
[Data Centric] 1. 데이터 제작의 중요성(1)
Data
- 한 AI 모델의 성능은 “모델 구조 + 데이터 + 최적화“ 의 조합으로 정해진다.
- 1차 산업 혁명에서 “석탄” 을 가지고 “증기기관” 이 움직일 수 있었던 것처럼, 오늘날 딥러닝의 시대에서는 “데이터” 를 가지고 “모델” 이 움직인다.
- 이처럼 실무에서 가장 많이 접하는 것 중 하나가 “데이터” 에 관한 일이다. 데이터가 있어야 모델을 학습시킬 수 있고, 데이터가 모델의 성능에 미치는 영향도 크다.
-
실무에서의 딥러닝의 시작인 데이터에 대해서 알아보자. 네이버 부스트캠프 AI Tech 6기 에서 배운 내용을 기반으로 이 포스트를 정리한다.

Software 1.0 vs. Software 2.0
- Software 1.0 과 Software 2.0 를 비교해보면 데이터 제작의 중요성을 느낄 수 있다.
Software 1.0
- Software 1.0 은 딥러닝이 아닌 Software 다. Python, C++ 같은 언어를 사용해서 명시적인 지시사항을 사람이 코딩하는 것이 Software 1.0 에 속한다.
- Software 1.0은 4가지 개발과정을 따른다.
- 문제 정의
- 큰 문제를 작은 문제들의 집합으로 분해
- 개별 문제 별로 알고리즘 설계
- 개별적인 솔루션들을 합쳐 하나의 시스템으로
- 예시를 들어보자.
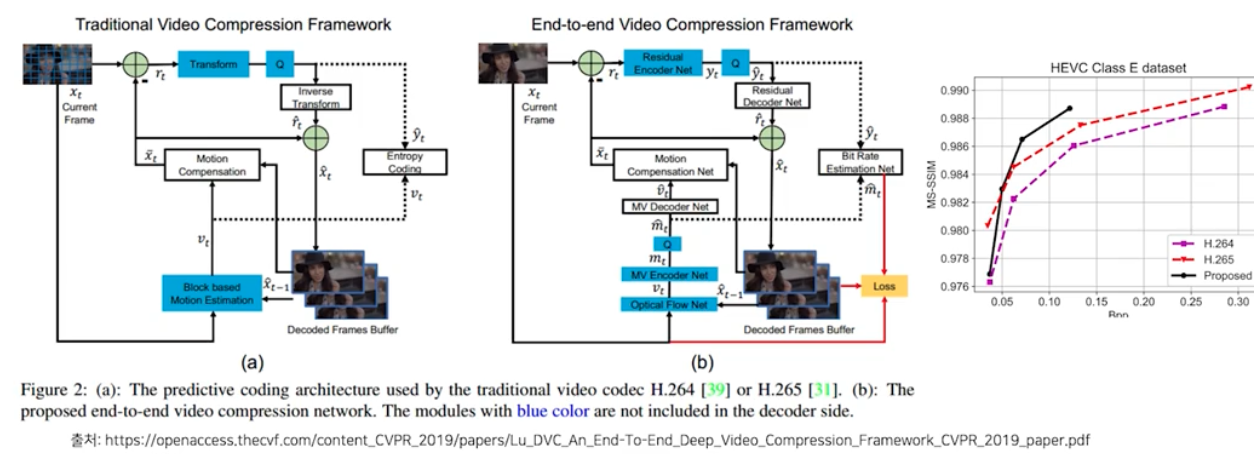
