
[MLOps] 9. Data & Model Management
Data & Model Management
- 여섯 가지 과정(ML development, Training operationalization, Continuous training, Model deployment, Prediction serving, Continuous monitoring)의 핵심은 데이터와 모델 관리이다.
- 데이터 및 모델 관리는 ML 아티팩트를 관리하여 감사 가능성, 추적성, 규정 준수, 공유 가능성, 재사용성, 발견 가능성을 지원하는 중요한 기능이다.
Dataset and feature management
- 데이터 과학과 ML 의 주요 도전 과제 중 하나는 학습을 위한 고품질 데이터를 생성하고 유지하며 재사용하는 것이다.
- 데이터 과학자들은 탐색적 데이터 분석(EDA), 데이터 준비, 데이터 변환에 많은 시간을 소요한다.
- 그러나 다른 팀들이 유사한 용도로 같은 데이터셋을 준비했지만 이를 공유하거나 재사용할 방법이 없을 때가 있다.
-
이러한 상황은 데이터셋을 다시 생성하는 데 시간 낭비를 초래할 뿐만 아니라, 동일한 데이터 엔터티의 정의와 인스턴스가 불일치할 수 있다.
- 또한, 예측 서비스 중에는 학습 데이터와 서비스 데이터 간의 불일치가 자주 발생한다.
-
이를 학습-서비스 불일치(training-serving skew)라고 하며, 학습과 서비스 동안 서로 다른 출처에서 서로 다른 형태로 데이터가 추출되어 발생한다. 학습-서비스 불일치는 프러덕션에 탑재된 모델의 성능에 영향을 줄 수 있다.
- 데이터셋과 feature 관리는 이러한 문제를 해결하기 위해 ML feature 와 데이터셋을 위한 통합 저장소를 제공한다.
-
아래 그림은 MLOps 환경에서 feautre & dataset repository 가 같은 데이터 엔티티의 다양한 활용을 위해 어떻게 데이터를 제공하는지 보여준다.
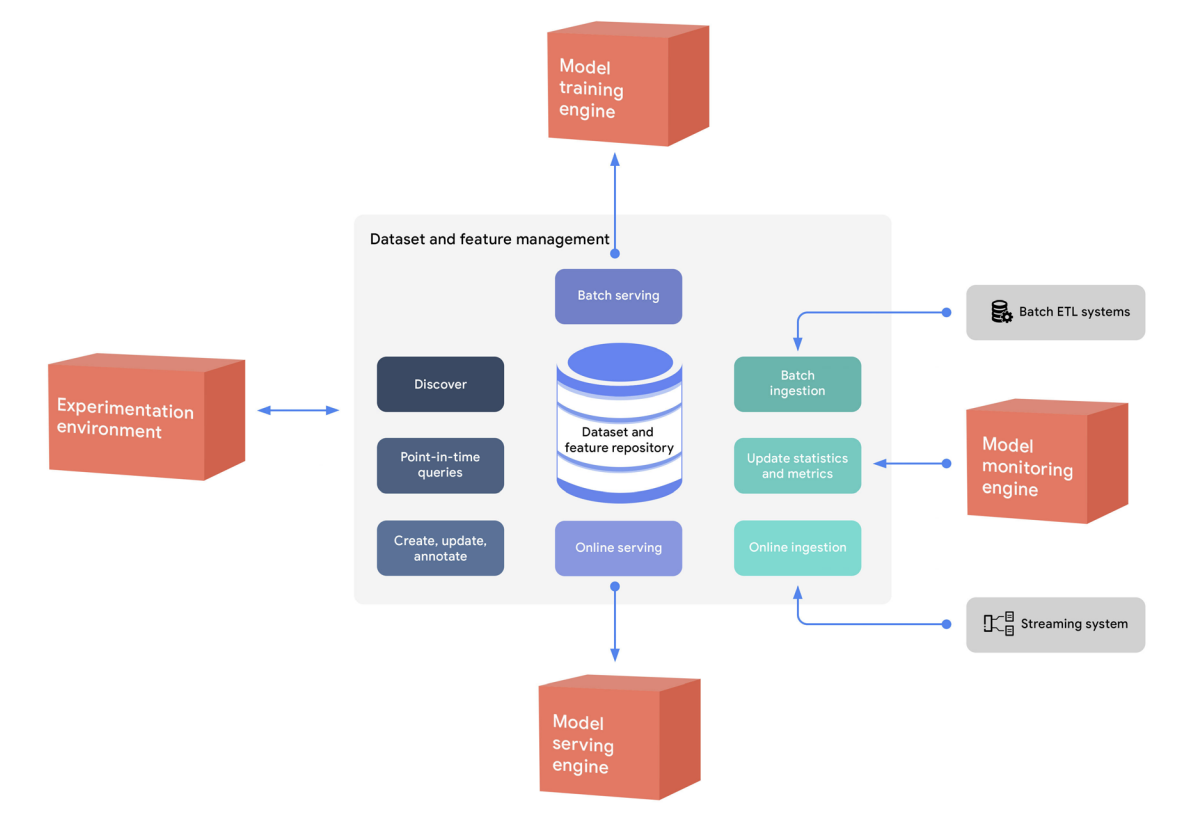 Using the dataset and feature repository to provide entities for multiple uses
Using the dataset and feature repository to provide entities for multiple uses - feature 와 데이터셋은 서로 다른 실험에서 생성, 발견, 재사용된다.
