
[GPU] Deep Learning for HPC
네이버 부스트캠프에서 들었던 특강으로 공부했던 내용을 정리해보자.
HPC
- HPC 란 High Performane Computing 의 약자로, 많은 뜻이 담겨 있지만 딥러닝에서 중요한 의미를 가진 것은 복잡한 계산을 병렬로 고속 처리하는 것이다.
- 하드웨어적 개념들이 많이 들어가 있다.
- 인공지능 뿐 아니라 하드웨어까지 이해하는 사람이 되어야지만 좋은 딥러닝 모델을 효율적으로 운용할 수 있다! 역시 가장 먼저 떠오르는 것이 바로 GPU 다.
- 우리는 왜 딥러닝을 하는데 하드웨어, 특히 GPU 가 왜 필요할까?
-
딥러닝의 근간은 인간의 뉴런을 모방한 인공신경망이다. 인공신경망에서 하는 연산을 추상화하면, 들어오는 input 과 weight 들은 모두 vector가 된다. input 과 weight 에 대해 내적을 하고 합을 구한 뒤 activation func 을 거쳐 output 이 만들어진다.
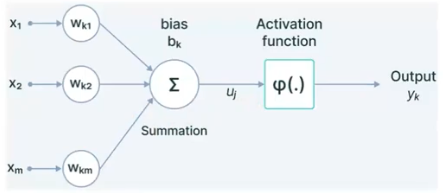
- 이 뉴런들은 하나만 있는 것이 아니고 병렬로 존재하고, 연산을 병렬적으로 무수히 많이 할 수 있는 특징을 가지고 있다!
- 그렇다면 내적도 병렬로 이루어질 것이고 내적을 병렬화 한 것은 행렬 곱셈과 같기 때문에, 딥러닝에서 가장 근간이 되는 연산은 input 과 weight 에 대한 marix(행렬) 곱셈이 된다!
- 또한 행렬 연산 이외에 activation func 같은 경우에도 하나의 뉴런만이 아니라 모든 존재하는 뉴런에 대해서 병렬적으로 적용하기 때문에 vector 연산이라고 볼 수 있다.
- 따라서 딥러닝에서 근간이 되는 연산은 행렬 연산과 벡터 연산이고, 이 두 연산 모두 병렬적으로 적용할 수 있는 연산이 된다. 이처럼 병렬적으로 처리하는 것이 매우 용이하기 때문에 선형대수를 적용할 수 있는 것이다.
- 또한 convolution 연산도 행렬로 표현할 수 있다! 즉 행렬연산으로 표현이 가능하다. 오른 대각선으로 값이 다 똑같은 Hankel matrix로 표현될 수 있는데, 이를 통해 행렬 연산을 진행할 수도, 증명할 수도 있다.
- 정리하면,
- 딥러닝의 연산 대부분은 행렬곱셈 연산이다.
- 이외의 다른 연산은 대부분 병렬화 가능한 벡터 연산이다.
- 마지막으로, 이러한 딥러닝 연산의 병렬적인 특성으로 인해서 특화된 하드웨어를 활용하는 것이 효율적인 솔루션이 될 수 있다. 그것이 바로 GPU 이다.
Parallel Hardware
-
Flynn’s Taxonomy
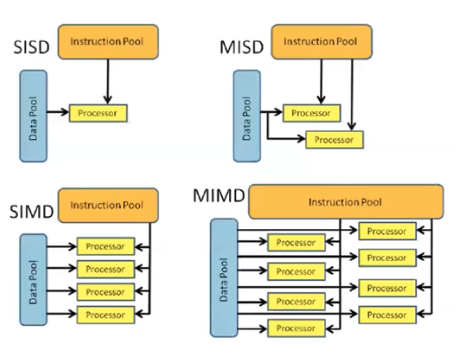
- Flynn 이 만든 분류방법이다. 일반적인 프로그래밍 방법을 SSID(Single Instruction Single Data)라고 부른다. 명령 하나를 내리면 데이터 하나에 대해서 명령이 처리됨을 의미한다. 일반적인 프로그래밍이나 개발 방식은 SSID 방식이다.
- 두 벡터의 덧셈을 for loop 으로 할 수 있지만 한 번에 덧셈을 하는 경우 SIMD(Single Instruction Multiple Data)에 해당한다. 이는 명령을 한 번 내리면 여러 데이터가 동시에 그 명령을 수행하는 방식이다. 실제로 하드웨어에 구현이 되어 있다.
- 여기서 더 나아가서 MIMD(Multiple Instruction Multiple Data) 방식이 있다. 여러 번에 거쳐서 다른 데이터에 다른 명령을 내리는 것은 시간이 오래걸리니, 한번에 여러 명령을 여러 데이터에 내리는 방식이다.
- MISD 는 실제로 쓰는 일이 없다.
- MIMD 방식이 우리가 다가가려고 하는 부분이다!
- CPU 에는 SIMD 까지 다 존재하고 있다. 이것이 벡터 연산에 많이 활용되고 있다.
CPU vs. GPU
-
GPU 와 CPU 는 근본적으로 다른 것을 목표로 하고 있다. 따라서 완전히 다른 구조와 다른 trade-off 를 가진다.
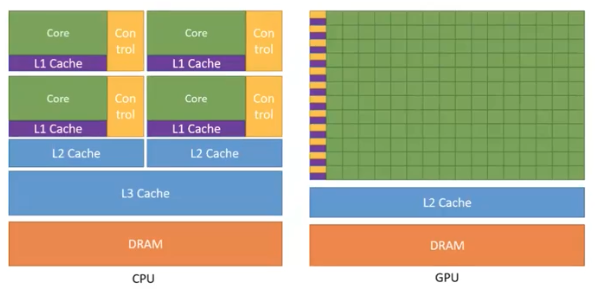
- CPU
- CPU 의 목적은 빠르게 하는 것도 중요하지만 많은 명령을 모두 다 해내는 능력이 더 중요하다.
- 이에 따라 복잡하고 논리적인 구조를 가지고 있고 명령이 들어올 때 다양한 제어 등의 프로세스를 거치게 된다. 따라서 실제로 연산하는 부분은 상대적으로 작아질 수 있다.
- GPU
- GPU 는 원래 게임에서 그래픽을 빠르게 연산하기 위해 만들어진 장비이기 때문에, 그래픽 혹은 병렬 연산이라는 한가지 과제에만 집중되어 있다.
- 따라서 상대적으로 논리 혹은 제어 등의 시스템에 사용되는 비중을 줄이고 연산을 하는 비중에 훨씬 더 집중했다. 그래서 연산기의 숫자가 훨씬 더 많다.
- 개별적인 연산기의 힘은 CPU 가 더 강하다. 그러나 많은 숫자로 인해서 훨씬 더 강한 힘을 내는 것은 GPU 이다.
- NVIDIA 의 경우 이러한 GPU 시스템을 보고 SIMT(Single Instruction Multiple Thread) 라고 부르고 있다. MIMD 와 유사하지만 약간의 명령 내릴 때 제약이 있는 형태인 것이다.
- GPU 로 병렬적인 연산을 효율적으로 진행할 수 있다. 그러나 CPU 에서는 하드웨어가 여러 제어를 도와주는 반면, GPU 에서는 하드웨어 제어가 상대적으로 적어서 개발자가 이를 담당해야 한다.
