
[Regularization] Regularization
Regularization
- Regularization 은 generalization 을 잘되게 하려는 목적으로 실행한다. 학습에 반대되는 위치에 있는 것으로 학습에 규제를 거는 것이다.
- Regularization은 모델의 학습을 방해하는 것을 목적으로 한다. 이 때 단순히 방해하는 것이 아니라, 학습 데이터에만 잘 동작하는 것이 아니라 테스트 데이터에도 잘 동작할 수 있게 만들어 주는 것이다! 아래에서 Regularization 의 도구들을 알아보자.
- 학습 데이터셋의 양을 늘리는 것은 over-fitting 문제를 해결하고 generalization 성능을 올릴수도 있지만, 학습 데이터를 추가로 확보하는 것은 일반적으로 어려운 일이다. 따라서 Regularization 을 사용하는 것이 도움이 된다.
Early Stopping
- 학습을 멈추는 것. validation error 를 활용한다. 학습에 활용되지 않은 데이터셋(validation set)에 지금까지 학습된 모델 성능을 평가해보고(주로 loss 를 본다), 그 loss 가 줄어들다가 커지기 시작하는 시점부터 멈추는 것이다.
- 이것을 위해서는 당연히 validation data 가 꼭 필요하다.
- patience 를 주어서 epoch 가 일정 횟수 loss 가 줄어들다가 크게 기록되었다면 학습을 중지한다.
Parameter norm penalty
- Parameter Norm Penalty 를 weight decay 라고 부르기도 한다.
- 모델의 Complexity 가 높은데 단순한 데이터로 인해 over-fitting 이 발생하는 상황으로 weight decay 이 설명될 수 있다.
- 데이터가 단순하고 모델이 복잡하면, 학습을 하면서 굉장히 작은 값이었던 weight 들의 값이 점점 증가하게 되면서 over-fitting 이 발생하게 된다. weight 값이 커질수록 학습 데이터에 영향을 많이 받게 되고, 학습 데이터에 모델이 딱 맞춰지게 된다. 이를 ‘local noise 의 영향을 크게 받아서, outlier 들에 모델이 맞춰지는 현상’ 이라고 표현한다.
- 딥러닝에 사용되는 데이터는 복잡하기 때문에, 모델의 구조를 단순하게 하는 것은 해결책이 아니다. 따라서 이런 문제를 개선하기 위해서 weight decay 기법이 제안되었다.
- 원래의 loss func 에 파라미터들을 다 제곱한 값(penalty term, $\parallel W \parallel^2$)을 더해서 새로운 loss func 을 만들어 내고, 이를 통해 모델의 파라미터(weight vector)가 너무 커지지 않게(decay) 하는 것이다.
- penalty term($\parallel W \parallel^2$) 는 $L_2 norm$ 으로 weight vector 의 크기(거리)를 의미한다.
- 즉 가중치 갱신이 이루어질 때, 현 시점의 가중치를 반영한 오차값에서 계산된 기울기를 가지고 갱신한다.
- 이렇게 되면 예측값과 정답값 사이의 오차(loss)를 줄이는 원래의 목적함수에서 loss 와 penalty term 을 같이 줄이는 새로운 목적함수로 바뀌게 된다. 만약 모델의 파라미터(weight vector)가 커지게 되면 모델은 학습 error 보다 weight norm($\parallel W \parallel^2$) 을 최소화하는데 집중하게 된다.
- 이 때 penalty term 을 얼마나 더해야 할까? 이를 조절하는 정규화 상수(regularization constant)인 λ
하이퍼파라미터(hyperparameter)가 그 역할을 한다. 즉 λ≥0 는 정규화(regularization)의 정도를 조절한다.
- λ=0 인 경우, 원래의 손실 함수(loss function)가 되고, λ>0 이면, $w$ 가 너무 커지지 않도록 강제한다.
- 제곱($L_2norm$)을 하는 이유는 가중치 벡터의 크기를 구하는 것도 있지만 1) 미분 계산이 쉬워지기 때문에 연산의 편의성을 위함이고, 2) 다른 하나는 작은 가중치 벡터(weight vector)들 보다 큰 가중치 벡터(weight vector)에 더 많은 패널티를 부여하는 것으로 통계적인 성능 향상을 얻기 위함이다.
