
[CNN] 4. CNN Visualization
CNN 시각화의 필요성과 방법론을 살펴보자. 특히 모델 자체의 일반적인 행위 특성을 분석하기 위한 시각화와 각 입력 데이터에 따른 모델이 한 결정을 해석하기 위한 시각화 방법론을 살펴보자.
Visualizing CNN
- CNN 을 시각화하는 대표적인 방법으로 filter visualization, t-SNE, saliency map 등이 있다.
- CNN 기반의 네트워크는 학습 가능한 conv 과 non-linear activation func 들의 step 으로 이루어진 단순한 연산기다.
- 그런데 학습 후 성능은 인간을 뛰어넘기도 한다. 그렇다면 어떤 원리로 CNN 이 잘 동작하는 것일까? 학습을 통해서 conv filter 들은 어떤 것들을 배우게 되는 것일까?
- CNN 을 구성해서 어떤 task 의 데이터셋으로 입력과 출력을 주고 학습을 했음에도 쉽게 학습이 잘 되지 않는 경우들도 있다. 이처럼 성능이 잘 안나오는 경우도 있는데, 왜 학습이 잘 안되는지 언제나 궁금하다.
- CNN 을 입력이 주어지면 출력이 나오는 하나의 기계라고 생각할 수 있다.
-
이 기계를 사용할 때 원하는 대로 동작을 잘 하지 않으면, 원인을 파악하기 위해 뜯어본다. 내부를 들여다 보고 원인을 판단하고자 하는 것이다.
- 그러나 CNN 은 여러 단계에 걸친 학습을 통해서 정해진 weight 들의 조합으로 복잡하게 연결되어 있다. 그래서 사실상 black box 시스템이라 할 만큼 해석이 안된다.
- 우리는 CNN 을 시각화함으로써 CNN 내부를 들여다볼 수 있다. 내부가 어떻게 되는가를 파악하고, 왜 성능이 잘 나오는지도 가늠해보며, 어떻게 하면 더 성능을 높일 수 있는지 힌트를 얻을 수 있는 방법이 바로 시각화다.
- CNN 을 시각화 한다는 것 또는 일반적인 NN 을 시각화한다는 것은 디버깅 툴을 갖는 것과 동일하다. 네트워크 안에 뭐가 들어있고 왜 좋은 성능이 나오고, 왜 실패를 하고 어떤 개선을 할지를 알 수 있는 단서를 제공해주기 때문이다.
-
CNN 의 layer 들이 각 위치에 따라서 어떤 지식을 배웠는지, conv 의 역연산인 deconvolution 을 이용해서 시각화를 시도한 2013년 ZFNet 연구가 있었다.
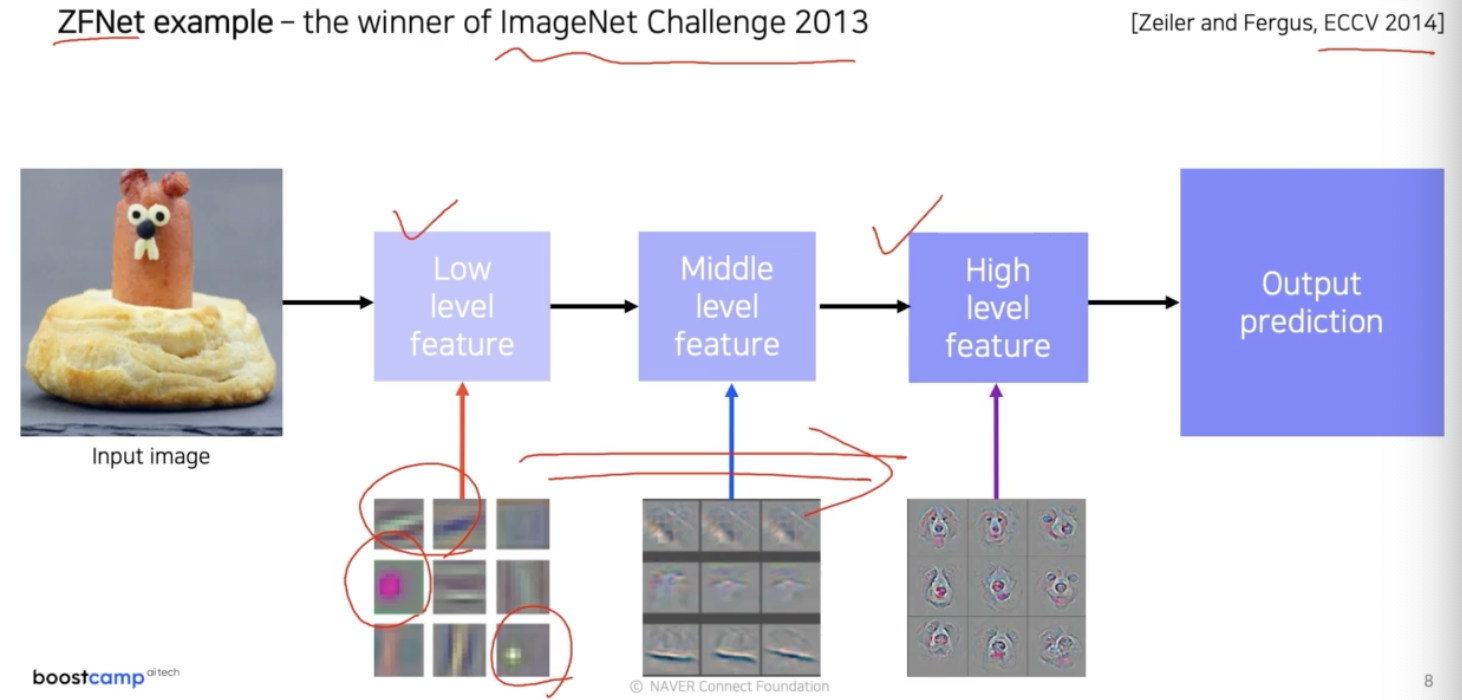
- 이 연구를 통해서 낮은 계층에는 좀 더 방향성이 있는 선을 찾는 filter들 또는 동그란 블록을 찾는 그런 기본적인 이미지 처리 filter들처럼 생긴 것들이 많이 분포함을 확인했다.
- 그리고 더 나아가서 중간계층, 높은 계층으로 가면 점점 high-level 의 의미가 있는 표현을 학습했다는 것을 파악했다.
- CNN 의 feature map 은 semtantic level 에 따라 low level, middle level, high level feature 로 분류할 수 있다.
- ZFNet 논문은 이를 통해서 눈으로 보면서 CNN 을 튜닝 했고, 이를 통해 ZFNet 을 제안했다. 실제로 2013년에 가장 좋은 성능을 거두기도 했다.
- 이를 통해 시각화가 그냥 눈이 호강하기 위한 잔기술이 아니라 중요한 기술임이 강조되었다.
filter visualization
- 가장 간단한 시각화 방법을 보자.
- 가장 간단한 방법은 filter 를 visualization 하는 것이다.
-
AlexNet 의 첫번째 conv layer 의 filter 는 11x11 사이즈 이고, 입력 채널이 3채널이기 때문에 filter 도 3채널을 가져 컬러 이미지로 출력이 가능하다.
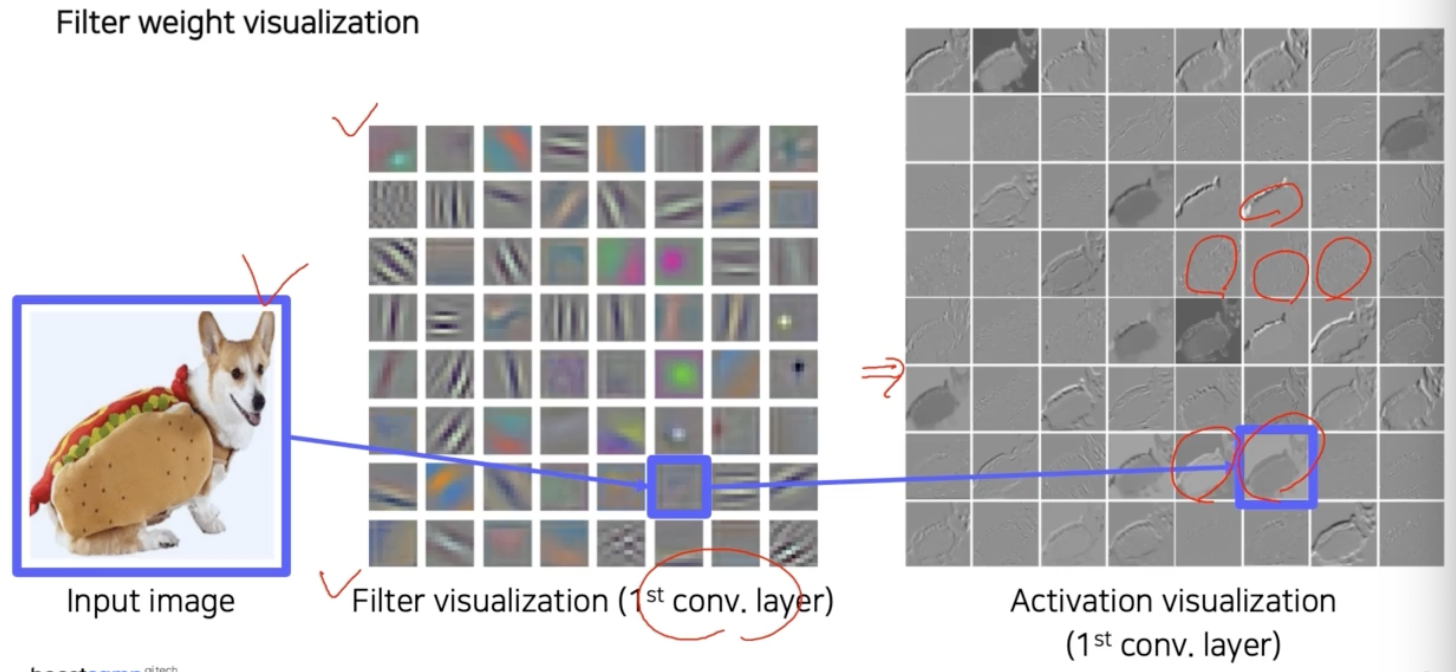
- 각 filter 를 띄워보면 이미지 처리 filter 와 같이 color edge detector, angle, block 같은 다양한 기본적인 operation 들이 학습됨을 알 수 있다.
- 입력 이미지에 이 filter 를 입혀서 conv 를 취한 activation map 또한 시각화가 가능하다.
- 각 filter 마다 처리 결과는 하나의 채널로 나오기 때문에 여기서는 흑백으로 표현된다.
- 이렇게 각각의 특성을 가진 filter 를 이미지에 conv 를 취해서 나온 activation map 의 결과는 어떤 것은 image의 45도에 해당하는 결과, 어떤 것은 잔 디테일 강조, 색깔 반영, high response 발휘 등의 서로 다른 결과가 나온 것을 확인할 수 있다.
- 이렇게 간단한 시각화로 CNN 의 첫 layer 가 어떤 것을 보고, 어떤 행동을 하는지를 조금은 이해할 수 있다.
- 위 예제는 첫번째 layer 에 대한 시각화다. 그런데 왜 두번째, 세번째 등 높은 계층은 해석하려 하지 않을까?
- 뒤쪽 layer 는 filter 자체의 (채널)차원수가 높다. 즉 위 예제처럼 3채널로 되어 있어서 컬러로 시각화할 수 있는 그런 형태가 아니다.
- 이처럼 뒤로 갈수록 filter 의 차원수가 높아서, 시각화 하는 것이 사람이 직관적으로 알아볼 수 있는 형태가 나오질 않는다.
- 즉 시각화를 해서 그 역할을 하려면 사람의 해석이 가능해야 한다. 높은 계층일수록 차원수가 높다보니 그것을 사람이 직관적으로 해석하기 쉽지 않다.
