
[Object Detection] 4. Neck
-
Neck
💡 object detection 모델 구조에서 Neck 을 사용하는 이유 → Backbone의 다양한 layer 는 서로 다른 scale의 객체 탐지에 특화된 feature map을 만들어낸다. 기존의 detection 모델들에서는 최종 layer의 feature map만을 사용하였지만, Neck 구조는 다양한 scale의 객체들을 더 잘 탐지할 수 있게 하기 위해서 backbone의 여러 feature map들을 적절히 사용할 수 있도록 detection head 와 연결해주는 역할을 한다.
FPN (Feature Pyramid Network)은 다양한 feature map들의 채널을 동일하게 맞춰주는 단계 → channel을 맞춰준 feature map들을 top-down형식으로 적절히 섞어주는 단계 → 최종 3x3 convolution을 통과하여 RPN으로 입력될 feature를 만들어주는 단계 그 중 channel 을 맞춰준 feature map 들을 top-down 형식으로 적절히 섞어주는 단계는
laterals[i-1] += F.interpolate(laterals[i], size=prev_shape)상위 feature map인
laterals[i]를, 현재 feature map인laterals[i-1]의 size에 맞춰 upsampling(F.interpolate사용)한 후 섞어준다.DetectoRS의 주요 모듈 중의 하나로, neck의 정보를 다시 backbone에 입력하여 feature pyramid를 반복함으로써, backbone의 low level에서도 high level의 정보를 학습할 수 있도록 하는 모듈은 Recursive Feature Pyramid (RFP) 모듈이다. → DetectoRS는 backbone의 low level에서도 high level 정보를 입력받아 학습할 수 있도록 feature pyramid를 반복해서 학습하는 Recursive Feature Pyramid (RFP) 모듈을 제안했다. neck의 정보를 다시 backbone에 입력하여 반복 학습하여 정보를 더 다양하게 학습하지만, 반복하는만큼 flops가 증가하게 된다는 단점이 있다.
- Neck 이 왜 등장했는지, Neck 이 무엇이고 여러 연구들에서 어떻게 처리했는지 보자.
- Neck
-
overview
- FPN 앞에 yolo v1, SSD, yolov2 가 있지만, 여기에 Neck 의 개념이 등장하기 때문에 FPN 을 먼저 함.
- 2stage model 을 충분히 이해하고 있으면 FPN 을 이해하는데 어려움이 별로 없다.
-
2 stage model pipeline
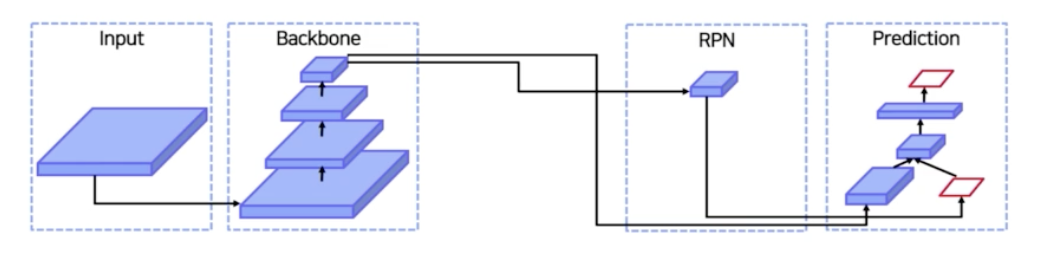
- input 이 backbone 을 통과한 후, backbone 의 가장 마지막 feature map 을 가지고 region proposal 을 한다. 즉 RPN 을 통해서 RoI 를 뽑아낸다.
- 그렇게 RPN의 RoI Projection 을 통해서 뽑힌 RoI 를 통해서 box head 와 cls head 를 통과시켜서 어떤 box 이고 실제적인 box 의 localization 을 수행한다.
- Neck 에서 중점을 둔 부분은, input 이 backbone 을 통과할 때 backbone 의 마지막 feature map 을 활용한다는 점. 왜 마지막 feature map 을 활용할까?
- 중간 중간에 생기는 feature map 을 사용하지 않고 마지막 feature map 을 사용해야 하는 이유가 있을까?
-
그래서
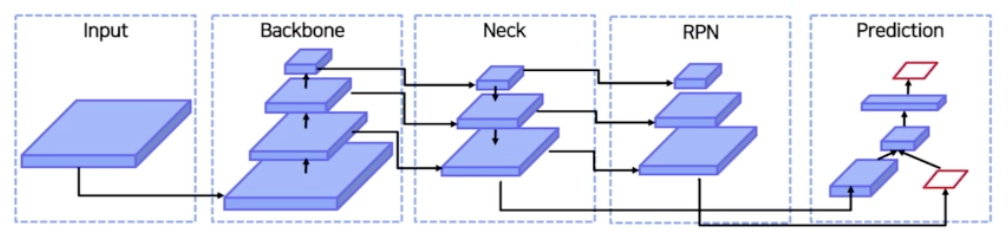
- backbone 중간에도 feature map 이 나오니까 굳이 마지막 feature map 만으로 RoI 를 뽑아내는 것이 아니라 중간 feature map 도 활용하자는 것. 어차피 모델을 통과하면서 나오는 feature map 이기 때문에.
-
그러면 Neck 이 왜 필요한가?

- 하나의 이미지에는 여러 크기의 객체들이 존재함.
- 만약 Neck 이 없다면 최종적으로 backbone 을 통과한 같은 크기의 feature map 에서 다양한 크기의 객체를 예측해내야 함.
- 그러나 만약에 여러 크기의 feature map 을 사용하게 된다면, 또 각각의 feature map 에서 다양한 이미지 크기를 대응할 수 있다면, RoI head 에서 보는 feature map 이 되게 풍부해지게 될 것이고, 다양하게 될 것이다.
- 따라서 일반적으로 알려진 사실이 작은 feature map 일수록 큰 범위를 보고, 큰 feature map 일수록 작은 범위를 본다고 알려져 있다.
- 즉 작은 feature map 의 경우 low level 에서 등장한 feature map이다. low level 에 등장한 feature map 의 경우 작은 객체를 볼 수가 있고, backbone 을 충분히 통과한 high level 의 feature map 같은 경우는 큰 객체를 볼 수 있다고 알려져 있다.
- 왜냐하면 low level 의 feature map 정보는 일반적으로 object 또는 이미지의 fine 한(미세한) 정보들을 포착함. 선이나 점, 기울기 등을 많이 포착한다는 것.
- 반면 high level, backbone 을 충분히 통과한 feature map 의 경우는 객체의 semantic 정보를 잘 표현할 수 있다고 한다. 그래서 일반적으로 큰 객체를 많이 표현할 수 있는 편이다.
- 따라서 최종 level 의 feature map 만 사용하게 되면 작은 객체를 포착할 수 없게 된다.
- 이를 해결하기 위해서 다양한 크기의 feature map 을 활용하자는 아이디어가 등장했다.

- 위 그림은 high level 의 feature map 에서 포착할 수 있는 객체의 정보이다.
- 대부분 큰 객체를 포착할 수 있음. 작은 객체를 포착하기에는 high level 의 feature map 만으로는 힘들다.

- 이게 중간정도 level 의 feature map 이 볼 수 있는 범위.

- 이게 가장 low level 의 feature map 이 볼 수 있는 객체의 범위다.
- 그래서 Neck 이 왜 필요하냐면,
- 다양한 크기의 객체를 더 잘 탐지하기 위해서이다.
- 일반적으로 object detection 의 난제는 큰 객체는 어느정도 잘 잡는데, 작은 객체는 못 잡는 것이 object detection 의 문제였다. 이 문제가 최근까지도 계속 이어지고 있다.
- 작은 객체를 어떻게 잘 잡을 것인가. 이것이 object detection 에서 중요한 부분인 것. 이에 따라 작은 객체도 잘 잡기 위해서 Neck 이라는 새로운 존재가 나타나게 된 것.
