
[Object Detection] 2. 2 Stage Detectors
-
2 Stage Detectors
💡 R-CNN은 object detection 분야에 CNN을 적용시킨 2-stage detector의 초기 모델이다. R-CNN 은 다음과 같은 pipeline 으로 동작한다.
- 입력이미지에서 selective search 방식을 통해 약 2k개의 후보 영역(RoI)을 추출한다.
- 추출된 RoI를 CNN에 입력하기 위해 모두 동일한 사이즈로 warping 한다.
- Warping 된 2k개의 RoI를 모두 CNN에 통과시켜 feature vector를 추출한다. 4-1. 총 C+1 개로 classification 할 수 있도록 Linear SVM 을 사용하여 각 영역의 클래스를 예측한다. 4-2. Bounding box regression 을 통해 각 영역의 좌표를 보정하여 bbox 를 예측한다.
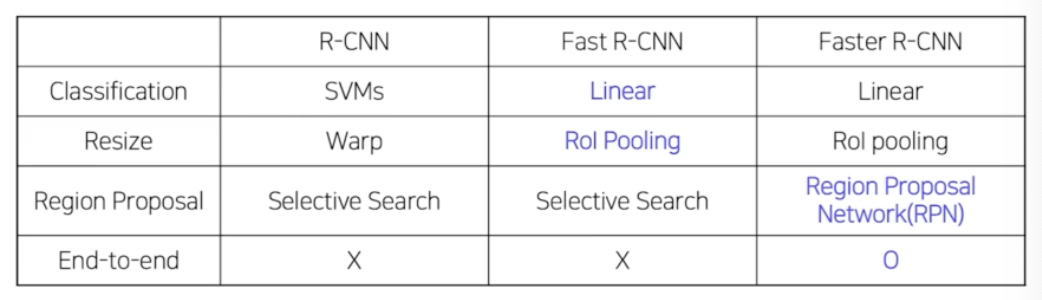
2 stage 초기 모델인 R-CNN은 1) 약 2000개의 RoI 마다 모두 CNN 연산을 따로 수행해야 하며, 2) CNN의 fc layer의 입력 사이즈에 맞추기 위해 RoI를 강제로 warping 해야한다는 단점이 있었다. → Fast R-CNN은 이 단점들을 해결하기 위해 1) 단일 CNN 연산으로 feature map을 추출하고, RoI를 이 feature map상에 매핑하는 RoI Projection 을 사용하여 연산량을 크게 줄였으며, 2) 매핑된 feature map 상의 각 RoI 들을 고정된 크기의 vector로 변환해주는 RoI Pooling 을 사용하여 성능과 속도를 모두 개선할 수 있었다. 즉, Fast R-CNN 은 다음 두가지 모듈을 사용하여 R-CNN 의 단점을 해결.
- RoI projection : 입력 이미지를 통째로 CNN에 통과시켜 feature map을 추출하고, 입력 이미지로부터 따로 추출한 RoI를 feature map 위에 그대로 매핑하는 방법을 사용하여 약 2000번의 CNN 연산을 단 한번으로 줄일 수 있었다.
- RoI pooling : CNN의 fc layer에 입력하기 위해서는 고정된 크기의 벡터가 필요하기 때문에 R-CNN에서는 강제 warping을 사용하였다. 이 방식은 정보 또는 성능의 손실 가능성이 있기 때문에, SPPNet의 아이디어를 차용하여 고정된 크기의 vector로 변환해주는 RoI pooling 방식으로 대체하였다.
Faster R-CNN에서 제안된 RPN(Region Proposal Network)은 convolution 연산을 통해 각 anchor box에 대한 classification과 bounding box 정보를 가지고 있는 feature를 추출한다.
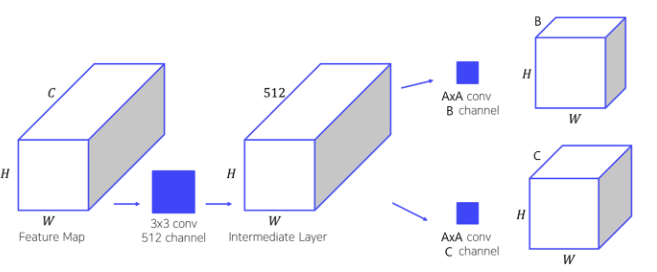
CNN에서 나온 feature map을 input으로 받음 → Input feature map에 3x3x512 convolution을 수행하여 intermediate layer 생성 → Intermediate layer에 AxAxB convolution을 수행하여 binary classification 수행 → Intermediate layer에 AxAxC convolution을 수행하여 bounding box regression 수행
- A: Feature map의 width, height를 유지하며 channel만 변화시키기 위한 1x1 convolution을 사용
- B : Binary classification을 위해 각 anchor box에 대한 2개의 score(object or not)를 출력
-
C : Bounding box regression을 위해 각 anchor box에 대한 4개의 좌표값을 출력
- detection 접근 전략
- 입력 이미지 → 계산(Semantic 정보) → Localization → Classification (2 Stage Detector)
- 지금부터 배울 2 stage model 들은 객체가 있을 법한 위치를 먼저 특정짓고(localization), 해당 객체가 무엇인지(classification)에 대해서 예측. 이 두가지 단계를 거치는 모델을 2 stage detector 라고 한다.
- R-CNN
- 딥러닝을 응용해서 객체 검출을 풀고자 함.
- 초기 모델인 만큼 그 구조가 직관적.
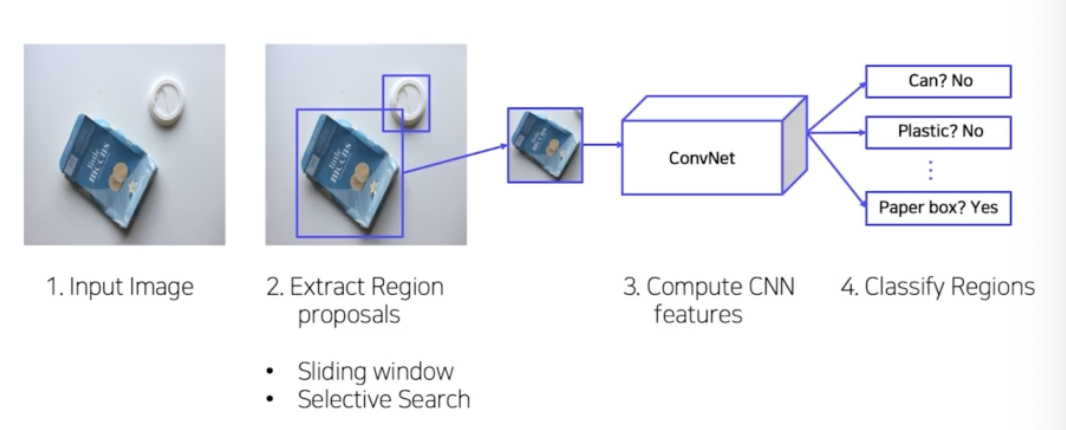
- 사람이 이미지를 보고 판단하는 과정과 다르지 않음.
- 입력이 주어지면, 해당 이미지로부터 객체가 있을 법한 후보 영역에 대해서 예측을 함. 후보 영역을 예측하는 알고리즘에는 sliding window, selective search 등이 있음.
- 예측된 후보 영역을 고정된 사이즈로 resize(warping).
- 고정된 사이즈의 이미지를 사전학습된 CNN 에 넣어서 semantic feature vector 즉 고정된 아웃풋 vector 를 얻고, 이로부터 classification 을 함.
- 객체가 있을 법한 후보 영역을 어떻게 뽑을까?
- Sliding Window
- 여러가지의 sliding window 가 존재. window size 는 다양함.

- 윈도우를 이미지에 sliding 으로 통과시킴. 그렇게 뽑힌 region 들을 후보영역이라고 사용함.
- 이렇게 뽑으면 무수히 많은 후보 영역이 나옴. 실제로 그 무수히 많은 후보 영역이 객체를 포함할 가능성도 매우 낮음. 대부분 다 배경.
- 따라서 이런 식의 후보 영역을 뽑는 알고리즘을 더 이상 R-CNN 에서 사용하지 않음.
- Selective Search
- 이미지가 주어지면 이미지의 색깔, 또는 질감(texture), 이미지의 shape 등 이미지에 존재하는 특성들을 활용해서 이미지를 무수히 많은 작은 영역으로 나누고 이 영역을 점차 통합해가는 방식으로 후보 영역을 추천함.
