
[Object Detection] 5. 1 Stage Detectors
-
1 Stage Detectors
💡 YOLO 는 You Only Look Once 의 약자이며, YOLO는 전체 이미지를 한 번에 보고 객체의 위치(localization)와 클래스를 검출(classification)하는 one stage detector의 특징을 가진다.
2 Stage detector와 비교해서 YOLO, SSD, RetinaNet 와 같은 1 stage detector들의 경우,
- 전체 이미지를 한 번에 보고 객체의 위치와 클래스를 검출하는 특징이 있기 때문에 객체에 대한 맥락적 이해가 높다.
- 전체 이미지에 대해 특징 추출, 객체 검출이 이루어진다.
- Localization, Classification이 동시에 진행한다.
- 속도가 매우 빠르다 (Real-time detection)
One stage detector 방식의 architecture 들 특징
- SSD: VGG를 backbone 으로 사용하고, Non maximum suppression을 training 시 수행
- YOLO v3: skip connection을 제안하고 Feature Pyramid network를 사용함
- YOLO v2: DarkNet을 사용하고, word tree 를 구성함
- YOLO : Region proposal 단계가 없다
-
Retina Net: focal loss를 제안하여 배경과 객체에 class imbalance 을 해결하는데 그 중 배경보다는 객체를 잘 분류하고자 한다
- FPN 은 작은 object 를 더 잘찾도록, 즉 다양한 객체를 더 잘 찾기 위해서 어떻게 했는지 알아봤다면 이제 1 stage detector 에 대해 알아보자.
- 2 stage detector 가 속도가 느려서 real time 에서 활용할 수 없다는 단점이 있었는데, 1 stage detector 를 보면서 real time object detector 에 대해 알아보자.
- 1 Stage Detectors
- 2 stage detector 를 보면 RCNN, Fast RCNN , SPPNet, Faster RCNN 등의 모델들은 첫번째로 Localization (후보 영역 찾기) 을 수행한다.
- 두번째로 이렇게 찾은 후보 영역에 대해서 Classification(후보 영역에 대한 분류) 을 진행하게 된다.
- 이 2 stage 모델들에서 한계점은, 속도가 매우 느려서 Real World 에서 응용할 수 없다는 것이다. 이 Real World 에서 응용 가능한 Object Detector 들은 없을까? 에서부터 시작된 것이 바로 1 stage detector 들이다.
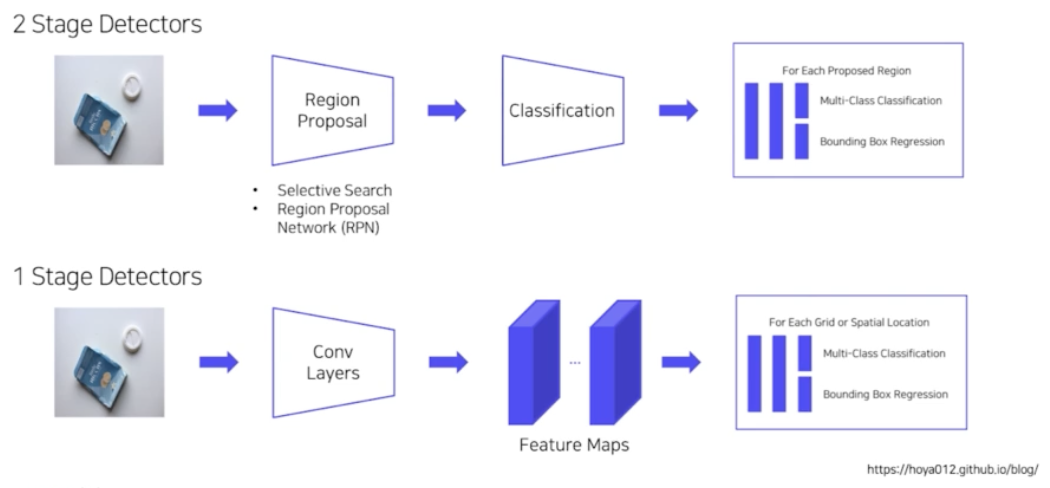
- 2 stage 는 이미지가 존재할 때 RPN 을 통과해서 RoI 가 나오고 이 RoI 로부터 classification 을 진행한다.
- 반면에 1 stage 는 CNN 을 통과해서 feature map 까지 나오는 과정은 2 stage 와 동일하다. 그러나 이 feature map 으로부터 따로 RPN 을 통과하지 않고 feature map 에서 바로 객체의 위치와 객체의 종류를 찾아내는 예측을 한다.
- RPN 과정이 아예 사라짐. feature map 으로부터 바로 객체를 뽑고 바로 그 객체의 cls 뽑고, 위치를 뽑는다.
- 즉, Localization 과 Classification 이 동시에 진행된다.
- 전체 이미지에 대해 특징 추출 후 객체를 검출하기 때문에 간단하고 쉬운 디자인이다.
- 또 RPN 과정이 따로 없기 때문에 Real time 으로 작동할 수 있다.
- 영역을 추출하지 않고 전체 이미지로부터 Localization 과 classification 을 수행하기 때문에 context 에 대한 이해가 상당히 높다. 즉 background error 가 낮다.
- 대표적인 예시로 YOLO, SSD, RetinaNet 이 있다.
- YOLO v1
- You Only Look Once
- v1 부터 v8 까지 다양하게 있다. 여기서는 v3 까지 보자.

- RCNN 같은 2stage 모델은 입력 이미지가 있을 때 입력 이미지의 위치를 보고 각 위치에서 localization 해서 classification 을 진행한다.
- YOLO 같은 1stage 모델은 입력 이미지가 있을 때 입력 이미지로부터 위치와 클래스에 대한 예측이 동시에 이루어진다.
- 즉 Region Proposal 단계가 없다.
- 전체 이미지에서 bbox 예측과 클래스 예측을 동시에 진행한다. 즉 이미지와 물체를 전체적으로 관찰하여 추론하기 때문에 맥락적 이해가 높아진다.
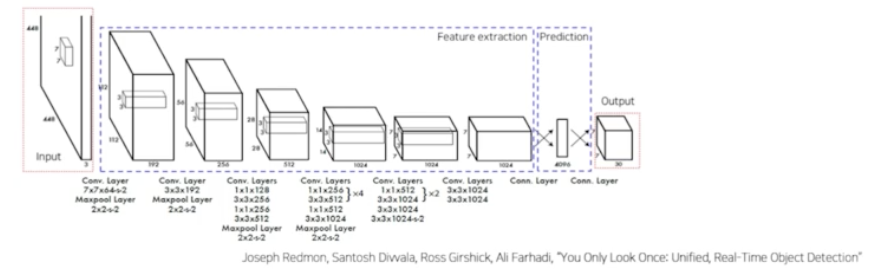
- Network 는 GoogLeNet 을 변형해서 사용한다.
