
[Serving] Serving Pattern
ML/AI 서비스를 위해 Serving 하는 것에도 몇 가지 패턴이 있다. 이에 대해 정리해보자.
Serving
- 머신러닝 모델 서빙은 모델의 예측 결과를 요청한 클라이언트에게 제공하는 과정이다.
- 클라이언트는 프로그래밍 관점에서 웹이나 앱 혹은 서버 등을 의미하며, 클라이언트로부터 입력된 데이터에 기반하여 모델 예측 결과를 제공한다.
- 또한 Serving 은 Production(Real World) 환경에 모델을 사용할 수 있도록 배포하는 것을 의미한다. 이는 모델을 연구하는 환경 이후에 진행되는 작업이다.
- Serving 의 종류에는 크게 2 가지 방식이 있다.
-
Batch Serving

- Batch 란 일괄, 묶음을 의미한다.
- 데이터를 일정 묶음 단위로 서빙한다. 이 때 묶음에도 기준이 필요하다. 예를 들어 매일 14~15 시 사이에 생성된 데이터 등으로 설정할 수 있다.
- Batch Serving 은 많은 양을 일정한 주기에 따라 한꺼번에 서빙하는데 사용한다.
-
Online(Real Time) Serving

- 연결, 실시간이라는 특징을 가진다.
- 클라이언트가 요청할 때 서빙하는 방식이다. API Request 를 사용하며 클라이언트가 요청할 때 데이터를 같이 제공해준다.
- Online Serving 은 한번에 하나씩 포장해서 배송하는 것과 같다. 따라서 동시에 여러 주문이 들어올 경우 확장 가능하도록 준비해야 한다.
- 아래에서 다루겠지만, Online Serving 에도 종류가 여러 가지가 있다.
- Serving 을 사용하는 기준에는 정답이 없다. 문제의 상황, 문제 정의, 제약 조건, 개발 인력 수, 데이터 저장 형태, 레거시 유무 등에 따라 결정한다.
- 쉬운 난이도의 문제를 먼저 풀고, 난이도를 높여 푸는 것이 sprint 또는 애자일 방식이라고 한다. 즉 문제 정의가 크면 오래 걸리기 때문에 빠르게 런칭하고 피드백을 받아서 개선하는 것이 중요하다.
- 제약 조건에는 법, 가격, 도메인 지식 등이 있다.
- 데이터 저장 형태(DB, AWS S3, 메시지 시스템)에 따라 서빙이 결정되기도 한다. 이는 데이터 엔지니어링 영역이다.
- 레거시란 예전 개발 흐름 또는 정해진 템플릿을 의미한다. 예를 들어 과거 레거시로 Batch Serving 을 많이 썼으면, Batch Serving 으로 먼저 개발하고 Online Serving 으로 들어간다.
- 중요한 것은 주어진 문제 상황에서 적절한 것을 선택하는 것이 최선이라는 점이다.
Batch Serving
- 실시간 응답이 중요하지 않은 경우나 데이터 처리, 모델 예측에 일정 시간이 소요되어도 괜찮은 경우에 사용하는 Serving 방식이다. 또는 대량의 데이터를 처리하거나, 정기적인 일정으로 수행할 때 사용할 수 있다.
- 인력이 적은 경우 Batch Serving 이 Online Serving 보다 쉬울 수 있다. 스크립트 파일(Python)을 거의 수정하지 않고 실행할 수 있도록 만들고 스케줄링 작업을 하면 된다.
- Airflow 같은 경우 기존의 함수를 바꿔서 실행하는 것이 가능하다.
- Batch Serving 의 데이터 저장 형태는 RDB 또는 분석을 위한 데이터 웨어하우스(AWS Redshift, GCP BigQuery, Snowflake 등)를 사용한다. 대량의 데이터를 Python 이나 Spark 등을 사용해서 서빙한다.
- Batch Serving 으로 먼저 개발하고 이후 Online Serving 으로 바꾸기도 한다.
- 일정 기간 단위로 예측 후 DB 에 저장한다. 이후 서비스 서버는 DB 에 저장된 예측 결과를 사용한다.
