
[Serving] 모델 관리와 모델 평가
ML/AI 서비스에서 모델은 서비스의 핵심 중 하나다. MLOps 에서 알아두면 좋은 모델 관리와 모델 평가 개념에 대해 알아보자.
모델 관리
- 모델 관리 기본은 모델 버전관리다. 어떤 파라미터 조합, 모델 구조 등을 사용했는지 기억해야 모델을 재현할 수 있다.
- 머신러닝 모델링은 많은 실험으로 여러 시행착오를 겪는다. 그 중 가장 성능이 좋았던 모델을 토대로 production(서비스) 에서 사용하게 된다.
- 이러한 실험 중 모델 Artifact, Image 등의 부산물이 생긴다. 그리고 모델은 여러 종류가 될 수 있으며 모델 생성일, 모델 성능, 모델 메타정보 등이 모두 다르기 때문에 기록해야 한다. 더욱이 조직 규모가 커지고 문제를 많이 풀수록 여러 모델을 운영한다.
- 이 관리를 잘하게 되면, 이해 관계자와의 싱크도 이룰 수 있고 팀별로 모델을 만들 때 지켜야 하는 원칙을 준수하는데 도움이 된다.
- 모델 관리에는 기본적으로 아래와 같은 3 가지를 신경써야 한다.
- 모델 메타 데이터
- 모델이 언제 만들어졌고, 어떤 데이터를 사용해서 학습했는지를 저장한 데이터다. 이 때 성능도 같이 저장한다.
- 모델 아티팩트
- 모델 아티팩트란 모델의 학습된 결과물이다. pickle, joblib 등의 모델 파일이 된다.
- Feature / Data
- 모델 학습에 필요한 Feature, Data 다.
- Data 도 레이블링 변경 등의 버전에 따라 업데이트 될 수 있다.
MLflow
- 위 모델 관리를 효율적으로 할 수 있는 도구가 바로 MLflow 다. 관련 오픈소스 중 굉장히 유망하며 Saas 중에 Wandb 가 경쟁 상대다.
- 핵심 기능은 아래와 같다.
- Experiment Management & Tracking
- 머신러닝 관련 실험들을 관리하고 각 실험의 내용들을 기록할 수 있다.
- 여러 사람이 하나의 MLflow 서버 위에서 각자 자신의 실험을 만들고 공유할 수 있다. 이 때 best Model 등의 태그도 설정할 수 있다.
- 실험을 정의하고 실험을 실행할 수 있다. 이 실행은 머신러닝 학습 코드를 실행한 기록으로 남는다.
- 각 실행에 사용한 소스코드, 하이퍼 파라미터, Metric, 부산물(모델 아티팩트, Chart Image) 등을 저장할 수 있다.
- Model Reistry
- MLflow 로 실행한 머신러닝 모델을 Model Registry(모델 저장소)에 등록할 수 있다.
- 모델 저장소에 모델이 저장될 때 마다 해당 모델의 버전이 자동으로 올라간다.
- 모델 저장소에 등록된 모델은 다른 사람들에게 쉽게 공유 가능하고, 쉽게 활용할 수 있다.
- Docker Image 로 올린 서버에서 모델을 빼고, 모델 저장소에서 받아갈 수도 있다. 팀원들이 모델 파일을 필요로 하면 모델 저장소에서 받아가라고 할 수 있다.
- Model Serving
- Model Registry(모델 저장소)에 등록한 모델을 REST API 형태의 서버로 만들어서 Serving 할 수 있다.
- 이 때 API 에서 받은 input 은 Model 의 input 이 되고, output 은 Model 의 output 이 된다.
- 직접 Docker Image 를 만들지 않아도 생성할 수 있다. 따라서 가볍게 쓰기 좋다.
- MLflow 를 사용한 Serving 을 실제로 사용하는 케이스는 꽤 적다. MLflow 는 실험 관리와 모델 저장소로 쓰는 게 일반적이다.
MLflow Core Component
- Tracking
- 머신러닝 코드 실행, 로깅을 위한 API 를 제공한다. 이를 통해 기록할 수 있다.
- 파라미터, 코드 버전, Metric, Artifact 등을 로깅한다.
- 웹 UI 도 제공한다.
- MLflow Tracking 을 사용해서 여러 실험 결과를 쉽게 기록하고 비교할 수 있다. 웹 UI 같은 프론트도 같이 연결되어 시각화에도 좋다.
- 팀에선 다른 사용자의 결과와 비교하며 협업할 때 Tracking 을 사용한다.
- Model Reistry
- 모델 관리를 위한 체계적인 접근 방식을 제공한다.
- 모델 버전 관리에 용이하다. 태그, 별칭 지정, 버저닝, 계보(어떤 흐름으로 이 모델이 만들어졌는지)를 포함한 모델의 전체 수명 주기를 관리한다.
- Projects
- 머신러닝 코드, Workflow, Artifact 의 패키징을 표준화한다.
- 재현이 가능하도록 관련된 내용을 모두 포함하는 개념이다.
MLflow 예제
pip install mlflow을 통해 설치해주고,mlflow server --host 127.0.0.1 --port 8080로 MLflow UI 를 실행한다. 이후localhost:8080으로 MLflow UI 에 접속한다.- Experiment(실험)
- MLflow 에서 제일 먼저 Experiment 를 생성한다. 이는 프로젝트 폴더와 비슷하다.
- 하나의 Experiment 는 진행하고 있는 머신러닝 프로젝트 단위로 구성하는 것이 좋다.
- 정해진 Metric(RMSE, MSE, MAE, Accuracy) 으로 모델을 평가한다.