- 또한 뒤쪽 layer 의 filter 들은 앞쪽 layer 의 filter 들과 합성이 되어서 더 추상적인 역할을 하게 된다.
- 그래서 사람이 해석 가능한 정보가 별로 없고, 여러 filter 들의 합성으로 제 역할이 결정되기 때문에 단독으로 시각화하는 것이 크게 의미가 없다. 이러한 이유로 뒤쪽 layer 로 갈수록 시각화를 잘 하지 않는다.
- 따라서 전체적인 NN 을 해석하기 위해서는 filter visualization 보다 복잡한 시각화 방법이 필요하다.
-
이런 배경에서 NN 를 분석하기 위한 시각화 방법이 다양하게 연구되어 왔다.
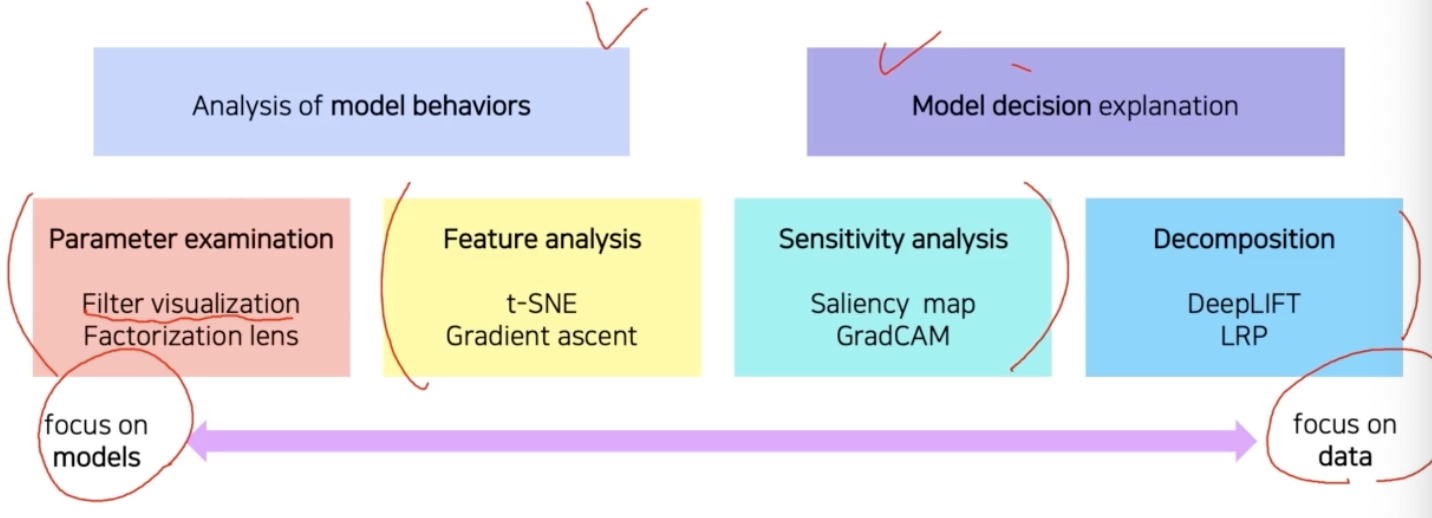
- Analysis of model behaviors 은 모델 자체의 특성을 분석하는데 방점을 둔 방법론이다.
- Model decision explanation 은 하나의 입력 데이터부터 모델이 어떤 결론을 냈을 때 어째서 그런 결론에 도달하는지 출력을 분석하는 방법론이다.
- 왼쪽으로 갈수록 모델을 이해하기 위한 노력에 가깝고 오른쪽에 갈수록 데이터 결과를 분석하는데 초점을 맞춘다.
- 지금까지 본 것이 CNN 의 trainable parameter 인 filter 를 시각화한 filter visualization 방법이다.
1. Analysis of model behaviors
- 모델의 특성을 분석하는 방법이다.
1-1. Embedding feature analysis
-
첫번째 방법으로 low → middle → high level layer 를 거쳐서 얻게 된 feature 들을 분석하는 방법을 보자.
1-1-1. Nearest neighbors(NN) in a feature space (high level feature)

- Nearest neighbors(NN) search 방법을 사용한다.
- DB 가 먼저 존재하고, DB 안에 분석을 위한 예제 데이터 셋을 저장해놓는다.
- 이후 질의, query data 가 들어오면 쿼리 이미지와 유사한 이웃 이미지들을 찾기 위해서 DB 내에서 검색을 한다. 그래서 유사한 이미지 몇 개를 거리에 따라서 정렬하게 된다. 이것을 통해서 여러가지 해석이 가능하다.
- 위 예제는 쿼리 데이터를 줬을 때 비슷한 이미지들이 검색이 쭉 되고, 가장 유사한 6개의 example 을 출력한 것이다.
- 결과를 보면 의미가 있는 개념을 제대로 이해했음을 파악할 수 있다. 왜냐하면 의미론적으로 비슷한 컨셉들끼리 clustered 되어 있기 때문이다.
- 질의 이미지가 들어왔을 때 심플하게 픽셀 별로 비교를 통해서 이미지 검색을 할 수도 있다. 이미지가 하나 더 있으면 두 이미지의 distance 를 계산해서 검색할 수도 있다. 그렇게 찾을 경우에는 비슷한 image이 아닌 것들도 있을 수 있다. 즉 위 치가 다르거나 다른 포즈를 취한 같은 물체들이 찾아지기도 한다.
- 그럼에도 불구하고 nearest neighbors search 를 했을 때 가장 가까운 이웃 6개가 골라졌고, 그 안에 포즈, 위치가 다른 같은 물체들이 들어있다.(위 예제에서 강아지)
- 이를 통해서 학습된 feature 가 물체의 위치 변화에 강인하게, 컨셉을 잘 학습했음을 알 수 있다.
-
Nearest neighbors 를 통한 예제 검색이 구체적으로 어떻게 동작하는지 살펴보자.
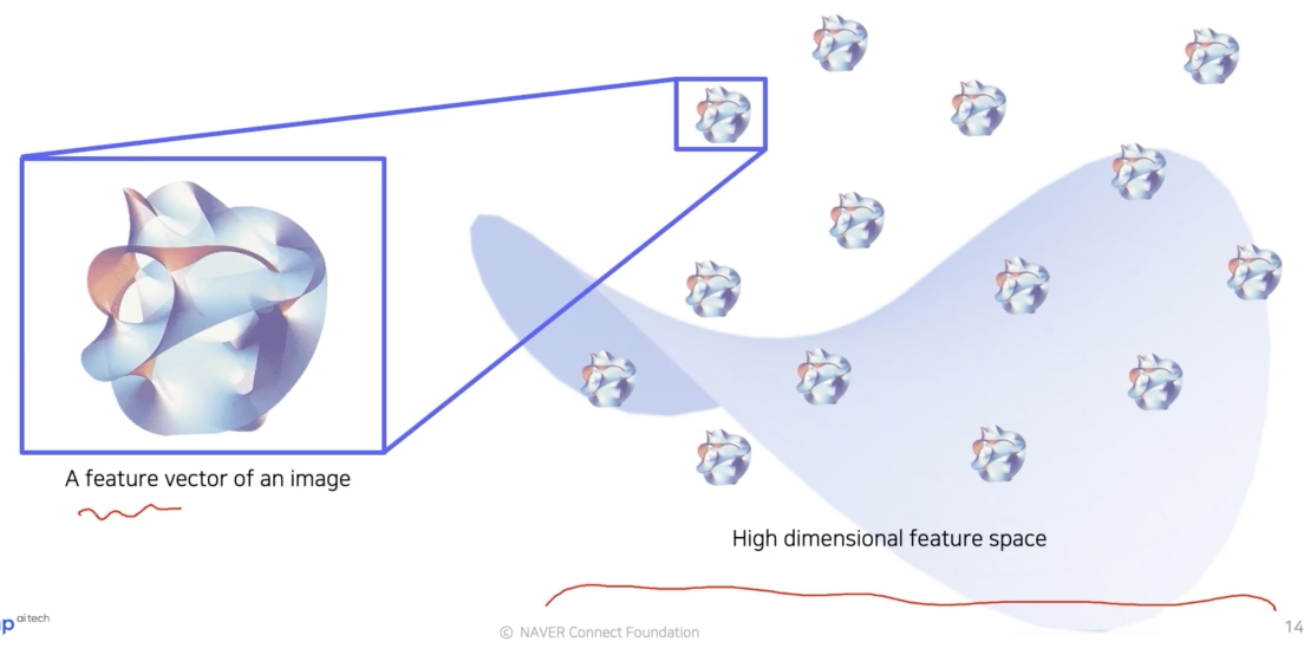
-
위 그림은 embedding space 를 표현한 것이다. 이 공간 위에 놓인 것들은 고차원 공간에 있는 각각의 embedding feature vector 를 표현하는 것이라 생각할 수 있다. 즉 각각의 vector 에 해당하는 이미지들이 존재한다.
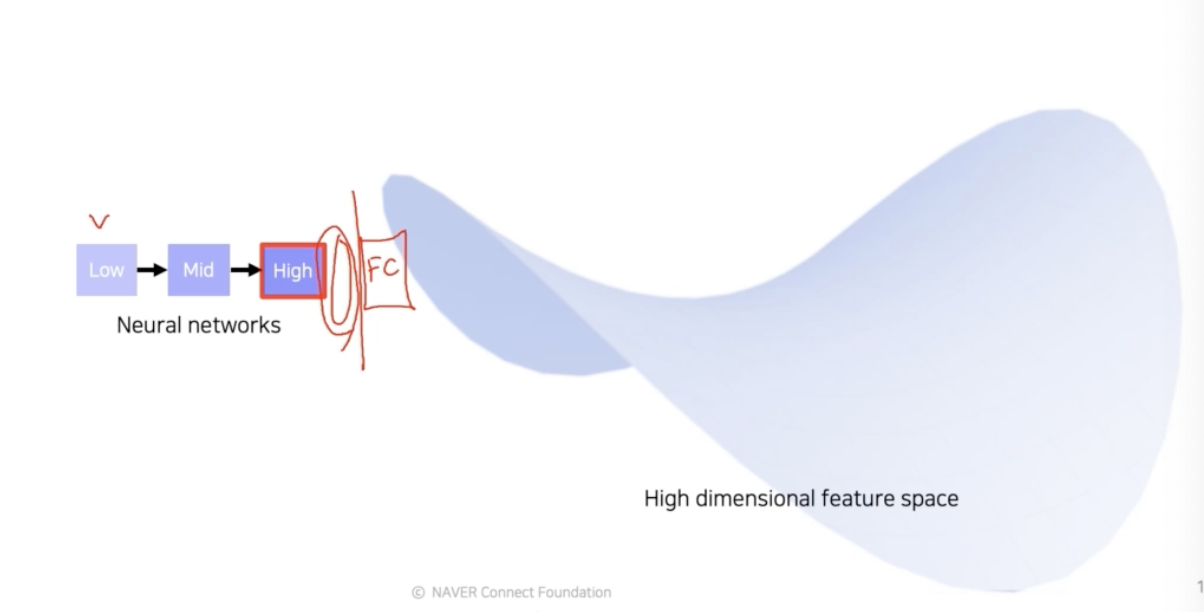
-
실제 구현에서는 미리 학습된 네트워크를 준비하고, 제일 뒤쪽의 fc layer 를 잘라내서 feature 를 추출할 수 있도록 준비를 해놓는다. 그렇게 추출된 feature 는 뒤쪽에서 생성된 feature 로 high level 의 feature 다.