Online Serving
- 실시간 응답이 중요한 경우나 즉각적으로 응답을 제시하는 경우에 사용하는 Serving 방식이다.
- 개별 요청에 대한 맞춤 처리가 중요하거나 데이터가 지속적으로 변하는 경우 등 동적인 데이터에 대응할 때 유용하다.
- Online Serving 개발 인력은 API 서버, 실시간 처리 등의 경험이 필요하다.
- Online Serving 의 데이터 저장 형태는 요청이 오면 데이터를 제공하기 떄문에 API request, 메시지 시스템 등을 사용한다.
- 즉 Online Serving 은 요청(request)이 오면 바로 이에 대한 응답(response)을 제공한다.
Serving Pattern
- 여러 회사에서 많이 사용하는 패턴들이 존재한다. 소프트웨어 개발 분야에도 패턴이 존재하고, 이를 디자인(설계) 패턴이라 부른다.
- 이러한 패턴에는 소프트웨어의 구조, 구성요소의 관계, 시스템의 전반적인 행동 방식이 담겨있다. 즉, 소프트웨어를 어떻게 구성하고, 어떻게 상호 작용할지를 담은 내용이다.
- 아래에서 다룰 머신러닝 디자인 패턴은 템플릿 으로, 이러한 패턴들을 인지하고 알고 있으면 많은 도움이 된다.
- 해당 패턴들은 과거부터 문제를 해결한 사람들이 반복한 내용을 패턴으로 정리한 것이며, 코드의 재사용성, 가독성, 확장성 등을 향상시키기 위한 목적으로 도입된 것이다.
- 주로 객체 지향 프로그래밍에서 사용되지만 다른 프로그래밍 패러다임에서도 유용하다. 개발 과정의 커뮤니케이션에서 이런 패턴을 사용하기도 한다.
- 패턴 중에서 안티패턴(Anti Pattern)은 일반적으로 좋지 않다고 알려진 패턴이다. 이에 대해서도 아래에서 살펴보자.
머신러닝 디자인 패턴
- 소프트웨어 개발에서는 Only Code 지만, Data, Model, Code 로 이루어진 머신러닝의 특수성으로 별도로 생긴 디자인 패턴이다.
- 여기에는 머신러닝 서비스를 개발하면서 고민할 수 있는 아래의 특수한 포인트들이 담겨있다.
- 대용량 Model Load
- 버전 업데이트, 성능 향상 등 Model 관리
- 데이터를 대량으로 가져와서 전처리
- 데이터를 통계적으로 확인하여 이상치 제외
- 예측 요청 후, 모델 연산으로 인해 오래 소요될 수 있는 반응 시간
- 최근에는 LLMOps 라고 해서, 머신러닝 디자인 패턴이 계속 변하고 있다. 디자인 패턴은 상황에 따라 다르기에 항상 베스트인 패턴은 없다. 그러나 설계 및 구현하기 전에 참고할 수 있기 때문에 잘 알아두자.
- 개발할 때는 설계가 중요하다. 아래에서 소개하는 여러 패턴을 합쳐서 하나의 패턴으로 만들 수 있으니 여러 case 들을 살펴보는 것이 좋다. 그리고 모든 패턴을 외울 필요는 없고, 어떤 맥락에서 쓰면 좋은지를 이해해야 한다.
- 일반적으로 서비스 아키텍처는 앱/웹(프론트, 클라이언트) → 서버 → DB → 서버 → 앱/웹 의 흐름을 따른다.
- 서비스 서버에서 ML request 에 대한 예측을 줄 수 있지만, 별도의 추론/예측 서버를 두기도 한다. 즉 예측 서버와 서비스 서버가 연결되어, 서비스 서버가 예측 서버에 request 를 보내고 response 를 받아서 클라이언트한테 보낼 수 있다.
- 이 경우 예측 서버는 추론 서버로 추론 결과를 DB 에 적재하고, 서비스 서버는 서비스가 잘 동작하는 것에 집중한다.
Batch Serving
- Batch Serving 에 해당하는 패턴을 보자.
