
[Segmentation] 2. FCN 의 한계를 극복한 모델들 (1)
- FCN의 한계를 극복한 모델들 [DeconvNet, SegNet(encoder-decoder), FCDenseNet, UNet (Skip connection),DeepLab v1, DilatedNet (Receptive Field)]
- 성능적인 측면에서의 극복
- FCN 의 한계점
- 객체의 크기가 크거나 작은 경우 예측을 잘 하지 못함
- 큰 object 의 경우 지역적인 정보만으로 예측함. → 즉 같은 object 여도 다르게 labeling 될 수 있음.
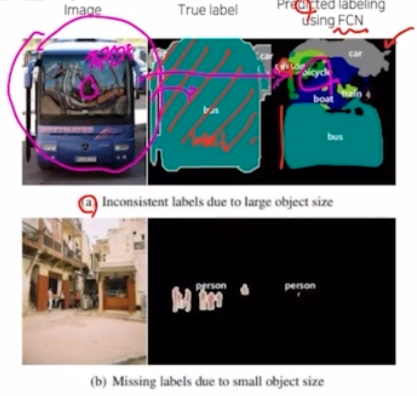
- Conv 자체의 receptive field 에 의한 문제점이라고 생각할 수 있음. Conv 가 입력 이미지를 지나면서 특징을 추출했을텐데, 큰 object 를 한번에 보고 prediction 이 아니라 Conv kernel size 만큼만 보고 그 부분에 대해 prediction 을 진행할 경우 잘못 분류할 수 있음.
- 즉 위 사진처럼 유리창에 비친 것을 보고 잘못 labeling 할 수 있음.
- 또한, 작은 object 가 무시되는 문제가 있음. 작은 object 가 max pooling 혹은 deep 한 conv 를 통과하면서 작은 정보들이 이미지에서 feature 를 추출할 때 삭제되었을 가능성이 있음.
- 이를 segmentation 하면 작은 object 에 대한 정보들이 사라질 수 있음.
- 두번째로, Object 의 디테일한 모습이 사라지는 문제가 발생함.
- FCN-8s 의 결과를 보면, 디테일한 부분에 대해서 디테일을 잃어버림.
- FCN-8s 와 Deconvnet 과 비교해보면, FCN 은 디테일한 측면들에 차이가 있음을 알 수 있음.
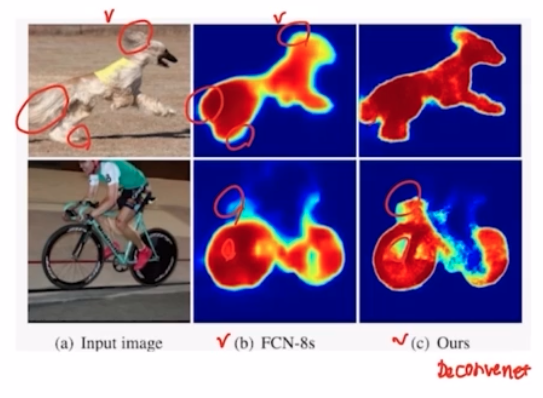
- FCN은 Deconvolution 절차가 간단해서 경계를 학습하기 어려움.
- FCN-32s 의 경우 transposed conv 하나로 32배 키우는 구조. 이게 단순해서 16s, 8s 에서는 이전 max pooling 에 의한 결과를 sum 했는데, 이렇게 skip connection 을 하더라도 아직까지 단순함.
- 객체의 크기가 크거나 작은 경우 예측을 잘 하지 못함
- Decoder 를 개선한 models
- FCN 의 위와같은 2가지 한계에 따라, DeconvNet 과 SegNet 은 encoder-decoder 구조를 통해 한계점을 극복하려고 시도함.
-
DeconvNet

- backbone 으로 VGG16 을 사용했으며, 13개의 층으로 이루어져 있고, ReLU 와 Pooling 이 conv 사이에서 이루어짐. 7x7, 1x1 conv 를 활용함.
- Encoder 와 Decoder 를 대칭으로 만듬.
- Deconv 는 transposed conv 를 의미함.
- 가운데의 1x1 conv 를 기점으로 pooling, unpooling 이 대칭됨.
- Encoder의 하나의 conv block 은 conv-BN-ReLU 로 이루어짐.
- Decoder 에서는 unpooling 과 transposed conv(Deconv) 가 반복되는 구조.
- Decoder
- unpooling 부분은 디테일한 경계를 포착함.
- Transposed conv(deconv) 는 전반적인 모습을 포착함.
-
Unpooling
- 디테일한 경계를 포착하는 역할을 함.
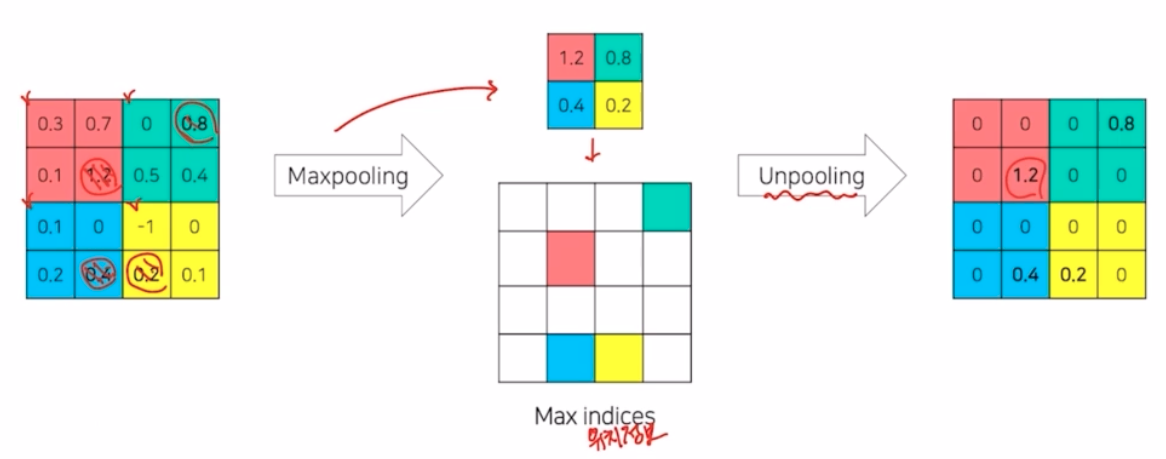
- maxpooling 은 kernel size 안에서 가장 큰 값을 추출하는 과정.
- 이럴 경우 위치에 대한 spatial 한 정보를 잃어버림.
- unpooling 은 maxpooling 이 어느 위치에서 나왔는지에 대한 위치정보를 기록했다가, 해당 영역을 복원해나가는 과정
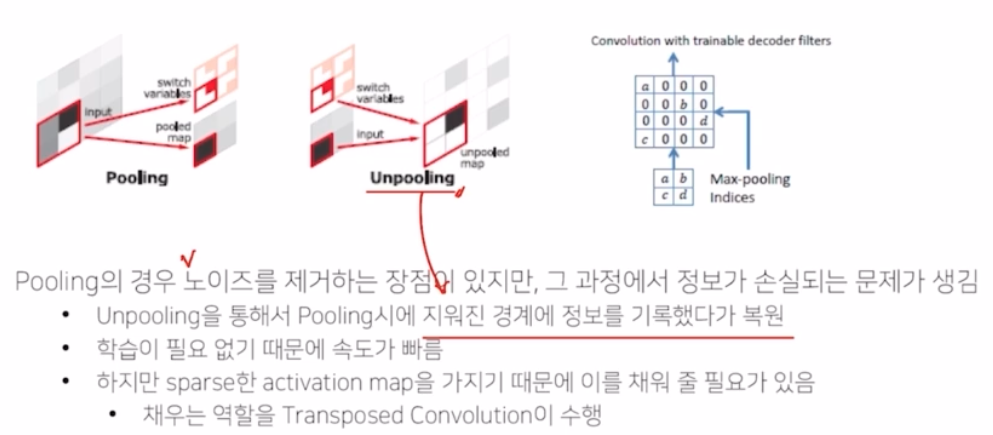
- pooling 은 대표값을 추출해서 노이즈를 제거하거나 가장 중요한 부분을 추출해서 일반화를 가능하게 하고 해상도를 줄이기 때문에 메모리의 효율성을 높여주는 장점이 있었음.
- 그러나 seg 에서는 max pooling 과정에서 위치 정보를 잃어버리는 문제점이 있기 때문에 잃어버린 정보를 복원해줄 필요가 있음. 이것을 가능하게 해주는 것이 unpooling 과정
- unpooling 은 pooling 시 지워진 경계에 대한 위치 정보를 기록했다가 복원함.
- 이러한 복원 과정에서 object 의 디테일한 모습들, max pooling 에 의해 잃어버린 디테일한 모습들이 복원되는 것.
- unpooling 의 결과는 대부분이 0으로 채워진 sparse 한 매트릭스임. 따라서 seg task 를 수행하려면 이러한 부분을 dense 하게 만들어줄 장치가 필요함.
- 이를 가능하게 해주는 것이 transposed conv(Deconvolution)
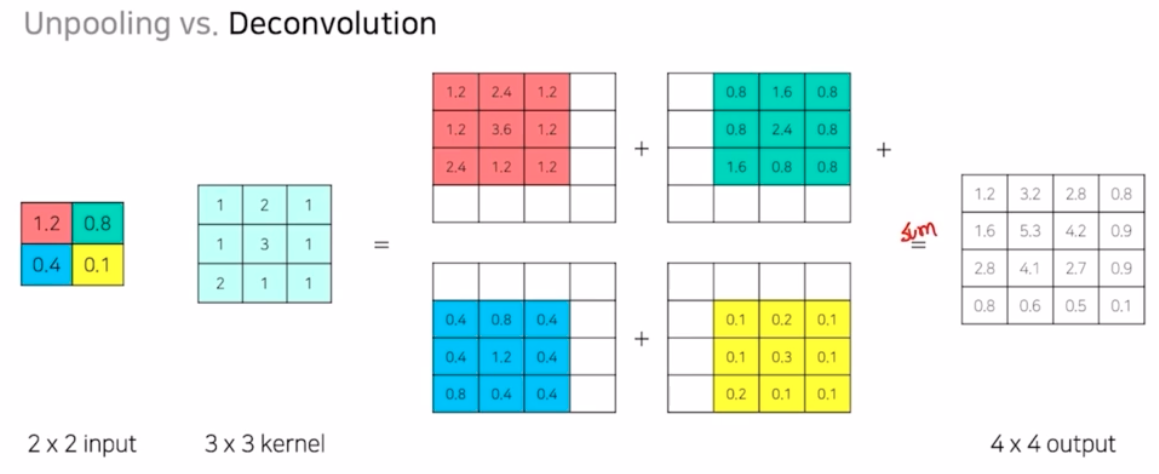
- unpooling 이 object 의 경계를 복원했다면, deconv 는 그 안의 내용을 복원하는 방법.
