
[MLOps, Service] MLOps 개론
모델 개발 프로세스
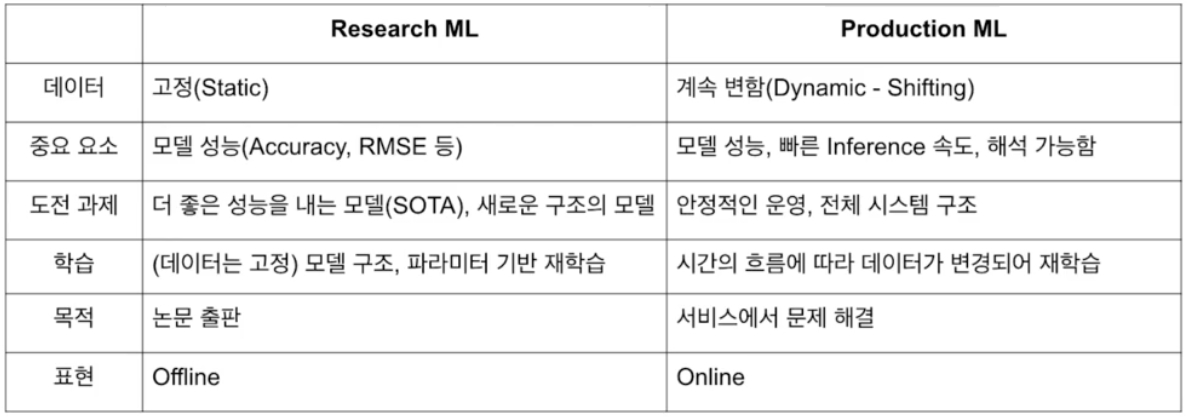
- Research
- 문제정의 $\rightarrow$ EDA $\rightarrow$ Feature Engineering $\rightarrow$ Train $\rightarrow$ Predict
- 위 프로세스는 자신의 컴퓨터나 서버 인스턴스 등에서 실행한다. 그리고 고정된 데이터를 사용해 학습한다.
- 학습된 모델을 앱, 웹 서비스에서 사용할 수 있도록 만드는 과정이 필요하다. 이를 “Real World, Production 환경에 모델을 배포 한다“고 표현한다.
- Production
- 문제정의 $\rightarrow$ EDA $\rightarrow$ Feature Engineering $\rightarrow$ Train $\rightarrow$ Predict $\rightarrow$ Deploy
- Deploy 는 모델에게 데이터(input)을 제공하면서 결과(output)를 예측해달라고 요청하는 것이다.
- 이 때 모델의 결과값이 이상한 경우, 원인 파악이 필요하다.
- 대표적으로 input 데이터가 이상한 경우가 존재한다. 이 경우 Research 할 땐 Outlier 로 제외할 수 있지만, 실제 서비스에선 제외가 힘든 상황이기 때문에 별도 처리가 필요하다.
- 또한 모델의 성능이 계속해서 변경되는 이슈가 존재한다. 따라서 성능을 파악하기 위해 예측값과 실제 레이블을 알아야 한다. 이 때 정형(Tabular) 데이터에서는 정확히 알 수 있지만, 비정형 데이터(이미지 등)는 잘 모를 수 있다.
- 이 외에도 새로운 모델을 사용할지 말지 등의 다양한 이슈가 존재한다.
Research 와 Production
-
production ML 에서는 빠른 inference 속도(이탈 가능성 줄이기 위해)와 해석이 가능한 것이 중요하다.