Batch Pattern
- 예를 들어 영화를 추천해주는 모델의 개발은 완료되었다고 가정해보자. 이제 이 모델을 가장 간단하고 최대한 적은 비용으로 운영 환경에 배포하고 싶은 상황이다.
- 주기적으로 이 추천 모델에 사용자가 본 영화 데이터(histroy)를 input 으로 넣어 예측하고, output 으로 나오는 사용자 별 추천 영화를 DB 에 저장한다.
-
추천 결과를 활용하는 서비스 서버 쪽에서는 이 DB 에 주기적으로 접근하여 추천 결과를 노출한다.
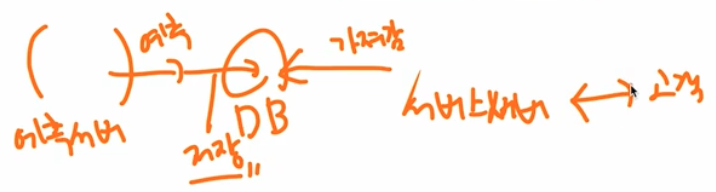
- 서비스 서버는 보통 AI 조직이 아닌 개발 조직에서 개발하게 된다. AI 쪽에서 처리한 결과를 넘기고, 개발 쪽에서 받아가는 형태다.
-
실시간성이 필요없는 경우 주기적으로 예측 결과를 DB 에 저장하고, 활용하는 쪽은 DB 에서 결과를 읽어와 사용한다.
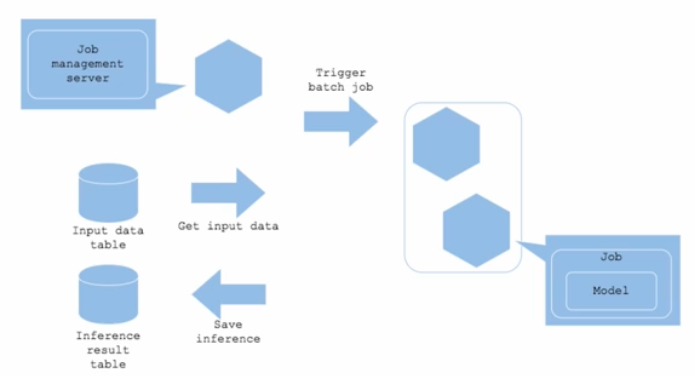
- Job management Server
- 데이터 전처리, 데이터 예측 등의 작업을 실행하는 서버다.
- Apache Airflow 등을 주로 사용하고, 특정 시간에 주기적으로 Batch Job 을 실행시키는 주체다.
- 스케줄링에 따라 시간표가 있다. 서버가 시간표를 보고 Trigger 를 주면 job 이 실행되는 것이다.
- Job
- 어떤 작업 실행에 필요한 모든 활동이다.
- job 이 실행되는 과정에 model load, data load 가 포함된다. data load 에는 SQL 을 사용해서 데이터를 가져오는 것 또는 다른 저장소에서 가져오는 것을 포함한다.
- Python 스크립트를 그냥 실행시키는 경우도 있고, Docker Image 로 실행하는 경우도 존재한다.
- Data
- 서비스에서 사용하는 DB(AWS RDS 등) 또는 데이터 웨어하우스에 저장된다.
- 서비스 서버에서도 데이터를 불러오는 스케줄링 job 이 존재한다. 예측한 결과를 계속 save 하는 것이 이에 해당한다.
- input 데이터 테이블에서 input 데이터를 가져가서 예측하고 예측한 결과를 저장한다. 이 예측 결과를 서비스 서버에서 계속 가져간다.
- job management server 는 특정 시간 단위로 데이터를 가지고 계속 예측하고, 서비스 서버는 그 예측 데이터를 가져간다.
- Batch Pattern 의 장점
- 기존에 사용하던 코드를 재사용할 수 있다.
- API 서버를 개발하지 않아도 되어 단순하다. 즉 airflow 와 같은 job managment 서버만 있으면 된다.
- 서버 리소스를 유연하게 관리할 수 있다. 오래 걸릴 job 에 서버 리소스를 추가 투입할 수 있다.