- 데이터를 배치 단위로 서빙하는 것은 실험, 지속적인 학습(CT), 배치 예측에 사용되며, 온라인 데이터 서빙은 실시간 예측에 사용된다.
Feature management
- feature 는 비즈니스 엔터티의 속성으로, 표준 비즈니스 규칙—집계, 파생, 플래그 등에 따라 정리되고 준비된다.
- 엔터티의 예로는 제품, 고객, 위치, 프로모션 등이 있다.
- 중앙 집중식 저장소에서 데이터 엔터티를 관리하여 학습과 서빙을 위한 정의, 저장, 접근을 표준화할 수 있다.
- feature repository 는 데이터 과학자와 연구자들이 다음과 같은 작업을 수행하는 데 도움을 준다.
- 새로 데이터셋을 생성하지 않고도 이미 사용 가능한 feature 세트를 발견하고 재사용할 수 있다.
- feature 의 중앙 정의를 설정할 수 있다.
- feature 저장소를 실험, 지속적인 학습(CT), 온라인 서빙의 데이터 소스로 사용하여 학습-서비스 불일치(training-serving skew)를 피할 수 있다.
- 최신 feature 값을 feature 저장소에서 제공받을 수 있다.
- 새로운 엔터티와 feature 를 정의하고 공유할 수 있다.
- feature 를 공유함으로써 데이터 과학자와 연구팀 간의 협업을 개선할 수 있다.
- 배치 ETL 시스템에서는 학습 파이프라인이 배치로 feature 를 가져올 수 있다. 또한 온라인 서비스의 경우, 서비스 엔진은 요청된 엔터티와 관련된 feature 값을 가져올 수 있다.
- 이렇게 feature repository 의 업데이트는 배치 ETL 또는 스트리밍 시스템에서 수집될 수 있다. 이 외에도 모니터링 서비스가 feature 에 대한 통계와 metric 을 업데이트할 수 있다.
Dataset management
- feature 는 여러 ML 작업과 용도에 사용되는 여러 데이터셋에서 사용될 수 있다.
- 반면 dataset 은 특정 ML 작업이나 용도에 사용된다. 보다 정확하게는, feature repository 는 일반적으로 레이블이 붙은 데이터 인스턴스(예측 가능한 목표가 있는 인스턴스)를 포함하지 않는다. 대신 재사용 가능한 feature 값을 다양한 엔터티에 대해 포함한다.
-
다른 엔터티의 feature 는 결합되어 레이블이 포함된 다른 트랜잭션 데이터와 조인되어 데이터셋을 생성할 수 있다.
- 예를 들어, feature repository 에는 고객 엔터티가 포함되어 있을 수 있다. 이 고객 엔터티에는 고객의 인구통계학적 정보, 구매 행동, 소셜 미디어 상호작용, 감정 점수, 제3자 금융 플래그 등이 포함된다.
- 고객 엔터티는 이탈 예측, 클릭률 예측, 고객 생애 가치 추정, 고객 세분화, 추천 등 여러 작업에 사용될 수 있다.
- 각 작업에는 고객 feature 와 작업에 관련된 다른 엔터티의 feature 를 포함하는 데이터셋이 있다.
