
[Serving] Online Serving 을 위한 웹 프로그래밍
ML/AI 서비스에서 Online Serving 은 굉장히 많이 사용된다. 문제 정의에 따라 설계 패턴을 정하게 되지만 개인적으로 모델 학습이나 데이터 파이프라인 등은 Batch 가 적절하다고 생각하고, 개별 요청과 즉각적인 응답이 중요한 서비스를 더 흔하게 볼 수 있는 지금 Online Serving 에 대해 잘 알아두는 것이 좋다. Online Serving 을 위해서 API 서버, 실시간 처리 등의 경험이 필요한데, 이를 위한 웹 프로그래밍 개념들을 다뤄보자.
Online Serving
- 실시간으로 데이터를 처리하고 즉각적인 결과를 반환한다. 따라서 실시간성을 요구하는 서비스인 경우 유용하다.
- Cloud 혹은 On-Premise 서버에서 모델을 호스팅한 후 요청이 들어오면 모델의 예측을 반환하는 구조다.
- Online Serving 을 구현하는 데에는 크게 3가지로 나눌 수 있다.
- 직접 웹 서버 개발
- Flask, FastAPI, Django, Go 등을 활용해서 직접 서버를 구축하는 방법이다.
- 웹 서버를 만드는 것은 쉽다. 가장 단순하게
localhost도 본인의 컴퓨터에서만 접속할 수 있는 웹 서버라고 볼 수 있다.localhost는 일반적으로127.0.0.1이라는 루프백(loopback) IP 주소를 의미한다. 이 주소는 해당 컴퓨터 자체를 가리키는 주소로, 외부에서(다른 컴퓨터나 휴대폰에서) 이 주소로 접속해도 해당 기기의 localhost 를 가리키는 것이지, 자신의 컴퓨터에는 접속할 수 없다.
- 아래와 같이 URL 이
/로 끝나는 경우는 home 또는 root 라고 보면 된다.
# Flask from flask import Flask app = Flask(__name__) @app.route("/") def hello_world(): return "<p>Hello, World!</p>" # FastAPI from fastapi import FastAPI app = FastAPI() @app.get("/") def read_root(): return {"Hello" : "World"}- 클라우드 서비스 활용
- AWS 의 SageMaker, GCP 의 Vertex AI 등의 클라우드 서비스를 이용하는 방법이다. TPU 를 쓰고자 한다면 GCP 의 Vertex AI 가 baseline 이다.
- managed 서비스는 클라우드 서비스 제공자가 인프라의 설정, 유지 관리, 보안, 확장성 등을 대신 처리해주는 서비스다. 사용자는 해당 서비스에 대한 관리나 운영에 대해 걱정할 필요 없이, 서비스의 기능을 사용하는 데만 집중할 수 있다. 이로 인해 운영에 필요한 시간과 자원을 절약할 수 있다. Batch Serving 에 사용되는 Airflow 에도 managed 시스템이 있다.
- 다양한 서비스들이 생기고 있기 때문에 한번 테스트 해보는 것이 권장된다.
- 클라우드 서비스 활용의 장점은, MLOps 의 다양한 부분을 이미 클라우드 회사에서 구축하여 제공하기 때문에 사용자는 활용만 하면 된다. 초기에 클라우드 서비스에 익숙해져야 하는 러닝 커브가 있지만 이 커브만 극복하면 유용하게 활용할 수 있다.
- 회사에서 사람이 적은 경우(=리소스가 적은 경우)에 사용하는 것이 추천된다.
- 단점은, managed 서비스를 이용하면 직접 서버를 구축하는 것 대비 운영 비용이 더 나갈 수 있다. 또한 사용하는 서비스에 dependancy 가 생겨 자유도가 떨어지고, 내부 구현 방식을 정확히 확인하지 못하는 경우도 있다. 이렇게 되면 디버깅이 답답해진다.
- 오픈소스 활용
- Tensorflow Serving, Torch Serve, MLFlow, BentoML, ONNX 등을 사용하는 방법이다.
