
[OCR] 2. Text Detection
Text Detection
- 객체 검출 특히 글자 영역 검출에 대해서 알아보자.
- 글자 영역 검출은 OCR 에서 앞 부분에 해당한다. 글자 영역을 검출한 뒤 글자 영역 내 글자를 인식하기 때문이다.
- 이러한 글자 영역 검출에 들어가는 기술들이 Computer Vision task 의 기술들이다.
일반 객체 영역 검출 vs. 글자 영역 검출
-
예측하고자 하는 정보가 다르다.

- 일반 객체 검출 : 클래스와 위치를 예측하는 문제
- 글자 검출 : Text 라는 단일 클래스 → 위치만 예측하는 문제
-
객체의 특징
- 글자 객체는 다른 일반 객체와 다르다.
-
매우 높은 밀도를 가진다.
 매우 높은 밀도
매우 높은 밀도 -
극단적 종횡비를 가진다.
 극단적 종횡비
극단적 종횡비 -
특이 모양(구겨진 영역, 휘어진 영역, 세로 쓰기 영역, 폰트 등)이 많다.



- 모호한 객체 영역
- 단어 단위로 box 를 지정해도 일반 객체 검출과는 다르게 유난히 box 로 지정되는 형태가 작업자마다 달라서 어노테이션 가이드 작성 시 상당히 신경써야 한다.
- 크기 편차가 크다.
- 한 이미지 내에서 작은 글자, 큰 글자 다 있을 수 있다.
글자 영역 표현법
- 글자 영역을 실제로 어떻게 표현할까?
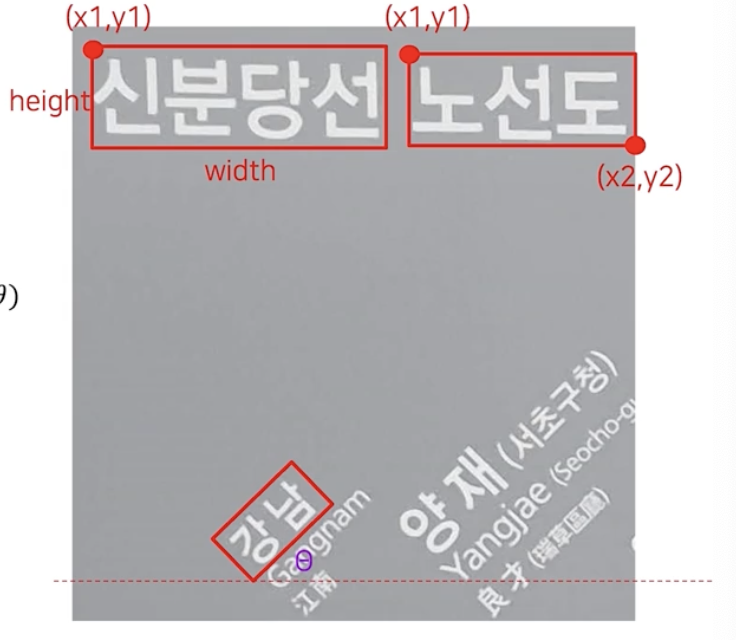
- 직사각형은 좌상단 위치(x1,y1), 가로세로 길이값(w,h) 혹은 좌상단 위치(x1,y1)와 우하단 위치(x2,y2)를 사용한다. 따라서 $(x_1, y_1, width, height)$ 또는 $(x_1, y_1, x_2, y_2)$ 로 표현한다.
-
직사각형 + 각도(회전)로 표현할 수도 있다. 이 때는 직사각형과 회전 정보인 각도값을 같이 사용하여 $(x_1, y_1, width, height, \theta)$ 또는 $(x_1, y_1, x_2, y_2, \theta)$ 로 표현한다.
-
임의의 사각형은 첫 글자의 좌상단 위치 좌표를 시작으로 시계방향으로 표현한다.
 (x1, y1) 부터 시계방향
(x1, y1) 부터 시계방향 - 다각형(Polygon) 은 주로 왜곡이 존재하는 글자영역을 표현하기 위해서 사용한다.
- $(x_1, y_1, \cdots, x_N, y_N)$ 로 점들을 찍어서 글자영역을 표현한다. 영역이 굴곡진 부분 기준으로 차례대로 점을 찍는다.
- 다각형은 학계에서 사용하는 benchmark 가 휘어진 글자영역을 다루는데 이에 적합한 글자 영역 표현법이다.
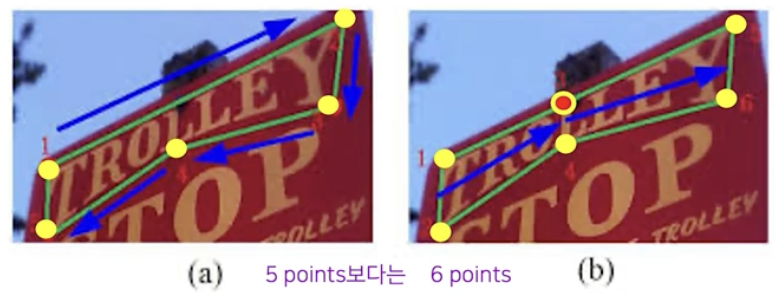
- 후처리 등의 이유로 다각형 사용시 짝수개 점을 사용하고 영역의 상하 점들이 쌍을 이루도록 배치하는 것이 일반적이다.
-
아래 예시같은 경우 점 5개 보다는 위아래 점들이 대응되도록 짝수개 즉 6개의 점으로 표현한다.
-
점을 찍을 때 항상 위 아래 점을 동시에 찍음을 염두해 두고 아래와 같이 점을 배치한다.

Taxonomy
- 글자 영역 검출 관련한 여러 기술들을 다양한 관점에서 비교 분석해보자.
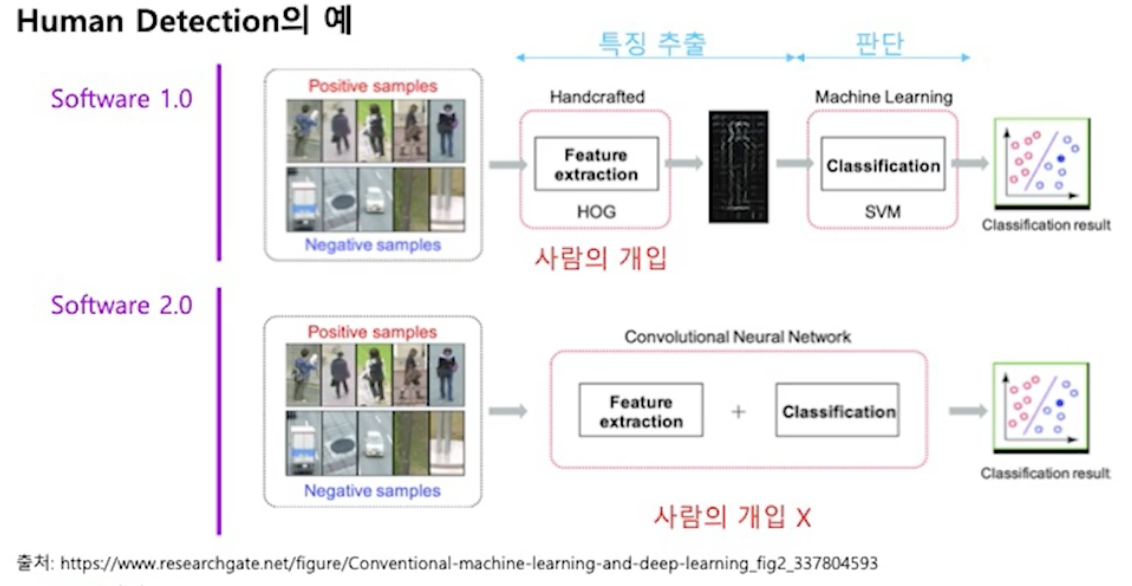
SW 1.0 vs SW 2.0
-
SW 2.0 으로 넘어오면서 비약적인 발전이 있었다.
 Human Detection 에서의 발전
Human Detection 에서의 발전 - SW 2.0 으로 오면서 사람의 개입 없이 특징 추출, 판단 연산이 모두 모델 구조, 데이터, 최적화 방식에 의해서 자동으로 정해진다.
-
Text Detection 에서도, 사람 영역 검출에서 사람이 개입해서 만든 HOG 라는 특징 추출 방식을 사용했던 것처럼 HOG 와 유사한 MSER, SWT 와 같은 특징 추출 방식을 SW 1.0 방식에서 사용했었다.
