
[OCR] 5. Metric for OCR
Metric for OCR
- AI 모델의 성능 평가는 실무에서 매우 중요하다.
- 모델을 런칭했을 때 언제나 문제점이 발견된다. 그 문제점을 사전에 알고 이게 개선되어지고 있다고 판단할 수 있으려면 성능 평가 방식이 잘 정립되어 있어야 한다.
- 그렇다면 OCR 관련해서 어떤 성능평가 방식이 좋은지를 살펴보자.
성능평가의 중요성
- 모델을 잘 설계하고 loss 함수를 잘 정의하여 모델을 학습하는 것은 필수 절차다.
- 또한 모델이 보지 못한 데이터에 대해서 얼마나 잘 작동하는지 파악하는 것도 굉장히 중요하다. 따라서 모델 평가를 할 때는 학습 데이터 뿐 아니라 새로운 데이터(학습에 사용되지 않은)가 들어왔을 때 얼마나 잘 동작하는지를 측정한다.
- 모델이 새로운 데이터에도 좋은 성능을 보이면 일반화 성능이 좋다고 할 수 있다.
-
성능 평가 시 데이터 분리는 모델의 성능을 제대로 평가하기 위해서 하는 작업이다.
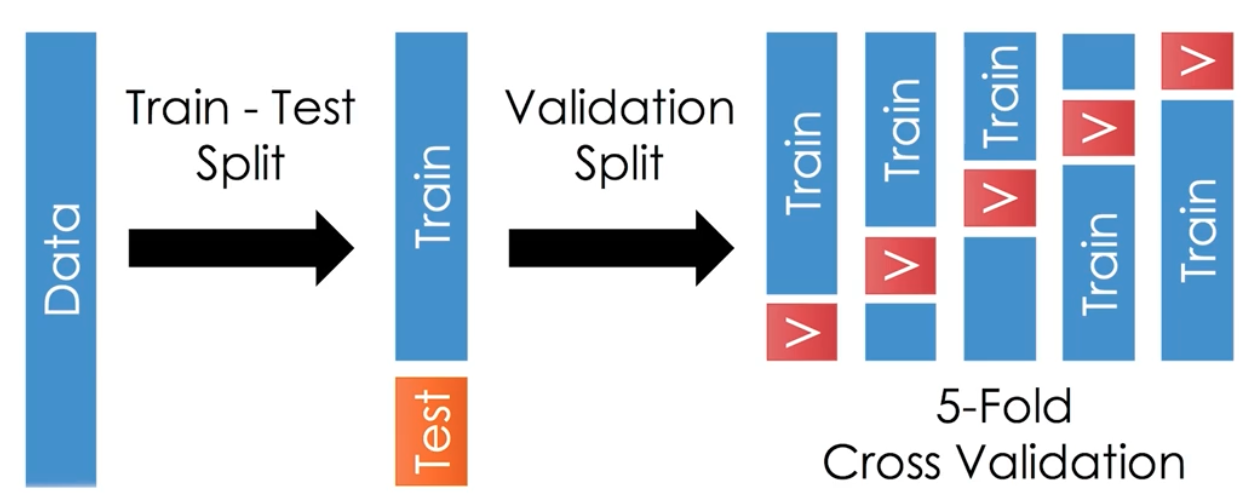 train, valid, test
train, valid, test- 학습 데이터와 평가 데이터를 구분한다.
- 학습 시에는 사용하지 않았던, 즉 한번도 보지 못한 새로운 데이터로 성능을 측정한다.
- 학습에 사용했던 데이터로 성능 평가까지 하면, 모델이 학습 데이터를 외워서 잘하는 것인지, 의도대로 잘 배워서 동작을 잘 하는 것인지 구분하기 어렵기 때문이다. 따라서 학습데이터와 평가데이터는 분리해서 사용한다.
- 구분된 학습 데이터셋 중 일부를 검증용 데이터로 빼기도 한다. 검증용 즉 valid 데이터셋은 학습된 모델들 중 어떤 모델로 최종 성능을 측정할 것인지를 결정하기 위해 사용된다. 따라서 검증 데이터셋은 모의고사 정도라고 생각할 수 있다.
- 교차 검증(Cross Validation)과 같이 검증 데이터셋으로 여러 번 측정해서 최종 모델을 선택할 수도 있다.
- 또한 교차검증을 통해 하나의 모델을 선택할 수도 있고, 앙상블로 최종 성능 평가를 진행할 수도 있다.
- 이러한 노력의 궁극적 목적은, 우리가 학습시킨 모델이 서비스로 출시되었을 때 학습 시에는 보지 못한 데이터가 입력으로 들어왔을 경우 성능이 어떨 것인지를 서비스 출시 전에 파악해보는 것에 있다.
- 성능 평가가 잘못되어 성능이 안 좋은 모델이 서비스로 출시되면, 고객으로부터 많은 실패 사례들을 리포트 받는다. 따라서 교차검증을 통해서 신중히 모델을 선택하는 것은 당연한 절차 중 하나이다.
-
성능이 좋은 모델을 선택하기 위해, 하나의 정량 평가 뿐 아니라 추가 분석도 진행한다.
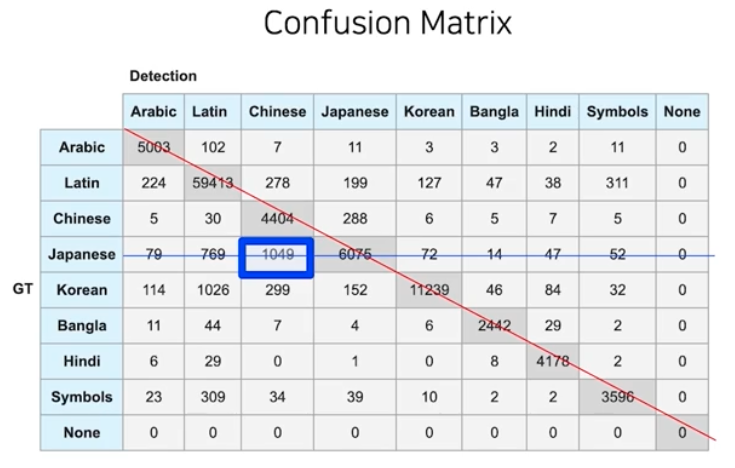
- 분류 문제에서 Confusion Matrix 는 각각의 정답과 어떤 예측을 했는지에 대한 숫자를 세어서 하나의 Matrix 형태로 표현한 것이다. 이렇게 되면 대각선에 위치한 숫자들이 정답을 맞춘 경우를 의미한다.
