
[Object Detection] 8. Advanced Object Detection (2)
-
Advanced Object Detection 2
💡 YOLO v4는 당시의 최신 딥러닝 기법들을 도입하고, 이를 적절히 조합하여 성능이 가장 높은 최적의 조합을 사용했다. 사용된 기법은 크게는 BOF(Bag-Of-Freebies)와 BOS(Bag-Of-Specials)로 구분될 수 있다. BOF는 inference 비용을 늘리지 않고 정확도를 향상시키는 방법이며, BOS는 inference 비용이 조금 증가하지만 정확도를 크게 향상시키는 방법이다.
- Feature Integration : Feature map을 통합하여 사용하는 방법으로, inference 비용이 증가하기 때문에 BOS에 속한다.
- Data augmentation : 이미지 데이터를 인위적으로 변형하여 모델의 robustness를 증가시키고자 하는 방법으로, 이미지의 형태가 변형될 뿐 inference 연산량에는 영향을 미치지 않기 때문에 BOF에 속한다.
- Activation function : 최적의 activation function을 선정하여 gradient가 더 효율적으로 전파하도록 하는 방법으로, inference 비용이 증가하기 때문에 BOS에 속한다.
- Post-processing method : 같은 객체를 예측하는 불필요한 bounding box를 제거하는 NMS 방법으로, inference 비용이 증가하기 때문에 BOS에 속한다.
- Enhancement of receptive field : Feature map의 receptive field를 키워서 검출 성능을 높이는 방법으로, inference 비용이 증가하기 때문에 BOS에 속한다.
M2Det 모델의 FFM(Feature Fusion Module) 구조. (모든 convolution의 padding은 1이며, 다른 모든 연산 세팅은 M2Det을 그대로 따라간다고 가정)
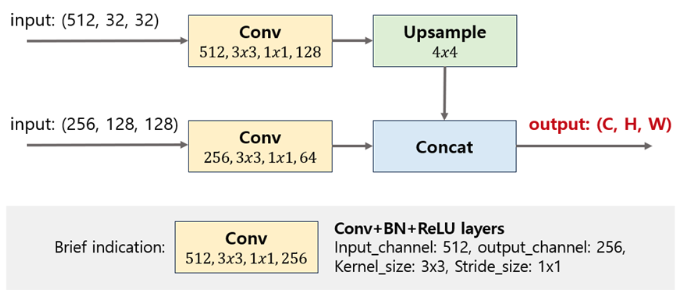
input shape 이 (512, 32, 32), (256, 128, 128) 일 때 output feature map의 shape 은?
- 상단의 convolution을 통과하면 (128, 32, 32)가 되고, 4배로 upsampling을 하기 때문에 (128, 128, 128)의 feature map이 생성된다.
- 하단의 convolution을 통과하면 (64, 128, 128)가 되고, 상단의 feature map과 concat하면 최종 (C, H, W) = (128+64, 128, 128) = (192, 128, 128)의 output이 생성된다.
CornerNet은 anchor box의 단점을 해결하기 위해, anchor를 제거하고 corner를 이용하여 객체를 검출하는 anchor-free detector이다. 다음 중 CornerNet에서 지적한 anchor box의 단점은,
- 엄청나게 많은 수의 anchor box를 생성해야 하며, 대부분의 box가 객체를 탐지하지 못한 negative sample 이다.
-
anchor box를 설계하는 과정에 hyperparameter를 고려해야 한다. 이 두가지의 anchor box 단점을 지적하며 이를 해결할 수 있는 방법을 제시했다.
- YOLO v4
- 기존의 YOLO 구조와 크게 다르지 않지만, 기존 YOLO 구조에 많은 최신 기법을 적용해보는 실험 레포트라고 보면 된다.
- 즉 이 YOLO v4 에서 어떤 실험을 했는지 참고하면 추후 competition 등에서 많은 아이디어를 얻을 수 있다.
- 실험 레포트 외에도 object detection task 에 대해서 잘 정리해뒀기 때문에 한번쯤 YOLO v4 paper 를 읽어보는 게 좋다.
- Background
- 최근 2 stage detector 들의 발전으로 정확도는 크게 향상했지만 실시간 동작이 힘든 경우가 많았다.
- training 과 inference 하는데 많은 양의 GPU 와 batch size 를 요구한다.
- 최신의 object detector 는 어떤 니즈들이 요구되냐면, 단순하게 성능만 좋다기 보다는 빠르면서 정확도가 높은 detector 가 요구되고 있다.
- YOLO v4 에서 이런 detector 의 디자인을 실현하기 위해서 그 시작을 열었다.
- Contribution
- 하나의 GPU 에서 훈련할 수 있는 빠르고 정확한 Object Detector. 어느 정도 속도와 성능을 보장한다.
- 모델에 적용 가능한 다양한 메소드를 크게 2가지 형태로 구분했다.
- BOF(Bag of Freebies): inference 비용을 늘리지 않고 정확도를 향상시키는 방법. 그러나 training 단계에서 학습 cost 는 어느정도 증가할 수 있다.
- BOS(Bag of Specials): inference 비용을 조금 높이지만 정확도가 크게 향상하는 방법. 예를 들어 Cascade 나 Deformable RCNN 같은 것들이 BOS 방법들 중 하나가 될 수 있다.
- 위 메소드들을 대상으로 많은 실험을 시도하고 증명하면서 베스트 성능을 보이는 조합을 찾았다.
- 이런 BOF 와 BOS 방법들을 GPU 학습에 더 효율적이고 적합하도록 변형했다.
- 저자는 하나의 GPU 에서 훈련 가능한 방법들에 대해서 제시했다. 이 부분이 어떤 이점을 가져올 수 있을까? Competition 혹은 현업에서 제한된 리소스를 사용해야 한다면, 이 부분이 큰 메리트로 다가올 수 있다.
-
Detection task pipeline
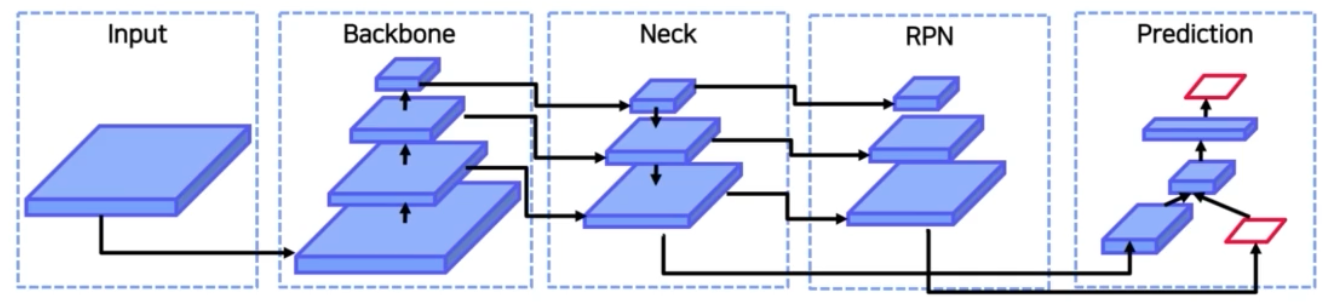
- input 으로 원본 이미지, 혹은 Patches(transformer), 혹은 Image Pyramid 형태가 올 수 있다.
- 이후 input 들이 backbone 을 거쳐서 semantic 을 가지는 feature map 으로 바뀌게 된다. GPU platform 상에서 학습 가능한 모델들은 VGG, ResNet, ResNext, DenseNet 등이 있겠고 CPU platform 에서 학습 가능한 경량화된 모델들은 SqueezeNet, MobileNet, ShuffleNet 등이 있다.
- 다음으로 Neck 이 있다. DetectoRS 를 리뷰할 때 Neck 정보를 backbone 에 넘겨줄 때 ASPP 라는 pooling 기법을 사용했었고, Neck 에서 RoI 를 뽑을 때 고정된 feature size 를 얻기 위해서 SPP 라는 pooling 방법을 사용했었다. 또한 high-level feature map 과 low-level feature map 을 섞어주기 위해서 FPN, PAN, NAS-FPN, BiFPN 등의 구조를 이용했다.
- 마지막 Head 부분은 1 stage detector 의 경우 RPN 이 따로 존재하지 않아 feature map 의 각 픽셀에 anchor box 를 할당해주고 바로 객체와 클래스의 위치에 대해서 인식했었다. 대표적인 예시로 YOLO, SSD, RetinaNet, CornerNet, FCOS 등이 있다. 2 stage detector의 경우 모든 픽셀에서 예측하는 것이 아니라 feature map 에서 객체가 있을 법한 위치를 추천받는 RPN 을 활용했다. RPN 에서 proposal 들이 나오면 이를 다시 feature map 에 Projection 한 뒤 RoI Pooling 을 통해 최종 cls head, box head 에 vector 를 넘겨주었다. 대표적 예시로 Faster R-CNN, R-FCN, Mask R-CNN 등이 있다. Mask R-CNN 은 segmentation 모델이다. Dense Prediction 에서 RPN 은 최종적으로 feature map 으로 부터 region proposal 을 뽑아내는 dense prediction이라 할 수 있다. 즉 RPN 은 1 stage 가 아니라 2 stage 를 위해서 region 을 뽑아내주는 region proposal network 이다.
- Bag of Freebies
- inference cost 를 늘리지 않는 방법들이다. 즉 모델의 real time 을 보장한다면 Bag of Freebies 방법을 사용한다고 해서 real time 속도가 늘어나지는 않는다는 것을 의미한다.
- 크게 3가지 카테고리로 나뉠 수 있다.
-
Data Augmentation

