
[MLOps] 7. Prediction Serving
Prediction Serving
- 모델이 목표 환경에 배포된 후, 예측 서빙(Prediction Serving) 과정에서 모델 서비스는 예측 요청(서빙 데이터)을 수락하고, 예측을 포함한 응답을 제공하기 시작한다.
-
다음 그림은 예측 서빙의 요소들을 보여준다.
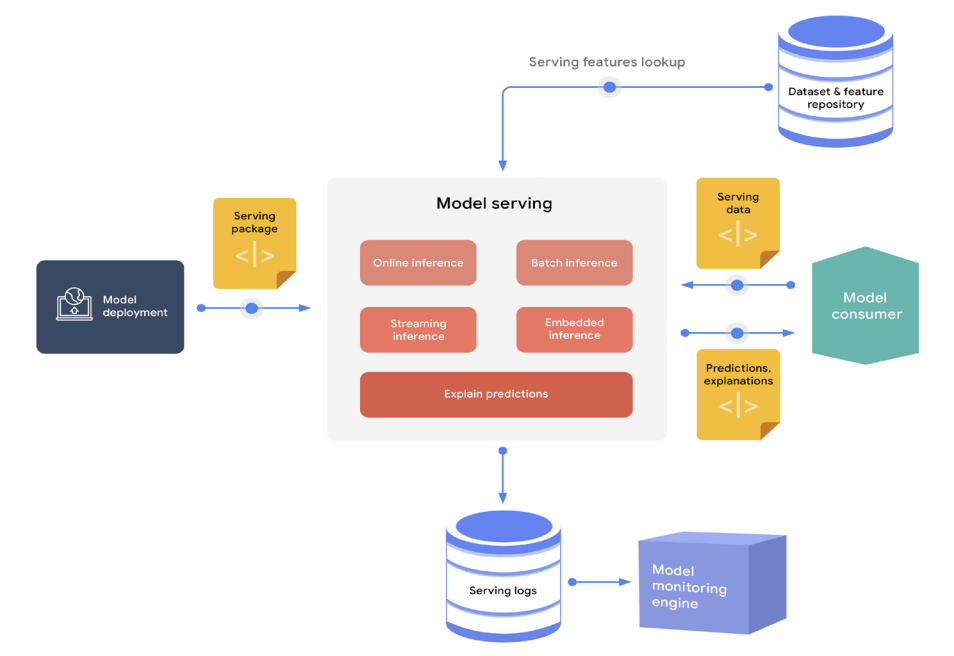 Elements of the prediction serving process
Elements of the prediction serving process - 서빙 엔진은 다음과 같은 형태로 소비자에게 예측을 제공할 수 있다.
- REST 나 gRPC 같은 인터페이스를 사용하여 고빈도 단일 요청(또는 소형 배치 요청)에 대해 거의 실시간으로 온라인 추론을 수행한다.
- 이벤트 처리 파이프라인을 통해 거의 실시간으로 스트리밍 추론을 수행한다.
- 대량 데이터 스코어링을 위한 오프라인 배치 추론을 수행하며, 보통 ETL(추출, 변환, 로드) 과정과 통합된다.
- 임베디드 시스템이나 엣지 장치의 일부로 임베디드 추론을 수행한다.
- 예측 서빙의 일부 시나리오에서는 서빙 엔진이 요청과 관련된 feature 값을 조회해야 할 수 있다.
- 예를 들어, 고객과 제품의 특정 feature 집합을 기반으로 특정 제품을 구매할 가능성을 예측하는 모델이 있을 수 있다.
-
하지만 요청에는 고객과 제품 식별자만 포함된다. 따라서 서빙 엔진은 이러한 식별자를 사용해 feature 저장소(repository)에서 고객과 제품 feature 값을 가져와 이를 모델에 입력한 후 예측을 생성한다.
- ML 시스템에 대한 신뢰를 가지는 중요한 요소 중 하나는 모델을 해석하고 예측에 대한 설명을 제공할 수 있는 능력이다.
- 설명은 예측에 대한 논리를 이해할 수 있도록 제공되어야 하며, 예를 들어 특정 예측에 대한 feature 기여도를 생성하여 제공할 수 있다.
-
feature 기여도는 각 feature 가 예측에 얼마나 기여했는지를 점수 형태로 나타낸다.
- 추론 로그와 기타 서빙 지표는 지속적인 모니터링과 분석을 위해 저장된다.
Summary
- 예측 서빙 과정에서 일반적으로 생성되는 자산은 다음과 같다.
- 서빙 로그 저장소에 저장된 요청-응답(request-response) 페이로드
- 예측의 feature 기여도
- 예측 서빙 과정에서 핵심 MLOps 기능은 다음과 같다.
- 데이터셋 및 feature 저장소
- 모델 서빙
댓글 남기기