-
전체적으로 보면
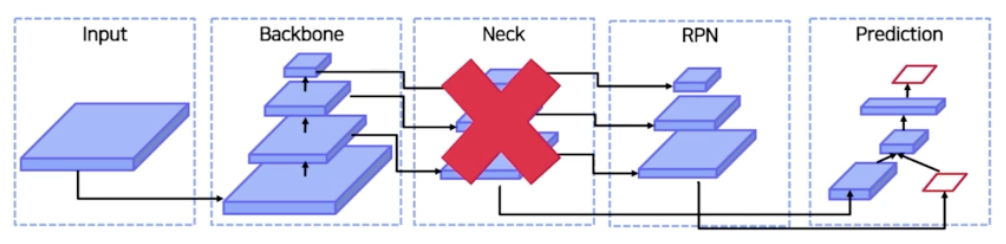
- Neck 을 따로 두지 않고 backbone 을 통과하면 중간 level 부터 high level feature map 이 나오게 되는데, Neck 이라는 feature map 을 섞어주는 과정 없이 high level feature map 에서도 그냥 region 을 뽑고 low level feature map 에서도 region 을 뽑으면 되지 않을까?
- 사실 그렇게 생각할 수도 있지만, 그런 것보다 feature map 을 섞어주는 것이 훨씬 좋다. 왜냐하면 low level 에는 high level 정보들이 많이 부족하고, 즉 semantic 정보들이 어느정도 부족하다. 그리고 high level 에서는 semantic 정보가 풍부한 반면 low level 의 localization 정보가 많이 부족한 편이다.
- 따라서 high level 에는 low level 의 localization 정보를 올려주고 high level 의 semantic 정보를 low level 로 낮춰 줌으로써 feature 를 서로 풍부하게 만들어주는 효과가 있는 것이 바로 Neck 이다.
- 따라서 Neck 이 또 필요한 이유는, 하위 level 의 feature 는 semantic 이 약하므로 상대적으로 semantic 이 강한 상위 feature(high-level) 와의 교환이 필요하기 때문이다.
-
Feature Pyramid Network(FPN)
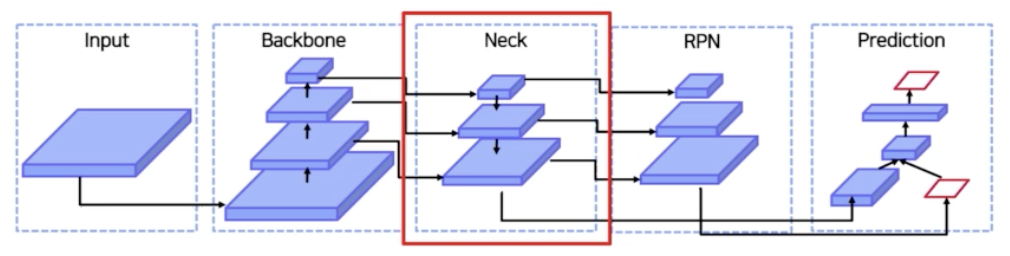
- 원래대로라면 input 이 backbone 을 통과해서 마지막 feature map 을 활용해서 RPN 이나 prediction 을 진행했다면,
- FPN 의 도입으로 input 이 backbone 의 low level 부터 high level 의 모든 feature map 들을 가지고 feature map 들을 적절하게 섞어준 다음에 그 섞인 feature map 으로 부터 region 을 뽑아내고 prediction 을 진행하는 것.
- 그렇게 함으로써 작은 객체를 훨씬 더 잘 잡을 수 있게 됐다.
-
Neck 최초의 페이퍼인 Feature Pyramid Network, FPN 에 대해서 보자.

- FPN 이전에 사람들이 작은 객체를 더 잘 잡기 위해 low level feature 를 어떻게 활용하려고 했는지 보자.
- image pyramid 를 쌓아서 그로부터 feature 를 추출하는 방법이 있다.
- 오른쪽 그림 같이, 이미지를 점점 크기를 작게 resize 를 하고, 큰 이미지로부터 feature 뽑고 작은 이미지로 feature 뽑는 방식. 이런 식으로 이미지 자체의 사이즈를 조절하는 경우가 있었다.

- 그 외에는 Faster RCNN 비슷하게, 한 이미지가 있으면 이미지의 마지막 feature map 으로 부터 prediction 을 하는 방법이 있었음.

- 마지막 feature map 말고 중간중간 마다 나오는 feature map 을 그대로 활용하자는 아이디어도 있었다. 이게 SSD 라는 모델에서 사용한 아이디어다.
- 이 과정은 high level 의 feature map 이 low level 의 feature map 에 섞이지가 않는다. 그래서 semantic 이 골고루 섞이지 않는 한계점이 존재한다.
-
따라서 FPN 에서는 top-down path way 를 추가한다.
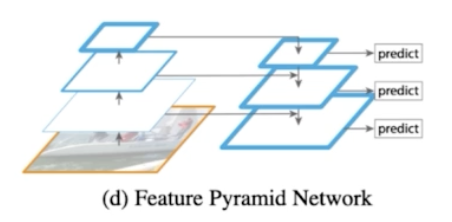
- high level 에서 low level 로 semantic 정보를 전달해주기 위해서 다음과 같이 중간 feature map 을 그대로 활용하는 것이 아니라 high level 의 feature map 의 정보를 low level 에 전달해주고 중간 level 의 feature map 의 정보를 다시 low level 에 전달해주는 식.
- 이런 식으로 위에서부터 아래로 정보를 전달해주는 top-down path way 를 추가해준 것.
- Pyramid 구조를 통해서 위에 있는 정보를 아래에 전달해주게 되는 것.
- 용어를 정리해보면,
- Low level = Early Stage = Bottom = 하위
- High level = Late Stage = Top = 상위
-
Bottom-up
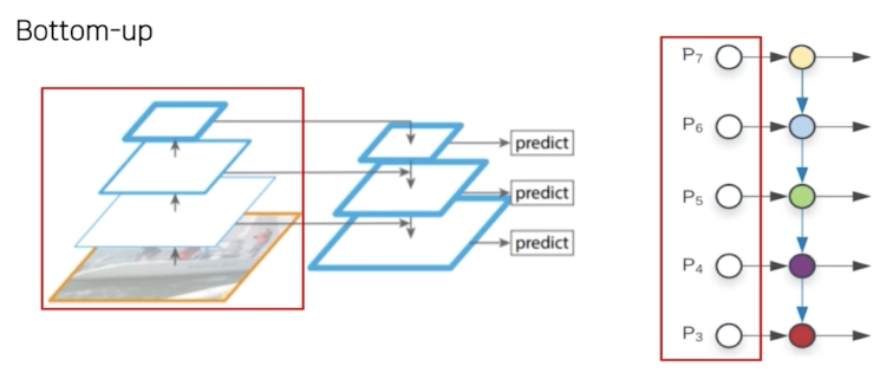
- Low level 에서 high level 로 feature 가 전달되는 과정.
- 일반적인 CNN backbone network 를 통과하는 것과 같다.
-
Top-down
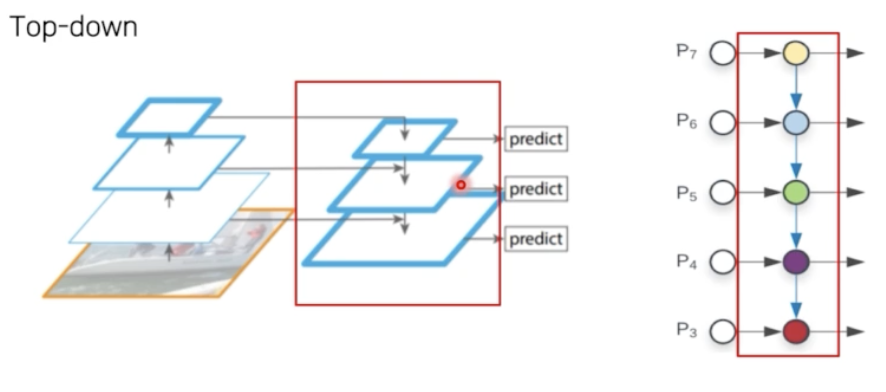
- high level feature 정보를 low level 의 feature 에 전달하는 과정.
