
[Object Detection] 6. EfficientDet
-
EfficientDet
💡 딥러닝 모델의 성능을 효율적으로 올리기 위해 사용하는 scale up 방식으로는 대표적으로 (1) width scaling, (2) depth scaling, (3) resolution scaling 이 있다. EfficientNet에서는 이 세가지를 모두 사용하여 최적의 scaling 방법을 제안했고 그 방법이 바로 Compound scaling 이다.
EfficientNet 에서 parameter 를 통해 스케일을 설정하는 방법.

EfficientNet 은 b0 부터 b7까지 다양한 모델 구조가 존재하는데, 이 구조의 종류를 결정하는 파라미터는 phi ($\phi$) 이다. → 위의 compound scaling 수식에서 $\alpha$ , $\beta$ , $\gamma$ 는 각각 depth, width, resolution 방향으로 얼마나 scaling 할건지를 담당하는 파라미터이다. alpha, beta, gamma 값은 고정한 후에, **$\phi$의 값을 조절하여 EfficientNet-b0, b1, b2 … 등의 여러 모델을 설계**하였다.
EfficientDet은
- Object detection은 실생활에 사용되기 위해 efficiency가 중요하기 때문에, 더 높은 정확도와 효율성을 가지는 구조를 만들고자 제안되었다.
- 서로 다른 feature map을 단순합하지 않고, 각각의 input을 위한 학습 가능한 weight를 두는 BiFPN을 사용한다.
- 특정 layer의 정보가 detection 학습에 방해가 될 경우, BiFPN에서 해당 layer의 weight는 0값으로 학습된다. BiFPN에서 모든 weight는 ReLU를 거치기 때문에 항상 0 이상의 값을 가진다.
- EfficientNet과 동일한 scaling 방식을 활용하기 위해, backbone으로 efficientNet b0~b6을 사용한다.
-
EfficientDet b0부터 b7까지 증가함에 따라 input image의 해상도는 증가한다.
- object detection 에서 efficiency 를 추구한 EfficientDet 에 대해서 공부해보자.
- Object Detection 은 크게 2가지 요소로 평가 가능.
- 성능: mAP
- 속도: fps. 얼마나 빠르게 객체를 detection 할 것인가.
- EfficientDet 은 성능도 좋게하면서 속도도 빠르게 하는 초점으로 연구를 진행했다.
- Efficient in Object Detection
- Model Scaling
- 과거 ImageNet 챌린지 이후 딥러닝 모델은 점점 더 크고 복잡해졌다.
- 일반적으로 모델을 키울수록 성능이 증가하는 경향성이 있다.
- 예를 들어 ResNet 은 기본 Res Block 을 일정 수준으로 쌓은 18 보다 더 깊은 101이 더 좋은 성능을 가져온다.
- 그러나 어느 순간부터 이렇게 단순하게 깊게 쌓는다고 해서 모델이 성능적인 gain 을 얻는 것이 한계가 있었다.
- 깊게 쌓을수록 모델은 무거워지고 속도는 느려지는데, 성능에서 얻을 수 있는 이점이 거의 없어진다는 것이다.
- 따라서 이 부분에는 분명히 모델을 쌓을 때 잘 쌓는 방법이 존재할 것이라고 생각했다.
- 그렇다면 어떻게 모델들을 잘 쌓을 수 있을까? 효과적으로 쌓을 수 있을까? 즉 조금만 쌓아서 가장 좋은 성능을 얻을 수 있을까? 집중했다.
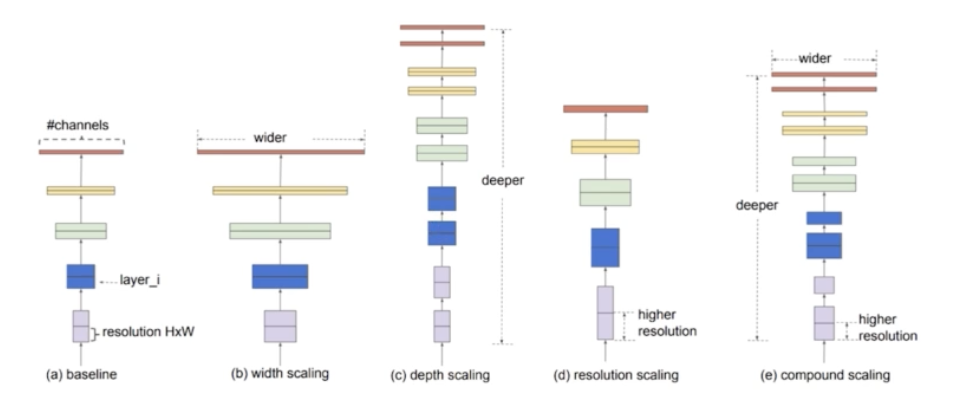
- 모델을 쌓는 것을 일반적으로 Model Scaling 또는 Scale up 이라고 한다.
- 기존 연구들이 어떤 방법의 Scale up 을 했는지에 대해서 한 번 보자.
- 기존 연구들은 baseline model 이 있을 때 크게 3가지 방향의 scaling 을 사용했다.
- 먼저, (c) 의 depth scaling 처럼 모델을 깊게 쌓을 수 있다.
- 또한 (b) 의 width scaling 처럼 채널을 크게 줄 수 있다.
- 마지막으로 (d) 의 resolution scaling 처럼 input image 를 큰 이미지를 쓸 수 있다.
- 종합적으로 이 3가지 scaling 을 다 한 것이 (e) 의 compound scaling 이다. 즉 깊게 쌓고 채널을 크게 주고, resolution 도 크게 준 것이다.
