
[OCR] 6. Bag of Tricks for OCR
Bag of Tricks
- “Bag of Tricks for Image Classification with Convolutional Neural Networks” 논문은 2019년 CVPR 에서 발표된 논문이다. 이 논문은 CNN의 성능을 높이기 위해 이용할 수 있는 다양한 기법들을 소개하며 많은 주목을 받았다.
- 여기서는 Text Detection 을 학습시킬 때 사용할 수 있는 여러 팁들을 소개한다.
Synthetic Data
- 좋은 데이터를 많이 확보하기 어렵기 때문에, 정답을 만들어낼 수 있는 합성 데이터를 사용하는 경우도 많다.
- 합성 데이터를 만들 수 있는 tool 이 있으면 좋고 활용하면 좋다. 또한 공개된 합성 데이터셋을 써도 좋다.
- 모델 성능 향상에 있어서 양질의 데이터를 확보하는 것이 가장 중요하지만, 양질의 real data 를 확보하는 것은 항상 어려운 일 이다. Real Data의 확보는 Public dataset 에서 가져온 것과 직접 만드는 방법이 있다.
- 그러나 Text Detection 분야의 공개된 public dataset 은 전체 샘플 수가 Image Classification, Object Detection task 에 비해 규모가 매우 적다.
- SVHN 은 규모가 좀 되지만, 숫자 이미지로만 구성되어 있고, LSVT 는 train set 이 weak labeled 상태로 주어져 annotation 이 온전하지 않다.
- 또한 도메인을 한정하면 가용할 수 있는 데이터 수가 더 줄어든다. 한국어 scene text data 를 찾는다고 하면 MLT 데이터 중 일부 데이터만 해당된다. 따라서 Public dataset 에만 의존하기에는 한계가 있다.
- 그러다보니 데이터를 직접 확보하는 작업이 불가피하다.
- 그러나 웹에서 수집할 때는 라이센스의 제약이 있다. 또 원하는 도메인에 적합한 이미지가 잘 없을수도 있다. 그러면 직접 촬영해서 수집해야 한다. 그렇게 직접 수집하면 Annotation 작업을 진행해야 한다. 이는 난이도도 높고 비용이 많이 들어간다.
- 이처럼 Text Detection 데이터셋 제작이 어려운 이유는, 이미지에 글자가 많은 경우 작업량이 매우 많고, 글자들의 모양이 직사각형이 아닌 경우에도 그 모양에 따라 polygon 을 만들어야 해서 작업량이 늘어나기 때문이다. 또한 검출 방법론에 따라 글자 단위 annotation 이 필요한 경우에는 그 비용이 엄청 늘어난다.
- 이렇듯 고품질의 실제 데이터를 확보하는 것은 매우 어려운 일이다.
- 이 때 합성 데이터를 이용하면 적은 비용으로 데이터를 확보할 수 있다. 가상의 이미지이기 때문에 개인정보, 라이센스에 자유롭고, 글자 단위의 정답 혹은 화소 단위의 정답까지 쉽게 얻을 수 있다.
SynthText
-
Text Detection 분야에서 이용하는 가장 대표적인 합성 데이터셋이다. 지금까지도 많이 이용한다.

- 800K dataset 과 글자 이미지 합성 코드를 제공한다.
- 코드를 사용할 때는 원본이미지와 글자에 관한 text dataset 을 준비해야 한다.
- 이 때 원본이미지는 배경이미지로 간주된다. 따라서 원본 이미지에 글자가 포함되면 해당 글자에 대한 annotation 은 없게 되므로 오히려 그 글자를 배경으로 간주하게 된다. 이는 학습에 악영향을 줄 수 있다.
- 따라서 수작업으로 글자를 포함하지 않도록 제한해서 합성 데이터로 만들어야 한다. 그렇게 되면 Fully annotated dataset 을 보장할 수 있다.
-
준비된 배경이미지 위에 준비된 글자 데이터셋을 활용하여 글자를 가상으로 넣는다. 이미지의 아무 위치에나 글자를 넣으면 실제상황에는 발생하지 않는 경우도 생성될 수 있어 데이터로서 효용이 떨어진다.
 실제상황에서 발생하지 않는 경우 예시
실제상황에서 발생하지 않는 경우 예시 - 학습된 모델이 추론해야 할 대상은 대부분 실제 이미지다. 따라서 합성 데이터셋도 현실에 있을 법하게 만들어줘야 효과적으로 이용할 수 있다.
-
따라서 SynthText 에서는 이미지에 글자를 삽입하기 전에 Depth Estimation 을 통해 이미지에 대한 Depth map 을 추정한다.

- 이렇게 만들어진 Depth map 을 기반으로 인접한 픽셀들 중 depth 가 비슷한 것끼리 묶으면 super-pixel(유사성을 지닌 픽셀들을 일정 기준에 따라 묶어서 만든 하나의 커다란 픽셀) 과 같은 그룹이 만들어진다. 이렇게 만들어진 영역을 Text Region 이라고 한다.
- SynthText 는 글자를 삽입할 때, 삽입될 글자들이 하나의 Text region 안에만 놓이고 경계선에 걸치지 않게 함으로써 비 현실적인 합성이미지가 현실되지 않게 했다.
- 실제상황에서 글자들이 존재하는 위치는 대부분 평면 위다. SynthText 는 평면 위라는 것을 Depth 가 유사한 것으로 간주한 것이다.
- 추정한 depth map 으로부터 normal vector 를 계산할 수 있다. 삽입할 글자의 geometry 를 이 normal vector 에 맞춰 조정하면 더 실제와 같은 결과물을 얻어낼 수 있다.
SynthText3D
- 3D 의 가상세계를 이용해 합성이미지를 만들어낸 dataset 이다.
- 가상 엔진은 이미지 렌더링에 사용되는 Unreal Engine을 이용했다.
-
공식 마켓 플레이스에 있는 30개의 3D 장면을 활용한다.