- FastAPI 등을 활용할 수 있지만, 처음에 서버에 대한 이해가 충분하지 않으면 어려울 수 있다. 또한 다양한 방식으로 개발을 하다보면, 매번 추상화된 패턴을 가질 수 있다. 이 때 추상화된 패턴을 잘 제공하는 오픈소스를 사용해볼 수 있다.
- 이러한 오픈소스 도구들은 간단하게 Serving 해볼 때 유용하다.
- 직접 웹 서버 개발
- Online Serving 을 어떤 방식으로 하느냐는 주어진 환경에 따라 다르다. 일반적으로 클라우드 managed 서비스 → 직접 서버 개발 → 서빙 오픈소스 활용 방식 순으로 권장된다.
BentoML 예시
- BentoML 을 가지고 iris dataset 으로 classification 을 하는 예시를 보자.
-
먼저 BentoML 서비스를 정의한다.
iris_classifier.py에 BentoML 기반 iris classification 코드를 작성한다. 이를 통해 요청이 들어오면 예측 결과를 반환하게 된다.import bentoml from bentoml.io import JSON, NumpyNdarray import numpy as np @bentoml.service() # BentoML 서비스 클래스임을 선언. class IrisClassifier: # 모델 추론 API 정의 @bentoml.api(input=JSON(), output=JSON()) # 이 서비스가 REST API 로 제공할 함수임을 선언. JSON 입출력 형식 사용. Numpy Ndarray 도 가능하다. def predict(self, input_data): # 입력 데이터를 numpy array로 변환 data = np.array(input_data["instances"]) # 모델로 예측 predictions = self.artifacts.model.predict(data) # 아래의 pack('model', clf)에서 등록된 모델 return {"predictions": predictions.tolist()} -
예측 결과를 제공할 모델을 학습시키기 위한 코드와 해당 모델을 BentoML 로 패킹하는 코드를
train_and_save.py에 작성한다.from iris_classifier import IrisClassifier from sklearn.datasets import load_iris from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split # 데이터셋 로드 iris = load_iris() X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target) # 모델 학습 clf = RandomForestClassifier() clf.fit(X_train, y_train) # BentoML 서비스 인스턴스 생성 및 모델 패킹 service_model = IrisClassifier() service_model.pack("model", clf) # 저장 saved_path = service_model.save() print(f"Model saved to: {saved_path}") - 이후 CLI 에서
bentoml serve iris_classifier:latest명령어를 입력하면 배포된다. 해당 명령어는 로컬에서 REST API 서버를 열어주고, 기본 포트는 localhost 의 3000 번 포트다. -
이제 아래와 같이
curl로 테스트해볼 수 있다.curl -X POST http://localhost:3000/predict -H "Content-Type: application/json" -d '{"instances": [[5.1, 3.5, 1.4, 0.2]]}' -
이외에 Python 으로 요청을 보내 확인해볼 수 있다.
import requests response = requests.post( "http://localhost:3000/predict", json={"instances": [[5.1, 3.5, 1.4, 0.2]]} ) print(response.json())
주요 고려사항
- Docker
- 서빙할 때 Python 버전, 패키지 버전 등 dependency 가 굉장히 중요하다. 이를 위해 Docker Image, Docker Compose 를 익숙하게 사용하면 도움이 된다.
- Docker 는 Container 기반 가상화를 제공하는 플랫폼이다. 즉 Docker 를 통해 애플리케이션과 그 종속성을 포함한 독립된 환경인 Container 를 생성하고 실행할 수 있다. 이는 무거운 가상 머신(VM)보다 빠르게 시작되고 자원을 효율적으로 사용한다.
- Docker Compose 는 여러 개의 Container 를 정의하고 실행하기 위한 도구이다.
- Latency
- Online Serving 은 실시간 예측을 하기 때문에 예측할 때 지연시간(latency)을 최소화해야 한다.
- 대표적인 Latency 최소화 방법은 아래와 같다.