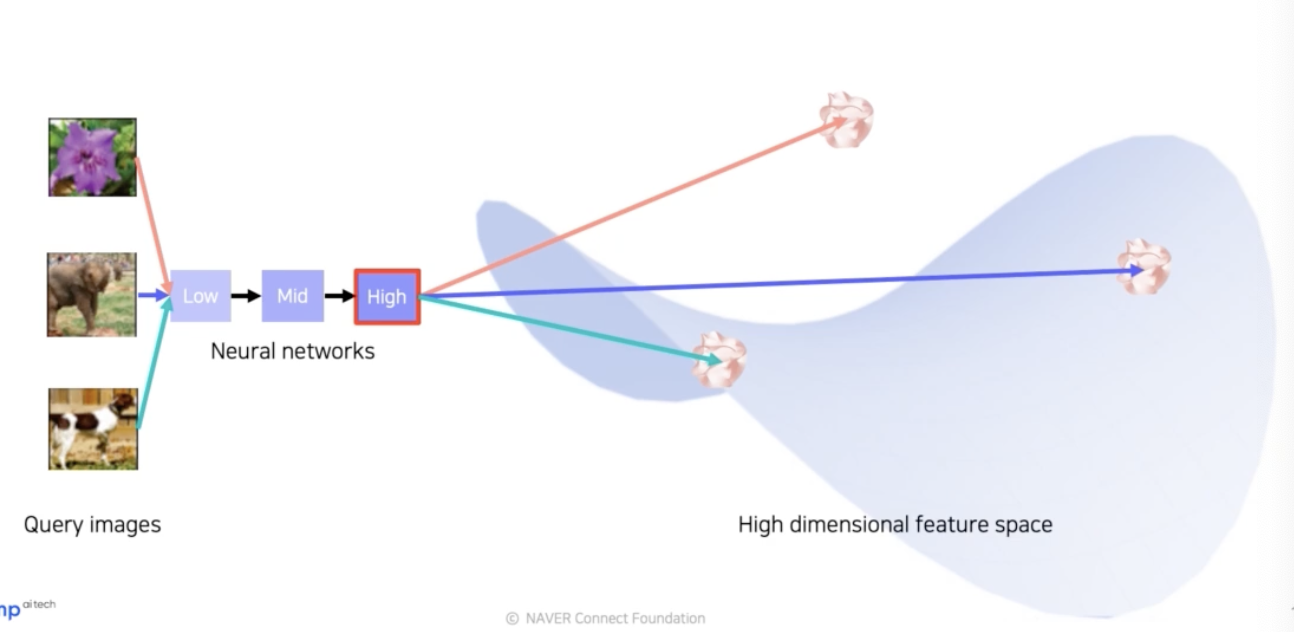
-
그렇게 네트워크에 쿼리 이미지를 넣어주면 특징이 추출이 되고, 그 추출된 특징이 고차원 공간 어딘가에 위치하게 된다. 즉 이미지를 넣을 때마다 특징 공간에 특징을 위치시킬 수 있다.
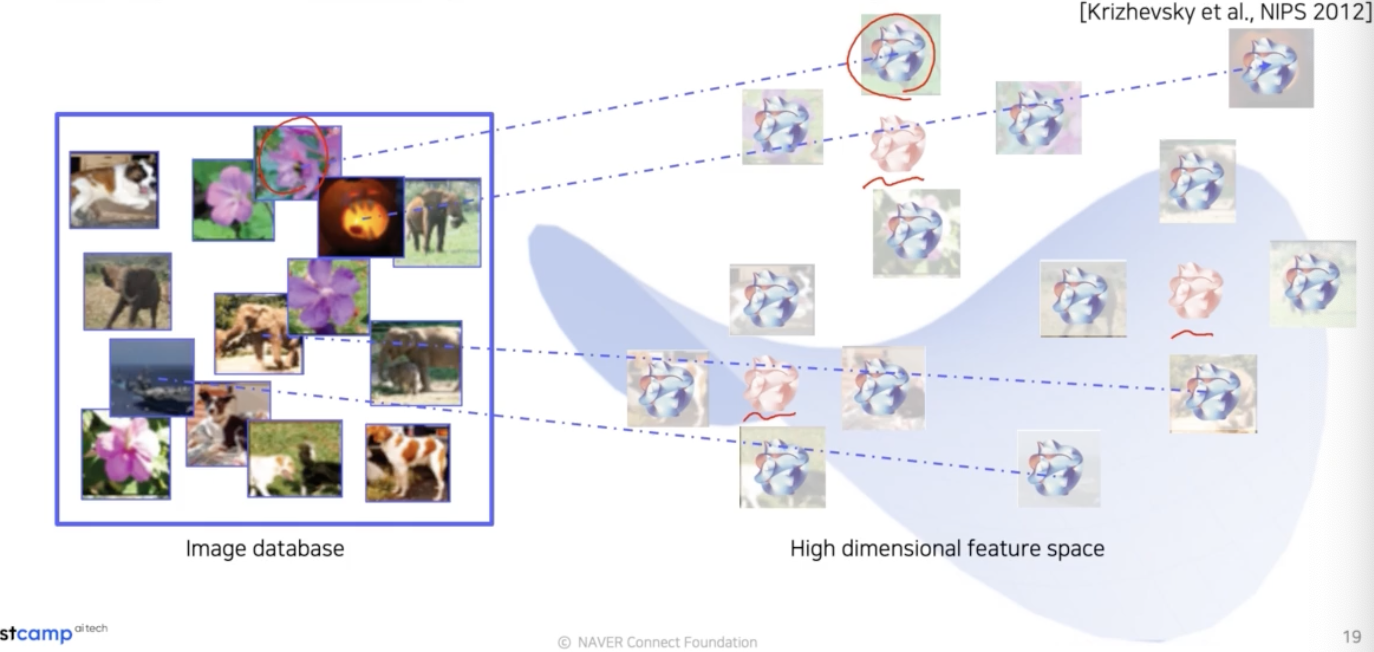
-
모두 뽑은 데이터의 feature 들은 고차원 공간 상에 존재하고 있다. 이제 미리 뽑은 feature 들을 DB 에 저장한다. 이렇게 DB 에 저장된 feature 들은 원래 이미지와 연결되어 있다(association). 즉 각 위치의 feature 들은 그에 해당하는 이미지들이 존재하는 형태인 것이다.
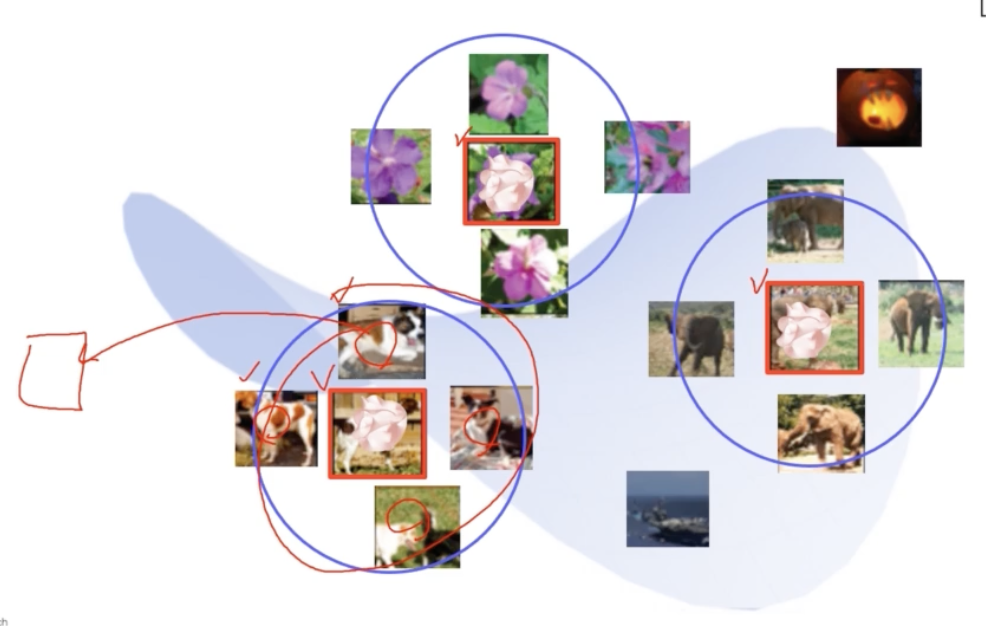 빨간 테두리가 질의 이미지다.
빨간 테두리가 질의 이미지다. - 이제 질의 이미지를 넣는다. 테스트를 위해 쿼리 이미지를 넣으면 마찬가지 방식으로 특징을 뽑는다. 그 후 해당 특징과 거리가 가까운 이미지들을 찾아서 리턴한다.
- 질의 이미지에 해당하는 feature vector 근처에 feature vector 들이 있었을 것이고(파란 원), original DB 에서의 근처에 위치한 feature vector 에 해당하는 이미지들을 찾아서 그것을 리턴하는 것이다.
- 그러나 이렇게 검색된 결과를 통해서 모델의 특성을 분석하는 방법은 전체적인 그림을 파악하기 어렵다는 단점이 있다.
1-1-2. Dimensionality reduction (high level feature)
- backbone 네트워크를 활용해서 특징을 추출하게 되면, 고차원 feature vector 가 나오게 되는데 이는 너무 고차원이라서 우리가 해석하기 힘들다.
- 3차원 보다 고차원으로 가면 그 공간이 어떻게 생겼는지 상상하기 어렵다. 이런 문제를 해결하기 위해서, 고차원 space 에 있는 vector 의 분포들을 저차원으로 내려서 표현하는 방법, 즉 차원축소 방법을 통해서 눈으로 쉽게 확인 가능한 분포를 얻어내는 방법이 있다.
-
대표적 차원축소 방법으로 t-distributed stochastic neighbor embedding (t-SNE) 가 있다.
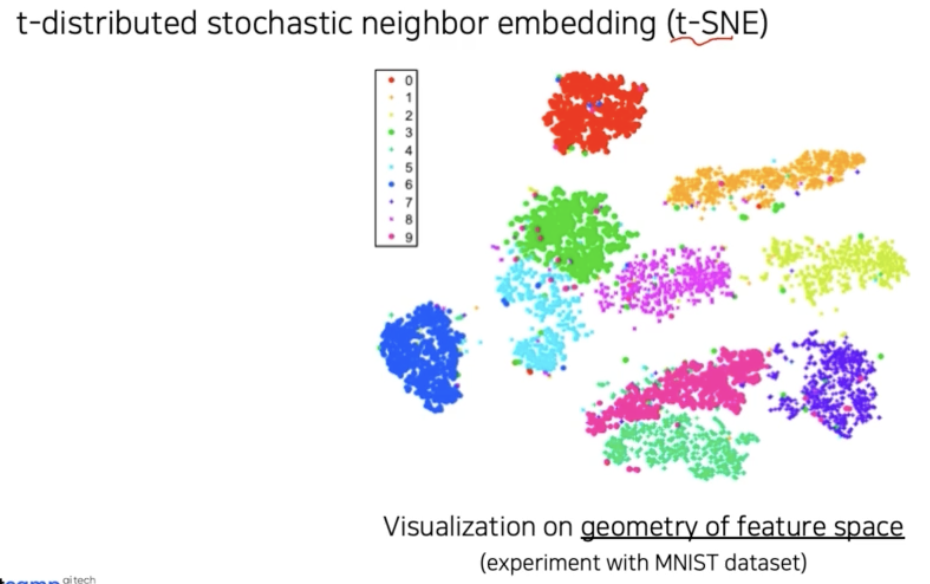
- 위 예시는 MNIST 데이터셋의 특징 분포를 t-SNE 를 통해서 저차원으로 매핑한 분포다. 각 클래스마다 다른 색을 가지고 있다.
- 전반적으로 비슷한 클래스끼리 잘 분포됨을 알 수 있다. 이것으로 볼 때 모델이 잘 학습되어서 클래스끼리 구분을 잘 할 수 있음을 알 수 있다.
- 또한 클래스 간의 분포를 볼 수 있다. 3과 5과 8 이 3개의 숫자는 분포가 맞닿아 있다. 모델은 이 3개의 숫자 클래스들을 유사하게 바라보고 있고, 그 경계에서 헷갈리기 쉬울 것임을 알 수 있다.
- 시각화를 통해서 이러한 큰 그림을 파악하고 개선을 시도할 수 있다.