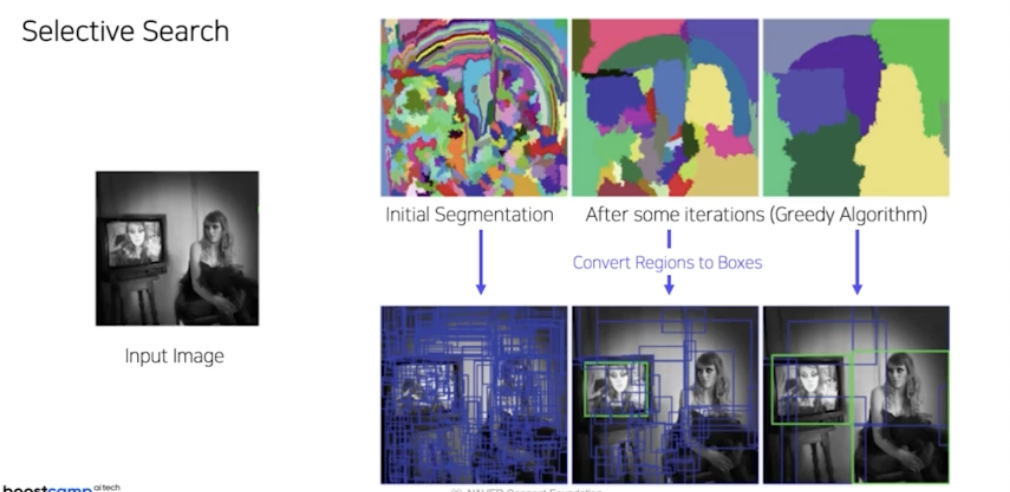
- 정말 많은 후보영역을 그대로 사용하면 sliding window 랑 다를 것이 없음. selective search 로 segmentation 된 영역들을 점차 통합해가면서 줄여나감. 그러면 후보영역이 줄어듦.
- R-CNN 에서는 selective search 방법을 후보영역 추출로 활용함.
- Sliding Window
- Pipeline
- 1) 입력이미지 받기
- 2) Selective search 를 통해 약 2000개의 RoI(Region of Interest)를 추출.
- 무수히 많은 segmentation(selective search 결과)으로 나눠서, 이 영역이 총 2000개가 될 때까지 merge 를 반복. 즉 한 이미지에 2k 개의 후보영역(RoI)을 뽑음.
- 3) 추출된 후보영역은 모두 다른 사이즈를 가짐. 사이즈가 다양하기 때문에 RoI(Region of Interest)의 크기를 조절해 모두 동일한 사이즈로 변형함(Warping). → 이 후보 영역을 이후 CNN 연산을 수행해야하기 때문. CNN 의 마지막 fc layer 의 입력 사이즈가 고정되어 있기 때문에, 따라서 모든 후보 영역의 이미지 사이즈가 같아져야 함. 그래서 Warping 을 진행함.
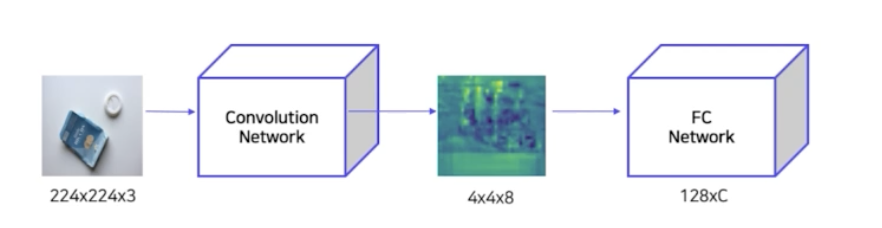
→ 이미지 사이즈가 달라지면 FC layer 에 인풋으로 넣어줄 수 없음. 따라서 이미지 사이즈를 고정되게 만들어주는 Warping 과정이 반드시 필요하게 됨.
- 4) RoI 를 CNN 에 넣어서 feature 를 추출.
- 동일한 사이즈의 2k개 후보 영역이 어떤 객체인지 예측하는 과정이 필요. 이를 위해서 이 후보 영역들을 유의미한 semantic 정보를 포함하고 있는 feature vec로 변환해줘야 함. → 이 과정에서 pretrained 된 AlexNet 이 사용됨.
- 한 이미지에서 2k개의 후보 영역을 뽑고 고정된 사이즈로 Warpping 을 해서 pretrained 된 AlexNet 을 통과해서 총 4096 dim 을 갖게끔 feature vector 로 변환함.
- 5-1) pretrained AlexNet 을 통과한 feature vec 은 semantic 정보를 포함. 이 semantic 정보를 포함하고 있는 2k 후보 영역에 대해서 각각의 cls 를 예측해야 함. 이 cls 예측을 위해서는 linear SVM 알고리즘을 활용함.(R-CNN)
- Output 은 Class(C+1) 와 Confidence score
- 클래수 개수(C) + 배경 여부(1개) = C+1 개로 예측
- 5-2) 후보 영역에 대해서 배경을 포함한 cls 까지 예측함. 마지막으로 selective search 로 나온 후보 영역의 위치를 미세 조정을 해서 정확한 위치로 변환.
- 객체가 존재할만한 위치의 경우, 중심점의 좌표, 가로, 세로의 길이로 객체를 모델에 넣어줌. 이를 bounding box 라고 명명함. selective search 를 통해서 나온 bbox 의 경우 매우 러프함. 즉 객체가 존재할만한 위치를 정확히 예측하는 것이 아니라 대충 예측해주는 알고리즘.
- 따라서 우리가 하는 일은 대충 예측된 bbox 를 gt 에 맞춰서 미세조정을 해주는 regressor 를 학습해야 함.
- bbox 의 중심점을 실제 gt 의 중심점으로 옮겨주고(델타), bbox 의 w와 h 를 gt 와 맞게 변화하는 것(델타)을 학습시켜야 함.
- 정리하면, 입력 → selective search → 2k RoI(per image) → 고정된 사이즈로 Warping → Warped 2k RoI to CNN → 2000 x 4096(2k RoI 의 dim) → SVM 에 넣어서 cls 예측 + localization 수행(bbox regressor)
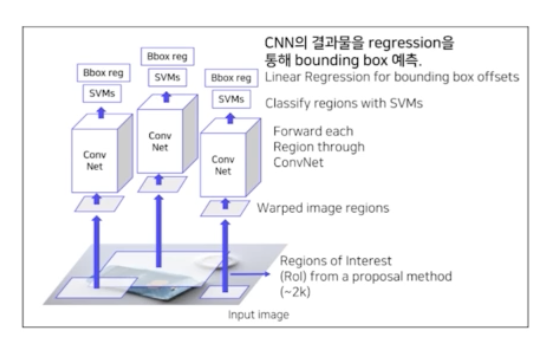
- Training
- AlexNet → domain specific finetuning. gt 와 RoI 를 계산할 때 IoU thr 를 0.5
- Linear SVM → Hard negative mining(배경으로 식별하기 어려운 샘플들을 강제로 다음 배치의 negative sample 로 mining). FP 는 모델이 구분해내기 어려운 샘플들. 이 샘플들을 강제로 다음 배치에 포함시켜 학습시켜서 어려운 샘플도 구분해내도록 하는 것. 실제로 detection 의 2k 의 region 들 중 객체를 포함하는 영역은 매우 적음. 대부분은 다 배경(label 이 0)
- Bbox regressor → IoU 0.6 이상 샘플들을 positive sample 로 이용. 배경(negative sample)들은 bbox 가 없어서 포함시키지 않음. MSE loss 사용. 학습 대상은 중심점을 얼마나 바꿀 것인지(델타), w와 h를 어느정도로 변화시킬 것인지에 대해서 학습함.
- Shortcomings
- 2000개의 Region 을 각각 CNN 통과.
- selective search 를 통해 각각의 2k 개의 후보 영역을 각각 CNN에 통과시켰다는 것이 단점. CNN 연산이 총 2000번 이뤄지는 것. 연산량이 엄청 많은 편. 따라서 속도가 매우 느림
- 강제 Warping, 성능 하락 가능성
- 객체 크기가 정말 다양한데 고정된 사이즈로 맞춘 것. 어느정도 객체 정보가 손실됨. 이에 따른 성능 하락 가능성 있음.
- CNN, SVM classifier, bbox regressor 다 따로 학습
- End-to-End X
- CNN, SVM, bbox regressor 각각 따로 있으니 완벽한 End-to-End 가 아님.
- 2000개의 Region 을 각각 CNN 통과.
- 이후 연구들은 R-CNN 의 한계점들을 개선하는 방향으로 이루어짐.
