
[Data Centric] 1. 데이터 제작의 중요성(2)
Lifecycle of an AI Project
- 데이터 제작의 중요성을 확인하기 위한 하나의 관점으로 AI 프로젝트가 어떤 프로세스를 거쳐 진행되는지 생애주기를 살펴보고 왜 데이터가 중요한지를 깨달아 보자.
AI Research vs. AI Production
-
보통 학교/수업/연구 에서는 정해진 데이터셋과 평가 방식에서 더 좋은 모델을 찾는 일을 한다. 즉 모델 구조, 학습 방법을 바꿔가면서 성능이 최대화되는 모델을 찾아간다.
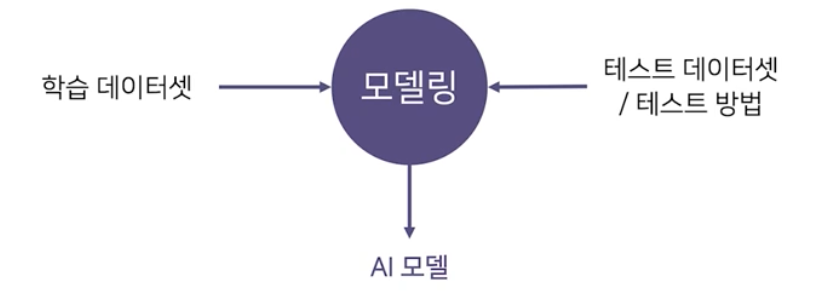
-
그러나 서비스 개발 시에는 데이터셋은 준비되어 있지 않고 요구사항만 존재한다.
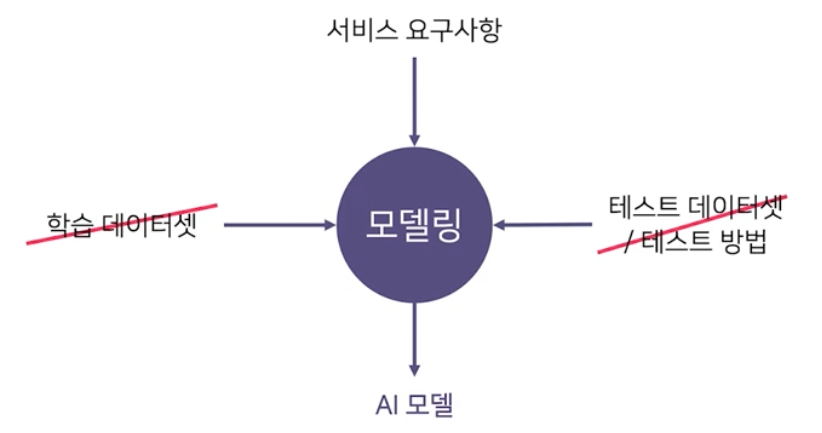
-
또한 실제 서비스에 적용되는 AI 개발 업무의 비율을 볼 때, 상당 부분이 데이터셋을 준비하는 작업이다.
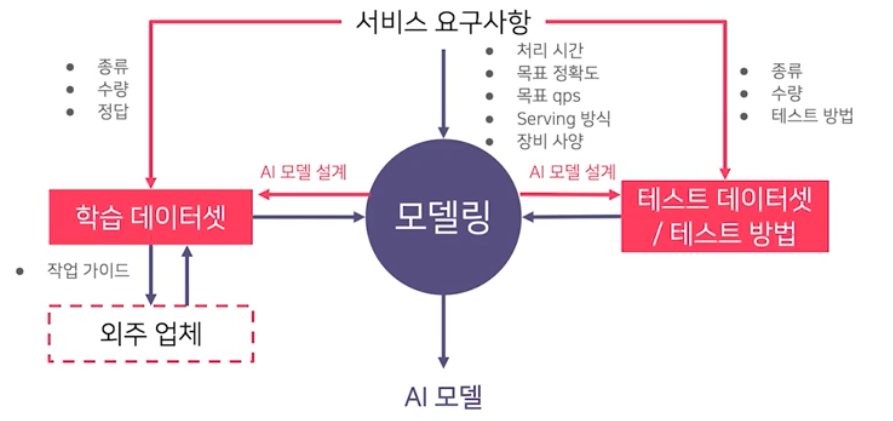
Production Process of AI Model
-
서비스향 AI 모델 개발 과정은 크게 4가지 단계로 구성된다.