- high level feature 를 어떻게 low level 로 전달할 수 있을까?
-
Lateral connections
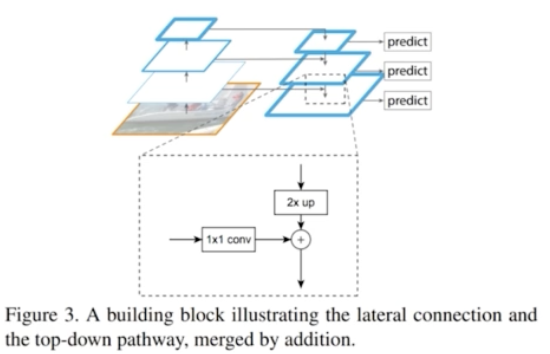
- bottom-up 과정에서 나오는 feature map 과 top-down path 의 과정에서 위에서 등장하는 feature 가 있다.
- 이 두 feature 를 어떻게 섞어줄 수 있을까?
- top-down path way 에는 Up conv 을 진행. bottom-up path way 에 있는 feature map 의 경우는 1x1 conv 을 진행해줌.
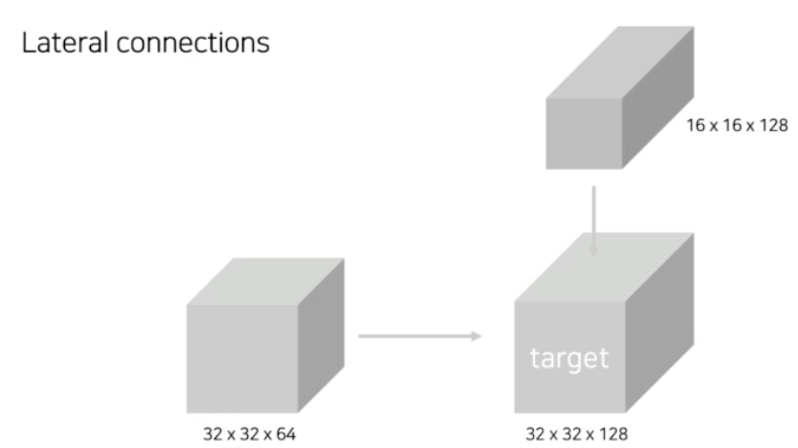
- 왼쪽에 있는 feature map 이 bottom up 과정에서 나온 feature map(32x32x64) 이다.
- 위에 있는 feature map 이 top-down 과정에서 나온 feature map(16x16x128) 이다.
- 이 두 feature map 을 같이 섞어줘야 함. 두 개의 shape 을 보면, bottom up 과정의 feature map 은 채널이 부족하고, top down 과정의 feature map 은 spatial dimension 이 부족함(width, height)
- bottom up 과정에서 나온 feature map 은 1x1 conv 를 수행해서 width 와 height 는 그대로 유지하면서 채널의 수를 맞춰줄 수 있다.
- top down 과정에서 나온 feature map 은 16x16 feature map 을 Upsampling 을 진행해서 32x32 로 맞춰주는 것.
- 그렇게 되면, 두 feature map 의 shape 이 맞게 되니까 단순하게 element wise 하게 더해질 수 있다.
-
Nearest Neighbor Upsampling
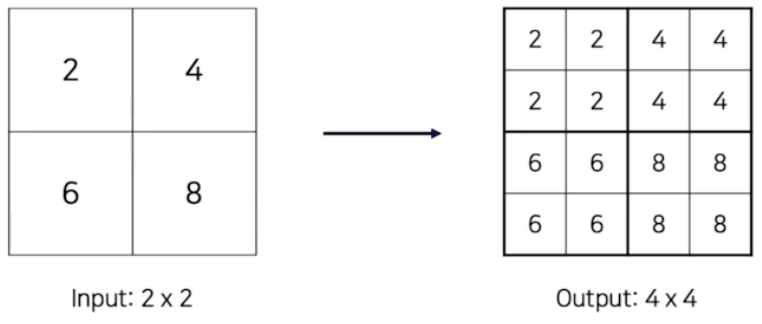
- upsampling 의 한 예시인 nearest neighbor upsampling
- 2x2 → 4x4 일 때, 단순하게 크기를 늘려줄 수 있다.
- FPN 에서는 Nearest Neighbor Upsampling 을 사용했다.
-
전반적인 FPN 의 Pipeline 을 살펴보자.
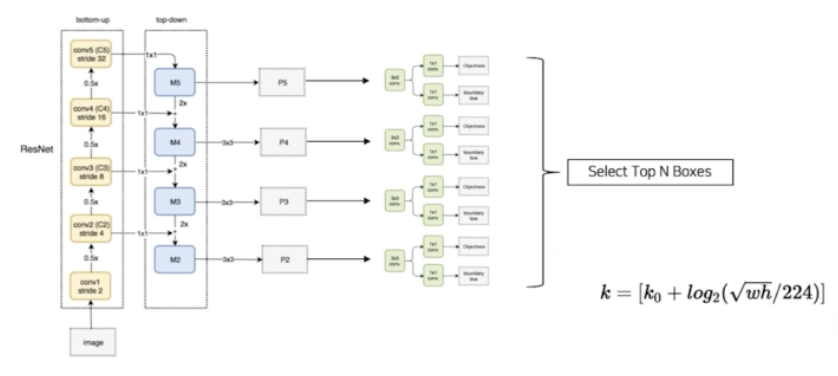
- Backbone 으로는 ResNet 을 썼다. ResNet 의 경우 크게 stage 가 4가지가 존재함.
- conv2, conv3, conv4, conv5 stage 가 존재함. 한 stage 안에서는 residual block 연산이 여러번 이루어짐. output size 가 각 stage 안에서는 동일하다.
- max pooling 과정에서 width, height 가 줄어들 때 stage 를 구분한 것.
- 그래서 이미지가 존재할 때, 이미지를 ResNet 을 통과시킬 때 각각 이미지 사이즈가 줄어드는 4개의 stage 가 있었는데, 각 4개의 stage 를 기준으로 해서 각 stage 마다 feature 들을 뽑아낸다.
- 이렇게 뽑힌 feature 가 bottom-up path 과정에서 나온 feature 들인 것이다.
- 그 4개의 feature map 을 대상으로 top down path way 로 Lateral connection 과정으로 섞어준다.
- 이렇게 lateral connection 을 해서 최종적으로 P5, P4, P3, P2 가 나오게 된다. 이 각 feature map 에 RPN 을 통과시키면 최종적으로 RoI 가 여러개 나온다.
- 그 전체 RoI 에 NMS 를 적용해서 Top N 개의 RoI 를 Select 하게 된다. 최종 RoI 를 1000개를 뽑는다.
- Faster RCNN 의 경우 single stage 라서 RoI 가 어느 stage 에서 나왔는지 자명하다. 즉 RoI 가 나온 feature map 이 무엇인지 알 수 있다.
- 그러나 FPN 의 경우 input stage 가 4개가 있음. 그래서 RoI 를 select 를 하면 P5, P4, P3, P2 어디서 왔는지 모른다. 따라서 RoI 를 어느 stage 에서 왔는지 stage mapping 과정이 필요하다.
- 그 때 $k = [k_0 + log_2(\sqrt{wh}/224)]$ 로 mapping 하게 된다. $k_0$ 는 기본적으로 숫자 4. 즉 4번째 stage 가 기본이 된다는 것.
- 따라서 4번째 stage 로부터 연산을 통해서 최종 stage 를 계산을 하게 됨. feature map 의 크기가 작으면 작을수록 low level 의 feature map 으로부터 RoI projection 을 진행하겠다는 것.
- 즉 최종 1000개의 RoI 를 Projection 을 진행하기 위해서 Projection 대상이 되는 feature map 이 필요한데, 이 대상이되는 feature map 을 선택하는 방법이 위 식으로 선택하는 것. RoI 의 w 와 h 가 작으면 작을수록 k 의 값은 작아지게 됨. 반면에 RoI 의 w 와 h 가 크면 클수록 k 값이 커지게 된다. 그래서 상위 stage 의 feature map 에서 RoI projection 을 진행하게 된다.