- SPPNet
- 기존의 R-CNN

- R-CNN 한계점
- CNN 의 입력 이미지가 고정되어 있음. → 이미지를 고정된 크기로 자르거나(crop), 비율을 조정(warp) 해야 한다.
- RoI(Region of Interest) 마다 CNN 통과 → 하나의 이미지에 대해서 2000번의 CNN 을 통과해야함. 시간이 매우 오래걸림.
- SPPNet 은 이 두가지 단점을 개선함.
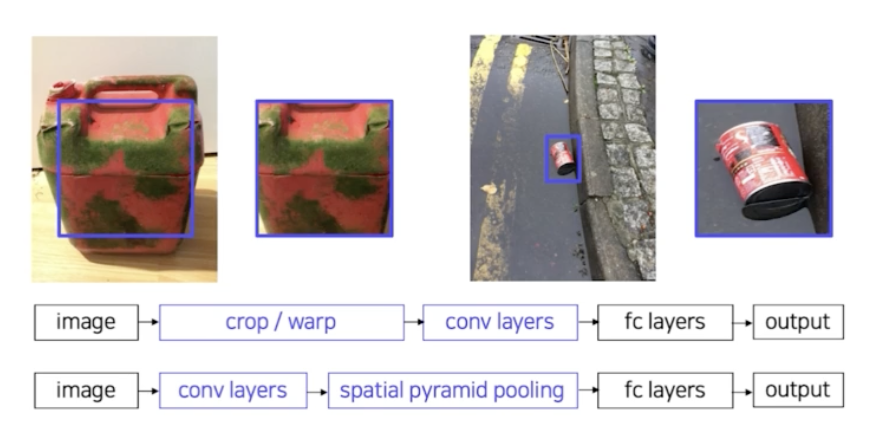
- 이미지를 먼저 CNN 에 통과시킴. 따라서 하나의 고정된 feature map 을 얻음. 즉 CNN 연산을 딱 1번만 수행하게 되는 것.
- 그리고 이 공통 feature map 으로 부터 region 들을 뽑아냄. → 뽑아낸 region 들을 warping 하지 않고, SPPNet 에서 제안한 spatial pyramid pooling(spp) 기법을 써서 warping 을 하지 않고 고정된 사이즈의 feature vector 로 변환하는 방법을 제안함.
- 그 이후 과정은 R-CNN 과 같음.
- Overall Architecture(좌: R-CNN, 우: SPPNet)
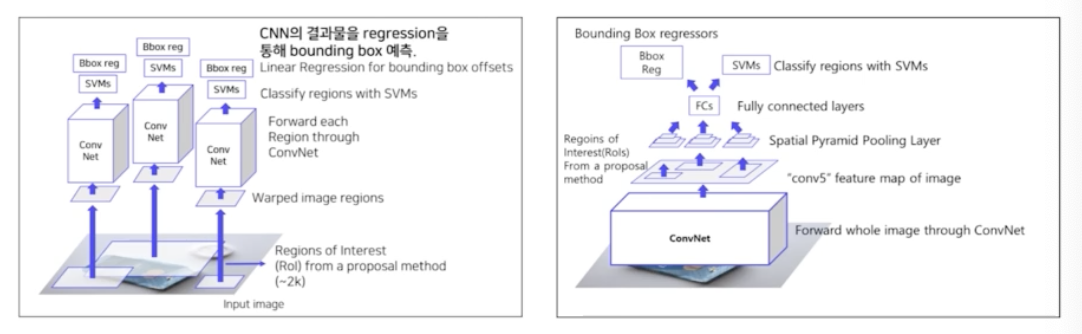
- 가장 큰 차이점은 RCNN 은 2천개의 region 을 뽑고 그 2천개를 2천번의 conv 연산을 함. 반면에 SPPNet 은 한번의 conv 연산을 해서 나온 feature map 으로부터 2000개의 region 을 뽑아냄.
- 두번째 차이점은 RCNN 은 뽑아낸 2k개의 region 을 고정된 사이즈로 warping. 반면에 SPPNet 은 뽑힌 region 들을 warping 하는 것이 아니라 spatial pyramid pooling layer 를 통해서 고정된 사이즈로 변환함.
- SPPNet 을 이해하기 위해 크게 두가지를 이해해야 함.
- 첫번째로 conv 을 통과한 feature map으로 부터 2k개의 region 을 뽑아내는 과정. → Fast RCNN 에서 다루자.
- 두번째로 spatial pyramid pooling layer
- Spatial Pyramid Pooling
- Fast R-CNN 의 RoI projection 이라는 방법을 통해서 feature map 으로부터 2k 개의 RoI 를 뽑아냄. 고정된 사이즈가 아니라 객체의 크기에 따라서 다양한 사이즈로 이루어져 있음(RoI). 이를 고정된 사이즈의 feature vec 으로 변환하기 위해서 spatial pyramid pooling layer 를 통과해야 한다.
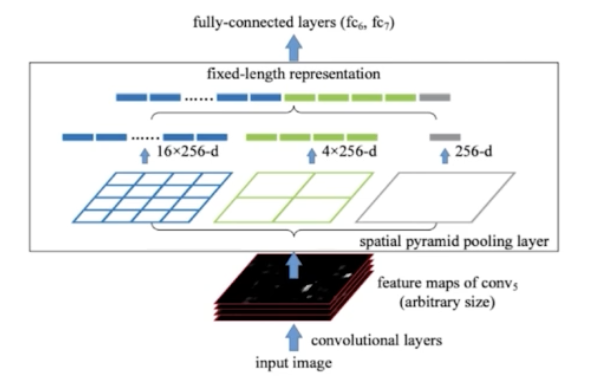
- target bin size 를 먼저 지정함. feature map 으로부터 RoI 사이즈가 다양한데, 다양한 RoI 로부터 feature map 의 size 를 정하는 것.
- 위 이미지는, 첫번째로 target feature map size 가 4x4. 두번째는 2x2, 세번째는 1x1.
- 1x1 은 global pooling 을 의미하는 것. 2x2 는 RoI 를 2x2가 되게끔 binning 을 한 다음에 각각의 영역에 대해서 pooling 을 진행해서 총 4개의 feature 를 뽑아내게 되는 것.
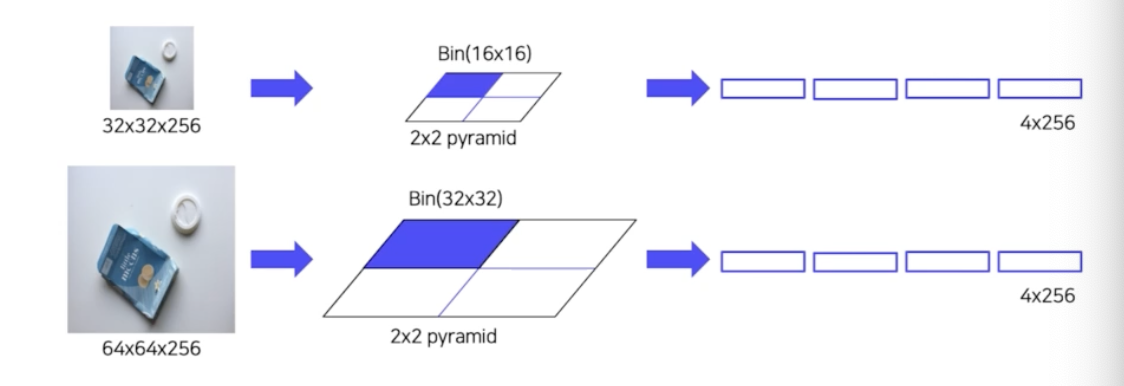
- 2개의 RoI 가 존재할 때, 첫번째는 32x32 shape. 두번째는 64x64. 첫번째 RoI를 target size 가 2x2. 첫번째 RoI 를 2x2 로 binning 하기 위해서는 각각의 셀이 16x16 으로 binning 함. 그래서 target size 에 맞게끔 input feature map 을 binning 하는 것. 그렇게 될 때 16x16 의 셀에서 max pooling 을 하든 average pooling 을 하든 하나의 feature 를 뽑음. 그러면 각 영역마다 하나씩 뽑힘. 4개의 16x16 영역에서 뽑히는 것. 총 4개의 feature 가 나옴.
- 반면에 64x64 는 target size 를 2x2 로 binning 하려면 각 셀마다 32x32 로 binning. 각 셀마다 하나의 feature 를 뽑아냄. 그렇게 되면 input size 즉 RoI size 가 어떻게 되든지 간에 고정된 feature size 를 뽑아낼 수 있게 됨.
