
[MLOps] 3. ML Development
ML Development
- 실험은 ML 개발의 핵심 활동이다.
- 이 과정에서 데이터 과학자들은 데이터 준비와 ML 모델링에 대한 여러 아이디어를 빠르게 시도할 수 있다.
- 실험은 다음 질문들에 대한 답변이 명확해지면 시작된다.
- task 가 무엇인가?
- 비즈니스 영향력을 어떻게 측정할 것인가?
- 평가 기준(evaluation metric)은 무엇인가?
- 관련 데이터는 무엇인가?
- 학습과 서빙의 요구 사항은 무엇인가?
- 실험의 목표는 주어진 ML task 를 위한 효과적인 프로토타입 모델을 만드는 것이다.
- 실험 외에도, 데이터 과학자들은 ML 학습 절차를 공식화해야 한다. 이는 end-to-end 파이프라인을 구현하는 것이고, 이 파이프라인은 운영화되어 프로덕션에서 실행할 수 있게 된다.
-
아래 그림은 ML 개발 과정을 보여준다.
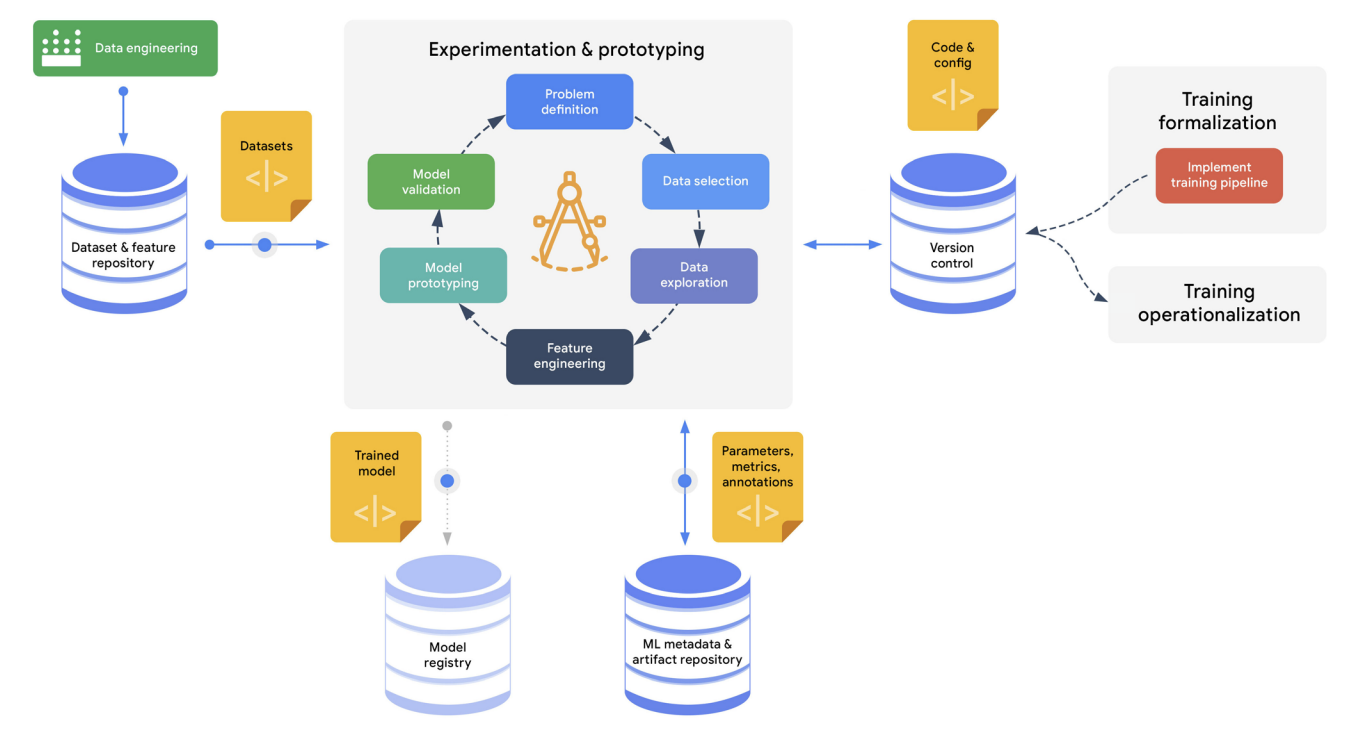 ML Development Process
ML Development Process - 실험 중 데이터 과학자들이 일반적으로 수행하는 단계는 다음과 같다.