- 입력 이미지에 transform 연산을 가해서 overfitting 을 막고 다양한 환경에서 모델이 robust 해질 수 있게 만들어주는 방법들을 의미한다.
- 대표적인 예시로 brightness, hue, saturation 을 바꾸는 color transform, shift, rotate 같은 geometric transform 이 있다.
- 최근에는 훨씬 다양한 기법들이 연구되고 있다. 이미지의 특정 부분을 마스킹 처리 해버리는 CutOut 이나 한 이미지의 patch 를 다른 이미지에 섞어 버리는 CutMix, 두 이미지를 아예 섞어버리는 Mixup 등의 방법이 있다.
- 이 때 ground truth 라벨도 패치 영역만큼 비율로 섞어준다.
- Semantic Distribution Bias
- 데이터셋에 불균형이 존재할 때 이를 해결할 수 있는 방법들을 의미한다.
- 특히 detection task 의 경우 객체보다 배경이 압도적으로 많기 때문에 이 방법을 이용하면 큰 성능향상을 가져올 수 있다.
- 어려운 배경을 강제로 batch 에 더 많이 포함시키는, 즉 hard negative sample 을 batch 에 더 많이 포함시키는 hard negative mining 이 있고, 어려운 예제로부터 gradient 를 크게하는, 즉 쉬운 예제에서는 gradient 가 작게, 어려운 예제에서는 gradient 를 크게 하는 Focal Loss 등이 있다.
- 또한 Label Smoothing 이 있다.
- 원래 학습을 할 때 label 을 0 또는 1로 설정하는데, smoothing 에서는 0 또는 1이 아니라 smoothing factor 를 줘서 label 을 soft 하게 만든다.
- 예를 들어 원래 0이었던 label 을 0.1 로 부여하고 1 이었던 label 을 0.9 로 부여한다.
- 이런 식으로 학습했을 때 label 에 noise 가 많이 끼어있다면, 즉 잘못된 label 의 비율이 많다면, 이런 label smoothing 을 활용하면 학습이 더 잘 될 수 있다.
- 또 모델의 overfitting 을 어느정도 막아주는 regularization 효과가 있다.
- Bounding Box Regression
- 지금까지 bbox 를 학습할 때 MSE loss 를 사용했다. 하지만 일반적으로 bbox 를 평가할 때는 mse loss 가 아니라 IoU 방법을 사용한다.
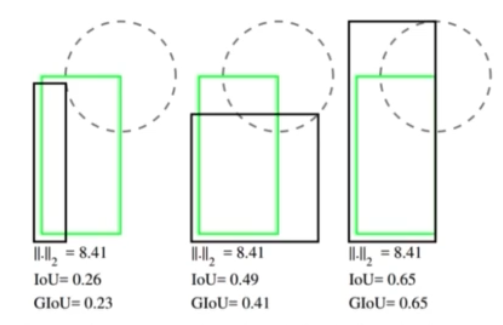
- 예를 들어 위 그림은 모두 L2, 즉 MSE value 가 8.41 로 동일하다. 하지만 제일 왼쪽의 경우 GT 와 pred 의 IoU 가 0.26 이고 3가지 경우가 모두 다르다. 즉, MSE 가 동일하더라도 IoU 를 계산했을 때는 차이가 있을 수 있다.
- 따라서 MSE 를 Loss 로 사용하는 것은 IoU 를 완벽히 반영한다고 말하기 힘들다.
- 애초에 모델이 학습할 때 GT 와 IoU 를 높이는 방향으로 학습하게 할 수 있다. 즉 IoU loss 를 사용하는 것이다.
- 대표적으로 CIoU, DIoU, GIoU 등이 있다. CIoU 와 DIoU 는 GIoU 를 변형한 것이기 때문에 GIoU 에 대해 보자. (Generalized Intersection over Union)
- GIoU 는 IoU 기반 Loss 이다. 일반적인 IoU 가 0일 때는 box 가 얼마나 떨어져 있든지 간에 모두 IoU 값이 0으로 나오는 경우가 있다.
- 예를 들어 먼 box 는 좀 더 loss 가 크게 반영이되어야 하는데, IoU 는 두 박스가 겹치지 않으면 0으로 할당해버리기 때문에 박스가 얼마나 멀리 있든지 신경쓰지 않고 다 loss 가 0이 되어버린다.
- 따라서 GIoU 는 두 박스의 거리를 반영해서 새롭게 IoU loss 를 디자인했다.
- Bag of Specials
- inference 단계에서 어느정도 cost 가 발생하지만 성능 향상에 큰 도움이 되는 방법들이다.
- 크게 5가지 카테고리로 나뉠 수 있다.
-
Enhancement of Receptive Field
- feature map 의 receptive field 를 키워서 검출 성능을 높이는 방법이다.
- SPP 나 ASPP 또는 transformer 의 SW-MSA 이 있을 수 있다.
-
Attention Module

- Squeeze-and-Excitation block 과 Convolutional Block Attention Module 이 있다.
- SE 와 CBAM 은 크게 다르지 않은데, feature map 에 어떤 global attention 을 추가해주는 방법들이다.
- 예를 들어서 SE 의 경우, feature map 이 존재할 때 이 feature map 을 그대로 이용하는 것이 아니라 feature map 에 global 정보를 추가해준다. 먼저 각 feature map 의 channel 별로 GAP(global average pooling) 연산을 가해줘서 feature map 의 shape 을 (1x1xC) 로 만들어준다.
- 이후 linear, activation, sigmoid 등 일련의 연산을 가해서 최종적으로 vector 의 값이 0에서 1 사이의 값이 나오도록 바꿔준다.
- 이렇게 만들어진 feature map 은 채널의 중요도를 담당한다고 판단할 수 있다.
- 따라서 이를 원래의 feature map 과 channel wise 하게 곱해주면, 원래의 feature map 에 채널의 중요도가 반영되었다 라고 생각할 수 있다.
- CBAM 도 비슷한 맥락에서 channel attention 과 spatial attention 도 input feature map 에 추가해서 사용하게 된다.
- 그렇게 되면 feature map 에 attention 정보가 추가되면서 context 관점에서 좀 더 중요한 feature map 에 집중할 수 있게 된다.
-
Feature Integration
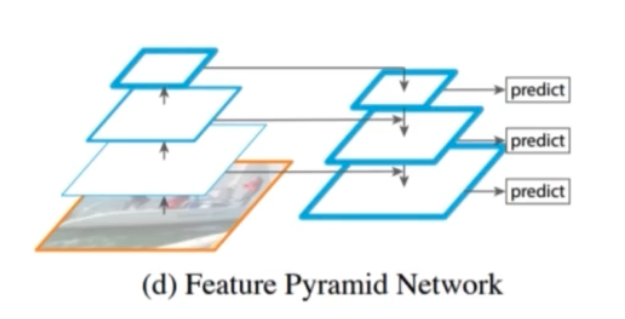
- backbone 중간중간 나온 feature map 정보들을 통합해주는 방법들이다.
- 이는 Neck 과 동일하다.
- Activation Function
- 다양한 Activation Func 도 사용할 수 있다. 좋은 activation func 은 gradient 가 더 효율적으로 전파된다.
- ReLU, Swish, Mish 등이 있다.
- 이를 그래프로 그리면 아래 그림과 같다.
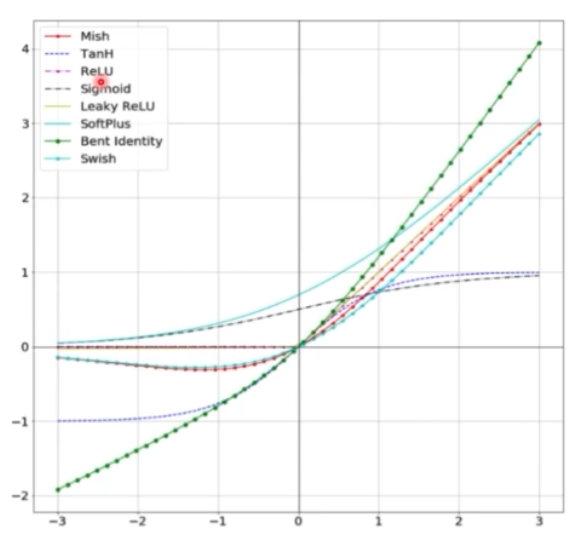
- 일반적인 ReLU 의 경우 시그모이드의 gradient vanishing 문제를 해결하기 위해 등장한 활성화함수인데, 음수값은 아예 0으로 처리를 해버린다. 따라서 음수값에 대해서는 학습하지 않는 문제가 있다.
- 이에 약간의 음수를 허용하는 Swish, Mish 와 같은 방법이 새롭게 등장하게 되었다.
-
Post-processing method

- 겹치는 박스를 제거하는 NMS 와 같은 후처리 방법들이다.
- 최종적으로 BoF 와 BoS 를 정리하면 아래와 같다.