- 이런 식으로 target size 를 1x1, 2x2, 4x4, 16x16 이런 식으로 pyramid 형식으로 배열해서 feature 를 뽑아내고, concat 을 해서 고정된 사이즈의 feature vec 으로 변환함.
- 이렇게 고정된 size 의 feature vec 이 fully connected layer 에 통과되면 앞서 RCNN 에서 warping 한 효과와 같은 결과를 가져오게 되는 것.
- SPP는 2k 개의 RoI 를 각각 CNN 통과시키지 않고, 먼저 CNN 을 통과해서 RoI 를 뽑아내고, warping 을 하지않고 SPP 를 활용해서 고정된 feature vec 으로 변환.
- 그렇게 해서 RCNN 의 각각의 CNN 을 통과(2k) 한다는 단점과 강제 warping 으로 정보 손실 가능성이 있다는 단점을 해결했다.
- 그러나 아직, CNN, SVM classifier, bbox regression 모두 따로 학습한다는 단점과 End-to-End 학습이 안된다는 단점은 해결되지 않았음.
- Fast R-CNN
- CNN, SVM classifier, bbox regression 모두 따로 학습한다는 단점을 해결하기 위해서 등장함.
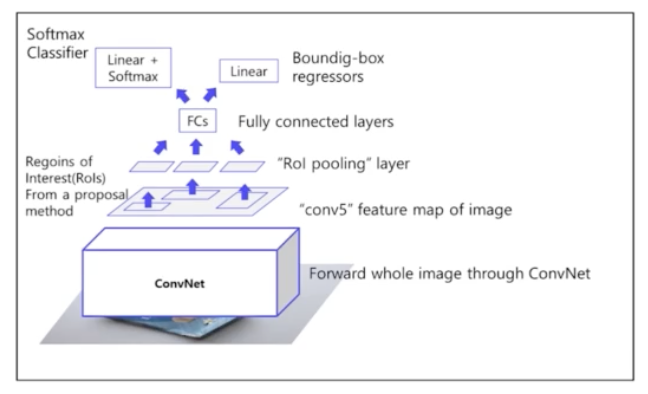
- SPPNet 과 크게 다르지 않음.
- 이미지 → CNN(고정된 feature map) → RoI → RoI Pooling(spp 와 다름) → 고정된 size 의 feature vec → fc layer → (softmax layer → classifier) / (bbox regressor)
- Pipeline
- 1) 이미지를 CNN 에 넣어 feature 추출(CNN을 한번만 사용) → backbone CNN 으로 VGG16 사용.
- 2) RoI Projection 을 통해 feature map 상에서 RoI 를 계산 → feature map 상에서 RoI 를 뽑아냄. RoI projection 을 통해서 뽑음. RCNN 에서는 원본이미지의 색, 텍스쳐 이런 기타 정보를 통해서 selective search 를 했고 이에 따라 RoI 를 뽑아냄. 하지만 Fast RCNN 의 경우 원본 이미지가 아니라 feature map. feature map 이기 때문에 selective search 방법을 feature map 에 그대로 적용하는 것이 불가능. 따라서 feature map 으로 부터 RoI 를 어떻게 뽑아내는지는 projection 이라는 용어에 힌트가 있음. 원본 이미지로부터 selective search 를 진행하는 것은 똑같음. 원본 이미지로부터 2k 개의 RoI 를 뽑아내고 이렇게 뽑힌 2k 개의 RoI 를 feature map 상에서 projection 함.
-
RoI projection
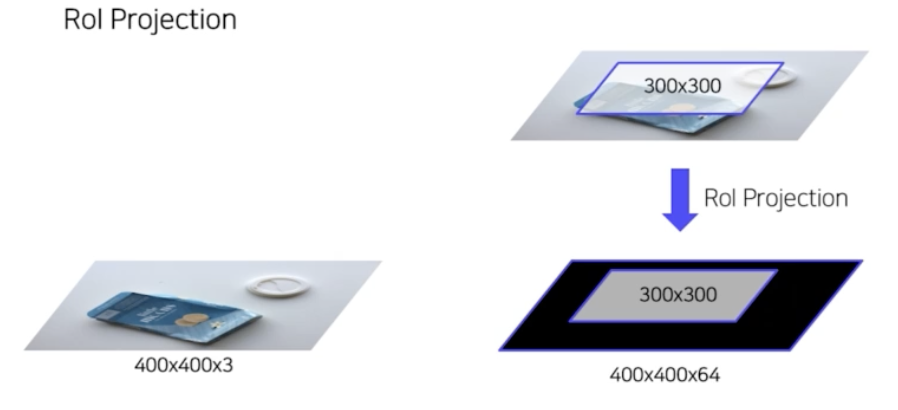
- 원본 이미지로부터 selective search 를 통해 2k 개의 region 을 뽑아내고, 원본이미지를 CNN 을 통과시켜서 feature map 을 얻고, feature map 의 영역에 그대로 selective search 에서 만든 region(RoI) 을 투영시킴. 그러면 feature map 으로 부터 RoI 를 계산할 수 있게 됨.
- 중심점과 w, h 를 그대로 feature map 에 RoI 를 projection 하게 되면 그대로 feature map 에서 RoI 가 나옴.

- 그러나 만약 CNN 을 통과해서 feature map 이 원본 이미지의 사이즈보다 줄어들었을 때, RoI 를 그대로 투영시키면 region 이 feature map 보다 사이즈가 커지게 됨. 따라서 region 의 사이즈도 비율에 맞춰서 축소시켜줌.
- 그렇게 축소된 region 들을 그대로 projection. 이렇게 RoI projection 을 통해서 feature map 으로부터 다양한 사이즈의 RoI 를 뽑아낼 수 있음.
- 3) RoI Pooling 을 통해 일정한 크기의 feature 가 추출
- RoI 들을 고정된 사이즈의 feature vec 로 추출하는 것.
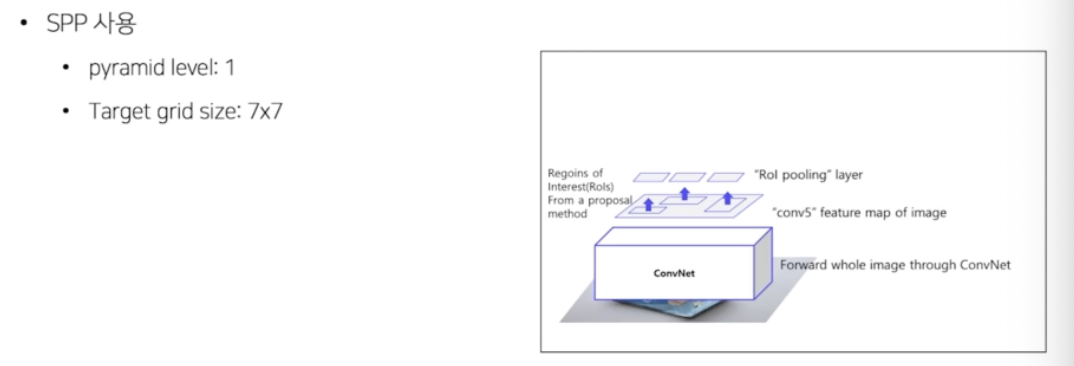
- 이 과정에서 RoI Pooling 을 이용. 이는 SPP 와 완벽하게 똑같음. 다만 SPP 는 pyramid 사이즈가 target size 가 1x1, 2x2, 4x4 등으로 여러가지 였는데, RoI Pooling 은 target 사이즈가 7x7 하나만 이용을 하게 됨.
- RoI Pooling

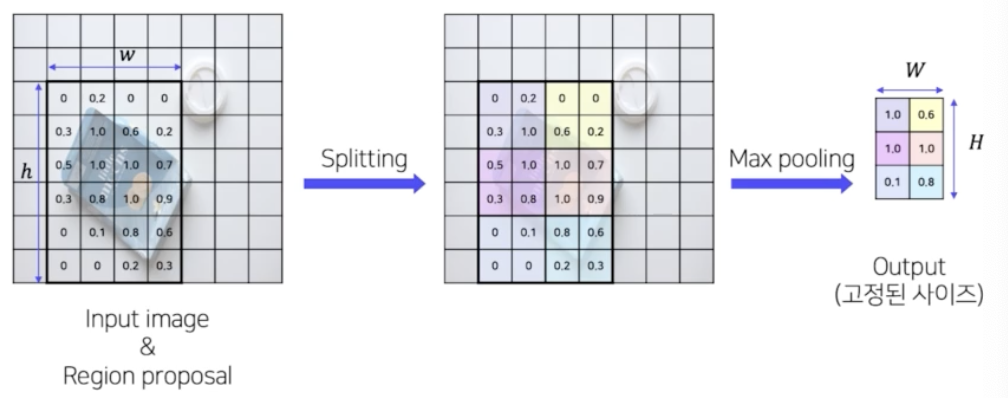
- output 사이즈에 맞춰 region 을 binning 을 하고 각 셀마다 max 혹은 average pool 을 해서 고정된 사이즈의 output vec 으로 뽑아냄. spp 와 완벽하게 동일함.