- 하나의 Experiment 는 여러 Run(실행)을 가진다.
mlflow experiments create --experiment-name my-first-experiment을 통해 Experiment 를 생성한다. 이후ls -al명령어를 사용하면./mlruns라는 폴더가 생기는 것을 확인할 수 있다.mlflow experiments search명령어로 실험의 리스트를 확인할 수 있다.-
아래와 같이 머신러닝 코드를 짜보자. 이 때
.log_param()과 같이 기록할 수 있다.import numpy as np from sklearn.linear_model import LogisticRegression import mlflow import mlflow.sklearn if __name__ == "__main__": X = np.array([-2, -1. 0, 1, 2, 1]).reshape(-1, 1) y = np.array([0, 0, 1, 1, 1, 0]) penalty = "elasticnet" l1_ratio = 0.1 lr = LogisticRegression(penalty=penalty, l1_ratio=l1_ratio, solver="saga") lr.fit(X, y) score = lr.score(X, y) print("Score: %s" % score) mlflow.log_param("penalty", penalty) mlflow.log_param("l1_ratio", l1_ratio) mlflow.log_param("score", score) mlflow.sklearn.log_model(lr, "model") - 프로젝트(MLProject)
- MLflow 를 사용한 코드의 프로젝트 메타 정보를 저장하는 파일이다.
- 프로젝트를 어떤 환경에서 어떻게 실행시킬지 venv, conda, docker 등을 정의한다.
- 패키지 모듈의 상단에 위치하고, 같은 폴더에
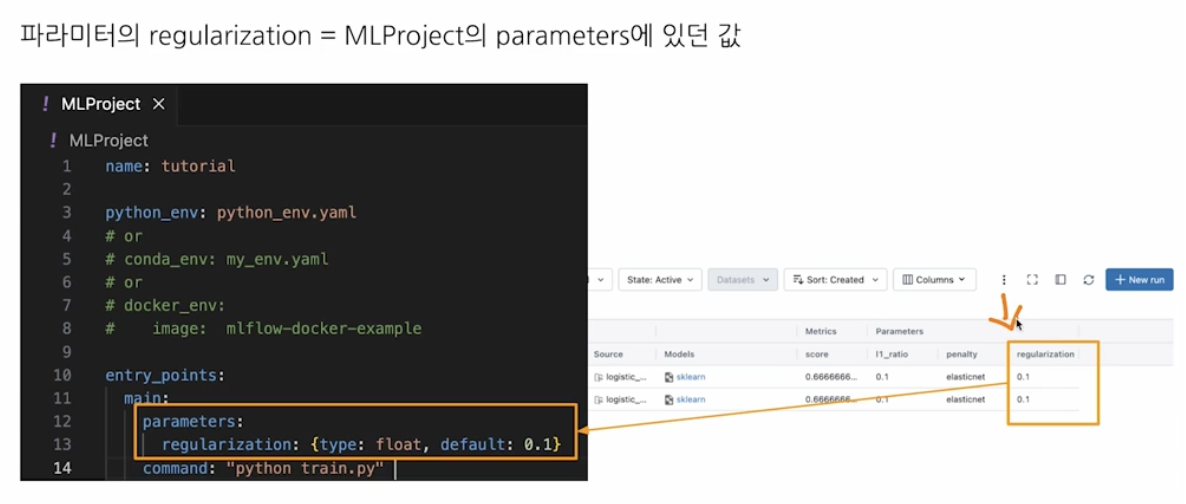
MLProject,python_env.yaml을 아래와 같이 정의한다. - 아래의 MLProject 에서
entry_points는 어떤 걸 실행할 것인지와 커맨드 위치를 지정한다.
name: tutorial python_env: python_env.yaml # or # conda_env: conda_env.yaml # or # docker_env: # image: mlflow-docker-example entry_points: main: parameters: regularization: {type: float, default: 0.1} command: "python train.py"- 그리고
python_env.yaml은 어떤 python 환경에서 실험을 실행할 것인지를 적어준다.python_env.yaml을 실행하면 적혀있는대로 가상환경을 만들어서 실행하게 된다.
python: "3.9.13" # 패키지를 빌드할 때 필요한 dependency(Optional) build_dependencies: - pip - setuptools - wheel==0.37.1 # 프로젝트 실행할 때 필요한 dependency dependencies: - mlflow==2.10.0 - scikit-learn==1.4.0 - pandas==2.2.0 - numpy==1.26.3 - matplotlib==3.8.2 - Run
- 하나의 실험 안에 여러 실행(Run)이 있다. 하나의 Run 은 코드를 1 번 실행한 것을 의미한다. 보통 Run 은 모델 학습 코드를 실행한다.
- 즉, 한번의 코드 실행을 위해서 하나의 Run 을 생성해야 한다.
- Run 을 하면 여러 가지 내용이 기록된다. MLflow 에 logging 했던 내용들이 기록된다.
- Source : 실행한 Project 의 이름
- Version : 실행 Hash
- Start & end time
- Parameters : 모델 파라미터
- Metrics : 모델의 평가 지표, Metric 을 시각화할 수 있다.
- Tags : 관련된 Tag
- Artifacts : 실행 과정에서 생기는 다양한 파일들(이미지, 모델 Pickle 등)
mlflow run logistic_regression --experiment-name my-first-experiment와 같이 명령어를 입력하면 Run 으로 실행하게 된다.- 이 때
python_env.yaml에 정의된 가상환경을 생성하고 실행한다. - 옵션으로 아무것도 주지 않으면 가상환경을 만든다. 만약 가상환경을 만드는 시간이 길다면,
--env-manager=local옵션을 주면 된다. - 즉, 가상환경을 추가로 생성하지 않고 내가 지금 사용하고 있는 local 터미널에서 실행하는 것이다.
- 이 때
- 이처럼 Run 은 커맨드를 실행할 때 argument 를 포함해서 넘겨주지 않아도, MLProject 에서 포함하기 때문에 Run 마다 적용될 수 있도록 한다. 이러한 방식으로 원하는 파라미터를 사용할 수 있다는 것이다.
-
아래 그림과 같이 UI 에서 기록된 데이터들을 표시하도록 할 수 있다.