- 데이터 탐색, 선택, 탐구
- 대화형 데이터 처리 도구를 사용한 데이터 준비 및 feature 엔지니어링
- 모델 프로토타이핑 및 검증
- 이러한 반복적인 단계를 수행함으로써 데이터 과학자들은 문제 정의를 더욱 정밀하게 다듬을 수 있다.
-
예를 들어, 데이터 과학자나 연구자들이 과제를 회귀 분석에서 분류 문제로 바꾸거나, 다른 평가 기준을 선택할 수도 있다.
-
개발 데이터의 주요 출처는 데이터셋 및 feature 저장소다. 이 저장소에는 entity-features 수준이나 전체 데이터셋 수준에서 관리되는 정제된 데이터 자산이 포함되어 있다.
- 일반적으로 이 과정의 주요 성공 요소는 실험 추적, 재현성, 그리고 협업이다.
- 예를 들어, 데이터 과학자들이 새로운 ML 과제를 시작할 때, 유사한 과제를 가진 이전 실험을 찾고 그 실험 결과를 재현할 수 있다면 시간을 절약할 수 있다. 그런 다음 데이터 과학자들은 이 실험을 현재 과제에 맞게 조정할 수 있다.
-
또한, 데이터 과학자들은 여러 실험과 동일한 실험의 다양한 실행을 비교해 모델의 예측 성능 변화와 성능 향상의 요인을 이해할 수 있어야 한다.
- 실험을 재현하려면 데이터 과학 팀은 각 실험의 설정(configurations)을 추적해야 한다. 여기에는 다음이 포함된다.
- 버전 관리 시스템에서 학습 코드의 버전을 가리키는 포인터
- 사용된 모델 아키텍처 및 사전 학습 모듈
- 하이퍼 파라미터, 자동 하이퍼 파라미터 튜닝 및 모델 선택 시도의 정보
- 사용된 학습, 검증, 테스트 데이터 분할 정보
- 모델 평가 지표와 사용된 검증 절차
- 모델을 정기적으로 재학습할 필요가 없는 경우, 실험의 결과로 생성된 모델은 모델 레지스트리에 제출된다.
- 그런 다음 이 모델은 검토, 승인, 배포 준비가 되어 목표 서빙 환경에 배포된다.
-
또한, 모델 개발 과정에서 생성된 모든 관련 메타데이터와 아티팩트는 메타데이터 추적 저장소에 기록된다.
- 그러나 대부분의 경우, 새로운 데이터가 들어오거나 코드가 변경되면 ML 모델을 정기적으로 재학습해야 한다.
- 이 경우, ML 개발 과정의 결과물은 프로덕션에 배포할 모델이 아니라, 대상 환경에 배포할 continuous training 파이프라인의 구현물이 결과물이다.
- code-first, low-code 또는 no-code 도구를 사용해 continuous training 파이프라인을 구축하더라도, 개발 아티팩트(소스 코드 및 configurations 포함)는 버전 관리 시스템(ex. Git 기반 소스 제어 시스템)을 통해 관리해야 한다.
- 이를 통해 코드 리뷰, 코드 분석, 자동 테스트와 같은 표준 소프트웨어 엔지니어링 관행을 적용할 수 있다.
-
또한, CI/CD 워크플로우를 구축해 continuous training 파이프라인을 대상 환경에 배포할 수 있다.
- 실험 활동은 일반적으로 새로운 feature 와 데이터셋을 생성한다.
