
[RNN] 2. LSTM (Long Short-Term Memory), GRU (Gated Recurrent Unit)
Vanila RNN
- RNN 의 제일 큰 단점은 short-term dependencies 하다는 것이었다.
- 즉 과거에 얻어진 정보들이 다 취합되어서 미래에서 그것을 고려해야 하는데, RNN 자체는 어떤 하나의 fixed rule 로 이 정보들을 계속 취합하기 때문에, 이전 과거의 정보가 미래까지 살아남기 힘들다는 것이다.
- 그래서 현재에서 몇 스텝 전의 정보는 고려가 잘 되는데 한참 멀리 있는 정보는 현재에서 고려가 잘 되지 않는 문제점이 있었다.
-
RNN 의 가장 기본적인 구조는 아래와 같다.
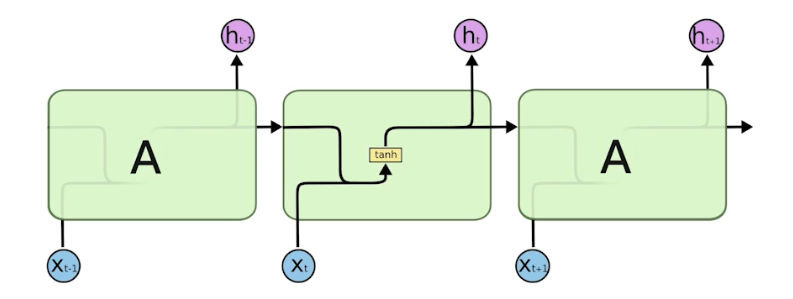
- RNN 의 long-term dependencies 는 못잡는 문제점을 해결하기 위해서 LSTM 이 등장했다.
LSTM
-
LSTM 구조는 아래와 같다.
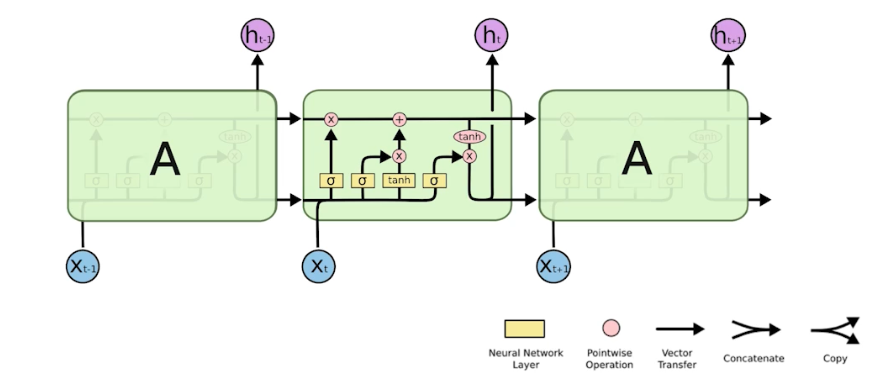
- LSTM 각각의 컴포넌트가 어떻게 동작하고 이게 왜 Long-term dependencies 를 잡는데 도움이 될까?
-
실제로 LSTM 은 많은 작업에서 기본 RNN 보다 더 나은 성능을 보이지만, 항상 그런 것은 아니다. 작업 및 데이터의 특성에 따라 LSTM 과 기본 RNN 사이의 성능 차이가 발생할 수 있다.
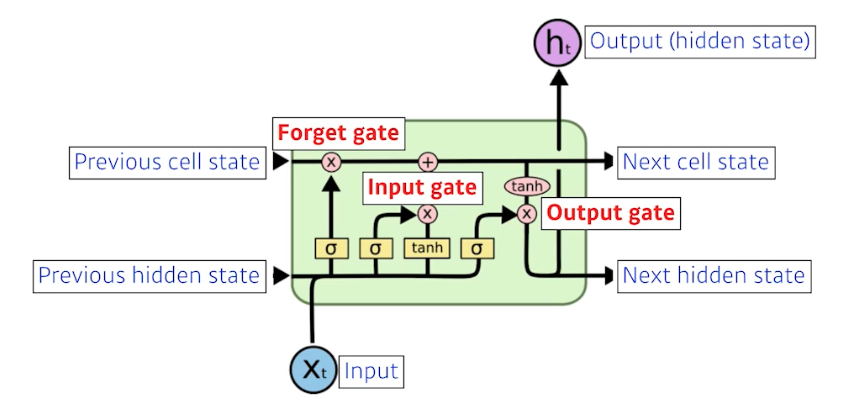
cell state- LSTM 안에서만 흘러간다.