-
이를 가지고 또 다른 분석도 가능하다. 정답을 못 맞춘 경우, 어떤 것으로 가장 많이 예측 했는지를 살펴볼 수 있다. 그 오분류를 좀 더 분석하면 효과적이다.
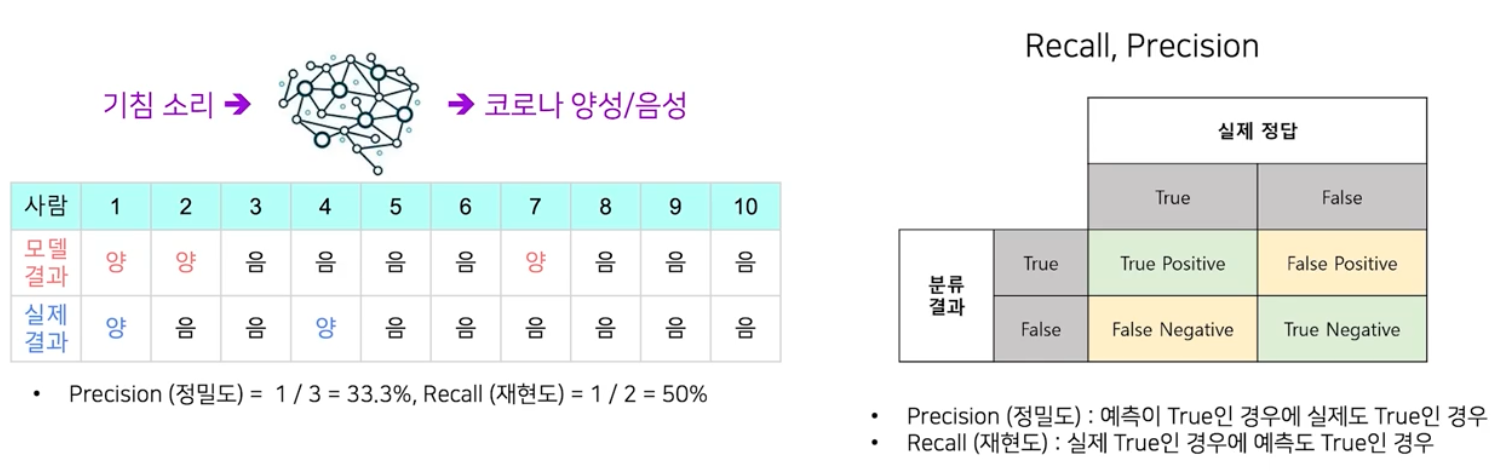
- 대표적인 것이 Recall & Precision 이다. Precision(정밀도)는 모델이 참이라고 분류한 것 중 실제로 참인 것의 비율이다. Recall(재현율)은 실제 참인 것들 중에서 모델이 참이라고 예측한 것들의 비율이다.
- precision 과 recall 수치에 따라 AI 모델의 느낌이 다르다. 위 예시처럼 Precision 이 1이면 모델이 양성이라고 판단하는 사람은 실제 전부 양성이다. 그러나 그게 다가 아니다. Recall 의 결과를 보면 양성인 사람 전부를 찾지 못할 수도 있다.
- 반대로 recall 이 1인 모델은 실제 양성인 사람은 전부 다 찾아낼 수 있지만, 양성이 아닌 사람도 양성이라고 할 수 있다.
- 정량평가 & 정성평가
-
OCR 결과가 아래와 같은 경우 점수를 매긴다면 어떻게 될까?

-
위 두 예시에서 정량평가 방식을 무엇으로 하냐에 따라 결과가 완전 달라진다.

- 이렇게 정량 평가의 기준에 따라 결과가 달라지기 때문에 서비스에 맞는 정량 평가 기준을 잘 잡아야 하고, 하나의 정량평가로 부족하다면 여러 개의 정량평가를 사용하는 것도 방법이 될 수 있다.
- 정성평가는 사람마다 두 결과를 보고 0~1 사이의 점수를 매기라고 하면 각자 나름의 기준으로 점수를 매길 것이다.
- 사람들의 정성평가 결과를 평균을 냈을 때, 그 점수는 해당 모델이 서비스로 출시 되었을 때 사람들이 체감하는 품질의 평균값이라고 볼 수 있다.
- 따라서 정량평가는 되도록이면 정성평가에 해당하는 점수가 나오는 정량평가를 고안하는 것이 바람직하다.
-
Text Detection 모델의 평가 방식 및 각각의 장단점
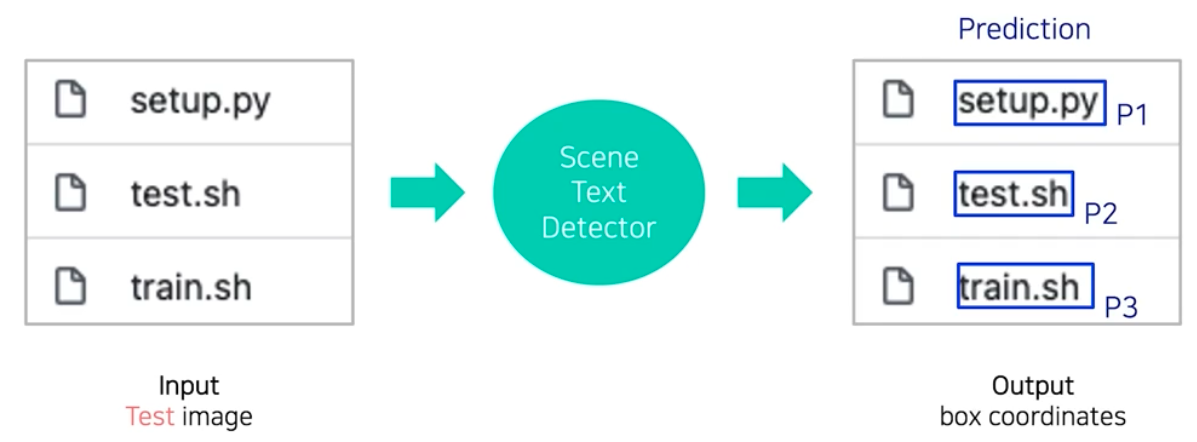
-
Detection 모델 평가 방식의 1단계는 테스트 이미지에 대해 결과값을 뽑는다.