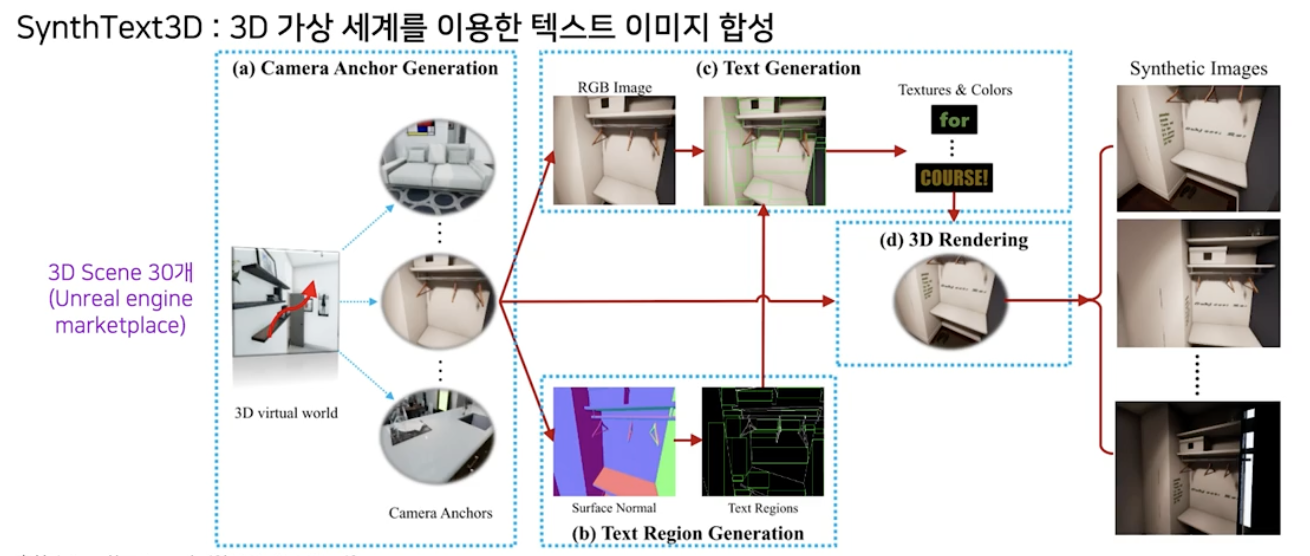
- 3D 가상세계를 이용해 합성이미지를 만들면 기존의 2D 버전 대비 장점이 있다.
- geometry 정보를 갖고 있어 글자의 위치를 더 정확하고 사실적으로 잡아줄 수 있다.
- illumination 과 view 의 조정을 통해서 같은 장면에서도 다양한 이미지를 만들어낼 수 있다.
- 기존의 SynthText 보다 사람의 노력이 상대적으로 덜 들어간다.
- 3D 라서 가려짐 혹은 그늘진 경우 등 특수한 조건의 이미지도 생성할 수 있다.
UnrealText
-
Unreal engine 으로 3D 장면에 글자를 배치하고 랜더링해서 이미지를 얻어내는 방식이다.
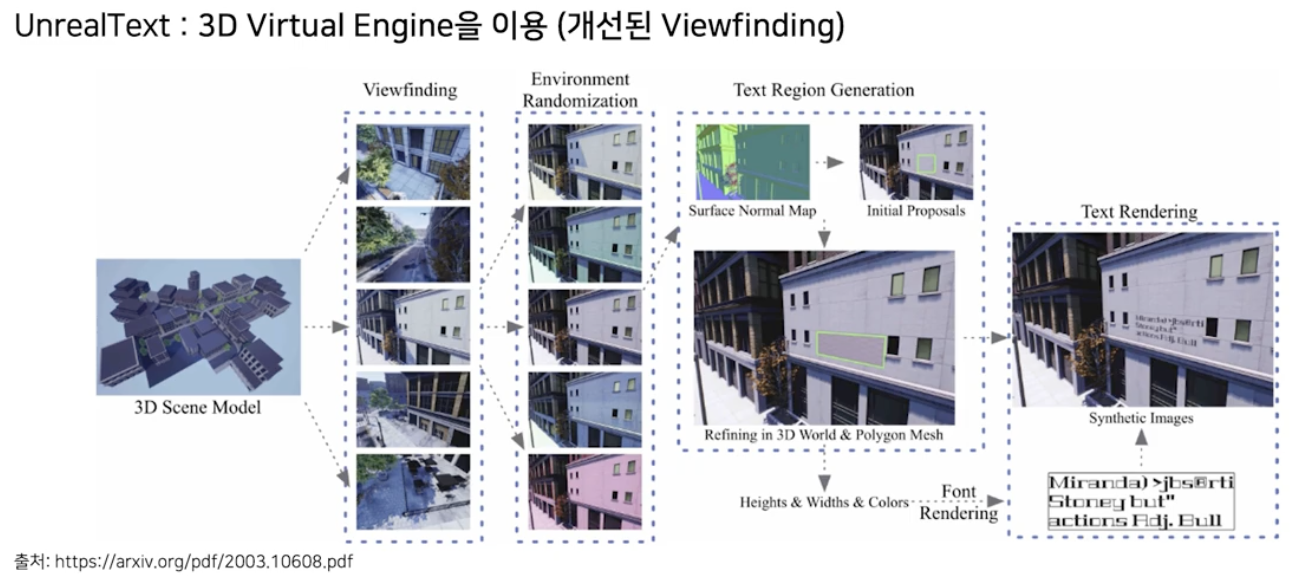
- SynthText 3D 와 매우 비슷하다.
- 차이점은, SynthText3D 는 카메라 view 를 정할 때 사람이 미리 정해둔 앵커에 의존해야 한다. 이는 현실적이지 않은 view 가 설정되는 것을 방지하기 위해서이다.
- UnrealText 에서는 실제로 있을법한 view 를 자동으로 탐색하는 방법론을 고안해서 이 목적을 달성했다.
- 미리 정해진 view 가 아니라 자동으로 탐색한 view 를 이용하기 때문에 UnrealText 는 더 다양성이 높은 합성 데이터를 만들어낼 수 있다.
