
[OCR] 4. Data for OCR
Data for OCR
- Text Detection task 를 하기 위한 모델을 학습시킬 때 어떤 데이터가 필요한 지를 살펴보자.
- 글자 영역 검출만 해당하는 데이터셋은 잘 없고, 보통 OCR 전체에 해당하는 데이터셋이 많다.
- 따라서 OCR 관련 데이터셋에 대해서 살펴보자.
- 모델에 대한 이해, task 에 대한 이해도 중요하지만, 데이터 자체에 대한 이해도 굉장히 중요하다.
Data Collection
-
Public Dataset vs. Created Dataset
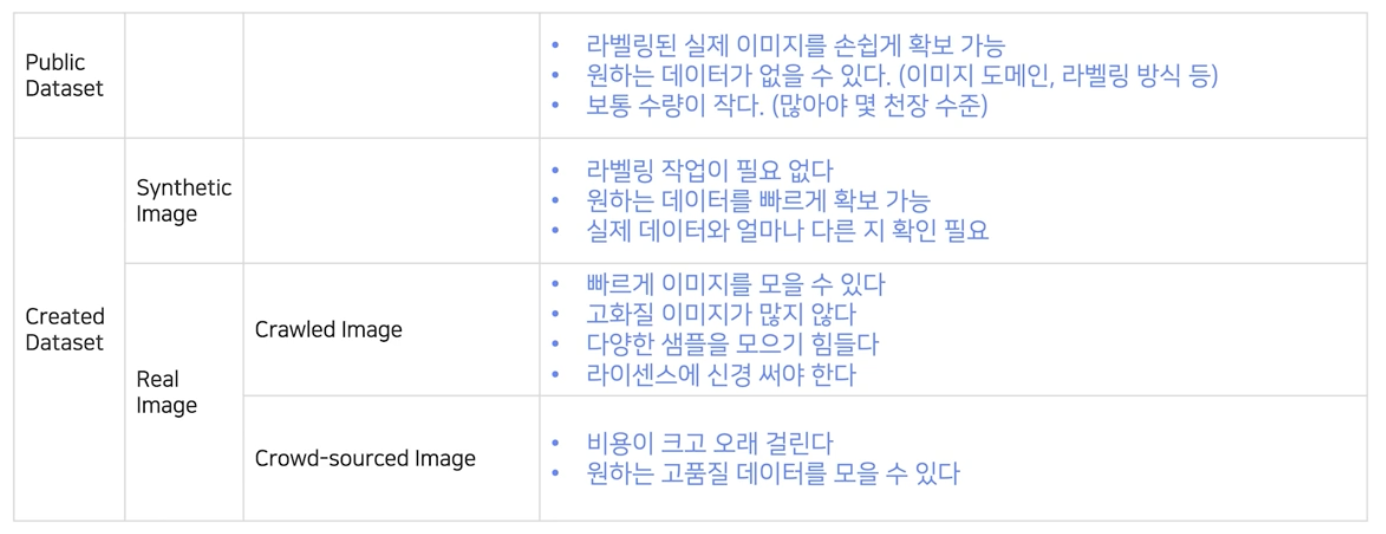
 public dataset
public dataset - public dataset 은 라벨링된 실제 이미지를 손쉽게 확보 가능하다는 장점이 있지만 원하는 데이터가 없을 수 있다.
-
요즘에는 AI Hub 와 같은 공개 데이터셋을 모아둔 사이트에 들어가면 많은 양의 데이터를 얻을 수 있다. 다만 내가 원하는 task 에 맞는 데이터는 없을 수 있다.
