
[Segmentation] 4. U-Net 계열의 모델들
- High Performance를 자랑하는 U-Net 계열의 모델들
- UNet
- bio medical image 분야에서 나온 논문.
- 네트워크 구조가 좋고 성능이 많이 향상되어 seg 에서 많이 활용됨.
-
의료 시장은 데이터가 부족함.

- 환자의 개인정보.
- train data 를 구했더라도 labeling 을 일반인이 하기에는 쉽지않고 도메인 전문가들이 해야함 → 자원, 시간 비용이 훨씬 많이 듦.
- 딥러닝은 파라미터 수가 많고 네트워크가 깊어서 많은 학습데이터를 필요로 하는데 의료쪽은 데이터 부족으로 딥러닝 학습이 어려웠음.
-
같은 클래스가 인접한 셀 구분이 어려움.

- 인접한 세포 구분 어려움.
- 다른 cell 이라고 구분지어줄 선이 매우 작아서 seg 에서 무시될 가능성이 매우 높음.
- 이러한 한계점을 극복한 논문이 UNet
- Contracting Path 와 Expanding Path 가 U 자 형태로 대칭인 모습을 보임.
-
Encoder - Contracting Path

- 입력 이미지의 전반적인 특징을 추출해서 context 를 포착함 → max pooling 을 이용하여 down sampling 을 수행
-
Decoder - Expanding Path

- 줄어든 정보를 up sampling 해주면서 차원을 늘림. 그리고 localization 을 가능하게 함.
-
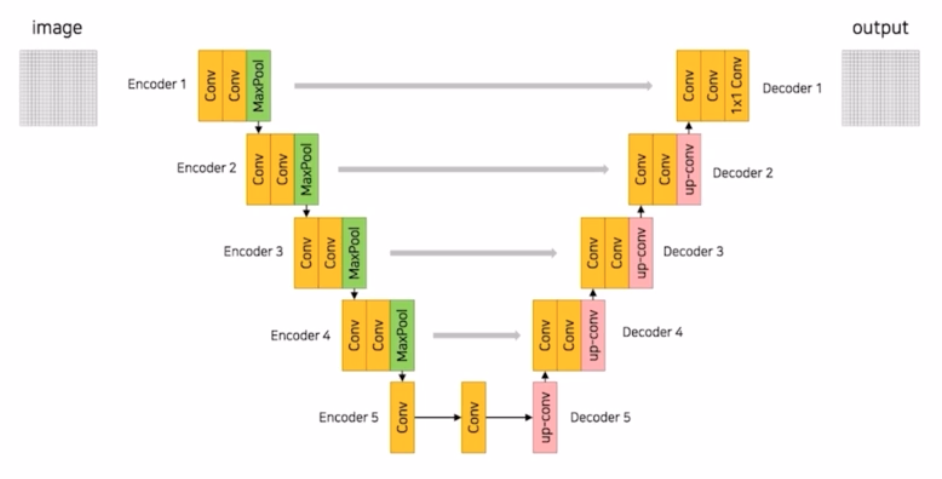
UNet Architecture
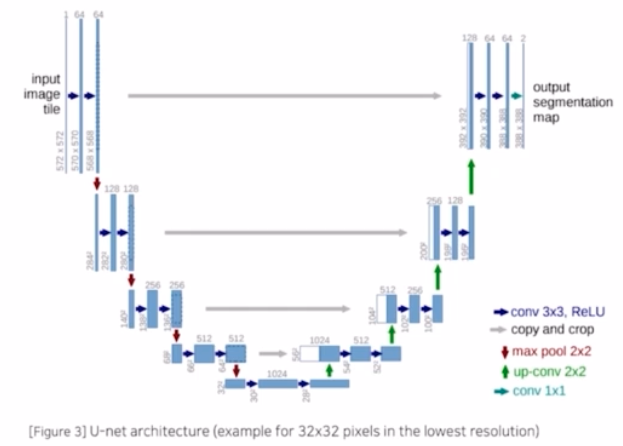
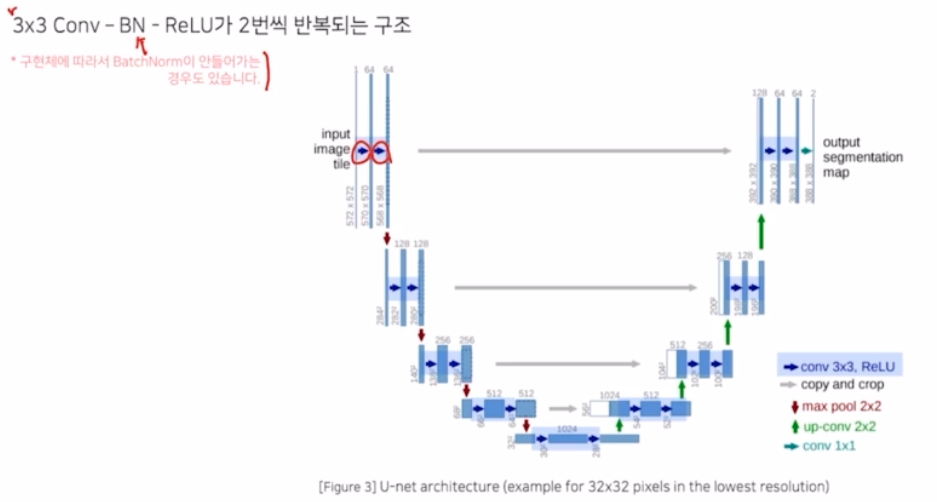
- 3x3 conv, BN, ReLU 가 2번씩 반복되는 구조. 구현체에 따라서 BN 이 안들어가는 경우도 있음.
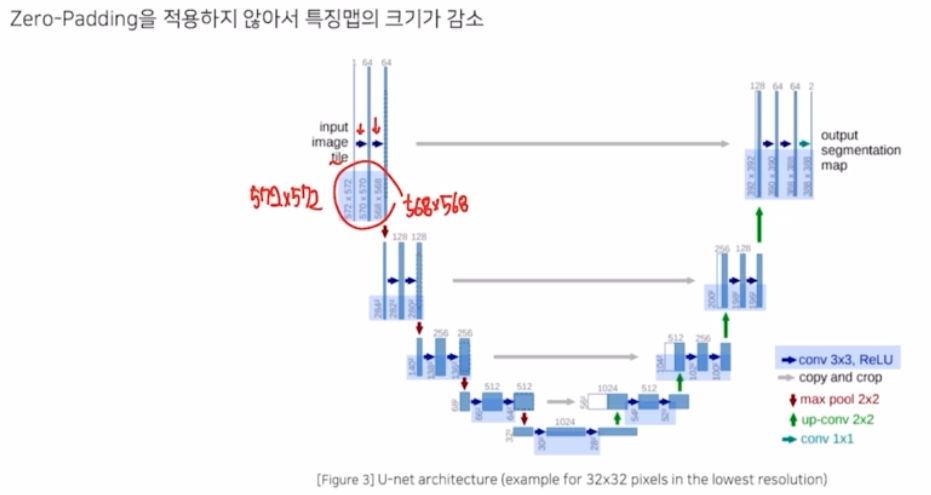
- 기존 입력 타일은 572x572 였는데 각 conv 에 zero padding 을 적용하지 않아서 크기가 572 → 570 → 568 로 감소함.
- Contracting Path 에서는 각 conv 마다 채널의 수를 64, 128, 256, 512, 1024 로 2배씩 키워감.
- Expanding Path 부분에서는 1/2 로 감소시키면서 1024, 512, 256, 128, 64 형태로 진행됨.
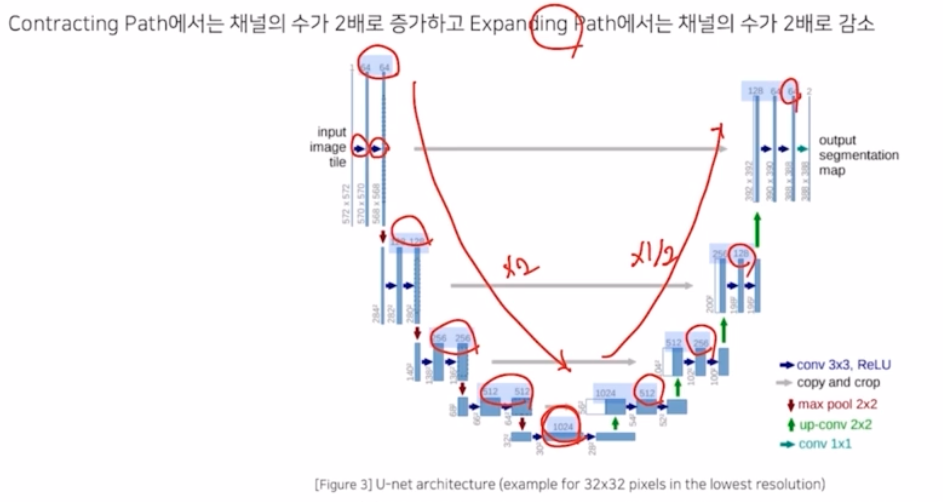
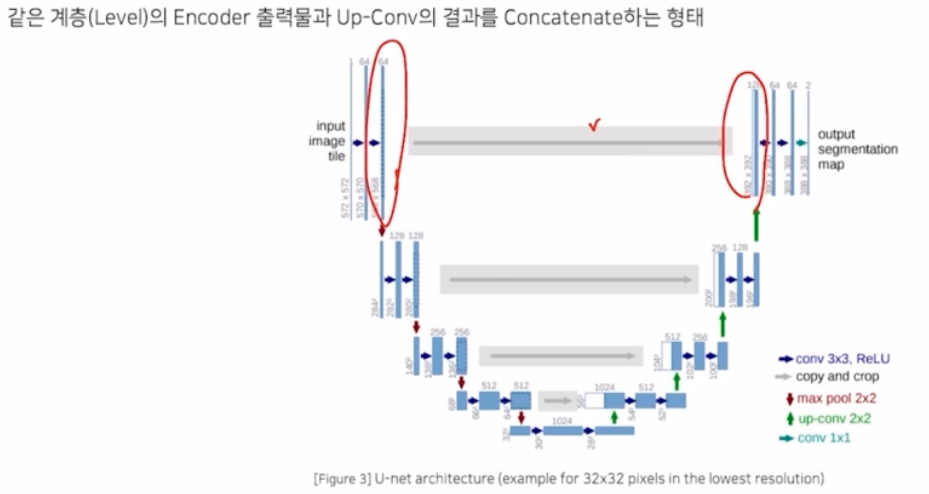
- 같은 계층(Level)의 encoder 의 출력결과와 decoder 의 입력 부분에 concatenate 를 해주어서 skip connection 을 적용했음.
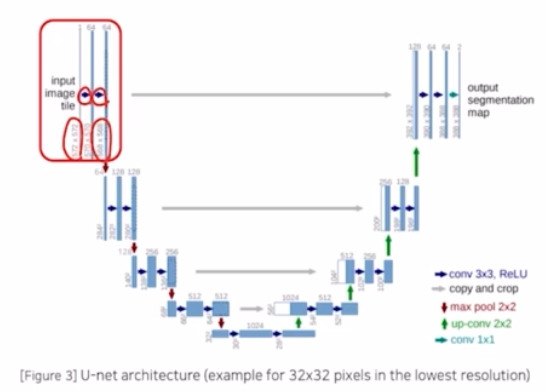
- Contracting Path : 이미지 특징 추출
- (3x3 conv, BN, ReLU) x 2 → no zero padding 으로 patch-size 가 conv 를 진행할 때 마다 크기가 감소함.