MLOps 개론
-
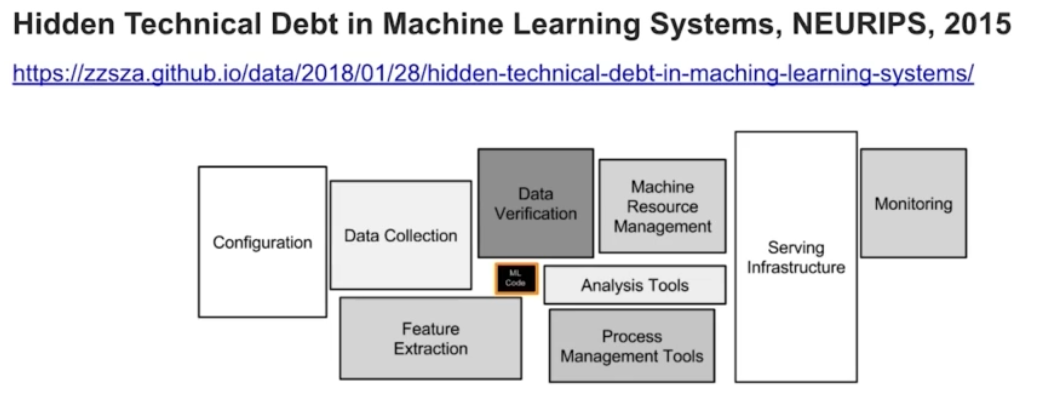
머신러닝 모델링 코드는 머신러닝 시스템 중 일부에 불과하다.
- MLOps 는 ML(Machine Learning) + Ops(Operations) 을 합친 용어다.
- 머신러닝 모델을 운영하면서 반복적으로 필요한 업무를 자동화시키는 과정이다.
- 여기에는 머신러닝 엔지니어링 + 데이터 엔지니어링 + 클라우드 + 인프라 의 과정이 들어간다.
- 즉 머신러닝 모델 개발(ML Dev)과 머신러닝 모델 운영(Ops)에서 사용되는 문제, 반복을 최소화하고 비즈니스 가치를 창출하는 것이 목표다.
- 모델링에 집중할 수 있도록 관련된 인프라를 만들고, 자동으로 운영되도록 만드는 일이 MLOps 인 것이다.
- Production 환경에 배포하는 과정에는 Research 에서 개발된 모델이 재현 가능해야 한다. 또한 현실의 Risk 있는 환경에서 잘 버틸 수 있어야 한다.
- 즉, MLOps 의 목표는 빠른 시간 내에 가장 적은 위험을 부담하며 아이디어 단계부터 Production 단계까지 ML 프로젝트를 진행할 수 있도록 기술적 마찰을 줄이는 것이 된다.
- MLOps 에 대해서 공부할 때는, MLOps 의 각 Component 에서 해결하고 싶은 문제는 무엇이고, 그 문제를 해결하기 위한 방법으로 어떤 방식을 활용할 수 있는지를 학습하는 것이 좋다.
MLOps Component
- MLOps 의 구성요소에 대해 다뤄보자.
Infra(Server, GPU)
- MLOps 에서는 인프라 를 고려해야 한다. 아래는 그에 해당하는 고민들이다.
- production 에서 예상하는 트래픽(서비스에서 이 모델을 얼마나 사용할 것인가)이 얼마나 되는가?
- 서버의 CPU, Memory 성능은 어느정도 할 것인가?
- 스케일 업, 스케일 아웃이 가능한가?
- 자체 서버 구축 혹은 클라우드를 사용할 것인가?
- 금융권 등의 특정 회사에서는 클라우드를 사용하지 못하는 경우가 있다.
- 딥러닝에서는 GPU infra 도 중요하다. 클라우드 GPU 를 임대해서 사용하는 경우, GPU 를 사서 사용할 수 있다. 이는 투자에 따라 다르다.
- 클라우드에는 대표적으로 AWS, GCP, Azure, NCP 등의 서비스가 있고, 온 프레미스(On premise)는 회사나 대학원의 전산실에 서버를 직접 설치하는 DGX, 조립식 컴퓨터 등을 의미한다.