- 데이터 전처리 서버 분리(혹은 feature 미리 가공 - feature store)
- 모델 경량화
- 병렬 처리
- 예측 결과 캐싱
- 실제로 OnlineServing 을 해보면, 병목 지점이 모델 서버가 아닌 데이터를 가져오는 DB 인 경우가 많다. 따라서 유동적으로 성능을 확인해서 어디서 문제가 발생하는지 파악하고 해결하는 역량이 필요하다.
Server 아키텍처
- Online Serving 을 구축하는데 있어서 자주 사용되는 Server 아키텍처들이 있다. 이는 하나의 큰 API 서버를 운영하는지, 아니면 여러 대의 작은 API 서버들을 운영하는지에 따라 다르다.
모놀리스 아키텍처
-
하나의 큰 서버를 가진 아키텍처다.
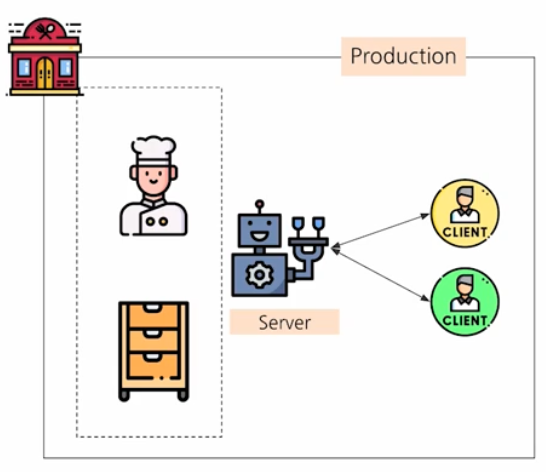
- 위 예시 그림과 같이, 모든 로직이 하나의 거대한 코드 베이스에 저장된다. 그리고 일반 서비스와 ML 서비스 코드가 혼재한다.
- 따라서 배포해야 할 코드 프로젝트가 하나다. 즉 github 에서 하나의 repo 에 모두 저장되어 있는 모노 repo 방식이다.
- 클라이언트는 하나의 서버에게 요청을 하고, 서버는 이를 내부적으로 처리하여 요청을 반환한다.
- 장점은 아래와 같다.
- 서비스 개발 초기에는 단순하고 직관적이기 때문에, 초기에 많이 사용하게 된다.
- 관리할 코드 베이스가 하나이기 때문에 굉장히 심플하다.
- 단점은 아래와 같다.
- 모든 서비스 로직이 단 하나의 저장소에 저장되기 때문에, github 등이 꼬일 수 있다.
- 이후 서비스 규모가 커지게 되면 복잡도가 증가하여 이해하기 어려울 수 있다. 즉 서비스 코드 간 결합도가 높아서 추후 수정이나 추가 개발이 어려울 수 있다.
- 의존성 및 환경을 하나로 통일해야 한다.
- Usecase
- 서비스 초기단계에 개발하는 경우
- 협업하는 개발자가 많지 않은 경우
- 아직 코드와 결합도에 대한 복잡성을 느끼지 못하는 경우
마이크로서비스 아키텍처
-
작은 여러 개의 서버를 가진 아키텍처다. 즉 아래 그림과 같이 기능 별로 각각의 서버를 두고 있다.
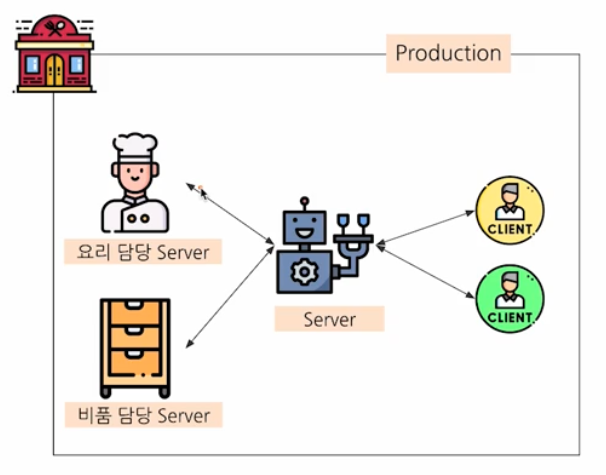
- 모든 로직이 각각의 개별 코드에 저장된다. 그리고 일반 서비스와 ML 서비스 코드가 분리된다.