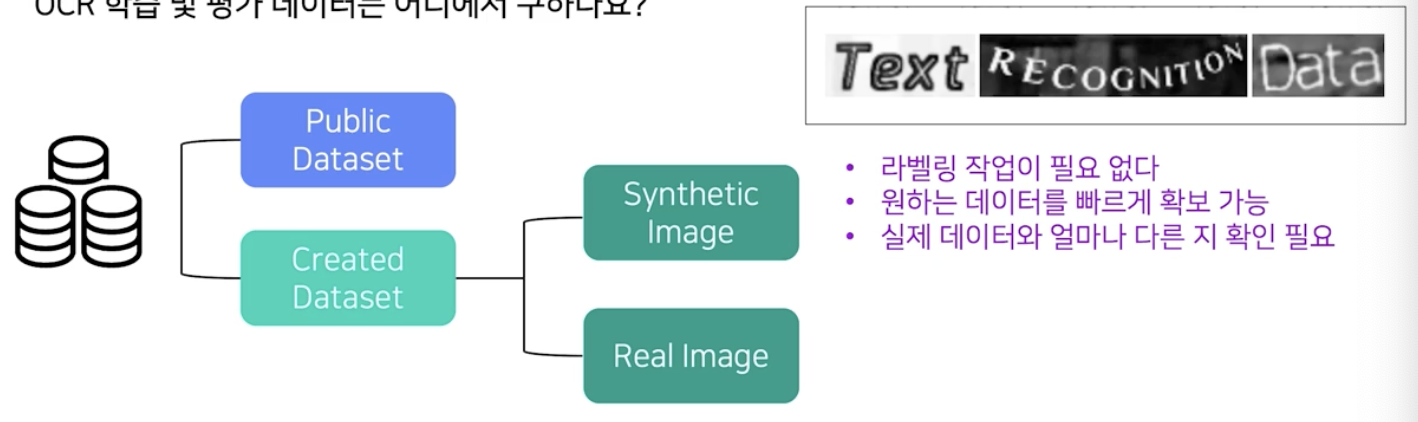 creadted dataset - synthetic image
creadted dataset - synthetic image - 합성 데이터(synthetic image)가 실제 데이터와 가까운 task 일수록 합성데이터를 활용하는 의미가 크다.
-
특히 OCR 의 경우 글자 자체가 사람이 만들어낸 인위적인 texture 이기 때문에 합성 데이터가 의미있게 활용될 수 있다.
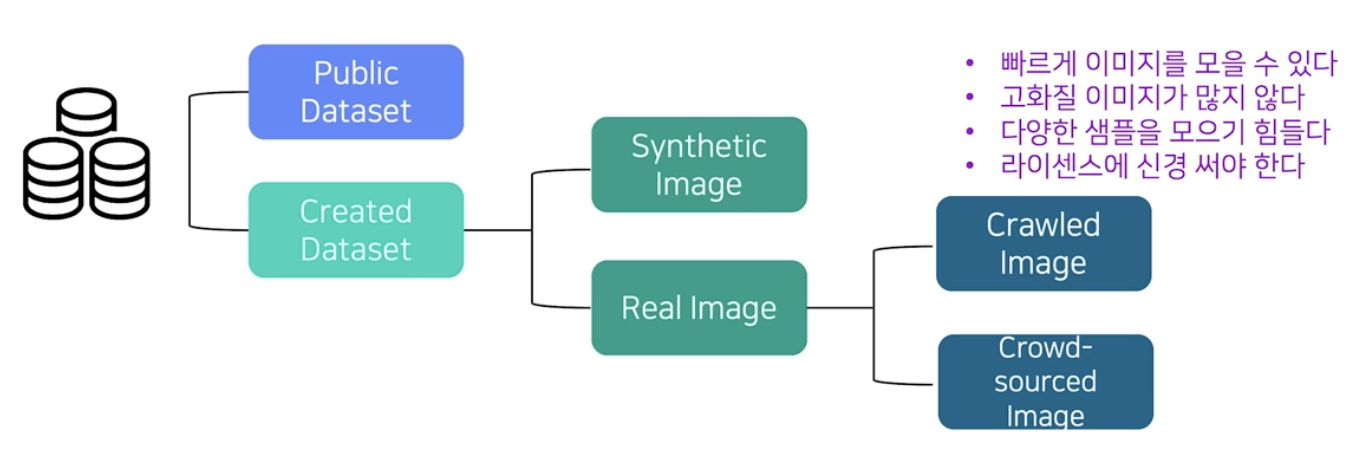
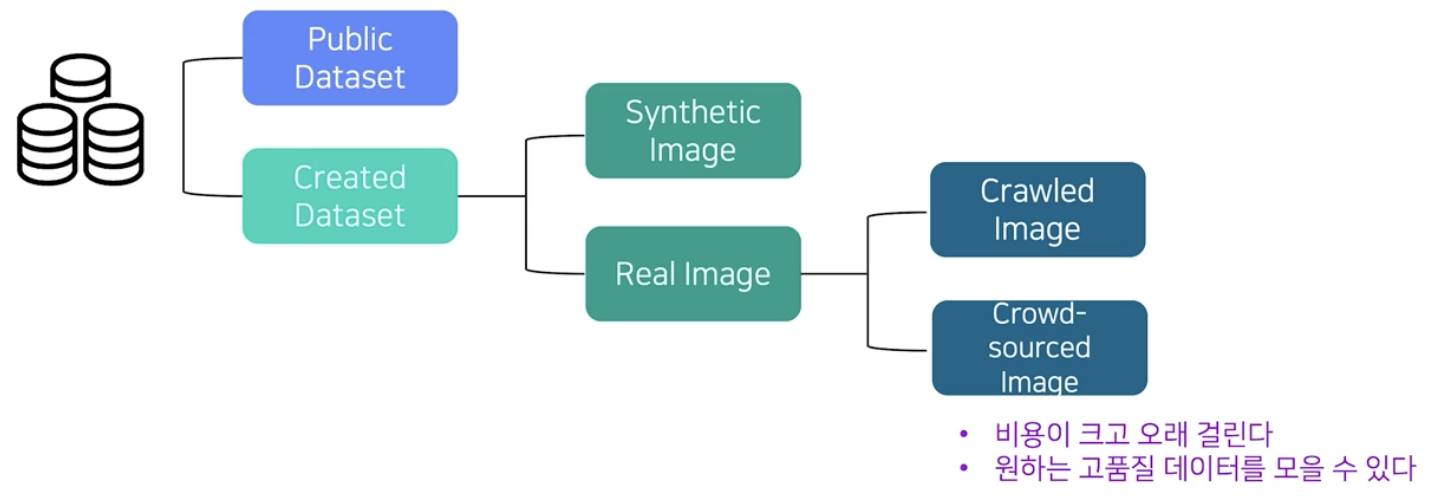
- 손쉽게 얻을 수 있는 데이터 이외에 필요한 데이터를 Crowd-sourced image 방식으로 수집하기도 한다. 이를 위한 별도 회사가 존재하기도 한다.
- 또한 잘 알려진 방식으로 크롤링도 있다. 이 때에는 라이센스 등을 신경써야 한다.
-