- 2x2 max pooling (stride = 2) → feature map 크기가 절반으로 감소. (568→284)
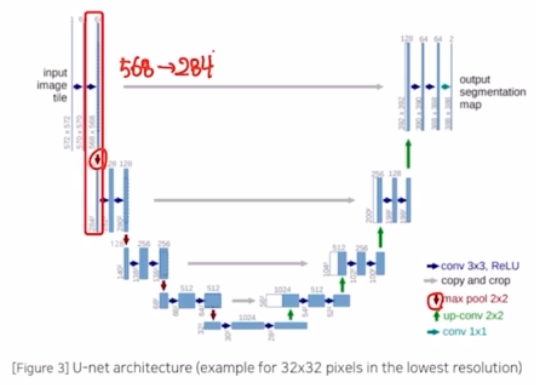
- Max pooling 이후 conv 를 적용한 결과를 보면 채널 수가 2배 증가함. → 이 때도 padding 을 적용하지 않았기 때문에 타일 크기가 284 → 280 으로 감소함. (max pooling 으로 타일 크기는 절반 감소, 이후 conv 를 통해서 채널은 2배 증가)
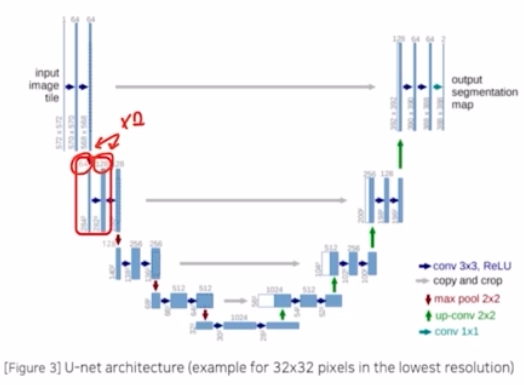
- 이후 동일한 모습을 계속 보임. 이 과정을 통해서 input image tile 이 들어왔을 때 encoder, contracting path 를 통해서 이미지 특징을 추출할 수 있음. → 이렇게 추출한 이미지 특징을 가지고 output 의 seg map 을 만드는 decoder 과정인 Expanding path 과정을 진행하게 됨.
- Expanding Path : localization 을 가능하게 함.
- 2x2 up conv 사용 (transposed conv) → feature map 크기 2배 증가, 채널의 수를 1/2 만큼 감소
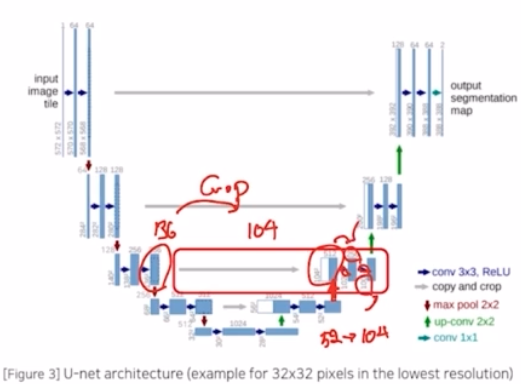
- 이 때, contracting 에서 얻은 feature map 과 concat 을 진행하는, skip connection 을 통해서 합쳐줌.
- contracting 연산에서 얻은 것을 resolution 크기를 맞춰주기 위해 crop 과정을 통해서 내부만큼을 잘라내서 합침.
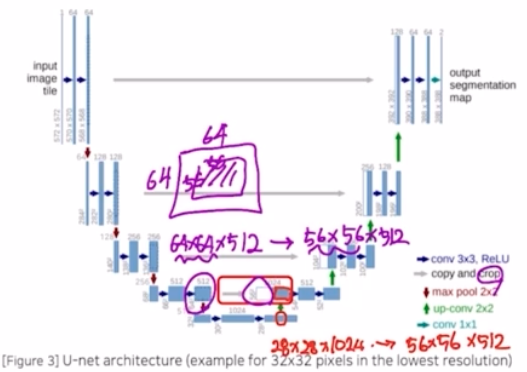
- 마찬가지로 2개의 conv 를 거치면서 no zero padding 으로 patch-size 가 감소함. 또한 채널 수도 1/2 만큼 감소함. 채널 수는 skip connection 으로 concat 했기 때문에 늘어나 있기 때문.
- 다음 과정도 동일하게 transposed conv 를 이용해서 feature map 크기를 2배 증가시키고, concatenate 를 수행하는데 contracting 에서 오는 것에 대해 crop 과정으로 resolution 을 맞춰주고 concatenate 를 해줌. 여기에 conv 2개를 취해서 no zero padding 으로 인해 크기도 4만큼 줄어들고 채널을 절반으로 줄임.
- 다음, 그 다음 과정도 동일한 연산을 진행함.
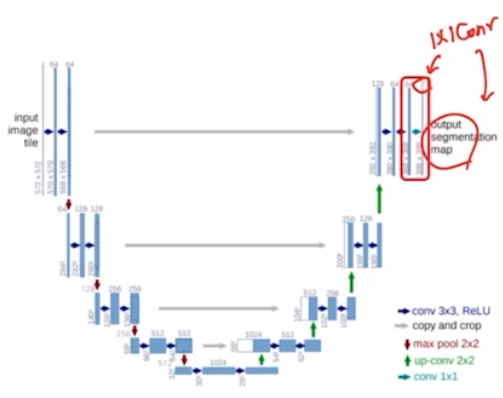
- 마지막에는 output 의 segmentation map 을 만들기 위해서 num class 를 채널로 가지는 1x1 conv 를 진행해주고 그 결과로 output segmentaiton map 을 얻음.
- contribution
- 되게 단순하지만 해당 아키텍쳐가 효과적이었던 이유는,
- encoder 가 확장함에 따라 채널 수를 1024 까지 증가시켜 좀 더 고차원에서 정보를 매핑.
- 각기 다른 계층의 encoder 의 출력을 decoder 와 결합시켜서 이전 레이어의 정보를 효율적으로 활용함.
- 성능적 측면에서도 랭킹 1등을 달성함.
- UNet 에 사용된 techniques
-
data augmentation
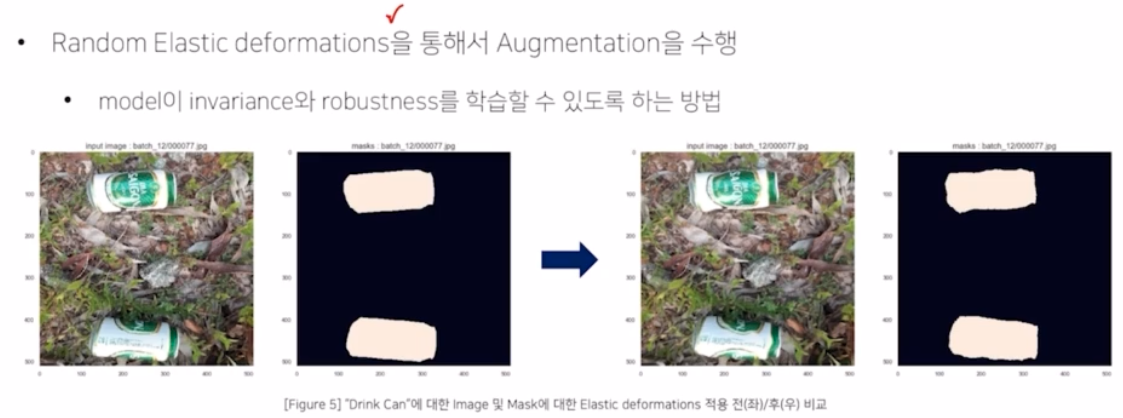
- random elastic deformations 를 적용함. → 물체에 외부적인 압력을 주어서 변형시키는 aug 기법.
- biomedical 에서는 세포가 사람마다 다르고, 세포의 모양이 다 달라서 이런 aug 를 통해서 세포의 모양을 다양하게 만들어주고, 이를 모델이 학습함으로써 모델이 좀 더 robust 하게 됨. → robust 하게 모델이 학습함.
- 이 방법이 모든 분야에서 통용되는 것은 아님. → 상황에 유의
- 경계부분을 더 잘 분류하기 위해서 가중치 맵을 사용함.
-
Pixel-wise loss weight 를 계산하기 위한 weight map 을 생성.
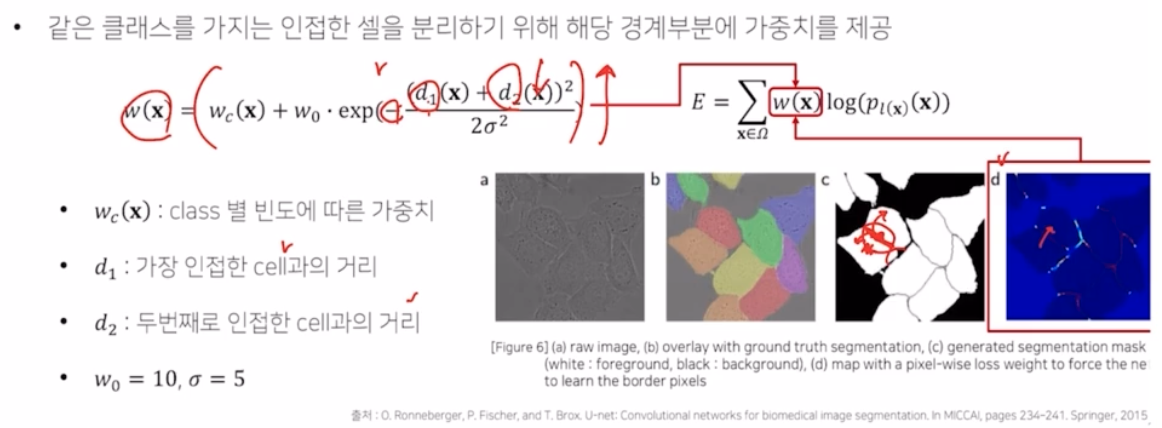
- 인접한 cell 의 모습을 가지는 픽셀일수록 더 가중치를 줘서 훨씬 loss 를 계산할 때 크기를 많이 반영하도록 함.
- $d_1$, $d_2$ 가 각각 의미하는 것은 인접한 셀과의 거리를 의미함.
- 세포의 중심 부분일수록 인접한 셀과의 거리가 멀어져, $d_1 + d_2$ 가 커지고 - 를 받아서 exp 값이 작아짐. 이를 통해 weight 가 작아짐.
- 반대로 경계 영역의 경우 인접한 셀과의 거리인 $d_1 + d_2$ 가 작아지고, -가 반영되어 exp 가 커짐. 이를 통해 weight 가 커짐 → 이 부분을 더 잘 계산하기 위해서 loss 가 반영됨.
-
-
Code
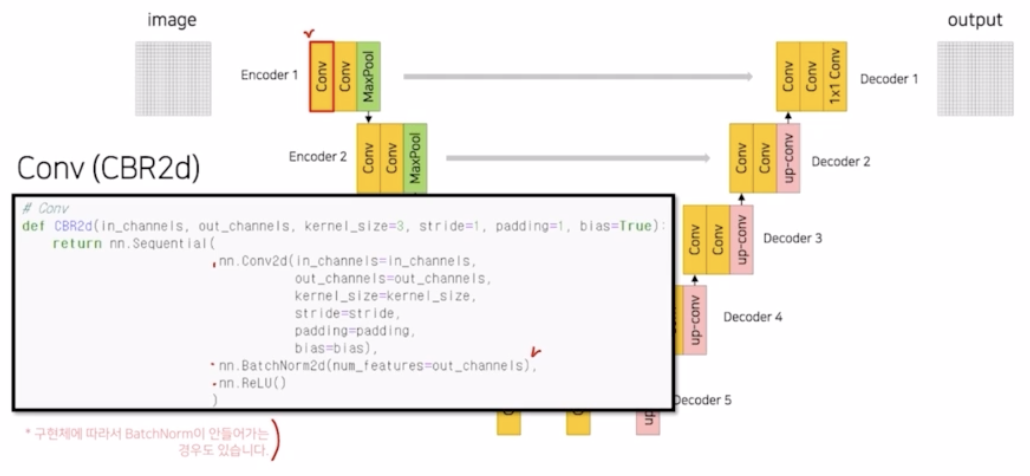
-
Conv(CBR2d) → Conv - BN - ReLU. BN 은 구현체에 따라 들어가는 경우가 있고 안들어가는 경우가 있음.
