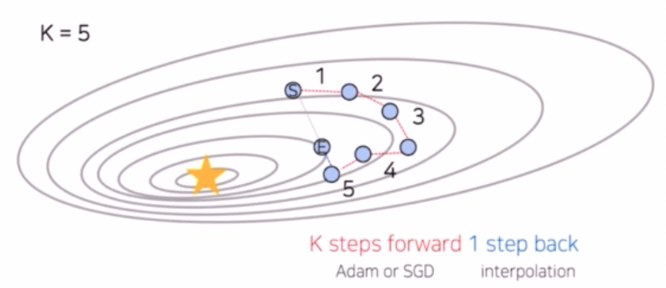
- Lookahead Optimizer
- Adam 이나 SGD 를 통해 k 번 업데이트 한 후, 처음 시작했던 point 방향으로 1 step back 후, 그 지점에서 다시 k번 업데이트를 하는 방법이다.
- 이는 Adam 이나 SGD 로는 빠져나오기 힘든 local minima 를 빠져나올 수 있게 한다는 장점이 있다.
-
Loss
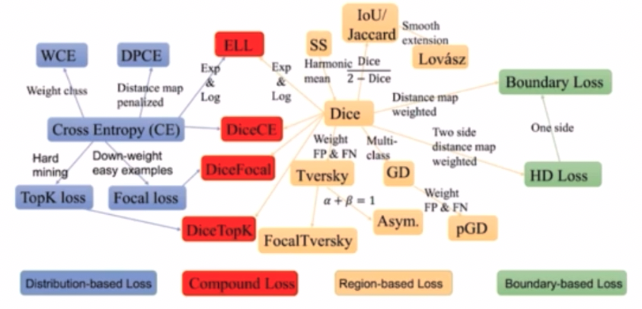
- Compound Loss 계열은 imbalanced segmentation task 에 강인한 모습을 보인다. 이는 loss 를 여러가지로 결합해서 사용하는 DiceCE, DiceFocal 등을 뜻한다.
- 하이브리드 형태의 loss 는 많이 사용한다.
-
- 디버깅 모드: 실험 환경이 잘 설정되었는지 체크하기 위한 과정
- SMP
- Semantic Segmentation 대회에서 사용하는 방법들2
- Ensemble
-
5-Fold Ensemble
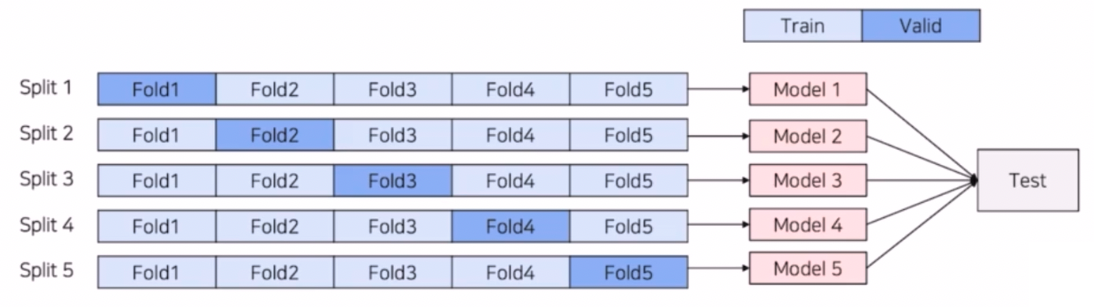
- 5-Fold Cross Validation 을 통해 만들어진 5개의 모델을 앙상블하는 방법
-
Epoch Ensemble(checkpoint ensemble)
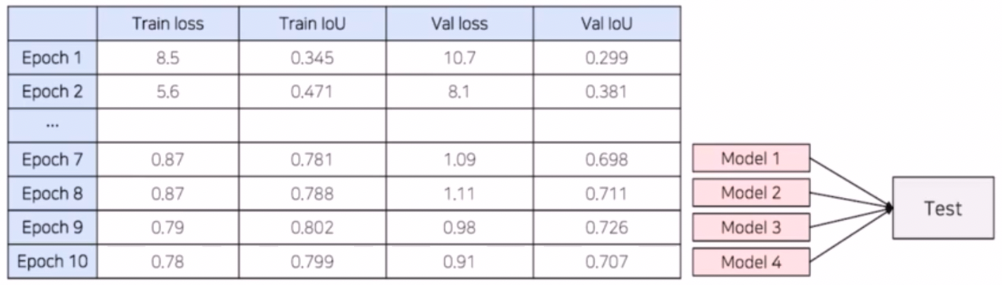
- 학습을 완료한 후, 마지막부터 N개의 weight 를 이용해 예측한 후 결과를 앙상블 하는 방법이다.
- 혹은 loss, metric 을 기준으로 N 개의 weight 를 이용해서 앙상블할 수도 있다.
-
SWA(Stochastic Weight Averaging)
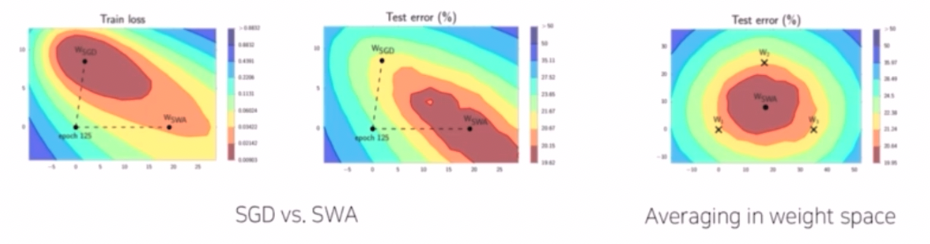
- 각 step 마다 weight 를 업데이트 시키는 SGD 와 달리 일정 주기마다 weight 를 평균 내서 새로운 가중치를 만드는 기법이다.
- SWA 의 장점은 SGD 대비해서 일반화 성능이 많이 좋아진다.