- unpooling 과 deconv 가 반복되는 구조를 가지면서 unpooling 은 객체의 외곽, deconv 는 그 안의 내용을 채워가면서 segmentation object 의 결과를 만들어내는 것.
- 이러한 반복 구조에서, 얕은 층은 전반적인 모습을, 깊은 층은 구체적인 모습을 잡아냄.
- ZFNet 논문에 따르면, Low level 의 feature 의 경우 직선, 곡선, 색상 등의 정보들의 특징이 나타난다고 함. High level 에서는 복잡하고 포괄적인 객체 정보들이 나타난다고 함.
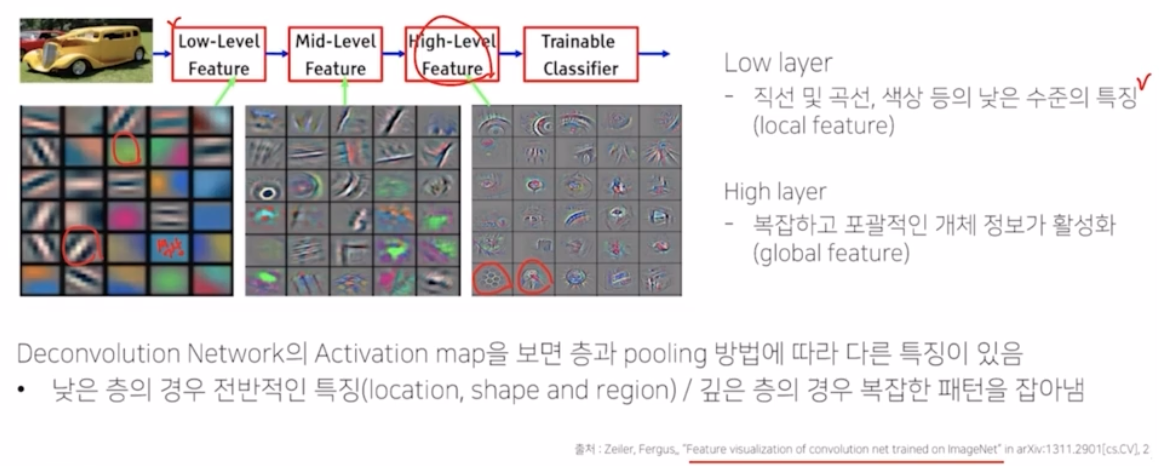
- deconv network 의 activation map 을 보면 층과 pooling 방법에 따라서 다른 특징들이 보여짐.

- 위 그림에서 b, d, f, h, j 가 transposed conv 의 결과
- unpooling의 구조적인 모습을 기반으로 내용물을 채워가는 과정을 거침.
- 초반에는 색깔 등 전반적인 형상에 대한 모습을 가졌다면, layer 가 깊어지면서 자전거 자체의 모습이 제대로 포착됨을 알 수 있음.
- 즉 마지막 층으로 갈 수록 색상 등의 low level 한 정보들이 깊은 층에 가서 더 복잡하고 디테일한 모습을 갖게 되는 것.
- c, e, g, i 는 unpooling에 의한 결과
- 내부의 값이 0으로 채워져 있음. 자전거의 모습에서 경계 위주의, example-specific 한 구조를 나타내는 것을 볼 수 있음. 그리고 layer 가 깊어지면서 구조의 모습이 좀 더 자전거의 형상에 가깝게 변화가 됨
-
위 과정을 통해서 input feature 가 계속 deep 한 layer 로 진행되는 것.

- 이렇게 decoder 구조(unpooling → deconv 반복)를 이용해서 반복적으로 unpooling 과 transposed conv 를 이용했을 때 FCN 과 DeconvNet 의 activation map 결과를 비교해보면 훨씬 더 디테일한 모습들이 잘 살아남을 볼 수 있음.
- 성능향상이 많이 됨.
- DeconvNet Network Code
- Convolution Network
- Conv - BN - ReLU(CBR) 가 순서대로 적용됨.

- Deconv
- Transposed conv - BN - ReLU

- CBR - CBR - max pooling. 이 때 max pooling 은 kernel size 2, stride 2
- max pooling 에서 return_indices 부분을 True → Max pooling 시 어떤 위치에서 max pooling 이 수행되었는지 위치 정보를 반환(출력)하는 것.
- 그 다음 conv block 도 CBR block 2번과 max pooling(return_indice True) 가 반복됨.
- 그 다음 fc layer(가운데). 7x7 의 CBR 을 수행하고 channel은 VGG 16에서 본 구조를 그대로 사용함. 1x1 conv 를 수행한 뒤 그 다음부토 decoder 구조가 시작됨.
- 첫번째 7x7 Deconv 는 DCB(transposed conv - BN - ReLU) 를 7x7 kernel size 로 수행.
- 그 이후 max unpool2d 를 사용해서 unpooling 함. kernel 2, stride 2 로 입력 해상도를 2배만큼 키워줌.
- unpooling 은 forward 부분에서 파란색 부분으로 수행됨.

- max_pooling 시 return_indices=True 로 뒀기 때문에 어느 위치에서 max pooling 이 되었는지 인덱스 정보를 가질 수 있음. 이 인덱스 정보를 unpooling 시에 입력 인자로 건네줘서 unpooling 이 실행될 때, 이 인덱스 정보를 바탕으로 unpooling 을 수행함.
- 이 때 unpooling 의 결과가 sparse matrix 형태이기 때문에 이를 복원해주기 위해서 3개의 transposed conv(DCB) 이 적용되는 것.
- 3개의 DCB 같은 경우 matrix 의 sparse 한 부분을 dense 하게 변경해주지만 resolution 은 변경해주지 않음. 왜냐면, kernel size, stride, padding 을 그렇게 조절했기 때문에. 그래서 resolution 의 변화는 일어나지 않지만 sparse 한 matrix 를 dense 하게 변경해줌.
- 이것을 encoder-decoder 대칭 형태로 반복해서 진행됨. decoder 의 채널도 encoder 와 대칭되게 구성됨.
- 마지막으로 1x1 conv 를 통해서 num_classes 만큼 채널을 가지도록 output을 생성해줌.
- Convolution Network
- SegNet
- DeconvNet 과 비슷하지만 다른 분야에서 encoder-decoder 구조로 발전한 모델이 SegNet
- 성능 측면 보다는 속도 측면에서 real-time semantic seg 를 가능하게 함.
- 자율 주행 등에서 빠른 속도로 inference 해서 결과를 내는 것이 중요함.
- SegNet 은 FCN 의 성능을 높이면서 속도를 개선하려고 노력한 논문.
-
아래는 DeconvNet 과 SegNet 의 비교
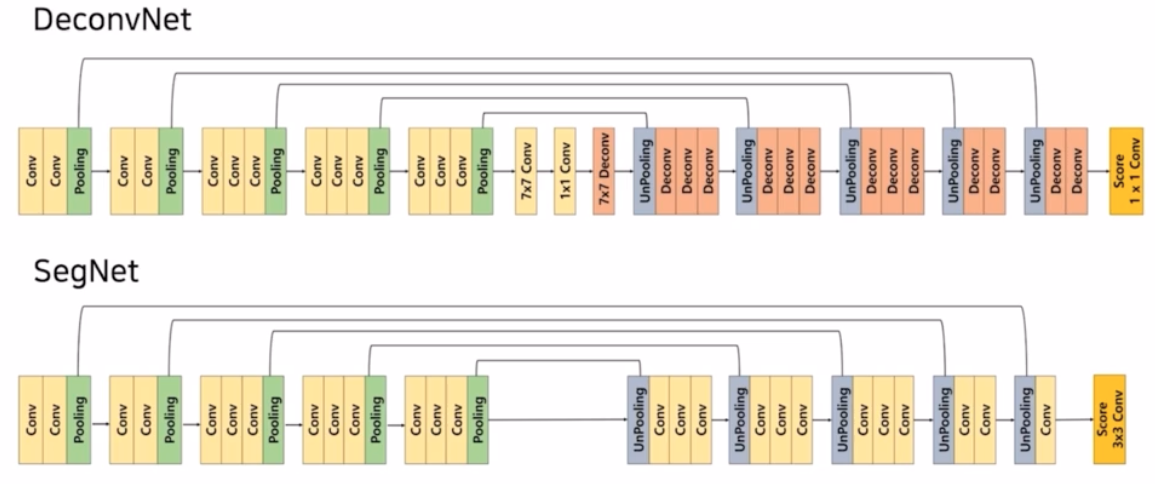
- 어떤 차이점을 통해서 속도를 향상시켰는가?
- DeconvNet 의 가운데 부분 fc layer 부분 (7x7 conv, 1x1 conv, 7x7 deconv) 을 제거하면서 파라미터 수를 감소시킴 → 속도의 향상을 가져옴. 가장 real-time 을 가져올 수 있게 한 부분
- unpooling 은 동일하지만 크기를 키우는 부분을 transposed conv 가 아니라 unpooling 을 통해서 키우기 때문에 학습을 필요로 하지 않음(DeconvNet 과 동일)
- sparse matrix 를 채우는 부분에서, deconv 가 아닌 conv 를 사용함.
- 마지막 하나의 deconv 부분을 제거하고, 3x3 conv 으로 score 를 생성함.
