
[Object Detection] 3. MMdetection
-
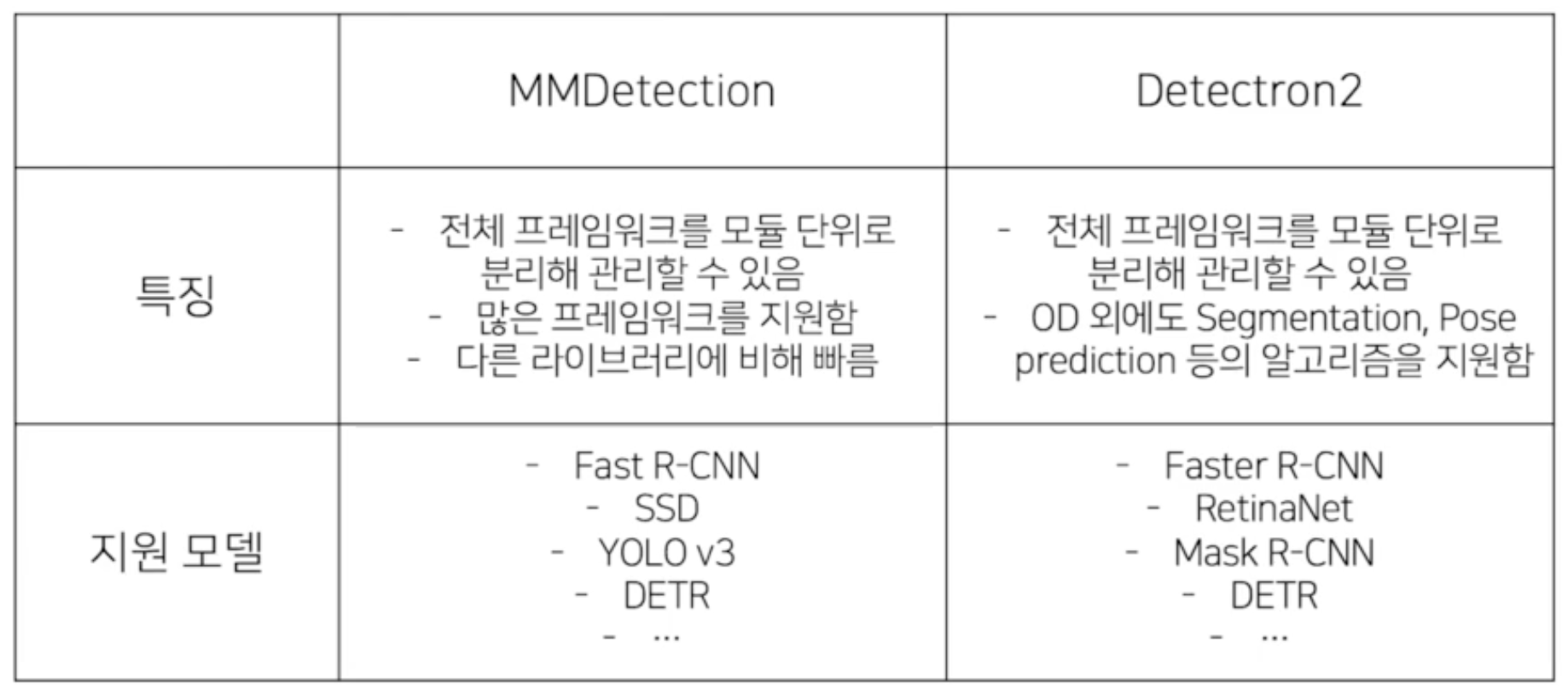
Object Detection Library 💡 MMDetection 라이브러리는 Object Detection 작업을 config 설정으로 엔지니어링 할 수 있도록 도와주는 유용한 툴. solver는 detectron2에서 설정할 수 있는 config
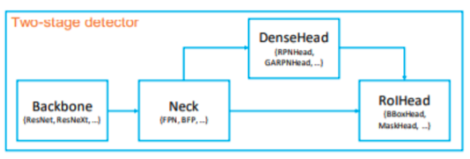
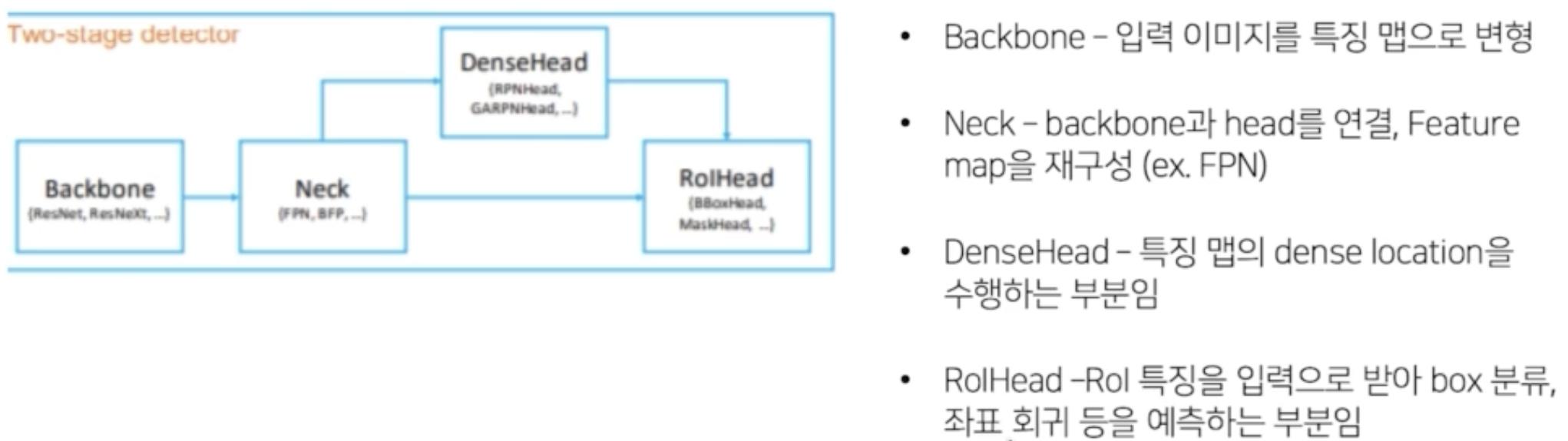
- Backbone : 입력 이미지를 특징 맵으로 변형한다. ResNet, VGG 등
- Neck : Backbone 과 head 를 연결하고 Feature map 을 재구성한다.
- DenseHead : 특징 맵의 dense location 을 수행하는 부분.
- RoIHead : RoI 특징을 입력으로 받아 box 분류, 좌표 회귀(regressor) 등을 예측
Detectron2 라이브러리에서 모델 관련 config로는 solver, RoI_BOX_HEAD, RoI_HEADS, Anchor generator 가 있다. Neck 은 mmdetection 에서 설정할 수 있는 config 로, Detectron2 에서는 동일한 역할을 하는 모듈을 config 에서 FPN 으로 관리.
-
mmdetection 분석

- DenseHead 가 RPN Network → localization 부분. RoI 가 나온다.
- RoIHead 가 RPN 에서 나온 RoI 가 통과하는 Box head 와 Cls head 이다.
