
[OCR] 3. Advanced Text Detection
Advanced Text Detection Models
- OCR 관련 최신 논문을 보자.
DBNet
- 2020년에 나온 모델의 추론 속도에 중점을 둔 논문이다.
- Differentiable Binarization 이 key feature 다.
- 기존 segmentation 기반 방법이 다양한 모양의 텍스트 영역을 유연하게 잡아낼 수 있지만(휘어진 영역도 잘 검출된다), 인접한 개체 구분이 어렵다는 점을 지적했다. DBNet 에서는 이를 극복할 수 있는 방법을 제안했다.
-
인접 개체 구분이 어렵다는 문제를 해결하기 위해서 기존에 다양한 시도의 연구가 있었다.
-
Pixel embedding

- 글자 영역 별로 같은 영역 내 화소끼리는 가깝게, 다른 영역 화소들은 멀게 Pixel embedding 을 학습 시켜서, 글자 영역을 결정짓기 위한 후처리 작업에 pixel embedding 정보에 기반한 클러스터링 기법을 사용할 수 있다.
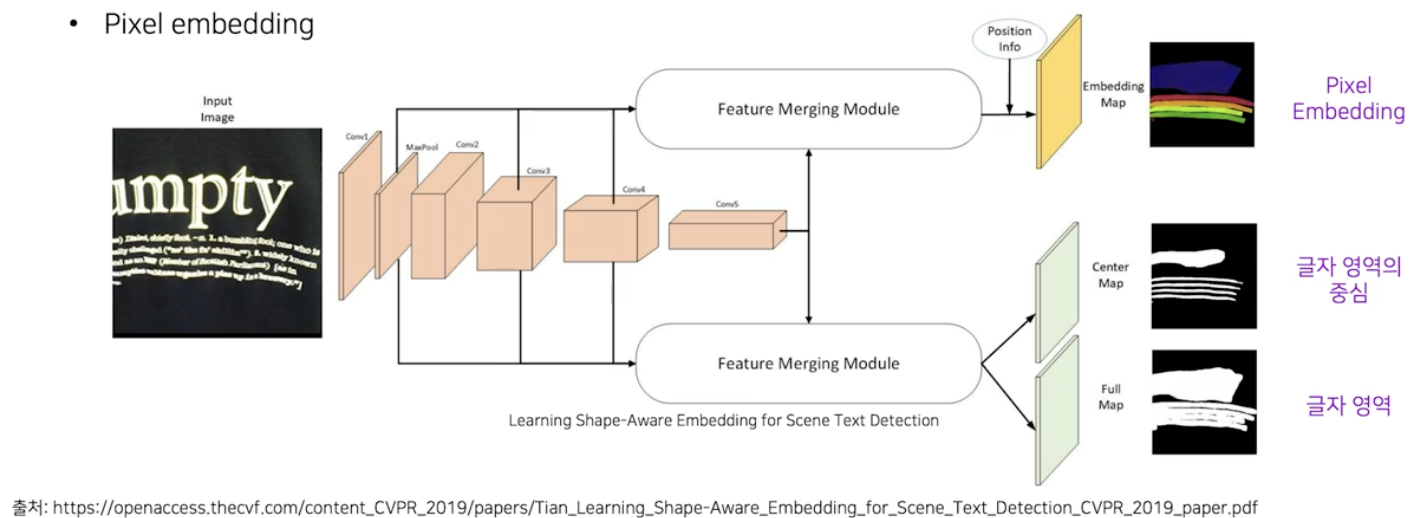
- 네트워크의 출력으로 기본적 글자 영역 외에 Pixel embedding 정보와, 글자 영역 간 구분을 더 잘하기 위한 글자 영역의 중심 을 사용한다.
-
PSENet
- 글자 영역인 $S_n$ 에서 좀 더 글자 중심 영역으로 줄어든 $S_{n-1}$ 이후로 계속 좀 더 줄어든 영역을 만들어가면서, 마지막에는 text 의 center line 에 가까운 영역을 추정한다.
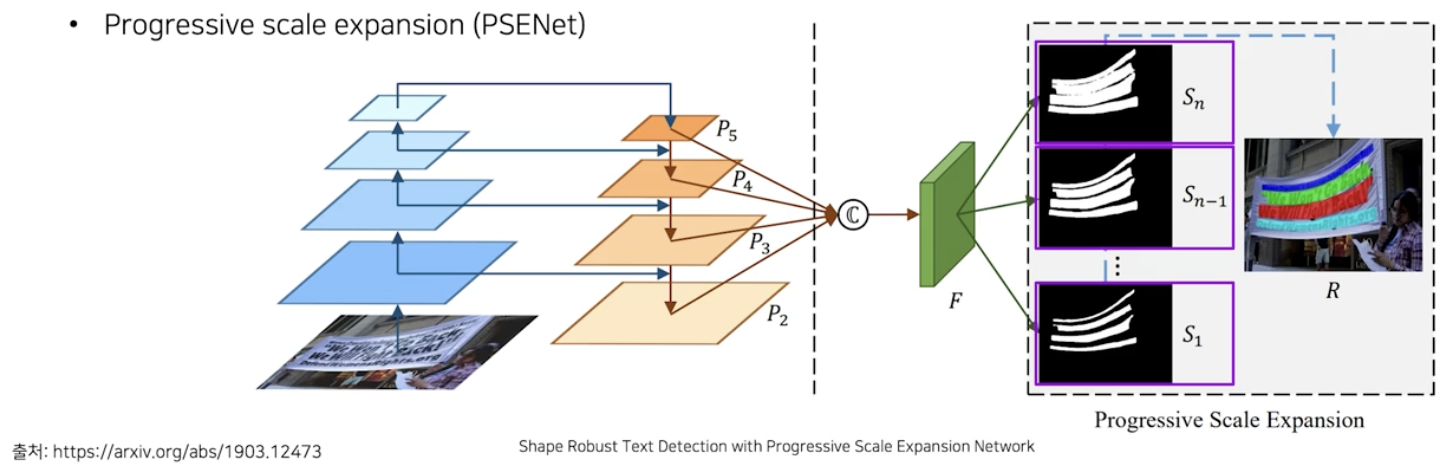
- 다양한 scale 에서 map 을 확보한 후에는 제일 작은 영역부터 시작하여 글자 영역을 확정 지은 뒤, 차례대로 그 다음 맵을 가져오면서 해당 정보를 활용하여 글자 영역을 키워나가고 구분해 나간다.
-
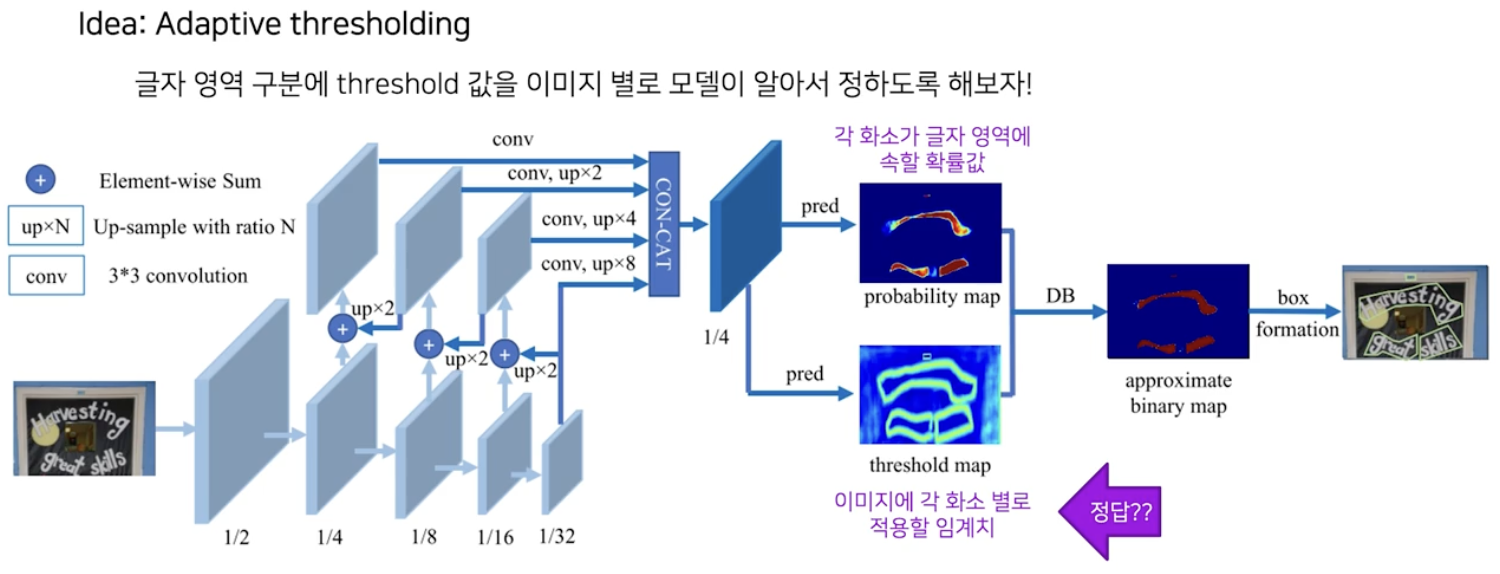
핵심 아이디어
- DBNet 은 모델이 글자 영역 구분을 잘 할 수 있도록, 글자 영역을 구분짓는 근간인 임계치를 잘 생성하면 어떨까 라는 생각으로 출발했다.