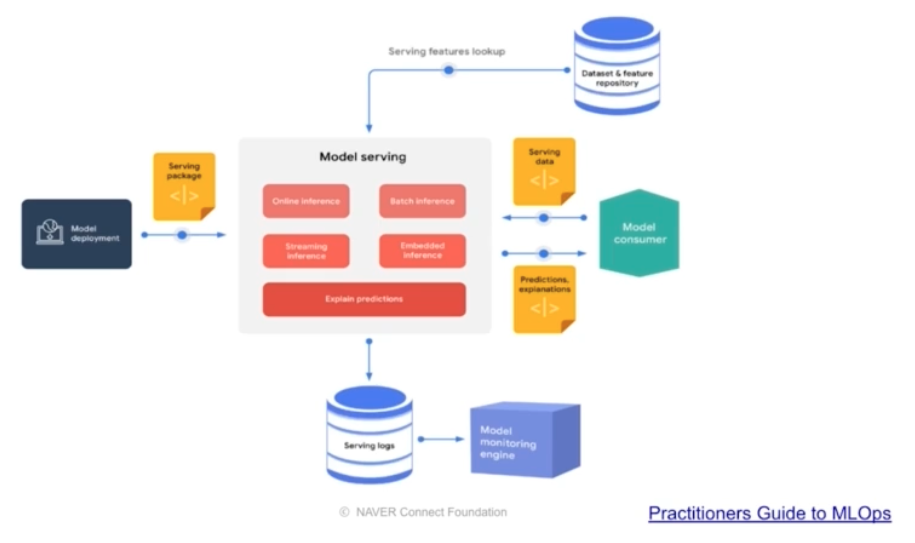
Serving
- Batch Serving 은 많은 양(=많은 데이터)을 일정 주기로 한꺼번에 예측(서빙)하는 것을 의미한다.
- 주피터 노트북에서 실행하는 방식은 함수화해서 대부분 Batch Serving 으로 쉽게 변경 가능하다. ex. Dataframe 의 데이터를 한번에 예측
- 반면에 Online Serving 은 한번에 하나씩 (=실시간으로) 예측하는 것을 의미한다.
-
동시에 여러 input 이 들어올 경우 병목이 없어야 하고 확장 가능하도록 준비해야 한다.
-
-
Serving 을 위한 라이브러리도 여러가지가 있다. 아래 그림을 보자.
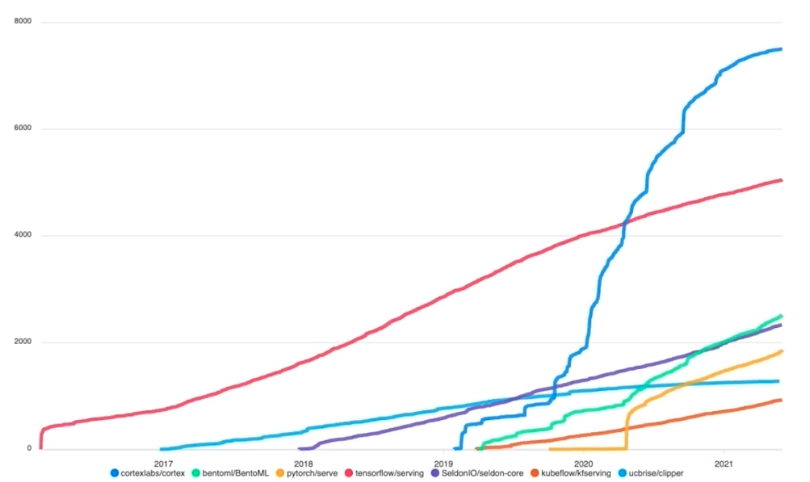
- x 축은 시간, y 축은 star 개수를 의미한다. 이러한 라이브러리들을 계속 follow up 하는 것이 필요하다.
Experiment, Model Management
- 파라미터, 모델 구조 등을 기록하면서 실험해야 어떤 조합이 좋은지를 알 수 있다. 이 때 여러 시행착오를 겪게 되는데, 성능이 제일 좋았던 모델을 Production 에 사용한다.