- FPN 의 Contribution
- 여러 scale 의 물체를 탐지하기 위해 설계되었다.
- 이를 달성하기 위해서는 backbone 의 여러 크기의 feature 를 사용해야 할 필요가 있음.
- 특히 그냥 활용하는 것이 아니라 high level 의 feature 를 low level 의 feature 에 섞어주는 것이 필요했음.
- 정리하면
- backbone 이라는 bottom up 과정에서 다양한 크기의 feature map 을 추출하고, 다양한 크기의 feature map 의 semantic 을 교환하기 위해서 top-down path way 를 추가했다는 것.

- 성능을 보면 FPN 을 사용한 case 가 Average Recall(box 에 대한 metric) 값이 훨씬 좋아지게 되었다. 즉, 더 많이 더 잘 찾는 것.
- 특히 small box 에서 성능 변화가 드라마틱하고, large box 는 성능 변화가 미미하다. 이렇게 보면, 작은 객체를 잘 잡을 수 있게 되었다는 것.
- Code
- bottom up 과 top down 의 feature 를 섞어주는 lateral connection 이 필요하다.
-
Build laterals: 각 feature map 마다 다른 채널을 맞춰주는 단계

-
Build Top down: 채널을 맞춰 준 후 top down 형식으로 feature map 교환

- 아래 단계는 윗단계의 feature map 을 더해주는 것
-
Build Output: 최종적으로 두 feature 를 element wise 하게 더해줘서 RPN 에 들어갈 feature 를 완성하게 되는 것.

-
Path Aggregation Network(PANet)
- Problem in FPN
- FPN 의 큰 단점을 해결한 연구가 PANet
- FPN 은 backbone 을 통과하는 bottom up 이후에 top feature 를 bottom feature 에 더해주는 top down path way 를 응용해서 semantic 을 섞어 줬음.
- 그러나 bottom up 과정에서 문제점이 있다. 각 feature 간에 정보 전달 path 가 짧아보이지만, backbone 으로 활용하는 것이 ResNet 이다. ResNet 을 보면 network 가 매우 길다. 따라서 bottom up 과정에서 low level 의 feature 가 제대로 high level 의 feature 로 전달될 수 있냐는 문제점이 제기될 수 있음.
- ResNet 안에서 많은 conv 연산과 pooling 연산이 존재해서 low level 의 feature map 이 high level 의 feature map 에 제대로 전달될 수 없다는 것.
-
PANet
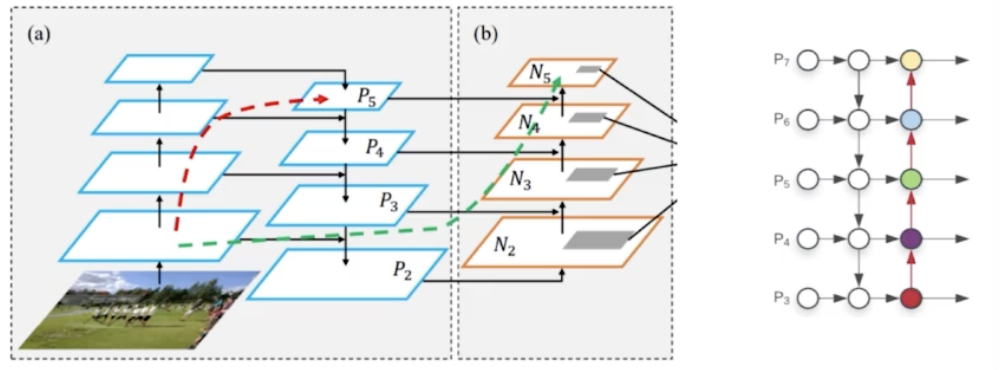
- 그래서 PANet 이 문제를 해결했다.
- FPN 에서 top down path way 를 추가해줬는데, FPN 과 동일하게 bottom up path way 를 하나 더 추가했다.
- 처음 bottom up 하고 top down 해서 나온 4개의 feature map 을 대상으로 다시 한 번 bottom up 해준 것이다. 즉, low level 의 feature 를 다시 high level feature 로 정보를 전달해준 것이다.
- 이렇게 새롭게 path 를 만들어주면 deep 했던 information flow 가 간단해지게 된다. 즉 맨 처음 backbone ResNet 은 많은 conv 와 pooling 이 있지만 새로운 bottom up path 는 4개의 stage 만 통과하면 된다.
- 이로써 low level 에 대한 정보가 high level 에 정확하게 전달이 될 수 있다.
-
Adaptive Feature Pooling
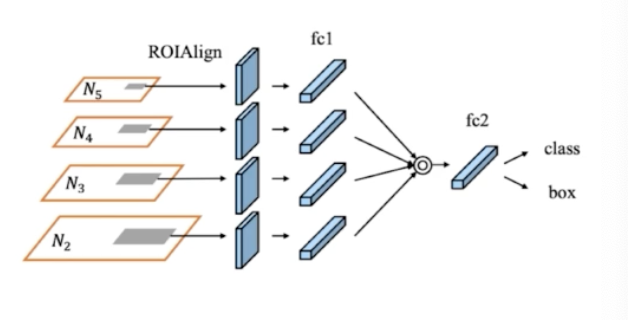
- FPN 처럼 각 stage 의 feature map 을 RPN 에 입력해서 RoI 를 뽑아내게 되는데, PANet 은 instance seg 를 target 으로 하기 때문에 RoIAlign 이라고 표기되어 있는 것이고, object detection 에서는 RoI Pooling 이라고 이해하면 된다.
- top down, bottom up 이후 최종적으로 feature map 이 나오면, 이 feature map 으로부터 RPN 을 통과해서 RoI 를 뽑아내게 된다.
- 각 RoI 에 대해서 이 RoI 가 몇 번째 stage 의 RoI 인지 $k = [k_0 + log_2(\sqrt{wh}/224)]$ 이 공식으로 알아낼 수 있었다.
- 그러나 위 공식은 경계에 있는 RoI 들에 대해서는 제대로 대응할 수 없다. 예를 들어 RoI 가 10픽셀의 차이가 발생을 해도 어떤 것은 stage 가 4, 어떤 것은 3로 간다.
- RoI 픽셀의 차이가 얼마 나지 않지만 Projection 을 하는 대상이 달라지게 된다는 것. RoI 는 별 차이가 없는데 Projection 을 하는 feature map 에 큰 차이가 발생하게 되는 것이다.
- low level feature map 은 물체의 localization 정보를 많이 포함하고(fine information), high level feature map 은 semantic 한 정보를 많이 포함한다. projection 단계에서 특정 stage 의 feature map 만 가지고 projection 하는 것이 많은 정보를 활용할 수 없다고 제안하는 것.
- 따라서 RoI 를 공식에 의해서 하나의 feature map 을 정해서 거기서 Projection 하는 것이 아니라 모든 feature map 으로부터 RoI Projection 을 하고 그 이후 RoI Pooling 을 해서 fc layer 를 만들고, 이 layer 를 channel-wise 하게 max pooling 을 해서 최종적으로 fc2 를 만들어내자는 것.
- 그것이 바로 adaptive feature pooling 의 아이디어 이다.
- 정리하면, FPN 에서는 각 RoI 의 stage(Projection 대상) 를 하나만 정해서 사용했는데(식에 의해서), 그러기엔 나머지 stage 를 버리는 것이 아까우니, 나머지 stage 에서도 다 뽑아내자는 것이 adaptive feature pooling 이다.
- Problem in FPN
-
- After FPN
- FPN 과 PANet 이후 Neck 에 대한 연구가 활발히 이루어짐. 그 중 굵직한 연구를 뽑아 보자.
- DectectoRS
- 2020 년 6월 아카이브에 소개되어 있다. 2021 년 CVPR 에 accept 되었다. 성능이 꽤 좋은 편이다.