- $W_{SGD}$ 의 경우 train loss 에서 낮은 곳에 있지만 test error 에서는 더 높은 곳에 있다. 반면에 $W_{SWA}$ 의 경우 train loss 보다 test error 에서 더 낮은 곳에 있다. 이는 일반화가 좀 더 잘 됐다고 생각해볼 수 있다.
-
알고리즘
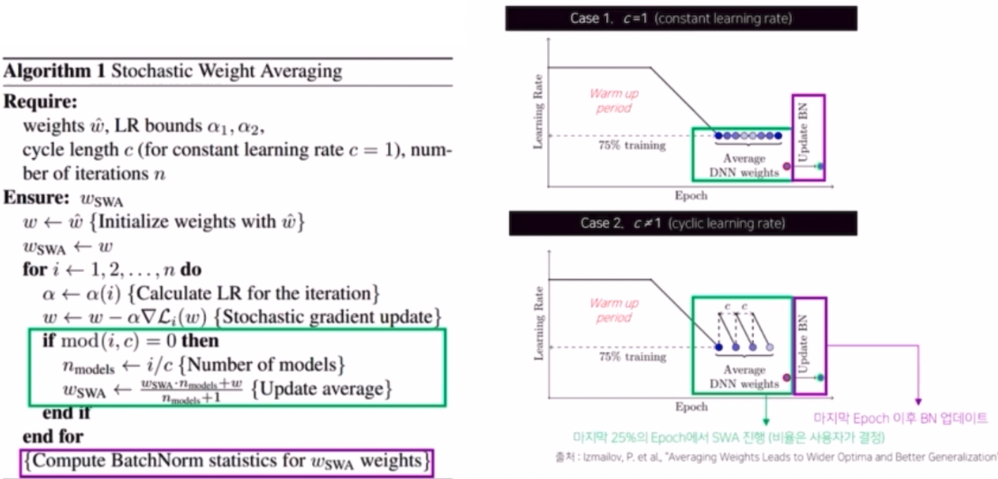
- weight 를 평균낸다는 관점에서 생각해보면 컨셉 자체는 간단하다.
- constant lr rate 와 cyclic lr rate 를 사용하는 case 로 살펴볼 때, 설정한 epoch 의 75% 까지 일반적인 학습을 진행한다.
- 남은 25% 에 대해서 SWA 를 진행한다.
- constant 의 경우 바로 weight 들을 average 하고, cyclic 의 경우 낮아진 point 의 weight 들만 가지고 average 를 낸다.
- 마지막 epoch 이후에 BatchNorm 을 업데이트 한다. 실제 average 를 만들어낸 weight 의 경우 기존 train data 의 BN 의 통계치와 다르기 때문에 이를 보정해주는 작업이다.
torch.optim.swa_utils의AveragedModel과SWALR을 사용할 수 있다.- AveragedModel 로 학습시킬 model 을 감싸고, SWALR 로는 optimizer 를 감싼다.
- 전체 epoch 중 내가 설정한 swa_start 이후에 SWA 를 진행한다.

- 그 때 SWA model 에 대한 update 가 진행된다.

- 그 이후 scheduler 에 의한 update 가 진행된다. 즉 내가 설정한 epoch 이후 부터는 SWA 업데이트, 그 이전에는 일반적인 schduler 에 의한 step 을 진행하는 것이다.

- 마지막으로 BN 에 대한 업데이트를 진행한다.

- Seed Ensemble
- loss, optimizer, 학습 파라미터 등 모든 요소들을 다 동일하게 남긴 채로 단순하게 Seed 하나만을 바꿔서 앙상블을 하는 기법이다.
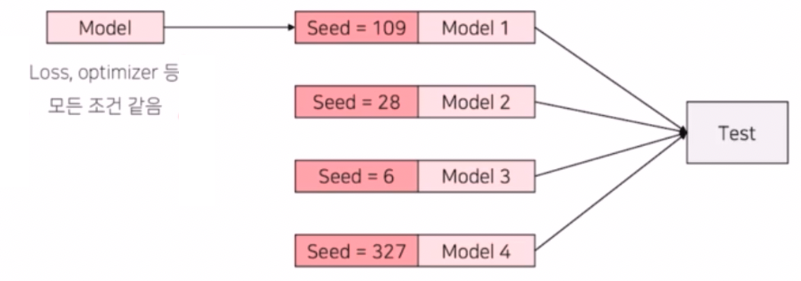
- 즉 Random 한 요소를 결정짓는 Seed 만 바꿔가며 여러 모델을 학습시킨 후 독립적인 모델 여러개를 만들어 각각에 대해 inference 하고 앙상블 해주는 기법이다.
- seed 를 바꾸는 것은 private data 에 대해서 일반성이 좋아질 수 있다. 대회를 하다보면 public 에만 높고 private 에는 낮은 상황이 발생하게 된다. 이 때 단순히 seed 하나만이 아니라, seed 여러개를 동일한 조건 하에서 모델을 만들고 앙상블 하여 결과를 낸다.
- 그렇게 되면 public 뿐 아니라 private 에서도 좀 더 robust 한 결과물을 기대할 수 있다.
- Resize Ensemble
- input 이미지의 size 를 다르게 학습해서 ensemble 하는 방법이다.
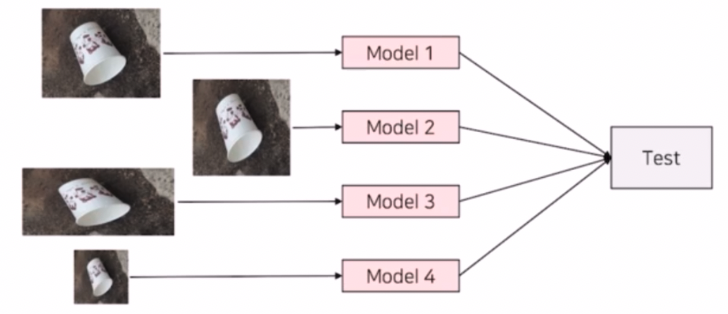
- 다양한 resolution 으로 학습시킨 모델들을 만들어서 앙상블 시킨다. 이렇게 하면 각 모델이 객체의 크기에 따라 잘하는 부분이 있을텐데, 큰 객체, 작은 객체, 중간 객체에 대해서 각각 잘하는 모델들의 시너지를 기대해볼 수 있다.