-
MSER 같은 사람이 설계한 특징 추출 모듈 뿐 아니라, 사람이 설계한 다른 연산인 Edge detection, Image enhancement 들도 연속적으로 사용하여 글자 영역을 검출했다.
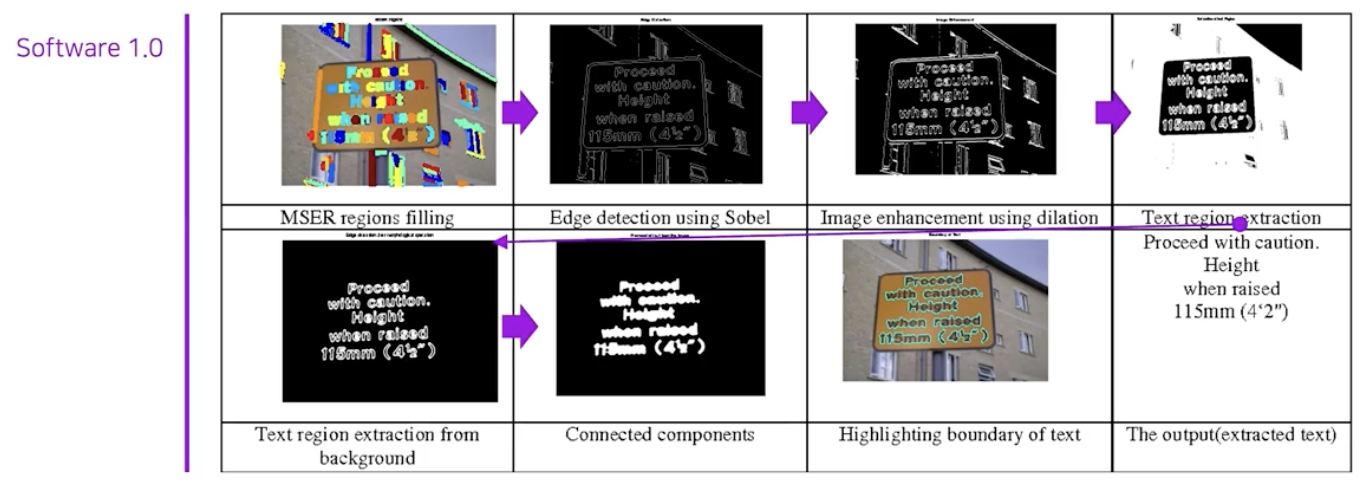
-
그러나 SW 1.0 방식은 태생적으로 많은 모듈들이 결합되는 구조여서 전체 파이프라인 복잡도가 높다. 반면에 SW 2.0 은 파이프라인의 단순화와 사람의 개입의 정도를 현저히 줄였다.
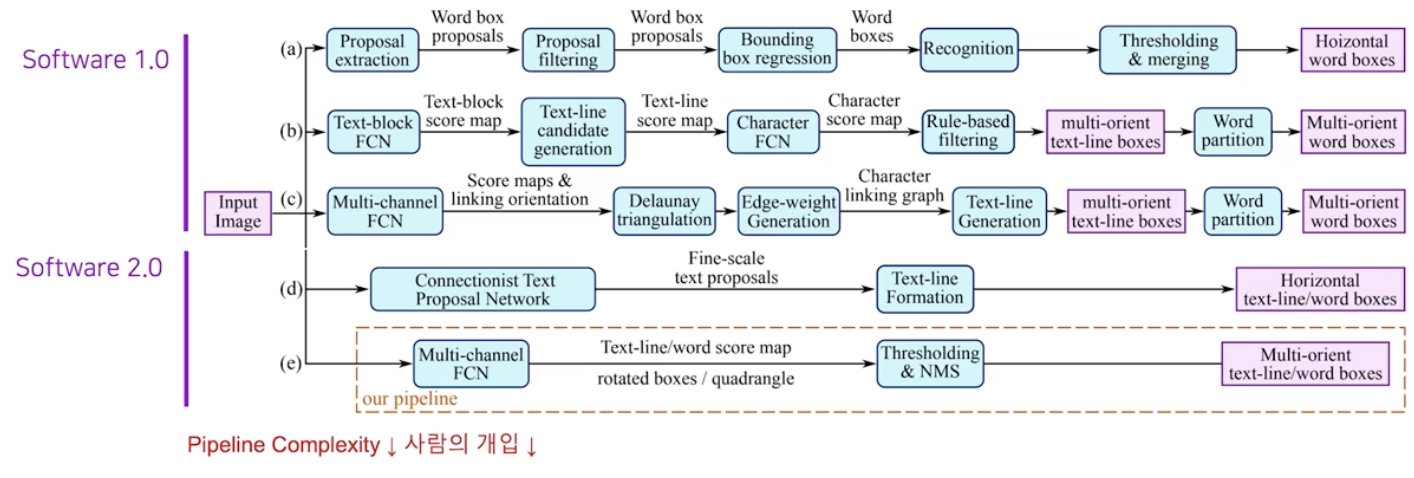
-
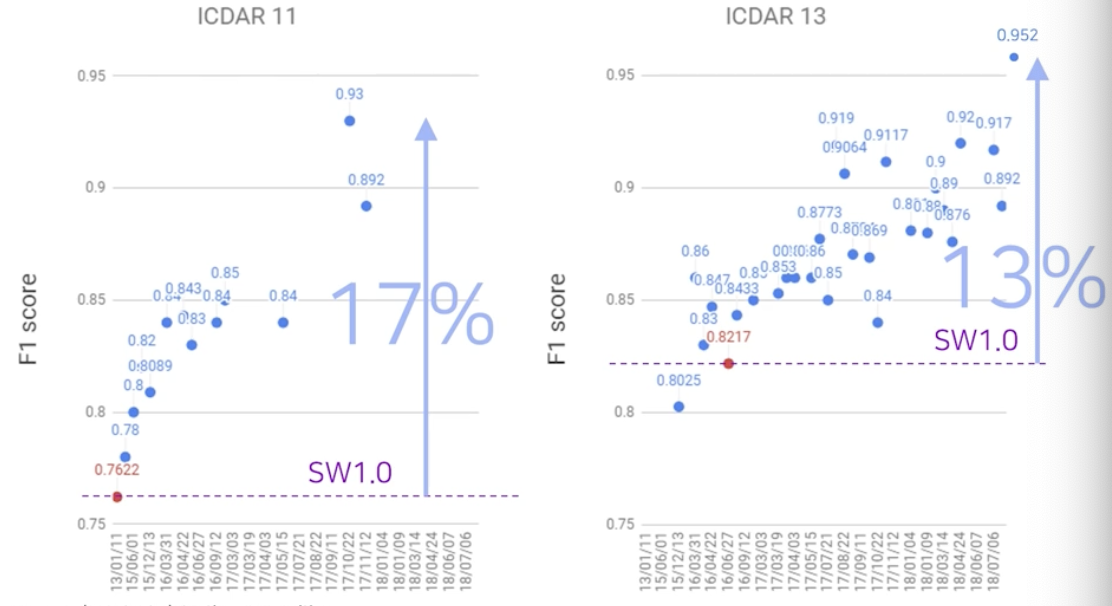
뿐만 아니라 성능에서도 큰 향상을 이뤄냈다. 글자 검출 영역의 대표적 데이터셋인 ICDAR 11, ICDAR 13 에서의 결과를 보자.
Regression-based vs. Segmentation-based
-
Text Detection 은 Regression 기반과 Segmentation 기반으로 작동한다.