- 그래서 모델의 출력으로 글자 영역에 해당되는 확률값과 이 영역에 적용할 임계치에 대한 map 을 사용한다.
-
문제는 이 임계치 map 에 대한 정답을 어떻게 넣어주느냐가 문제된다.
-
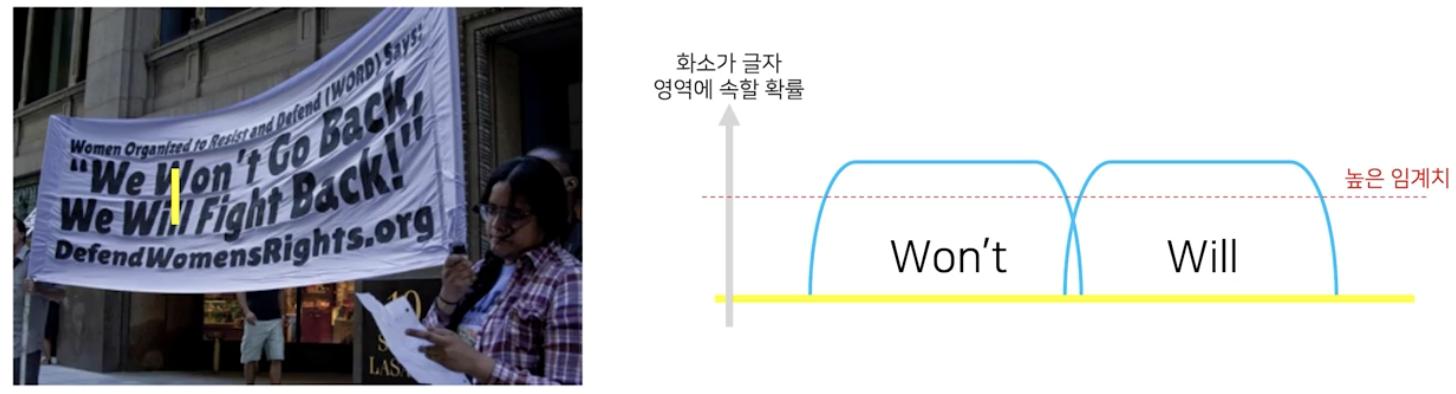
임계치 map 에 대한 정답을 어떻게 줄까에 대한 아이디어로 DBNet 은 경계선 부분에서는 더 높은 값으로 임계치를 적용하자는 생각을 했다.
-
왜 그럴까? 글자 영역 간 거리가 가까이 있는 경우에는 임계치가 너무 낮으면 두 글자 영역이 하나로 합쳐질 수 있기 때문이다. 따라서 임계치를 높게 잡아야 두 글자 영역이 구분이 잘 된다.

- 한 글자 영역에 대해서는 깔끔하게 확률분포가 나오면 좋겠지만, 실제로는 글자별 위치 정보를 어느정도 보기 때문에 분포가 다를 수 있다. 즉 하나의 글자 영역 안에 들어있는 각각의 글자들도 영역을 가지고 있다는 것이다. 따라서 임계치를 너무 높게 잡으면, 한 글자 영역이 여러 영역으로 쪼개질 수 있다.
-
이런 관찰을 한 문장으로 정리하면, 글자 영역 경계부분에서만 높은 임계치, 나머지 영역은 낮은 임계치를 적용하자로 정리될 수 있다.
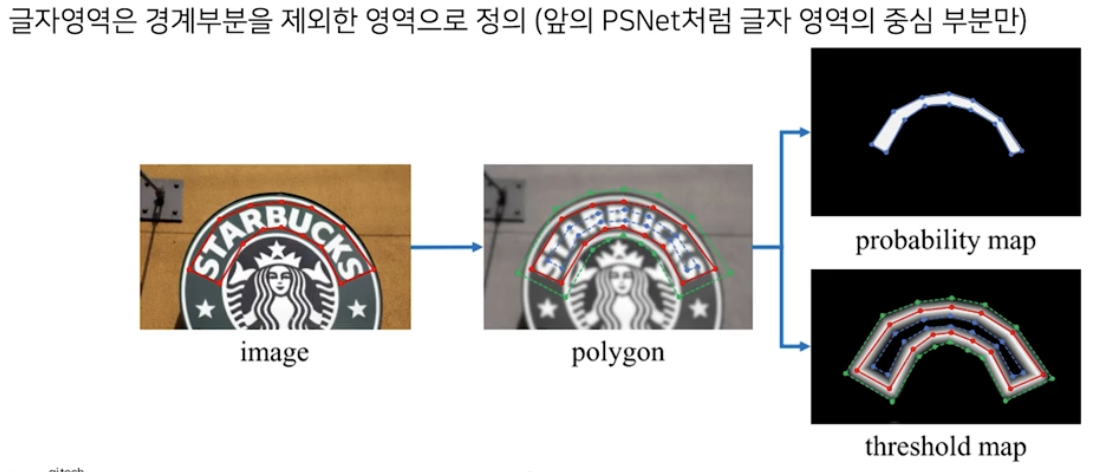
- 글자 외곽 영역에 임계치를 높게 적용한다는 것은, 상대적으로 글자 영역에 속할 확률값을 낮춰주는 것이기도 하기 때문에, adaptive thresholding 을 보다 효과적으로 적용하기 위해서 글자 영역은 경계 부분을 제외한 영역으로 정의한다.
-
임계치 map 을 학습을 통해서 얻고자 할 때, 가장 큰 문제점은 임계치를 통한 이진화 과정이 미분 불가능이어서 end-to-end 로 학습이 불가능하다는 것이다.

- 따라서 논문에서는 이를 미분 가능하면서 최대한 이진화 연산에 가까운 Differentiable binarization 을 제안했다.
Loss function
-
총 3개의 map 에서 loss 를 계산해야 한다.
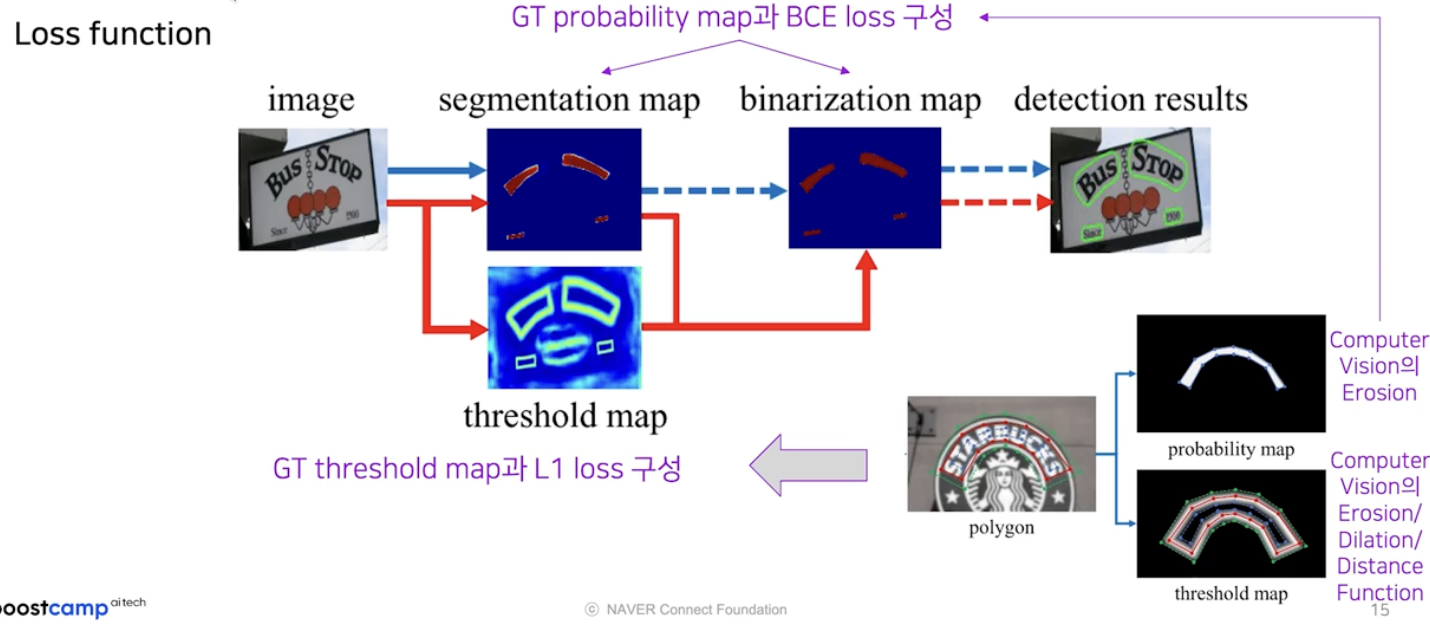
- segmentation map 와 binarization map 은 글자영역 GT(GT probability map) 와 BCE(binary cross entropy) loss 를 계산한다.
