
[Deep Learning, d2l] MLP 구현 (1)
거대한 데이터셋과 강력한 하드웨어와 더불어, 뛰어난 소프트웨어 도구들은 딥러닝의 급속한 발전에 필수적인 역할을 해왔다. 2007 년에 출시된 Theano 라이브러리를 시작으로, 유연한 오픈소스 도구들은 연구자들이 모델을 신속하게 프로토타입화할 수 있게 했으며, 표준 구성 요소를 재활용하면서도 반복 작업을 줄이고 수정의 필요성을 줄였다. 시간이 지나면서 딥러닝 라이브러리들은 점점 더 높은 수준의 추상화를 제공하는 방향으로 진화해 왔다. 개별 neuron 의 동작을 생각하는 단계에서 전체 layer 로 네트워크를 구상하는 방식으로 변화해 왔고, 이제는 훨씬 더 큰 블록 단위로 architecture 를 설계하는 경우가 많아졌다. 이를 가능하게 해주는 대표적인 딥러닝 라이브러리는 Pytorch, Tensorflow 등이 있다.
여기서는 Pytorch 를 활용하여 MLP 를 직접 구현하면서, 모델 구성, parameter 접근 및 초기화, 사용자 정의 layer 와 block 설계, 모델 읽기 및 쓰기, 그리고 GPU 를 활용한 속도 향상에 대해 다룰 예정이다. 이를 통해 딥러닝 라이브러리의 이점을 최대한 활용하면서도 자신이 직접 설계한 복잡한 모델을 구현할 수 있는 유연성을 가져볼 수 있다. 또한 이후 CNN 이나 RNN, Transformer 등 발전된 다양한 모델의 토대가 된다.
Layers and Modules
- Neural Network 를 처음 배울 때는 단일 출력을 가진 linear model 을 다룬다. 이 linear model 은 단일 neuron 으로 구성된다.
- 단일 neuron 은 (i) 입력을 받아들이고, (ii) 이에 대응하는 스칼라 출력을 생성하며, (iii) 특정 objective function 을 최적화하기 위해 조정 가능한 parameter 집합을 가진다.
- 이후 다중 출력을 가진 네트워크를 공부할 때는 벡터화된 연산을 이용해 전체 layer 를 설명할 수 있다.
- 단일 neuron 과 마찬가지로, layer 는 (i) 입력 집합을 받고, (ii) 이에 대응하는 출력을 생성하며, (iii) 조정 가능한 parameter 로 구성된다.
- softmax regression 에서 공부한 것처럼 single layer 가 모델 자체였던 경우와 마찬가지로 MLP 에서도 모델이 동일한 기본 구조를 유지한다.
- MLP 의 경우, 전체 모델은 input(특징) 을 받아들여 출력을 생성하고(예측), 모든 구성 layer 의 parameter 를 합친 parameter 집합을 가진다.
- 마찬가지로, 각 개별 layer 는 이전 layer 로부터 제공된 입력을 받아들여 다음 layer 로 전달할 출력을 생성하며, 역전파 신호에 따라 조정 가능한 parameter 를 가지고 있다.
- neuron, layer, 모델이라는 추상화 개념만으로도 충분할 것 같지만, 실제로는 개별 layer 보다 크고 전체 모델보다 작은 구성 요소를 다루는 것이 편리한 경우가 많다.
- 예를 들어, 컴퓨터 비전 분야에서 널리 사용되는 ResNet-152 아키텍처는 수백 개의 layer 로 구성되며, 이 layer 들은 layer 그룹의 반복 패턴으로 이루어져 있다. 즉 layer 를 하나씩 구현하는 번거로운 과정을 해결해주며 성능적 측면에서도 좋은 성과를 거두었다.
- ResNet 아키텍처는 2015 년 ImageNet 과 COCO 컴퓨터 비전 대회에서 Recoginition 과 Detection 부문 모두에서 우승했으며, 현재까지도 많은 비전 작업에서 기본 아키텍처로 자리잡고 있다. 또한 layer 가 다양한 반복 패턴으로 배열된 아키텍처는 이제 자연어 처리 및 음성 처리와 같은 다른 분야에서도 흔히 사용된다.