- motivation
- Looking and thinking twice
- RPN 에서 영감을 받았다. 모델이 바로 객체를 뽑아내는 것이 아니라 객체가 있을 법한 위치를 한 번 생각을 하고 거기서부터 cls 와 box 를 뽑아내는, 두번 생각했다고 해서 영감을 얻었다.
- Cascade 도 RoI pooling 을 여러번 한다. 그 과정에서 반복적으로 하는 것이 좋은 성능이 나오는지 고민해봤다고 한다.
- 크게 2가지 모듈을 제안했다.
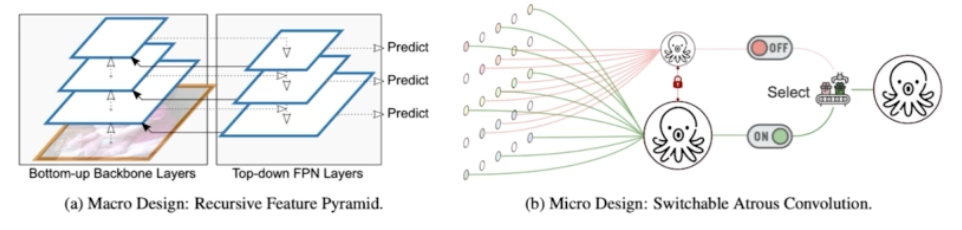
-
Recursive Feature Pyramid(RFP)
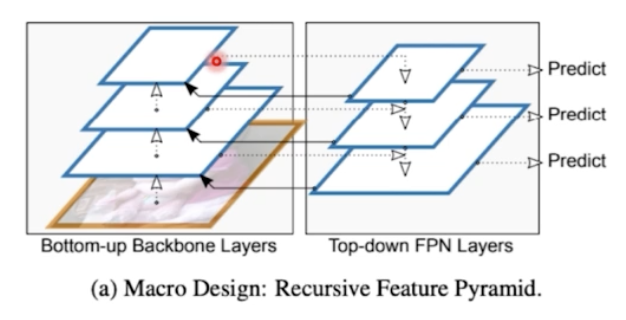
- Neck 과 관련된 부분.
- FPN 을 말그대로 recursive 하게 진행한다.
- backbone 에서부터 bottom up 하고 top down 하는 것은 FPN 과 동일하다. 여기에 하나의 새로운 화살표가 추가되었다.
- FPN 으로부터 다시 backbone 으로 화살표가 넘어간다.
- feature pyramid 를 반복하는데, Neck 만 반복하는 것이 아니라 Neck 정보를 다시 backbone 에 전달을 해서 backbone 도 Neck 정보를 이용해서 다시 한번 학습을 하게끔 의도했다.
- 이렇게 되면 low level feature 가 top level feature 를 어느정도 이해할 수 있다. top down path 로 high level 정보가 low level 에 흘러들어왔기 때문에, 그 Neck 의 low level feature 를 low level backbone 에 넘겨주게 되면 high level 정보가 전달될 수 있다.
- 그러나 보면 backbone 연산을 n 번 반복하기 때문에 Flops 가 엄청 증가하게 되는 단점이 있다. 그래서 학습 속도가 많이 느리다.
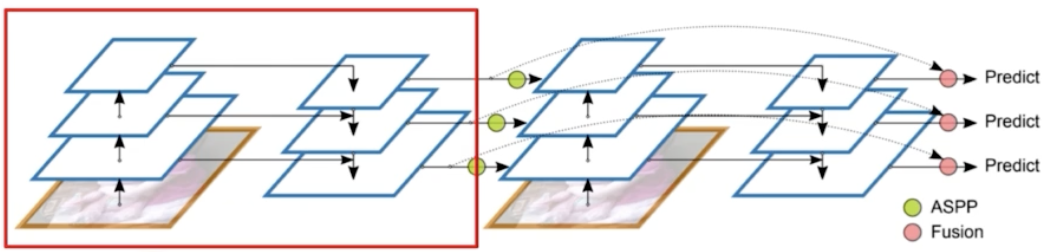
- 앞의 두 과정은 FPN 과 동일하다. FPN 결과인 Neck 을 다시 backbone 에 전달한다. 다시 backbone 을 학습 후에 한 번 더 FPN 을 진행하게 되는 것. 위 그림이 하나의 stage 가 된다.
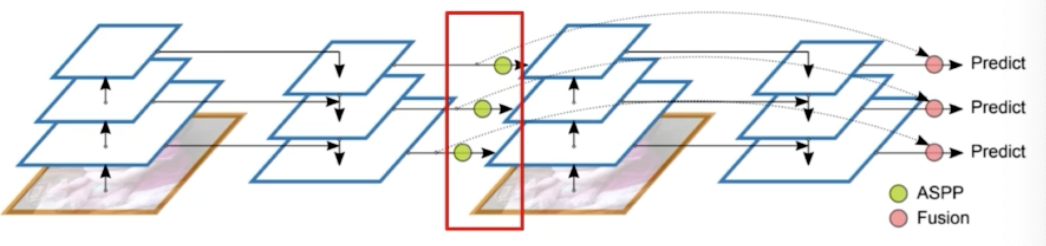
- FPN 결과가 ASPP 라는 연산을 통해서 다시 한번 backbone 에 concat 된다.
- 즉 backbone 의 stage 2 는 backbone 의 stage 1 과 FPN 의 stage 2의 결합으로 이루어진다.
- FPN 의 정보를 backbone 에 넘겨줄 때 단순히 넘겨주는 것이 아니라 ASPP 과정이 포함된다.
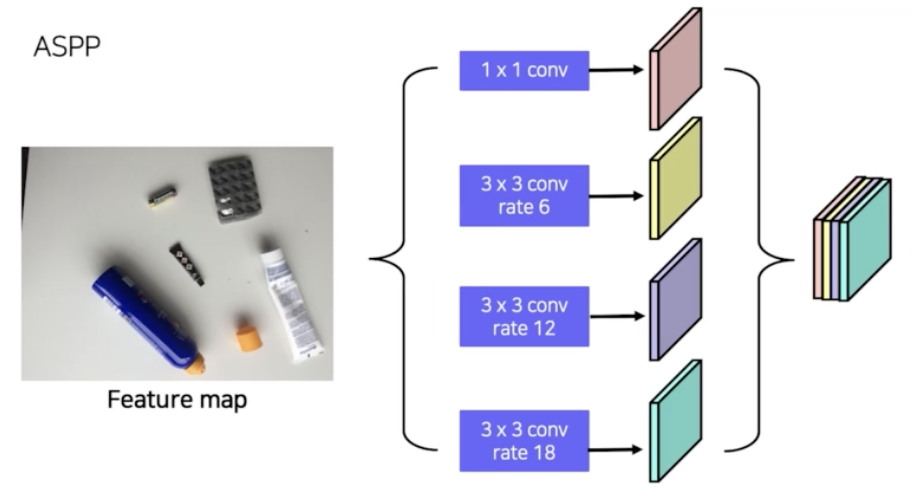
- ASPP
- semantic seg 에서 더 학습하게 될 개념
- Atrous Conv, Dilation Conv 는 Receptive Field 를 늘릴 수 있는 방법이다.
-
Atrous Convolution
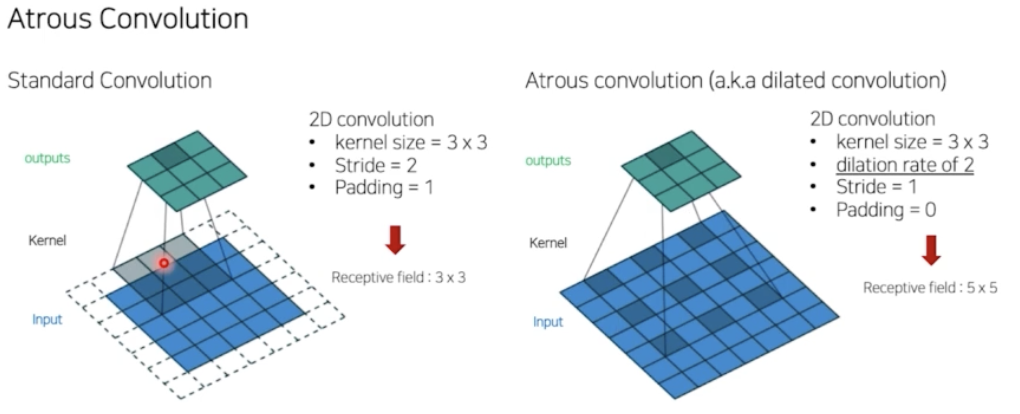
- input 이 있고 conv filter 가 있을 때, filter 를 통과하면서 output 결과를 얻어낸다. conv filter 가 원래 연속적이지만, 오른쪽 그림처럼 한칸씩 띄워서 통과시킬 수가 있다.