합성데이터 활용 방법
- Pretraining
- 합성 데이터를 pretraining set 으로 이용할 수 있다.
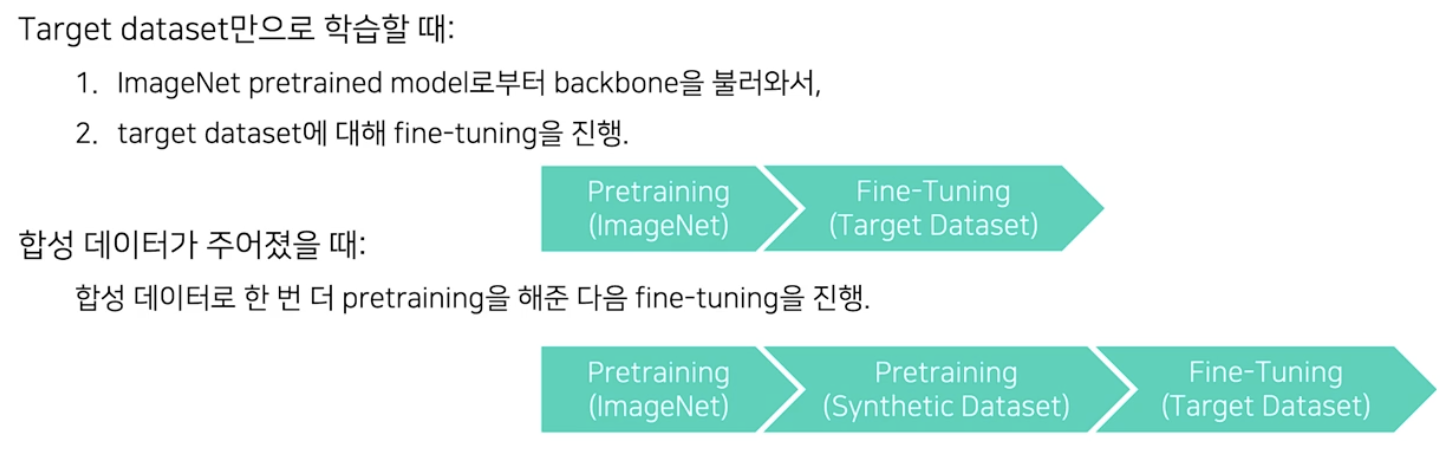
- target dataset 으로 fine-tuning 을 하기 전에 합성 데이터로 한 번 더 pretraining 을 해주고 나서 target dataset 으로 fine-tuning 을 진행하는 것이다.
- 즉 pretrained backbone 을 불러와서 합성 데이터로 한 번 더 pretraining 하는 것이다.
- 실제 데이터로 fine-tuning 전에 합성 데이터로 pretraining 해주는 것의 효과는 아래와 같다.
- target dataset 없이 각각의 합성데이터를 10k 씩 이용해서 학습한 결과
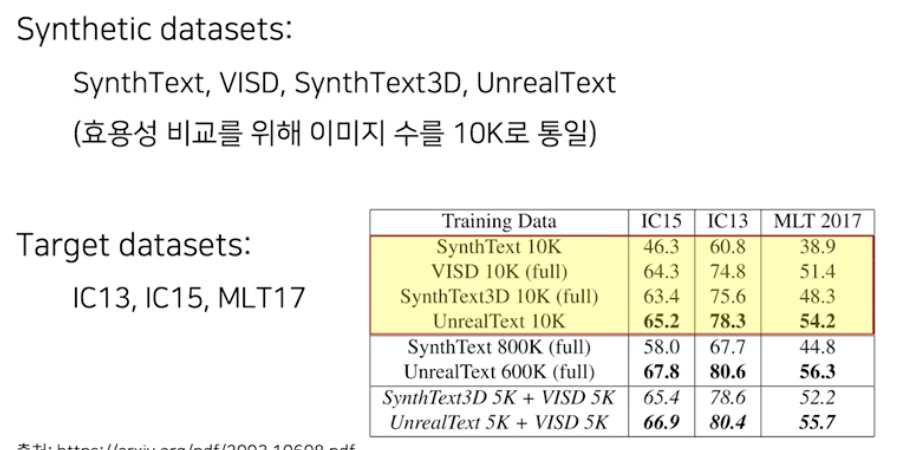
- 10k 가 아닌 전체 데이터를 이용해서 학습한 결과 (VISD, SynthText3D 는 원래 전체가 10k 정도)
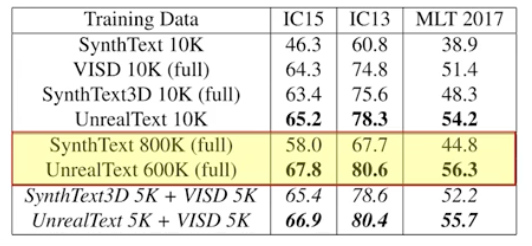
- 생성된 데이터의 다양성 측면에서 기왕이면 여러 생성 도구를 활용하는 것이 낫다는 것을 아래의 결과로 알 수 있다.
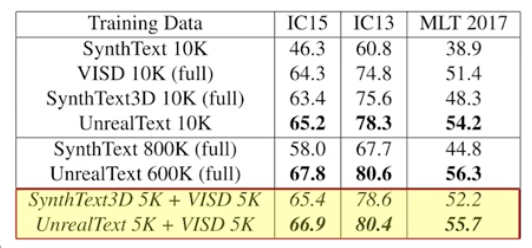
- target dataset 만 이용했을 때와 합성 데이터 pretraining 했을 때의 차이점
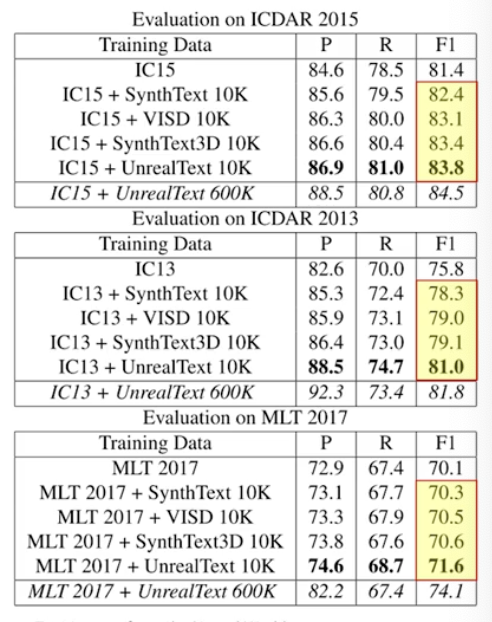
- 위 예시에서는 UnrealText 가 가장 큰 효용을 보였지만 이 결과를 일반화시킬 순 없다.