학습 데이터를 모으는 총 4가지 방법에 대해서 장단점을 살펴보자. 주어진 기간, 예산, 목적에 맞게 이 4가지 방법을 적절히 선택적으로 사용해야 한다. 따라서 수집 방법 별 특징을 숙지해두면 실무에서 큰 도움이 된다.
Public Dataset
- 공개되어 있는 OCR 데이터셋 전반을 알아보자.
- 서비스향 AI 모델 개발 시 한시라도 빨리 답을 가지고 있어야 하는 질문들은 아래와 같다.
- 몇 장을 학습시키면 어느 정도 성능이 나오는가?
- 한 모델을 학습시킬 때 필요한 데이터 수의 감을 잡기 위함이다.
- 어떤 경우가 일반적이고 어떤 경우가 희귀 케이스인가?
- 데이터를 모을 때 어떤 경우를 신경써서 모아야 하는지 감을 잡기 위함이다.
- 현재 최신 모델의 한계는 무엇인가?
- 우리가 풀고자 하는 문제가 현실적으로 풀릴 수 있는 문제인지를 확인하기 위함이다.
- 몇 장을 학습시키면 어느 정도 성능이 나오는가?
- 이 모든 질문들에 답하기 위해 가장 좋은 방법은, 공개되어 있는 데이터셋으로 공개되어 있는 최신 모델을 학습시켜 성능을 분석하는 것 이다.