- 그렇게 되면 기존보다 Receptive field 가 kernel size 는 그대로지만, 3x3 에서 5x5 로 커지는 효과가 있다.
- 이런 식으로 Receptive field 를 키우는 연산을 Atrous conv 또는 dilation conv 라고 부른다.
- ASPP 는 하나의 feature map 에서 pooling 을 진행하는데, atrous conv 의 dilation late 를 6, 12, 18 이런 식으로 줘서 receptive field 를 점점 키워나가면서 pooling 을 진행한다.
- 그렇게 pooling 된 feature map 을 concat 을 해서 사용을 하는 것이 atrous feature pooling 이라고 보면 된다.
- ASPP 를 하는 이유는 결국 Receptive Field 를 키워주고 싶기 때문에 진행하는 것.
- ASPP 된 FPN 의 정보가 backbone 에 추가되는 식으로 학습이 되는 것이 RFP 이다.
- Flops 가 굉장히 높다. backbone network 가 n 번 반복되기 때문이다. 그래서 학습시간이 오래 걸린다. 그러나 high level feature map 의 정보가 low level 에 전달되는 효과가 있고, backbone 자체도 feature map 의 정보를 풍부하게 표현할 수 있기 때문에 성능이 좋다.
- Bi-directional Feature Pyramid(BiFPN)
- EfficientDet 에서 제안된 내용.
- Neck 부분만 보자.
- 효율성을 위해서 기존의 PANet 을 아래 그림과 같이 바꾼다.
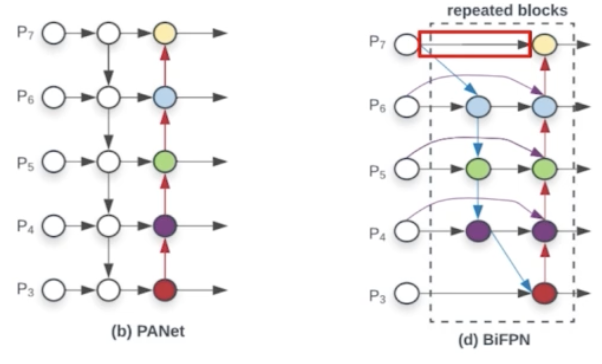
- BiFPN 을 보면 없앤 노드가 있다.
- 효율성을 위해서 feature map 이 한 곳에서만 오는 노드들을 다 제거했다.
- 그렇게 하면 파라미터와 flops 를 줄일 수 있다. 그래서 BiFPN 구조를 반복적으로 쌓을 수 있다고 한다.
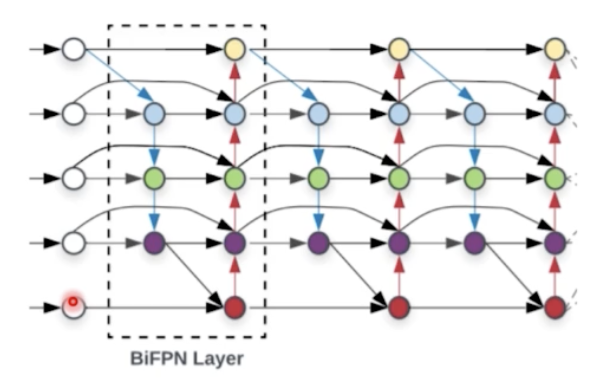
- PANet 에서 없앨 노드들을 없애고 간단한 구조의 PANet 을 만들어낸 것.
- BiFPN 에서 또 하나 채택한 방법은, bottom up path 의 feature map 과 top down path 의 feature map 두 개를 lateral connection 을 해서 하나는 채널을 늘리고, 하나는 upsampling 해서 두 feature map 을 더해주게 되는데, 이 과정에서 왜 그냥 더하는지 문제를 제기했다.
- 단순합에 문제점을 제기한 것. 각 feature map 별로 담고 있는 정보가 다 다르다. 모델의 정보 교환상 semantic 정보가 제대로 섞일 수가 없다는 것이다. 이에 weighted feature fusion 이라는 새로운 메서드를 제안했다.
- feature 를 단순하게 더하지 말고, feature 별로 앞에 가중치를 둬서 가중합을 하는 것이다.
-
Weighted Feature Fusion
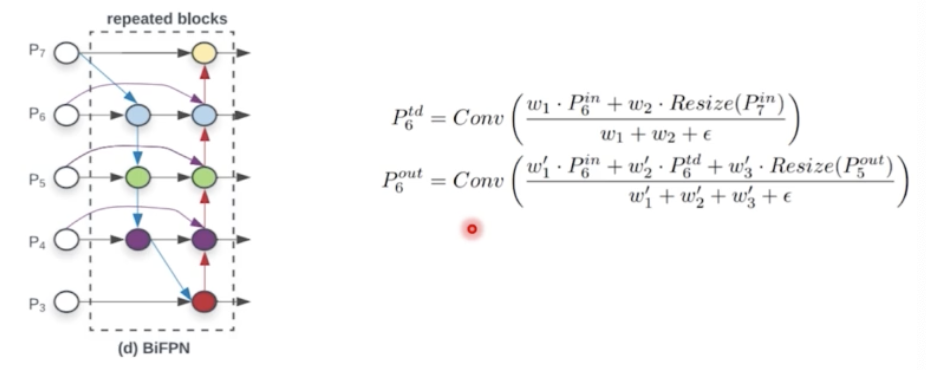
- 단순합이 아닌 weight 를 붙혀서 가중합을 하고 weight 의 summation 으로 normalization 을 한다!
- $P^{td}$ 는 top down path way 에서 나온 feature map
- $P^{out}$ 은 bottom up path way 에서 나온 최종 feature map
- $P^{out}$ 을 보면 top down 의 feature map 과 bottom up 의 feature map 뿐 아니라, residual 처럼 $P^{in}$ 도 더해준다. 따라서 3개의 정보가 weighted sum 이 된다.
- 실제적으로 weight 자체도 학습 가능한 파라미터로 둬서, 어떤 layer 의 weight 를 얼마나 중요하게 반영하느냐를 학습하게끔 의도했다.
- NASFPN
- 그 동안 FPN 의 구조를 사람이 휴리스틱하게 만들어줬고 단순 일방향을 많이 사용했다.
- 그러면 FPN 의 구조에 따라서, 정보가 top down → bottom up 말고 다른 방법 등 다양한 구조가 있을 텐데 이 다양한 구조를 효율적으로 찾아보면 어떨까?
- NAS(Neural Architecture Search) 를 통해서 FPN 아키텍처를 찾아보자! 해서 만든 것이 NASFPN 이다.
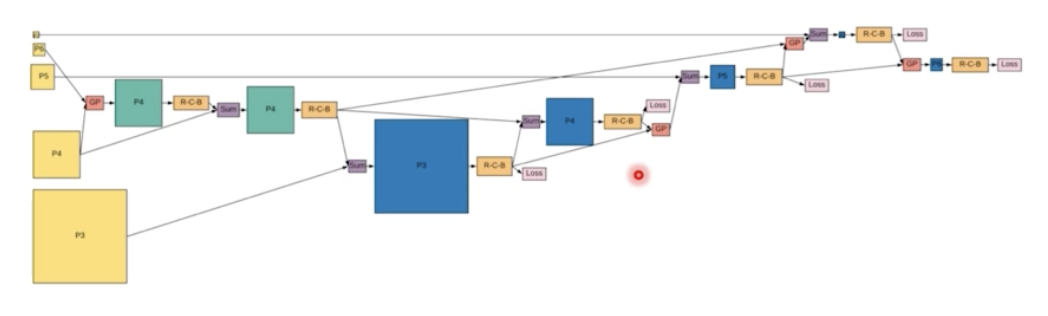
- 기본적인 cell 들을 정의를 하고 강화학습, 유전학습 등을 통해서 가장 좋은 성능을 낼 수 있는 FPN 모듈들을 찾는다. 자세한 내용은 paper 를 보자.