- 우리가 갖고 있는 target dataset 에 대해서는 항상 직접 실험을 통해 가장 좋은 합성 데이터셋을 찾아봐야 한다.
- 따라서 합성 데이터를 잘 이용하면 성능향상을 꾀할 수 있는 상황이 많다!
- Weakly Supervised Learning
- 합성 데이터가 이용되는 또 하나의 시나리오다.
- Text Detection 모델들 중 알고리즘 상 내부적으로 글자들의 개별 위치를 검출하는 모델들이 있다. CRAFT, TextFuseNet 이 그것이다.
- 이 모델들은 글자들의 개별 위치를 학습해야 해서 학습 데이터에서 글자단위 annotation 을 필요로 한다. 그러나 대부분의 공개 데이터는 단어 단위 annotation 만 포함하고 있어서 위 같은 모델을 학습 시키는데에는 어려움이 있다.
- 이럴 때 합성 데이터를 이용한 Weakly Supervised Learning 방식을 이용할 수 있다.
- 글자 단위 annotation 을 제공하는 합성 데이터로 full supervision 을 줘서 모델을 학습시킨다. 즉 합성 데이터로 pretraining 된 모델을 생성하는 것이다.
- 먼저 합성 데이터로 pretrained 된 모델을 target data 에 적용해서 개별 글자들을 검출해내고, 이를 pseudo annotation 으로 사용하는 것이다.
- 최종적으로 pseudo annotation 을 이용해서 target dataset 에 대한 fine-tuning 을 진행한다.
- 이렇게 합성 데이터를 활용하면 글자 단위의 annotation 이 없는 real dataset 에 대해서도 글자들의 개별 위치를 검출할 수 있게 된다.
Data Augmentation
- NN 을 학습시키면 그 NN 이 가진 정보는 학습에 활용했던 데이터들을 대상으로 풀고자 하는 task 에 맞도록 정보가 응축되었다고 생각할 수 있다.
- 그러나 데이터에는 언제나 bias 가 존재한다. 사람들이 찍은 data 이기 때문이다. 실제로 각 클래스에 대한 mean 이미지들을 보면 유사하게 패턴들이 존재한다.
- 데이터에 bias 가 있는게 왜 문제가 될까?
- 우리가 찍은 샘플(데이터)들은 실제 distribution 을 다 표현하지 못한다.
- 학습에 사용하는 샘플 하나가 real data 에 대한 분포를 표현하게 되는데, 샘플들에 bias 가 있으면 그로 인해 유추하는 실제 데이터가 왜곡되게 된다.
- 따라서 학습 데이터에 존재하는 bias 는 위험한 문제이다.
- 낮에 찍은 동물 이미지를 학습한 NN 를 테스트 할 때, 밤에 찍은 동물 이미지를 input 으로 넣으면 모델은 밤에 동물을 본 적이 없기 때문에 인지를 하지 못하게 된다. 이런 식으로 실제 데이터의 분포를 표현하지 못했을 때 문제점이 생긴다.
- 이를 해결하기 위한 방법으로 data augmentation 을 활용한다.
- 데이터를 수집하는 비용은 정말 많이 든다. 따라서 Augmentation 방법들이 제안이 많이 되고 있다.
- 알고 있는 sample 로부터 transform 등 augmentation 방법을 적용해서 그 주변의 real data 분포를 표현하도록 data 샘플을 추가하는 작업이 바로 Data Augmentation 이다. Rotate, Brightness, Crop 등의 기법이 여기에 속한다.
-
OpenCV, Numpy, Albumentation 라이브러리 등을 활용해서 data augmentation 을 많이 쓰고 있다.
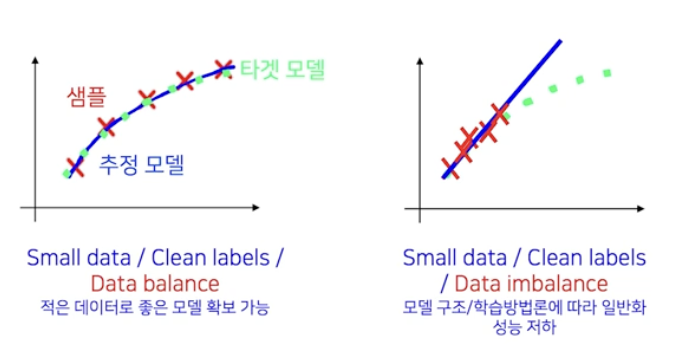

- data augmentation 은 한쪽으로 치우쳐진 분포(imbalance)를 주어진 샘플들에 변형을 가해서 골고루 만들어주는 작업이다. 여기서 데이터 분포는 3가지 관점의 분포가 있다.
- 각 분포에 따라 적용되는 augmentation 기법이 다르다.
- 색상 분포 관점 : color jittering 등
- 촬영 각도 관점 : Rotation 등
- 이미지 크기 관점 : Resize 등
- Image Data Augmentation
-
Geometric transform

- 이미지의 global level 에 변화를 주는 변형이다.
-
Style transform

- 이미지의 local level 에 변화를 주는 변형이다.
-
Other transform
- Geometric, Style 어디에 속하기 애매한 변형이다.
-
- 그러나 모든 Augmentation 기법이 항상 효과적인 것은 아니다. 문제와 데이터에 따라 적합한 augmentation 기법이 있고, 이를 잘 파악해야 한다.