- 이것이 결과론적으로 말하면 지금의 타임 스텝까지의 정보를 다 취합해서 summarize 해주는 정보가 된다.
hidden state- output 이다. 위로도 가지만 아래로도 흘러간다.
- 아래로 흘러가는 것이 다음 번($t+1$) LSTM 의
previous hidden state로 흘러간다.
- LSTM 의 입력으로 들어가는 것은 이전의 출력값(
previous hidden state)과 밖으로 나가지 않는previous cell state, 그리고현재 t의 입력이다. - 즉 들어오는 입력이 3개이고 나가는 입력도 3개다. 실제 output 은 hidden state 다.
- 또한 $\sigma$ 가 3개있다. 각 gate 마다 연관되어 있다.
- LSTM 을 이해할 때는 Gate 위주로 이해하는 것이 좋다.
-
LSTM 의 가장 큰 아이디어는 현재까지 들어온 정보를 요약하는 일을 수행하며 중간에 흘러가는 cell state다.
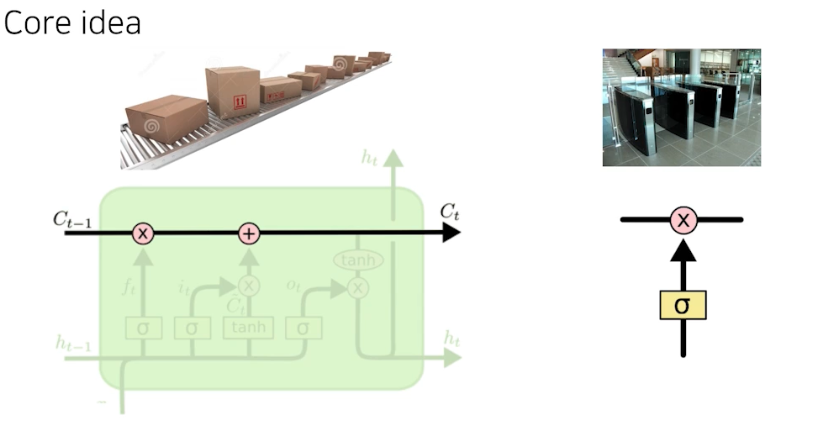
- Gate 는 어떤 걸 올리고 어떤 걸 빼고 어떤 걸 조작할 지에 대한 정보를 가지고 있다. 즉 어떤 정보가 유용하고 유용하지 않은지를 가지고 잘 조작해서 다음 스텝에 넘겨준다.
Forget Gate
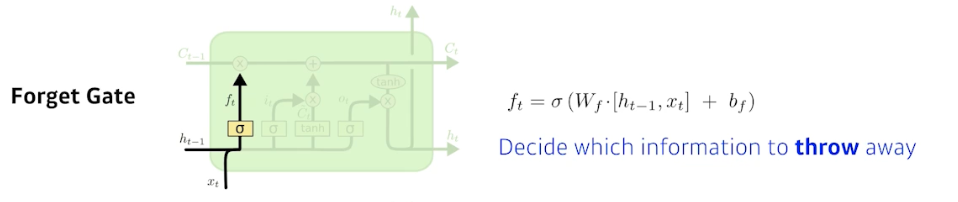
- 어떤 정보를 버릴지 판단하는 역할을 한다.
- 입력으로 들어가는 것은 현재 입력($x_t$)과 이전의 아웃풋($h_{t-1}$)이다.
- 출력은 $f_t$ 다. 이 때 시그모이드를 통과하기 때문에 항상 0에서 1사이 값을 가진다.
- $f_t$ 는 이전의 cell state 에서 나오는 정보 중 어떤 걸 버리고 살릴 지를 정해주게 된다.