- Batch Pattern 은 API 서버가 없는 대신 별도의 스케줄러 서버(apache airflow)가 필요하다.
- usecase
- 예측 결과를 실시간으로 얻을 필요가 없는 경우
- 대량의 데이터에 대한 예측을 하는 경우
- 예측 실행이 시간대별, 월별, 일별로 스케줄링해도 괜찮은 경우
Online Serving
- Online Serving 에 해당하는 패턴을 보자.
Web Single Pattern
- Online Serving 에서는 Web Single Pattern 이 제일 대표적이다. 이 안에서 동기, 비동기로 나뉜다.
- Web 은 웹 기반 애플리케이션을 뜻하고, Single 은 단일, 즉 하나의 요청을 처리하는 것을 의미한다.
- 예를 들어 Batch Pattern 으로 서빙했더니, 결과 반영에 시간 term 이 존재한다고 해보자. 이를 더 실시간에 가깝게 하려면 어떻게 해야할까?
- 모델이 항상 Load 된 상태에서 예측을 해주는 API 서버를 만들고, 추천 결과가 필요한 경우 서비스 서버에서 예측 서버에 직접 요청을 하도록 설계할 수 있다.
- 즉 핵심은 API 서버 코드에 모델을 포함시킨 뒤 배포하는 것이다. 이 때 모델을 불러오거나 클라우드 저장 후 다운로드 하여 실행되도록 할 수 있다.
-
클라이언트나 서비스 서버와 같이 예측이 필요한 곳에서 직접 Request 를 예측 서버로 보낸다. 이후 예측 서버는 모델 예측 결과에 대한 Response 를 반환한다.
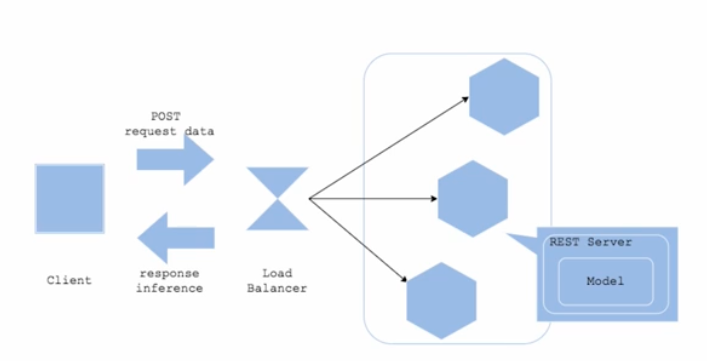
- 예측/추론 Server
- 위 그림에서는 REST Server 에 해당한다.
- FastAPI, Flask 등으로 단일 REST API 서버를 개발한 후 배포한다. 예를 들어
POST api-server-url/predict를 통해 예측을 실시한다. - API 서버가 실행될 때 모델을 로드한다.
- API 로직 내에 전처리도 같이 포함하며, 예측 서버가 전처리하고 결과를 내려줄 수 있다. 이후에는 API 로직이 아니라 전처리만 해주는 서버를 따로 만들어두기도 한다.
- Client
- 앱에서 직접 요청할 수도 있고, 앱이 서비스 서버에 요청하고 서비스 서버가 예측 서버에게 요청할 수도 있다. 이는 개발을 어떻게 했는지에 따라 다르다.
- 즉 클라이언트는 상대적이다. 예측 서버를 기준으로 어디서 요청했는가를 보면 클라이언트를 알 수 있다. 예측 서버에 요청하는 곳이 클라이언트라고 할 수 있다.
- 웹 페이지라면 브라우저에서 요청한다. 즉 브라우저도 하나의 클라이언트라고 볼 수 있다.
- Data
- 예측 서버에 요청할 때 데이터를 같이 담아 요청한다.
- 상황에 따라 데이터의 용량 제한이 있을 수 있다. 또한 이미지 데이터의 경우 해상도에 따라 시간이 걸릴 수도 있다.
POST로 data request 를 보내고 response inference 를 클라이언트가 받는다.
- Load Balancer
- Load Balancer 는 트래픽을 분산시켜서 서버에 과부하를 걸리지 않도록 해주는 도구다.