- SegNet code
- encoder 는 deconvNet 과 거의 동일함. Conv - BN - ReLU 를 가짐. max pooling 시 동일하게 return indice 해주어서 max pooling 이 어느 위치에서 진행되었는지에 대한 인덱스 정보도 반환시켜줌.

- 이러한 과정이 총 5개의 conv block. 이를 통해 feature map 을 생성해내고, max pooling 이 5개이기 때문에 1/32 만큼 크기가 줄어듦.
- 동일하게 대칭구조로 5번에 걸쳐 크기를 키워줌.
- MaxUnpool2d 를 이용해서 2배만큼 크기를 키워주고, deconv 가 아니라 conv 연산을 통해서 sparse → dense 하게 변경해줌.
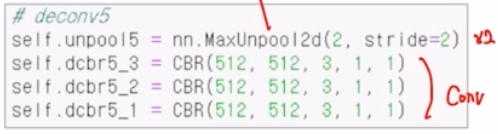
- 이게 5개의 block 으로 이루어짐 (encoder-decoder 대칭)
- 마지막은 score 를 내줄 때 1x1 이 아니라 3x3 conv 로 score 를 num_classes 채널을 가지도록 output 을 출력함.
-
DeconvNet vs. SegNet

- 두 모델 모두 FCN 에서 8, 16, 32 배씩 복원했던 이미지를 2배씩 복원해 나가는 세련된 decoder 구조를 가져옴.
- 참고로 FCN 과 동일하게 encoder 부분은 모두 VGG 16 을 사용함. 그러나 내부에 BN 이 들어감.
- DeconvNet 은 encoder 에 fc layer 를 이용해서 정확도를 더 높히려 했지만, SegNet 은 fc layer 를 제거해서 파라미터 수를 줄였음. 이를 통해 학습과 추론 시간을 감소시키는 모습을 보임.
- fc layer 에 대해서 차이를 보이는 이유는 서로의 목적이 성능 vs. 속도의 차이점인 것.
- Skip Connection 을 적용한 models
-
이전 FCN 에서, 성능을 올리기 위해서 이전 layer의 feature map 을 더해주는 skip connection 을 봄. pooling 에 의한 결과를 마지막 결과와 sum 하는 것으로, 이전 layer 의 정보를 활용해서 seg 을 수행하던 것. 이러한 skip connection 으로 이전 정보를 활용해줬기 때문에 FCN-32s 에서 8s 로 갈수록 성능 향상이 일어났었음.
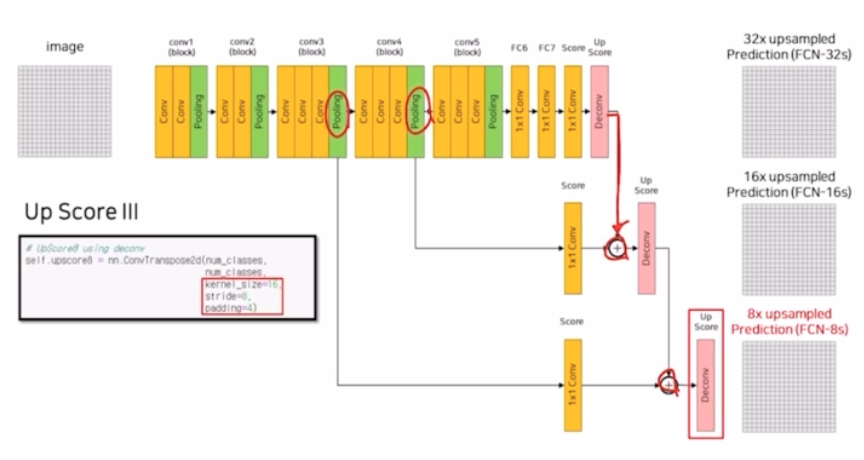
- 이 FCN 에서 본 것처럼 skip connection 을 좀 더 세련되게 바꿔 성능을 향상시킨 모델들.
- FC DenseNet
- ResNet 에서는 input 과 output 을 sum 해서 학습을 더 용이하게 해줌. 이는 이전 layer의 정보를 줌으로써 layer 간의 gradient 가 흐르는 것을 더 쉽게 만들어주고 결과적으로는 깊은 layer 에 대해서 성능을 더 좋게 만들었음.
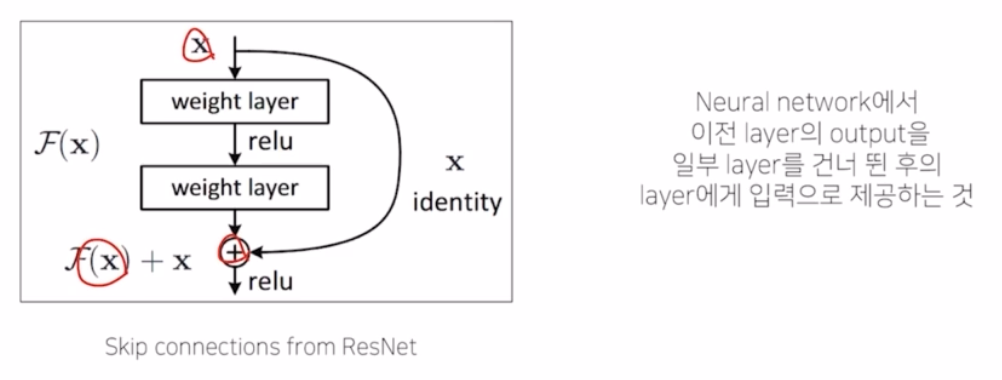
- 이러한 resnet 을 개선한 DenseNet 은, 여기서는 단순하게 이전 layer 의 정보만을 던져주는 것이 아니라, block 내부에 모든 이전 정보를 건네주는 방식. 즉 모든 이전 layer의 정보들을 다 활용해서 최종 output 을 생성함.
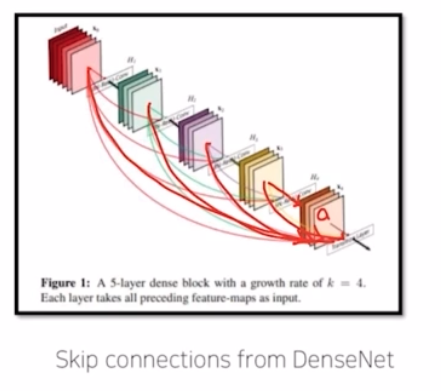
- FC DenseNet 은 이러한 DenseNet 의 skip connection 을 활용한 network 이다.
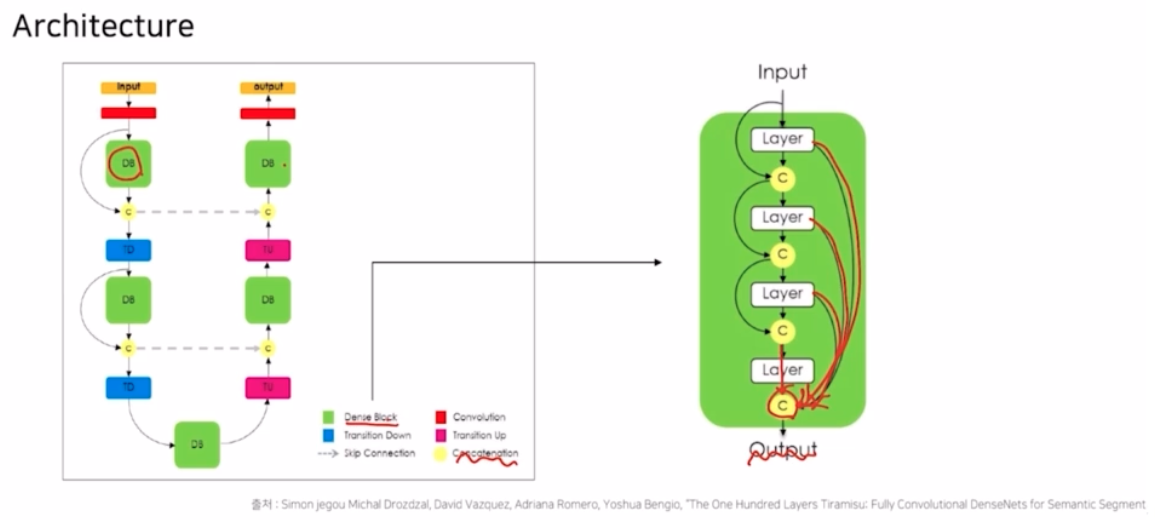
- 가운데의 DB 라는 dense block 형태를 보면, output 을 내기 전을 보면 이전 모든 layer의 정보들을 다 활용해서 concatenate 하는 부분이 있음.
- 추가적으로 encoder 에서 decoder 로 건네주는 또 하나의 skip connection 이 있음 (가로방향)
- FCN 에서 skip connection 은 sum 의 형태인데, 여기서는 채널별로 concatenation 을 해주는 방법을 적용함.
-
UNet
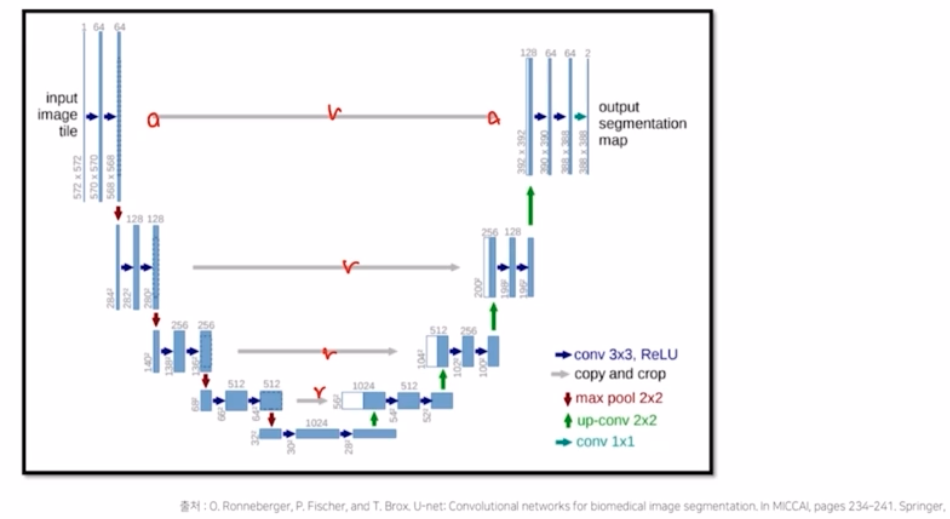
- encoder 의 정보를 skip connection 을 통해 decoder 로 건네주는 부분이 4개가 있음.