-
Encoder1
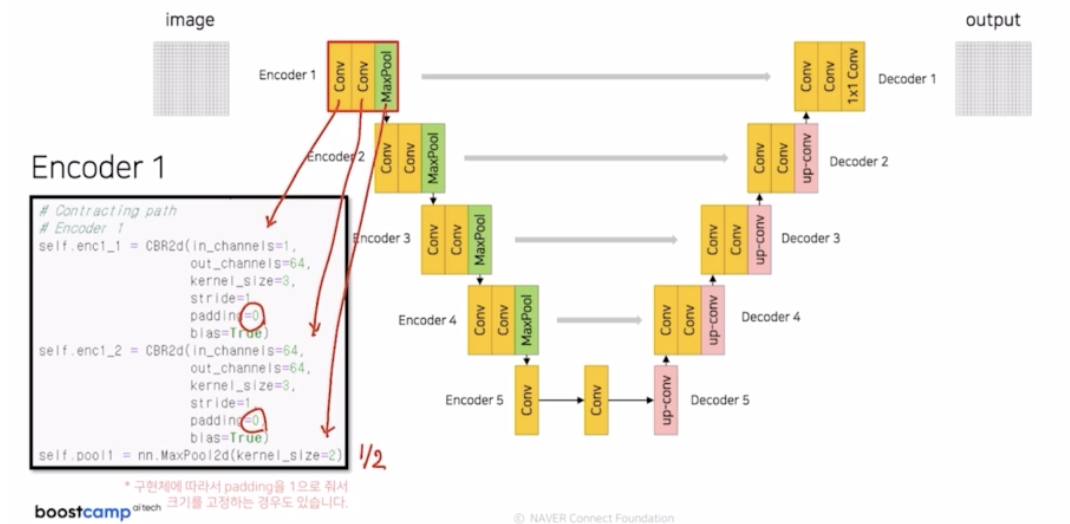
- CBR, CBR, max pooling → 크기를 1/2. padding 을 0 으로 줘서 크기에 변동을 줌.
- 구현체에 따라 padding 을 1 로 크기를 고정하는 경우도 있음.
- Encoder 1 을 지나고 나서 skip connection 을 위해서 enc1_2 의 결과를 따로 저장해둠.
-
Encoder 2
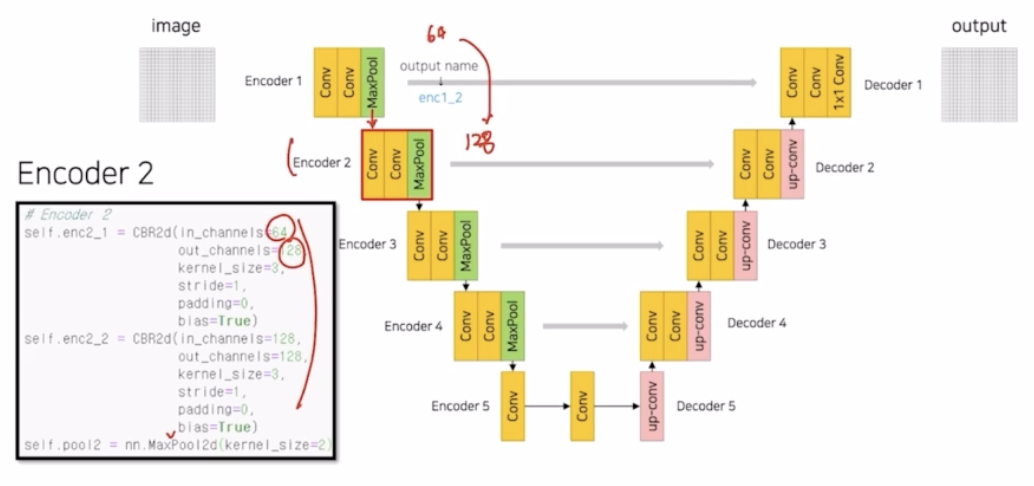
- Enc 1 의 max pooling 결과를 전달. 똑같이 kernel 3 의 CBR 을 2번 반복하고 max pooling.
- CBR 에서 채널을 두배씩 키움.
- skip connection 을 위해서 enc2_2 를 저장해둠.
-
Encoder 3
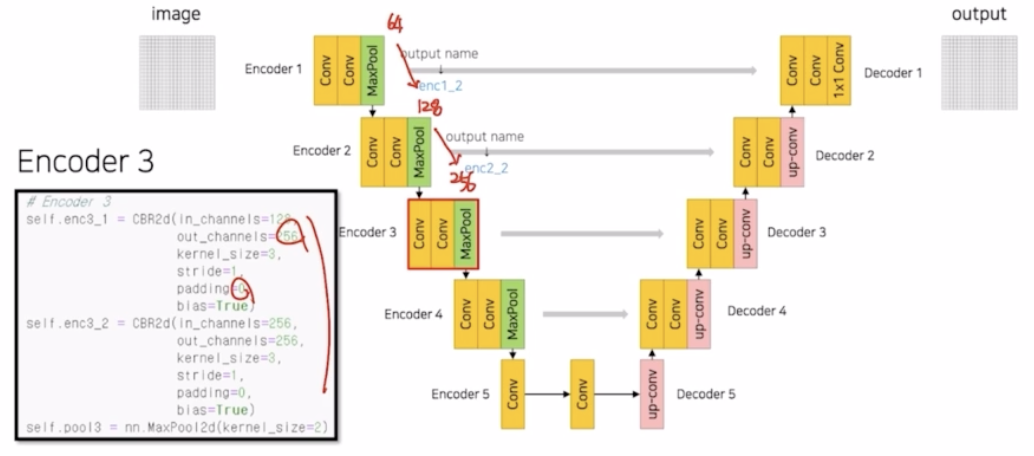
- 똑같이 진행. 채널을 두배 증가시킴. 계속 padding 0을 주어서 크기를 감소시키고 있음.
- enc3_2 을 저장해둠.
-
Encoder 4
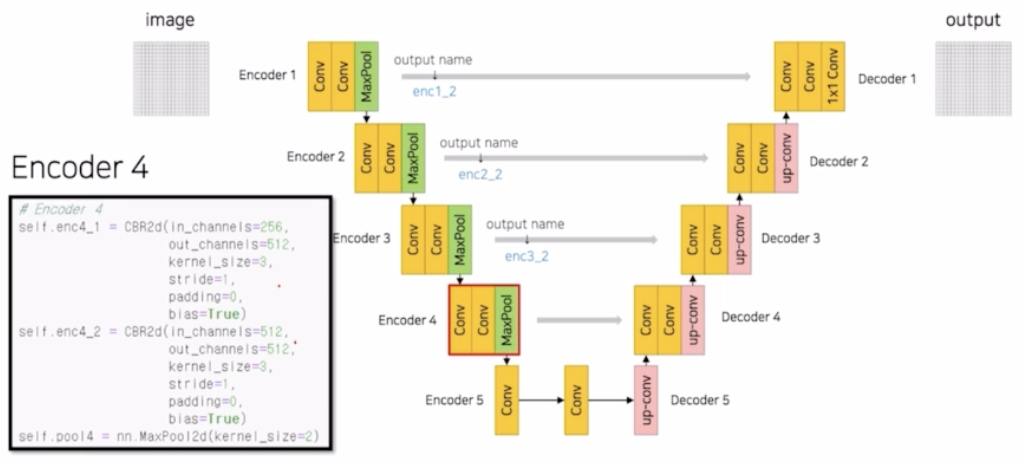
- 동일한 연산. enc4_2 도 저장함.
- skip connection 을 위해서는 출력 결과를 계속 해서 저장. 그러나 많아질수록 메모리 부담도 커짐.
-
Encoder 5 Decoder 5 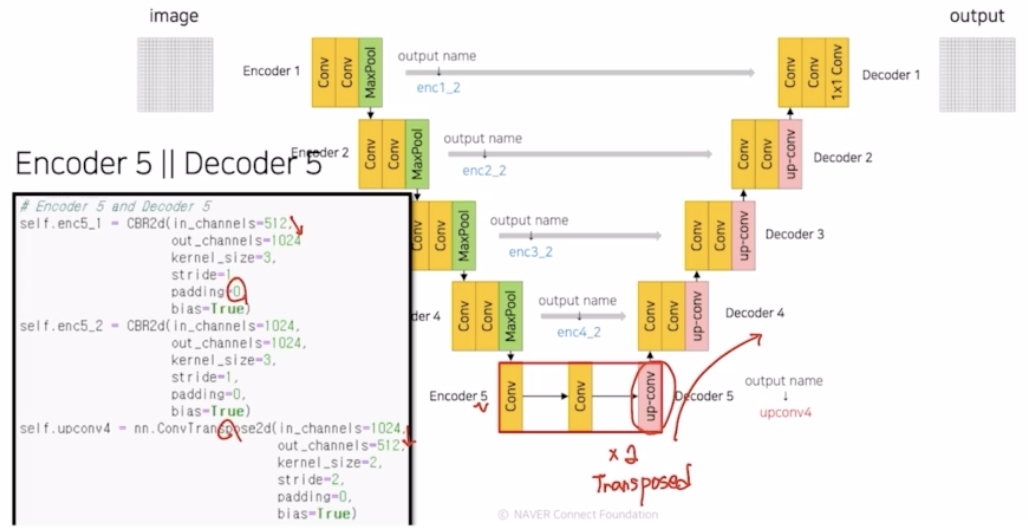
- 채널 2배 증가. padding 0
- decoder 부분으로 넘어감. transposed conv 를 통해서 2배 만큼 크기(resolution)를 키워줌. 채널은 1024 → 512 로 1/2 배 감소함.
-
Concat 4
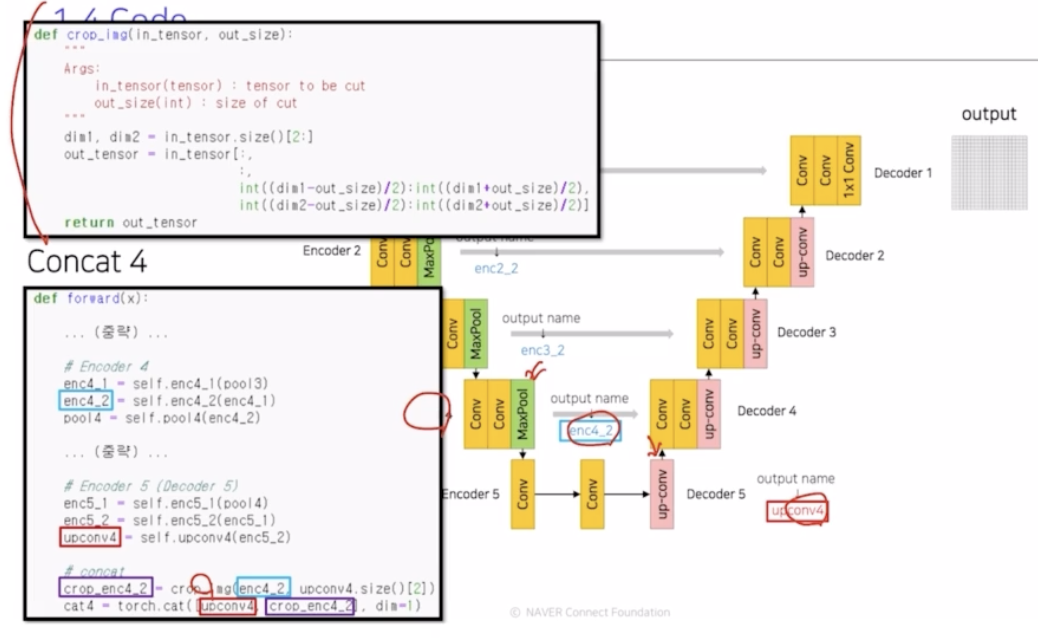
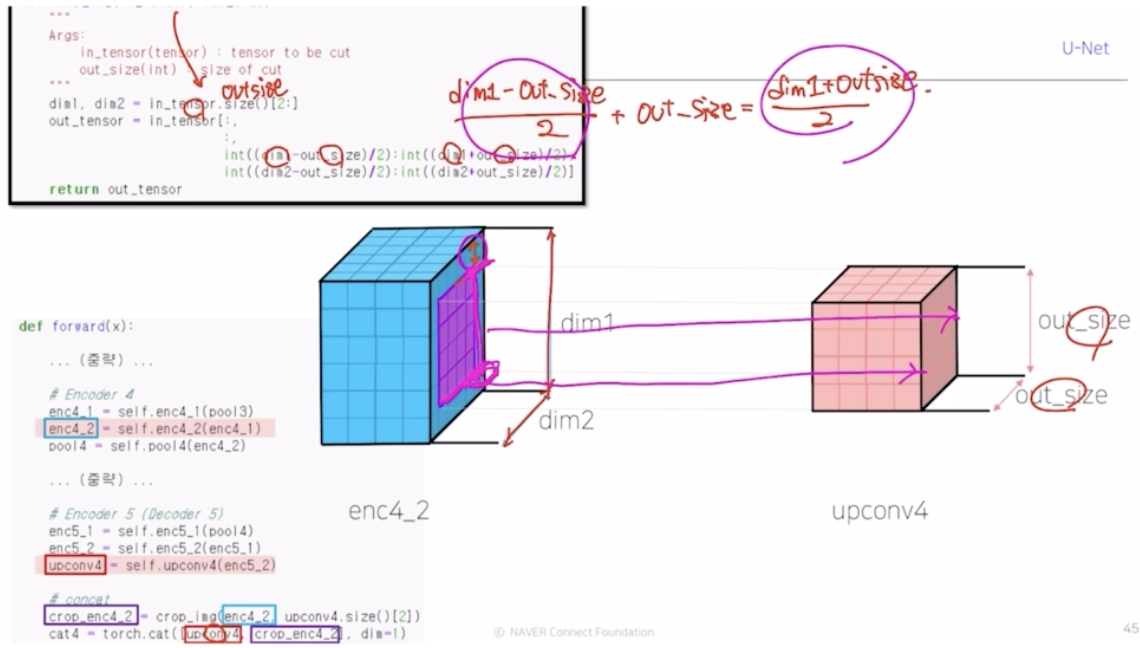
- up conv 의 결과인 upconv4 와 enc4_2 를 결합. 그러나 upconv4와 enc4_2 가 padding 에 의해서 resolution 크기가 다름. 이 크기를 맞춰주기 위해서 crop_img 라는 함수를 통해서 크기를 맞춰줌.