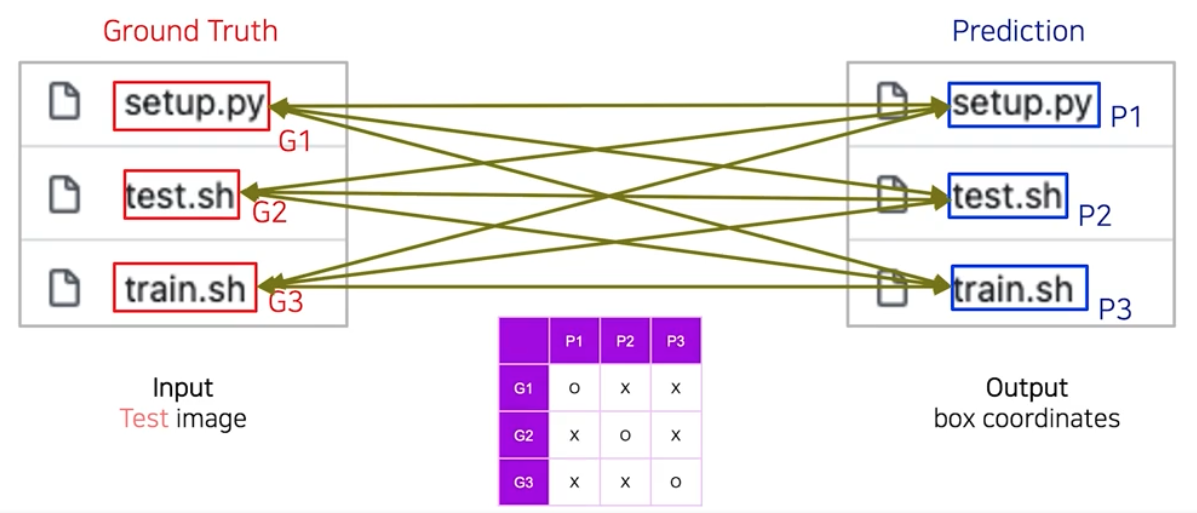
-
2단계는 예측 결과와 정답 간 매칭/스코어링 과정을 거쳐 평가한다. 정답과 예측 사이의 각 영역 간에 서로 매칭이 되었는지를 1차적으로 판단한다. 이런 매칭을 모든 관계에 대해서 다 파악하여 matrix 값을 채워나간다.
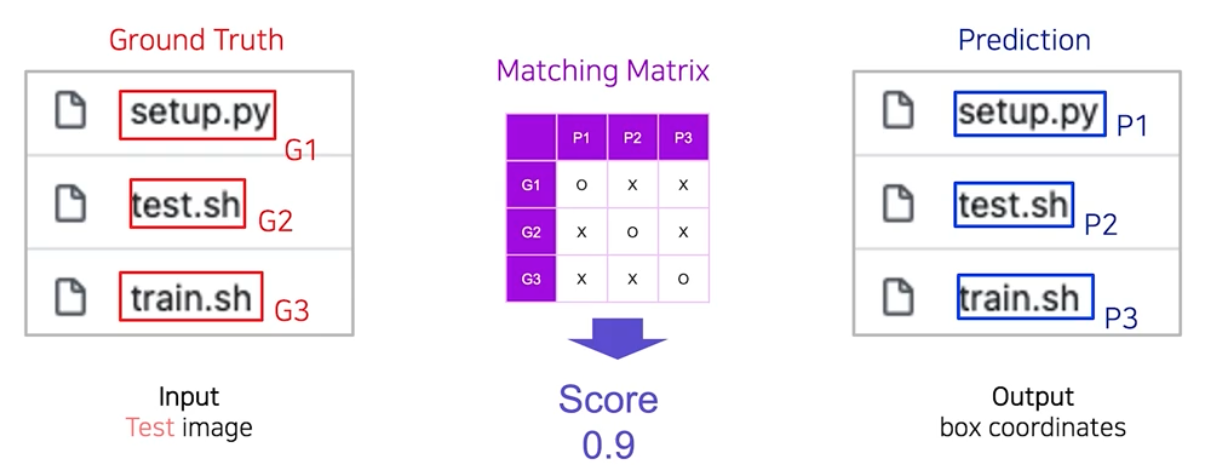
- 이 매칭 행렬로 부터 예측과 정답 사이의 유사도를 하나의 수치로 뽑아낸다. 이 과정을 스코어링이라고 한다.
- 이처럼 Text Detection 모델 평가를 위해서는 정답 영역과 예측 영역이 매칭되었는지 판단하는 방법(매칭 행렬 계산)과,매칭 행렬로부터 유사도 수치 하나를 뽑아내는 방법(유사도 계산) 이 두 가지가 정의되어야 한다.
- 매칭 여부 판단
- 두 영역 간의 매칭 여부를 판단하기 위해서 사용되는 방법은 IoU(Intersection of Union) 가 있다.