- 따라서 배포해야 할 코드 프로젝트가 여러 개다.
- 클라이언트가 하나의 서버에게 요청하는 것은 동일하지만, 해당 서버는 이 요청을 처리할 각각의 내부적인 서버로 다시 요청을 보낸다.
- 내부에 위치한 서버들이 이 요청을 처리하고 다시 요청했던 서버로 반환하고, 이 서버는 응답을 받아 필요에 맞게 변환한 후 클라이언트에게 반환하는 구조다.
- 장점은 아래와 같다.
- 거대한 코드 베이스를 작게 나눌 수 있다.
- 필요에 따라 각 담당 서버 단위로 scale up 또는 scale out 이 가능하다.
- 이는 서버 확장 전략으로, scale up 은 서버 자체의 사양을 증가시키는 것이고, scale out 은 비슷한 사양의 서버를 여러 대 두어 확장하는 방법이다.
- scale up 은 하나의 서버의 사양을 업그레이드 하기 때문에 수직 scale 로 불리고, scale out 은 여러 대의 서버로 나눠 시스템을 확장하기 때문에 수평 scale 로 불린다.
- scale out 은 서버가 여러 대로 나뉘기 때문에 각 서버에 걸리는 부하를 균등하게 해주는 로드밸런싱이 필수적으로 동반되어야 한다.
- 의존성 및 환경을 담당 서버 별로 다르게 둘 수 있다. 서버 별 API 만 나눠져 있기 때문에 요청하고 반환하는 프로세스 규칙만 있으면 된다.
- 단점은 전체적인 구조와 통신이 복잡해진다는 점이다.
- Usecase
- 서비스가 어느정도 고도화되고, 서비스와 개발 팀의 규모가 커졌을 경우 많이 사용한다.
- 서비스 별 독립된 환경, 의존성, scale up 또는 scale out 이 필요한 경우에 사용한다.
비교
- 규모가 작고, 개발 조직이 하나인 회사인 경우
- 모놀리스 아키텍처를 사용할 가능성이 크다.
- 서버 코드가 Python 으로 개발된 경우, 보통 해당 서버 코드의 환경 및 의존성 패키지를 따라야 한다.
- 만약 Python 이 아닌 경우, 내가 개발한 Python 코드를 메인 서버 로직에서 스크립트성으로 실행시킬 가능성이 있다.
- 규모가 좀 있고, 개발과 ML 이 분리된 경우
- 마이크로서비스 아키텍처를 사용한다.
- 개발 팀과는 주로 API 스펙을 통해서 커뮤니케이션을 하게 된다.
- 메인 서비스 코드와 분리되어 있기 때문에, 서버 코드의 환경 및 의존성 패키지를 서비스 로직과 별도로 가져갈 수 있다.
- 다음에 다룰 FastAPI 를 사용할 때는 마이크로서비스에 가깝게 쓰려는 경우가 많다.
웹 프로그래밍 개념
- Online Serving 을 구축할 때 알면 도움이 되는 웹 프로그래밍 개념에 대해 알아보자.
API
- API 란 Application Programming Interface 의 준말로 소프트웨어 응용 프로그램들이 서로 상호 작용하기 위한 인터페이스를 총칭한다.
- 특정 소프트웨어에서 다른 소프트웨어를 사용할 때의 인터페이스(약속)다. 이는 기본적으로 사람을 위한 인터페이스(User Interface, UI)가 아니라 소프트웨어를 위한 인터페이스다.
- API 의 구현에는 웹 API, 라이브러리, OS 시스템 콜 등 다양한 종류가 존재한다. 따라서 pandas 나 pytorch 와 같은 라이브러리들도 API 라고 부를 수 있다.
- Web API
- Web 에서 사용되는 API 로, 주로 HTTP 를 통해 웹 기술을 기반으로 하는 인터페이스다. 라이브러리 API 나 시스템 콜 등의 API 는 Web 에서 사용되지 않는다.