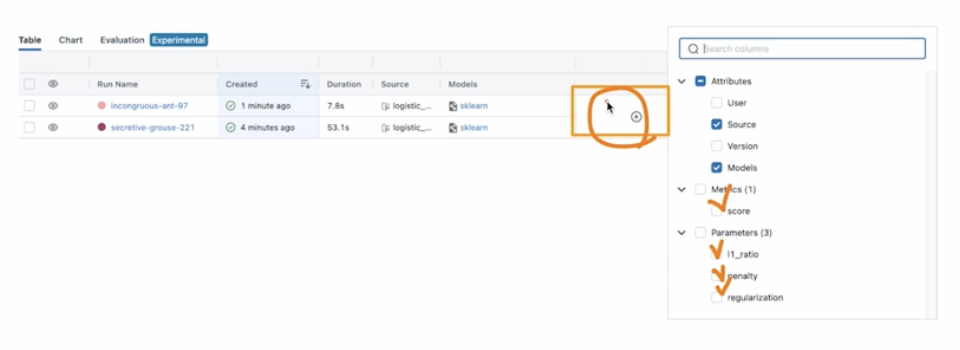
-
이는 만들어준 머신러닝 코드에서
log_param으로 로깅했던 값들이 UI 에 기록되는 것이다.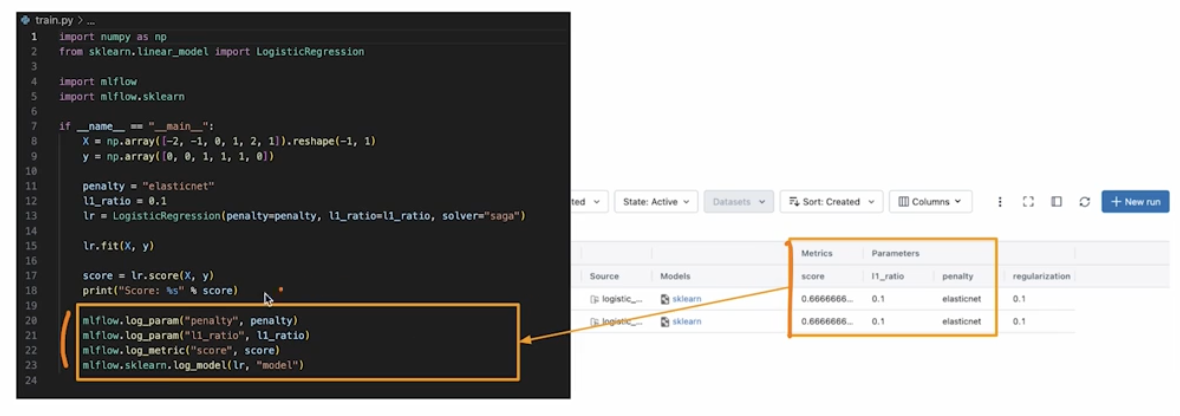
- 모델 학습 시 로깅이 필요한 시점에
mlflow.log_param을 쓰면 된다. 또한 위와 같이log_model을 통해 모델 저장도 가능하다. -
Run Name 을 클릭하면 아래와 같이 Run 에 대한 상세한 정보 기록이 나온다.
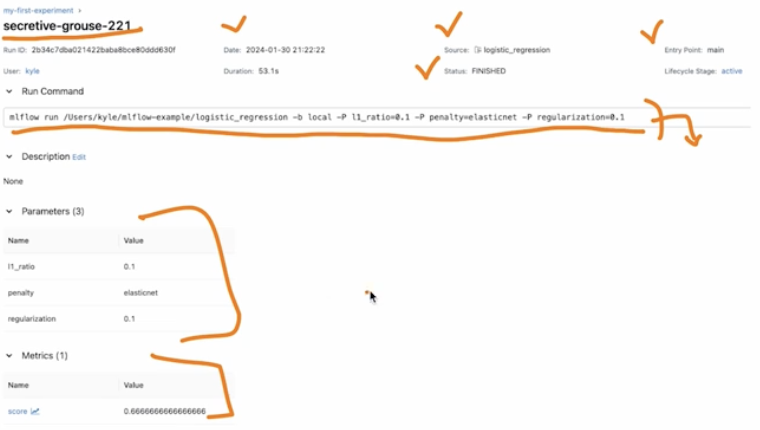
-
하단에는 Artifacts 가 있다. 여기에는 모델 학습 과정에서 생성된 내용들이 저장되고, MLflow Model 을 사용해서 예측하는 방법도 알려준다.
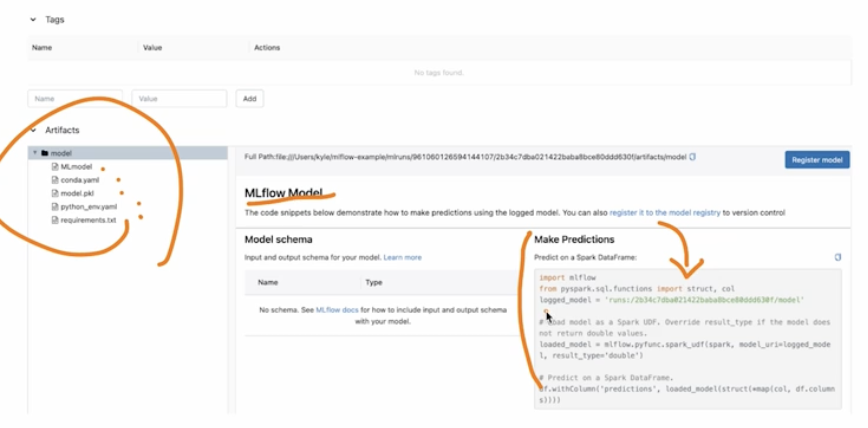
-
Experiment 와 Run 의 관계
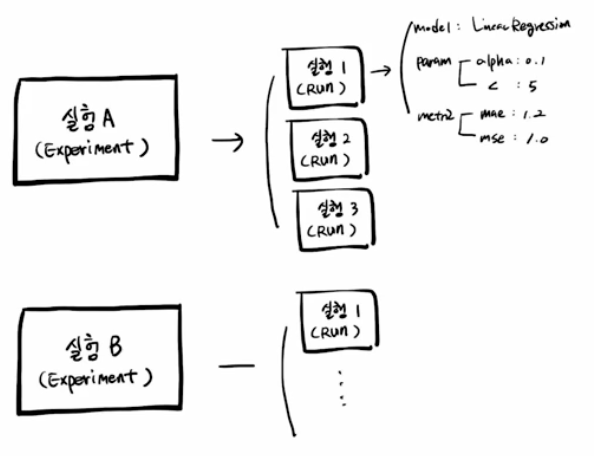
- 프로젝트 단위를 Experiment 단위로 할 수 있다.