-
4) Fc layer 이후 softmax classifier 와 bounding box regressor
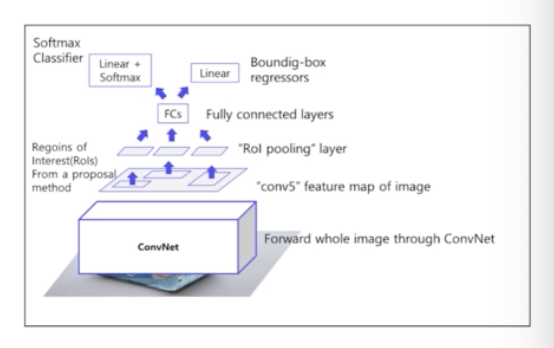
- RoI Pooling 으로 뽑힌 feature vec 으로부터 softmax classifier 를 통과함. 클래스의 개수 + 배경 여부로 C+1 개
- bbox regressor 도 같이 통과함.
- Training
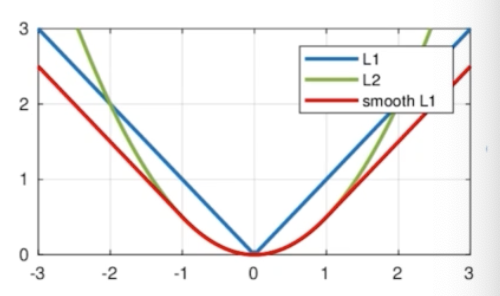
- multi task loss 사용
- classification loss(CE) + bbox regression loss(Smooth L1)
- Smooth L1 이 일반적인 L1, L2 보다 outlier 에 덜 민감하다고 알려짐.
- RCNN 과 다르게 Fast RCNN 은 End-to-End 구조.
- selective search 과정을 제외한 CNN 부터 softmax classifier, bbox regression 모두 하나의 neural network 로 구성됨.
- Dataset 구성
- 2k 개의 region 들 중에서 gt 와 RoI 를 계산했을 때
- IoU > 0.5 : positive sample
- 0.1 < IoU < 0.5 : negative sample
- Positive sample 25%, negative sample 75% (1 batch 안에)
- Hierarchical sampling 활용
- RCNN 은 이미지에 존재하는 RoI 를 전부 저장해서 사용. RoI 묶음에서 positive RoI, negative RoI 를 뽑아서 하나의 배치 안의 각 RoI 에서 이미지들이 막 섞인 경우가 많았음.
- 그러나 Fast RCNN 부터는 하나의 배치 안에서 하나의 이미지의 RoI 만을 포함함. 한 배치 안에서 같은 이미지에 대한 연산과 메모리를 공유
- multi task loss 사용
- Shortcomings
- CNN, SVM, bbox regressor 를 따로 학습하는 RCNN 의 한계점을 해결함. 거의 End-to-End.
- 그러나 완벽한 End-to-End 가 아님. Fast RCNN 은 selective search 를 통해서 region 을 추출하기 때문에 selective search 는 cpu 상에서 돌아가는 알고리즘.
- 따라서 학습 가능한 알고리즘이 아니라 cpu 상에서 돌아가는 알고리즘이라 진정한 end-to-end 라고 말하기 어려움.
- 따라서 selective search 한계에서 벗어나서 아예 region 자체를 추천해주는 Region Proposal Network, 즉 딥러닝 기반의 region 을 추천해주는 네트워크를 이용. 그것이 바로 Faster R-CNN
- Faster R-CNN
- Fast R-CNN vs. Faster R-CNN
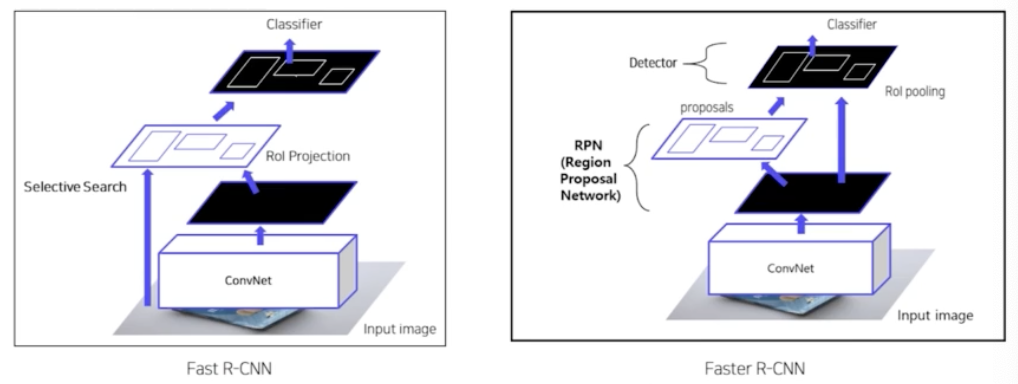
- 큰 차이는 없음. Fast RCNN 에서 selective search 로 region 을 추출하는 부분을 Faster RCNN 에서는 제거하고, 그 대신에 Region Proposal Network 라는 딥러닝 기반의 네트워크 도입. 따라서 RPN 도 학습가능한 형태로 바꿔준 것. 즉, End-to-End 로 모델을 디자인 한 것.
- RPN 이 selective search 를 대체하게끔 구성한 것이 Faster R-CNN. 즉 RPN 이 추가된 것.
- Pipeline
- 1) 이미지를 CNN 에 넣어(backbone) feature maps 추출(CNN을 한번만 사용)
- 2) RPN 을 통해 RoI 계산 (region 을 뽑아내는 것)
- 기존의 selective search 대체
- Anchor box 개념 사용
-
Anchor box
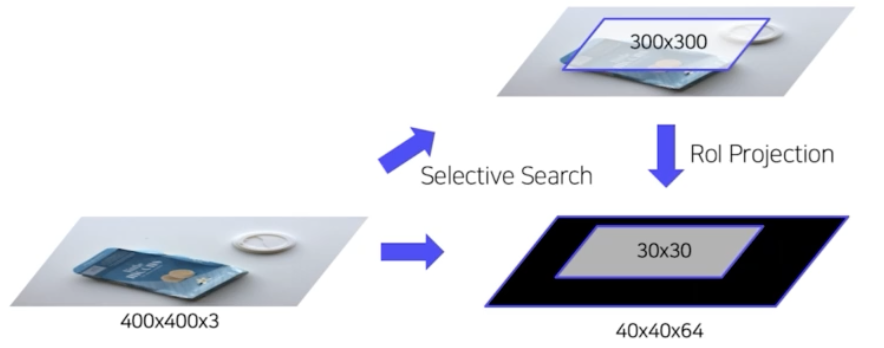
- Fast R-CNN 은 위 이미지처럼 RoI projection 을 진행했음. selective search 를 통해서 원본 이미지로부터 region 을 뽑아내고, CNN 을 통과해서 얻은 feature map 위에 원본 region 을 projection 해서 RoI 를 뽑아냈음. (RoI Projection)
- 그러나 RPN 에서는 selective search 가 사라짐. 원본 이미지로 CNN feature map 을 얻는 것은 동일한데, 이 CNN feature map 으로부터 어떻게 region 을 뽑아낼 수 있을까?
- 가장 쉬운 방법은 feature map 의 각 셀마다 박스 하나씩 포함하고 있다고 예측할 수 있음. 이렇게 되면 큰 단점은 박스 크기가 무조건 고정됨(셀 하나당 박스 하나라면). 그러면 고정된 크기를 넘어서는 객체에 대해서는 대응을 할 수 없게 됨.
- 따라서 각 셀마다 다양한 크기의 box 를 또는 다양한 비율의 box 를 미리 정의해둘 수 있음. 이렇게 정의된 박스가 Anchor box. 즉 각 셀마다 scale 을 다르게 두고 비율을 다르게 둬서(가로, 세로) 각 셀마다 N 개의 anchor box 를 미리 정의할 수 있음.