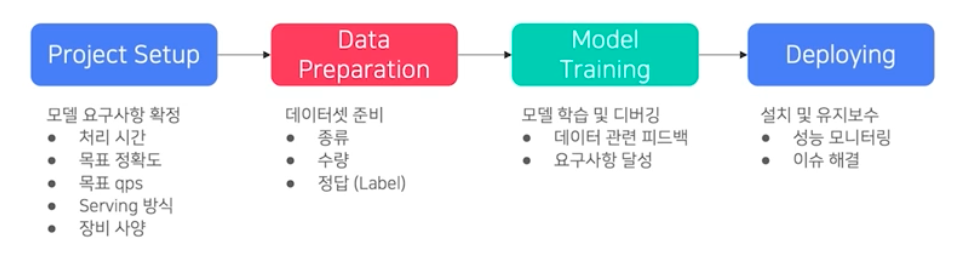
- Project Setup
- 모델 요구사항 확정을 확정한다.
- 처리시간, 목표 정확도, 목표 qps(초당 처리할 수 있는 query의 양. B2C 할 때 사용자 수를 감안해서 장비 세팅을 하기도 한다.), Serving 방식(CPU/GPU, 디바이스), 장비 사양 등등
- 이게 확정이 되어야 개발자들이 열심히 달려갈 수 있다.
- 모델 요구사항은 당연하게 서비스 요구사항에서 정해진다.
- Data Prepration
- 데이터셋 준비 : 종류, 수량, 정답(Label)
- 모델링하는 사람, 모델 학습을 하는 사람 입장에서 볼 때 바로 사용할 수 있는 데이터가 있느냐에 해당된다.
- Model Training
- 모델 학습 및 디버깅 : 데이터 관련 피드백, 요구사항 달성
- 한번에 되지는 않는다. 하다보면 데이터를 들여다 볼 수 밖에 없다.
- 그렇게 되면 데이터 관련 피드백을 데이터 준비하는 사람에게 줘서 데이터가 보완된다.
- 모델 구조를 생각할 때 처리 시간, 목표 정확도 등 요구사항이 충족되어야 한다. 즉 앞에서 정해진 요구사항을 달성하도록 모델링 해야 한다.
- Deploying
- 설치 및 유지보수 : 성능 모니터링, 이슈 해결
- 성능이 계속 처음처럼 안나오는 경우가 대부분이다. 따라서 모니터링이 반드시 필요하다.
- 전체 과정을 본다면, 요구사항을 충족시키는 모델을 지속적으로 확보하는 것이 전체 production 과정의 가장 중요한 가치를 가진다. 왜 지속적이나면, deploy 이후 처음처럼 성능이 안나오기 때문이다.
-
모델을 지속적으로 확보하는 방법은 두 가지가 있다.
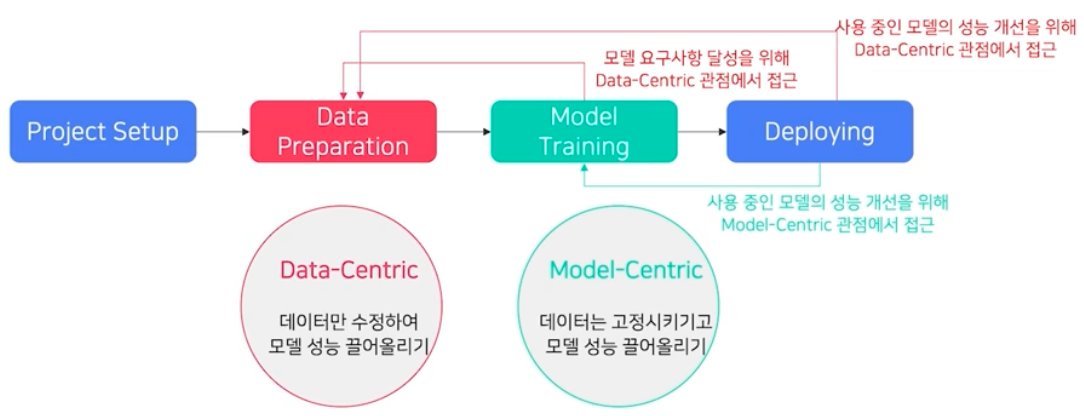
- Data-Centric
- 데이터만 수정해서 모델 성능을 끌어올리는 방법이다. 따라서 Data preparation 단계에서 수정이 일어난다.
