
[Object Detection] 9. Object Detection Competition
-
Ready for Competition
💡 주어진 데이터의 클래스 분포가 심하게 imbalance 되어있어서, 미리 분리해둔 validation set에 대한 성능과 최종 test set에 대한 성능 차이가 심하게 나는 경우에는 Stratified K-fold validation 를 시도해볼만 하다. → 데이터의 imbalance가 심한 경우, random split으로 validation을 분리하면 valid set에 여러 class가 골고루 포함되어 있지 않을 수 있다. 이 경우에는 각 fold 마다 유사한 데이터 분포를 갖도록 하는 Stratified K-fold validation 방법을 사용해볼 수 있다.
동일한 architecture 를 사용한 모델들이 서로 다른 local minima 에 빠진 경향이 보이는 이를 해결하고자 시도해볼만 가장 적절한 ensemble 기법은 ⇒ Snapshot ensemble은 동일한 아키텍처이지만 서로 다른 local minima에 빠진 신경망을 앙상블 하는 방법
하나의 이미지에서 동일한 객체에 대해 너무 많은 box 를 prediction 했을 때, 이를 위한 해결 방법으로 Soft-NMS 와 같은 TTA를 통해 객체에 대한 box들을 통합할 수 있다.


-
mAP 에 대한 오해

-
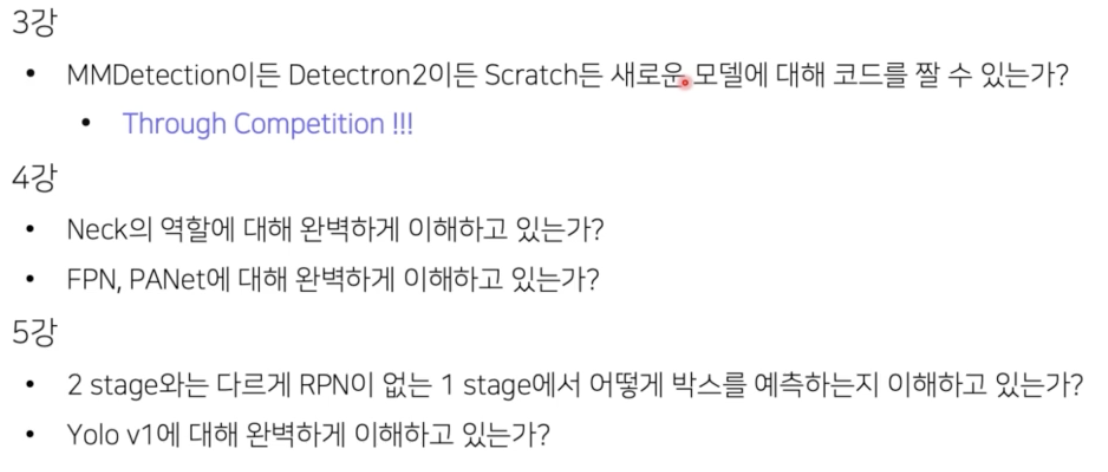
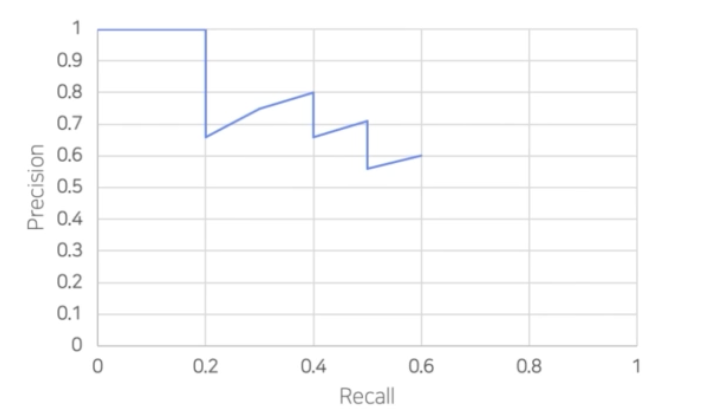
mAP score 가 오른쪽이 더 높을 때, Detection 이 잘 됐다고 말할 수 있을까?

- 시각화시 왼쪽은 bbox thr 를 높게 준 경우이고, bbox thr 를 낮게 준 경우다.