- 24개의 conv layer 로 특징을 추출한다.
- 맨 마지막에 2개의 fc layer 가 box 의 좌표값 및 확률을 계산한다.
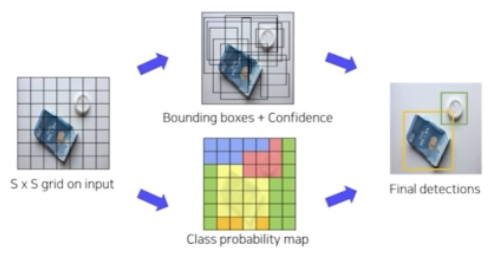
- 맨 먼저, 입력이미지를 SxS 그리드 영역으로 나눈다. 위 예제에서 S 는 7이다.
- 각 그리드 영역마다 B 개의 bbox 와 confidence score 를 계산한다. 위 예제에서 B 는 2 다. 즉 하나의 그리드마다 box 를 2개씩 예측한다는 것. 이 때 신뢰도(confidence)는 box 에 object 가 존재할 확률 x gt 와 pred 의 IOU 로 구하게 된다. ($Pr_{(Object)} \times IOU_{pred}^{truth}$)
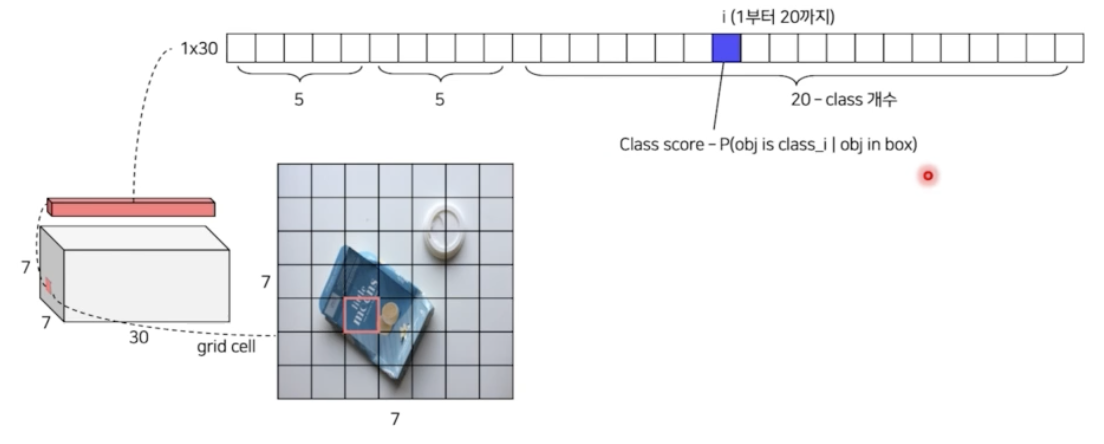
- 각 그리드 영역마다 C 개의 class 에 대한 해당 클래스일 확률을 계산한다.(class probability map) 위 예제에서 C 는 20 이다. 첫번째 그리드에서 box 2개를 예측하고 첫번째 그리드가 어떤 클래스를 포함하고 있을지 C 개의 클래스에 대한 확률을 계산한다. ($Pr(Class_i \mid Object)$)
- 맨 마지막으로 두 가지 정보(bounding box + confidence, class probability map)를 혼합을 해서 최종적으로 detection 을 한다.

- input 이미지가 GoogLeNet 을 통과하고 fc layer 를 거치면 output size 가 7x7x30 이 된다.
- 그 이유는 feature map 의 최종 output size 를 7x7 로 하면 input 을 7x7 그리드로 나눈 것과 같은 효과가 있다고 한다. 즉 output 의 한 그리드가 input 의 7x7 영역을 담당하는 것이다.
- 최종적으로 feature 는 30개를 사용한다.
-
모델의 예측이 7x7x30 인 것을 정밀히 분석해보자.
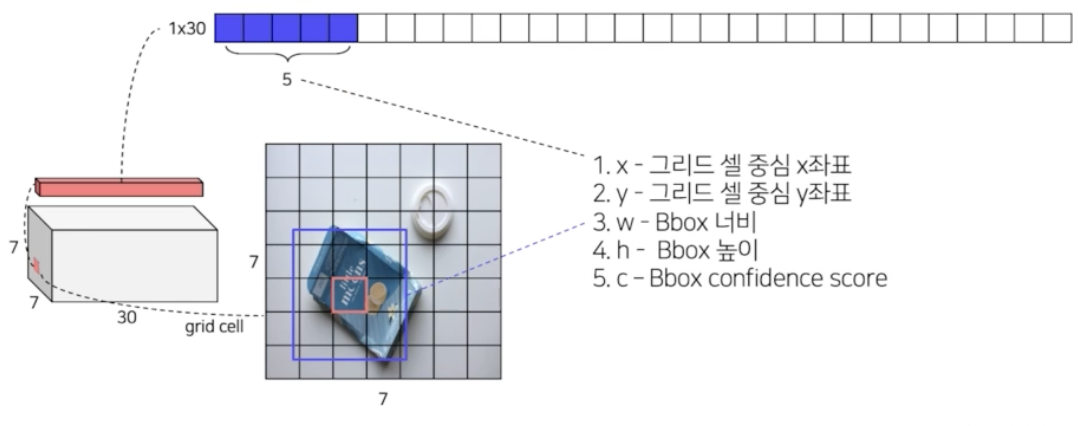
- 하나의 그리드 입장에서 생각해볼 때, 하나의 그리드는 채널이 30개이다. 왜 채널이 30개일까?
- 처음 5개는 첫번째 bbox 에 대한 정보를 담고 있다. YOLO 에서는 그리드별로 총 2개의 bbox 를 예측하는데, 그 2개 중 첫번째 bbox 에 대한 정보인 것이다.
- 각각 그리드 셀의 중심 x, y 좌표, w, h, 그리고 confidence score(예측한 bbox 가 object를 포함하는지 아닌지) 해서 5개이다.