- config
-
./configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py
{ "model": { "type": "fasterRCn", "backbone": { "type": "Resnet", "depth": 50, "num_stages": 4, "out_indices": "(0, 1, 2, 3)", "frozen_stages": 1, "norm_cfg": { "type": "Bn", "requires_grad": true }, "norm_eval": true, "style": "pytorch", "init_cfg": { "type": "Pretrained", "checkpoint": "torchvision resnet50" } }, "neck": { "type": "fPn", "in_channels": [ 256, 512, 1024, 2048 ], "out_channels": 256, "num_outs": 5 }, "rpn_head": { "type": "RPnHead", "in_channels": 256, "feat_channels": 256, "anchor_generator": { "type": "AnchorGenerator", "scales": [ 8 ], "ratios": [ 0.5, 1, 2 ], "strides": [ 4, 8, 16, 32, 64 ] }, "bbox_coder": { "type": "DeltaXYWHBBoxCoder", "target_means": [ 0, 0, 0, 0 ], "target_stds": [ 1, 1, 1, 1 ] }, "loss_cls": { "type": "CrossEntropyLoss", "use_sigmoid": true, "loss_weight": 1 }, "loss_bbox": { "type": "L1Loss", "loss_weight": 1 } }, "roi_head": { "type": "StandardRoIHead", "bbox_roi_extractor": { "type": "SingleRoIExtractor", "roi_layer": { "type": "RoIAlign", "output_size": 7, "sampling_ratio": 0 }, "out_channels": 256, "featmap_strides": [ 4, 8, 16, 32 ] }, "bbox_head": { "type": "Shared2fCBBoxHead", "in_channels": 256, "fc_out_channels": 1024, "roi_feat_size": 7, "num_classes": 80, "bbox_coder": { "type": "DeltaXYWHBBoxCoder", "target_means": [ 0, 0, 0, 0 ], "target_stds": [ 0.1, 0.1, 0.2, 0.2 ] }, "reg_class_agnostic": false, "loss_cls": { "type": "CrossEntropyLoss", "use_sigmoid": false, "loss_weight": 1 }, "loss_bbox": { "type": "L1Loss", "loss_weight": 1 } } }, "train_cfg": { "rpn": { "assigner": { "type": "MaxIoUAssigner", "pos_iou_thr": 0.7, "neg_iou_thr": 0.3, "min_pos_iou": 0.3, "match_low_quality": true, "ignore_iof_thr": -1 }, "sampler": { "type": "RandomSampler", "num": 256, "pos_fraction": 0.5, "neg_pos_ub": -1, "add_gt_as_proposals": false }, "allowed_border": -1, "pos_weight": -1, "debug": false }, "rpn_proposal": { "nms_pre": 2000, "max_per_img": 1000, "nms": { "type": "nms", "iou_threshold": 0.7 }, "min_bbox_size": 0 }, "rcnn": { "assigner": { "type": "MaxIoUAssigner", "pos_iou_thr": 0.5, "neg_iou_thr": 0.5, "min_pos_iou": 0.5, "match_low_quality": false, "ignore_iof_thr": -1 }, "sampler": { "type": "RandomSampler", "num": 512, "pos_fraction": 0.25, "neg_pos_ub": -1, "add_gt_as_proposals": true }, "pos_weight": -1, "debug": false } }, "test_cfg": { "rpn": { "nms_pre": 1000, "max_per_img": 1000, "nms": { "type": "nms", "iou_threshold": 0.7 }, "min_bbox_size": 0 }, "rcnn": { "score_thr": 0.05, "nms": { "type": "nms", "iou_threshold": 0.5 }, "max_per_img": 100 } } }, "dataset_type": "CocoDataset", "data_root": "data/coco/", "img_norm_cfg": { "mean": [ 123.675, 116.28, 103.53 ], "std": [ 58.395, 57.12, 57.375 ], "to_rgb": true }, "train_pipeline": [ { "type": "LoadImagefromfile" }, { "type": "LoadAnnotations", "with_bbox": true }, { "type": "Resize", "img_scale": "(1333, 800)", "keep_ratio": true }, { "type": "Randomflip", "flip_ratio": 0.5 }, { "type": "normalize", "mean": [ 123.675, 116.28, 103.53 ], "std": [ 58.395, 57.12, 57.375 ], "to_rgb": true }, { "type": "Pad", "size_divisor": 32 }, { "type": "DefaultformatBundle" }, { "type": "Collect", "keys": [ "img", "gt_bboxes", "gt_labels" ] } ], "test_pipeline": [ { "type": "LoadImagefromfile" }, { "type": "MultiScaleflipAug", "img_scale": "(1333, 800)", "flip": false, "transforms": [ { "type": "Resize", "keep_ratio": true }, { "type": "Randomflip" }, { "type": "normalize", "mean": [ 123.675, 116.28, 103.53 ], "std": [ 58.395, 57.12, 57.375 ], "to_rgb": true }, { "type": "Pad", "size_divisor": 32 }, { "type": "Imagetotensor", "keys": [ "img" ] }, { "type": "Collect", "keys": [ "img" ] } ] } ], "data": { "samples_per_gpu": 2, "workers_per_gpu": 2, "train": { "type": "CocoDataset", "ann_file": "data/coco/annotations/instances_train2017.json", "img_prefix": "data/coco/train2017/", "pipeline": [ { "type": "LoadImagefromfile" }, { "type": "LoadAnnotations", "with_bbox": true }, { "type": "Resize", "img_scale": "(1333, 800)", "keep_ratio": true }, { "type": "Randomflip", "flip_ratio": 0.5 }, { "type": "normalize", "mean": [ 123.675, 116.28, 103.53 ], "std": [ 58.395, 57.12, 57.375 ], "to_rgb": true }, { "type": "Pad", "size_divisor": 32 }, { "type": "DefaultformatBundle" }, { "type": "Collect", "keys": [ "img", "gt_bboxes", "gt_labels" ] } ] }, "val": { "type": "CocoDataset", "ann_file": "data/coco/annotations/instances_val2017.json", "img_prefix": "data/coco/val2017/", "pipeline": [ { "type": "LoadImagefromfile" }, { "type": "MultiScaleflipAug", "img_scale": "(1333, 800)", "flip": false, "transforms": [ { "type": "Resize", "keep_ratio": true }, { "type": "Randomflip" }, { "type": "normalize", "mean": [ 123.675, 116.28, 103.53 ], "std": [ 58.395, 57.12, 57.375 ], "to_rgb": true }, { "type": "Pad", "size_divisor": 32 }, { "type": "Imagetotensor", "keys": [ "img" ] }, { "type": "Collect", "keys": [ "img" ] } ] } ] }, "test": { "type": "CocoDataset", "ann_file": "data/coco/annotations/instances_val2017.json", "img_prefix": "data/coco/val2017/", "pipeline": [ { "type": "LoadImagefromfile" }, { "type": "MultiScaleflipAug", "img_scale": "(1333, 800)", "flip": false, "transforms": [ { "type": "Resize", "keep_ratio": true }, { "type": "Randomflip" }, { "type": "normalize", "mean": [ 123.675, 116.28, 103.53 ], "std": [ 58.395, 57.12, 57.375 ], "to_rgb": true }, { "type": "Pad", "size_divisor": 32 }, { "type": "Imagetotensor", "keys": [ "img" ] }, { "type": "Collect", "keys": [ "img" ] } ] } ] } }, "evaluation": { "interval": 1, "metric": "bbox" }, "optimizer": { "type": "SGD", "lr": 0.02, "momentum": 0.9, "weight_decay": 0.0001 }, "optimizer_config": { "grad_clip": "none" }, "lr_config": { "policy": "step", "warmup": "linear", "warmup_iters": 500, "warmup_ratio": 0.001, "step": [ 8, 11 ] }, "runner": { "type": "EpochBasedRunner", "max_epochs": 12 }, "checkpoint_config": { "interval": 1 }, "log_config": { "interval": 50, "hooks": [ { "type": "textLoggerHook" } ] }, "custom_hooks": [ { "type": "numClassCheckHook" } ], "dist_params": { "backend": "nccl" }, "log_level": "InfO", "load_from": "none", "resume_from": "none", "workflow": [ "(train, 1)" ], "opencv_num_threads": 0, "mp_start_method": "fork", "auto_scale_lr": { "enable": false, "base_batch_size": 16 } } -
./configs/faster_rcnn/faster_rcnn_x101_64x4d_fpn_1x_coco.py
