
[Optimizer] Optimizer
Goal of Optimization
- 딥러닝에서 Optimization 의 본질적인 목적은 loss func 을 최소화하는 optimal 을 찾아가는 것이다.
- 딥러닝의 목적과 Optimization 의 목적은 같은 것 같으면서도 다른 점이 있는데, 딥러닝의 목적은 genralization error 를 줄이는 것이고 Optimization 의 목적은 train 단계에서 목적 함수(loss func)를 최소화하는 것이다.
- 일반화 성능을 높이기 위해서 overfitting 에 대해 신경써야 하는데, 여기에 training error 를 줄이는 optimization 을 사용한다.
- 이 Optimization 에 대한 방법론들이 Optimizer 이다.
Optimizer
 유명한 Optimizer 의 발달 계보
유명한 Optimizer 의 발달 계보
- 각각의 optimizer 의 특징을 이해해보자.
(Stochastic) Gradient Descent
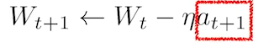
- $W$ 는 네트워크의 가중치. Gradient descent 를 통해 loss func 의 optimal 을 찾아가며 학습하기 때문에 딥러닝 프레임워크가 기본적으로 해주는 것은 gradient를 계산해준다($g$). 여기에 학습률($\eta$)에 곱해서 가중치($W_t$)에서 빼주면 다음 가중치($W_{t+1}$)가 업데이트가 되는 것이다.
- 여기서 가장 어려운 것은 lr rate, 즉 학습률(step size)을 적절하게 하는 것이 매우 어렵다. 너무 크면 학습이 잘 안되고 너무 작아도 학습이 안된다.
Momentum
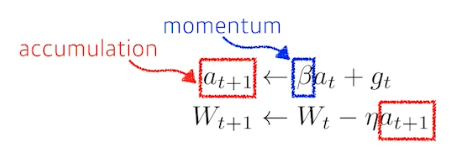
- gradient 정보($g$)를 똑같이 활용하는데 어떻게 더 효율적인 학습을 시켜줄 수 있을까 고민한 방법론
- 직관적으로 gradient가 흐른 방향으로 좀 더 이어가자는 것이 큰 컨셉. 우리가 mini batch 를 사용하니까, 이전 batch 에서 가지고 있던 gradient 의 방향을 활용해보자!
- $\beta$ 하이퍼 파라미터가 추가된다. 이 $\beta$ 라는 모멘텀과 현재 gradient 를 합친 accumulation gradient 로 업데이트를 시킨다.
- 한번 흘러가기 시작한 gradient 를 유지시켜서, 왔다갔다 하더라도 어느정도 잘 학습이 됨.
- 모멘텀은 local minimum 에서 벗어나 전역 minimum 을 찾기 위해 사용할 수 있는 최적화 기술 중 하나이다.
Nesterov Accelerated Gradient(NAG)
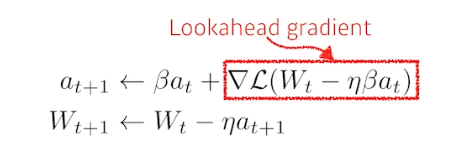
- 컨셉만 보면, $a$ 라는 accumulated gradient 가 gradient descent 의 결과물인데 이 gradient 를 계산할 때 Lookahead gradient 를 계산한다.
- 모멘텀은 현재 주어진 파라미터에서 기울기를 계산해서, 그 기울기를 가지고 모멘텀을 누적한다.
- 반면에 NAG 는 한 번 이동을 한다. 현재 정보($a_t$)가 있으면 그 방향으로 한 번 가보고, 그 간 곳에서 기울기(Lookahead gradient)를 계산해서 accumulation 한다.
-
Momentunm vs. NAG
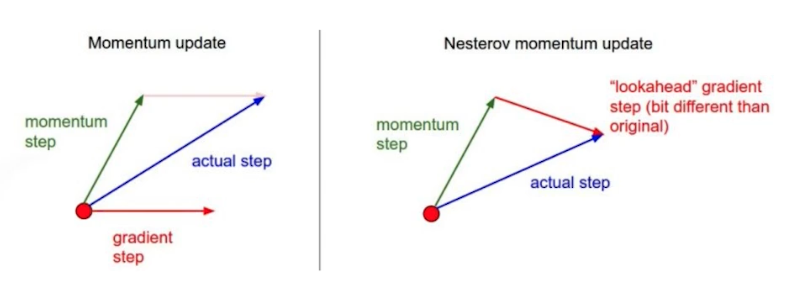
- 모멘텀을 관성이라고 해석해보자. 만약 minimum 을 지나서 반대편으로 갔을 때, 관성 때문에 반대 방향(minimum 방향)으로 흘러가야 함에도 올라가게 된다. 그래서 왔다갔다 하는 것.