- threshold map 은 생성된 GT 와 L1 loss 로 계산한다. 이 때 threshold map 에 대한 GT 는 CV 에서 많이 사용되는 Erosion, Dilation, Distance function 의 조합으로 쉽게 생성 가능하다.
DBNet 정성적 결과
 우상단은 threshold map, 우하단은 글자 영역 probability map
우상단은 threshold map, 우하단은 글자 영역 probability map
- threshold map 은 논문의 설계대로 글자 영역 경계 부분에서만 높은 값을 가진다. 글자 영역 probability map 의 경우 글자 영역의 중심 부분에서만 높은 값을 가지도록 설계했기에 거의 text center line 에 가까운 부분만 높은 값을 가진다.
- 이 두 map 의 조합으로 한글에 대해서도 훌륭한 결과를 보여준다.
- RRC site
- Robust Reading Competition. OCR 전문 학회인 ICDAR 에서 격년으로 개최되는 컴피티션을 관리하는 사이트다.
- highlight 된 것이 실제 챌린지 기간 때 제출된 것이다. 즉 Online competition 때 제출본이다.
- 대회 기간이 끝난 후 제출한 Offline competition 같은 경우, 제출 횟수에 제한이 없으므로 일종의 cheating 이 가능하다.
- Debugging 에서는 제출본의 상세 내용을 볼 수 있다. 샘플 별 결과 요약, 각 샘플 별 더 자세한 결과를 확인할 수도 있다.
- Debugging-Samples list 에서 이미지 별로 어떤 이미지인지 recall, precision, h-mean 등을 확인 가능하다. 또한 csv 결과 파일도 다운 가능하다.
- Debugging-Per sample details 에서는 이미지별 GT 와 pred 확인 가능하다. 평가 metric 계산의 중간 과정인 IoU Matrix(각 영역 별 IoU 계산) Evaluation log 가 모두 제공된다.
- 이런 수치들을 잘 활용하면 모델 성능 분석 시 요긴하다.
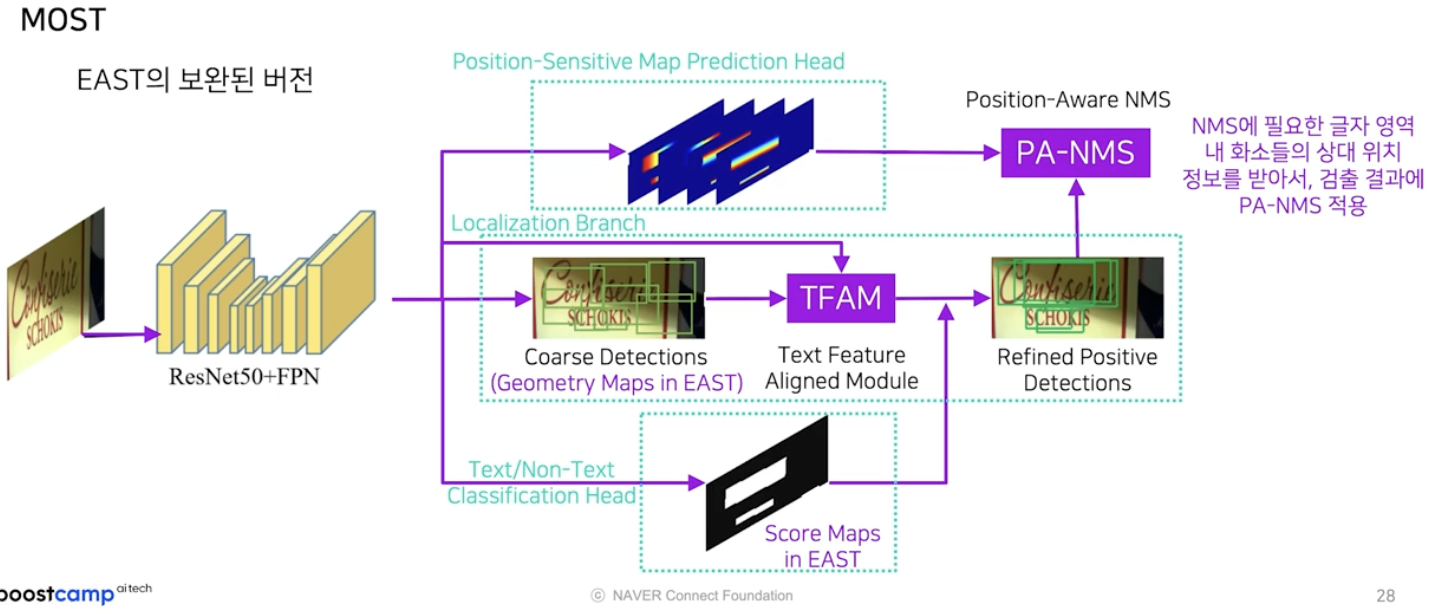
MOST
- EAST 의 후속 버전이자 개선판이다.
-
논문 도입 부분에서는 EAST 의 장단점 언급한다.
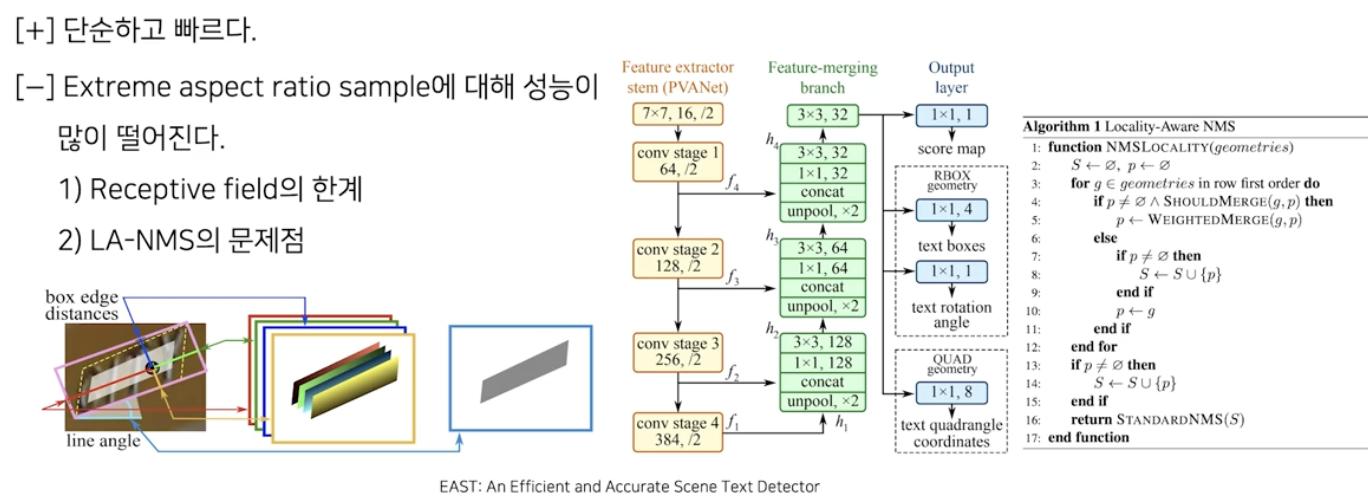
- EAST 는 작동 방식이 단순하고 속도가 빠르다는 장점이 있지만, 종횡비가 큰 샘플에 대해 정확도가 떨어진다는 단점이 있다.
- 이에 대한 원인의 첫번째로 모델의 receptive field 자체가 큰 종횡비를 감당하지 못하게 설계되었다는 것이다.
- 두번째로 EAST 에서 제안한 LA-NMS(locality aware non-maximum suppression) 자체의 한계점을 꼽았다.
핵심 아이디어
- EAST 문제점을 몇 가지 기법의 도입을 통해 보완했다.
- 기존 EAST 의 출력물인 geometry map 과 score map 을 같이 활용하기는 하지만, pipeline 상으로는 두가지의 모듈을 더 추가해서 최종 결과를 만들었다.