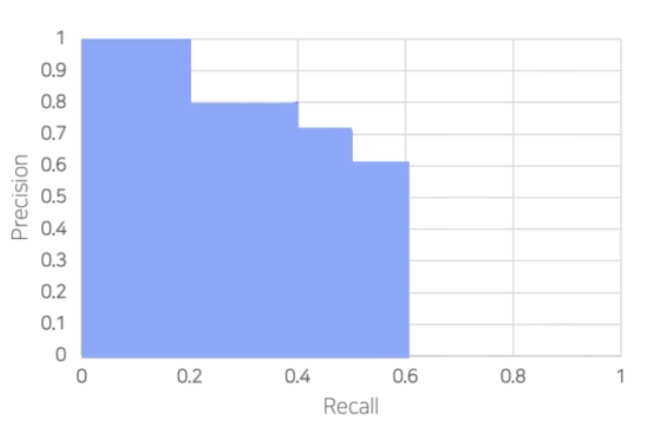
- mAP 연산은 recall precision 을 그래프로 찍었을 때 그 아랫면적을 AP 로 계산한다.
- 그 말은 recall 이 1에 가까울수록 추가적인 성능향상이 존재한다는 것이다.
- 즉 box 를 100, 1000, 10000개 예측하던지 box 의 개수에 따라서는 AP 의 성능이 증가되면 증가됐지 절대 감소하지 않는다.
- 예를 들어 precision이 0보다 클 때 Recall 이 증가하면 아래면적이 더 생기게 된다. 그러면 기존의 AP 보다 좀 더 추가되는 것이다.
- 그러면 무조건 많이 예측하는 것이 AP 를 올리는데 유리하다.
- 그 말은 thr 를 낮출 경우, 오히려 PR Curve 의 면적이 증가한다는 것이다.
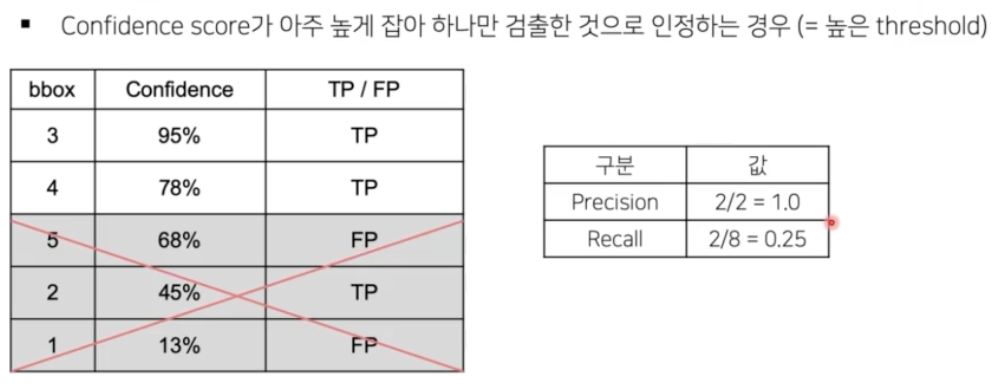
- 높은 thr 를 사용하면 그럴싸한 box 만 남지만, AP 가 낮은 thr 보다 줄어들게 된다.
- 따라서 AP 를 올리기 위해서 box 를 많이 예측하는 것이 훨씬 더 유리하다. 그래서 사람이 눈으로 보기에는 안좋은 경우가 더 점수가 높은 것이다.
- 앙상블을 할 때도 각 모델의 예측 box 를 합치는데, box 개수가 많아지면서 mAP 가 높아질 수 있다.
- 하나의 현상이자 mAP 의 특성이다!
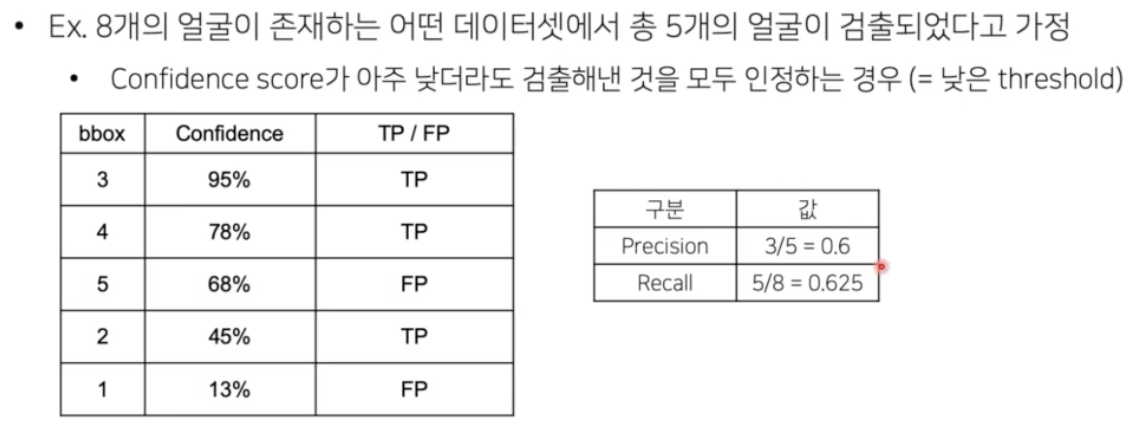
- 실제 detection 연구에서는 맨 마지막에 class thr 를 0.05 로 두고, 0.05 이상 예측한 bbox 들을 실제로 예측한 경우로 생각한다.