-
in_tensor 는 enc4_2 가 와서 output size(upconv4) 를 가지고 연산함. 그림에서 보라 부분을 제외한 파란 부분의 위 아래 부분을 구함. (인덱싱을 통해서)
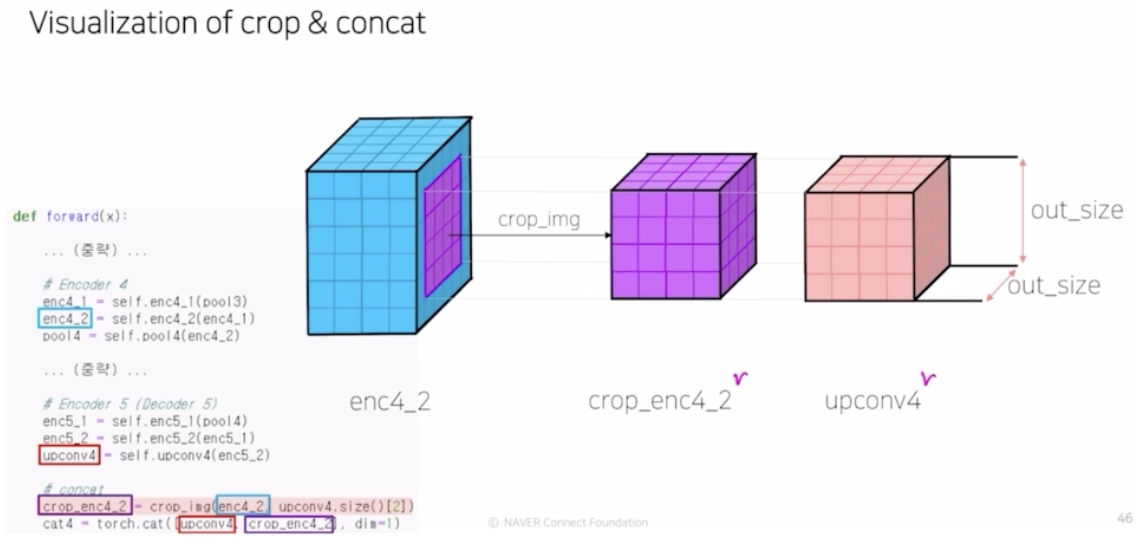
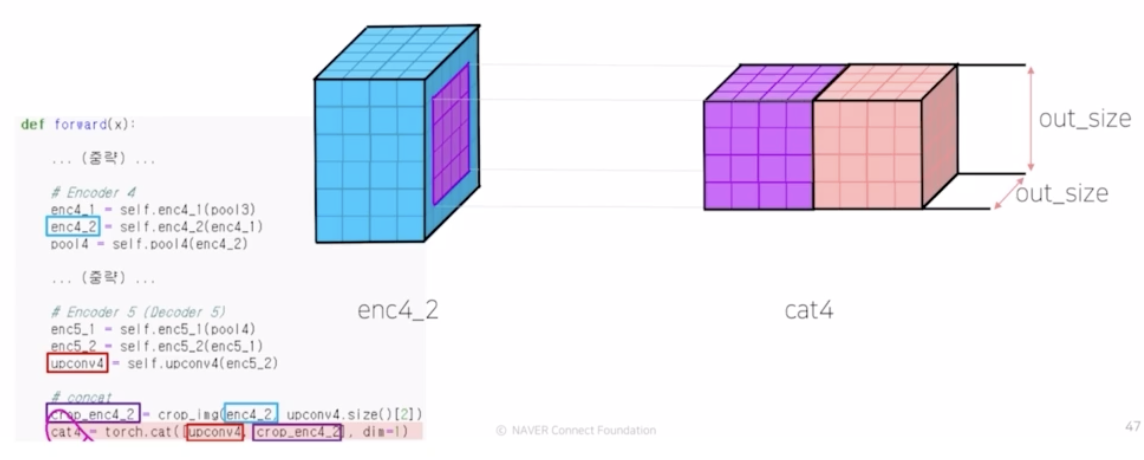
- crop 으로 보라색 영역이 건네져서 둘 간의 사이즈가 맞음. 그래서 concatenate 가 가능해짐. 그 결과 cat4 가 만들어짐.
-
Decoder 4
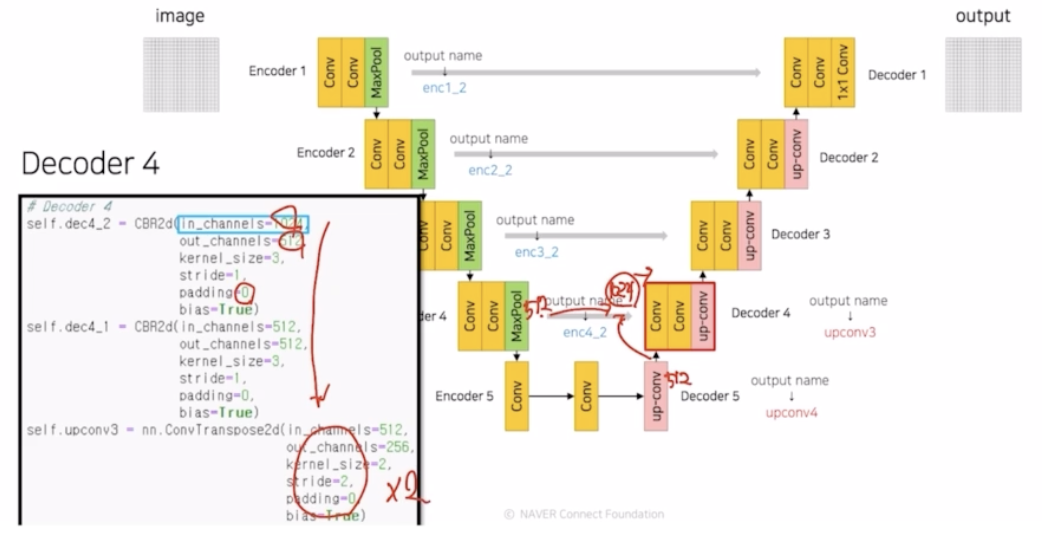
- CBR 이용. concatenate 를 통해서 채널이 512+512 로 1024가 됨. 1024 의 feature map 을 512 로 채널을 1/2 만큼 감소시킴. padding 0 동일 적용.
- Transposed conv 를 이용해서 2배만큼 사이즈를 키움.
-
Concat 3
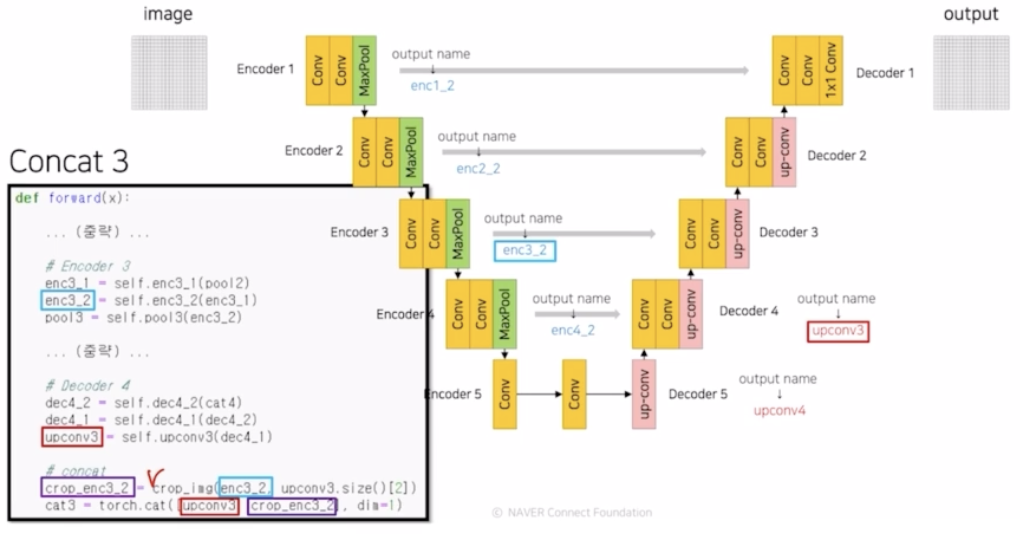
- 사이즈가 다르니 crop_img 로 사이즈를 맞춰주고 concatenate 진행.
- Decoder 3 & Concat 2
- 동일하게 진행됨.
- Decoder 2 & Concat 1
- 동일하게 진행됨.
-
Decoder 1
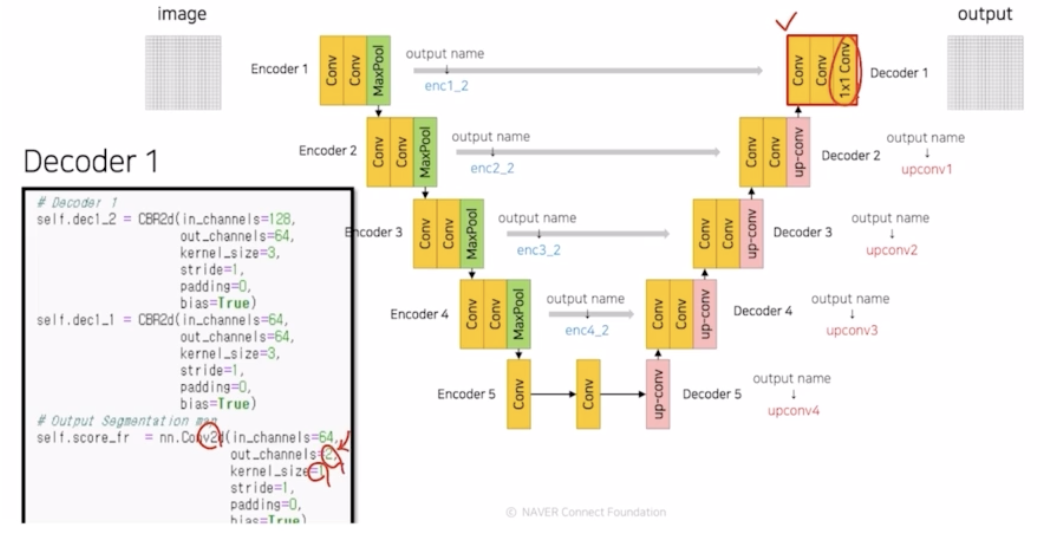
- 동일하게 진행됨.
- 마지막에 segmentation 에 대한 probability map 을 만들기 위해서 1x1 conv 에 output 채널을 num_classes 로 연산을 진행함.