{ "model": { "type": "FasterRCNN", "backbone": { "type": "ResNeXt", "depth": 101, "num_stages": 4, "out_indices": "(0, 1, 2, 3)", "frozen_stages": 1, "norm_cfg": { "type": "BN", "requires_grad": true }, "norm_eval": true, "style": "pytorch", "init_cfg": { "type": "Pretrained", "checkpoint": "open-mmlab://resnext101_64x4d" }, "groups": 64, "base_width": 4 }, "neck": { "type": "FPN", "in_channels": [ 256, 512, 1024, 2048 ], "out_channels": 256, "num_outs": 5 }, "rpn_head": { "type": "RPNHead", "in_channels": 256, "feat_channels": 256, "anchor_generator": { "type": "AnchorGenerator", "scales": [ 8 ], "ratios": [ 0.5, 1, 2 ], "strides": [ 4, 8, 16, 32, 64 ] }, "bbox_coder": { "type": "DeltaXYWHBBoxCoder", "target_means": [ 0, 0, 0, 0 ], "target_stds": [ 1, 1, 1, 1 ] }, "loss_cls": { "type": "CrossEntropyLoss", "use_sigmoid": true, "loss_weight": 1 }, "loss_bbox": { "type": "L1Loss", "loss_weight": 1 } }, "roi_head": { "type": "StandardRoIHead", "bbox_roi_extractor": { "type": "SingleRoIExtractor", "roi_layer": { "type": "RoIAlign", "output_size": 7, "sampling_ratio": 0 }, "out_channels": 256, "featmap_strides": [ 4, 8, 16, 32 ] }, "bbox_head": { "type": "Shared2FCBBoxHead", "in_channels": 256, "fc_out_channels": 1024, "roi_feat_size": 7, "num_classes": 10, "bbox_coder": { "type": "DeltaXYWHBBoxCoder", "target_means": [ 0, 0, 0, 0 ], "target_stds": [ 0.1, 0.1, 0.2, 0.2 ] }, "reg_class_agnostic": false, "loss_cls": { "type": "CrossEntropyLoss", "use_sigmoid": false, "loss_weight": 1 }, "loss_bbox": { "type": "L1Loss", "loss_weight": 1 } } }, "train_cfg": { "rpn": { "assigner": { "type": "MaxIoUAssigner", "pos_iou_thr": 0.7, "neg_iou_thr": 0.3, "min_pos_iou": 0.3, "match_low_quality": true, "ignore_iof_thr": -1 }, "sampler": { "type": "RandomSampler", "num": 256, "pos_fraction": 0.5, "neg_pos_ub": -1, "add_gt_as_proposals": false }, "allowed_border": -1, "pos_weight": -1, "debug": false }, "rpn_proposal": { "nms_pre": 2000, "max_per_img": 1000, "nms": { "type": "nms", "iou_threshold": 0.7 }, "min_bbox_size": 0 }, "rcnn": { "assigner": { "type": "MaxIoUAssigner", "pos_iou_thr": 0.5, "neg_iou_thr": 0.5, "min_pos_iou": 0.5, "match_low_quality": false, "ignore_iof_thr": -1 }, "sampler": { "type": "RandomSampler", "num": 512, "pos_fraction": 0.25, "neg_pos_ub": -1, "add_gt_as_proposals": true }, "pos_weight": -1, "debug": false } }, "test_cfg": { "rpn": { "nms_pre": 1000, "max_per_img": 1000, "nms": { "type": "nms", "iou_threshold": 0.7 }, "min_bbox_size": 0 }, "rcnn": { "score_thr": 0.05, "nms": { "type": "nms", "iou_threshold": 0.5 }, "max_per_img": 100 } } }, "dataset_type": "CocoDataset", "data_root": "data/coco/", "img_norm_cfg": { "mean": [ 123.675, 116.28, 103.53 ], "std": [ 58.395, 57.12, 57.375 ], "to_rgb": true }, "train_pipeline": [ { "type": "LoadImageFromFile" }, { "type": "LoadAnnotations", "with_bbox": true }, { "type": "Resize", "img_scale": "(1333, 800)", "keep_ratio": true }, { "type": "RandomFlip", "flip_ratio": 0.5 }, { "type": "Normalize", "mean": [ 123.675, 116.28, 103.53 ], "std": [ 58.395, 57.12, 57.375 ], "to_rgb": true }, { "type": "Pad", "size_divisor": 32 }, { "type": "DefaultFormatBundle" }, { "type": "Collect", "keys": [ "img", "gt_bboxes", "gt_labels" ] } ], "test_pipeline": [ { "type": "LoadImageFromFile" }, { "type": "MultiScaleFlipAug", "img_scale": "(1333, 800)", "flip": false, "transforms": [ { "type": "Resize", "keep_ratio": true }, { "type": "RandomFlip" }, { "type": "Normalize", "mean": [ 123.675, 116.28, 103.53 ], "std": [ 58.395, 57.12, 57.375 ], "to_rgb": true }, { "type": "Pad", "size_divisor": 32 }, { "type": "ImageToTensor", "keys": [ "img" ] }, { "type": "Collect", "keys": [ "img" ] } ] } ], "data": { "samples_per_gpu": 4, "workers_per_gpu": 2, "train": { "type": "CocoDataset", "ann_file": "../../dataset/cleaned_train.json", "img_prefix": "../../dataset/", "pipeline": [ { "type": "LoadImageFromFile" }, { "type": "LoadAnnotations", "with_bbox": true }, { "type": "Resize", "img_scale": "(512, 512)", "keep_ratio": true }, { "type": "RandomFlip", "flip_ratio": 0.5 }, { "type": "Normalize", "mean": [ 123.675, 116.28, 103.53 ], "std": [ 58.395, 57.12, 57.375 ], "to_rgb": true }, { "type": "Pad", "size_divisor": 32 }, { "type": "DefaultFormatBundle" }, { "type": "Collect", "keys": [ "img", "gt_bboxes", "gt_labels" ] } ], "classes": [ "General trash", "Paper", "Paper pack", "Metal", "Glass", "Plastic", "Styrofoam", "Plastic bag", "Battery", "Clothing" ] }, "val": { "type": "CocoDataset", "ann_file": "data/coco/annotations/instances_val2017.json", "img_prefix": "data/coco/val2017/", "pipeline": [ { "type": "LoadImageFromFile" }, { "type": "MultiScaleFlipAug", "img_scale": "(1333, 800)", "flip": false, "transforms": [ { "type": "Resize", "keep_ratio": true }, { "type": "RandomFlip" }, { "type": "Normalize", "mean": [ 123.675, 116.28, 103.53 ], "std": [ 58.395, 57.12, 57.375 ], "to_rgb": true }, { "type": "Pad", "size_divisor": 32 }, { "type": "ImageToTensor", "keys": [ "img" ] }, { "type": "Collect", "keys": [ "img" ] } ] } ] }, "test": { "type": "CocoDataset", "ann_file": "../../dataset/test.json", "img_prefix": "../../dataset/", "pipeline": [ { "type": "LoadImageFromFile" }, { "type": "MultiScaleFlipAug", "img_scale": "(512, 512)", "flip": false, "transforms": [ { "type": "Resize", "keep_ratio": true }, { "type": "RandomFlip" }, { "type": "Normalize", "mean": [ 123.675, 116.28, 103.53 ], "std": [ 58.395, 57.12, 57.375 ], "to_rgb": true }, { "type": "Pad", "size_divisor": 32 }, { "type": "ImageToTensor", "keys": [ "img" ] }, { "type": "Collect", "keys": [ "img" ] } ] } ], "classes": [ "General trash", "Paper", "Paper pack", "Metal", "Glass", "Plastic", "Styrofoam", "Plastic bag", "Battery", "Clothing" ] } }, "evaluation": { "interval": 1, "metric": "bbox" }, "optimizer": { "type": "SGD", "lr": 0.02, "momentum": 0.9, "weight_decay": 0.0001 }, "optimizer_config": { "grad_clip": { "max_norm": 35, "norm_type": 2 } }, "lr_config": { "policy": "step", "warmup": "linear", "warmup_iters": 500, "warmup_ratio": 0.001, "step": [ 8, 11 ] }, "runner": { "type": "EpochBasedRunner", "max_epochs": 12 }, "checkpoint_config": { "max_keep_ckpts": 3, "interval": 1 }, "log_config": { "interval": 50, "hooks": [ { "type": "TextLoggerHook" } ] }, "custom_hooks": [ { "type": "NumClassCheckHook" } ], "dist_params": { "backend": "nccl" }, "log_level": "INFO", "load_from": "none", "resume_from": "none", "workflow": [ "train", 1 ], "opencv_num_threads": 0, "mp_start_method": "fork", "auto_scale_lr": { "enable": false, "base_batch_size": 16 }, "seed": 2022, "gpu_ids": [ 0 ], "work_dir": "./work_dirs/faster_rcnn_x101_64x4d_fpn_1x_trash", "device": "cuda" }
-
-
mmdetection 의 Config 시스템 분석 & 커스터마이징
Learn about Configs — MMDetection 3.3.0 documentation
- 불러오는 config 파일은
cfg = Config.fromfile('./configs/faster_rcnn/faster_rcnn_x101_64x4d_fpn_1x_coco.py')이런 식으로 하나의 py 파일을 불러온다. -
config 파일(.py)은 아래와 같이 구성되어 있다.
_base_ = [ '../_base_/models/faster_rcnn_r50_fpn.py', '../_base_/datasets/coco_detection.py', '../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py' ] - 이 .py 의 config 파일은 여러 config 파일들을 한 군데로 모아주는 역할을 한다.