 여기서 λ 는 $\alpha$ 로 표현되었다
여기서 λ 는 $\alpha$ 로 표현되었다
- 해석적인 의미는, 뉴럴 네트워크가 만들어내는 함수의 공간 속에서 함수를 최대한 부드러운 함수로 만드는 것이다. 이 때의 가정은, 부드러운 함수일수록 일반화 성능이 높을 것이라는 가정을 가진다.
Data augmentation
- 데이터는 딥러닝에서 가장 중요한 요소 중 하나이다.
- 데이터가 적으면 딥러닝이 잘 안되는 경우가 많다. 데이터가 커지면 기존의 ML 은 많은 수의 데이터를 표현할 표현력이 부족하다. 그러나 universial approximation theorem(1개의 히든 레이어를 가진 뉴럴 네트워크를 이용해 어떠한 함수든 근사시킬 수 있다는 이론. 당연히 활성함수는 비선형함수이다.) 등 여러가지 이유로 딥러닝은 많은 데이터를 다 표현할 만큼의 능력이 있다.
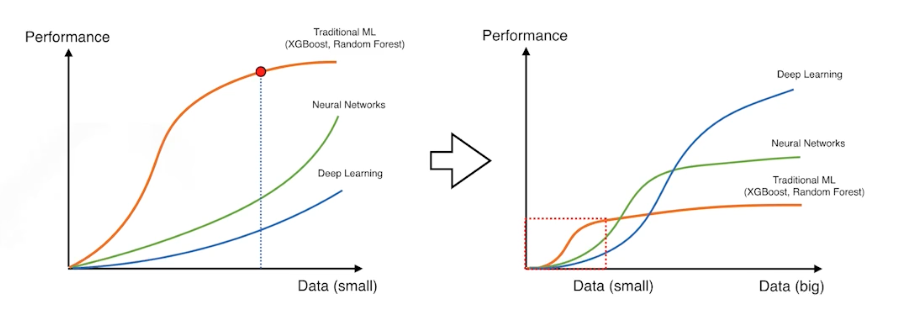 데이터가 적을 때는 딥러닝 보다 기본적으로 사용하는 Random Forest 같은 방법들이 잘될 때가 많음을 나타낸다.
데이터가 적을 때는 딥러닝 보다 기본적으로 사용하는 Random Forest 같은 방법들이 잘될 때가 많음을 나타낸다.
- 많은 경우에 데이터는 한정적이다.
- 이 때 데이터를 만들어 낼 수 없으니 데이터 증강(data augmentation)을 이용한다. 다양한 기법들이 존재한다.
- 중요한 것은 label 이 변환되지 않는 조건 하에서 data augmentation 을 하는 것이다. label preserving augmentation 은 90도 회전, 왜곡 등 이런 변환을 했을 때도 나의 이미지의 label이 바뀌지 않는 한도 내에서 변환을 시키는 것이다.
-
예를 들어 MNIST dataset 에서 6을 뒤집어서 9가 되면 label이 바뀐다. label이 유지되면 뒤집거나 flip 해도 상관없다.
Noise robustness
- 입력 데이터에 노이즈를 집어넣는 기법이다. 데이터 증강과 비슷하지만, 차이는 노이즈를 데이터 뿐 아니라 weight 에도 집어넣는 것이다. weight 를 학습시킬 때 weight 를 매번 흔들어주면(노이즈) 성능이 더 잘 나온다는 실험적 결과가 있다.
- 노이즈를 input, weight 에 중간중간 집어넣게 되면, 그 네트워크가 테스트 단계에서도 잘될 수 있다는 결과를 얻은 바 있다.

Label smoothing
- data augmentation 과 비슷한데 차이점은, 학습 단계에서 가지고 있는 학습 데이터 2개를 뽑아서 섞어 주는 것이다.
- 일반적인 분류문제에서는 이미지가 존재하는 공간에서 decision boundary 를 찾고자 한다. 즉 2개의 클래스를 잘 구분할 수 있는 이미지 공간 속에서의 경계를 찾아서 이것을 가지고 분류가 잘 되게 하는 것이 목적이다.