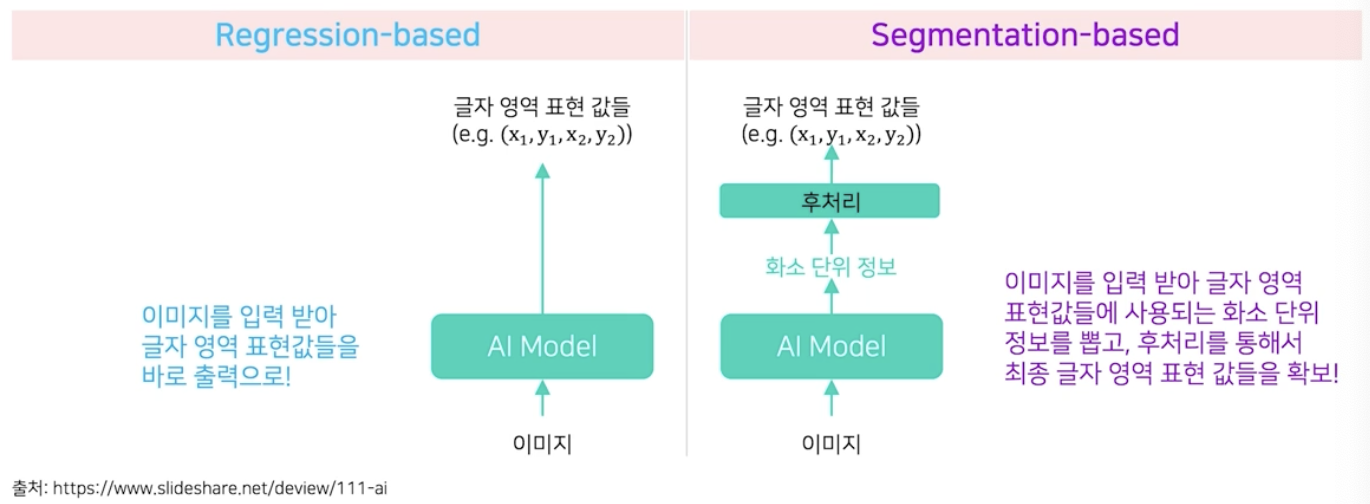
- Regression 기반
- 이미지를 입력 받아서 글자 영역을 표현해주는 값(사각형 좌표)을 바로 출력한다.
- 대표적으로 TextBoxes 모델이 있다.
- 일반 Object Detection 에서 많이 사용하는 SSD 를 Text Detection task 에 맞게 수정한 모델이다.
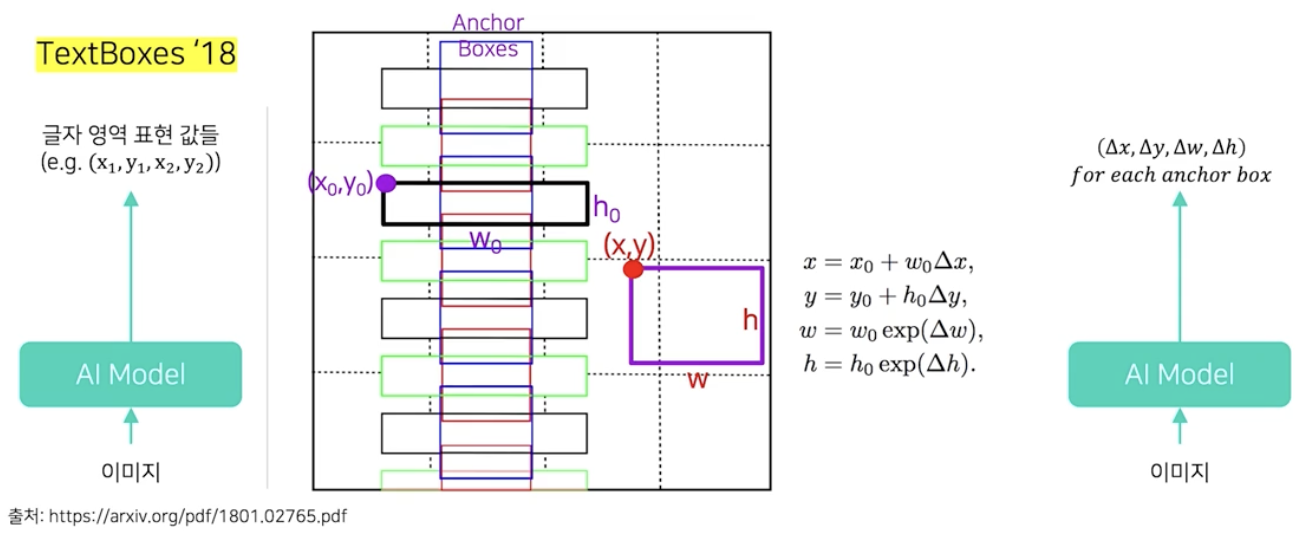
- SSD 처럼 고정 위치, 고정 크기의 앵커박스들을 사용한다. 이 때 글자 특성에 맞게 앵커박스의 밀도와 종횡비를 수정한다.
- 모델에서 추정하는 것은 특정 앵커 박스를 기준으로 실제 글자영역에 해당하는 박스와의 차이값을 추정한다.
- 이 차이값과 앵커박스의 정보를 이용하여 실제 글자 영역의 위치를 표현할 수 있다.
- 정리하면, TextBoxes는 Regression 을 기반으로 이미지를 입력받아 각 앵커박스 별로 실제 글자 영역의 상대위치와 상대크기 값을 추정하는 모델이다.
 TextBoxes 결과
TextBoxes 결과- 단점은, 주로 사각형 위주의 글자 표현 방식이 효과적으로 대응된다. 따라서 불필요한 영역을 포함하는 임의의 형상을 가진 글자 영역(Arbitrary-shaped text)은 적절히 표현하기 힘들다. 이는 bbox 표현 방식의 한계이기도 하다.
- 또 다른 문제점으로 앵커 박스보다 훨씬 큰 종횡비를 갖는 글자 영역이 있는 경우 성능이 떨어지게 된다(Extreme aspect ratio). 즉 receptive field 의 한계로 bbox 의 정확도가 하락한다.
- Segmentation 기반
- 출력값이 화소단위의 정보다.
- 여기서 화소단위의 정보란 간단한 후처리를 통해서 최종 글자 영역의 표현값들을 말한다.
- 즉 이미지를 입력 받아서 글자 영역 표현값들에 사용되는 화소 단위 정보를 뽑고, 후처리를 통해서 최종 글자 영역 표현 값들을 확보한다.
- 대표적으로 PixelLink 모델이 있다.
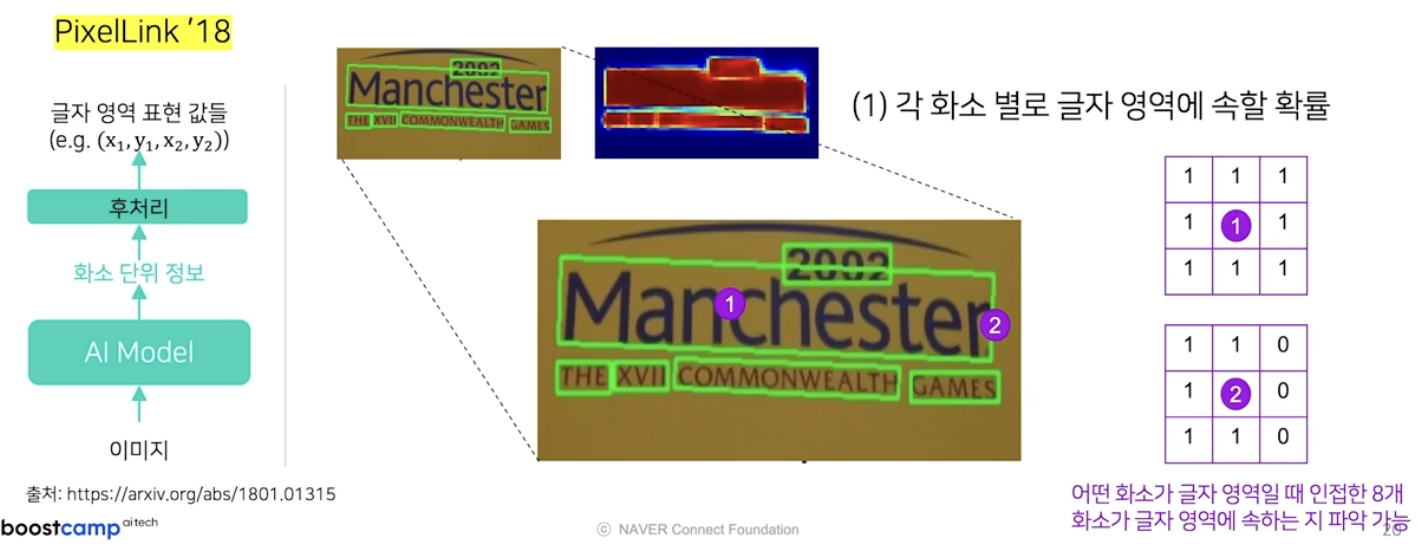
- 화소단위로 뽑는 정보는 각 화소 별로 글자 영역에 속할 확률을 뜻한다.
- 화소 간의 관계에 관한 것으로, 위 예시와 같은 상황에서 한 화소가 글자 영역에 속할 때 그 주위의 8개의 인접한 화소도 글자 영역에 속하는지에 대한 정보를 뽑아낸다.
- 또한 글자 영역 경계에 있는 화소에 대해서도 인접한 8개의 화소에 대한 연결성 여부를 알아낼 수 있다.
