
[OS] 13. Python GC, GIL, Process, Thread
Garbage Collector(GC)
- GC 는 쉽게 말해 메모리에 굳이 남아있을 필요가 없는 쓰레기들을 주워가는 쓰레기 콜렉터이다.
- GC 의 작동 방식을 이해하면 메모리 누수나 성능 저하, 오버플로우와 같은 문제를 미리 예방할 수 있다!
- 우리가 쓰고 있는 대부분의 언어는 매니지드(managed) 언어라고 불린다.
- 흔히 매니지드 언어, 매니지드 코드라고 하는 건 쉽게 말해 언어에 런타임 환경이 더해진 언어다.
- 언매니지드 언어는 하드웨어에서 직접 실행될 수 있지만 매니지드 언어는 런타임 환경에 의존적인 코드이다.
- 런타임 환경은 개발자를 위해 많은 서비스를 제공해주는데, 이 중 가장 대표적인 것이 Garbage Collection 이다.
- 가비지가 수집되는 과정은 두가지 쓰레드로 나눠볼 수 있다. 하나는 뮤테이터고 하나는 콜렉터다.
뮤테이터
- 객체를 할당하고 참조에 따라 그래프를 변형시키는 역할을 한다.
- 즉, 뮤테이터는 우리가 작성하는 코드 그 자체라고 할 수 있다.
- 따라서 우리가 작성하는 코드이기 때문에 참조되고 변화하는 이 과정은 잘 이해하고 있다.
콜렉터
- 뮤테이터 쓰레드에서 접근할 수 없는 쓰레기 메모리가 된 것들을 찾아 저장공간을 회수하는 역할을 한다.
- 실질적인 GC 라고 할 수 있는 해당 쓰레드 과정의 알고리즘은 정확히 알기가 어렵다.
- 콜렉터 쓰레드에서 일어나는 대표적인 알고리즘은 레퍼런스 카운팅, 마크앤 스윕, 제너레이션 가비지 컬렉션 등이 있다.
- 레퍼런스 카운팅
- 레퍼런스 카운팅은 Garbage 의 Detection, 즉 쓰레기를 찾는 것에 초점이 맞추어진 초기 알고리즘이다.
-
각 Object 마다 Reference Count 를 관리하여 Reference Count 가 0이 되면 GC 를 수행한다.
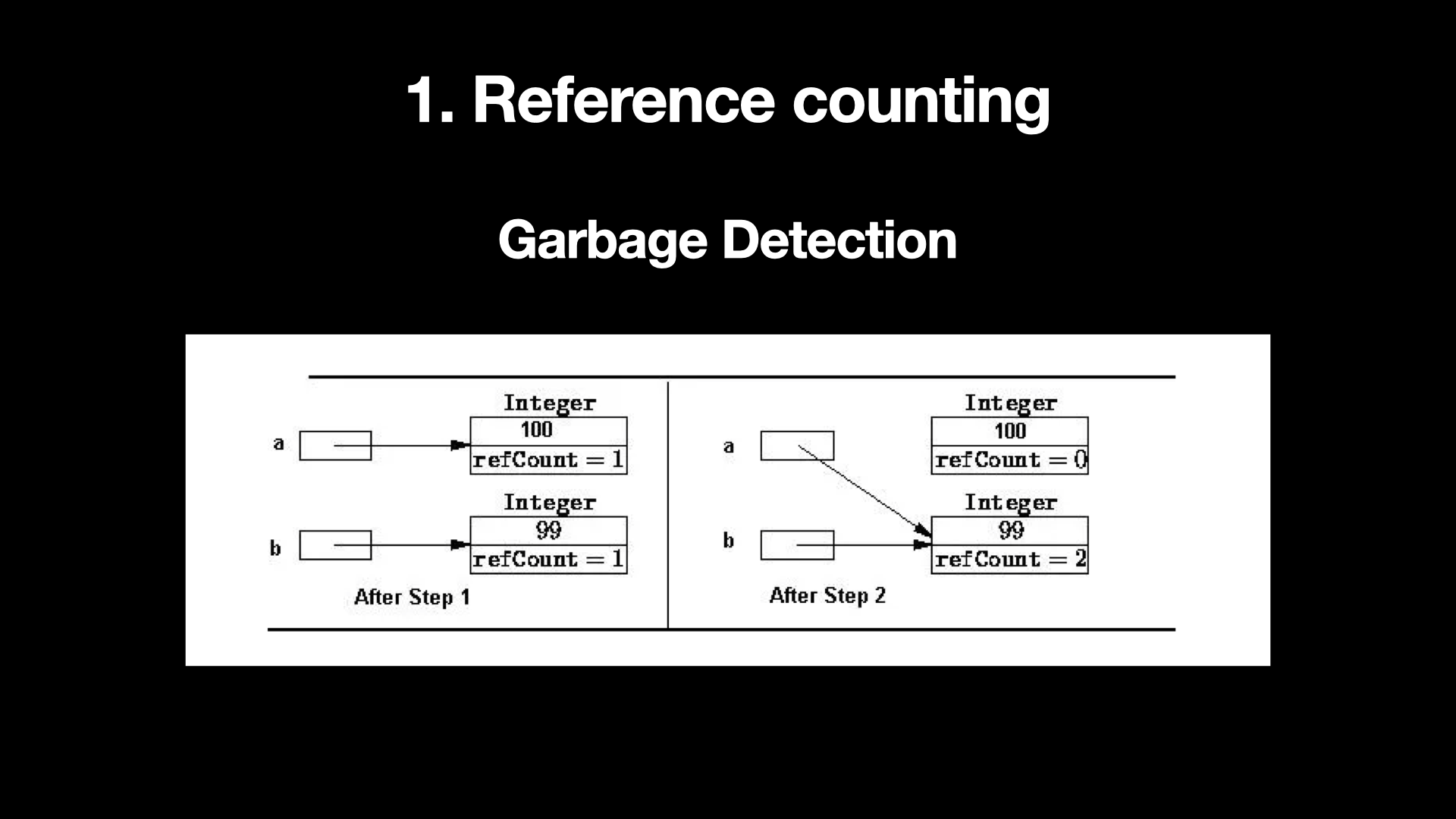
- 위 그림에서 a 와 b 는 각각 100, 99 의 값을 갖는 Integer Object 로 선언된다.