- YOLO 저자들은 BoF 와 BoS 외에 backbone 모델을 개선했다. 이 때 다음 세가지에 중점을 두고 모델 구조를 설계했다.
- 작은 물체를 검출하기 위해서 Resolution이 큰 이미지를 사용했다. 즉, 작은 물체를 검출하기 위해서 큰 네트워크 입력 사이즈가 필요했다.
- 이에 따라 네트워크 입력 사이즈가 증가했기 때문에 큰 receptive field 를 필요로했다. 이를 위해 layer 의 개수를 증가시켰다.
- 하나의 이미지에서 다양한 사이즈의 물체를 검출하기 위해서 모델 파라미터를 키웠다.
-
Overall Architecture
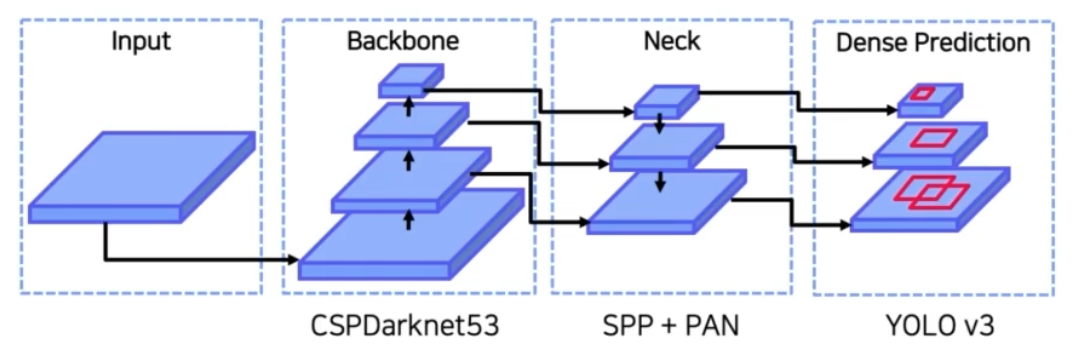
- Neck 은 SPP 에 PAN 을 사용했다.
- Head 는 YOLO v3 를 사용했다.
- Backbone 인 CSPDarknet 에 대해 살펴보자.
- Cross Stage Partial Network (CSPNet)
- YOLO v4 에서는 기존 YOLO v2 부터 사용되던 Darknet 에 Cross Stage Partial 이라는 새로운 알고리즘을 변형해서 사용했다.
- YOLO v4 는 모델 구조 설계 상 모델의 사이즈가 커질 수 밖에 없다. 따라서 성능 향상을 위해서는 어느정도 경량화가 필요했다.
- CSP 를 적절해서 변형해서 사용하면 정확도를 유지하면서 모델을 가볍게 만들어줄 수 있다.
-
기존 DenseNet
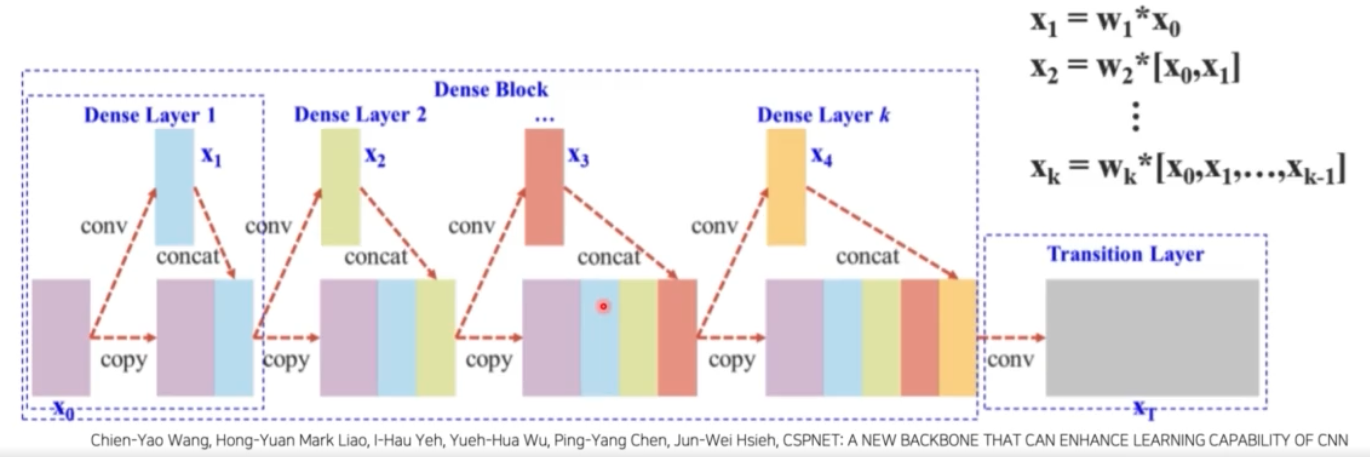
- input feature map($\mathbf{X}_0$)가 존재한다고 할 때, $\mathbf{X}_0$ 에 conv 연산을 가해서 $\mathbf{X}_1$ 을 만들어낸다. 그 이후 $\mathbf{X}_0$ 와 $\mathbf{X}_1$ 을 channel dimension 으로 concat 해준다.
- 이렇게 concat 된 새로운 feature map 에 conv 연산을 해서 $\mathbf{X}_2$ 를 만들어낸다. 이 $\mathbf{X}_2$ 와 concat 된 feature map 을 다시 concat 해준다. 또 여기서 conv, concat 을 $k$ 번 반복한다.
- 이렇게 해서 최종적으로 feature map $\mathbf{X}_T$ 를 만들어 낸다.

- 이 때 기존 DenseNet 의 문제는, 똑같은 conv feature 가 이후 feature 를 구성할 때 반복적으로 사용된다는 점이다.
- 따라서 backward 로 가중치를 업데이트할 때, 오른쪽이 gradient funcion 인데, gradient 정보가 재사용되는 것을 확인할 수 있다.
- 이에 YOLO v4 저자는 계산량을 줄이기 위해서 반복적으로 사용되는 gradient 를 줄이는 것에 집중했다.
-
CSPDenseNet
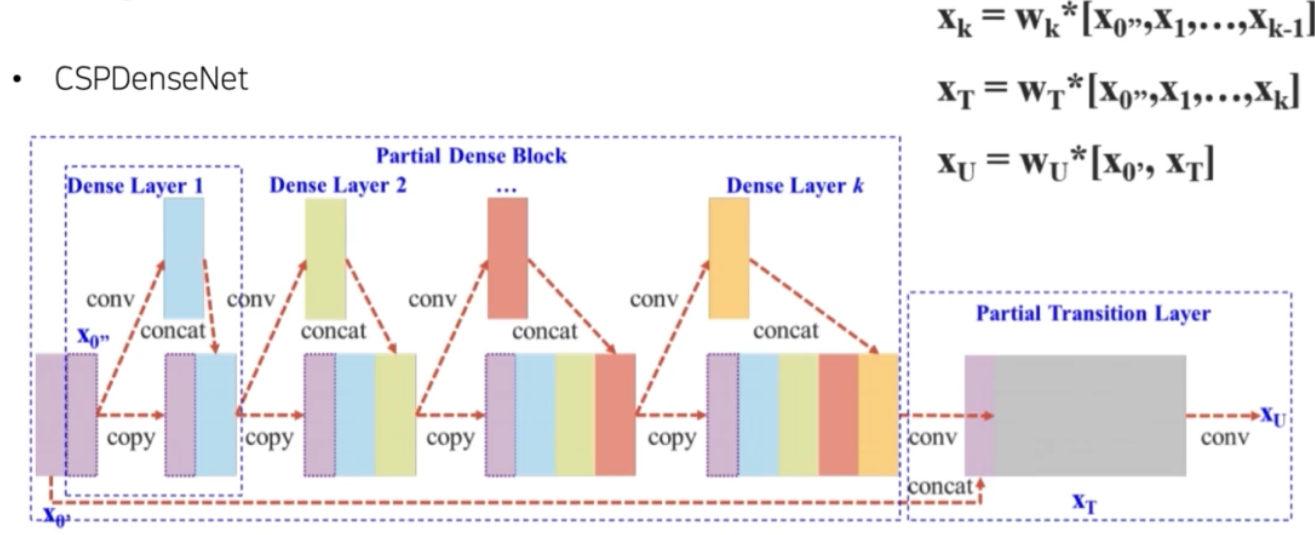
- $\mathbf{X}_0$ 를 두 개의 partial 로 구분한다. channel 로 자른 것이다.
- 잘린 부분 중 한 파트를 앞선 과정과 똑같이 conv 연산 후 concat 을 반복한다.
- 앞의 일반적인 DenseNet 은 input feature map 의 모두를 사용했다면, YOLO v4 에서 사용된 CSPDenseNet 은 일부의 feature map 을 사용했다.
- 이후 그렇게 만들어진 $\mathbf{X}_T$ 에 input 의 나머지 feature map 을 concat 을 하면 최종적으로 feature map 이 나오게 된다.
- 왼쪽은 forward, 오른쪽은 backward 과정이다.
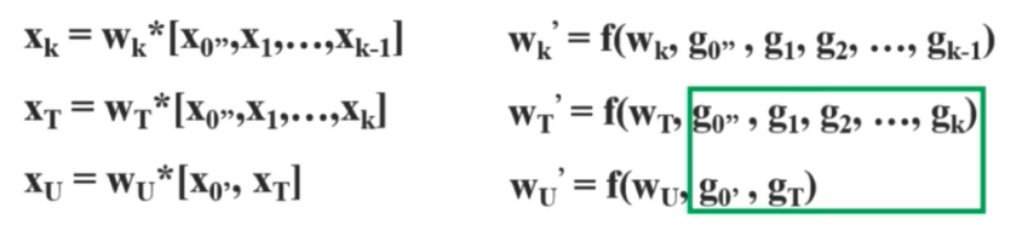
- CSPDenseNet 처럼 input feature 를 2개로 나눠준 후 한쪽은 연산에 참여 시키지 않고 나중에 concat 해줌으로써 그 feature map 에 대한 cost 를 줄일 수 있고, gradient flow 를 나눠줘서 학습에 좋은 영향을 끼친다고 한다. 즉 gradient information 이 많아지는 것을 방지한다.
- CSPNet 의 장점은 backbone 을 크게 바꾸지 않고 모든 backbone 에 적용할 수 있고, 유명한 모델들의 성능을 향상시켰다.
- 이후 YOLO v4 에서 새롭게 시도한 방법들이 있다.
- 새로운 data augmentation
-
Mosaic