- 크게 4가지의 config 로 구성됨. model, dataset, schedule, runtime
- model - 모델 구조 변경
- datasets - 사용할 데이터에 대한 정보 기입
- schedules - epoch 나 lr 수정
- runtime - weight 파일 저장 주기 수정
cfg.keys()
dict_keys([‘model’, ‘dataset_type’, ‘data_root’, ‘img_norm_cfg’, ‘train_pipeline’, ‘test_pipeline’, ‘data’, ‘evaluation’, ‘optimizer’, ‘optimizer_config’, ‘lr_config’, ‘runner’, ‘checkpoint_config’, ‘log_config’, ‘custom_hooks’, ‘dist_params’, ‘log_level’, ‘load_from’, ‘resume_from’, ‘workflow’, ‘opencv_num_threads’, ‘mp_start_method’, ‘auto_scale_lr’])
model- 만약 모델을 커스텀을 한다면 아래처럼 할 수 있음.
_base_ = './faster_rcnn_r50_fpn_1x_coco.py' # faster_rcnn_r50_fpn_1x_coco.py 에 정의된 model, dataset, schedule, runtime 가져옴. # 여기서 모델을 새로 정의. 아니면 configs/_base_/models 안에 .py 파일로 모델을 정의할 수 있음(단 아래처럼 dict 형태로) model = dict( backbone=dict( type='ResNeXt', depth=101, groups=64, base_width=4, num_stages=4, out_indices=(0, 1, 2, 3), frozen_stages=1, norm_cfg=dict(type='BN', requires_grad=True), style='pytorch', init_cfg=dict( type='Pretrained', checkpoint='open-mmlab://resnext101_64x4d'))) # 중요한 것은 커스텀한 model.py 안에 train_cfg, test_cfg 가 들어가야함.(rpn 등의 하이퍼파라미터 조정용) train_cfg = dict( # Config of training hyperparameters for rpn and rcnn rpn=dict( # Training config of rpn assigner=dict( # Config of assigner type='MaxIoUAssigner', # Type of assigner, MaxIoUAssigner is used for many common detectors. Refer to https://github.com/open-mmlab/mmdetection/blob/main/mmdet/models/task_modules/assigners/max_iou_assigner.py#L14 for more details. pos_iou_thr=0.7, # IoU >= threshold 0.7 will be taken as positive samples neg_iou_thr=0.3, # IoU < threshold 0.3 will be taken as negative samples min_pos_iou=0.3, # The minimal IoU threshold to take boxes as positive samples match_low_quality=True, # Whether to match the boxes under low quality (see API doc for more details). ignore_iof_thr=-1), # IoF threshold for ignoring bboxes sampler=dict( # Config of positive/negative sampler type='RandomSampler', # Type of sampler, PseudoSampler and other samplers are also supported. Refer to https://github.com/open-mmlab/mmdetection/blob/main/mmdet/models/task_modules/samplers/random_sampler.py#L14 for implementation details. num=256, # Number of samples pos_fraction=0.5, # The ratio of positive samples in the total samples. neg_pos_ub=-1, # The upper bound of negative samples based on the number of positive samples. add_gt_as_proposals=False), # Whether add GT as proposals after sampling. allowed_border=-1, # The border allowed after padding for valid anchors. pos_weight=-1, # The weight of positive samples during training. debug=False), # Whether to set the debug mode rpn_proposal=dict( # The config to generate proposals during training nms_across_levels=False, # Whether to do NMS for boxes across levels. Only work in `GARPNHead`, naive rpn does not support do nms cross levels. nms_pre=2000, # The number of boxes before NMS nms_post=1000, # The number of boxes to be kept by NMS. Only work in `GARPNHead`. max_per_img=1000, # The number of boxes to be kept after NMS. nms=dict( # Config of NMS type='nms', # Type of NMS iou_threshold=0.7 # NMS threshold ), min_bbox_size=0), # The allowed minimal box size rcnn=dict( # The config for the roi heads. assigner=dict( # Config of assigner for second stage, this is different for that in rpn type='MaxIoUAssigner', # Type of assigner, MaxIoUAssigner is used for all roi_heads for now. Refer to https://github.com/open-mmlab/mmdetection/blob/main/mmdet/models/task_modules/assigners/max_iou_assigner.py#L14 for more details. pos_iou_thr=0.5, # IoU >= threshold 0.5 will be taken as positive samples neg_iou_thr=0.5, # IoU < threshold 0.5 will be taken as negative samples min_pos_iou=0.5, # The minimal IoU threshold to take boxes as positive samples match_low_quality=False, # Whether to match the boxes under low quality (see API doc for more details). ignore_iof_thr=-1), # IoF threshold for ignoring bboxes sampler=dict( type='RandomSampler', # Type of sampler, PseudoSampler and other samplers are also supported. Refer to https://github.com/open-mmlab/mmdetection/blob/main/mmdet/models/task_modules/samplers/random_sampler.py#L14 for implementation details. num=512, # Number of samples pos_fraction=0.25, # The ratio of positive samples in the total samples. neg_pos_ub=-1, # The upper bound of negative samples based on the number of positive samples. add_gt_as_proposals=True ), # Whether add GT as proposals after sampling. mask_size=28, # Size of mask pos_weight=-1, # The weight of positive samples during training. debug=False)), # Whether to set the debug mode-
dataset‘dataset_type’, ‘data_root’, ‘img_norm_cfg’, ‘train_pipeline’, ‘test_pipeline’, ‘data’ 에 해당하는 키
-
데이터셋 만드는 부분
datasets = [build_dataset(cfg.data.train)] "data": { "samples_per_gpu": 2, "workers_per_gpu": 2, "train": { "type": "CocoDataset", "ann_file": "data/coco/annotations/instances_train2017.json", "img_prefix": "data/coco/train2017/", "pipeline": [ { "type": "LoadImagefromfile" }, { "type": "LoadAnnotations", "with_bbox": true }, { "type": "Resize", "img_scale": "(1333, 800)", "keep_ratio": true }, { "type": "Randomflip", "flip_ratio": 0.5 }, { "type": "normalize", "mean": [ 123.675, 116.28, 103.53 ], "std": [ 58.395, 57.12, 57.375 ], "to_rgb": true }, { "type": "Pad", "size_divisor": 32 }, { "type": "DefaultformatBundle" }, { "type": "Collect", "keys": [ "img", "gt_bboxes", "gt_labels" ] } ] },def build_dataset(cfg, default_args=None): from .dataset_wrappers import (ClassBalancedDataset, ConcatDataset, MultiImageMixDataset, RepeatDataset) if isinstance(cfg, (list, tuple)): dataset = ConcatDataset([build_dataset(c, default_args) for c in cfg]) elif cfg['type'] == 'ConcatDataset': dataset = ConcatDataset( [build_dataset(c, default_args) for c in cfg['datasets']], cfg.get('separate_eval', True)) elif cfg['type'] == 'RepeatDataset': dataset = RepeatDataset( build_dataset(cfg['dataset'], default_args), cfg['times']) elif cfg['type'] == 'ClassBalancedDataset': dataset = ClassBalancedDataset( build_dataset(cfg['dataset'], default_args), cfg['oversample_thr']) elif cfg['type'] == 'MultiImageMixDataset': cp_cfg = copy.deepcopy(cfg) cp_cfg['dataset'] = build_dataset(cp_cfg['dataset']) cp_cfg.pop('type') dataset = MultiImageMixDataset(**cp_cfg) elif isinstance(cfg.get('ann_file'), (list, tuple)): dataset = _concat_dataset(cfg, default_args) else: dataset = build_from_cfg(cfg, DATASETS, default_args) return dataset
mmdetection/mmdet/datasets/builder.py 내에서 mmcv.utils 의 build_from_cfg 를 import
그리고 mmcv 에서는
Registry를 쓰는데, 이는 문자열을 주면 mapping 방식으로 해당 클래스로 찾아가게 하는 것.DATASETS = Registry('dataset')이걸로 인해서 아래처럼@DATASETS.register_module()을 찾아갈 수 있음.