- deploy 후 성능이 안나오면 성능을 올려야 하기 때문에 요구사항이 변경된다. 이 때 그 요구사항을 충족시키기 위해서 데이터 중심으로 성능을 끌어올리는 방법인 것이다.
- 데이터를 수정하고 다시 학습시켜서 deploy 한다.
- deploy 하기 전 모델링 할 때 요구사항(목표 정확도 등)을 달성해야 하는데, 이 때 데이터도 바꿔가는 요구사항이 생길 수 있다. 즉 모델 요구사항 달성을 위해 Data-Centric 관점에서 접근하는 것이다.
- 또한 deploy 한 후 사용 중인 모델의 성능 개선을 위해서 Data-Centric 관점에서 접근할 수도 있음.
- Model-Centric
- 데이터는 고정시키고 모델 성능 끌어올리는 방법이다. 모델 혹은 코드만 수정하는 것이다.
- 가장 많이 접하는 방식이다.
- 사용 중인 모델의 성능 개선을 위해 Model-Centric 관점에서 접근한다.
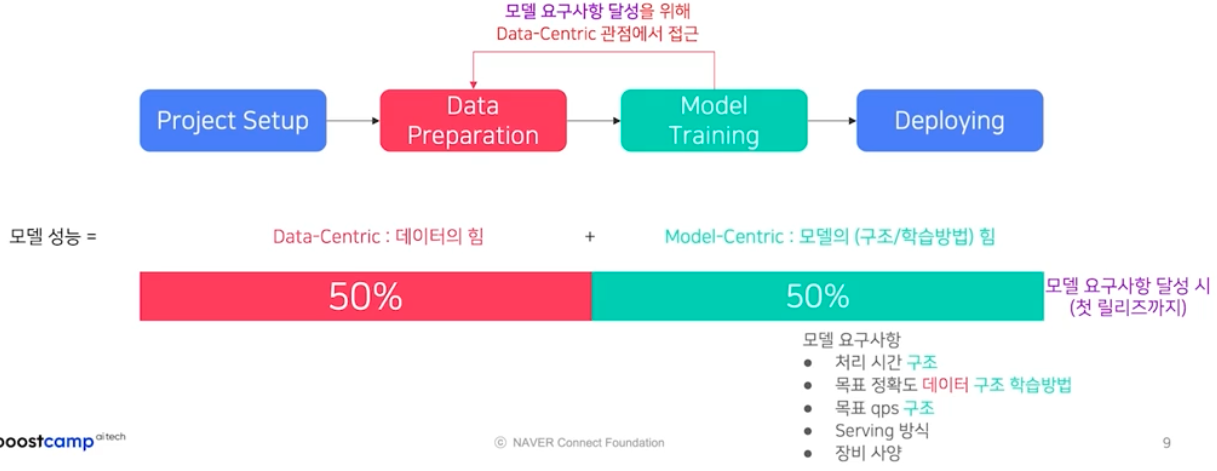
- 모델 성능을 달성하기 위해서 접근하는 data centric, model centric 두 옵션 중 비중은 어떻게 될까? 데이터의 힘으로 성능을 올리는 작업과 모델의 구조 혹은 학습방법을 바꿔서 성능을 올리는 작업의 비중을 보자.
- deploy 하기 전
- 처음 setup 된 모델에 대한 요구사항을 달성하기 위해서 데이터, 모델을 바꿔보기도 한다. 그럴 때 작업량의 비율은 1:1 이다.