- Data Augmentation 은 아무 제한 없이 무작위로 이미지를 만들어내면 의도치 않은 결과가 만들어질 수 있다.
- Text Detection 문제 특성 상 좀 더 주의깊게 봐야할 augmentation 은 특히 geometric transformation 이 밀접하게 연관되어 있다.
- augmentation 된 이미지가 글자를 포함하지 못한 경우
- positive sample 의 비중이 너무 낮으면 성능 저하가 발생할 수 있다.
- 딥러닝 모델 학습에 있어서 데이터 구성 비율을 적절히 맞춰주는 것은 매우 중요하다.
- 특히 object detection, segmentation 에서는 이미지 전체에서 객체가 차지하는 영역의 비율이 매우 작아서, 애초에 positive sample 과 negative sample 간에 심한 class imbalance 문제를 겪는다.
- 그런데 augmentation 결과로 positive sample 에서 객체 영역의 비중이 너무 낮은 이미지들이 생성되면 class imbalance 문제가 더욱 심해진다. 이는 결국 모델 성능의 하락으로 직결된다.
- 글자가 온전하게 나타나지 못하고 일부만 잘려서 나타나는 경우
- class imbalance 와 별개의 문제로 글자가 잘린 영역을 positive sample 로 학습하면 모델에 혼동을 줄 수 있다.
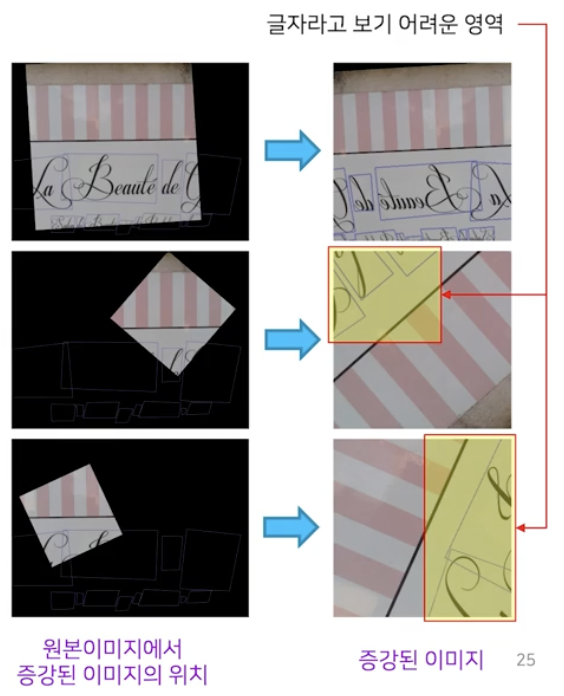
- augmentation 을 통해 글자가 잘려도 주어진 annotation 상으로는 글자 영역에 해당되기 때문에 positive sample 로 모델이 학습된다. 그러면 모델은 혼동하게 되고 이는 모델 성능 저하로 이어진다.
- 글자가 잘린 positive sample 이 많아지면 모델은 글자와 부분적으로 유사하게 생긴 배경에 대해서 false positive(잘못 예측) 를 발생시키기 때문이다. 즉 모델이 정답이 아닌데 정답이라고 하는 것이다.
- augmentation 된 이미지가 글자를 포함하지 못한 경우
- 따라서 geometric transform 에 몇가지 규칙을 추가할 수 있다.
- positive ratio 를 보장해주기 위해서, 변형 후의 이미지에 글자 개체가 적어도 1개는 포함되어야 한다.
-
그렇게 되면 모든 patch 에 글자 개체가 포함되니 positive sample ratio 는 보장이 가능하다. 그러나 글자 개체와 멀리 떨어져 있는 배경 영역에서는 sampling 이 일어날 가능성이 적어진다.

- 그 결과 글자 개체와 먼 배경에 hard negative sample 이 있어도 모델이 이를 학습하지 못하게 된다.
- 이 문제는 hard negative mining 기법을 도입함으로써 해결할 수 있다.
- positive sample 위주로 모델을 학습시키고, 그 모델로 전체 데이터셋에 대한 결과를 뽑은 후 false positive 를 포함하는 patch 들만 모아서 hard negative set 으로 이용하는 것이다.
-
- 잘려서 부분적으로 나타나는 개체를 금지한다.
- 변형 후의 이미지에 나타나는 모든 개체들은 온전해야 한다는 것이다.
- 이는 글자가 잘려 들어오는 것을 막아서 모델에게 혼동을 주는 샘플 발생 방지에 효과가 있다.
- 그러나 개체 밀도에 대한 sampling bias 가 발생하는 문제점이 발생한다.
-
즉 글자 개체가 빽빽한 영역에서는 patch 가 글자 개체의 경계선에 닿지 않도록 위치를 잡기가 어렵기 때문에 개체의 밀도가 높은 곳에서 sampling 이 일어날 가능성이 오히려 낮아진다.
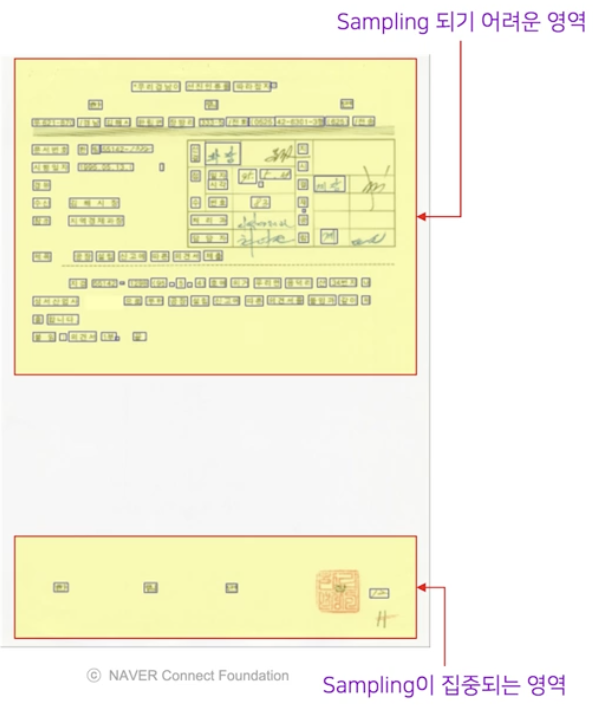
- 위 예시에서 위쪽 영역은 글자 개체들이 빽빽하게 몰려 있어서 무작위로 sampling 할 때 글자 영역의 경계와 간섭이 생길 가능성이 매우 높다.