- Text Feature Aligned Module(TFAM)
-
추가된 첫번째 모듈은 Text Feature Aligned Module 이다.
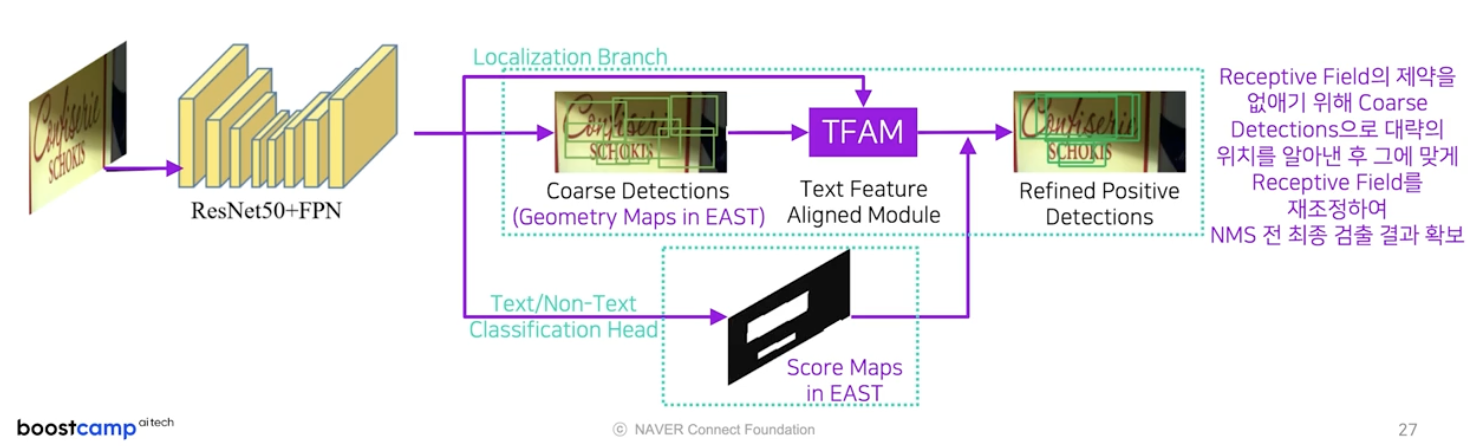
- receptive field 의 제약을 없애기 위해서, Coarse Detection 으로 글자 영역의 대략의 위치를 알아낸 후 그에 맞게 receptive field 를 재조정하여 검출 결과를 확보한다.
-
localization branch 내 존재하며, TFAM 이 입력으로 받는 것은 coarse detection 의 결과다.
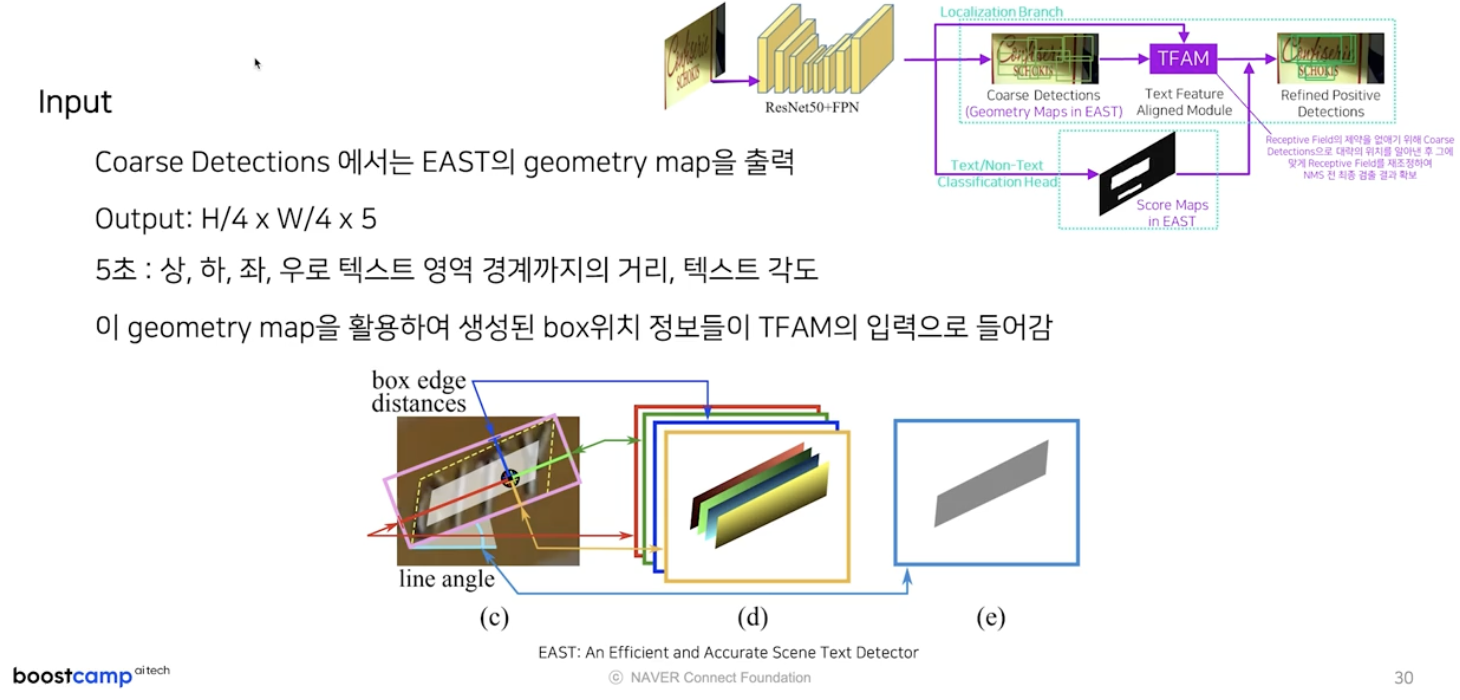
- coarse detection 모듈의 출력은 EAST 의 geometry map 과 동일해서 입력 이미지 가로세로 길이보다 $\frac{1}{4}$ 씩 작은 크기의 5개의 채널 값이 된다.
- 5개 채널은 글자 영역의 중심 화소에서 해당 사각영역의 상하좌우 경계까지의 거리값 4개와 사각영역의 각도값 1개로 구성된다.
- 차이점은 원래 EAST 에서는 score map 이 특정 임계치 이상인 샘플에 대해서만 사각영역을 복원하는데, MOST 에서는 모든 샘플들에 대해서 사각영역을 복원하고, 해당 박스 위치 정보들이 TFAM 의 입력으로 들어간다.
-
TFAM 은 새로운 방식의 Deformable Convolution 으로 구성된다.

- 원래 convolution 연산은 중심 좌표 $p_0$ 를 기준으로 kernel size 가 3x3이라고 가정했을 때, 중심포함 총 9개의 인접한 좌표 $p_n$ 에서 element-wise 로 곱하고 총합을 구하는 연산이다.
- $p_n$ 의 위치는 중심위치 $p_0$ 로부터 벗어나 있는 정도인 offset 으로 표현할 수 있다. 따라서 기존 convolution 연산의 경우
(-1,-1) ~ (1,1)까지 총 9개의 offset 값이 있다. - 원래 Deformable convolution 은 기존 offset $p_n$ 에 추가로 $\Delta p_n$ 의 offset 을 주고 $\Delta p_n$ 의 값을 학습을 통해 정한다.
- 그래서 convolution 연산하는 module 에서 branch 로 $\Delta p_n$ offset 을 계산해주는 layer 가 있고 여기서 계산되는 offset 을 추가 반영하여 conv 을 수행한다.
-
이러한 원래의 deformable convolution 를 feature-based(FB) sampling 이라고 하면, MOST 에서 새로 제안하는 deformable convolution 방식은 Localization-based(LB) sampling 이다.