- TTA (Test Time Augmentation)
- Test set 으로 모델의 성능을 테스트할 때, augmentation 을 수행하고 앙상블을 하는 기법이다.
- 원본이미지와 함께 augmetnation 을 거친 N 장의 이미지를 모델에 입력하고, 각각의 결과를 평균낸다.
- 기존의 train 상황에서 만들어진 모델을 고정시킨 상태로, inference 할 때 입력 이미지만 augmentation 해주는 것이다.
- 단순하게 rotate, flip 등을 통해서 augmentation 된 이미지들을 만들고, 각각에 대해서 seg 를 수행한 다음에, 각 결과를 앙상블해서 최종 inference 결과물을 만드는 것이다.
- Segmentation 은 원본 이미지에 대해 픽셀 단위로 분류를 하기 때문에 객체의 형상을 그대로 유지해야 하는데, augmentation 된 결과를 보면 형상이 달라질 수 있다. 따라서 앙상블 하기 전에는 augmentation 된 결과를 원본 이미지와 같은 형태로 원복해준 뒤에 앙상블 해야 한다.
- 장점이 있다면, k fold 나 seed, resize 앙상블들은 모델의 학습을 여러번 해야했는데, TTA 는 train 에서 만든 모델은 고정한채로 test 시에만 입력 이미지를 바꿔주면 되기 때문에 학습 속도는 그대로인 채로 test inference 속도만 조금 늘어난다. 따라서 속도 측면에서 장점이 있다.
- TTA 는 Segmentation 에서는 augmentation 된 이미지를 원본 이미지로 돌려주어야 하는 것도 주의해야 한다.
- 이 때 어떤 augmentation 을 사용해야 할지 고민해야 한다. 실제 학습에 사용한 augmentation 을 사용하게 되면 좀 더 의미가 클 수 있다. 혹은 몇 개의 augmentation 을 사용해서 앙상블 할지, 원본이미지 말고 augmentation 된 이미지에 가중치를 부여하는 것에도 고려해볼 수 있다.
- TTA 기법 중 하나로 resize 앙상블을 이용한 TTA 도 있다. 학습 때와 다른 size 의 input 이미지를 이용해 test 하는 방법도 일종의 TTA 가 될 수 있다.
- 일반적으로 512 x 512 로 학습했다면 test 도 512 x 512 로 한다. 이 때 256, 1024 등도 사용해서 TTA 를 진행해서 그 결과를 앙상블을 해볼 수 있다.
- 이는 multi_scale_predict 함수로 코드를 짤 수 있다. scale 을 주어 resize 를 하고 다시 원본 이미지의 size 로 복원하는 과정이 있다.
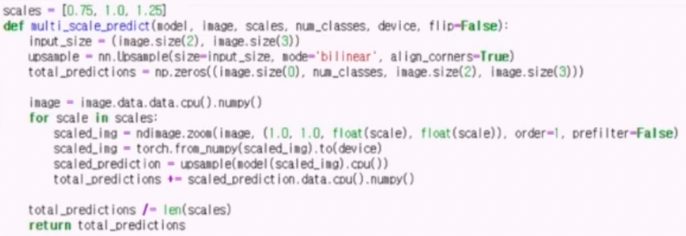
ttach라는 TTA library 도 있다.
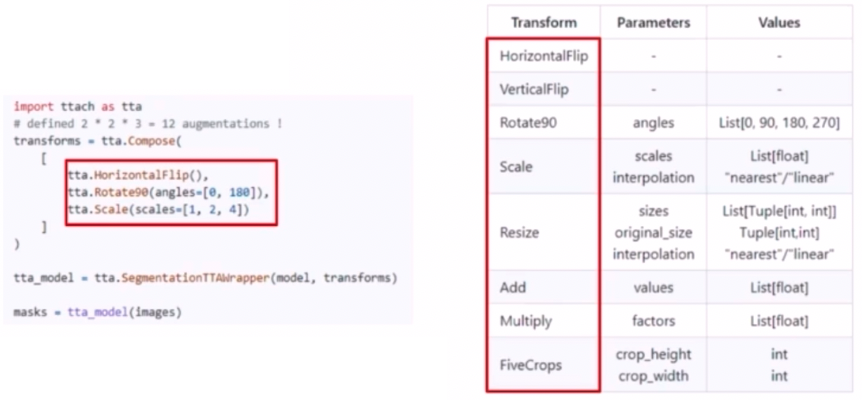
- 사용법이 굉장히 간단하고 지원해주는 transform 이 있어서 바로 적용해볼 수 있다.
- augmentation 수행할 때처럼
Compose로 TTA 시 어떤 augmentation 을 사용할지 결정할 수 있다. - 참고해야 할 점은 Compose 안에 있는 기법들은 각각 독립적으로 사용되는 것이 아니라, 입력으로 주어진 TTA 들을 조합해서 여러가지 TTA case 를 설정한다. 위 예제에서는 flip 을 할지 안할지 2가지 경우, rotate90의 angles 2가지, scale 의 3가지 경우를 통해서 12가지의 TTA case 를 만든다.
- 위 예제에서
SegmentationTTAWrapper를 통해 생성한 object는 model 과 Compose 의 결과물을 입력으로 받아 한 이미지에 대해 12 가지의 TTA 를 적용하고 결과물을 평균 내어 return 한다.