-
그 이유는 모델 요구사항의 처리시간, 목표 정확도, 목표 qps 는 모델 구조에 의해서 정해지는 것이다. 요구사항 중 반 정도는 모델 구조 자체에서만 비롯되기 때문에 모델 구조를 신경써서 짜야한다.
- deploy 한 후
- 요구사항이 충족되어 한 번 deploy 를 했을 때, 처음 project setup 에서 생각 못한 이슈가 발생할 수 있다. 이 때도 data, model 관점에서 접근할 수 있다.
-
그러나 이 때는 data 의 힘이 더 크다. 또한 모델에서는 구조 보다는 학습방법론의 비율이 높다.
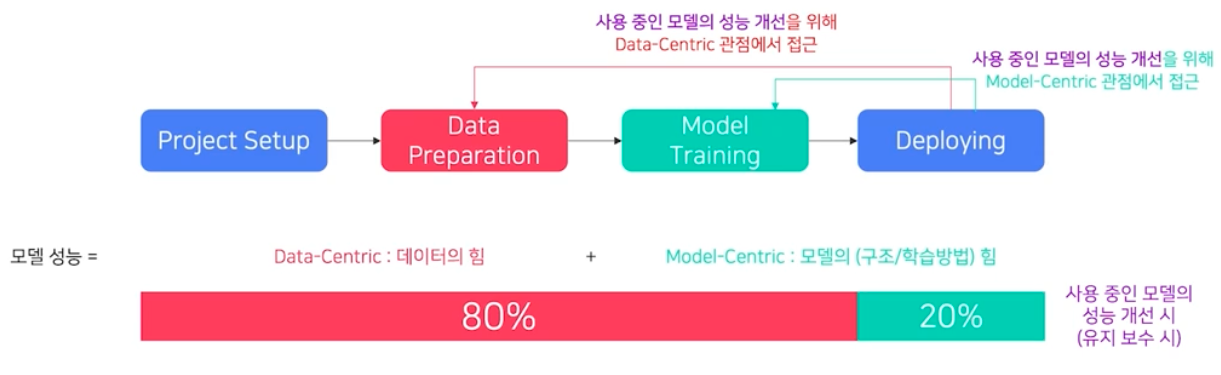
- 왜냐하면 1) 서비스 출시 후에는 정확도에 대한 성능 개선 요구가 제일 많다. 속도가 느리다는 것은 project setup 단계에서 어느정도 알 수 있다. 따라서 서비스 출시 후에 나오는 VOC(성능 개선 요구사항)는 정확도에 대한 성능 개선 요구사항이 많다. 2) 이 때 정확도 개선을 위해 모델 구조를 변경하는 것은 처리속도, qps, 메모리 크기 등에 대한 요구사항 검증도 다시 해야 하므로 비용이 크다. 즉 모델 구조를 변경하면 여파가 많다는 것이다. 따라서 가능하면 서비스 출시 이후 모델 구조를 안 건드리는 것이 좋다.
- 이를 통해 서비스 출시 이후 정확도 개선 시, data-centric 관점에서 개선하는 것이 비용이 적음을 알 수 있다.
-
따라서 데이터를 중심으로 모델 성능을 끌어올리는 방법의 비중이 크고, 데이터가 중요함을 깨달을 수 있다.

Data-related tasks
- 요구사항 충족과 모델 성능의 달성을 위해서 모델 출시 전에는 data 와 model 의 비중이 비슷했고, 출시 후에는 데이터의 힘이 더 컸다.
- 그렇다면 Data Centric 한 세부적인 작업들은 뭐가 있을까?
- 데이터에 관련된 일은 모델에 관련된 일들보다 어떻게 하면 좋을지에 대해서 상대적으로 알려져 있지 않다.
- 모델 구조에 대한 hint 들은 여러 논문들에 많이 언급된다. 실제로 AI, 딥러닝 관련 출간 논문에서 데이터를 다루는 논문과 모델 쪽 논문의 비율을 볼 때, 거의 99% 가 모델 구조, 모델 학습방법에 대한 일이다.