-
모델을 만드는 과정에서 생기는 모델 Artifact, 이미지 등을 저장한다. 모델은 다양한 종류가 있으므로 모델 생성일, 모델 성능, 모델 메타 정보 등을 기록해둘 수 있다. 이를 통해 여러 모델을 운영할 수 있다.
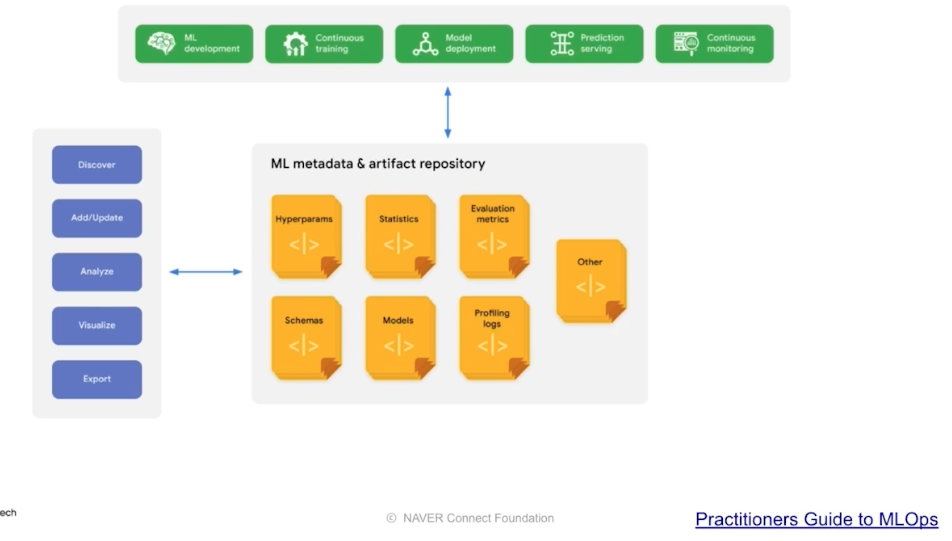
-
mlflow 는 대표적인 experiment management 도구다. 아래와 같이 auto logging 기능이 있다.

- team project 공용 mlflow 서버를 띄워서 여기에 실험을 기록할 수 있다. 협업할 때도 많이 사용되기 때문에, 별도로 포스트를 두어 정리할 것이다.
Feature Store
- 모델별로 사용되는 데이터 등이 중복될 수 있다. 이에 따라 머신러닝에서 사용되는 Feature 를 집계한 Feature Store 를 둘 수 있다.
- 이를 통해 데이터 전처리 시간을 줄일 수 있다. 이러한 Feature Store 는 정형 데이터에서 많이 발전했고, 비정형과 같은 딥러닝 데이터에서는 발전이 살짝 부족하다.
-
로컬과 서버가 같은 feature, data 를 사용하도록 구축한다.
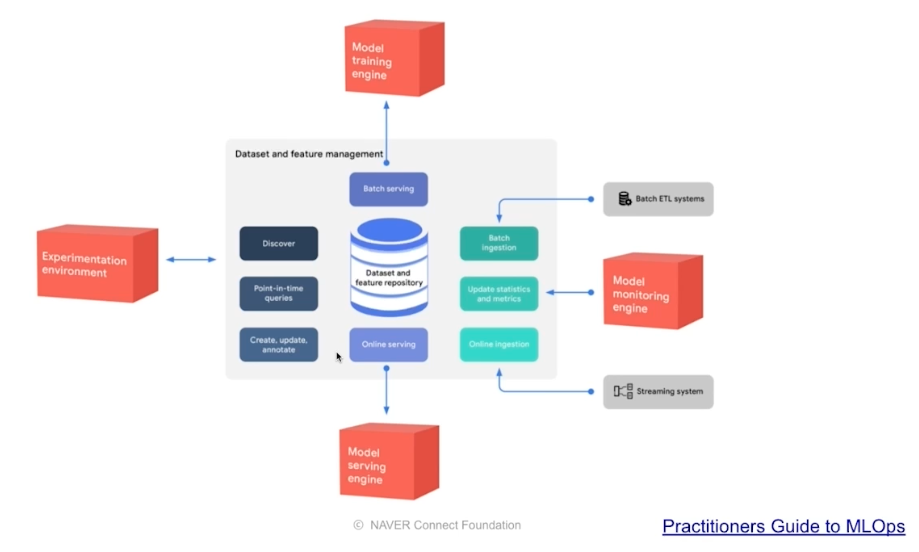
-
FEAST 라이브러리는 feature store 중 거의 유일한 라이브러리다.