-
즉 위 예시 이미지에서 (2)에 해당하는 화소는 글자 영역의 경계에 있기 때문에 우측에 존재하는 인접한 화소들은 글자 영역에 속하지 않는다.
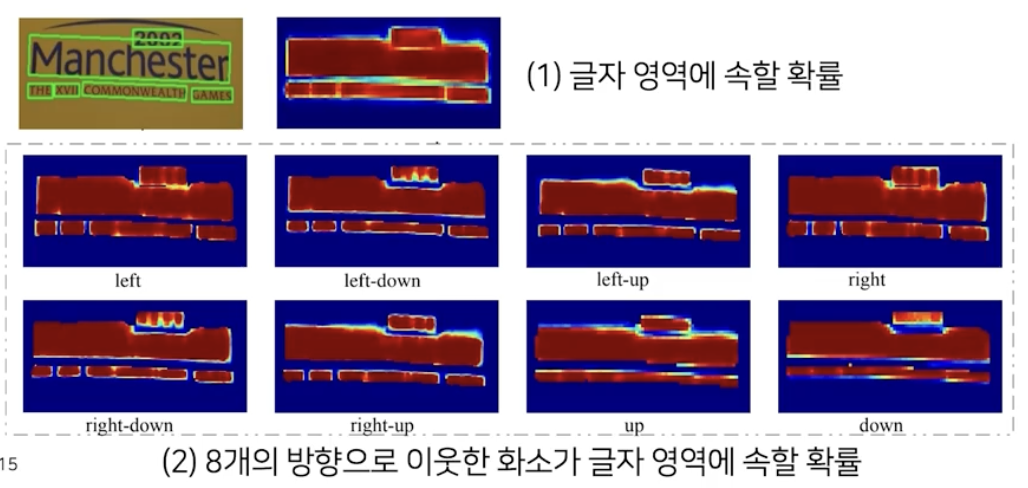
- 특정 화소가 글자 영역에 속할 때, 8개 방향으로 인접한 화소도 글자 영역에 속하는 지를 8개의 채널로 나타낸다.
-
화소단위 정보를 뽑은 후에는 후처리를 통해서 글자 영역의 표현값들을 얻어낸다.
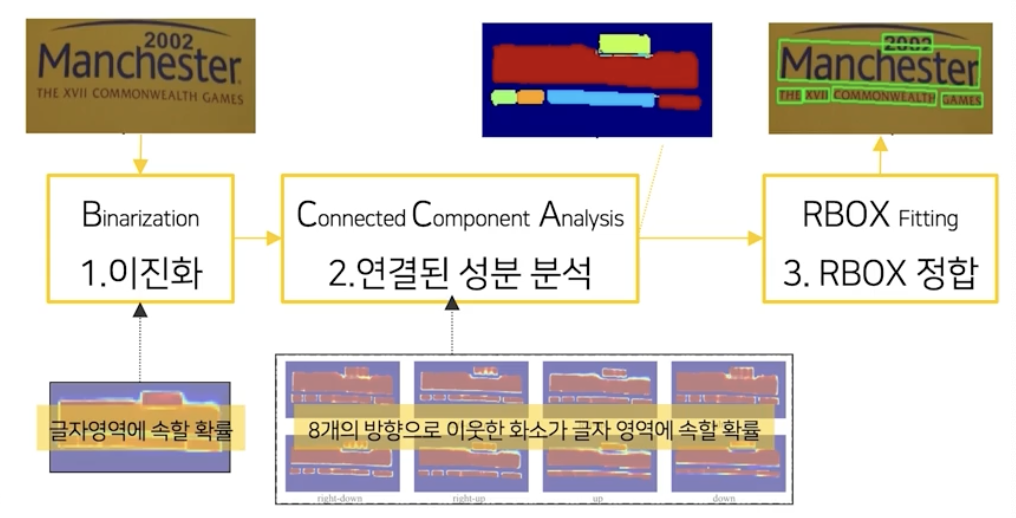
- 이미지를 입력 받으면 모델의 출력값으로 글자 영역에 속할 확률과, 8개 방향으로 이웃한 화소가 글자영역에 속할 확률에 대한 화소단위 정보를 뽑는다.
- 첫 후처리로는 글자 영역에 속할 확률에 대해서 임계치를 적용하여 실제 글자 영역을 뽑아낸다.(이진화)
- 실제 글자 영역 화소별로 8개의 방향으로 이웃한 화소가 글자 영역에 속할 확률값을 활용하여 CCA(Connected Component Analysis) 라는 Computer Vision 에서 많이 사용하는 기법을 적용시키면 실제 글자 영역들을 뽑아낼 수 있다.
- 마지막으로 RBOX(rotated box, 직사각형 + 각도) 형태로 글자영역을 표현하고 싶으면 CV 라이브러리인 open-cv 를 활용해서 RBOX 에 필요한 파라미터 값들을 쉽게 찾아낼 수 있다.
-
Segmenataion-based 의 단점
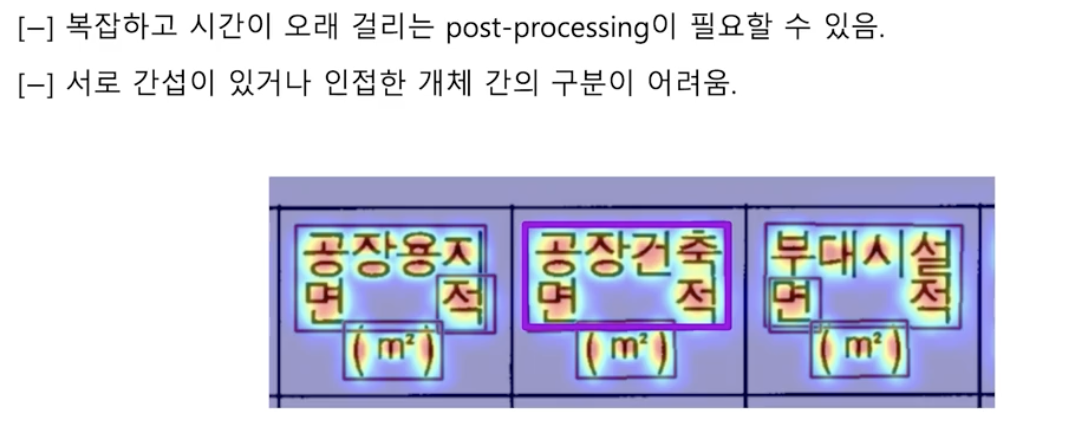
- 고성능을 위해서 생각보다 후처리가 복잡해질 수 있다.
- 즉 후처리 적용 시간이 길어져서 이미지 처리 속도가 저하될 수 있다.
- segmentation 기반 방법들은 기본적으로 글자 영역에 속할 확률값을 활용한다. 그런데 글자 영역이 서로 인접해 있으면, 원래는 별도 영역이어야 하는데 하나의 영역으로 검출될 확률이 높다.
- Hybrid
- Regression-based 로 대략의 사각영역 + Segmentation-based 로 해당 영역에서 화소 정보 추출
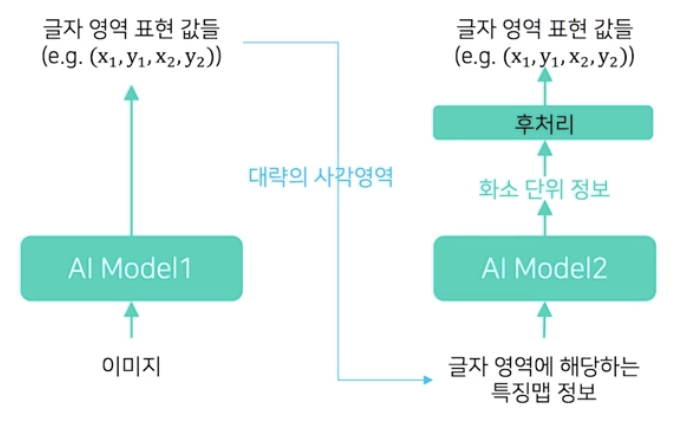
- Regression 방법으로 글자 영역 별로 대략의 사각영역을 찾은 뒤, 해당 사각 영역에서 segmentation 기반 방법으로 정밀한 글자 영역을 찾는 접근이다.
-
대표적으로 MaskTextSpotter 가 있다.