-
새로운 데이터 자산이 다른 ML 및 분석 과제에서도 재사용될 수 있는 경우, 데이터 엔지니어링 파이프라인을 통해 이들을 feature 및 데이터셋 저장소(repository)에 통합할 수 있다.
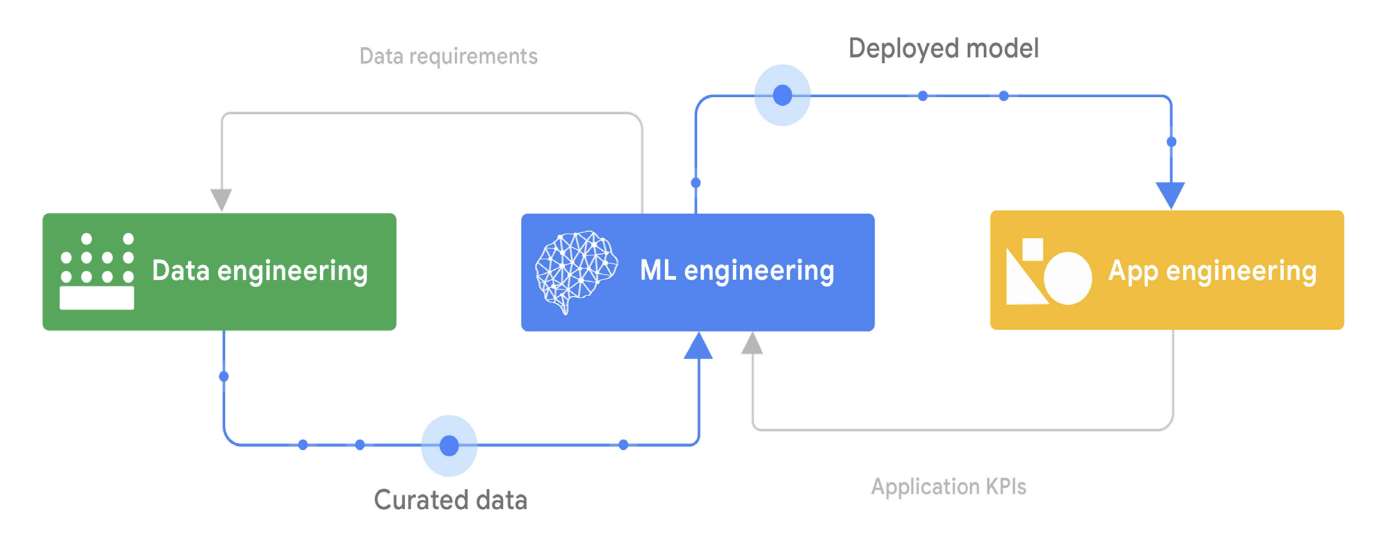 데이터 엔지니어링, ML 엔지니어링, 애플리케이션 엔지니어링의 관계
데이터 엔지니어링, ML 엔지니어링, 애플리케이션 엔지니어링의 관계 - 따라서 실험 단계의 일반적인 결과물은 상위 데이터 엔지니어링 파이프라인에 대한 요구 사항이다(위 그림 참조).
Summary
- ML 개발 단계에서 생성되는 일반적인 자산은 다음과 같다.
- 실험 및 시각화를 위한 노트북
- 실험의 메타데이터 및 아티팩트
- 데이터 스키마
- 학습 데이터에 대한 쿼리 스크립트
- 데이터 검증 및 변환을 위한 소스 코드 및 설정
- 모델 생성, 학습 및 평가를 위한 소스 코드 및 설정
- 학습 파이프라인 워크플로우에 대한 소스 코드 및 설정
- 유닛 테스트 및 통합 테스트용 소스 코드
- ML 개발 단계에서 핵심 MLOps 기능은 다음과 같다.
- 데이터셋 및 feature repository
- 데이터 처리
- 실험
- 모델 학습
- 모델 레지스트리
- ML 메타데이터 및 아티팩트 저장소
댓글 남기기