- 그러한 기능을 가진 Nginx, Amazon ELB(Elastic Load Balancing) 등을 사용한다.
- 내부적으로 서버를 여러 개 띄울 수 있는데, 한 서버에 부하가 많이 생기면 다른 서버로 보내는 작업들을 한다.
- Web Single Pattern 의 장점
- 보통 하나의 프로그래밍 언어로 진행한다.
- 아키텍처가 단순하고, 처음 사용할 때 좋은 방식이다.
- 모델, 전처리 코드 등 구성 요소가 바뀌면 전체 업데이트가 필요하다.
- 모델이 큰 경우, 로드에 시간이 오래 걸릴 수 있다. 따라서 모델이 크면 어떻게 할까에 대한 고민이 필요하다.
- 요청 처리가 오래 걸리는 경우, 서버에 부하가 걸릴 수 있다. 따라서 서버 모니터링도 잘 해야한다.
- usecase
- 예측 서버를 빠르게 출시하고 싶은 경우
- 예측 결과를 실시간으로 얻을 필요가 있는 경우
- Web Single Pattern 을 기본으로 삼고 이어지는 Pattern 들을 적용한다. 데이터를 어떻게 처리할지, 고객이 response 를 어떻게 받을 것인지 등 이런 것들이 Web single 패턴에 이어지는 패턴으로 나온다. 이 경우 패턴들을 조합하여 사용하게 된다.
Synchronous Pattern
- 동기식 패턴으로, response 를 동기적으로 받는다. 즉 하나의 작업이 끝날 때까지 다른 작업을 시작하지 않고 기다리고, 작업이 끝나면 새로운 작업을 시작하는 방식이다.
- FastAPI 로 모델을 Web Single 패턴으로 구현했을 때, 클라이언트는 API 서버로 요청을 한 뒤 이 요청이 끝날 때까지 기다려야 한다.
-
Web Single Pattern 을 동기적(synchronous)으로 서빙한 것이며, 기본적으로 대부분의 REST API 서버는 동기적으로 서빙하게 된다.
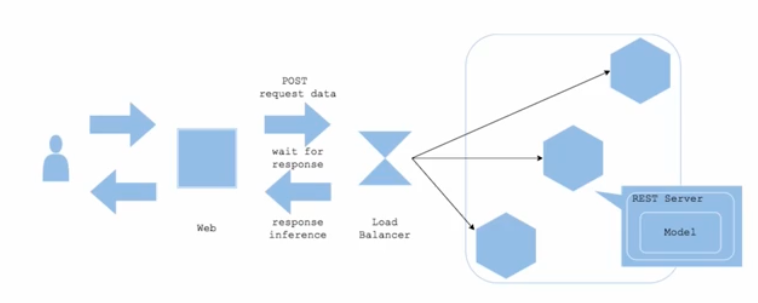
- 위 그림과 같이 Wait for response 가 있다. 다른 작업이 실행하기 전에 응답을 기다리고, 하나의 작업이 끝나야 새로운 작업이 추가되는 것이다.
- Synchronous Pattern 의 장점
- Web single 패턴에서 기본적으로 많이 사용하는 방식으로 아키텍처는 단순하다.
- 예측이 완료될 때까지 프로세스가 다른 작업을 할 필요가 없어 Workflow 가 단순해진다.
- 그러나 예측 속도에서 병목이 발생한다. 동시에 1000 개의 요청이 올 경우 대기 시간이 길어지거나 Drop 혹은 Timeout 이 생긴다. 따라서 예측 지연으로 사용자 경험이 악화될 수 있다. 이 경우 패턴 개선을 고민해야 한다.
- usecase
- 예측의 결과에 따라 클라이언트의 로직이 즉각적으로 달라져야 하는 경우
- 예를 들어 예측 결과가 강아지냐 고양이냐에 따라 클라이언트에서 보여줘야 하는 페이지가 다른 경우가 있다.
- 이 경우 예측 결과가 어떻게 되는지 알아야 클라이언트나 다른 곳에서 처리해서 보여줄 수 있다. 따라서 동기적으로 실시해야 한다.
