
[MLOps] 8. Continuous Monitoring
Continuous Monitoring
- 연속 모니터링(Continuous Monitoring)은 MLOps 에서 중요한 부분으로, 프로덕션 환경에서 모델의 효과성과 효율성을 모니터링하는 과정이다.
- 모델 성능이 저하되지 않도록 정기적이고 선제적으로 확인하는 것이 필수적이다.
- 시간이 지남에 따라 서빙 데이터(prediction request)의 속성이 모델을 학습하고 평가하는 데 사용된 데이터의 속성과 다르게 변하기 시작하며, 이는 모델의 실질적인 성능 저하로 이어진다.
-
또한, 예측 요청을 생성하는 상위 시스템의 변화나 오류는 서빙 데이터의 속성에 변화를 일으켜, 결과적으로 모델에서 부정확한 예측이 생성될 수 있다.
-
아래 그림에 나타난 것처럼 모니터링 엔진은 추론 로그를 사용하여 이상 현상(편향 및 이상치)을 식별한다.
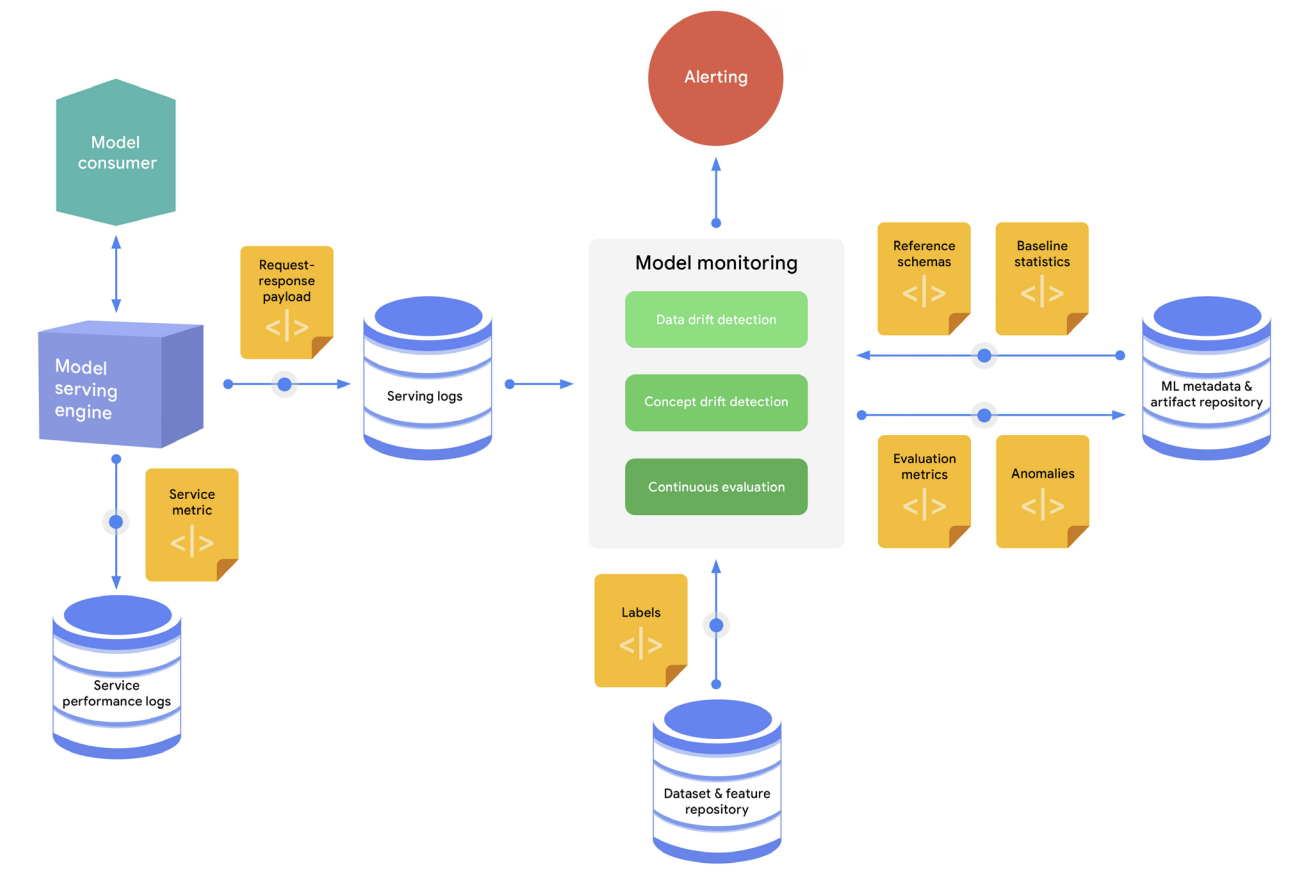 continuous monitoring process
continuous monitoring process - 일반적인 연속 모니터링 과정은 다음 단계로 구성된다.