- 문제정의 : 비디오를 고화질로 촬영하면 용량이 점점 커지는데 적은 용량으로 품질 저하 없이 저장할 수는 없을까? $\rightarrow$ 비디오 내 품질 저하 없이 아주 적은 용량의 데이터로 표현해서 저장(video encoder)하고, 재생할 때 원 비디오로 복원(decoder)하자! (Video Codec)
- 큰 문제를 작은 문제들의 집합으로 분해
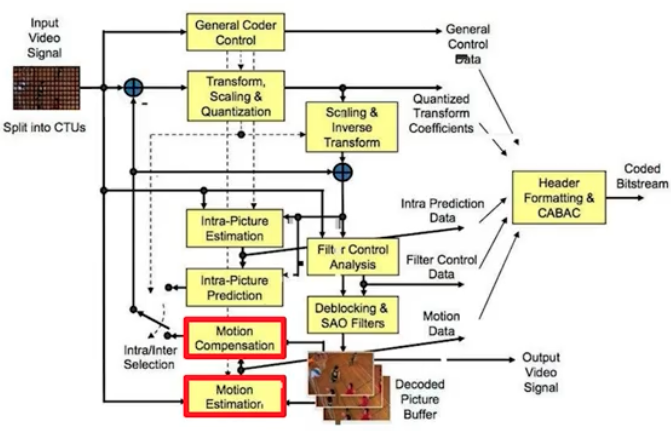
- 개별 문제 별로 알고리즘 설계
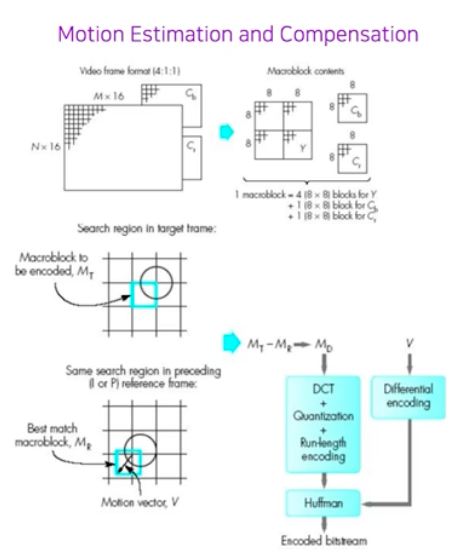
- 솔루션들을 합쳐 하나의 시스템으로
- 이 4가지 개발과정은 계속해서 큰 성과를 이루었다.
- 실제로 여러 모듈들이 software 1.0 으로 개발되어 있음.
- 예를 들어 TCP/IP Stack(internet), Android Stack(smartphone) 등이 있다.
- Visual Recognition Task 도 처음에는 software 1.0 철학으로 개발되었다.
- Human Detection 은 아래와 같은 task 이다.
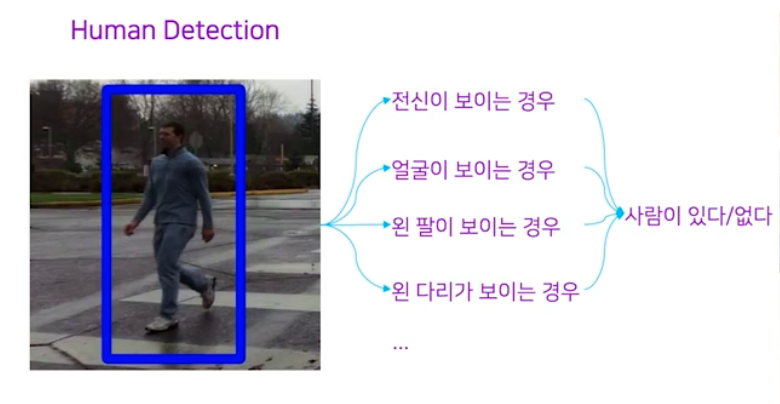
- Human Detection task 의 Deformable Parts Model(DPM) 알고리즘을 살펴보면 Software 1.0 철학에서 가장 잘됐던 방법론을 따름을 알 수 있다.