1-2. Activation investigation
-
각 layer 의 가중치(혹은 filter)를 이미지에 입힌 activation 을 확인할 수도 있다.
1-2-1. Layer activation (Mid & High layer)

- 모델의 중간 layer 와 높은 layer 의 activation 을 분석함으로써 모델의 특성을 파악하는 방법이다.
- 각 activation 의 채널을 생성하는 filter 를 CNN 에서는 hidden node 로 표현할 수 있다. 왜냐하면 각 filter 는 입력 데이터의 특정 패턴을 학습하고 activation map 을 생성하여, 마치 hidden node 가 입력 데이터의 특징을 학습하고 활성화 값을 생성하는 것과 유사한 역할을 하기 때문이다.
- 이렇게 activation 을 통해 각 layer 의 hidden node 들의 역할을 파악할 수 있다. 예를 들어 위 그림처럼 이 채널은 얼굴을 찾는 노드, 이 채널은 계단을 찾는 노드 라고 이해할 수 있는 것이다.
- 이를 통해 CNN 은 중간중간 hidden unit 들이 각각 간단한 detection 을 다층으로 쌓아서 그것들의 조합을 통해서 물체를 인식하는 거구나 라고 해석할 수 있다.
1-2-2. Maximally activating patches (Mid)

- layer activation 을 분석하는 방법 중에 patch 를 뜯어서 사용하는 방법이다.
- 각 layer 의 filter 에서 하는 역할을 판단하기 위해서, 그 filter 즉 hidden node 에서 가장 높은 값을 가지는 위치의 근방의 patch 를 뜯어내는 것이다.
- 위 그림에서 세로축은 서로 다른 hidden node 인데, 각 hidden node 들은 어떤 역할을 수행하는지 알 수 있다.
- 이 방법은 중간 계층을 분석하는데 적합하다. 국부적인 patch 만 보게 되니까 전반적인 큰 그림을 보기 보다는 중간 그림을 보는 알고리즘에 적합하다.
-
이 방법을 구현하는 과정을 보자!
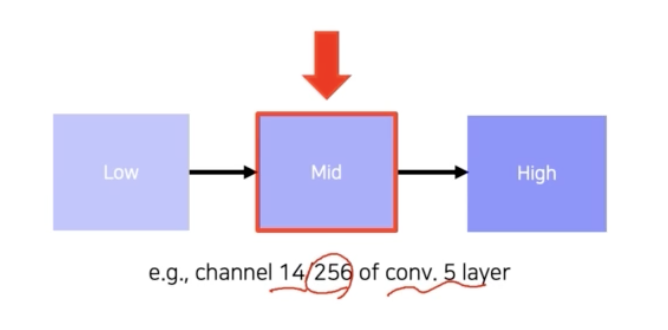
-
CNN 에서 분석하고자 하는 특정 layer 를 하나 정한다. 위 예제에서는 conv 5 layer 의 256개의 채널 중에서 14번째 채널을 골랐다.
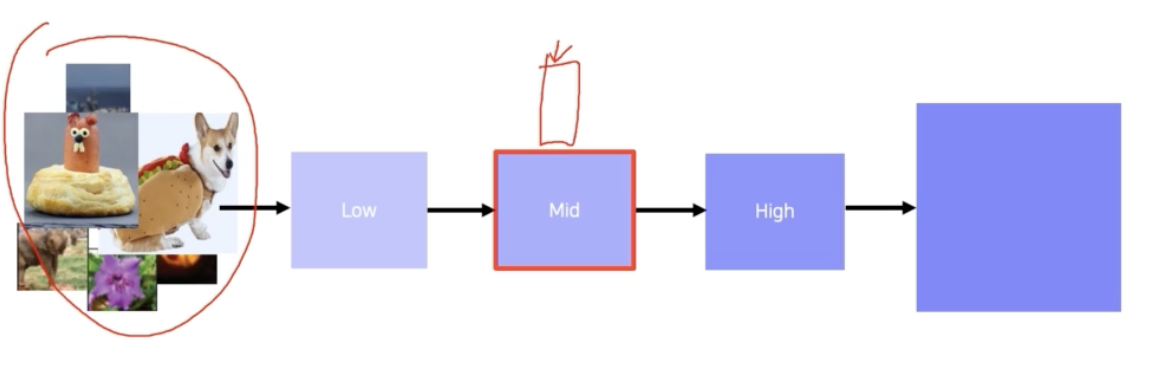
-
그리고 예제 데이터를 backbone 네트워크에 넣어서 각 layer 의 activation 을 다 뽑는다. 이 때 14번째 채널의 activation 을 저장한다.

- 그리고 저장된 해당 채널의 activation 값들 중에서 가장 큰 값을 가지는 위치를 파악한다.
- 이 때 해당 activation 을 얻기 위해 입력 된 값이 있을 것이고, 그 입력에서의 maximum 값을 도출하게 된 receptive field 가 있을 것이다. 그 receptive field 를 계산을 하고 그 영역에 해당하는 입력 이미지의 patch 를 뜯어온다.
- 이런 방식으로 뽑은 patch 를 hidden node 별로 나열한다. 그러면 그 hidden layer 가 어떤 것을 주의깊게 살펴보고 있는지 컨셉을 확인할 수 있다.
1-3. Class visualization
- 지금까지는 activation 을 분석하기 위해서 데이터를 사용했다. 여기서는 데이터를 사용하지 않고, 네트워크가 내재하고 기억하고 있는 이미지가 어떤 것인지 분석하는 방법을 보자.
 최종 출력을 보고 모델을 분석한다.
최종 출력을 보고 모델을 분석한다.- 예를 들어서 각 클래스를 판단할 때 이 네트워크는 어떤 모습을 상상하고 있구나 이런 것을 확인할 수 있는 방법이다.

- 위 모델은 새를 판단하기 위해서 해당 물체만 찾는 것이 아니라 다른 나무 같은 것도 같이 찾고 있음을 알 수 있다.
- 이런 이미지는 어떻게 추출하는 것일까?
- 간단한 연산으로는 구현할 수 없고, gradient descent 같은 최적화를 통해서 저런 합성 이미지를 찾아나가는 과정을 거친다.
- 모델을 학습할 때 역전파 알고리즘을 통해서 gradient descent 로 목적함수인 Loss 들을 최소화하는 과정을 겪었던 것과 마찬가지로 접근한다.
-
합성 이미지를 만들기 위해서는 일단 Loss 를 만들어줘야 한다. 최적화를 통해서 이미지를 합성하게 되는데, Loss 는 어떻게 디자인하는지 먼저 보자.
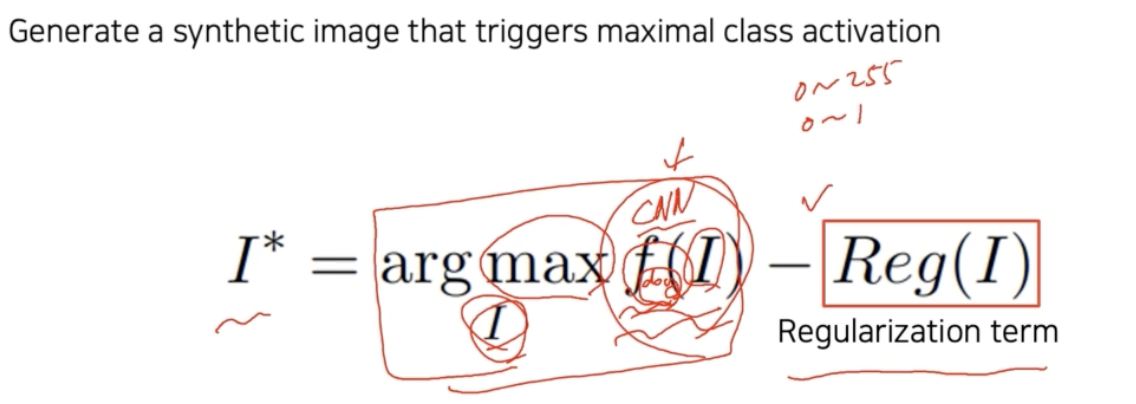
- 두 개의 Loss 를 합성해서 사용한다. $f(I)$ 와 regularization term 인 $Reg(I)$ 다.
- 먼저 $I$ 는 input image 다. 어떤 입력을 주었을 때 CNN 모델 $f$ 를 거쳐서 출력된 하나의 class(강아지라면) score $f_{dog}(I)$ 를 고려한다.
- $\text{argmax} \; f(I)$ 는 그 score 를 maximize 하는 $I$ 를 찾는 것이다. 즉 랜덤한 image 를 넣어주면 class score 가 낮을텐데, 그 낮은 class score 를 높히는 input image $I$ 를 찾으라는 것이다.
- 이 때 score 를 높히는 임의의 input image 를 찾다보면 더 이상 image 가 아닌 것들도 찾게 될 수 있다.
- 예를 들어 이미지는 0 ~ 255 또는 0~1(normalization) 사이 값으로 bound 된 형태로 표현되는데, 최적화 과정을 거쳐서 나온 출력 $f(I)$ 들에 대한 $\text{argmax}\;f(I)$ 가 너무 큰 값으로 나오면 곤란하다. 즉 $f(I)$ 가 해석 불가능한 이미지일 수 있다.
-
그것을 막고, 우리가 이해할 수 있는 이미지를 유도하기 위해서 간단한 Loss 인 regularization term 을 추가한다.
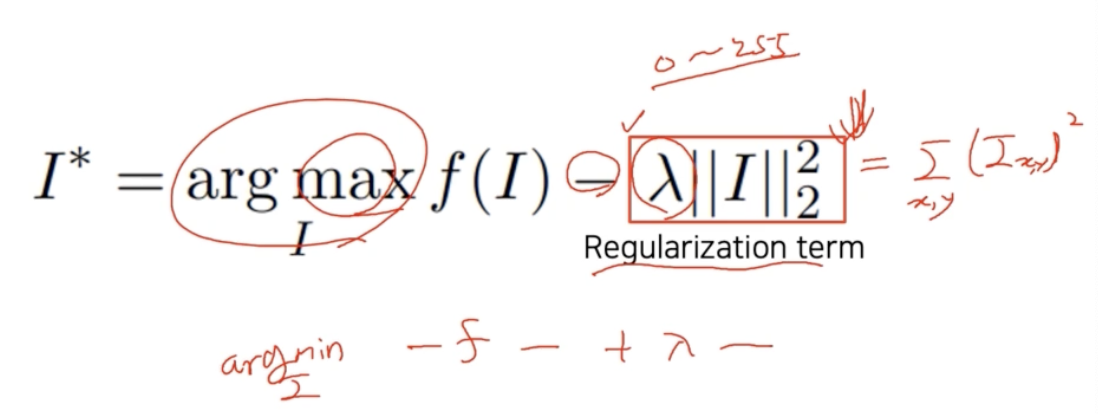
- regularization term 은 찾는 이미지의 L2 Norm, 즉 각 픽셀의 square 의 sum 이다.
- $\text{argmax}\;f(I)$ 에서 maximization 을 하기 때문에, regularization term 에 음수가 붙어서 $\lambda \parallel{I}\parallel_2^2$ 가 된다.
- 작은 값을 가졌으면 좋겠다라는 바램을 regularization term 으로 넣어준 것이다. 이 때 작아져야 하는 정도를 $\lambda$ 로 통제한다. 0 ~ 255 혹은 0 ~ 1 사이에 값이 반드시 들어가야한다 이정도까지는 아니다.
- NN 을 학습할 때는 Loss 를 최소화하는 방식으로 최적화를 했는데, 여기서는 반대로 최대화를 한다. 따라서 여기서는 gradient descent 가 아니라 gradient ascent 최적화 방법을 사용한다.
- 그러나 앞에 부호만 반대로 바꿔주면 minimization 문제로 바뀌게 되고 일반적인 gradient descent 방법을 사용하면 된다.
-
step by step 으로 보자.