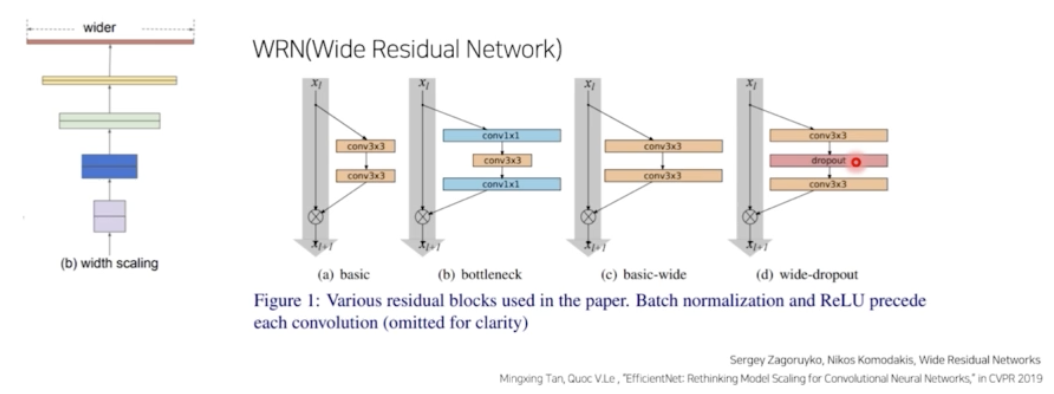
- Width Scaling 의 대표적인 예시는 WRN(Wide Residual Network) 가 있다.
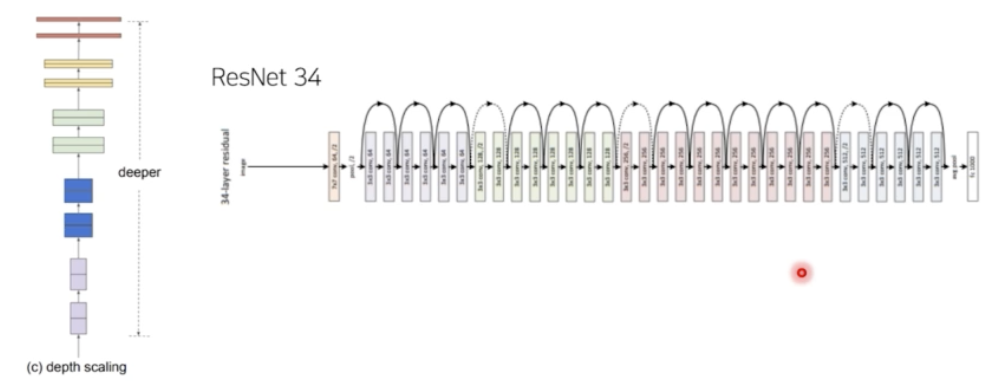
- Depth Scaling 의 대표적 예시는 ResNet
- 이처럼 모델을 키우는 방법이 있더라도 지금까지는 휴리스틱하게 모델을 키웠다. 따라서 특정 순간 부터는 모델을 키워도 성능의 이점이 없고 속도만 느려지게 됐다. 즉 trade-off 에 의해서 속도는 매우 느려지는데 성능을 많이 얻을 수 없게 됐다.
- 그렇다면, 모델을 키우는데 더 높은 정확도와 더 높은 효율성을 보장하면서 모델을 효과적으로 키우는 방법(scale up)은 없을까?
- Google 의 EfficientNet 연구 팀은 네트워크의 폭(width), 깊이(depth), 해상도(resolution) 모든 차원에서의 균형을 맞추는 것이 중요하다는 것을 보여줬다. 그리고 이러한 균형은 각각의 크기를 일정한 비율로 확장하는 것으로 달성할 수 있었다.
- 즉, 무작정 scaling factor 들(width, depth, resolution)을 키우는 것이 아니라, 균형을 맞추면서 키우는 것이 중요하다는 것을 실험적으로 증명했다.
- 이 세가지를 키우는 최적의 조건을 찾아서 가장 효과적으로 scaling 을 하는 방법을 제안했다.
-
결과부터 보면,
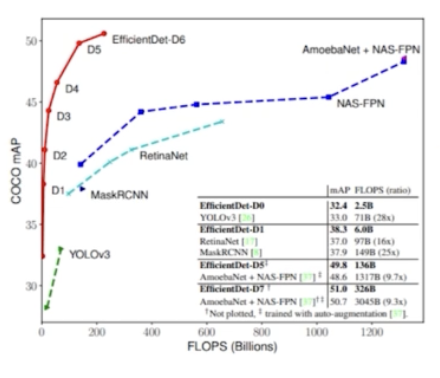
- flops 가 엄청 작음에도, 성능이 좋은 것을 볼 수 있다. 동일 flops 에서 EfficientDet 이 다른 1 stage model 들 보다 2배 이상의 성능을 가진다. 같은 성능을 보장하는 모델들을 비교해봐도 EfficientDet 의 flops 가 매우 작다.
- 따라서 EfficientDet은 성능적으로도 우수하면서 속도적으로도 빠른, Accuracy 와 Efficiency 를 모두 잡았다.
- Model Scaling
- EfficientNet
- EfficientDet 을 이해하기 앞서 먼저 EfficientNet 을 이해해야 한다.
- 등장배경
- 모델들의 파라미터 수가 점점 많아지고 있다.
- 그러나 CNN 은 모델이 커짐에 따라서 점점 더 정확해지고 있다. 즉 파라미터 개수가 많아지면서 정확도 성능이 향상됐다.
