
[MLOps] 앞으로 공부할 내용
현업에서 프로젝트를 진행하면 일반적으로 서비스화하는 경우가 많다. 내가 하고 싶은 것도 ML/AI 를 활용한 서비스를 통해 사용자들에게 유의미한 경험을 전달하는 것이기 때문에, 앞으로 끊임없이 공부해야 할 내용들을 언급하고 시간이 날 때마다, 그리고 현장에서 직접 배워보자.
1. 개발 능력
- 엔지니어로서 코드 레벨에서의 깊은 이해와 고민이 필요하다. 데이터 엔지니어도 데이터를 처리하기 위해서 개발에 대한 학습이 필요한 것처럼 ML 엔지니어에게도 당연히 수반된다.
- 데이터 분석가에 가깝다고 하면 데이터 분석 역량에 집중해야 하지만, 코드 역량이 뛰어나면 퍼포먼스가 좋아진다.
- 아래는 알아두면 더 좋은 것들이다.
- Python
- Generator, Decorate, GIL 등
- 멀티프로세싱
- Python 을 사용하면 메모리 영역에서 어떤 일이 발생하는가?
- Linux
- 서버에서 사용하는 Linux 는 앞으로도 계속 함께할 OS 다.
- Linux 파일 시스템, 유저 권한, 프로세스
- Linux 커널
- 쉘 스크립트
- 더 좋은 코드 퀄리티
- 클린 코드
- 클린 아키텍처
- DDD (Domain Driven Development)
- DDD(Domain-Driven Development)는 도메인 주도 설계의 약어다.
- 소프트웨어 개발 방법론의 일종으로, 기존의 어플리케이션 설계가 비즈니스 Domain 에 대한 이해가 부족한 상태에서 설계 및 개발되었다는 반성에서 출발한 개념
- DDD 에서는 기존의 현업에서 IT 로의 일방향 소통 구조를 탈피하여, 현업과 IT의 쌍방향 커뮤니케이션을 매우 중요하게 생각한다.
2. 데이터 엔지니어링
- ML/AI 엔지니어에게는 데이터 모델링과 데이터 개발 영역을 같이 커버하는 것을 원하는 추세다. 즉 점점 더 데이터 처리를 잘 해야 한다.
- 실시간 데이터를 어떻게 전처리하고 가져올 지에 대한 이해도가 있을수록 좋다.
- 데이터 엔지니어링 관련 생태계도 엄청 넓다. 시간이 날 때마다 하나씩 격파해보자.
- 아래는 현업에서 자주 사용하는 도구들이다.
- 실시간 데이터 처리 : Kafka, Apache Spark Streaming, Flink
- 메세지 시스템 : Kafka, Redis, AWS SQS, GCP PubSub, Celery
- 분산 처리 : Ray, Apache Spark
- 데이터 웨어하우스(데이터 분석을 위한 DB) : GCP BigQuery, AWS Redshift
- 캐싱 : Redis
- BI(Business Intelligence) : 데이터 시각화 도구. Superset, Redash, Metabase
- ETL 파이프라인을 구현하는 것도 이제는 ML/AI 엔지니어에게는 필요한 역량이다!
3. CS(Computer Science)
- 당연하게도 기초 소양이다.
- CS 에 대해 잘 알면 어떤 것을 구현할 때 아이디어를 떠올릴 수 있다.
- 네트워크 (통신, 패킷 등), OS, 자료 구조, 알고리즘
4. Infra & Cloud
- 큰 회사의 경우에는 온프레미스지만, 클라우드 환경 작업이 점점 익숙해지는 상황이다.
- 현업에서 인프라에 대한 이해가 있을수록 인프라 엔지니어와 이야기할 때 수월하다.
- Docker 에서 더 나아가 쿠버네티스(k8s) 까지 학습하면 좋다.
- CI/CD 를 더 잘하기 위한 방법도 고민해보자.
- IaaC
- GUI 에서 클릭하면서 클라우드 서비스를 사용했으나, 인프라를 코드로 관리할 수 있는 Terraform 이라는 도구도 있다. 인프라 환경을 설정할 경우 매우 유용하다.
