
[AI Math] 1. 선형대수 for Deep Learning
행렬과 벡터는 인공지능과 기계학습에서 가장 많이 쓰이는 개념 중 하나다. 그리고 행렬 연산은 딥러닝의 핵심 중의 가장 중요한 연산이다. 따라서 딥러닝을 제대로 이해하기 위해서는 행렬 연산을 아주 정확히 이해해야 한다.
벡터
- 벡터는 숫자를 원소로 가지는 리스트(list) 또는 배열(array)이다.
-
수식으로 하면 아래와 같다. 이 때 세로는 열벡터, 가로는 행벡터라고 부른다.
\[\mathbf{x} = \begin{bmatrix} 1 \\ 7 \\ 2 \end{bmatrix} \quad \mathbf{x}^T = \begin{bmatrix} 1, 7, 2 \end{bmatrix}\] - 코드로 하면 아래와 같다.
import numpy as np x = [1, 7, 2] x = np.array([1, 7, 2]) - numpy 에서는 보통 행벡터를 기준으로 한 array 로 벡터를 표현한다.
-
각각의 벡터들마다 차원을 정의하는데, 벡터 내 숫자의 개수가 벡터의 차원이다. 즉 아래에서 $d$ 가 벡터의 차원이 된다.
\[\mathbf{x} = \begin{bmatrix} x_{1} \\ x_{2} \\ \vdots \\ x_{d} \end{bmatrix}\] -
이러한 벡터는 공간에서 한 점을 나타낸다.
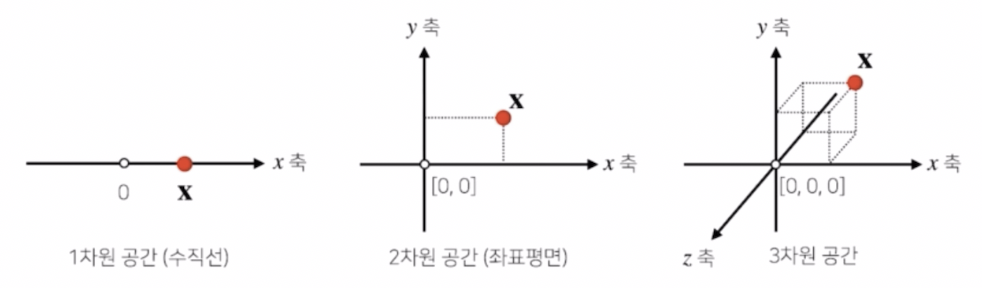
- 보통 딥러닝에서 다루는 벡터는 훨씬 큰 차원의 벡터들을 다룬다. $n$ 차원의 공간의 벡터는 $n$ 개의 축을 가지는 좌표평면 내에서 표현되는 한 점으로 이해할 수 있다.
-
또한 벡터는 원점으로부터 상대적 위치를 표현한다.
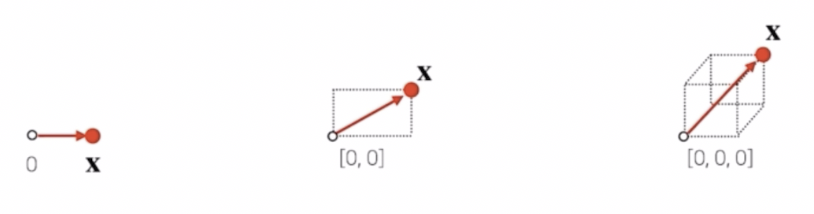
- 벡터를 화살표로 이해할 때, 길이나 방향을 자유롭게 조절할 수 있다.
스칼라곱
- 한 벡터에 스칼라, 혹은 숫자를 곱해주면 방향은 그대로이고 길이만 변한다. 이 연산을 스칼라곱이라고 부른다. 즉, 스칼라곱은 원점에서 그 벡터를 표현하는 화살표를 스칼라곱을 통해서 길이를 변환시켜주는 연산으로 이해하면 된다.
-
벡터에 스칼라곱을 하면 각각의 구성성분에 해당 스칼라를 곱해준다.
\[a\mathbf{x} = \begin{bmatrix} ax_{1} \\ ax_{2} \\ \vdots \\ ax_{d} \end{bmatrix}\] -
이처럼 스칼라곱은 주어진 벡터의 길이를 변환시키는 것으로서 숫자의 크기가 1보다 크면 원래 벡터의 길이를 더 길게하고, 1보다 작으면 원래 벡터의 크기를 1보다 작은 벡터의 크기로 줄이는 연산을 하게 된다.
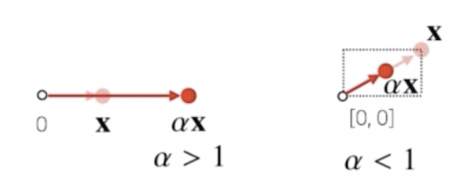
-
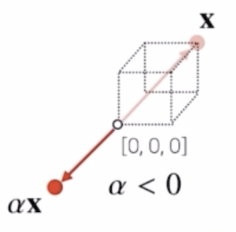
만약 곱해주는 실수의 값이 0보다 작으면 벡터의 방향이 반대 방향이 된다.
벡터의 덧셈, 뺄셈
-
벡터는 숫자를 원소로 가지는 리스트 혹은 배열이다. 이 때 벡터끼리 같은 모양을 가지면 덧셈, 뺄셈을 계산할 수 있다.
\[\mathbf{x} = \begin{bmatrix} x_{1} \\ x_{2} \\ \vdots \\ x_{d} \end{bmatrix} \; \; \; \mathbf{y} = \begin{bmatrix} y_{1} \\ y_{2} \\ \vdots \\ y_{d} \end{bmatrix} \; \; \; \mathbf{x} \pm \mathbf{y} = \begin{bmatrix} x_{1} \pm y_1 \\ x_{2} \pm y_2 \\ \vdots \\ x_{d} \pm y_d \end{bmatrix}\] - 차원이 같은 두 벡터의 덧셈과 뺄셈은 각각의 구성성분 끼리의 덧셈과 뺄셈으로 정의할 수 있다.
- 만약 같은 모양이 아니라면 보통은 불가능하다. 따라서 파이썬에서 numpy 를 가지고 다른 모양의 array 를 덧셈/뺄셈을 한다면 에러가 발생한다.
- 따라서 벡터의 차원을 중요하게 생각하고 다른 모양을 가지는지를 체크해야 한다.
-
벡터의 덧셈은 다른 벡터로부터 상대적 위치이동을 표현한다.
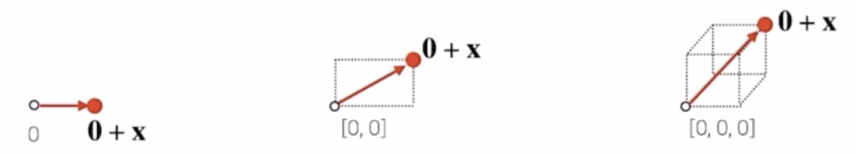
- 원점을 영벡터라고 부르게 되면, 벡터 $\mathbf{x}$ 는 영벡터와 $\mathbf{x}$의 덧셈으로 표현할 수 있다.
-
영벡터 대신에 다른 벡터를 사용하게 되면 다음과 같다.