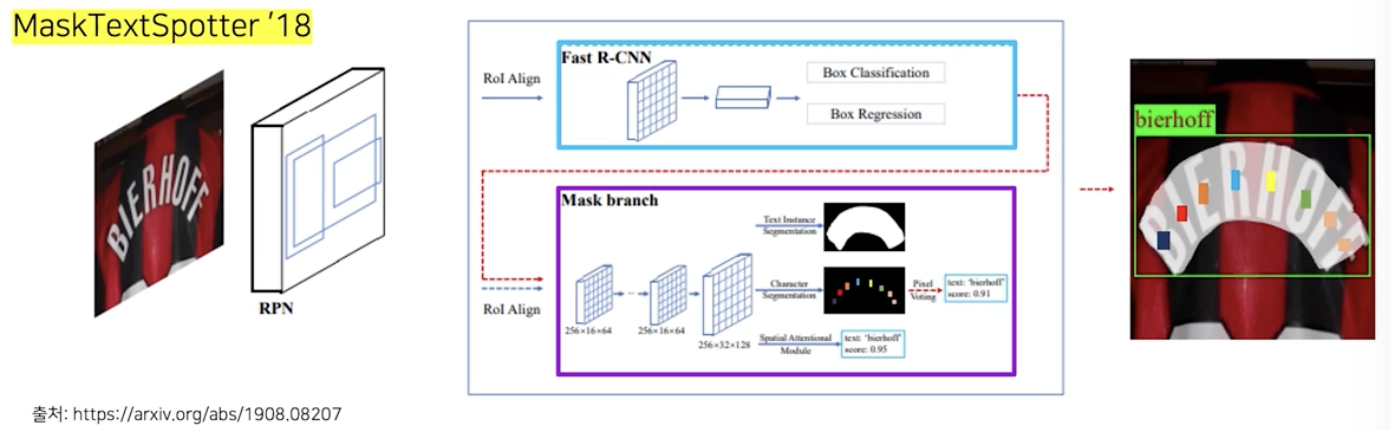
- Fast R-CNN 으로 사각영역을 찾는다. (Regression)
- Mask branch 에서 해당 사각영역에서 글자 영역을 좀 더 찾아내기 위한 화소별 정보를 뽑아낸다. (Segmentation)
Character-based vs. Word-based
-
글자 기반 검출 vs 단어 기반 검출

- Character-based (글자 기반)
- 글자들의 개별 위치를 먼저 찾고 이를 조합하여 단어 단위의 위치를 예측한다.
- 이런 식으로 모델을 설계할 경우 글자 단위 위치 정보를 라벨링 해야 하는 단점이 있다.
- CRAFT 모델

- Character region 과 affinity(연결성)을 예측하고 Word 로 조합한다.
- 위 이미지처럼 Segmentation 기반으로 동작한다. 이 때 뽑는 화소별 정보는 글자별 위치정보와 글자간의 연결이 되어있는지에 대한 정보다.
- 이 두 정보를 겹쳐 놓고 이진화를 수행하면 쉽게 글자영역을 확보할 수 있다.
- 이렇게 동작이 되려면 글자별 위치에 대한 라벨링이 필요하다.
- CRAFT 에서는 단어 단위 라벨링이 있으면 이로부터 글자 단위 라벨링을 추정하는 Weakly-Supervised Learning 방식을 제안했다.
- Word-based (단어 기반)
- 대부분의 접근론이 취하고 있는 방법이다.
- 별도의 글자단위 라벨링이 필요없어서 선호되고 있다.
EAST
- EAST: An Efficient and Accurate Scene Text Detector. CVPR, 2017
-
논문 제목에서부터 Efficient 하고 Accurate 한 모델이라고 소개하고 있다. SW 2.0 방식으로 개발되어 제대로 성과를 낸 첫번째 논문이다.
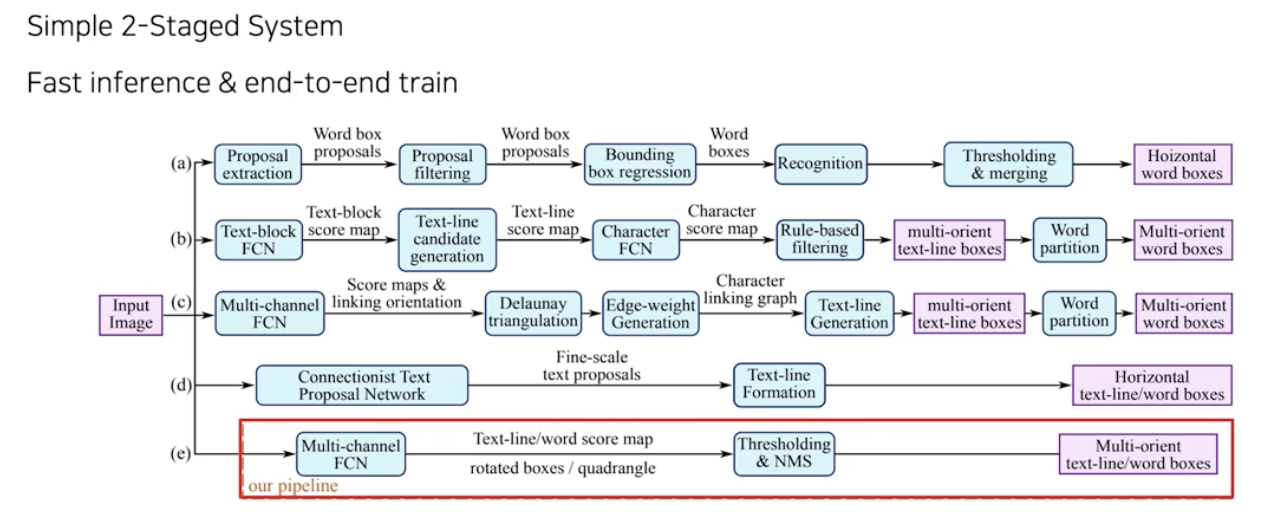
- SW 1.0 방식들과 비교하여 단순한 파이프라인 구조를 가져서 속도도 빠르고 성능도 좋은 모델이다.
-
일종의 segmentation 기반의 방법으로 AI 모델을 통해서 화소단위 정보를 뽑고 후처리를 통해서 글자영역을 검출한다.
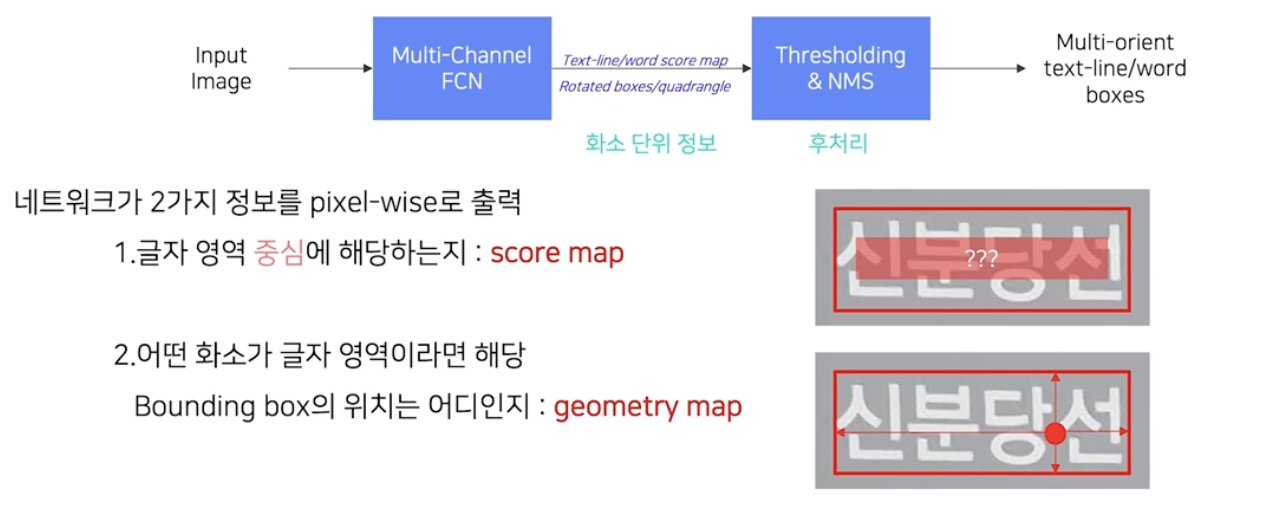
- 화소정보로는 score map 과 geometry map 을 얻는다.
- 각 화소가 글자 영역의 중심에 해당하는지에 대한 score map
- 글자 영역 내 중심에 해당되는지를 나타낸다.
- 어떤 화소가 글자영역이라면 해당 bbox 의 위치는 어디인지에 대한 geometry map
- 어떤 화소가 글자 영역 내에 있으면 해당 bbox 의 위치에 대한 정보를 나타낸다.