- 두번째 박스도 5개 존재한다. x, y, w, h, c
- 즉 grid cell 마다 2개의 bbox 가 존재
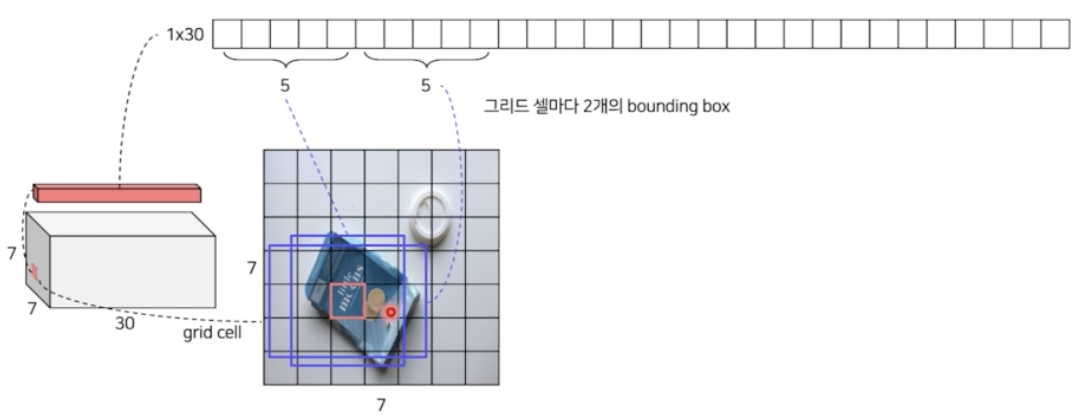
- 그러면 나머지 20개는 무엇일까? class 의 개수이다.
- YOLO 가 사용한 데이터셋은 클래스가 20개이고 20개의 클래스를 사용했다. 그리고 Faster RCNN 에서는 background 여부를 포함했는데 YOLO 에서는 포함하고 있지 않다.
- 그 다음으로 inference 는 첫번째 bbox 의 confidence score 와 20개 클래스의 확률을 다 곱한다. 30개의 채널 중 20개가 class 의 개수인데, 각 채널은 해당 클래스일 확률을 나타낸다. 그러면 각각의 cell 이 의미하는 것은 첫번째 bbox 가 해당 클래스일 확률을 뜻하게 된다.
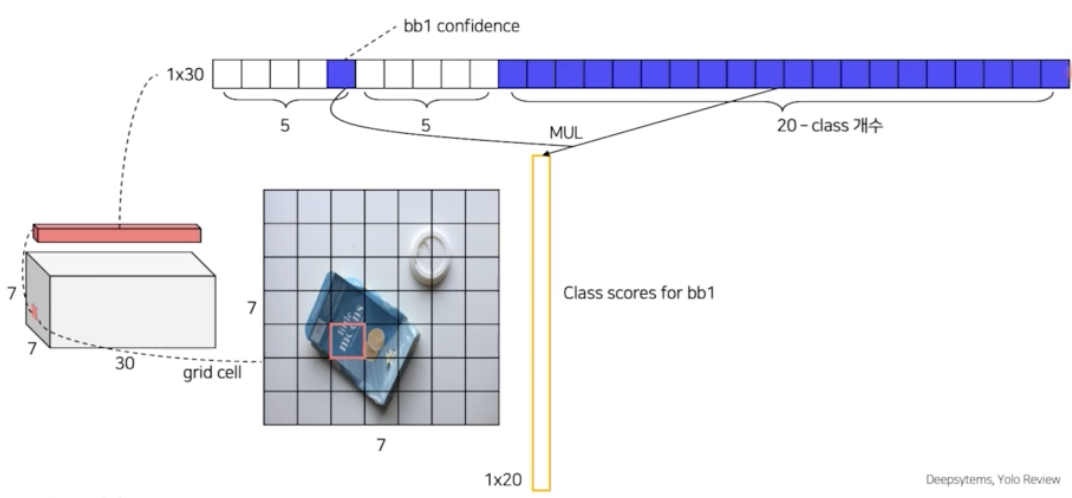
- 마찬가지로 2번째 bbox 의 confidence score 도 각각의 클래스일 확률을 곱해주게 되면 2번째 bbox 가 해당 클래스일 확률을 구할 수 있다.
- 이렇게 되면 하나의 grid cell 에서 총 2개의 값이 나오게 된다. 즉 2개의 bbox 각각이 어떤 클래스일 확률인지.
- 이렇게 grid cell 마다 이 연산을 다 수행해준다. 그러면 총 49개의 grid cell 에서 2개씩 나오니 98개의 box 가 나오게 된다.
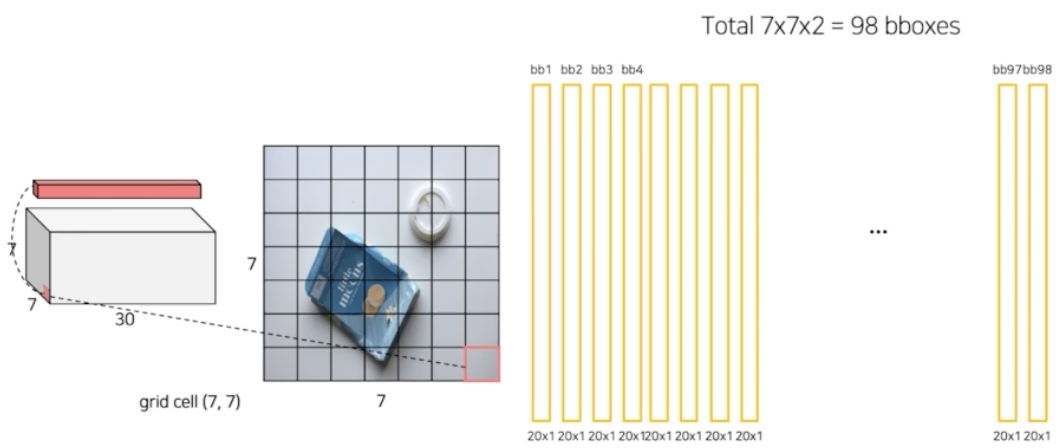
- 그 다음에 각 클래스에 대한 score 들을 대상으로 특정 thr 보다 작은 것들을 0으로 만들 수 있다. thr 는 하이퍼 파라미터다. thr 보다 작은 score 는 고려하지 않겠다는 것이다.
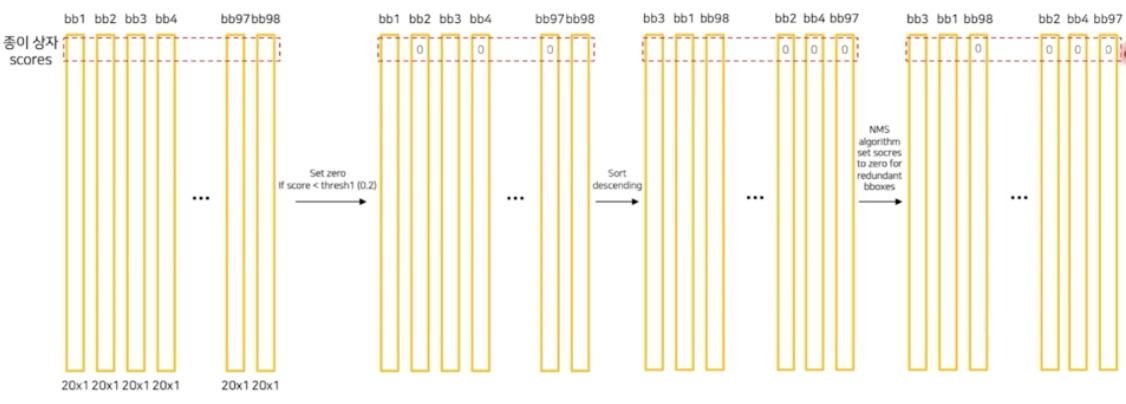
- 그리고 이를 descending 으로 정렬한다. 그 다음에 정렬된 bbox 들을 대상으로 NMS 연산을 진행한다. 그렇게 되면 사라지는 box 들이 생긴다.