- 추후에 자세히 다룰 것(6강)
-
- Receptive Field 를 확장시킨 models
- 이전의 encoder-decoder 대칭 방법과 skip connection 을 발전시킨 방식이 있었는데, 이제 receptive field 를 확장시켜서 성능 향상을 했던 deeplab v3+ 까지 가는 과정을 살펴볼 것.
- Receptive Field 란?
-
뉴런이 얼마만큼의 영역을 바라보고 있는지에 대한 정보, 영역 등을 의미함.
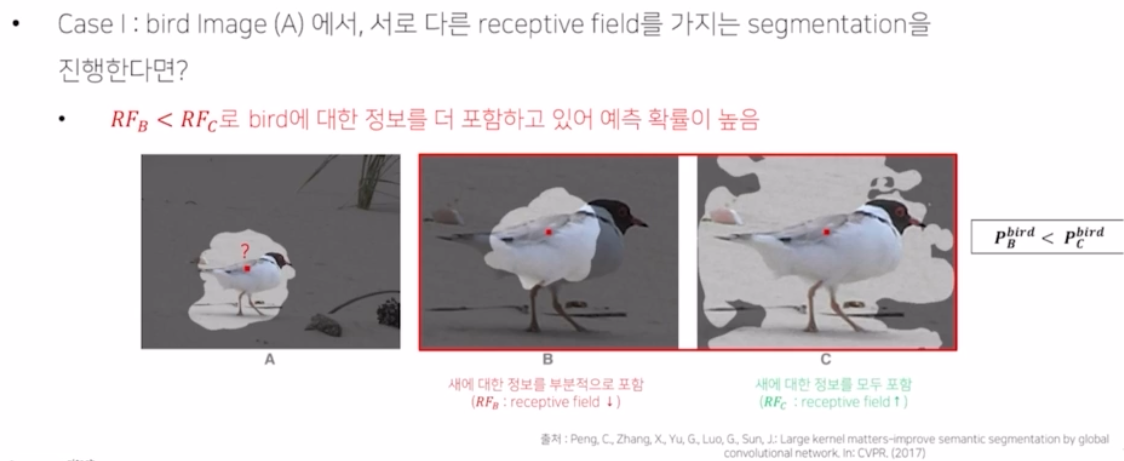
- 3개의 그림이 있을 때, B 와 C 를 보면 B 는 몸통만, C 는 몸통 뿐 아니라 다리, 얼굴까지 전부 바라보고 있음.
- B 와 C 를 비교했을 때 아무래도 부분적인 정보보다는 새 날개, 다리, 머리 등 전체적인 모습을 바라보고 object 가 새라고 판단하는 것이 더 효과적일 것.
-
그리고 이러한 정보를 가지고 seg 를 수행해야 더 정확한 정보를 얻을 수 있을 것.
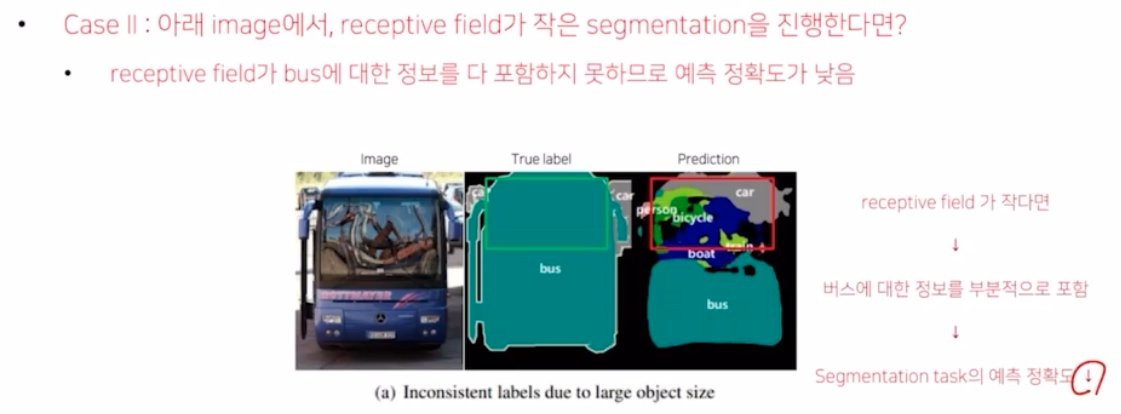
- 이전에 FCN 의 한계로 나온 버스 이미지를 보면, 너무 지엽적인 receptive field 만 가지고 예측을 수행했기 때문에 앞 범퍼는 잘 예측 했지만 유리창에 비친 모습은 여러가지 class 로 분류해버림.
- 만약 receptive field 가 작다면 버스에 대한 정보를 부분적으로 포함해서 예측하기 때문에 실패할 가능성이 높아지고 seg 예측 정확도는 낮게 나올 수 밖에 없음.
- 보통의 Network 에서는 어떤 식으로 receptive field 를 넓힐까?
-
10x10 input 에 3x3 conv 를 적용하는 예시. 이때의 conv 는 stride 1, padding 0 을 줘서 입력 이미지의 크기를 변화시키는 경우임.
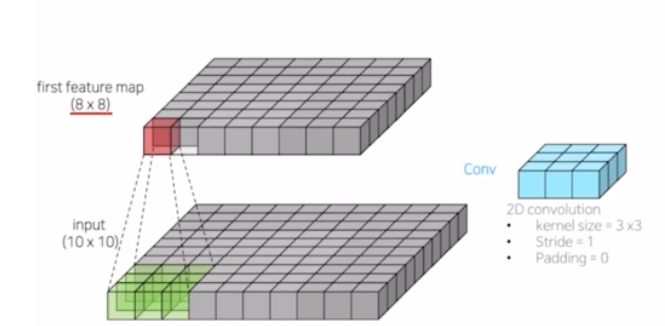
- padding 이 없어서 8x8 의 feature map 이 나옴.
-
하나의 픽셀은 인풋 이미지의 3x3 에 해당하는 영역을 바라보고 있음.
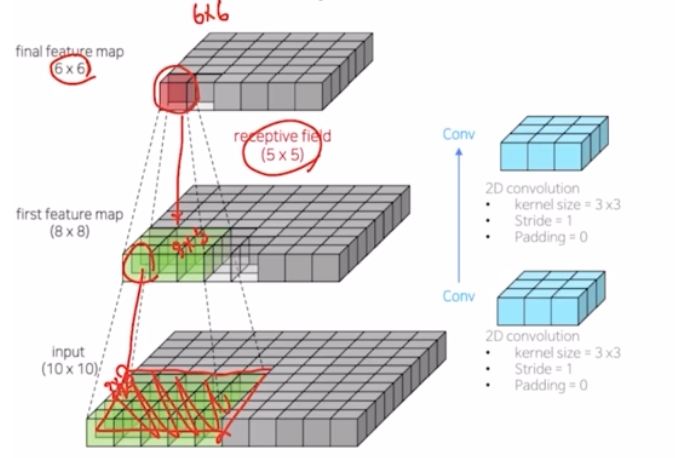
- 하나의 conv 를 더 적용시키면 6x6 의 feature map 이 나오고, 이 픽셀이 바로 전 feature map 의 3x3 을 바라보지만 input image 에서 receptive field 가 5x5 의 영역을 바라보게 되는 것.
-
max pooling 연산을 넣으면 결과가 어떻게 될까?
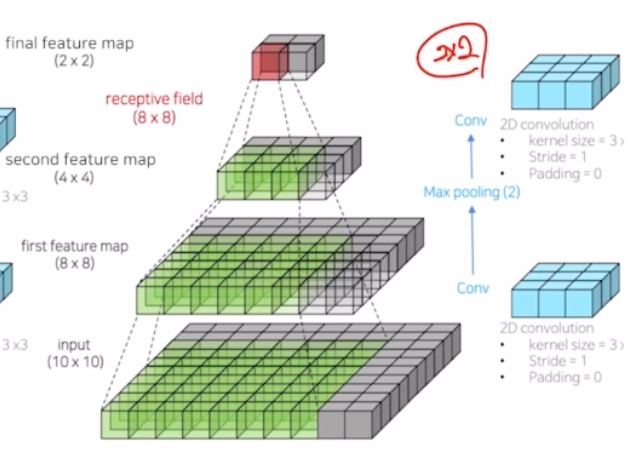
- 동일하게 3x3 conv 를 적용했을 때 10x10 → 8x8 이 됨. 여기에 max pooling 을 적용하게 되면, 8x8 의 feature map 이 4x4 로 감소한 다음에 다시 conv 를 적용하면 2x2 로 크기가 줄어들게 됨.
- 2x2 의 하나의 픽셀은 input image 에 대해서 얼만큼의 영역을 바라보는지 receptive field 를 보면 8x8 로, 기존의 5x5 에 대비해서 훨씬 커진 것을 살펴볼 수 있음.
-
즉 정리하면 conv 과 max pooling 을 적절히 섞어서 적용하면 효율적으로 receptive field 를 넓힐 수 있다! 그래서 max pooling 에 의해서 노이즈를 제거하고 이미지 크기를 줄여서 메모리를 효과적으로 활용한 것 이외에도, receptive field 를 넓힐 수 있는 장점이 한 가지 더 있다는 것.