Deep Learning by GPU
-
다시 한번 말하면, 딥러닝 연산의 근간은 행렬 곱셈 연산과 벡터 연산이다! 그렇다면 이 중에 행렬 연산을 GPU 가 어떻게 수행할까?
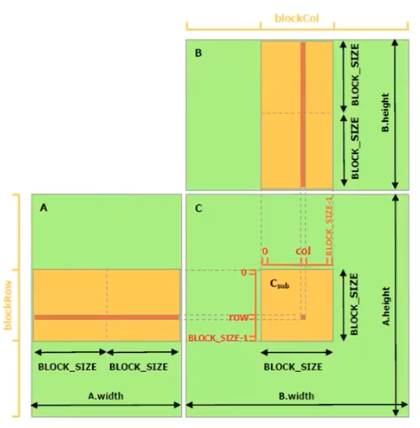
- 위 그림이 GPU 에서 행렬 연산을 처리하는 근간인 Tiled Matrix Multiplication 이다.
- 선형대수에는 Blocked Matrix Multiply 라는 개념이 있다.
- 행렬 곱셈을 할 때 기본은 row 1 개와 column 1 개를 가지고 원소별로 곱한 뒤 summation 을 해서 새로운 1 칸을 채워나간다.
- 이 때, 수학적으로 block 단위로 행렬을 쪼개서 block 을 가지고 행렬 곱셈을 해서 결과를 출력하더라도 수학적으로 동일하다.
- 이 블로그에 잘 정리되어 있다.
- 실제로 컴퓨터의 경우 block 단위로 잘라서 행렬 곱셈을 처리하는 Blocked Matrix Multiply 를 한다.
- 왜 이렇게 block 으로 잘라서 연산할까?
- 컴퓨터에는 cache 라는 읽기 빠르지만 크기가 작은 메모리가 있다. 이 cache 내에 들어갈 수 있는 정도의 tile(block)을 잘라서 읽어들인 다음에 행렬곱셈을 처리해서 출력을 한다. CUDA 도 이 tiling 을 이용하고 있다.
- 그렇다면 어떻게 병렬화 할 수 있을까?
- 행렬 연산은 한번의 행렬 곱셈에서 사용되는 행과 열을 고려해볼 때 각각의 행렬 곱셈 연산에서 서로 아무런 상호작용이 없다.
- 최종적으로 summation 이 있지만, 그 전의 연산 중에는 서로 영향을 주지 않는다. Block Matrix Multiply 도 마찬가지다.
- 이처럼 행렬 연산이 병렬 가능한 특징을 가지고 있기 때문에 block 단위로 쪼개서 연산을 진행하면서, 병렬화 처리를 해서 GPU 같은 병렬 하드웨어에서 효율적으로 처리할 수 있다.
- GPU 이외의 다른 하드웨어를 가지고도 딥러닝 연산을 할 수 있다! 대표적인 하드웨어가 Systolic Arrays 이다.
- 일반적으로 연산을 할 때는 연산기에서 레지스터라는 메모리로 연산을 할 때마다 데이터를 주고받는 과정을 처리한다. 행렬 연산만 한다면 행과 열의 데이터만 들어오고 결과를 내면 되기 때문에 간단하다.
- 그렇다면 데이터를 매번 왔다갔다 하는 것보다 단번에 통과하는 것이 더 편할 것이다. 이렇게 단번에 통과시켜주는 것이 Systolic Array 이다.
-
데이터를 읽어들인 시점에서 연산기에서 다음 연산기, 다음 연산기 이렇게 넘겨주는 방식을 채택하고 있다.
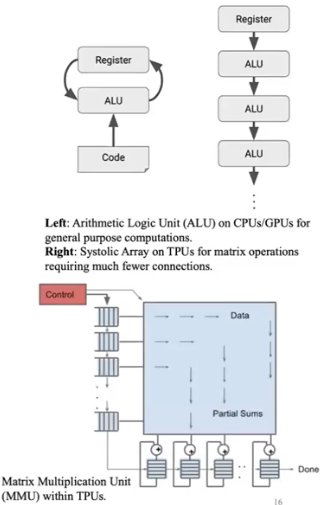
- NVIDIA GPU 에서 tensor core 라는 것을 볼 수 있는데, 이 tensor core 또한 systolic array 의 구조를 가지고 있다. 구글의 TPU, 인텔의 가우디도 systolic array 구조를 가지고 있다.
- 이 systolic arrays 구조의 장점은 행렬 연산을 위한 하드웨어를 구성한 것이기 때문에 복잡도, 전력소모, 비용을 낮출 수 있다. 물론 연산 속도도 더 빨라진다.
GPU 를 효율적으로 활용하는 방법
-
아래는 무어의 법칙을 나타내는 그림이다.
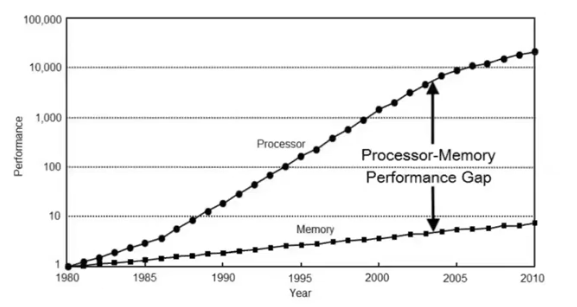
- 위 그림을 보면, 연산기의 속도는 exponential 하게 증가하고 있지만 그에 비해 메모리의 속도는 따라잡지 못하고 있다. 이런 문제점이 지금도 계속되고 있다.
- 연산 속도가 빨라지게 되면서 연산기는 메모리에서 데이터를 읽어 들일 때까지 할 일이 없이 가만히 있어야 하는 문제가 많이 발생한다. 이러한 이유로 상당수의 현대 workload 는 연산량이 아니라 메모리에 의해서 병목이 발생하는 경우가 흔하다!
- 따라서 데이터를 어떻게 이동시키는가가 최적화에서 매우 중요한 이슈가 된다.
- HPC 에서 8-90% 는 데이터를 어떻게 이동하는가, 이동하지 않는가를 다루는 문제이다. 그만큼 프로그램을 최적화하는데에는 메모리를, 즉 데이터의 이동을 어떻게 최소화할 수 있는지에 집중되어 있다.
Cache and Data Locality
- DRAM 은 Dynamic Acess Memory 의 약자로 정보를 읽을 때 순차적으로 읽는 것이 아닌, 랜덤하게 읽을 수 있기 때문에 데이터의 읽기/쓰기 속도가 매우 빠른 특성을 가지는 메모리다. 각종 데이터를 기억하고 저장하는 역할을 수행한다.
- A100 이라는 GPU 는 데이터센터에서 쓰는 고사양 GPU 이다. A100 의 DRAM 인 HBM 에서 사용하는 메모리의 속도는 초속 2TB 이지만 A100 에서 최대 연산 속도는 bf16 연산을 행렬곱셈하는데 312 TFLOP 이다.
- 이 의미는 1byte 를 읽으면 312 / 2 를 해서 156개의 FLOP 연산을 해야지만 메모리를 읽는 것에 대해서 연산을 saturation 을 시킬 수 있다.