- Mosaic 은 train 이미지 4장을 하나의 이미지로 합쳐버리는 방법이다.
- 앞서 배운 CutMix 는 2장을 하나로 합쳤는데, Mosaic 는 4장의 이미지를 하나로 합쳤다. 즉 하나의 input 으로 4개의 이미지를 배울 수 있어서 batch size 가 커지는 효과를 얻을 수 있다.
- 또한 작은 batch size 를 사용을 해도 학습이 잘 된다고 한다.
-
Self-Adversarial Training(SAT)
- 2 stage 를 걸쳐 수행되는 방식이다.
- 첫 번째 stage 에서는 원본 이미지를 변형시켜 이미지 안에 객체가 없어보이게 하는 adversarial perturbation 을 추가하게 된다.
- 2번째 stage 에서는 이 변형된 이미지를 사용해서 학습을 한다.
- adversarial example 이라는 눈에 보이지 않는 perturbation 을 추가해서 모델의 오작동을 유도하는 sample 들이 있다. 이 adversarial example 들에 대해 robust 하게끔 adversarial example 을 training dataset 에 추가해서 학습하는 방법이 self-adversarial training(SAT) 다.
-
-
기존 방법 변형
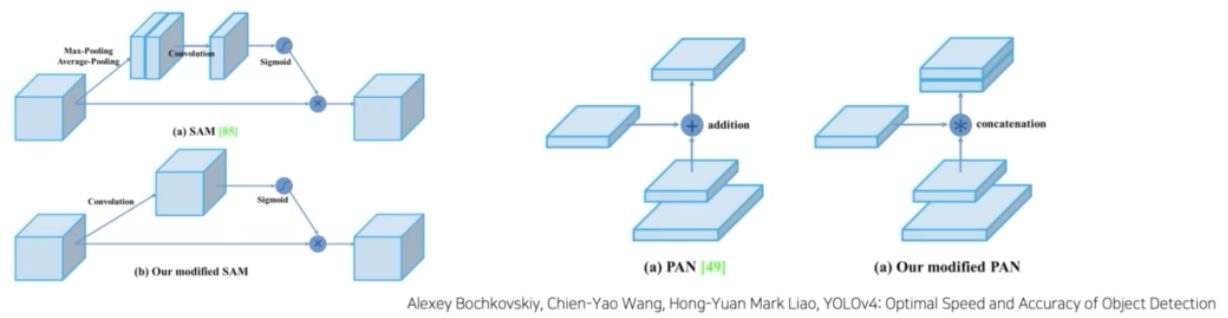
- modified SAM(Spatial Attention Module)
- Spatialwise attention 을 Pointwise attention 으로 변형했다.
- modified PAN(Path Aggregation Network)
- Add 연산을 Concat 연산으로 대체해서 사용했다.
-
Cross mini-batch Normalization (CmBN)
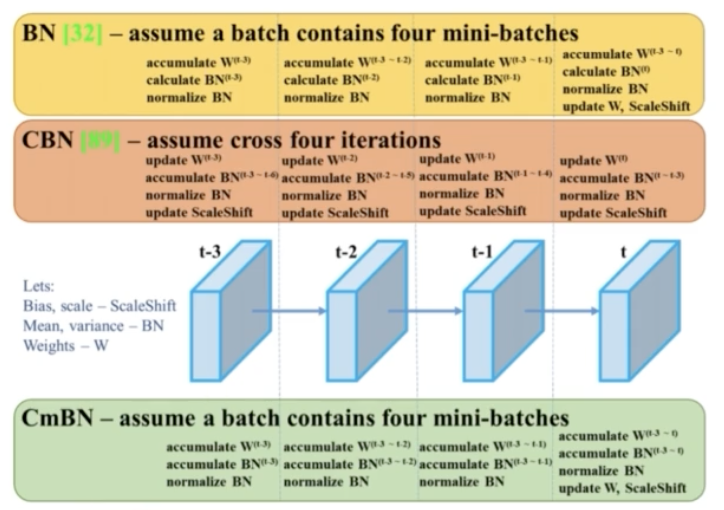
- 일반적인 BN 은 각 mini batch 마다 batch norm 을 계산했다. 만약 mini batch 의 사이즈가 작으면 그 작은 샘플로 평균과 분산을 추정했어야 했다.
- 이에 CmBN 은 각 mini batch 에서 batch norm 을 계산하는 것이 아니라 batch norm 을 accumulate 해서 마치 batch size 가 큰 것과 같은 효과를 부여했다.
- modified SAM(Spatial Attention Module)
- 새로운 data augmentation
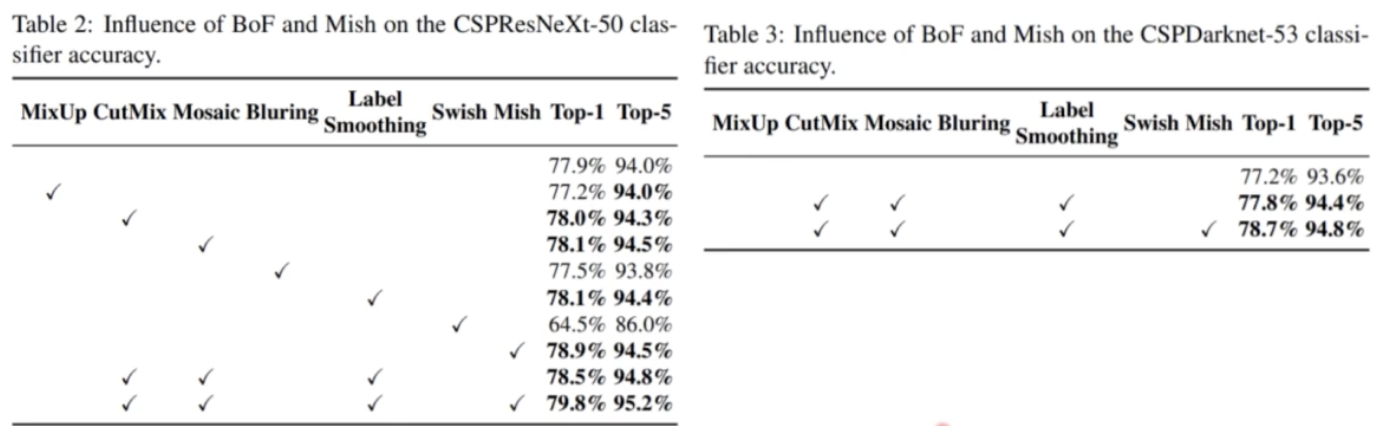
- Backbone 실험 결과
- BoF 와 BoS 들 중에서 YOLO v4 가 backbone 에 성능 향상을 위해서 채택한 방법들이 아래에 나타나있다.

- 추가로 새롭게 시도한 방법들 중에서는 Mosaic augmentation 을 사용했다.

- 어떤 기법을 적용했을 때 score 가 어떻게 바뀌는지 한 번 보자.
- Detector 실험 결과
- 다음으로 detector 에서 사용한 BoF 와 BoS 방법들이다.

- 추가로 새롭게 시도한 방법들이다.