- Label Smoothing 은 decision boundary 를 부드럽게 만들어 주는 것이다. 그렇게 함으로써

- Mixup 은 두 개의 이미지를 고른 다음에 그 두 개의 이미지 뿐 아니라 label 도 같이 섞는다.
- Cutout 은 이미지 한 장에서 일정 영역을 떼버리는 기법.
- CutMix 는 Cutout 처럼 일정부분을 떼고 다른 이미지를 섞어주는데, 섞어줄 때 Mixup 처럼 블렌딩하는 게 아니라 특정 영역이 나뉜다.
- 위 기법들은 data augmentation 기법에 속한다. 위 기법들을 사용하면 성능이 올라간다고 알려져 있다. 따라서 데이터셋이 한정적이고 더 얻을 방법이 없다면 위 방법론을 활용해보는 것이 좋다. 들인 노력 대비 성능을 올릴 수 있기 때문이다.
- 일반적인 label smoothing 과 Mixup/CutMix의 차이점은, 전자는 기존 학습 데이터의 label 을 조정(1.0->0.9)하는데 그치는 반면, 후자는 다수의 샘플을 결합해서 새로운 레이블과 새로운 데이터까지 생성한다는 데에서 차이점이 있다. Hard labeling 방식의 “확신에 찬” 예측이 초래하는 문제를 완화시키기 위해 이와 같은 증강 기법을 활용할 수 있다.
When Dose Label Smoothing help? (2019, NeuralPS)
- Label Smoothing 은 Regularization 테크닉 가운데 하나로 간단한 방법이면서도 모델의 일반화 성능을 높여 주목을 받았지만, 내부 작동 원리 등에 대해서는 거의 밝혀진 바가 없이 ‘해봤더니 그냥 잘 되더라’ 정도였다. 제프리 힌튼 교수의 연구팀이 2019 NeuraIPS에 제출한 When Does Label Smoothing Help? 논문은 Label Smoothing 이 언제 잘 되고 그 이유에 대해 고찰하는 논문이다.
Dropout
- 뉴럴 네트워크 weight 를 0으로 바꾸는 것. dropout ratial($p$) 가 0.5 면 뉴럴 네트워크가 Inference 할 때 외에는 뉴런의 50% 를 layer 마다 0으로 바꿔준다.
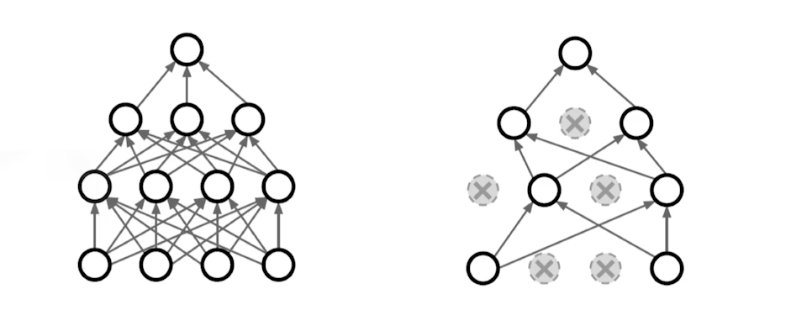
- 수학적 증명은 아니지만 해석적으로는, 각각의 뉴런들이 좀 더 robust 한 feature 를 잡을 수 있다고 한다.
- Dropout 은 같은 모델에서 값이 0이 되는 뉴런이 매번 달라져서 앙상블의 효과를 가져올 수 있다고 알려져 있다.
- 보통 쓰면 성능이 올라간다. 그러나 항상은 아니다.
Batch Normalization
- 2015년도에 Batch Normalization 을 제안하는 논문이 나왔는데 이는 논란이 많다. Internal Covariate Shift 가 논란의 주요한 원인이다.
- BN 을 적용하려는 layer의 statistics 를 정규화 시키는 것이다. 뉴럴 네트워크 각각의 layer가 1000개의 파라미터로 된 히든 layer라면, 1000개의 파라미터 각각의 값들에 대한 statistics가 mean 0 이고 variance 1 이도록 만드는 것.
- 즉 원래의 값들에서 평균을 빼주고 표준편차로 나눠주는 것.
- 논문에서 설명하는 BN 의 효과는, internal covariate shift 를 줄인다고 설명하고 있다. 그래서 네트워크가 잘 학습된다고 설명하지만, 이 부분에 대해서는 뒤에 나오는 많은 논문이 동의하지는 않았다.