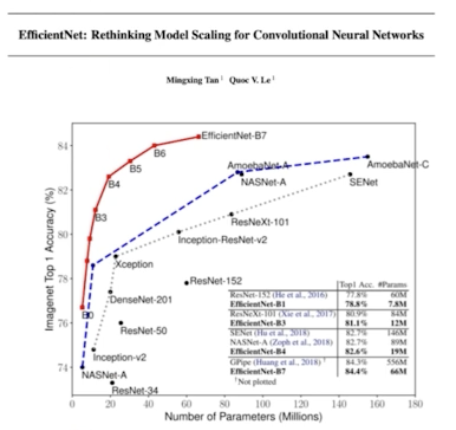
- 주목할 점은, 2014 년과 2017 년의 ImageNet 챌린지를 비교했을 때 1등 모델인 GoogLeNet 과 SENet 의 정확도는 각각 74.8, 82.7 인 것에 비해 파라미터의 개수는 각각 6.8M, 145M 이다.
- 즉 성능에 비해 파라미터의 개수가 너무 많이 증가했다!
- 이렇게 모델 정확도를 높이기 위해서 큰 모델을 사용하는 것은 당연한데, 현업에서 한없이 큰 모델을 사용하는 것은 한계가 있다. 왜냐하면 현업에서는 하드웨어 리소스의 제한도 있고 서비스 타임이 중요하기 때문에 모델의 사이즈를 줄여서 모델의 속도를 높이는 것이 중요한 편이다.
- 따라서 서비스 타임을 줄이기 위해서 점점 빠르고 작은 모델에 대한 요구가 증가하고 있다.
- 효율성과 정확도의 trade-off 를 통해 모델 사이즈를 줄여 효율성을 가져오는 것이 일반적이다. 대표적으로 SqueezeNet 과 MobileNet 이 있다.
- 하지만 큰 모델에 대해서는 모델을 어떻게 압축시킬지가 불분명했다. 어떻게 줄여야 가장 효율적으로 줄일 수 있을까에 대해서 잘 모르고 있었다.
- 따라서 이 EfficientNet paper 는 정말 큰 SOTA CNN 의 efficiency 를 확보하는 것을 목표로 연구를 수행했다.
- 그래서 작은 모델을 점점 효과적으로 scaling 하는 방법을 통해서 위 목표를 달성했다.
- 기존의 모델 scaling 방법에 대해서 다시 알아보자.
-
Baseline
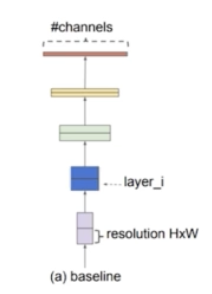
- 모델을 scale up 하는 방법에는 크게 3가지 방향이 있다. Resolution, Depth, Width
-
Width Scaling
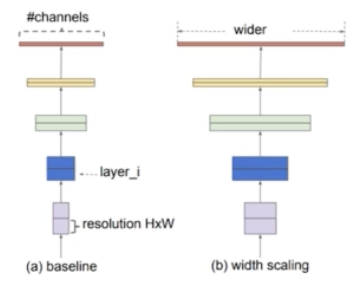
- 채널을 channel wise 하게 키우는 방법을 width scaling 이라 한다.
- 이 방법은 작은 모델에서 주로 사용된다(ex. MobileNet, MnasNet).
- 더 wide 한 네트워크는 미세한 특징을 잘 잡아내는 경향도 있고 학습도 쉬운 편이다.
- 하지만 극단적으로 넓지만 얕은 모델은 high level semantic feature 들을 잘 잡지 못하는 경향이 있다.
-
Depth Scaling
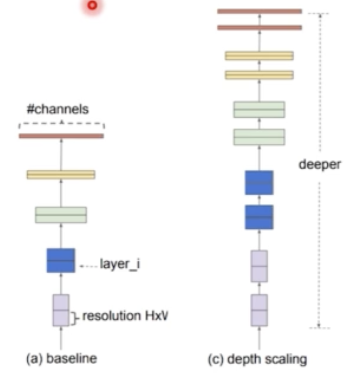
- 네트워크를 깊이 쌓는 방법. 깊이 쌓는 방법은 CNN 에서 정말 많이 쓰이는 방법이다. DenseNet, Inception, ResNet 등에서 이 방법을 많이 이용한다.
- 깊은 CNN 은 더 풍부하고 복잡한 semantic feature(특징) 들을 잡아낼 수 있고 새로운 task 에서도 잘 일반화가 되는 경향성이 있다.
- 하지만 깊은 네트워크는 gradient vanishing 문제가 있어 학습이 어렵다.
-
Resolution Scaling
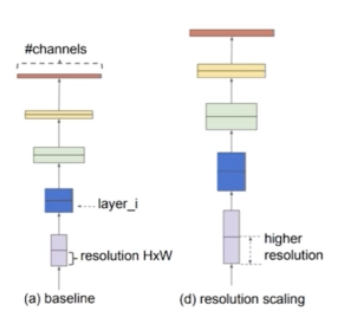
- 이미지 size 를 키우는 것을 의미한다.
- 고화질의 input 이미지를 이용하면 CNN 은 미세한 패턴을 더 잘 잡아낼 수 있다.
