
[Deep Learning, Pytorch] Custom Dataset 및 DataLoader 제작
머신러닝 및 딥러닝 모델을 학습시키기 위해서는 데이터를 효과적으로 로드하고 전처리하는 과정이 필수적이다. PyTorch 는 이를 지원하기 위해 다양한 종류의 데이터를 쉽게 처리하고 학습할 수 있도록 유용한 도구인 Dataset 및 DataLoader 를 제공한다. 그러나 현업에서는 표준 데이터셋 이외의 사용자 정의 데이터셋을 사용해야 하는 경우가 많기 때문에, Custom Dataset 및 DataLoader 를 구축하는 능력이 중요하게 된다.
이번 포스트에서는 다양한 데이터 유형(정형 데이터, 이미지 데이터, 텍스트 데이터)을 기반으로 각 데이터 유형에 맞게 어떻게 데이터를 전처리하고 PyTorch 에서 사용할 수 있는 형식으로 Custom Dataset 및 DataLoader 를 만드는 방법을 알아보자.
Import & Settings
- 아래는 custom Dataset 과 DataLoader 를 제작할 때 자주 사용하는 모듈들이다. 물론 다 사용하지는 않고 필요한 것만 사용하면 되며, 아래 섹션들에서 다룰 예제들에 필요한 것들을 작성했다.
import os
import sys
import random
import collections
from tqdm import tqdm
import warnings
import re
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
from PIL import Image
from sklearn.datasets import load_iris
from sklearn.feature_extraction.text import CountVectorizer
import torch
import torchdata
import torchtext
import torchvision
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import transforms, utils
from torch.utils.data import Dataset, DataLoader, random_split, SubsetRandomSampler, WeightedRandomSampler
- 추가적으로 Dataset 과 DataLoader 에는 random 요소가 들어가 있는데, 이에 대한 seed 값을 고정해준다. 이를 통해 재현성을 보장할 수 있다.
- random seed 고정에 대한 자세한 내용은 해당 포스트에서 정리했다.
- 추가적으로 중요하지 않은 에러 출력을 무시하고 시각화를 위한 유니코드 깨짐 현상을 방지한다.
# Set random seed
SEED = 42
random.seed(SEED)
np.random.seed(SEED)
os.environ["PYTHONHASHSEED"] = str(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED) # type: ignore
torch.backends.cudnn.deterministic = True # type: ignore
torch.backends.cudnn.benchmark = True # type: ignore
# 중요하지 않은 에러 무시
warnings.filterwarnings(action='ignore')
# 유니코드 깨짐현상 해결
mpl.rcParams['axes.unicode_minus'] = False
Dataset
- 딥러닝 하기 전에 학습시킬 데이터를 준비하는 것은 사실 모델을 학습하는 것만큼 충분히 복잡하다.
- Pytorch 는 멀티 스레딩을 통한 데이터 병렬화, 데이터 augmentation 및 batch 처리와 같은 여러 복잡한 작업을 추상화하는 여러 유틸리티 클래스를 제공한다.
- Pytorch 에서 데이터를 다루기 위한 몇 가지 모듈들을 알아보자.
torch.utils.data- 데이터셋의 표준을 정의하고 데이터셋을 불러오고 자르고 섞는데 쓰는 도구들이 들어있는 모듈이다.
- Pytorch 모델을 학습시키기 위한 데이터셋의 표준을
torch.utils.data.Dataset에 정의한다. Dataset모듈을 상속하는 파생 클래스는 학습에 필요한 데이터를 로딩해주는torch.utils.data.DataLoader인스턴스의 입력으로 사용할 수 있다.
torchvision.datasettorch.utils.data.Dataset을 상속하는 이미지 데이터셋의 모음이다.- MNIST 나 CIFAR-10 과 같은 데이터셋을 제공해준다.
torchtext.datasettorch.utils.data.Dataset을 상속하는 텍스트 데이터셋의 모음이다.- 기본적으로 IMDb 나 AG_NEWS 와 같은 데이터셋을 제공해준다.
torchvision.transforms- 이미지 데이터셋에 쓸 수 있는 여러 가지 transform 필터를 담고 있는 모듈이다.
- 예를 들어 이미지를 Tensor 로 변환한다던지, 크기 조절(Resize)과 잘라내기(Crop) 등으로 이미지를 수정할 수 있고 밝기(Brightness)와 같은 값을 조절하는데 사용될 수 있다.
torchvision.utils- 이미지 데이터를 저장하고 시각화하기 위한 도구가 들어있는 모듈이다.
Dataset 의 기본 구성 요소
- 기본적으로 custom Dataset 을 구성할 때는 PyTorch 의
torch.utils.data에서Dataset 클래스를 상속해서 만든다. - 이렇게 생성된 custom Dataset 클래스는 크게 아래 코드와 같이 3가지 메서드로 구성된다. 즉
__init__()메서드와__len__()메서드, 그리고__getitem__()메서드로 구성된다.
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self,):
"""
데이터의 위치나 파일명과 같은 초기화 작업을 위해 동작
"""
pass
def __len__(self):
"""
Dataset 의 최대 요소 수를 반환하는데 사용
"""
pass
def __getitem__(self, idx):
"""
데이터셋의 idx 번째 데이터를 반환하는데 사용
"""
pass
dataset_custom = CustomDataset()
- 이런 방식은
map-style dataset과 같은 Dataset 일 때에만 가능하다. PyTorch 공식문서에 보면 나와있지만, Pytorch Dataset 은map-style dataset과iterable-style dataset이 있다.- 해당 Pytorch 공식문서에서 두 dataset 사이의 차이를 확인할 수 있다.
map-style dataset은__getitem__()과__len__()을 가지고, index 와 key 로 data sample 에 접근할 수 있다.
from torch.utils.data import Dataset
class MapDataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, index):
return self.data['text'][index]
iterable-style dataset은IterableDataset을 상위 클래스로 가지고,__iter__()프로토콜을 이용해서 data sample 을 iterable 하게 접근한다. 데이터셋을 랜덤하게 읽기 어렵거나 불가능할 경우에 적합한 데이터셋이다. 주로 메모리에 학습 데이터를 다 올릴 수 없는 경우 사용된다고 한다.
from torch.utils.data import IterableDataset
class IterableDataset(IterableDataset):
def __init__(self, data_path):
self.data_path = data_path
def __iter__(self):
iter_csv = pd.read_csv(self.data_path, sep='\t', iterator=True, chunksize=1)
for line in iter_csv:
line = line['text'].item()
yield line
map-style dataset의 경우 index 를 통해 데이터에 접근할 수 있지만iterable-style dataset은next를 통해서 접근하기 때문에 sampler 를 사용하기 어렵다. 따라서 random shuffle 을 원할 경우 임의로 미리 shuffle 을 진행한 후 사용해야 한다.- 그렇다면 우리가 자주 사용할
map-style dataset의 기본 메서드에 대해 알아보자.__init__메서드- 일반적으로 해당 메서드에서는 데이터의 위치나 파일명과 같은 초기화 작업을 위해 동작하ㄴ다.
- 일반적으로 CSV 파일이나 XML 파일과 같은 데이터를 여기서 불러온다. 이를 통해 모든 데이터를 메모리에 로드하지 않고 효율적으로 사용할 수 있다.
- 또한 여기에 이미지를 처리할 transforms 들을
Compose해서 정의해둔다.
__len__메서드- 해당 메서드는 Dataset 의 최대 요소 수를 반환하는데 사용된다.
- 해당 메서드를 통해서 현재 불러오는 데이터의 index 가 적절한 범위 안에 있는지 확인할 수 있다.
- 즉
len(dataset)을 하면__len__의 return 을 출력한다.
__getitem__메서드- 해당 메서드는 데이터셋의 idx 번째 데이터를 반환하는데 사용된다.
- 일반적으로 원본 데이터를 가져와서 전처리하고 데이터 증강하는 부분이 모두 여기에서 진행된다.
- 즉
dataset[idx]로 접근했을 때__getitem__의 return 을 출력한다.
- 이러한
map-style은 Python 의 list 가 가지는 메서드를 가지고 있다고 생각하면 된다. - 추가적으로 학습 시 Dataset 에서 필요한 정보인 labels, target class 등을 가져오는 메서드를 정의할 수 있다.
Dataset 예제: Iris
- Iris 데이터셋은 통계학자 Ronald A. Fisher 가 1936 년에 소개한 다변량 데이터셋이다.
- 이 데이터셋은 세 종류의 붓꽃(Iris setosa, Iris virginica, Iris versicolor) 각각 50 개씩, 총 150 개의 샘플로 구성되어 있다.
- 각 샘플에는 꽃받침(sepal)과 꽃잎(petal)의 길이와 너비를 나타내는 4 개의 특성이 포함되어 있다.
- 데이터셋 구성은 아래와 같다.