- 최종 실험 결과(논문 8p)
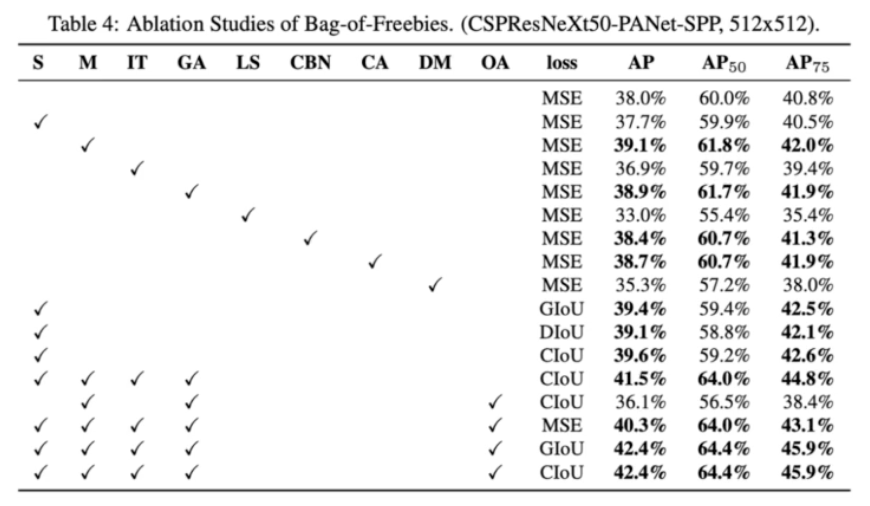
- YOLO v4 는 BoF 와 BoS 를 포함해서 다양한 실험을 했다. 여기서 아이디어를 얻어서 새롭게 실험을 디자인하거나, YOLO v4 에서 성능이 좋았던 실험들을 적용하는 것도 좋다.
- 주의할 점은, YOLO v4 에서 실험한 내용은 해당 데이터셋과 해당 모델에만 성립하는 내용이다. 즉 모든 detection task 에 일반화 된다고 단언할 수 없다.
- 데이터셋에 따라 YOLO v4 에서 안좋았던 실험 결과가 좋아질 가능성이 있다는 것이다.
- 따라서 실험을 할 때 모든 가능성을 열어 두고 최대한 많은 실험을 통해서 본인만의 직관을 기르는 것이 중요하다.
- M2Det
- 1 stage detector 에서 Multi-level Multi-scale 을 활용해서 성능 향상을 노린 모델이다.
- 앞서 다양한 크기의 객체를 인식하기 위해서, 즉 작은 객체와 큰 객체를 인식하기 위해서 이미지 피라미드를 쌓거나 또는 하나의 이미지에서 하나의 backbone 을 통과시켰을 때 중간 stage feature map 을 이용하는 Neck 구조에 대해서 학습했다.
- 특히 feature pyramid network(FPN) 은 Neck 구조 중 가장 기본이 되는 내용으로 high level feature map 이 갖고 있는 semantic 정보를 low level 로 전달해 전체적인 feature map 의 semantic 이 더 풍부해지게끔 만들어 줬다.
- 하지만 M2Det 은 FPN 이 다음의 한계점이 존재함에 집중했다. (Multi Scale)
- FPN 이 feature pyramid 를 구성하는 과정을 살펴보면 backbone 을 N 개의 stage 로 나눈 뒤, 각 stage 의 feature map 을 쌓아서 pyramid 를 구성한다.
- 이 때 backbone 은 원래 classification task 를 위해서 설계되었기 때문에 object detection task 를 수행하기에는 충분치 않다.
- 특히 backbone 에서 나오는 각 feature map 은 single-level layer 로 구성되어 있고 이에 객체의 크기가 비슷하더라도 어떤 외형, 객체 복잡도에 따라서 성능 차이가 발생한다.
- 즉 FPN 이 single level 이기 때문에 존재하는 한계점이다.
- 기존 FPN 같은 경우 객체의 크기 즉 작은 객체에 대해서도 잘 예측하기 위해서 FPN 이라는 Neck 이 등장했다. 다시 말해서 FPN 은 Multi scale feature map 을 지원하고, 이 multi scale feature map 을 통해서 다양한 크기의 객체를 찾아낼 수 있다는 것이다.
- 하지만 FPN 의 single level feature map 은 두 객체의 차이를 충분히 담지 못한다. 일반적으로 low level feature 는 더 간단한 외형, high level feature 는 복잡한 외형에 적합하다고 이 paper 가 말하고 있다.
- 즉 기존의 FPN 은 객체의 크기에 대응하기 위해서 multi scale feature pyramid 를 이용했지만 이 경우에는 객체의 shape 즉 외형, 복잡도에 대해서 충분히 대응할 수 없다는 단점이 존재하는 것이다.
-
Multi level
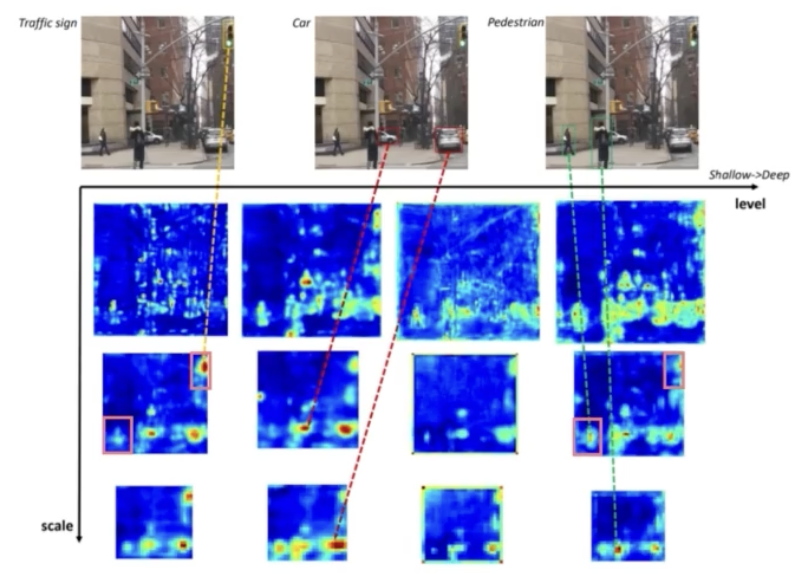
- x 축이 level 이고 세로축이 scale 이다. 세로축은 FPN 의 중간중간 feature pyramid 의 stage 라 할 수 있다.
- 신호등, 자동차, 사람을 포착해야 한다.
- shallow level(가장 왼쪽)의 2번째 scale 의 feature map 에서 신호등, 사람, 어느정도 자동차도 포착하고 있다. 다만, 첫번째 level 은 어떤 객체를 강하게 포착하는지 보자.
- 신호등이라는 객체에 대해서 강하게 포착하고 있다. 이것이 single level 에서는 상대적으로 간단한 신호등이라는 객체를 잘 포착하고 있다는 것이다.
- 반면에 level 이 deep 해질수록, 신호등에서 자동차로, 자동차에서 사람으로 복잡한 외형을 가지는 객체를 점점 더 잘 포착하는 것을 확인할 수 있다.
- 즉 shallow level 의 multi scale 은 FPN 을 의미한다(가장 왼쪽 column). 이 FPN 을 보면 복잡한 외형을 갖는 객체는 충분히 포착하지 못한다고 할 수 있다.
- 그렇다면 어떻게 multi level 로 level 을 다양하게 줄 수 있을까?
- 그 과정을 M2Det 에서 제안했다. M2Det 은 single level multi scale 의 feature map 에서 multi level multi scale 의 feature pyramid 인 MLFPN 에 대해서 새롭게 제안했다.
- 이 MLFPN 을 기존 SSD 아키텍처에 통합해 M2Det 이라는 1 stage detector 를 제안했다.
-
Overall Architecture
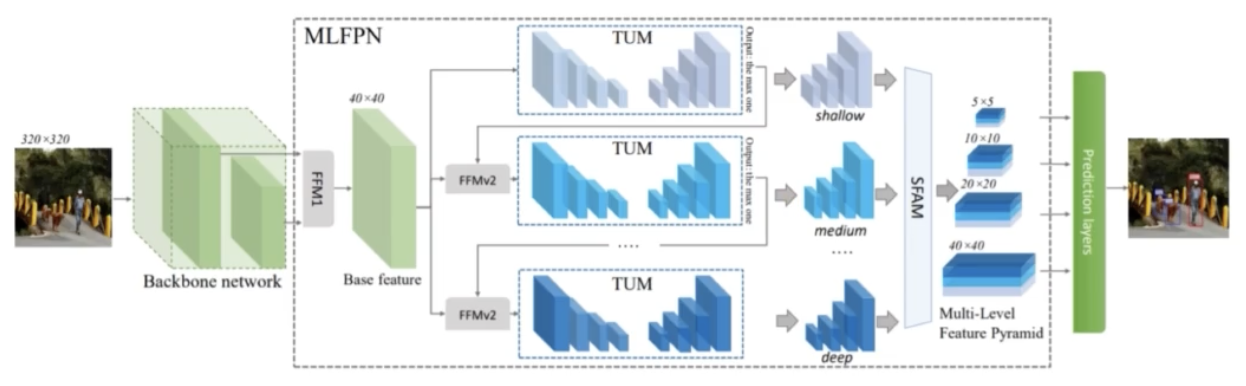
- 크게 backbone, MLFPN, SSD 이렇게 3 부분으로 구성되어 있다. 그 중에 MLFPN 은 3가지 모듈(FFM, TUM, SFAM)로 구성되어 있다.
- 먼저 backbone 에서 2개의 stage 로부터 feature map 을 골라 이를 concat 해준다. 그 concat 해주는 연산이 FFM v1 이다.
- FFM v1 은 backbone 의 서로 다른 2개의 feature map 을 통합해 하나의 base feature map 을 만드는 일을 한다.
- 이 base feature map 을 TUM 모듈에 통과시킨다. TUM 은 Unet 인코더와 Unet 디코더 구조로 구성되어 있다.
- 이 중 UNet 디코더의 output 을 가져와서 각각이 scale 이 다르기 때문에 이 output 을 multi scale 이미지로 볼 수 있다.
- 첫번째 TUM 을 통과한 것이 첫번째 level 이다. 정리하면, 첫번째 level 의 결과는 TUM의 UNet 디코더의 output 이 되고, 이 중 가장 큰 scale 을 가지는 feature map 을 가져와서 앞선 base feature map 과 다시한번 concat 해준다.
- 이 concat 에 사용되는 것이 FFM v2 이다. FFM v2 결과를 다시 한번 TUM 모듈에 통과하고 이 때를 2번째 level 이라 할 수 있다. 이 2번째 level 의 결과도 가장 큰 feature map 을 가져와서 FFM v2 연산을 통해 base feature map 과 혼합한다. 그리고 TUM 을 거치고 같은 과정을 반복한다.
- 이러한 작업을 반복적으로 N 번 진행하게 되면 마지막 level 의 output 이 가장 deep 한 level 이라고 볼 수 있다. 이후 각 level 별로 multi scale feature map 이 존재하는데, 이 multi scale feature map 들을 SFAM 을 통해 적절하게 concat 해주고 attention 을 가해준 뒤 feature map 을 만들어 낸다.
- 그 이후에 SSD head 를 통과하게 되면 M2Det 의 완성이다.
- FFM(Feature Fusion Module)
- FFM v1: backbone 으로부터 나온 2개의 feature map 을 channel dimension 으로 concat 해서 base feature 를 생성한다.
- Base Feature: 서로 다른 scale 의 2 feature map 을 합쳐 semantic 정보가 풍부하다.
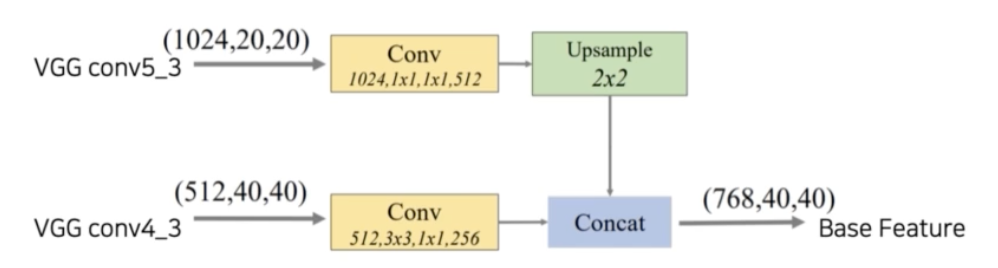
- 예를 들어 VGG 의 경우 5번째 stage 의 feature map 의 channel 이 1024 이고 4 번째 feature map 이 channel 이 512 일 때, FFM v1 에서 해야할 일은 이 두 feature map 을 적절하게 concat 해줘야 한다.
- 그러기 위해서는 먼저 resolution 을 맞춰줘야 한다. 따라서 작은 5번째 stage 의 feature map 을 Upsampling 한다. 그리고 각각 channel 을 절반씩 줄인다.
- 이를 channel 차원으로 concat 해주게 되면 768, 40, 40 이 최종적으로 base feature 가 갖는 shape 이 된다.
- 이렇게 만들어진 feature map 을 가장 기본 feature map 으로 이후 네트워크에 통과시키게 된다.
- FFM v2: base feature 와 이전 TUM 출력 중에서 가장 큰 feature 를 concat 한다. 이는 다음 TUM 의 입력으로 들어간다.
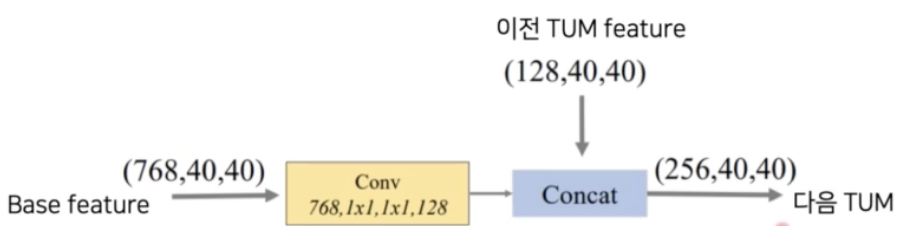
- FFM v1 과 거의 동일하다. base feature 와 이전 TUM feature map 을 적절하게 channel wise 하게 concat 해준다. 이 feature map 이 다음의 TUM 모듈에 들어가게 되는 것이다.
- TUM(Thinned U-shape Module)
- 이 TUM 을 base feature map 이 통과하게 된다.
- TUM 은 UNet 처럼 Encoder-Decoder 구조이다.
- Encoder 에서는 pooling 같은 메서드를 활용해서 base feature map 을 점점 작은 scale 의 feature map 으로 만들어준다.
- Decoder 에서는 deconv 같은 방법을 활용해서 점점 큰 scale 의 feature map 으로 계산하게 된다.
- 이 때 decoder 의 결과를 쭉 모으게 되면 다양한 scale 의 이미지가 생성되는 것이다.
- 이 경우를 현재 level 에서의 multi scale feature map 이라고 말할 수 있다.
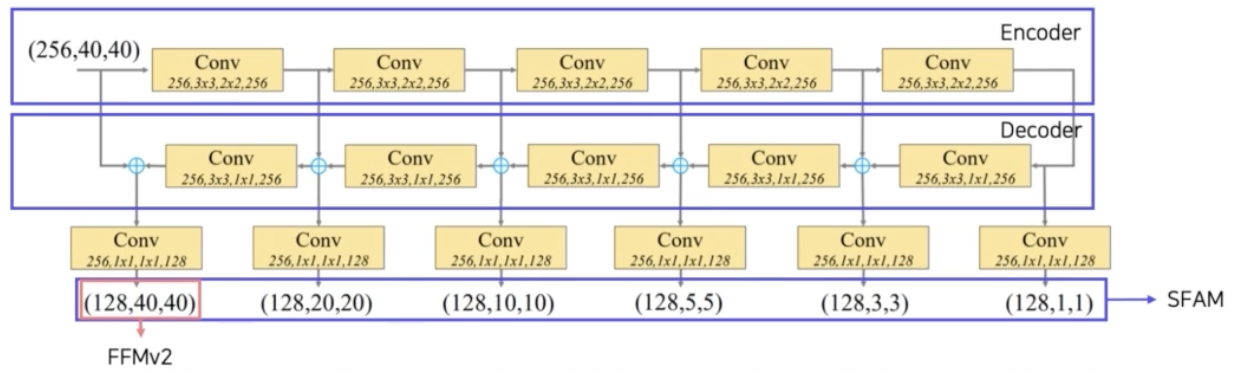
- 앞에서 만들어진 base feature map 이 Encoder의 conv 연산을 쭉 통과한다. 이 때 stride 를 보면 2x2 이다. 따라서 각 conv 를 통과하면 w 와 h 가 1/2 씩 줄어들게 된다.
- Decoder 에서는 deconv 연산과 input 의 residual 을 더해주면서 최종적으로 맨 밑의 multi scale feature map 을 만들어내게 된다.
- 그 중에서 가장 resolution 이 큰 feature map 을 따로 뽑아서 base feature 와 FFM(feature fusion)을 해준다. 그 때 사용되는 모듈이 FFM v2 이다.
- FFM v2 를 통과하면, 첫번째 level 과 비슷하게 2번째 level 에서 또 feature map 이 나오고 제일 큰 resolution 을 갖는 마지막 feature map 을 다시 base feature 와 feature fusion(FFM v2) 을 하고 다시 TUM 을 통과해서 또 multi scale 의 feature map 이 나올 수 있게 된다.
- 이렇게 나온 multi scale 들은 N 번 반복을 하게 되면, N 개의 level 에서 feature map 을 얻을 수 있다. 따라서 Multi level feature map 이라고 하며, 각 level 안에서 multi scale 을 가진다.
- 따라서 Multi-level Multi-scale 이라고 할 수 있다. 그 중에서 가장 첫번째 feature map 을 가장 얕은 feature map, 가장 마지막 N 번째 feature map 을 딥하다고 할 수 있다.
- deep level 의 feature map 은 복잡한 외형을 가지는 객체를 더 잘 식별하고, 얕은 level 의 feature map 은 간단한 외형을 가지는 신호등 같은 객체를 식별하는데 더 유리하다고 한다.
- 이제 해야할 일은 이렇게 만들어진 Multi level Multi scale feature map 을 SSD 연산을 수행할 수 있게 해줘야 한다.
- SFAM(Scale-wise Feature Aggregation Module)
- Scale wise 하게 각 feature 를 concat 해준다. 즉 TUMs 에서 생성된 multi-level multi scale 을 합치는 과정이다.
- 그림을 보면 각각 multi level 에서 5x5, 10x10 .. 묶어준다. 그러면 multi scale 의 feature map 이 존재하고, 각각의 하나의 scale 안에서는 multi level 의 형태를 가진다.
- 이렇게 묶어주는 과정을 SFAM 이 담당한다.
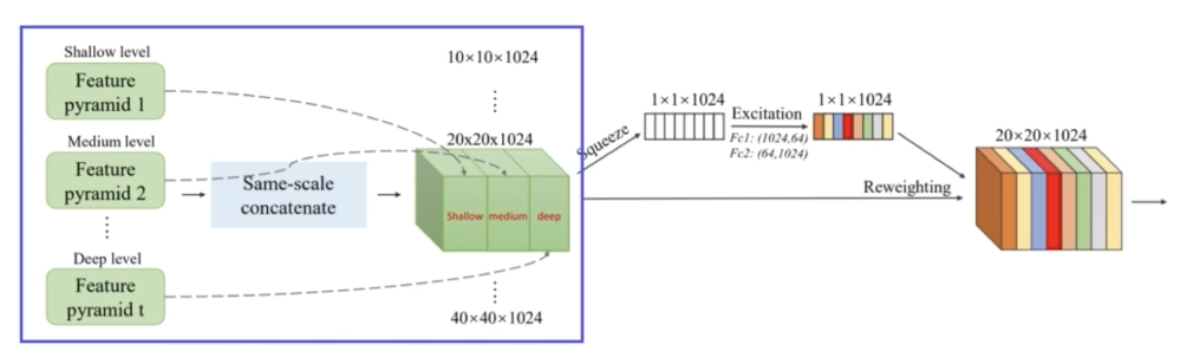
- 먼저 동일한 크기를 가진 feature 들끼리 연결한다(scale-wise concatenation). 각 level 에서 같은 scale 을 가지는 feature map 을 쭉 합쳐주는 것이다.
- 그렇게 합쳐진 feature map 안에는 shallow level 부터 deep level 까지 있다.
- 이미지 scale 이 총 S 개 있다고 한다면(즉 TUM decoder 결과로 S 개의 feature map 이 나온다면), SFAM 을 통과하면 S개의 feature map 이 최종적으로 나온다.
- 이 때 SFAM 을 통과한 multi scale 중 하나의 feature map 에는 multi level 각각이 합쳐져 있기 때문에, 각 scale 의 feature map 은 객체 외형에 대한 다양한 semantic 을 이해하고 있다고 볼 수 있다.
- 이후 바로 SFAM 결과의 feature map 을 SSD 에 넣어줘도 되지만, SSD 전에 channel wise attention, 즉 SE 연산을 수행해준다.
- 앞서 YOLO v4 와 같이, 채널별로 중요도를 계산하고 이를 원래 feature map 에 반영해준다.
-
SSD
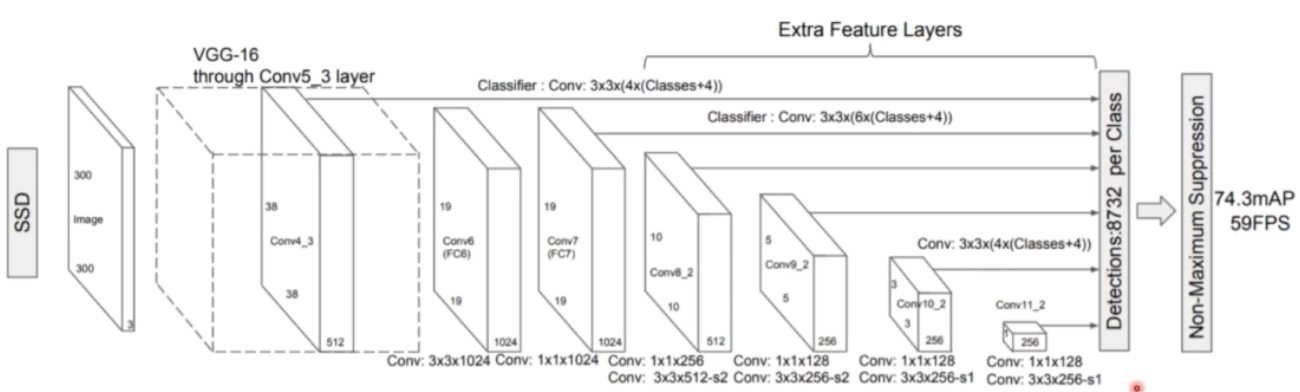
- SE 까지 이렇게 구성된 feature map 은 SSD head 연산을 수행한다.
- 각각 multi scale 의 feature map 으로부터 각 픽셀에 anchor box 를 적용해서 최종 detection 까지 이뤄낸다.
- SSD 에서는 multi scale feature map 을 만들어주기 위해서 extra conv 연산을 진행했었는데, M2Det 에서는 SSD 의 extra conv 연산을 생략하고 위 과정을 통해 만들어진 feature map 을 각 scale 의 feature map 으로 이용한다.
- 즉 SSD feature map 은 다 single level 이기 때문에 객체의 외형, 복잡도에 대한 semantic 을 이해할 수 없지만, M2Det 은 multi level 이기 때문에 객체의 외형 semantic 을 포함하고 있고, detection task 를 훨씬 더 잘 수행할 수 있다.
- 구체적으로 총 8개의 TUM 을 사용했고, 6개의 scale features 를 사용했다. 즉 8개의 level, 6개의 scale 이다.
- detection stage 에서 anchor box 는 각 픽셀마다 6개를 사용했다. 최종 결과에는 NMS 기법의 일종인 soft-NMS 를 적용했다.
- 실험결과
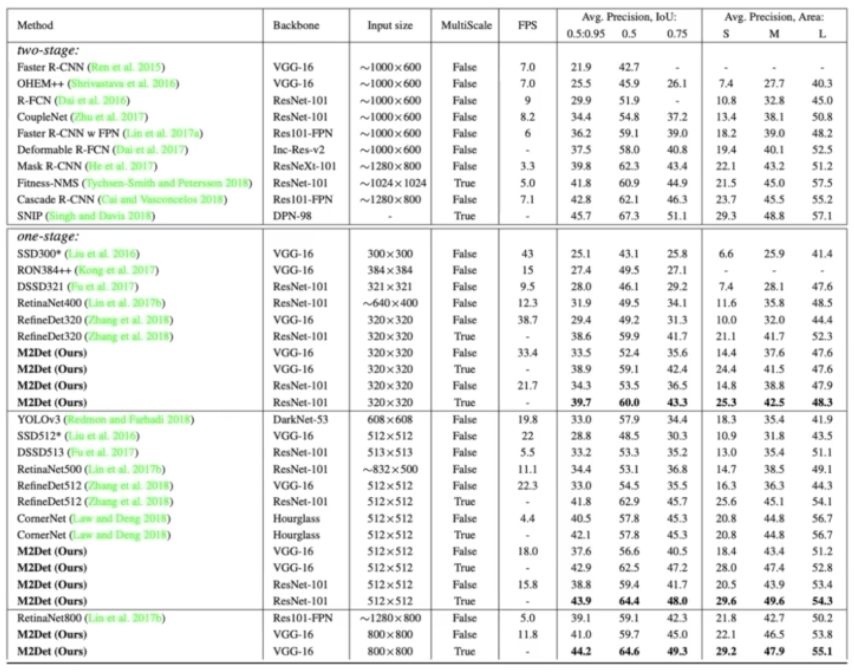
- M2Det 은 기존의 multi scale 이 다양한 크기의 객체를 검출할 수 있었지만, 객체 외형 복잡도 정보를 이해하는 것에는 한계가 있다는 점을 찾아내고, multi level feature map 을 구성해서 이를 해결했다.
- CornerNet
- Anchor box 를 없애고 학습의 속도 향상을 노린 모델이다. 즉 free anchor model 이다.
- 2 stage, 1stage detector 들이 anchor box 의 도입으로 학습의 편의성과 성능 향상에 엄청난 이점을 가져왔다. 하지만 몇 가지 단점들이 존재한다.
- Anchor box 의 수가 너무 많다.
- feature map 의 각 픽셀마다 N 개의 anchor box 가 생성되기 때문이다.
- 이에 대부분의 box 가 객체(positive sample)가 아닌 배경(negative sample)을 담고 있고 따라서 class imbalance 문제가 발생한다.
- Anchor box 를 사용할 때 하이퍼 파라미터를 고려해야 한다.
- anchor box 의 개수, 사이즈(scale), 비율(ratio) 등을 사람이 휴리스틱하게 정해줘야 한다.
- Anchor box 의 수가 너무 많다.
- 이에 CornerNet 은 Anchor box 를 없앤 1 stage detector 에 대해서 제안했다.
- 객체가 있을 법한 위치에 좌측 상단과 우측 하단점을 이용해서 객체를 검출했다.
- 즉 기존의 경우는 center(중심점), w, h 이렇게 총 4개를 예측했는데, CornerNet 은 좌측상단과 우측하단 2가지 값만 예측하면 된다.
- 중심점(x, y)이 아니라 모서리(Corner)를 사용하는 이유는, 중심점의 경우 4개의 값을 고려해야 하지만 코너는 두 개의 면만 고려하면 되기 때문이다.
-
Overall Architecture
- 이미지가 Hourglass Network 를 통해서 feature map 이 나오게 되고 이 feature map 은 2개의 prediction module 이라는 head 를 통과하게 된다.
- 왜 2개냐 하면 각각 top-left corner, bottom-right corner 를 예측하게 된다.
- 이 때 prediction module 같은 경우는 Heatmaps, Embeddings, Offsets 를 예측한다.
- Heatmap 같은 경우는 input image 와 유사하게 h x w x c 의 feature map 으로 이루어져 있고 여기서 C 는 카테고리의 개수를 의미한다.
- 구체적으로는 각 채널의 코너의 위치에 해당하는 binary mask 라고 할 수 있다. 즉 한 클래스에 대해서 코너가 있으면 1, 없으면 0 이런 식으로 masking 된다.
- Embedding 의 경우는 top-left 와 bottom-right 를 따로 예측하고 있는데, 만약에 한 클래스에 대한 객체가 여러개 있을 때 top-left 와 bottom-right 를 mapping 해주어야 한다.
- mapping 을 위해서 사용하는 것이 Embedding 이다.
- 즉 Embedding vector 의 거리가 가까우면 같은 객체를 담당하는 top-left 코너와 bottom-right 코너 라고 생각할 수 있다.
- offset 같은 경우는 이미지가 Hourglass 의 conv 연산을 통과하는데, 그러면 down sampling 이나 upsampling 에 의해서 소수점 상실이 발생할 것이고 따라서 작은값의 상실이 작은 bbox 에는 큰 영향을 미친다고 판단했다.
- 따라서 이런 문제를 해결하기 위해서 Offset 을 도입해서 코너의 위치를 구체적으로 adjust 하게 된다.
- Hourglass
- Human pose estimation task 에서 사용하는 모델이다.
- global 정보와 local 정보 모두 추출 가능하다.
- Encoder-Decoder 구조이다. Encoder 에서는 입력으로부터 특징을 추출하고 Decoder 는 Reconstruct 를 한다.
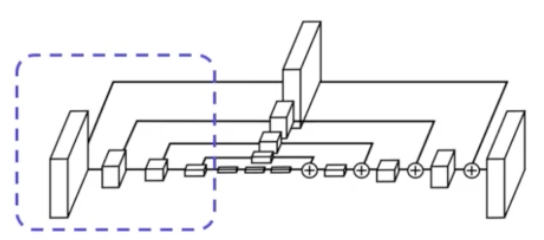
- Encoding Part
- feature 를 추출한다. conv 연산과 max pooling 을 조합한다.
- 각각의 별도의 branch 를 둬서 각 scale 마다 conv 연산을 진행해서 feature map 을 추출한다. 이는 Upsampling 과정에서 조합한다.
- CornerNet 에서는 max pooling 대신에 stride 2 로 사용해서 input 의 scale 을 점점 축소시키고 총 5번 감소시킨다.
- Decoding Part
- Encoder 과정에서 나온 scale 별 feature map 들이 있는데 이를 decoder 의 conv 후 나오는 feature map 과 조합하게 된다.
- Upsampling 과정에서는 Nearest Neighborhood Sampling, feature 조합에서는 element-wise addition 을 사용한다.
- UNet 구조와 많이 비슷하다.
- 이렇게 Hourglass Network 를 통과한 feature map 으로부터, 객체가 있을법한 위치의 top-left, bottom-right 두 가지 값을 예측해야 한다.
- 따라서 top-left 만 담당하는 prediction module 1개, bottom-right 만 담당하는 prediction module 1개로 총 2개 모듈이 생긴다.
-
Prediction Module
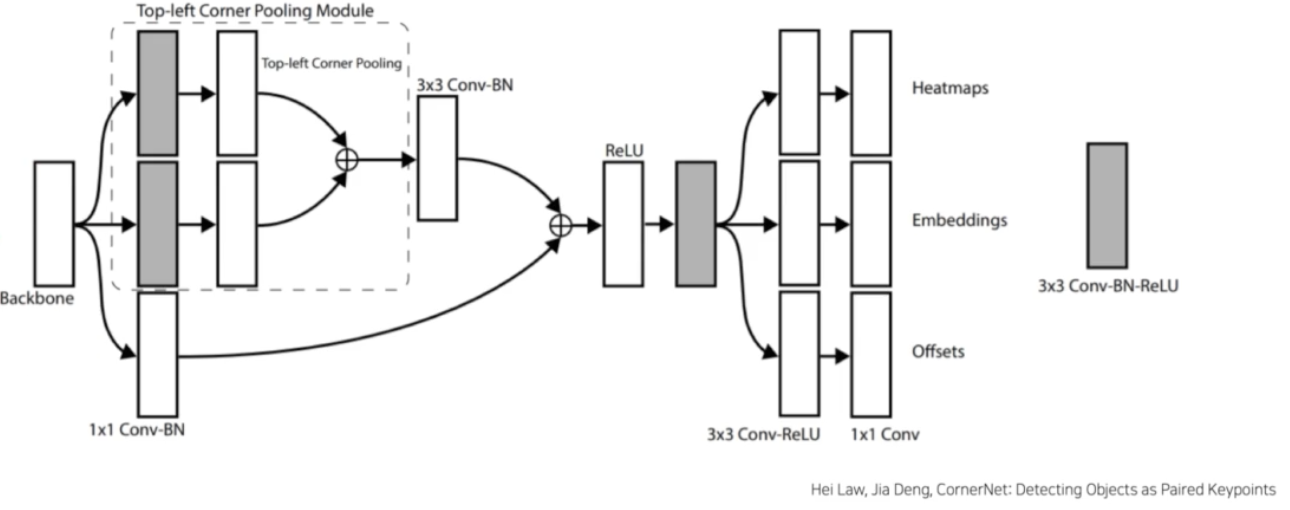
- 각 역할은 Hourglass 를 통해 나온 feature map 으로부터 좌상단, 우하단 코너를 예측하는 것이다.
- backbone feature map(Hourglass) 으로부터 최종적으로 Heatmap, Embedding, Offset 을 예측하게 된다.
- 다양한 conv, BN 등 다양한 연산을 조합해서 최종적으로 3개를 예측하는 것이다.
- Heatmap, Offset 은 top-left, bottom-right 정보를 예측하고, Embedding 은 top-left 와 bottom-right 의 mapping 을 한다.
- 중간에 Corner Pooling 이 존재한다.
- Heatmap(Detecting Corner, 코너의 위치)
- Heatmap 의 shape 은 HxWxC 로 구성되어 있다. 이 때 C 는 category 로서 class 에 해당하는 코너의 위치를 나타내는 binary mask 이다.
- 예를 들어 top-left heatmap 의 경우, 채널이 클래스 개수만큼 있는데 그 중 0번째 클래스라고 생각해보자. 그러면 0번째 feature map 을 가져온다.
- 여기에 담겨있는 의미는 0번 클래스에 대한 box 들이 여러개 있는데 그 box 들의 top-left 코너 정보가 예측된다. 반면에 bottom-right heatmap 의 채널 0 번째의 feature map의 경우 0번 클래스에 대한 box 들의 bottom-right 정보가 예측된다.
- 이론적으로는 top-left heatmap 에서 예측되는 코너의 개수와 bottom-right 에서 예측되는 코너의 개수가 동일해야 한다.