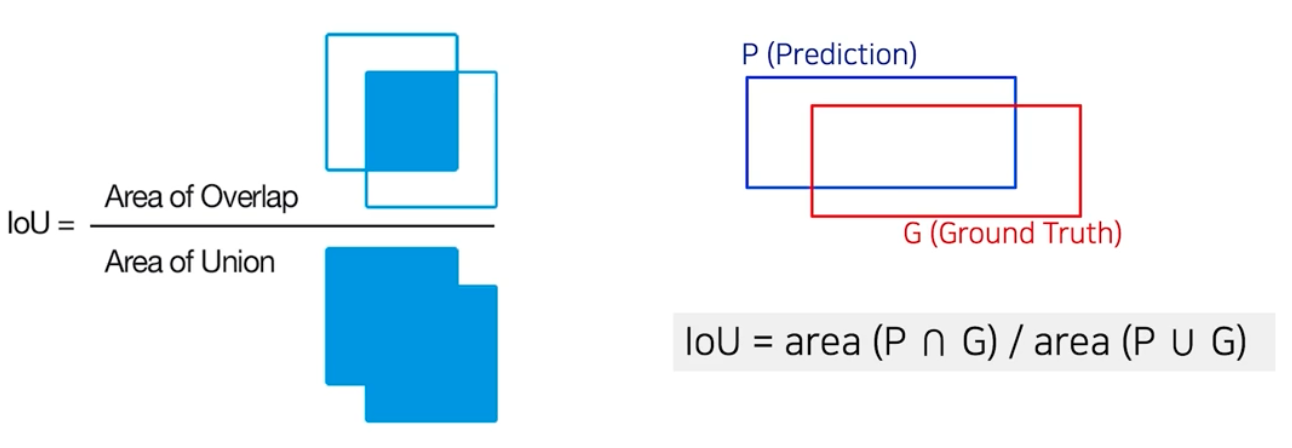
- pred 와 gt 가 있을 때 이 두 영역간의 매칭 정도를 IoU 방식으로 계산한다.
- 두 영역 간의 유사도를 두 영역의 합집합 크기 분의 두 영역의 교집합 크기로 정의한다.
- 두 영역 간 유사도 계산
- Area Recall 과 Area Precision 을 이용한다.

- 영역 개념으로 가져온 Area Recall 은 정답 기준의 계산이므로 정답과 예측의 교집합 영역의 넓이를 정답의 영역으로 나눈 값이다.
- Area Precision 은 예측 기준의 계산이므로 정답과 예측의 교집합 영역의 넓이를 예측의 영역으로 나눈 값이다.
- 매칭 행렬에서 유사도 수치 하나를 뽑는 스코어링 과정의 필요한 용어를 살펴보자.
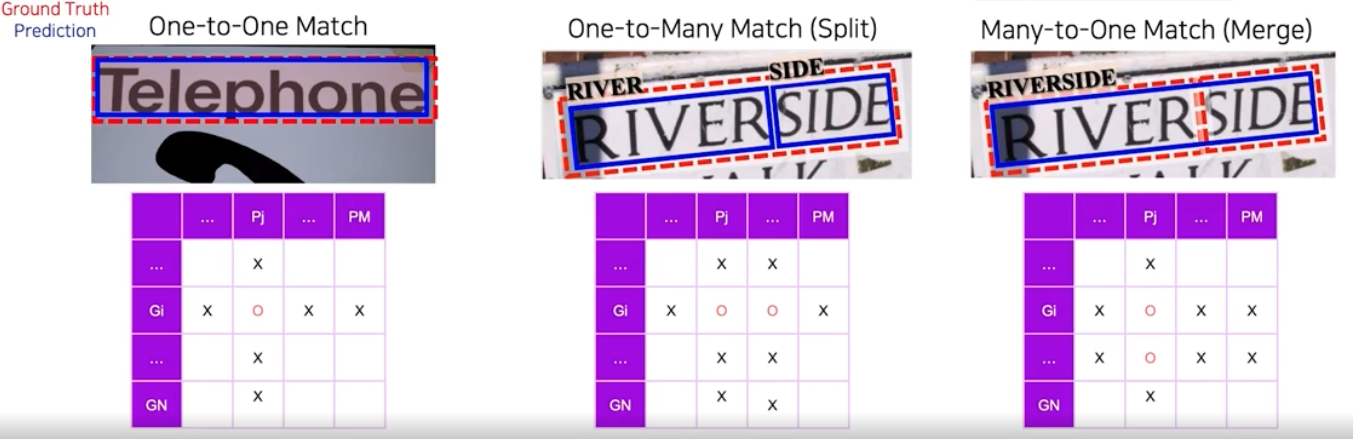
- One-to-One
- 정답에 해당되는 영역 하나가 예측에 해당되는 여러 영역들 중 하나의 영역으로만 매칭되는 경우
- One-to-Many
- 정답에 해당되는 영역 하나에 여러 예측 영역들이 매칭되는 경우. 하나의 정답 영역이 여러 개로 쪼개져서 예측되는 경우이기 때문에 split case 라고도 한다.
- Many-to-One
- 여러 정답 영역이 하나의 예측 영역에 매칭되는 경우. 여러 정답 영역이 하나로 합쳐져 예측되는 경우라 merge case 라고도 한다.
DetEval
-
2013 ICDAR 에서 사용된 평가방식으로, 현재 가장 많이 사용된다.
 DetEval
DetEval -
제일 먼저 하는 것은 매칭 행렬의 값을 채우는 작업이다. 이 때는 한 매칭당 area recall, area precision 둘 다 계산한다. 즉, 매칭 행렬의 한 셀을 볼 때 그 셀에 해당되는 정답 영역과 예측 영역 사이의 area recall, area precision 을 모두 계산한다. 관계 하나마다 두 개의 수치를 확보하는 것이다.