- 각 Integer Object 는 Referece Count 가 1로 설정되어 있다. 이 상태에서
a=b로 변경하게 되면 a 가 참조하고 있던 100 의 값을 갖는 Integer Object 는 참조가 없어지기 때문에 Reference Count 가 0 으로 감소하게 되고 GC 가 수행된다. - 이 단순한 방식은 Reference Count 가 0이 될 때마다 GC 가 발생하기 때문에 시간 작업에도 거의 영향을 주지 않고 즉시 메모리에서 해제된다는 장점이 있다.
- 그러나 각 Object 마다 Reference Count 를 변경해 주어야 하고 참조를 많이 하고 있는 Object 의 Reference Count 가 0 이 될 경우 연쇄적으로 GC 가 발생할 수도 있다. 또한 Reference Count 의 관리 비용도 크다.
- 또한 대표적인 문제는 Linked List 와 같은 순환 참조 구조에서 Memory Leak(메모리 누수)가 발생할 가능성도 크다는 것이다.
- Memory Leak : 응용 프로그램에서 데이터를 메모리에 올렸다가 이것이 쓸모 없어지는 시점에서 적절하게 제거되지 않는 것을 ‘누수’에 빗댄 말.
- 이러한 이유로, 레퍼런스 카운팅 방식만으로는 모든 경우에 대응하기 어렵다. 따라서 다른 가비지 컬렉션 방식들이 필요하게 된다.
- 마크앤 스윕
- Reference Counting 알고리즘의 단점을 극복하기 위해 나온 알고리즘으로 대표적인 것은 마크앤 스윕 방식 이다.
- 이 방식은 Root 에서 시작해 참조의 관계를 추적해 나간다. 그래서 Tracing 알고리즘이라고도 부른다.
- 이름에서 유추할 수 있듯이 Mark Phase 와 Sweep Phase 로 나뉜다.
- 이 알고리즘은 죽은 객체와 산 객체의 판단을 힙 영역이 아닌 객체로부터 닿을 수 있는가로 판단하게 된다.
- 다시 말해서, 힙이 아닌 영역에서 참조를 하고 있으면 해당 객체는 산 객체, 힙이 아닌 영역에서 닿을 수 없는 객체는 죽은 객체로 판단한다.