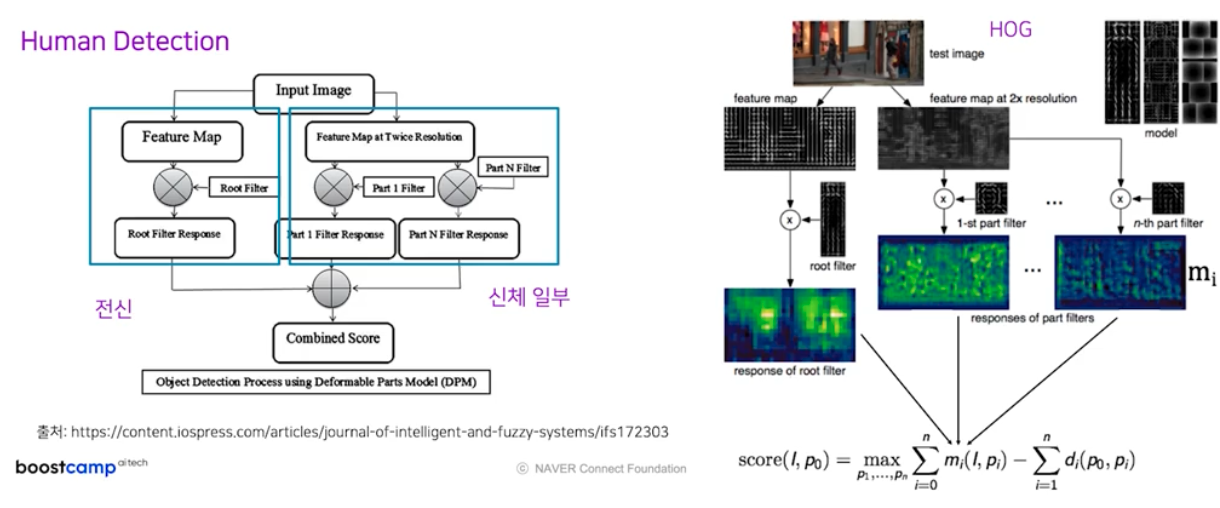
- software 1.0 처럼 작은 문제로 쪼개는 파이프라인을 그대로 따라간다. 즉 입력 이미지에 대해서 전신, 신체 부위별 모듈을 적용시킨 것이다.
- faeature map 을 뽑을 때에는 HOG(Histogram of Oriented Gradients) 연산을 사용했다. HOG 연산을 통해 사람 전신이 있을 확률이 구한다.
- Histogram of Oriented Gradients 연산
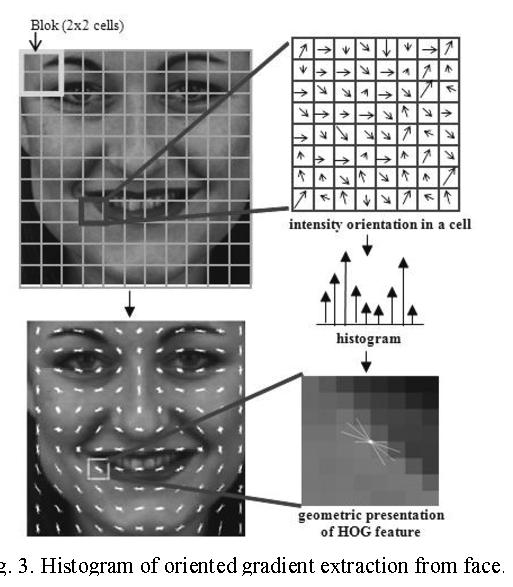
- 여러 개의 cell 이 모인 block 단위로 normalize 를 진행한다.
- 이미지의 수평 및 수직 gradient 를 계산하는 부분이 포함되어 있다.
- gradients 를 바탕으로 주어진 이미지의 유용한 특징을 추출하는 알고리즘이다.
- 어느정도 shift 에도 강인하다.
- gradient 를 이용해서 cell (8x8 pixels) 별로 histogram 을 만들어 feature를 계산한다.
- 이 HOG 연산들의 값을 합쳐서 하나의 수치로 만든다. 이후 Classification(사람인지 아닌지)에는 SVM 을 이용한다.
- Support Vector Machine(SVM)
- 각 클래스 샘플 중 다른 클래스 샘플과 가장 가까운 샘플 (support vector) 간의 거리를 마진 값으로 사용한다.
- Support vector란 각 클래스 셋의 샘플 중 클래스의 경계에 가장 가까운 샘플들을 의미한다.
- 다른 클래스간의 마진을 최대화 하는 것이 목적함수이다.
- Binary classification을 위한 알고리즘이다.
- 선형분리가 어려울 경우 slack variable을 도입하여 soft-margin SVM으로 수정할 수 있다.
