
[Airflow] Airflow 아키텍처 및 실무 활용
Airflow 아키텍처와 실무에서 Airflow 를 구축하는 과정에 대해 알아보자.
Airflow 아키텍처
- 기본 아키텍처에는 Worker, DAG dir, Scheduler, Webserver, Metadata db 등이 있다.
Scheduler
-
Scheduler 는 아래 그림과 같이 각종 메타 정보의 기록을 담당한다.
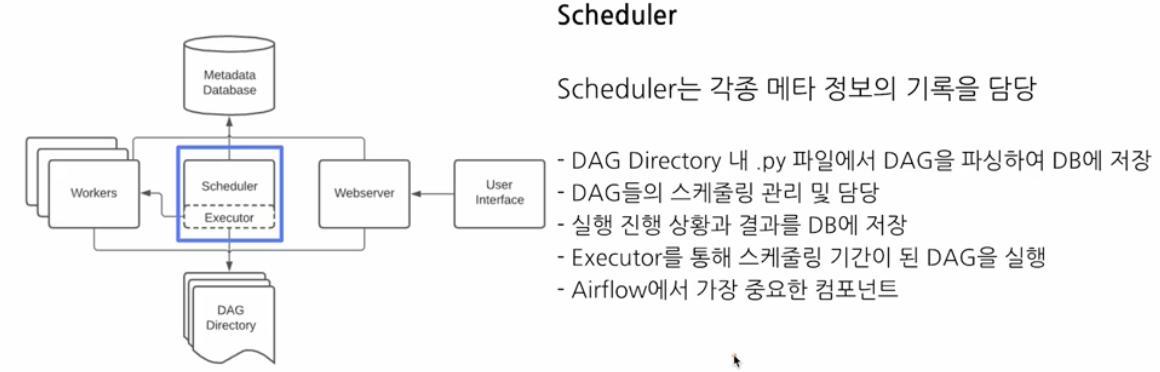
- DAG dir 내
.py파일에서 DAG 를 파싱하여 DB 에 저장한다. - DAG 들의 스케줄링을 관리하고 담당한다.
- 실행 진행상황과 결과를 DB 에 저장한다.
- Executor 를 통해 스케줄링 기간이 된 DAG 를 실행한다.
- Airflow 에서 가장 중요한 컴포넌트다.
- DAG dir 내
-
중요한 것은 Scheduler 와 WebServer 는 항상 띄워줘야 한다.
Executor
- Executor 는 Worker 와 비슷한 개념으로, 스케줄링 기간이 된 DAG 를 실행하는 객체다. 즉 Executor 는 Airflow 의 실행 엔진으로서, 사용자가 정의한 DAG 의 Task 들을 어떻게 분산하고 실행할 지를 결정하는 역할을 한다.
- Airflow 에서는
LocalExecutor,SequentialExecutor,CeleryExecutor등 다양한 Executor 가 있으며, 각각의 특성에 따라 Task 실행 방식이 다르다. - 크게 2 종류로 나뉜다.
- Local Executor
- DAG run 을 프로세스 단위로 실행한다.
- 하나의 프로세스에서 모든 DAG run 을 처리한다. 즉 순차적이다. 따라서 기본적으로 Sequential Executor 다.
- Airflow 의 기본 Executor 로, 별도 설정이 없으면 해당 Executor 를 사용한다. Airflow 를 테스트로 잠시 운영할 때 적합하고, 실무에서는 잘 사용하지 않는다.
- 즉 Local Executor 는 하나의 DAG run 을 하나의 프로세스로 띄워서 실행하여 Airflow 를 간단하게 운영할 때 적합하다.
- 최대로 생성할 프로세스 수를 정해야 한다.
- Remote Executor
- DAG run 을 외부 프로세스로 실행한다.
- Celery Executor
- 비동기로 처리하고 싶을 때 사용한다.
- DAG run 을 Celery Worker Process 로 실행하는 것으로, Celery 에 DAG 를 보내는 것이다.
- 보통 Redis 를 중간에 두고 같이 사용한다. Redis 는 중간에서 데이터를 저장하는 공간이다.
- 이는 Airflow Celery Executor 에서 Broker(브로커)에 대한 내용이다. 즉 작업에 대한 메시지를 전달하는 메시지 큐 시스템으로 Redis 를 많이 사용한다.
- Airflow Celery Executor 는 메시지 큐 시스템 기반으로 Task 를 병렬로 실행하도록 지원하며 HA 구성과 Scale-Out 설정에 용이하다.
- Broker 는 Task 를 전달하는 역할을 담당하며, RabbitMQ, Redis, Apache Kafka 등으로 설정할 수 있다.