- 학계에서 데이터를 다루기 힘든 이유는 좋은 데이터를 많이 모으기 힘들고, 라벨링 비용이 크고, 작업 기간이 오래 걸리기 때문이다. 학교에서는 정해진 시간 내에 연구적 결과물이 나와야 하기 때문에 데이터 쪽에 접근하기 특히 어렵다.
- 또한 현업에서도 보통 힘들어 하는 것이 모델링 외적인 부분이다.
Data Labeling 의 어려움
-
데이터 라벨링 작업은 생각보다 많이 어렵다. 또한 데이터가 많다고 모델 성능이 항상 올라가는 것은 아니다.
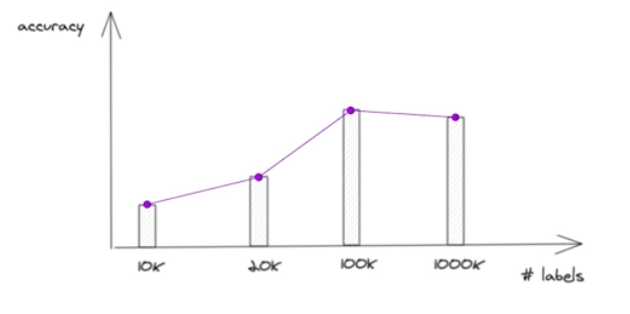 데이터가 많다고 모델 성능(정확도)가 항상 올라가는 것은 아니다.
데이터가 많다고 모델 성능(정확도)가 항상 올라가는 것은 아니다. - 라벨링 된 데이터 내에서 라벨링 잘못 되었거나, 일관되지 않을 수 있다. 즉, 라벨링 결과에 대한 노이즈(라벨링 작업에 대해 일관되지 않음의 정도)를 상쇄할 정도로 깨끗한 라벨링 데이터가 많아야 한다. 그래야 노이즈를 무시하고 제대로 학습이 이루어진다.
- 경험적으로 잘못 작업된 라벨링 결과를 모델이 학습 시 무시하게 하려면 적어도 깨끗이 라벨링된 결과가 2배 이상 필요하다.
- 회귀 분석을 가지고 예시를 들어보자. 아래 예시 그래프에서는 입력값이 있고 출력값이 있을 때, 올바른 참 관계가 초록색 점으로 나타난다. 참 관계를 얻기 위해서 데이터를 모으고 annotation 후 모델을 학습시켰을 때, 결과가 어떻게 나오는지 보자.
-
데이터가 작고 노이즈가 많은 경우
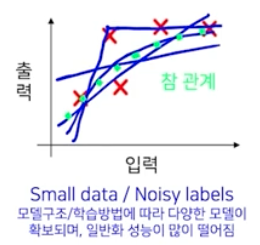
- 노이즈가 적다는 것은 모델의 출력이 참 관계에 올라간다는 것이다. 반대로 라벨링이 잘못된, 노이즈가 많으면 참 관계에서 벗어난 지점에 점들이 찍힌다.
- 모델구조/학습방법에 따라 다양한 모델이 확보되며, 일반화 성능이 많이 떨어진다.
-
데이터가 많고 노이즈도 있는 경우
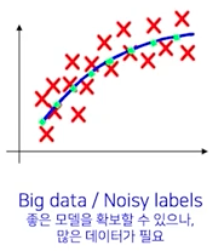
- 참 관계를 찾아낼 수는 있다. 그러나 이 때는 라벨링 노이즈를 상쇄할 정도로 참 관계에 해당하는 좋은 샘플들이 많이 있었기 때문에 참 관계를 찾을 수 있는 것이다.
- 즉 좋은 모델을 확보할 수 있지만, 라벨링 노이즈를 상쇄하기 위해서 많은 데이터(깨끗한 라벨링 데이터를 포함한)가 필요하다.
-
적은 데이터지만 라벨링이 잘 된 경우
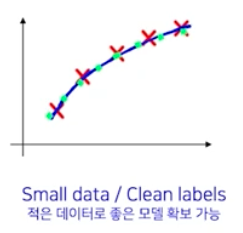
- 적은 데이터로 좋은 모델 확보가 가능하다.