- 각 화소가 글자 영역의 중심에 해당하는지에 대한 score map
모델 구조
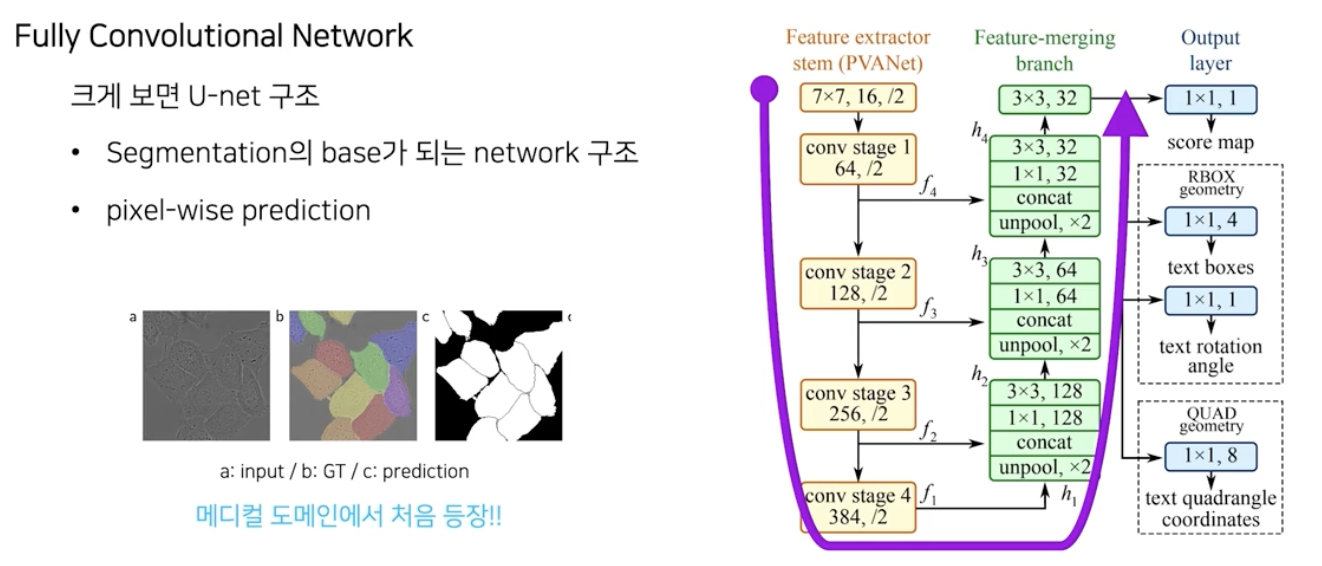
- segmentation 에서 많이 사용되는 U-Net 구조를 사용했다.
- U-Net 은 의료영상 분석 task 에서 처음 등장하고 segmentation task 에서 많이 사용된다.
- 크게 세가지 부분으로 구성된다.
- Feature Extractor Stem(backbone)
- 이미지를 입력 받아서 가장 작은 크기의 feature map 까지 추출한다.
- 고속처리를 위한 PVANet 을 비롯해서 VGGNet, ResNet50 등을 사용할 수 있다.
- Feature merging branch
- feature map 을 키워가며 여러 레벨들의 특징들을 합쳐준다.
- feature map 의 크기를 계속 키워주므로 Unpool operation 을 사용한다.
- Output layer
- 화소단위 정보를 만들어준다. H/4 x W/4 x C maps
- Feature Extractor Stem(backbone)
- 좀 더 자세히 모델의 출력을 살펴 보자.
-
Score map
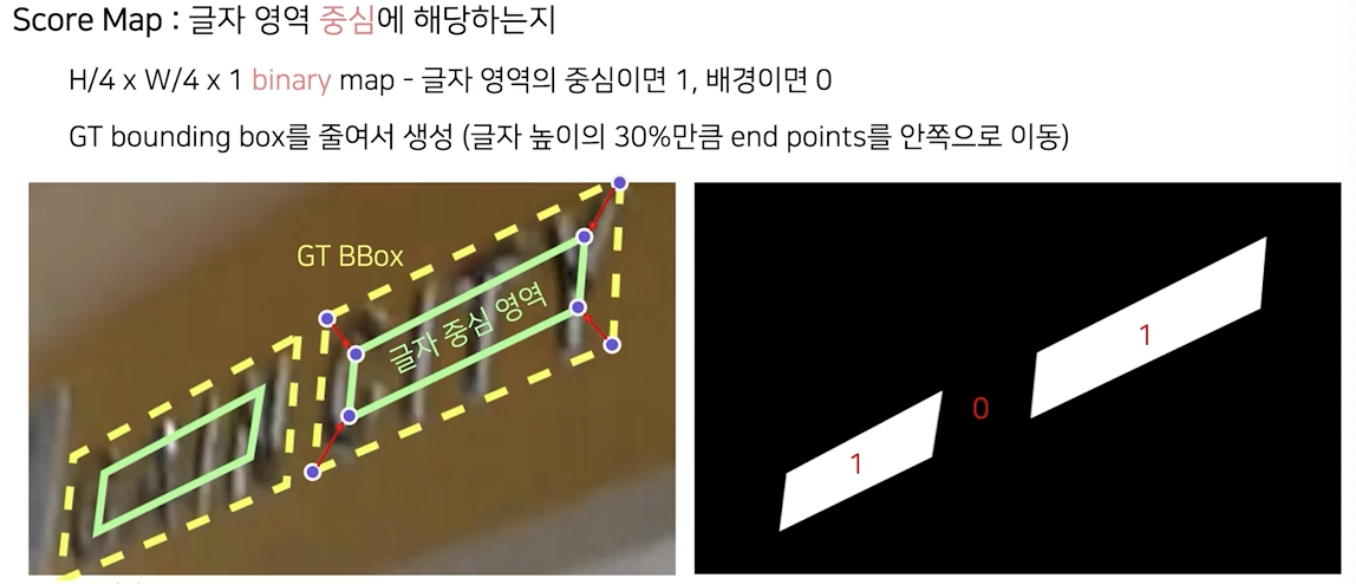
- 글자 영역 중심에 해당하는지 를 나타낸다.
- 이미지 크기는 가로 세로 별로 1/4 축소된 binary map이다.
- 값이 binary 인 이유는 1의 값이면 글자 영역 중심, 0이면 해당하지 않음을 표현하기 위해서다.
- 정답을 만들어 낼때는 GT bbox 에서 중앙으로 영역을 줄여서 글자 중심 영역을 만들고 이진값으로 map 을 채운다.
- 단, 추론할 경우에는 score map 을 예측할 때 0과 1 사이의 실수값이 나오도록 하여 글자 영역 중심의 속할 확률로 해석한다.
-
Geometry map
- 어떤 화소가 글자 영역이라면 해당 bbox 의 위치는 어디인지 를 나타낸다.
- RBOX(rotated box, 직사각형 + 각도) 형식으로 글자영역을 표현한다면, 각도에 대한 정보를 가진 채널과 직사각형에 대한 정보를 가진 4개의 채널을 사용한다.

- 각도값의 경우 글자 중심영역의 모든 화소와 연관되어 있는 바운딩 박스는 하나이고 그 각도값을 $\theta$ 라고 할 수 있다. 그 각도값에 대한 채널은 글자 중심영역에 대해서 동일한 각도값으로 채워넣을 수 있다.
- 직사각형에 대한 정보의 경우, 첫번째 채널은 글자 중심영역의 어떤 화소에서 해당 바운딩박스의 좌변까지의 거리값으로 값을 채울 수 있다.
- 이 때 좌변에서 멀어질수록 큰 값을 가지게 된다.