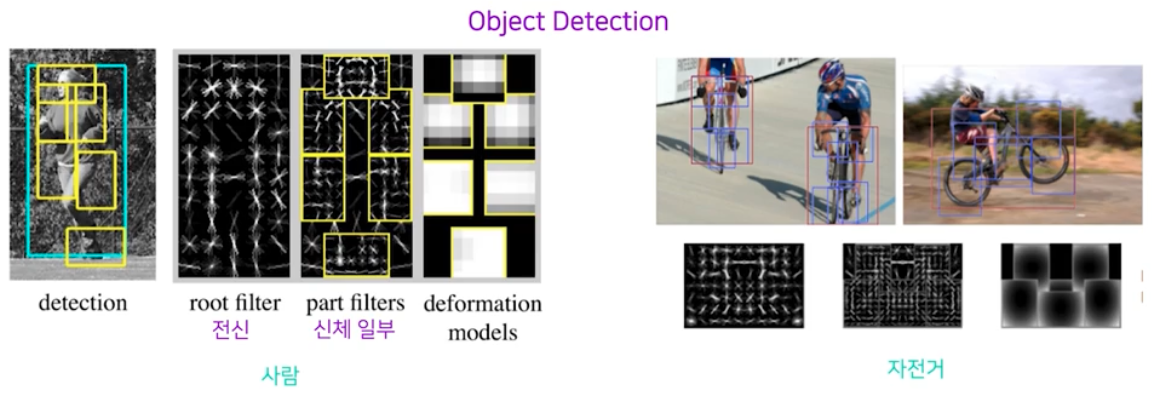
- 이러한 DPM-v1 알고리즘은 2008년에 VOC 2007 dataset 대상으로 mAP 기준 21.0% 성능을 가져왔다. 지금 보면 매우 안 좋은 성능이다. 이후 발전을 거듭하여 2014년 DPM-v5 가 33.7% 를 뽑아낸 바 있다.
- Detection 분야에서 이에 대한 해결책으로 결국 Software 2.0 이 등장했다. 2020년 기준으로 Software 2.0 방법을 쓴 모델(딥러닝)이 89.3% 의 성능을 뽑아냈다.
- 이를 보면 이미지 인식 기술에서는 Software 2.0 방식이 더 잘 동작함을 알 수 있다. 물론 항상 맞다고는 볼 수 없다.
-
아래의 그림은 Object Detection 에 대한 주요 논문 현황으로 Software 2.0 이후 연구 결과가 많이 소개된다.
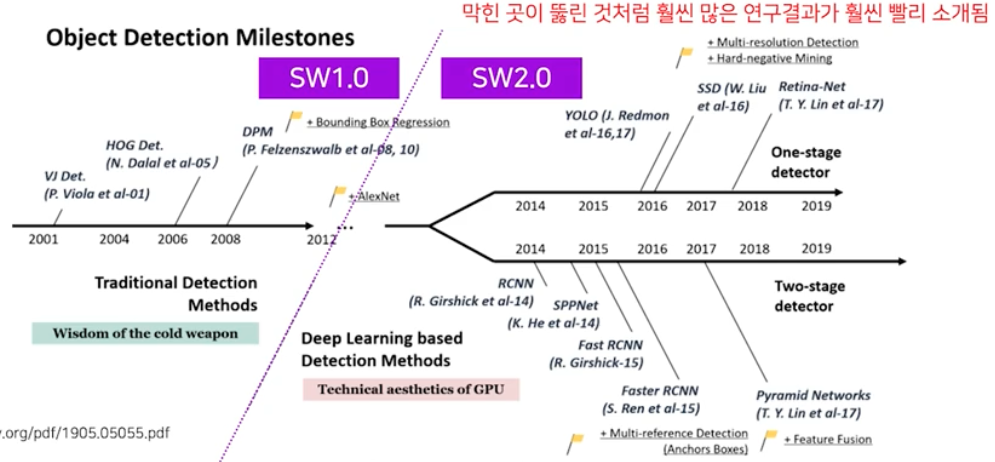
Software 2.0(Deep Learning)
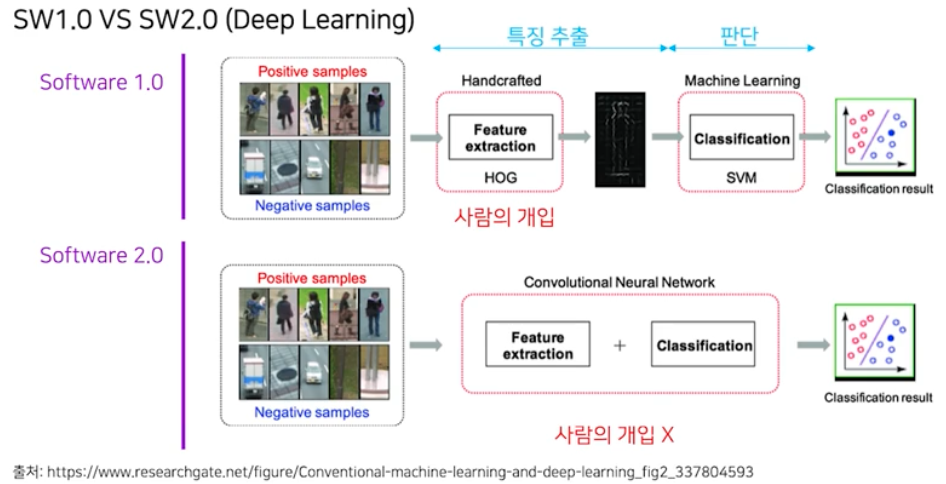
- Software 1.0 과 2.0의 차이는 전체 파이프라인에 대한 연산을 정할 때 사람의 개입이 1.0에서는 다 개입 했었고 2.0에는 거의 개입을 하지 않는 것에 있다.