-
Compound Scaling
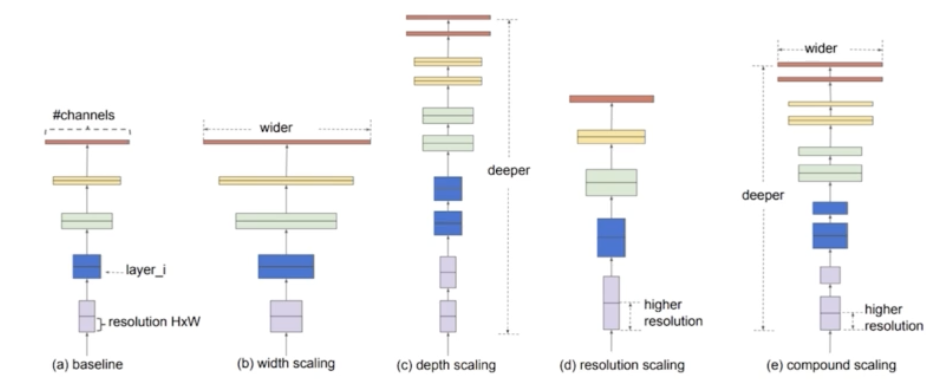
- 3가지 scaling 을 전부 통합한 compound scaling
- width, depth, resolution 을 모두 사용한다.
-
- Better Accuracy & Efficiency
- EfficientNet 연구진은 compound scaling 을 달성하기 위해서 먼저 object function 을 정의했다.

- 먼저 큰 의미에서 살펴보면, $\mathcal{N}$ 이 모델을 의미하고, 모델의 accuarcy 를 max 로 하는 $d, w, r$ 을 찾는 것이다. 이것이 better accuarcy 를 뜻한다.
- 단, 조건으로 모델의 메모리는 target memory 보다 작거나 같아야 하고, 모델의 FLOPs 는 target_flops 보다 작거나 같아야 한다. 이런 조건 하에 $d, w, r$ 을 조절하면서 모델의 accuracy 를 최대화하는 것이다. 이것이 better efficiency 를 뜻한다.
- $d$ 는 layer 를 뜻하는 $L$ 앞에 붙어있다. 모델의 depth 를 조절하는 factor 이다.
- $w$ 는 channel 을 뜻하는 $C$ 앞에 붙어있다. 모델의 channel, 즉 width 를 조절하는 factor 이다.
- $r$ 은 이미지의 width 와 height 를 의미하는 $H, W$ 앞에 붙어있다. 즉 모델의 resolution 을 조절하는 factor 이다.
-
각각의 Notation 을 좀 더 보면, 아래와 같다.

- 그래서 NN 은 각각의 layer 를 뜻하는 $\mathcal{F}_i$ 의 합성곱($\odot$) 으로 표현되어 있다. 즉 여러 layer 를 통과하는 것이다.
- 위에서 $d, w, r$ 은 scale factor 이다.
- Observation
- Object Function 을 정의한 뒤, $d, w, r$ 을 바꿔가며 여러 실험을 진행했고, 다음과 같은 관찰을 했다.
- 네트워크의 폭, 깊이, 혹은 해상도를 키우면 정확도가 향상된다. 하지만 더 큰 모델에 대해서는 정확도 향상 정도가 감소한다. 즉 향상되는 효과가 모델이 커질수록 점점 줄어든다는 것이다.
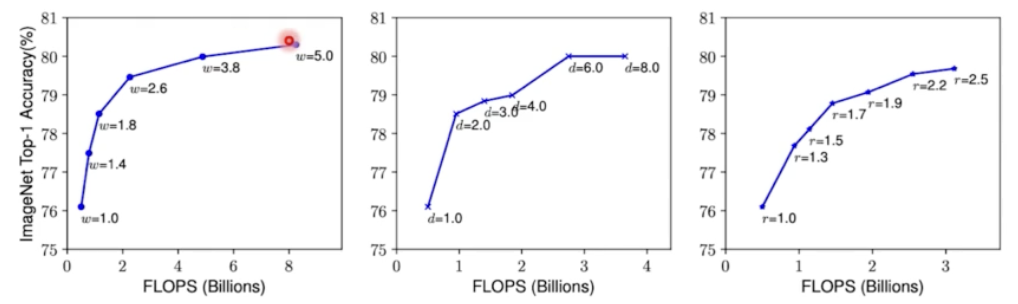
- w, d, r 이 점점 커질수록 accuracy 가 점점 올라가지만, 그 증가폭이 점점 감소하고 있다. 위 그림에서 한 가지 factor 를 증가시킬 때, 나머지 factor 는 고정을 시켰다.
- 더 나은 정확도와 효율성을 위해서는, CNN 스케일링 과정에서 네트워크의 폭, 깊이, 해상도의 균형을 잘 맞춰주는 것이 중요하다.
- 즉 3가지 factor 를 동시에 바꾸는 실험을 진행한 뒤 관찰한 결과이다.
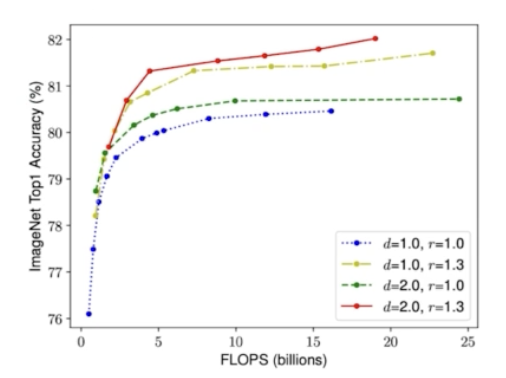
- 즉, $d, w, r$ 을 동시에 바꾸는데, 균형있게 바꾸는 것이 모델의 accuracy 를 향상시키는데 가장 좋은 방법임을 실험적으로 증명했다.
-
Compound Scaling Method

- 실험 결과에 따라 다음 조건을 만족하는 Compound scaling 방법에 대해서 새롭게 제안을 했다.