위 cfg 에서 type이 CoCoDataset 이었기 때문에, mmdetection/mmdet/datasets/coco.py 로 가고, 여기서 CoCoDataset 은 CustomDataset 을 상속
CustomDataset 은 torch.utils.data 의 Dataset 을 상속

# filter images too small and containing no annotations if not test_mode: valid_inds = self._filter_imgs() # 너무 작은 img 들을 필터링함 self.data_infos = [self.data_infos[i] for i in valid_inds] # 여기서 이미지 정보, annotation 정보를 업데이트 if self.proposals is not None: self.proposals = [self.proposals[i] for i in valid_inds] # set group flag for the sampler self._set_group_flag() # processing pipeline self.pipeline = Compose(pipeline)-
mmcv 의 Compose
class Compose: """Compose multiple transforms sequentially. Args: transforms (Sequence[dict | callable]): Sequence of transform object or config dict to be composed. """ def __init__(self, transforms): assert isinstance(transforms, collections.abc.Sequence) self.transforms = [] for transform in transforms: if isinstance(transform, dict): transform = build_from_cfg(transform, PIPELINES) self.transforms.append(transform) elif callable(transform): self.transforms.append(transform) else: raise TypeError('transform must be callable or a dict') def __call__(self, data): """Call function to apply transforms sequentially. Args: data (dict): A result dict contains the data to transform. Returns: dict: Transformed data. """ for t in self.transforms: data = t(data) if data is None: return None return data def __repr__(self): format_string = self.__class__.__name__ + '(' for t in self.transforms: str_ = t.__repr__() if 'Compose(' in str_: str_ = str_.replace('\n', '\n ') format_string += '\n' format_string += f' {str_}' format_string += '\n)' return format_string
→ 위 과정에서 data augmentation 이 적용됨. 위 cfg 내에 pipeline 참고
def pre_pipeline(self, results): """Prepare results dict for pipeline.""" results['img_prefix'] = self.img_prefix results['seg_prefix'] = self.seg_prefix results['proposal_file'] = self.proposal_file results['bbox_fields'] = [] results['mask_fields'] = [] results['seg_fields'] = [] def __getitem__(self, idx): """Get training/test data after pipeline. Args: idx (int): Index of data. Returns: dict: Training/test data (with annotation if `test_mode` is set \ True). """ if self.test_mode: return self.prepare_test_img(idx) while True: data = self.prepare_train_img(idx) if data is None: idx = self._rand_another(idx) continue return data def prepare_train_img(self, idx): """Get training data and annotations after pipeline. Args: idx (int): Index of data. Returns: dict: Training data and annotation after pipeline with new keys \ introduced by pipeline. """ img_info = self.data_infos[idx] ann_info = self.get_ann_info(idx) results = dict(img_info=img_info, ann_info=ann_info) if self.proposals is not None: results['proposals'] = self.proposals[idx] self.pre_pipeline(results) return self.pipeline(results)- mmdetection/base/datasets/coco_detection.py 를 수정하거나, train.py 를 하나 만들어서 거기서 cfg.data.train 의 인자를 변경해주는 식으로 커스텀 할 수 있음.
-
coco_detection.py
# dataset settings dataset_type = 'CocoDataset' data_root = 'data/coco/' img_norm_cfg = dict( mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True) train_pipeline = [ dict(type='LoadImageFromFile'), dict(type='LoadAnnotations', with_bbox=True), dict(type='Resize', img_scale=(1333, 800), keep_ratio=True), dict(type='RandomFlip', flip_ratio=0.5), dict(type='Normalize', **img_norm_cfg), dict(type='Pad', size_divisor=32), dict(type='DefaultFormatBundle'), dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']), ] test_pipeline = [ dict(type='LoadImageFromFile'), dict( type='MultiScaleFlipAug', img_scale=(1333, 800), flip=False, transforms=[ dict(type='Resize', keep_ratio=True), dict(type='RandomFlip'), dict(type='Normalize', **img_norm_cfg), dict(type='Pad', size_divisor=32), dict(type='ImageToTensor', keys=['img']), dict(type='Collect', keys=['img']), ]) ] data = dict( samples_per_gpu=2, workers_per_gpu=2, train=dict( type=dataset_type, ann_file=data_root + 'annotations/instances_train2017.json', img_prefix=data_root + 'train2017/', pipeline=train_pipeline), val=dict( type=dataset_type, ann_file=data_root + 'annotations/instances_val2017.json', img_prefix=data_root + 'val2017/', pipeline=test_pipeline), test=dict( type=dataset_type, ann_file=data_root + 'annotations/instances_val2017.json', img_prefix=data_root + 'val2017/', pipeline=test_pipeline)) evaluation = dict(interval=1, metric='bbox') -
dataset config 수정
# dataset config 수정 cfg.data.train.classes = classes cfg.data.train.img_prefix = root cfg.data.train.ann_file = root + 'cleaned_train.json' # train json 정보 cfg.data.train.pipeline[2]['img_scale'] = (512,512) # Resize cfg.data.test.classes = classes cfg.data.test.img_prefix = root cfg.data.test.ann_file = root + 'test.json' # test json 정보 cfg.data.test.pipeline[1]['img_scale'] = (512,512) # Resize
-
- 데이터 처리 파이프라인
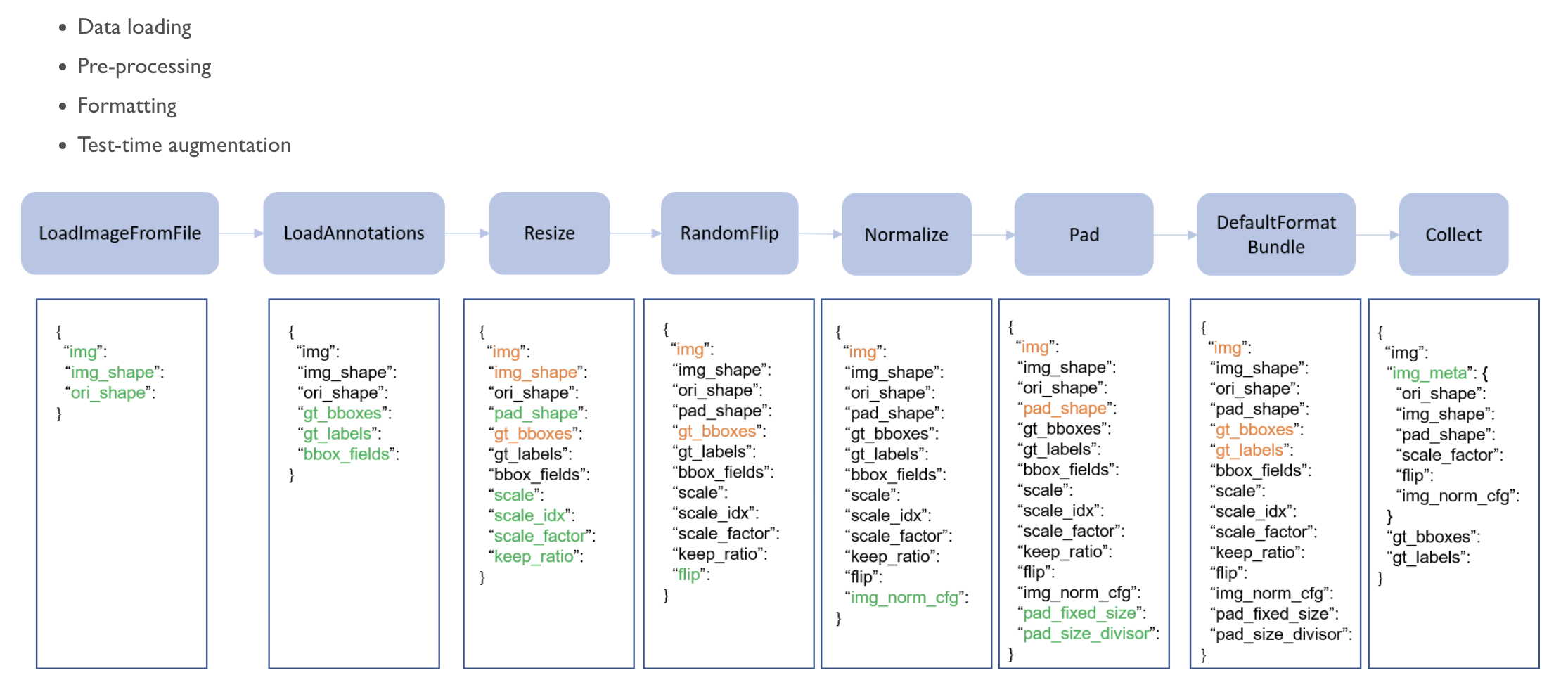
-
dataloader- 베이스라인에서는 딱히 loader 를 지정해주지 않음.