- 그러나, 적은 데이터도 골고루 있어야지 너무 유사한 데이터만 있으면 안된다.
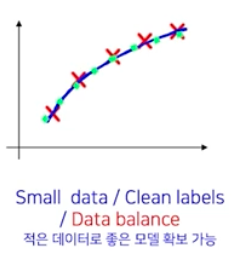
- 즉 적은 데이터로 깨끗하기만 해선 안된다. 데이터가 골고루 뽑히면서, 라벨링도 깨끗히 되면 좋은 모델을 확보할 수 있다.
-
적은 데이터로 깨끗하게 라벨링 되어 있지만, 데이터가 imbalance 한 경우
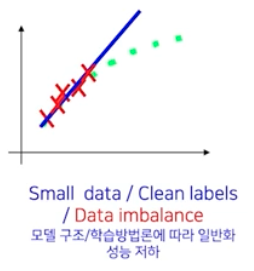
- 만약 적은 데이터로 깨끗하게 라벨링이 되었더라도, 데이터가 골고루 있지 않다면 위와 같은 그래프를 얻게된다.
- 따라서 되도록 1) 골고루(data balance) 2) 일정하게 라벨링 된(라벨링 노이즈가 적은) 데이터가 많아야 한다.
-
-
라벨링 노이즈와 일반 상황에서의 데이터 분포는 연관이 있다.
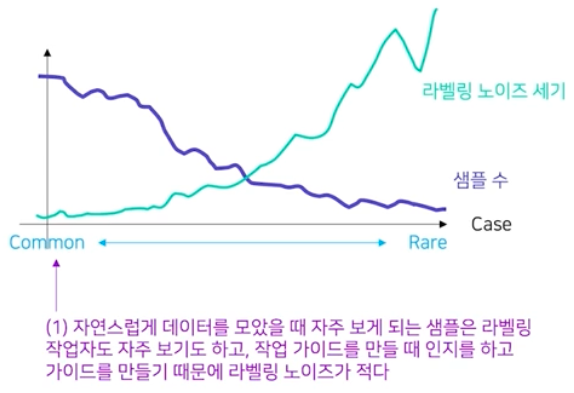 데이터 수가 적은 특이 케이스에서는 라벨링 노이즈 세기가 높다.
데이터 수가 적은 특이 케이스에서는 라벨링 노이즈 세기가 높다. - 즉 샘플 수가 적을수록 라벨링 노이즈 세기가 커진다. 왜냐하면 굉장히 드물게 관찰되는 데이터의 경우에는 작업 가이드에서 다루지 않을 수 있고 작업자 별로 달리 생각하여 작업할 가능성이 크기 때문이다.
- 따라서 일반적으로 데이터를 모을 때, 흔한 데이터의 경우는 작업 가이드와 어노테이션 작업자들이 잘 인지하여 라벨링이 꽤 일관된다. 그러나 희귀한 데이터의 경우 가이드에서 빠질 수도 있고 작업자들도 개개인마다 다르게 해석해서 노이즈가 클 수밖에 없다는 것이다.
-
예를 들어 OCR task 에서 단어 단위로 사각형으로 annotation 하는 예시를 들어보자.





- 좌측 상단 글자의 경우 common sense 가 있어서 어느정도 일관된다.
- 그러나 손글씨의 경우 작업자마다 annotation 결과가 달라질 수 있다. 위 예시에서는 취소선, 쌍따옴표에 대해 작업자들이 다르게 해석했다.
- 이렇게 라벨링 가이드에 포함되지 않는 희귀 케이스가 나오면, 이를 가이드에 포함시켜서 업데이트 되어야 한다.
- 또한 OCR task 에서 글자 영역 내에 최대한 다른 글자 영역이 안 들어오게 해서 모델이 오인식 하지 않도록 박스 크기를 줄이는 경우도 생길 수 있다. 이렇게 되면 라벨링 결과가 달라져 라벨링 노이즈가 생기는 것이다. 따라서 글자 영역 겹침에 관해서도 라벨링 가이드에 포함되어야 한다.