- $\alpha, \beta, \gamma$ 는 각각 depth, width, resolution 을 얼마나 바꿀 것인지에 대한 파라미터 이다. 단, $\alpha, \beta, \gamma$ 는 제약조건을 가진다.
- 이 제약조건에서 width 와 resolution 이 왜 square 가 붙냐면, 예를 들어 resolution 은 가로세로 동시에 늘어나기 때문이다.
- 이 때 $\phi$ 는 scaling factor 이다. 제약조건을 만족하는 $\alpha, \beta, \gamma$ 의 value 가 고정될 수 있는데, 이 때 $\phi$ 를 늘려나가면서 depth 와 width, resolution 세 방향으로 scale up 하는 factor 로 제안한 것이다.
- 정리하면, compound scaling method 를 통해서 $d, w, r$ 을 정의할 수 있고, 이 $d, w, r$ 을 기존에 정의한 object function 에 넣어서 모델 아키텍처를 만들 수 있다.
- 이렇게 되면, 구체적인 d, w, r 구체적인 값에 대해서 계산해야 하는데, 그럴려면 $\alpha, \beta, \gamma$ 의 값을 찾아야하고 base module 이 되는 $\mathcal{F}_i$ 를 아직 모르기 때문에 layer 에 대해서 찾아야 한다. ResNet 이 될 수도 있고 VGG 가 될 수도 있다. 임의의 layer 가 될 수 있다!
- EfficientNet 연구팀은 MnasNet 에 영감을 받아서 NAS 를 이용을 해서 layer 를 찾는 것을 목표로 했다.
- Efficient 가 앞에 붙어있으니, FLOPs 를 최소화할 수 있는 NAS 기반으로 모델 아키텍처를 찾고자 한 것이다.
- $ACC(m) \times \lbrack \frac{FLOPS(m)}{T} \rbrack^W$ 를 최적화하는 것을 목표로 했다.
- 이렇게 Accuracy 와 FLOPs 를 모두 고려한 새로운 NN 을 개발했다.
-
NAS 결과 EfficientNet-B0 가 나왔다.
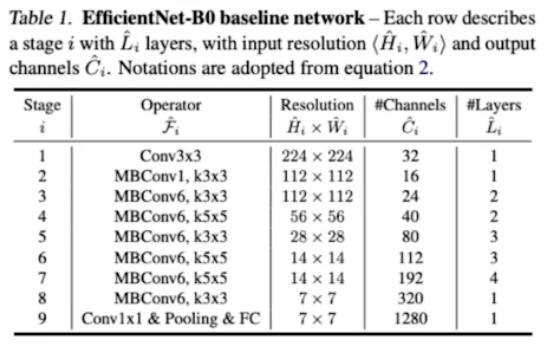
- NAS 로 찾은 결과이다.
- 그러면 NAS 로 $\mathcal{F}_i$ 를 찾게된 것이다. 그리고 object function 을 가지고 있다.
- 남은 과정은 $\alpha, \beta, \gamma$ 값을 찾으면 된다.
- step 1
- $\phi$ 를 1로 고정시킨다. 이후 $\alpha, \beta, \gamma$ 를 small grid search 를 통해서 찾는다. 즉 범위를 정하고 그 범위 안에서 grid search 기반으로 휴리스틱하게 $\alpha, \beta, \gamma$ 의 값을 찾는다.
- 그 때 제약조건을 만족하면서 가장 best score 를 가지는 $\alpha, \beta, \gamma$ 는 각각 1.2, 1.1, 1.15 가 된다.
- 이를 object function 애 곱해서 resolution 과 depth 와 channel 을 늘린다.
- 이 때 $\phi$ 가 1 이기 때문에 EfficientNet-B1 이 된다.
- step 2
- $\alpha, \beta, \gamma$ 는 상수로 고정을 하고, 다른 $\phi$ 를 사용해서 scale up 을 한다.
- $\phi$ 를 점점 늘려나갔을 때, EfficientNet-B1 부터 B7 이 된다. 예를 들어 $\phi$ 가 6이면 EfficientNet-B6 이다.
- 성능 결과
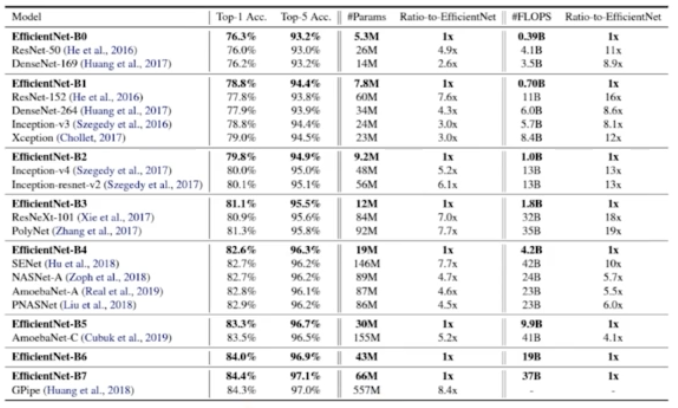
- B7 을 보면 파라미터 개수는 동일한 성능 대비 많이 줄었는데 아주 좋은 성능을 보여주고 있다.
- 이렇게 해서 EfficientNet 은 효과적으로 모델을 scaling up 하는 방법을 제안했다.