from mmdet.apis import train_detector에서from mmdet.datasets import (build_dataloader, build_dataset, replace_ImageToTensor)로 build_dataloader 를 불러오고,-
bulid_dataloader
def build_dataloader(dataset, samples_per_gpu, workers_per_gpu, num_gpus=1, dist=True, shuffle=True, seed=None, runner_type='EpochBasedRunner', persistent_workers=False, class_aware_sampler=None, **kwargs): """Build PyTorch DataLoader. In distributed training, each GPU/process has a dataloader. In non-distributed training, there is only one dataloader for all GPUs. Args: dataset (Dataset): A PyTorch dataset. samples_per_gpu (int): Number of training samples on each GPU, i.e., batch size of each GPU. workers_per_gpu (int): How many subprocesses to use for data loading for each GPU. num_gpus (int): Number of GPUs. Only used in non-distributed training. dist (bool): Distributed training/test or not. Default: True. shuffle (bool): Whether to shuffle the data at every epoch. Default: True. seed (int, Optional): Seed to be used. Default: None. runner_type (str): Type of runner. Default: `EpochBasedRunner` persistent_workers (bool): If True, the data loader will not shutdown the worker processes after a dataset has been consumed once. This allows to maintain the workers `Dataset` instances alive. This argument is only valid when PyTorch>=1.7.0. Default: False. class_aware_sampler (dict): Whether to use `ClassAwareSampler` during training. Default: None. kwargs: any keyword argument to be used to initialize DataLoader Returns: DataLoader: A PyTorch dataloader. """ rank, world_size = get_dist_info() if dist: # When model is :obj:`DistributedDataParallel`, # `batch_size` of :obj:`dataloader` is the # number of training samples on each GPU. batch_size = samples_per_gpu num_workers = workers_per_gpu else: # When model is obj:`DataParallel` # the batch size is samples on all the GPUS batch_size = num_gpus * samples_per_gpu num_workers = num_gpus * workers_per_gpu if runner_type == 'IterBasedRunner': # this is a batch sampler, which can yield # a mini-batch indices each time. # it can be used in both `DataParallel` and # `DistributedDataParallel` if shuffle: batch_sampler = InfiniteGroupBatchSampler( dataset, batch_size, world_size, rank, seed=seed) else: batch_sampler = InfiniteBatchSampler( dataset, batch_size, world_size, rank, seed=seed, shuffle=False) batch_size = 1 sampler = None else: if class_aware_sampler is not None: # ClassAwareSampler can be used in both distributed and # non-distributed training. num_sample_class = class_aware_sampler.get('num_sample_class', 1) sampler = ClassAwareSampler( dataset, samples_per_gpu, world_size, rank, seed=seed, num_sample_class=num_sample_class) elif dist: # DistributedGroupSampler will definitely shuffle the data to # satisfy that images on each GPU are in the same group if shuffle: sampler = DistributedGroupSampler( dataset, samples_per_gpu, world_size, rank, seed=seed) else: sampler = DistributedSampler( dataset, world_size, rank, shuffle=False, seed=seed) else: sampler = GroupSampler(dataset, samples_per_gpu) if shuffle else None batch_sampler = None init_fn = partial( worker_init_fn, num_workers=num_workers, rank=rank, seed=seed) if seed is not None else None if (TORCH_VERSION != 'parrots' and digit_version(TORCH_VERSION) >= digit_version('1.7.0')): kwargs['persistent_workers'] = persistent_workers elif persistent_workers is True: warnings.warn('persistent_workers is invalid because your pytorch ' 'version is lower than 1.7.0') data_loader = DataLoader( dataset, batch_size=batch_size, sampler=sampler, num_workers=num_workers, batch_sampler=batch_sampler, collate_fn=partial(collate, samples_per_gpu=samples_per_gpu), pin_memory=kwargs.pop('pin_memory', False), worker_init_fn=init_fn, **kwargs) return data_loader
기존의 파이토치 DataLoader 처럼 불러들임. 베이스라인에서는 sampler 나 이런 것들은 지정되어 있지 않고, cfg.data.samples_per_gpu = 4 로 batch_size 를 4로 주고 있음. (batch_size = num_gpus * samples_per_gpu)
-
- custom
- 위 Dataset 과 함께 Custom 가능. 역시 dict 형식으로 주어야 함.
dataset_type = 'CocoDataset' # Dataset type, this will be used to define the dataset data_root = 'data/coco/' # Root path of data backend_args = None # Arguments to instantiate the corresponding file backend train_pipeline = [ # Training data processing pipeline dict(type='LoadImageFromFile', backend_args=backend_args), # First pipeline to load images from file path dict( type='LoadAnnotations', # Second pipeline to load annotations for current image with_bbox=True, # Whether to use bounding box, True for detection with_mask=True, # Whether to use instance mask, True for instance segmentation poly2mask=True), # Whether to convert the polygon mask to instance mask, set False for acceleration and to save memory dict( type='Resize', # Pipeline that resizes the images and their annotations scale=(1333, 800), # The largest scale of the images keep_ratio=True # Whether to keep the ratio between height and width ), dict( type='RandomFlip', # Augmentation pipeline that flips the images and their annotations prob=0.5), # The probability to flip dict(type='PackDetInputs') # Pipeline that formats the annotation data and decides which keys in the data should be packed into data_samples ] test_pipeline = [ # Testing data processing pipeline dict(type='LoadImageFromFile', backend_args=backend_args), # First pipeline to load images from file path dict(type='Resize', scale=(1333, 800), keep_ratio=True), # Pipeline that resizes the images dict( type='PackDetInputs', # Pipeline that formats the annotation data and decides which keys in the data should be packed into data_samples meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'scale_factor')) ] train_dataloader = dict( # Train dataloader config batch_size=2, # Batch size of a single GPU num_workers=2, # Worker to pre-fetch data for each single GPU persistent_workers=True, # If ``True``, the dataloader will not shut down the worker processes after an epoch end, which can accelerate training speed. sampler=dict( # training data sampler type='DefaultSampler', # DefaultSampler which supports both distributed and non-distributed training. Refer to https://mmengine.readthedocs.io/en/latest/api/generated/mmengine.dataset.DefaultSampler.html#mmengine.dataset.DefaultSampler shuffle=True), # randomly shuffle the training data in each epoch batch_sampler=dict(type='AspectRatioBatchSampler'), # Batch sampler for grouping images with similar aspect ratio into a same batch. It can reduce GPU memory cost. dataset=dict( # Train dataset config type=dataset_type, data_root=data_root, ann_file='annotations/instances_train2017.json', # Path of annotation file data_prefix=dict(img='train2017/'), # Prefix of image path filter_cfg=dict(filter_empty_gt=True, min_size=32), # Config of filtering images and annotations pipeline=train_pipeline, backend_args=backend_args)) val_dataloader = dict( # Validation dataloader config batch_size=1, # Batch size of a single GPU. If batch-size > 1, the extra padding area may influence the performance. num_workers=2, # Worker to pre-fetch data for each single GPU persistent_workers=True, # If ``True``, the dataloader will not shut down the worker processes after an epoch end, which can accelerate training speed. drop_last=False, # Whether to drop the last incomplete batch, if the dataset size is not divisible by the batch size sampler=dict( type='DefaultSampler', shuffle=False), # not shuffle during validation and testing dataset=dict( type=dataset_type, data_root=data_root, ann_file='annotations/instances_val2017.json', data_prefix=dict(img='val2017/'), test_mode=True, # Turn on the test mode of the dataset to avoid filtering annotations or images pipeline=test_pipeline, backend_args=backend_args)) test_dataloader = val_dataloader # Testing dataloader config
evaluation- validation 과정에 metric 을 줄 수 있음.
val_evaluator = dict( # Validation evaluator config type='CocoMetric', # The coco metric used to evaluate AR, AP, and mAP for detection and instance segmentation ann_file=data_root + 'annotations/instances_val2017.json', # Annotation file path metric=['bbox', 'segm'], # Metrics to be evaluated, `bbox` for detection and `segm` for instance segmentation format_only=False, backend_args=backend_args) test_evaluator = val_evaluator # Testing evaluator config- test 과정에서 evaluation은 validation 과 똑같이 거치고, 그 결과를 저장하게 할 수 있음.