- 입력(feature): 꽃받침의 길이와 너비, 꽃잎의 길이와 너비
- 출력(label): 3 가지 붓꽃의 종류 (Iris setosa, Iris virginica, Iris versicolor)
- 학습 데이터: 총 150 개 (각 붓꽃 종류별 50개씩)
- 데이터셋 저작권 및 출처: UCI Machine Learning Repository
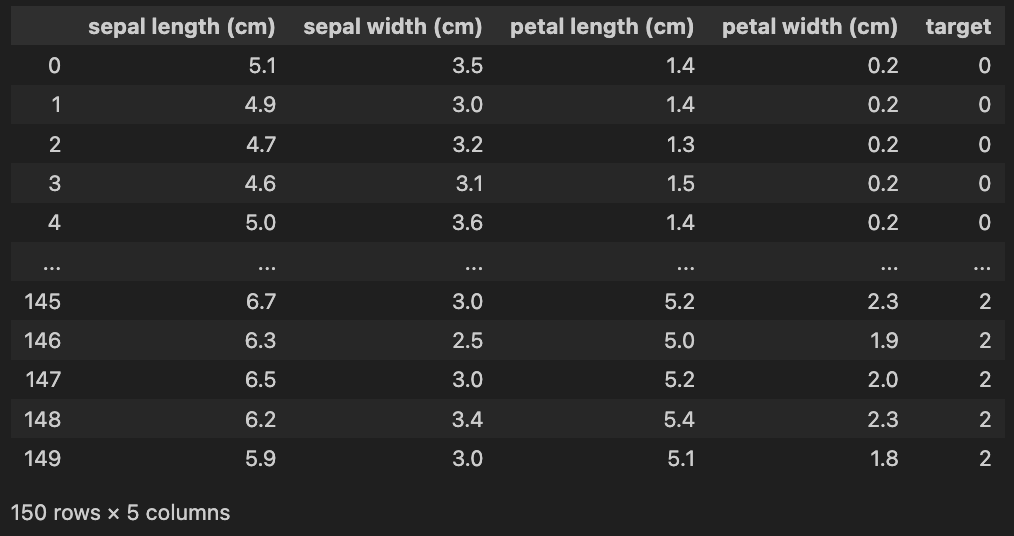
- scikit-learn 에서 제공하는 Iris 데이터셋을 이용해서 간단한 Dataset 을 만들어보자. 아래와 같이 구성되어 있다.
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
iris_df = pd.DataFrame(iris['data'], columns=iris['feature_names'])
iris_df['target'] = iris['target']
iris_df
- 이 때 Dataset 에서 sample 을 불러오면 feature(X) 와 label(Y) 가 나와야 한다.
class IrisDataset(Dataset):
def __init__(self):
iris = load_iris()
self.X = iris['data']
self.y = iris['target']
self.feature_names = iris['feature_names']
self.target_names = iris['target_names']
def __len__(self):
len_dataset = len(self.X)
return len_dataset
def __getitem__(self, idx):
X = torch.tensor(self.X[idx],dtype=torch.float)
y = torch.tensor(self.y[idx],dtype=torch.long)
return X, y
- 위처럼 Dataset 을 정의하고 나면, 아래와 같이 인스턴스를 만들어 접근할 수 있다. 또한 각 메서드를 실행할 수 있다.
dataset_iris = IrisDataset()
len(dataset_iris) # 150
iris_df.iloc[0, :] # pandas
# sepal length (cm) 5.1
# sepal width (cm) 3.5
# petal length (cm) 1.4
# petal width (cm) 0.2
# target 0.0
# Name: 0, dtype: float64
dataset_iris[0] # torch Dataset
# (tensor([5.1000, 3.5000, 1.4000, 0.2000]), tensor(0))
dataset_iris[0][-1].dtype == torch.long # True
DataLoader
- Dataloader 는 모델 학습을 위해서 데이터를 mini batch 단위로 제공해주는 역할을 한다. Dataset 을 정의했으면 학습 알고리즘에는 Dataloader 가 필요하다.
- PyTorch 공식문서를 확인해보면 아래와 같이
DataLoader가 정의되어 있는 걸 확인할 수 있다.
DataLoader(dataset, # Dataset 인스턴스
batch_size=1, # 배치 사이즈 설정
shuffle=False, # 데이터를 섞어서 사용할지 여부
sampler=None, # Pytorch 제공 sampler 나 새로 정의하여 index 를 컨트롤
batch_sampler=None, # batch 단위로 sampler 적용
num_workers=0, # 데이터를 불러올때 사용하는 서브 프로세스 개수
collate_fn=None, # map-style 데이터셋에서 sample list 를 batch 단위로 바꾸기 위해 사용
pin_memory=False, # Tensor 를 CUDA 고정 메모리에 할당
drop_last=False, # 마지막 batch 사용 여부
timeout=0, # data 를 불러오는데 제한시간
worker_init_fn=None # 어떤 worker 를 불러올 것인가를 list 로 전달
)
dataloader_custom = DataLoader(dataset_custom)
- 여기서
dataset은 앞서 만든Dataset을 인자로 넣어주면 된다. - 위 argument 들 중에는 보통
batch_size나collate_fn와 같은 인자를 주로 사용한다. 아래에서 모든 argument 를 정리해보자.
DataLoader Arguments
- DataLoader 에는 앞서 생성한 Dataset 인스턴스가 들어간다.
next(iter(DataLoader(dataset_iris))) # [tensor([[5.1000, 3.5000, 1.4000, 0.2000]]), tensor([0])]
batch_size는 뜻 그대로 batch size 를 의미한다. 전체 학습 데이터셋을 여러 작은 그룹으로 나누었을 때 batch size 는 하나의 소그룹에 속하는 데이터 수를 의미한다.
next(iter(DataLoader(dataset_iris, batch_size=4)))
# [tensor([[5.1000, 3.5000, 1.4000, 0.2000],
# [4.9000, 3.0000, 1.4000, 0.2000],
# [4.7000, 3.2000, 1.3000, 0.2000],
# [4.6000, 3.1000, 1.5000, 0.2000]]),
# tensor([0, 0, 0, 0])]
shuffle은 데이터를 DataLoader 에서 섞어서 사용할 지 여부를 설정할 수 있다. 위 경우와 다르게 데이터가 섞이는 것을 확인할 수 있다.
next(iter(DataLoader(dataset_iris, shuffle=True, batch_size=4)))
# [tensor([[4.4000, 3.0000, 1.3000, 0.2000],
# [7.9000, 3.8000, 6.4000, 2.0000],
# [5.1000, 3.8000, 1.6000, 0.2000],
# [5.0000, 2.0000, 3.5000, 1.0000]]),
# tensor([0, 2, 0, 1])]
sampler와batch_sampler에서sampler는 index 를 컨트롤하는 방법이다. 즉 데이터의 index 를 원하는 방식대로 조정한다.- index 를 컨트롤하기 때문에
sampler를 사용할 때shuffle은 기본값인False여야 한다. - 이처럼
sampler는map-style dataset에서 컨트롤하기 위해 사용하며__len__과__iter__를 구현하면 된다.
class AccedingSequenceLengthSampler(Sampler[int]):
def __init__(self, data: List[str]) -> None:
self.data = data
def __len__(self) -> int:
return len(self.data)
def __iter__(self) -> Iterator[int]:
sizes = torch.tensor([len(x) for x in self.data])
yield from torch.argsort(sizes).tolist()
class AccedingSequenceLengthBatchSampler(Sampler[List[int]]):
def __init__(self, data: List[str], batch_size: int) -> None:
self.data = data
self.batch_size = batch_size
def __len__(self) -> int:
return (len(self.data) + self.batch_size - 1) // self.batch_size
def __iter__(self) -> Iterator[List[int]]:
sizes = torch.tensor([len(x) for x in self.data])
for batch in torch.chunk(torch.argsort(sizes), len(self)):
yield batch.tolist()
- 그 외에 Pytorch에서 미리 정의해 둔 Sampler 는 다음과 같다.
SequentialSampler(data_source): 항상 같은 순서로 샘플링한다.RandomSampler(ata_source, replacement=False, num_samples=None, generator=None): 랜덤하게 샘플링하면서, replacement(복원추출) 여부와 개수를 선택할 수 있다. 복원추출이 아니라면 shuffled dataset 에서 샘플을 가져오는 것과 같다.SubsetRandomSampler(indices, generator=None): 복원추출 없이 주어진 index list 로부터 랜덤하게 샘플링한다.WeightRandomSampler(weights, num_samples, replacement=True, generator=None): 주어진 weight 에 따른 확률로[0,..,len(weights)-1]에서 샘플링한다.BatchSampler(sampler, batch_size, drop_last): sampler 를 batch 단위로 샘플링하도록 만든다.DistributedSampler(dataset, num_replicas=None, rank=None, shuffle=True, seed=0, drop_last=False): 분산처리(torch.nn.parallel.DistributedDataParallel) 와 함께 사용한다.
- 불균형 데이터셋의 경우, 클래스의 비율에 맞게 데이터를 제공할 필요가 있다. 이럴 때 사용하는 옵션이 바로 sampler 다.
- 이 블로그에서 sampler 나 batch_sampler 와 관련하여 더 많은 예시를 코드로 다루고 있다.
num_workers & pin_memory
num_workers와pin_memoryargument 는 데이터를 불러오는 속도와 관련이 있다.- 이와 관련해서는 [Pytorch, Hardware] Pytorch 학습 관련 Tip 포스트에서 정리했다.