- Monitoring
- 모니터링을 더 잘하기 위한 고민도 필요하다. 이는 서버, 인프라, 모델에 대한 모니터링을 모두 포함한다.
- 실시간으로 데이터가 들어오면 로깅을 서버 안에 저장하는 것이 아니라, 모니터링 도구에 보내고, 웹에서 볼 수 있으면 좋다.
- 자주 사용하는 도구로는 Prometheus, Grafana 등이 있다.
- 실제로 모니터링을 잘 해야 더 개선 가능하다. AB Test 도 모니터링 결과가 있어야 비교 가능하다.
5. Database
- 데이터를 저장하는 곳에는 Object Storage, NoSQL 도 있지만, 여전히 RDB 에 저장을 많이 한다. 이 때 효율적으로 저장하려면 어떻게 해야할까에 대한 고민도 필요하다. 즉 인덱스 전략, ORM 등에 대한 고민이다.
- 저장한 데이터를 추출할 수 있도록 SQL 쿼리를 효율적으로 짜야 한다.
- 데이터 웨어하우스로 데이터를 옮기기 위한 고민이 필요하다.
6. Modeling
- ML/AI 엔지니어는 당연하게도 인프라, 개발에 대한 역량도 중요하지만 머신러닝 모델링에 대한 이해가 반드시 탄탄해야 한다.
- Research 나 Scientist 분들에게 이해를 바탕으로 한 제안을 할 수 있는 사람이 되면 좋다.
- 최근 논문의 방향성, SOTA 등을 어느 정도 파악해두는 정도는 꼭 필요하다.
7. Serving 패턴
- 기본적인 서빙 패턴 외에도 복잡한 서빙 패턴이 존재한다. 예를 들어 kafka 를 설계 안에 넣어서 전처리와 예측 레이어를 분리할 수도 있다.
-
Serving 패턴에 대한 이해를 위해서 kafka, infra, CS 를 알면 좋다.
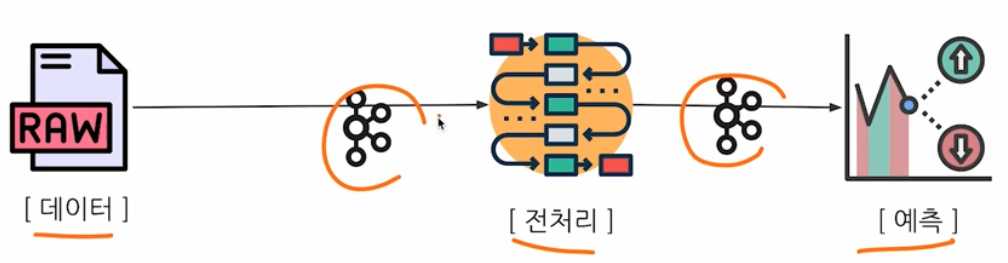
-
예측 결과를 저장하여, 동일한 예측이면 캐싱을 활용하는 방법도 많이 사용한다.
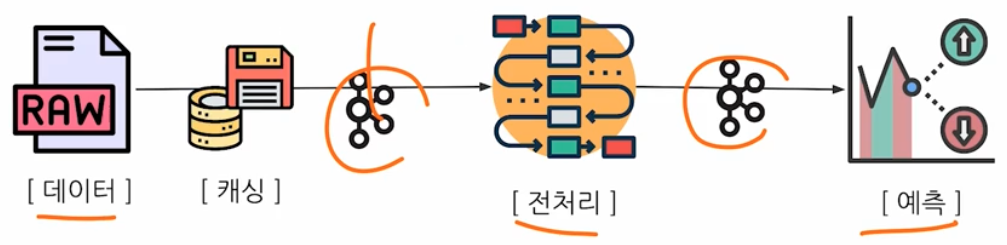
- 캐싱에는 Redis 가 많이 사용된다. Redis 를 공부할 때는 Network, CS 등 복합적인 내용을 알아야 한다.
-
예측 결과를 가지고 또 예측하는 경우도 존재한다.