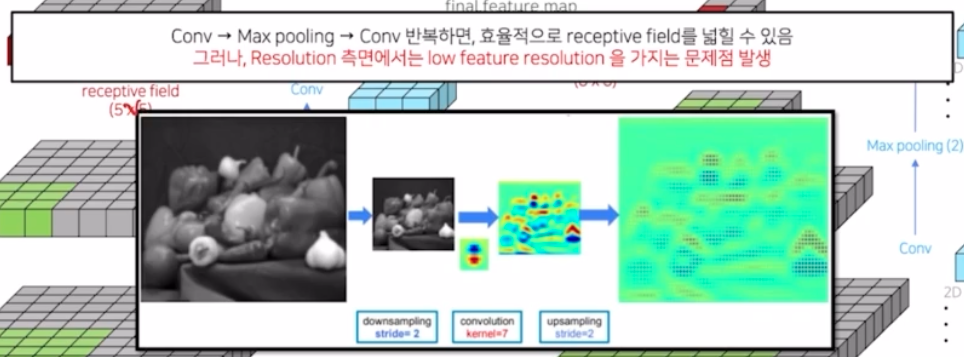
- 그러나, 이러한 max pooling 을 적용하는 방법에는 한가지 한계점이 있음. seg 에서는 각 픽셀마다 classification 을 해야하기 때문에 모든 픽셀에 대한 정보가 중요함. 그러나 이미지의 크기를 많이 줄인 상황에서, conv 이후에 upsampling 을 하면 해상도가 많이 줄어드는 문제점이 발생함. 즉 resolution 측면에서 low feature resolution 을 가지는 문제점이 발생함.
- down sampling 후 conv 하고 upsampling 을 하고 나서 activation map 을 보면 알 수 있음. 그렇다고 max pooling 을 적용하지 않고 recepive field 를 키우기 위해 kernel size 를 키우는 것은 파라미터가 너무 많이 증가하는 문제점이 있음.
- 따라서 이미지의 크기는 많이 줄이지 않고 파라미터의 수도 변함이 없는 채로 receptive field 만 넓게 하는 방식에 대해서 사고가 확장이 됨.
- 이를 가능하게 했던 방법이 dilated conv, 혹은 atrous conv 라고 불리는 기법들.
- 이 방법은 앞에서 나온 문제점을 해결함. 즉 파라미터 수는 동일하면서도 receptive field 는 넓혀서 좀 더 기존보다 high resolution 을 유지한 방법이다.
-
-
- Dilated Convolution(Atrous Convolution)
-
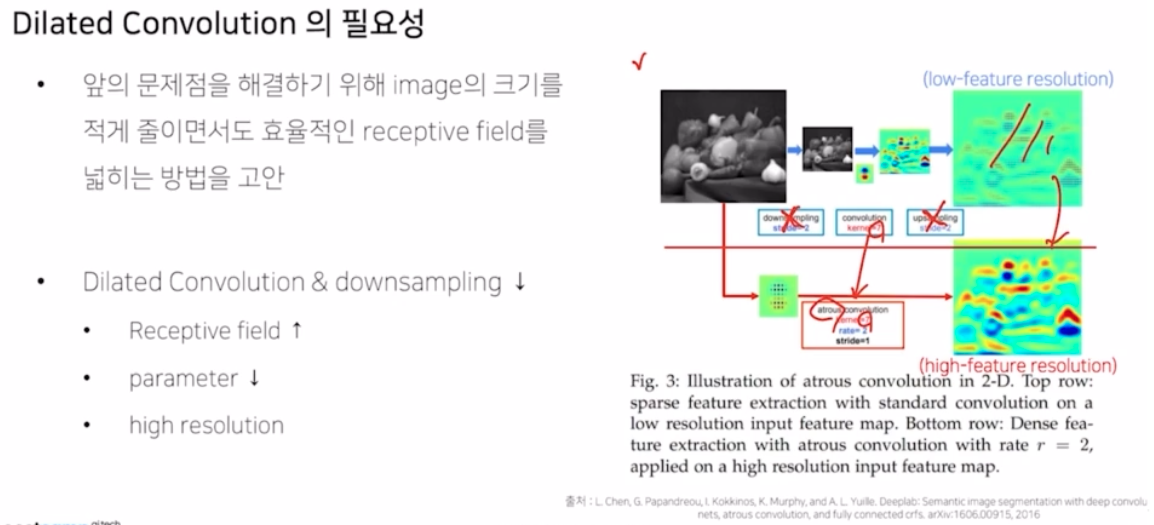
기존의 방식이 low feature resolution 을 가지는 문제점이 있었다면, dilated conv 을 적용한 방식은 down 과 up sampling 을 없애고, conv 를 kernel size 는 동일하지만 dilate 혹은 atrous conv 를 이용해서 low feature resolution 이 아니라 훨씬 더 activation이 많이 된 high feature resolution 을 가지게 만들어줌.
-
dilated conv 나 standard conv 는 3x3 일 때 파라미터 개수는 9개로 동일함. 그러나 바라보고 있는 영역이 dilated conv 가 훨씬 큼. dilated conv 에서 내부의 빈 값은 0으로 채워짐. 그래서 receptive field 가 효율적으로 늘어나는 것.
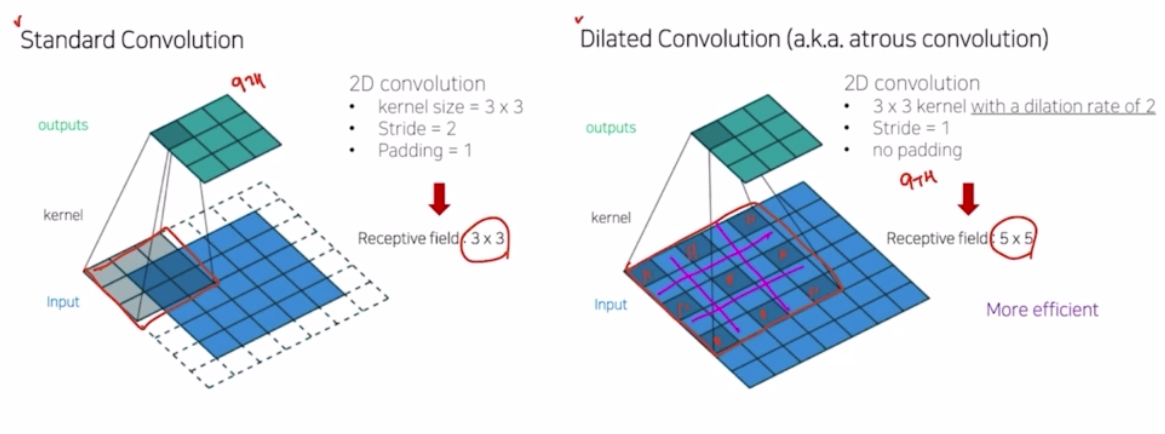
-
파라미터의 개수는 9개로 둘 다 동일하지만 receptive field 만 더 넓어졌다고 볼 수 있음.
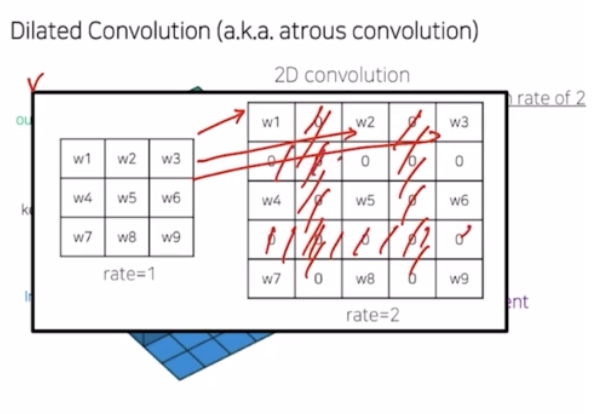
-
위 그림에서 파라미터 개수는 9개로 동일하지만 내부값은 0으로 채워지는 걸 볼 수 있음.
-
- DeepLab v1
-
dilated conv 를 적용한 DeepLab v1 을 보자.
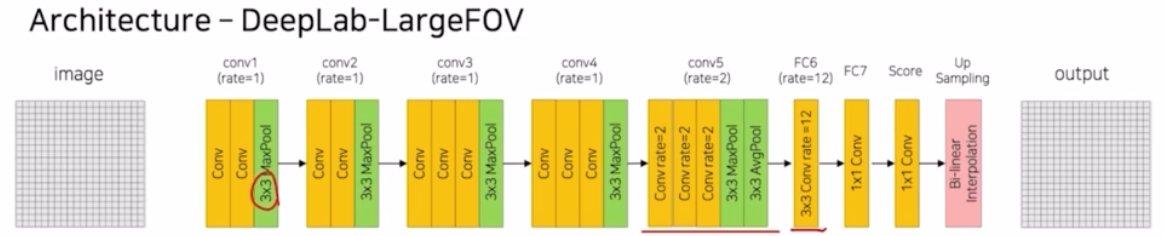
- VGG net 과 비슷한 모습을 보이지만 다른 점이 보임.
- 2x2 max pooling → 3x3 max pooling
- conv 5번째 블록과 FC6 부분에 그냥 conv 가 아니라 dilated conv 를 사용함.
-
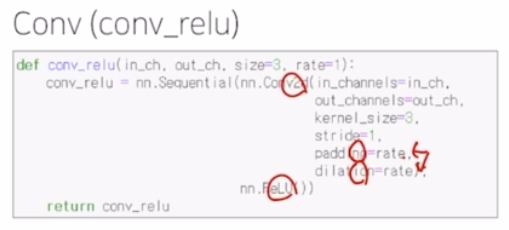
Conv 는 conv2d 와 relu 가 반복되는 구조. (conv_relu)

- conv1 (첫번째 conv block) 에서는 2개의 conv_relu 이후 max pooling (3x3, stride 2, padding 2) 이 적용됨. max pooling 으로 인해서 입력 이미지의 크기가 정확히 1/2 만큼 줄여줌.
- max pooling 을 이렇게 한 이유는 좀 더 receptive field 영역을 넓혀서 더 큰 영역에서 max pooling 을 수행했다는 것.
- conv2, conv3 도 동일한 연산을 수행함.
-
conv4 부터는 차이점이 있음.