- 즉 모멘텀이 관성이라면 minimar 로 수렴해야 하는데 그 지점을 사이에 두고 왔다갔다(오뚜기처럼) 하게 되는 것이다. 그래서 minimar 를 수렴하지 못하게 된다.
- NAG 는 한 번 지나간 그 지점에서 기울기를 계산하기 때문에, 적절하게 local minimar 를 찾을 수 있다. 즉 봉우리(최소점)에 좀 더 빨리 수렴할 수 있다.
- 이론적으로도 증명 가능
- 여기까지가 보통 모멘텀 방법이라고 한다. 기울기를 계산하고, 그 기울기를 다음 번 계산할 때 같이 활용하는 것
Adagrad(Adaptive)
- 여기부터는 네트워크의 파라미터가 지금까지 어떻게 변해왔는지를 본다. 많이 변한 파라미터에 대해서는 적게, 많이 안 변한 파라미터에 대해서는 많이 변화시키고자 하는 것이다. 각 파라미터가 얼만큼 변했는지 저장하는 값이 바로 $G$이다.
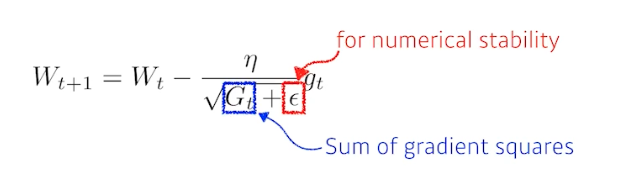
- $G$ 는 얼마나 gradient 가 변했는지를 제곱해서 더한 것이다. 따라서 계속 커진다. 이 때 이 $G$ 를 역수에 집어넣었기 때문에 많이 변한 파라미터는 적게 변환, 적게 변한 파라미터는 많이 변환하게 된다. 이를 adaptive learning 이라고 한다.
- 엡실론($\epsilon$)은 0 으로 나눠주지 않기 위한 것.
- Adagrad 의 가장 큰 문제는, $G$ 가 계속 커지기 때문에 결국 $G$가 무한대로 가면, 뒤로 가면 갈수록 학습이 멈춰지는 현상이 생기는 것이다. 이를 해결하기 위한 방법이 Adam 등이다. 즉 $G$ 가 계속 증가하는 것에 의해서 gradient 가 0으로 가는 문제를 해결하고자 하는 방법론들이 뒤에 나온다.
Adadelta
- Adagrad 의 $G$ 가 계속해서 커져 gradient 가 0으로 가는 현상을 막고자 한다.
- 이론적으로 가장 쉬운 방법은 현재 타임 스텝($t$)에서 윈도우 사이즈 만큼의 파라미터, 시간(윈도우 사이즈)에 대한 gradient 제곱의 변화를 볼 수 있다.
- 문제는 윈도우 사이즈를 100으로 잡으면 이전 100개 동안의 $G$라는 정보를 들고 있어야 한다. 즉 엄청 많은 파라미터가 있는 모델을 쓰게 되면 너무 많은 파라미터가 있어서 용량 문제가 발생할 수 있다.
- 이를 막을 방법이 exponential moving average(EMA; 이동평균법)이다. 어느 정도 타임 윈도우 만큼의 값을 저장하고 있는 것처럼 볼 수 있다. EMA 를 통해 $G_t$ 를 업데이트 하는 것이 Adadelta 이다.
- $H$ 라는 파라미터가 들어간다. 그러나 밑의 식에 보면 학습률($\eta$)이 존재하지 않아서 우리가 바꿀 수 있는 요소가 없기 때문에 많이 활용되지 않는다.
- 학습률($\eta$)이 없는 이유는 $H_t$ 가 그 안에 업데이트 하려는 weight 의 변화값도 들고 있기 때문이다.

- 정리하면 Adadelta 는 Adagrad 에서 가지는 학습률이 $G_t$ 를 역수로 가지고 있어 기울기가 점점 0이 되는 현상을 막는 방법이다.