- corner 를 학습하는 방법을 보자.
- heatmap 을 보면 C 가 여러개가 있는데, 그 중 종이 박스에 해당하는 채널의 feature map(W, H, 1) 를 가져올 수 있다. 이 heatmap 을 우리가 살펴보면, 객체가 한 개이기 때문에 픽셀 중에 단 한 개만이 위치값을 갖게된다. 위치가 존재하면 1 로 활성화가 되는 것이다.
- 즉 그 객체 클래스의 top-left 에 해당하는 픽셀 부분만 1이 된다. bottom-right feature map 도 bottom-right 픽셀에 1이 활성화된다.
- 나머지 픽셀들은 전부 다 negative 로 0 이다.
- 그렇다면 실제 Loss 를 계산할 때 모든 0, negative 에 대해서 패널티를 동일하게 부여하지 않는다. 예측을 GT 와 가깝게 예측한 case 에 대해서는 점점 더 잘 예측하고 있다는 것이니까 loss 의 패널티를 줄여줘야 한다. GT 에서 멀리 예측한 case 에 대해서는 loss 에 패널티를 크게 줘야 한다.
- 따라서 GT 점에 원을 그리고 해당 원 안에 존재하는 예측에 대해서는 loss 의 패널티를 감소시킨다. 즉 postive location 반지름 안에 들어오는 negative location 들은 패널티를 감소시킨다.
- 이 때 원의 크기는 객체 크기에 따라서 정해진다. 그리고 거리에 따라 패널티가 감소한다.
- 위 그림에서 빨간 box 가 GT, 초록 box 가 pred 일 때, 주황색 원 안에 코너가 들어와 있으므로 GT 와 근접했다고 볼 수 있다. 따라서 위 case 는 loss 의 패널티가 감소하게 된다.
- Loss func 의 경우 Focal loss 를 변형한다.
- 아래 그림에서 보라색 파트가 GT 에 근접한 위치들의 패널티를 감소시키는 부분이다.
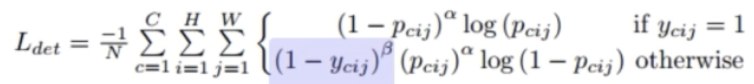
- Offset(Detecting Corner, 코너의 위치 미세조정)
- 이제 Heatmap 을 예측했으니 객체가 있을법한 위치를 알 수 있다. 다만, heatmap 만 사용하는 것은 한계점이 있다.
- conv 연산을 통과하면서 많은 upsampling, downsampling 을 진행하기 때문에 소수점 아래를 버리게 된다. 즉 heatmap 에 floating point loss 가 발생한다.
- 이는 작은 객체의 box 를 예측할 때 큰 영향을 미칠 수 있다. 또 heatmap 을 원본 이미지 size 와 크기를 맞추고자 mapping 시킬 때 차이가 발생하게 된다.
- 이를 조정하기 위해서 Offset 이라는 새로운 output 을 사용한다.
- 즉 Offset 을 이용해서 예측의 위치를 조정해준다.
- Loss 의 경우에는 SmoothL1Loss 를 사용한다.