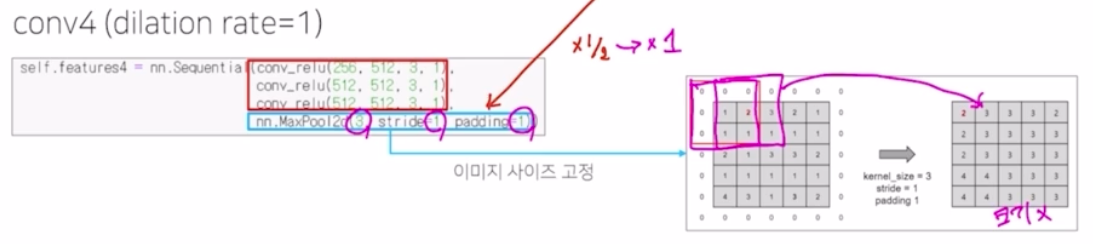
- 그 전에는 max pooling 에 의해서 계속해서 input image 를 1/2 만큼 줄였다면, 여기부터는 입력 사이즈를 그대로 유지함. 그래서 3x3 kernel size 의 max pooling 을 수행하지만 stride 는 1, padding 도 1 을 적용함. 그래서 크기 자체가 변동이 없어짐.
-
conv5 부분도 2개의 pooling 을 적용하지만 입력 이미지의 크기는 3x3, stride 1, padding 1 을 줘서 고정을 함.

- 특히 conv5 의 3개의 conv_relu 에서는 기존과 달리 dilation rate 를 2를 적용해서 훨씬 더 receptive field 를 효율적으로 넓게 가지는 conv 를 적용함.
- pooling 에서는 max pooling 과 avg pooling 을 같이 두는 테크닉을 활용함.
-
FC6 부터 score 를 내는 부분을 보자.
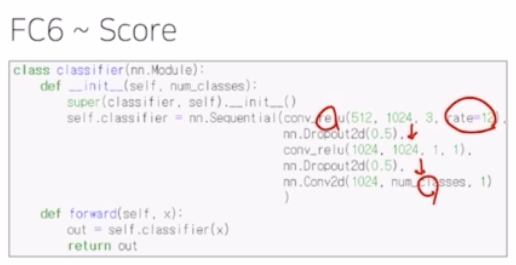
- fc6 부분도 conv_relu, dropout 이 사용되는 구조인데, 여기서는 dilation rate 를 12로 굉장히 크게 줌. 그 이후 1x1 conv 를 거친뒤 conv 에 num_classes 를 output 채널로 출력함.
-
여기까지 3개의 max pooling 에 의해서 크기가 1/8 로 줄었고(conv4, conv5 에서는 변함없음), 이 크기를 맞춰주기 위해서 Up sampling 을 함.
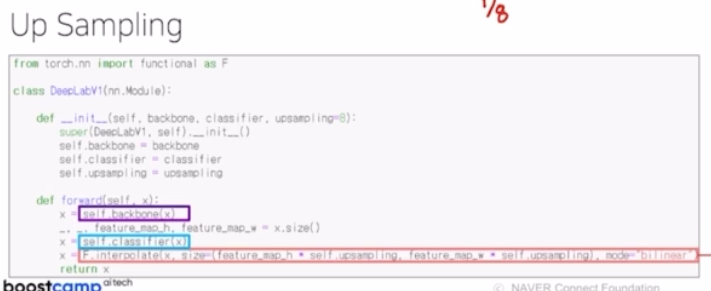
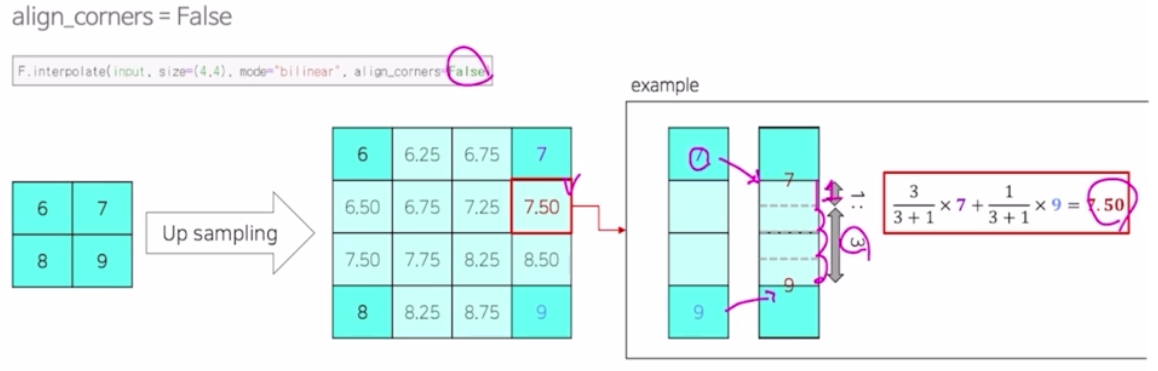
- 복원을 위해서 F.interpolate 즉 bilinear interpolation 이란 기법을 통해서 8배 만큼 크기를 키워주는 테크닉을 보여줌.
-
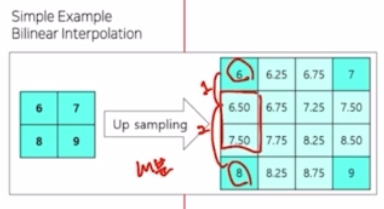
bilinear interpolation 은 내분의 과정을 통해서 내분을 통해서 비율이 얼마나 되는지 그 값을 통해서 채워주는 과정임. (여기서는 1:2)
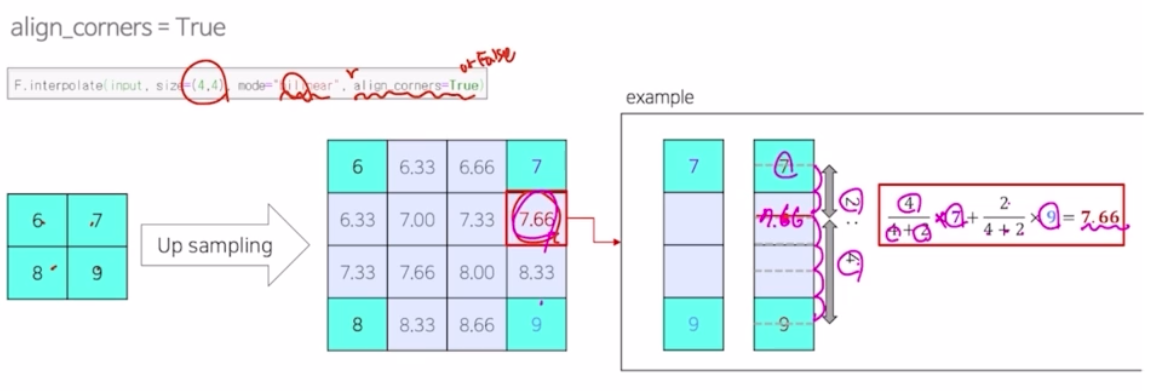
- bilinear interpolation 에서, align_corners 라는 인자가 있고, size 를 몇으로 키울지, 어떤 모드를 사용할지를 인자로 받음.
-
모드가 bilinear 일 때, 그 안에 내분을 어떻게 채워주는지 보면 비율을 따짐. 내분이라는 개념을 이용해서 내부의 값을 채워주게 됨.
-
align_corners 를 false 로 변경하게 되면 7 과 9의 위치가 조금씩 옮겨져서 계산이 됨. 그래서 내분을 구할 때의 비율이 달라짐. 즉 동일한 연산을 수행하지만 결과가 달라짐.
- DeepLab 에서 활용된 Dense CRF 라는 기법을 보자.
-
Dense Conditional Random Field(CRF) a.k.a Fully-Connected CRF
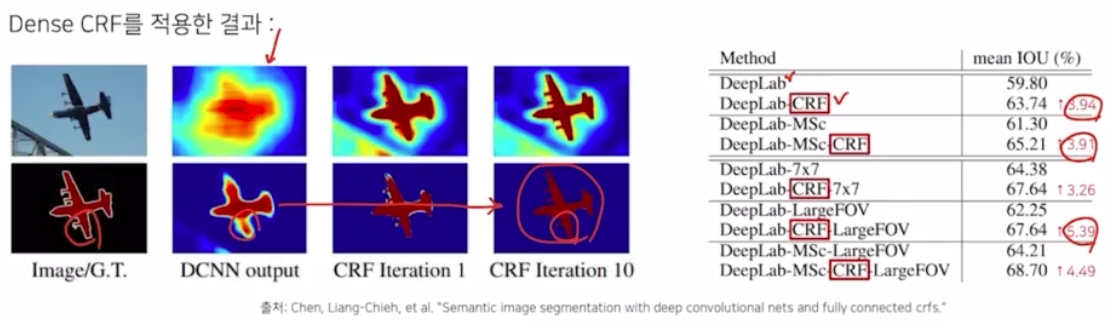
- bilinear interpolation 만 수행하면 다음과 같이 결과의 디테일함이 많이 사라짐.(DCNN)
- 그래서 deeplab v1 에서는 이를 정교하게 만들어주기 위해서 dense CRF 후처리 기법을 적용함.
- dense CRF 적용 결과가 성능 증가를 불러옴을 확인할 수 있음. 이미지 측면에서도 정교해짐.
-
-
Dense CRF
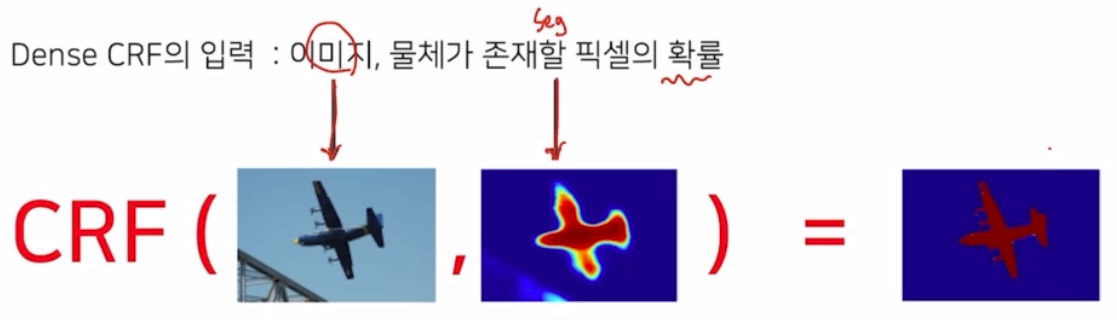
- 입력 이미지로 ‘원본 이미지’와 ‘seg output 의 각 픽셀 별 확률’을 입력으로 주면, 이를 통해서 정교하게 만들어줌.