- 그렇게 NMS 를 진행한뒤 남아있는 box 들을 이미지에 그려주면 inference 가 수행된 것이다.
- Loss
- YOLO 의 loss 는 정말 간단하다. 각각 Localization, Confidence, Classification 이 있다.

- Localization Loss
- 첫번째 시그마가 의미하는 것은 각 그리드 셀별로, 두번째 시그마는 box 를 의미한다.
- 그러면 각 그리드 셀의 각 bbox 별로 중심점의 위치를 계산을 한다.
- 이 때 각 그리드 셀의 각 bbox 가 object 를 포함하고 있을 때 중심점의 위치를 계산한다.
- object 를 포함하고 있다면 중심점의 위치를 Regression Loss 를 부여한다.
- 이 때 x, y, w, h 를 다 계산한다.
- 이 첫번째 loss term 에서 $\lambda_{coord}$ 가 localization loss term 에 대한 하이퍼 파라미터가 된다.
- Confidence Loss
- 똑같이 각 그리드 셀의 각 박스 별로, object 가 있을 때 confidence loss 를 계산하고, 각 그리드 셀의 각 박스 별로 object 가 없는 bbox 에 대상으로 confidence scroe 를 계산해서 더해준다.
- $\lambda_{noobj}$ 가 밸런스를 조절하는 하이퍼 파라미터다.
- Classification Loss
- class 의 경우 각 그리드셀별로 할당이 된다.
- 각 그리드 셀 별로 object 가 있을 때, 즉 그리드가 object 를 포함하고 있을 때 클래스에 대한 확률에 대해 MSE 를 계산하게 된다.
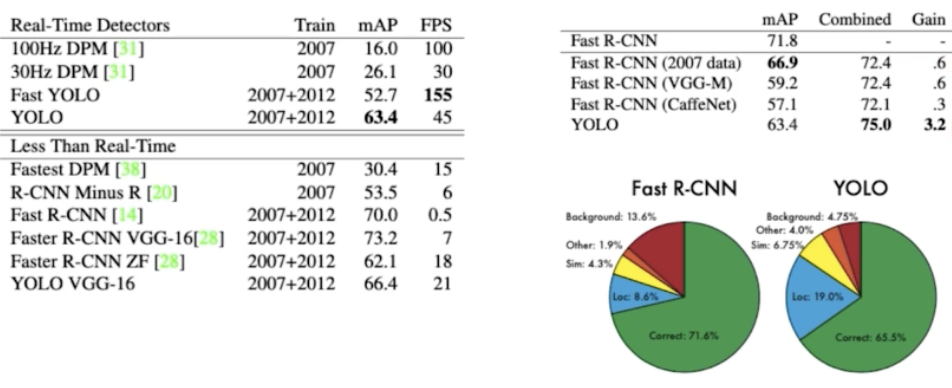
- 이런 식으로 YOLO 를 사용했을 때, 다른 real-time detector 와 비교했을 때 뒤쳐지지 않는다. 또한 RCNN 보다 훨씬 빠르다. FPS 가 3배 정도 빠르다.
- 그리고 오른쪽 표를 보면 YOLO 가 background error 가 상당히 낮은 편인데, Fast RCNN 은 background error 가 높다. YOLO 를 토대로 background error 를 미리 솎아내고 Fast RCNN 을 했을 때 mAP 가 훨씬 높게 나옴을 알 수 있다.
- 즉 두 가지를 앙상블하면 궁합이 좋다!
- 장점
- Faster RCNN 에 비해 6배 속도가 빠르다.
- 다른 real time detector 에 비해 2배 높은 정확도를 보여준다.
- 이미지 전체를 보기 때문에 클래스와 사진에 대한 맥락적 정보를 가지고 있다. 그래서 background error 가 낮은 편이다.
- 물체의 일반화된 표현을 학습한다. 따라서 사용된 데이터셋 외의 새로운 도메인 이미지에 적용했을 때 좋은 성능을 보이는 편이다.
- SSD
- YOLO 의 단점
- 7x7 grid 로 나눠서 bbox pred 를 진행했다. 따라서 7x7 grid 보다 작은 물체는 식별할 수 없다. 7x7 grid 에 해당하거나 그거보다 큰 물체만 식별할 수 있다.
- 신경망을 통과하며 마지막 feature 만을 사용했기 때문에 정확도가 하락된다. 이는 FPN 이 등장하는 배경과 일맥상통한다.
-
YOLO vs SSD
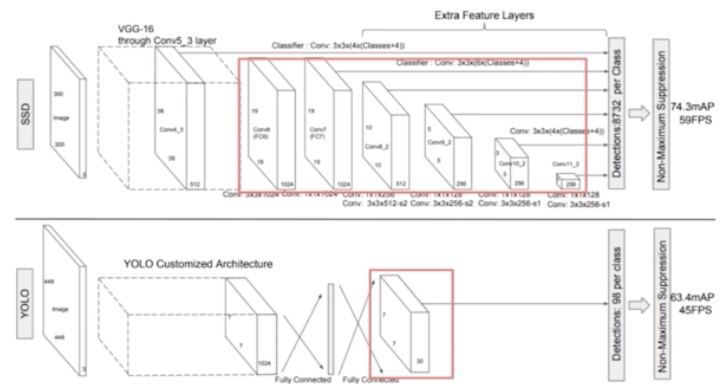
- 아래는 YOLO 모델이고 위에는 SSD 모델이다.
- 가장 큰 차이점은 YOLO 는 448 x 448 이미지를 활용했고 SSD 는 300 x 300 이미지를 활용했다.
- 그 이후 YOLO 는 fc layer 가 존재한다. 그래서 어느정도 속도를 느리게 했는데, SSD 는 1x1 conv 를 사용하기 때문에 fc layer 가 사라졌다.