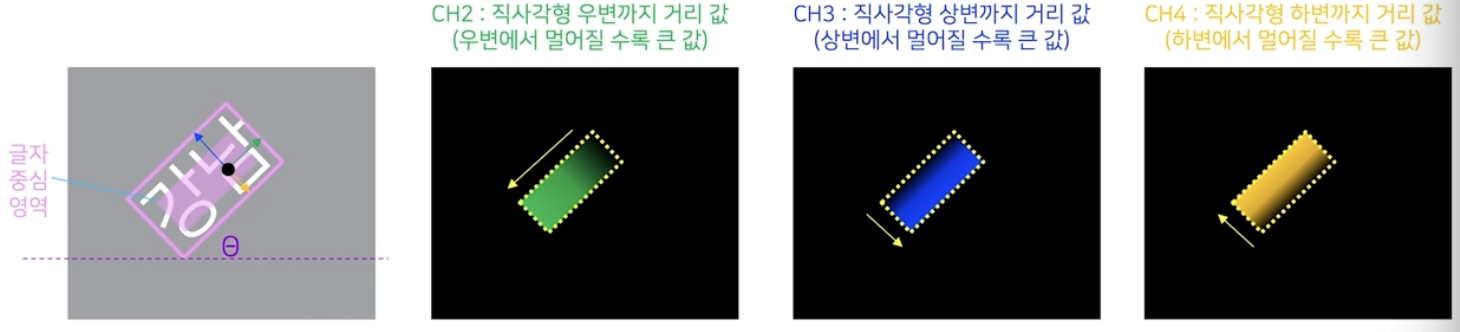
- 두번째 채널은 글자 중심영역 화소에서 바운딩 박스의 우변까지의 거리값으로 채우고,
- 세번째 채널은 상변까지의 거리값, 마지막 네번째 채널은 하변까지의 거리값으로 채운다.
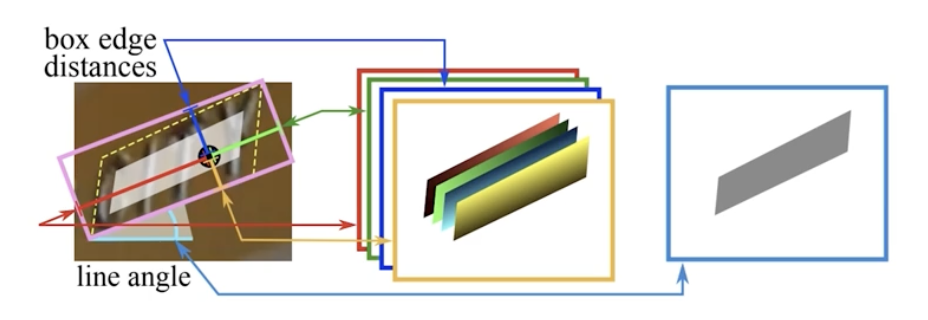
- 종합해서 보면, 글자 중심영역의 화소 위치에서 5개의 채널에 해당하는 값을 채워넣는다. 하나는 각도값, 나머지 넷은 바운딩 박스에 대한 거리값으로 채운다.
- RBOX 가 아닌 임의의 사각형 QUAD(quadrilateral, 좌표 4개) 형식으로 글자영역을 표현할 수도 있다.
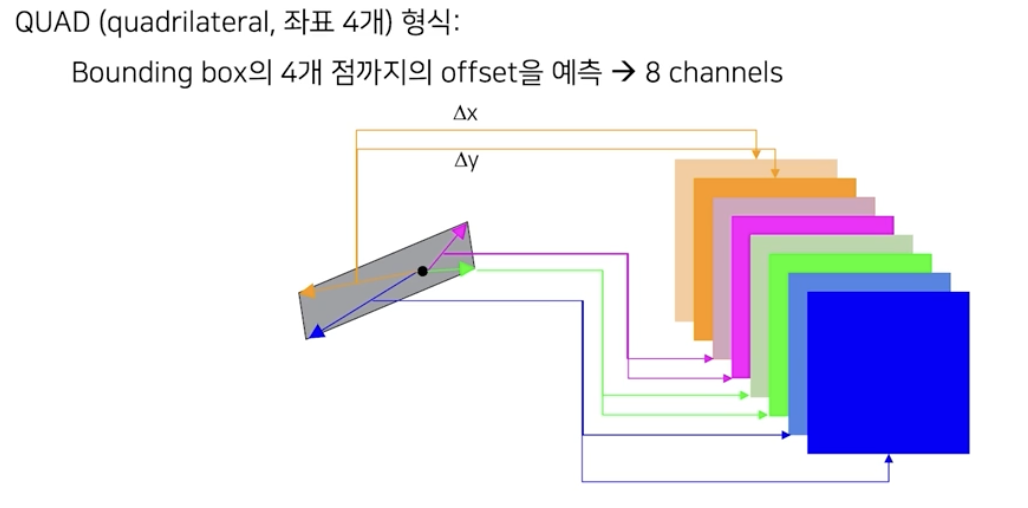
- 좌표가 4개 이므로 offset 은 좌표당 x, y 두 개에 해당하는 값으로 구한다. 따라서 총 8개의 값을 얻는다.
- 즉, 글자 중심 영역의 어떤 위치에서 첫 두 채널은 bbox 의 첫번째 좌표까지의 좌표값의 차이를 x, y 별로 따로 계산하여 채우고, 유사하게 나머지 채널값들도 채운다. 그렇게 해서 총 8개의 채널로 geometry map 을 구성한다.
-
후처리
- 화소단위 정보를 획득한 다음에는 후처리를 통해서 글자 영역의 표현값을 계산해야 한다.
-
Post-processing : RBOX 기준
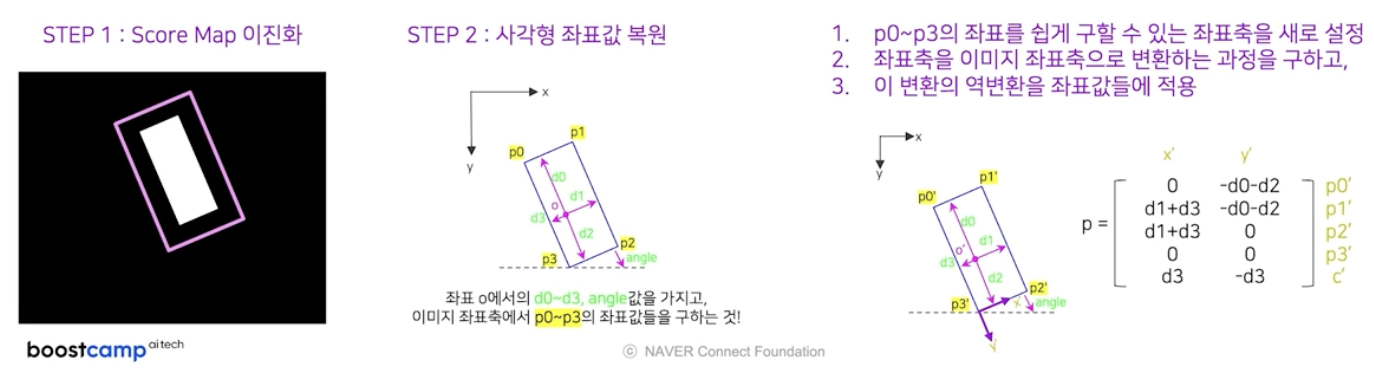
- step1 : score map 을 임계치를 통해서 이진화한다.
- 그러면 1의 값을 가진 위치는 글자영역 중심이라고 판단 가능하다.
- step2 : 사각형 좌표값 복원
- 우리가 알고 있는 것은 좌표 o 에서 직사각형 각 변까지의 거리값인 $d_0$ 부터 $d_3$ 와 각도값이다. 이를 바탕으로 $p_0$ 부터 $p_3$ 4개의 좌표값들을 구한다.
- 이를 위해 총 3단계를 거친다.
- $p_0$ ~ $p_3$ 의 좌표를 쉽게 구할 수 있는 좌표축을 새로 설정한다.
- 좌표축을 이미지 좌표축으로 변환하는 과정을 구한다.
- 이 변환의 역변환을 좌표값들에 적용한다.
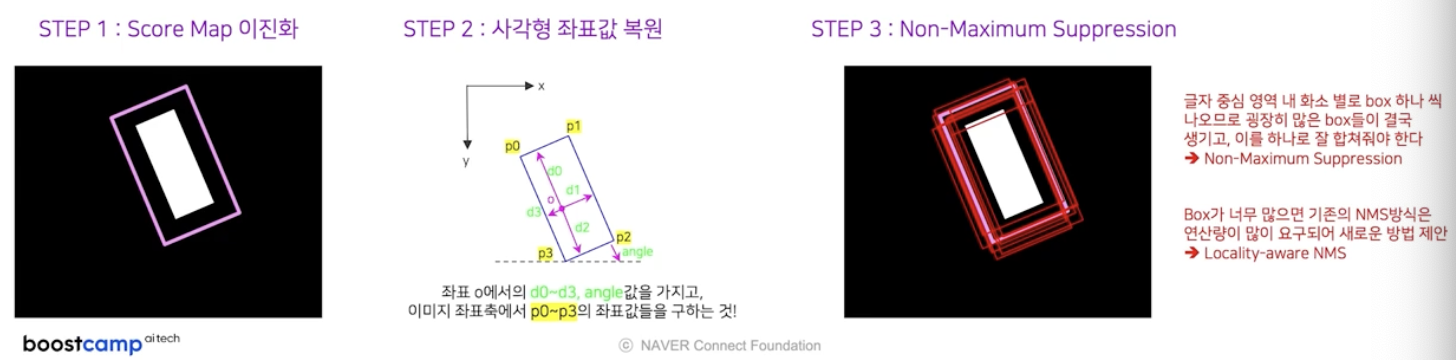
- step3 : Non-Maximum Suppression(NMS)
- 사각형 좌표값이 복원되었다면, 글자 중심영역 좌표 하나 당 예측 bbox 가 하나 나오게 된다.