- 적용하는 분야의 특징에 따라서 thr 를 바꿀 수 있다.
- 예를 들어 시각화를 잘 해줘야하는 분야에는 그럴싸한 박스만 남기는 것이 중요하다. 따라서 분야에 따라 thr 나 평가 metric 을 설정하는 것이 좋다.
-
- EDA 를 토대로 데이터로부터 인사이트를 얻어서 모델링과 파이프라인 구축을 진행한다.
- Baseline 모델 정할 때
- 어떤 라이브러리? 직접 구현? 다른 사람이 공유한 코드?
- Validation Set 찾기 (CV strategy)
- competition 을 수행하는데 있어서 대부분의 시간이 CV 구축에 할당되어야 한다.
- 좋은 validation set 을 찾아야 public 리더보드에 오버피팅되지 않고 일반화된 결과를 가져올 수 있다.
- 우리 데이터를 최대한 대표하는 대표셋으로 validation 을 구성해야 한다.
- Random Split 등으로 validation set 을 만들 수 있다.
- public 리더보드는 실시간 랭킹이 반영되지만, private 리더보드는 대회가 완전히 종료되어야 한다.
- 일반적으로 좋은 valid set은
- valid set 스코어가 올랐을 때 public score 가 올라가는 것
- valid set 스코어가 올랐을 때 private score 가 올라가는 것
- public 과 private 둘 다 올라야 두 데이터셋의 대표성을 valid set 이 띄는 것이다.
- Validation 전략
-
Random split

- 전체 데이터를 랜덤하게 train / valid 로 분리한다.
- train 은 학습, valid 는 검증
-
K fold validation
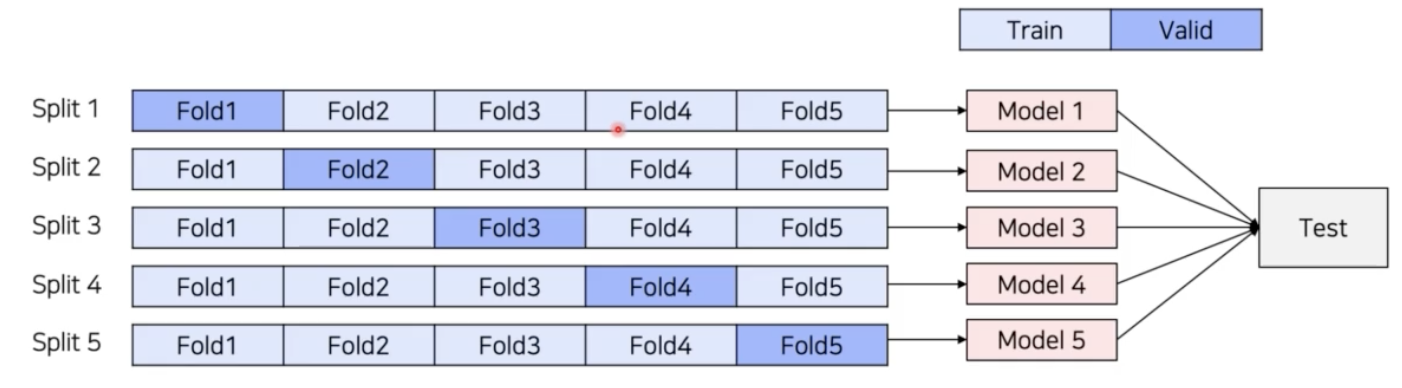
- 전체 데이터를 일정 비율로 train / valid 분리
- split 수 만큼 독립적인 모델을 학습하고 검증
-
Stratified K-fold
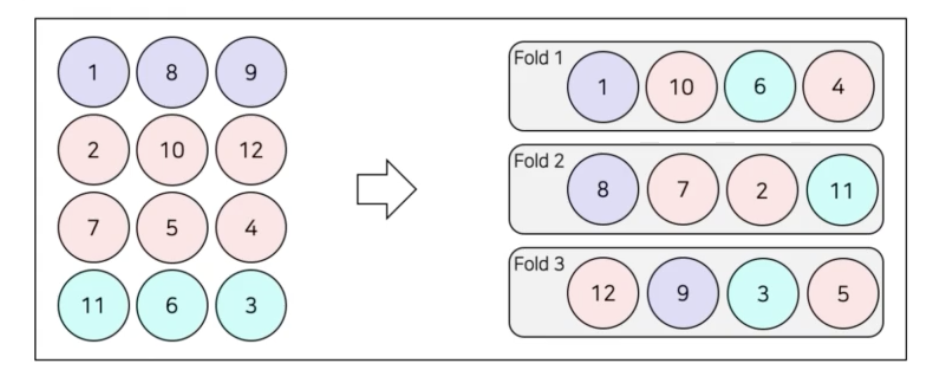
- random, k-fold 는 데이터셋의 분포를 고려하지 않는다.