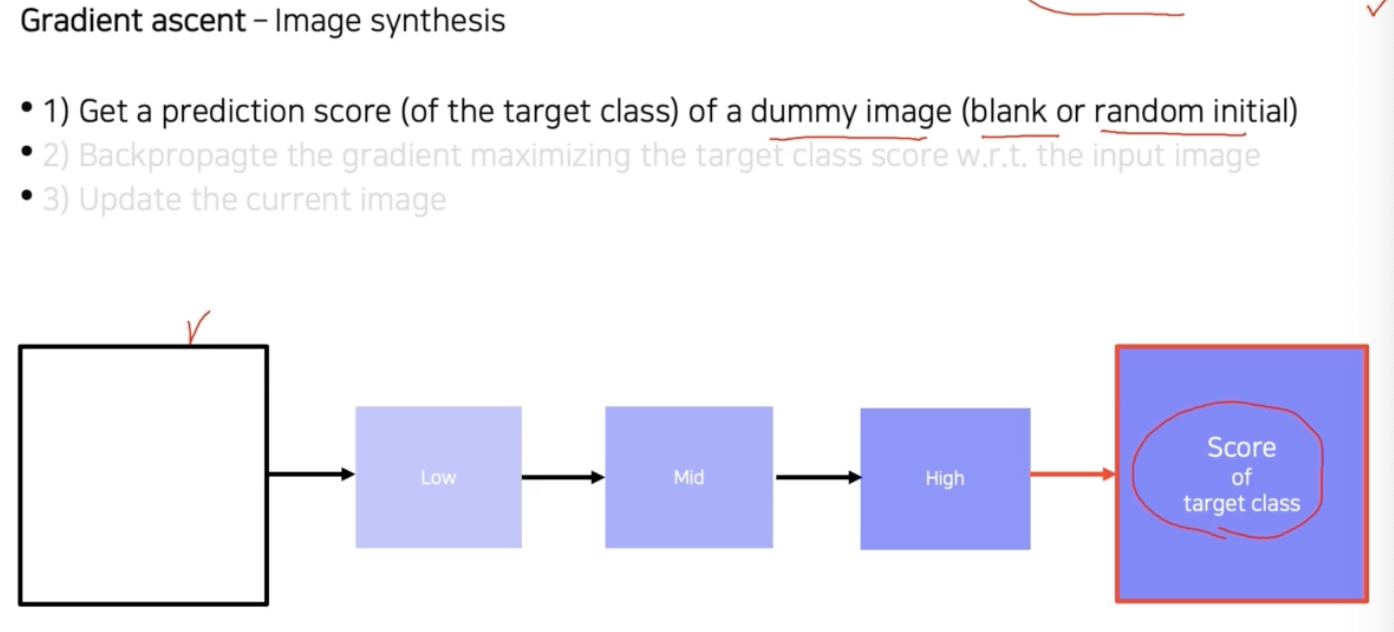
- 임의의 이미지를 분석하고자 하는 CNN 모델에 입력으로 넣어준다. 그리고 관심 클래스에 대한 score 를 추출한다.
-
이 방법은 중간 단계를 분석하는 것이 아니라, 최종 출력을 보고 CNN에 대한 해석을 내놓는 방법이다.
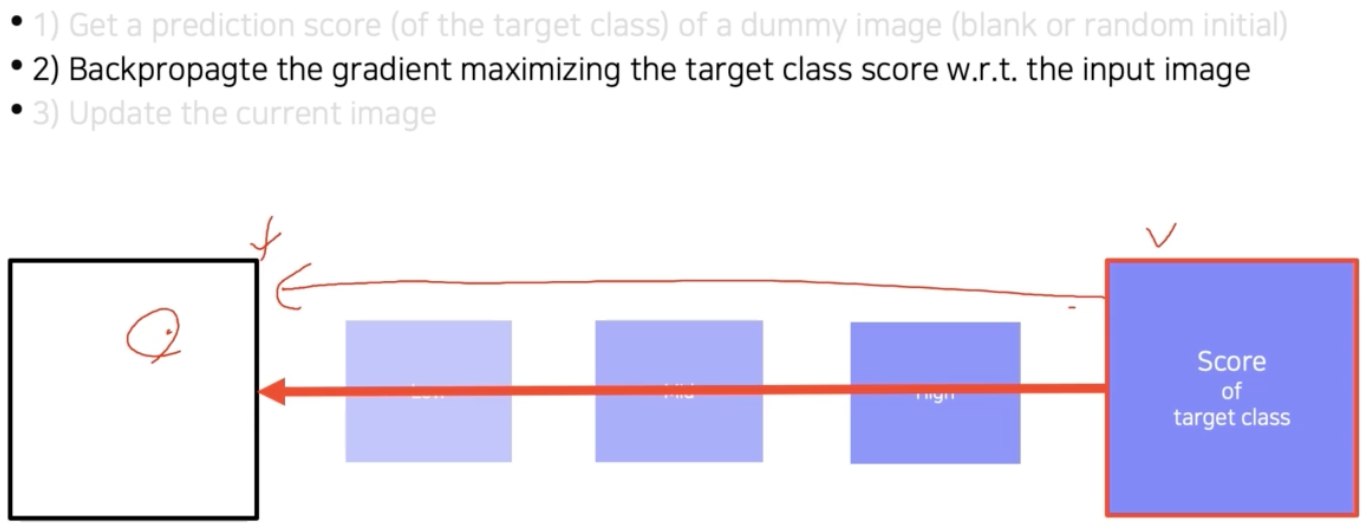
- 이후 역전파를 통해서 입력단의 gradient 를 구하고 입력까지 내려간다. 입력이 어떻게 변해야지 target class score 가 높아지는지를 찾는 것이다.
- 그리고 target score 를 높이는 방향으로 input image 를 업데이트 한다. 업데이트 방식은 gradient 를 더해준다.
-
Loss 를 측정할 때 score 값에 - 를 붙혀서 내려가는 방향으로 만들어놓고, gradient 를 계산하면 이전에 NN 학습할 때 사용했던 gradient descent 알고리즘을 그대로 사용하면 된다.

- 그렇게 한번 input image 를 업데이트 하고, 다시 위 과정을 업데이트 된 이미지로부터 반복한다. 다시 score 를 계산하고 역전파하고 또 업데이트한다.
- 이렇게 여러번 반복을 하면 몽환적인 느낌의 그림을 구할 수 있다.
- 맨 처음에 input image 를 넣어줄 때, input image 의 형태로 임의의 여러가지 초기값을 고려할 수 있다(blank or random initial).
- input image 는 단조로운 image 도 괜찮고, 어떤 이미지든지 상관없다. 그러나 어떤 입력을 넣어주냐에 따라서 그 입력에서부터 적절하게 바뀐 image 가 나온다.
- 왜냐면 gradient descent 는 현재 image 를 어떤 식으로 업데이트를 할지 local search 를 하는 것이기 때문이다. 해당 image 근처에 조금씩 변화를 주면서 최종적으로 score 를 올리는 방법을 찾는 것이다.
- 바꿔서 얘기하면, 초기값을 어떻게 설정하냐에 따라서 다양한 결과를 얻을 수 있다는 것이다. 따라서 이 NN 이 하나의 클래스에 대해서 어떤 이미지를 상상하고 있는지는 여러 번 위 과정을 거쳐서 다양한 image 들을 만들어놓고 그 패턴들을 보고 분석해 볼 수 있다.
- 이렇게 gradient ascent 방법으로 maximal class activation 을 가지는 synthetic image(합성 image)를 얻음으로써 classification 에 대한 visualization을 수행할 수 있다.
2. Model decision explanation
- 앞서 모델 자체의 행동에 대해서 분석하는 방법에 대해 살펴봤다.
- 이번에는 모델이 특정 데이터를 입력으로 받았을 때, 이 특정 데이터를 어떤 각도로 바라보고 있는지 해석하는 방법을 보자.
2-1. Saliency test 계열의 방법
-
image 가 주어졌을 때, 그 image 가 제대로 판정되기 위한 각 영역의 중요도(saliency)를 추출하는 방법이다.
2-1-1. Occlusion map
-
Occlusion map 을 활용하면, masking 되는 부분에 따라 classification score 가 변화하는 것을 바탕으로 salient heatmap 을 통해 classification 에 대한 visualization 을 수행할 수 있다.
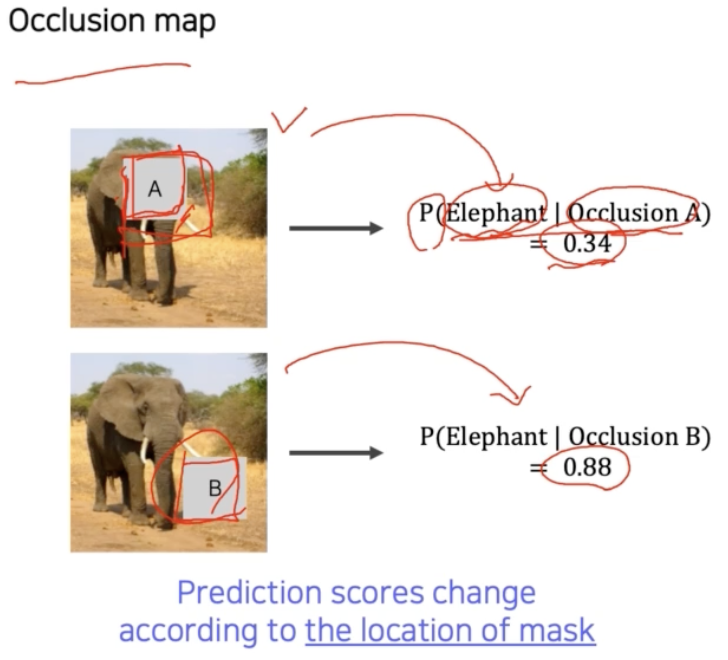
- 먼저 CNN 을 score 로 확률값을 출력하는 모델이라고 해보자. 입력으로 image 를 넣어주는데 그냥 넣어주는 것이 아니라, A 라는 큰 패치를 이용해서 가려준 즉 occlusion 된 image 를 넣어준다.
- 어떤 위치를 occlusion patch 로 가려주느냐에 따라서 score 가 달라진다. 예제에서 볼 수 있듯 물체의 중요한 부분을 가리면 score 가 떨어지고, 물체와 상관없는 배경 영역을 가리면 score 에 영향을 거의 주지 않는다.
-
이 점을 활용해서 쉽게 해석할 수 있는 맵으로 만들 수 있다.
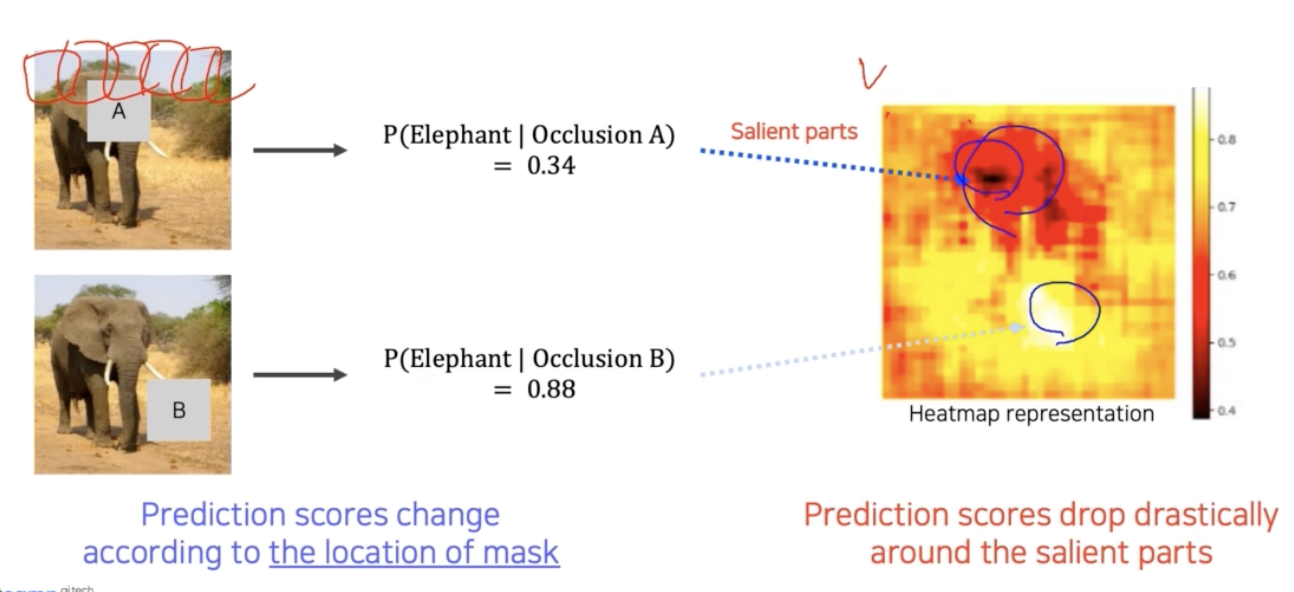
- 각 occlusion patch 의 위치를 하나하나 바꿔가며 테스트 할 수 있다.