- 이 논힙 영역(힙이 아닌 영역)을 루트라고 부르며 이 루트는 실행 중인 쓰레드가 될 수 있고, 전역 변수, 정적변수, 로컬변수 등이 될 수 있다.
- Mark Phase 에서는 이 루트(힙이 아닌 영역)에서 시작하여 접근 가능한 모든 객체를 탐색하며 사용 중인 객체에 마크를 표시한다.
- Sweep Phase 에서는 마크되지 않은 객체를 해제한다. 이렇게 하면, 사용 중인 객체가 아닌 객체는 자동으로 해제되어 메모리를 확보할 수 있다.
-
아래의 의사 코드로 설명해보자.

-
Mark Phase 에서 도달할 수 있는 객체들을 넣어두는 곳을 파란
worklist라고 해보자.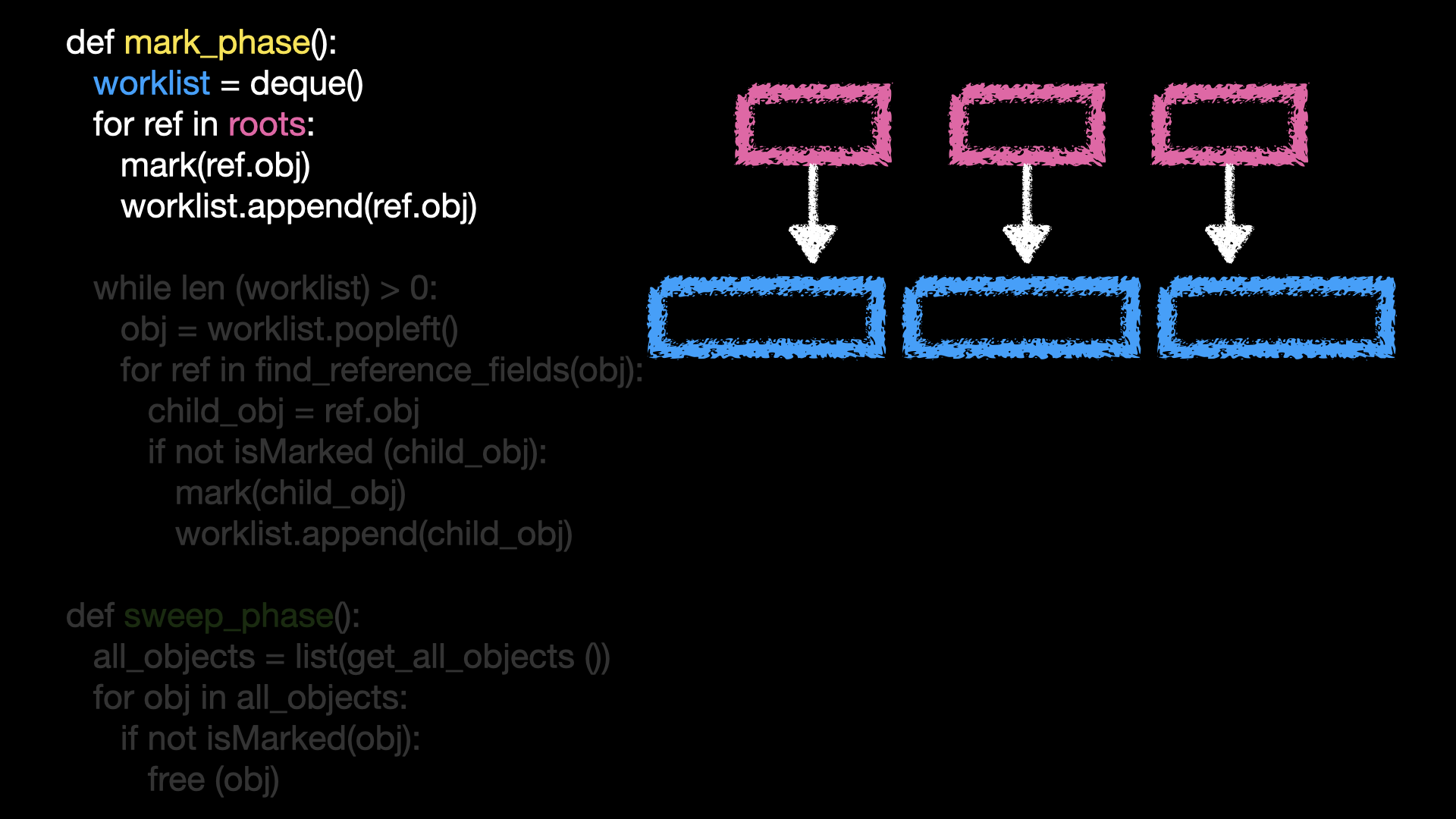
-
루트를 돌면서 도달할 수 있는 객체들에 마크를 하고
worklist에 넣는다. 분홍색roots의 정보들은 GC 가 가지고 있다.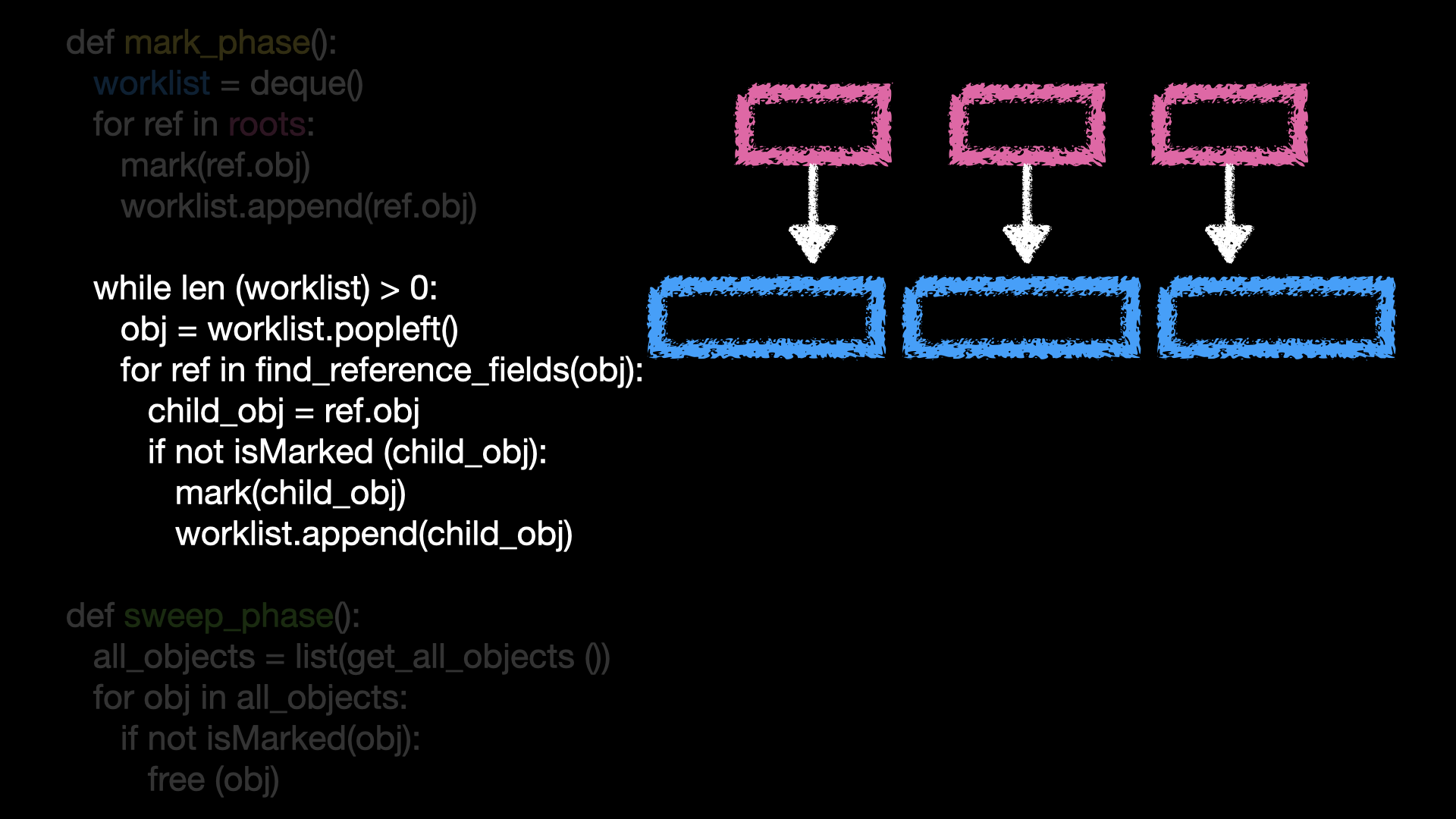
worklist를 하나씩 돌며 접근 가능한 모든 객체에 마크 표시를 한다.-
즉 해당 객체가 참조하는 것이 있는지, 해당 객체에 참조 공간이 있는지 확인한다. 만약 참조 공간이 있다면, 해당 객체는 참조하는 객체 또한 도달 가능한 객체이기 때문에 마크를 해주고
worklist에 넣어주는 것이다.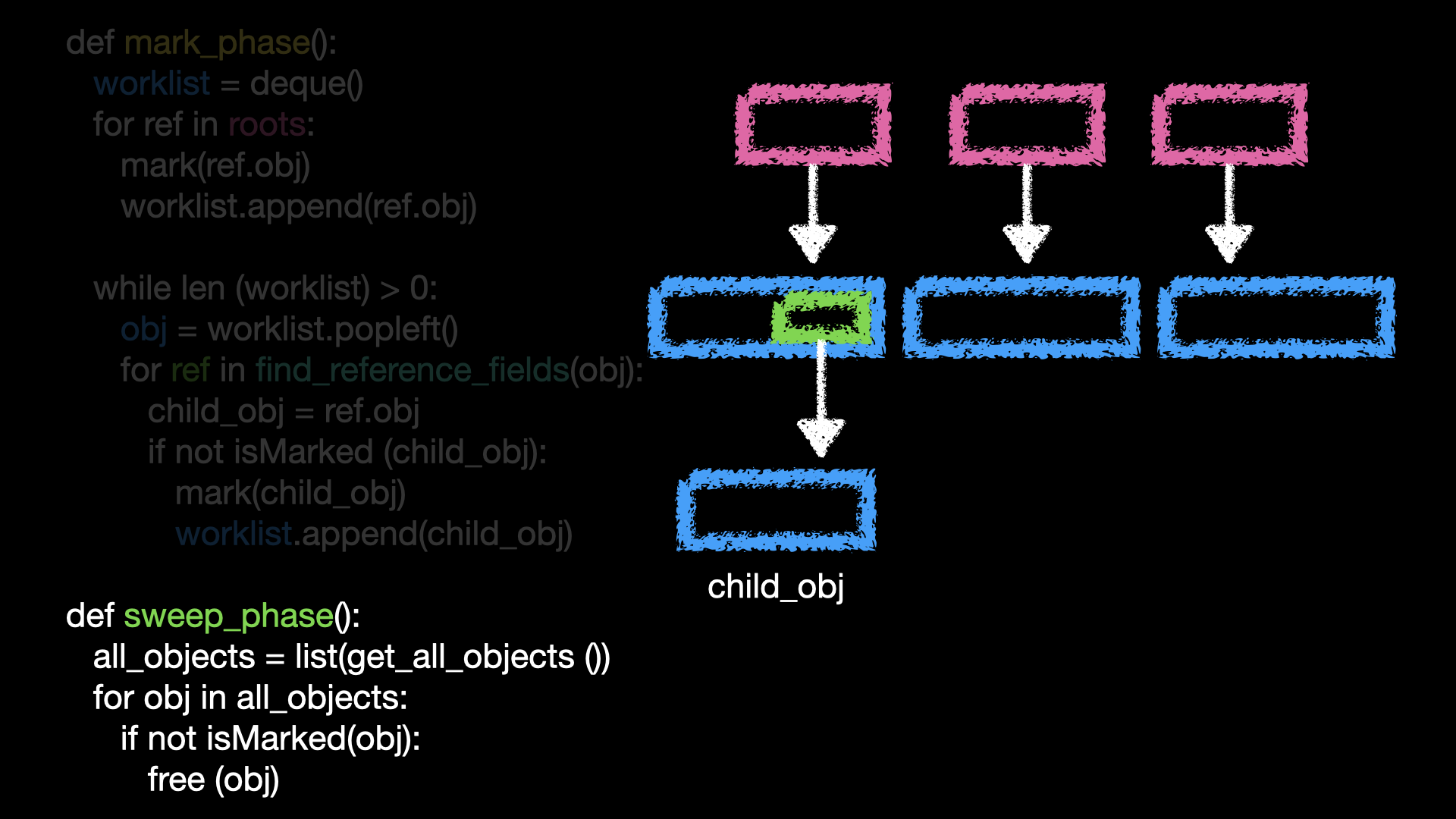
- Sweep Phase 에서는
worklist에 해당하지 않는, 즉 닿을 수 없는 객체들을free를 통해 해제시켜준다. - 마크 앤 스윕 방식은 레퍼런스 카운팅 방식보다 강력하다. 레퍼런스 카운팅 방식에서는 순환 참조 문제를 해결하지 못하는데, 마크 앤 스윕 방식은 순환 참조 문제도 해결할 수 있기 때a문이다.
-
하지만 큰 단점으로는 마크 앤 스윕 방식은 메모리 해제를 위해 일시적으로 프로그램 실행을 중지해야 하는 ‘Stop the World’ 상황이 발생할 수 있다는 점이다.