- stratified 는 각 fold 마다 클래스의 개수가 동일하게 들어가도록 한다.
-
Group K-fold
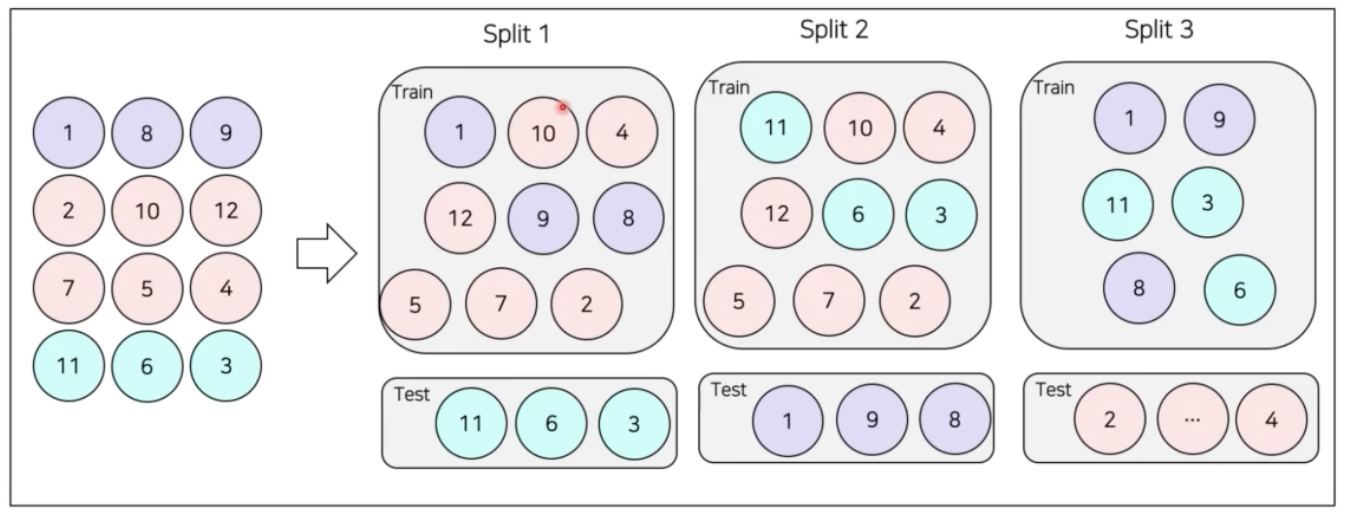
- validation 을 group 기준으로 나눈다.
-
- Data Augmentation - Albumentation
- CutMix 가 일반적으로 backbone 에 많이 적용되는데, detector 를 직접 training 할 때 사용할 수 있을까? 있다!

- 그러나 두 이미지에서 box 가 없는 부분만 잘라서 붙힌 이미지가 나올 수 있다.
- 또한 작은 box 만 붙혀서 작은 box 가 많이 생길 수 있다.

- 이를 해결하기 위해 Mosaic 기법을 쓸 수 있다.

- 독립된 4개의 이미지를 concat 해서 사용한다.
- 또는 전부다 이용할 필요가 없으니 각 이미지의 일부만으로 Mosaic 하는 custom mosaic 도 가능하다.
- 또한 mini box 가 안 생기게끔 cropping 도 할 수 있다.
- Ensemble & TTA
- 가장 높은 성능을 낼 수 있다.