- HTTP(Hyper Text Transfer Protocol)
- 웹 상에서 정보를 주고 받을 때 지켜야 하는 통신 프로토콜(규약, 약속)이다.
- HTTP 는 기본적으로 80 번 포트를 사용하고 있으며, 서버에서 80 번 포트를 열어주지 않으면 HTTP 통신이 불가능하다.
- HTTP 는 주로 텍스트 기반의 통신을 사용하지만, 이는 HTTP 의 특징 중 하나일 뿐이다. HTTP/1.1 부터는 바이너리 데이터를 포함하여 다양한 형식의 데이터를 전송할 수 있다. 따라서 “HTTP 는 클라이언트와 서버 간의 텍스트 기반 통신을 사용한다”는 설명은 정확하지 않다.
- HTTP 는 기본적으로 연결을 유지하지 않는 stateless 프로토콜이다.
- HTTP/3 은 TCP 대신에 UDP 를 기반으로 하는 프로토콜이다.
- HTTPS 는 HTTP 의 보안 버전으로, 암호화된 통신을 지원한다.
- Web API 종류는 아래와 같다.
- REST(Representational State Transfer)
- GraphQL
- RPC(Remote Procedure Call)
- REST API
- 자원을 표현하고 상태를 전송하는 것에 중점을 둔 API 다. 정확히 말하면 REST 라고 부르는 아키텍처 “스타일” 로, HTTP 통신을 활용한다.
- 요청의 모습을 보고 어떤 일을 하는지를 알 수 있기 때문에, 가장 대중적이고 대부분의 서버들이 이 API 방법을 채택하고 있다.
- 물론 REST API 를 사용하지 않고, API 를 임의로 만들 수 있다. 예를 들어
https://www.naver.com/1이 네이버 블로그 접속이라고 해보자. 이는1이 무엇을 의미하는지 알아야 한다. 따라서 협업할 때 번거롭다. /blog, /cafe등으로 endpoint 를 정해주는 것이 명시적인 REST 다. 따라서 REST 라는 형식의 API 는 각 요청이 어떤 동작이나 정보를 위한 것인지를 요청 모습 자체로 추론할 수 있다.- 기본적인 데이터 처리를 지원한다. 즉 조회 작업, 새로 추가, 수정, 삭제가 가능하다. 이를 CRUD(Create, Read, Update, Delete) 라고 한다.
- Resource, Method, Representation of Resource 로 구성된다.
- Resource 는 Unique 한 ID 를 가지는 리소스로 URI 라고 한다.
- Method 는 서버에 요청을 보내기 위한 방식이다. GET, POST, PUT, PATCH, DELETE 가 있다.
- URL(Uniform Resource Locator) 은 인터넷 상 자원의 위치를 뜻한다.
- URI(Uniform Resource Identifier) 는 인터넷 상의 자원을 식별하기 위한 문자열의 구성이다. 즉 URI 는 URL 을 포함하게 되고, URI 가 더 포괄적인 범위다.
-
아래 그림은 Github 의 REST API 예시다.