- 현재 뮤테이터 스레드가 멈춰야 현재 메모리에서 살아있는 객체를 잘 식별할 수 있기 때문이다. 이것을 stop the world 라고 한다.
- 물론 마크 앤 스윕 방식 말고도 모든 가비지 컬렉션 알고리즘이 stop the world 상황이 발생한다. stop the world 의 시간을 줄이기 위해 여러가지 알고리즘을 사용한 여러 종류의 가비지 컬렉션들이 개발되었다.
- 결론적으로, 마크앤 스윕 방식은 레퍼런스 카운팅의 단점을 보완해주지만 stop the world 상태를 야기시킨다 정도로 정리할 수 있다.
-
제너레이션 가비지 컬렉션

- 메모리 내의 객체를 여러 세대로 분류하여, 각 세대마다 다른 가비지 컬렉션 알고리즘을 적용하는 방식이다.
- 이 방식은 빈번한 객체 생성과 동시에 짧은 생명주기를 가진 객체가 많은 경우에 효과적이다.

- 일반적으로, Young Generation 에서는 복사 방식을 사용, Old Generation 에서는 마크앤 스윕 방식을 채택해 사용한다.
- 객체가 막 생성된 시점에는 Young Generation 에 속한다. 대부분의 객체는 생성된 후 짧은 시간 동안만 유효하며 오랫동안 유효한 객체는 일부에 불과하다는 약한 세대 가설을 전제로 해당 GC 알고리즘이 만들어졌기 때문이다.
- 따라서 일단 생성되면 Young Generation 으로 들어게 된다. Young Generation 에서 Garbage Collection 이 빈번하게 발생하는 이유도 대부분의 객체가 짧은 생명 주기를 가진다는 전제 때문이다.
- 가비지 컬렉션의 주요 기술 중 하나인 “복사(Copying)” 방식은 Young Generation 을 두 영역으로 나눈 후, 객체를 한쪽에 할당하고, 그 공간이 가득 차면 살아있는 객체를 판단하고 나머지 영역으로 살아있는 객체를 이동시킨다. 이렇게 이동하는 것을 반복하게 된다.
-
복사 방식의 장점

- 메모리를 사용한 후, 쓰지 않는 객체들을 모아 한 번에 삭제할 수 있다.