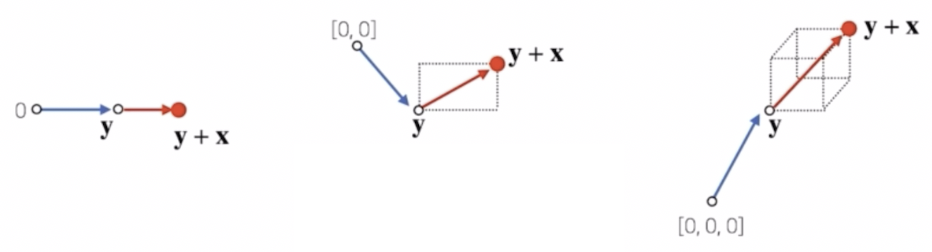
- 이처럼 두 벡터의 덧셈은 영벡터에서 $\mathbf{y}$ 벡터로 간 후에, $\mathbf{y}$ 벡터에서 $\mathbf{y+x}$ 벡터로 향하는 것이다.
- 벡터의 덧셈을 상대적 위치이동으로 표현할 수 있듯이, 뺄셈도 마찬가지다.
-
벡터에 음수의 스칼라를 곱하면 해당 벡터의 반대방향으로 움직인다. 즉 벡터의 뺄셈은 $\mathbf{x}$ 라는 벡터를 더하는 대신에 $-\mathbf{x}$ 벡터를 더하는 것으로 이해하면 된다.
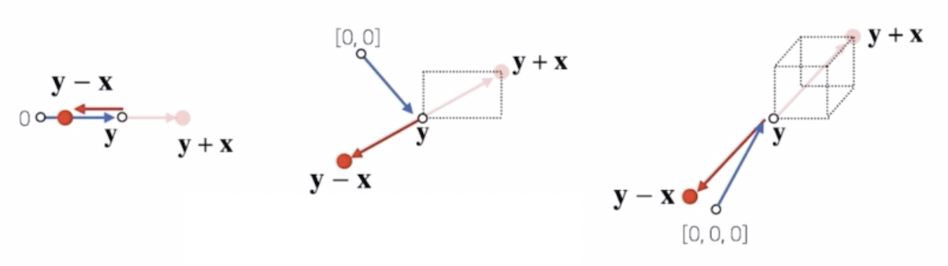
- 즉, 영벡터에서 $\mathbf{y}$ 벡터로 이동하고, $-\mathbf{x}$ 벡터(원래 $\mathbf{x}$ 벡터의 반대방향으로 움직이는 벡터) 를 더해주는 것과 같다.
벡터의 곱셈
-
또한 벡터끼리 같은 모양을 가지면 성분곱(Hadamard product)을 계산할 수 있다.
\[\mathbf{x} = \begin{bmatrix} x_{1} \\ x_{2} \\ \vdots \\ x_{d} \end{bmatrix} \; \; \; \mathbf{y} = \begin{bmatrix} y_{1} \\ y_{2} \\ \vdots \\ y_{d} \end{bmatrix} \; \; \; \mathbf{x} \odot \mathbf{y} = \begin{bmatrix} x_{1}y_1 \\ x_{2} y_2 \\ \vdots \\ x_{d}y_d \end{bmatrix}\] - 성분곱은 Hadamard Product, 혹은 element-wise product 라고 부르게 된다. 두 벡터의 구성성분끼리를 곱해주는 연산이 성분곱이다.
- numpy 에서 숫자의 곱셈 연산에 사용되는 곱셈기호(
*)를 사용해서 두 벡터를 연산하면 성분곱으로 계산이 된다.
벡터의 노름
- 벡터의 노름(norm)은 원점에서부터의 거리를 말한다.
-
$\Vert \cdot \Vert$ 기호가 노름(norm)을 나타낸다.
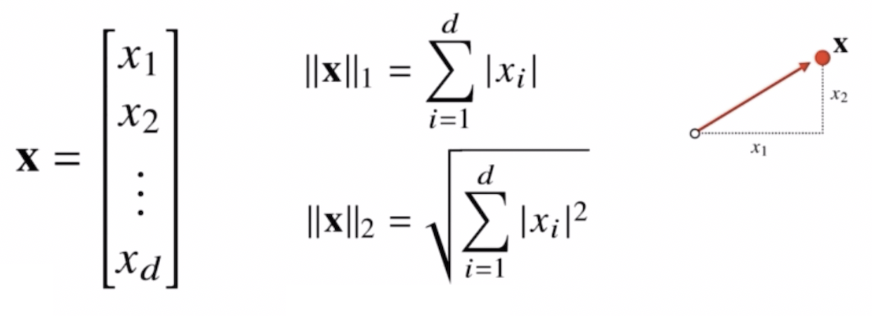
- 주어진 벡터가 공간상의 한 점을 나타낸다고 했을 때, 벡터의 노름은 원점에서부터 그 한 점 사이의 거리를 표현하는 것이다.
- 여러 종류의 노름이 정의되어 있다. 보틍은 2가지다.
- $\mathbf{x}$ 의 $L1$ 노름인 $\Vert \mathbf{x} \Vert_1$ 가 있고, $L2$ 노름인 $\Vert \mathbf{x} \Vert_2$ 가 있다.
- 이 때 노름이라는 기호는 임의의 차원 $d$ 에 대해서 성립한다. 즉 1, 2, 3차원 뿐 아니라 거리는 임의의 차원에서 계산할 수 있는 개념이다. 따라서 벡터의 노름은 벡터의 차원, 즉 구성성분 원소의 개수에 상관없이 계산할 수 있다.
- $L1$ 노름은 각 성분의 변화량의 절대값을 모두 더하는 개념이다. 각각의 구성성분의 절대값을 모두 더하는 것이다. 좌표평면에서 각 좌표축을 따라서 움직이는 거리들로 이해하면 된다.
- $L2$ 노름은 원점에서 $\mathbf{x}$ 라는 벡터로 직접 바로 연결되는 선의 거리를 뜻한다. 피타고라스 정리를 이용해 유클리드 거리를 계산한다.
-
코드로 보면 다음과 같다.
def l1_norm(x): x_norm = np.abs(x) x_norm = np.sum(x_norm) return x_norm def l2_norm(x): x_norm = x*x x_norm = np.sum(x_norm) x_norm = np.sqrt(x_norm) return x_norm - 왜 두 노름을 다르게 정의할까?
-
바로 노름의 종류에 따라 공간상에서 표현되는 기하학적 성질이 달라지기 때문이다.
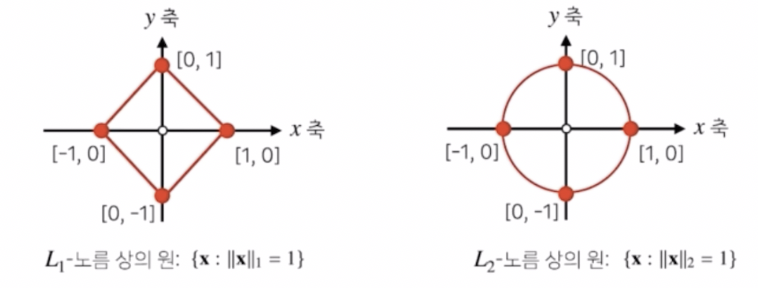
- 위 그림에서 보듯 $L1$ 노름 상의 원과 $L2$ 노름 상의 원이 다르다.
- 원의 정의는 원점으로부터 거리가 1인 점들의 집합이다. 이 때 거리를 $L2$ 노름 거리로 사용하면 보통 알고 있는 원 모양이 정의된다. 반면 $L1$ 노름을 사용하면, 보통 알고 있는 원 모양이 아니라 마름모로 정의된다.