- 다음으로 YOLO 는 backbone 을 통과하고 마지막 feature map 에서 detection 을 수행했다면 SSD 는 VGG 16 backbone 을 통과하고 마지막 feature map 으로부터 추가 extra conv 를 진행한다. 그래서 새롭게 feature map 몇 개를 더 만들고 새롭게 만들어진 feature map 으로부터도 conv 연산을 수행한다.
- SSD 의 특징
- extra conv layer 로부터 나온 feature map 모두를 detection 에 이용한다.
- 마지막 feature map 을 포함해서 총 6개의 서로 다른 scale 의 feature map 을 사용한다.
- 큰 feature map (early stage feature map) 에서는 작은 물체를 탐지한다.
- 작은 feature map (late stage feature map) 에서는 큰 물체를 탐지한다.
- Fully connected layer 대신 conv layer 를 사용해서 속도를 향상시켰다.
- Default box 를 사용했다(anchor box). Faster RCNN 의 anchor box 개념인데, 이 때 anchor box 들은 서로 다른 scale 과 비율을 가진 미리 계산된 anchor box 들이다.
- extra conv layer 로부터 나온 feature map 모두를 detection 에 이용한다.
-
SSD Pipeline
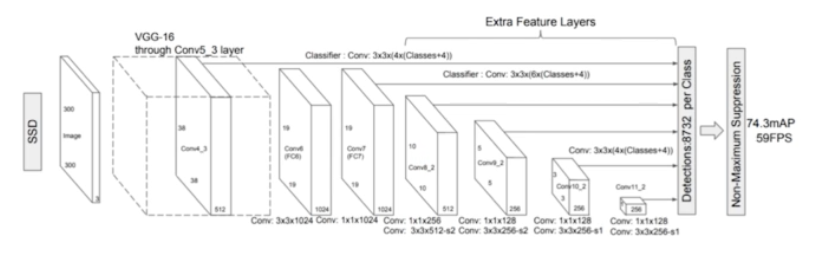
- backbone 으로 VGG-16 사용하고, 6개의 feature map 을 얻기 위해서 Extra conv layer 를 두었다.
- 입력 이미지 사이즈는 300 x 300 이다.
- Multi-scale feature maps
- 이 중 예시로 5x5x256 feature map 을 통해서 SSD 에서 anchor 를 어떻게 사용했는지 보자.
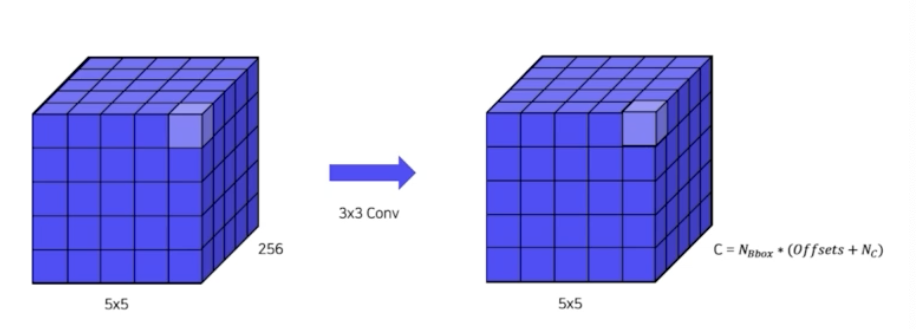
- 채널이 256인데 3x3 conv 를 통해서 정해진 채널로 바꿔준다. 채널의 shape 은 box 의 개수 곱하기 각 box 별로 offset 과 box 별로 예측될 클래스로 채널을 설정해준다. $C = N_{Bbox} * (Offsets + N_c)$
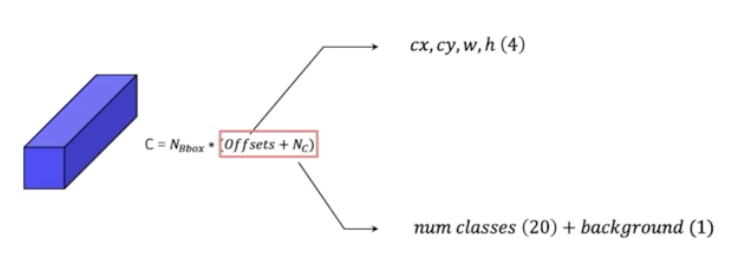
- 각 box 의 offset 은 anchor box 들의 중심점 좌표, w, h 4개의 value 를 가진다.
- 클래스는 클래스의 개수와 배경 여부를 포함한다. YOLO 에서는 background 를 포함하지 않았지만 SSD 에서는 배경 여부를 포함해서 총 21 개를 가진다.
- box 별로 offset 4 개 class 21 개로 총 25개를 예측하게 된다.
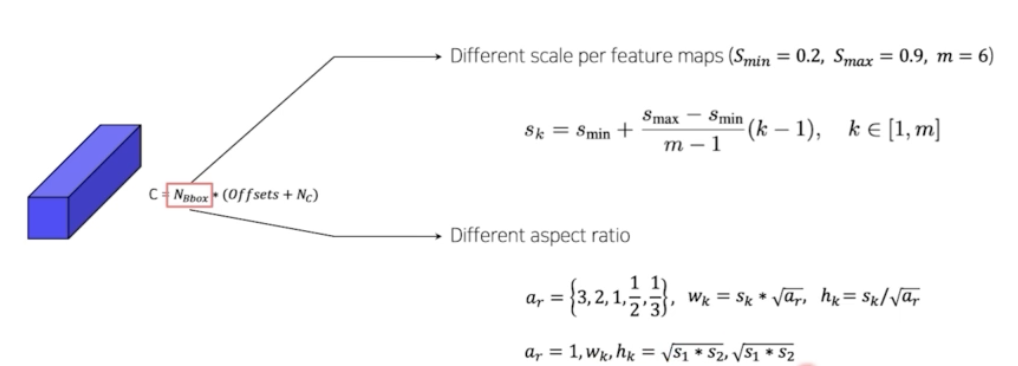
- box 개수(anchor box 개수)를 정할 때는, scale 을 부여한다. 각 feature map 별로 scale 을 부여할 때는, 최소값을 0.2 부터 0.9 까지 scale 을 늘려나간다. 위 식에 따라 k 가 1 일 때는 0.2 가 나오고, k 가 마지막 m 일 때는 0.9 가 나온다. 즉 0.2 부터 0.9 까지 선형적으로 scale 을 증가시킨다.
- aspect ratio(box 의 비율)도 다르게 사용한다. SSD paper 는 정사각형(1) 부터 가로가 긴 직사각형(3,2), 세로가 긴 직사각형(1/2, 1/3) 까지 둬서 여러가지 aspect ratio 를 가지고 있는 scale 의 anchor box 를 활용했다.
- box 의 w와 h 는 scale 과 aspect ratio 로 결정된다.