- 객체를 복사하는 과정에서 객체가 사용될 때마다 카운팅하는 레퍼런스 카운팅 방식보다 훨씬 간단하게 처리할 수 있다.
- 한 영역이 가득 찰 때마다 전체 객체를 검사하고 이동시키기 때문에 GC 가 언제 메모리를 회수할지 미리 알 수 있으므로, 전체적인 메모리 관리의 성능을 예측 가능하다.
-
복사 방식의 단점

- 가장 큰 단점은 메모리 공간이 두 배로 필요하다는 것이다.
- 또한, 객체가 복사되는 과정에서 영역이 이동하므로, 포인터가 가리키는 위치를 계속해서 업데이트 해줘야 한다. 이는 부하를 유발할 수 있다.
- 큰 객체가 복사될 때는 메모리 복사 시간이 길어질 수 있다.
- 일부 객체는 짧은 생명 주기를 가지지 않고, 오랫동안 살아남아야 할 필요가 있을 수 있다. 이런 객체는 Old Generation 으로 이동하게 된다.
- Old Generation 에서는 Young Generation 과는 달리, 가비지 컬렉션이 적게 발생한다.
- 따라서, Old Generation 에서는 ‘Mark and Sweep’ 알고리즘이 사용된다. 객체가 Mark 되면서 사용되고 있는지 여부를 확인하고, 사용되지 않는 객체는 Sweep 하여 해제한다.
- 레퍼런스 카운팅
Python GC
- 파이썬은 참조 카운트(reference counting)와 세대별 가비지 컬렉션(generational garbage collection)을 사용하여 가비지 컬렉션을 수행한다.
- 기본적으로 Python 객체의 reference count 는 객체가 참조될 때마다 증가하고 객체의 참조가 해제될 때 감소한다.
- 객체의 reference count 가 0이 되면 객체의 메모리 할당이 해제된다.
- Python 은 메모리 관리를 위한 reference counting 외에도 generational garbage collection(세대별 가비지 컬렉션)이라는 방법을 사용한다. reference counting이 주로 사용되는 방법이고 보조로 가비지 컬렉션을 사용한다는 것이다.
- 참조 횟수를 증가시키는 방법은 변수에 객체를 할당하는 방법, 혹은 list 에 추가하거나 class instance 에서 속성으로 추가하는 등의 data structure 에 객체를 추가하는 방법 그리고 객체를 함수의 인수로 전달하는 방법이 있다.
-
sys모듈을 사용하면 특정 객체의 reference counts(참조 횟수)를 확인할 수 있다.import sys a = 'hello' sys.getrefcount(a) # 2 b = [a] sys.getrefcount(a) # 3 c = {'first': a} sys.getrefcount(a) # 4 - 위 코드의 참조 카운팅에서 첫번째로 2가 나온 이유가 뭘까? 변수를 생성할 때 1이 올라가고 a를
getrefcount함수의 인수로 전달할 때 1이 올라가기 때문이다. - Python 은 메모리 관리를 위한 reference counting 외에도 generational garbage collection 방법을 사용하는데, 앞에서 봤듯 reference counting 의 경우 순환 참조 문제가 발생하기 때문에 파이썬은 이 문제를 generational garbage collection 으로 해결한다.
-
예를 들어보자.
a = [] a.append(a) del a - 위 코드에서 a 의 최종 참조 횟수는 1 이지만 이 객체는 더 이상 접근할 수 없으며 레퍼런스 카운팅 방식으로는 메모리에서 해제될 수 없다.
- 이러한 유형의 문제를 reference cycle(순환 참조)이라고 하며 reference counting 으로는 해결할 수 없다.
- 파이썬의 generational garbage collection 는 내부적으로 generation(세대)과 threshold(임계값)로 가비지 컬렉션 주기와 객체를 관리한다.
- 세대는 0~2 세대로 구분되고 최근 생성된 객체는 0세대(young)에 들어간다.
- 오래된 객체일수록 1 세대와 2 세대(old)로 이동한다. 당연히 한 객체는 단 하나의 세대에만 속하게 된다.
- GC 는 0 세대일수록 더 자주 가비지 컬렉션을 하도록 설계되어 있다.
- 이는 약한 세대 가설을 따르도록 설계가 된 것이다.
- 만약 0 세대에서 수명이 오래되는 객체가 있다면, 해당 객체는 1 세대로 이동한다.
- 1 세대에서는 mark and sweep 알고리즘을 사용하여 가비지 컬렉션을 수행한다.
- 이러한 방식으로, 0 세대에서 순환 참조가 발생하더라도 1 세대로 넘어갈 때 메모리 누수를 방지하게 된다.
약한 세대 가설
-
자바 GC 의 가설이다.
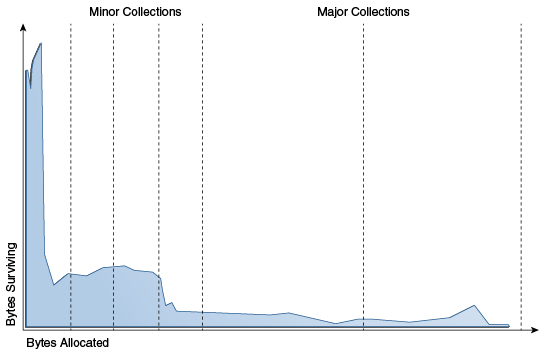
- y 축은 측정된 object 의 lifetime, x 축은 lifetime 이 있는 개체의 총 Byte 다.
- 이 결과를 통해 대부분의 object 들은 생성되고 얼마 안가서 소멸된다는 것을 알 수 있다.
- 가비지 컬렉션은 에이징과 함께 세대별 청소를 사용해 힙 영역의 공간을 최대한 확보한다.
- root set 으로부터 접근 불가능한 모든 object 들은 쓰레기로 간주되어 GC 에 의해 수집된다. 하지만 가비지 컬렉션이 수행될 때마다 하나하나 추적하는건 부하가 너무 큰 일이다.
- 이 대목에서, 대부분의 응용프로그램에서 위 그래프를 통해 대부분의 object 들이 짧은 시간동안만 살아있다는 사실에 따른다. 이를 약한 세대 가설(weak generational hypothesis)이라고 한다.