- 이러한 복잡한 네트워크를 구현하기 위해, 우리는 Nueral Network Module 이라는 개념을 도입한다. 모듈은 단일 layer 를 설명할 수도, 여러 layer 로 구성된 컴포넌트를 나타낼 수도, 전체 모델을 설명할 수도 있다.
-
모듈 추상화를 활용하는 장점은 모듈을 반복적으로 더 큰 구조로 결합할 수 있다는 것이다. 아래 그림과 같이, 모듈이 가진 임의의 복잡성을 필요에 따라 생성하는 코드를 정의함으로써 매우 간결한 코드로도 복잡한 Network 를 구현할 수 있다는 것을 보여준다.
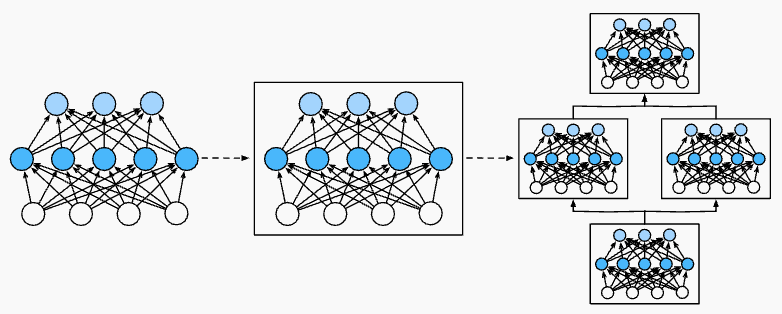 Multiple layers are combined into modules, forming repeating patterns of larger models.
Multiple layers are combined into modules, forming repeating patterns of larger models. - 프로그래밍 측면에서 모듈은 클래스로 표현된다. 이 클래스의 하위 클래스는 반드시 입력을 출력으로 변환하는 forward propagation 메서드를 정의하고 필요한 parameter 를 저장해야 한다. 그러나 일부 모듈은 parameter 가 필요하지 않을 수도 있다.
- 마지막으로, 모듈은 gradient 를 계산하기 위한 back propagtaion 메서드를 가져야 한다. 그러나 다행히도, Pytorch 와 같은 딥러닝 라이브러리는 자동 미분(autograd) 기능을 가지고 있다. 따라서 모듈을 정의할 때 parameter 와
forward메서드만 신경 쓰면 된다. - 먼저 아래 코드를 보자.
import torch
from torch import nn
net = nn.Sequential(
nn.LazyLinear(256),
nn.ReLU(),
nn.LazyLinear(10)
)
X = torch.rand(2, 20)
net(X).shape # torch.Size([2, 10])
- 위 예제는 256 개의 유닛과 ReLU 활성화함수가 있는 하나의 fully connected layer 와, 활성화 함수가 없는 10 개의 유닛을 가진 fully connected layer 를 생성한다.
- 여기서 실행해야 할 layer 들을
nn.Sequential에 순서대로 인수로 전달해 인스턴스화하여 모델을 구성했다. - 즉
nn.Sequential은 Module 의 특별한 형태로, Pytorch 에서 모듈을 나타내는 클래스이다. 이 클래스는 구성 요소가 되는 Module 들의 순서가 정해진 목록을 유지한다. - 두 개의 fully connected layer 각각은 Module 의 하위 클래스인
nn.LazyLinear클래스의 인스턴스다.nn.Linear와nn.LazyLinear는 모두 linear transformation 을 수행한다는 점에서 기능적으로 완전히 동일하다. 그러나 작은 차이가 있다.nn.Linear는 미리 입력값과 출력값의 크기를 지정해야 한다.nn.Linear(5, 10)와 같다. 또한torch.nn.parameter를 사용하며 layer 생성 시에parameter(W, b)를 초기화한다.nn.LazyLinear는 위 예시와 같이 출력값의 크기만 지정한다. 입력값의 크기는 첫 forward 를 진행할 때 자동으로 확인하여 지정한다. 또한torch.nn.UninitializedParameter를 사용하며 layer 생성 후 첫 forward 진행 중에parameter(W, b)를 초기화한다.- 따라서
nn.LazyLinear는 입력값의 크기가 변화해도 스스로 그 크기 변화에 맞추어 적절한 크기의Parameter(W, b)로 초기화하기 때문에 입력값의 크기에 유연하게 대응한다는 장점이 있다. 그러나 많이 사용되지는 않는다.