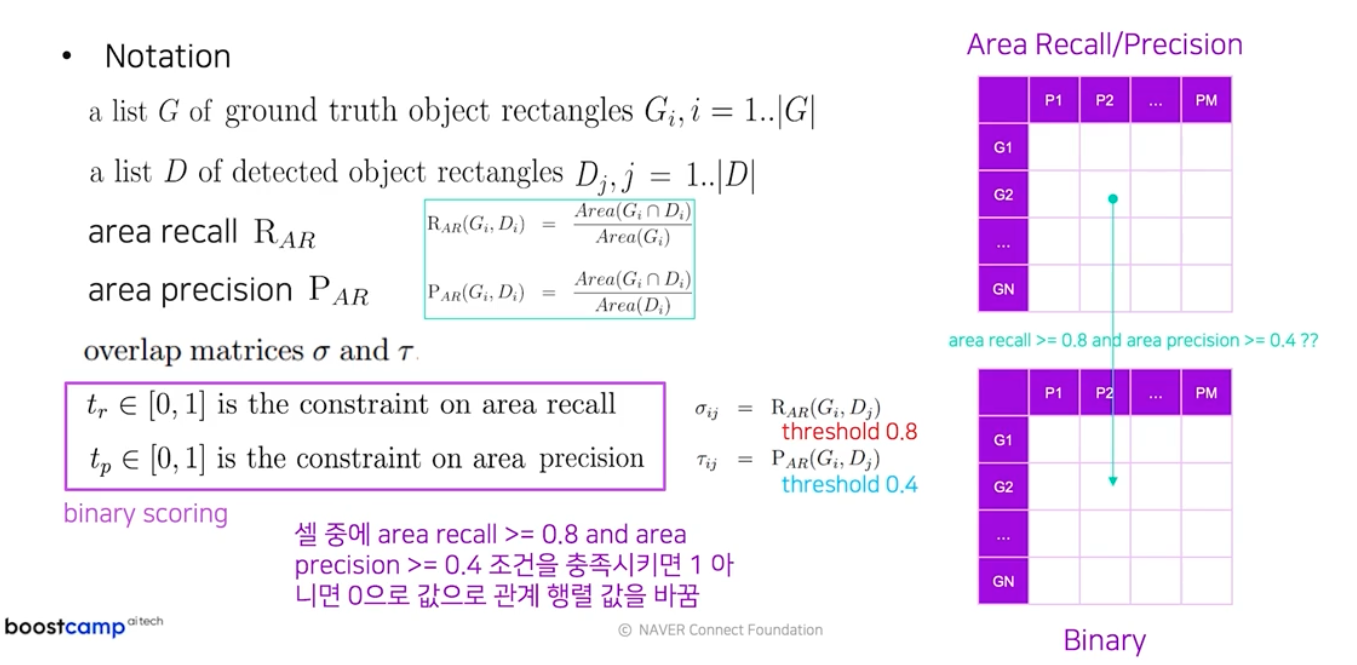
-
이후 각 셀별로 area recall 이 0.8 이상, area precision 이 0.4 이상인 조건을 충족시키면 1, 그게 아니면 모두 0의 값으로 매칭 행렬의 값을 이진수로 변환한다.

- 마지막으로 이진 매칭 행렬값을 보면서 one-to-one, one-to-many, many-to-one 의 관계를 찾는다.
- 매칭 행렬의 최종 수치는 one-to-one, many-to-one 관계는 그대로 1의 값을 사용하고 one-to-many 는 split의 경우로 이를 지양하기 위해서 1이 아닌 약간 작은 숫자인 0.8 로 바꾼다.
-
아래의 예시를 보자.

- 과연 merge(many-to-one) 는 허용하고 split(one-to-many) 은 방지하는 것이 더 나은 정량평가 인지는 서비스 마다 고민이 필요하다.
- 여기까지 하면 테스트 이미지 하나에서 매칭 행렬값을 도출하는 것까지 하게 된 것이다.
-
이제 원하는 것은 테스트 이미지 한 장에 대한 DetEval 방식으로 평가했을 때의 숫자 하나가 된다.
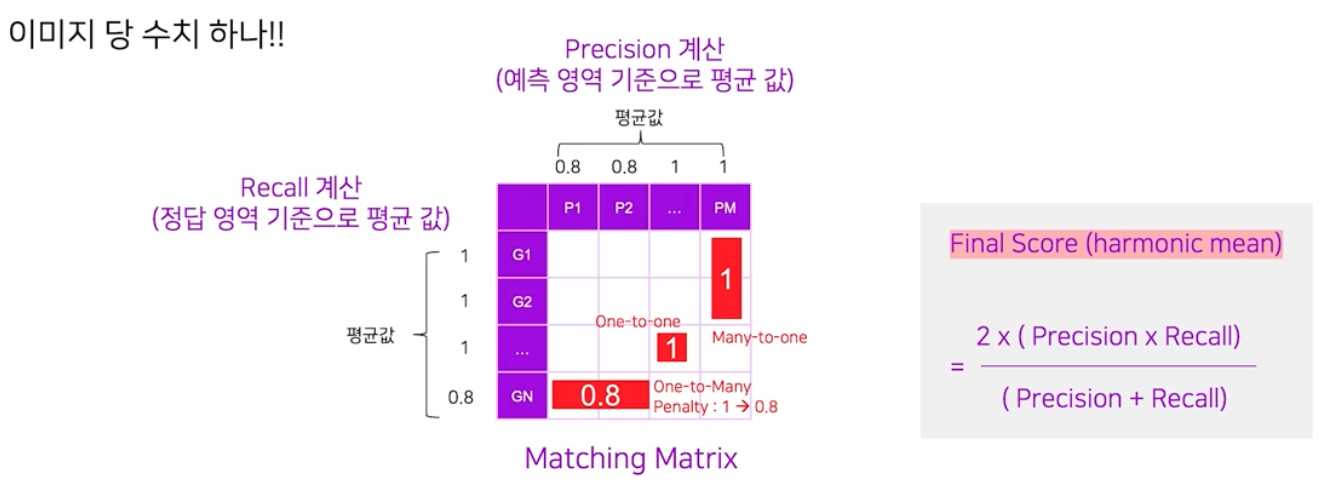
- 이를 위해서 이미지 단위에서의 Recall 과 Precision 을 계산해야 한다.
- Recall 은 정답 영역 별 매칭 행렬의 값을 가져온다. 그 값들을 평균을 내면 Recall 이 계산된다.
- Precision 은 예측 영역 별 매칭 행렬의 값을 가져온다. 그 값들을 평균을 내면 Precision이 계산된다.
- 마지막 최종 수치는 Precision 과 Recall 에 대한 조화평균 값으로 계산된다.
IoU
- ICDAR 에서 2013 년에 DetEval 을 사용했다면, 2015년에는 IoU 를 채택했다.
-
IoU 는 매칭 행렬 값을 채울 때 IoU 의 값으로 채운다.