- 먼저 deeplab v1 을 통해서 segmentation 을 수행 → output 결과를 만들어냄. output 과 실제 target(GT) 를 보면 디테일한 부분들이 아직 많이 부족한 것을 확인할 수 있음. 실제 확률 측면에서도 확인해보면, 디테일한 부분들에서 0이어야 하는데 안좋은 값을 가지고 있음.
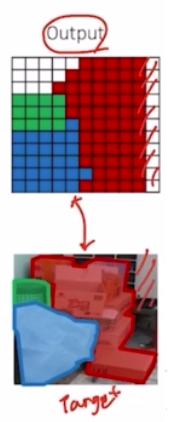
-
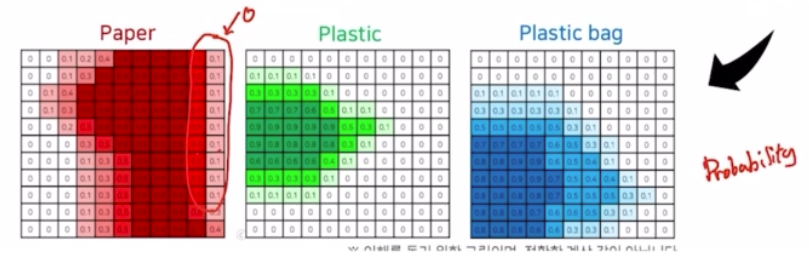
이 결과를 이용해서 CRF 를 수행함. CRF 자체가 수학적으로는 복잡해서 원리를 살펴보자. 원리 자체는 간단함.
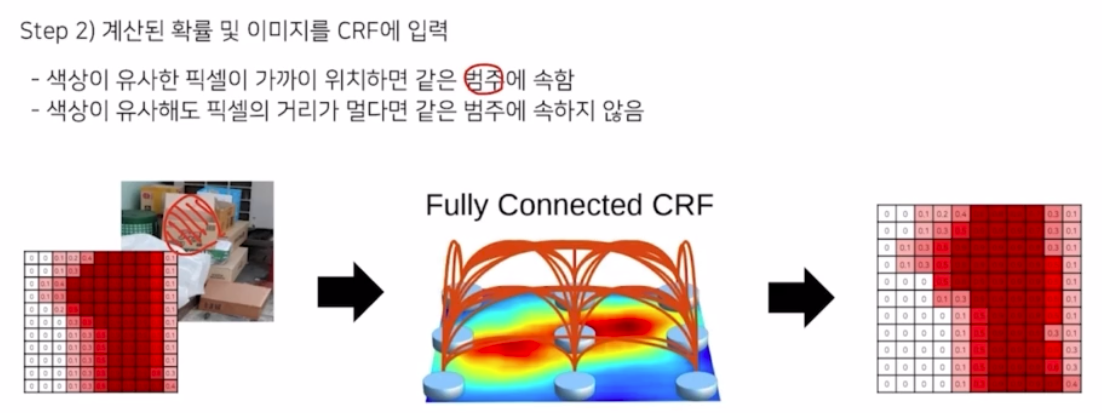
- 색상이 유사한 픽셀이 가까이 위치하면 같은 범주에 속함. 색상이 유사해도 픽셀의 거리가 멀다면 같은 범주에 속하지 않음.
-
즉 같은 유사한 색상을 가지면 같은 class 를 가지도록 후처리를 하는 방법.
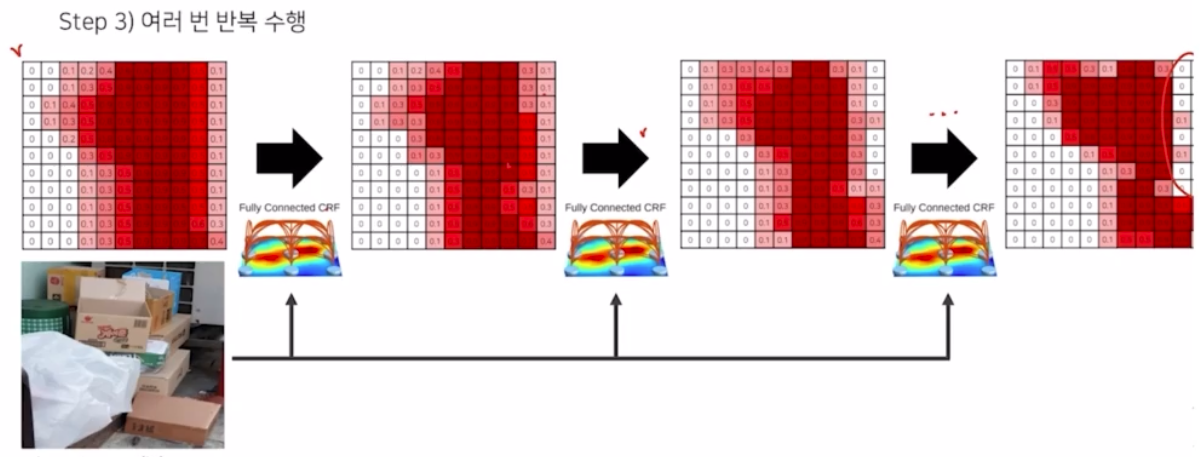
-
그래서 dense CRF 수행과정을 보면 확률 map 이 있을 때 CRF 를 여러번 반복적으로 수행했을 때 디테일함이 살아남을 볼 수 있음.
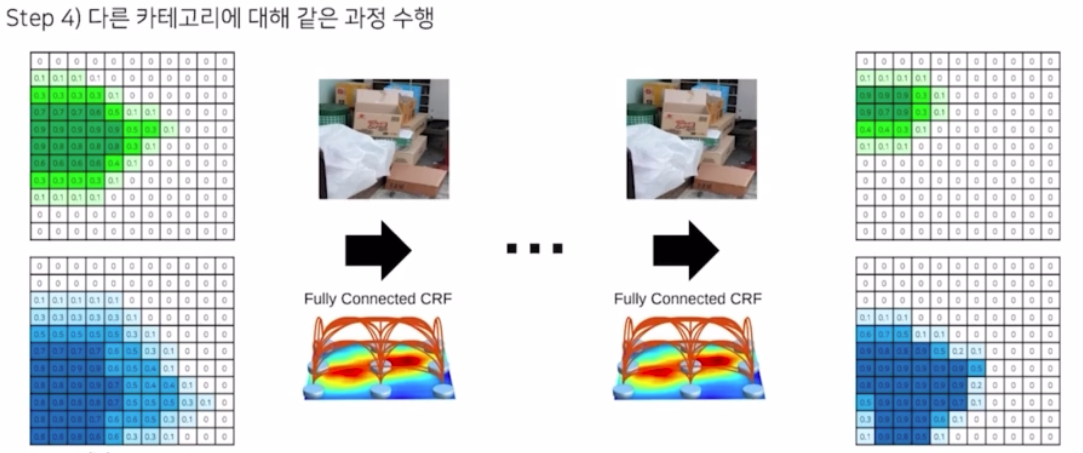
-
그리고 이를 모든 클래스에 대해서 수행

-
그 결과를 다 합쳐서 각 픽셀 별 가장 높은 확률을 갖는 카테고리를 선택하여 최종 결과를 도출함.
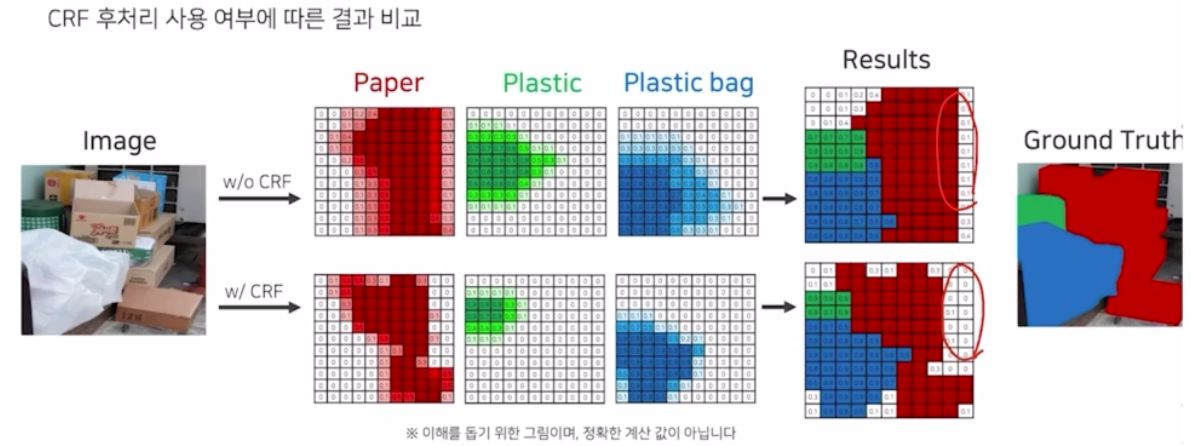
- CRF 를 사용한 결과와 아닌 결과를 비교해보면 GT 대비 CRF 를 적용하지 않은 결과는 디테일함이 떨어지고, CRF 를 적용하면 디테일한 모습이 살아나서 성능이 많이 증가함을 예상할 수 있음
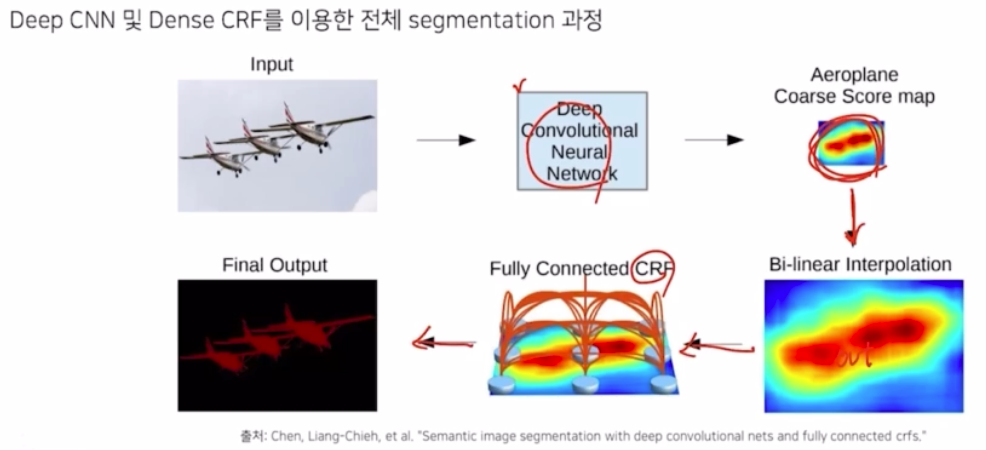
- 이렇게 deeplab v1 에서는 seg model 을 이용해서 확률 맵(probability map) 을 생성해내고 → 이를 bi-linear interpolation 으로 probability map 크기를 키워 output 을 생성한 다음 → CRF 를 반복 통과하여 정교한 final output 을 생성함.