- 여기서는 간단하게만 정리하고 각 기능에 대해서는 위 포스트를 참고하자.
num_workers는 데이터를 불러올때 사용하는 subprocess 개수다. iris 데이터셋보다 훨씬 큰 데이터셋을 생성해보자.
class RandomDataset(Dataset):
def __init__(self, tot_len=10, n_features=1):
self.X = torch.rand((tot_len, n_features))
self.y = torch.randint(0, 3, size=(tot_len, ))
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
x = torch.FloatTensor(self.X[idx])
y = self.y[idx]
return x, y
dataset_big_random = RandomDataset(tot_len=5000)
dataset_more_big_random = RandomDataset(tot_len=50000)
- 위에서 데이터 수가 5000 일 때 표시되는 시간은 데이터 수가 많아질수록 계속해서 증가한다.
%%time
for data, label in DataLoader(dataset_big_random, num_workers=0):
pass
# CPU times: user 101 ms, sys: 2.64 ms, total: 104 ms
# Wall time: 104 ms
%%time
for data, label in DataLoader(dataset_more_big_random, num_workers=0):
pass
# CPU times: user 862 ms, sys: 4.69 ms, total: 866 ms
# Wall time: 880 ms
- 일반적으로
num_workers가 높아질수록 데이터를 읽어오는 속도가 빨라진다. 그러나 무작정num_workers를 높이는 것이 좋은 것은 아니다. - 딥러닝 모델은 GPU 를 통해 학습이 이뤄지는데, CPU 와 GPU 사이에서 많은 교류가 일어나면 오히려 병목이 일어날 수 있다.
- 다음으로
pin_memory에 대해 알아보자. - DataLoader 에서
pin_memory를True로 바꾸면 Tensor 를 CUDA 고정 메모리에 할당시킨다. - 고정된 메모리에서 데이터를 가져오기 때문에 데이터 전송이 훨씬 빨라진다.
Pageable Memory: Memory 내용(contents)이 DRAM 에서 하드디스크(Secondary Storage Device)로 page out 되거나 반대로 하드디스크에서 DRAM 으로 page in 이 가능한 메모리를 의미한다.- Page in/Page out 을 하기 위해서는 CPU(Host) 의 도움이 필요하다. 보통 OS 에서 User Memory Space 의 경우 Pageable Memory 다.
Non-Pageable Memory: Pageable Memory 와 반대로 page in/page out 이 불가능한 메모리를 Non-Pageable Memory 라고 한다.- 결과적으로 하드디스크로 데이터를 page out/page in 하는 작업이 필요 없다. OS 에서 Kernel Memory Space 는 보통 Non-Pageable Memory 라고 한다.
collate_fn
- 생각보다 많이 쓰는 옵션이다. 보통 map-style 데이터셋에서 sample list 를 batch 단위로 바꾸기 위해 필요한 기능이다.
-
zero-padding 이나 Variable Size 데이터 등 데이터 사이즈를 맞추기 위해서 많이 사용한다. 실제로 collate 는 ‘함께 합치다’ 라는 의미다.
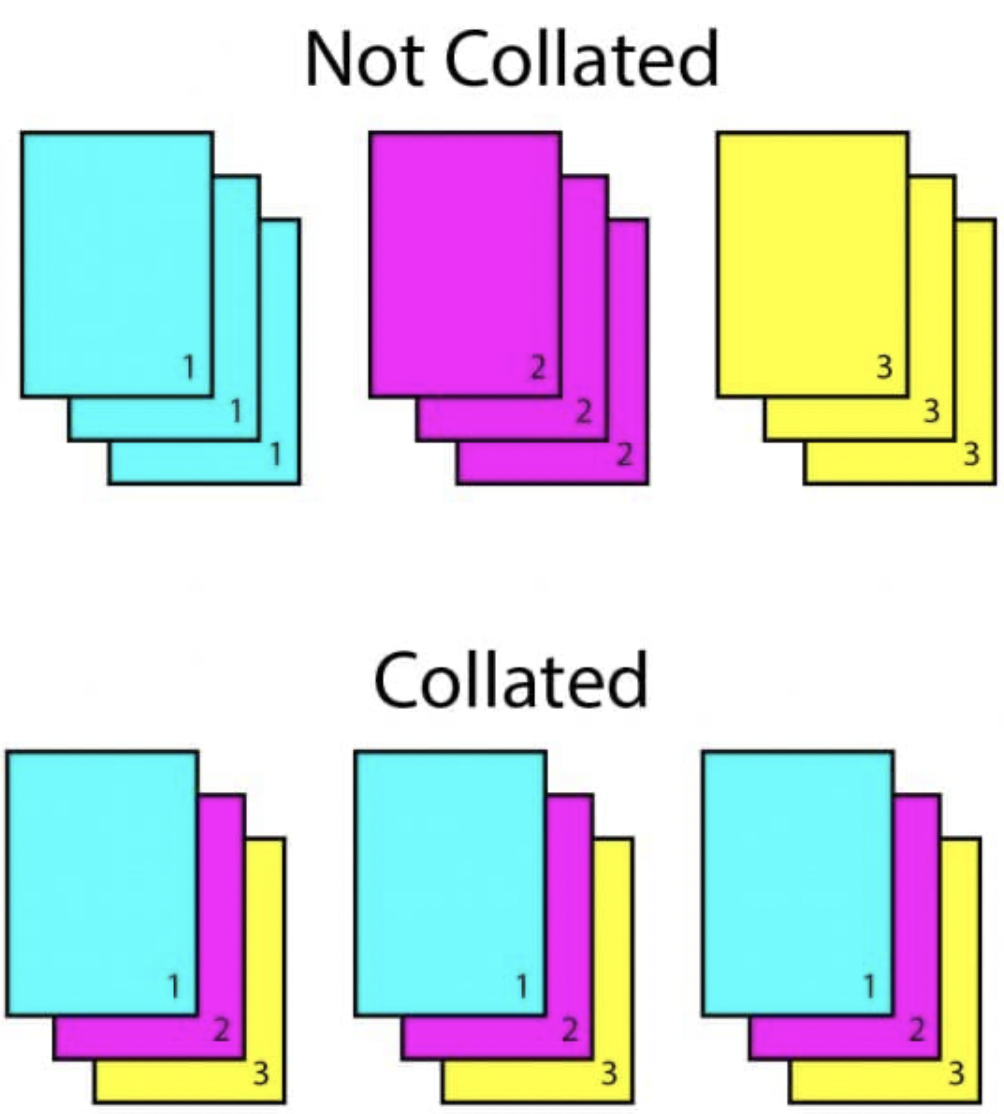
collate_fn을 쓰면 위 그림처럼 ((피처1, 라벨1) (피처2, 라벨2)) 와 같은 배치 단위의 데이터가 ((피처1, 피처2), (라벨1, 라벨2)) 와 같이 바뀐다.- 즉 직관적인 예시로 프린터기에서 인쇄할 때, “묶어서 인쇄하기” 와 같은 기능이라고 생각하면 된다.
dataset_random = RandomDataset(tot_len=10)
def collate_fn(batch):
print('Original:\n', batch)
print('-'*100)
data_list, label_list = [], []
for _data, _label in batch:
data_list.append(_data)
label_list.append(_label)
print('Collated:\n', [torch.Tensor(data_list), torch.LongTensor(label_list)])
print('-'*100)
return torch.Tensor(data_list), torch.LongTensor(label_list)
- 위 코드의 결과를 확인해보면 feature 는 feature 끼리, label 은 label 끼리 합쳐지는 것을 확인할 수 있다.
next(iter(DataLoader(dataset_random, collate_fn=collate_fn, batch_size=4)))
# Original:
# [(tensor([0.1531]), tensor(2)), (tensor([0.7069]), tensor(1)), (tensor([0.3808]), tensor(0)), (tensor([0.6095]), tensor(1))]
# ----------------------------------------------------------------------------------------------------
# Collated:
# [tensor([0.1531, 0.7069, 0.3808, 0.6095]), tensor([2, 1, 0, 1])]
# ----------------------------------------------------------------------------------------------------
collate_fn을 활용하여 다양한 길이의 데이터를 통일한 길이로 패딩할 수 있다. 아래 Dataset 을 보자.
class ExampleDataset(Dataset):
def __init__(self, num):
self.num = num
def __len__(self):
return self.num
def __getitem__(self, idx):
return {"X":torch.tensor([idx] * (idx+1), dtype=torch.float32),
"y": torch.tensor(idx, dtype=torch.float32)}
- 해당
ExampleDataset은 각 샘플의 길이가 다르기 때문에batch_size를 2 이상으로 하면 에러가 발생한다.
dataset_example = ExampleDataset(10)
dataloader_example = torch.utils.data.DataLoader(dataset_example)
for d in dataloader_example:
print(d['X'])
# tensor([[0.]])
# tensor([[1., 1.]])
# tensor([[2., 2., 2.]])
# tensor([[3., 3., 3., 3.]])
# tensor([[4., 4., 4., 4., 4.]])
# tensor([[5., 5., 5., 5., 5., 5.]])
# tensor([[6., 6., 6., 6., 6., 6., 6.]])
# tensor([[7., 7., 7., 7., 7., 7., 7., 7.]])
# tensor([[8., 8., 8., 8., 8., 8., 8., 8., 8.]])
# tensor([[9., 9., 9., 9., 9., 9., 9., 9., 9., 9.]])
- 위 예제는 batch_size 가 default 값인 1 이기 때문에 문제가 없다. 그러나 2 이상으로 설정하면 아래와 같은 에러가 발생하게 된다.