- 즉 메모리와 연산의 비율이 그만큼 괴리가 많이 벌어져 있다는 것이다. 그러나 실제로 매번 그렇게 하면 연산기가 연산을 하기 너무 힘들다.
-
일반적으로 가장 최근에 쓴 물건이 다음에도 많이 쓸 가능성이 높듯이, memory에도 위계가 존재한다.
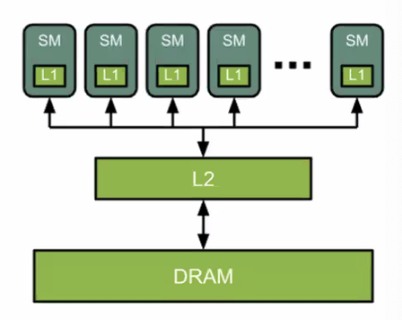
- CPU 는 L3 cache 까지 있는 반면, GPU 는 L2 cache 와 L1 cache 가 있고, SM 이라는 streaming processor 내에 연산기가 있다.
- L1 cache 가 가장 빠른 메모리이다. L2 cache 는 DRAM 보다 빠르지만 L1 cache 보다 공간이 더 크다.
- 빠르면 빠를 수록 비용도 더 비싸고 메모리 크기가 더 작아진다는 단점이 있다. 이러한 현실적 제약으로 가장 빠른 메모리는 가장 작게 존재하고 가장 느린 메모리가 가장 많이 존재하는 위계구조를 가지고 있다. 이것이 GPU 내부에서의 메모리 위계이다.
- 중요한 것은 대부분의 연산이 메모리에 의해 병목이 발생하는 memory-bound 이기 때문에 FLOP count 보다 데이터를 어떻게 이동시키는가가 더 중요하다.
GPU 와 CPU 사이의 데이터 전송
- computer vision 분야에는 매우 많은 양의 데이터를 CPU 에서 GPU 로 전송해주어야 한다.
-
A100 의 HBM(DRAM)의 속도는 초속 2TB 의 속도인데, 일반적으로 CPU 와 GPU 를 연결하는데 쓰는 PCI bus 같은 경우 한쪽 방향은 초속 16GB 밖에 되지 않는다. 이는 양방향 합치면 초속 32GB 밖에 되지 않는 것이다. 이렇게 GPU DRAM 의 읽는 속도보다 훨씬 느리다.
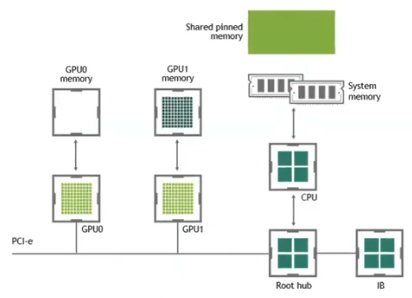
- 이 때문에 CPU 와 GPU 사이의 데이터를 통신하는 것을 최소화하는 것이 DRAM 내부에서 데이터 이동을 최소화하는 것 만큼이나 중요하다.
Storage 와 Device 사이의 데이터 전송
-
한 단계 더 나아가서 RAM 도 중요하지만 우리는 storage 에서 데이터를 읽어온다.
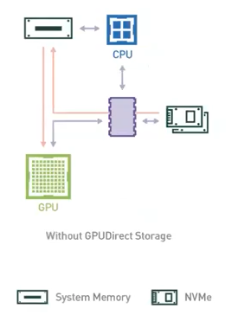
- 가장 용량이 많은 HDD, SSD 에서 읽어들이게 되는데, 이는 PCI bus 보다도 더 병목이 된다.
- 일반적인 HDD 의 경우 초속 100MB, 가장 고성능 SSD 도 초속 8GB 정도의 속도를 보인다.
- 연산기에 도달하기 위해서 가장 빠른 메모리는 Cache 메모리 이고, 다음으로 용량은 크지만 더 느린 메모리가 GPU 내의 DRAM, 그 다음이 CPU 호스트가 가지고 있는 RAM 이 보다 더 용량이 크지만 더 느리고, 마지막으로 가장 느리지만 가장 용량이 많은 HDD, SSD 가 있다.
- 효율적인 프로그램은 항상 다른 여러 메모리 위계들 사이에서 이동을 최소화하는 것을 목표로 해야 한다.
- HPC 의 상당 부분은 이렇게 메모리 이동을 최소화 시키거나 제거하는 것으로 이루어져 있다!
Parallel Computing 의 컨셉
-
네트워크의 경우, 네트워크의 속도가 빠르다는 의미는 중의적이다. 네트워크의 속도가 빠르다는 것은 크게 3가지 의미로 분류해볼 수 있다.
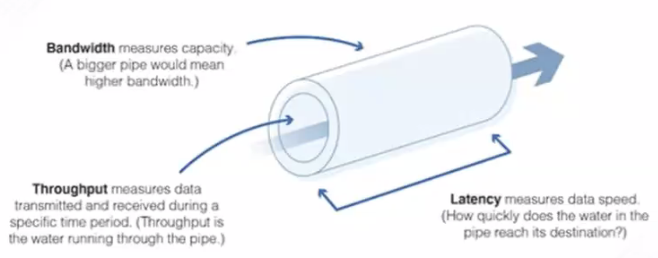
- Bandwidth : optimal, 이상적인 환경 속에서 낼 수 있는 단위 시간 내의 최대한의 속도. 위 그림에서 통의 크기라고 할 수 있다.
- Throughput : 아무리 통의 크기가 크더라도 그 안에 흘러가는 물의 양은 적을 수 있다. 이 물의 양을 Throughput 이라고 부른다. 실제로 단위 시간 내에 처리되는 일의 양을 말한다.
- Latency : 하나의 작업이 끝나는데 필요한 시간이다.
- Latency 와 Throughput 의 차이
- Latency 는 하나의 output 을 얻기 위해 필요한 시간
- Througput 은 분모와 분자를 바꿔서 단위 시간 당 처리할 수 있는 작업의 양이다.
- Real-time(online)에서는 latency 가 우선이고, batch-processed(offline) 에서는 Throughput 이 중요하다.
-
연산과 메모리 측면에서 작업에 대해 분류를 해볼 수 있다.
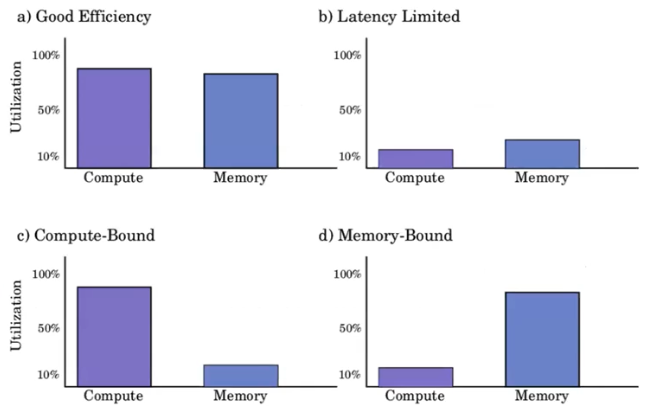
- Good Efficiency 가 가장 효율적인 상황이다. 연산량과 메모리 사용량 모두 거의 100% 에 도달하고 있고, 많은 작업을 처리하고 있다.