- 서로 다른 노름을 사용하게 되면 거리의 개념이 달라지기 때문에 원점에서부터의 거리로 정의되는 원의 기하학적인 모양들이 바뀌게 된다. 이처럼 같은 좌표평면계라고 하더라도 노름을 다르게 사용함으로써 기하학적 성질이 달라진다.
- 성질이 달라진 기하세계에서 학습을 진행하게 되면 다른 성질들이 성립하게 된다. 이렇게 다른 성질들을 이용해서 기계학습에서 다양한 종류의 학습 방법이나 정규화 방법들을 사용할 때 응용할 수 있다.
- 머신러닝에서는 서로 다른 노름들을 사용해서 최적화나 학습에 이용하기 때문에 이 개념들을 잘 이해해두면 좋다.
- 여러 기계학습 방법론에서는 어떤 노름을 사용할 지를 정할 때 이런 기하학적 성질에 의존하기 때문에, 어떤 노름이 어떤 기하학적 성질에 따라서 사용되는지 이해하고 있어야 한다.
- 예를 들어 $L1$ 노름은 Robust 한 학습과 Lasso 회귀에서 사용되고, $L2$ 노름은 Laplace 근사, Ridge 회귀에서 사용된다.
- 따라서 기계학습에서 원하는 목적에 따라 서로 다른 노름을 사용할 수 있기 때문에 각각의 필요에 따라 서로 다르게 적용될 수 있다는 사실을 기억하자.
두 벡터 사이의 거리
- $L1$, $L2$ 노름을 이용해서 두 벡터 사이의 거리를 계산할 수 있다.
- 벡터 사이의 거리를 계산한다는 것은, 두 점이 주어졌을 때 두 점 사이의 거리를 계산하는 것이다.
- 거리를 계산하는 방법 또한 $L1$ 노름과 $L2$ 노름에 따라 서로 다른 값을 가질 수 있다.
-
두 벡터 사이의 거리를 계산할 때는 벡터의 뺄셈을 이용한다.
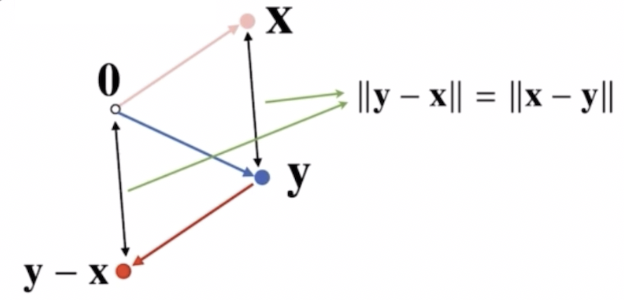
- 벡터의 뺄셈은 $\mathbf{x}$ 를 반대방향으로 이동시키는 벡터를 이용해서 영벡터에서 $\mathbf{y}$ 벡터로 이동한 다음, $\mathbf{y}$ 벡터에서 $\mathbf{y-x}$ 벡터로 상대적 위치를 이동하게 된다.
- 이 때 영벡터에서 $\mathbf{y-x}$ 벡터로 이동한 거리가 $\mathbf{x}$ 라는 점에서 $\mathbf{y}$ 라는 점으로 이동한 거리와 일치하게 된다. 이 성질을 이용해서 두 벡터 사이의 거리를 계산할 때 이용한다.
- 이 때 $\mathbf{y-x}$ 가 아니라 $\mathbf{x-y}$ 를 해도 거리가 똑같이 계산이 된다.
두 벡터 사이의 각도
- 두 벡터 사이의 거리를 계산할 수 있기 때문에 두 벡터 사이의 각도도 계산할 수 있다.
- 단, 각도는 $L1$ 노름이 아니라 $L2$ 노름에서만 계산 가능하다.
- 두 벡터 사이의 거리를 $L2$ 노름으로 계산할 때는 피타고라스 정리에 의해서 유클리드 거리로 계산하게 된다.
-
유클리드 거리로 두 점 사이의 거리를 계산할 수 있으면, 영벡터와 $\mathbf{x}$ 벡터와 $\mathbf{y}$ 벡터로 이루어진 삼각형을 이용해서, 여기에 제2코사인 법칙을 적용시켜 두 벡터 사이의 각도를 계산할 수 있다.
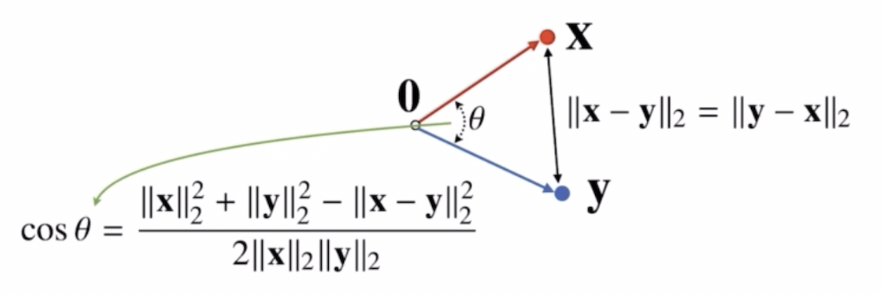
- $d$ 차원 벡터에서도 이러한 각도를 계산하는 것이 가능하다. $L2$ 노름을 정의한 이유가 각도라는 개념을 2, 3차원이 아니라 일반적인 $d$ 차원에서 계산할 수 있도록 하기 위해서다.
-
각도를 계산할 때 제2코사인 법칙의 분자의 수식을 $L2$ 노름에 따라 전개하면 내적과 관련이 있다.
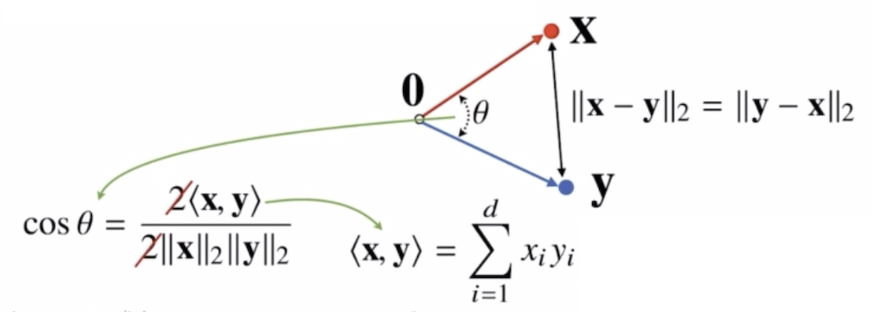
- 내적은 두 벡터들에 성분곱을 취한 후 그 성분곱을 취한 벡터들의 모든 성분들을 다 더해주는 연산이다. 이러한 내적은 inner product 라고 부른다.
- 분모 항은 $\mathbf{x}$ 벡터의 거리와 $\mathbf{y}$ 벡터의 거리의 곱으로 표현된다. 분자가 $\mathbf{x}$ 와 $\mathbf{y}$ 두 벡터의 내적으로 표현될 수 있다.
- 두 벡터 사이의 각도를 계산할 때는 이처럼 내적 연산과 $L2$ 노름 연산을 이용해서 각도를 계산할 수 있다.
-
코드로 보면 다음과 같다.
def angle(x, y): v = np.inner(x, y) / (l2_norm(x) * l2_norm(y)) theta = np.arccos(v) # cos 의 역 return theta - 두 벡터 사이의 각도를 계산하는 것은 두 벡터가 굳이 2, 3차원에 있을 필요없이 임의의 $d$ 차원에서 각도를 계산할 수 있기 때문에 항상 각도를 계산할 수 있다.