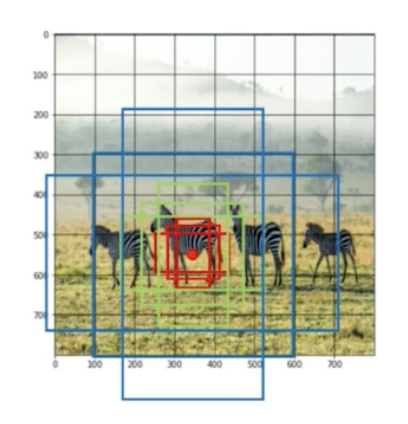
- 그렇게 되면 고정된 크기가 아닌 객체의 사이즈가 다양하더라도, 객체의 사이즈가 작으면 작은 anchor box 로부터, 크면 큰 anchor box 로부터 객체의 크기에 대한 대응이 가능해짐.
-
Region Proposal Network (RPN)
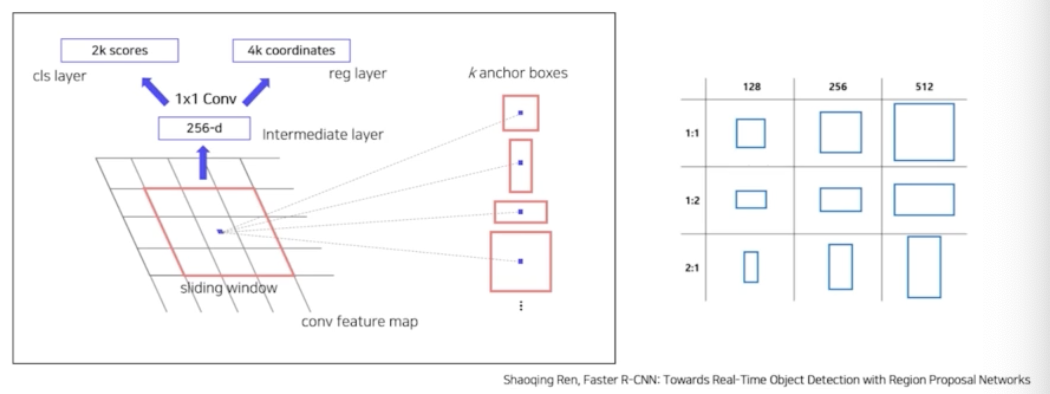
- CNN 을 통과한 feature map의 각 셀마다 다양한 scale 과 비율을 가진 k 개의 anchor box 가 존재하게 되는 것.
- feature map 이 64x64 이고, 9개의 anchor box 를 사용한다면 총 64x64x9 해서 36,000 개의 RoI 가 생김. 그렇게 되면 anchor box 가 너무 많음. Fast RCNN 과 RCNN 은 2k 개의 RoI 를 활용했음.
- 또한 각 anchor box 마다 객체를 매우 러프하게 포함하고 있음. 즉 정확하게 anchor box 가 객체를 포함하는 것이 아님.
- 이 anchor box 들을 대상으로 이 anchor box 가 객체를 포함하고 있는지 아닌지 솎아 내야 하고, 이 anchor box 의 좌표를 미세조정을 할 필요가 있음. ⇒ anchor box 를 솎아내는 네트워크가 RPN. 앵커박스들 중에서 top N 개만 쓰고 싶기 때문에 앵커 박스에 score 를 매겨줘야 함. 이런 score 를 매겨주는 과정이 RPN 이 담당하는 것.
- 즉, RPN 이 하는 일은 anchor box 들이 1) 객체를 포함하고 있는지 예측을 하는 판단 근거를 주고, 2) 만약 객체를 포함하고 있다면 구체적으로 이 anchor box 의 bbox 를 어떻게 미세조정 해야할지 예측하는 일을 함.
- 다시 정리하면, 이미지마다 feature map 이 존재하고, 각 feature map 의 각 셀마다 k 개의 anchor box 가 존재할 때, RPN 이 하는 일은 anchor box 가 객체를 포함하는지를 판단하고, 만약 포함하고 있다면 구체적으로 중심을 얼마만큼 이동하고 w, h 는 얼만큼 이동할지 미세조정을 예측하는 일을 함.
- RPN 은 예측을 위해서 각 픽셀 별로 2개의 head를 통과함.
- k 개의 anchor box 가 있을 때 각 anchor box 가 객체를 포함하고 있는지 아닌지를 예측하는 classification head 가 있음. 또 각 anchor box 의 위치를 미세조정하는 coordinates head 가 존재함.
- 정리하면, 미리 정의된 anchor box 들을 대상으로 객체 여부 score 를 계산하고(classification head), bbox 의 위치 즉 중심점을 얼마나 옮겨야 하는지, 가로와 세로는 얼마나 바꿔야 하는지 예측(coordinates head)을 RPN 이 담당함.
- Faster R-CNN 에서는 총 3가지 scale, 3가지 비율을 포함한 9개의 anchor box 를 이용함. 이후에 이 anchor box 개념이 계속 사용되기 때문에 이해를 꼭 할 것.
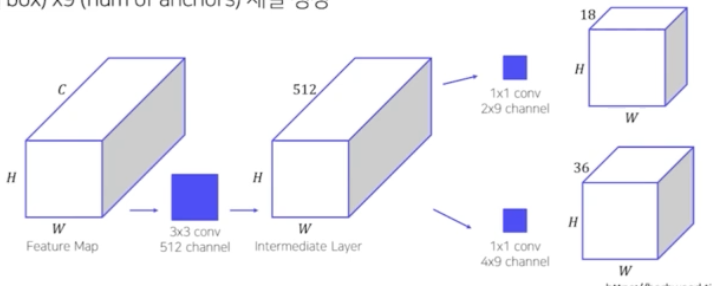
- 다음과 같이 원본 이미지가 backbone 을 통과한 feature map, 즉 CNN 에서 나온 feature map 을 input 으로 받음.
- 이 feature map 으로 부터 3x3 conv 를 수행하여 intermediate layer 를 생성함.
- intermediate layer에서 1x1 conv 를 수행하여 binary classification 을 수행. 즉, 하나의 cell 마다 총 18개의 channel 로 conv 를 수행함. object 여부를 판단하는 2가지, anchor box의 개수 9가지 해서 총 18개의 channel로 conv 연산을 수행함. → 각 픽셀별로 9개의 anchor box 가 객체인지 아닌지를 channel 에 정보가 포함되어 있는 것.
- intermediate layer 에서 1x1 conv 를 수행하여 bounding box regression 을 수행. bbox 예측을 위해서 channel 을 36개로 예측함. 왜 36이냐하면 각 anchor box 별로 중심점의 좌표 x, y, 그리고 가로와 세로 w, h 총 4개의 값을 예측. 그리고 anchor box 가 총 9개 존재하기 때문에 4x9 로 36 channel.
- 이 두 과정을 통해서 각 픽셀 별로 9개의 anchor box 에 대해서 객체를 포함하고 있는지 여부와, 만약 포함하고 있다면 anchor box 를 어떻게 미세조정해야하는지 예측하는 것을 RPN 이 담당하는 것.
-
다시 정리
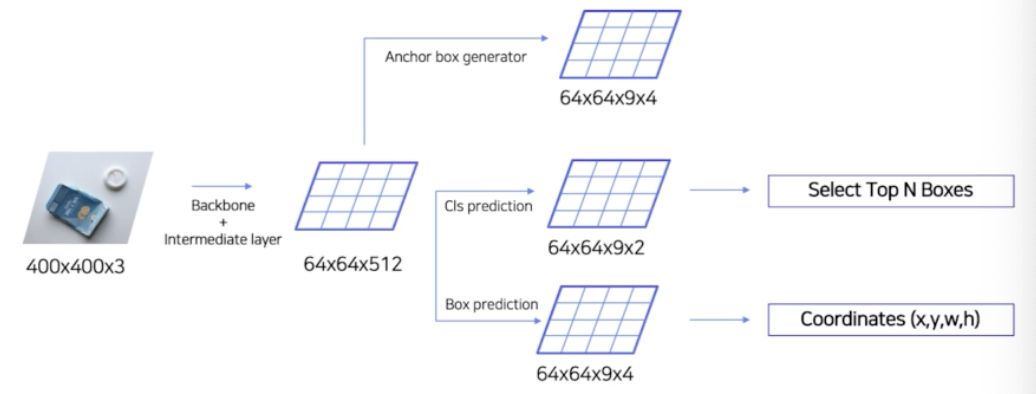
- input image 가 존재할 때, input image 가 backbone network(CNN) 을 통과해서 feature map 이 나옴.