- Embedding(Grouping corner, 두 코너의 mapping)
- 이미지 안에 한 클래스의 객체가 여러개 있을 수 있다. 예를 들어 한 이미지로 사람을 예측할 때, 사람에 대한 top-left feature map, bottom-right feature map 을 가져올텐데, top-left 에서 1로 활성화되어 있는 부분이 여러개가 있을 거고 bottom-right 에서 1로 활성화되어 있는 부분이 여러개가 있을 것이다.
- 그렇게 됐을 때 top-left 의 특정 픽셀과 bottom-left 의 특정 픽셀을 mapping 시켜줘야 한다. 즉 top-left 코너와 bottom-right 코너의 짝을 맞춰주는 과정이 필요하다.
- 짝을 맞춰주기 위해서 embedding vector 를 이용한다. 즉 embedding vector 의 거리가 비슷할수록 같은 짝이라고 생각할 수 있다. 그래서 학습단계에서 같은 코너의 embedding 은 거리가 가깝게 학습을 시켜주고, 다른 코너들끼리는 거리가 멀게 학습을 시킨다.
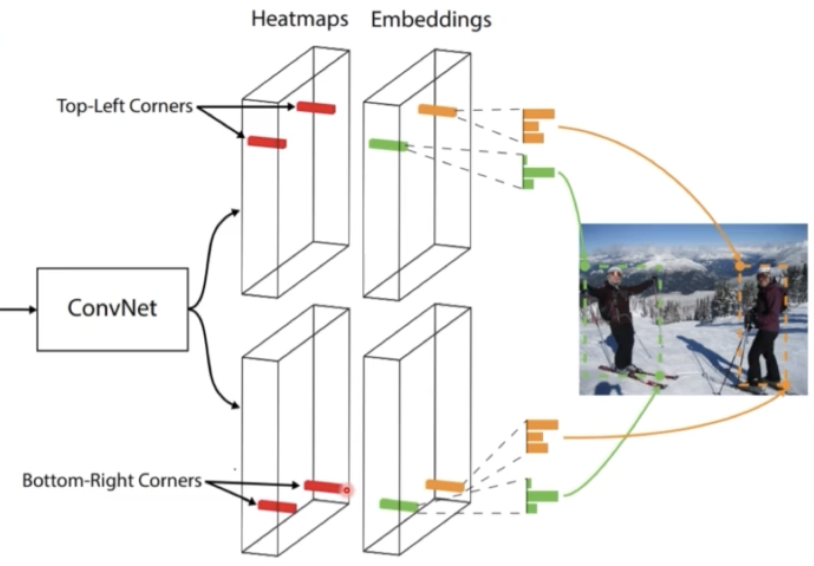
- top-left feature map 과 bottom-right feature map 을 보면 1로 활성화된 부분이 2개씩있다. 여기서 해야할 것은 top-left 와 mapping 되는 bottom right 가 무엇인지 찾아야 한다.
- 그러기 위해서 embedding vector 의 거리 유사도를 계산하고, 가까운 bottom right 를 짝으로 mapping 시킨다.
- 만약 embedding vector 가 없다면 같은 클래스를 가리키는 top-left, bottom-right 끼리 묶이지 않아서 하나의 box 안에 객체가 여러개 들어가거나 크게 그려질 수도 있다.
- 이를 embedding vec 으로 방지해줄 수 있다.
-
Corner Pooling