- 주의할 점은 각도를 계산하는 것은 오로지 $L2$ 노름에서만 가능하고 $L1$ 노름에서는 각도를 계산할 수 없다.
내적의 해석
- 우리가 딥러닝을 하면서 마주치게 될 내적은 모델 속에서 매우 흔하게 이뤄지는 연산이며 각 벡터의 요소끼리 곱하고 모두 더하여 나오는 스칼라 값이다. 그러나 내적이 뭔가? 라고 물어봤을 때 왜 이런 연산을 하는 건지 그 이유를 알아보자.
- 내적은 정사영(orthogonal projection)된 벡터의 길이와 관련 있다.
-
정사영은 $\mathbf{x}$ 벡터와 $\mathbf{y}$ 벡터가 있을 때, $\mathbf{x}$ 벡터에 $\mathbf{y}$ 벡터 방향으로 빛을 쐈을 때 그림자를 보는 것처럼 $\mathbf{y}$ 벡터 상의 $\mathbf{x}$ 벡터의 그림자를 표현하는 것을 정사영이라 한다.
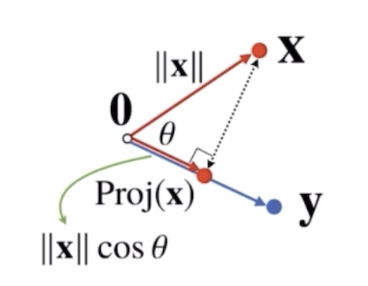
- $\text{Proj}(\mathbf{x})$ 가 $\mathbf{y}$ 벡터에 정사영된 $\mathbf{x}$ 벡터의 그림자로서 새로운 벡터다. 이 $\text{Proj}(\mathbf{x})$ 의 길이는 코사인법칙에 의해서 $\Vert \mathbf{x} \Vert \text{cos} \; \theta$ 가 된다.
- 즉 정사영된 벡터의 길이는 원래 벡터의 길이에 $\mathbf{y}$ 벡터와 $\mathbf{x}$ 벡터 사이의 각도에 따른 cos $\theta$ 를 곱하는 것과 일치한다.
-
내적은 정사영된 벡터의 길이를 벡터 $\mathbf{y}$ 의 길이 $\Vert \mathbf{y} \Vert$ 만큼 조정한 값이다.
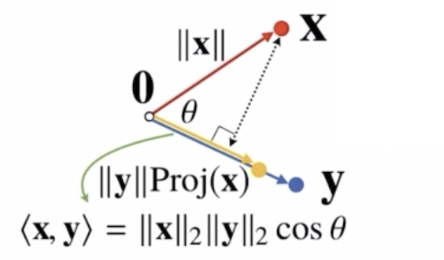
- 벡터의 스칼라곱은 벡터의 길이를 늘려주거나 줄여주거나 반대 방향으로 조정해주는 개념이다.
- 내적은 이렇게 정사영된 벡터의 길이를 벡터 $\mathbf{y}$ 의 길이만큼 스칼라곱을 취해줌으로써, 정사영된 벡터의 길이를 $\mathbf{y}$ 벡터의 크기에 맞춰서 조정하는 것이다. 따라서 내적은 정사영된 벡터를 벡터 $\mathbf{y}$ 의 길이만큼 조정한 값으로 이해하면 된다.
- 이러한 내적은 두 벡터 사이의 유사도(similarity)를 측정하는데 많이 사용한다.
- 즉 내적의 의미는 두 벡터가 얼마나 유사한지, 영향을 주는지, 닮았는지를 나타내는 연산이다. 내적 연산에 포함된 $\cos$ 연산을 생각해보면 두 벡터가 같은 방향일 때 값이 크고, 직각일 때 0 이 되고, 반대 방향일 때 음의 크기가 나오는 것을 알 수 있다.
- 이처럼 머신러닝이나 기계학습에서는 두 데이터가 얼만큼 유사한가 또는 두 패턴이 얼만큼 유사한가를 볼 때, 두 벡터의 내적을 이용해서 유사도를 측정해서 두 벡터가 얼만큼 비슷한 방향으로 가고 있는지를 측정한다.
행렬
- 벡터는 숫자를 원소로 가지는 1차원 배열이었다면, 행렬(matrix)은 벡터를 원소로 가지는 2차원 배열이다.
-
수식으로 하면 다음과 같다.
\[\mathbf{X} = \begin{bmatrix} 1 & -2 & 3 \\ 7 & 5 & 0 \\ -2 & -1 & 2 \end{bmatrix}\] - 코드로 하면 다음과 같다.
X = np.array([[1, -2, 3], [7, 5, 0], [-2, -1, 2]])- 각각의 행벡터를 하나의 array 안에 담는 것이다.
- 행렬은 행 과 열이 섞여 있다. 행렬을 열벡터를 원소로 가지는 2차원 배열로 생각할 수도 있지만, numpy 에서는 열벡터가 아니라 행벡터를 원소로 가지는 2차원 배열이다.
- 많은 딥러닝 프레임워크의 기반이 되는 numpy 에서 행렬을 행벡터로 표현한다는 사실은 딥러닝 연산의 근간인 행렬 연산이나 행렬의 곱셈을 이해할 때 명확히 이해하고 계산할 수 있다. 따라서 행렬은 행벡터를 원소로 가지는 2차원 배열로 이해하자.
-
$n$ 개의 행과 $m$ 개의 열을 가지는 행렬, 즉 $n \times m$ 행렬을 표현해보자.
\[\mathbf{X} = \begin{bmatrix} \mathbf{x}_1 \\ \mathbf{x}_2 \\ \vdots \\ \mathbf{x}_n \end{bmatrix} = \begin{bmatrix} x_{11} & x_{12} & \cdots & x_{1m} \\ x_{21} & x_{22} & \cdots & x_{2m} \\ \vdots & \vdots & x_{ij} & \vdots \\ x_{n1} & x_{n2} & \cdots & x_{nm} \end{bmatrix}\] - 기호를 통일하고 이해하면 논문이나 여러 문서를 읽을 때 도움이 된다.보통 벡터는 소문자 $\mathbf{x}$ 이고 행렬은 대문자 $\mathbf{X}$ 로 표현한다.
- 행렬 $\mathbf{X}$ 는 $n$ 개의 행벡터로 이루어진 배열이다. 각각의 행벡터는 $m$ 개의 원소 성분으로 이루어진 벡터이다.
-
행렬의 행은 row 이고 열은 column 이라 부른다. 즉 행렬은 인덱스를 2개를 가진다. 이 때 순서를 명확히 알아야 한다.
\[\mathbf{X} = (x_{ij})\] - 행렬을 표시할 때 원소들의 인덱스 순서는 행을 먼저 쓰고 열을 쓰게 된다. 즉, $i$ 번째 행벡터에 있는 $j$ 번째 원소를 뜻한다.
- 딥러닝과 기계학습 논문을 볼 때 굉장히 많은 표기법을 가지고 행렬을 표현하기 때문에 이런 표기법들을 익혀두자. 그리고 행렬의 연산에서 행벡터와 열벡터 사이에 어떻게 연산이 이루어지는지를 유심히 보면서 이해하자.
전치행렬
\[\mathbf{X}^T = (x_{ji})\] \[\mathbf{X}^T = \begin{bmatrix} x_{11} & x_{21} & \cdots & x_{n1} \\ x_{12} & x_{22} & \cdots & x_{n2} \\ \vdots & \vdots & x_{ji} & \vdots \\ x_{1m} & x_{2m} & \cdots & x_{nm} \end{bmatrix}\]- 전치행렬은 행과 열의 인덱스가 바뀐 행렬을 뜻하며, transpose matrix 라고 부른다.