-
-
- UNet 의 한계점
-
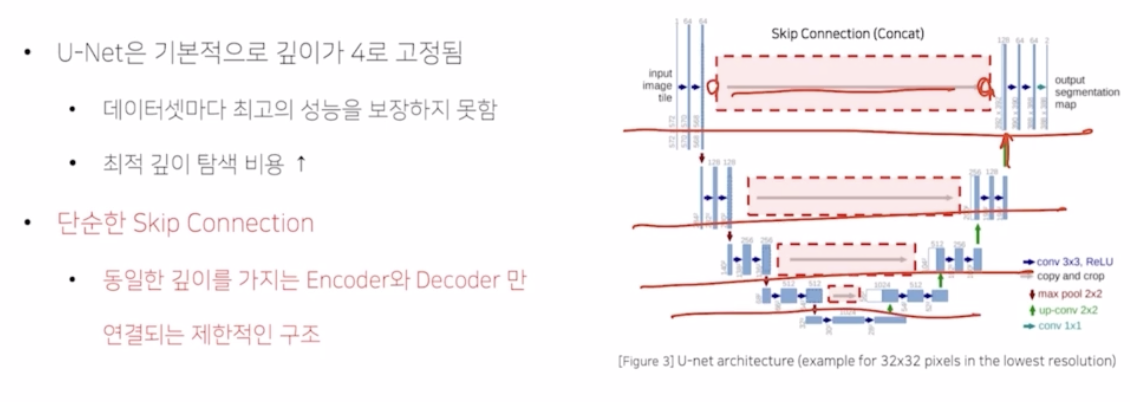
UNet 은 기본적으로 깊이가 4로 고정됨. → 데이터셋마다 최고의 성능을 보장하지 못함. 최적 깊이 탐색 비용이 높아짐.(데이터셋이 달라지면)

- EM, Cell, Brain Tuma 각각의 데이터셋에 대해서 아키텍처 레벨(어디까지 사용했는지)에 대해서 결과를 비교해보니 성능이 가장 좋은 부분이 다름. → 기본적으로 깊이가 4로 고정되어 있기 때문에 데이터셋마다 최고의 성능을 보장하지 못한다는 것.
-
단순한 skip connection 을 적용함. encoder 에서 나온 output 과 decoder 에 들어가기 전에 upconv 의 결과를 단순하게 concatenate 해서 같은 계층에 대해서만 적용하는데 그게 너무 심플한 구조인 것.
-
- UNet++
- UNet++ 에서는 UNet 의 2가지 한계점을 해결하기 위한 새로운 형태의 아키텍처를 제안하고 성능향상을 가져옴.
-
Encoder 를 공유하는 다양한 깊이의 UNet 을 생성함.
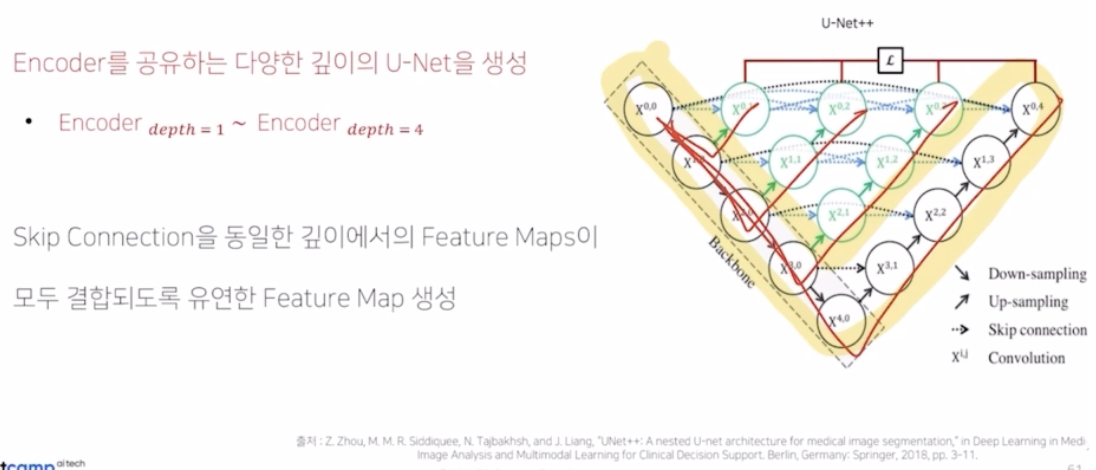
- 다양한 깊이란, depth 가 1인 UNet, depth 2, depth 3, depth 4 UNet 이 있는 것처럼 depth 를 가지도록 함.
- UNet 의 두번째 한계인 simple skip connection 해결 -> Skip connection 을 동일한 깊이에서의 feature map 들이 모두 결합되도록 유연한 feature map 을 생성함.
- UNet 의 skip connection 구조는 enc 의 결과와 upconv 의 결과를 concatenate 해주고 conv 를 취해주는 구조를 모든 레벨(계층) 에 대해서 각각 수행해줌.
-
UNet++ 에서는 심플한 한계점을 극복하기 위해서 DenseNet 에 있던 Dense Skip Connection 구조를 가져옴.
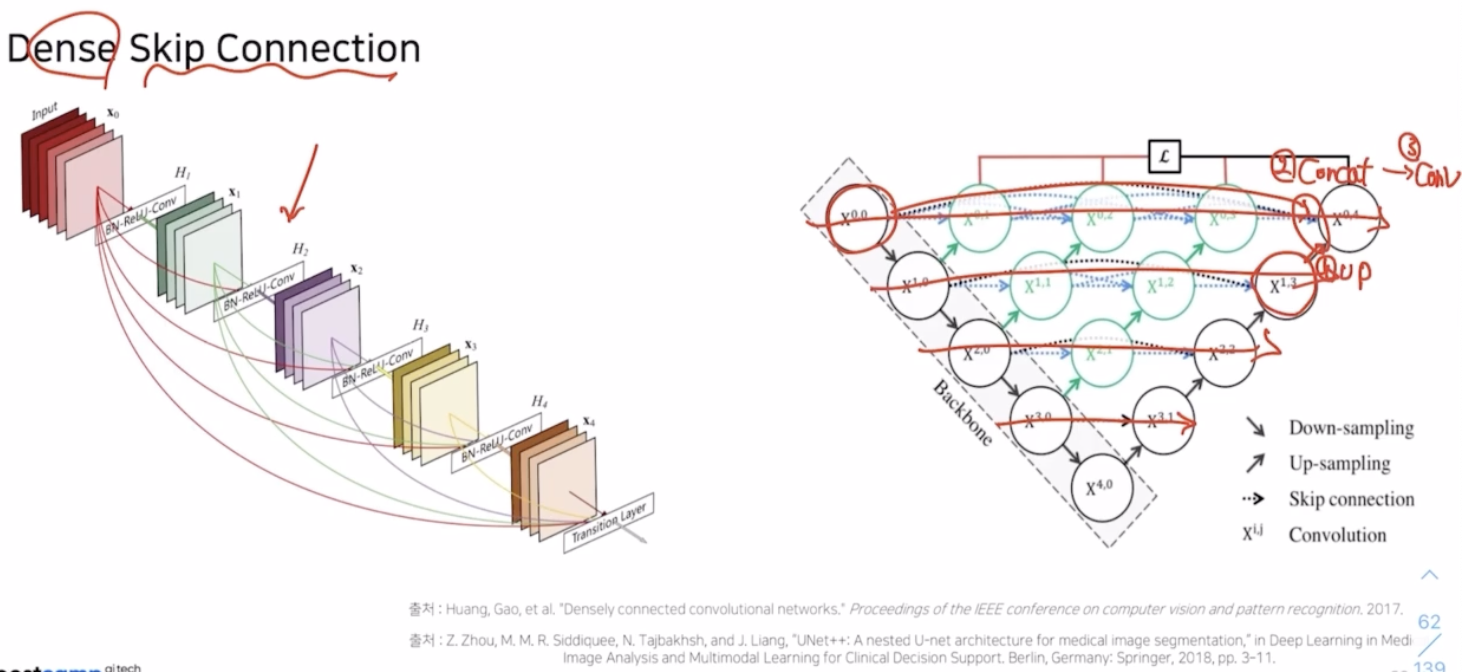
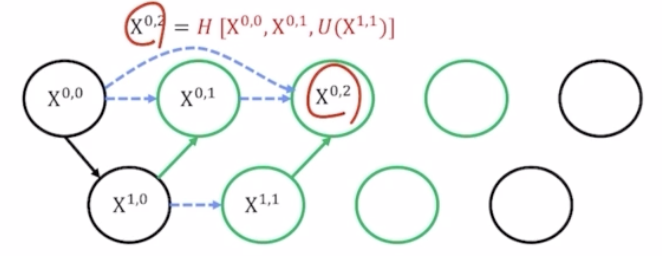
- U 는 up sampling, D 는 down sampling, H 는 conv 를 의미.
- $X^{1,0}$ 는 $X^{0,0}$ 에 Down sampling 후 conv 를 취한 결과.
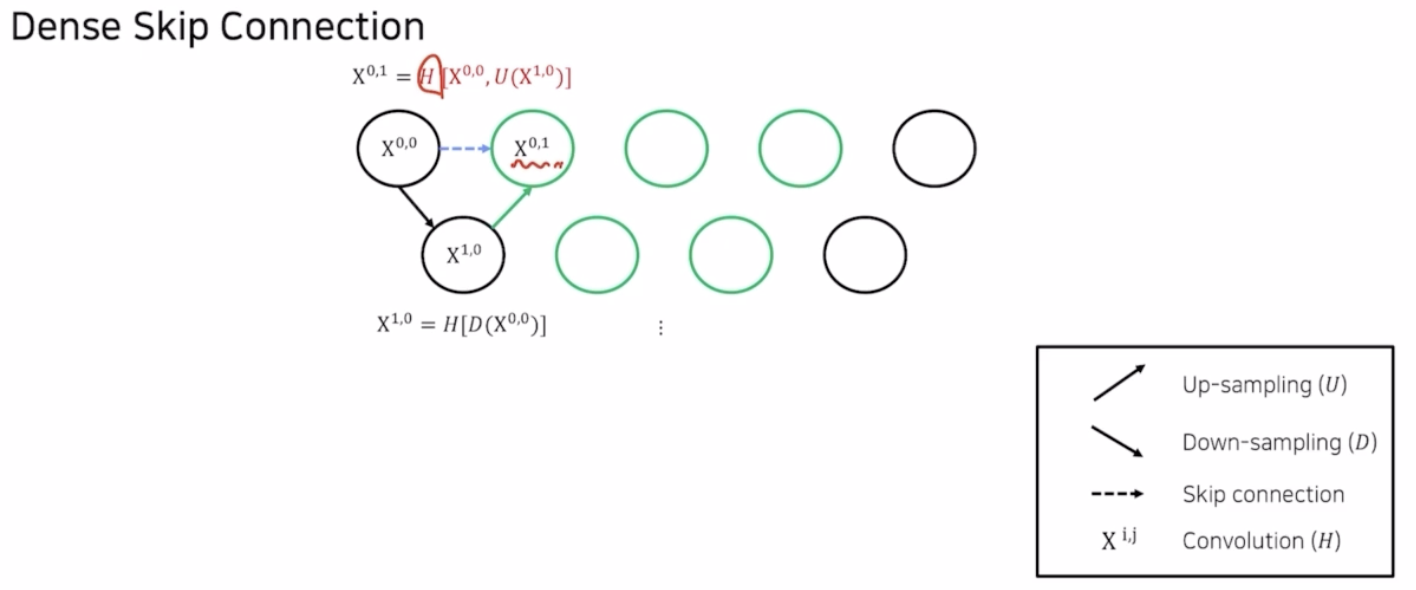
- 기존 UNet 에는 없었으나 UNet++ 에서 새로 생긴 가운데 부분을 채워주기 위해서 $X^{1,0}$ 을 up sampling 해준 결과와 $X^{0,0}$ 을 concatenate([ ]) 해주고 여기에 conv(H) 를 취해줘서 $X^{0,1}$ 이라는 값을 채워줄 수 있음.
- 마찬가지로 $X^{1,1}$ 도 구할 수 있음.