- 위에서 살펴본 HOG 알고리즘은 histogram 을 만들 때 bin 의 범위를 인간이 설정하는 등 수동적으로 설계된다.
- Software 2.0 에서는 어떻게 사람의 개입 없이 연산들이 정의될 수 있을까?
-
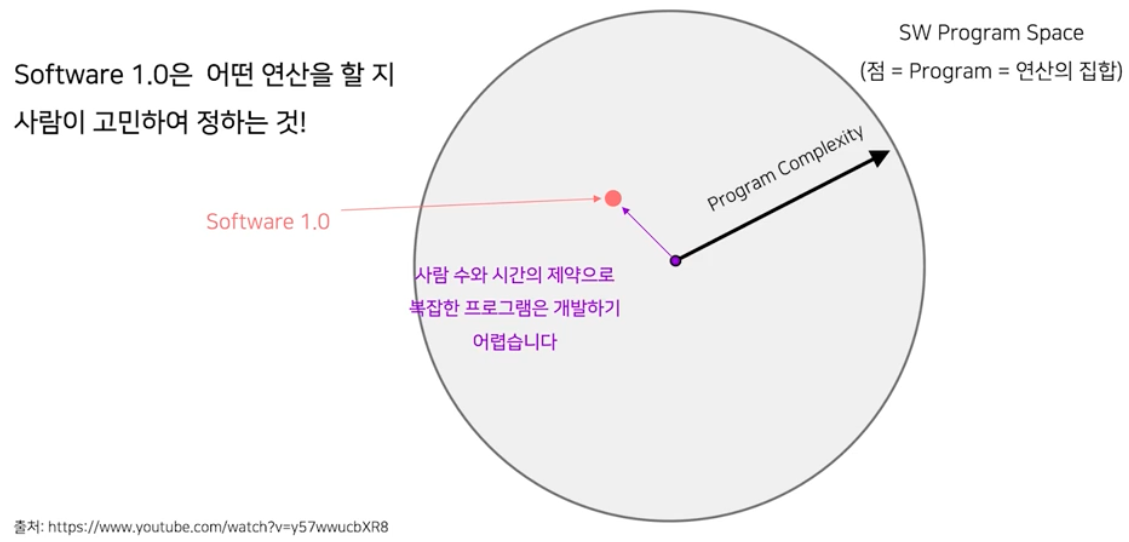
먼저 Software 1.0 은 아래와 같이 사람 수와 시간의 제약으로 복잡한 프로그램의 개발은 물리적으로 어려움이 있었다.
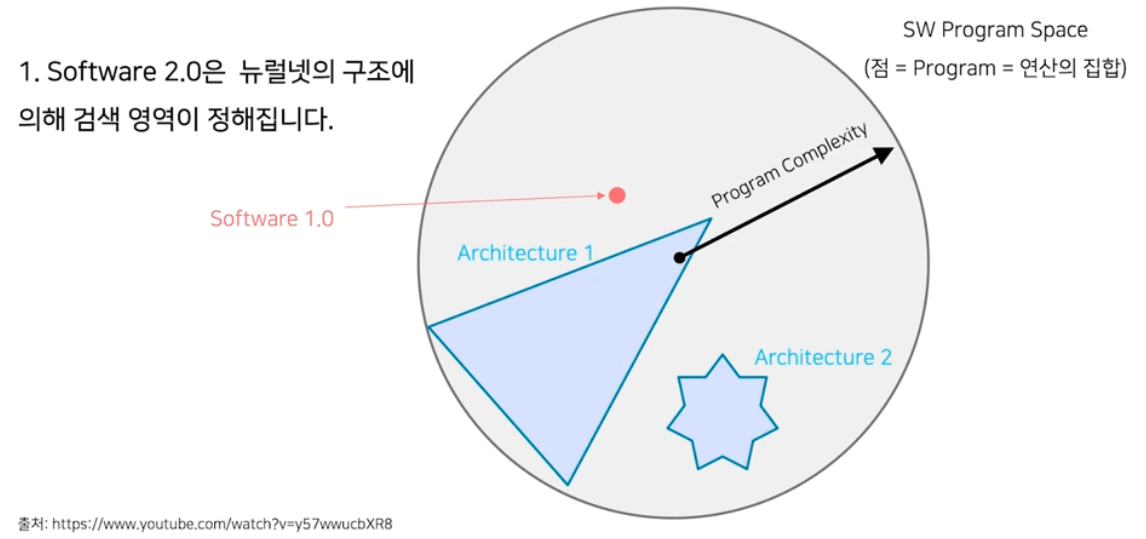
- 반면에 Software 2.0 은 아래의 과정을 통해서 하나의 프로그램을 찾는다.