- 행렬 $\mathbf{X}$ 를 전치시키면 우측 상단에 $T$(transpose) 를 붙인다.
- 행렬에 들어있는 모든 원소들의 행과 열의 인덱스를 바꿔서, 열을 행으로, 행을 열로 보내는 연산을 취하게 된다. 즉 원래 $n$ 개의 행과 $m$ 개의 열로 이루어진 행렬은 $m$ 개의 행과 $n$ 개의 열로 이루어진 행렬로 바뀌게 된다.
- 이러한 전치행렬은 행렬의 연산을 할 때 굉장히 많이 사용된다.
- 만약 벡터에 전치연산을 하게 되면, 행벡터가 열벡터로 바뀌고, 열벡터가 행벡터로 바뀌게 된다. 즉, 전치연산은 행렬과 벡터 둘 다 성립한다.
행렬을 이해하는 방법(1) - 데이터
-
벡터가 공간에서의 한 점을 의미한다면 행렬은 여러 점들을 나타낸다. 행렬은 여러 개의 벡터들로 이루어져 있는 배열이기 때문에 각각의 벡터가 한 점을 의미한다면 행렬은 여러 개의 점들로 구성된 개념으로 보는 것이다.
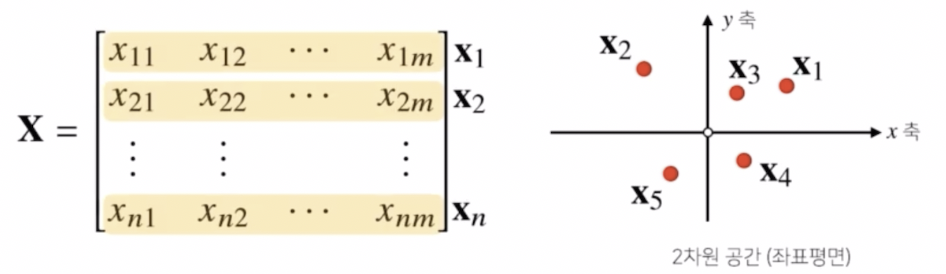
- 행렬에 들어있는 각각의 행벡터를 어떤 데이터로 이해할 때, 행렬은 이 데이터를 모은 배열로 이해할 수 있다. 즉 행렬의 행벡터 $\mathbf{x}_i$ 는 $i$ 번째 데이터를 의미한다.
- 이처럼 기계학습이나 통계학에서 행렬을 사용할 때는 첫번째 데이터, 두번째 데이터 해서 전체 데이터를 모아 놓은 것을 표현할 때 행렬을 사용하게 된다.
- 각 행렬의 행 벡터를 공간 상의 여러 점들로 표현하게 될 것이고, 이렇게 여러 점들을 전체 데이터 집합으로 표현하게 될 때 행렬을 이용할 수 있다.
- 행렬의 $x_{ij}$ 는 $i$ 번째 데이터의 $j$ 번째 변수의 값을 말한다.
- 이렇게 행렬을 공간상에서의 데이터들의 모임으로 이해한다면, 어떤 데이터의 몇 번째 변수의 값이 얼마인지 행렬을 이용해서 값을 뽑을 수 있다.
행렬의 덧셈, 뺄셈, 성분곱, 스칼라곱
- 행렬은 벡터를 원소로 가지는 2차원 배열이다. 벡터끼리는 모양이 같으면 덧셈, 뺄셈, 곱셈이 가능했다.
-
행렬도 마찬가지로 같은 모양을 가지면 덧셈, 뺄셈을 계산할 수 있다.
\[\mathbf{X} \; \pm \; \mathbf{Y} = (x_{ij} \pm y_{ij})\] - 벡터의 덧뺄셈과 다를 게 없이, 두 행렬의 덧셈 뺄셈 또한 각 행렬의 구성 성분들의 덧셈 뺄셈과 같다.
-
행렬의 성분곱도 벡터와 똑같이 표현할 수 있다. 성분곱은 각 인덱스 위치끼리 곱한다. 즉 두 행렬 사이의 성분곱은 두 행렬 각각의 성분들의 각 인덱스 위치에 따른 곱으로 표현할 수 있다.
\[\mathbf{X} \; \odot \; \mathbf{Y} = (x_{ij}y_{ij})\] - 이처럼 $\mathbf{X}$ 의 $i$ 번째 행의 $j$ 번째 원소와 $\mathbf{Y}$ 의 $i$ 번째 행의 $j$ 번째 원소의 곱으로 행렬의 성분곱을 표현할 수 있다.
-
행렬의 스칼라곱 또한 벡터의 스칼라곱과 같다.
\[a\mathbf{X} = (ax_{ij})\] - 벡터의 스칼라곱이 각 배열의 원소에 똑같은 숫자를 곱해주듯, 행렬의 스칼라곱도 모든 성분에 똑같은 숫자를 곱해주면 된다.
행렬의 곱셈
- 그러나 행렬 곱셈은 벡터의 곱셈과 다르다. 벡터의 곱은 성분곱이고 이는 행렬의 곱셈이 아닌 행렬의 성분곱과 같다.
- 행렬 곱셈(matrix multiplication)은 $i$ 번째 행벡터와 $j$ 번째 열벡터 사이의 내적을 성분으로 가지는 행렬을 계산한다.
-
$\mathbf{X}$ 행렬과 $\mathbf{Y}$ 행렬의 곱셈은 $\mathbf{X}$ 행렬이 먼저 왔기 때문에 $\mathbf{X}$ 행렬의 행벡터, $\mathbf{Y}$ 행렬의 열벡터 두 벡터의 내적으로 계산되는 것이 $\mathbf{X, Y}$ 두 행렬의 곱셈의 $ij$ 원소로 이해할 수 있다.
\[\mathbf{XY} = \left( \displaystyle \sum_k x_{ik}y_{kj}\right)\] - 행렬곱은 $\mathbf{X}$ 의 열의 개수와 $\mathbf{Y}$ 의 행의 개수가 같아야 한다.
- 왜냐하면 두 행벡터와 열벡터 사이의 내적을 계산하려면 행벡터와 열벡터 사이의 원소의 개수가 같아야 하기 때문이다. 따라서 $\mathbf{X}$ 행렬의 열과 $\mathbf{Y}$ 행렬의 행의 개수가 같아야 연산이 실제로 가능하게 된다.
- 행렬곱의 순서를 바꿔서, 즉 $\mathbf{XY}$ 가 아니라 $\mathbf{YX}$ 행렬을 계산하게 되면, 두 행렬의 곱셈은 서로 다른 곱셈이 된다.
- 이렇게 행렬의 곱셈은 숫자의 곱셈과 달리 순서가 굉장히 중요한 역할을 한다. 어떤 행렬을 앞에다 두는지에 따라 결과가 달라지기 때문이다.
-
코드로 보면 다음과 같다.
X = np.array([[1, -2, 3], [7, 5, 0], [-2, -1, 2]]) Y = np.array([[0, 1], [1, -1], [-2, 1]]) X @ Y # 행렬곱 # 출력 #array([[-8, 6], # [5, 2], # [-5, 1]]) - $\mathbf{XY}$ 행렬의 첫번째 원소는 $\mathbf{X}$ 의 첫번째 행벡터와 $\mathbf{Y}$의 첫번째 열벡터 사이의 내적이다. 즉 $\mathbf{XY}$ 의 $ij$ 번째 원소의 값은, $\mathbf{X}$ 행렬의 $i$번째 행벡터와 $\mathbf{Y}$ 행렬의 $j$번째 열벡터의 내적값이다.