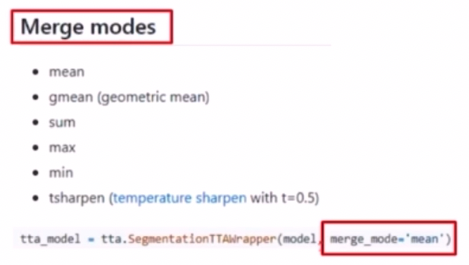
- 단순 평균이 아니라 다양한 연산으로 Merge 할 수도 있다.
- Seg 는 TTA 시 이미지를 augmentation 하면 다시 원본 이미지로 돌리는 과정이 필요한데, ttach 는 라이브러리 안에 그 과정이 포함되어 자동으로 수행된다.
- 이 외에도 모델, backbone 들을 다르게 하거나, loss 를 다르게, optimizer 를 다르게 앙상블을 해도 좋다.
- 앙상블을 할 때 단순히 하는게 아니라, 최대한 다양성을 보장해주기 위해서 모델의 inference 결과를 보고 어떤 class 를 잘 예측하는 모델이 다르다면 그 다양성을 활용해서 앙상블하면 더 좋은 결과가 있을 수 있다.
-
-
Pseudo Labeling
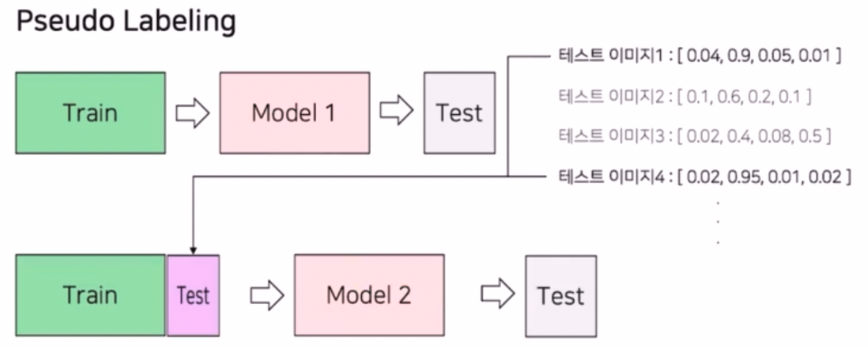
- 가짜 label 이라는 의미. 실제 label 이 없는 데이터에 대해서 가짜 label 을 생성해서 학습에 이용하고 추론까지 하는 작업이다.
- 실제 대회에서는 test data 에 대해서 pseudo label 을 만들어서 다시 학습에 참여시킨다.
- 먼저 모델 학습을 진행한다.
- 성능이 가장 좋은 모델에 대해 test 데이터셋에 대한 예측을 진행한다.
- 이 때 Softmax 를 취한 확률값이나, Softmax 를 취하기 전의 값, torch.max 를 취하기 전의 값을 예측한다. 즉 모든 클래스별 확률을 구한다.
- test 데이터셋은 모델의 예측값이 threshold 보다 높은 결과물을 이용한다. 즉 강한 확신을 갖고 예측한 것을 가지고 train dataset 에 포함시킨다.
- train data 양이 늘어나는 장점 뿐만 아니라 test data 를 일부 사용했으니 test data 의 분포 또한 학습하는 것이다.
- 그렇게 일부 thr 를 넘는 test data 와 train data 를 결합해서 새롭게 학습을 진행한다.
- 이런 pseudo labeling 은 한 번만 하는 것이 아니고 계속해서 진행할 수 있다.
- 외부 데이터 활용
- 외부 데이터를 사용해서 성능을 높일 수 있다.
- pretrained weight 를 사용하는 경우도 있고, 다양하다.
-
Classification 결과를 활용하는 방법
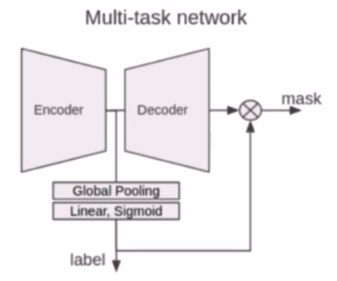
- Encoder head 마지막 단에 Classification head 를 달아서 같이 활용할 수도 있다.
- 즉 Classification 결과도 같이 학습해서 모델의 수렴을 도와주는 경우이다.
- 또한 Classification 결과를 Seg 결과와 곱해서 후처리에 활용하는 기법도 있다.
- 최근 딥러닝 이미지 대회 Trend (Segmentation)
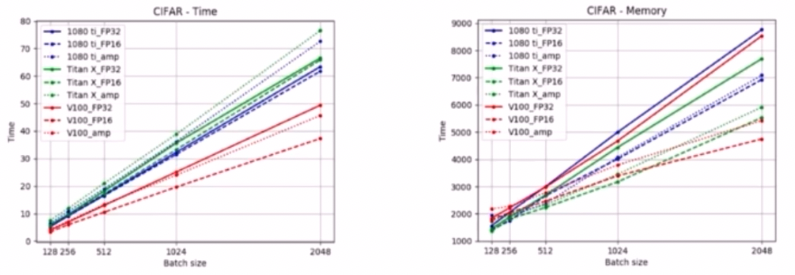
- 데이터의 크기가 커지고 양이 많아졌다.
- 학습 이미지가 많고 큰 경우에는 네트워크를 한번 학습하는데 시간이 오래 걸려서 충분한 실험을 하지 못한다.
- 이를 해결하기 위해 FP16(부동 소수점 변경), 실험 간소화, 가벼운 모델 사용이 해결책이 될 수 있다.
- Mixed Precision
- weight 의 소수점 자리를 32에서 16으로 대체해서 배치를 키우는 방법
- 내부적 연산은 복잡하지만 사용은 코드적으로 간단하다.
- AutoMixedPrecision(AMP) 없이는 모든 계산이 default precision 인 torch.float32 로 계산된다. 즉 fp32로 loss 의 계산과 backward 가 진행된다.