- 또한, 지도 학습 작업의 경우 각 데이터셋에는 자체 레이블이 있다.
- 데이터셋 관리는 다음과 같은 작업에 도움을 준다.
- 데이터셋과 분할을 생성하는 스크립트를 유지하여 다양한 환경(개발, 테스트, 프로덕션 등)에서 데이터셋을 생성할 수 있다.
- 팀 내에서 데이터셋 정의와 구현을 일관되게 유지하여 다양한 모델 구현과 하이퍼 파라미터에 사용할 수 있다. 이 데이터셋에는 분할(학습, 평가, 테스트 등)과 필터링 조건이 포함된다.
- 팀원들이 동일한 데이터셋과 작업에서 협력하는 데 유용한 메타데이터와 주석을 유지할 수 있다.
- 재현성과 계보 추적(lineage tracking)을 제공한다.
Model management
-
조직이 대규모로 프로덕션에 모델을 추가하게 되면, 모든 모델을 수동으로 추적하기가 어려워진다. 따라서 조직은 위험을 관리하고 ML 모델을 책임감 있게 구현하며, 규정을 준수하기 위한 통제 장치가 필요하다.
- 이를 위해 조직은 강력한 모델 관리 시스템을 구축해야 한다. 모델 관리는 MLOps의 중심에 있는, 다양한 과정에 걸친 작업이다. 여기에는 ML 메타데이터 추적과 모델 거버넌스가 포함된다.
- ML 수명 주기 전반에 걸쳐 모델 관리를 수행하면 다음과 같은 사항을 보장할 수 있다.
- 수집되어 모델 학습과 평가에 사용되는 데이터가 정확하고, 편향되지 않으며, 데이터 프라이버시 위반 없이 적절하게 사용된다.
- 모델이 효과성 품질 지표와 공정성 지표에 따라 평가되고 검증되어, 프로덕션에 배포할 준비가 되어 있는지 확인된다.
- 모델이 해석 가능하고, 필요한 경우 결과를 설명할 수 있다.
- 배포된 모델의 성능이 지속적으로 평가되고, 모델의 성능 지표가 추적되고 보고된다.
- 모델 훈련이나 예측 서비스에서 발생할 수 있는 잠재적인 문제가 추적 가능하고, 디버깅 가능하며, 재현 가능하다.
ML metadata tracking
- ML 메타데이터 추적은 일반적으로 다양한 MLOps 프로세스와 통합된다.
- 다른 프로세스에서 생성된 artifact 들은 보통 ML 아티팩트 저장소에 프로세스 실행 정보와 함께 자동으로 저장된다.
- 캡처된 ML 메타데이터는 파이프라인 실행 ID, 트리거, 프로세스 유형, 단계, 시작 및 종료 날짜와 시간, 상태, 환경 구성, 입력 매개변수 값 등을 포함할 수 있다.
- 저장되는 아티팩트의 예로는 처리된 데이터 분할, 스키마, 통계, 하이퍼 파라미터, 모델, 평가 지표 또는 사용자 정의 아티팩트가 있다.
-
아래 그림은 metadata tracking 을 보여준다.