- prediction module 의 corner pooling 이 왜 필요하냐면, 위 이미지 처럼 코너에는 어떠한 특징이 없다.
- 그냥 배경 픽셀이고 모든 코너들이 비슷한 값을 가질 것이다. 이런 정보를 가지고 코너를 정밀하게 예측하는 것은 상당히 어렵다.
- 따라서 코너에 객체에 대한 정보를 집약시켜줄 수 있어야 한다. 이 집약 과정을 Corner Pooling 이라고 한다.
- 먼저 top-left corner 를 보자.
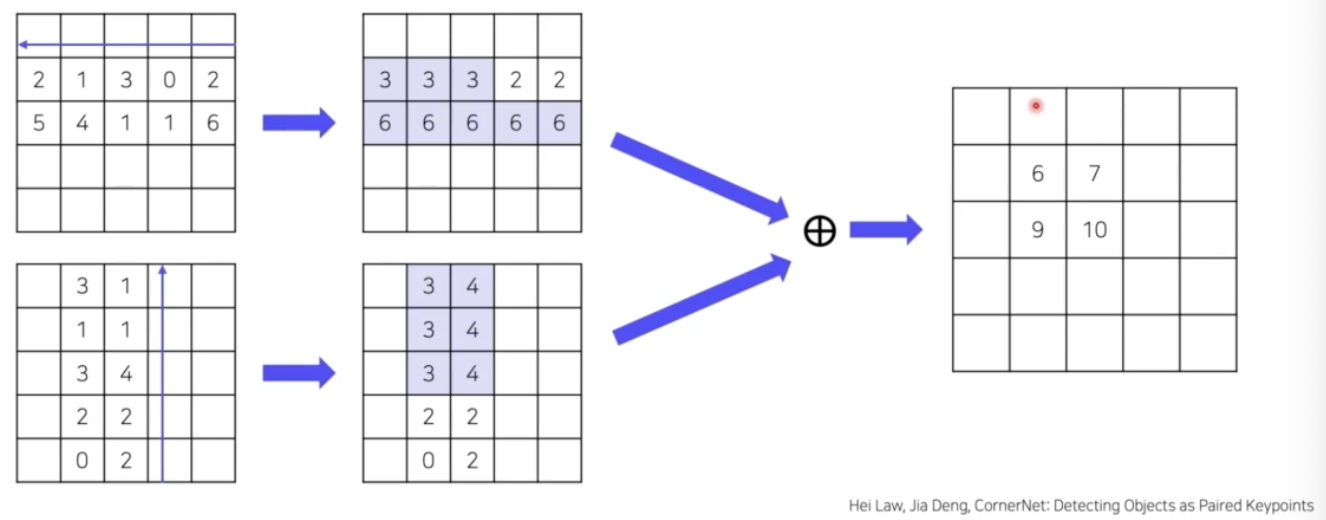
- 오른쪽부터 왼쪽으로 진행하면서 가장 큰 값으로 채워준다.
- 그 다음에 아래에서 위로 진행하면서 가장 큰 값으로 채워준다.
- 이후 이 두가지 feature map 을 add 연산을 한다.
- 그러면 corner 에 가장 큰 픽셀 value 가 할당되게 된다.
- 다시 말해서, 각 객체를 담고 있는 feature map 의 max 값이 corner 값이 되고 이는 어떤 객체에 대한 semantic 을 더 많이 담고 있을 것이다.
- 이후 이렇게 corner pooling 된 feature map 으로부터 heatmap, offset, embedding 을 계산하게 된다.
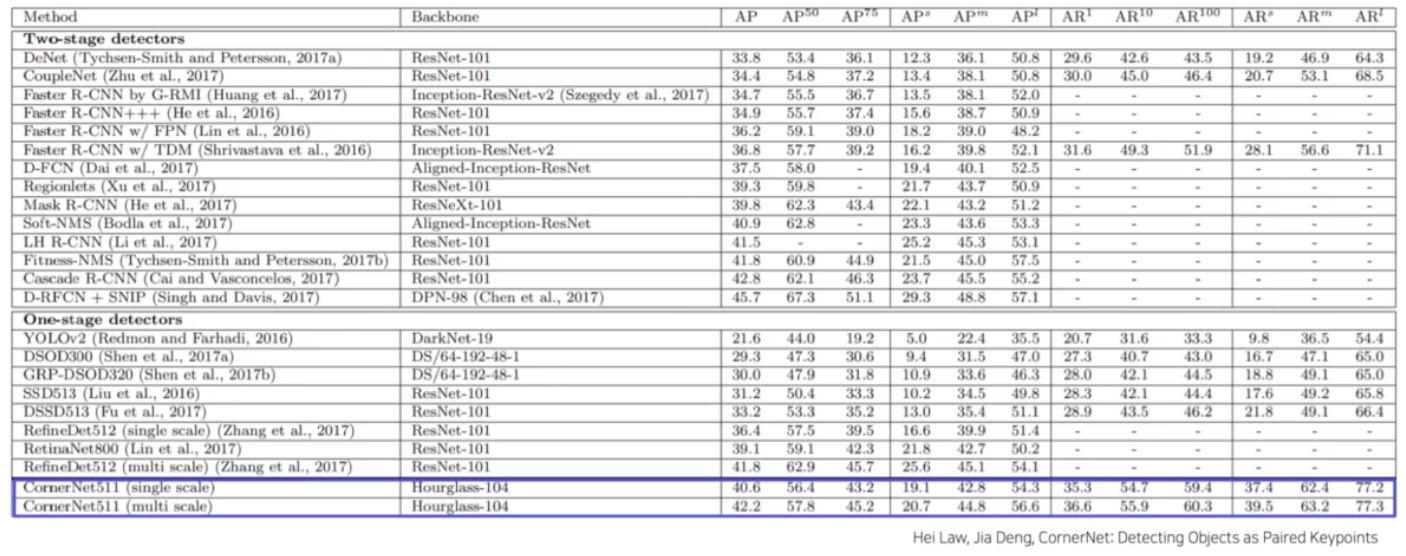
- Result
- 일반적인 1 stage detector 보다 성능이 좋은 편이다. 반면에 2 stage detector 와 유사한 성능이 나왔다.
- 중요한 것은 anchor 가 없이 free anchor 라는 것이다.
- 그 이후에 또 다른 free anchor model 들이 나왔다.
-
keypoint heatmap 을 사용해서 중심점을 예측해서 단 하나의 anchor box 를 생성하는 CenterNet 이 나왔다.

- keypoints grouping 과정이 필요 없어 시간을 단축했다. NMS 과정이 없다.
-
중심점으로부터 바운딩 박스의 경계까지의 거리를 예측하는 FCOS 도 있다.

- FPN 을 통해 multi-level 예측을 한다.
댓글 남기기