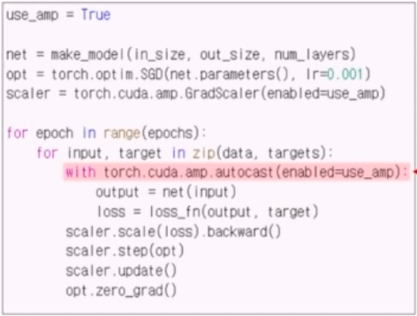
- 이 때
torch.cuda.amp.autocast()를 이용하면 간단하게 AMP 적용이 가능하다. 이렇게 fp16 연산이 가능하다. - 또한
torch.cuda.amp.GradScaler는 AMP 활용 시 발생할 수 있는 underflow 문제를 방지한다. backward 와 step 호출 시에 필요하기 때문에 미리 scaler 를 준비해둔다. - scaler 가 기존의 loss term 을 감싸줘서 scaling 을 한 다음에 backward 와 step 의 update 과정을 거쳐준다.
-
실험 간소화
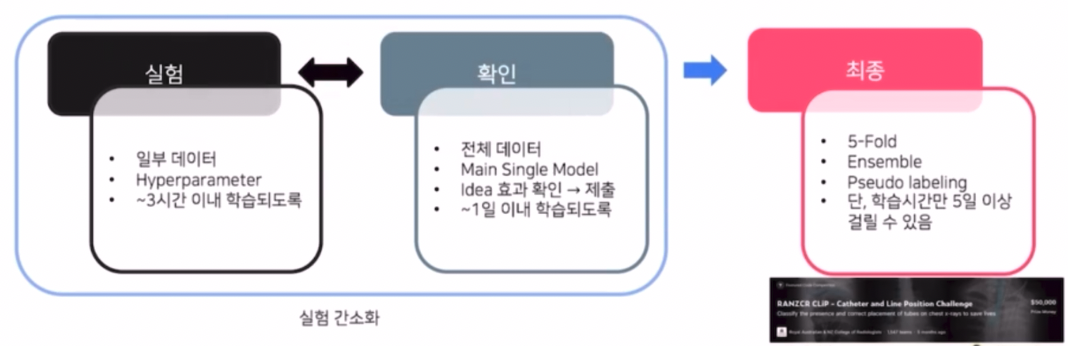
- 일부 데이터를 사용할 수 있다.
- 학습할 때는 단일 Fold 로 검증하고 최종 제출때만 5-Fold 로 진행할 수 있다. k-fold 의 장점이 앙상블을 통해 모델의 성능이 높아지고, 전체 데이터셋에 대해서 검증을 진행하기 때문에 신뢰성이 높다.
- 그러나 이 방식은 Hold-out 방식이기 때문에 상대적으로 모델의 성능과 신뢰성은 낮아지지만 속도적 측면에서 이득을 볼 수 있다.
- 따라서 실험을 Hold out 으로 진행하고 제출을 K-fold 로 할 수 있다.
- 위처럼 신뢰성이 낮아지는 문제를 보완해주기 위해서 Validation part 가 LB score 와 어느정도 상관관계가 있어야 한다.
- 신뢰성이 낮아지긴 했지만 LB 와는 상관관계가 있어서 Hold out 실험도 의미가 있다는 것을 보면 좋다.
- 즉 실험은 간소하게 해서 빠른 시간 내에 의미있는 실험을 체크하고, 실제 결과를 낼 때 Ensemble, 5-Fold, pseudo labeling 등을 적용해서 성능을 낼 수 있다.
- 입력이미지가 큰 경우, 높은 해상도를 유지하면서 실험할 수 있는 방법으로 down conv 를 활용할 수도 있다.
-
Down Convolution
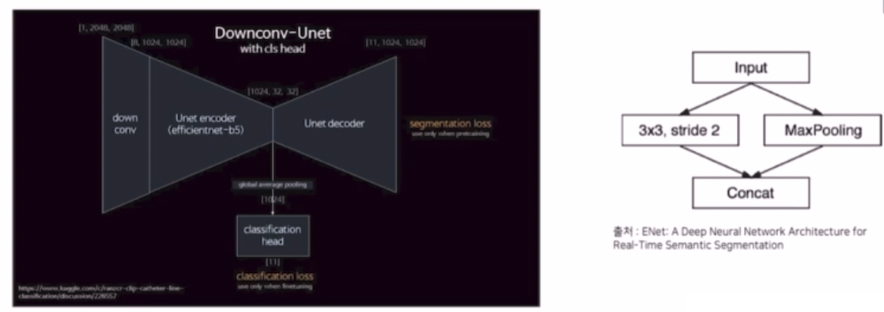
- 채널은 늘리고 resolution 은 줄이는 기법이다. real-time semantic segmentation 에서 많이 활용되는 기법이다.
- input 이미지가 들어왔을 때, 이미지 사이즈를 줄이는 기법으로 pooling 과 conv(3x3, stride2) 를 활용해서 이미지 사이즈를 줄인 다음에 그 두개를 concat 해서 사용하는 방식이다.
- conv 로 인해서 줄어드는 resolution 은 채널을 늘림으로써 정보를 더 담게 해주고, pooling 을 통해서 크기를 줄인 것도 concat 해주어 정보량을 풍부하게 만들어줄 수 있다.
-
가벼운 모델로 실험
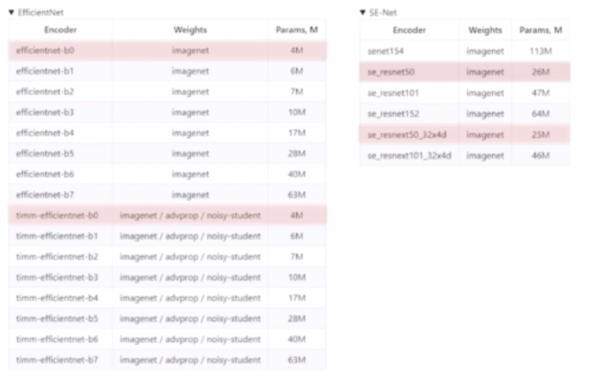
- params 가 적은 모델들로 실험하고 최종은 성능이 잘 나오는 모델로 한다.