RuntimeError: stack expects each tensor to be equal size, but got [1] at entry 0 and [2] at entry 1
- 위 Dataset 에서 batch_size 값이 2 이상일 때에도 정상적으로 돌아갈 수 있도록 아래와 같은
collate_fn을 정의할 수 있다.
def collate_fn(batches):
collate_X = []
collate_y = []
max_len = max([len(sample['X']) for batch in batches])
for batch in batches:
diff = max_len-len(sample['X'])
if diff > 0:
zero_pad = torch.zeros(size=(diff,))
collate_X.append(torch.cat([batch['X'], zero_pad], dim=0))
else:
collate_X.append(batch['X'])
collate_y = [batch['y'] for batch in batches]
return {'X': torch.stack(collate_X),
'y': torch.stack(collate_y)}
- 즉
collate_fn이 2 이상의 batch 샘플을 전달받으면 같은 batch 내의 샘플들의 길이가 같아지도록 zero-padding 하게 된다.
dataloader_example = torch.utils.data.DataLoader(dataset_example,
batch_size=3,
collate_fn=collate_fn)
for d in dataloader_example:
print(d['X'], d['y'])
# tensor([[0., 0., 0.],
# [1., 1., 0.],
# [2., 2., 2.]]) tensor([0., 1., 2.])
# tensor([[3., 3., 3., 3., 0., 0.],
# [4., 4., 4., 4., 4., 0.],
# [5., 5., 5., 5., 5., 5.]]) tensor([3., 4., 5.])
# tensor([[6., 6., 6., 6., 6., 6., 6., 0., 0.],
# [7., 7., 7., 7., 7., 7., 7., 7., 0.],
# [8., 8., 8., 8., 8., 8., 8., 8., 8.]]) tensor([6., 7., 8.])
# tensor([[9., 9., 9., 9., 9., 9., 9., 9., 9., 9.]]) tensor([9.])
drop_last & time_out & worker_init_fn
drop_last는 batch 단위로 데이터를 불러 올 때 batch_size 에 따라 마지막 batch 의 길이가 달라질 수 있는데, 이 경우drop_last=True로 두어 마지막 batch 를 사용하지 않을 수 있다.- batch 의 길이가 다른 경우에 따라 loss 를 구하기 어려운 경우도 있고, batch 크기에 따라 의존도가 높은 함수를 사용할 때
drop_last를 통해 마지막 batch 를 사용하지 않는다.
- batch 의 길이가 다른 경우에 따라 loss 를 구하기 어려운 경우도 있고, batch 크기에 따라 의존도가 높은 함수를 사용할 때
class RandomDataset(Dataset):
def __init__(self, tot_len=10, n_features=1):
self.X = torch.rand((tot_len, n_features))
self.y = torch.randint(0, 3, size=(tot_len, ))
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
x = torch.FloatTensor(self.X[idx])
y = self.y[idx]
return x, y
dataset_random = RandomDataset()
for data, label in DataLoader(dataset_random, num_workers=0, batch_size=4):
print(len(data)) # 4, 4, 2
for data, label in DataLoader(dataset_random, num_workers=0, batch_size=2, drop_last=True):
print(len(data)) # 4, 4
time_out은 양수로 주어지는 경우 DataLoader 가 data 를 불러오는데 제한시간으로 작용한다.- 마지막으로
num_worker가 worker 의 개수라면,worker_init_fn은 어떤 worker 를 불러올 것인가를 list 로 전달한다.
Dataloader 예제
- 앞서 말했듯 Pytorch 에서는
DataLoader를 이용하여 데이터 샘플을 불러오고, 이를 model 에 입력시킨다. 아래 예제는 대표적인DataLoader사용 방법이다. torchvision을 통하여 import 한datasets에는 사용할 수 있는 많은 데이터셋이 있기 때문에 매우 유용하다. 아래 예제에서는 간단하게 MNIST 데이터셋을 추가해보자. 아래의mean과std는 예제이기 때문에 상황이나 EDA 에 맞춰 사용해야 한다.
import torch
from torchvision import datasets, transforms
batch_size = 32
test_batch_size = 32
# train 데이터 - train_loader
train_loader = torch.utils.data.DataLoader(
datasets.MNIST(
root = "datasets/",
train = True,
download = True,
transform = transforms.Compose([
transforms.ToTensor(), # tensor 타입으로 데이터 변경
transforms.Normalize(mean = (0.5,), std = (0.5,)) # data normalize
])
),
batch_size=batch_size,
shuffle=True
)
# test 데이터 - test_loader
test_loader = torch.utils.data.DataLoader(
datasets.MNIST(
root = "datasets/",
train = False,
download = True,
transform = transforms.Compose([
transforms.ToTensor(), # tensor 타입으로 데이터 변경
transforms.Normalize(mean = (0.5,), std = (0.5,)) # train 과 동일한 조건으로 normalize
])
),
batch_size = test_batch_size,
shuffle = True
)
- 위의
train_loader와test_loader는generator처럼 동작하기 때문에next를 사용하여 샘플을 생성할 수 있다.
image, label = next(iter(train_loader))
print(image.shape)
# torch.Size([32, 1, 28, 28])
print(label.shape)
# torch.Size([32])
- 학습과정에서는 다음과 같이 모델, 옵티마이저, Loss function 들을 정의하고 학습 또는 transfer learning 을 실시한다.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from model import CustomNet
from dataset import ExampleDataset
from loss import ExampleLoss
# 모델 생성
model = CustomNet()
model.train()
# 옵티마이저 정의
params = [param for param in model.parameters() if param.requires_grad]
optimizer = optim.Example(params, lr=lr) # optim.SGD, optim.Adam 등
# 손실함수 정의
loss_fn = ExampleLoss() # CrossEntropy, MSE 등
# 학습을 위한 데이터셋 생성
dataset_example = ExampleDataset()
# 학습을 위한 데이터로더 생성
dataloader_example = DataLoader(dataset_example)
# 학습
for e in range(epochs):
for X,y in dataloader_example:
output = model(X)
loss = loss_fn(output, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
Pytorch 제공 Dataset
- 지금까지 Dataset 과 DataLoader 를 알아봤다. 이제 Pytorch 에서 제공하는 데이터셋을 살펴보자. 이를 이용해서 CustomDataset 을 만들고 제작한 모델을 학습시킬 수 있다.
torchvision MNIST
- MNIST(Modified National Institute of Standards and Technology) 데이터셋은 손으로 쓴 숫자 이미지들을 모은 대형 데이터베이스로, 다양한 이미지 처리 시스템을 학습하기 위해 자주 사용된다.
- MNIST 는 개별적인 숫자들의 이미지로 구성되어 있으며, 딥러닝 및 머신러닝 연구자들에게 기본적인 벤치마크 역할을 한다.
- 그러나 요즘은 딥러닝 및 머신러닝 모델들이 복잡한 문제들을 풀 수 있는 만큼 더 복잡한 문제들을 풀기 위한 벤치마크 데이터셋이 더 자주 사용되며, MNIST 는 공부 등의 목적으로 사용된다.
- 데이터셋 구성은 다음과 같다.
- 입력(이미지) : 28x28 픽셀의 흑백 이미지로 표현된 손으로 쓴 숫자
- 출력(숫자) : 주어진 이미지에 대응되는 숫자 (0~9)
- 학습 데이터 : 60,000 개
- 테스트 데이터 : 10,000 개
- 데이터셋 저작권 및 출처
- 제작자: Yann LeCun, Corinna Cortes, Christopher J.C. Burges
- MNIST 웹사이트

- MNIST 를 이용해서 Custom Dataset 을 만들기 전에, torchvision 에서 제공하는 데이터셋을 사용해보자.
dataset_train_MNIST = torchvision.datasets.MNIST('data/MNIST/', # 다운로드 경로 지정
train=True, # True 를 지정하면 학습 데이터로 다운로드
transform=transforms.ToTensor(), # tensor 로 변환
download=True)
dataset_train_MNIST
# Dataset MNIST
# Number of datapoints: 60000
# Root location: data/MNIST/
# Split: Train
# StandardTransform
# Transform: ToTensor()
len(dataset_train_MNIST) # 60000
dataset_train_MNIST.classes
# ['0 - zero',
# '1 - one',
# '2 - two',
# '3 - three',
# '4 - four',
# '5 - five',
# '6 - six',
# '7 - seven',
# '8 - eight',
# '9 - nine']
- 이를 이용하여 DataLoader 를 만들어보자.
torchvision.datasets.MNIST로 만들어진 Dataset 인스턴스 또한next와iter로 데이터 샘플에 접근 가능하지만, DataLoader 를 통해 batch 단위로 가져올 수 있다.
dataloader_train_MNIST = DataLoader(dataset=dataset_train_MNIST,
batch_size=16,
shuffle=True,
num_workers=0)
images, labels = next(iter(dataloader_train_MNIST))
plt.figure(figsize=(12,12))
for n, (image, label) in enumerate(zip(images, labels), start=1):
plt.subplot(4,4,n)
plt.imshow(image.numpy().squeeze(), cmap='gray')
plt.title("{}".format(dataset_train_MNIST.classes[label]))
plt.axis('off')
plt.tight_layout()
plt.show()
-
시각화를 통해 이미지를 살펴보면 다음과 같다.