- forward propagation 메서드 역시 매우 간단하게 구성된다. 이 메서드는 목록에 있는 각 모듈을 연쇄적으로 호출하여 각 모듈의 출력을 다음 모듈의 입력으로 전달한다.
- 위에서 우리는
net(X)를 통해 모델의 출력을 얻었는데, 이는 사실net.__call__(X)의 축약형이다. - 이처럼 모듈에 input 을 넣고 호출하면 출력을 얻는 형태가
forward다. 이러한forward는 이후 복잡한 모델들에서는 연산이 추가되기 때문에 함수로서 작성한다.
torch.nn
-
torch.nn은 공식문서에서 보면 그래프를 만들기 위한 basic building block 이라고 설명된다. 따라서 다양한 모델 아키텍처를 이루는 Layer 에 포함되는 클래스들이 모여있다.
- 이 중에서 Containers 에 있는
Module,Sequential,ModuleList,ModuleDict는 모두 block 을 쌓기 위해 사용되는 클래스다. - 밑에서 구체적으로 구현해보겠지만,
nn.Module클래스는 여러 기능들을 한 곳에 모아놓는 상자 역할을 한다. 또한nn.Module안에는 다른nn.Module를 포함할 수도 있다. - 이를 어떻게 사용햐느냐에 따라
nn.Module은 다른 의미를 가질 수 있다.nn.Module안에 기능들을 가득 모아놓은 경우basic building block가 된다.nn.Module안에basic building block으로 동작하는nn.Module들을 가득 모아놓은 경우 딥러닝 모델이 된다.nn.Module안에 딥러닝 모델로 동작하는nn.Module들을 가득 모아놓은 경우 더욱 깊고 큰 딥러닝 모델이 된다.
- 이처럼
nn.Module은 빈 상자일 뿐 이를 어떻게 사용할지는 온전히 설계자의 몫이다.기능과basic building block과딥러닝 모델을 혼재해서 마구잡이로 담을 수도 있고,기능은기능끼리block은block끼리 계층적으로 담을 수도 있다.
Custom Module
- 모듈이 어떻게 작동하는지에 대한 직관을 얻는 가장 쉬운 방법 중 하나는 직접 모듈을 구현해보는 것이다. 그 전에, 각 모듈이 제공해야 할 기본 기능을 간략히 요약해보자.
- forward propagation 메서드의 argument 로 입력 데이터를 받아야 한다.
- forward propagation 메서드가 값을 반환하여 출력을 생성해야 한다. 출력은 입력과 다른 차원을 가질 수 있다. 예를 들어 위 예제에서 첫번째 fully connected layer 는 임의의 차원의 입력을 받아 256 차원의 출력을 반환한다.
- back propagation 메서드를 통해 출력의 입력에 대한 gradient 를 계산할 수 있어야 한다. 일반적으로 이는 자동으로 수행된다.
- forward propagation 계산을 수행하는 데 필요한 parameter 를 저장하고 접근할 수 있어야 한다.
- 필요한 경우 모델 parameter 를 initialization 해야 한다.