- 최종적으로 한 이미지에 대해서 박스가 엄청 많이 생기게 된다.
- 이를 fusion 하는 과정이 필요하다.
-
NMS(Non-Maximum Suppression)
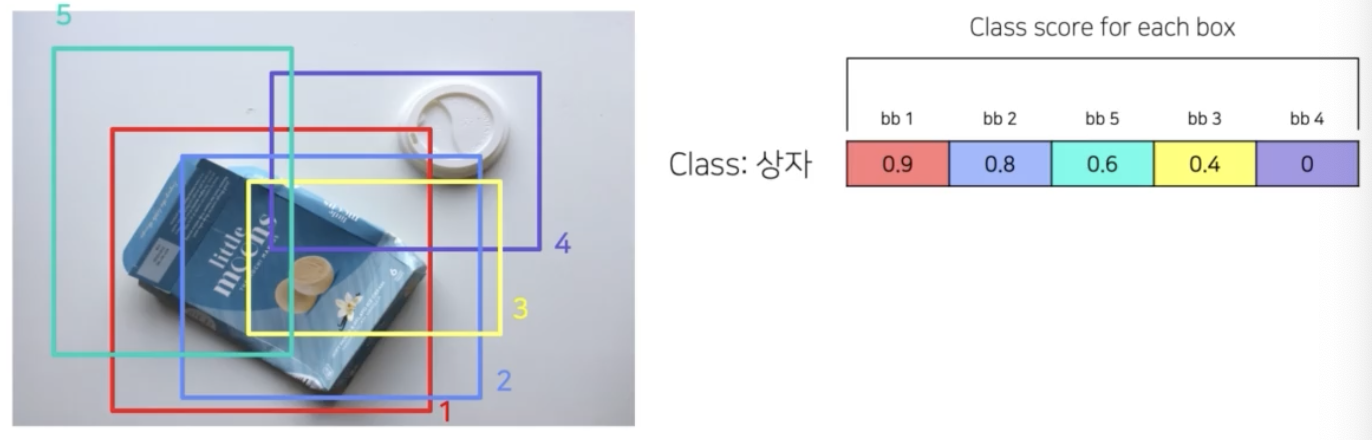
- class score 가 가장 높은 box 기준으로 IoU 를 계산해서 IoU 가 특정 기준 이상이면 같은 박스로 보고 겹치는 박스를 제거하는 것.
-
Soft NMS

- NMS 에는 문제가 있다. best box 하나만 선택하고 나머지는 제거하는 문제가 있다.
- 위 이미지와 같이 박스가 여러개 겹쳐있으면, 베스트가 노란색일 때 빨간색과 파란색이 IoU thr 이상이면 없애버린다.
- 따라서 soft NMS 에서는 box 를 아예 없애는 것 보다는 나머지 겹치는 박스들의 score 를 낮춘다.

-
WBF(Weighted Box Fusion)
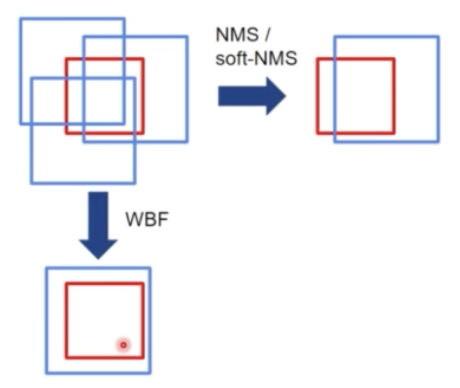
- NMS 나 soft NMS 는 원래 기존에 있었던 box 의 위치를 옮기지 않는다.
- 그러나 WBF 는 GT 주변에 예측들이 있을 때, NMS 나 soft NMS 는 가장 많이 겹치는 box 를 기준으로 남기거나 아니면 나머지 스코어를 조절하는데, WBF 는 GT 와 겹치는 비율대로 새로운 박스를 생성한다.
- WBF 는 정말 강력한 앙상블 기법이다. 따라서 많은 캐글 OD 대회에서 사용한다.