- 위 그림에서 오른쪽 salient heatmap 은 occlusion patch 의 위치에 따라 변하는 score 의 지도다.
- 색으로 score 를 표현했는데, 이를 보면 검은색 영역은 물체의 검출에 민감한 영역이고, 밝은 부분은 상관없는 영역임을 파악할 수 있다. 즉 색이 진한 부분 근처가 image 내에서 image classification 에 굉장히 중요한 부분이 밀집된 지역임을 알 수 있다.
2-1-2. via Backpropagation
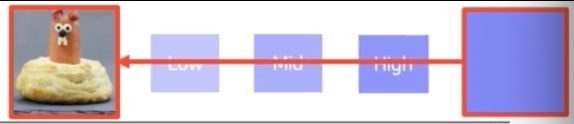
-
앞서 gradient ascent 를 이용해서 몽환적인 합성 이미지를 생성했던 방법과 유사한 방법이다.
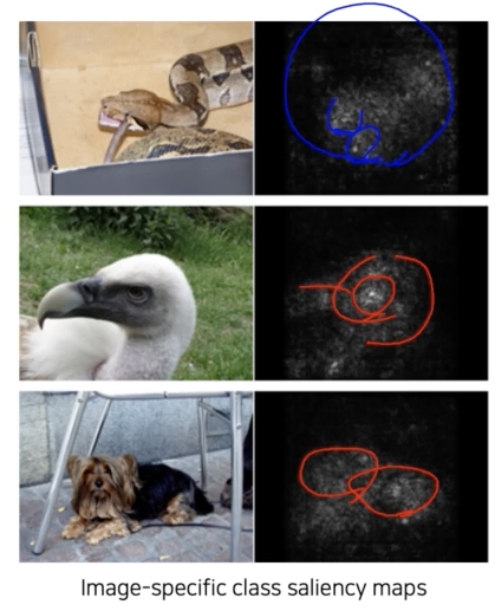 최종 결론에 결정적으로 영향을 미친 부분이 오른쪽에 히트맵 형태로 표현되어 있다.
최종 결론에 결정적으로 영향을 미친 부분이 오른쪽에 히트맵 형태로 표현되어 있다. - 이번에는 랜덤 이미지가 아니라, 특정 이미지를 classification 해보고, 최종 결론이 나온 클래스에 결정적으로 영향을 미친 부분이 어디인지 히트맵 형태로 나타내는 기법이다.
- 위 예제에서 히트맵을 보면 관심물체의 영역에 밝은 값들이 분포함을 확인할 수 있다. 이런 영역을 보고 최종 score 가 결정되었다고 해석할 수 있다.
-
이 방법을 어떻게 구현할까?
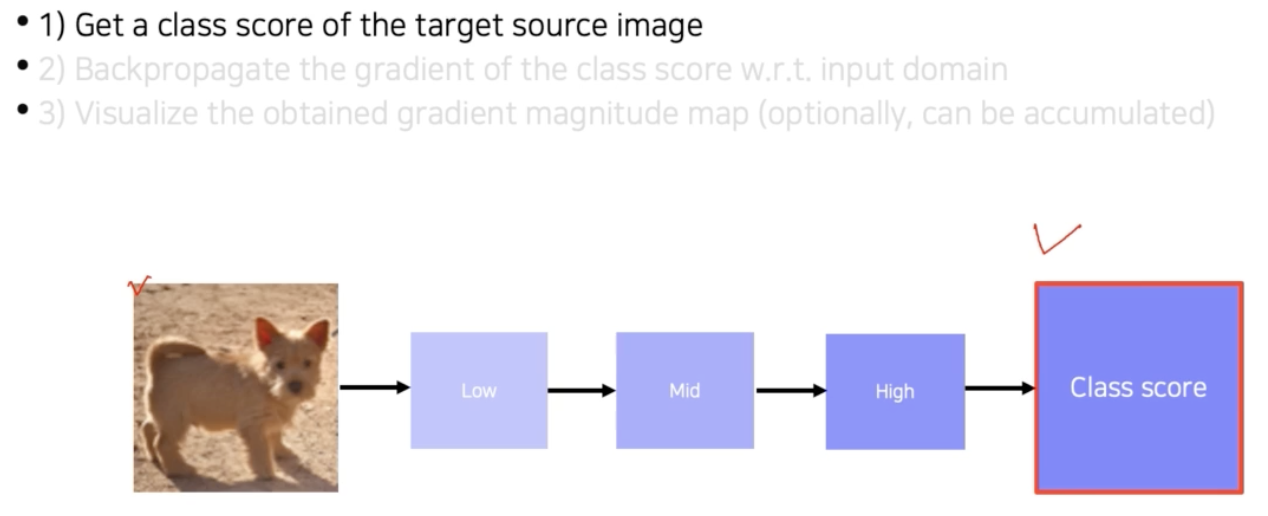
-
먼저 input image 을 넣어주고 하나의 클래스 score 를 얻는다.
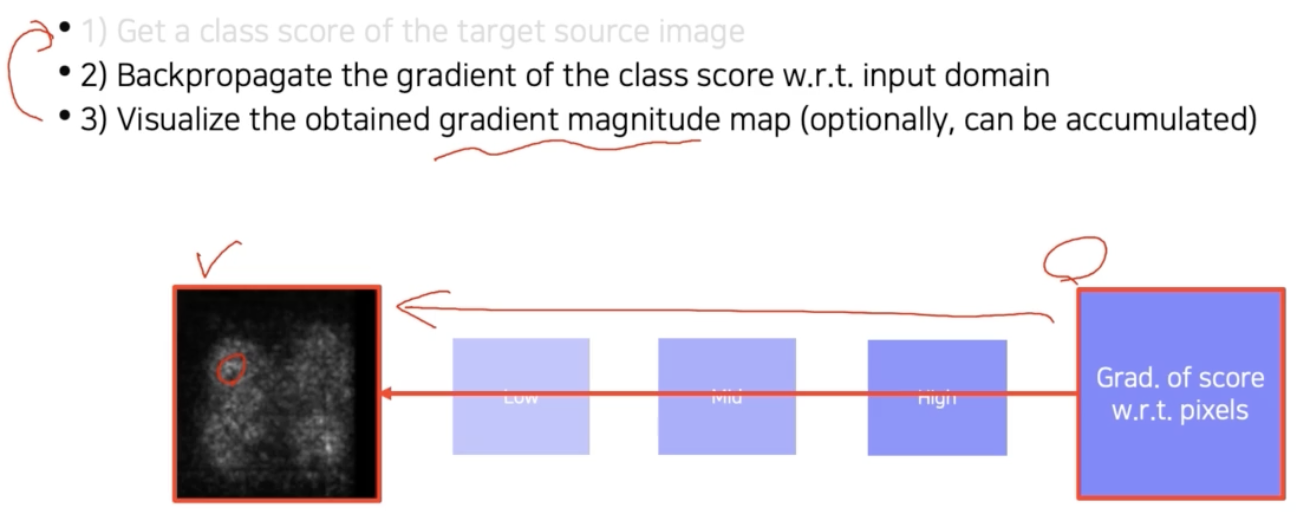
- 이후 역전파를 input image 까지 쭉 진행한다. Loss 를 변경해주는 gradient 를 얻는 것이다.
- 그렇게 얻어진 gradient 에 절대값을 취해주거나 제곱을 해서 gradient 의 절대적인 크기를 구한 후 이미지 형태로 출력한다.
- 여기서 절대값이나 제곱을 취하는 이유는 gradient 의 크기 자체가 중요한 정보로서 입력에서 이 부분이 많이 바뀌어야 score 가 바뀐다는 것을 의미하기 때문에 그곳이 민감한 영역임을 나타내주기 위함이다.
- 따라서 부호보다는 절대적인 크기를 중요하게 생각해서 절대값 혹은 제곱을 취해서 gradient 의 magnitude 를 구해서 시각화한 것이다.
- 위 예제에서는 한번만 한 것을 보여줬는데, 이를 반복적으로 누적해서 사용해 볼 수도 있다.
- 이 방법은 결국, 최종 출력에 대해서 input image 단에서 어떤 부분이 민감했는지 찾는 방법이다.
- 위에서 몽환적인 이미지를 구했던 Class visualization, 즉 CNN 이 클래스에 대해서 어떤 이미지를 상상하는지 알아내는 방법과 매우 유사하다.
- 그러나 차이점은 Class visualization 에서는 입력으로 의미없는 blank 나 random initial 가 들어가지만, 여기서는 현재 데이터가 어떻게 해석되는지를 보고싶기 때문에, 데이터에 dependent 한 해석방법이다. 즉 input image 를 어떻게 넣어주냐가 달라지게 되는 것이다.
2-1-3. Backpropagation-based saliency
- 좀 더 advanced 한 역전파를 활용하여 saliency map 을 구하는 방법은 여러가지가 있다.
- saliency map 이란, CNN 이 최종 결과를 내리기까지 각 pixel 이 기여하고 있는 정도를 시각화하여 나타낸 것으로 activation map 이라고도 불린다.
-
Rectified unit(backward pass)
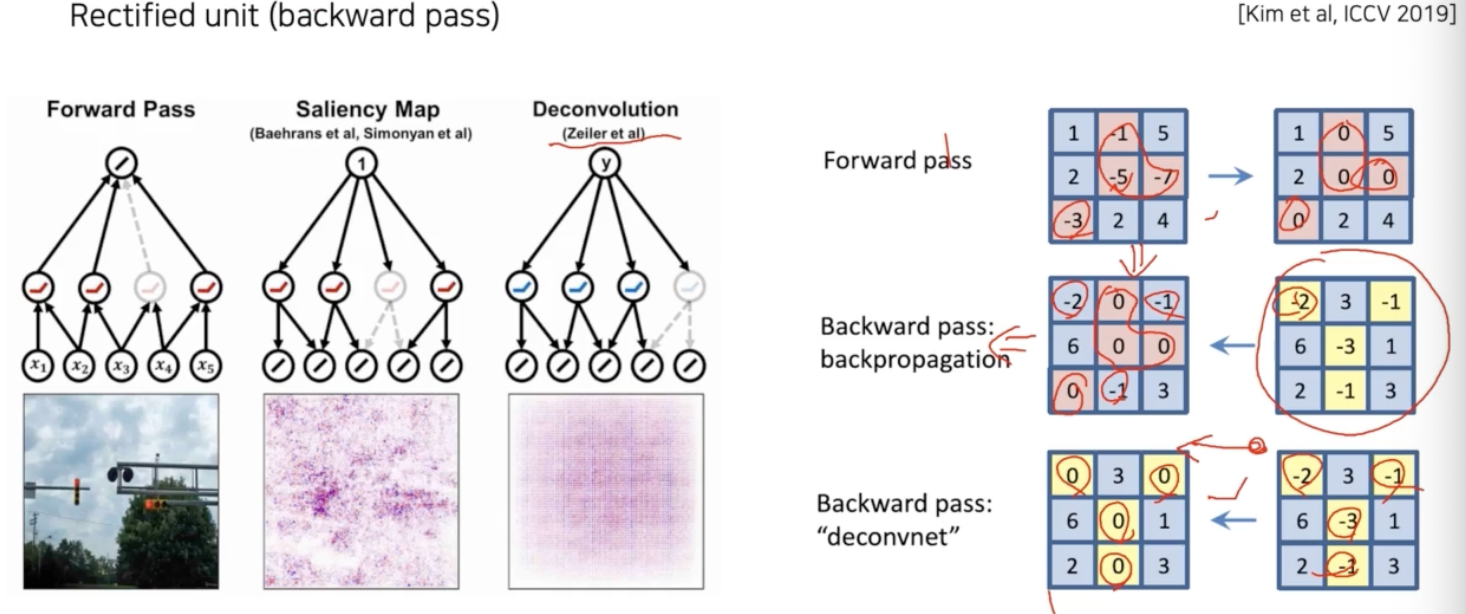
- 일반적으로 CNN 에서는 activation function 으로 ReLU 가 많이 사용된다.