- 요청-응답 페이로드의 샘플이 캡처되어 서빙 로그 저장소에 저장된다.
- 모니터링 엔진은 최신 추론 로그를 주기적으로 로드하고, 스키마를 생성하며, 서빙 데이터에 대한 통계를 계산한다.
- 모니터링 엔진은 생성된 스키마를 기준 스키마와 비교하여 스키마 편향(schema skew)을 식별하고, 계산된 통계를 기준 통계와 비교하여 분포 편향(distribution skew)을 식별한다.
- 서빙 데이터에 대한 실제 라벨(정답)이 있는 경우, 모니터링 엔진은 이를 사용하여 서빙 데이터에 대한 모델 예측 효과성을 사후 평가한다.
- 이상이 발견되거나 모델의 성능이 저하되는 경우, 경고가 다양한 채널(ex. 이메일 또는 채팅)을 통해 전송되어 소유자에게 모델을 검사하거나 새로운 재학습 사이클을 시작하도록 알릴 수 있다.
-
효과성 성능 모니터링은 모델 (성능)저하를 감지하는 데 목적이 있으며, 모델 저하는 주로 데이터 드리프트와 개념 드리프트의 측면에서 정의된다.
- 데이터 드리프트는 모델을 학습, 튜닝 및 평가하는 데 사용된 데이터셋과 모델이 스코어링을 위해 수신하는 프로덕션 데이터 간의 편향이 커지는 현상을 설명한다.
- 즉 모델의 학습 시 “입력 데이터(특징량, 설명변수)”의 통계적 분포와 테스트 시 실제 배포 환경에서의 “입력 데이터”의 통계적 분포가 어떠한 변화에 의해 차이가 발생하고 있는 것을 의미한다. Feature drift 나 Covariate shift 라고 불린다.
- 개념 드리프트는 입력 예측자(input predictor)와 목표 feature 간의 관계가 진화하는 것을 의미한다.
-
즉 입력 데이터(특징량, 설명변수)에서부터 예측하려고 하는 “정답 라벨(목적 변수)”의 의미/개념/통계적 특성(즉 데이터와 라벨의 관계성, 데이터의 해석 방법)이 모델 훈련때와 비교하여 변화가 있음을 의미한다.
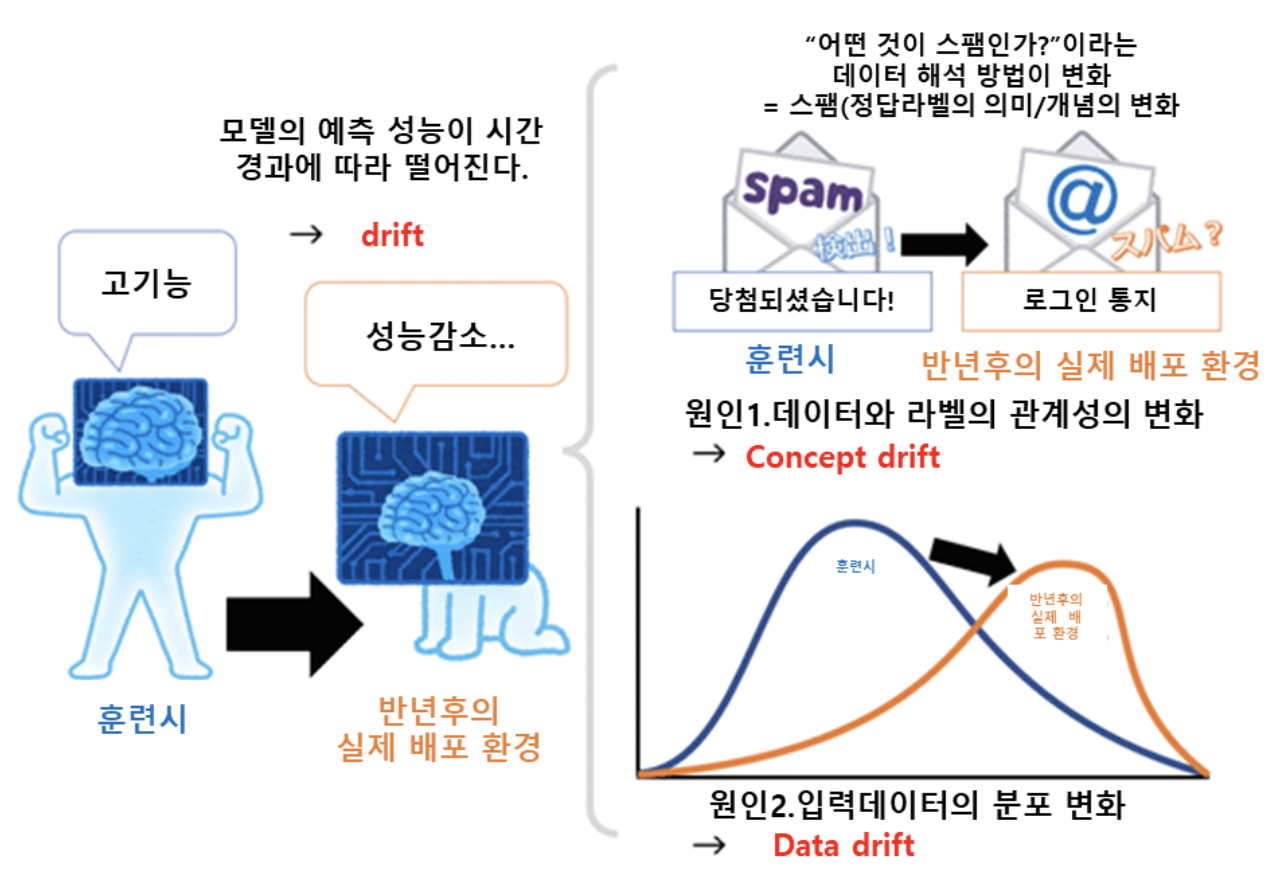 출처: https://engineer-mole.tistory.com/278