- 공개되어 있는 데이터셋 검색 방법
- 대회 → Kaggle(OCR 관련 대회), RRC(Robust Reading Chanllenges, 2년마다 열리는 OCR 전문 대회)
- 논문 → OCR 데이터셋 논문, Arixv(AI 모든 논문), CVPR, ICCV, AAAI, ICDAR(OCR 전문학회)
- 전문 사이트 → Google Datasearch(데이터 전용 검색 플랫폼), Zenodo.org(공개된 데이터셋을 모아서 보여주는 사이트), Datatang(데이터 유료 구매)
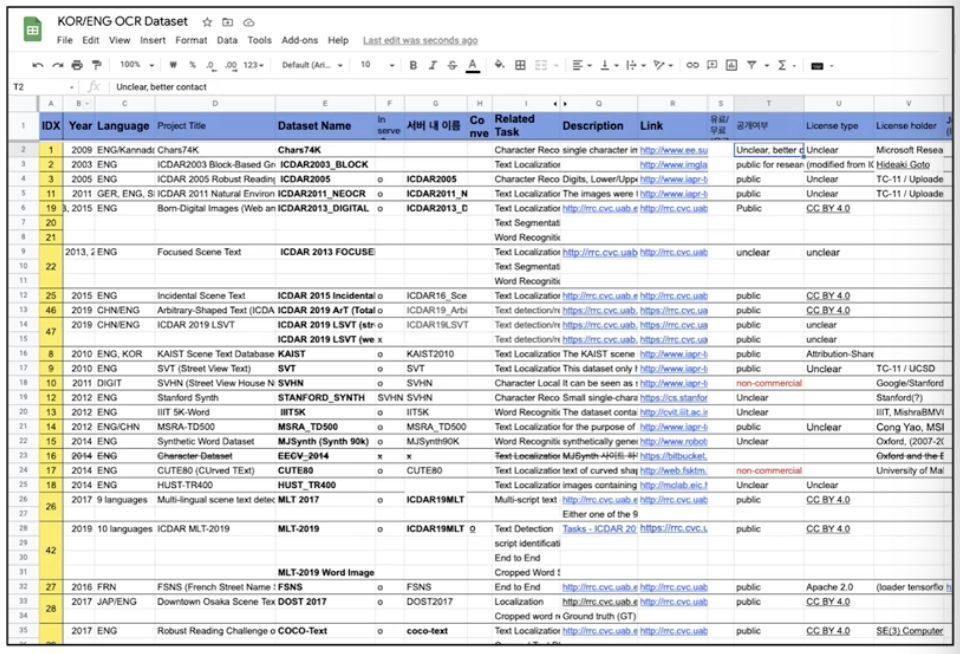
- 주의깊게 확인해야 할 각 데이터셋의 특징들
- 언어, 용도(Detector 와 Recognizer End-to-End(둘 다)), 데이터 수량, 라이센스 종류, 데이터 저장 format, 특이사항
-
이 주 요소들을 잘 정리해두면 목적에 따라 데이터를 취사 선택하여 모델 학습에 훨씬 효율적으로 작업 가능하다.
 주의깊게 확인해야 할 데이터셋의 특징들 정리
주의깊게 확인해야 할 데이터셋의 특징들 정리
-
OCR 데이터에 포함되는 요소들
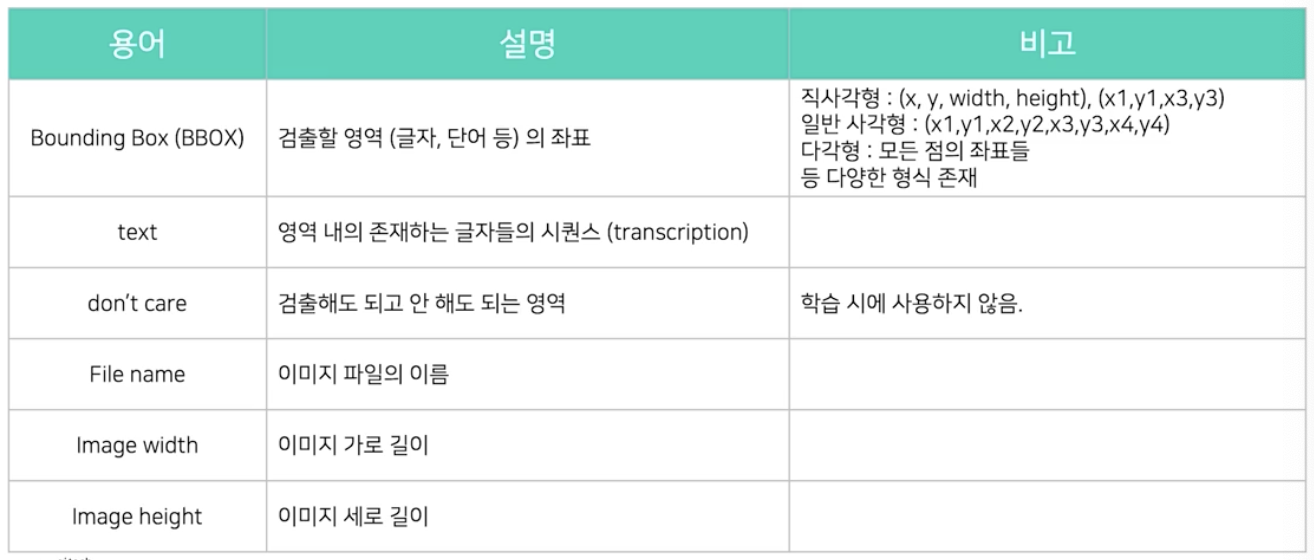
- 글자 영역은 보통 bounding box 사각형의 형태로 표현한다. 이 때 좌표형식은 데이터셋마다 다양한 형식으로 표현된다.