- 이미지 예측에서 데이터를 넣었을 때 기다리라고 하는 것이 동기식이다.
Asynchronous Pattern
- 하나의 작업을 시작하고, 결과를 기다리는 동안 다른 작업을 할 수 있다. 즉 response 를 비동기적으로 받는다.
- 작업이 완료되면 시스템에서 결과를 알려준다. 음식점에서 진동벨을 사용하는 경우가 비동기식과 유사하다.
- 항상 비동기 방식이 좋은 것은 아니다. 문제 요구조건에 따라 다르다. 고객이 기다릴 수 있는 경우인지, 고객이 기다리지 못하고 나중에 알려줘야 하는지 등 이런 상황에 따라 동기/비동기를 결정하면 된다.
- 예를 들어 동기식 패턴으로 서빙할 때 API 서버에서 수많은 요청을 감당할 수 없는 경우가 생긴다. 이 경우 API 서버가 계속 부하가 걸려 모든 요청에 대한 응답이 느려지기 시작한다.
- 이 때 응답이 느려지기 때문에, 동기식 패턴에서 클라이언트에서도 응답 받은 이후의 로직을 진행하지 못한다.
- API 서버의 CPU 와 메모리를 증가시키면 해소되긴 하겠지만, 이는 단기간의 해결이고 요청이 늘어나면 결국 똑같은 문제가 발생한다.
- 쇼핑몰에서 블랙 프라이데이와 같은 예시처럼, 필요한 경우 단기간에 서버 리소스를 올리기도 하지만, 장기적으로 좋은 해결 전략은 아니다.
- 따라서 API 서버의 부하가 늘지 않도록 요청을 하며 다 처리할 수 있어야 한다. 그리고 클라이언트는 당장 결과를 받지 않더라도, 최종적으로 결과를 받아야 한다.
-
아래 그림과 같이 Web Single Pattern 을 비동기적으로 서빙할 수 있다.
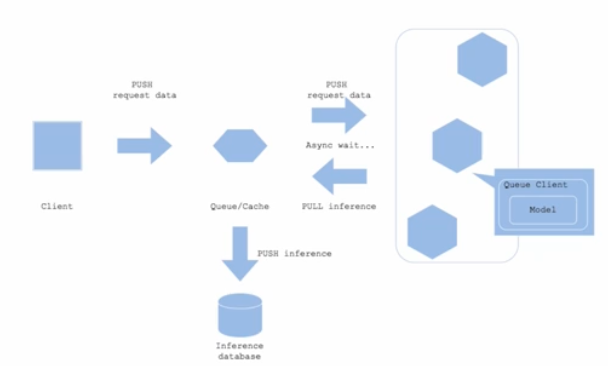
- Queue(메시지 시스템)
- 클라이언트와 예측 서버 사이에 메시지 시스템(Queue)을 추가하는 것으로, 비동기 Pattern 에서 핵심 역할을 한다.
- 대표적인 메시지 시스템 프레임워크는 Apache Kafka, Redis 등이 있다.
- 이는 지하철 물품 보관소와 유사한 역할을 한다. Queue 에 요청을 계속 넣어두고 예측 서버는 해당 Queue 에서 요청을 가져가 처리한다.
- 비동기 패턴에서 핵심적 역할을 수행하는 Queue 에 대해 관리하는 것은 난이도가 있다. 따라서 Online Serving REST API 로 먼저 요청을 받은 뒤 Kfaka queue 에 넣은 뒤 Batch 혹은 비동기 방식으로 모델을 돌리는 구조다.
- 즉 실시간처럼 보이지만 실제로는 효율적인 비동기 Batch 서빙 아키텍처를 쓰는 것이라 할 수 있다.
- Push 는 메시지를 저장하는 것이고, Pull 은 메시지를 가지고 와서 작업(예측)을 수행하는 것이다.
- Asynchronous Pattern 의 장점
- 클라이언트와 예측 프로세스가 분리되어 관계가 의존적이지 않다.