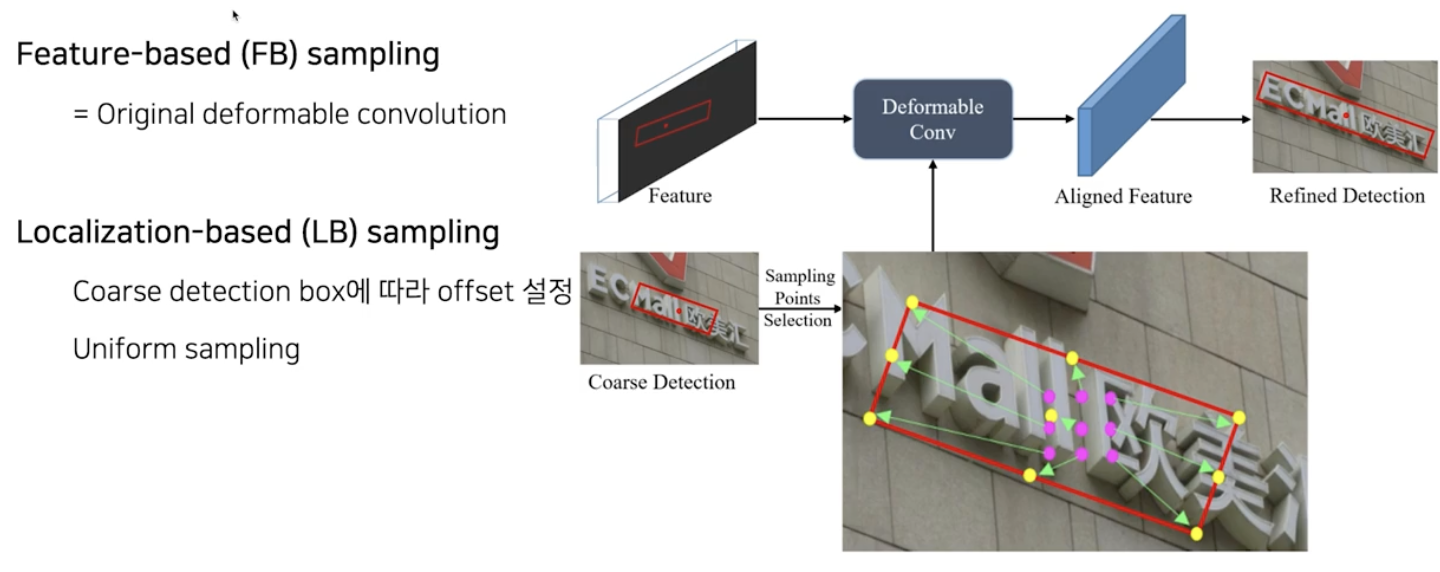
- 아이디어는 간단하다. 특정 화소 중심으로 geometry map 을 통해서 사각영역을 추정할 수 있기 때문에, 사각영역에 맞춰서 receptive field 를 키운다는 것이다.
- 즉, deformable conv 에서 추가 offset을 계산해주는 module 을 Coarse Detection 결과를 활용하는 것이다.
- 이렇게 되면 아무래도 글자 영역에 맞춰지는 방향으로 receptive field 가 조정되기 때문에 종횡비가 큰 경우에도 대응이 가능해진다.
-
- Position-Aware NMS(PA-NMS)
-
두번째 모듈은 Position-Aware NMS 다.
-
이 모듈은 position sensitive map 이라는 일종의 글자 영역 내 화소들의 상대 위치 정보를 활용하여 검출 결과들을 효과적으로 하나로 합쳐주는 모듈이다.

- EAST 에서 제안한 LA-NMS 는 IoU 값이 높은 위쪽에 있는 box 들로부터 IoU 값이 임계치를 넘어가면, 해당 박스의 score map 을 확인하여 weighted merge 를 하고, 어느정도 합쳐진 다음 기존의 NMS 를 적용하는 방식이다.
- MOST 는 LA-NMS 에서 두 글자 영역을 합치는 모듈을 새롭게 제안했다.
-
기존의 방식인 LA-NMS 의 한계는 두 글자 영역을 합칠 때 기준 샘플에서 score map 에 근간을 하여 weighted average 를 했기 때문에, 예측점이 실제 경계에서 멀리 있을수록 정확도가 낮아진다는 것이었다.
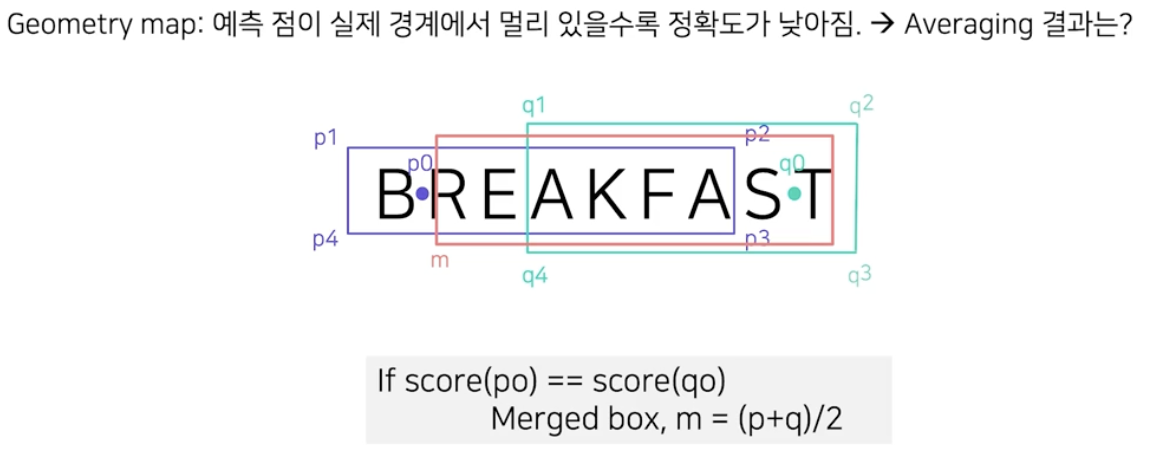 m 이 merged box 인데, 결과가 좋지 않다.
m 이 merged box 인데, 결과가 좋지 않다. - 위 예시처럼 기준 샘플이 글자 영역의 경계에 있으면, 종횡비가 큰 글자영역에 대한 NMS 결과가 좋지 않다.
- 이를 개선하기 위해서 기준 샘플의 score 점수가 아닌, 기준 샘플의 글자 영역 내 상대 위치로 weighted average 하자는 것이 주된 아이디어다.
- 즉, 실제 경계에서 가까운 곳에서 예측한 정보일수록 가중치를 많이 주자는 것이다.
-
이를 위해서 position-sensitive-map 을 구한다. 이는 EAST 의 geometry map 과 굉장히 유사하다.
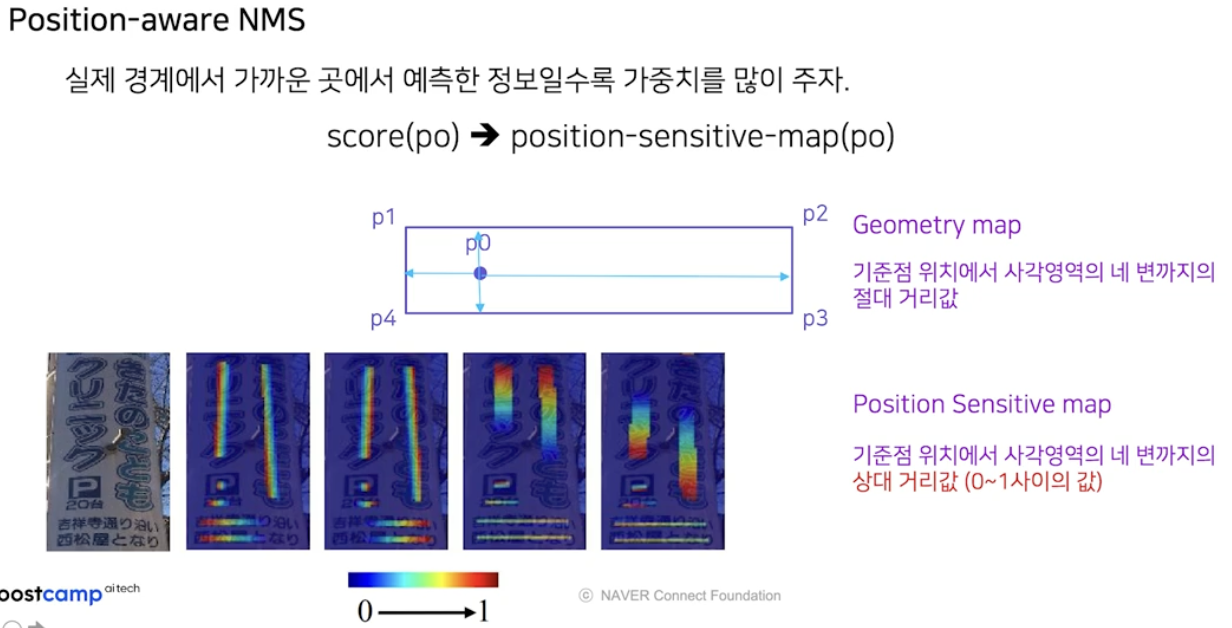
- Geometry map 은 기준점 위치에서 사각영역의 네 변까지의 절대 거리값이다.
-
Position Sensitive map 은 기준점 위치에서 사각영역의 네 변까지의 상대 거리값이다. 따라서 항상 0~1 사이의 값을 가진다. 즉, Position Sensitive map 은 입력 이미지에 대해서 4개의 채널로 사각영역의 네 변까지의 상대 거리값을 0~1 사이의 값으로 표현해주는 map 이다.