- ReLU 를 사용하면 Forward pass 에서 음수는 ReLU 에 의해 0 으로 masking 이 된다.
- 이런 masking 을 저장해뒀다가, 역전파 과정에서 양수하고 음수가 합쳐진 gradient 가 오면 저장되어 있는 음수 masking 패턴에 따라 음수를 masking 을 해준다.
- 즉 음수가 역전파로 오면 0으로 만들어주면서 역전파에서 gradient 자체의 음수는 신경쓰지 않는다. 이것이 backward pass 에서 일어나는 일이다.
- 그런데 Zeiler 가 사용한 방법은 forward 시의 ReLU 패턴을 사용하는 것이 아니라 deconvolution 된 activation 이 backward 로 내려올 때 그 때의 activation 의 양수하고 음수값을 따져서 음수 마스킹을 한다.
- 즉, backward 연산을 할 때 gradient 자체에 ReLU 를 적용하게 되는 것이다.
-
이를 수식으로 표현하면 아래와 같이 나타낼 수 있다.
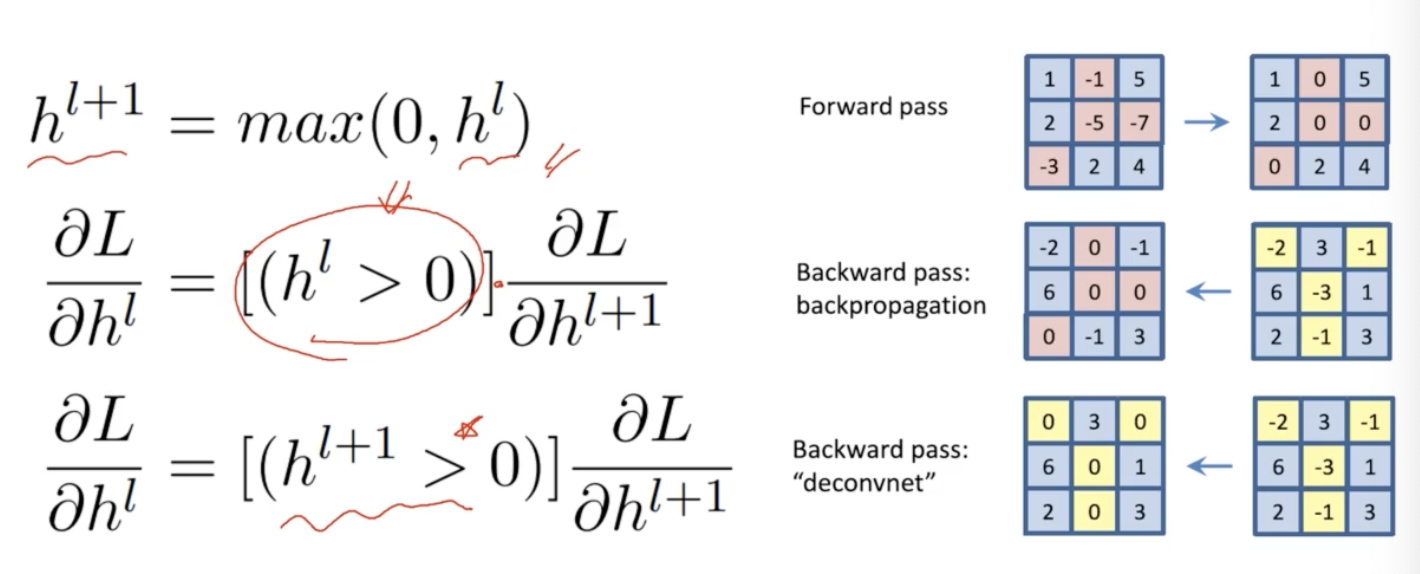
- 첫번째 수식은 forward path 에서 ReLU 를 적용시키는 것이다. $h^l$ 은 ReLU 를 통과하는 현재 activation, $h^{l+1}$ 은 ReLU 를 통과한 다음의 activation 을 나타내는 것이다.
- 두번째 수식을 보면, 기존의 역전파 gradient 를 구할 때는 forward path 에서 사용했던 마스크 패턴을 그대로 사용해서 곱해서 스위칭을 해줬다.
- 그런데 세번째 수식인 deconvolution 를 보면, backward 당시에 사용하는 패턴은 forward path 상위의 activation($h^{l+1}$) 에 ReLU 를 적용한 마스크를 사용하는 것이 큰 차이점이다.
- 이렇게 되면 수학적으로 역전파를 위한 것도 아니고, 그냥 gradient 가 아닌 제3의 무언가가 된다. 뭔지는 확실하게 모르지만 이렇게 했더니 경험적으로 좀 더 잘 된다고 알려져 있다.
-
여기서 더 나아가서, 더 이상하게 만든 패턴을 사용해 볼 수 있다. 바로 Guided backpropagation 이다.
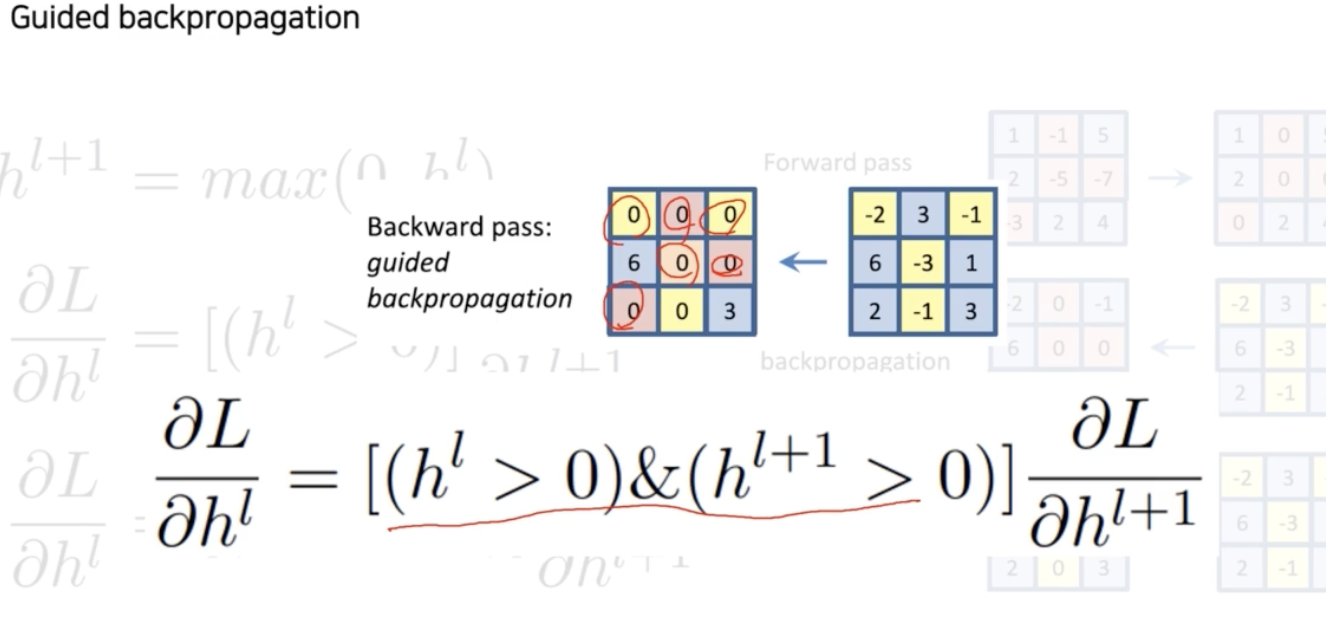
- And gate(&) 를 사용한다. $h^l$, $h^{l+1}$ 마스크를 둘 다 And 로 써서 forward 로 올라갈 때 ReLU 의 패턴도 0으로 만들어주고, 반대로 backward 에도 음수값을 다 0으로 만들어준다.
-
이것을 왜 이렇게 하지? 생각이 들 수 있지만, 실제로 쓰는 방식이고 수학적 의미를 찾기 보다는 이게 뭐하는 건지 해석을 해볼 수는 있다. 결과를 보고 왜 이렇게 하는지 이유를 유추해보자.

- 위 saliency map 들을 보면, 고양이 이미지가 들어왔는데 고양이로 인식하면서 어떤 부분을 주로 보면서 고양이라고 인식한 것일까 해석해보니 귀, 얼굴 부분을 주로 봤다는 것을 확인할 수 있다.
- 역전파를 그냥 쓰거나, deconv 방법보다도 guided backprop 방법이 굉장히 깨끗하게 이해가 되는 것 같다. 어떻게 보면, 두 mask 를 모두 사용한 것이 forward 를 할 때도 결과에 긍정적 영향을 미친 양수들을 참조를 하고(음수는 0으로 cancel out), 동시에 backward 를 할 때도 gradient 를 통해서 더 강화하는 방향으로 움직이는 activation 들을 고른 것이다.
- 이 두 개의 조건을 다 만족하는 activation 들이 실제적으로 최종 결과를 만들었을 때 더 깨끗하고 좋은 게 아닐까라고 생각할 수 있다.
- 즉, 양방향에서 모두 클래스 결정에 도움이 되는 부분만 본 것이 guided backpropagation 이라 볼 수 있다. 이렇게 보면 경험적 방법이지만 결과적으로 효과적 방법이 유도되었다 볼 수 있다.
-
2-2. Class activation mapping (CAM)
-
가장 유명하고 가장 많이 사용되는 시각화 알고리즘이다.
-
CAM 을 사용하면 아래와 같이 어떤 부분을 참조해서 어떤 결과가 나왔는지 보기 좋은 부드러운 히트맵 같은 형태로 표현해줄 수 있다.

- 이 방법을 잘 사용하면, 즉 threshold 를 잘 구하면 bounding box 까지 그려서 물체를 탐지할 수도 있다.
- CAM 알고리즘은 네트워크의 일부를 개조해야 한다.
-
Class activation mapping(CAM) 이라는 방법은, 기존 FC layer 로 학습된 layer 를 global average pooling(GAP) 으로 변경하여 activation map 을 확인하는 방법이다.
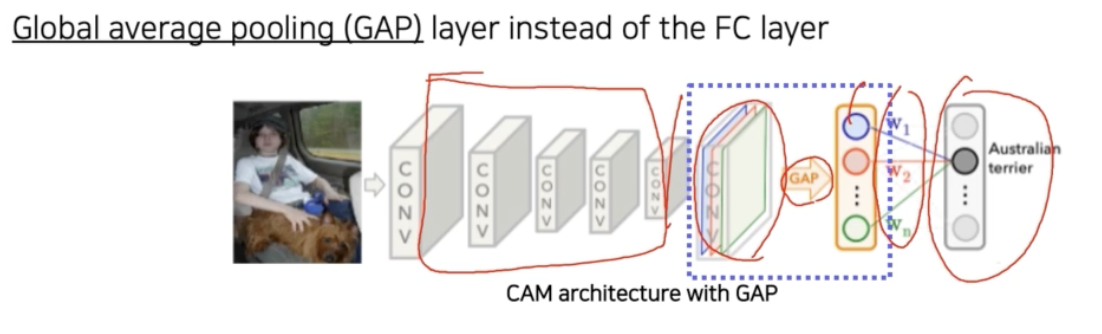
- 마지막 conv layer 에서 나온 feature map 을 fc layer 에 바로 통과시키지 않고 GAP 를 하도록 바꿔줘야 한다.