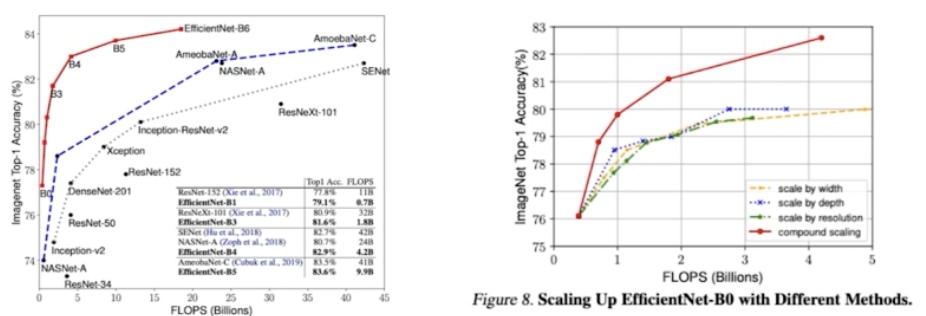
- 오른쪽 그림은 scale 방법에 따른 성능 차이를 보여주고 있다. 각각 scale 하는 것보다 3개를 동시에 balance 맞춰서 하니까 같은 FLOPs 대비 성능이 훨씬 좋음을 보여주고 있다.
- EfficientDet
- EfficientNet 이 classification 에서 모델을 어떻게 scale up 해서 성능과 속도를 보장한 연구 내용이라면, EfficientNet 의 알고리즘을 그대로 detection 에 적용한 것이 EfficientDet 이다.
- EfficientDet 에서도 Compound scaling 을 그대로 적용을 해서 성능과 속도를 동시에 보장했다.
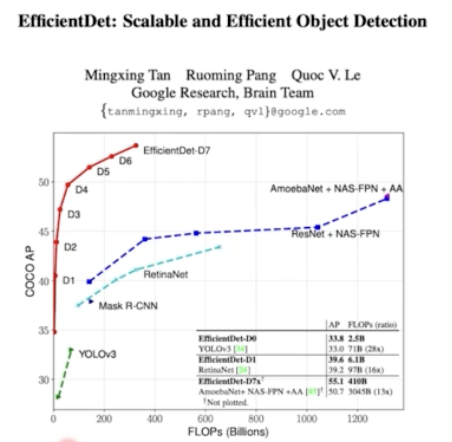
- 먼저 결과부터 보자. EfficientNet 처럼 동일 연산량 대비 최고의 성능을 가져온다. 또한 같은 성능 대비 FLOPs 가 거의 1/10 수준이다. 말그대로 Efficient 한 Detection 이다.
-
Detection Pipeline
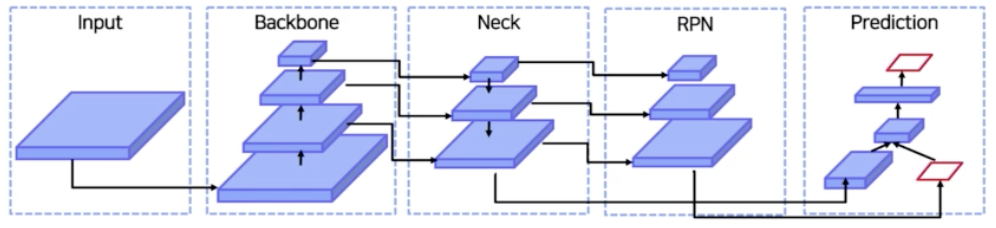
- 일반적으로 detection task 는 input 이 있으면 backbone 으로부터 input feature map 을 여러 stage 로 뽑아낸다.
- 여러 stage 의 feature 를 Neck 에서 섞어주면서 feature map 의 정보를 강화하고, 각각의 feature map 으로부터 RoI 를 뽑아내고 RoI Projection을 해서 객체가 있을법한 위치로부터 box 와 cls 를 뽑아내거나(2 stage) 또는, RoI 를 뽑아내고 바로 cls 와 box 를 뽑아낼 수 있다(1 stage).
- EfficientDet 은 YOLO 나 SSD 같이 1 stage detector 라고 볼 수 있다.
- 등장배경
- object detection 은 특히 속도가 중요한 domain 이다.
- 모델이 실생활에서 사용되기 위해서는 모델의 사이즈와 대기 시간에 제약이 있기 때문에, 모델의 사이즈와 연산량을 고려해 활용 여부가 결정된다.
- 이러한 제약으로 인해 Object detection 에서 Efficiency 가 중요해지게 된다.
- 그 동안 속도를 줄이기 위한 정말 많은 시도들이 있었다.
- 1 stage Model 활용 : YOLO, SSD, RetinaNet …
- Anchor free model : CornerNet
- 그러나 속도를 줄이면 가장 큰 단점이 Accuracy 가 너무 낮다는 것이다. 2 stage 에 비해서 쓸 수 없는 수준이다.
- 이에 따라 EfficientDet 연구팀은 자원의 제약이 있는 상태에서 더 높은 정확도와 효율성을 가진 detection 구조를 만드는 것이 가능할지 연구했다.
- 다시말해서 detection 모델의 구성요소인 backbone, Neck, head 3가지를 적당히 scale up 해서 성능과 속도 두 마리 토끼 모두 잡는 것이 가능할지 연구했다.
- 정답은 당연히 Yes 다! 우리는 classification task 로부터 성능과 속도 두 마리 모두 잡은 EfficientNet 을 봤다.
- 따라서 EfficientNet 처럼, Compound Scale 이라는 방법을 detection task 에 적용하면 성능과 속도 모두를 잡을 수 있다.
- 이제 해야할 것은 classification task 에서는 backbone 인 CNN 만 scale up 하면 됐지만, detection task 에서는 backbone, feature map, pyramid network, box classification head, cls classification head 등을 동시에 scale up 하면 된다!