- 또한 띄어쓰기, 라벨링 단어 단위 등도 정해주어야 한다.
- 이처럼, 이미지가 희귀해질수록 해석이 점점 다양해진다. 그렇게 되면 라벨링 노이즈가 커지게 된다.
Data Imbalance 의 어려움
- Data Labeling 이 깨끗한 라벨링, 일관된 라벨링에 관한 것이다. 그러나 위에서 봤듯이 우리는 데이터를 골고루 갖추는 것도 중요하다.
- 데이터를 되도록이면 골고루(희귀케이스, 일반케이스 비율 고르게), 일정하게 라벨링(라벨링 노이즈가 적게)된 데이터가 많아야 한다는 것이다.
-
이러한 데이터 불균형을 바로 잡기 또한 많이 어려운 작업이다.
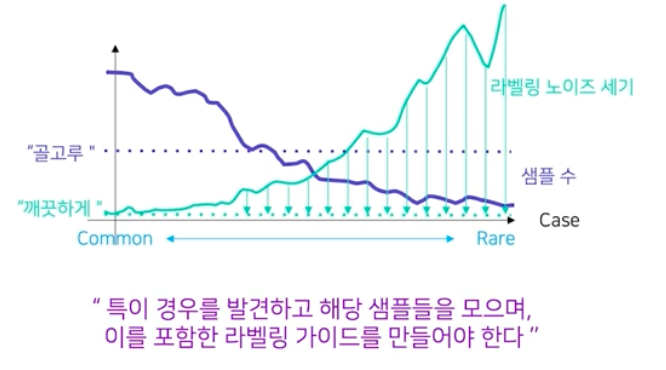
골고루, 깨끗하게
- 골고루 가 의미하는 것은 데이터를 그냥 모으면 안되는 것을 의미한다. 골고루 모으겠다는 것은 특이한 경우를 의도적으로 신경을 많이 쓰고 의도적으로 좀 더 많이 모아줘야 한다.
- 라벨링 노이즈가 없어지도록 깨끗하게 모은다는 것은 특이한 경우에 대해서 어떻게 어노테이션 할 지가 라벨링 가이드에 잘 반영이 되어 있어야 한다.
- 이러한 작업을 효율화하기 위한 방법은 2가지가 있다.
- 작업하고 있는 해당 task 에 대한 경험치가 잘 쌓여야 한다.

- 결국 도메인 지식이 많을수록 예외 경우, 특이 케이스에 대해서 미리 인지를 할 수 있다.
- 글자 영역 검출에서 혼란을 야기하는 케이스들에 대해 경험치가 있어야 한다. 특이 케이스에 대해서 인지하고, 이런 것들이 잘 반영된 어노테이션 가이드를 만들려고 노력해야 한다.
- 실제로 테슬라에서는 자율 주행에서의 예외 경우를 트리거라 지칭하고 221가지를 정의한 후 세심히 관리한다. 이를 기반으로 데이터셋을 모으고, 평가방법 등을 체계적으로 관리하는 것이다.
- 완벽하게 모든 경우를 알고 데이터를 모으고 라벨링 가이드를 만드는 것은 불가능 하다는 것을 인지하고 이를 반복적이고 자동화된 작업으로 만들어가야 한다.
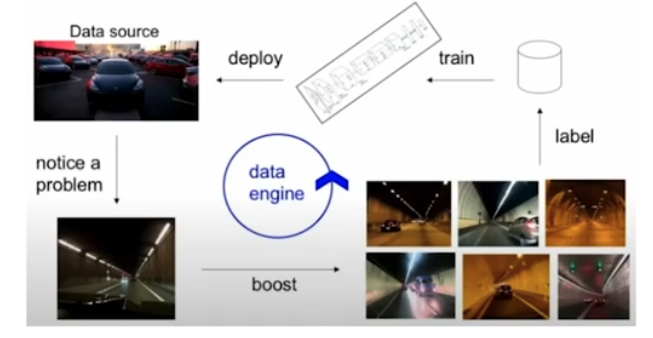 Data Flywheel
Data Flywheel
- 잘못된 경우가 발견되면 데이터를 더 모으고 라벨링을 잘해서 학습시켜야 한다. 그러나 잘못된 경우는 보통 한 번으로 끝나지 않는다. 반복이 중요하다. 따라서 이런 흐름 자체를 원활히 하기 위해서 tool 들을 갖춰나가는 것이 좋다.