- NN 구조를 짠다. 이는 SW program space 에서 machine 이 자동으로 찾아가는 검색 영역을 정한다고 볼 수 있다.
- 영역이 정해졌으면 최적화를 한다. 최적화를 통해서 목적에 제일 부합하는 프로그램을 찾는 것이다.
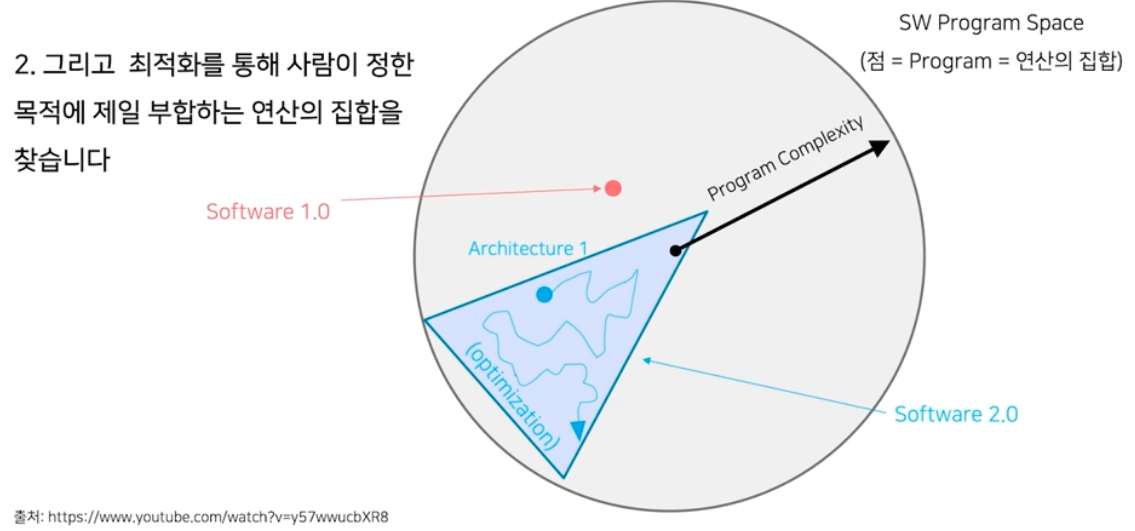
- 데이터와 최적화 방법에 의해서 제일 좋은 프로그램을 찾아간다. 그 과정 자체가 자동으로 이루어지는 것이다. 이 때 데이터와 최적화 방법에 따라 시작점, 도착점이 다를 수 있다.