# inference on test dataset and # format the output results for submission. test_dataloader = dict( batch_size=1, num_workers=2, persistent_workers=True, drop_last=False, sampler=dict(type='DefaultSampler', shuffle=False), dataset=dict( type=dataset_type, data_root=data_root, ann_file=data_root + 'annotations/image_info_test-dev2017.json', data_prefix=dict(img='test2017/'), test_mode=True, pipeline=test_pipeline)) test_evaluator = dict( type='CocoMetric', ann_file=data_root + 'annotations/image_info_test-dev2017.json', metric=['bbox', 'segm'], # Metrics to be evaluated format_only=True, # Only format and save the results to coco json file outfile_prefix='./work_dirs/coco_detection/test') # The prefix of output json files-
trainmmdet.apis.train.py 에서 실행됨. 이 때 dataset, dataloader, optimizer, scheduler 등이 모두 불러와짐.
train 은 mmcv 의 runner 에서 실행됨.
optimizer, scheduler- schedule_1x.py 에서 정의됨.
# optimizer optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001) optimizer_config = dict(grad_clip=None) # learning policy lr_config = dict( policy='step', warmup='linear', warmup_iters=500, warmup_ratio=0.001, step=[8, 11]) runner = dict(type='EpochBasedRunner', max_epochs=12)1x는 12 epoch,2x는 24 epoch이며 8/16번째와 11/22번째 epoch 에서 lr이 10분의 1이 된다.20e는 cascade 모델에서 사용되는 것으로 20 epoch으로 10분의 1이 되는 시점은 16/19번째이다.- 아래 처럼 커스텀할 수 있음.
optim_wrapper = dict( # Optimizer wrapper config type='OptimWrapper', # Optimizer wrapper type, switch to AmpOptimWrapper to enable mixed precision training. optimizer=dict( # Optimizer config. Support all kinds of optimizers in PyTorch. Refer to https://pytorch.org/docs/stable/optim.html#algorithms type='SGD', # Stochastic gradient descent optimizer lr=0.02, # The base learning rate momentum=0.9, # Stochastic gradient descent with momentum weight_decay=0.0001), # Weight decay of SGD clip_grad=None, # Gradient clip option. Set None to disable gradient clip. Find usage in https://mmengine.readthedocs.io/en/latest/tutorials/optimizer.html ) # gradient를 clip 해서 볼 수 있는 옵션도 있는 걸 보니 활용하면 좋을 것 같네요.- optim_wrapper 를 살펴보면, 이것 또한 mmcv 에서 만들어짐
# Copyright (c) OpenMMLab. All rights reserved. import copy from mmcv.runner.optimizer import OPTIMIZER_BUILDERS as MMCV_OPTIMIZER_BUILDERS from mmcv.utils import Registry, build_from_cfg OPTIMIZER_BUILDERS = Registry( 'optimizer builder', parent=MMCV_OPTIMIZER_BUILDERS) def build_optimizer_constructor(cfg): constructor_type = cfg.get('type') if constructor_type in OPTIMIZER_BUILDERS: return build_from_cfg(cfg, OPTIMIZER_BUILDERS) elif constructor_type in MMCV_OPTIMIZER_BUILDERS: return build_from_cfg(cfg, MMCV_OPTIMIZER_BUILDERS) else: raise KeyError(f'{constructor_type} is not registered ' 'in the optimizer builder registry.') def build_optimizer(model, cfg): optimizer_cfg = copy.deepcopy(cfg) constructor_type = optimizer_cfg.pop('constructor', 'DefaultOptimizerConstructor') paramwise_cfg = optimizer_cfg.pop('paramwise_cfg', None) optim_constructor = build_optimizer_constructor( dict( type=constructor_type, optimizer_cfg=optimizer_cfg, paramwise_cfg=paramwise_cfg)) optimizer = optim_constructor(model) return optimizer-
mmcv runner optimizer
# Copyright (c) OpenMMLab. All rights reserved. import copy import inspect from typing import Dict, List import torch from ...utils import Registry, build_from_cfg OPTIMIZERS = Registry('optimizer') OPTIMIZER_BUILDERS = Registry('optimizer builder') def register_torch_optimizers() -> List: torch_optimizers = [] for module_name in dir(torch.optim): if module_name.startswith('__'): continue _optim = getattr(torch.optim, module_name) if inspect.isclass(_optim) and issubclass(_optim, torch.optim.Optimizer): OPTIMIZERS.register_module()(_optim) torch_optimizers.append(module_name) return torch_optimizers TORCH_OPTIMIZERS = register_torch_optimizers() def build_optimizer_constructor(cfg: Dict): return build_from_cfg(cfg, OPTIMIZER_BUILDERS) def build_optimizer(model, cfg: Dict): optimizer_cfg = copy.deepcopy(cfg) constructor_type = optimizer_cfg.pop('constructor', 'DefaultOptimizerConstructor') paramwise_cfg = optimizer_cfg.pop('paramwise_cfg', None) optim_constructor = build_optimizer_constructor( dict( type=constructor_type, optimizer_cfg=optimizer_cfg, paramwise_cfg=paramwise_cfg)) optimizer = optim_constructor(model) return optimizer
위 코드를 보면, torch 에서 optimizer 를 가져옴. optimizer 를 여러개 시험할 때, torch 의 각 Optimizer 가 가지는 argument 들을 주면 될 것으로 예상.
- mmcv의 build_runner 에서 scheduler 또한 정의함. (파이토치)
- 커스텀
param_scheduler = [ # Linear learning rate warm-up scheduler dict( type='LinearLR', # Use linear policy to warmup learning rate start_factor=0.001, # The ratio of the starting learning rate used for warmup by_epoch=False, # The warmup learning rate is updated by iteration begin=0, # Start from the first iteration end=500), # End the warmup at the 500th iteration # The main LRScheduler dict( type='MultiStepLR', # Use multi-step learning rate policy during training by_epoch=True, # The learning rate is updated by epoch begin=0, # Start from the first epoch end=12, # End at the 12th epoch milestones=[8, 11], # Epochs to decay the learning rate gamma=0.1) # The learning rate decay ratio ]custom_hooks- hook 을 따로 주지 않으면 default_hook 이 적용됨.
default_hooks = dict( timer=dict(type='IterTimerHook'), # Update the time spent during iteration into message hub logger=dict(type='LoggerHook', interval=50), # Collect logs from different components of Runner and write them to terminal, JSON file, tensorboard and wandb .etc param_scheduler=dict(type='ParamSchedulerHook'), # update some hyper-parameters of optimizer checkpoint=dict(type='CheckpointHook', interval=1), # Save checkpoints periodically sampler_seed=dict(type='DistSamplerSeedHook'), # Ensure distributed Sampler shuffle is active visualization=dict(type='DetVisualizationHook')) # Detection Visualization Hook. Used to visualize validation and testing process prediction results- custom hook 을 주고,
print(cfg.text)로 확인하면 깔끔하게 cofing를 확인 가능 - default_runtime 에서 log_config 가 수정된다.
checkpoint_config = dict(interval=1) # yapf:disable log_config = dict( interval=50, hooks=[ dict(type='TextLoggerHook'), # dict(type='TensorboardLoggerHook') ]) # yapf:enable custom_hooks = [dict(type='NumClassCheckHook')] dist_params = dict(backend='nccl') log_level = 'INFO' load_from = None resume_from = None workflow = [('train', 1)] # disable opencv multithreading to avoid system being overloaded opencv_num_threads = 0 # set multi-process start method as `fork` to speed up the training mp_start_method = 'fork' # Default setting for scaling LR automatically # - `enable` means enable scaling LR automatically # or not by default. # - `base_batch_size` = (8 GPUs) x (2 samples per GPU). auto_scale_lr = dict(enable=False, base_batch_size=16)- Ignore some fields in the base configs
_delete_=True를 주면 base config 의 일정 부분을 덮어쓸 수 있음.
model = dict( type='MaskRCNN', backbone=dict( type='ResNet', depth=50, num_stages=4, out_indices=(0, 1, 2, 3), frozen_stages=1, norm_cfg=dict(type='BN', requires_grad=True), norm_eval=True, style='pytorch', init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')), neck=dict(...), rpn_head=dict(...), roi_head=dict(...))와
_base_ = '../mask_rcnn/mask-rcnn_r50_fpn_1x_coco.py' model = dict( backbone=dict( **_delete_=True,** type='HRNet', extra=dict( stage1=dict( num_modules=1, num_branches=1, block='BOTTLENECK', num_blocks=(4, ), num_channels=(64, )), stage2=dict( num_modules=1, num_branches=2, block='BASIC', num_blocks=(4, 4), num_channels=(32, 64)), stage3=dict( num_modules=4, num_branches=3, block='BASIC', num_blocks=(4, 4, 4), num_channels=(32, 64, 128)), stage4=dict( num_modules=3, num_branches=4, block='BASIC', num_blocks=(4, 4, 4, 4), num_channels=(32, 64, 128, 256))), init_cfg=dict(type='Pretrained', checkpoint='open-mmlab://msra/hrnetv2_w32')), neck=dict(...))이렇게 하면 덮어씌워진다! 즉 _base_에서 mask-rcnn_r50_fpn_1x 를 불러왔지만, 모델 config 를 HRNet 을 backbone 으로 하는 모델로 교체하는 것!