- 이런 식으로 scale 과 aspect ratio 를 토대로 기본적인 anchor box 들을 미리 정의해둔다.
- 그리고 하나의 anchor box 를 더 사용한다. aspect ratio 가 1 인 case 에 한해서, 다음 scale 과 현재 scale 중간 크기의 정사각형(1) box 를 하나더 anchor box 로 추가한다.

- 따라서 하나의 그리드 셀 별로 default 6개의 anchor box 가 구성된다.
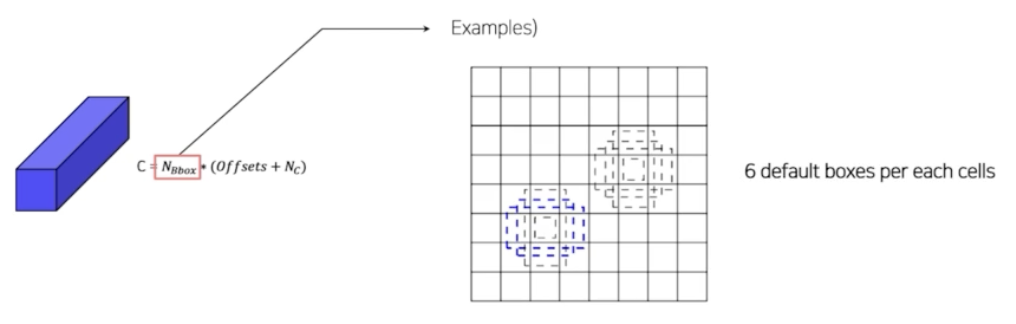
- 그러면 5x5 에서, 3x3 conv 로 채널을 맞춰줄 때, anchor box 6개와 offset 4, class 21 로 연산을 통해서 채널을 맞춰주게 된다. $C = N_{Bbox} * (Offsets + N_c)$
- 즉 default box 는 feature map 의 각 셀마다 서로 다른 scale, 서로 다른 비율을 가지는 미리 정해진 box 를 생성하는 것이다.
- 이 부분이 Faster RCNN 의 anchor box 와 매우 유사하다.
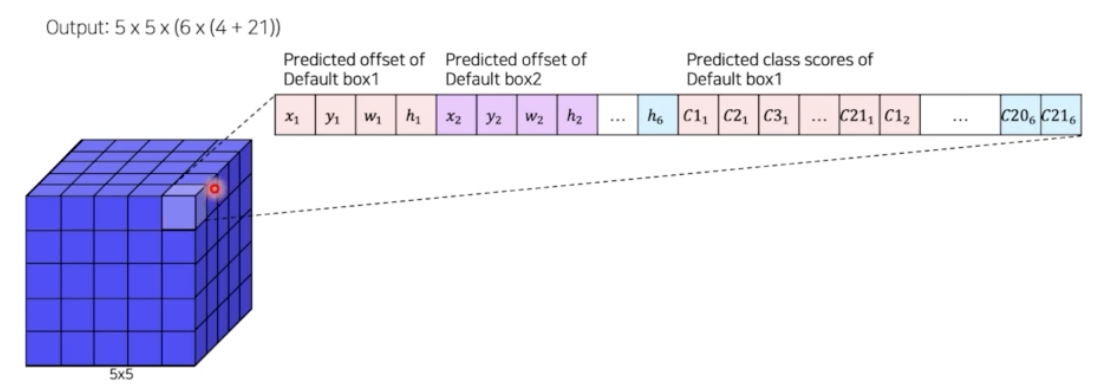
- 그래서 최종 채널은 첫번째 box 의 좌표 부터 6번째 box의 좌표가 나타난다. 그리고 첫번째 box 가 가질 클래스부터 6번째 box가 가질 클래스도 나타난다.
- 그러면 5x5x(6x(4+21)) 이 된다. 한 픽셀별로 6개의 box 를 활용한다.
- 그렇게 해서 전체 SSD 의 6개의 모든 feature map 에 대해서 각 셀마다 default box 가 나오게 되고 예측을 하게 된다. 그러면 SSD 에서 total box 의 개수는 다음과 같다.
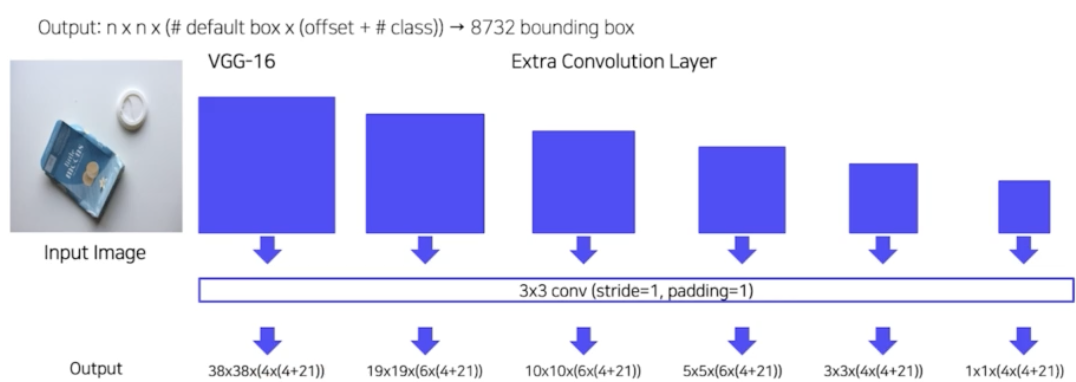
- 그러면 SSD 의 총 default box 의 개수만 8,732 개가 된다.
- 모델이 8,732 의 box 에서 예측을 하게 되는 것이다.

- 이렇게 해서 8x8 feature map 의 low level feature map 은 작은 물체 탐지에 유리하고, 4x4 feature map 의 high level feature map 은 큰 물체 탐지에 유리하다.
- SSD Training
- Hard negative mining 을 수행
- box 가 많으니 NMS(Non maximum suppression)를 수행하게 된다.
-
Loss

- 일반적인 loss func 은 classification loss 와 localization loss 가 존재한다.
- localization loss 는 Smooth L1 을 활용하고, cls loss 는 Softmax 를 활용한다.
- Localization Loss
- anchor box 에서 gt box 로 가려면 얼마나 가야 하는지 $d$ 대해서 학습한다.