- 그 feature map shape 이 64x64x512 라면, 각 셀마다 먼저 anchor box 를 generation 할 수 있음. anchor box generator 가 anchor box 를 만듦.
- 각 셀 마다 9개의 anchor box 를 만들기 위해 anchor box generator 를 통과한 anchor box shape 은 64x64x9x4. 9개의 anchor box 와, 중심점(x, y), w, h 를 가지기 때문에 4 도 곱해줌.
- 64x64x512 feature map 으로부터 classification head 와 bbox head 를 통과시켜줌.
- 동시에 anchor box generator 가 만든 anchor box 를 전부다 활용하면 좋지만 그러면 Fast R-CNN 에 넘겨지는 RoI 가 너무 많아져서 앵커박스를 평가할 만한 RPN 가 필요함. 즉, RPN 이 하는 일은 각 앵커박스에 대해서 score 를 매겨주고 각 앵커박스의 위치를 세부적으로 조정함.
- cls head 같은 경우 9개의 anchor box 에 대해서 객체를 포함하고 있는지 아닌지(2)를 예측. 따라서 cls head 의 channel 은 18
- bbox regressor 는 9개의 anchor box 에 대해서 anchor box 의 위치 즉 중심점은 얼마나 바꿀지, w와 h 는 얼마나 바꿀지(4)를 예측함. bbox regressor 의 channel 은 36
- 각 픽셀 별로 9개의 anchor box 가 존재하고 9개의 anchor box 가 객체를 포함하는지 여부를 예측하는 cls head, 9개의 anchor box 가 구체적으로 위치를 어느정도 미세조정 해야하는지 위치를 이동시켜주는 box prediction head
- 2가지 head 를 통과했을 때, cls head 를 통과하면 약 3.6k 개의 anchor box 들 중에서 각각 anchor box 의 score 가 나옴. score 가 높으면 이 anchor box 는 객체를 포함할 확률이 높다고 하는 것. score 가 낮으면 이 anchor box 가 객체를 포함하고 있지 않을 가능성이 높다고 예측하는 것.
- score 기준으로 쭉 정렬하면 위에서부터 자를 수 있음. 그렇게 Top N 개의 anchor box 를 선정.
- 그렇게 선정된 Top N개의 anchor box 를 대상으로 구체적으로 중심점을 얼마나 옮겨야 하고 w와 h 를 얼마나 늘리고 줄여야 하는지 coordinates 를 적용할 수 있음.
- 그러면 RPN 으로부터 약 N 개의 RoI 즉 w 와 h 가 재조정된 RoI 가 나옴.
- NMS
- RPN 결과 총 N 개의 region 에 대해서 예측함. RoI 를 총 N 개 뽑아낸 것.
- N 개의 RoI 들에는 겹치는 영역이 무수히 많음.
- 따라서 겹치는 영역을 어느정도 줄여줄 필요가 있고, cls score 를 기준으로 proposals 들을 분류를 하고 분류된 RoI 들 중에서 서로 겹치는 것이 70%(IoU ≥ 0.7) 이면 중복된 영역으로 판단하고 box 를 제거하는 과정들이 필요함.
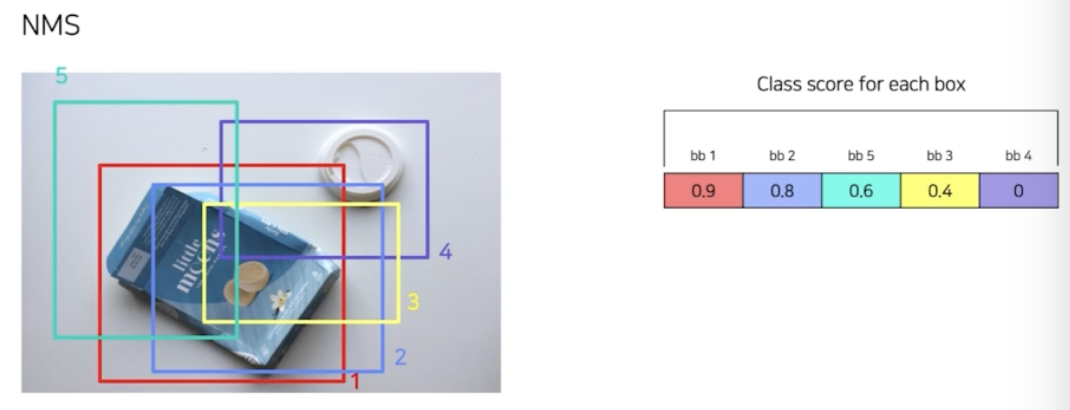
- 위처럼 RPN 결과 5개의 영역이 나왔다고 해보자.
- 5가지 영역에 대해서 각각의 box 에 대한 score 를 계산할 수 있음. 그 score 를 쭉 정렬. 제일 높은 score 의 bbox 를 기준으로 가장 score 가 높으니 그 bbox 와 겹치는 애들을 제거하게 되는 것.

- 위 그림에서는 bb1 을 기준으로 IoU score 를 계산하게 됨.(겹치는 정도)
- bb1 과 bb2 는 80% 겹치고, 사전에 nms thr 로 정한 70% 이상이기 때문에, bb2 는 bb1 과 크게 다를 것 없다고 판단하여 bb2 를 없앰. 따라서 bb2 에 대한 cls score 를 0으로 바꿈.
- 다음으로 bb2 는 사라졌으니 bb5 를 기준으로 겹치는 정도를 계산하여 nms 를 할 수 있음.
- 이런식으로 유사한 box 를 제거하는 알고리즘이 NMS 알고리즘.
- RPN 결과로 나온 N 개의 RoI 중에서 NMS 를 통해서 약 1000개 에서 2000개 사이의 RoI 가 나오게끔 NMS 를 수행하는 것.
- Fast R-CNN vs. Faster R-CNN
- input image → CNN → feature map → RPN → N 개의 region(nms 포함) → N개의 region 을 원래 feature map projection → Fast R-CNN 과 동일(bbox regression, softmax classification) ⇒ 최종적으로 객체의 localization 과 classification 을 수행하게 되는 것.
- Training
- Faster R-CNN 에서는 RPN 과 일반적 Fast R-CNN 과 나눠서 학습
- RPN 학습
- RPN 단계에서 classification 과 regressor 학습을 위해 앵커박스를 positive/negative samples 구분 (앵커에 대한 labeling)
- 데이터셋 구성
- IoU > 0.7 or highest IoU with GT : positive samples
- IoU < 0.3 : negative samples (배경)
- Otherwise : 학습데이터로 사용 X
-
Loss
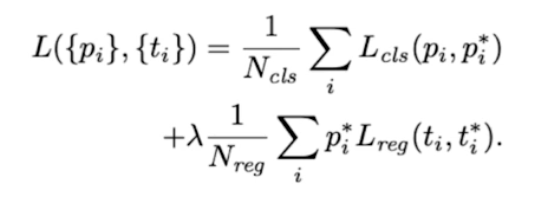
- cls loss, reg loss
- cls loss 는 CE, reg loss 는 MSE loss 를 활용
- reg loss 앞에 $p_i^*$ 가 있는데, 이는 해당 $i$ 번째 앵커 박스가 객체를 포함하고 있는지 포함하고 있지 않은지에 대한 index 지표. 객체를 포함하고 있으면 1, 객체를 포함하고 있지 않으면 0이 됨.
- 따라서 reg loss 의 경우 객체가 있을 때, 즉 객체를 포함하고 있는 positive anchor box 에 한해서만 regression 을 수행함.
- region proposal(RPN) 이후 Fast RCNN 학습을 위해서 똑같이 positive/negative samples 를 구분해야 한다.
- anchor box 들 중에서 IoU > 0.5 : positive sample → 32 개
- IoU < 0.5 : negative samples → 96개
- 128개의 samples 로 mini-batch 구성
- 이 dataset 으로 Fast R-CNN 을 학습함.
- RPN 을 학습하기 위해서 사용하고 있는 IoU 기준과, Fast R-CNN 을 학습하기 위해서 사용하고 있는 IoU 의 기준이 다름.
- Loss 는 Fast R-CNN 과 동일하게 됨.
- RPN 과 Fast R-CNN 학습을 위해서 paper 에서는 4가지 step 의 alternative training 을 활용함.
- step 1) ImageNet pretrained backbone load + RPN 학습
- step 2) ImageNet pretrained backbone load(새롭게) + RPN from step 1 + Fast RCNN 학습
- step 3) step 2 finetuned backbone load & freeze + RPN 학습
- step 4) step 2 finetuned backbone load & freeze + RPN from step 3 + Fast RCNN 학습
- 학습 과정이 매우 복잡함. 최근에는 loss 를 한번에 묶어서 backward 를 시켜버리는 Approximate Joint Training 을 활용 → 즉 step 을 나눠서 학습하지는 않음.