- Run 은 여러명이 동시에 각자 실행하고 합칠 수도 있다.
- MLflow 에서는 위 그림과 같은 구조처럼, 실험 단위를 만들고 그 안에서 Run 을 한다. 또한 Run 할 때 logging 을 같이 해주면 데이터가 기록된다. 그리고 웹 UI 가 있어 쉽게 확인하고 비교할 수 있다.
MLflow Autolog
mlflow.autolog()는 로깅을 더 편하게 하는 방법이다. 이는 MLflow 가 지정한 몇 가지를 자동으로 기록해준다.-
다음은 기존과 같이
log_param으로 기록한 것이다.import numpy as np from sklearn.linear_model import LogisticRegression import mlflow import mlflow.sklearn if __name__ == "__main__": X = np.array([-2, -1. 0, 1, 2, 1]).reshape(-1, 1) y = np.array([0, 0, 1, 1, 1, 0]) penalty = "elasticnet" l1_ratio = 0.1 lr = LogisticRegression(penalty=penalty, l1_ratio=l1_ratio, solver="saga") lr.fit(X, y) score = lr.score(X, y) print("Score: %s" % score) mlflow.log_param("penalty", penalty) mlflow.log_param("l1_ratio", l1_ratio) mlflow.log_param("score", score) mlflow.sklearn.log_model(lr, "model") -
다음은
autolog로 기록한 것이다.import numpy as np from sklearn.linear_model import LogisticRegression import mlflow import mlflow.sklearn if __name__ == "__main__": mlflow.sklearn.autolog() X = np.array([-2, -1. 0, 1, 2, 1]).reshape(-1, 1) y = np.array([0, 0, 1, 1, 1, 0]) penalty = "elasticnet" l1_ratio = 0.1 lr = LogisticRegression(penalty=penalty, l1_ratio=l1_ratio, solver="saga") with mlflow.start_run() as run: lr.fit(X, y) score = lr.score(X, y) print("Score: %s" % score) autolog를 쓰게 되면with mlflow.start_run() as run:구문이 생긴다.- 이렇게 autolog 로 바꾼 뒤 run 으로 실행할 때 폴더 바깥으로 나와 뭐가 기록되는지 보면, 새로운 Run 기록이 존재하고 기존보다 더 자세하게 로깅되는 것을 확인할 수 있다.
-
아래 그림처럼 Run Command, parameter, metrics 등 별도로 코드에서 지정하지 않은 것들이 기록된다.
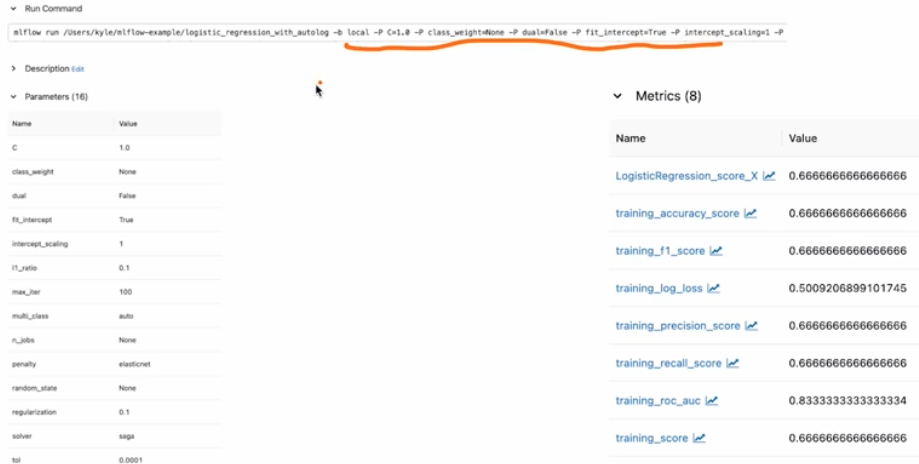
-
-
Artifact 도 자동으로 저장된다. 아래와 같이 confusion matrix 이미지도 저장되는 것을 볼 수 있다.
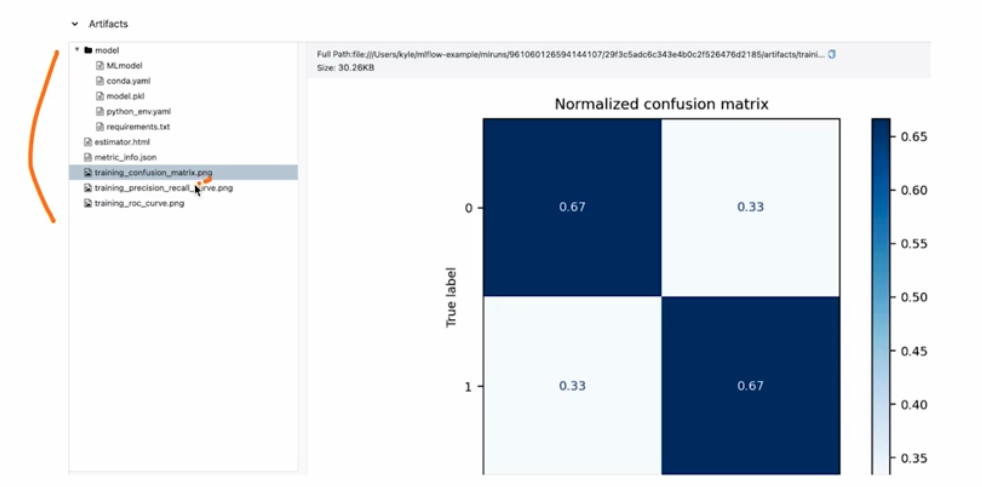
- 이처럼
autolog를 사용하면 로깅에 대해 크게 신경쓰지 않을 수 있다. 그러나, 모든 프레임워크에서 사용 가능한 것은 아니다.- 즉 MLflow 에서 지원해주는 프레임워크들이 존재한다.
pytorch.nn.Module은 지원하지 않지만,pytorch lightning은 지원하고 있다.