- 이렇게 되면 학습해야 하는 positive sample 들이 풍부한 영역이 모델에 입력되지 않는 문제가 발생한다.
-
그 결과 rule 1 과 rule 2 에 의해 아래와 같은 positive sample 들만 모이게 된다.
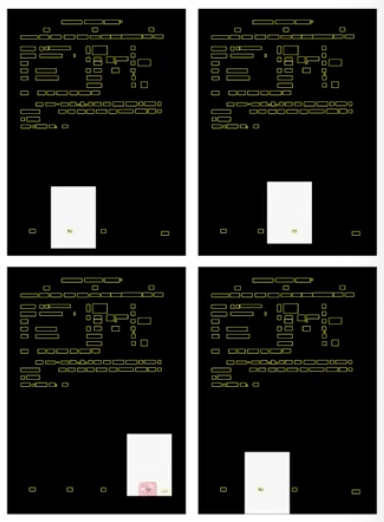
- 잘리는 개체가 하나도 없어야 한다는 조건에서 patch 의 위치를 잡기는 너무 어렵다. sampling 이 가능한 위치가 존재한다 하더라도 실제 patch cropping 은 랜덤하게 수행하면서 조건을 충족할 때까지 iteration 을 도는 방식으로 보통 구현된다. 따라서 현실적 가능성이 매우 낮다.
- 이 조건을 약간 완화함으로써 문제를 해결해보자.
- 최소 하나의 개체는 잘리지 않고 온전하게 포함되도록 하고 다른 개체들에 대해서는 경계가 잘리는 것을 허용하도록 조건을 완화할 수 있다.
-
대신 잘려서 나타나는 개체들에 대해서는 masking 을 통해서 gradient 전파를 막아서 학습에서 무시하게 만들 수 있다. 이렇게 되면 결과적으로 학습에 사용하는 개체는 잘린 곳이 없는 온전한 개체들만 나타나게 된다.
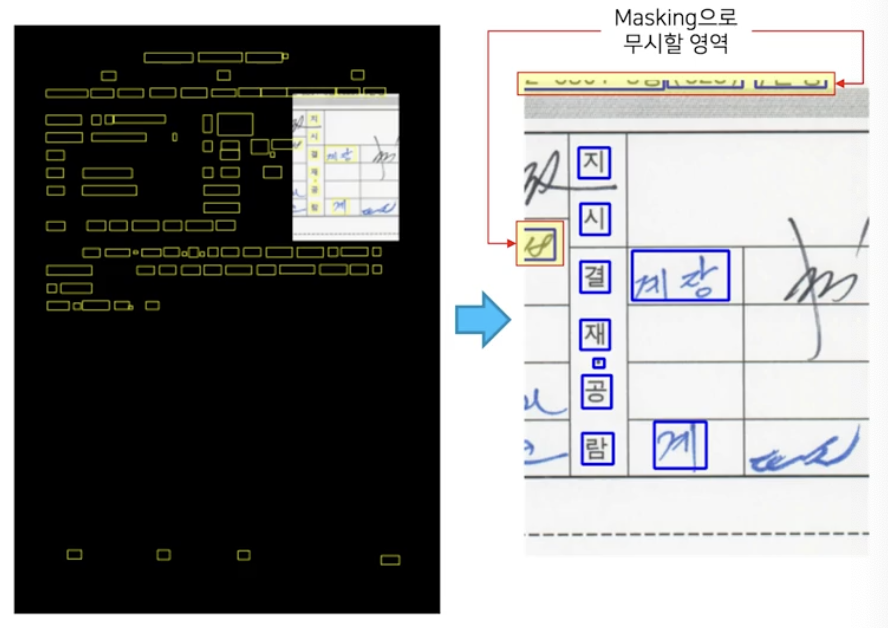
- positive ratio 를 보장해주기 위해서, 변형 후의 이미지에 글자 개체가 적어도 1개는 포함되어야 한다.
- 이처럼 augmentation 적용 시 실전에서는 도메인에 따라 특수한 문제가 발생하는 경우가 많다.
- 따라서 일반적인 방법부터 적용해보고 분석해가며 상황에 맞게 특화해 나가는 접근이 바람직하다.
- 이를 위해 실제로 모델에 입력되는 이미지 관찰하고, 특히 이미지 단위 혹은 영역 단위로 loss 가 크게 발생하는 영역들을 잘 분석해서 rule 을 업데이트하는 피드백이 필요하다.
Multi-Scale Training(MST)
- Object Detection task 에서도 Scale variation 을 잘 다루는 것은 중요한 문제다.
- 이미지에서 글자들은 매우 다양한 크기로 나타난다. 그리고 scale variation 은 Text Detection 문제의 난이도를 높이는 주요 원인이다.
- 작은 크기의 글자 미검출이 발생한다.
- 크기가 큰 글자는 개체가 온전하게 검출되지 않고 부분검출이 발생하는 경우가 많다.
-
이를 해결하기 위한 방법으로 Multi-scale training 이 있다.