- 아래 코드에서는 256 개의 hidden 유닛을 가진 하나의 hidden layer 와 10 차원의 출력 layer 를 갖는 MLP 를 모듈로 구현한 것이다.
import torch
from torch import nn
from torch.nn import functional as F
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.hidden = nn.LazyLinear(256)
self.out = nn.LazyLinear(10)
def forward(self, X):
return self.out(F.relu(self.hidden(X)))
mlp = MLP()
X = torch.rand(2, 3)
output = mlp(X)
print(output.shape) # torch.Size([2, 10])
- 위 MLP 클래스는 모듈을 나타내는 클래스
nn.Module을 상속받는다. 따라서 커스텀한 모듈 안에 Python 에서의 생성자(__init__메서드)와 forward propagation(forward) 메서드를 구현하면 커스텀한 모듈이더라도nn.Module클래스의 메서드를 사용할 수 있다. - 먼저 forward propagation 메서드에 집중해 보자. 이 메서드는
X를 입력으로 받아 활성화함수(F.relu)를 적용한 hidden representation 을 계산하고 로짓(logits)을 출력한다. - 이 MLP 구현에서는 두 개의 layer 가 인스턴스 변수로 설정된다. 따라서 두 개의 MLP, 즉
mlp1과mlp2를 생성하고 서로 다른 데이터로 학습시키면, 이 모델들은 서로 다른 모델을 나타낼 것이다. - 다음으로
__init__(self)생성자에서 MLP 를 구성할 layer 들을 인스턴스화하고 이 layer 들을 forward propagation 메서드에서 호출한다. 여기서 몇 가지 주요 사항을 기억해야 한다. - 먼저, 커스터마이즈된
__init__(self)메서드 안에super().__init__()를 추가하여nn.Module클래스의__init__()메서드를 호출함으로써 대부분의 모듈에 적용되는 boilerplate 코드를 반복할 필요가 없다. - 이후 두 개의 fully connected layer 를 인스턴스화하여
self.hidden과self.out에 할당한다. - 여기서 새로운 layer 를 구현하지 않는 한, back propagation 메서드나 parameter initialization 에 대해 걱정할 필요가 없다. 구현한 클래스에서 해당 메서드들을 자동으로 생성해준다.
- 모듈 추상화의 중요한 장점은 그 유연성에 있다. 모듈을 서브클래스로 만들어 layer(e.g. fully connected layer class), 전체 모델(e.g. MLP, CNN) 또는 중간 복잡도의 다양한 구성 요소를 생성할 수 있다.
Sequential Module
- 이제
nn.Sequential클래스가 어떻게 작동하는지 좀 더 자세히 살펴보자.nn.Sequential은 다른 모듈들을 연쇄적으로 연결하도록 설계되었다. - 우리가 직접 간소화된
MySequential을 만들기 위해 두 가지 주요 메서드를 정의한다.- 주어진 모듈을 하나씩 목록에 추가하는 메서드
- 입력을 추가한 순서대로 체인에 연결된 모듈들을 통과시키는 forward propagation 메서드
- 아래
MySequential클래스는 기본nn.Sequential클래스와 동일한 기능을 제공한다.
class MySequential(nn.Module):
def __init__(self, *args):
super().__init__()
for idx, module in enumerate(args):
self.add_module(str(idx), module)
def forward(self, X):
for module in self.children():
X = module(X)
return X
mlp = MySequential(nn.LazyLinear(256), nn.ReLU(), nn.LazyLinear(10))
X = torch.rand(2, 3)
output = mlp(X)
print(output.shape) # torch.Size([2, 10])
__init__(self, *args)메서드에서는add_modules메서드를 호출해 인자로 주어진 각 모듈을 추가한다. 이렇게 추가된 모듈은 children 메서드를 통해 접근할 수 있다. 시스템은 이렇게 추가된 모듈을 인식하여, 각 모듈의 parameter 를 적절히 초기화하게 된다.
for child in mlp.children():
print(child)
# Linear(in_features=3, out_features=256, bias=True)
# ReLU()
# Linear(in_features=256, out_features=10, bias=True)
MySequential의 forward propagation 메서드가 호출(mlp(X))되면, 모듈들이 추가된 순서대로 실행된다. 따라서 구현한MySequential클래스를 사용해 MLP 를 다시 구현할 수 있다.- 이러한
MySequential을 사용하는 방식은 이전에nn.Sequential클래스를 위해 작성한 코드와 동일하다.