-
이제 MNIST 를 이용해서 위에서 본 것처럼 Custom Dataset 과 DataLoader 를 만들어보자. 이를 위해서 MNIST Dataset 을 다운 받은 상태여야 한다.
import os
BASE_MNIST_PATH = 'data/MNIST/MNIST/raw'
TRAIN_MNIST_IMAGE_PATH = os.path.join(BASE_MNIST_PATH, 'train-images-idx3-ubyte.gz')
TRAIN_MNIST_LABEL_PATH = os.path.join(BASE_MNIST_PATH, 'train-labels-idx1-ubyte.gz')
TEST_MNIST_IMAGE_PATH = os.path.join(BASE_MNIST_PATH, 't10k-images-idx3-ubyte.gz')
TEST_MNIST_LABEL_PATH = os.path.join(BASE_MNIST_PATH, 't10k-labels-idx1-ubyte.gz')
TRAIN_MNIST_PATH = {
'image': TRAIN_MNIST_IMAGE_PATH,
'label': TRAIN_MNIST_LABEL_PATH
}
- 위 코드를 보면 MNIST 가 있는 가장 상위 폴더를
BASE_MNIST_PATH로 두고os를 이용해서 path 를 정의했다. 주의할 점은 MNIST 데이터셋을 다운받으면gz, 즉gzip형태로 다운된다.gzip라이브러리를 사용하면 쉽게 데이터를 압축해제 할 수 있다. - 해당 글에서는 byte 형태로 된 gzip 속 데이터를 읽어 이미지로 바꾸는 코드를 설명하고 있다.
def read_MNIST_images(path):
with gzip.open(path, 'r') as f:
# first 4 bytes is a magic number
magic_number = int.from_bytes(f.read(4), 'big')
# second 4 bytes is the number of images
image_count = int.from_bytes(f.read(4), 'big')
# third 4 bytes is the row count
row_count = int.from_bytes(f.read(4), 'big')
# fourth 4 bytes is the column count
column_count = int.from_bytes(f.read(4), 'big')
# rest is the image pixel data, each pixel is stored as an unsigned byte
# pixel values are 0 to 255
image_data = f.read()
images = np.frombuffer(image_data, dtype=np.uint8)\
.reshape((image_count, row_count, column_count))
return images
def read_MNIST_labels(path):
with gzip.open(path, 'r') as f:
# first 4 bytes is a magic number
magic_number = int.from_bytes(f.read(4), 'big')
# second 4 bytes is the number of labels
label_count = int.from_bytes(f.read(4), 'big')
# rest is the label data, each label is stored as unsigned byte
# label values are 0 to 9
label_data = f.read()
labels = np.frombuffer(label_data, dtype=np.uint8)
return labels
int.from_bytes(f.read(4), 'big')에서big은 Endian(엔디언)과 관련된 개념이다.- Endian 은 컴퓨터의 메모리와 같은 1차원의 공간에 여러 개의 연속된 대상을 배열하는 방법을 뜻하며, byte 를 배열하는 방법을 특히 byte order라 한다.
- byte order 는 크게 big Endian 과 litte Endian 으로 나눌 수 있다. big Endian 은 사람이 숫자를 쓰는 방법과 같이 큰 단위의 byte 가 앞에 오는 방법이고, little Endian 은 반대로 작은 단위의 byte 가 앞에 오는 방법이다.
- 위 함수를 이용해서 MNIST 데이터셋으로부터 이미지와 label 을 불러올 수 있다.
class CustomMNISTDataset(Dataset):
def __init__(self, path, transform, train=True):
self.path = path
self.X = read_MNIST_images(self.path['image'])
self.y = read_MNIST_labels(self.path['label'])
self.classes = ['0 - zero', '1 - one', '2 - two', '3 - three', '4 - four',
'5 - five', '6 - six', '7 - seven', '8 - eight', '9 - nine']
self.train = train
self.transform = transform
self._repr_indent = 4
def __len__(self):
len_dataset = len(self.X)
return len_dataset
def __getitem__(self, idx):
X = self.X[idx]
if self.transform:
X = self.transform(X)
if self.train:
y = self.y[idx]
return torch.tensor(X, dtype=torch.double), torch.tensor(y, dtype=torch.long)
def __repr__(self):
head = "Custom Dataset : MNIST"
data_path = self._repr_indent*" " + "Data path: {}".format(self.path['image'])
label_path = self._repr_indent*" " + "Label path: {}".format(self.path['label'])
num_data = self._repr_indent*" " + "Number of datapoints: {}".format(self.__len__())
num_classes = self._repr_indent*" " + "Number of classes: {}".format(len(self.classes))
return '\n'.join([head, data_path, label_path, num_data, num_classes])
- 위 Custom 데이터셋의
__init__에서는read_MNIST_images와read_MNIST_labels를 통해 이미지와 label 을 불러와 각각X, y에 할당한다. 또한 class, train 여부, transform 을 정의한다. 그 외에 단순히 Dataset 의 인스턴스를 실행했을 때 등장하는 출력을 위해_repr_indent를 정의한다. __len__에서는 전체 데이터 포인트의 개수를 반환하고,__getitem__에서는 index 로 접근했을 때의 출력을 정의했다. 이 때 transform 과 train 여부에 따라 처리를 다르게 한다.- transform 의 경우 학습 데이터와 테스트 데이터가 동일한 transform 을 처리해야 한다면 위 코드로 진행하면 되고, Data Augmentation 등이 사용되어 테스트 데이터에는 다른 transform 을 사용한다면 따로 처리해주면 된다. 보통은 train dataset class 와 test dataset class 를 따로 두는 편이다.
- 또한 학습 때는 데이터 포인트와 같은 index 의 label 을 반환한다.
__repr__은 아래와 같이 데이터셋 인스턴스를 만들고 호출하면 나타나는 내용을 정의한 것이다.
dataset_train_MNIST = CustomMNISTDataset(path=TRAIN_MNIST_PATH,
transform=transforms.Compose([
transforms.ToTensor()
]),
train=True)
dataset_train_MNIST
# Custom Dataset : MNIST
# Data path: data/MNIST/MNIST/raw/train-images-idx3-ubyte.gz
# Label path: data/MNIST/MNIST/raw/train-labels-idx1-ubyte.gz
# Number of datapoints: 60000
# Number of classes: 10
- 이제 이를 아래와 같이 Pytorch 의 DataLoader 의
datasetargument 에 전달하고,batch_size등을 적절히 하여 인스턴스를 만들면 완성이다.
dataloader_train_MNIST = DataLoader(dataset=dataset_train_MNIST,
batch_size=16,
shuffle=True,
num_workers=0)
images, labels = next(iter(dataloader_train_MNIST))
plt.figure(figsize=(12,12))
for n, (image, label) in enumerate(zip(images, labels), start=1):
plt.subplot(4,4,n)
plt.imshow(image.numpy().squeeze(), cmap='gray')
plt.title("{}".format(dataset_train_MyMNIST.classes[label]))
plt.axis('off')
plt.tight_layout()
plt.show()
-
아래와 같이 torchvision 에서 제공하는 Dataset 과 동일하게 데이터를 가져올 수 있다.

CIFAR-10
- CIFAR-10 데이터셋은 일상생활에서 자주 볼 수 있는 총 10 개의 클래스를 가지고, 클래스 당 6000 개의 이미지를 포함하고 있다. 각 클래스는 32x32 크기의 컬러 이미지로 구성된다.
- 총 데이터 수에서 학습 이미지는 50000 개이고 테스트 이미지는 10000 개다. 즉 CIFAR-10 데이터셋은 각각 10000 개의 이미지로 구성된 5 개의 학습 batch 와 1 개의 테스트 batch 로 나뉜다.
- 테스트 batch 에는 각 클래스 별로 랜덤으로 선택한 정확히 1000 개의 이미지가 포함된다. 학습 batch 에는 나머지 이미지가 임의 순서대로 포함되어 있기 때문에 일부 batch 에는 한 클래스의 이미지가 다른 클래스보다 더 많이 포함될 수 있다.
-
그러나 총 학습 batch 로 따져보면 각 클래스의 이미지가 정확히 5000 개 포함되어 있다.