- Latency Limited 가 최악의 경우다. 슬프게도 가장 흔한 경우이다. 연산량도 메모리 사용량도 잘 활용하지 못하고 있는 것이다. 병렬화의 부족, 코드의 문제 등 여러가지 문제점이 있을 수 있다.
- Compute-Bound 는 연산이 너무 많아서 연산기들이 연산량을 감당하지 못하고 연산에 시간을 계속 할애하는 것. 메모리는 데이터가 많이 필요하지 않아 여유로운 경우이다.
- Memory-Bound 는 반대의 경우로, 연산기는 이미 작업을 다 처리해서 할 일이 없는데 메모리는 계속 연산기에 데이터를 가져다 줘야 하기 때문에 메모리가 saturation 되어 있는 경우이다.
- 이를 숙지해두면, workload 의 특성과 문제를 이해하는데 많은 도움이 될 수 있다.
BLAS
- 선형대수를 위한 루틴들을 정리해놓은 표준이다. 즉 자주 보게되는 GEMM(Dense 한 행렬곱셈) 연산 등을 정의를 하고 기본적인 operator 를 제공해주는 표준이자, Computational Linear Algebra 에서 가장 오래되고 근간이 되는 표준이다.
- 넘파이나 파이토치 같은 라이브러리들은 BLAS 에 담겨있는 구현체들을 API 를 통해서 호출하는 방식으로 적용하고 있다.
- 따라서 매우 효율적으로 행렬연산을 진행할 수 있다.
Array View
- 우리는 행렬, 텐서를 다룰 때 다차원적인 모양을 생각한다. 그러나 컴퓨터 메모리는 1차원적 구조를 가진다. 그렇다면 1차원적인 메모리를 어떻게 다차원적으로 표현할 수 있을까?
-
이 때 읽는 방향과 간격을 통해서 표현할 수 있다.
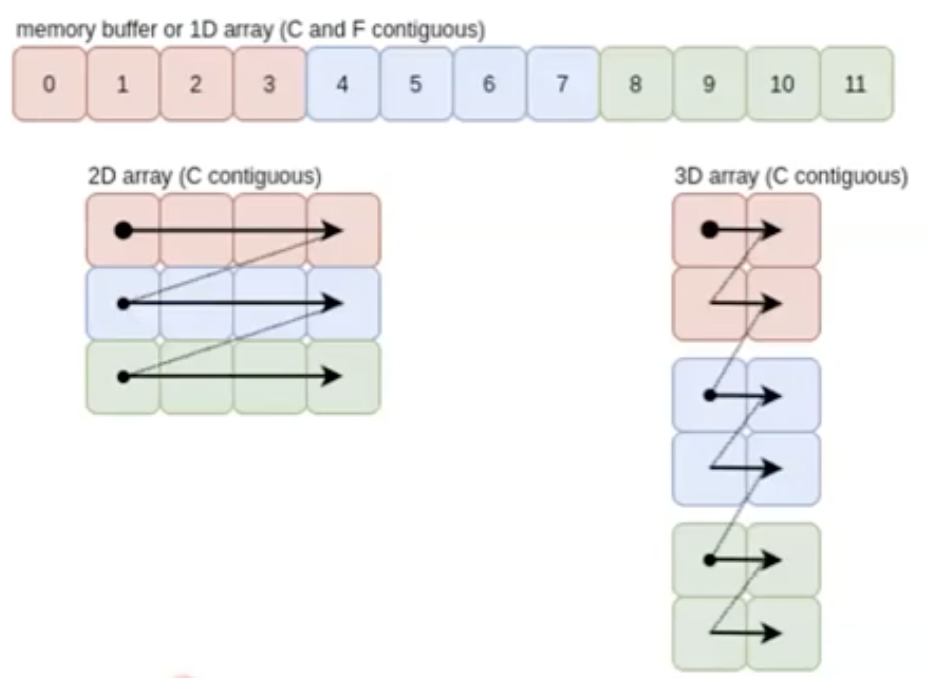
- 실제 데이터는 1차원적으로 있더라도, 위 그림처럼 읽어서 2차원 행렬로 해석할 수 있는 것이다. 물론 3차원적으로 해석할 수도 있다.
- 행 방향, 열 방향 어느 방향으로 읽을 것인가 생각해볼 수 있다.
- Row-major : Python, CUDA, C++ $\rightarrow$ C 언어에서 처음 나왔기 때문에 C contiguous 방향이라고 부른다.
- Column-major : $\rightarrow$ MATLAB, R 등의 언어는 수학을 위해 만들어진 프로그램 언어라서 column-major 로 데이터를 읽는다. 이를 보고 F contiguous 라고 한다.
- 읽는 방향을 정의를 함으로써 차원을 정의한다면, 읽는 방향을 바꿔서 transpose 같은 연산이 가능하다.
- 전체 메모리를 읽어서 실제로 메모리 상 transpose 를 하는 것보다, 읽는 방향만 바꿔서 마치 transpose 를 한 것처럼 할 수 있다. 이를 non-contiguous view 라고 한다.
- 차원의 순서를 뒤집거나 읽는 방향을 뒤집거나 하는 연산 처리를 했을 때에는 불연속(non-contiguous)적인 view 를 만들고, 기저에 있는 메모리는 동일하게 있는데 메모리를 읽는 방식을 바꿈으로써 2차원을 3차원 Array 로 바꾼다던지, Transpose 연산을 적용한다던지 할 수 있다.
- 즉 동일한 데이터에 대해서 다른 view 를 제공하는 방식을 쓸 수 있다. 실제로 pytorch doc 에서도 어떤 view 가 존재하는지에 대해서 정리가 되어 있다.
- slicing 도 마찬가지로 포인터만 제공하면 되기 때문에 view 형태로 제공할 수 있고, 기타등등 많은 tensor operation 들이 실제 메모리를 deep copy 하는 것이 아니라 shallow 하게 포인터만 전달해주는 방식으로 연산을 진행할 수 있다.
Fundamental Array Concepts with NumPy
-
Numpy 에서도 논문을 낸다. 아래 그림은 Numpy 논문에서 발췌한 내용이다.