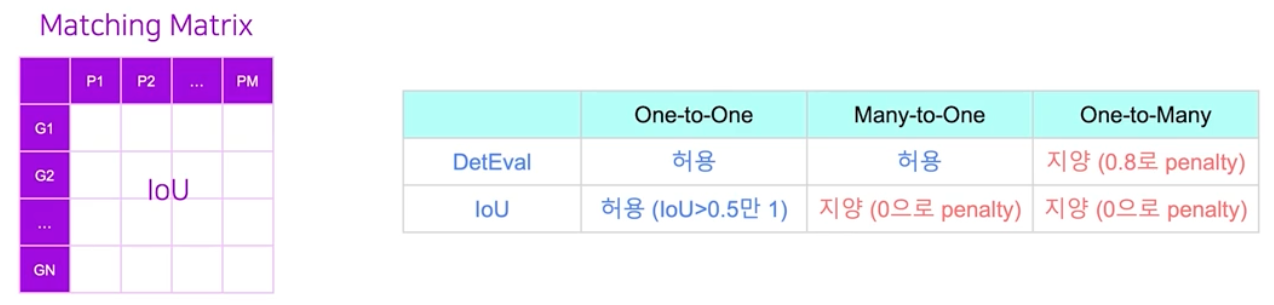
- DetEval 과의 또 다른 차이점은, IoU 에서는 split 과 merge 를 허용하지 않고 오직 one-to-one 매칭만 허용한다.
- one-to-one 매칭 조건에 성립하면서 IoU > 0.5 일 경우에만 1 로 되고 나머지는 0 이 되는 binary scoring 방식을 따른다.즉 매칭 행렬에서 IoU 값이 0.5 이상이고 one-to-one 인 셀만 1, 나머지는 0으로 한 뒤 최종 스코어를 계산하는 것이다.
-
예시를 보자.

- 3번째 예시는 one-to-many 의 관계이고 두 예측 영역이 IoU 가 0.5 미만이기 때문에 0 이 된다.
- 그러나 만약 3번째 예시에서 1개의 예측 박스가 IoU 0.5 이상이 되는 경우를 생각해보자.
- 이 때는 GT 박스 1개와 Prediction 박스 1개가 맞은 걸로 판단된다. 따라서 Recall 1(1/1), Precision 0.5(1/2) 로 계산되어 조화평균을 취하면 score 가 약 0.67 이 된다.
TIoU(Tightness-aware IoU)
-
기존 DetEval 이나 IoU 의 정량평가 방식으로 대응이 안되는 경우가 있다고 판단하여 제안된 Metric 이다.
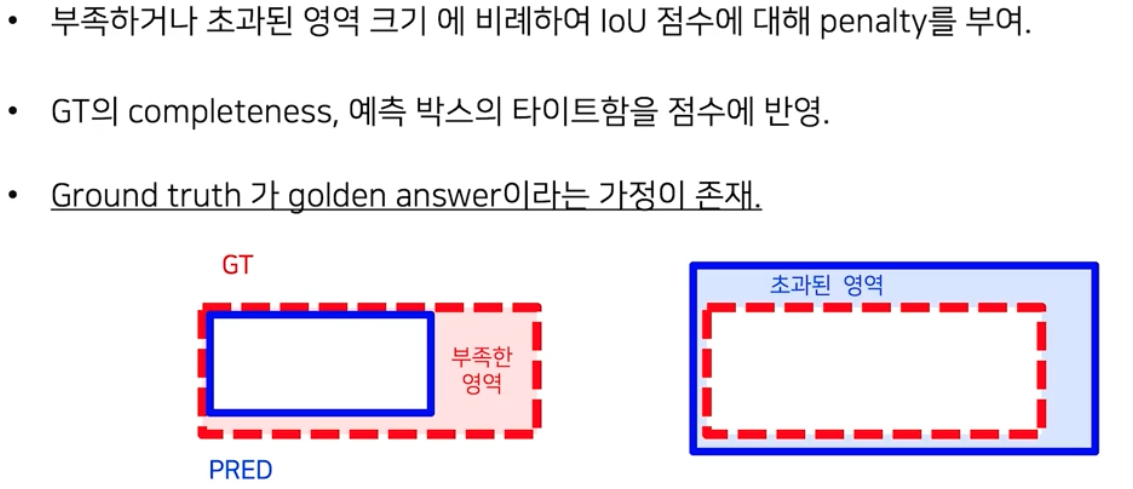
- 전반적인 과정은 IoU 와 동일하지만, 매칭 행렬 계산 시 IoU 에서 약간의 수정을 가한 TIoU 를 사용한다.
- TIoU 는 얼마나 정답에 가깝게 예측이 되었느냐를 중시하는 지표다.
- 모자르게 잡거나 초과되게 잡으면, 그 영역의 크기만큼 수치에 패널티를 준다.
- 그러나 이런 식으로 계산을 하게 되면 정답 자체가 잘못되었을 때 그 여파가 크게 생길 수 있다.
- 원래 IoU 계산 방법에서 TIoU 는
IoU * (1 - penalty)로 표현되고 penalty 는 0에서 1 사이의 값을 가진다. - penalty 는 2종류다.
- 부족한 영역의 경우,
부족한 영역 크기 / 정답 영역 크기로 구한다. 정답 영역 기준의 상대적인 값이기 때문에 TIoU Recall 이라고 볼 수 있다. - 초과한 영역의 경우,
초과된 영역 크기 / 예측 영역 크기로 구한다. 예측 영역 기준의 상대적인 값이기 때문에 TIoU Precision 이라고 볼 수 있다.
- 부족한 영역의 경우,
-
따라서 최종 수치는 아래와 같다.

-
예제를 보자.

- 여기서 TIoU 의 단점을 확인할 수 있다.
- 위 예시처럼 부족하게 예측한 경우, 하나(두번째)는 전체적으로 타이트하고, 다른 하나(세번째)는 한 글자를 빼고 잡았는데 점수가 동일하다.
- 글자 인식 관점에서 두번째의 경우 Recognizer가 완벽하면 모든 글자가 다 인식 가능하다. 그러나 세번째의 경우 Recognizer 가 완벽하더라도 마지막 글자는 인식이 불가능하다.
CLEval(Character-Level Evaluation)
- TIoU 의 단점과 같은 동기로부터 개발된 정량 평가 방식이다.
- CLEval 의 핵심 철학은 Detector 의 성능은 Recognizer 관점에서 바라봐야 한다는 것이다.