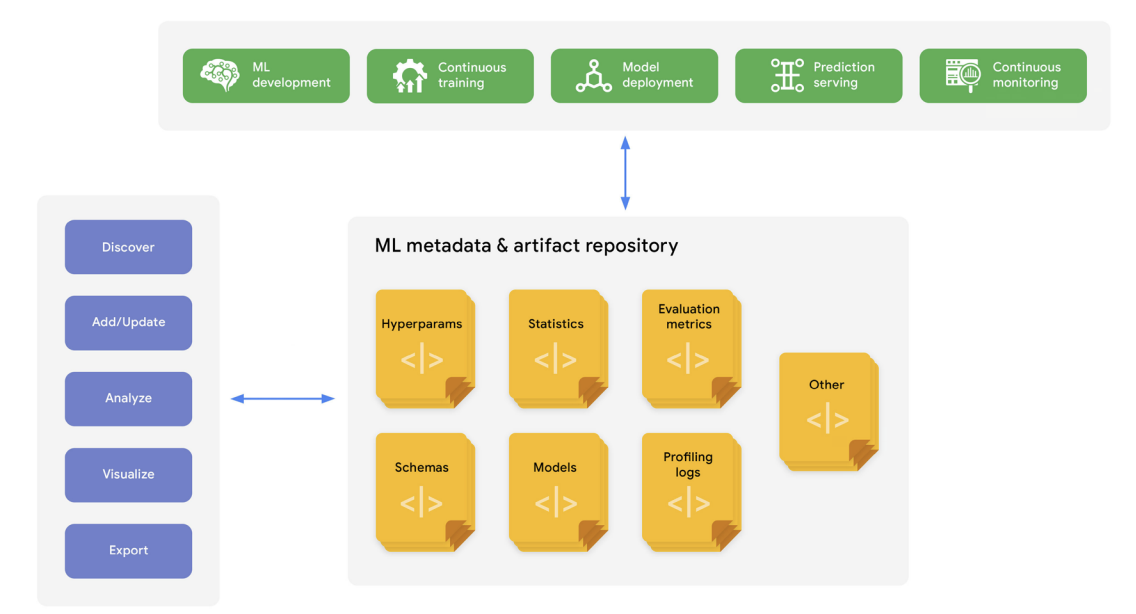 Metadata tracking
Metadata tracking - ML 메타데이터 추적을 통해 데이터 과학자와 ML 엔지니어는 실험 매개변수와 파이프라인 구성을 추적하여 재현성과 계보 추적을 할 수 있다.
-
또한, ML 메타데이터 추적을 통해 사용자는 기존의 ML 모델과 아티팩트를 검색, 발견, 내보낼 수 있다.
- 데이터 과학자와 ML 엔지니어는 ML 메타데이터 추적을 사용해 추적된 ML 실험과 실행에 주석을 추가하거나 업데이트할 수 있다. 이는 발견 가능성을 높여준다.
- 더불어, ML 메타데이터 추적은 다양한 실험과 ML 파이프라인 실행에서 생성된 메타데이터와 아티팩트를 분석, 비교, 시각화하는 도구를 제공한다. 이를 통해 데이터 과학자와 ML 엔지니어는 파이프라인의 동작을 이해하고 ML 문제를 디버깅할 수 있다.
Model governance
- 모델 거버넌스는 모델을 배포하기 위해 등록, 검토, 검증, 승인하는 과정이다.
- 조직, 모델의 규제 요구 사항, 특정 사용 사례에 따라 모델 거버넌스 과정이 다를 수 있다.
- 이 과정은 자동화, 반자동화, 또는 완전 자동화될 수 있으며, 모든 경우에 여러 릴리즈 기준을 사용해 ML 모델이 프로덕션에 배포될 준비가 되었는지 결정한다.
-
또한, 모델 거버넌스는 배포된 모델의 성능에 대한 보고를 지원해야 한다.
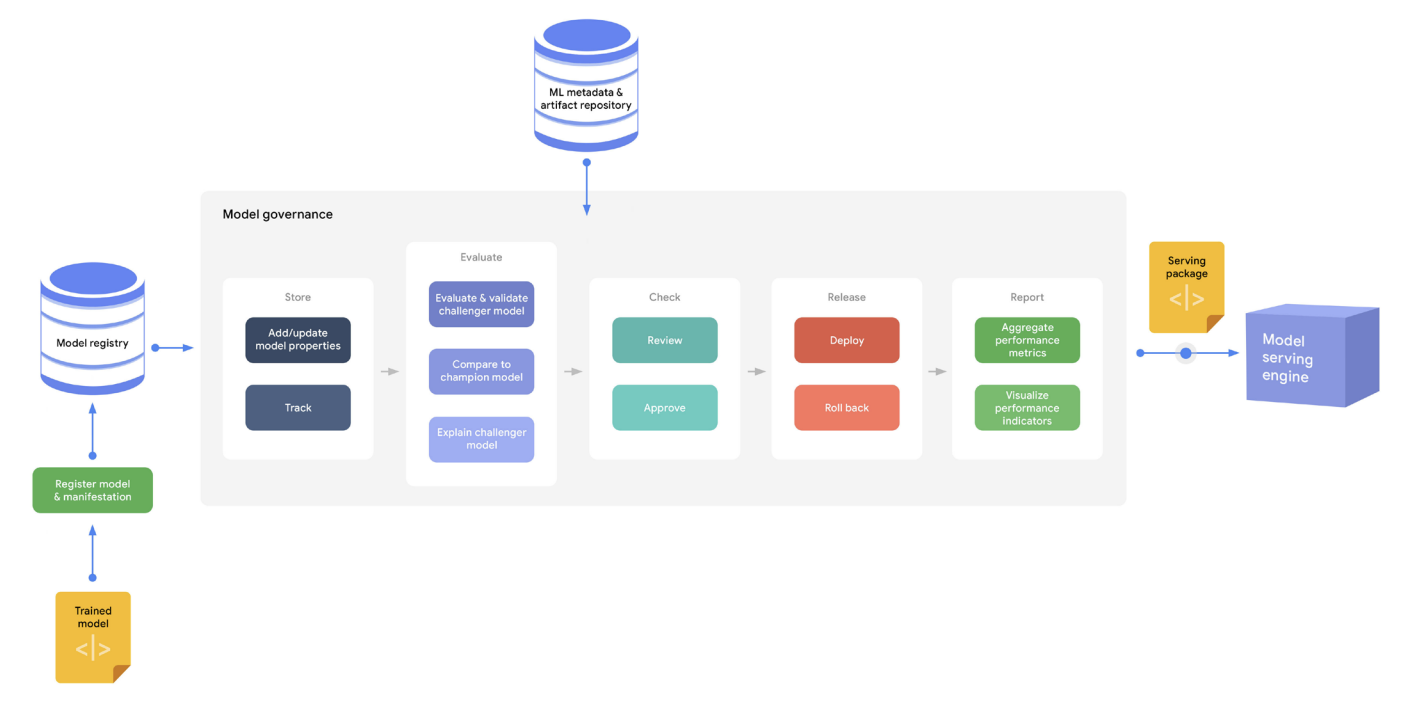 Tasks involved in model governance
Tasks involved in model governance - 위 그림은 모델 거버넌스에 포함된 작업들을 보여준다. 모델 거버넌스는 ML 메타데이터와 모델 레지스트리에 있는 정보를 활용해 다음과 같은 작업들을 수행할 수 있다.