행렬의 내적
- 행렬은 벡터에서 정의한 내적을 계산할 수 있을까?
- numpy 의
np.inner는 두 행렬 사이의 $i$ 번째 행벡터와 $j$ 번째 행벡터 사이의 내적을 계산해준다. - 위에서 본 행렬의 곱셈은 $i$ 번째 행벡터와 $j$ 번째 열벡터 사이의 내적을 계산했다면, numpy 의 내적
np.inner는 $i$ 번째 행벡터와 $j$ 번째 행벡터 사이의 내적을 계산하는 것이다. - 수학에서는 보통 두 행렬 사이의 행렬곱을 계산한 후에 trace(대각합) 를 계산한 $\text{tr}(\mathbf{XY}^T)$ 을 내적으로 계산한다.
- numpy 의
np.inner에서 계산하는 내적은 수학에서 말하는 내적과 개념이 다르다. 즉 numpy 를 가지고np.inner를 사용하면 $\mathbf{X}$ 행렬과 $\mathbf{Y}$ 행렬의 전치행렬을 서로 행렬곱(matrix multiplication)한 것과 같은 결과를 얻게 된다. -
따라서 행렬곱이 두 행렬의 행벡터와 열벡터를 내적하는 것이라면,
\[\mathbf{XY}^T = \left(\displaystyle \sum_k x_{ik}y_{jk} \right)\]np.inner는 $\mathbf{X}$ 행렬과 $\mathbf{Y}$ 의 전치행렬 두 행렬의 행렬곱을 계산하는 것이다. -
이렇게 보통 수식에서 다루는 행렬의 내적과 코드에서 다루는 행렬의 내적이 다르기 때문에 결과가 다르게 나온다는 사실을 이해해야 한다.
X = np.array([[1, -2, 3], [7, 5, 0], [-2, -1, 2]]) Y = np.array([[0, 1, -1], [1, -1, 0]]) np.inner(X, Y) # 출력 #array([[-5, 3], # [5, 2], # [-3, -1]]) - 정리하면,
np.inner를 사용해서 내적을 계산할 때는 두 행렬의 행벡터의 내적을 계산하는 것이기 때문에, 두 행렬의 행벡터들의 크기가 같아야만 계산이 가능하다. 즉np.inner를 사용하면 $\mathbf{X}$ 행렬과 $\mathbf{Y}$의 전치행렬 사이의 행렬곱을 계산한 것과 같은 결과를 계산할 수 있다. - 이렇게
np.inner에서는 그냥 행렬곱과 차이가 있으므로 주의해야 한다. 행렬곱에서는 $\mathbf{X}$ 의 열의 개수와 $\mathbf{Y}$ 의 행의 개수가 같아야 한다. 그러나np.inner에서는 $\mathbf{X}$ 의 행의 개수와 $\mathbf{Y}$ 의 행의 개수가 같아야 한다.
행렬을 이해하는 방법(2) - 선형변환
- 앞서 행렬을 데이터들의 모임, 한 공간상의 점들의 모임으로 해석하는 것은 행렬을 이해하는 한 가지 방법이다.
-
또 다른 방법은, 데이터를 저장하는 것 뿐 아니라 서로 간에 다른 데이터들을 연결시키는 하나의 연산자로서 이해할 수도 있다. 즉 행렬은 벡터공간에서 사용되는 연산자(operator)로 이해할 수 있다.
\[z_i = \displaystyle \sum_j a_{ij}x_j\] \[\begin{bmatrix} z_1 \\ z_2 \\ \vdots \\ z_n \end{bmatrix} = \begin{bmatrix} a_{11} & a_{12} & \cdots & a_{1m} \\ a_{21} & a_{22} & \cdots & a_{2m} \\ \vdots & \vdots & & \vdots \\ a_{n1} & a_{n2} & \cdots & a_{nm} \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \\ \vdots \\ x_m \end{bmatrix}\]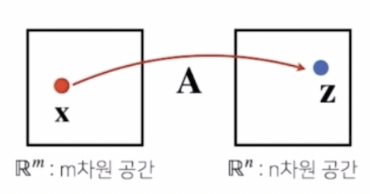
- 그림에서 볼 수 있듯, 행렬 $\mathbf{A}$ 를 $m$ 차원 공간상에 있는 한 점 $\mathbf{x}$ 와 $n$ 차원 공간상에 있는 한 점 $\mathbf{z}$ 사이를 연결시켜주는 함수로 생각해볼 수 있다.
- 이러한 함수의 역할을 행렬곱을 이용해서 설명할 수 있다. $m$ 개의 원소로 이루어진 열벡터에 $\mathbf{A}$ 행렬을 곱해준다.
- 벡터를 $m$ 개의 행과 하나의 열을 가지고 있는 열벡터로 이해하게 되면 행렬과 벡터의 곱셈을 할 수 있다.
- $\mathbf{A}$ 행렬과 $\mathbf{x}$ 벡터를 곱해주면, 자연스럽게 $\mathbf{z}$ 라는 새로운 열벡터가 나온다. 이 때 $\mathbf{A}$ 는 $n$ 개의 행과 $m$ 개의 열로 이루어져 있다. 결과물인 $\mathbf{z}$ 는 $n$ 개의 행으로 이루어져 있는 열벡터가 나오게 된다.
- $\mathbf{z}$ 와 $\mathbf{x}$ 는 $\mathbf{A}$ 와 어떻게 연결이 되냐면, $\mathbf{z}$ 의 $i$ 번째 원소는 $\mathbf{x}$ 의 $j$ 번째 원소에 대해서 $a_{ij}$ 를 통해서 $z_i$ 로 보내주는 연산을 취해주게 된 것이다.
- 이 연산이 행렬 $\mathbf{A}$ 와 벡터 $\mathbf{x}$ 사이의 곱으로 표현되는 연산과 똑같다. 이렇게 $\mathbf{z}$ 와 $\mathbf{x}$ 두 벡터를 $\mathbf{A}$ 행렬을 통해서 이어줄 수 있는 것이다.
- 이렇게 이어주는 함수의 역할을 벡터공간에서 사용되는 연산자로 이해할 수 있다. 따라서 행렬을 이용해서 두 벡터를 연결지어 줄 수 있다. 즉 하나의 $m$ 차원 공간 상에 존재하는 벡터를 다른 $n$ 차원 공간 상의 벡터로 매핑해주는 연산자로 행렬을 활용할 수 있다.
- 행렬을 연산자로 행렬곱을 이용하면 어떤 하나의 벡터를 다른 차원의 공간으로 보낼 수가 있고, 이런 행렬곱의 특징을 이용해서 주어진 데이터에서 패턴을 추출하거나 아니면 주어진 데이터를 압축할 수도 있다. 기계학습에서는 이렇게 패턴 추출, 데이터 압축을 할 때 행렬을 굉장히 많이 사용한다.
- 행렬을 연산자로 사용하는 것을 영어로는 linear transform, 즉 선형변환으로 부른다.
- 모든 선형변환은 행렬곱으로 계산할 수 있기 때문에, 행렬곱을 이해해야만 기계학습에서 사용되는 선형 모델과 선형변환들을 이해할 수 있다.