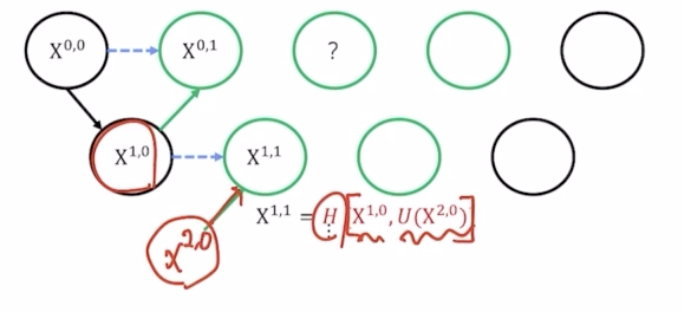
- $X^{0,2}$ 는 $X^{1,1}$ 을 up sampling 후 이를 $X^{0,1}$ 과 $X^{0,0}$ 까지 같이 concatenate 를 해줌. 기존 UNet 은 가장 첫번째 $X^{0,0}$ 만 이용해서 concatenate 를 해줬는데 UNet++ 에서는 같은 레벨에 있는 모든 값을 concatenate 해주는 것이 차이점.
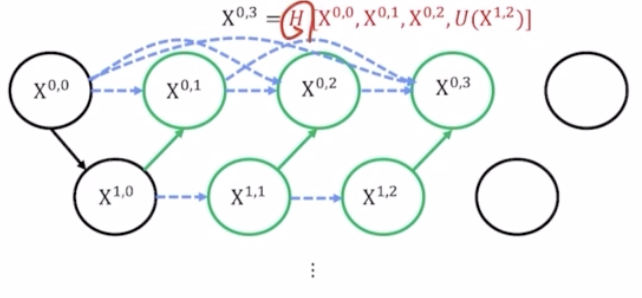
- $X^{0,3}$ 도 마찬가지.
- $X^{0,4}$ 도 마찬가지. 같은 층에 있는 모든 결과를 같이 concatenate 해준 다음에 conv(H) 까지 취해서 최종 결과를 생성해냄.
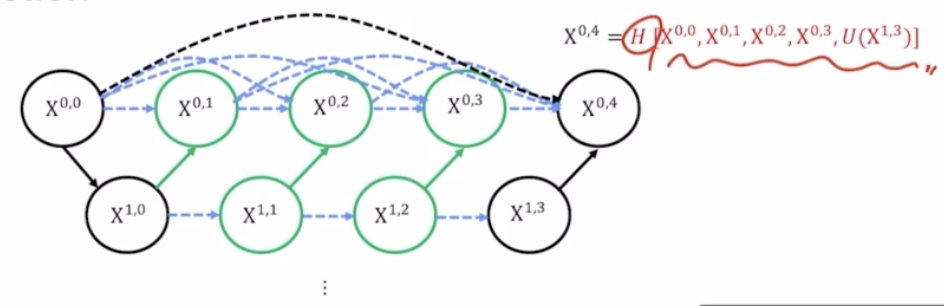
- 기존에 봤던 검은색 하나만 활용했던 simple 한 skip connection 이 아니라, 같은 층에 있는 모든 결과를 활용해주는 dense 한 skip connection 으로 단순한 skip connection 의 한계를 극복함.
- UNet++ 의 장점
-
Ensemble
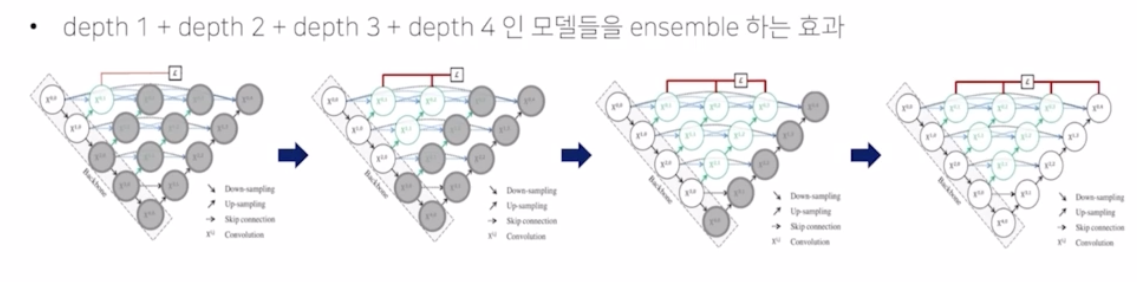
- depth 가 1 인 모델, depth2, depth3, depth 4 모델을 전부 앙상블한 효과가 있음.
- UNet++ 은 UNet 4개를 단순하게 앙상블한 UNet$^e$ 에 대비해서 훨씬 더 성능이 많이 증가함.
-
- 추가 테크닉
-
Hybrid Loss
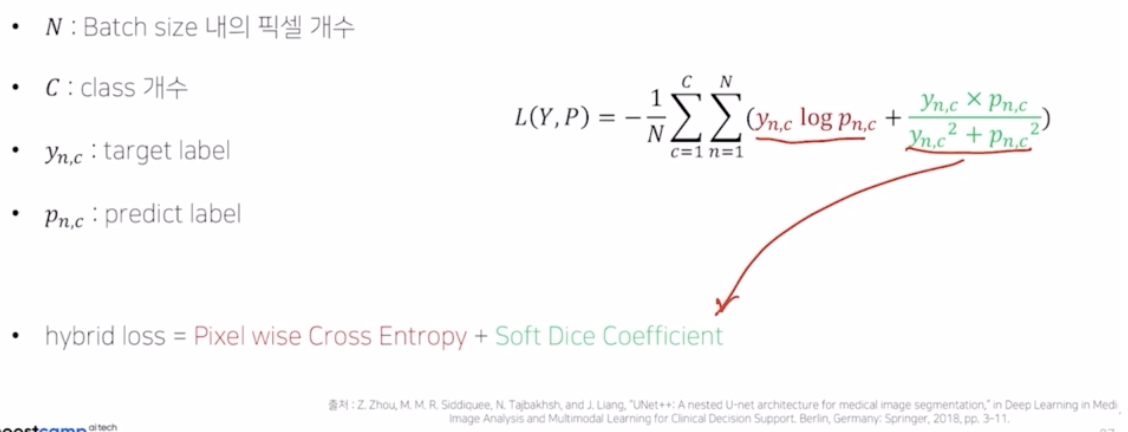
- 기존의 pixel-wise 의 CE 만 적용한 게 아니라 Dice Coefficient 도 같이 loss 에 적용함.
-
Deep Supervision
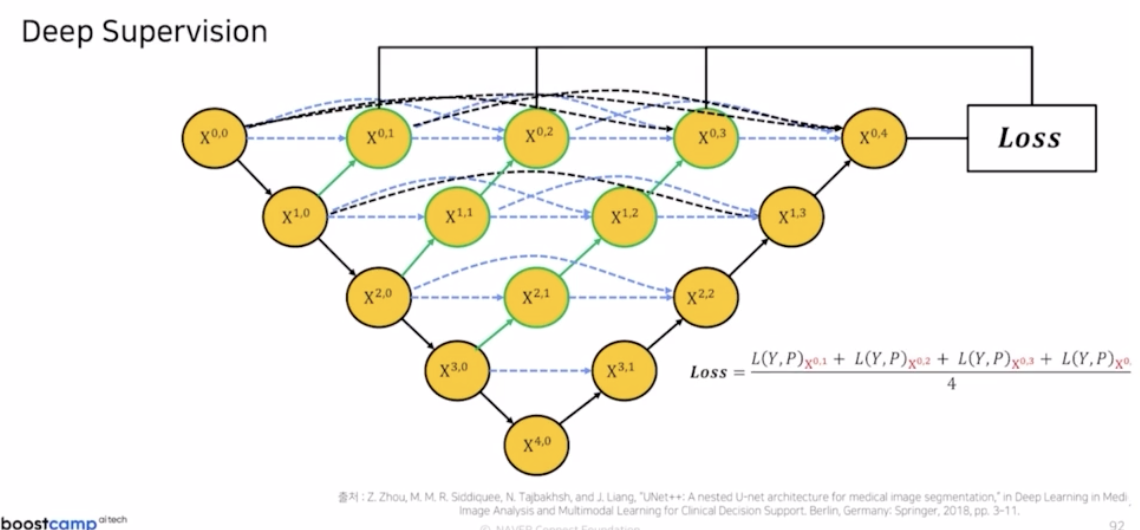
- loss 의 계산을 마지막 UNet 의 $X^{0,4}$ 뿐만 아니라 $X^{0,1}, X^{0,2}, X^{0,3}, X^{0,4}$ 4가지 결과를 같이 loss 로 활용함.
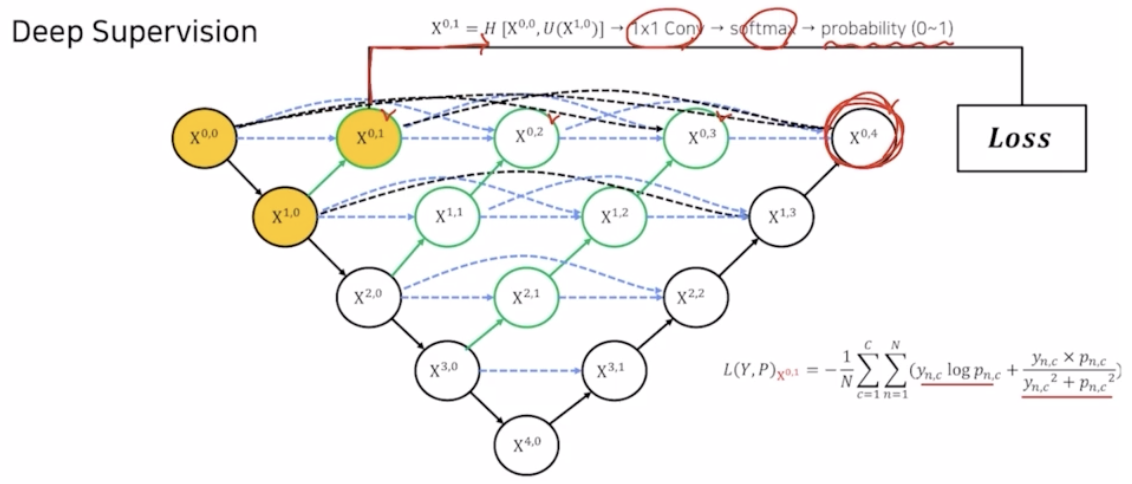
- $X^{0,1}$ 에서 나온 결과에 1x1 conv → softmax → probability(0~1) 후 아까 봤던 pixel wise CE 와 dice coefficient 를 결합한 hybird loss 를 통해서 $X^{0,1}$ 에 대한 loss 를 계산해줌.
- 이 과정을 $X^{0,1}, X^{0,2}, X^{0,3}, X^{0,4}$ 모두 loss 를 만들어준 다음에 최종적인 loss 는 4개의 loss 를 평균내서 사용함.
-
-
UNet++ 의 한계점
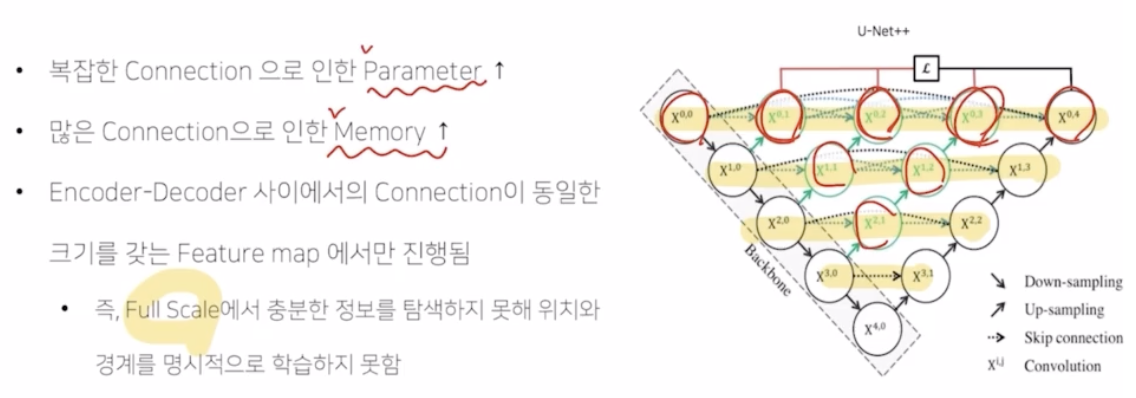
- 기본적으로 파라미터와 메모리가 많이 증가함. 기존의 simple connection 을 딥한 skip connection 으로 바꾸어 좋은 성능은 가져왔지만, 많은 conv 때문에 파라미터 수가 많이 증가함. 또한 deep 한 skip connection, UNet 에서 언급했던 것처럼 skip connection 을 위해서는 feature map 을 저장해서 이를 메모리에 둬서 활용해야 하는데, 같은 계층의 결과를 모두 활용해야 하기 때문에 계속해서 정보를 저장해야 하는 메모리의 부담감이 큼.