-
그외 앙상블

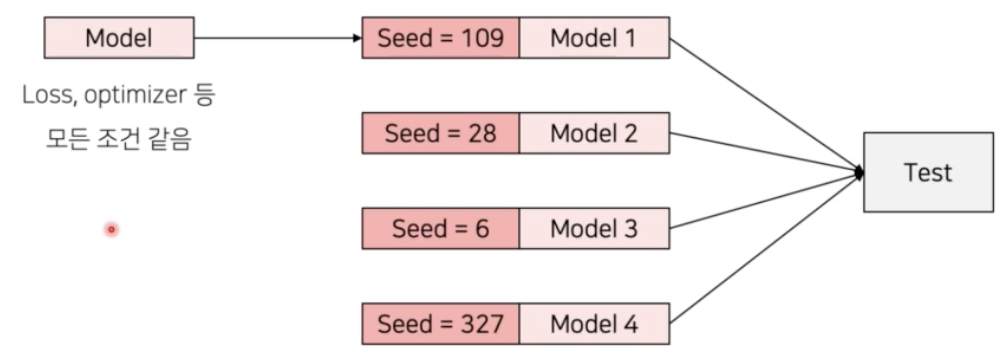
- Seed Ensemble
- Random 한 요소를 결정 짓는 seed 를 바꿔가며 여러 모델을 학습시킨 후 앙상블 하는 방법.
- Framework Ensemble
- 캐글에서 종종 사용된다.
- MMdetection, Detectron2, 등 라이브러리를 여러개 사용하는 것.
- 이런 식으로 다양성이 추가될수록 모델은 더 general 한 학습이 가능해서 private 데이터에도 잘할 가능성이 높아진다.
- Snapshot Ensemble
- 동일한 아키텍처이지만 서로 다른 local minima 에 빠진 신경망을 앙상블하는 방법이다.
- local minima 에 빠진 epoch 를 저장해두고, 각 epoch 의 모델 결과를 앙상블 하는 것이다.
-
Stochastic Weight Averaging(SWA)
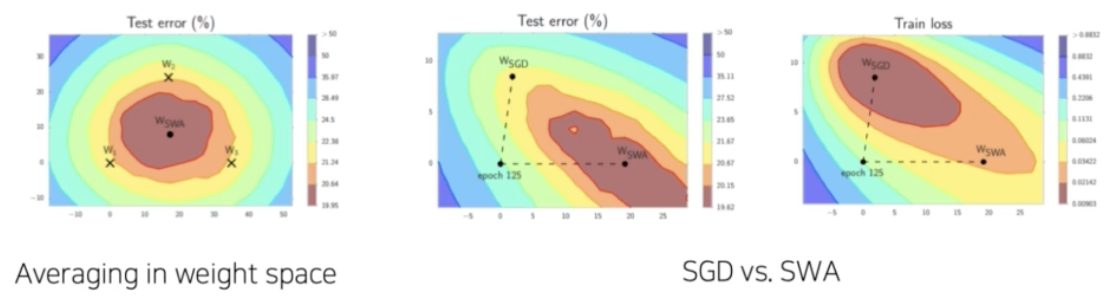
- 일정한 step 마다 weight 를 업데이트시키는 SGD 와 달리 일정 주기마다 weight 를 평균내는 방법이다.
- 즉, Snapshot Ensemble 은 weight 를 저장하고 output 을 계산해서 output 을 앙상블 하지만, SWA 는 모델의 weight 자체를 average 시킨다.
- 일정 주기마다 특정 weight 들을 평균내버린다. 평균을 내서 general 한 값을 가지게끔 학습하는 것이다.
- Seed Ensemble
- 앙상블은 다양성을 부여하는 것! 모델에 다양성을 부여하는 것은 일반화된, 즉 범용적인 성능을 가진 딥러닝 모델을 학습하는데 있어서 중요한 부분이다. 오버피팅을 방지하거나 robustness 를 추가해주는 것도, Regularization 을 추가해주는 것도 전부 다 모델이 특정점으로 편향되는 것을 방지하는 방법이다.
- 따라서 다양성이 부여가 되면 일반적으로 웬만한 데이터셋에 대해서 좋은 성능을 낼 것이다. 그러면 private dataset 에서도 좋은 성능을 낼 수 있다!
-
-
Object Detection in Kaggle
💡 VinBigData Chest X-ray Abnormalities Detection의 top solution에서 공유한 방법 중 하나로, ⇒ 고정된 사이즈로 학습한 이후, 작은 객체들을 더 잘 탐지하기 위해서 보다 큰 이미지를 사용하여 fine-tuning하는 기법을 사용했다. 512x512로 학습한 경우, 이보다 큰 사이즈인 2048x2048 또는 1024x1024를 사용해야 작은 객체에 대한 성능 향상에 도움이 될 수 있다.