torchvision.datasets을 이용해서 CIFAR-10 데이터셋을 불러올 수 있다.
dataset_train_CIFAR10 = torchvision.datasets.CIFAR10(
root='data/CIFAR10/', # 다운로드 경로 지정
train=True, # True: 학습 데이터로 다운로드
transform=transforms.Compose([
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
transforms.Normalize(
(0.5, 0.5, 0.5),
(0.5, 0.5, 0.5)
)
])
download=True,
)
dataset_train_CIFAR10
# Dataset CIFAR10
# Number of datapoints: 50000
# Root location: data/CIFAR10/
# Split: Train
# StandardTransform
# Transform: Compose(
# RandomVerticalFlip(p=0.5)
# ToTensor()
# Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
# )
len(dataset_train_CIFAR10) # 50000
dataset_train_CIFAR10.classes
# ['airplane',
# 'automobile',
# 'bird',
# 'cat',
# 'deer',
# 'dog',
# 'frog',
# 'horse',
# 'ship',
# 'truck']
- 위 코드를 보면 CIFAR-10 은 비행기, 자동차, 새, 고양이, 사슴, 강아지, 개구리, 말, 배, 트럭 총 10개의 클래스로 이루어져 있음을 확인할 수 있다.
image, label = next(iter(dataset_train_CIFAR10))
plt.imshow(transforms.ToPILImage()(image*0.5+0.5)) # Normalize 처리를 복구
plt.title("{}".format(dataset_train_CIFAR10.classes[label]))
plt.axis('off')
plt.show()

- CIFAR-10 을 이용해서 DataLoader 를 만들어보자.
dataloader_train_CIFAR10 = DataLoader(dataset=dataset_train_CIFAR10,
batch_size=16,
shuffle=True,
num_workers=0)
images, labels = next(iter(dataloader_train_CIFAR10))
plt.figure(figsize=(12,12))
for n, (image, label) in enumerate(zip(images, labels), start=1):
plt.subplot(4,4,n)
plt.imshow(transforms.ToPILImage()(image*0.5+0.5)) # Normalize 처리를 복구
plt.title("{}".format(dataset_train_CIFAR10.classes[label]))
plt.axis('off')
plt.tight_layout()
plt.show()

- 이 외에 torchvision 에서는 여러가지 데이터셋을 제공한다.
dir(torchvision.datasets)를 실행하면 어떤 데이터셋을 사용할 수 있는지 알 수 있다. 이를 지금까지 했던 것처럼 Dataset 으로 만들고 시각화를 통해 살펴볼 수 있다.
그 외
torchvision말고도torchtext,torchaudio에서도 각각 텍스트 데이터셋과 오디오 데이터셋을.datasets로 접근할 수 있다.torchtext의 AG_NEWS 데이터셋은 100만개가 넘는 뉴스 기사 모음이다. 데이터셋의 구성은 아래와 같다.- 입력: 뉴스 기사의 텍스트
- 출력: 뉴스 기사의 카테고리 (예: 스포츠, 비즈니스, 과학/기술, 엔터테인먼트 등)
- 학습 데이터: 약 120,000 개 (각 카테고리당 30,000 개)
- 테스트 데이터: 약 7,600 개 (각 카테고리당 1,900 개)
- 데이터셋 저작권 및 출처: ComeToMyHead의 공식 웹사이트
torchtext는 자연어 처리에 특화된 Pytorch project 라이브러리로서Vocab,FastText등의 임베딩과 ROBERTA 와 같은 모델들을 제공하기도 한다. 그러나 자연어 처리의 경우 Huggingface 를 더 많이 사용한다.- 또한 Huggingface를 이용하면 훨씬 편하게 Dataset 와 DataLoader 를 사용할 수 있다. 기회가 되면 관련된 내용을 정리해 볼 것이다.
torchvision transform
- torchvision 에서 제공하는 transform 함수들에 대해 알아보자. 그전에, transform 을 하는 이유가 뭘까?
- 딥러닝 모델의 학습을 위해서는 고정된 입력값이 보장되어야 한다.
- 그러나 수집한 모든 데이터의 크기가 동일하지 않을 수 있다. 오히려 동일하지 않은 경우가 많다. 가령 이미지의 경우 정사각형 형태의 이미지가 있는 반면 직사각형 형태의 이미지가 있을 수 있다.
- PyTorch 에서는 이처럼 다른 크기의 이미지를 고정된 입력값으로 만들어주기 위해서 이미지를
Resize하는 함수 등을 제공한다. - 아래 섹션들에서 PIL 과 OpenCV 에 대해 간단히 알아보고, transform 의 일부 기법들을 살펴보자.
PIL & OpenCV
- 기억하면 좋을 것은
torchvision에서transforms.Resize,transforms.RandomCrop와 같은 일부 transform 은PIL(Pillow) 객체의 이미지를 입력으로 기대한다. 따라서 numpy 배열이나 numpy 배열을 반환하는 opencv 등의 이미지는 PIL 이미지 객체로 변환해주어야 한다. - PIL(Pillow) 는 Python Imaging Library 의 확장 버전으로 직관적이며 다양한 포맷(JPEG, PNG, BMP 등)을 지원한다. 주로 이미지 처리, 시각화, 텍스트 추가 등에 사용한다.
- 이미지를 RGB 형식 (Red-Green-Blue)으로 처리한다.
- Pillow 에서 읽은 이미지는
PIL.Image.Image객체로 반환되며, NumPy 또는 OpenCV 배열과 다르다. - 이미지 데이터를 다룰 때
HWC(Height-Width-Channel) 순서를 유지한다. - PIL 로 이미지를 읽을 때는 아래와 같은 코드를 이용하며, NumPy, OpenCV 와도 쉽게 변환 가능하다.
- OpenCV 는 빠르고 강력한 컴퓨터 비전 라이브러리로, 다양한 이미지와 비디오 처리가 가능하다.
- 주의할 점은 PIL 과 다르게 이미지를 BGR 형식 (Blue-Green-Red)으로 처리한다.
- 또한 NumPy 배열과 긴밀하게 통합되어 NumPy 배열로 이미지를 읽고 처리한다.
- 앞서 말한 것처럼 OpenCV 에서 읽은 이미지는 채널 순서가 BGR 이므로, 다른 라이브러리와 호환하려면 채널 순서를 변경해야 한다.
- 시각화를 할 때
Matplotlib은 RGB 순서로 이미지를 시각화하기 때문에 OpenCV 이미지를 바로 시각화하면 색이 왜곡되므로 채널 순서 변환이 필요하다.
- 또한 이미지 데이터는 단순히 NumPy 배열로 표현 가능하다. NumPy 는 이미지를 빠르게 연산하고 조작할 때 유용하다.
from PIL import Image
import cv2
import numpy as np
import matplotlib.pyplot as plt
# PIL <-> NumPy
image = Image.open("image.jpg")
numpy_array = np.array(image)
numpy_array = np.random.randint(0, 256, (100, 100, 3), dtype=np.uint8)
image = Image.fromarray(numpy_array)
# PIL <-> OpenCV
image = Image.open("image.jpg")
opencv_image = cv2.cvtColor(np.array(image), cv2.COLOR_RGB2BGR)
opencv_image = cv2.imread("image.jpg")
pil_image = Image.fromarray(cv2.cvtColor(opencv_image, cv2.COLOR_BGR2RGB))
# NumPy <-> OpenCV
opencv_image = cv2.imread("image.jpg")
numpy_array = np.random.randint(0, 256, (100, 100, 3), dtype=np.uint8)
opencv_image2 = numpy_array # 직접 사용 가능
# OpenCV 시각화
plt.imshow(cv2.cvtColor(opencv_image, cv2.COLOR_BGR2RGB))
plt.show()
- 기억하면 좋을 것은 OpenCV 는 BGR 형식, Pillow 와 NumPy 는 RGB 형식을 기본으로 사용한다는 것이다. 따라서 각 라이브러리 간 변환 시
cv2.cvtColor를 사용하여 채널 순서를 맞추는 것이 중요하다. - 또한 이미지 데이터는 대부분 0~255 범위의
np.uint8형식으로 처리한다. float32 로 변환하면 계산이 편리하지만 저장 시 다시 uint8 로 변환이 필요하다. - 마지막으로 이미지는 HWC(Height-Width-Channel) 순서가 기본이다. 그러나 PyTorch 와 TensorFlow 는 CHW(Channel-Height-Width) 의 차원 순서로 처리하므로 변환이 필요하다.
- OpenCV 는 대용량 이미지 처리에서 더 빠르고, PIL(Pillow) 는 간단한 작업에 적합하다.
- torchvision 은 PIL 의 Image 객체를 입력으로 기대하기 때문에, PIL 을 이용해서 이미지를 불러오고 이 이미지를 통해서 transform 의 효과에 대해 알아보자.
url = 'https://images.unsplash.com/photo-1583160247711-2191776b4b91?ixid=MnwxMjA3fDB8MHxzZWFyY2h8MTN8fGdvbGRlbnJldHJpZXZlcnxlbnwwfHwwfHw%3D&ixlib=rb-1.2.1&auto=format&fit=crop&w=500&q=60'
im = Image.open(requests.get(url, stream=True).raw)
im.size # (500, 333)

- 위 이미지는 오픈 사이트인 unsplash 에서 가져온 500x333 크기의 강아지 이미지다.