- connection 을 보면 알겠지만 같은 계층의 정보만 활용해서 connection 하는 것도 simple 해서 다양한 scale 의 정보를 반영하지 못하는 문제점도 있음.
- UNet 3+
- UNet++ 의 한계를 극복함.
- 기존 UNet, UNet++ 의 한계점

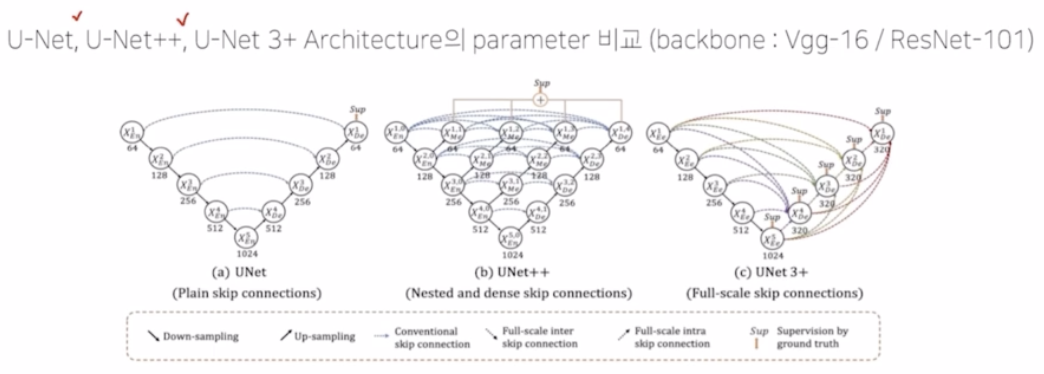
- UNet 3+ 에서는 full scale 에 대한 skip connection 을 적용해주기 위해서 총 3가지 구성요소인 conventional, inter, intra 로 다양한 scale 의 정보를 받아서 skip connection 을 진행함.
-
conventional

- same-scale 의 feature map 을 받는 구성
- 즉 같은 encoder - decoder 레벨의 feature map 을 말함.
-
inter

- 자기보다 더 scale 이 큰 부분에서 low level feature map 을 받음.
- 더 풍부한 공간 정보를 통해서 경계 강조
- smaller scale 은 이미지의 크기가 작다는 것이 아니라, 하나의 픽셀이 담고 있는 원본 이미지의 크기가 작다는 것.
-
intra

- decoder layer 로부터 larger scale 의 high level feature map 을 받음.
- 어디에 위치하는지 위치 정보를 구현함.
-
conventional 부분은 단순하게 simple skip connection 을 의미함. 이 때 채널 수를 맞춰주기 위해서 3x3 conv 에 64의 채널을 가지는 conv 를 적용함.
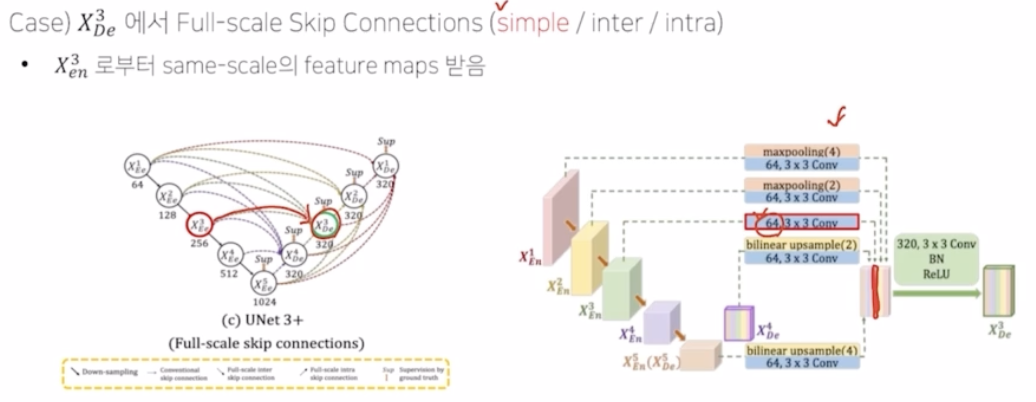
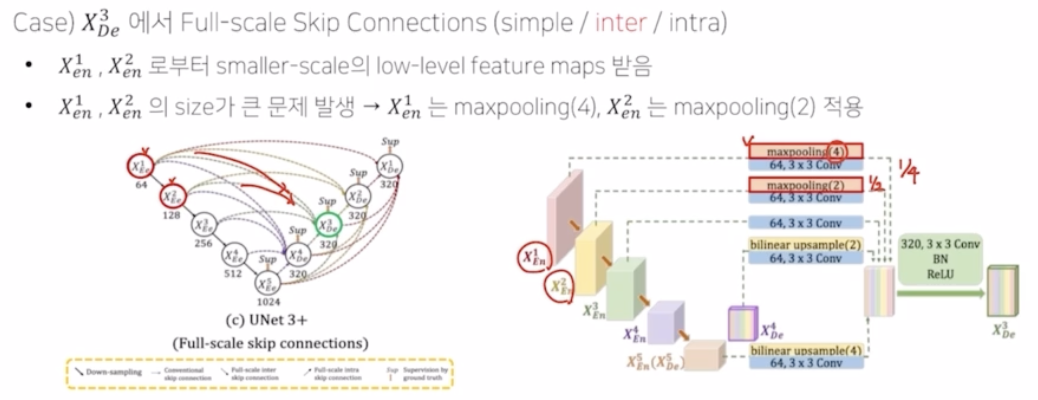
- inter 부분은 encoder 의 smaller scale low level feature maps을 전달해줌. resolution 크기가 맞지 않기 때문에 맞춰주는 작업이 필요함. 각각 max pooling 을 통해서 크기를 맞춰줌. 이후 똑같이 3x3 conv 에 64 채널을 적용해서 채널 수를 64로 통일해줌.
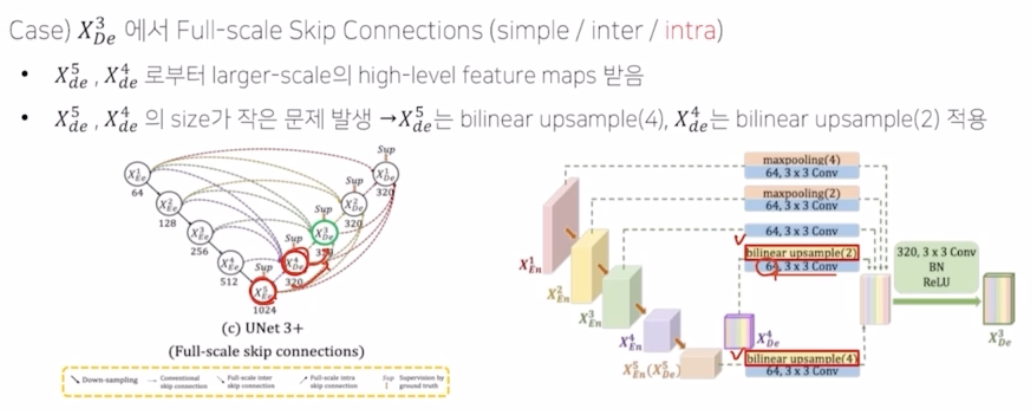
- intra 부분은 larger scale high level feature maps 를 전달받음. 사이즈가 맞지 않으니 bilinear up sampling 을 통해서 크기를 키워줌. 이후 3x3 conv, 64 c 를 통해서 채널을 64로 고정해서 맞춰줌.
- 여기까지 다양한 scale 의 정보를 skip connection 하는 full scale skip connection 을 통해서 UNet++ 에서 본 같은 계층의 정보로만 skip connection 하는 한계를 극복함.
-
- 파라미터와 메모리 문제
- UNet3+ 에서는 모든 decoder layer 의 channel 수를 320으로 통일해서 해결함.
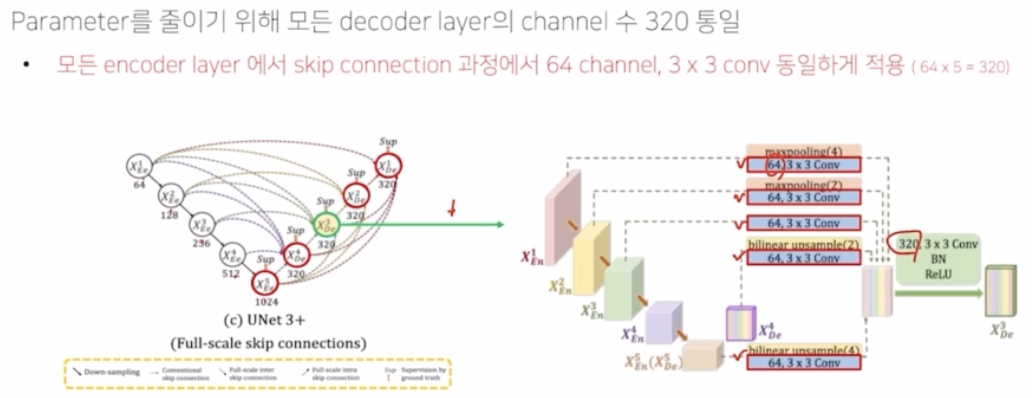
- 이를 위해서 3x3 conv 를 적용해서 각 채널을 64로 고정해서 이를 concatenate 해서 320 을 만들어주고, 기존에는 512, 1024 로 큰 채널을 320 까지 고정했다는 점에서 굉장히 많은 파라미터에 대한 효율적인 연산이 가능해짐.
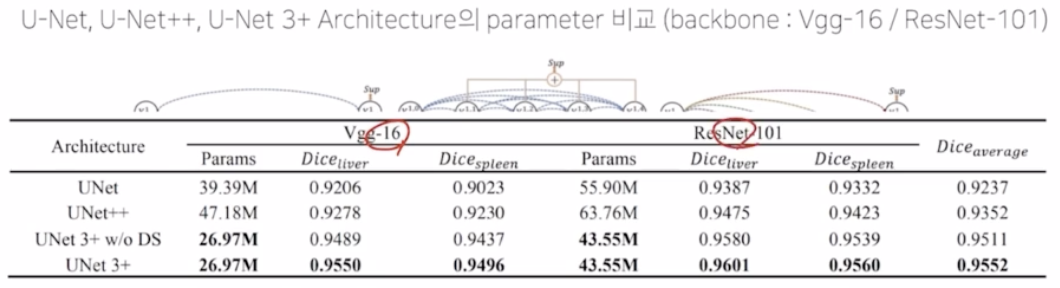
- UNet 3+ 와 UNet, UNet 2++ 아키텍처를 backbone VGG-16, ResNet-101 로 파라미터 수를 비교해보면 아래와 같음. UNet 3+ 가 파라미터 수가 훨씬 적음.
- UNet 3+ 에 적용된 테크닉
- Classification-guided Module(CGM)
- noise 나 false positive 문제를 해결하기 위해서 도입한 모듈

- false-positive 는 실제는 없는데 있다고 잘못 예측한 부분.
- 이를 해결해주기 위해서 extra 로 classification task 를 진행해서 좀 더 정확도를 높이고자 한 기법.

- high level feature map 인 $X_{en}^5(X_{de}^5)$ 를 활용함. 여기에 dropout, 1x1 conv, adaptivemaxpooling, sigmoid 를 통과해서 classification 의 확률값을 만들고, 여기에 BCE loss 를 계산하고 argmax 를 통해서 Organ 이 없으면 0, 있으면 1 출력.