- dataset 도 선택 가능하게 되어 있으나, 추후에 API 가 변동될 가능성도 존재한다. 공식문서 상에 Experimental 이라고 나와있다.
- 안정적으로 되면, Data 와 Code 모두 바꿔가며 실험이 가능해진다. 즉 Data management 도 할 수 있게 되는 것이다.
MLflow Parameter
- 지금까지는 머신러닝 코드에서 parameter 를 직접 지정했지만, MLflow 에서는 아래와 같은 방식으로도 parameter 를 지정할 수 있다.
-
MLProject 파일을 아래와 같이 작성한다. 즉
entry_points의main에 parameter 를 지정하고command에서 실행 인자로 건네준다.name: tutorial2 python_env: python_env.yaml entry_points: main: parameters: solver: type: string defualt: "saga" penalty: type: string defualt: "l2" l1_ratio: type: float default: 0.1 command: "python train.py {solver} {penalty} {l1_ratio}" -
이제 위와 같은
command형태를 사용하기 위해서train.py에서 Parameter 를 지정 부분을 변경한다.import argparse import sys import numpy as np from sklearn.linear_model import LogisticRegression import mlflow import mlflow.sklearn if __name__ == "__main__": mlflow.sklearn.autolog() X = np.array([-2, -1. 0, 1, 2, 1]).reshape(-1, 1) y = np.array([0, 0, 1, 1, 1, 0]) lr = LogisticRegression(penalty=sys.argv[2], l1_ratio=float(sys.argv[3]), solver=sys.argv[1]) #parser = argparse.ArgumentParser() #parser.add_argument("--solver", type=str, default="saga") #parser.add_argument("--penalty", type=str, default="l2") #parser.add_argument("--l1_ratio", type=float, default=0.1) #args = parser.parse_args() #lr = LogisticRegression(penalty=args.penalty, l1_ratio=float(args.l1_ratio), solver=args.solver) with mlflow.start_run() as run: lr.fit(X, y) score = lr.score(X, y) print("Score: %s" % score) - 위와 같이 MLProject 파일에서 Parameter 지정해주면,
train.py내에서argparse혹은sys.argv로 파라미터를 설정할 수 있다. - 이렇게 하면 하이퍼파라미터 튜닝과 같이 동일한 환경에서 일부 설정을 변경하면서 ML 모델을 탐색하는 활동에 유리하다. 즉 제어가 가능하다.
-
이후 Mlflow Run 을 할 때,
-P옵션으로 파라미터를 지정해준다.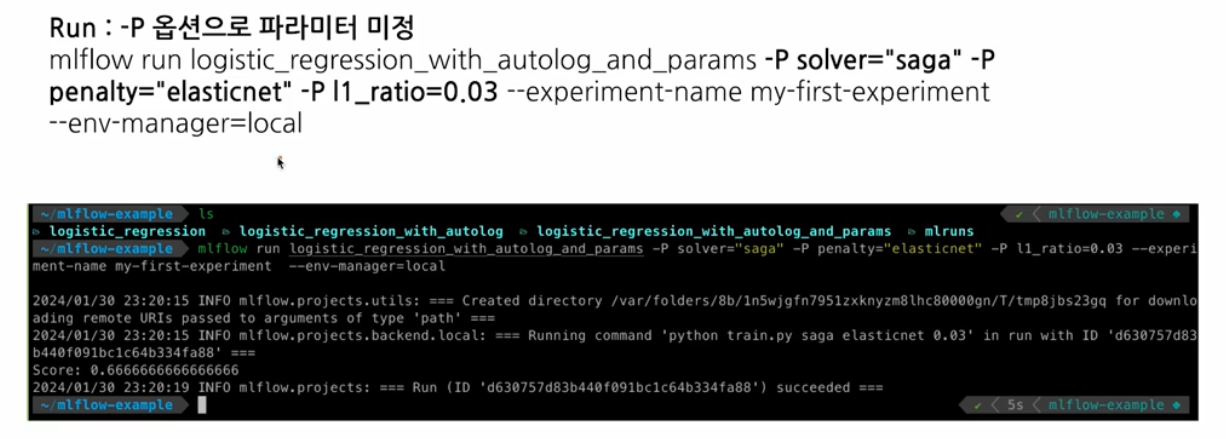
- 이제 Mlflow Run 할 때마다 파라미터를 바꿀 수 있고, 더 나아가서 FastAPI 등을 활용하여 특정 API endpoint 로 접근하면 실험이 실행되도록 할 수 있다.
- Chart 내 Run 을 선택하고 Compare 를 실행하면 결과가 다른 Run 이 있으면 시각화도 가능하다.
MLflow 활용
-
현업에서 Data Scientist(DS) 와 MLOps Engineer 가 MLflow 를 이용해서 협업할 수 있다.
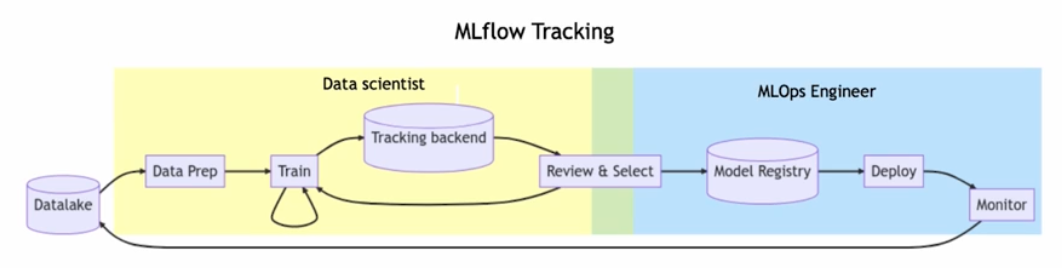 일반적으로 모니터링은 배포 후에 같이 담당한다.