- EfficientNet 은 성능도 좋고 속도도 빠른 모델이다. 이 경우 b0 부터 b7까지 있는데, b0 는 파라미터가 적어서 학습속도가 빠르고 b7 는 파라미터가 많아서 학습속도, 수렴속도는 상대적으로 더 느리지만 성능은 더 높게 나올 수 있다.
- 실험할 때는 b0 등 작은 모델로 실험해보고, 실제 제출할 때는 성능이 더 좋은 걸로 제출하는 것이 좋다.
- 이 때도 CV Strategy 는 중요하다.
- 또한 최근 딥러닝 대회는 학습 이미지의 수가 늘어남과 동시에 학습 이미지의 크기도 커졌다.
- 이미지의 크기(resolution)이 매우 큰 경우 모델이 학습하는 시간이 매우 오래 걸린다.
- 또한 GPU 상에 아예 안 올라갈 수도 있다.
-
이를 해결하기 위해 Resize 를 생각해볼 수 있다.
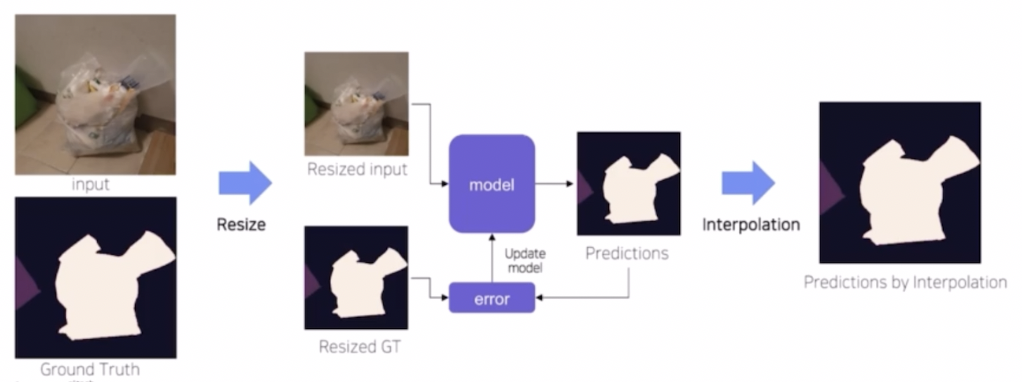
- train 과 test 시 resize 를 활용하는 것이다.
- input image 를 resize 하여 크기를 작게 만들고 이를 가지고 학습과 추론을 실시한다. 이후 interpolation 을 통해서 원본 이미지 사이즈로 복원해준다.
- 이는 이미지 resolution 이 성능에 중요한 경우 잘 working 하지 않을 가능성이 있다.
- 이를 해결해주기 위한 기법으로 생각해볼 수 있는 것이 Sliding Window 기법이다.
- input image size 가 크기 때문에 window 단위로 잘라서 input 으로 넣는 기법이다.
- window 가 원본 이미지를 훑으면서 patch 화된 input image 를 만들게 되고, 이러한 이미지들이 모델에 학습된다.
- 이러한 sliding window 를 사용할 때는 두가지 하이퍼 파라미터인 window size 와 stride size 를 고려해야 한다.
-
window size > stride size (overlapping)

- window size 는 윈도우의 크기, stride size 는 window 가 얼마만큼 이동할지에 대한 크기이다.
- 이 경우에는 중복되는 영역이 발생한다. 따라서 실제 patch 에도 중복되는 영역이 발생한다.
-
window size = stride size (non-overlapping)

- 같은 경우에는 중복되는 영역이 없이 patch 가 만들어진다.
- window size 가 크면, input image 가 커지고 그만큼 하나의 patch 에 담긴 정보도 크다. 반대로 window size 가 작으면 의미없는 영역이거나 부족하고 한정된 정보만 받을 수 있다.
- stride 가 작으면, input image 의 수가 많아지고, 겹치는 영역이 증가하면서 다양한 정보를 patch 에 담을 수 있다. 즉 다양한 상황을 담을 수 있다.
- window size 가 stride 보다 클 때, Stride 를 작게 설정하면 크게 설정했을 때보다 상대적으로 object 를 구분하기 위한 필요한 정보를 포함시킬 수 있다.
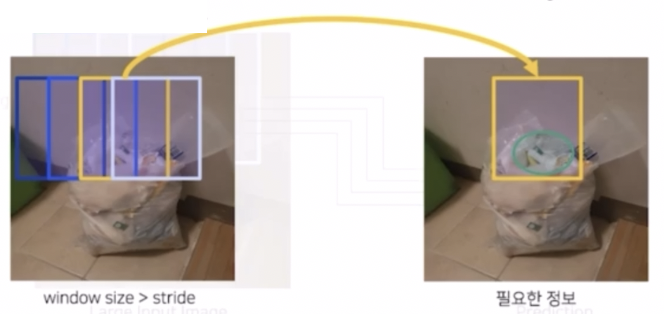
- 또한 inference 할 때 stride 를 작게 설정하면 data 의 양이 늘어나고 중복되는 부분을 ensemble 해서 약간의 성능 향상을 얻을 수 있다.
- 단점은, 일반적으로 겹치게 자르면 다양한 정보를 얻을 수 있지만 학습데이터의 양이 많이 늘어날 수 있으며, 늘어난 데이터 간 중복되는 정보가 많아 상관성이 높고, 학습데이터가 늘어나는 양에 비해서 성능의 차이는 적고 학습 속도가 오래 걸리는 문제가 발생한다.