- Challenge
- 기존의 detection task 의 문제점을 해결하고자 했던 알고리즘의 한계점을 보자.
-
Efficient multi-scale feature fusion
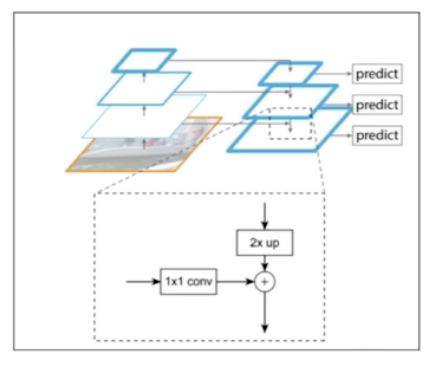
- 기존의 FPN 을 기반으로 한 Neck 에서는 high level feature map 과 low level feature map 을 더할 때 채널과 resolution(h, w) 을 맞춰서 단순합을 했다는 점이다. (lateral connection)
- Model Scaling
- 기존의 detection model 들이 model scaling 을 할 때 backbone size 와 image size 를 무작정 크게 키우는데 집중했다는 점이다.
- 지금부터 EfficientDet 이 2가지 Challenge 를 어떻게 해결했는지 보자.
- Efficient multi-scale feature fusion
- detection 에서는 feature map 의 정보를 풍부하게 하기 위해서 high level 의 정보를 low level 에 섞어주고 low level 의 정보를 high level 에 섞어주기 위해서 FPN, PANet, NASFPN, AugFPN 같은 feature fusion 알고리즘들이 많이 이용됐다.
- 하지만 대부분의 기존 연구는 단순하게 서로 다른 stage 의 feature map 을 lateral wise 하게 단순합만 해줬다. 과연 서로 다른 resolution 을 가지고 서로 다른 정보를 가지고 있는 feature map 을 단순합을 하는게 맞을까?
- 따라서 EfficientDet 연구팀은 각각의 input 을 위한 학습 가능한 weight 를 두는 Weighted Feature Fusion 방법으로 BiFPN 을 제안했다.
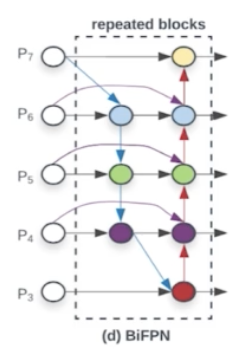
- 단순합 대신 가중합을 하는 BiFPN(Bi-directional feature pyramid network) 을 제안한 것이다.
- 특히 기존 FPN 과 PANet 의 모델 구조를 계산했는데, 모델의 efficiency 의 향상을 위해서 다음과 같은 cross-scale connections 방법을 이용했다.
- 다음과 같은 프로세스로 PANet 의 아키텍처를 개선했다.
- 하나의 간선을 가진 노드는 제거
- output 노드에 input 노드 간선 추가. 즉 residual 을 추가했다.
- 양방향 path 각각을 하나의 feature layer 로 취급하여 repeated blocks 를 활용했다.
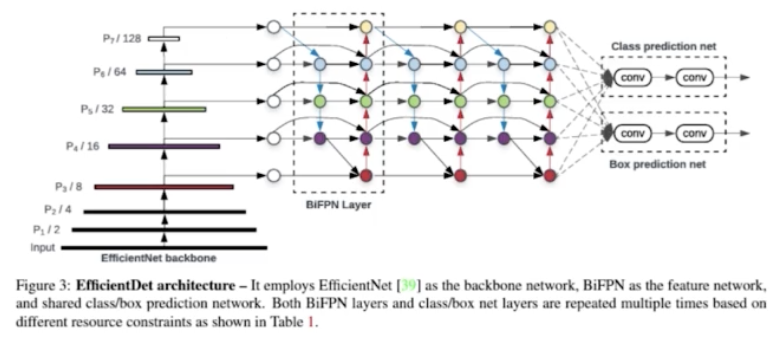
- 위 그림처럼 Bi-FPN 구조를 3번 반복해서 그 결과를 최종적으로 각 픽셀별로 box 와 cls head 를 통과시킬 수 있다.
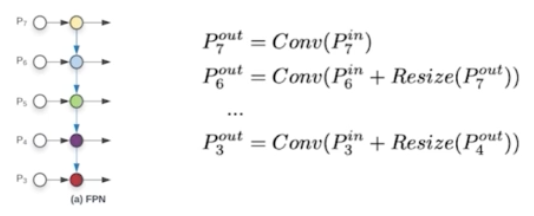
- 두번째로 EfficientDet 은 여러 resolution 의 feature map 을 단순합이 아니라 가중합을 했다. 기존의 FPN 은 feature map 의 resolution 차이를 resize 를 통해 조정한 후 합했다.
- 위 그림에서 식을 보면 FPN 은 $P_6^{out}$ 을 만들어주기 위해서 $P_6^{in}$ 과 $P_7^{out}$ 을 summation 을 했다. 이 때 $P_7^{out}$ 을 resize 를 하고 $P_6^{in}$ 의 channel 을 맞춰줘서 단순 summation 을 했다.
- Bi-FPN 은 단순합에 대해 문제제기를 했다.
- 서로 다른 resolution 을 가지고 있기 때문에 가지고 있는 정보가 다르고 따라서 단순합이 아닌 가중합을 해야한다는 구조를 제안했다.