- Classification Loss
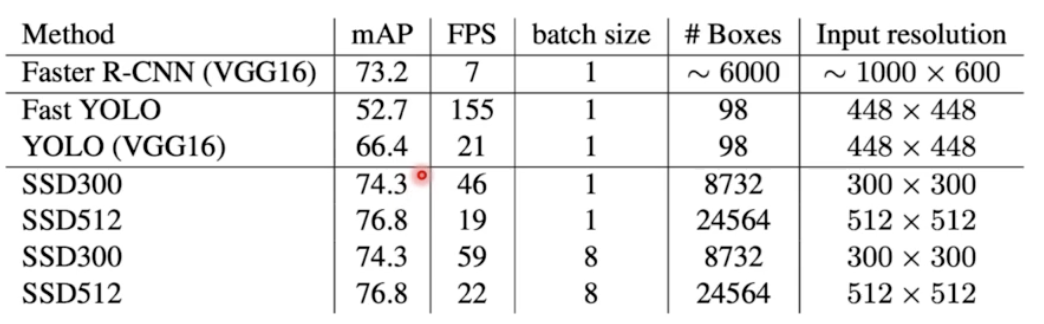
- 결과를 보면 기존의 VGG 16 을 사용했던 YOLO 의 FPS 가 21이다. fc layer 가 있어서 느렸는데, SSD 300(이미지 사이즈) 를 보면 fps 가 거의 2배 이상인데, mAP 가 더 높다. 즉 속도와 성능 모두가 개선된 것이다.
- YOLO 의 단점
- YOLO v2
- 3가지 파트에서 모델을 향상시켰다.
- 정확도 향상, 속도 향상, 더 많은 클래스 예측
- 정확도 향상(Better)
- Batch Normalization → mAP 2% 향상
- High Resolution Classifier
- YOLO v1 에서는 VGG 가 224x224 로 pretrained 되고 448x448 detection task 에 적용됐었다.
- 이에 따라 VGG 를 448x448 이미지로 새롭게 fine tuning 했다. → mAP 4% 향상
- Convolution with anchor boxes
- SSD 와 유사하게, anchor box 를 도입했다.
- 속도를 느리게 하는 fc layer 를 제거했다.
- YOLO v1 의 경우 각 grid cell 마다 bbox 를 random initialization 해서 random 으로 학습했는데, YOLO v2 에서 기준이 되는 anchor box 를 도입했다. 그래서 anchor box 로부터 w, h 를 얼마나 더 바꿔야 하는지 학습해서, 좀 더 학습을 편하게 만들어주었다.
- anchor box 를 총 몇 개 사용했냐하면, COCO datasets 의 box 들을 K means cluster 로 분석해서 최종적으로 5개의 anchor box 를 활용했다.
- 또한 좌표 값을 그대로 맞추기보다, offset 을 예측하게끔 바꿨다. 즉 기존의 anchor box 로부터 어느정도 가야하는지 offset 을 예측하도록 바꿨기 때문에 학습하기 쉬워졌다.
- 이 과정을 통해서 mAP 가 5% 향상됐다.
- Fine-grained features 활용
- 크기가 작은 feature map 은 low level 의 정보가 부족하다. 크기가 작은 feature map 은 conv 가 충분히 진행됐기 때문에 low level 의 정보가 부족하다.
- 그러나 Early feature map 은 작은 low level 정보를 함축하고 있다.
- 이에 Early feature map 을 late feature map 에 합쳐주는 passthrough layer 를 도입했다.
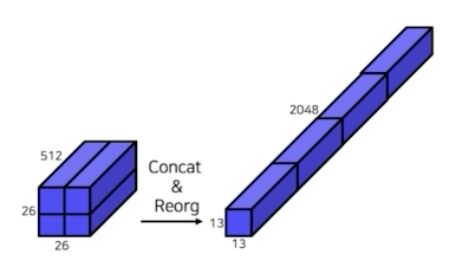
- early stage 에 26x26 feature map 이 존재한다고 했을 때, 이를 13x13 으로 분할 후에 channel wise 하게 결합(concat)한다.
- 이 concat 해준 feature map 을 나중에 late stage 인 13x13 feature map 에 정보를 추가해주는 역할을 하게 된다. 이 concat 된 feature map 이 fine-grained feature 가 된다.
- Multi-scale training 진행
- 이미지 사이즈를 448x448 말고도 320 부터 608 까지 다양한 scale 의 이미지로 학습을 진행함.
- 위에서 본 multi-scale feature map 을 사용한 것은 아니고, 이미지 크기 자체를 작게부터 크게까지 multi scale image 를 사용한 것이다.
- 속도 향상(faster)
- Backbone model
- GoogLeNet → Darknet-19
-
Darknet-19 for detection
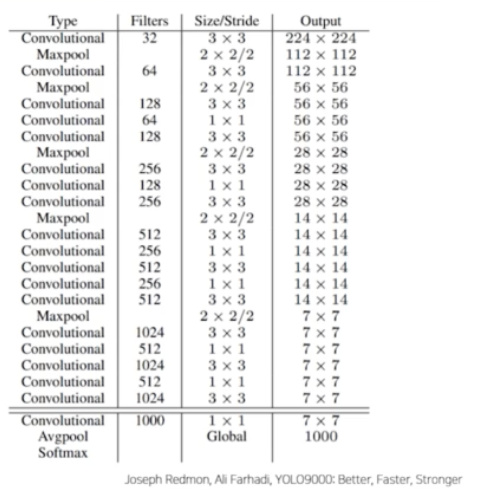
- YOLO 가 새롭게 디자인한 Darknet 아키텍처
- 마지막 fc layer 를 제거했다.
- 대신 3x3 conv 로 대체했다.
- 1x1 conv 를 추가했다.
- anchor box 가 5개이기 때문에, 채널의 수는 5x(5+20) 으로 125로 맞춰주었다.
- Backbone model
- 더 많은 클래스 예측(Stronger)
- 일반적인 20개, 80개 가 아니라 9000개의 데이터셋에 대해서 예측했다.
- 이 때 YOLO v2 에서는 Classification 데이터셋 ImageNet 과 detection 데이터셋 COCO 를 함께 사용했다.
- detection dataset : 일반적인 객체 class 로 분류
- classification dataset : 세부적인 객체 class 로 분류
- 그러나 “개” 와 “진돗개” 가 배타적 class 로 분류하면 안된다.
- 따라서 WordTree 를 구성했다. 계층적인 트리이다.
- 즉 “진돗개” 이면, 물리적객체(최상위노드) - 동물 - 포유류 - 개 - 진돗개(최하위 노드) 이런 식이다.
-
ImageNet 데이터셋과 COCO 를 합쳐서 9418 개의 범주를 만들었다.