Forward Propagation
nn.Sequential클래스는 모델 구성을 용이하게 하여, 자체 클래스를 정의하지 않고도 새로운 아키텍처를 쉽게 조합할 수 있게 한다.- 하지만 모든 아키텍처가 단순히 직렬 연결만으로 구현되는 것은 아니다. 더 유연한 구조가 필요할 때는 직접 블록을 정의해야 한다.
- 예를 들어, forward propagation 메서드 내에서 Python 의 while 문과 같은 control flow 를 실행하고자 할 수 있다. 또한, 단순히 미리 정의된 layer 에 의존하지 않고 임의의 수학 연산을 수행하고자 할 수도 있다.
- 지금까지 구현한 네트워크에서 모든 연산은 활성화함수와 parameter 에만 작용되고 있었다. 하지만 경우에 따라 이전 layer 의 결과나 업데이트 가능한 parameter 가 아닌 항을 추가하고자 할 수 있다. 이를 constant parameter 라고 한다.
- 예를 들어, $f(\mathbf{x},\mathbf{w}) = c \cdot \mathbf{w}^\top \mathbf{x}$ 와 같은 함수를 계산하는 layer 를 원한다고 가정하자.
- 여기서 $\mathbf{x}$ 는 입력이고, $\mathbf{w}$ 는 parameter , $c$ 는 최적화 중에 업데이트되지 않는 상수다.
class FixedHiddenMLP(nn.Module):
def __init__(self):
super().__init__()
self.rand_weight = torch.rand((20, 20))
self.linear = nn.LazyLinear(20)
def forward(self, X):
X = self.linear(X)
X = F.relu(X @ self.rand_weight + 1)
X = self.linear(X)
while X.abs().sum() > 1:
X /= 2
return X.sum()
- 위 예제에서는
self.rand_weight가 인스턴스화 시 무작위로 초기화되고 그 이후에는 상수로 유지되는 hidden layer 를 구현한 것이다. - 이
self.rand_weight는 모델의 parameter 가 아니므로 back propagation 에 의해 업데이트되지 않는다. 즉, gradient 가 계산되지 않아 학습 과정에서 constant 로 취급된다. - 이후 네트워크는 이 고정된(fixed) layer 의 출력을 fully connected layer 로 전달한다. 이 때
self.linear는 처음 단계에서 입력값의 크기가 정해지기 때문에, 두번째 fully connected layer 로 전달될 때 차원에 주의해야 한다. 즉 fully connected layer 에서 첫번째와 두번째의 입력값의 크기가 같아야 한다. 이는 다시 말하면, 같은 module 이기 때문에 parameter 를 공유하기 때문이다. - 그리고 출력을 반환하기 전에 모델은 특이한 작업을 수행한다. 출력 vector 의 $\ell_1$ norm 이 1 보다 크면
X를 2 로 나누고, 1 보다 작아지면X.sum()을 반환한다. - 일반적인 neural network 에서 이러한 작업을 수행하지는 않는다. 그러나 이 예시는 neural network 계산 흐름에 임의의 코드를 통합하는 방법을 보여주기 위한 것이다.
fixed_mlp = FixedHiddenMLP()
X = torch.rand(2,20)
fixed_mlp(X) # tensor(0.2227, grad_fn=<SumBackward0>)
- 또한 다양한 모듈 조합 방식을 사용할 수 있다. 아래 예제를 보자.
class NestMLP(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(nn.LazyLinear(64), nn.ReLU(),
nn.LazyLinear(32), nn.ReLU())
self.linear = nn.LazyLinear(16)
def forward(self, X):
return self.linear(self.net(X))
chimera = nn.Sequential(NestMLP(), nn.LazyLinear(20), FixedHiddenMLP())
chimera(X) # tensor(0.1121, grad_fn=<SumBackward0>)
Summary
- 이처럼 각 layer 는 모듈이 될 수 있다. 또한 여러 layer 로 모듈을 구성할 수 있고, 여러 모듈도 하나의 모듈이 될 수 있다.
- 각 모듈은 코드를 포함할 수 있다. 모듈은 parameter initialization 과 back propagation 같은 여러 가지 관리를 수행한다. layer 와 모듈의 순차적 연결은 Sequential 모듈로 처리된다.
댓글 남기기