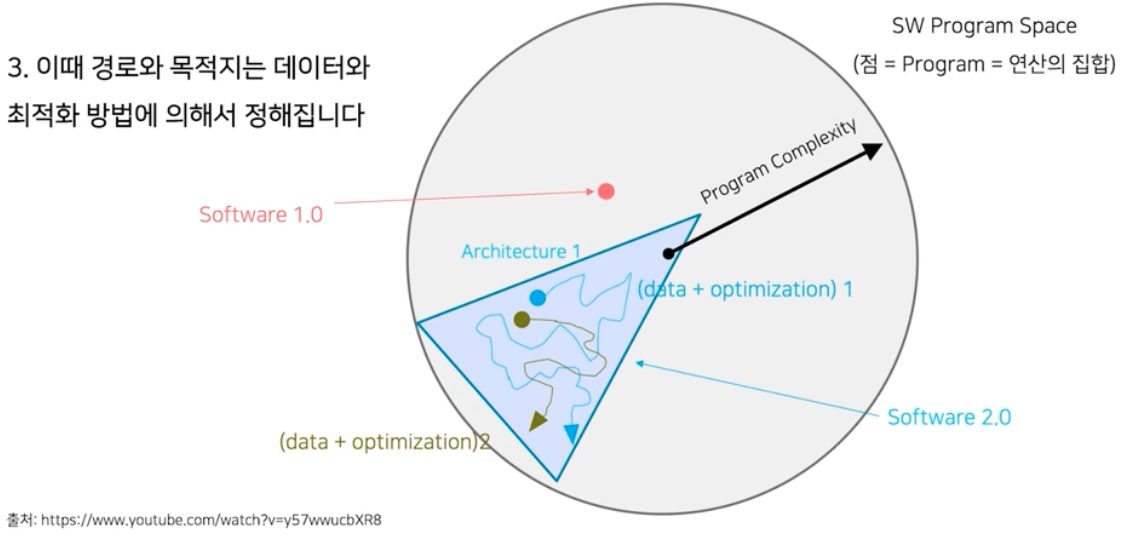
- NN 구조를 짠다. 이는 SW program space 에서 machine 이 자동으로 찾아가는 검색 영역을 정한다고 볼 수 있다.
- 이런 방식으로 프로그램을 정해가는 것이 바로 Software 2.0 이다.
- 정리하면, Software 1.0 은 사람이 고민하여 프로그램을 만든 것이고, Software 2.0 은 AI 모델의 구조로 프로그램의 검색 범위를 한정하고, 데이터와 최적화 방법을 통해서 최적의 프로그램을 찾는 것이다.
- 여기서 AI 모델의 성능이 “모델 구조 + 최적화 방법 + 데이터” 로 정해지는 것을 다시 보면, AI 모델의 성능은 “코드 + 데이터” 라고 볼 수 있다. 모델의 구조와 최적화 방법은 코드로 구현하는 것이기 때문이다.
- 물론 모델 구조 설계에도 사람의 개입이 들어간다. 그러나 예전에 비해 점점 개입의 정도가 줄어들었다. 그리고 요즘에는 최적화에 더 신경을 쓴다.
- 데이터 측면에서는 DPM, HOG 등은 사람의 개입이 전부였기 때문에, 사람이 볼 수 있는 데이터 양에 한계가 있었다. 적은 데이터를 보면서 고민해서 하드 코딩으로 고안한 연산을 만들어가는 작업이 많았던 것이다.
-
이제 아래 그림 처럼 Software 2.0 으로 넘어오면서 사람의 개입은 점점 줄어들고, 더 많은 데이터를 활용하게 된다.
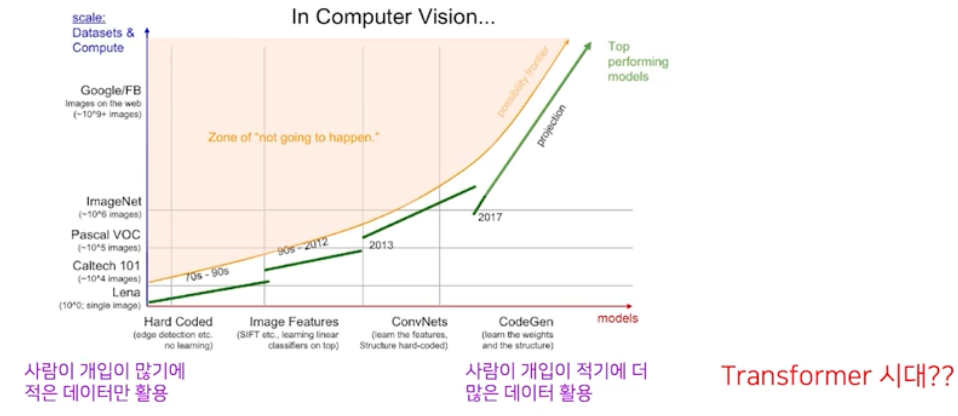
- Software 2.0 은 Computer Vision 분야말고도, 다양한 분야에서 성과를 내고 있다. Transformer 가 그 대표적인 예이다.