일반적으로 모니터링은 배포 후에 같이 담당한다. - 특정 Run 검색
- 이 경우
search_runs()를 사용하면 된다. 여기에는 query 문법을 넣을 수도 있고, 특정 metric 을 기준으로 확인할 수도 있다.
from mlflow import MlflowClient from mlflow.entities import ViewType query = "params.l1_ratio = '0.03' and metric.`training_score` >= 0.65" run = MlflowClient().search_runs( experiment_ids = "961060126594141107", # Run 이 속한 experiment 의 Experiment ID # filter_string = '', # 아무 조건을 주고 싶지 않을 때 filter_string = query, run_view_type = ViewType.ACTIVE_ONLY, max_result = 1, order_by = ["metrics.trainig_score DESC"], )[0] print("Run Info", run)-
위 코드를 실행시키면 아래와 같이
mlflow.runName을 찾을 수 있다.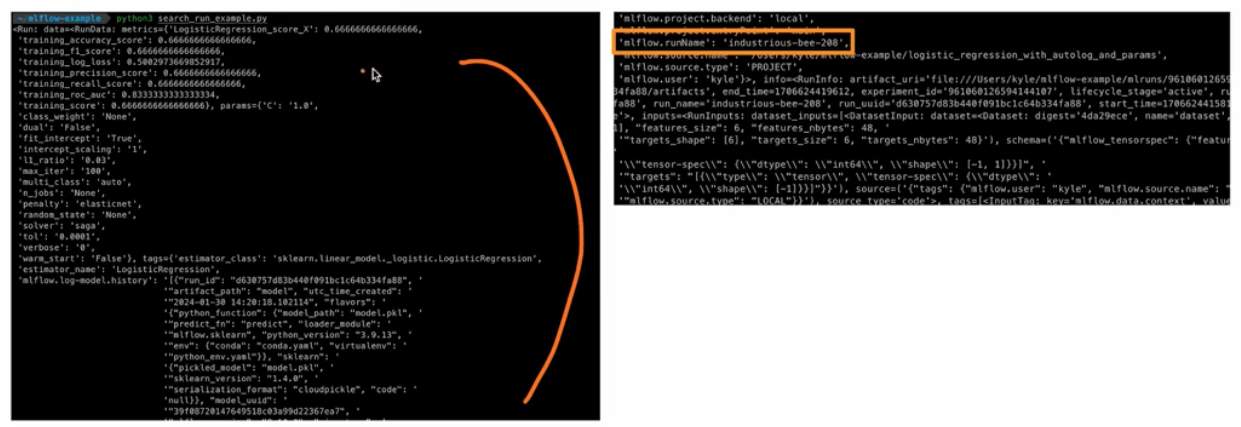
- 배포하는 과정에서 MLOps 엔지니어는 MLFlow 에서 조회 후 성능이 제일 좋은 것을 가져다 쓰거나, 혹은 협업하며 정리되고 지정된 Tag 를 보고 “배포 레디” 와 같은 태그가 지정된 것을 가져다 쓴다.
- 이 때 위와 같이
search_runs()를 사용하여 실험을 받아오고 진행할 수 있다.
- 이 경우
- Run 검색 후 다운로드
- MLflow 에서는 Run 을 search 후 download 할 수 있다.
from mlflow import MlflowClient from mlflow.entities import ViewType query = "params.l1_ratio = '0.03' and metric.`training_score` >= 0.65" run = MlflowClient().search_runs( experiment_ids = "961060126594141107", # Run 이 속한 experiment 의 Experiment ID # filter_string = '', # 아무 조건을 주고 싶지 않을 때 filter_string = query, run_view_type = ViewType.ACTIVE_ONLY, max_result = 1, order_by = ["metrics.trainig_score DESC"], )[0] # print("Run Info", run) def download_model(run_id, model_name="model"): print("Download Model") artifact_url = f"runs:/{run_id}/{model_name}" artifacts.download_artifacts(artifact_url, dst_path='.') print("Download Model Finish") download_model(run_id=run.info.run_id)-
위 코드에서
model_nameargument 에는 Artifacts 의 폴더 이름을 주면 된다.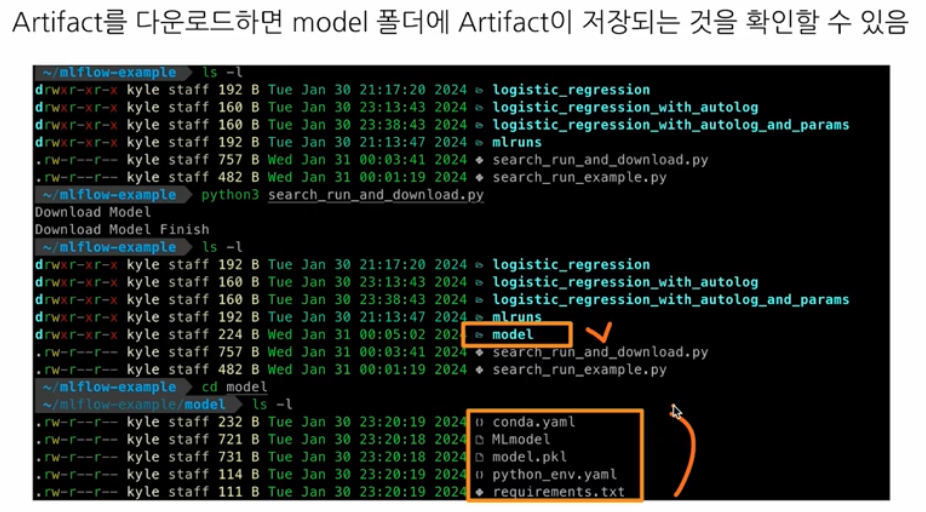
- 이렇게 하면 DS 가 작업한 것을 가져다 쓸 수 있다.
- 정리해보자.
- MLflow 를 사용하면 모델을 학습하는 과정의 데이터, Artifact(부산물) 등을 저장할 수 있다.