- 일반적으로 Local Executor 를 사용하다가, Airflow 운영 규모가 더 커지면 Celey Executor 로 전환한다.
- Kubernetes Executor
- k8s 상에서 Airflow 를 운영할 때 사용한다.
- 하나의 DAG run 이 하나의 Pod 에서 실행된다. 이는 k8s 의 컨테이너와 같은 개념이다.
- Airflow 운영 규모가 큰 팀에서 사용한다.
Workers
- Executor 로 작업을 전달하면, 결국 Worker 들이 실제 작업을 수행한다.
- 즉 스케줄러에 의해 생기고 DAG 의 작업을 수행한다.
- DAG run 을 실행하는 과정에서 생긴 로그를 저장한다.
Metadata Database
- 스케줄러에 의해 메타데이터를 저장한다. 예를 들어 스케줄이 지났는지, 몇 번 실행했는지와 같은 정보를 저장한다.
- 보통 MySQL, PostgreSQL 를 사용한다.
- 또한 파싱한 DAG 정보, DAG run 상태와 실행 내용, Task 정보 등을 저장한다.
- 이외에 User 와 Role(RBAC, 역할 기반 접근 제어)에 대한 정보를 저장한다.
- 스케줄러와 더불어 핵심 컴포넌트다.
- 모든 데이터가 저장된다.
- TroubleShooting 시 디버깅을 위해 직접 DB 에 연결해 데이터를 확인하기도 한다.
- 실제 운영 환경에서는 GCP Cloud SQL 이나 AWS Aurora DB 등 클라우드 DB 를 사용한다.
WebServer
- WEB UI 를 담당한다.
- 메타데이터 DB 와 통신하며 유저에게 필요한 메타데이터를 웹브라우저에 보여주고 시각화한다.
- 보통 Airflow 사용자들이 웹서버를 이용하여 DAG 을 on/off 하고, 현 상황을 파악한다.
- REST API 도 제공하므로, 꼭 UI 를 안써도 DAG on/off 를 할 수 있다.
- 웹서버가 당장 작동하지 않아도, Airflow 에 큰 장애가 발생하지 않는다. 반면에 스케줄러의 작동 여부는 매우 중요하다.
Flow
-
아래 그래프는 Airflow Task 의 status 를 나타내는 그래프다.
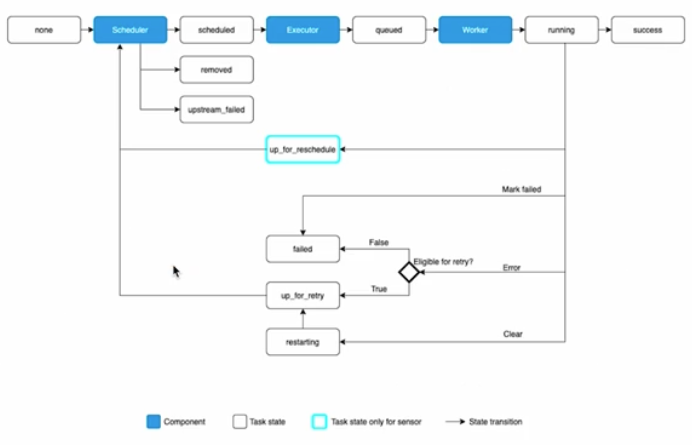
- 이를 통해 Task 가 어떻게 동작하는지 큰 흐름을 이해할 수 있다. 사이사이에 Scheduler, Executor, Worker 개념이 들어가 있다.
- 위 그림을 보면, Executor 는 스케줄러에 의해 scheduled 된 작업을 queue 에 담는 역할을 하고, Worker 는 queue 에 있는 작업을 실제 수행하는 역할을 하는 것을 알 수 있다.
실무 구축 Usecase
- Airflow 를 구축하는 방법으로 보통 3 가지 방법을 사용한다.
- Managed Airflow (GCP Composer, AWS MWAA 등)
- VM + Docker Compose
- Kubernetes + Helm
Managed Airflow
-
클라우드 서비스 형태로 Airflow 를 사용하는 방법이다.
- 클라우드 서비스에서 managed 가 붙은 제품들은 서비스를 대신 운영해준다.
- 즉 클라우드에서 Airflow 를 띄워주고 인프라를 관리하며, 사용자는 Airflow DAG 만 만들면 되는 것이다. 따라서 Airflow 를 처음 구축할 때 많이 사용한다.
- 보통 별도의 데이터 엔지니어가 없고, 분석가로 이루어진 데이터 팀이 초기에 활용하기 좋다. 인프라 관리 등의 개발 리소스를 아낄 수 있기 때문이다.
- 장점은 아래와 같다.