RMSprop
- 많이 사용됐었던 방법론
- 제프리 힌튼이 강의에서 소개한 방법이다.
- 아이디어는 간단하다. Adadelta 처럼 gradient squares($G$) 에 대한 것을 그냥 더하는 것이 아니라 EMA 를 취하고, 이를 분모에 넣으면서 stepsize(학습률, $\eta$) 도 같이 활용하는 것이 전부이다.
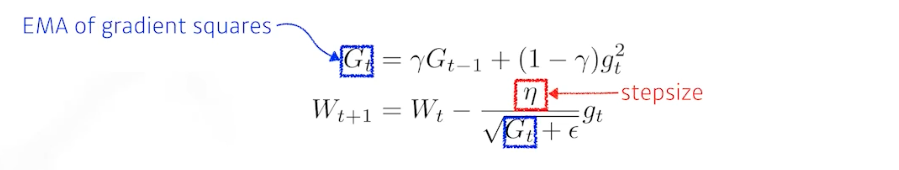
Adam(Adaptive Moment Estimation)
- 일반적으로 가장 잘된다. 즉 가장 무난한 것이 Adam 이다.
- 컨셉적으로 gradient squares($G$) 를 EMA 로 가져감과 동시에, 모멘텀 방식을 적용한 것이다.
- gradient($g$) 크기가 변함에 따라서 Adaptive 하게 학습률을 바꾸는 것 + 이전의 gradient 정보에 해당하는 모멘텀 두 개를 잘 합친 것이 Adam
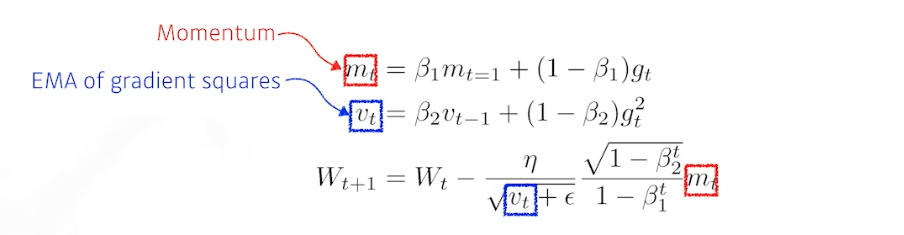
- $\beta_1$: 모멘텀을 얼마나 유지시킬 것인가에 대한 정보
- $\beta_2$: gradient squares 에 대한 EMA 정보
- 여기에 학습률($\eta$)과 $\epsilon$.
- 이 4개의 하이퍼 파라미터를 조정하는 것이 중요하다.
- 여러가지 하이퍼 파라미터가 들어가고, 실제로는 division by zero 를 막기 위한 $\epsilon$ 값을 잘 바꿔주는 것이 중요하다고 알려져 있다.
- Adam 은 momentum 과 adaptive learning rate 를 합친 것이다.
생각해볼 점
- 그러면 왜 SGD 와 Momentum 이 차이가 날까?
- Momentum 은 결국에 이전의 gradient 를 활용해서 다음번에도 쓰겠다는 게 들어가 있다. SGD 와 차이점은 그것 뿐이다. adaptive learning 개념은 안 들어가 있다.
- 그러면 왜 mini-batch 학습에서 Momentum이 좋을까? 첫번째 batch 에서 gradient가 흘러갔는데, 이 gradient 정보가 다음 번에 활용되지 않으면 어떻게 될까?
- 전체 데이터가 많은데, 이 중의 mini-batch 는 사소한 영역만을 모델링하는 것이다. 즉 그 영역만 표현하는 데이터인 것이다. SGD 만 쓰면 많은 iteration 이 있어야 전체 데이터가 수렴 할 때까지 갈 수 있다. 그러나 Momentum은 이전의 얻어진 정보, 이전 batch 에서 얻어진 gradient 정보를 현재도 반영해서 가중치를 업데이트 하기 때문에 데이터를 더 많이 보는 효과가 있는 것.
- Adam 은 그 Momentum 에다가 adaptive learning 까지 합쳐서 어떤 파라미터에서는 학습률을 올리고 줄이는 것을 왔다갔다 하기 때문에 훨씬 더 빠르게 학습이 된다.
- SGD 가 제일 큰 peak 위주로 잡는 이유는?