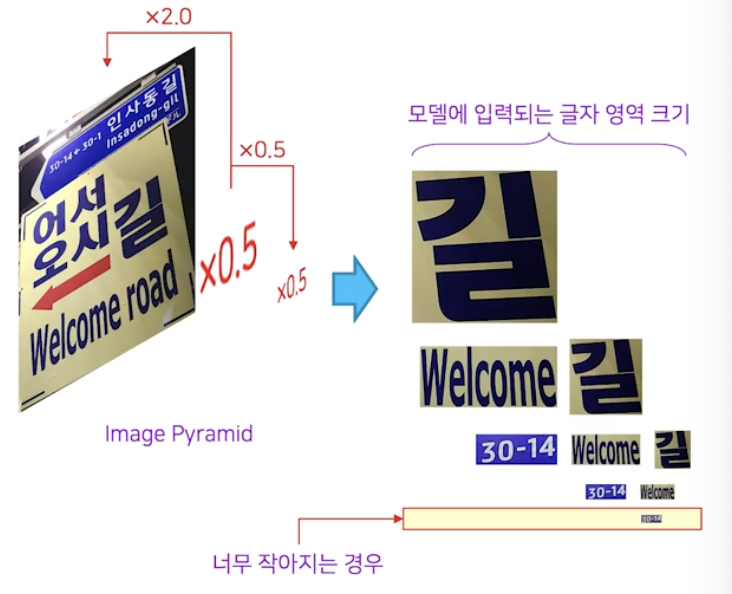
- 모델의 입력 이미지를 crop & resize 연산을 통해 augmentation 한다.
- Image pyramid 와 같이 입력 이미지를 모델 구조 내에서 다양한 크기로 변화시켜 대응하는 것도 방법이다.
- 이러한 방법들은 다양한 크기의 글자 영역들을 만드는데, 때로는 너무 작아져서 글자인지 아닌지 파악하기 힘든 경우가 생길 수 있다.
- 또한 때로는 너무 커서 모델 구조상 해당 개체 크기는 대응이 불가할 수도 있다.
-
따라서 scale normalization 으로 이런 경우를 대응하기도 한다.

- SNIP (Scale Normalization for Image Pyramid)
- 개체 크기의 적정 범위를 정해놓고 그것을 벗어나는 경우는 학습에서 무시한다.
- 영역이 너무 작거나 너무 크면 학습에서 무시하는 것이 바로 scale normalization 다.
- 이는 학습 뿐 아니라 추론 시에도 사용한다.
-
NMS 를 적용하기 전에, 예측 영역들 중 너무 크거나 너무 작은 영역들을 제외시켜서 적정 크기의 영역들만을 가지고 NMS 를 수행하는 것이다.

-
Scale Normalization 의 정량적 효과
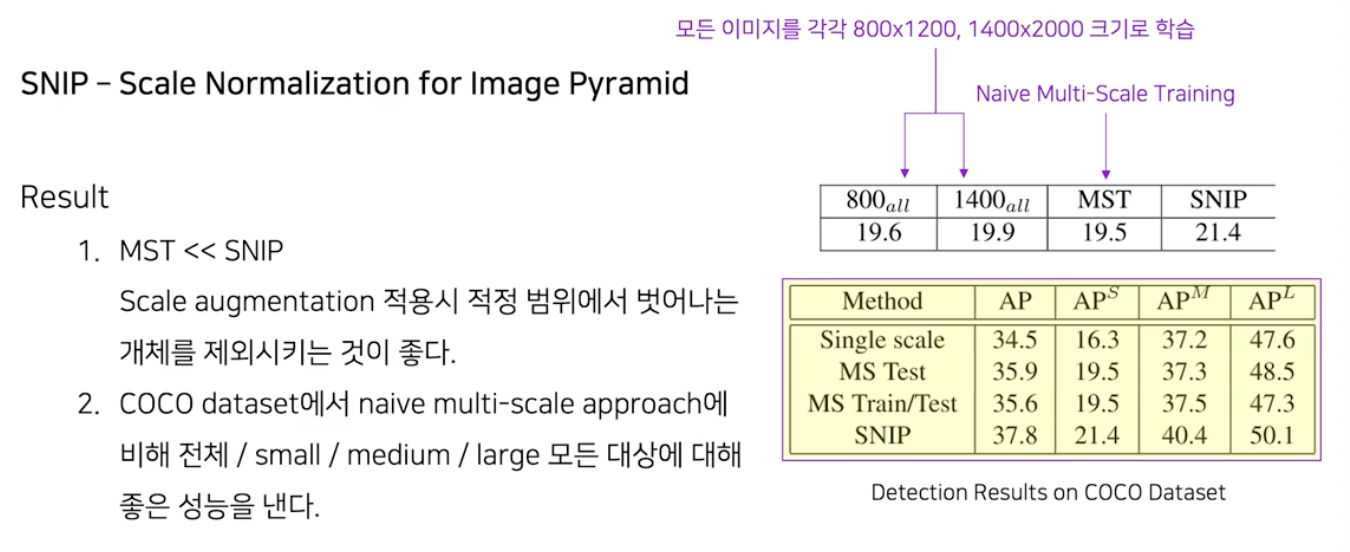
- multi scale training 보다 scale normalization 의 성능이 더 좋다.
- 작은 개체 크기, 중간 개체 크기, 큰 개체 크기로 구분지어 따로 성능평가를 하더라도 더 좋은 성능을 보인다.
추론 시 사용하는 MS(multi scale) 대응 전략
- 입력 이미지 자체를 특정 범위 내의 개체 크기가 오도록 여러 크기로 조절하는 방법이 있다.
- 이 방법은 계산량이 많고 여러 이미지 크기들에서 각각 나타나는 false positive 들이 누적되어 나타날 수 있다.
- Adaptive Scaling
- 모델에 원본 이미지를 그대로 입력하지 않고, 이미지에서 실제로 글자가 있을만한 영역들에 대해서 이 영역의 크기가 적당히 되도록, 각 영역들의 크기를 조정해서 모델에 입력하자는 것이다.
- 이를 위해서 글자가 있는 영역의 위치와 글자들의 크기에 대한 대략적인 정보가 필요하다.
- 따라서 두번에 거친 추론작업이 필요
- 첫번째 추론에서는 글자의 대략적인 위치와 크기를 예측한다.
- 두번째 추론에서는 첫번째 결과를 기반으로 적당히 재구성한 이미지를 다시 모델에 입력해서 최종결과를 얻는다.