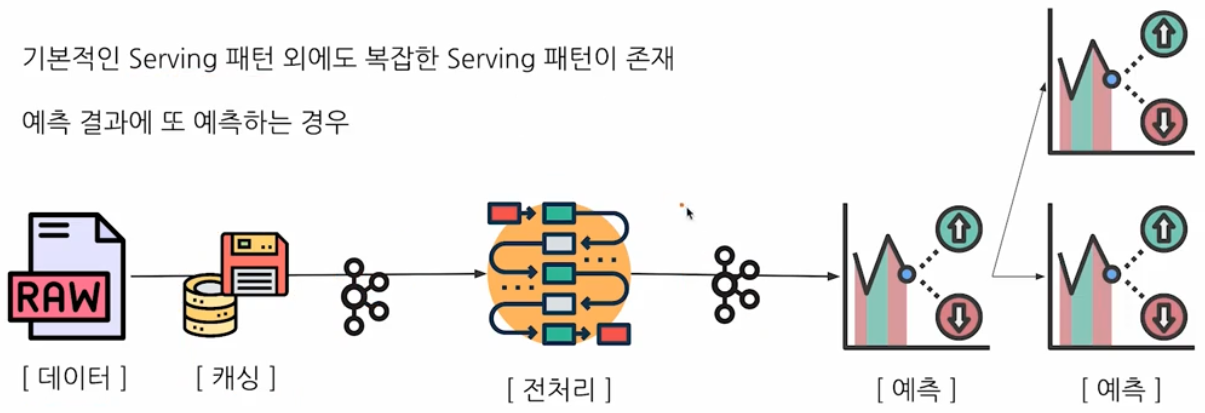
- 이 때 서로 dependency 가 있을 수 있다. 만약 앞선 예측이 병목인 경우에는 어떻게 처리할 지 고민해야 한다.
- 머신러닝 디자인 패턴은 서빙 외에도 다양하게 존재한다. 이 패턴들은 실무에서 반드시 사용된다.
-
머신러닝 시스템 디자인 패턴에 대한 개념이 잘 설명된 링크가 존재한다.

- 위와 같은 패턴들은 단순히 개념만으로는 감이 잘 안오기 때문에, 구현된 코드까지 보는 것이 좋다.
- ml-system-in-actions github 에서는 정답 코드는 아니지만 참고하기 매우 좋은 구현들이 공유되어 있다.
onnx,proto등 코드 레벨로 확인하면서 익숙하지 않은 내용은 추가로 학습해야 한다.- 서빙 패턴에 굉장히 여러 유형이 있고, 패턴 사이에 어떤 차이가 있는지를 비교해보자.
-
- 정리하면, 머신러닝 시스템 디자인은 대규모 시스템 설계와 연관되는 부분이다. 현업에서는 트래픽을 점점 많이 받으면 어떻게 설계해야 할까에 대한 고민이 굉장히 중요하다.
- ML/AI 분야가 발전하면서 더 공부하면 좋을 내용들은, 대부분 기본적인 분야이며 빠르게 알수록 좋은 분야들이다.
- 따라서 Core 에 대해 잘 알아두면 스스로 경쟁성을 확보할 수 있는 좋은 시기다.
참고하면 좋을 자료
- 기술 블로그 & 발표 영상 & 논문 & 각종 회사의 기술 블로그
- 어떤 기술을 왜 사용? 어떤 상황? 어떻게 문제 정의? 를 파악하면 간접 경험을 하는 효과를 얻을 수 있다. 내가 푸려는 문제를 이렇게 풀었구나도 알 수 있다.
- 이는 취업이 아니라 긴 커리어를 가지기 위해서도 좋다.
- MLOps 에 대해서는 Uber, Door Dash, Airbnb 의 자료가 좋다.
- 또한 회사별로 진행하는 컨퍼런스를 챙겨보자.
- 네이버 DEVIEW, 카카오 IFKAKO, 토스 SLASH, 우아한형제들 우아콘, 데이터야놀자, PyCon
- 기술 블로그와 마찬가지로 왜 이 기술을 사용했는가를 고민하자.
- 시간의 흐름에 따라 트렌드가 바뀐다. 해당 흐름을 잡아가면 좋다.
댓글 남기기