- 실제 예측 결과는 글자 중심영역 내 화소별로 다 구한다. 그렇게 되면 엄청 많은 bbox 가 나오게 된다.
-
이를 하나로 합쳐주는 작업을 NMS 로 한다. bbox 가 너무 많으면 기존의 NMS 방식은 연산량이 많이 요구되어 본 논문에서는 새로운 방식을 제안했다.

- 그 방식은 기존의 Standard NMS 와 구분하여 Locality-Aware NMS 라고 부른다.
- 아이디어는 간단하다. IoU 가 높은 bbox 가 많으므로 이를 빠르게 합치고 그 후에 기존 NMS 를 적용하는 것이다.
- 위쪽에 있는 box 들부터 IoU 값이 임계치를 넘어가면 합쳐주는데, 그냥 합쳐주는 것이 아니라 해당 box 의 score map 값을 활용하여 weighted merge 를 한다.
- 이렇게 어느정도 합쳐준 다음에는 기존의 NMS 를 적용한다.
- step1 : score map 을 임계치를 통해서 이진화한다.
-
Loss Terms
- RBOX 기준 Loss Term 을 알아보자.
-
전체 Loss func 은
loss for score map + loss for geometry map이다.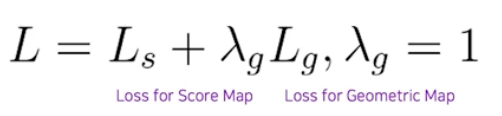
-
$L_{s}$ : Score map loss

- 결국 예측 확률값 과 GT(ground trunt) 의 값에 대한 Loss 다.
- 이 때 목적함수로 Class-balanced CE 를 사용한다.
- segmentation task 에서 주로 사용하는 Dice-Coefficient 를 사용하기도 한다.
- GT 와 prediction 의 교집합을 구하는 연산과 절대치를 구하는 연산으로 구성된다. 교집합은 element-wise 로 값들을 곱하는 것으로 구현, 절대치 연산은 score 의 합으로 계산한다.
-
$L_{g}$ : Geometry map loss

- 사각형 정보에 해당하는 IoU loss 값과 각도값에 해당하는 cosine loss 값으로 최종 loss 값을 계산한다.
- $L_{AABB}$ 는 정답 사각 영역과 예측 사각 영역에 대한 loss 값이다.
- 이는 IoU 기반의 계산식으로 계산이 이루어진다. 분모에서 두 사각 영역의 합집합에 대한 절대값을 구해야 하는데, 교집합에 대한 절대값과 각 영역에 대한 절대값을 통해서 계산이 가능하다.
- $L_{\theta}(\hat{\theta}, \theta^*)$ 은 cosine 기반의 loss 값을 사용한다.
-
Results
-
학습된 EAST 모델의 성능을 보자.
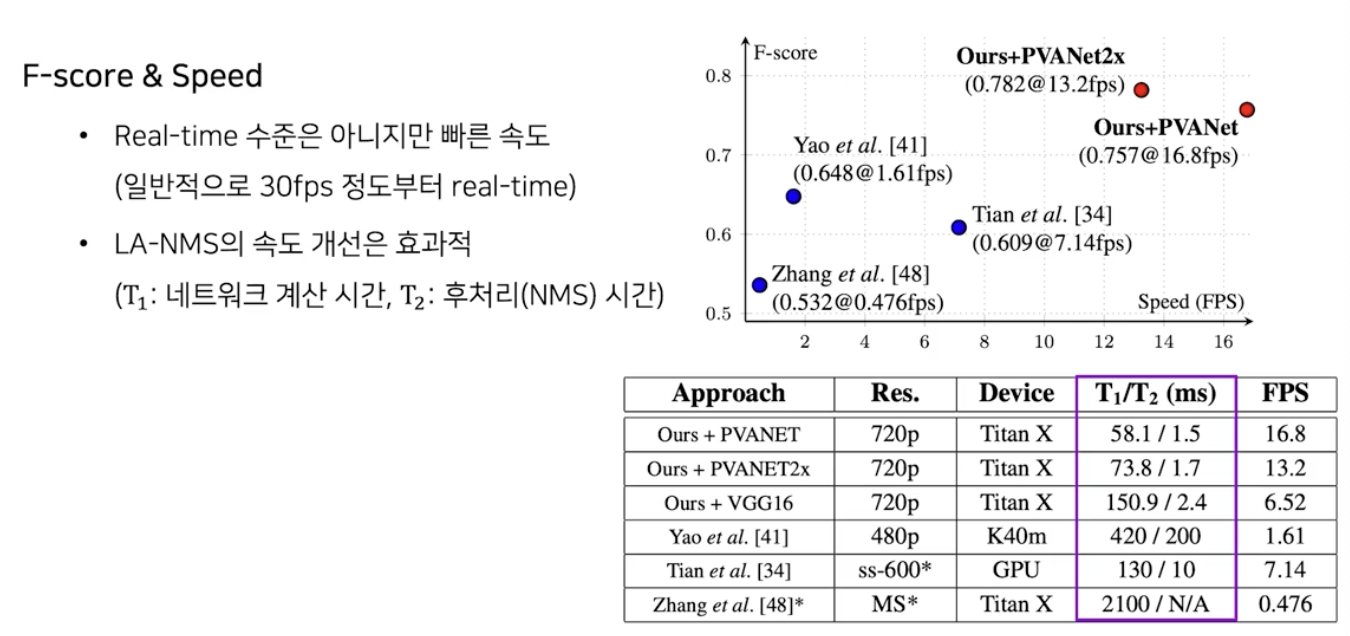
- PVANet backbone 의 경우 초당 17장 정도 처리 가능하다. (일반적으로 30fps 정도부터 real-time)
- 추론 속도는 모델 계산 시간인 $T_1$ 과 후처리인 NMS 를 처리하는 시간 $T_2$ 의 합이다. 논문에서 제안한 LA-NMS 방식을 사용하면 $T_1$ 에 비해서 $T_2$ 는 거의 무시될 정도의 시간만 소요된다.
-
다양한 데이터셋에서 크게 문제 없이 글자영역을 잘 찾아낸다.

- EAST 는 ICDAR2015 에서 좋은 성능을 거뒀다.
정리
- 글자 영역 검출
- 객체의 가로-세로 비율이 매우 극단적이다.
- 객체는 구부러지거나 구겨진 영역 등 특이한 모양을 갖는다.
- 검출 대상이 글자(text) 단일 클래스 이므로, 위치만 예측하는 문제이다.
- 객체는 매우 높은 밀도를 갖는다.
- 검출하고자 하는 대상 객체는 텍스트 영역밖에 없다.
- regression-based vs segmentation-based
- Regression-based 방법은 이미지를 입력으로 받아 bounding box를 바로 출력한다.
- Regression-based 방법은 receptive field의 한계로 인해 극단적 종횡비를 갖는 경우 정확도가 하락한다.
- Segmentation-based 방법은 이미지를 입력으로 받아 화소 단위 정보를 뽑은 뒤 후처리를 통해 글자 영역 표현 값을 출력한다.
- Segmentation-based 방법에서의 화소 단위 정보는 글자 영역에 속할 확률과 8개의 방향으로 이웃한 화소가 글자 영역에 속할 확률을 의미한다.
- Segmentation-based 방법은 후처리가 필요하기 때문에 이미지 처리 속도가 느려질 수 있다.
- EAST
- EAST의 아키텍처는 크게 보면 U-net 구조라고 할 수 있다.
- 1 X 1, 3 X 3 convolution 으로 채널 수를 조절한다.
- Feature extractor stem (backbone)에는 PVANet, VGGNet, ResNet50 이 사용되었다.
- Score map 이란 해당 영역이 글자 중심에 해당하는지 아닌지를 나타낸 것이다.
- Locality-aware NMS 란 IoU가 높은 bounding box들은 같은 text instance 일 가능성이 높으므로 하나로 합친 후 NMS를 적용하는 방법이다.
댓글 남기기