- 일반 사각형의 경우 좌상단 점을 기준으로 시계방향으로 이동하며, 총 4개의 좌표 혹은 8개의 좌표값들을 모두 제공한다.
- 다각형의 경우 모든 점의 좌표를 다 제공한다.
- text 는 영역 내 존재하는 글자들의 시퀀스로, transcription 이라 부르기도 한다.
- don’t care 는 글자지만 육안상 알아보기 어렵거나 라벨링 하기 비용이 크거나 혹은 어떻게 해석할지 잘 모르는 난해한 경우에 해당한다. 이 경우의 데이터는 학습 시 사용하지 않는다.
ICDAR(International Conference on Document Analysis and Recognition)
- 대표적인 OCR 대회다.
- 2년마다 한번씩 열리는데, 이 때 사용하는 데이터셋이 가장 공신력있는 데이터셋이다.
- 많은 OCR 논문에서 benchmark 데이터셋으로 활용한다.
- 기술 발전에 따라 ICDAR 대회의 난이도도 어려워지면서 데이터셋도 자연스럽게 더 어려워졌다.
- ICDAR 15
- Incidental Scene Text : 풍경 이미지 속에 우연히 글자가 잡힌 경우
-
총 1,500 장의 이미지와 그에 해당하는 GT (text file) 를 제공한다.

- 위 예시처럼 8개의 좌표값과 해당 영역에서의 글자 sequence(transcription) 가 제공된다.
- 좌표 순서의 경우 글자 영역의 좌상단(x1,y1) 부터 해서 시계방향으로 4개의 점이 표시가 된다.
-
글자 영역 중에 don’t care 는 transcription 을 ### 으로 나타낸다.

- 시각화하면 care 는 초록박스, don’t care 는 빨간박스로 나타난다.
- 글자 영역별로 care, don’t care 로 구분하여 전사한다.
- care : 검출할 영역, 라틴문자
- don’t care : 검출하지 않을 영역. 육안상 알아보기 힘든 글자, 라틴문자가 아닌 글자(한자 등)
- ICDAR 17
- Multi-lingual Scene Text(MLT)
- 다양한 언어를 다루고자 한 데이터셋이다. 9가지 언어, 6가지 문자로 구성된다.
-
총 18,000 장의 이미지와 그에 해당하는 GT 를 제공한다.

- Focused(Intentional) Scene Text
- 우연히 찍힌 글자가 아닌, 글자 영역을 위주로 촬영된 이미지다.
- 길거리 표지판, 광고판, 가게 간판 등
- GT 파일 라벨링 형식은 ICDAR 15 와 매우 유사하다.
- ICDAR 2019
- ArT(Arbitrary shaped Text)
- 기존의 사각형 형태의 글자 영역 외에도 다양한 글자영역을 포함시킨 데이터셋이다.
-
난이도가 상당히 높다.

- AI Hub
- 한국어 공개 데이터셋이 존재한다.
- 최근 국가 사업으로 구축되는 OCR 데이터셋도 많이 생겼다.
- 야외 실제 촬영 한글 이미지
- 글자 영역에 초점을 주어 촬영된 Focused Scene Text 다.
- 1600x1200 해상도 한글 이미지가 50만건 제공된다.