- 실제 sliding window 로 train 과 inference 를 할 때 꼭 같은 window size 를 적용할 필요는 없다. inference image 의 sliding window 의 크기가 더 커지면 더 많은 주변 정보를 통해서 prediction 할 수 있으므로 성능의 정확도가 올라가는 경우가 경험적으로 많았다.
- Sliding Window 를 적용할 때 sampling 을 이용하는 것도 좋다.
- Sliding Window 를 적용하면 유의미하지 않은 영역들이 잡히는 경우가 많다. 즉 object 가 없는 background 만 수집된 부분이 많다.
- sliding window 를 쓰면 데이터의 양이 늘어나는데, 이 때 불필요한 영역을 줄여서 학습속도를 개선할 수 있다.
- sliding window 영역에 background class 만 있는 경우에는 샘플링을 한다. sliding window 안에 object 가 없으면 계속 진행하는 식으로 샘플링 해서 background 영역을 조금만 학습에 포함시킬 경우 학습 속도가 많이 향상된다.
-
또한 Sliding widow 를 적용했을 때 object 의 가장자리만 나오는 경우가 많다.
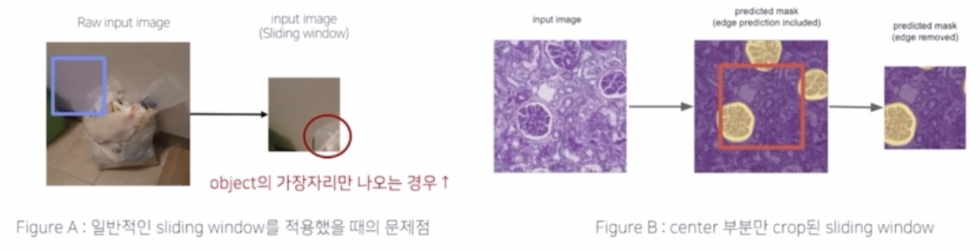
- 이는 의미가 없거나 상대적으로 적고, 예측하기 어려운 데이터가 된다.
- 이를 해결하기 위해서 prediction 후에 object 가 제대로 나온 center 부분만 Crop 하는 아이디어가 있다.
- input 이미지에 sliding window 로 나온 patch 에 대해서 실제 예측은 전체를 다 수행하지만, 실제 활용은 중심 파트만 활용하는 기법이다.(Edge Removed)
- 즉 center 부분만 crop 된 sliding window 를 활용했다고 볼 수 있다.
-
그 외에 Segmentation 이나 Object Detection 을 통해서 object 부분을 먼저 찾은 후 Crop 을 하는 방법도 쓸 수 있다.
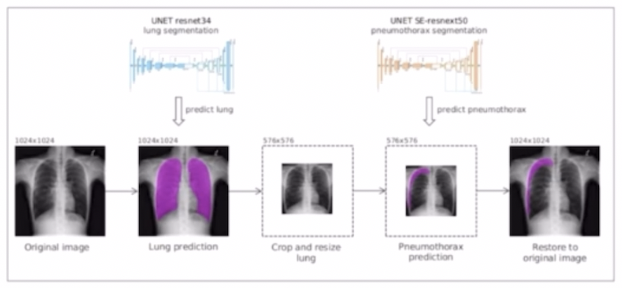
- 즉, 실제 이미지에서 object 외에도 다른 불필요한 영역이 너무 많은 특징이 있을 수 있다.
- 이 때 object 외에 유의미하지 않은 영역들에 대해서는 Crop 을 통해서 Object 영역만 남기는 테크닉이 캐글 대회에 있었다. 이 때 Object detection 이나 Segmentation 을 통해서 object 영역을 먼저 추출하고 이를 Crop 해서 다시 모델에 학습시켜 예측을 시킨다.
- Binary Classification
- 구분해야 할 class 가 오직 2개인 binary case 의 경우, thr 인 probability 를 0.5 로 끊는게 굳이 정답은 아닐 수 있다. 즉 thr 에 따라 실제 object 를 더 잘 잡는 경우가 있을 수 있다.
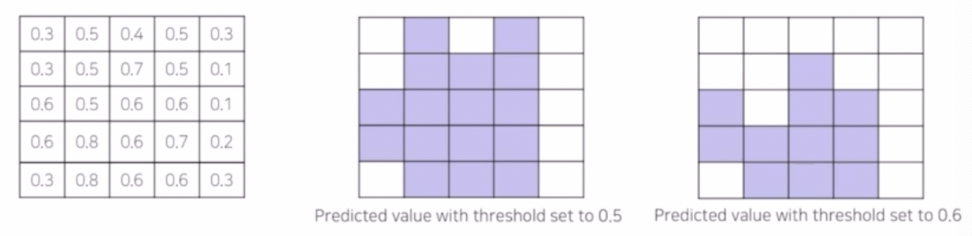
- 이 때 하이퍼 파라미터인 thr 를 잘 비교하면서 실험을 진행할 수 있다.
- 카테고리별로 binary threshold 를 적용해야 하는 상황이 있을 때 같은 0.5 가 아니라, 클래스나 카테고리 별로 다른 threshold 를 줄 수 있다.
- 모델 개선을 위한 tip
- validation 이나 inference 의 결과를 입력 이미지와 비교해보면서 어떤 점을 못하는지를 살펴보는 것이 중요하다.
- 클래스가 여러개 있는 경우, 각각의 class 를 찾아서 확인하기 어렵기 때문에 validation set 에서의 IoU 값을 확인할 수 있다. 즉 내 모델이 잘 맞추고 있는 클래스와 잘 못 맞추고 있는 클래스를 구분해서 내 모델의 약점을 확인할 수 있다.
- 특정 클래스에 대해 IoU 가 상대적으로 낮으므로 모델의 성능을 높이기 위해 해당 클래스를 잘 고려할 수 있는 아이디어를 생각해낼 수 있다.