- 딥러닝은 선형 변환과 비선형 함수들의 합성으로 이루어져 있기 때문에 딥러닝의 이해에는 행렬곱 연산을 이해하는 것이 필수적이다.
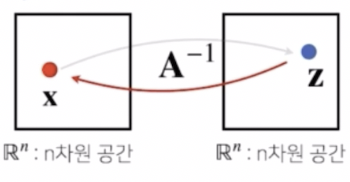
역행렬
- 행렬에는 어떤 두 개의 서로 다른 공간에서 벡터 $\mathbf{x}$ 를 벡터 $\mathbf{z}$ 로 보내주는 연산자의 기능이 있음을 봤다.
- 이것을 거꾸로 돌리는 연산이 역행렬(inverse matrix)이다.
- 조심해야 할 것은 연산을 거꾸로 돌리는 역행렬을 가능하게 하려면 행과 열 숫자가 같아야 하고, 행렬식이라고 부르는 determinant 값이 0 이 아닌 경우에만 역행렬을 계산할 수 있다.
-
이 역행렬을 통해서 $\mathbf{x}$ 벡터를 $\mathbf{z}$ 벡터로 갔다가 다시 되돌아오게 하는 것이 가능하다.
-
$\mathbf{A}$ 행렬에 역행렬($\mathbf{A}^{-1}$) 을 곱해주게 되면 순서에 상관없이(행렬곱은 순서가 민감하지만) 항등행렬($\mathbf{I}$)이라는 행렬이 결과값으로 나온다.
\[\mathbf{AA}^{-1} = \mathbf{A}^{-1}\mathbf{A} = \mathbf{I}\] - 좌하단으로 향하는 대각선의 원소들이 다 1 이고 나머지는 0 에 가까운 항등행렬은 임의의 벡터 혹은 행렬을 곱해줬을 때 자기 자신이 나오게 하는 역할을 한다. 그래서 이름이 항등행렬이고 identity matrix 라 부르게 된다.
- 행렬식을 이용해서 원래 행렬의 연산을 거꾸로 되돌리는 역행렬을 구할 수 있다. 이 역행렬로 굉장히 많은 응용들이 가능하다.
- numpy 의
np.linalg를 이용해서 역행렬을 사용할 수 있다.np.linalg.inv는 주어진 행렬의 역행렬을 계산할 수 있다. - 여기서 주의할 점은, 역행렬을 계산하기 위해서는 1) 행과 열의 수가 같아야 하고, 2) 주어진 행렬의 determinant 가 0 이 아니어야 한다.
- 이 두 조건을 만족시키는 게 쉽지 않을 수 있다. 그래서 역행렬을 계산할 수 있는지 확인하는 것도 하나의 일이 된다.
- 만약 행과 열이 같은 경우에는 역행렬 계산을 시도해볼 수 있지만, 행과 열의 수가 다르게 되면 역행렬 대신 다른 것을 사용해 볼 수 있다.
-
사실 연산을 되돌린다는 개념은 차원이 달라도 사용할 수 있다. 역행렬 대신에 pseudo-inverse, 즉 유사역행렬을 사용하는 것이다. 이를 다른 이름으로 Moore-Penrose 역행렬 이라 부른다.
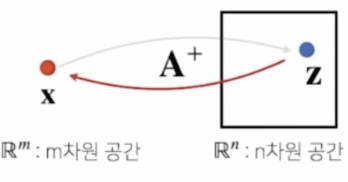
- 이 유사역행렬은 굳이 행과 열의 수가 같을 필요 없이 행과 열의 수가 달라도 계산할 수 있다.
- 유사역행렬에는 보통 역행렬에 사용되는 -1 기호가 사용되지 않고 $+$ 기호를 사용한다. 선형대수에서 보통 사용되는 기호다.
-
즉 행과 열의 숫자가 달라도 역행렬과 유사한 기능을 하는 행렬을 사용할 수 있다는 것이다. 그러나 주어진 행렬에서 행의 개수($n$)가 더 많은 경우와 열의 개수($m$)가 더 많은 경우에 따라서 유사역행렬을 계산하는 방식이 달라지게 된다.
\[\text{if} \; \;n \geq m, \; \; \mathbf{A}^+ = (\mathbf{A}^T\mathbf{A})^{-1}\mathbf{A}^T \\ \text{if} \; \; n \leq m, \; \; \mathbf{A}^+ = \mathbf{A}^T(\mathbf{AA}^T)^{-1}\] - 위 수식처럼, 행의 개수($n$)가 열의 개수($m$)보다 많아지게 되면 $\mathbf{A}$ 행렬과 전치행렬을 곱해주는 순서가 달라지게 된다. 이 때 전치행렬과 원래 행렬을 곱했을 때 과연 역행렬을 계산할 수 있을지가 문제된다.
- 만약 행이 열보다 더 많을 때($n \geq m$), 전치행렬을 취하면 $n \times m$ 이 $m \times n$ 이 되고 전치 행렬과 원래 행렬을 곱해주게 되면 $m \times m$ 행렬이 되어 역행렬을 계산해볼 수 있다.
- 이런 계산방식을 통해서 역행렬을 구할 수 없더라도 항등행렬과 비슷한 행렬을 유도할 때 유사역행렬을 활용할 수 있다.
- 실제로 $m$ 차원 공간상에 존재하는 벡터 $\mathbf{x}$ 와 $n$ 차원 공간상에 존재하는 벡터 $\mathbf{z}$ 를 연결하는 연산자 $\mathbf{A}$ 가 있을 때, 이 연산을 다시 되돌리는 유사역행렬 또는 무어-펜로즈 역행렬을 이용해서 굉장히 많은 기계학습, 통계학에서 응용하고 있다.
- numpy 코드에서 유사역행렬은
np.linalg.pinv를 이용하면 유사역행렬을 구할 수 있다. 또한 유사역행렬을 이용하게 되면 역행렬과 같은 기능을 하는 행렬을 사용할 수가 있다. - 단 조심할 점은, 행과 열의 개수가 다를 때 유사역행렬의 기능이 달라지게 된다. 만약 행($n$)이 열($m$)보다 더 많으면 유사역행렬은 원래 행렬보다 먼저 곱해줘야 항등행렬이 나온다. 만약 유사역행렬과 행렬의 곱셈 순서가 바뀌면 다른 결과가 나온다.
- 즉, $n \geq m$ 이면 $\mathbf{A}^+\mathbf{A} = \mathbf{I}$ 가 성립하고, $n \leq m$ 이면 $\mathbf{AA}^+ = \mathbf{I}$ 만 성립한다.
행렬의 응용 - 연립방정식
-
np.linalg.pinv를 이용하면 연립방정식의 해를 구할 수 있다. n ≤ m 인 경우로, 식이 변수의 개수보다 작거나 같은 경우다.
n ≤ m 인 경우로, 식이 변수의 개수보다 작거나 같은 경우다. - 즉 연립방정식을 풀 때 행렬을 이용해서 문제를 풀 수 있다. 일반적으로 연립방정식의 해를 구하기 위해서는 식의 개수와 변수의 개수가 같아야만 해를 구할 수 있다.
- 만약 변수의 개수($m$)가 식의 개수($n$)보다 많은 경우에는 식을 만족하는 변수의 개수가 더 많아지게 되므로 해가 무한히 많거나 혹은 부정이 된다.
- 이 때 유사역행렬을 이용해서 해 중의 하나를 구할 수 있다.