- 즉 이전의 출력값인
previous hidden state($h_{t-1}$) 와 현재 입력($x_t$)을 가지고 weight 를 곱하고 activate func 을 통과시켜서 이전의 cell state에서 넘어오는 정보 중 버릴 것을 정하는 것이다. - 만약 forget gate 의 출력값인 $f_t$ 가 0 이 된다면, 이전 시점의 cell state 의 값인 $C_{t-1}$ 은 현재 시점의 cell state 의 값을 결정하기 위한 영향력이 0이 된다.
- 그러면 오직 input gate 의 결과만이 현재 시점의 cell state 의 값 $C_t$ 을 결정할 수 있다. 이는 forget gate 가 완전히 닫히고 input gate 를 연 상태를 의미한다.
- 반대로 input gate 의 $i_t$ 값을 0 이라고 한다면, 현재 시점의 cell state 의 값 $C_t$ 는 오직 이전 시점의 cell state 의 값 $C_{t-1}$ 의 값에만 의존한다. 이는 input gate 를 완전히 닫고 forget gate 만을 연 상태를 의미한다.
- 결과적으로 forget gate 는 이전 시점의 입력(
previous cell state)을 얼마나 반영할지를 의미하고, input gate 는 현재 시점의 입력(input)을 얼마나 반영할지를 결정하는 것이다.
Input Gate

- input gate 의 역할은 현재의 입력을 무조건 cell state 에 올리는 것이 아니라 이 정보들 중 어떤 정보를 올릴지 정하는 것이다.
- $i_t$ 는 이전의 previous hidden state($h_{t-1}$) 와 현재 입력($x_t$)을 가지고 만들어진다.
- 또한 시그모이드 함수를 통과하여 어떤 정보를 cell state 에 올릴 지에 결정한다.
- 이 때 올릴 정보를 어떻게 알까?
- $\tilde{C}_t$($g_t$) 에서 그것을 결정한다.
- 이전의 previous hidden state($h_{t-1}$)와 현재 입력($x_t$)이 들어와서 따로 학습되는 뉴럴 네트워크를 통해서 하이퍼폴릭 탄젠트를 통과하여 모든 값이 -1 ~ 1로 정규화된 $\tilde{C}_t$ 를 만들어낸다.
- 이 $\tilde{C}_t$ 가 현재 정보와 이전 출력값을 가지고 만들어지는 cell state 예비군이다.
- 그럼 이전까지 정보들이 summarize 되어 있던 cell state 와, 현재 정보와 이전의 hidden state 로 얻어진 $\tilde{C}_t$ 를 잘 섞어서 새로운 cell state 로 업데이트 해야한다.
Update Cell
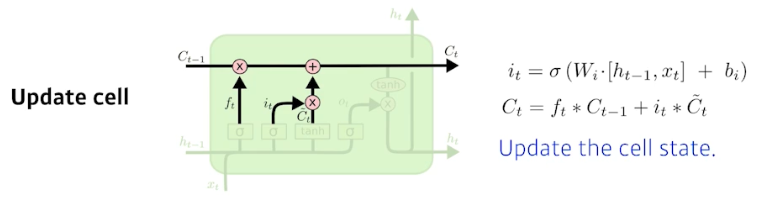
- $C_t = f_t \ast C_{t-1} + i_t \ast \tilde{C}_t$
- update cell 은 forget gate 에서 나온 $f_t$ 를 이전의 cell state($C_{t-1}$)를 곱해서 버릴 것은 버린다.
- 또한 input gate 에서 나온 $\tilde{C}_t$ 는 어떤 정보를 cell state 에 올릴지를 뜻하고 이를 $i_t$ 에 곱한다.
- 이 두 값을 combine 한 것을 새로운 cell state($C_t$) 로 만들어주는 것이다.
- 즉 이전의 버릴 것은 버리고(forget gate), 현재 정보 기준으로 쓸 것은 쓰고(input gate), 이를 합쳐서 지금까지의 time step 들을 summarize 하는 새로운 cell state 를 업데이트 하는 것이다.