- internal covariate shift
- covariate 는 feature(변수) 의 개념이다. 정확히는 공변량이라고 하는데, 독립변수와 종속변수의 관계를 명확히 밝히려 할 때 방해가 될 수 있는 요인이다.
- covariate shift 는 train data 의 분포와 test data 의 분포가 다른 현상을 의미한다. 즉 입력의 분포가 학습할 때와 테스트할 때 다르게 나타나는 현상이다. 이는 모델의 inference 성능에 영향을 미친다.
- covariate shift 가 뉴럴 네트워크 내부에서 일어나는 현상이 internal covariate shift 이다. 가중치 파라미터가 업데이트 됨에 따라 각각의 layer 들의 입력 분포가 매번 바뀌게 되는 것이다. 이는 layer 가 깊을수록 심화된다.
 출처: https://github.com/ndb796/Deep-Learning-Paper-Review-and-Practice
출처: https://github.com/ndb796/Deep-Learning-Paper-Review-and-Practice
- 다른 분포를 가지는 두 데이터를 같은 분포를 가질 수 있도록 변환하는 정규화(Normalization) 한다.
- 하지만 모든 데이터들이 평균 0, 표준편차 1이 되도록 변형시켜주는 것은 데이터를 제대로 학습하지 못한다. 학습 가능한 파라미터의 영향(bias 가 없어진다.)을 무시해버리기 때문이다.
- 또한 평균이 0 이고 표준편차가 1 인 데이터 분포를 가지게 되면 활성화 함수가 시그모이드일 때 비선형성을 잃어버리게 된다. 시그모이드 함수에서 선형구간에 위치하기 때문.
- 따라서 단순히 평균 0, 표준편차 1로 변환하는 것이 아니라 BN 은 주요한 특징을 가진다.

- training data 전체를 다 학습할 수 없으므로 일정 크기에 해당하는 mini batch 안에서 평균과 분산을 계산한다.
- 입력 데이터에 대하여 각 차원(feature)별로 normalization을 수행한다.
- division by zero 를 막기 위해 $\epsilon$ 을 추가한다.
- normailization 된 값들에 대해 Scale factor($\gamma$)와 Shift factor($\beta$)를 더하여 학습이 가능한 파라미터를 추가한다.
- Scale factor와 Shift factor를 두게 되면 입력 데이터의 원래 형태로 학습이 가능하여 각 층별로 입력 데이터의 optimal uncorrelated distribution을 구할 수 있게 된다. 또 위에서 언급했던 시그모이드와 같은 활성화 함수에서 비선형성을 잃어버리는 것을 방지할 수 있다. 정규화 이후에 사용되는 두 factors 가 학습됨에 따라 non-linearity를 유지하도록 해준다.
- 따라서 BN은 학습 가능한 파라미터가 존재하는 하나의 레이어 구조가 되며 이 기법이 발표된 이후 기존의 딥러닝 구조에서 Convolution Layer와 Activation Layer 사이에 BN Layer가 들어간 형태로 발전했다.
- 이 논문 전에 layer 수가 많아지면 학습이 잘 안되는 근본적인 문제를 해결하지 못했지만, BN 을 활용하면, 특히 레이어가 깊을 때 성능이 올라간다.
- How Does Batch Normalization Help Optimization?(2018, NIPS)
- 그러나 실제로 BN 은 inner covariate shift 문제를 해결한 것이 아니라 optimization scope 를 smooth 하게 만들어 좋은 성능을 내는 것이라 밝혀졌다.
- 정리하면,
- Batch Normalization은 Internal Covariate Shift 현상을 해결하지 못한다.
- Internal Covarate Shift 현상이 있더라도 학습에 나쁜 영향을 주지 않는다.
- Batch Normalization이 학습 성능을 높여주는 이유는 Optimization Landscape를 smooth하게 만들어주기 때문이다. 이는 BN 말고도 다른 정규화 방법(L1,L2)으로도 같은 효과를 낼 수 있다.

- 위 그림을 보면 BN 을 사용하게 되면 학습 속도가 빨라져서 빠르게 수렴하지만(왼쪽 그래프), 특정 layer 의 입력 데이터 분포를 살펴볼 때 layer 가 깊을수록 분포가 바뀌고(inner covariate shift) BN 이 추가되더라도 이 현상이 없어지지 않는다(오른쪽).