- “Labeling is an iterative process”
- 이러한 작업을 잘하기 위한 한 번의 사이클을 Data Engine 혹은 Data Flywheel 이라고 부른다.
- 즉 이 사이클을 효율화하기 위한 tool 들을 마련하는 것에 집중하는 것이 오히려 낫다는 것이다.
- 작업하고 있는 해당 task 에 대한 경험치가 잘 쌓여야 한다.
Data Engine / Flywheel
- Data Engine / Flywheel 을 위한 tool 을 만든다고 한다면 어떤 모습일까?
- SW 2.0 개발 작업 중에는 Data Engine 에 속한 작업이 많이 필요하다.
- 그렇다면 Data Engine 을 위한 tool 은 Data engine 의 pipeline 을 효율적으로 갖춘 IDE(Integrated Development Environment) 라고 부를 수 있다.
- Data Engine 을 위한 IDE 를 잘 만드는 것이 전체 AI 모델의 성능을 올리는데 효과적일 수 있다.
- SW 1.0 의 IDE 는 VScode 등 여러 개발 tool 이 존재한다. 그렇다면 SW 2.0 에서 Data Engine, Flywheel 관점에서 IDE 는 어떤 기능을 갖춰야 할까?
- 데이터셋 시각화
- 데이터/레이블 분포 시각화
- 레이블 시각화
- 데이터 별 예측값 시각화 등등을 시각화 하면서 어떤 데이터가 예외이고 더 모아야 하는지를 알려줄 수 있어야 한다.
- 데이터 라벨링
- 특이한 경우를 다루기 위해 어노테이션 가이드가 계속 개선되고, 그 개선된 가이드에 맞게끔 작업자들이 어노테이션을 해야한다. 그 어노테이션 작업을 효율화하기 위한 여러 데이터 라벨링 기능이 있어야 한다.
- 라벨링 UI
- task 특화 기능 (bounding box, polygon 등)
- 라벨링 일관성 확인
- 라벨링 작업 효율 확인
- 자동 라벨링
- 데이터셋 정제
- 데이터를 한 번 더 깨끗하게 만드는 작업이 필요하고 그 기능이 담겨 있어야 한다.
- 반복 데이터 제거
- 라벨링 오류 수정
- 데이터셋 선별
- 라벨링이 되지 않은 데이터는 굉장히 많다. 어떤 데이터를 모델 성능 향상을 위해서 라벨링 해야 할까?
- 모델이 deploy 되어 돌아가고 있고, 모델의 성능 개선을 위해 라벨링이 안된 데이터에서 가져와서 성능을 올릴 수 있다. 이 때 어떤 데이터를 가져와야 할 지에 대해서 신경을 써야 한다.
- 데이터셋 시각화
정리
- 실제 실무에서 Data Centric 접근으로 deploy 된 모델의 성능을 끌어올리는 경우가 많다.
- 이 때 라벨링되지 않은 데이터를 가져온 후 새로 라벨링하여 모델에 새롭게 학습시켜줄 수 있다. 또한 deploy 하기 전이라도 데이터를 라벨링해서 모델에 학습시켜줄 수 있다.
- 따라서 라벨링이 데이터 제작을 대표하는 작업이다. 그리고 라벨링의 중요도는, SW 2.0 에서 코딩과 같다.
- 왜냐하면 SW 2.0 에서 데이터의 중요도가 높은데, 그 데이터가 모델의 성능에 도움이 될지를 좌우하는 것이 라벨링이기 때문이다.
- 실제로 SW 2.0 IDE 의 상당 부분은 데이터에 관련된 모듈들이다. 대표적으로 DVC 등이 있다.
댓글 남기기