- 출력 후 이 결과를 이용해서 위에서 얻은 각 decoder layer 에서 얻은 결과에 classification 결과를 곱해서 없는 부분에 0 이 곱해져서 제대로 pixel wise 분류될 수 있도록 함.
- 그 결과 성능이 훨씬 향상됨.
- Full-scale Deep Supervision (loss function)
- 기존의 UNet ++ 에서 본 것처럼 hybrid loss 를 UNet3+ 에서도 적용함.
- 경계부분을 잘 학습하기 위해서 Loss 를 여러가지 결합함.
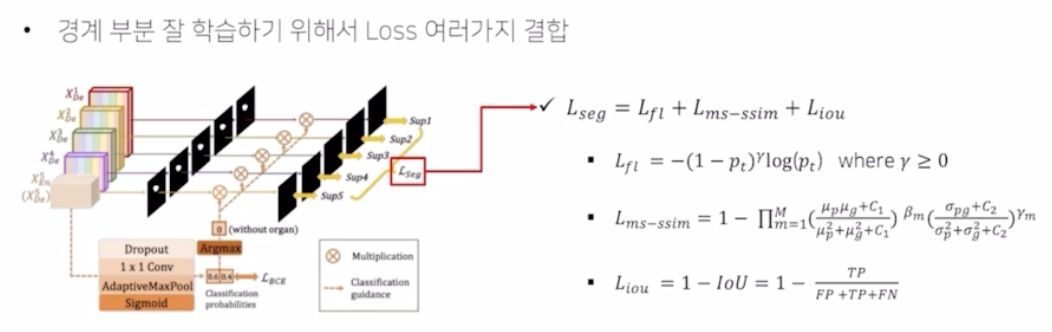
- Focal loss($L_{fl}$) → 클래스의 불균형 해소
- ms-ssim loss($L_{ms-ssim}$) → boundary 인식 강화
- IoU ($L_{iou}$) → 픽셀의 분류 정확도를 상승시킴
- Classification-guided Module(CGM)
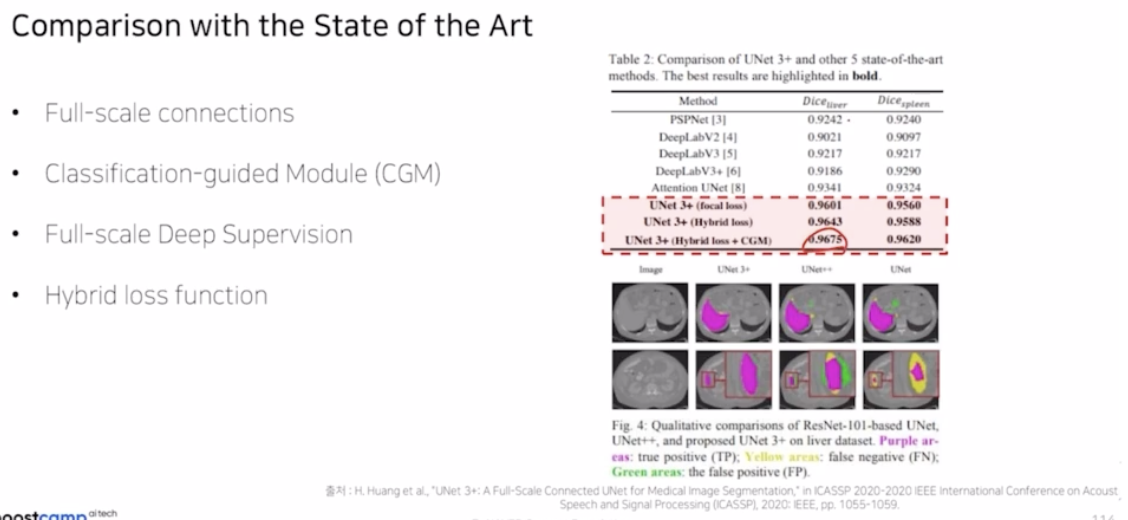
- 결론
- Unet3+ 는 다른 네트워크 대비해서 성능을 보면 굉장히 높음.
- Another version of UNet
- UNet의 encoder 부분만 여러가지 backbone 네트워크를 사용해서 바꾼 UNet 들
-
Residual UNet
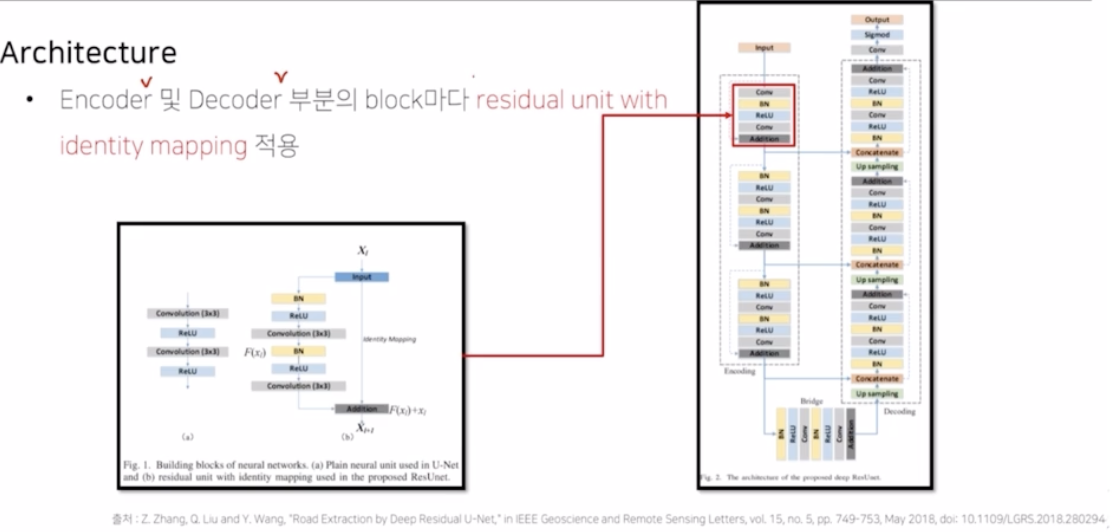
- encoder 및 decoder 부분의 block 마다 residual unit with identity mapping 적용.
-
Mobile UNet
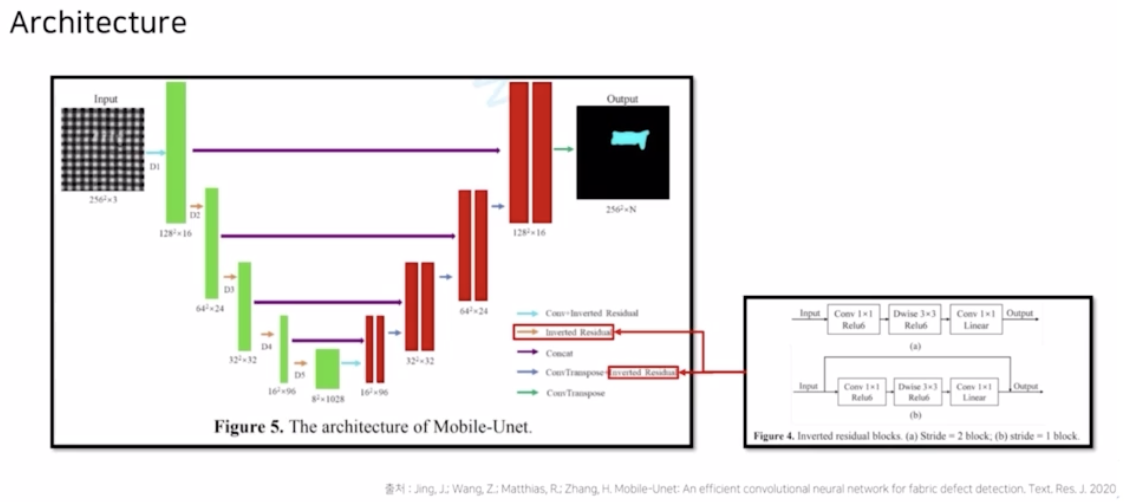
- backbone 을 MobileNet 을 사용해서 좀 더 빠른 속도로 application 을 가능하게 함.
-
Eff-UNet
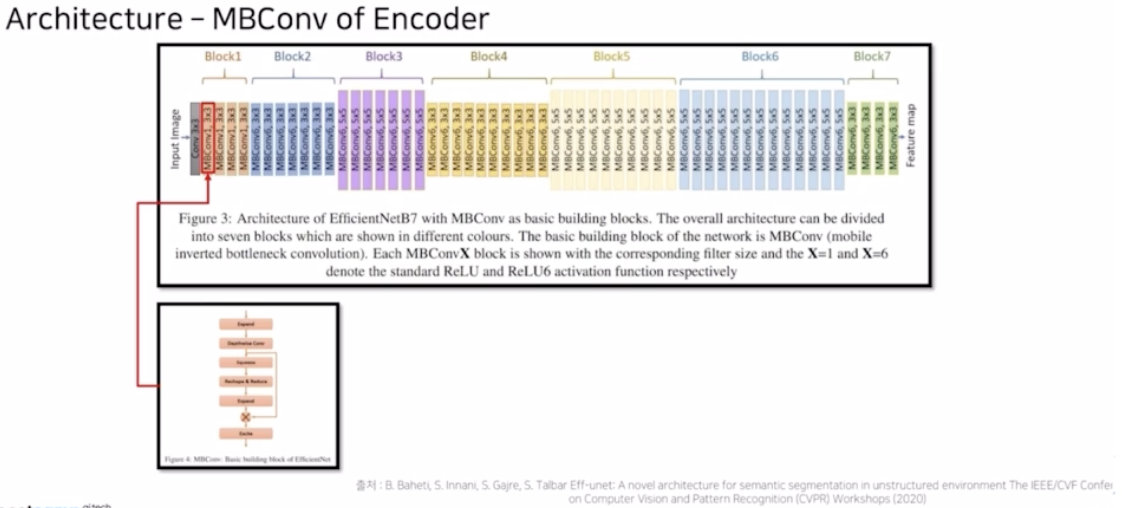
- EfficientNet 을 backbone, decoder 는 UNet
- 높은 성능을 달성함.
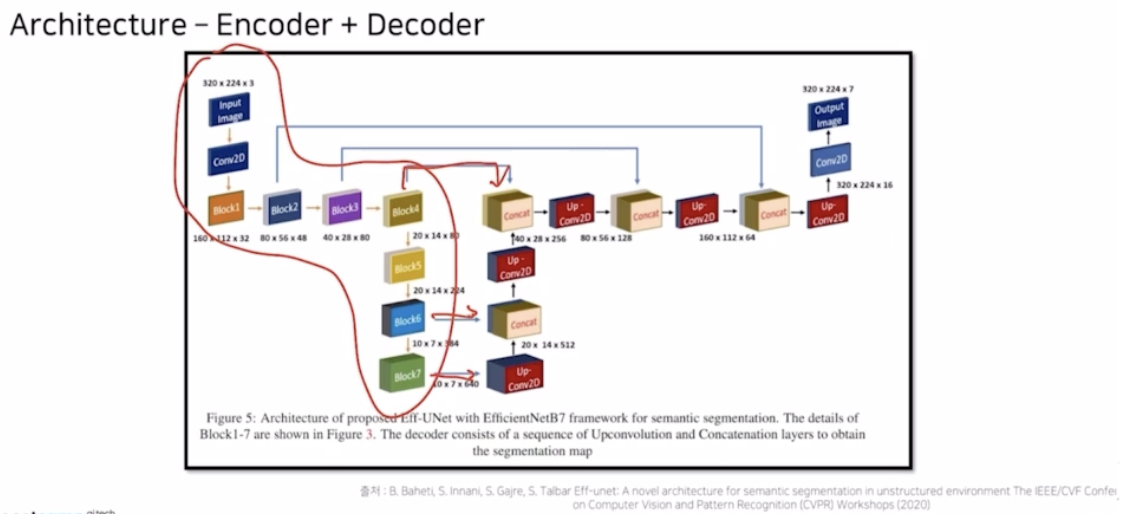
- encoder 를 efficientNet, decoder 는 skip connection 을 적용해서 UNet 과 같은 모습을 가짐.
- 결론
- UNet, UNet++, UNet3+, encoder 만 다르게 한 3가지 UNet 을 봄.
- UNet
댓글 남기기