- MLflow 의 Web UI 를 통해 쉽게 결과를 비교할 수 있다.
- MLflow 를 통해 모델을 개발하고, 적절한 기준 이상을 배포하는 프로세스로 협업할 수 있다.
- MLflow + FastAPI 를 통해서 특정 API 에서 모델의 결과를 나타나게 하는 코드를 작성하는 것 가능하다. 즉 특정 API 를 요청했을 때 MLflow 와 연동시키는 것이다.
모델 평가
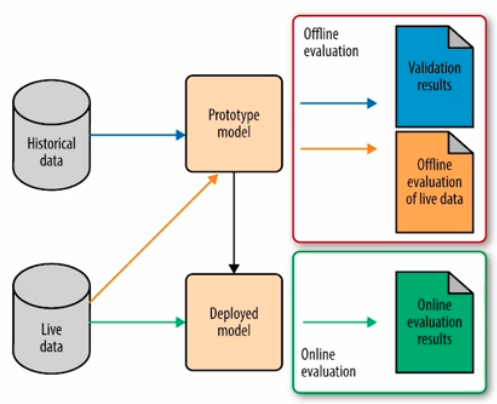
- 현업에서 모델을 평가하는 방법에 대해 알아보자. 크게 offline 과 online 으로 나눌 수 있다.
- offline
- 단순함, 과거 데이터를 기반, 주기성 혹은 batch, 학습 후 정적인 모델 평가
- local 컴퓨터에서 하는 개발 단계는 대부분 offline 이라고 볼 수 있다.
- online
- 배포 후, 실제 데이터가 들어올 때 성능을 확인
- 복잡함, 실시간 데이터에 기반, 즉각적인 성능 평가, 모델의 동적인 변화에 빠르게 대응
- online 으로 평가했는데 지표가 떨어지고 있으면 대응 필요
offline 모델 평가
-
Hold-out Validation
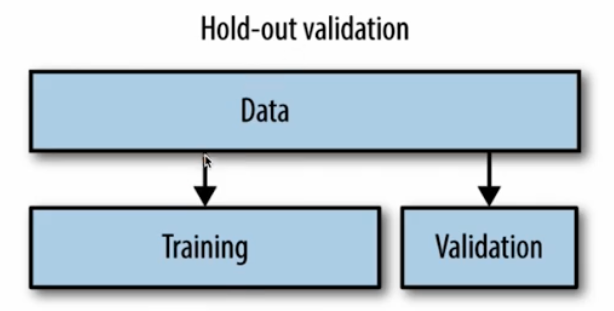
- 데이터를 학습 세트와 테스트 세트로 나누어서 모델을 학습하고 평가한다. 즉 일정 비율의 데이터를 테스트 데이터로 예약하여 모델의 일반적인 성능을 평가하는 일반적인 방법이다.
-
k-fold cross validation
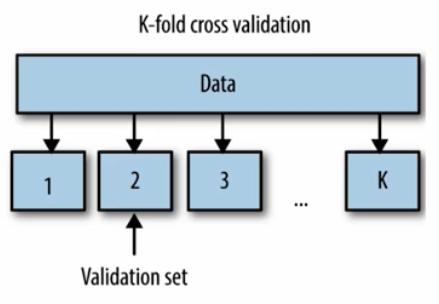
- 데이터를 $k$ 개의 부분 집합(fold)으로 나누고, 각 fold 를 한번씩 테스트 셋으로 사용하면서 나머지를 학습 셋으로 활용하여 모델을 $k$ 번 평가하는 기술이다.
- 모델의 일반적인 성능을 더 정확하게 평가할 때 활용한다.
-
Bootstrap Resampling
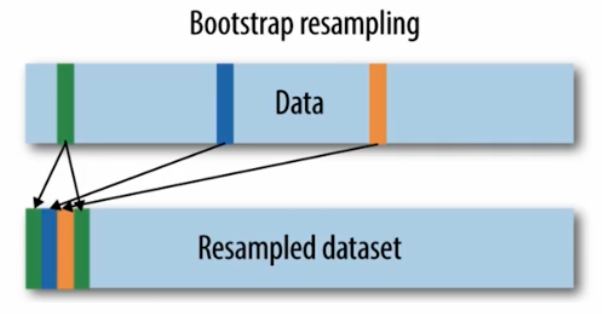
- 중복을 허용하면서 원본 데이터셋에서 샘플을 랜덤하게 추출하여 여러 개의 부분집합을 생성한다. 이를 가지고 모델을 반복적으로 학습 및 평가하여 일반화 성능을 추정한다.
- 데이터셋의 분산을 고려하면서 모델의 성능을 더 견고하게 평가할 수 있다.
online 모델 평가
- AB Test
- 같은 양의 트래픽을 두 개 이상의 버전에 전송하고 예측한다. 이후 예측 결과를 비교 및 분석한다.
- 일반적인 AB 테스트는 통계적 유의미성을 얻기까지 시간이 매우 오래 걸리기 때문에, Multi-Armed Bandit 과 같은 최적화 기법을 쓰기도 한다.
-
A, B 를 나눌 때 트래픽을 반반으로 하거나, user_id 와 같은 값을 해싱하여 홀/짝으로 나누기도 한다.
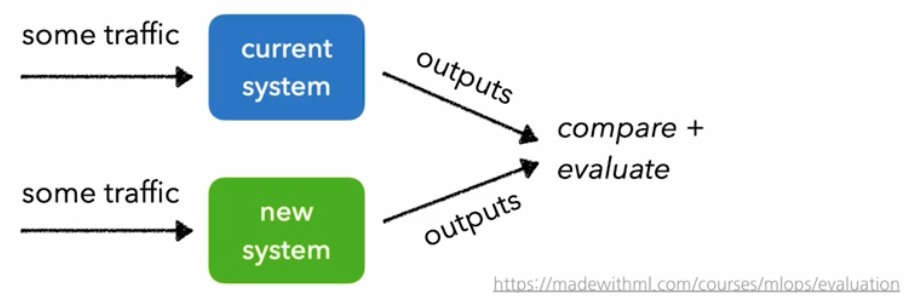
- 위 그림과 같이 현재 배포되어 있는 ML 모델과 새로운 ML 모델을 대상으로 예측 결과를 비교하고 평가한다. 이 때 새로운 시스템에 10 %, 현재 시스템에 90 % 로 시작해서 점진 확대를 하기도 한다.