- PA-NMS 를 적용하면, 합쳐진 영역의 좌상단 좌표의 x 좌표값은 두 박스 좌상단 x 좌표의 weighted average 가 된다.
- 이 때 합쳐진 영역의 좌상단 좌표의 x 좌표값은 사각영역의 좌변과 관련 있으므로 $p_1$ 의 weight 는 $p_0$ 에서 사각영역 좌변과 관련된 position-sensitivie map $L$(left-sensitive map) 의 값이 된다.
- 즉 $p_1$ 의 weight 는 $L(p_0)$ 가 되고, $q_1$ 의 weight 는 $L(q_0)$ 가 된다.
-
이를 모든 merged box 의 좌표에 대해서 구하게 된다.
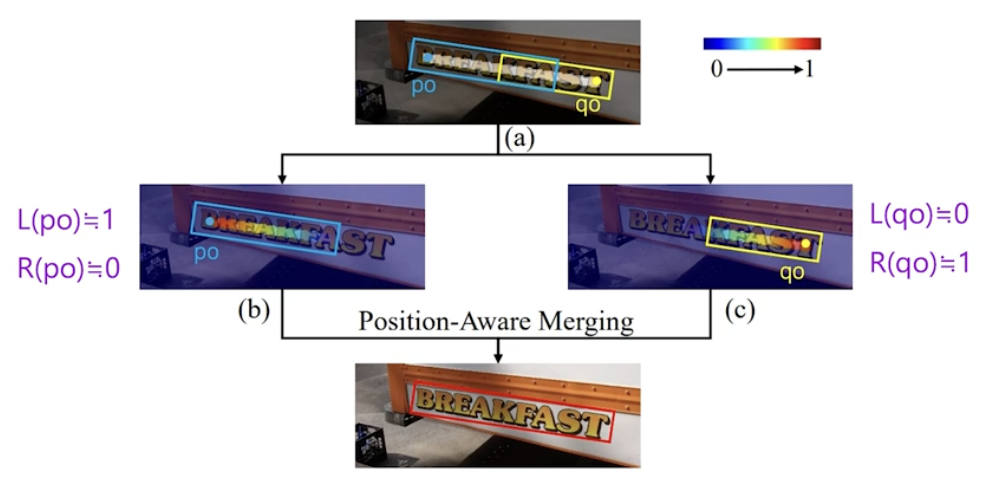
- 위처럼 position-sensitive map 의 값을 활용하면 효과적으로 글자영역들을 합칠 수 있다.
-
-
전체 파이프라인
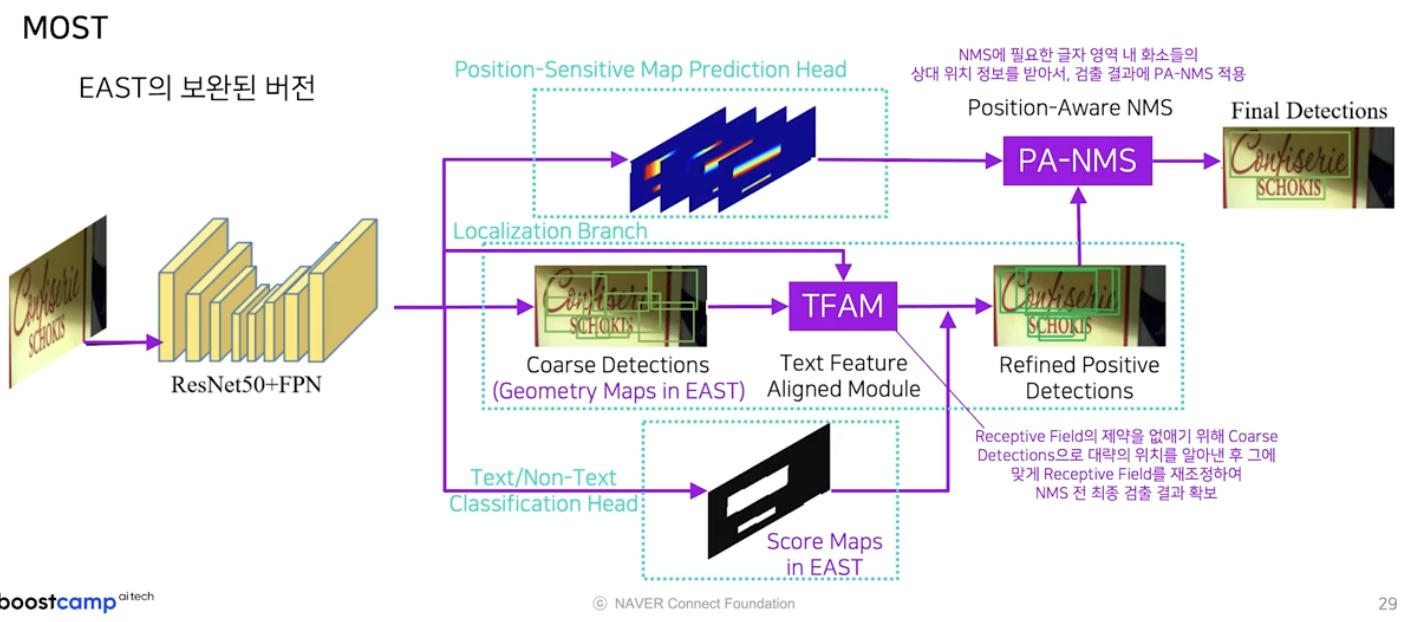 TFAM, PA-NMS
TFAM, PA-NMS
Loss function
-
MOST 에서는 loss 에도 변화를 줬다.

- 기존 EAST 의 IoU loss 는 글자 영역 별로 그냥 합치는 반면, MOST 의 Instance-wise IoU loss 는 IoU 를 글자 별로 합칠 때 그냥 합치지 않고 글자 영역의 크기로 정규화 한 뒤에 합친다.
- 이는 Detector 성능평가 방식과 관련이 있다. 글자 영역의 크기에 비례하여 점수를 더 주는 것이 아니라 각 글자 영역 별로 찾았느냐 못 찾았느냐로 정량 평가를 수행하기 때문이다.
- 그래서 글자 영역 크기와 무관한 loss 가 더 좋은 성능을 보인다.
-
따라서 전체 loss term 은 아래와 같다.
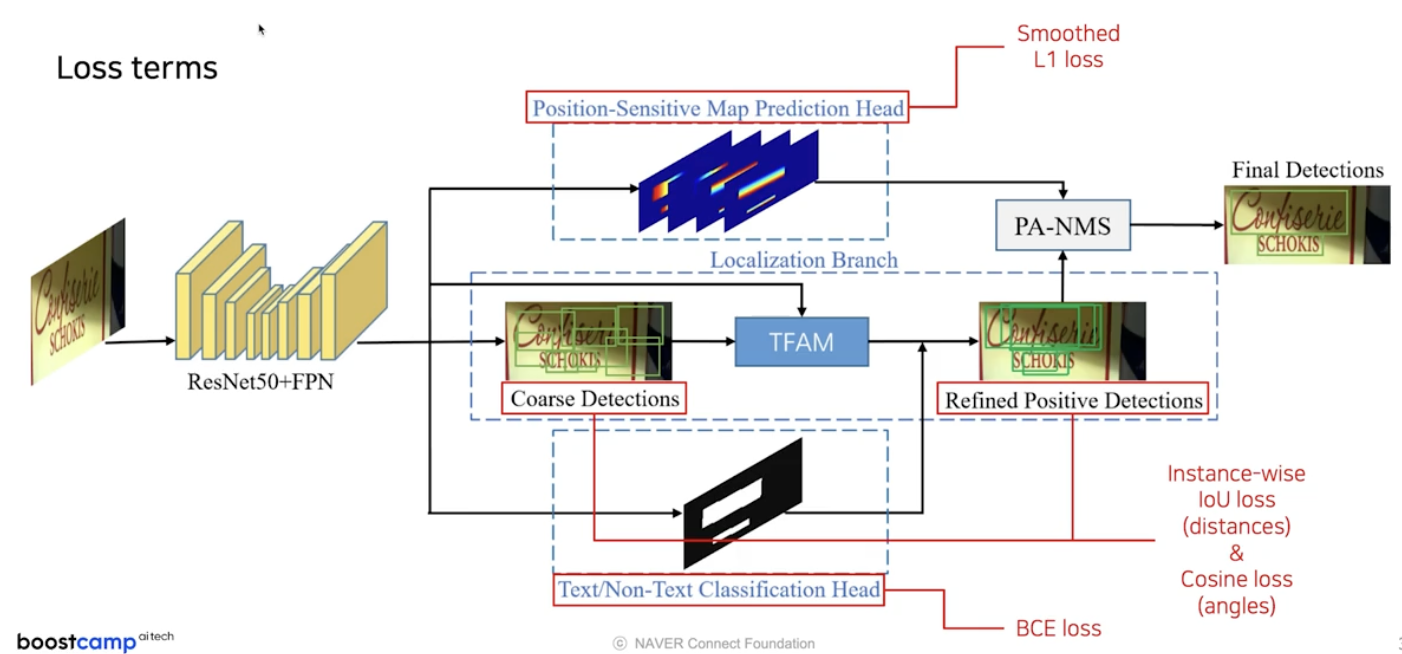
- score map 은 BCE loss 를 사용한다.