Output Gate
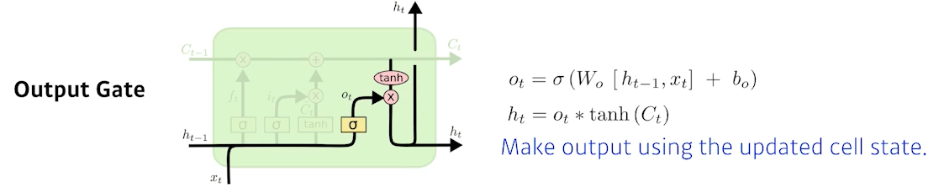
- cell state 가 업데이트 되었으니 출력값을 뽑아야 한다.
- GRU 는 그대로 cell state 를 output 으로 뽑는다. 그러나 LSTM 에서는 output gate 로 한 번 더 조작한다.
- output gate 는 어떤 값을 밖으로 내보낼지를 정한다.
- 그 output gate 의 값($o_t$)만큼 element-wise 로 cell state($C_t$)에 곱해서 $h_t$ 를 구한다. 이것이 현재 output 이 된다.
- 또한
next hidden state로 흘러간다. - 결과론적으로 보면,
- 이전까지 들어온 정보($C_{t-1}$)를 현재 입력을 바탕으로 지울지 그리고 현재 입력을 바탕으로 어떤 값을 새롭게 쓸지 이 두 정보를 취합($C_t$)하는 것이 update cell 이다.
- 그리고 이 취합된 cell state 를 한 번 더 조작해서 어떤 값을 밖으로 빼낼지를 정하는 것이 output gate 다.
LSTM 의 파라미터
- RNN 은 파라미터 수가 많다.
- 특히 LSTM 안에 기본적으로 들어가는 3개의 gate 는 결국 dense layer 다.
- 이 dense layer 들의 dimension 을 잘 뜯어보면 각 gate 별로 input 과 이전 상태의 hidden state 별로 들어온다.
- 그러면 가중치는 input 입장에서 보면
4 * hidden dim * input이고, hidden state 입장에서 보면4 * hidden dim * hidden dim이 된다. - 따라서 파라미터 숫자가 많을 수 있다. 보통 RNN 의 4배이다. forget gate($W_f$), input gate($W_C, W_i$), output gate($W_o$) 이 있기 때문이다.
- 따라서 LSTM 의 파라미터 수를 줄이려면
hidden dim을 줄여야 한다.
GRU(Gated Recurrent Unit)
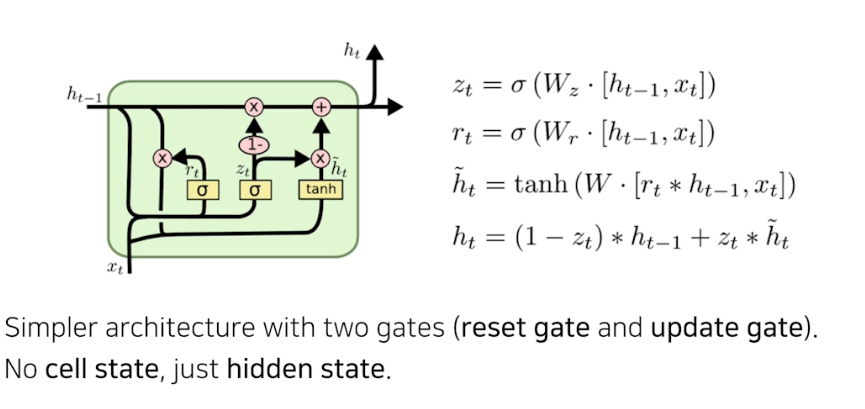
- GRU 는 gate 가 두 개 뿐이다. reset gate, update gate 가 바로 그것이다.
- LSTM 은 cell state 가 하나 흘러 가고 그것을 한 번 더 manipulation 해서 output hidden state 가 나왔다.
- GRU 에는 그 과정이 없다. hidden state 가 곧 output 이다. 그리고 바로 다음 타임 스텝에 들어가게 된다.
- 즉, output gate 가 필요없어진 것이다.
- reset gate 는 forget gate 와 비슷하다.
- GRU 가 LSTM 보다 성능이 좋은 경우가 많다.
- 그 이유는 네트워크 파라미터 수가 적기 때문이다.
- 일반적으로 적은 파라미터로 동일한 output 을 내면 generalization performance 가 올라간다. 그런 관점에서 GRU 를 많이 활용한다.
댓글 남기기