모델의 사이즈가 커짐에 따라 처리 속도가 현저하게 느려졌을 때, 정확도를 유지하면서 연산 속도를 높이고자 하는 경우 Mixed precision 이 사용될 수 있다. → Global Wheat Detection의 top solution에서 공유한 방법 중 하나이다. 모델의 정확도는 유지하면서 연산 속도를 높이고, batch size를 키우고 싶은 경우에는 Mixed precision 기법을 활용할 수 있다. FP16, FP32 등 다양하게 섞어서 메모리 사용량 및 연산 처리량을 효율적으로 만들 수 있다.
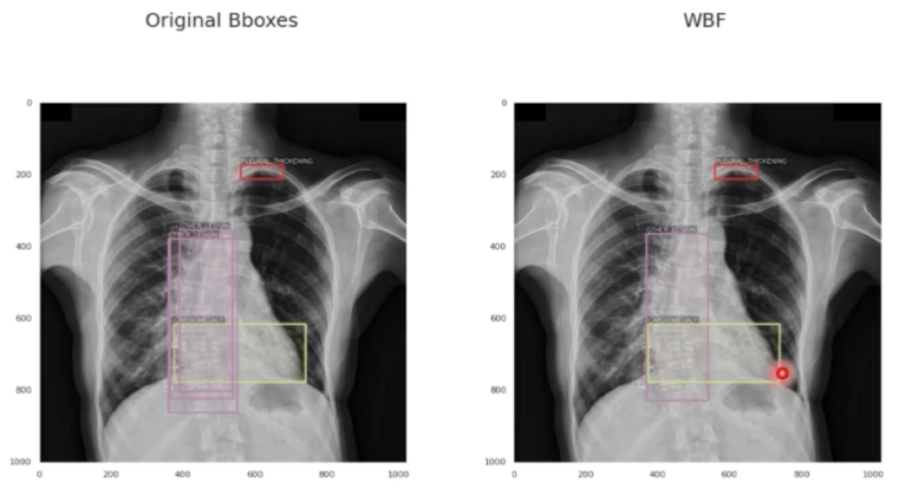
Test data는 객체당 하나의 bounding box를 가지고 있는 상황에서, train data는 같은 객체에 대한 bounding box가 여러 개씩 labeling 되어 있는 경우 WBF (Weighted Boxes Fusion) 를 고려해볼 수 있다. → VinBigData Chest X-ray Abnormalities Detection의 top solution에서 공유한 방법 중 하나이다. Train data 내에서 같은 객체에 대한 bounding boxes를 통합하고 제거하는 것이 모델 성능과 안정성 향상에 가장 적합하다. 따라서 preprocessing 단계에 WBF(Weighted Boxes Fusion)을 사용하여 annotation을 수정할 수 있다.
- Heavy Augmentation 은 여러가지 Augmentation 기법을 많이 썼다는 것이다.
- TTA (Test time augmentation)
- 일반적으로 고정된 test 이미지를 통과시키고 output 을 submission 하는데,
- TTA 는 test 할 때 그냥 이미지 한 장과 augmentation 이미지 한 장에 대한 평균값을 제출하는 것이다.
- 일반적으로 복잡한 augmentation 을 쓰진 않고, HorizontalFlip, Vertical, Rotate90 을 사용한다. 또한 TTA 횟수는 8번 정도로 많이 사용한다.
- multi-scale training 을 했으면 multi-scale testing 도 가능하다. 이미지 사이즈를 다르게 예측해서 두 예측 결과를 앙상블하는 것이다.
- 마지막으로 현업에서는 절대 사용할 수 없는 메소드인 Pseudo labeling 을 쓴다. 캐글이나 컴피티션에서만 쓸 수 있다.
- 진짜 training 데이터셋이 아니라 dummy 의 training dataset 을 만든다.
- 이 때 train 시킨 모델에 test data 를 넣으면 label 이 mapping 된다. 그 중 우수한 애들을 가져와 새롭게 training 을 추가적으로 진행한다.
- 그러면 public, private 데이터 분포가 비슷하면 성능에 엄청 큰 이득이 생긴다.
- Heavy Augmentation
- RandomCrop, HorizontalFlip, VerticalFlip, GaussNoise, RandomBrightnessContrast, HueSaturationValue 는 어떤 컴피티션을 가도 항상 등장하고 있다.
- Mixed Precision(16fp, 32fp, floating point)
- batch size 가 더 늘어나고 학습 속도가 빨라지는 효과를 얻을 수 있다.
- OOF 는 out-of-folds 로서, cross validation 한 fold 의 output
- CV strategy
- 아무리 public LB 가 좋다고 한들 private LB 에서 뒤집어질 수 있다.