- 즉 Recognizer 성능이 완벽할 때, 모든 글자들을 잘 인식할 수 있느냐의 관점에서 Text Detection 모델을 평가 하는 것이다.
- 이는 결국 Text Detection 모델 평가는 글자 단위 평가에 기반을 둘 수밖에 없다는 결론이 된다. 즉 인식까지 했을 때 결과가 잘 나오느냐의 관점을 따른다.
-
따라서 CLEval 은 얼마나 많은 글자(Character)를 맞추고 틀렸느냐를 가지고 평가한다. 또한 Detection 뿐 아니라 end-to-end, Recognition 에 대해서도 평가가 가능하다.

- 위 예시처럼 Recognizer 성능이 완벽하다는 가정 하에 Detector 와 Recognizer 성능을 동시에 측정하는 기존의 방식으로 하면 0점이 나오는데, CLEval 은 글자 수 기반이라 0.9 점수가 나온다.
-
CLEval 은 글자 레벨의 평가인데, 이를 수행하기 위해서는 글자 각각의 위치에 대한 정답을 가지고 있어야 한다. 그러나 보통 공개 데이터셋에는 이러한 정보는 없고 글자 영역의 위치 정보와 transcription 즉 글자 시퀀스만 정답으로 제공된다.
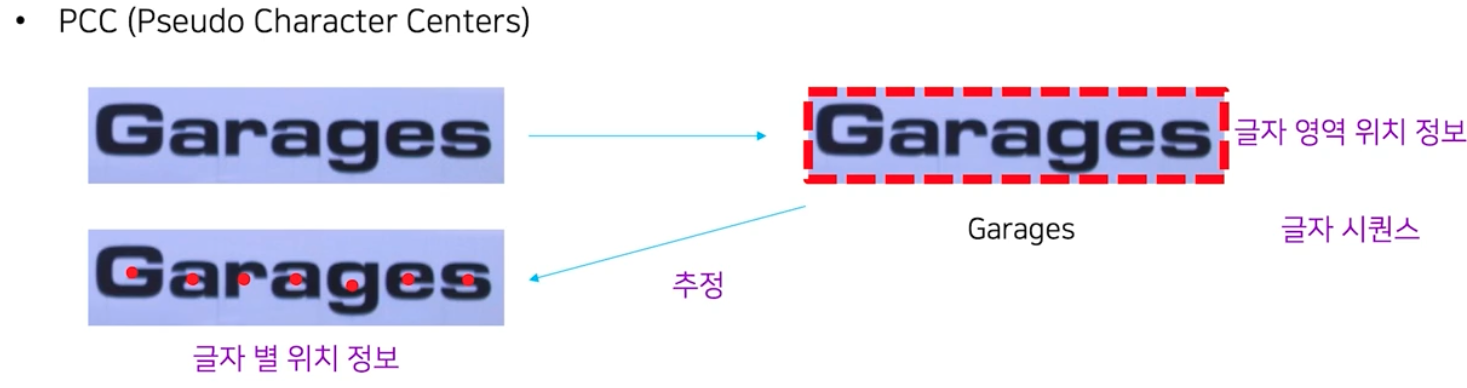
- 그래서 CLEval 의 핵심은 제공되는 글자 영역의 위치정보와 글자 시퀀스 정보로부터 글자 별 위치정보를 추정하는 모듈이 된다.
-
PCC(Pseudo Character Centers)
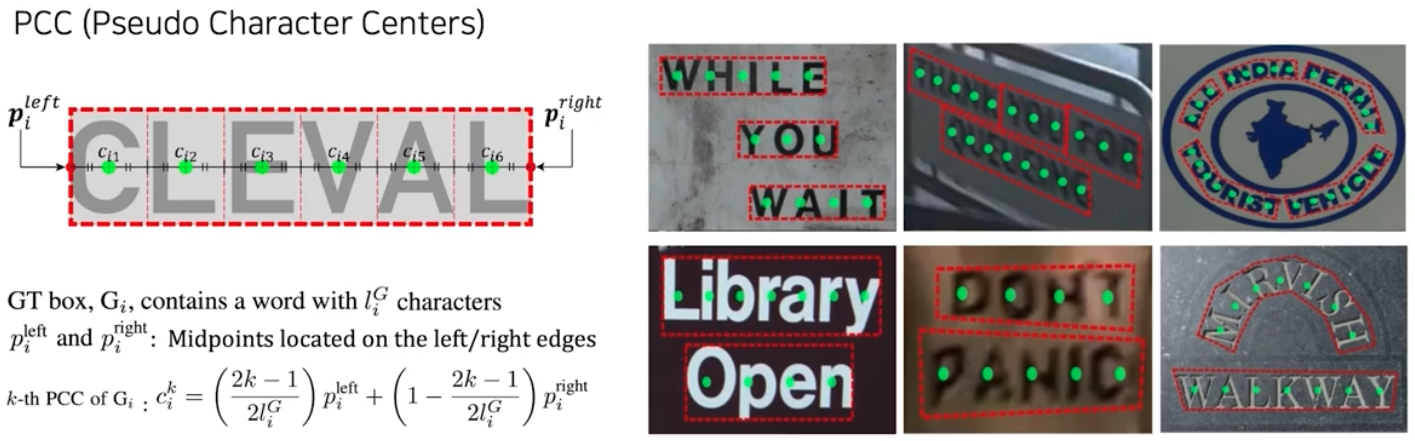
- 글자 수에 대한 정보가 있으므로 글자 영역을 글자 수만큼 등분해서 나누고, 각 영역 별 센터 좌표를 구한 것이 결국 그 글자의 중심위치 라고 판단할 수 있다. 이렇게 구한 글자 중심 위치를 PCC 라고 한다.
- 다른 평가 방식과 유사하게 Matching Matrix 도 값을 정의해서 채워야 한다.
- 이 때 셀 하나의 값은 score가 된다. 이는
(CorrectNum - GranualPenalty) / TotalNum으로 구할 수 있다. - 이 계산법도 크게 정답 기준 스코어와 예측 기준 스코어로 나뉜다.
-
정답기준 스코어는 정답 영역 기준이므로 Recall 로 볼 수 있다.