- 위 그림은 $a_{ij}$ 와 $b_i$ 들이 주어진 상황에서 방정식을 만족하는 $x_j$ 를 구하는 상황이다. 즉 연립방정식이 위처럼 주어졌을 때, $a$ 는 계수로 볼 수 있고, 구하고자 하는 해가 $x$ 이다. 이 때 이 연립방정식을 만족하는 $x_1$ 부터 $x_m$ 까지의 값을 구하는 게 문제가 된다.
- 이 연립방정식 문제를 행렬과 벡터의 곱으로 표현하면 $\mathbf{A}\mathbf{x} = \mathbf{b}$ 로 표현할 수 있다. 즉 연립방정식의 좌변을 행렬 $\mathbf{A}$ 와 벡터 $\mathbf{x}$ 의 곱으로 표현한 것이다. $\mathbf{b}$ 도 벡터로 표현할 수 있다.
- 이 행렬방정식에 유사역행렬을 적용하면 해를 구할 수 있다. 식의 개수($n$)보다 변수의 개수($m$)가 더 많은 상황이므로, 유사역행렬을 $\mathbf{A}$ 의 오른쪽에 곱할 수 있다. 유사역행렬을 $\mathbf{A}$ 의 오른쪽에 곱해주게 되면 항등행렬이 되고, 이제 $\mathbf{b}$ 의 왼쪽에 유사역행렬을 곱해줄 수 있다.
-
그러면 연립방정식을 만족하는 $\mathbf{x}$ 의 해 중 하나를 구할 수 있다.
\[\begin{aligned} \mathbf{x} &= \mathbf{A}^+\mathbf{b} \\ &= \mathbf{A}^T(\mathbf{AA}^T)^{-1}\mathbf{b} \end{aligned}\] - $\mathbf{A}$ 는 비록 행과 열의 개수가 다르지만 유사역행렬을 이용해서 구하게 된 $\mathbf{x}$ 를 가지고 실제 식에 대입하면 연립방정식을 만족하는 해가 된다.
행렬의 응용 - 선형회귀분석
- 위에서 유사역행렬을 이용하여 변수의 개수가 식의 개수보다 많은 경우의 연립방정식 문제를 풀 수 있다.
- 그러나 변수의 개수($m$)보다 식의 개수($n$)가 많은 경우는 변수 개수보다 데이터의 개수가 많은 경우다. 이러한 경우는 선형회귀분석에서 많이 보는 상황이다.
- 이 또한 유사역행렬을 이용해서 선형모델에 해당하는 선형회귀식을 찾을 수 있다.
-
여러 개의 점을 하나의 행렬로 표현한 행렬 $\mathbf{X}$ 에 계수 벡터 $\beta$ 를 곱해주면 아래 그림에서 초록선으로 표현되는 선형모델식을 상상해볼 수 있다.
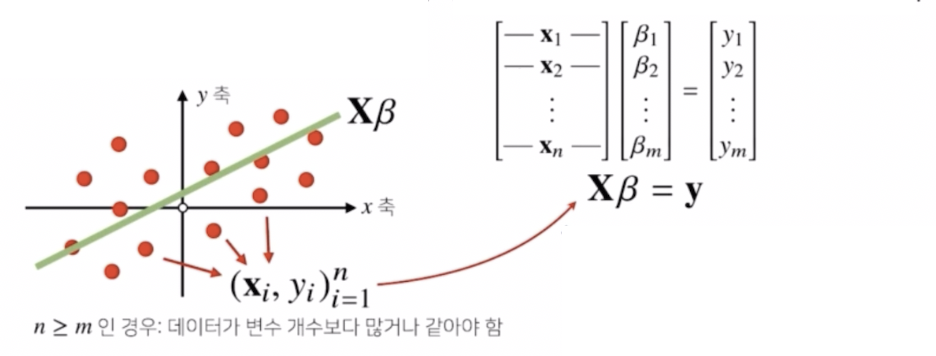
- 이 때 어떤 $\beta$ 를 써야 이 빨간 점들을 잘 표현하는 선형 모델식을 찾을 수 있느냐고 물어보는 것이 바로 선형회귀 분석이다.
- 그렇다면 $\beta$ 는 어떻게 찾을까?
- 선형회귀분석은 연립방정식과 달리 행(식, $n$)이 더 많기 때문에, 방정식을 푸는 것은 불가능하다. 즉 $\mathbf{X}\beta = \mathbf{y}$ 를 만족하는 $\mathbf{X}$ 를 찾는 것은 불가능하다.
- 또한 보통 선형회귀분석은 데이터 $\mathbf{X}$ 가 주어진 상태에서 $\beta$ 를 찾는 것이지만, $\mathbf{X}\beta$ 가 $\mathbf{y}$ 를 만족하는 식을 찾는 것은 데이터가 선형식에 전부 다 올려져 있지 않으면 사실 불가능하다.
- 우리가 할 수 있는 것은 이 $\beta$ 라는 계수를 곱했을 때 $\mathbf{X}$ 로 표현되는 선이 주어진 데이터를 최대한 잘 표현할 수 있는 선을 찾는 것이 최선이 된다.
- 이 때 $\mathbf{X}$ 가 선이 될 수 있는 건 행벡터 $\mathbf{x}_i$ 로 이루어진 하나의 벡터로 볼 수 있기 때문이다.
- 최선의 선형모델식은, 우리가 찾은 선형모델식이 데이터의 $\mathbf{y}$ 값(정답값)을 예측할 때 데이터에서 주어진 정답과의 차이가 최소화되는 선을 찾았을 때 예측을 가장 잘했다고 표현할 수 있고, 가장 적절한 선형모델이라고 할 수 있다.
- 이 때 어떤 측면에서 차이를 최소화하냐면, $L2$ 노름을 이용해서 $L2$ 노름을 최소화하는 계수 $\beta$ 를 찾게 되면 선형모델을 이용해서 주어진 데이터를 잘 표현했다고 얘기할 수 있다.
- 유사역행렬(무어-펜로즈 역행렬)을 이용하게 되면, $L2$ 노름을 이용했을 때 $\mathbf{y}$ 에 가장 근접하는 $\hat{\mathbf{y}}$ 을 찾을 수 있다.
-
행렬 $\mathbf{X}$ 의 무어-펜로즈 역행렬을 $\mathbf{y}$ 에 곱해주게 되면 $\beta$ 를 구할 수 있고, 이러한 $\beta$ 중에서도 $L2$ 노름이 최소화되는 $\beta$ 우리가 찾고자 하는 가장 최적의 선형회귀 계수가 된다.
\[\begin{aligned} \mathbf{X}\beta &= \hat{\mathbf{y}} \approx \mathbf{y} \\ \Rightarrow \beta &= \mathbf{X}^+\mathbf{y} \\ &= (\mathbf{X}^T\mathbf{X})^{-1}\mathbf{X}^T\mathbf{y}, \; \; \displaystyle \text{min}_{\beta} \|\mathbf{y}-\hat{\mathbf{y}}\|_2 \end{aligned}\] sklearn의LinearRegression을 사용하면 선형회귀분석을 통해 최적의 계수를 찾을 수 있다. 그러나 무어-펜로즈 역행렬과 결과값이 좀 다르게 나온다.- 왜냐하면 선형회귀분석을 돌릴 때 행렬과 함께 y 절편 항도 같이 고려해줘야 한다.
sklearn은 y 절편을 자동으로 더해서 추정해준다. 무어-펜로즈 역행렬로 선형회귀분석을 할 때는 y 절편 항을 직접 추가해줘야 한다.
댓글 남기기