-
모델 파인튜닝
# optimizer # lr is set for a batch size of 8 optim_wrapper = dict(optimizer=dict(lr=0.01)) # learning rate param_scheduler = [ dict( type='LinearLR', start_factor=0.001, by_epoch=False, begin=0, end=500), dict( type='MultiStepLR', begin=0, end=8, by_epoch=True, milestones=[7], gamma=0.1) ] # max_epochs train_cfg = dict(max_epochs=8) # log config default_hooks = dict(logger=dict(interval=100)),→ 위는 공식문서에서 가져온 것인데, 저렇게 LR 을 두 개 주면, backbone, head 다르게 적용되는지는 아직 모르겠음.
Example 1: >>> model = torch.nn.modules.Conv1d(1, 1, 1) >>> optimizer_cfg = dict(type='SGD', lr=0.01, momentum=0.9, >>> weight_decay=0.0001) >>> paramwise_cfg = dict(norm_decay_mult=0.) >>> optim_builder = DefaultOptimizerConstructor( >>> optimizer_cfg, paramwise_cfg) >>> optimizer = optim_builder(model) Example 2: >>> # assume model have attribute model.backbone and model.cls_head >>> optimizer_cfg = dict(type='SGD', lr=0.01, weight_decay=0.95) >>> paramwise_cfg = dict(custom_keys={ '.backbone': dict(lr_mult=0.1, decay_mult=0.9)}) >>> optim_builder = DefaultOptimizerConstructor( >>> optimizer_cfg, paramwise_cfg) >>> optimizer = optim_builder(model) >>> # Then the `lr` and `weight_decay` for model.backbone is >>> # (0.01 * 0.1, 0.95 * 0.9). `lr` and `weight_decay` for >>> # model.cls_head is (0.01, 0.95).→ 이건 mmcv.runner.optimizer.default_constructor.py 에서 가져온 doc string. 음영 처리된 부분이 backbone, head 다르게 lr 을 줄 수 있는 것처럼 보임.
- 불러오는 config 파일은
- config 파일 구조

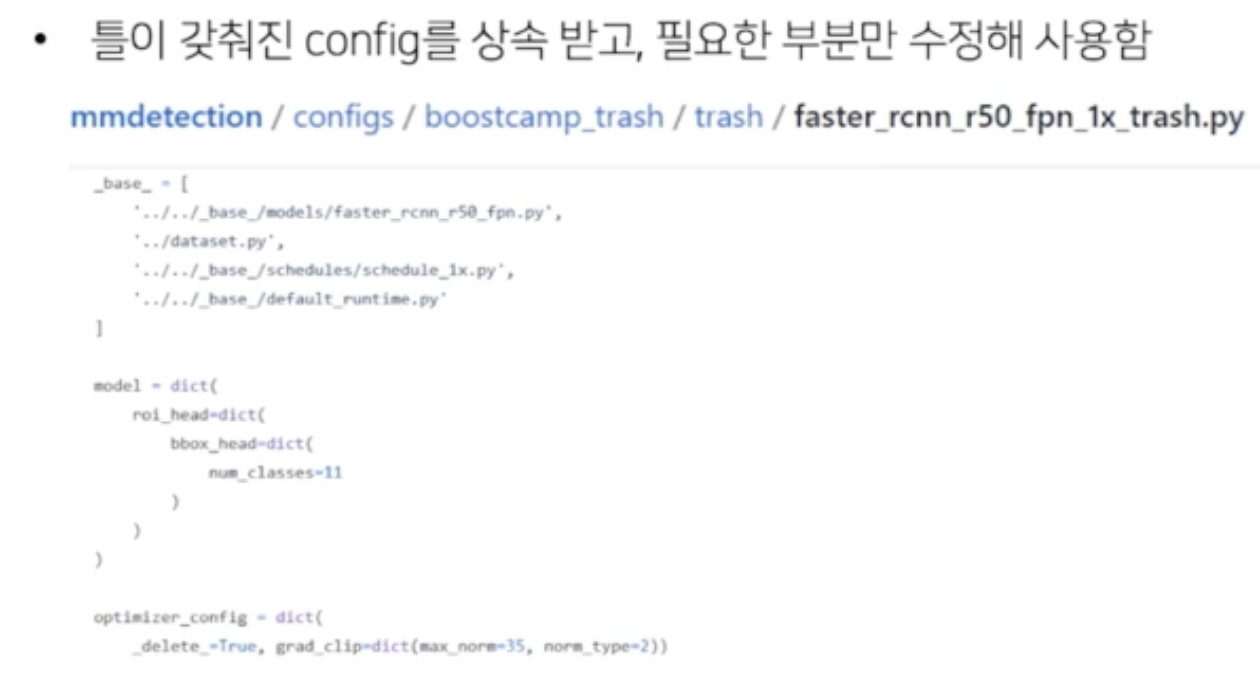
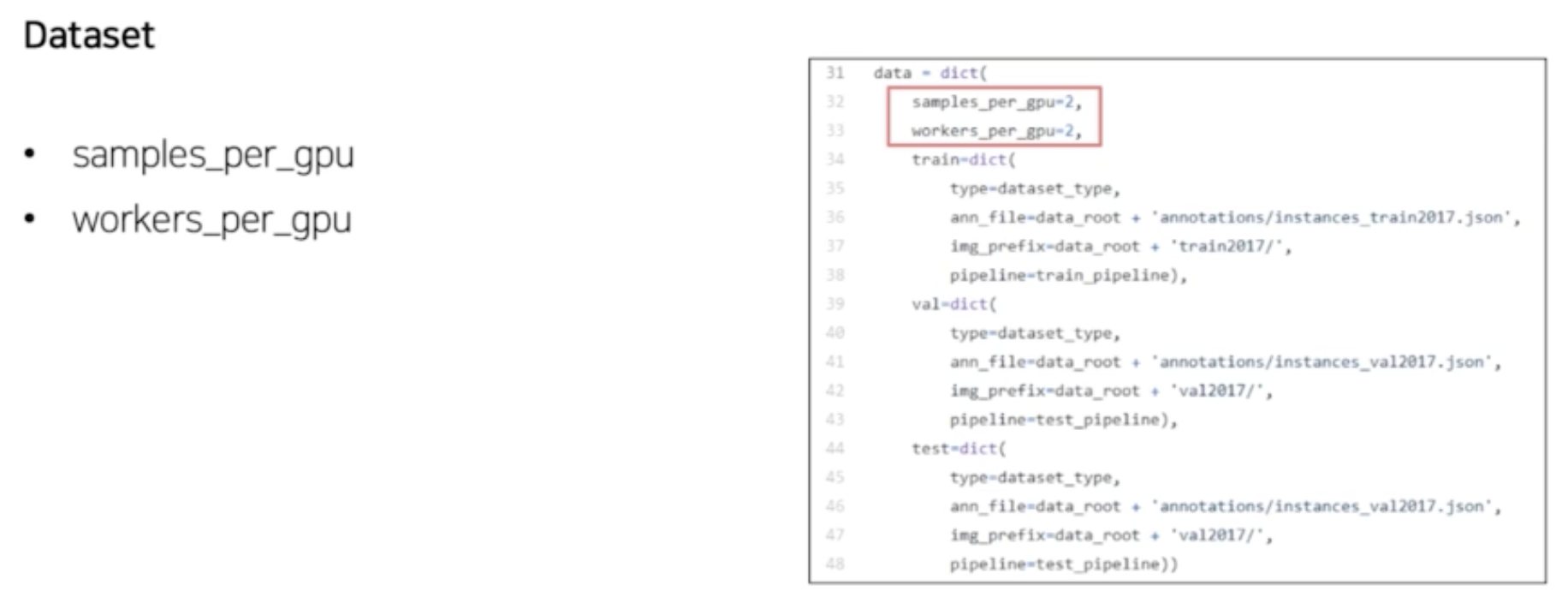
- register module
-
Detectron2
댓글 남기기