- geometry map 과 연관되어 있는 Coarse Detections 와 Refined Positive Detections 는 Instance-wise IoU loss 와 각도를 위한 Cosine loss 를 사용한다.
- 새로 제안한 Position-sensitive map 에서는 Smoothed L1 loss 를 사용한다.
MOST 정성적 결과


- 글자 영역이 합쳐지거나 침범하는 경우가 잘 대응된다. 또한 쪼개진 영역이 잘 합쳐진 것을 확인할 수 있다.
- 극단적인 종횡비에 해당되는 글자 영역이 많은데, 글 방향에 상관없이 MOST 에서는 잘 대응된다.
TextFuseNet
- 다양한 특징맵들을 조합하여 글자 검출을 잘 해보겠다는 논문으로, Instance Segmentation 기반의 방법을 사용했다.
-
기존에는 Mask RCNN 을 글자 영역 검출로 적용시킨 Mask TextSpotter 가 가장 유명했다.
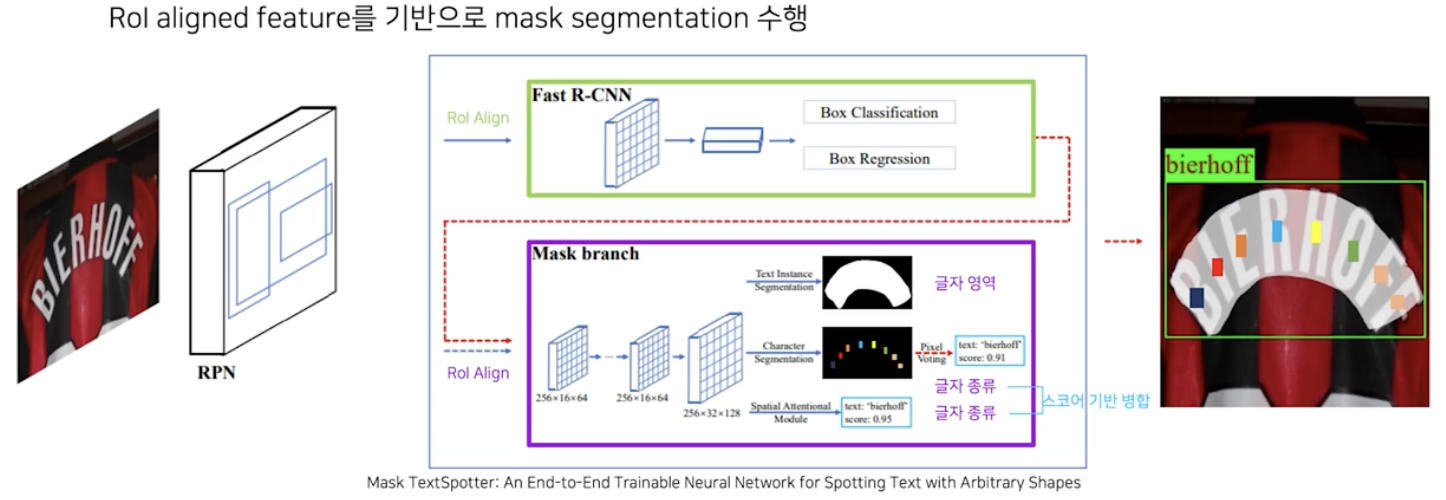
- Mask RCNN 처럼 RPN 을 통해 text region proposal 을 뽑고 RoI Align 을 거친 후, 각 RoI 별로 Fast RCNN 모듈을 수행하여 글자 영역인지 아닌지에 대한 정보(Box Classification)와 글자 영역이라면 사각영역이 어디인지에 대한 정보(Box Regression)를 뽑는다.
- 이후 글자 영역에 대해서는 RoI Align 을 거친 후에 글자 영역에 대한 정보와 글자 종류에 대한 정보를 뽑아낸다.
- 글자 종류를 뽑는 첫번째 방식은 Character Segmentation 기법으로 글자 영역 내 글자가 무엇인지 instance segmentation 기반으로 알아내는 것이다.
- 글자 종류를 뽑는 두번째 방식은 Text Recognizer 에서 디코더 부분만을 붙혀서 글자값을 뽑아내는 것이다.
- 인식 결과가 2개 이므로 score 기반으로 병합하여 최종 결과를 낸다.
- 이렇게 되면 글자 영역 검출과 영역 내의 글자 인식까지 같이 수행하는 일종의 End-to-End OCR 모델이 된다.
- 그러나 Mask TextSpotter 와 같은 방식의 가장 대표적 실패 사례는, 글자 영역이 이미지에서 끊어져 있는 경우 이를 합치기 쉽지 않다는 것이다.
-
그 이유를 TextFuseNet 에서는 단어기반, 글자 기반의 접근론의 한계라고 지적했다. 그리고 이를 이미지 전반적인 특징인 global 특징을 사용해야지 극복이 가능하다고 주장했다.

핵심 아이디어
-
TextFuseNet 에서는 먼저 semantic segmentation branch 에서 global level feature 를 추출한다. 여기서 뽑힌 feature map 은 이미지 전체에서 글자 영역을 추출하는 task 를 수행할 수 있다.
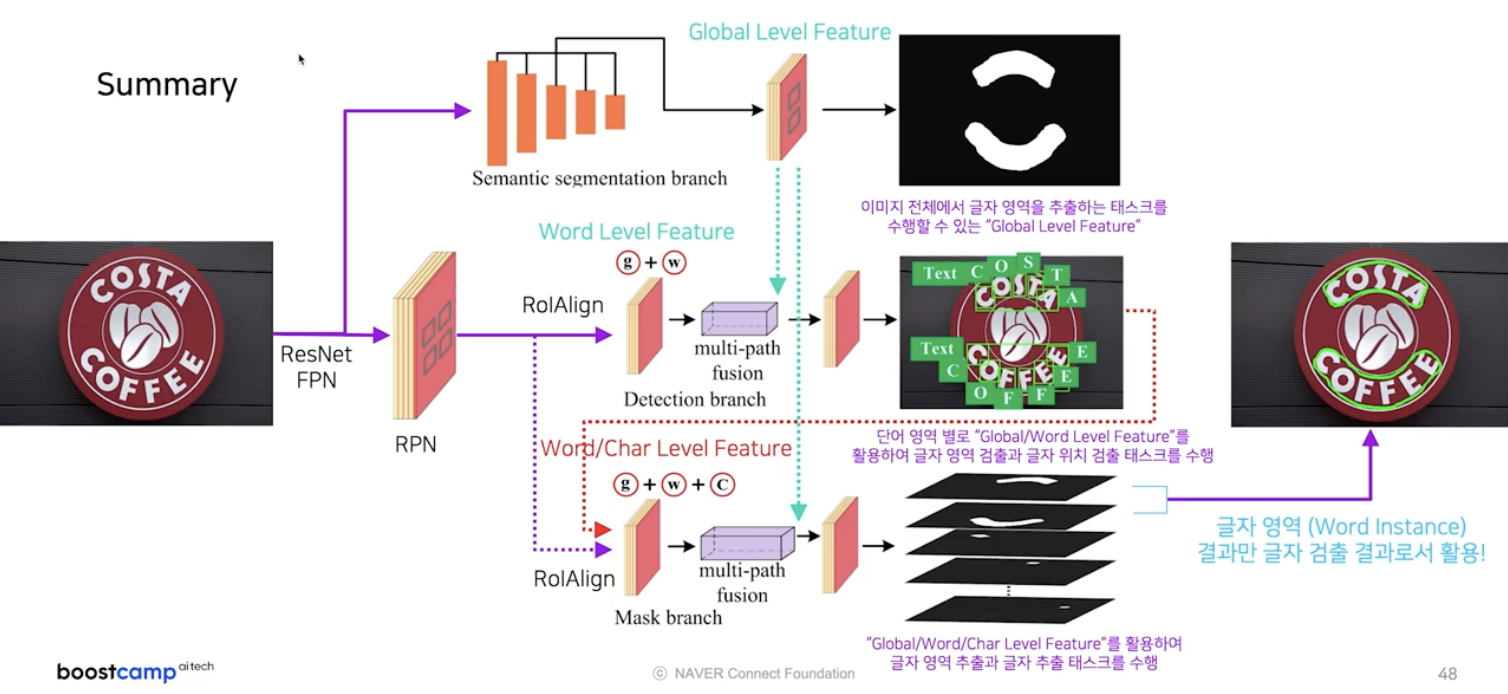
- 그 다음은 기존 TextSpotter 처럼 RPN 과 RoI Align 을 거치고 글자 영역을 예측한다. 이 때 앞에서 추출한 global level feature 를 같이 활용한다. 뿐만 아니라 글자 영역 만이 아닌 글자 단위의 위치 검출도 함께 수행한다.