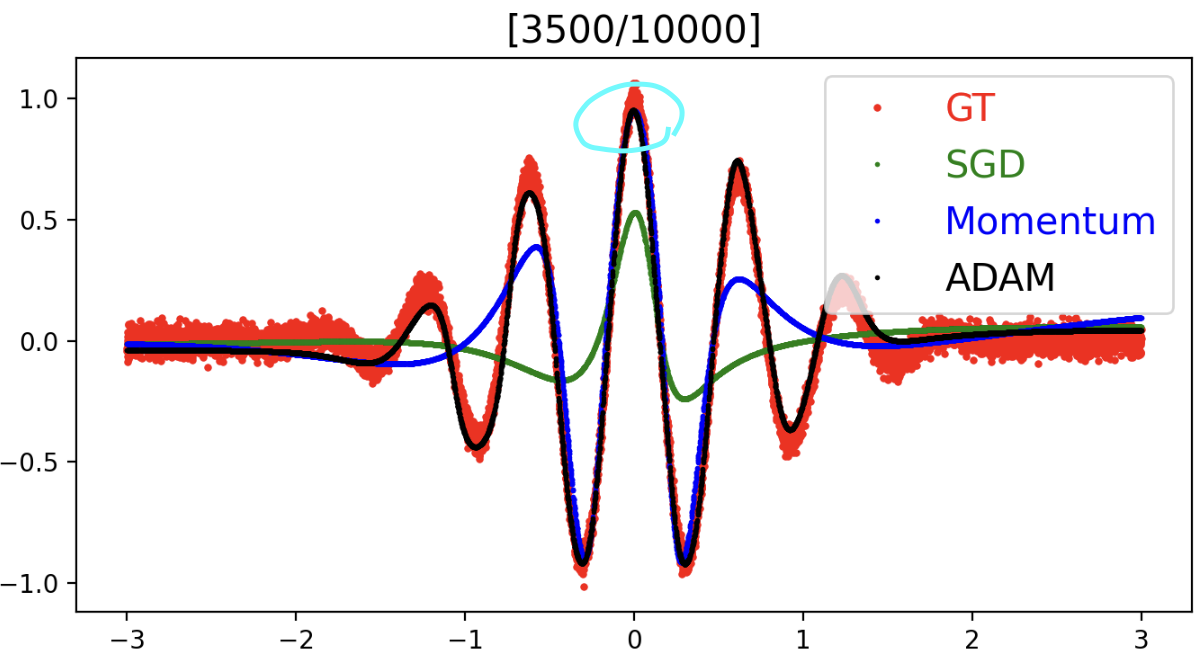
- loss 랑 이어지는 문제이다.
- squared loss 를 활용하면 큰 loss 는 제곱해서 증폭시킨다. 따라서 MSE 를 활용하면 많이 틀리는 곳을 더 많이 집중하게 되고 적게 틀린 곳을 덜 집중하게 된다. 이상치(outlier) 가 낀 경우에는 이런 식의 squared loss 를 활용하는게 좋지 않음을 알 수 있다.
- SGD 를 쓰면 많이 틀리는 Momentum 과 Adaptive learning 을 안 쓰기 때문에 전체 데이터에 수렴할 때까지 오래 걸리고, MSE 를 썼을 때 이상치(제일 큰 peak 와 유사)에 민감하게 반응하기 때문에 제일 큰 peak 위주로 잡아가는 것이다.
- 즉 내가 학습시키는 모델이 엄청 클 때, Adam 을 써서 1주일이 걸리면 SGD 를 쓴다면 몇 달이 걸릴 수도 있다. 바꿔 말하면, 모델을 잘 만들고 잘 동작할 수 있음에도 단순히 optimizer 를 적절히 선택 못하면 망할 수도 있다는 것이다.
- 따라서 처음에 Adam 을 써보는 것이 그럴싸한 결과를 얻을 수도 있다.
- 간단한 문제에도 다른 optimizer 가 꽤나 다른 성능차이를 보인다는 것을 알 수 있다.
- 사실은 위와 같은 Optimizer 들을 구현할 필요는 없고, torch 등에 이미 구현되어 있는 것을 잘 쓰면 된다.
- 결론은 Adam 을 먼저 써보는 것을 추천. 물론 SGD 가 오랜 시간이 있다면 더 잘될 가능성이 있다.
댓글 남기기