- 해당 클래스가 등장한 image 만 뽑아서 segmentation 결과를 보고, train 이미지를 살펴보면서 왜 해당 클래스가 다른 클래스 대비 성능이 나쁘게 나왔는지에 대한 관점으로 비교해볼 수 있다.
- Label Noise 가 있는 경우의 tip
- 실제 segmentation task 를 진행하다 보면 label 에 noise 가 껴있는 경우가 많다.
- labeling 이 덜 되었거나, 과하게 되는 경우가 있다.
- Segmentation task 는 특히 annotation 을 픽셀 단위로 하기 때문에 어려움이 존재한다. 또한 annotation guide 가 주어지더라도 사람마다 기준이 다를 수 있고 사람이 하는 작업이기 때문에 실수도 존재한다. 이러한 이유로 noise 가 많다.
- 이러한 noise 를 해결하기 위한 연구도 많이 진행되지만 몇 가지 noise 를 보완할 수 있는 기술들을 알아보자.
- Label Smoothing
- 가장 대표적으로 사용되는 방법으로 soft 한 loss 를 사용하는 방법이다.
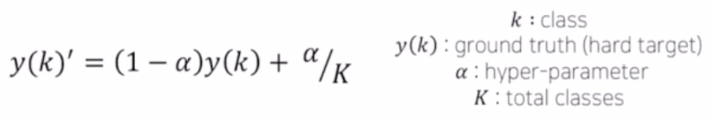
- 예를 들어 classification task 에서 [0,0,1,0] 이라는 label 이 있을 때, label noise 를 고려해서 실제 1이 아닐 수 있다는 관점 하에서 [0.025, 0.025, 0.925, 0.025] 로 변환시킨다.
- 이는 Hard 한 target 을 Soft 한 target 으로 변화를 줌으로써 더 낮은 확신을 가지도록 한다.
- 실제 segmentation 에서 label smoothing 을 적용하면 의미가 있는 경우가 많았다.
-
Pseudo labeling 을 활용한 label preprocessing
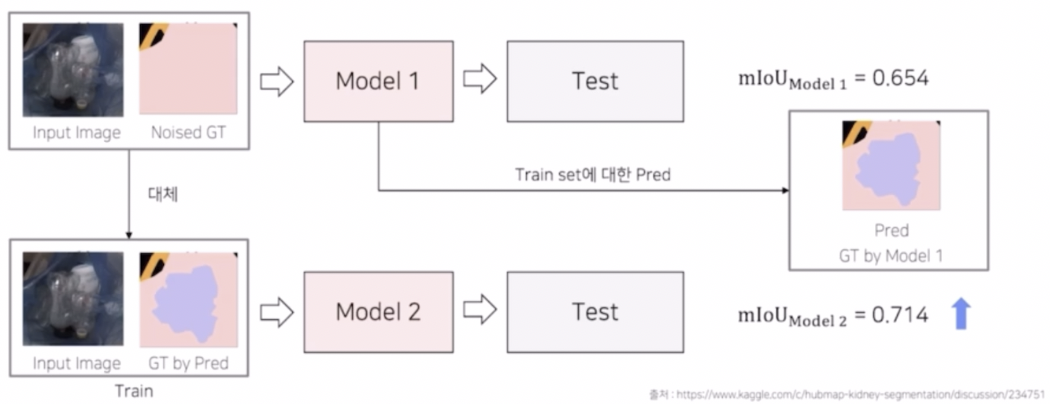
- label smoothing 은 train 데이터에 label noise 가 있다고 가정하고 target 을 바꿔서 loss term 계산을 바꾼 반면, pseudo labeling 을 활용한 label preprocessing 은 실제 입력 이미지에 있는 noise 한 label 을 전처리를 통해 제거하는 방법이다.
- train 후 validation 을 5-fold 로 전체 train set 에 대한 prediction 을 진행할 수 있다. 이 때 전체 데이터에 대한 실제 label 을 알고, 예측된 prediction 도 알게 된다.
- 이 때 실제값과 예측값에 대해 metric 을 비교할 수 있다. 실제 GT 가 잘 나오거나 멀쩡하면 metric 이 높을 것이다. 그러나 noise가 있는 GT 에 대해서는 metric은 낮게 나왔지만 예측에서 object 를 더 잘 잡은 경우가 있을 것이다. 예를 들어 noist GT 는 object 가 있는데 annotation 이 잘못된 경우, prediction 에는 다른 정상적인 데이터셋의 학습으로 object 를 잘 잡은 경우이다.
- 그렇다면 metric 이 낮은 case 들에 대해서 입력 이미지를 일부 버리거나, noise GT 를 활용하는 것이 아니라 prediction 결과를 다시 GT 로 활용해서 train 을 다시 할 수 있다. 그러면 기존의 noise 한 GT 를 가지고 학습한 것 대비 모델의 성능이 개선될 가능성이 있다.
- 최근 딥러닝 이미지 대회 평가 trend
- 요새는 성능 외에도 다른 요소들이 많이 포함된다.
- 학습시간이나 추론 시간에 제한이 있는 경우도 있고, 속도 평가를 하는 경우도 있다.
- 실제 추론에서 앙상블을 하는 것이 앙상블을 위해 모델을 학습하는 것보다 가성비가 좋다.
- fp16, 가벼운 모델, 경량화 기법
- Monitoring Tool
- Wandb
- 실험을 돌려 놓고 다른 작업을 진행하기 편함.
- 웹을 통해 결과를 실시간으로 확인 가능
- 모델에 대한 실험 결과를 비교 가능
- step, learning rate 에 따른 score, loss 등의 변화를 자세하게 볼 수 있다.
- 학습된 모델의 inference 결과를 웹에서 확인할 수 있다.
- Wandb
- Ensemble
댓글 남기기