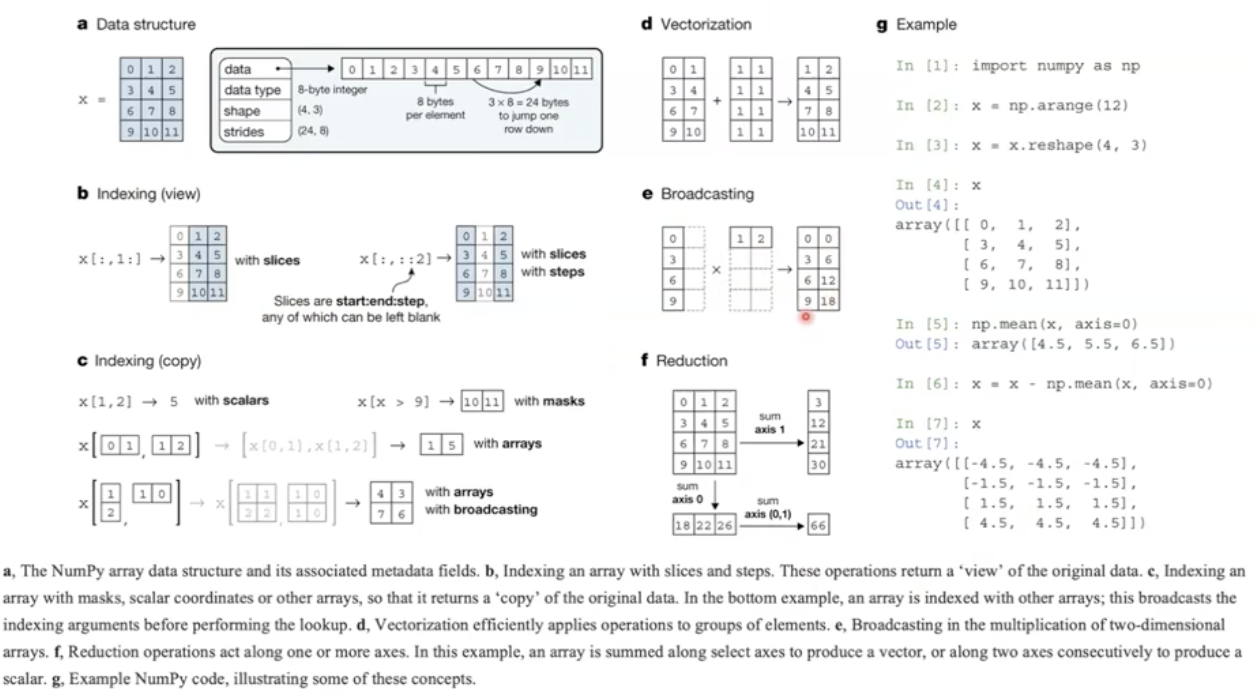
- Numpy 의 경우 여러가지 벡터와 행렬 연산을 하기 위한 최적화된 기술이 있다. 이를 모두 메모리 사용을 최소화하기 위해서 활용하고 있다. 이를 이해하면 좋다.
- 벡터화, 인덱싱을 view 로 제공해주는 것, 브로드캐스팅을 할 때 더 큰 메모리를 allocation 먼저 하지 않고 최종 output 만 allocation 하는 등 여러가지 모두 메모리 사용을 최소화하기 위해 만들어진 것이다!
Implications for Deep Learning Frameworks
- 메모리 사용을 최소화하는 것은 딥러닝 프레임워크에도 영향을 미쳤다.
- pytorch 의 경우 CNN 을 Channel 이 맨 먼저 위치($C \times H \times W$)한다.
- 왜 이런 방식을 채택했냐면,
- CNN 의 경우 가장 큰 차원이 activation 의 $H * W * \text{Depth}\text{(out_channels)}$ 차원이다. 여기서 depth 는 kernel 의 개수를 뜻한다.
- 공간 차원(spatial dimension, $H \times W$)이 연산을 처리해야 하는 부분이기 때문에, 이 spatial dimension 이 연속적이어야 한다. 이 때문에 Channel 을 맨 앞에 두고 spatial dimension 을 뒤에 두는 방식이다. 이렇게 되면 채널 간의 메모리 상의 연속성을 유지할 수 있게 되는 것이다.
- tensorflow 는 이렇게 하지 않았기 때문에 tensorflow 가 CNN 을 GPU 에서 사용하는데 비효율적이라고 알려져 있다.
- 더 나아가서도 transformer 모델들의 경우도, 실제 내부 API 를 살펴볼 때 Batch, Sequence, Feature 차원으로 되어있다.
- 왜나하면 Feature 에서 연산이 진행되어야 하기 때문이다. 따라서 Feature 를 연속적으로 읽어야 하기 때문에 가장 안쪽에 위치한 것이다.
- RNN 을 보면 반대로 Sequence, Batch, Feature 순으로 되어 있다. 이는 RNN 의 구조를 살펴보면 이해할 수 있다.
- torch 의
nn.Linear의 경우를 보자. 행렬 곱셉의 방식은 A 행렬의 행과 B 행렬의 열을 곱셉을 진행한다. 이 때 메모리 연속성을 고려하여 $\mathbf{y} = \mathbf{XA}^\top +\mathbf{b}$ 방식을 취하고 있다. -
$\mathbf{A}$ 에 transpose 를 해준 이유는, torch 와 같은 C 기반 프로그래밍 언어에서는 Row-major 이고 이를 transpose 를 취하면 Column-major 가 된다. 그러면 $\mathbf{X}$ 행렬의 행과 $\mathbf{A}$ 행렬의 열을 곱하는 것과 같은 효과를 얻을 수 있다.
💡
torch nn.linear에서의 transpose ?
torch 의 공식문서에 따르면 nn.linear 에서 weight argument 의 shape 은 아래 그림과 같이 $(\text{out_features, in_features})$ 이다.

내가 weight 에 대한 shape 을 결정할 수 있다면, 굳이 transpose 연산을 쓸 것이 아니라 맨 처음부터 $(\text{in_features, out_features})$ 로 weight 의 shape 을 미리 transpose 취한 형태로 주면, 연산도 알맞게 되고 transpose 연산도 할 필요가 없지 않을까? 라는 생각이 들었다. 그러나 transpose 를 하는 이유가 위에서 공부한 개념들로 설명이 된다. 이는 메모리 효율을 위한 것이다.