- GT 의 경우 json 형태로 제공된다.
- 주요 특징
- 이미지 내에 단어가 여러 개 있는 경우 transcription 은 가장 잘 보이는 순서대로 최대 3개까지만 라벨링했다.
- 그 외의 글자영역은 표시하지만 그 안에 있는 텍스트는 don’t care 로 표시했다.
- 따라서 Recognizer 로 활용할 수 있는 데이터가 전체 데이터에 비해 좀 작은 편이다.
- 글자 영역은 직사각형 형태로 제공된다. (4개의 숫자)
- 촬영된 이미지에 대한 메타데이터도 함께 제공된다.
-
지금까지 살펴본 모든 public dataset 은 글자 영역 검출기(Detector)에 필요한 정보를 담고 있기는 하지만, 데이터셋마다 글자영역을 표현하는 방식 및 구조가 각기 달라서, 실험의 용이성을 위해 일관된 포맷으로 통합하여 저장할 수 있는 어노테이션의 형식과 구조를 고민할 수밖에 없다.
 format 의 구조
format 의 구조
UFO(upstage format for OCR)
- 공개된 데이터가 많은데, 그 데이터들의 저장 format 을 보면 다른 경우가 많다.
- 그러면 공개된 데이터를 다 모아서 한 번에 모델에 넣어서 실험하고 싶을 때는 다른 데이터 format 에 맞춰서 데이터 I/O 를 짜야하는 경우가 있다.
- 이 때 하나의 format 을 정해놓고 데이터를 converting 해서 사용하는 경우가 많다.
- 즉 다양한 format 의 데이터셋을 한꺼번에 사용할 경우, 하나의 통일된 format 으로 변경 후 실험하는 것이 훨씬 효율적이다.
- 그 대안이 되는 data format 인 UFO 를 보자. public dataset 을 일관된 방식으로 읽어들이기 위한 일종의 통합 format 이다.
- 모든 public 데이터셋은 UFO 형태로 변경하여 저장할 수 있고, 실험 시 dataloader 부분이 매우 간단해지게 된다.
- UFO format 의 목적
- 여러 파일 형식을 하나로 통합(json, txt, xml, csv 등)
- detector(검출기), recognizer(인식기), Parser 등 서로 다른 모듈에서 모두 쉽게 사용할 수 있도록 설계되었다.
- 특히 모델 성능 개선을 위해서 여러 특이 경우들을 잘 관리해야 하는데, 이에 대한 정보를 데이터에 포함시킬 수 있도록 format 을 정했다.
- 예를 들어 이미지 단위에서 특이 케이스가 될 수 있는 손글씨 이미지 여부, 초점이 맞지 않는 경우에 대한 라벨링 정보가 포함된다. 또한 글자 영역 단위로도 가려짐이 있는지, 글자 진행 방향이 특이한 경우인지에 대한 정보도 포함시킬 수 있다.
- UFO format 의 특징
- 이미지 내에 들어있는 정보가 모두 병렬로 존재하게 구성되었다.
- Serializer(정렬기) 모델 개발을 위해서 문단 단위 정보를 불러오고 싶을 때, 특정 이미지 파일에서 paragraph 정보를 불러올 수 있다.
- 그러나 Recognizer(인식기) 모델 학습을 위해서 단어 단위로 정보를 불러오고 싶을 때는 이미지, paragraph, words 순서의 위계를 따라 들어가서 정보를 가져오는 것이 아니라 바로 이미지에서 단어 단위 정보를 불러올 수 있다.
- 유사하게 Parser 모델 학습을 위해 글자 단위 정보를 불러 오고 싶다면, 위계를 따르는 것이 아니라 바로 이미지에서 글자 단위 정보를 불러올 수 있게 format 이 만들어졌다.
- 아래는 각 레벨 별 알 수 있는 정보다.
- Dataset 레벨
- 하나의 데이터셋은 하나의 UFO 형식의 json 파일을 가지고 있다.
- 하나의 UFO 파일은 해당 데이터셋의 모든 이미지에 대한 GT annotation 을 담고 있다.
- 일반적으로 데이터셋은 크게 train, val, test 로 구분되어 있기 때문에 각각 데이터셋에 대한 UFO 파일을 만들게 된다.