- NAS 를 써서 기본적인 FPN 모듈로부터 AP 를 올려가는 형태로 FPN 구조를 develop 시키는 것.
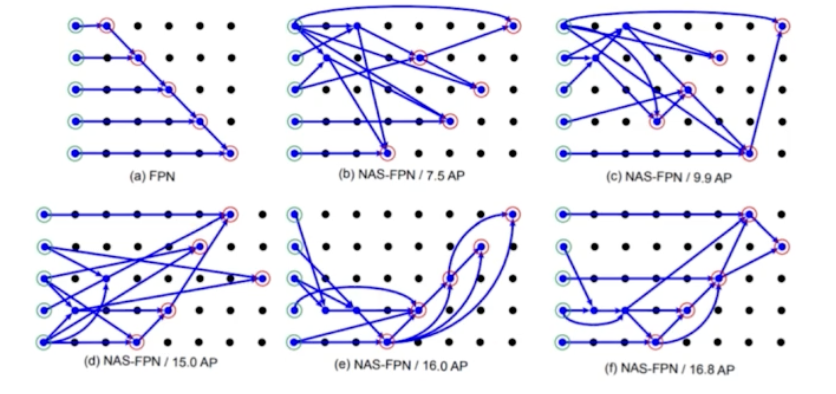
-
그렇게 해서 찾으면,
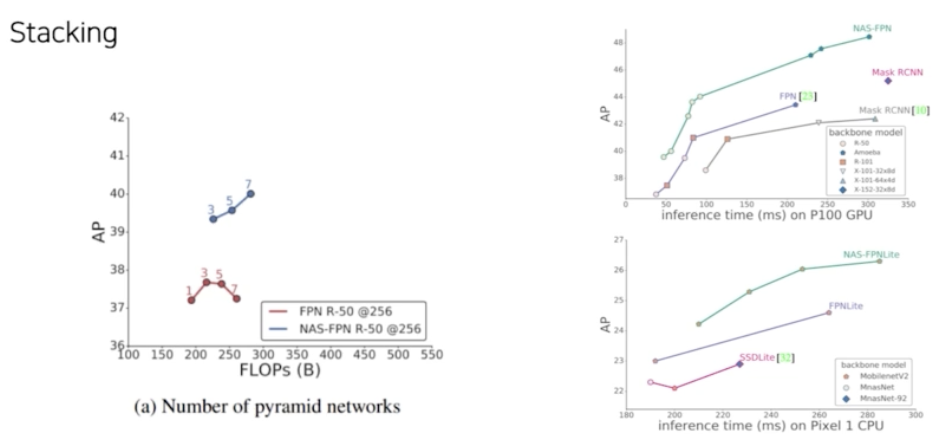
- 일반적인 FPN 보다 동일한 FLOPs 에서 좋은 성능을 보인다.
- 결론은 그냥 FPN 구조보다 NAS 형태로 FPN 구조를 찾으면 좋다는 것이다.
- 단점으로는 NASFPN 은 COCO dataset 이랑 ResNet 기준으로 찾았기 때문에 범용적이지 못하다. 그 아키텍처에만 성능이 좋은 FPN 이 되는 것이다.
- 데이터셋이나 backbone 이 바뀌면 새롭게 NAS 를 돌려서 맞는 구조를 찾아줘야 한다.
- 따라서 search cost 가 높은 편이다.
-
AugFPN
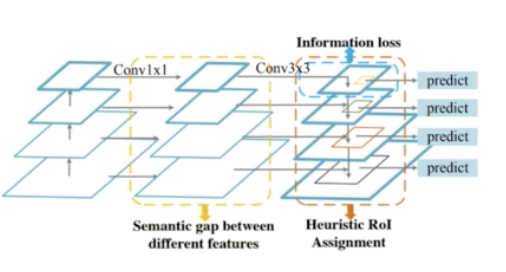
- FPN 에 존재하는 문제점을 크게 3가지로 봤다.
- 서로 다른 level 의 feature 간의 semantic 차이가 존재한다.
- highest feature map 의 정보 손실이 있다. low level 로 feature 를 전달해주기 위해서 채널을 줄여버리는 conv 연산을 수행했기 때문이다. 즉 highest feature map 은 더 위에 있는 feature map 이 없기 때문에 down 으로 정보 전달이 없다. 즉 정보 손실이 생길 수 밖에 없다.
- 기존 FPN 에서 1개의 feature map 에서 RoI 를 생성했다. PANet 에서는 이 문제를 어느정도 해결했다. 하나의 feature map 이 아니라 모든 stage 의 feature map 을 다 활용했었다.
-
각 문제점을 해결하기 위해서 3가지를 고안했다.
- Consistent Supervision
- Residual Feature Augmentation
- Soft RoI Selection
- 이 중에서 Neck 과 관련된 부붕는 Residual Feature Augmentation 과 Soft RoI Selection 이다.
-
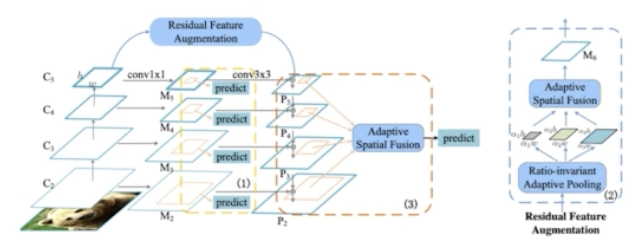
Residual Feature Augmentation
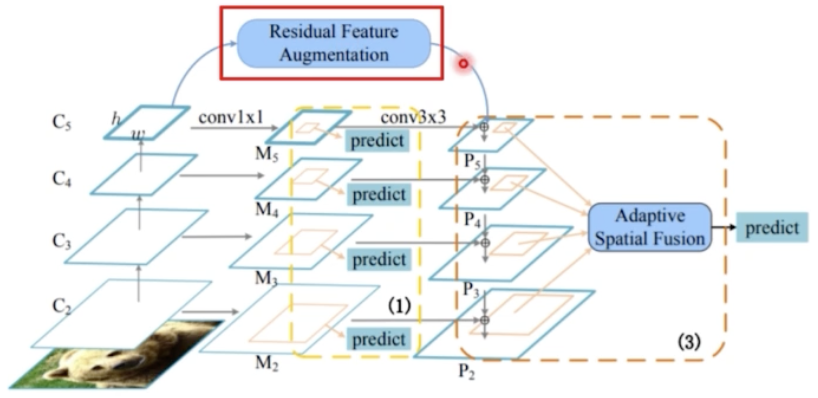
- FPN 에서 low level feature map 은 high level stage 의 semantic 정보가 내려오면서 추가된다.
- 마지막 stage 를 보면, P5 를 보면, 1x1 conv 과 3x3 conv 만 수행하기 때문에 기존 채널이 줄어드는 information 손실이 발생한다. 따라서 마지막 stage 에 더 높은 high level 정보를 보완해주는 것이 필요하다.
- 이를 Residual feature augmentation 을 통해서 feature 의 semantic 을 보강해줄 수 있다.
- 즉 Residual feature 는 C5 로부터 새롭게 M6 를 만들어주게 되는 것.
- M6 로부터 top down 정보가 P5 에 추가되도록 하는 것.
-
M6 feature 를 어떻게 만들까?
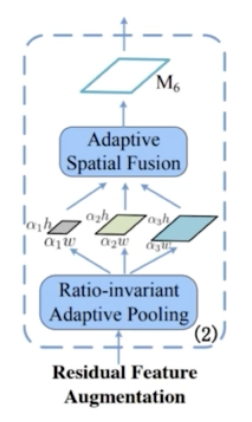
- C5 feature 를 기준으로 만들어진다.