- 특정한 기준과 관점을 가지고 믿을 수 있는 valid dataset 을 찾아야 한다. 변동이 적은 valid dataset 은 데이터의 distribution 을 대표할 수 있는 entity 들로 구성되어야 한다.
- Class → classification 과 다른 점은 한 이미지에 여러 개의 class 가 존재한다.
- 그래서 각 fold 별로 한 이미지의 class 개수와 한 이미지의 object 개수가 골고루 들어가는 것이 좋다.
- fold 별로 객체의 크기가 다양하게 골고루 들어가면 좋다.
- stratified 를 잘하자! 객체 크기 같은 연속적인 값은 binning 을 이용하면 좋을 것이다.
- MultilabelStratifiedKFold 라는 것도 있다!
- label 의 각 분포가 골고루 들어가는 것이 그냥 stratified 이면, Multi 는 여러개의 label 이 train 과 valid 에 골고루 들어가는 것이다.
- 모델 다양성은 정말 중요하다!
- Resolution(image size), Model 종류, 라이브러리, backbone, hyperparameter, seed 등
- Heavy Augmentations 은 거의 필수적이다. 다양한 augmentation 은 항상 상수였다.
- CV Strategy 를 잘 세우는 것은 shake up 방지에 있어서 정말 중요하다.
- 모델을 일반화할 수 있는 CV set 을 만드는 것이 중요하다.
- validation set 을 구성할 때 단순하게 train 이미지의 몇 퍼센트를 랜덤하게 하기보다는 EDA 를 해봐서 box 의 분포는 어떻고, box 의 사이즈, class 의 비율, M2Det 처럼 객체의 외형, 복잡도 등을 분석해볼 수 있다.
- 객체의 외형 복잡도라는 value 를 하나 뽑아낸다면 그 value 로 stratified 하게 validation set 을 만들수도 있다.
- 가장 대표성을 띄는 validation set 을 찾아라!
- 체계적인 실험 역시 정말 중요하다!
- Team up 은 성능향상의 엄청난 키가 될 수 있다! 단, 서로 다른 베이스라인을 갖는 경우.
- Object Detection 에서는 일반적으로 박스 크기에 따라 성능이 극명하게 나뉜다. 작은 박스는 예측을 잘 못하고 큰 박스는 잘한다. train dataset 이 큰 박스에 치중되어 있으면 이는 전체 데이터셋을 충분히 대표한다고 말할 수 없다. 따라서 Number of boxes 와 Median of box areas(box의 크기) 가 중요하다. 꼭 고려해야 한다.
- 같은 영역인데 박스가 여러개로 표현되어 있는 dataset 이 있을 수 있다.
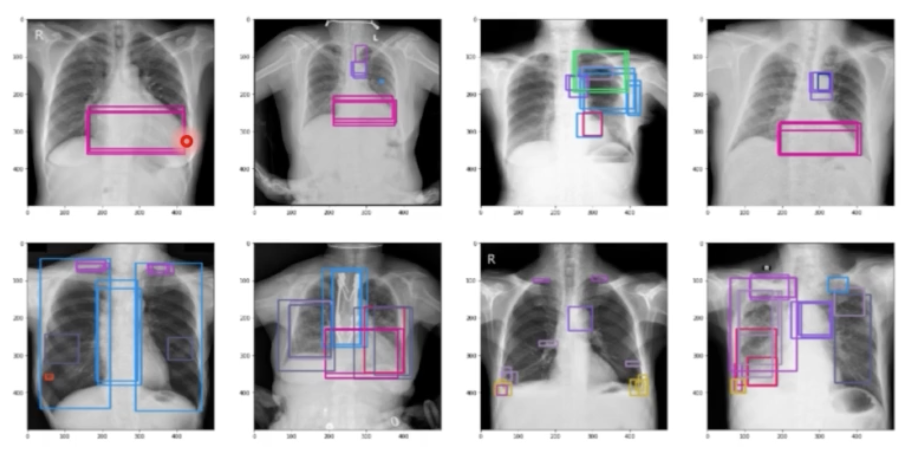
- 이는 특수한 경우로 한 이미지에 여러 명의 어노테이션이 들어가 있으면 그럴 수 있다. 그러면 하나의 object 에 여러개의 박스가 존재할 수 있다. 이러면 아래 그림처럼 사전에 preprocess 과정이 필요할 수 있다.
- 스케줄러, 옵티마이저는 휴리스틱한 하이퍼파라미터다! 뭐가 좋은지 모른다.
댓글 남기기