GC 임계값
- 각 세대마다 GC 모듈에는 임계값 개수가 있다. 객체 수가 해당 임계값을 초과하면 가비지 콜렉션이 콜렉션 프로세스를 추가한다.
- 해당 프로세스에서 살아남은 객체는 다른 세대로 옮겨지게 된다. 이는 자바의 age 와 비슷한 개념이다.
- 파이썬에서는 generational garbage collector의 동작을 변경할 수 있다는 점을 주목하자.
- garbage collection process 를 trigger 하기 위한 임계값 변경, garbage collection process 를 수동으로 trigger 하거나, garbage collection process 를 모두 비활성화할 수 있다.
-
gc모듈을 사용하여 가비지 컬렉션 통계를 확인하거나 GC 의 동작을 변경하는 방법이 존재한다.import gc gc.get_threshold() # (700, 10, 10) gc를 import 하고get_threshold함수를 사용하면 각각 0, 1, 2세대에 임계값이 나온다.-
위 결과는 0 세대에서 객체를 할당한 횟수가 700번을 초과하면 가비지 컬렉션이 수행된다는 것이다.
import gc gc.get_count() # (121, 9, 2) get_count()함수를 사용하여 각 세대의 객체 수를 확인할 수도 있다.- 위 예에서는 youngest generation(가장 어린 세대)에 121개의 객체, 다음 세대에 9개의 객체, oldest generation(가장 오래된 세대)에 2개의 객체가 있다는걸 확인할 수 있다.
GC 와 성능
- 가비지 컬렉션을 수행하려면 응용 프로그램을 완전히 중지해야 한다. 그러므로 객체가 많을수록 모든 가비지를 수집하는 데 시간이 오래 걸린다는 것도 분명하다.
- 가비지 컬렉션 주기가 짧다면 응용 프로그램이 중지되는 상항이 증가하고 반대로 주기가 길어진다면 메모리 공간에 가비지가 많이 쌓일 것이다.
- 시행착오를 거치며 응용 프로그램의 성능을 끌어 올려야 한다.
gcModule 에서gc.collect()메소드를 사용하여 수동 가비지 컬렉션 프로세스를 추적, 실행할 수 있다.-
gc.collect()가 반환하는 값은 수거기가 발견했지만 해제할 수 없는 도달 불가능한 객체 수다.gc.get_count() # (121, 9, 2) gc.collect() # 54 gc.get_count() # (54, 0, 0) - 가비지 컬렉션 프로세스를 실행하면 0 세대에서 67개, 다음 세대에서는 11개 정도의 객체가 정리된다.
-
gcmodule 에서set_threshold()method 를 사용하여 가비지 컬렉션 트리거 임계값을 변경할 수 있다.import gc gc.get_threshold() # (700, 10, 10) gc.set_threshold(1000, 15, 15) gc.get_threshold() # (1000, 15, 15) - 임계값을 증가시키면 가비지 컬렉션이 실행되는 빈도가 줄어든다. 죽은 객체를 오래 유지하는 cost(비용)로 프로그램에서 계산 비용이 줄어든다.
- 만일
gc.collect()로 수동으로 GC 를 실행시킨다면, 메모리 낭비는 줄일 수 있지만 프로그램 속도가 늦어진다. (계산 비용 증가) - 그러나 메모리를 확보하기 위해 수행하는 수동 가비지 컬렉션 프로세스는 원하지 않는 결과가 나올 수 있다.
- 위 경고를 무시하고 가비지 컬렉션 프로세스를 관리하려는 경우가 종종 있는데, 대표적인 예가 인스타그램의 경우다.
- Instagram 개발팀은 모든 세대의 임계값을 0 으로 설정하여 비활성화 했다.
- 이 변경으로 인해 웹 응용 프로그램이 10% 더 효율적으로 실행되는 좋은 결과를 얻었다고 한다.
- Instagram 의 서버는 자식 프로세스가 마스터와 메모리를 공유하는 마스터 차일드 메커니즘을 사용되어 실행된다고 한다.
- 이 때 자식 프로세스가 생성된 직후에 공유 메모리가 급격히 떨어진다는 사실을 발견하게 됐고 해당 이슈를 추적하다보니 이것은 파이썬 gc 모듈의
gc.collect()가 수행될 때의 문제로 밝혀졌다고 한다. - 이
gc.collect()는 특정 임계값에 도달했을 때 수행되기 때문에 이gc.collect()의 수행을 임계치를 0으로 하는 것으로 막아 문제를 해결했다고 한다. - Instagram 의 웹 어플리케이션 규모는 수백만 명이 사용하니까 어떤 방법을 사용해서든 웹 응용 프로그램의 모든 성능을 한계치로 끌어 올리는 것이 좋겠지만, 대부분의 개발자에게는 가비지 컬렉션과 관련된 Python의 표준 동작이 충분할 것이다.
- Luavis’ Dev Story - Instagram이 Python garbage collection 없앤 이유
- 정리하면, 가비지 컬렉션을 수행하려면 프로그램을 완전히 중지해야 한다. 따라서 객체가 많을수록 가비지를 컬렉션하기 위해 더 많은 시간이 필요하다. 가비지 컬렉션 주기가 짧다면 여유 메모리를 확보할 순 있지만 프로그램이 중단되는 상황이 많이 발생한다. 반대로 주기가 길다면 프로그램이 자주 중단되지는 않지만 메모리 공간에 가비지가 많이 쌓이게 된다.