- 클라이언트가 예측을 기다릴 필요가 없다. 예측이 완료되면 예측 서버는 다시 메시지를 넣어 두고, 클라이언트는 이 메시지를 꺼내서 알려주게 된다.
- 그러나 메시지 Queue 시스템을 만들어야 한다. 이는 또 다른 인프라를 쓰는 것과 마찬가지다. 따라서 전체적으로 구조가 복잡해진다.
- 메시지를 가져갈 때 시간이 소요될 수 있기 때문에 완전한 실시간 예측에는 적절하지 않다.
- usecase
- 예측과 클라이언트 진행 프로세스의 의존성이 없는 경우
- 예측 요청을 하고 응답을 바로 받을 필요가 없는 경우
- 예측을 요청하는 클라이언트와 응답을 반환하는 목적지가 분리된 경우
- 서비스 개발과 AI 개발이 나뉠 수 있는데, 개발팀은 API 서버를 관리하면서 데이터를 어디로 흐르게 할지 정의한다. 그러면 AI 개발 쪽에서 이를 가져가서 처리한다. 이러면 두 개의 조직이 각자 독립적으로 일을 할 수 있다.
- 요청에 따라 응답을 반환하고, 서비스 서버에 보내줄 수도 있고 서버 말고도 알림 등에도 보낼 수 있다. 여러 목적지로 보내고 싶을 때도 비동기를 써서 메세지를 사용할 수 있다.
Anti Serving
- Anti 는 권장되지 않는 Serving 패턴, 즉 주의해야 할 패턴이다.
- 중요한 것은 Anti Pattern 이 항상 Anti Pattern 은 아니며, 이를 해결하기 위해 또 다른 머신러닝 디자인 패턴이 생겼다는 점을 인지하는 것이다.
- 여기서는 좋아 보이는 것을 다 넣는 것이 좋지 않다는 것을 인지해야 한다.
Online Bigsize 패턴
- 실시간 대응이 필요한 온라인 서비스에서 예측이 오래 걸리는 모델을 사용하는 경우다.
- 즉 큰 사이즈의 모델을 사용하여 서버 실행에 몇 분씩 소요되고, 요청에 대한 응답이 몇 초씩 걸릴 경우에 해당한다.
- 일반적으로 큰 사이즈의 모델은 배포할 때 서버 실행과 서빙이 느리다. 따라서 속도와 비용 사이의 Trade-off 를 조절하여 모델을 경량화하는 작업이 필요하다.
- 아래의 대안이 가능하다.
- 실시간이 아닌 Batch 로 변경하는 것이 가능한지 검토한다.
- 중간에 캐시 서버를 추가한다. 캐시 서버는 임시 저장소로서, 과거의 동일한 예측이 있으면 그걸 사용할 수 있도록 캐싱한다.
- 전처리 서버를 분리하는 것도 Bigsize 를 탈피하는 방법 중 하나다.
All-in-one 패턴
- 하나의 서버에 여러 예측 모델을 띄우는 경우에 해당한다. 즉
\predict1,\predict2,\predict3으로 나눠서 하나의 서버에서 모두 실행하는 경우다. - 이렇게 되면 라이브러리의 선택 제한이 존재하게 된다.
- 또한 서버가 갑자기 다운되는 등 장애가 발생할 경우, 시스템이 마비된다. 이를 SPOF(Single Point Of Failure) 라고 한다.
- 따라서 모델 별로 서버를 분리하여 배포해야 한다. 이러한 것을 Micro-service Pattern 이라 한다.
- 정리
Serving 예시
- 중요한 것은 문제 정의다. 이는 Loss 정의에도 연관되어 있다.
- Online Serving, Batch Training 등을 고민한다.
-
아래와 같은 도식화가 중요하다.