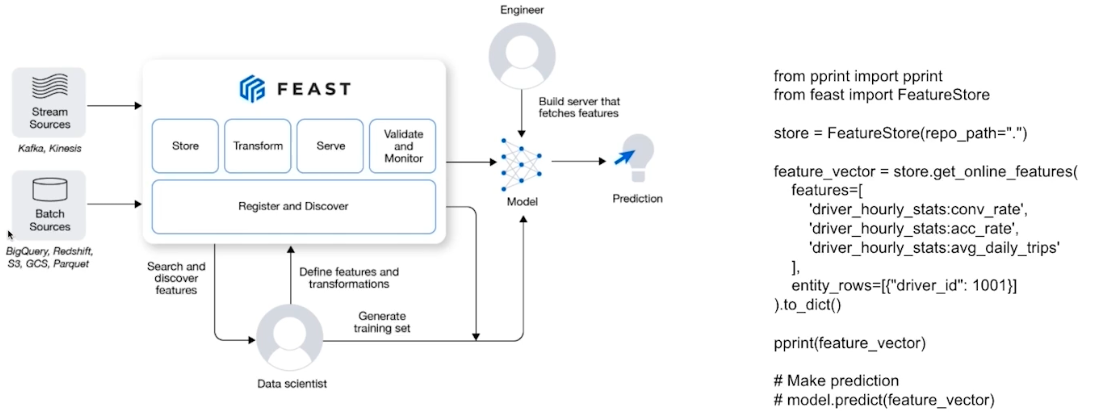
- 위 그림에서 online feature 는 stream source, offline 은 data warehouse 에 있는 batch sources 라고 볼 수 있다.
- Feature 를 data warehouse 에 저장한다거나 NoSQL 에 저장하는 식으로 발전하고 있다.
Data Validation
- Feature 의 분포를 확인할 필요가 있다. 이는 Research 와 Production 의 퀄리티 차이와도 직결되는데, Production 환경에 모델을 배포했는데 데이터가 변하면 성능이 달라질 수 있다.
-
즉 Production 에서는 데이터가 다이나믹하게 계속 들어오기 때문에, 학습할 때의 데이터 분포와 Serving 할 때의 데이터 분포 차이가 있을 수밖에 없다.
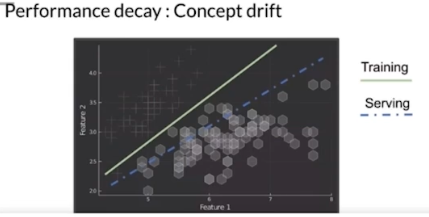
-
이러한 개념은 Data Drift, Model Drift, Concept Drift 로 설명될 수 있다.