Resize, RandomCrop, RandomRotation
transforms.Resize는 단어 뜻 그대로 이미지의 사이즈를 변환한다.
torchvision.transforms.Resize(size,
interpolation=InterpolationMode.BILINEAR,
max_size=None,
antialias=True)
im, transforms.Resize((200,200))(im)
# (<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x333>,
# <PIL.Image.Image image mode=RGB size=200x200>)
size에는 원하는 크기를 sequence 혹은 int 의 형태로 넣어주면 된다. 만약 int 형태로 넣어주게 되면 기존 H 와 W 의 비율을 유지하면서 resize 한다.interpolation은 보간법으로, 이미지 크기를 조정할 때 새로운 픽셀 값들을 기존 픽셀 값들을 기반으로 계산하는 방식이다. 어떤 보간법의 종류를 선택하느냐에 따라 결과 이미지의 품질과 속도에 영향을 준다.- torchvision 에서는
torchvision.transforms.InterpolationMode을 사용하며 NEAREST, BILINEAR, BICUBIC 등을 지원한다. 기본값은 인접한 4개의 픽셀 값을 선형 보간하는 Bilinear Interpolation 이다. - interpolation 기법들에 대해서는 따로 포스트를 두어 정리할 것이다. 여기서는 속도와 품질에 대해서만 비교한다.
- 속도 측면에서는 Nearest > Bilinear > Box > Bicubic > Lanczos 의 순서다.
- 품질 측면에서는 Nearest < Bilinear < Box ≈ Bicubic < Lanczos 의 순서다.
- torchvision 에서는
max_size는size가 int 로 주어졌을 때 동작하며 resized image 의 max size 를 결정한다.antialias는 안티앨리어싱 적용 여부를 결정한다.- 앨리어싱 현상은 계단 현상이라고도 부르며, 디지털 이미지에서 픽셀은 사각형이기 때문에 가장자리 부분이 계단 형식으로 나타나는 것을 의미한다. 안티앨리어싱이 적용되면 가장자리가 매끄러워진다.
-
이 옵션은 bilinear 또는 bicubic modes 의 PIL Image 또는 tensor 에만 영향을 준다.

transforms.RandomCrop은 지정된 이미지를 임의의 위치에서 자르는 변환이다.
torchvision.transforms.RandomCrop(size,
padding=None,
pad_if_needed=False,
fill=0,
padding_mode='constant')
im, transforms.RandomCrop((100,100), padding=(100,100))(im)
# (<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x333>,
# <PIL.Image.Image image mode=RGB size=100x100>)
- 원본 이미지의 임의의 위치에서 주어진
size만큼 crop 된 이미지를 반환한다. padding은 주어진 sequence 혹은 int 만큼 원본 이미지에 padding 을 적용하고 random crop 을 실시한다.pad_if_needed는 원본 이미지가 원하는 크기보다 작을 경우, 예외가 발생하지 않도록 이미지를 padding 하는 것이다. padding 후에 cropping 이 수행되므로, padding 이 랜덤한 위치에 추가되는 것처럼 보일 수 있다.fill은 number 혹은 tuple 을 받아 padding 시 고정 값으로 채울 픽셀 값을 뜻한다. 기본값은 0 이며, 길이가 3 인 튜플 형태의 값일 경우, (R, G, B) 채널 각각에 대해 값을 채운다. 또한 Constant padding 모드에서만 사용된다.-
padding_mode는 padding 유형을 지정한다. 기본값은fill매개변수로 지정되는 기본값으로 padding 을 채우는constant다.edge는 이미지 가장자리의 마지막 값을 사용해 padding 한다. 이 외에도reflect,symmetric이 있다.
transforms.RandomRotation은 주어진 이미지를 임의의 각도만큼 회전시킨다.
torchvision.transforms.RandomRotation(degrees,
interpolation=InterpolationMode.NEAREST,
expand=False,
center=None,
fill=0)
im, transforms.RandomRotation(30)(im)
# (<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x333>,
# <PIL.Image.Image image mode=RGB size=500x333>)
- 원하는 각도를
dregrees에 전달한다.interpolation은Resize에서의 argument 와 같은 역할을 한다. expand를 True 로 두면 회전한 이미지 전체를 다 담을 수 있는 크기의 이미지가 반환된다.-
center는 회전의 중심을 (x, y) 의 형태로 받을 수 있고,fill은 이미지 회전 후 바깥 영역을 채울 픽셀값을 뜻한다.
ToTensor, ToPILImage
- 위에서 배운 것들을 종합하여 아래와 같이 transform 을 적용할 수 있다.
- 여기서는 주어진 확률
p로 이미지를 수직으로 뒤집는transforms.RandomVerticalFlip(p=0.5)를 사용했다. - 또한 이미지의 중심에서 주어진 size 만큼 crop 하는
torchvision.transforms.CenterCrop(size)를 사용한다.
def get_transforms_img(im):
im = transforms.Resize((224,224))(im)
im = transforms.RandomVerticalFlip(0.5)(im)
im = transforms.CenterCrop(150)(im)
return im
get_transforms_img(im)
- 이제 Pytorch 로 설계한 모델에 이미지를 입력하기 위해선 PyTorch tensor 형식이어야 한다. 따라서 (H x W x C) 의 형태이고 [0, 255] 범위를 가지는 PIL 이미지 혹은 numpy 배열 형식의 이미지는
transforms.ToTensor()를 통해 tensor 로 변환해야 한다.
transforms.ToTensor()(im)
# tensor([[[0.3176, 0.3176, 0.3176, ..., 0.2667, 0.2667, 0.2667],
# [0.3216, 0.3216, 0.3216, ..., 0.2667, 0.2667, 0.2667],
# [0.3255, 0.3255, 0.3255, ..., 0.2667, 0.2667, 0.2667],
# ...,
# [0.1647, 0.1725, 0.1882, ..., 0.1922, 0.1922, 0.1882],
# [0.1569, 0.1608, 0.1608, ..., 0.1922, 0.1843, 0.1765],
# [0.1490, 0.1529, 0.1529, ..., 0.1922, 0.1804, 0.1725]],
# [[0.4118, 0.4118, 0.4118, ..., 0.2706, 0.2706, 0.2706],
# [0.4157, 0.4157, 0.4157, ..., 0.2706, 0.2706, 0.2706],
# [0.4235, 0.4235, 0.4235, ..., 0.2706, 0.2706, 0.2706],
# ...,
# [0.2314, 0.2392, 0.2431, ..., 0.1843, 0.1843, 0.1804],
# [0.2118, 0.2157, 0.2157, ..., 0.1843, 0.1765, 0.1686],
# [0.2000, 0.2039, 0.2000, ..., 0.1843, 0.1725, 0.1647]],
# [[0.4196, 0.4196, 0.4196, ..., 0.2471, 0.2471, 0.2471],
# [0.4235, 0.4235, 0.4235, ..., 0.2471, 0.2471, 0.2471],
# [0.4392, 0.4392, 0.4392, ..., 0.2471, 0.2471, 0.2471],
# ...,
# [0.1686, 0.1765, 0.1765, ..., 0.1882, 0.1882, 0.1843],
# [0.1608, 0.1647, 0.1647, ..., 0.1882, 0.1804, 0.1725],
# [0.1647, 0.1647, 0.1608, ..., 0.1882, 0.1765, 0.1686]]])
- 변환된 Tensor 는 (C x H x W) 의 형태에 [0.0, 1.0] 의 범위를 가진
torch.FloatTensor로 변환된다. - 이처럼 입력 이미지가 [0.0, 1.0] 범위로 스케일링되므로, target image masks 를 변환할 때는 이 변환을 사용하지 않는 것이 좋다.
- 또한 PIL 이미지가
L, LA, P, I, F, RGB, YCbCr, RGBA, CMYK, 1의 형식이거나, numpy 배열의 데이터 타입이np.uint8인 경우에 변환 가능하다. - 또한
transforms.ToPILImage(mode=None)를 이용하면 tensor 혹은 ndarray 스타일의 배열을 PIL 이미지로 바꿀 수 있다. 즉 (C x H x W) 형태의 tensor 혹은 ndarray 를 (H x W x C) 형태의 이미지로 바꾸는 것이다.
im_arr = torch.rand((3, 224, 224))
im_pil = transforms.ToPILImage(mode='RGB')(im_arr)
im_pil
-
이는
cv.imread나plt.imread와 같은 함수와 같이 쓰이며,mode에는 RGBA, RGB 같은PIL.Image의 mode 를 건네준다.
Compose
torchvision.transforms.Compose(transforms)을 쓰면 위get_transforms_img함수와 달리 여러 transform 들을 하나로 묶어서 처리해줄 수 있다.
transforms.Compose([transforms.Resize((224,224)),
transforms.RandomVerticalFlip(0.5),
transforms.CenterCrop(150)])(im)

dir(transforms)를 통해 활용할 수 있는 많은 transform 기법들을 확인하거나, Torchvision 공식문서를 확인해보자. 최근에는 bounding box, mask image, video 등에도 활용할 수 있고CutMix나MixUp등의 augmentation 기법이 transform 에 추가된torchvision.transforms.v2에 관한 내용도 살펴볼 수 있다.- 지금까지 위에서 본 것은 v1 에 해당하는 것이었다. 여기서 크게 달라지는 것도 없고, 앞으로
transforms.v2에만 새로운 기능이 생긴다고 하니 기존의 transform 을 포함하면서 더 빠른transforms.v2를 사용하도록 하자.
albumentations & imgaug
- torchvision 에서 제공하는 transform 이외에도 albumentations과 같이 다양한 transform 을 제공하는 라이브러리들이 있다.
- Object Detection 이나 Segmentation task 에서는 transformation 에 의해서 input 이 변하면 GT(ground truth) 값이 변하는 경우가 있다.