- Image 레벨
-
한 데이터셋에서 이미지 단위 정보를 보자.

- 해당 이미지에서의 문단 단위 정보, 단어 단위 정보, 글자 단위 정보, 이미지 크기, 속성, annotation 정보, 라이센스 정보가 담겨져 있다.
- 각각의 정보는 위계를 가지지 않고 parallel 하게 존재한다.
- 따라서 dataloader 부분에서 매우 간단해진다.
- 공통 요소
- Ids
- paragraph(문단), words(단어), character(글자) 레벨 각각에서 모두 id 넘버를 매긴다(순서는 의미 없음).
- points
- 각 라벨의 위치 좌표. 아이템에 대한 이미지상의 영역을 표시해주는 점들의 집합이다.
- 글자를 읽는 방향의 왼쪽 위에서부터 시계방향으로 X, Y 좌표를 nested list 형태로 기록했다.
- 영역은 4points의 bbox가 기본적이나, 6, 8 등 2n 개의 points로 이루어진 polygon도 가능하다.
- [[X1, y1], [x2, y2], [x3, y31, [×4, y4]]
- language : 사용된 언어
- tags
- 아이템 별로 특이 케이스를 다루기 위한 정보를 담았다.
- 성능에 영향을 주지만 별도로 기록하기 애매한 요소를 사전에 정의한 태그로 표시한다.
- 이미지 레벨의 image tag, 단어 레벨의 word tag
- confidence
- 해당 정보가 얼마나 정확한 지에 대한 수치를 담았다.
- OCR 모델이 예측한 pseudo-label 의 경우 confidence score 를 함께 표시한다.
- Ids
-
-
Paragraph 레벨

- 해당 문단의 영역, 위치 정보가 points 에 담긴다.
- 문단에서 사용된 해당 언어에 대한 정보가 language 에 담긴다.
-
Words 레벨

- 단어 내의 글자 정보에 대한 transcription, 단어 내 영역 정보 points, 단어 내 글자 진행 방향 orientation(가로, 세로 쓰기에 해당되지 않으면 irregular), 단어 내 사용된 언어 language 가 담겨있다.
- 또한 단어의 특이한 경우 관리를 위한 tags 정보도 있다.
- 음각/양각(embossing), 거울에 비친 글자(mirrored), 가려짐(occlusion), 초점(blur) 등, 또는 기 정의된 tag 외에도 신규로 자유롭게 tag 를 추가 가능하다.
- 단어가 읽을 만한 정보인지는 illegibility 에 담긴다.
-
Character 레벨

- 이미지 내의 글자별 위치와 해당 글자값을 알 수 있다.
-
데이터 라벨링 작업은 여러 번 개선을 거쳐야 하는 작업이기 때문에 이력을 관리하기 위해서 Annotation log 정보도 별도로 정의했다.

EDA for OCR Data
-
OCR 관점에서 주로 보는 데이터 분포는 아래와 같다.
- Image width, height 분포
- 이미지 당 단어 개수 분포
- 전체 단어 길이 분포
- 특이한 샘플들을 확인 가능하다.
- 정량 평가 방식에서 그 영향을 확인해볼 수 있다.
- 전체 태그 별 분포
- Image tag
- Word tag
- Orientation
- 전체 BBOX 크기 분포
- 넓이 기준
- Horizontal 한 단어의 aspect ratio(가로/세로)
- 종횡비인 aspect ratio 가 성능에 영향을 많이 미친다.
- 좋은 성능을 위해서는 종횡비가 큰 경우를 잘 다뤄야 한다.
- 종횡비가 1보다 작은 경우도 있는데, 폰트 스타일, 촬영 각도 등에 따라 발생할 수 있다.
정리
- UFO
- 요소 탐색의 용이성을 위해 graph structure 기반으로 만들어졌다.
- paragraphs, words, characters 등의 정보가 각 이미지 별로 담겨있다.
- confidence는 신뢰도 정보로 ocr 모델이 예측한 pseudo-label의 경우 함께 표기한다.
- 하나의 이미지 내의 정보는 parallel(병렬적) 하게 존재한다.
- points는 각 라벨의 위치 좌표로 bbox와 polygon 정보를 모두 표현할 수 있다.
댓글 남기기