- 요약하면 RoI Align 을 통해서 들어오는 word level 의 feature 와 앞에서 구한 global level feature 를 같이 합쳐서 단어, 글자 위치 모두를 추출하도록 특징맵을 학습시키는 것이다.
- 이렇게 되면 마지막 branch 에서 사용 가능한 정보가 semantic segmentation branch 에서의 global level feature, detection branch 에서의 word, character level feature 가 된다.
- 이 3가지 정보를 모두 활용하여 글자 영역 별, 글자 별 segmentation task 를 수행한다.
- 이 때 글자 영역(word instance)에 대한 결과만을 활용하여 최종 글자 검출 결과를 뽑는다.
-
마지막 branch 인 Mask branch 에서 여러 level(global, word, char) 의 feature 를 추출하는 방법을 살펴보자.
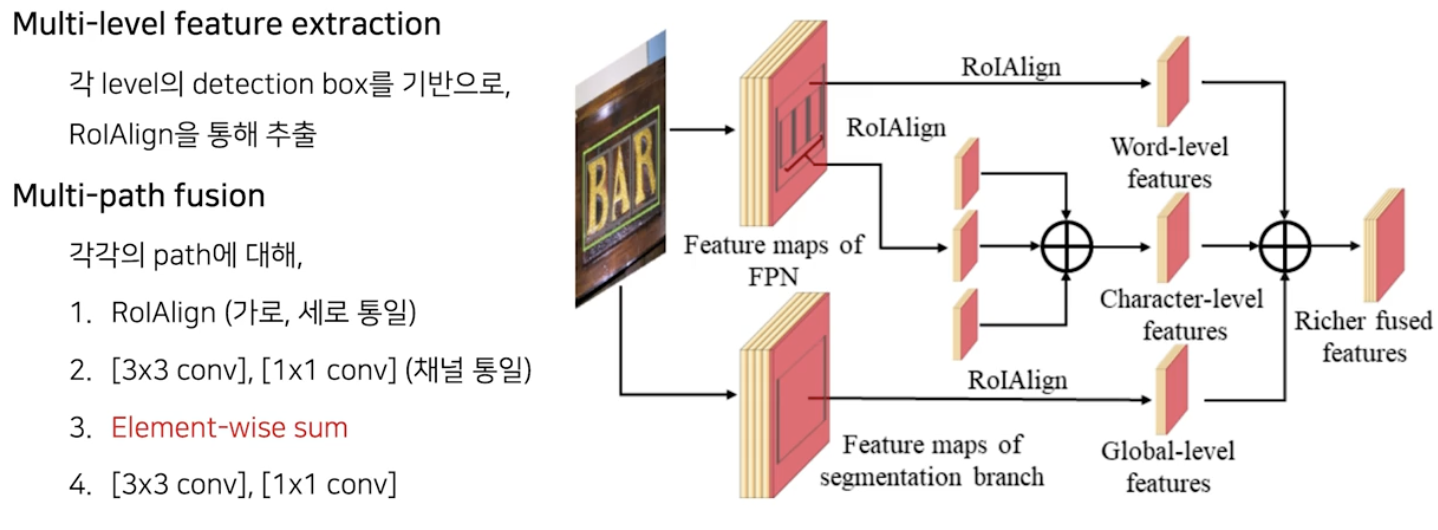
- global level feature 는 이미지 전체에 대한 semantic segmentation 를 수행하면서 확보된 feature map 이다.
- word/char level feature 는 detection branch 에서 예측한 word 단위의 bbox 와 char 단위의 bbox 에서 각각 RoI Align 을 통해서 추출된다.
- word level feature 와 global level feature 를 합칠 때는 word feature 에서 적용된 RoI Align 을 global feature 에 적용하게 되고, 합쳐주는 연산은 element-wise sum 으로 구현한다.
- TextFuseNet 에서는 글자 단위의 검출도 진행되므로 글자 단위의 라벨이 필요하다.
-
이를 human annotated 된 데이터 없이 진행하기 위해서, 글자 단위 라벨이 확보 가능한 합성데이터로 먼저 학습을 시키고 그 후에는 학습된 모델이 예측한 글자 단위의 위치값을 pseudo label 로 활용한다.

- 이 때 예측이 틀릴 수도 있기 때문에 예측한 글자 영역과 GT 단어 영역 간의 IoU 가 0.8 보다 큰 sample 만 학습에 사용한다.
TextFuseNet 정성적 결과


- 글자가 있는데 검출되지 않은 부분이 있음에도, f1-score 가 100 이 나왔다는 것은 검출되지 않은 그 해당 영역들은 검출되지 않아야 한다는 것을 의미한다. 즉 검출하지 않은 게 맞다는 것이다.
정리
- DBNet
- DBNet의 메인 아이디어는 글자 영역 구분의 threshold 값을 이미지 별로 모델이 생성하도록 하는 것이다.
- DBNet의 모델의 출력은 글자 영역에 해당하는 확률맵(probability map)과 적용할 임계치에 해당하는 맵(threshold map)이다.
- DBNet에서는 글자 영역 경계 부분에서는 높은 임계치, 나머지 영역에서는 낮은 임계치를 적용하는 전략을 사용하여 영역 구분을 효과적으로 한다.
- Threshold map 을 활용하여 그대로 학습할 경우, 미분 불가능으로 인해 end-to-end 학습이 불가능하다.
- 따라서 Differentiable binarization 방식을 사용하여 학습 시 역전파가 가능하게 만들었다.
- MOST
- EAST 의 기존 파이프라인에 두 가지 모듈을 추가하여 성능 개선을 이루었다.
- TFAM 은 Coarse Detection 으로 글자 영역의 대략의 위치들을 알아낸 후, 그에 맞게 Receptive Field 를 재조정하는 모듈이다.
- Receptive Field 측면에서 개선을 이룬 모듈은 TFAM 이다. TFAM 은 coarse detection 결과를 바탕으로 deformable convolution 을 통해 offset 을 예측하여, 글자 영역에 맞춰지는 방향으로 Receptive Field 를 조정할 수 있다. 이와 같은 방식으로 종횡비가 큰 케이스에도 커버가 가능하다.
- PA-NMS 는 일종의 글자 영역 내 화소들의 상대 위치 정보를 활용하여 검출 결과들을 효과적으로 하나로 합쳐주는 모듈이다.
- PA-NMS 는 Position-Aware NMS 로, NMS 방법 중 하나의 방법이고 실제 경계에 가까운 곳에서 예측한 정보일수록 가중치를 많이 주어 position-aware merging 을 제안하는 방식이다. 결과를 합치는 방법으로 receptive field 와는 연관이 없다.
- TextFuseNet
- TextFuseNet 은 Instance Segmentation 기반 방법이다.
- TextFuseNet 은 단어/글자 기반 접근론의 한계를 보완하기 위해 global 특징을 사용한다.
- TextFuseNet 은 Global/Word/Character Level Feature 를 활용하여 글자 영역과 글자 추출 task 를 수행한다.
- Global Feature 와 Word-level Feature 를 합쳐주는 연산으로는 Element-wise Sum 을 사용한다.
- Segmentation 기반 글자 검출 방법론
- Segmentation 기반 방법론은 다양한 모양의 텍스트를 유연하게 잡아낼 수 있다.
- Segmentation 기반 방법론은 인접한 개체 구분이 어려워, 자칫하면 인접한 영역끼리 합쳐져 글자 검출이 될 수 있다는 한계점이 있다.
- Segmentation 기반 방법론의 한계를 극복하기 위하여, Pixel Embedding 방식을 활용하는 아이디어가 제안되었다.
- Segmentation 기반 방법론의 한계를 극복하기 위하여, 다양한 스케일의 정보를 활용하는 아이디어가 제안되었다.(PSENet)
- Segmentation 기반 글자 검출 모델은 이미지를 입력으로 받아 화소 단위 정보를 뽑은 뒤 후처리를 통해 글자 영역의 표현 값을 출력하므로, 후처리로 인해 이미지 처리 속도가 느려질 수 있다.
댓글 남기기