- C5 feature 가 있을 때 이를 Ratio-invariant Adaptive Pooling 을 통해서 다양한 scale 의 feature map 으로 만들어준다.
- Adaptive Pooling 은 pooling stride 등을 통해서 target feature map 의 size 를 pyramid 형태로 작은 것부터 큰 것까지 다양한 크기로 만들어준다.
- 그 다음으로 이렇게 만들어진 다양한 크기의 feature map 을 fusion 해준다. 그 과정에서 Adaptive Spatial Fusion 을 활용해준다.
- 채널은 256 으로 맞춰준다.
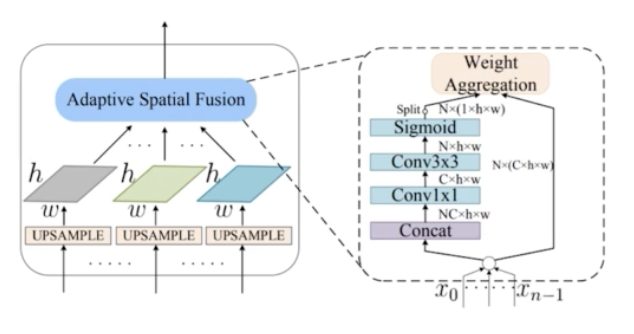
- Spatial Fusion 의 과정이 AugFPN 에서 transformer 처럼 중요도를 스스로 학습하는 과정이다.
- 다양한 scale 로 pooling 을 진행했다면, M6 로 만들어주기 위해서 size 를 동일한 size 로 만들어줘야 한다.
- Upsampling 을 통해서 동일한 size 로 만들어준다. 이미 채널은 Ratio-invariant Adaptive Pooling 을 통해서 256 채널로 맞춰줬기 때문에 채널은 256 이다.
- 3개의 feature map 을 단순하게 summation 해주면, C5 를 활용하는 거랑 크게 다를 게 없다. 이 feature map 들을 적절하게 fusion 해주어야 한다.
- 동일한 size 로 Upsampling 후에, N 개의 feature 에 대해 가중치를 두고 summation 을 해준다.
- 먼저 각 feature map 을 concat 을 한다. concat 을 하면 NC x h x w 가 된다. 위 그림에서 N 은 3이다.
- 이를 1x1 conv 연산을 수행해서 C x h x w 로 만들어준다.
- 이후 또 3x3 conv 연산으로 N x h x w 로 만들어준다.
- 이후 Sigmoid 연산을 channel-wise 로 실행해주면, N x (1 x h x w) 가 된다. 이는 각 픽셀별로 N 개의 value 가 나타나게 된다.
- 이는 각 픽셀의 중요도를 나타낸다. Sigmoid 라서 0~1 이기 때문에 각 픽셀을 어느정도 수준으로 반영할 지를 정할 수 있다. 즉, N x (1 x h x w) 는 각 픽셀에 대한 spatial weight 를 나타내는 것.
- 이렇게 하나의 weight 를 만들어주고, 원래의 feature map 을 가중합을 해준다.
- 그렇게 되면 위 그림에서 3개의 feature map 을 그냥 더하는 것이 아니라 가중합을 하게 되는 것이다.
-
Soft RoI Selection
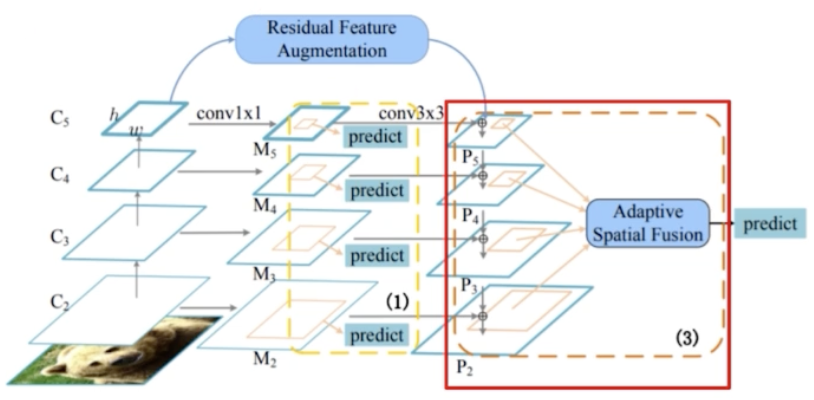
- Residual Feature Augmentation 을 해서 M6 가 나오는데, 이 M6 가 P5 에 Lateral 하게 connection 이 된다.
- 그렇게 되면 P5 에는 C5 로부터 추출된 high level 정보가 어느정도 보강된 것이다.
- 이제 RoI 를 추출해주는데, FPN 은 추출된 RoI 에서 stage 를 mapping 해줬는데, 이번에는 stage mapping 없이 PANet 과 비슷하게 모든 feature map 으로부터 RoI Projection 을 진행한다.
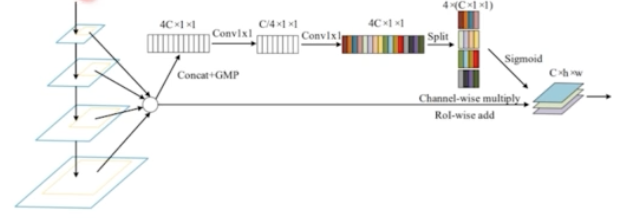
- FPN 과 같이 하나의 feature map 에서 RoI 를 계산하는 경우 sub-optimal 하기 때문에, PANet 은 모든 feature map 을 활용했지만 PANet 은 channel-wise 하게 max pooling 을 했기 때문에 정보 손실 가능성이 있다.
- 따라서 AugFPN 에서는 Soft RoI Selection 을 한 것이다.
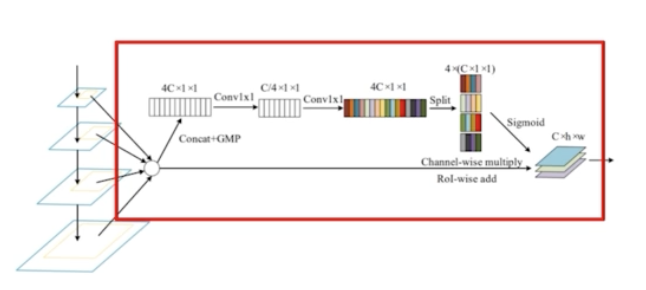
- 모든 scale 의 feature 에서 RoI Projection 을 진행한 후에 RoI Pooling 을 해서 고정된 feature vec 을 만들어준다.
- 다음과 같이 channel-wise 하게 가중치를 계산한다. 이후 Residual Feature Aug 와 비슷하게 weight 를 부여해서 가중합을 사용한다.
- PANet 의 max pooling 자체를 없애고 weight 라는 새로운 term 을 만들어서 weight 를 곱한 다음에 summation 을 진행하게 되는 것.
- FPN 에 존재하는 문제점을 크게 3가지로 봤다.
- AugFPN 은 기존 일반 모델에 AugFPN 을 달면 결과가 많이 좋아졌다.
- AugFPN 의 핵심 알고리즘은 feature map 을 단순하게 max pooling 하는 것은 비효율적이니 다 summation 을 하고 싶은데, 단순 summation 보다는 가중합을 해야한다! → 가중합을 하기 위해서 weight 를 뽑아내야 하는데 그 weight 를 뽑아내는 과정이 위에서 설명된 것.
- 최종적으로 4C 로 맞춰준 다음에 channel-wise 하게 sigmoid 를 해줘서 각각 weight value 를 갖게 하고, 그 weight 를 원래 있던 feature map 에 곱해서 더하게 되는 것이다.
- 그렇게 되면 weight 를 계산하는 부분도 학습가능하게 되는 것이 AugFPN 의 주장이다.
- 이렇게 배운 다양한 Neck 들을 활용해서, Neck Stage 이후 RPN 을 통과시키고 RoI 를 뽑아낸 이후 과정은 Faster RCNN 과 완벽하게 동일하다.
댓글 남기기