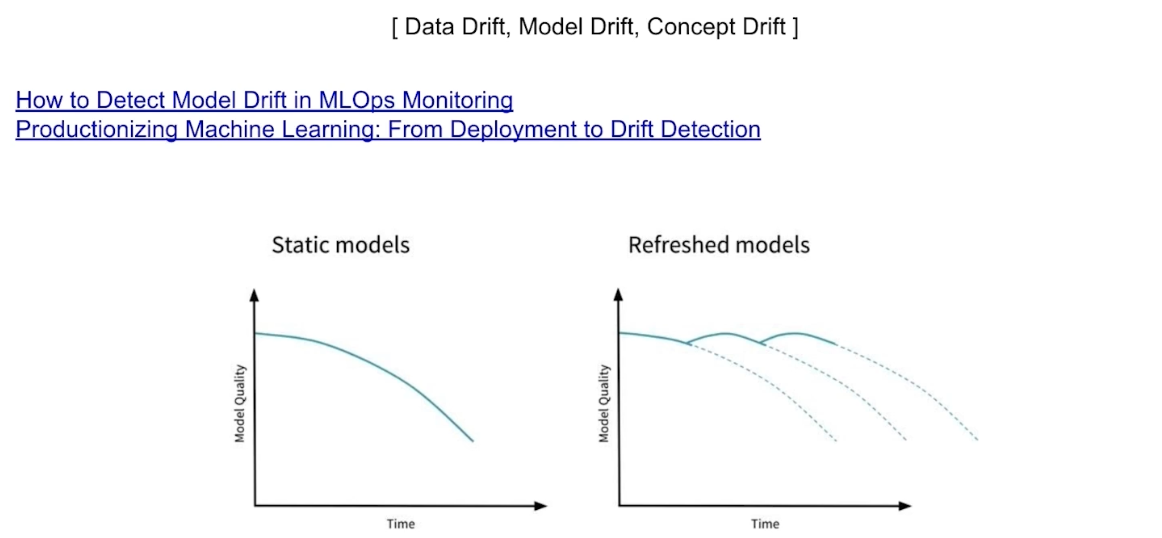
- static model 은 한번 학습하고 시간의 흐름에 따라서 그대로 가지만 모델의 퀄리티가 낮아지게 된다.
- refreshed model 은 시간이 흐르면서 학습을 다시 해서 모델 성능이 좋아지고, 또 다시 학습하고 이런 식으로 퀄리티를 유지한다.
- 즉 데이터의 분포도 중요하지만, 모델의 성능 파악도 중요함을 알 수 있다. Drift 개념을 알아두면 좋다.
- TFDV(Tensorflow Data Validation)
-
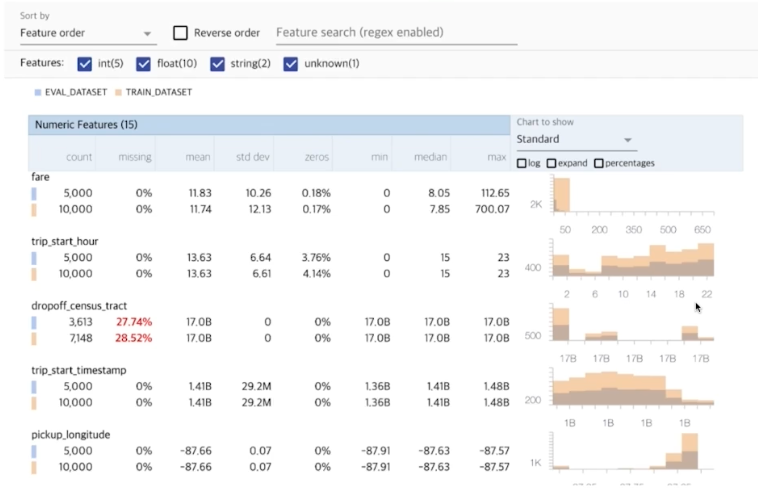
해당 라이브러리에서는 feature 별로 개수, 평균, 표준편차 등이 기록된다. train 데이터와 eval 데이터에서 얼마나 달라지는지 확인할 수 있다.
-
-
AWS Deequ 는 Unit Test for data, Data Quality 측정을 지원한다. 즉 데이터를 테스트해서, 데이터가 우리가 의도하는 데이터만 들어오는지 확인할 수 있다.