파이썬 GIL, Thread, Process
- 용어부터 보자.
program: 작업을 위해 실행하는 파일process: 운영체제가 생성하는 작업의 단위(=컴퓨터에서 실행중인 프로그램)thread: process 안에서 공유되는 메모리를 바탕으로 생성하는 작업의 실행 단위Thread safe: 하나의 스레드가 자원에 접근하여 작업을 수행하는 상태race condition(경쟁상태): 여러 스레드가 하나의 공유 자원이 동시에 접근하면서 발생하는 문제mutex(상호배제): 공유 자원에 하나의 스레드만 진입하며 작업을 처리할 수 있도록 만들어진 lock 개념
garbage collection: 파이썬에서 쓰이는 메모리 관리 기법. 프로그램이 동적으로 할당했던 메모리 영역 중에서 필요없게 된 영역을 해제하는 기능Reference counting: 쓰레기 수집(garbage collection)의 한 방식. 파이썬에서 주요 방식이다.context swich: 프로세스/스레드 전환. 사용 중이던 context(프로세스, 스레드)를 저장하고 다른 context 실행
GIL (Global Interpreter Lock)
-
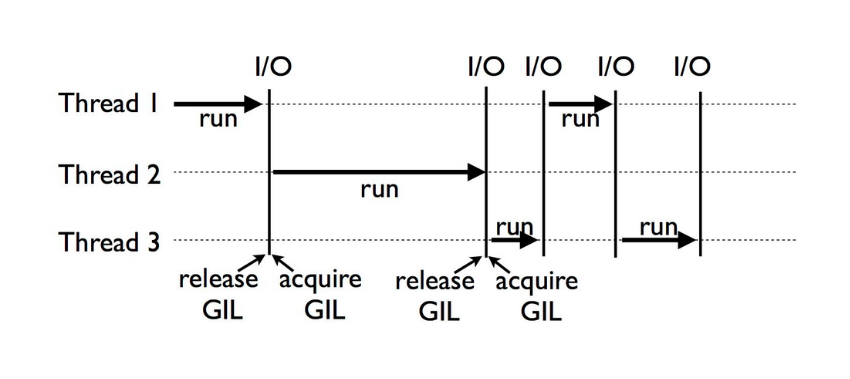
파이썬에서 GIL란, 파이썬 코드가 실행될 때 여러 개의 스레드 중 하나의 스레드만 실행될 수 있도록 하는 mutex(상호배제, Lock)다.
-
즉, 하나의 스레드가 모든 자원(리소스)을 차지하고 lock 을 걸면, lock 을 풀 때까지 다른 스레드는 실행할 수 없도록 접근을 막는 것이다.
def sum(x, y): return x+y thread1 = sum(1,2) thread2 = sum(3,4) - 위 코드를 예시로 보면, 한 스레드(thread1)가 함수를 사용 중일 때는 다른 스레드(thread2)는 대기 상태에 빠진다. 함수를 실행하는데 1초가 걸린다고 하면 두 스레드가 완료되는 시점은 2초가 지난 뒤일 것이다.
- 이렇듯 파이썬의 GIL 방식은 두 스레드를 전환(context swiching)하는데 시간이 걸리는 데다가 병렬 실행(스레딩 작업)이 제한된다.
- 파이썬이 다른 언어보다 속도가 느린 이유다.
- 즉 파이썬은 GIL 이 있기 때문에 인터프리터가 매 순간 1개의 스레드만 실행할 수 있다.
- 결국 파이썬에서의 멀티 스레딩은 병렬적(parallel)으로 실행되는 것이 아니라 대신 동시적(concurrent)으로 실행된다.
- 이 때 여러 스레드 중 실행될 1개의 스레드를 정하려면 스레드 스케줄러가 필요하다.
- 그러나 파이썬은 자체적인 스케줄러가 없어서 OS의 스레드 스케줄링을 그대로 활용한다.
- I/O block 이 발생할 경우 GIL 도 마찬가지로 Release(해제) 된다. 따라서 I/O bound 작업의 경우 멀티 스레딩으로 병렬 처리는 못해도 동시적으로 처리할 수 있다.
- 파이썬이 GIL 을 채택한 이유
- GIL 은 스레드를 직렬로 실행시키면서 멀티스레딩의 장점을 없애버린다.
- 그럼 왜 파이썬은 GIL 을 사용할까?
- 멀티 스레드 환경에서 발생할 수 있는 Race Condition(경쟁 상태) 을 방지하기 위함이다.
- 그러나 스레드 Race Condition 은 다른 언어에도 발생할 수 있다. 그럼에도 인터프리터를 Lock(Mutex, 상호 배제) 할 정도로 극단적으로 처리하는 이유는, 파이썬의 메모리 관리 방법 때문이다.
- 즉, 파이썬이
thread safe하지 않은garbage collection메모리 관리 정책을 사용하기 때문이다. - 파이썬의 주요 메모리 관리 방법인 Reference Counting(RC) 는 자동으로 메모리를 관리하는데, 객체를 참조하는 것이 아무것도 없는 경우 자동으로 객체의 메모리 할당을 해제한다.
- 자동화가 가능한 이유는 파이썬의 모든 것이 객체(Heap 영역의 객체를 참조하는 것)이기 때문이다. 이러한 RC 는 메모리 영역이 공유되지 않는 경우 잘 작동한다.
- 즉, 동적으로 메모리를 할당(Heap 영역)한 뒤, 그 메모리 공간이 필요가 없어지면 할당을 해지하는 관리 방법인데 이는 멀티 스레드가 발생하면 메모리 할당 순서가 꼬여버린다.
- 자원(객체)을 동시에 접근하는 경쟁 상태가 발생하고 삭제 되어야 할 객체가 그대로 있을 수도, 있어야 할 객체가 없을 수도 있는 것이다.
- 이러한 문제를 방지하려면 자원 공유가 불가능 하도록 Mutex(상호 배제)와 같은 Lock 이 필요하다.
- 그러나 파이썬의 모든 것은 객체이자 동적으로 메모리를 할당하여 공유되는 Heap 영역에 메모리를 할당하기에, 모두 Lock 하여 관리하는 것은 굉장히 비효율적이다. 그래서 파이썬은 객체 단위 Lock 대신, 인터프리터 단위 Lock을 도입했고 그것이 바로 GIL 이다.
-
예시를 보자. 아래 코드는
thread.py파일이다.import threading x = 0 def foo(): global x for _ in range(1000000): x += 1 thread1 = threading.Thread(target=foo) thread2 = threading.Thread(target=foo) thread1.start() thread2.start() thread1.join() thread2.join() print(x) print("time :", time.time() - start)$ python thread.py 1249039 time : 0.16225934028625488 $ python thread.py 1278083 time : 0.15707993507385254 $ python thread.py 1413184 time : 0.14516067504882812 - 100만을 더하는 함수를 두 번 돌렸으니 결과값이 200만이 나와야 하는데 그보다 못한 수가 나온다.