- 온라인 테스트의 대부분이 AB Test 로 실시된다. 이러한 AB 테스트는 인프라 영역과 관련이 깊다. 보통 Docker 혹은 쿠버네티스(k8s)에서 요청이 들어오면 트래픽을 나눠주기 때문이다.
- 이 때 코드 레벨에서 트래픽을 분기할 수도 있지만, 대부분의 회사에서는 인프라 레벨에서 제어한다.
- 프로젝트에서 실제 배포하게 될 때, 모델을 하나만 쓰지 말고 두 개를 같이 배포하여 AB Test 를 통해 모델을 평가해 볼 수 있다.
- Canary Test
- 카나리아는 석탄 광산에서 유독가스 누출의 위험을 알리는 용도로 사용했던 새다. 카나리아가 사람보다 먼저 죽기 때문에, 이것을 유독가스 누출의 지표로 사용하는 것에서 유래한 테스트 방법이다.
-
새로운 버전의 모델에 트래픽이 들어가도 문제가 없는지를 체크하는 방법이다. 위 AB Test 에서 본 것처럼 90%, 10% 로 테스트하는 것이 Canary Test (까나리 테스트)라고 볼 수 있다.
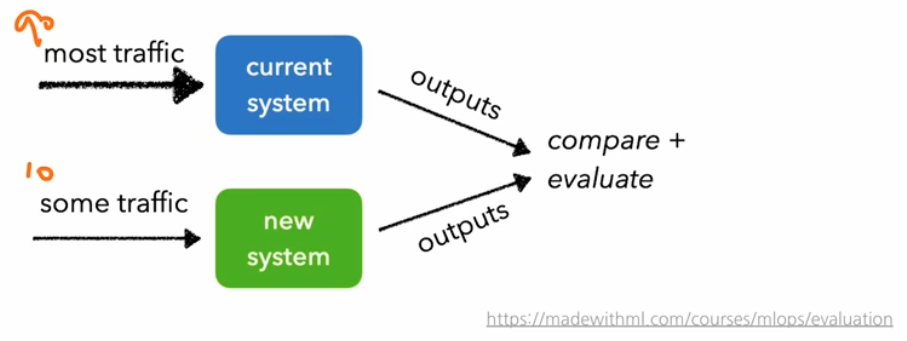
- 마찬가지로 결과물을 지속적으로 모니터링하여 큰 오차는 없는지, 결함은 없는지를 체크한다. 새로운 모델에 트래픽이 들어갔을 때 괜찮으면 점진적으로 늘려간다.
- Shadow Test
-
프로덕션(=운영 환경)과 같은 트래픽을 새로운 버전의 모델에 적용하는 방법이다.

- 위 그림과 같이 모든 트래픽은 현재 시스템에 전송하고, 그림자처럼 같은 트래픽을 새로운 버전에 복제해서 전송하는 방법이다.
- 기존 서빙은 그대로, 즉 트래픽 100% 가 흐르기 때문에, 기존에 배포된 모델에 대한 영향을 최소화 한다.
-
새로운 버전의 모델이 정상적으로 예측하는지를 확인한다. 이를 위해 트래픽 100% 를 새로운 모델에도 보낸다. 이 때 중요한 것은 클라이언트에게는 가지 않고 결과만 가지고 있는다.
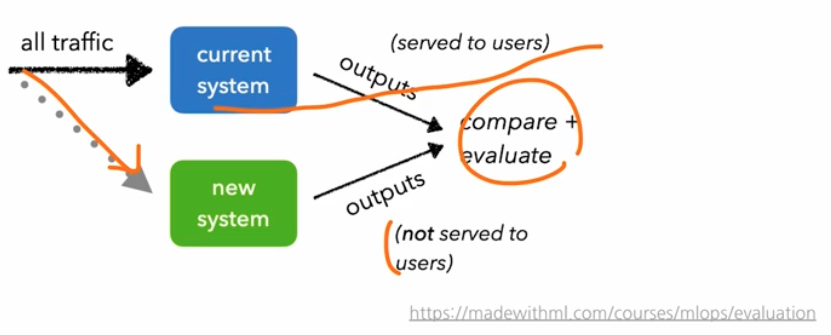
- 모델을 직접 배포하기 전에 리스크가 있을 수 있기 때문에 Shadow AB Test 나 Shadow Test 를 실시하고 고객한테는 전송되지 않지만, 동일한 feature 를 줬을 때 어떤 예측 결과가 나왔는지를 가지고 있다. 이를 비교한다.
- 유저에게 직접 결과물이 전달되지 않기 때문에 새 모델에 이슈가 있어도 안전하다. 고객에게 전달되는 것은 결국 기존 시스템이기 때문이다.
- 그러나 트래픽 복제 전송을 위한 인프라 구성이 필요하다.
-
-
궁극적으로 가야할 것은 End to End 다. Offline 과 Online 평가를 반복하면서 최적의 모델을 서빙할 수 있도록 지속적으로 개선해야 한다.
머신러닝 시스템 디자인 패턴
-
머신러닝 서빙 패턴을 정리한 포스트가 있는데, 이 중 QA pattern 이라는 것이 있다. 이는 예측 서버와 모델을 평가하기 위핸 디자인 패턴들이다.

- 현업의 실제 서비스에서 모델을 평가할 때는 거의 다 AB Test 를 진행한다.
- 개인 프로젝트를 진행하면서, FastAPI 를 사용하여 API 요청이 올 때 user id 를 받고 해싱 후 나눠서 처리하는 식으로 감을 잡아볼 수 있다.
- 즉 회사에서는 인프라 영역에서 처리하지만, 신입의 입장에서 공부할 때는 FastAPI 로직에서 처리해 볼 수 있다.
댓글 남기기