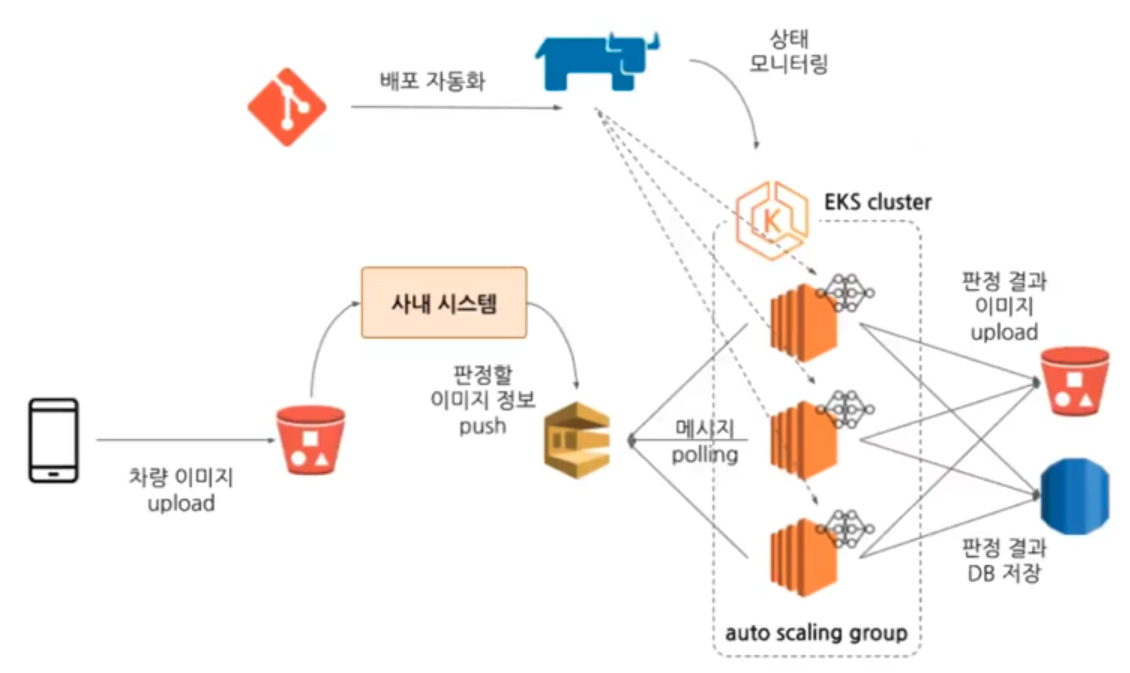
- 메세지 시스템은 Kafka, AWS SQS 등 어떤 것을 쓸 것인지? AWS SQS, GCP Pub/Sub 등 메시지 사이즈를 고려하자.
- Async Serving(비동기 서빙)에 대해 아래와 같은 것을 고민하자.
- 문제 정의 : 항상 중요한 부분. 어떤 문제를 해결할 것인가?
- Input / Output 확인 : 현재 사용할 수 있는 데이터가 있는가? (데이터 엔지니어링, Feature 와 관련된 부분)
- 배포를 어떻게 할 것인가?
- 모델 평가 : 어떻게 확인할 것인가?
- 모니터링 : 모니터링을 위해 데이터를 어떻게 저장하고 어디에 저장할 것인가?
- 제약조건
- 데이터 엔지니어링은 인프라와 관련이 있다.
- 인퍼런스 결과에 따라 Batch / Online / Streaming 을 정한다.
- Online Serving : Triton Inference Server or FastAPI 를 사용
- Message : Kafka
- Infra : Kubernetes? Docker?
- 모니터링 : Datadog(인프라) + 간단히 한다면 DB, Slack 등
- 모델 버전 관리 : MLflow
- 서비스 규모가 작으면 훨씬 더 Simple 한 구조로 만드는 것이 좋다. 기술은 기술일 뿐으로, 회사에서 돈이 없는 상황에서 k8s 를 고려하는 것은 오히려 좋지 않을 수 있다.
- 또한 법적인 이슈가 굉장히 중요하므로 신경써야 한다.
참고자료
- Uber의 Michelangelo 플랫폼에 관한 글로, 대규모 머신러닝 모델 서빙 방법에 대한 통찰을 살펴볼 수 있다.
- MLOps 분야의 대가이신 Chip Huyen님의 글. Batch Serving부터 Online Serving에 대한 내용을 살펴볼 수 있다.
댓글 남기기