Continuous Training
- 베포된 모델의 결과를 고객이 만족하지 않는 때가 올 수 있다. 그렇게 되면 신선하게 다시 Retrain 을 해줘야 한다.
-
이 때, 1) 새로운 데이터가 생긴 경우, 2) 일정기간(매일, 매시간), 3) Metric 기반, 4) 요청 의 경우에 재학습을 진행할 수 있다.
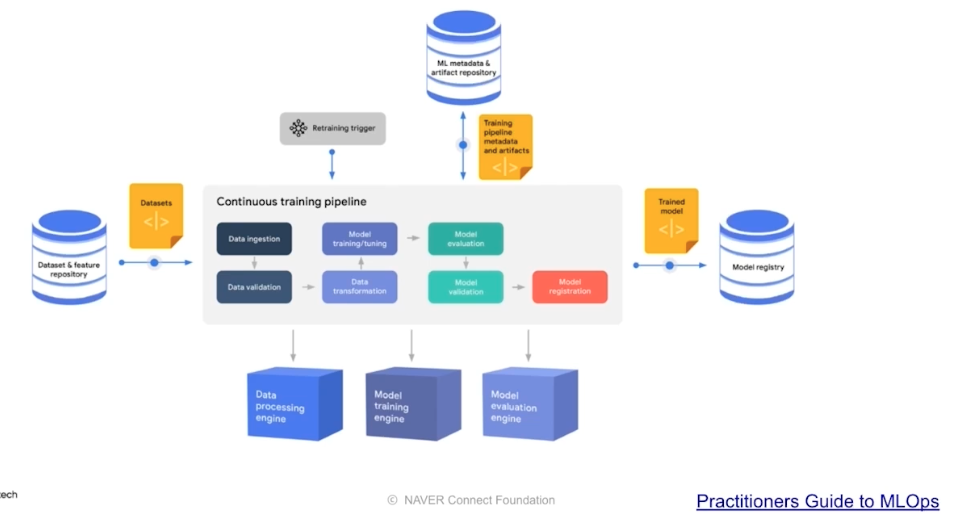
- 기존에 DevOps 에서 많이 사용하는 CICD 개념과 거의 비슷하다.
Monitoring
- 모델의 지표, 인프라의 성능 지표 등을 잘 기록해야 한다. 이를 통해 추가로 아이디어를 얻을 수도 있다.
- 모니터링을 잘 하면 이후에 모델을 어떻게 학습시킬 지 아이디어가 생길 수 있다.
- 대표적으로 오픈소스인 프로메테우스, 그라파나를 사용해볼 수 있다.
AutoML
- Research, Production 에서 AutoML 을 활용할 수 있다. 마이크로소프트 사의 NNI 라는 라이브러리가 있다. 이에 대해서는 별도 카테고리를 두고 정리한다.
정리
- 머신러닝 모델을 직접 운영하면서 신경써야 하는 부분들이 MLOps Component 다. 이러한 MLOps 에 대해 구글 논문에 한장으로 정리된 것이 있다.
- MLOps 는 회사의 비즈니스 상황과 모델 운영 상황에 따라 우선순위가 달라진다. 처음부터 진행하는 것이 비효율적일 수도 있다. 즉 앞선 모든 요소가 항상 존재해야 하는 것은 아니다.
- 처음엔 작은 단위의 MVP(Minimal Value Product)로 시작해서 점점 운영 리소스가 많이 소요될 때 하나씩 구축하는 방식을 활용한다. 대부분 반복되는 작업을 자동화 하기 위해서 MLOps 를 사용하기도 한다.
- Uber 의 MLOps 논문도 MLOps 공부에서는 매우 훌륭한 자료다.
- 앞으로 Google 의 MLOps 자료를 통해 MLOps 를 공부해보자.
댓글 남기기