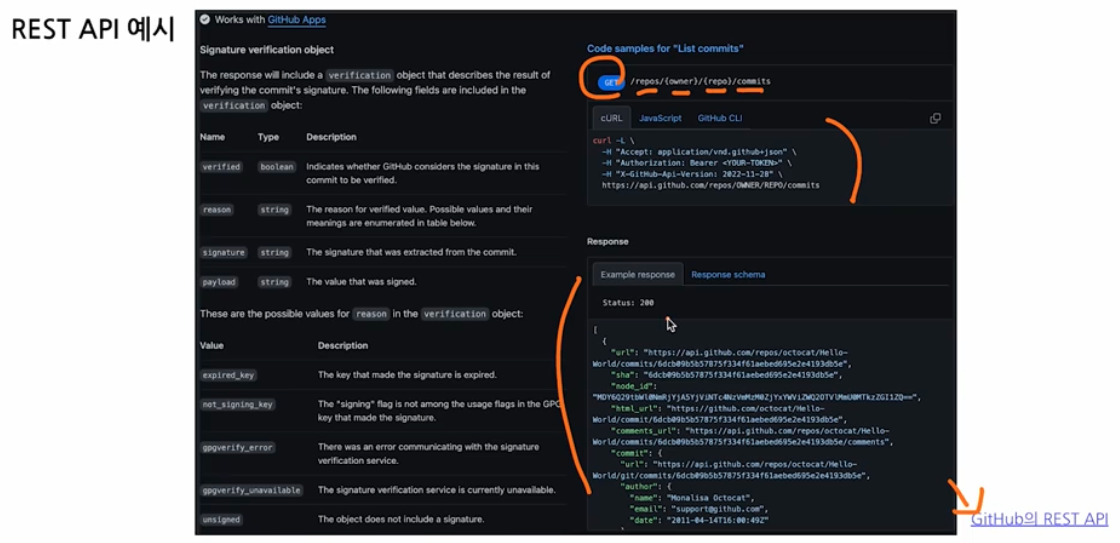
- API 프로토콜을 짜두면, 백엔드 개발자가 보고 어떻게 요청해야 하는지를 알 수 있다.
REST API
GET http://localhost:8080/users?name=bkkhyunn같은 REST API 요청을 예시로 보자.GET- HTTP Method 부분이다. Method 는 하고자 하는 것을 표현한다. 따라서 동사다. 반면에 REST API 의 endpoint 는 명사로 작성하는 것이 표준이며 권장된다.
- 아래와 같은 HTTP Method 가 있다.
- GET : 리소스를 조회
- POST : 리소스 생성
- PUT : 생성된 리소스 하나를 전체 업데이트
- PATCH : 생성된 리소스 하나를 부분 업데이트
- DELETE : 생성된 리소스 하나를 삭제
- 위 예시의 API 는
users라는 리소스를 조회(GET)하는 API 를 호출한 것이다.name=bkkhyunn이 파라미터가 된다.
http://localhost:8080/users?name=bkkhyunn- HTTP URL 부분이다. 다루고자 하는 대상이 되는 것을 주로 표현한다.
- 위 URL 은 Scheme(
http), Host(localhost), Port(8080), Path(/users), Query(?name=bkkhyunn) 으로 이루어져 있다. -
URI, URL, URN 의 차이는 아래와 같다.
용어 뜻 예시 설명 URI (Uniform Resource Identifier) 리소스를 식별하는 총칭 개념 http://localhost:8080/users?name=bkkhyunnURL 과 URN 을 모두 포함 URL (Uniform Resource Locator) 리소스의 위치(location)와 접근 방법을 포함 http://localhost:8080/users?name=bkkhyunn어디에 있고 어떻게 접근할지 설명. http라는 접근 방법과localhost:8080/users라는 위치가 존재한다.URN (Uniform Resource Name) 리소스의 이름(name)만 식별 (위치 X) urn:isbn:0451450523ISBN, DOI 처럼 위치는 몰라도 유일한 식별자. 위 예제는 위치에 의존하므로 URN 이 아니다. http://- URL 내 Schema 로, 사용하는 프로토콜(접근 방법)을 의미한다. 위 예제에서는 프로토콜로 HTTP 를 사용하겠다는 의미다.
- HTTP 의 경우 항상
http://혹은https://가 되어야 한다. - 만약 HTTP 를 사용하지 않는 Web API 의 경우, 이 부분은 바뀔 수 있다. 대표적으로
ftp://, file://등이 있다.
localhost- URL 내 Host 부분이다. IP 가 될 수도 있고, Domain Name 이 될 수도 있다.
- localhost 는
127.0.0.1이라는 IP 의 예약된 Domain Name 이다. 127.0.0.1은 외부 네트워크에서 접근 불가능한 내 컴퓨터의 로컬 IP 다. 어떤 컴퓨터든 이 IP 는 로컬임을 의미한다. 이를 외부에 공개하려고 한다면0.0.0.0이라고 쓰기도 한다.