-
작동방식
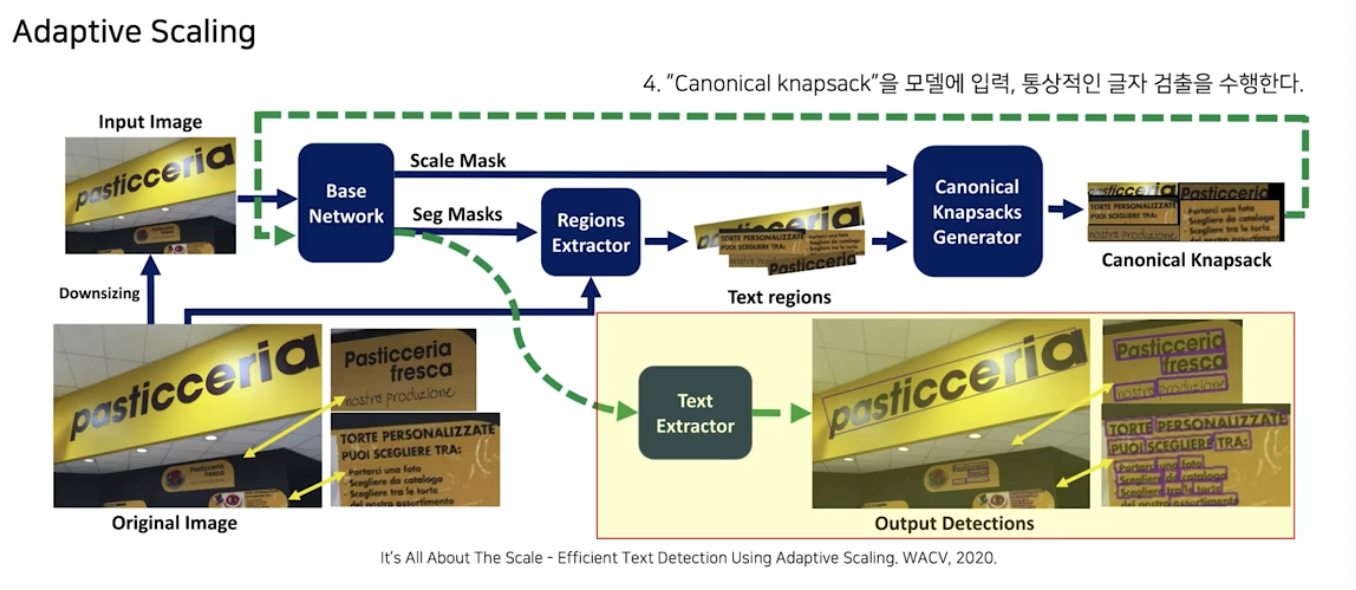
- 이미지에 down-sizing 으로 축소된 버전의 이미지를 만든다.
- 첫 사이클에서는 대략적 수준의 예측만 하면 되기 때문에 추가적인 overhead 를 줄이기 위해 축소된 이미지를 이용한다.
- 축소된 이미지를 모델에 입력해서 scale mask 와 seg mask 를 예측한다.
- 각 mask 는 각각 글자의 크기와 글자가 있는 곳의 위치를 나타내는 pixel-wise map 이다.
- 어떤 크기의 글자가 어디에 있는지 알고 있으니 이 정보를 이용해서 Canonical knapsack 을 만든다.
- Canonical Knapsack 은 원본 이미지에서 글자를 포함하는 영역만 따로 가져와서 각각의 글자가 적당한 크기를 갖도록 크기를 조정한 후, 짜집기로 이어붙힌 새로운 하나의 이미지다.
- Canonical knapsack 을 모델에 입력하고 통상적인 Text Detection 을 수행한다.
- 이미지에 down-sizing 으로 축소된 버전의 이미지를 만든다.
-
원본 이미지에서 만들어진 Canonical knapsack
 canonical knapsack. 글자 영역이 모두 표준 크기로 조절되어 있음을 확인할 수 있다.
canonical knapsack. 글자 영역이 모두 표준 크기로 조절되어 있음을 확인할 수 있다.- 원본이미지를 바로 검사하는 대신 재구성된 canonical knapsack 을 이용함으로써 얻을 수 있는 장점
- 전체 이미지의 대부분은 배경이 차지한다는 글자 이미지의 특징을 감안해서 글자가 없는 배경 영역에 대해 계산을 하지 않아 경제적(계산량)이다.
- 글자들의 크기가 통일되어 Text Detection 의 고질적 문제 중 하나인 scale variation 으로 인한 성능 저하를 방지할 수 있다. 왜냐하면 canonical knapsack 으로 재구성하면서 모두 표준적 크기로 조절되어 더 정확한 검출 결과를 기대할 수 있기 때문이다.
- 원본이미지를 바로 검사하는 대신 재구성된 canonical knapsack 을 이용함으로써 얻을 수 있는 장점
정리
- Synthetic Data
- Synthetic Data 는 구축에 비교적 적은 비용이 든다. 또한 개인정보나 라이선스에 관한 제약으로부터 자유롭다.
- Character-level, Pixel-level 등과 같이 세밀한 수준의 Annotation 을 얻을 수 있다.
- Real Data 에 대한 부담을 덜어준다.
- Synthetic Data 로 모델을 Pretraining 한 후, Real Data 로 Fine-tuning 하는 방법으로 모델 성능 개선을 이룰 수 있다.
- 항상 실험을 통해 실제 Target Text 의 특징과 잘 맞는 Synthetic Data 를 찾는 것이 중요하다.
- Weakly Supervised Learning 시나리오의 경우, Synthetic Data 로 모델을 Pretraining 하고 이 모델을 Target Dataset 에 적용하여 Pseudo Annotation 을 확보하여 Fine-tuning 에 활용한다.
- Data Augmentation
- Data Augmentation 의 목적은 데이터 분포의 균등화를 통해 일반화 성능이 좋은 모델을 확보하고자 함에 있다.
- Geometric transformation은 Global-level 관점에서 변화를 주는 변형 방법이다. 예시로는 Random Crop, Resize, Rotate, Filp 등이 있다.
댓글 남기기