 Optimization Landscape
Optimization Landscape - 모델 학습 성능이 좋아지는 것은 BN 이 위 그림처럼 Optimization Landscape 를 부드럽게 만들어주기 때문이다.
- Lipschiz(립시츠)함수는 연속적이고 미분 가능하며 어떤 두 점을 잡더라도 기울기가 K 이하인 함수인데, loss func 이 Lipshciz 를 따른다면 상대적으로 안정적인 학습을 진행할 수 있다.
- 이 논문에서는 BN 이 loss func 의 lipshizness 를 향상 시켜준다고 한다. 즉 현재 기울기 방향으로 step size 를 이동하더라도 이동한 뒤의 기울기의 크기와 방향이 이전 step 과 유사할 가능성이 높다는 것이다. 이는 learning rate 가 높더라도 기울기가 stable 하게 감소하고 학습이 잘 진행될 수 있도록 하는 역할을 BN 이 하고 있다는 것이다.

- 이는 BN 뿐만이 아니라 L1, L2와 같이 다른 정규화 기법을 사용하더라도 Lipschitzness를 향상시켜주는 효과가 있다고 하며 실험적으로 증명하였다.
- 같은 variance 로서 다양한 normalization 이 있다.
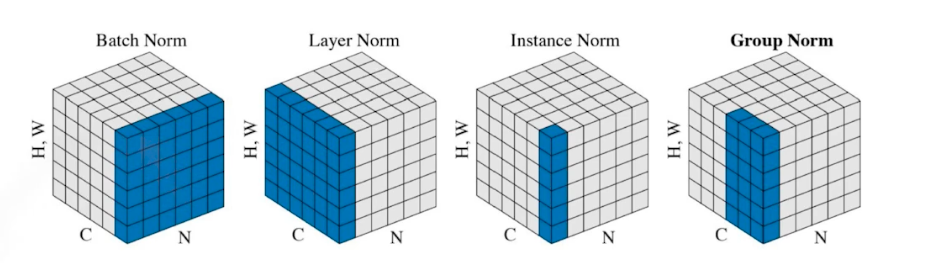
- Batch Norm 은 레이어 전체
- Layer Norm 은 각각의 레이어
- Instance Norm 은 데이터 한장 별로 statistics 를 정규화
-
Group Norm 은 그 중간.
- 간단한 분류문제를 풀 때 만큼은 BN 을 활용하는 것이 많은 경우에 성능을 높일 수 있다고 알려져 있다.
- 그러나 중요한 것은 BN 또한 inference 단계에서 쓰면 안된다. 학습되어 있는 파라미터를 그대로 써야 한다. 즉 mean 과 variance 를 update 하면 안된다.
생각해볼 점
- 네트워크를 만들고 데이터가 고정되어 있고 문제가 fix 되어 있을 때, 위 도구들을 사용하면서 일반화 성능을 볼 수 있다. train error 는 계속해서 줄어들겠지만, validation data 에 대해서 더 좋은 성능이 나오는 것들을 골라서 취사선택하는 것이 중요하다!
- Dropout, Convolution, Batchnorm, Activation 블록을 논리적인 순서대로 배치해보자.
- 보통은 Conv -> BN -> activation -> dropout 의 순서를 따른다.
- BN 을 activation func 뒤에 두는 이유는, 위에서 살펴 보았듯 다양한 범위의 입력 데이터 분포를 바로 activation 을 태우기보다 안정화된 값으로 만들어준 후 activation 을 취하면 학습이 안정될 것이라고 잘 알려져 있기 때문.
- dropout 이 맨 마지막에 나오는 이유는 dropout-sigmoid 관계를 생각해보면 알 수 있다.
- dropout 을 통한 뉴런은 값이 0이 된다. 이를 sigmoid 에 넣으면 값이 0.5 로 다시 되살아나게 된다. 이는 dropout 을 쓰는 이유에 위배된다.
Reference
- https://deepapple.tistory.com/6
- https://cvml.tistory.com/6
- https://ratsgo.github.io/insight-notes/docs/interpretable/smoothing
댓글 남기기