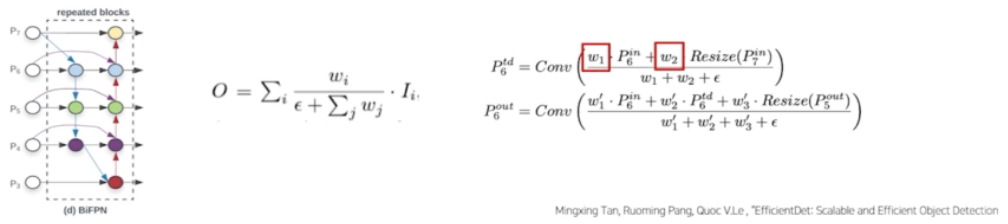
- 가중합을 할 때 weight 의 경우는 ReLU 를 통과한 값으로 항상 0 이상이다.
- 분모가 0이 되지 않도록 아주 작은 값 $\epsilon$ 을 더해줬다.
- 또한 모든 가중치의 합으로 가중치를 나눠주는 normalization 를 했다.
- 이런 식으로 feature map 의 resolution 이 다른데 단순합을 했던 문제를 해결했다.
- Model Scaling
- 더 좋은 성능을 위해서는 더 큰 backbone 모델을 사용해 detector 의 크기를 키우는 것이 일반적이다. 즉 더 큰 Backbone, Neck, Head size 를 키우는 것이 일반적이다.
- EfficientDet 은 EfficientNet 과 비슷하게 accuracy 와 efficiency 를 모두 잡기 위해서, size 를 키우는데 있어서 효과적으로 키우는 방법에 집중했다.
- 즉 여러 constraint 를 만족시키는 모델을 찾고자 했고 EfficientNet 과 비슷하게 width, depth, resolution 세 가지 측면으로 기존의 모델을 정의를 하고 scaling 할 factor 인 $\phi$ 를 둬서 이를 점점 크게 해가면서 scaling 하는 compound scaling 방식을 제안했다.
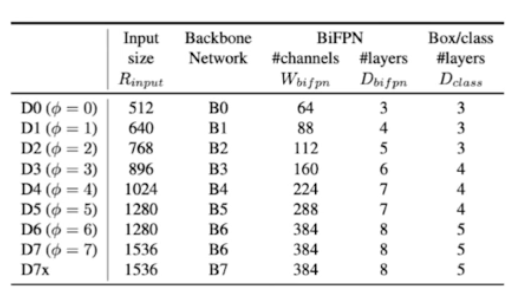
- backbone 아키텍처의 경우 EfficientNet-B0 ~ B6 를 사용했다.
- BiFPN 의 경우 네트워크의 width(channel)와 depth(layers)를 compound 계수에 따라 증가시켰다.
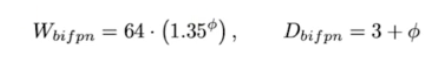
- 채널은 64 채널을 기본으로 해서 $1.35^{\phi}$ 만큼 증가시키고 있다.
- 그리고 BiFPN 을 몇번 반복할 것인지에 대한 depth wise 한 측면에서 3번 반복을 기본으로 하고
$\phi$ 만큼 더 반복하고 있다. - EfficientNet 에서 $\alpha, \beta, \gamma$ 도 grid search 로 찾은 것처럼 1.35 는 EfficientDet 연구진이 grid search 로 찾은 값이다.
- $\phi$ 를 점점 키워나가면서 FPN 의 width 와 depth 를 scale up 하는 것이다.
- 다음으로 Box/Class Predictor 의 width 는 FPN 의 width 에 맞춰 고정시켜주고 depth 는 아래 식에 따라 증가시켰다.
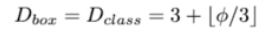
- 여기서 쓰인 [] 은 가우스 기호로, 가우스 기호란 무리수나 분수, 소수등의 정수가 아닌 숫자를 정수로 표현하는 기호다. 쉽게 말하면 반올림에서 배웠던 버림과 올림의 개념으로, 공식적인 설명으로 [x] 는 x보다 크지않은 최대 정수이다.
- input image resolution 은 아래 식과 같이 선형적으로 증가시켰다.
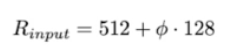
- 이렇게 Model scaling 을 했을 때, EfficientDet 의 아키텍처는 다음과 같다.
- Result
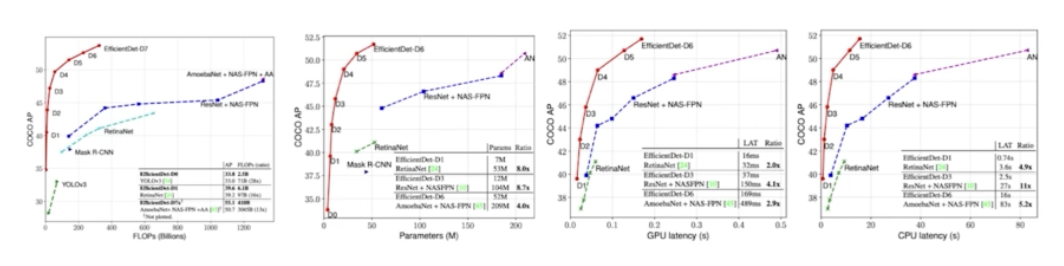
- COCO dataset 에 대한 성능(세로)과 속도(가로)에 따라 결과를 나타냈다.
- 같은 FLOPs 에서는 EfficientDet 의 성능이 압도적으로 높다. 성능이 동일할 때는 FLOPs 의 이득을 정말 많이 볼 수 있다. 파라미터 사이즈의 이득도 정말 많이 받는다.
- Efficient multi-scale feature fusion
- EfficientNet 의 compound scale up method 를 EfficientDet 에 적용해서 빠르면서 좋은 성능의 detection model 을 develop 했다.
댓글 남기기