8080- URL 내 Port 부분이다. 예를 들어 jupyter notebook 의 경우 8888 번 포트다.
localhost:3030,localhost:8080처럼 하나의 호스트 내에서도 여러 포트를 가질 수 있다.- 각 프로세스(서버)는 하나의 포트를 사용하여 네트워크 통신을 한다. 즉, 위 API 호출은 localhost(내 컴퓨터)의 8080 포트에서 리슨하고 있는 서버로 HTTP 요청을 하는 것이다.
- 위 요청에 대한 응답이 정상적으로 오려면, localhost(내 컴퓨터)의 8080 포트에 서버가 실행되고 있어야 한다.
/users- URL 내 Path 부분이다. API 엔드포인트(Endpoint) 라고도 불린다.
- 여기서는
/users라는 엔드포인트가 있고, 이 엔드포인트를 호출하면 유저 목록을 반환해줄 것이라 예상할 수 있다. - ML 관련 API 는 보통
/predict,/train과 같은 엔드포인트를 사용한다.
URL Parameters
- 위 예제에서
?name=bkkhyunn와 같은 URL Parameters 에 대해서 좀 더 자세하게 살펴보자. URL 내 파라미터 구성은 아래와 같이 2 가지 방식이 있다. - Query Parameter
?를 써서 URL 끝에 추가하며, 특정 리소스의 추가 정보를 제공 또는 데이터를 필터링할 때 사용한다.- API 뒤에 입력 데이터를 함께 제공하는 방식으로 사용한다.
- 파라미터가 Query String 에 저장된다. Query String 은 Key, Value 의 쌍으로 이루어지며,
&로 연결해 여러 데이터를 넘길 수 있다. - 위 예시와 같이
/users?name=bkkhyunn이 Query Parameter 방식을 쓴 것이다.
- Path Parameter
- 리소스의 정확한 위치나 특정 리소스를 찾을 때 사용한다.
- 파라미터가 Path 에 저장이 된다.
- 예를 들어
http://localhost:8080/users/bkkhyunn과 같은 방식이다. users/뒤에 나오는 Path Parameter 값은/users/chulsoo,/users/younghee처럼 바뀔 수 있다.
- 그렇다면 언제 어떤 방식을 사용할까?
- 정렬 또는 필터링을 해야하는 경우, 즉 선택적인 정보를 전달한다면 Query Parameter 가 더 적합하다.
- Resource 를 식별해야 하는 경우, 즉 필수적인 정보를 전달한다면 Path Parameter 가 더 적합하다.
HTTP Header, Payload
- HTTP Method 와 URL 뿐 아니라, 서버에 요청할 때는 HTTP Header 와 HTTP Payload 를 사용한다.
curl -X POST -H "Content-Type: application/json" -d '{"name":"bkkhyunn"}' http://localhost:8080/users과 같이 CLI 로 요청한다고 해보자.curl은 터미널(CLI) 환경에서 HTTP 요청을 할 때 주로 사용하는 도구다.-X POST는 HTTP 메소드로 POST 를 사용함을 의미한다.-H "Content-Type: application/json"-H는 HTTP Header 를 지정하는 옵션이다.- HTTP Header 에
"Content-Type: application/json"라는 key:value 를 추가한다. 이는 보내는 데이터가 JSON 타입임을 나타낸다. - HTTP Header 에 key:value 형태로 데이터를 저장할 수 있다.
- key 에는 Content-Type, Authorization, Accept, User-Agent 등이 있다.
-d '{"name":"bkkhyunn"}'-d는 data 를 의미한다. 주로 POST, PUT, PATCH 요청과 함께 사용되며 본문(body)에 데이터를 넣는다.- Payload(본문)는 클라이언트가 서버에 보내는 요청 본문(request body)이고, 주로 JSON 이나 폼 데이터가 들어간다.
- 즉 위 예제에서는 Payload 로 JSON 을 추가한 것으로, 데이터를 담아서 보내는 것이다.
- Payload 는 앞 뒤에 큰따옴표(”) 를 붙여야 한다.
http://localhost:8080/users- HTTP URL 부분이다. 요청을 어디로 보낼 것인지를 표현한다.