- 저장: 모델 속성을 추가하거나 업데이트하고, 모델 버전과 속성 변경 사항을 추적한다. 모델 레지스트리는 실험과 지속적 학습(CT) 단계에서 생성된 여러 모델 버전을 저장할 수 있어, 데이터 과학자들이 중요한 모델을 쉽게 재현할 수 있게 한다.
- 평가: 새로운 도전 모델을 챔피언 모델과 비교할 때, 평가 지표(정확도, 정밀도, 재현율, 특이도 등)뿐만 아니라 온라인 실험을 통해 수집된 비즈니스 KPI 도 함께 고려한다. 또한, 모델 소유자는 예측 결과를 이해하고 설명할 수 있어야 한다. 예를 들어, feature 기여도 방법을 사용해 프러덕션에 배포된 모델의 예측 품질을 보장할 수 있다.
- 확인: 비즈니스, 금융, 법률, 보안, 프라이버시, 평판, 윤리적 문제와 같은 위험을 통제하기 위해 모델을 검토하고, 변경 요청을 하며, 승인을 한다.
- 배포(Release): 모델 배포 프로세스를 호출하여 모델을 라이브로 전환한다. 이 작업은 카나리 또는 블루-그린과 같은 모델 릴리즈 유형과 해당 모델에 할당되는 트래픽 분할을 제어한다.
- 보고: 지속적인 평가 과정에서 수집된 모델 성능 지표를 집계하고, 시각화하며, 강조 표시한다. 이를 통해 프로덕션에 배포된 모델의 품질을 보장할 수 있다.
- 설명 가능성은 특히 의사결정 자동화의 경우에 중요하다.
- 거버넌스 과정은 위험 관리자와 감사자에게 계보와 책임성에 대한 명확한 관점을 제공해야 하며, 이들이 조직의 윤리적 및 법적 책임에 따라 결정을 검토할 수 있는 능력을 제공해야 한다.
Summary
- 데이터 및 모델 관리에서 MLOps의 핵심 기능은 다음과 같다.
- 데이터셋 및 feature 저장소
- 모델 레지스트리
- ML 메타데이터 및 아티팩트 저장소
댓글 남기기