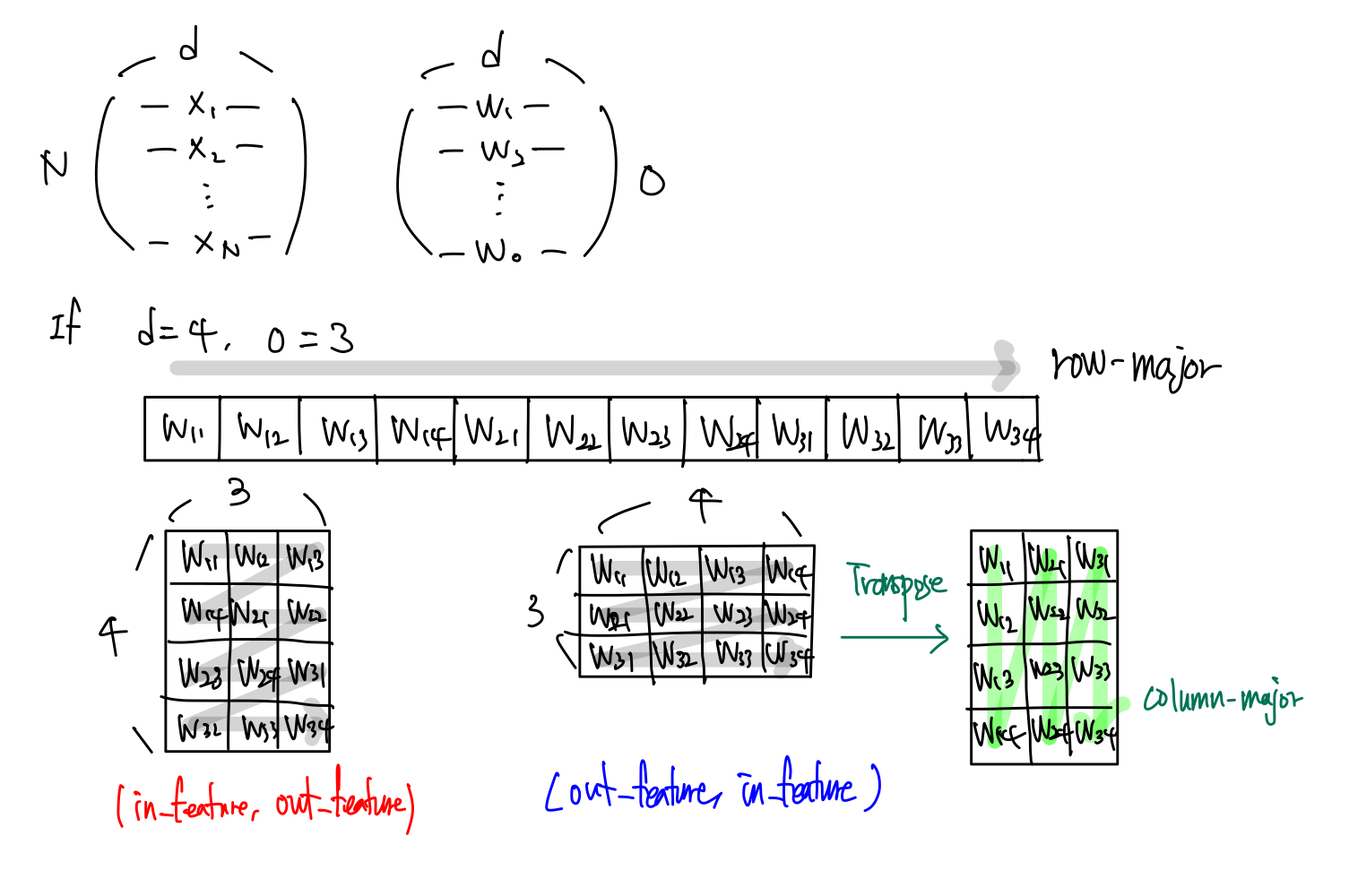
위 그림처럼 메모리는 1d array 로 이루어져 있고, torch 에서는 row-major 로 데이터를 읽는다. 이 때 transpose 를 미리 취한 shape 으로 $(\text{in_features, out_features})$ 을 해주면 행렬곱 연산에서 잘못된 값을 불러오게 된다. $(w_{11}, w_{12}, w_{13}, w_{14})$ 가 같은 column 에 위치하게 만들더라도, row-major 때문에 $w_{11}$ 이후에 $w_{12}$ 를 읽을 때 불필요한 데이터를 읽게 된다.
그러나 $(\text{out_features, in_features})$ 로 weight 의 shape 을 주고 transpose 를 하면 row-major 가 column-major 가 되어 읽는 방향이 달라진다. 더 효율적으로 데이터를 읽는 것이다.
실제로, 이 링크에서 잘 설명이 되어 있는데, transpose 는 BLAS 를 기반으로 한 연산에서 overhead 가 없다고 한다. 또한 transpose 가 들어간 matrix multiplication routine 이 5배는 더 빠르다고 한다. torch 에서는 이미 최적화가 되어 있어 별로 차이가 없다고 하지만 말이다.
CUDA
-
CUDA 는 Compute Unified Device Architecture 의 준말이다.
- NVIDIA 에서 NVIDIA GPU 를 프로그래밍하기 위해서 만든 C++ 기반의 프로그래밍 언어이다.
- C++ 과 매우 유사하지만 추가기능들이 덧붙혀 있어서 NVIDIA GPU 를 다룰 수 있도록 만들어진 별도의 프로그래밍 언어이다.
- Compute Capability 라는 웹사이트가 있는데, 하드웨어 세대번호를 CC 로 나타낸다. NVIDIA GPU 는 새로 나온 세대번호 마다 추가 기능이 제공된다. 예를 들어 V100 은 CC 7.0 이고 A100 은 CC 8.0 이다.
- 하드웨어 세대번호에 따라서 NVIDIA GPU 가 어떤 하드웨어 기능을 가지고 있는지, 어떤 CUDA 기능들이 제공되고 있는지가 결정되기 때문에 하드웨어와 소프트웨어 호환성을 고려하는데 매우 중요한 요소이다.
- C 언어는 Asembly 언어로 컴파일이 되는데, CUDA 의 경우 1차적으로 PTX 라는 high-level asembly 언어로 컴파일 된다.
- PTX 는 documentation 도 잘 되어 있고 안정적인 API 를 가지고 있다. 그러나 이 PTX 가 그대로 기계언어로 변환되는 것은 아니고 SASS 라는 Streaming Assembly 언어로 변환된다. 이것이 실제 NVIDIA GPU 를 작동되게 한다.
- 일반적으로 우리가 가장 밑으로 내려가는 것은 PTX 이고 SASS 를 분석하는 것은 극히 예외적이다.
CUDA Driver vs. Runtime APIs
- 우리가 CUDA 라고 부르는 것은 CUDA Runtime 이다.
- 실제로 CUDA 를 실행하기 전에는 host 에 CUDA Driver 를 설치해야 한다. 이 Driver 는 하드웨어와 직접 소통하는 부분이다.
- Driver 는 유저가 하드웨어를 직접 건드리지 않고 쓸 수 있도록 하는 high-level API 를 만들어준다.
- 프린터도 프린터 드라이버를 요구하는 것과 같다.
- 별도의 하드웨어를 사용하기 위해서는 OS 와 소통할 수 있는 Driver 가 꼭 필요하다. 이를 가장 먼저 host 에 설치를 해야 CUDA 를 이용할 수 있다.
- CUDA Driver 가 잘 설치되어 하드웨어와 호환이 된다면, 그 위에 CUDA Runtime 을 설치한다. 이 Runtime 이 CUDA 11.4 이런 버전을 가진다.
- CUDA Runtime 은 C++ 로 되어 있고, 우리가 사용하는 다수의 프로그램은 CUDA Driver 를 직접 건드리지 않고 CUDA Runtime 만을 이용해서 작성되어 있다.
- CUDA Driver 를 만져야할 경우는 굉장히 드문데, JIT(Just In Time compilation)을 쓰는 경우 드라이버와 통신할 경우가 있어 Driver 를 건드려야 한다. 대표적인 예가 Triton 이라는 JIT compiler 이다. 이는 단순한 파이썬 코드가 최적화된 PTX 코드가 될 수 있도록 도와주는 코드이다. 기억만 해두자!
PyTorch 의 Stack
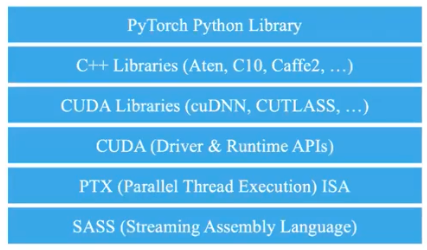
- 가장 밑에 하드웨어가 있고 그 하드웨어와 소통하기 위한 순수 기계어인 SASS 가 있다.
- SASS 를 조금 더 high-level 로 포장한 PTX 가 있고, PTX 로 컴파일되는 C 형태의 언어인 CUDA 가 있다.
- CUDA 를 바탕으로 cuDNN 같은 라이브러리가 존재하고, 이를 또 C++ 에서 포장하여 host 에서 사용하기 편하게 만들어준 것이 Aten, Caffe2 같은 라이브러리.