Software 1.0 + Software 2.0
-
거시적 관점에서 보자.
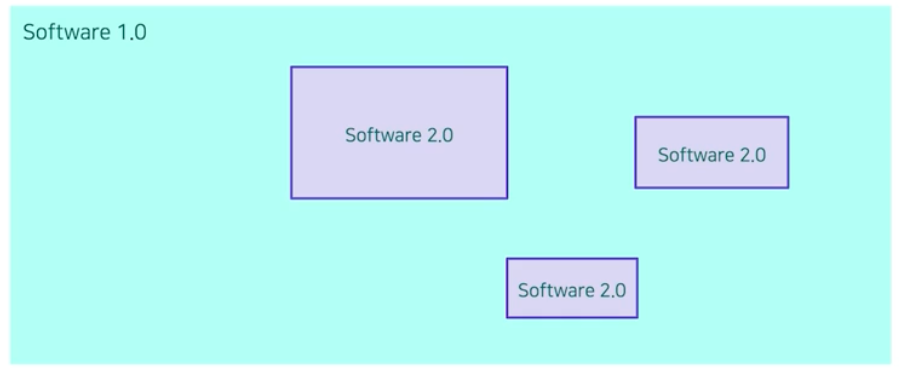 SW 1.0 내부에 SW 2.0이 있다.
SW 1.0 내부에 SW 2.0이 있다. - 전체 시스템을 생각해보면 프로그래밍 언어 같은 보통의 레거시 시스템은 SW 1.0 으로 작성되어 있다.
- 이 SW 1.0 안에서 딥러닝과 같은 특정 모듈이 SW 2.0 으로 개발된다.
- 파이썬으로 모델 구조를 짜고, 최적화를 구현하고 데이터를 처리하는 게 그 예시가 될 수 있다.
- 현재는 SW 2.0 의 기술 발달로 점점 그 차지하는 영역이 커지고 있다.
-
위에서 예시를 들었던 비디오 코덱도 예외가 아니다. 지금은 NN 조합으로만 구성이 되기도 한다. 그리고 실제로 사람의 고민만으로 이루어진 것보다 NN 조합이 더 효율이 좋다.
- 즉 SW 1.0 과 SW 2.0(딥러닝) 개발 방법이 근원적으로 다르고, SW 2.0 이 대세라고 하여 SW 1.0 을 아예 안쓴다거나 하는 것은 아니다. 파이썬, Git 등의 SW 1.0 은 지금도 많이 사용하고 버전업도 되고 있다. Huggingface 와 같은 대표적인 SW 2.0 은 SW 1.0 위에서 더더욱 발전의 가속을 받고 있는 것처럼 느껴진다.
- 여기서 얻어갈 것은, SW 2.0 에서는 사람의 개입이 적기에 더 많은 데이터를 활용할 수 있고, 그 데이터가 프로그램의 성능에 큰 영향을 줌을 아는 것이다. 이로써 데이터의 중요성을 알 수 있다.
- 실제로 AI 의 성능에 한 축을 데이터가 담당하고 있기 때문이다.
정리
- AI 모델 성능 결정 요소는 크게 “모델 구조”, “최적화 방법”, “데이터” 이다.
- Visual recognition task를 예로 들었을 때 Software 1.0의 경우 아래의 과정으로 프로그램을 만든다.
- 해당 태스크는 이미지가 주어졌을때 positive인지 negative인지 판별하는 문제로 정의하고,
- 이를 특징 추출과 판단 문제로 나누어,
- 특징 추출 알고리즘 (HOG), 판단 알고리즘 (SVM)을 설계,
- 이를 합쳐서 visual recognition을 수행하는 시스템을 구성한다.
- Software 2.0 의 특징
- 모델 구조에 의해 검색 영역이 정해지므로, 다른 모델 구조를 사용 시 검색 영역이 달라질 수 있다.
- 동일한 데이터와 모델을 활용하더라도 다른 최적화 방법을 사용한다면 결과(목적지)는 달라질 수 있다.
- 동일한 데이터와 최적화 방법을 사용해도 모델 구조가 다르다면 최종 결과가 달라질 수 있다.
- 최적화를 통해 사람이 정한 목적에 제일 부합하는 연산의 집합을 찾는다.
- Software 2.0 의 기술 발달로 점점 그 차지하는 영역이 커지고 있는 추세이다.
댓글 남기기