- 그리고 코드를 실행할 때마다 결과값이 다르다. 두 연산식이 꼬여버린 race condition, 경쟁 조건 이 발생한 것이다.
-
이제 함수에 lock 을 걸어서 한 스레드 작업이 끝날 때까지 다른 스레드가 접근할 수 없도록 하고 다시 실행해보자.
import threading import time start = time.time() LOCK = threading.Lock() x = 0 def foo(): LOCK.acquire() ### lock 설정 global x for _ in range(1000000): x += 1 LOCK.release() ### lock 해제 thread1 = threading.Thread(target=foo) thread2 = threading.Thread(target=foo) thread1.start() thread2.start() thread1.join() thread2.join() print(x) print("time :", time.time() - start)$ python thread.py 2000000 time : 0.14014029502868652 $ python thread.py 2000000 time : 0.13776636123657227 $ python thread.py 2000000 time : 0.13646340370178223 - Lock 을 걸어주니 결과값이 200만이 정상으로 나오고 속도도 빨라졌다.
파이썬에서 멀티 스레드 작업
- GIL 이 적용되면 병렬 실행이 안되니 멀티 스레드는 무조건 느릴 것이라고 생각할 수 있다. 하지만 위에서 든 예시를 보면 알겠지만 그렇지만도 않다.
- GIL 은 CPU 동작에서 적용이 되기 때문에, 스레드가 I/O 작업을 실행하는 동안에는 다른 스레드가 CPU 동작을 동시에 실행할 수 있다.
- 따라서 CPU 동작이 많지 않고 I/O 동작이 더 많은 프로그램에서는 멀티 스레드의 효과를 얻을 수 있다.
- CPU 작업
- 곱셈 등의 연산, 이미지 처리 등
- I/O 제외한 연산
- I/O 작업
- 파일 읽기/쓰기, 네트워크 통신 등
- 멀티 스레드가 발생해도 GIL 이 없어서 속도가 빠르다.
파이썬 Thread vs. Process
- 파이썬은 GIL 로 인해 여러 스레드가 순차적으로 실행되는 직렬 구조로 동작한다.
- 병렬 처리를 구현하기 위한 여러가지 모듈 중에서
thread와process모듈을 테스트해보자. - 두 모듈을 사용해서
x라는 변수에 1을 1000만번을 더하는 함수를 만들어 두 번씩 실행해 보자. - 변수
x의 최종값과, 코드를 실행하는데 걸리는 시간을 출력한다. -
단일 스레드
from threading import Thread import time start = time.time() def work(id, start, end, result): total = 0 for _ in range(start, end): total += 1 result.append(total) return if __name__ == "__main__": START, END = 0, 10000000 result = list() th1 = Thread(target=work, args=(1, START, END, result)) # 단일 스레드 th1.start() th1.join() print(f"Result: {sum(result)}") print("time :", time.time() - start) -
멀티 스레드
from threading import Thread import time start = time.time() def work(id, start, end, result): total = 0 for _ in range(start, end): total += 1 result.append(total) return if __name__ == "__main__": START, END = 0, 10000000 result = list() th1 = Thread(target=work, args=(1, START, END//2, result)) # 멀티 스레트 th2 = Thread(target=work, args=(2, END//2, END, result)) th1.start() th2.start() th1.join() th2.join() print(f"Result: {sum(result)}") print("time :", time.time() - start) - 결과 비교
-
단일 스레드
$ python thread.py 10000000 time : 4.517637014389038 $ python thread.py 10000000 time : 4.690451145172119 -
멀티 스레드
$ python thread.py 10000000 time : 5.116377830505371 $ python thread.py 10000000 time : 4.837747097015381 - 단일 스레드로 실행하나, 멀티 스레드로 실행하나 시간적 차이가 거의 없다.
- 오히려 직렬처리보다 병렬처리가 오히려 더 오래 걸린다.
-
-
단일 프로세스(CPU)
from multiprocessing import Process, Queue import time start = time.time() def work(id, start, end, result): total = 0 for _ in range(start, end): total += 1 result.put(total) return if __name__ == "__main__": START, END = 0, 100000000 result = Queue() th1 = Process(target=work, args=(1, START, END, result)) th1.start() th1.join() result.put('STOP') total = 0 while True: tmp = result.get() if tmp == 'STOP': break else: total += tmp print(f"Result: {total}") print("time :", time.time() - start) -
멀티 프로세스(CPU)
from multiprocessing import Process, Queue import time start = time.time() def work(id, start, end, result): total = 0 for _ in range(start, end): total += 1 result.put(total) return if __name__ == "__main__": START, END = 0, 100000000 result = Queue() th1 = Process(target=work, args=(1, START, END//2, result)) th2 = Process(target=work, args=(2, END//2, END, result)) th1.start() th2.start() th1.join() th2.join() result.put('STOP') total = 0 while True: tmp = result.get() if tmp == 'STOP': break else: total += tmp print(f"Result: {total}") print("time :", time.time() - start) - 결과 비교
-
단일 프로세스
$ python process.py 10000000 time : 4.4137938022613525 $ python process.py 10000000 time : 4.763975381851196 -
멀티 프로세스
$ python process.py 10000000 time : 2.2769172191619873 $ python process.py 10000000 time : 2.267723560333252 -
병렬처리 속도가 훨씬 빠르다.
-
-
표로 결과를 비교해보자.
Thread Process 장점 메모리 공간을 적게 차지한다.
다른 스레드로 전환이 빠르다.(context switching)다른 프로세스에 영향을 주지 않아 안정성이 높다. 단점 스레드 하나의 문제가 다른 스레드에 영향을 준다.
동기화 문제가 발생할 수 있다(병목현상, 데드락 등).CPU 시간을 많이 차지한다.
작업량이 많을수록 switching 이 많이 일어난다(오버헤드가 발생할 수 있다).
Reference
- https://velog.io/@samkong/garbagecollection1
- https://medium.com/dmsfordsm/garbage-collection-in-python-777916fd3189
댓글 남기기