- 이를 파이썬에서 사용하기 편하게 만들어준 것이 바로 Pytorch 이다. 이 Pytorch 를 기반으로 pytorch-lightening, huggingface 등 소프트웨어 시스템이 쌓여 있다.
- Pytorch 는 이렇게 많은 단계를 거치고서야 생성되는 매우 상위의 라이브러리다!
- 이 Pytorch 덕분에 SASS, PTX 와 같은 low level 을 잘 모르더라도 편하게 딥러닝을 진행할 수 있는 것이다.
Asynchronous Techniques
-
CUDA 에서 중요한 컨셉이 Asynchronous Execution 이란 컨셉이다.
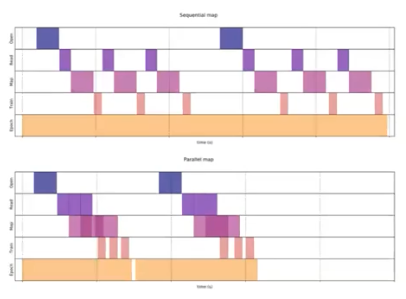
- CUDA GPU 를 device 라고 부르고, device 에 명령을 내리는 CPU 를 host 라고 부른다.
- CUDA는 device 와 host 를 강제로 동기화하지 않는 이상 비동기적으로 실행된다.
- CUDA 뿐 아니라 많은 프로그램에서는 비동기적 방식을 최대한 활용하려고 노력하고 있다. 효율적이기 때문이다.
- Pytorch 도 비동기성을 살리고자 노력하고 있다.
- 이 비동기성에서 제일 중요한 것이 연산과 데이터 전송을 중첩시키는 것이다.
- CUDA 에서 host 가 GPU 에게 명령을 보낼 때, CPU 는 명령이 끝날 때까지 기다려주지 않는다. 그 다음 자신의 일을 하러 넘어간다.
- 그래서 CPU 입장에서는 GPU 에게 일을 시키는 중에 자기 할 일을 하는 것이 효율적이다.
- 가장 대표적으로 발생하는 상황이 데이터를 읽어들여서 GPU 로 전송할 때이다.
- naive 한 방식은 그림에서 위 부분인데, CPU 가 파일을 열고 데이터를 읽고 GPU 에 전송하고 GPU 에서 연산을 한다. 이를 CPU 는 기다리면서 GPU 연산이 끝나면 다음 데이터를 읽는다.
- 위 방식은 너무 비효율적이다. CPU 가 파일을 열고 데이터를 읽는 도중 전송을 처리하고, 전송이 되자마자 GPU 에서 연산이 처리되면 훨씬 더 빠르게 작업이 진행된다.
- 코드에서 잘못 하는 것 중 하나는,
.item()과.cpu()를 적용시키는 것이다.- 이 두 함수를 호출하면 강제로 synchronize 를 시킨다.
- 즉 CPU 가 GPU 의 일이 끝날 때까지 기다리도록 하는 명령어이다. 이를 많이 쓰면 동기화를 계속 발생시키기 때문에 작업이 느려진다.
-
Pytorch 에서는 CUDA 의 비동기성을 살리기 위해서 default 로 asynchronous 하게 함수를 호출한다.

- pytorch 의 경우 CPU 에서 명령을 내리면 GPU 에서 연산을 처리하는 동안 CPU 는 다음 명령을 내리고 미리 기다리고 있다가 처리가 되는 방식이다.
- CPU 에서 명령의 stream 을 내리면 GPU 는 그보다 더 오래 걸리기 때문에 GPU 가 일을 하지 않는 구간이 발생하지 않는다.
- 이런 방식을 통해서 보다 더 효율적으로 작업을 진행할 수 있다.
Pinned Memory
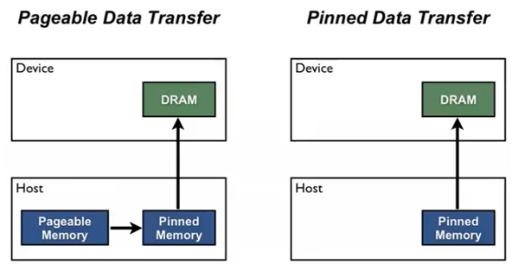
- CPU 가 GPU 한테 데이터를 전송해주기 위해서 비동기적으로 전송하는 것을 기본으로 할 수 있는 것 같지만, 사실 그렇지 않다.
- CPU 는 OS 에서 페이징을 할 수 있다. 페이징은 데이터의 메모리를 언제든지 다른 곳으로 옮길 수 있다.
- 그러나 Driver 입장에서는 OS 가 갑자기 데이터를 다른 곳으로 옮겨 버리면 어디가 있는지 알 방법이 없다. 그렇기 때문에 Driver 가 항상 같은 위치에서 데이터를 읽을 수 있게 해주기 위해서 Pinned Memory 를 할당 한다.
- Pinned Memory 는 OS 에 의해서 페이징이 될 수 없는 메모리이다. Driver 는 Pinned Memory 로 위치가 어디에 있는지 알 수 있기 때문에 데이터를 보고 연산으로 넘어갈 수 있다.
- 그렇지 않을 경우에는 Pagable memory 에서 pinned memory 로 복사하고 보내고를 반복해야 하기 때문에 느려지게 된다. 또한 Synchronous 한 데이터 전송을 하게 된다.
Data Pre-fetch
-
그러면 이제 연산을 하는 도중에 그 다음 데이터를 가지고 오는 것이 중요하다.
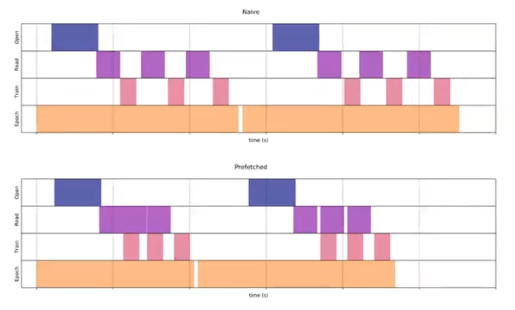
- GPU 로 보낼 때
.to(non_blocking=True)를 주면 Asynchronous 하게 데이터를 전송하기 때문에 보다 더 효율적으로 작업할 수 있다. - 또한 위 그림처럼 GPU 연산 간격을 줄일 수 있다.
PyTorch DataLoader
- DataLoader 에서 위에서 공부한 내용들이 모두 담겨져 있다.
- DataLoader 에는
pin_memory라는 argument 가 있다. - 이를 True 로 두면 DataLoader 가 Pinned Memory 로 데이터를 할당하게 되고 더 빠르게 데이터를 전송할 수 있다.
num_workersargument 는 병렬적으로 데이터를 읽어들이는 것을 처리할 수 있다.- 특히 computer vision 과 같이 데이터 사이즈가 큰 영역에서 더 잘 활용할 수 있다.