- results
- Faster R-CNN 결과 (mAP(성능), fps(속도))
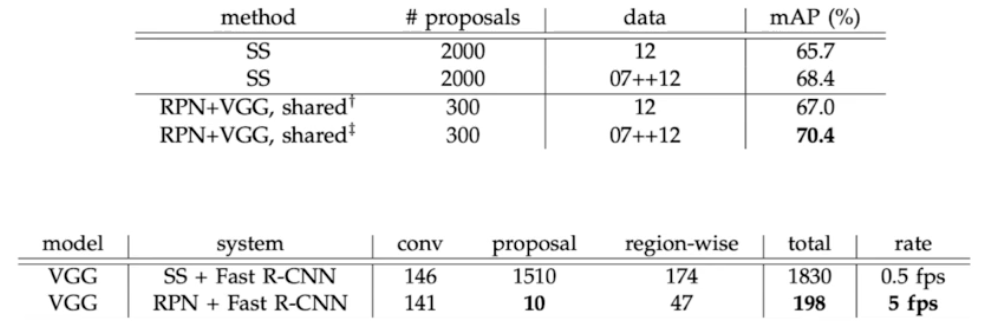
- SS 는 selective search. SS 에서 2k 개의 RoI 를 뽑았을 때의 mAP 보다 RPN 을 써서 300개의 RoI 를 뽑았을 때 score 가 더 높음. 65.7 → 67.0
- 속도 측면에서 fps 를 보면 ss(selective search)를 썼을 때보다 RPN 을 썼을 때 0.5 → 5 fps 로 엄청나게 증가함.
- proposal 이 ss 보다 RPN 이 훨씬 빨라짐. 속도, 성능 측면에서 Faster R-CNN 이 Fast R-CNN 보다 훨씬 우수함.
- 실제 Faster R-CNN paper 에서는, RPN 에서 몇개의 proposal 을 Fast R-CNN 에 넘겨주는지, 앵커 박스에 대한 scale을 어떻게 사용하는지에 따라서 실험 결과가 어떻게 바뀌는 지 ablation study 를 진행함.
- Faster R-CNN 을 살펴봤을 때, R-CNN 의 단점은 모두 해결함.
- 그러나 근본적으로 RPN 에서 나온 RoI 를 추출해야 하고, NMS 과정을 적용함. 그래서 R-CNN 보다 훨씬 성능을 빨라졌지만, 여전히 속도측면에서 한계가 있음. 2 track 으로 이루어져 있기 때문. region 을 뽑아내고 뽑아낸 region 에서 객체에 대한 classification, bbox regression 을 진행함. 따라서 속도에 한계가 있음.
- 그래서 여전히 real-time 활용은 어려움.
- 앞으로는 real-time 에서 detection 을 활용할 수 있을지 살펴볼 것. 2 stage 구조를 아예 새롭게 바꿔버린 1 stage detector 모델을 봐보자.
- 최종 요약
- Faster R-CNN 코드
- albumentation 은 이미지에 transform 을 가하면 bbox 에도 똑같이 transform 이 적용됨. 즉 label 에도 반영이 되는 것. (bbox_params)
- backbone → feature map
- RPN → 2000k region proposal(RoI)
- feature map → base anchor box 를 각 픽셀 별로 생성 → base anchor box 가 엄청 많은데 그것을 걸러내기 위해서 각 앵커 박스에 대해서 score 를 계산. 미세조정할 위치를 계산.
- score 기준으로 N 개를 잘라서, 그 N 개를 region proposal 로 활용하고, 그 N개에 대해서 RoI projection 후 head network 를 통과함.
- 그 과정이 1) Anchor box 생성 2) proposal 생성 3) region proposal network 정의
- Anchor box generator
- 한 픽셀 당 총 몇 개의 앵커박스가 생성되느냐가 generate anchor base 의 역할. ratio 와 scale 정보를 가지고 각 픽셀 별로 base anchor box 를 만듦
- output 은 최종적으로 anchor box 를 출력하고, shape 을 살펴보면 실습코드에서는 (9,4)
- proposal 생성
- Anchor box generator 에서 만든 base_anchor_box 에 대해 1) 미세조정할 위치와 2) base_anchor_box 를 평가할 score 를 예측 하는 2가지 부분을 정의함.
- 앵커박스의 위치를 미세조정하는 박스 정보와, 앵커박스를 걸러낼 수 있는 score 정보로 부터 앵커박스를 필터링하는 과정을 proposalcreator 가 진행함.
- RPN 에서 구한 rpn_loc 와 anchor 박스에서 구한 정보로 최종적으로 줄어든, 필터된 RoI 를 만들어내는 것.
- 많은 앵커박스들 중에서 score 로 바로 필터링 하는 것이 아니라, score 로 어느정도 필터링 하고, nms 과정 이후에 2k 개를 얻어내는 것. 사이에 nms 과정이 있는 것. 최종적으로 2000개를 출력해줌.
- 각 픽셀 별로 앵커박스 9개씩이 들어옴. 앵커박스의 위치를 미세조정할 loc 정보. 앵커박스의 score(object 객체를 담고 있는지)
- 앵커박스의 위치를 미세조정
roi = loc2bbox(anchor, loc) - 미세조정 한 것을 score 기준으로 잘라냄.
- 잘라내고 나서 nms 적용. 그 이후 최종적으로 2000개의 RoI 가 나옴.
- RPN
- 위 과정들을 RPN 에서 실행됨.
- RPN 이 하는 것은 base anchor box 의 위치를 어느정도로 바꿀지 미세조정하는 vector 를 만들어야 하고, 각 앵커박스 별로 score 를 계산한 vector 를 만들어야 함.
self.score가 9x2 로 anchor box 가 object 를 포함하는지 여부를 계산하는 conv2dself.loc가 9x4 로 anchor box 의 위치를 어느정도로 미세조정 할 것인가.- RPN 을 보면 먼저 feature map 을 받음.
- base anchor box 를 전체 픽셀에 확장을 함.
- 각 픽셀별로 bbox offset 계산을 해주는 것이
rpn_locs = self.loc(h) - 각 픽셀별로 score offset 계산을 해주는 것이
rpn_scores = self.score(h) - bbox, score offset 을 anchor box format 에 맞게 reshape 을 해줌.
- 이후 위에서 만든 ProposalCreator 에 넣고 2k 개의 RoI 를 return 받음.
- Faster R-CNN head 정의
RoIHead- 그 전에 RPN 을 통과한 RoI 들로부터 최종적으로 cls 와 bbox 위치를 예측함. 그 부분이 Faster R-CNN head.
- 즉 head 의 목적은 RPN 에서 얻은 RoI 를 projection 후 pooling 하고, 그 pooling 된 고정된 feature vec 으로부터 클래스 예측, 정확한 박스 예측. 즉 classifier, regressor
roi_size는 RoI 를 pooling 할 때 target size. target size 별로 binning 해서 pooling 을 진행하기 때문에 정의해야 함.- torchvision 에서 제공해주는
RoIPool함수 이용. 여기서 projection 까지 같이 진행해줌. - RoI 를 pooling 해주면 고정된 사이즈의 feature vector 를 가짐.
- 이를 flatten 해주고 fully connected 통과 후 classifier(softmax), regressor 를 통과시킴.
- output 은 box 정보와 cls 정보가 return 됨.
- 마지막으로 Faster R-CNN 을 정의.
- 지금까지 선언했던 클래스를 통합.
- feature extraction(feature map) → RPN(RoI) → Localization and Classification head
- Trainer 정의 (데이터셋 만들어내는 것)
- RPN 과 RoIHead 를 train 시켜야 함.
AnchorTargetCreator는 RPN 을 train 시켜줌.- anchor box 에 해당하는 GT bbox 를 매치시켜줘야 함.
- anchor box 로부터 어떤 앵커박스가 positive 이고 어떤 앵커박스가 negative sample 인지 계산해줘야 함.
- IoU 를 계산해서 positive sample 과 negative sample 을 만들어냄.
ProposalTargetCreator는 RoIHead 를 학습하기 위함.- RoI 를 positive / negative sample 로 나눔.
FasterRCNNTrainer- RPN loss 2개
- RoI loss 2개
- RPN 과 RoI 에 대해서 모델 weight 를 업데이트
- 각각 vector 들의 shape, 각 모듈들의 의미 들을 잘 보자!!
댓글 남기기