- 설치와 구축을 클릭 몇 번으로 클라우드 서비스가 다 진행해준다.
- 유저는 DAG 파일을 스토리지(파일 업로드) 형태로 관리하면 된다.
- 단점은 아래와 같다.
- 높은 비용과 자유도가 제한적이다.
- 클라우드에서 기능을 제공하지 않으면 불가능한 제약이 많다.
VM + Docker Compose
-
직접 VM 위에서 Docker Compose 로 Airflow 를 배포하는 방법이다.
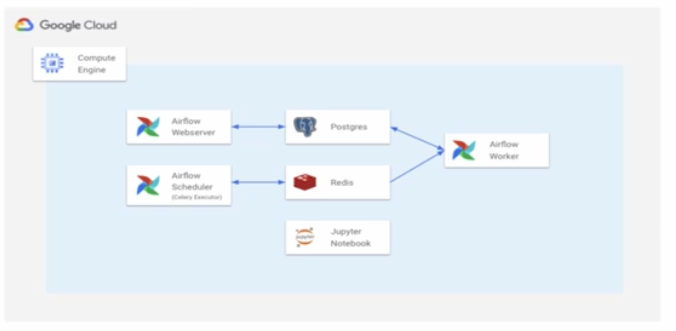
- 클라우드 서비스에 서버를 띄우고, 거기서 Docker Compose 를 써서 Airflow 를 배포하는 방법이다.
- 보통 데이터 팀에 데이터 엔지니어가 적게 존재하는 데이터 팀이 성장 초반에 사용하기에 적합하다.
- 장점은 아래와 같다.
- 클라우드의 Managed Service 보다는 살짝 복잡하지만, 어려운 난이도는 아니다.
- Docker 와 Docker Compose 에 익숙한 사람이라면 금방 익힐 수 있다.
- 하나의 VM 만을 사용하기 때문에 비교적 단순하다.
- 단점은 아래와 같다.
- 각 Docker Container 별로 환경이 다르므로, 관리 포인트가 늘어난다.
- 특정 Container 가 갑자기 죽을 수도 있다.
- 특정 Container 에 라이브러리를 설치했다면, 나머지 Container 에도 하나씩 설치해줘야 한다.
- Docker, kafka, Pytorch 등을 쓸 때, 특정 도구에 새로운 게 생기면 그것에 대한 관리 포인트가 늘어나게 된다.
Kubernetes + Helm
- k8s 환경에서 Helm 차트로 Airflow 를 배포하는 방법이다. Helm Chart 는 k8s 패키징 파일 컬렉션이다.
- k8s 는 여러개의 VM 을 동적으로 운영하는 일종의 분산환경으로, 리소스 사용이 매우 유연한 것이 대표적인 특징이다. 필요에 따라 VM 수를 알아서 늘려주고 줄여주기 때문이다.
- 이런 특징 덕분에 특정 시간에 Batch Process 를 실행시키는 Airflow 와 궁합이 매우 잘맞는다.
- 웹서버, 스케줄러가 별도의 VM 으로 실행이 되고, 두 서버가 독립적으로 운영이 되면서 k8s executor 에게 명령하여 worker 작업을 하는 것이다.
- Airflow DAG 수가 몇 백개로 늘어나도 Node Auto 스케일링으로 모든 프로세스를 잘 처리할 수 있다.
- 그러나 k8s 자체가 난이도가 있기 때문에 구축과 운영이 어렵다.
- 따라서 데이터 팀에 엔지니어링 팀이 존재하고, 자주 사용하는 배포 환경이 k8s 환경인 경우에 적극 사용할 수 있다.
Airflow for MLOps & Data Engineering
- 실무에서는 Data Engineering 전용 혹은 MLOps 전용 Airflow 를 띄울 수 있다.
- 이 때 Airflow 를 띄우는 것 자체가 컴퓨터(서버)를 사용하는 것이기 때문에, 비용을 생각하며 결정해야 한다.
- 운영하는 DAG 의 갯수가 적은 경우엔 Data Engineering + MLOps 통합 Airflow 1 개를 운영하는 경우도 존재한다.
- MLOps 에서는 “주기적인 실행“이 필요한 경우에 적극 사용할 수 있다.
- Batch Training : 1 주일 단위로 모델 학습
- Batch Serving(Batch Inference) : 30 분 단위로 인퍼런스
- 인퍼런스 결과를 기반으로 일자별, 주차별 모델 퍼포먼스 Report 생성
- MySQL 에 저장된 메타데이터를 데이터 웨어하우스로 1 시간 단위로 옮기기
- Feature Store 를 만들기 위해 Batch ETL 실행
댓글 남기기