- CorrectNum : 정답 영역 내 PCC 중 어느 예측 영역이라도 속하게 된 PCC의 개수
- GranualPenalty : 정답 영역 내 PCC 를 포함하는 예측 영역의 개수 - 1
- TotalNum : 정답 영역 내 PCC 개수
-
예측기준 스코어는 예측 영역 기준이므로 Precision 으로 볼 수 있다.

- CorrectNum : 예측 영역이 포함하고 있는 PCC 별로, 해당 PCC 를 포함하는 예측 영역의 개수로 나누어 합한다.
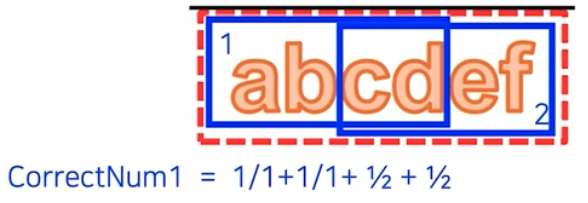 첫번째 예측 영역의 CorrectNum
첫번째 예측 영역의 CorrectNum- GranualPenalty : 예측 영역과 연관된 정답 영역의 개수 - 1 로 구한다. 이 때 정답 영역의 PCC를 이 예측 영역이 포함하고 있으면 서로 연관이 있다고 간주한다.
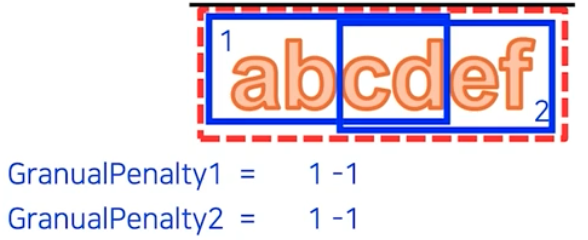
- TotalNum : 이 예측 영역이 포함하고 있는 PCC 의 개수
- 이 때 셀 하나의 값은 score가 된다. 이는
-
이렇게 구한 Recall 과 Precision 으로 최종 수치 하나를 계산한다.
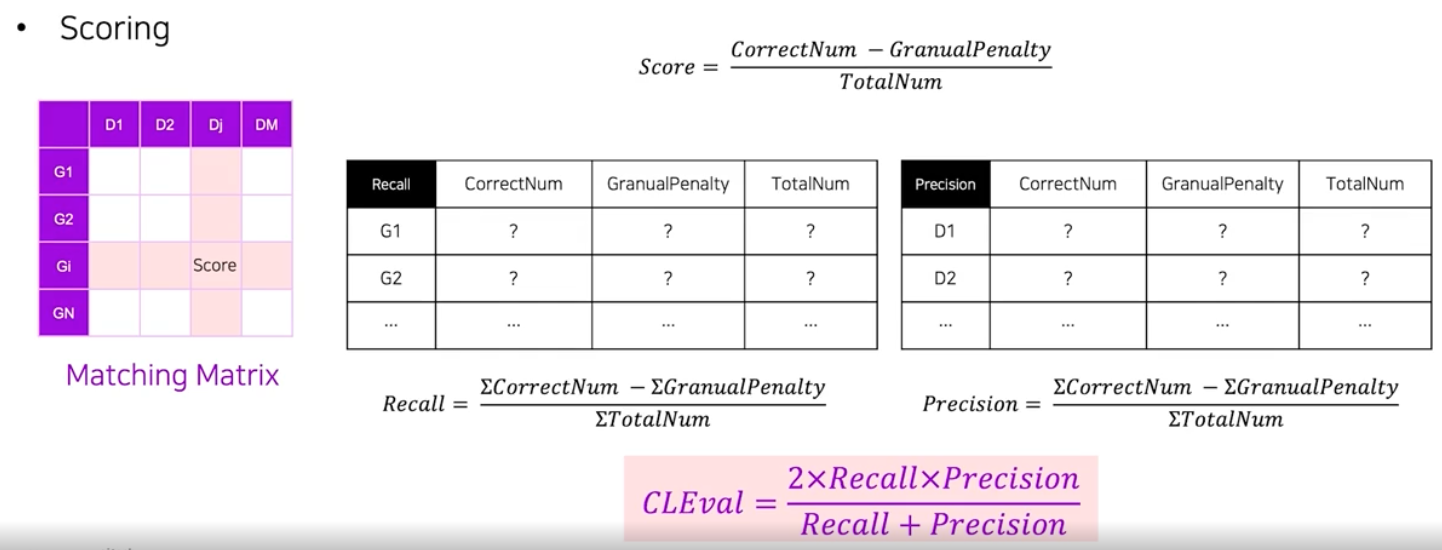
- 이 때 Recall 과 Precision 은 CorrectNum, GranualPenalty, TotalNum 모두 각각 합을 구해서 score 를 계산한다.
비교
-
DetEval, IoU, TIoU, CLEval 4가지 평가방식을 살펴봤다. 이제 예시를 통해 각각의 방법에 대한 계산을 보자.

- TIoU 에서 many-to-one, one-to-many 매칭을 허용하기 위해서는 별도로 line annotataion 이 필요하다.
- 여러 정량 평가 방식이 있지만 각각의 의도와 특징이 다르다. 정량적인 수치를 분석할 때, 정성평가까지 하면서 의미있게 수치가 낮아진 것인지, 정량평가 방법이 이상해서 수치가 낮아진 것인지 파악해볼 필요가 있다.
정리
- IoU(Intersection over Union)은 예측 영역과 정답 영역이 있을 때, 두 영역의 교집합 넓이를 합집합 넓이로 나눈 값이다.
- Area Recall 은 정답과 예측 영역의 교집합 넓이를 정답의 영역으로 나눈 값이다.
- Area Precision 은 정답과 예측 영역의 교집합 넓이를 예측의 영역으로 나눈 값이다.
- One-to-Many Match 는 정답 영역 하나에 여러 예측 영역들이 매칭되는 경우를 나타낸다. Split Case 라고도 불린다.
- CLEval 은 Recognizer 성능이 완벽할 때 결국 모든 글자들을 잘 인식할 수 있느냐의 관점에서 Text Detection 모델을 평가하는 방법이다. 따라서 Recognizer 성능에 의존적이라고 볼 수 있다.
댓글 남기기