-
DataLoader 를 쓰다보면,
num_workers가 0 보다 큰 숫자로 설정했을 때 작동하지 않는 문제가 발생할 수가 있다. 나도 실제로 겪었었다.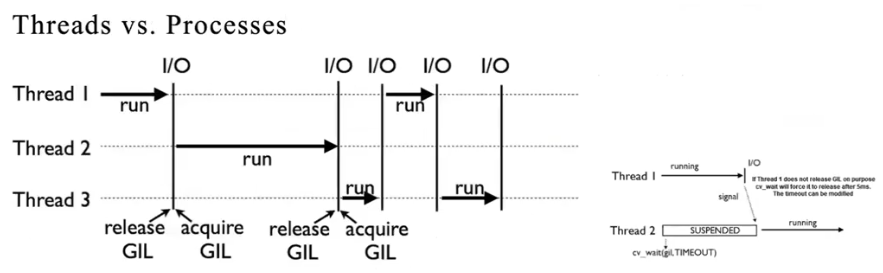
- 이 문제는 원론적인 이슈가 아니라 파이썬 때문이다.
- 파이썬은 병렬처리를 잘 하지 못한다. 파이썬의 GIL(Global Interprter Lock) 개념 때문이다. C 언어나 다른 프로그래밍 언어에서 하는 멀티쓰레딩을 진행할 수가 없다.
- 그래서 서로 다른 프로세스를 만들어야 하는데, 서로 다른 프로세스는 메모리를 공유하지 않는다. 이 때문에 서로 다른 프로세스 사이에서 데이터를 전송하기 위해서는 메세지를 보내야 한다. 파이썬에서는 이 메세지를 pickle 이라는 모듈로 압축을 해서 전송을 한다.
- 이것이 DataLoader 에서
num_workers숫자를 1 이상으로 했을 때Unpicleable object error가 발생하는 이유이다. 멀티 프로세싱을 하면서 pickling 을 통과해야 하는데, 이 pickling 을 통과할 수 없는 객체가 존재하기 때문이다. - 이는 근본적으로 파이썬의 문제이지, 멀티프로세싱 자체의 문제가 아니다. pickle 이 안되는 부분만 적당히 제거한다면 멀티프로세싱의 효과를 볼 수 있다.
Flash Attention
-
Flash Attention 은 최근에 대두된 Attention 기법인데 어떠한 최적화가 이루어져있고, 왜 필요한지에 대해서 알아보자.
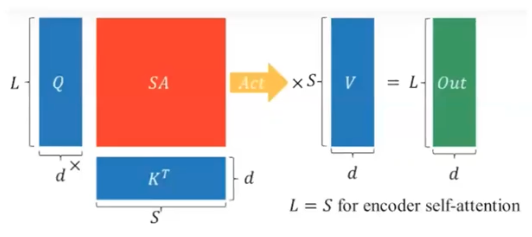 SA 는 self-attention 이다.
SA 는 self-attention 이다. - transformer 모델에서 근간이 되는 연산이 Attention Operation 이다. Attention 연산에서는 Query 와 Key transpose 가 행렬곱을 통해서 SA 를 만들고, 이 SA 에 대해서 softmax 를 적용한 후, Value 와 행렬곱을 해서 output 을 만들게 된다.
-
여기서 SA matrix 를 보면 sequence length($L$) 의 제곱에 비례한다. 즉 메모리 사이즈를 많이 차지하고 있다. 여기에 softmax 라는 operation 을 진행하면서 많은 메모리를 읽어야 하는 상황이 발생한다. 또한 사이즈가 워낙 크다보니 cache 안에 들어가지 않기 때문에 DRAM 에서부터 읽어야 한다.
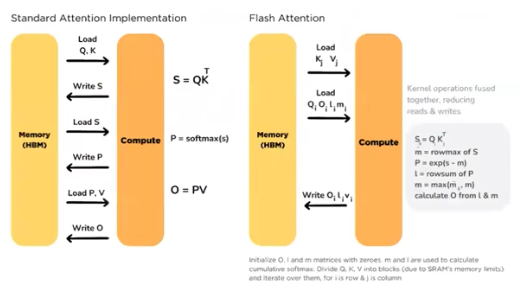
- SA 는 매우 중요한 연산이다. 그러나 이 SA 때문에 Memory-Bound 가 걸리게 된다.
- $Q, K, S$ 를 쓰고 읽는 과정을 계속 거쳐야 하는 것이 standard 한 attention 이다. 문제는 여기서 sequence length 가 길어지게 되면서 보다 더 큰 병목이 발생할 수 있다.
- 즉 Attention 은 연산도 $O(N^2)$ 일 뿐만 아니라 메모리 또한 $O(N^2)$ 이 되면서 병목이 심해지게 되는 것이다.
-
이 문제점에 대해서 제시된 해결책이 Flash Attention 이다.
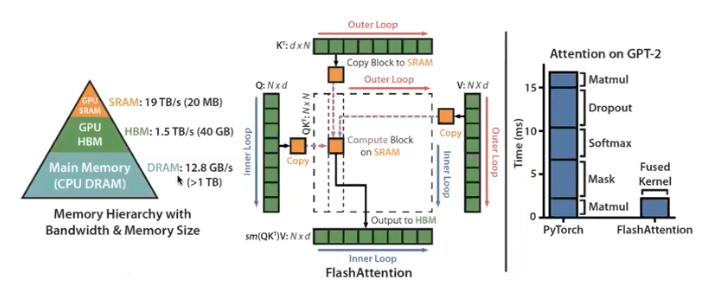
- CPU, GPU, SRAM(cache memory) 의 위계가 존재하는데 가장 빠른 부분만을 활용할 수 있도록 구성한 attention 이다.
- 이를 위해 SA 를 tiling 처리를 한다.
- 전부다 SRAM 에서만 읽고 쓰는 작업을 처리하게 한다.
- 맨 오른쪽 bar graph 를 보면 오른쪽의 fused kernel 이 Flash Attention 이다. 나중에 따로 포스트를 만들어 정리하도록 하자.
정리하면
- HPC 의 대부분은 Memory Management 이다.
- 가능한 선에서 데이터를 옮기지 말자. (CPU - GPU, DRAM - Cache, Cache - Core, etc)
- 가능한 데이터를 읽고 쓰는 과정을 최소화하자.
- Array 에 새로 메모리를 할당하지 말고 차라리 메타데이터를 활용해서 Array view 를 만들거나 중간 과정을 없애는 것이 좋다.
- Synchronize 를 하지 말자. Pytorch 에서
.item()이나.cpu()가 있으면 제거를 하는 것이 권장된다. - 그리고 가능한 선에서 모든 연산을 병렬적이고 비동기적으로 만드는 것이 좋다. 이를 위해 불필요한 의존성을 없애는 것이 좋다.
- 마지막으로 어디서 느려지는지 측정하는 프로파일링이 중요하다.
프로파일링
- 그렇다면 메모리의 이동 시간을 프로파일링 할 수 있는 tool 이 있을까?
- 사실 프로파일링이 정말 어려운 것이 어떤 디바이스 환경에서 측정하느냐에 따라 달라진다. 그러나 연산량과 연산에 들어가는 메모리는 변하지 않는다.
- CUDA 에는 비동기적인 것도 찍어볼 수 있는 기능이 있고, torch 내부에도 프로파일러가 있다. NVIDIA 의 nsight-system 은 레지스터 사이의 이동까지도 볼 수 있다.
- 가장 좋은 프로파일링은 파이썬의
time.time()이 제일 좋다.
댓글 남기기