- 예컨대 Object detection 의 경우, 물체의 위치 정보인 바운딩 박스(Bounding box)가 그렇다. 원본 이미지를 뒤집거나 회전시키면 그에 따라서 바운딩 박스도 좌표가 변환되어야 한다.
- albumentations 나 imgaug 와 같은 라이브러리는 image 와 함께 bounding box, mask 에도 원본 이미지와 같은 transform 을 적용해준다.
- 아래에서 왼쪽은 imgaug 의 transform 적용 범위 및 결과, 오른쪽은 albumentations 의 transform 적용 범위를 보여준다.

- 물론
torchvision.transforms.v2에서도 해당 공식문서를 보면 알 수 있듯이, 이제는 albumentations 와 imgaug 와 같은 기능을 적용시킬 수 있다. - 그러나 여전히
albumentations와imgaug는 활용성도 높고 데이터 증강에 있어 많이 사용되고 있다. 따라서 이후 Data Augmentation 카테고리에서 따로 포스트를 두어 정리할 것이다.
Custom Dataset & DataLoader 제작
- 이제 지금까지 공부한 내용을 종합하여 Custom Dataset 과 DataLoader 를 제작해보자.
- 정형데이터인 Titanic 데이터를 이용해보자. Titanic 데이터셋은 타이타닉 호 침몰 사고에서의 승객들의 정보와 그들의 생존 여부를 포함하고 있다. 머신러닝 초보 단계에서 분류 문제를 연습하기 위해 많이 사용된다.
- 데이터셋의 구성은 다음과 같다.
- 입력: 승객의 정보 (예: 이름, 성별, 나이, 승선 클래스, 승선 위치 등)
- 출력: 승객의 생존 여부 (생존: 1, 사망: 0)
- 학습 데이터: 약 891 개의 승객 정보
- 테스트 데이터: 별도의 테스트 데이터셋은 제공되지 않으나, 전체 데이터를 학습/테스트 용도로 분할하여 사용
- 데이터셋 저작권 및 출처: Kaggle Titanic Challenge 웹사이트
- Kaggle 에서 제공하는 해당 데이터를 다운로드 받고 진행한다.
class TitanicDataset(Dataset):
def __init__(self, path, drop_features, train=True):
self.data = pd.read_csv(path)
self.data['Sex'] = self.data['Sex'].map({'male':0, 'female':1})
self.data['Embarked'] = self.data['Embarked'].astype('category').cat.codes
self.train = train
self.data = self.data.drop(drop_features, axis=1)
self.X = self.data.drop('Survived', axis=1)
self.y = self.data['Survived']
self.features = self.X.columns.tolist()
self.classes = ['Dead', 'Survived']
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
X = self.X.iloc[idx].values
if self.train:
y = self.y.iloc[idx]
return torch.tensor(X), torch.tensor(y)
else:
return torch.tensor(X)
- 위 Custom Titanic Dataset 은 ‘Sex’ feature 에서 ‘male’ 과 ‘female’ 을 각각 0, 1 로 label encoding 하고, ‘Embarked’ 특성은 ‘S’ 를 0, ‘C’ 를 1, ‘Q’ 를 2 로 반환한다.
drop_features인자는 제외할 특성의 리스트를 받는다. 이 특성들은 데이터셋에서 제외된다.train인자는 데이터셋이 학습용인지 아닌지를 결정한다. True 로 설정하면 학습용, False 로 설정하면 테스트용으로 데이터셋이 구성된다.
dataset_train_titanic = TitanicDataset('./data/titanic/train.csv',
drop_features=['PassengerId', 'Name', 'Ticket', 'Cabin'],
train=True)
dataset_train_titanic.features
# ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
dataset_train_titanic.classes
# ['Dead', 'Survived']
next(iter(dataset_train_titanic))
# (tensor([ 3.0000, 0.0000, 22.0000, 1.0000, 0.0000, 7.2500, 0.0000],
# dtype=torch.float64),
# tensor(0))
- 이를 이용해서 DataLoader 를 만들면 아래와 같다.
dataloader_train_titanic = DataLoader(dataset=dataset_train_titanic,
batch_size=8,
shuffle=True,
num_workers=0,
)
features, labels = next(iter(dataloader_train_titanic))
features
# tensor([[ 3.0000, 0.0000, 45.5000, 0.0000, 0.0000, 7.2250, 1.0000],
# [ 3.0000, 1.0000, nan, 1.0000, 0.0000, 15.5000, 2.0000],
# [ 3.0000, 0.0000, 20.0000, 1.0000, 1.0000, 15.7417, 1.0000],
# [ 1.0000, 0.0000, 31.0000, 1.0000, 0.0000, 57.0000, 0.0000],
# [ 2.0000, 0.0000, 24.0000, 0.0000, 0.0000, 10.5000, 0.0000],
# [ 3.0000, 1.0000, 23.0000, 0.0000, 0.0000, 7.5500, 0.0000],
# [ 3.0000, 1.0000, nan, 3.0000, 1.0000, 25.4667, 0.0000],
# [ 3.0000, 1.0000, 26.0000, 0.0000, 0.0000, 7.8542, 0.0000]],
# dtype=torch.float64)
labels
# tensor([0, 1, 1, 1, 0, 1, 0, 1])
datasets.ImageFolder
- torchvision 에는 가지고 있는 데이터셋 폴더 아래에 클래스 별로 폴더가 구성되어 있다면 손쉽게 Dataset 을 만들 수 있다. 바로
ImageFolder를 이용하면 된다.
torchvision.datasets.ImageFolder(root: ~typing.Union[str, ~pathlib.Path],
transform: ~typing.Optional[~typing.Callable] = None,
target_transform: ~typing.Optional[~typing.Callable] = None,
loader: ~typing.Callable[[str], ~typing.Any] = <function default_loader>,
is_valid_file: ~typing.Optional[~typing.Callable[[str], bool]] = None,
allow_empty: bool = False)
root는 클래스 별 폴더가 있는 상위 폴더 경로를 주면 된다.transform과target_transform은 각각 학습 데이터셋과 테스트 데이터셋에 적용되는 transform 을 의미한다.torchvision.tansforms이나torchvision.tansforms.v2를 Compose 한 인스턴스를 넣어주면 된다.loader는 이미지 로드 방식을 결정하고,is_valid_file은 valid set 인지를 검사한다.- 가위바위보 이미지가 담겨있는 rps 데이터셋을 사용해서 ImageFolder 예제를 작성해보자. 먼저 rps 데이터셋을 아래의 코드를 이용하여 다운받을 수 있다.
import urllib.request
import zipfile
# 다운로드 후 압축 해제
url = 'https://storage.googleapis.com/download.tensorflow.org/data/rps.zip'
urllib.request.urlretrieve(url, './rps.zip')
local_zip = 'rps.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('./rps_dataset')
zip_ref.close()
- 다운받은
rps_dataset폴더는 아래와 같은 구조로 되어있다. 가장 상위rps폴더 아래에 3개의 클래스인paper, rock, scissors별로 폴더가 나뉘어져 있다. - 각 클래스 폴더에는
paper01-000.png형식의 학습 이미지와testscissors03-118.png형식의 테스트 이미지가 들어있다.
tree -L 2 ./rps_dataset/
# ./rps_dataset/
# └── rps
# ├── paper
# ├── rock
# └── scissors
- 이제 이를
ImageFolder로 불러오면 어떻게 되는지 보자. 총 3 개의 클래스가 자동으로.classes속성에 생긴다.
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from torchvision import transforms
dataset = ImageFolder(root='rps_dataset/rps',
transform=transforms.Compose([
transforms.ToTensor(),
])
)
data_loader = DataLoader(dataset,
batch_size=32,
shuffle=True,
num_workers=8
)
len(dataset) # 2520
dataset.classes # ['paper', 'rock', 'scissors']
images, labels = next(iter(data_loader))
images[0].shape # torch.Size([3, 300, 300])
- 이처럼
torchvision.datasets.ImageFolder을 이용하면 Custom Dataset 을 처음부터 설계하지 않아도 편리하게 Dataset 을 만들 수 있다. 또한 학습 데이터셋과 테스트 데이터셋에transform도 수행할 수 있어 굉장히 유용하다. - 마지막으로 rps 데이터셋을 시각화하면 아래와 같다. 참고로
ImageFolder로 데이터셋을 만들면 클래스 이름과 index 를 매핑한 결과를 반환하는class_to_idx의 메서드를 사용할 수 있다.
import matplotlib.pyplot as plt
# {'paper': 0, 'rock': 1, 'scissors': 2}
labels_map = {v:k for k, v in dataset.class_to_idx.items()}
figure = plt.figure(figsize=(12, 8))
cols, rows = 8, 4
images, labels = next(iter(data_loader))
for i in range(1, cols * rows + 1):
sample_idx = torch.randint(len(images), size=(1,)).item()
img, label = images[sample_idx], labels[sample_idx].item()
figure.add_subplot(rows, cols, i)
plt.title(labels_map[label])
plt.axis("off")
plt.imshow(torch.permute(img, (1, 2, 0))) # H, W, C
plt.show()

Reference
- 네이버 부스트캠프 AI Tech
- https://teddylee777.github.io/pytorch/pytorch-cnn-rps/
댓글 남기기