-
- DilatedNet
- deeplab v1 이후에 나온 dilatedNet 은 deeplab v1 과 구조는 매우 비슷하지만 dilated conv 를 좀 더 효율적으로 적용한 모델.
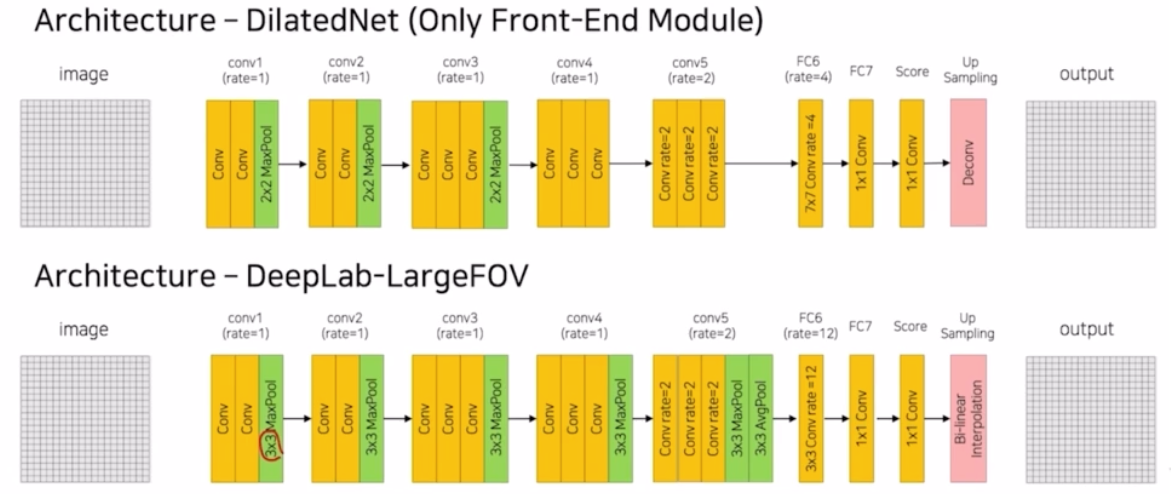
- 두 모델의 차이점은,
- deeplab v1 은 3x3 max pooling 을 적용했다면, dilatedNet 은 2x2 max pooling 적용
- conv4, conv5 부분에서 pooling 연산 자체가 사라짐. dilated conv 연산을 적용한 것은 동일함.
- fc6 부분에서는 deeplab v1 은 3x3 conv 에 dilated rate 를 12 를 줬는데, dilatedNet 은 7x7 conv 에 rate 를 4를 줌.
- 마지막으로 up sampling 과정에서 deeplab 은 bi-linear interpolation 을 사용했다면, dilatedNet 은 Deconv(transposed conv)를 이용함.
- dilatedNet 도 동일하게 하나의 conv 는 conv - ReLU 가 반복되는 구조를 이룸(conv_relu)
- 하나의 conv block 자체가 conv_relu 가 2개가 반복되고 max_pooling 이 적용되어 입력 이미지를 1/2 만큼 감소시킴(stride 2, padding 0)
- conv2, conv3 도 동일함.
-
conv4 부분은 max pooling 연산 자체가 사라짐.
- conv5 도 max pooling 연산 자체가 사라짐. conv5 에서 dilated rate 를 2를 줌. dilated rate 를 2를 줄 때, conv_relu block 에서 padding 과 dilation 의 rate 를 같은 값으로 설정해서 3x3 의 conv 를 적용할 때, dilate size 를 키워서 이미지의 입력 크기의 변동이 적용되지 않게 만들어주는 것이 중요한 포인트. → dilated conv 를 적용해서 입력 이미지의 크기가 변하지 않는다는 것을 padding 을 통해서 확인할 수 있음.
-
fc6 부분을 보면 7x7 conv 에 dilated rate 를 4를 주고 이때도 입력 이미지의 크기를 변동해주지 않기 위해서 padding 12 를 주어 변동을 막아줌. 이후 1x1 conv 2개를 거쳐 num_classes 만큼 output 채널을 구성해줌.
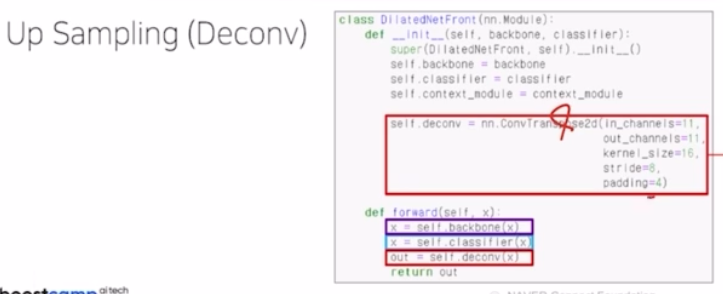
-
Up sampling 을 Deconv 를 이용해서 수행함. kernel size 16, stride 8, padding 4 를 주어 총 8배만큼 크기를 키워줌.

- DilatedNet 과 deeplab v1 의 결과를 비교해보면, DilatedNet Front end 가 좋은 성능을 거둠.
- DilatedNet 논문에서는 이러한 Front end 모듈만이 아니라 추가적으로 context module 을 추가로 제안함.
-
구조가 단순하게 score 다음에 등장함.
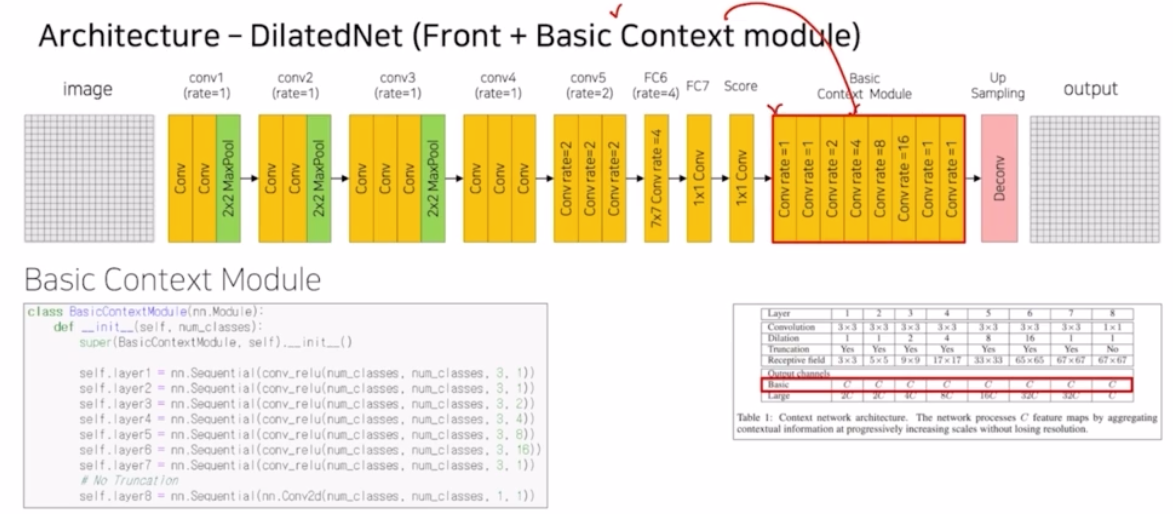
- dilated rate 를 1, 2, 4, 8, 16 다양하게 줌으로써 feature map 에서 추출할 때 크고 작은 object 모두 잘 추출되도록 적용한 부분.
- 실제 코드도 단순하게 conv_relu 에 3x3 kernel size 는 동일하지만 dilated rate 를 다양하게 줌. 이 때도 참고할 것이 dilation 과 padding 의 사이즈를 동일하게 적용함으로써 크기의 변동을 막음.
-
dilation 과 padding 의 크기가 같을 때 크기 변동이 안 일어나는 경우는 3x3 kernel 을 이용할 때다!
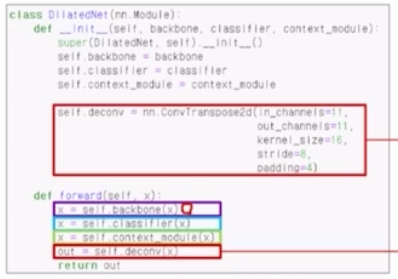
- forward 에서 backbone(conv1~5) → classifier(fc6~score) → basic context module → deconv(upsampling. 8배만큼 크기를 키움.)
- basic context module 은 정보를 더 복잡하고도 더 좋게 만들어줌.
- 이로 인해 성능이 상승함.
- 여기에 CRF 를 적용하면 결과가 더 좋아짐.
-
-
DeepLab v1 vs. DilatedNet

- DilatedNet 이 GT 와 비교했을 때 더 정교하고 디테일하게 나온다!
- 더구나 Front end 만 적용했을 때는 잘못 예측한 부분이 있었지만 basic context module 까지 적용시키면 오류들이 훨씬 더 많이 줄어든다.
댓글 남기기