출처: https://engineer-mole.tistory.com/278
-
- 데이터 드리프트는 두 가지 유형의 편향을 포함할 수 있다.
- 스키마 편향은 학습 데이터와 서빙 데이터(실제 배포 환경에서의 입력 데이터)가 동일한 스키마를 따르지 않을 때 발생한다.
- 분포 편향은 학습 데이터의 feature 값 분포가 서빙 데이터의 분포와 현저하게 다를 때 발생한다.
- 스키마와 분포 편향을 식별하는 것 외에도, 데이터 및 개념 드리프트를 감지하기 위한 다른 기법으로는 새로운 데이터 및 이상치 감지, 그리고 feature 기여도 변화가 포함된다.
-
자세한 내용은 Google Cloud 문서의 ML 모델 모니터링 참조 가이드를 참고하자.
- 일부 시나리오에서는 서빙 데이터에 대한 실제 라벨을 저장할 수 있다.
- 예를 들어, 모델이 추천한 제품을 고객이 구매했는지 여부를 캡처하거나, 모델이 예측한 주간 수요와 실제 주간 수요를 비교하여 정답 라벨로 사용할 수 있다.
-
이러한 정보는 데이터셋 및 feature 저장소에 저장되어 연속적인 평가와 추가 모델 학습 사이클(ex. CT)에 사용할 수 있다.
- 모델의 효과성을 모니터링하는 것 외에도, 모델 서빙 효율성을 모니터링하는 것은 다음과 같은 지표에 중점을 둔다.
- CPU, GPU, 메모리 등의 자원 활용도
- 온라인 및 스트리밍 배포에서 모델 서비스의 건강 상태를 나타내는 핵심 지표인 지연 시간(Latency)
- 모든 배포에서 핵심 지표인 처리량(Throughput)
- 오류율
- 이러한 지표를 측정하는 것은 시스템 성능을 유지하고 개선하는 데 유용할 뿐만 아니라, 비용을 예측하고 관리하는 데도 도움이 된다.
Summary
- 연속 모니터링 과정에서 일반적으로 생성되는 자산은 다음과 같다.
- 드리프트 감지 중 서빙 데이터에서 감지된 이상
- 연속 평가에서 생성된 평가 지표
- 연속 모니터링에서 핵심 MLOps 기능은 다음과 같다.
- 데이터셋 및 feature 저장소
- 모델 모니터링
- ML 메타데이터 및 아티팩트 저장소
댓글 남기기