-
HTTP Header 와 HTTP Payload 는 웹 브라우저에서 개발자 도구를 이용하여 아래와 같이 확인할 수 있다.
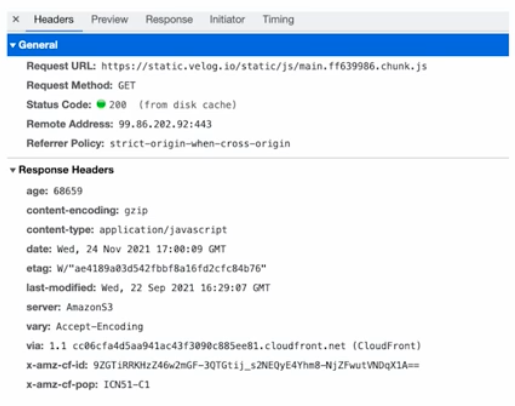
- 정리하면, 서버에 요청할 때 보내는 데이터의 타입을 Header 에서 명시하고, Payload 에 데이터를 담아 보내는 것이다.
Status Code
- 클라이언트 요청에 따라 서버가 어떻게 반응하는지를 알려주는 Code 다. 아래와 같은 Code 들이 있다.
1xx(정보) : 요청을 받았고, 프로세스를 계속 진행함2xx(성공) : 요청을 성공적으로 받았고, 실행함3xx(리다이렉션) : 요청 완료를 위한 추가 작업이 필요4xx(클라이언트 오류) : 요청 문법이 잘못되었거나 요청을 처리할 수 없음5xx(서버 오류) 서버가 요청에 대해 실패함
- 이처럼 Status Code 는 미리 정의되어 있다. mdn web docs에서 자세하게 확인할 수 있다.
- 일반적으로 맨 앞글자만 따서 100 번대, 200 번대와 같이 이해하면 된다.
- 예를 들어 Status Code 로 응답이 404 로 온 경우를 들어보자.
- 404 는 Resource Not Found 인 경우 사용하는 Status Code 다. 해당 리소스는 존재하지 않음을 뜻한다.
- 또한 4xx 번대 Status Code 이므로, 서버의 잘못이 아니라 클라이언트(사용자)가 잘못 요청한 경우다.
IP
- Internet Protocol 의 줄임말로, 인터넷 상에서 사용하는 주소체계다. 즉 네트워크에 연결된 특정 PC 의 주소를 나타내는 체계다.
- 숫자로 이루어진 4 개의 덩어리로 구성된 IP 주소 체계를 IPv4 라고 한다.
- 각 덩어리마다 0 ~ 255 로 나타낼 수 있다. 따라서 한 덩어리마다 $2^8$ 이고, 총 $2^{32}$(약 43 억)개의 IP 주소를 표현할 수 있다.
- Usecase
- 몇 가지 IP 들은 이미 용도가 정해져 있다.
localhost,127.0.0.1: 현재 사용중인 로컬 PC0.0.0.0,255.255.255.255: broadcast address, 로컬 네트워크에 접속된 모든 장치와 소통하는 주소- 개인 PC 보급으로 누구나 PC 를 사용해 IPv4 로 할당할 수 있는 한계점에 진입했다. 이에 따라 IPv6 이 등장했다.
- 자세한 것은 Network 카테고리에 정의한 포스트를 참고하자.
Port
127.0.0.1:8080에서8080과 같이 IP 주소 뒤에 나오는 숫자다. 이를 포트라고 하며, PC 에 접속할 수 있는 통로(채널)다.- 포트는 0 ~ 65535 까지 존재하며, 사용 중인 포트는 중복할 수 없다.
- Usecase
- 0 ~ 1023 사이의 포트는 통신을 위한 규약에 예약되어 있다. 따라서 사용하면 안된다.
- 22 번 포트는 SSH 를 위한 포트다.
- 80 번 포트는 HTTP 를 위한 포트다.
- 443 번 포트는 HTTPS 를 위한 포트다.
댓글 남기기