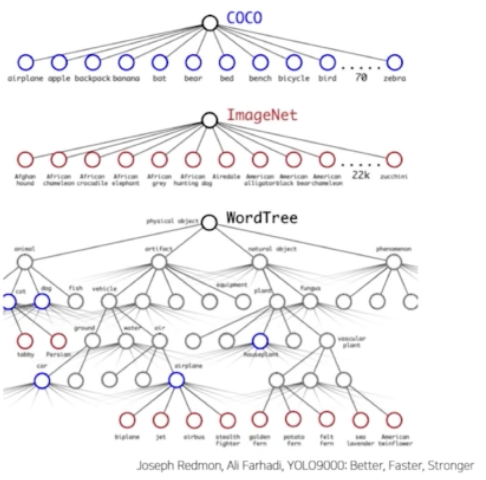
- 이렇게 범주를 만들어 냈을 때, YOLO v2 는 학습시키기 위해서 한 데이터셋에 ImageNet 데이터셋과 COCO 데이터셋을 4:1 로 주었다.
- Detection 을 할 때는 COCO 로 수행하고, ImageNet 데이터로는 Classification 을 수행하도록 했다.
- 즉, Detection 이미지 대상으로는 cls loss 와 detection loss 를 같이 계산한 것이고, Classification 이미지 대상으로는 cls loss 만 수행했다.
- 이렇게 수행했을 때, 실제로 cls data 에 대해서도 어느정도 detection 을 했다. 즉, 보지못했던 데이터셋에 대해서도 어느정도 Object Detection 을 수행한 것.
- 결과적으로 YOLO v1 보다 성능이 압도적으로 많이 증가했다.

- 3가지 파트에서 모델을 향상시켰다.
- YOLO v3
- YOLO v2 와 크게 다르지 않다.
-
Darknet-53

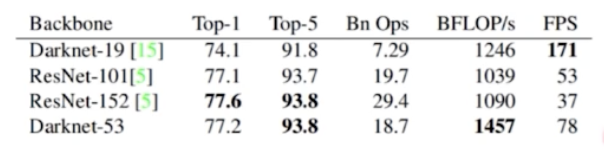
- YOLO v3 는 backbone 을 develop 했다.
- skip connection 를 이용했고, max pooling 을 없앴다.
- conv stride 를 2로 사용했다.
- ResNet 101, 152 와 성능은 비슷한데 FPS 가 높다.
- Multi-scale Feature maps 사용
- FPN 을 활용한 것. 즉 추가적인 Neck 구조를 사용한 것.
- 서로 다른 3개의 scale 을 사용했다. 52x52, 26x26, 13x13 3개의 feature map 을 뽑아서, FPN 을 이용해서 low level 의 정보와 high level 의 정보를 섞어줬다.
- 즉 high level 에서는 fine-grained 정보를 얻고, low level 에서는 semantic 의 정보를 얻을 수 있게 됐다.
- RetinaNet
- 1 stage detector 가 가진 고질적 문제점을 해결하려 한 paper
- 1 stage detector 문제점
- Class Imbalance
- region proposal network(RPN) 이 없어서, 이미지에서 객체가 있을 법한 후보 영역을 뽑는 것이 아니라 이미지를 그리드로 나눠서 각 그리드별로 bbox 를 무조건 예측을 하게 하는 training 을 사용한다.
- 그렇게 되면 2 stage 보다 background 를 포함하게 될 확률이 정말 많이 높아지게 된다.
- 그래서 positive sample(객체 영역) 보다 negative sample(배경 영역) 이 훨씬 많아지는 class imbalance 문제가 발생하게 되는 것이다.
- anchor box 대부분이 negative sample(background) 이다.
- 2 stage detector 의 경우 region proposal 에서 selective search, RPN 을 통해서 background sample 을 제거한다.
- Positive, negative sample 수를 적절하게 유지한다 (hard negative mining).
- 따라서 이 class imbalance 문제를 해결하려한 paper 가 RetinaNet 이다.
- Class Imbalance
- Focal Loss
-
새로운 loss function 인 focal loss 의 개념을 도입했다.
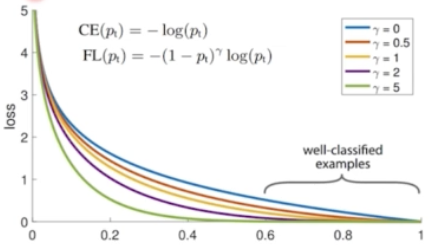
- 기존의 CE loss 를 그대로 이용하는데, scaling factor 를 둬서 CE 보다 좀 더 쉬운 예제에 작은 가중치를 두고, 어려운 예제에는 큰 가중치를 둬서 어려운 예제를 잘 해결할 수 있게끔 집중하게 만들었다.
- 그래프를 보면, $\gamma$ 가 0 인 case 가 일반적인 CE loss 이다.
- $\gamma$ 가 scaling factor 인데, 커지면 커질수록 그래프가 어려운 case 에 대해서 gradient 를 훨씬 더 강하게 주는 것을 알 수 있다.
- 결과적으로 loss 가 큰, 어려운 예제에 가중치를 더 크게 해서 더 강하게 학습하라는 방향성을 부여한 것.
- Focal Loss 는 object detection 에서만 사용하는 것이 아니라, class imbalance 한 problem 을 해결하기 위해 많이 사용된다. 딥러닝 학습 과정에서 많이 존재하는 problem 인데 범용적으로 사용될 수 있는 Loss 이다.
-
- Focal Loss 이후, 1 stage detector 의 단점이었던 imbalance 를 해결해서 성능에서 향상을 가져왔다.
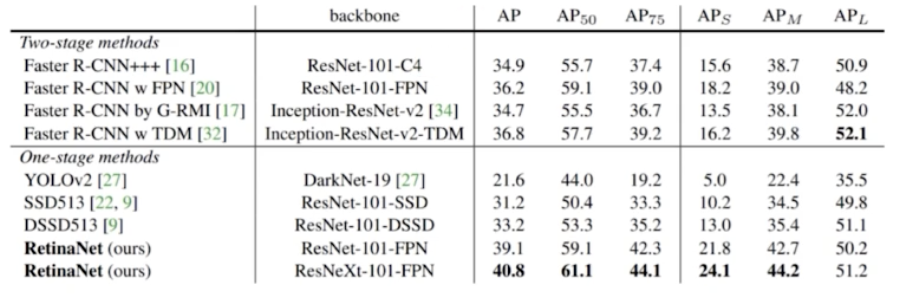
- 심지어 2stage 보다도 좋은 성능을 보이는 case 도 있다.
- 다시 정리하면, Focal Loss 는,
- Object Detection 에서 Background 와의 class imbalance 를 조정하고,
- Object Detection 뿐 아니라 아래와 같이 class imbalance 가 심한 Dataset 을 학습할 때 활용한다.
- Anchor develop, Anchor free model 의 방향으로 1 stage detector 가 발전하고 있다. 또한 multi scale feature map 을 더 잘 활용하기 위한 노력, Real time 을 위해 경량화를 위한 노력도 있다.
댓글 남기기