- 그 다음에 fc layer 를 하나만 통과시켜준다. 여기서 최종적으로 classification 을 하도록 만들어준다. 위 그림의 뒷부분 구조처럼 만들어줘야 한다는 것이다.
- 그리고 이미지 classification task 에 대해서 학습을 다시 해준다. 이 구조를 사용해서 CAM 아키텍처를 가지는 네트워크를 다시 학습을 해주는 것이다.
- CNN 구조가 마지막 부분이 위처럼 되면 CAM 을 사용할 수 있는데, 이 CAM 을 아까 같은 시각화를 유도하는지를 보자.
-
위 아키텍처를 구성해놓고 재학습한 pretrained network 로부터 CAM 을 유도해보자.
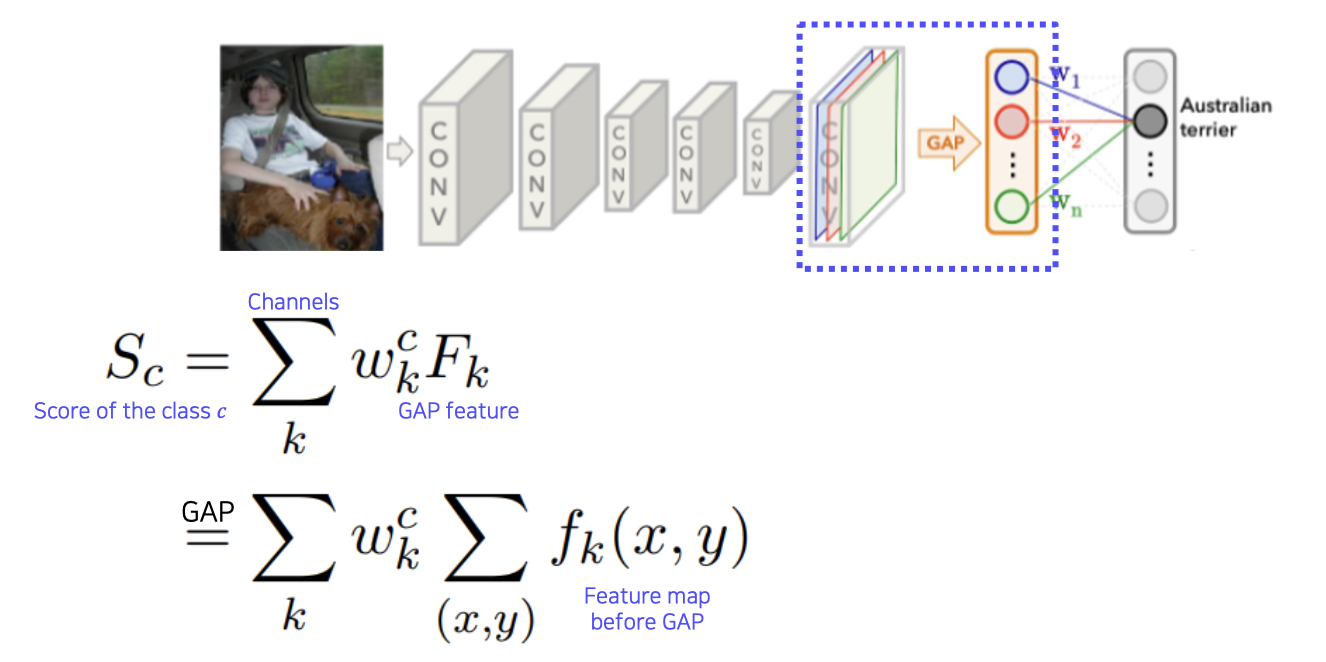
- 복잡하지만 수식을 통해 엄밀히 보자. 하나의 클래스 $c$ 에 대해서, score 를 $S_c$ 라고 하자.
- 이 score 는 마지막 fc layer 의 클래스 $c$ 에 해당하는
weight$w^c$ 와, 마지막에 GAP 로 각각 공간축(채널)의 평균값을 내서 만들어진 하나의 노드들인 $F_k$ 의 linear combination 으로 score 가 만들어진다. - 즉, 위 그림에서 GAP feature 는 주황색 박스를 말하고, 마지막 fc layer 안에 각각의 feature vector 들의 element 에 $w$ 가 linear combination 으로 곱해져서 최종적으로 score 를 만든다는 것이다.
- 그 다음에 $k$ 채널은 마지막 conv layer 의 채널 수를 뜻한다. GAP feature 는 conv feature map 의 모든 픽셀에 대해서 각 채널($k$)마다 평균을 취한 것이다. 따라서 $F_k$ 부분을 펼치면 $\sum_{(x,y)} f_k(x,y)$ 가 되고, $f_k$ 는 feature map 의 $k$ 번째 채널에서 $(x, y)$ 위치의 픽셀값이다.
-
여기까지 연산들을 보면 곱하기, 더하기로 이루어진 모두 linear combination 이다. 그래서 순서를 막 바꿔줄 수 있다.
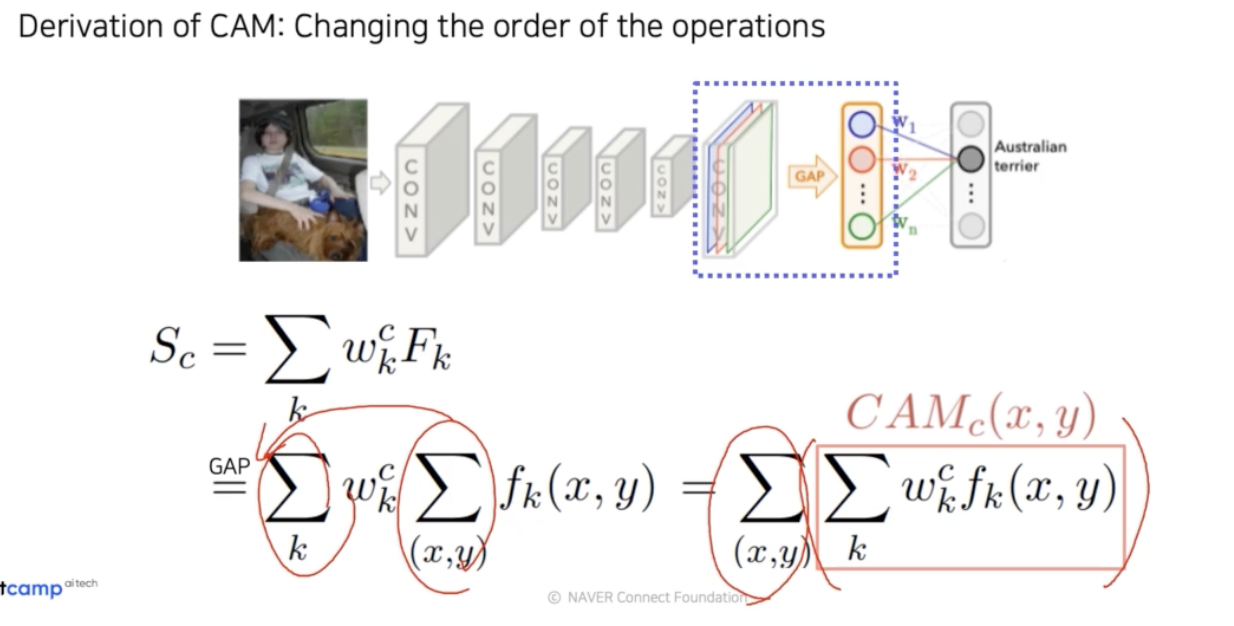
-
sum 의 위치를 바꾼 빨간 박스 부분을 CAM 이라고 부른다. GAP 가 $\sum_{(x,y)}$ 로 나타나고, CAM 은 위 식에 따르면 GAP 을 적용하기 전 이기 때문에 아직 공간에 대한 정보가 남아있다. 그래서 이 CAM 을 image 처럼 생각해서 시각화할 수 있다.
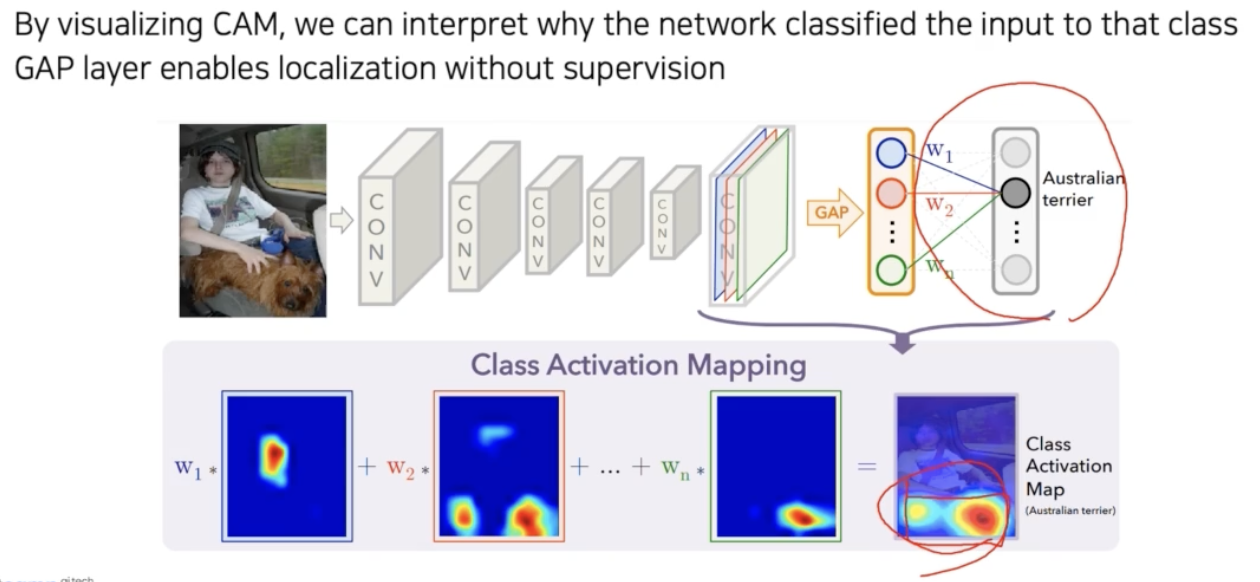
- 이처럼 어떤 부분을 참조했는지 결과가 눈에 보이게끔 히트맵 형태로 표현된다.
- CAM 은 다른 방법에 비해서 부드럽고 명확해서 압도적으로 좋은 성능을 보여주며 유용하다.
- 그리고 이 결과는 단순히 해석적인 이미지 형태를 출력해주는 것 뿐만 아니라, dataset 에서 어떤 물체의 위치정보를 주지 않았는데도 불구하고 spatial 한 공간 정보도 없이 단순한 image 인식기를 학습했는데 위치를 파악할 수 있었다는 것이다.
- 즉 어떤 위치에 대한 annotation 정보도 주지 않고, image 인식만 하라고 했는데 위치도 찾을 수 있는 제3의 task 가 공짜로 해결된 것이다.
- 실제로 이런 히트맵에서 적당하게 threshold 를 통해서 bounding box 를 만들어주면 object detection 이 된다.
-
이러한 학습방식, 즉 object detection 과 같이 좀 더 정교한 task 를 좀 더 러프한 image 인식 task 같은 걸로 데이터를 사용해서 간접 해결하는 방법을 weakly supervised learning 이라고 부른다.
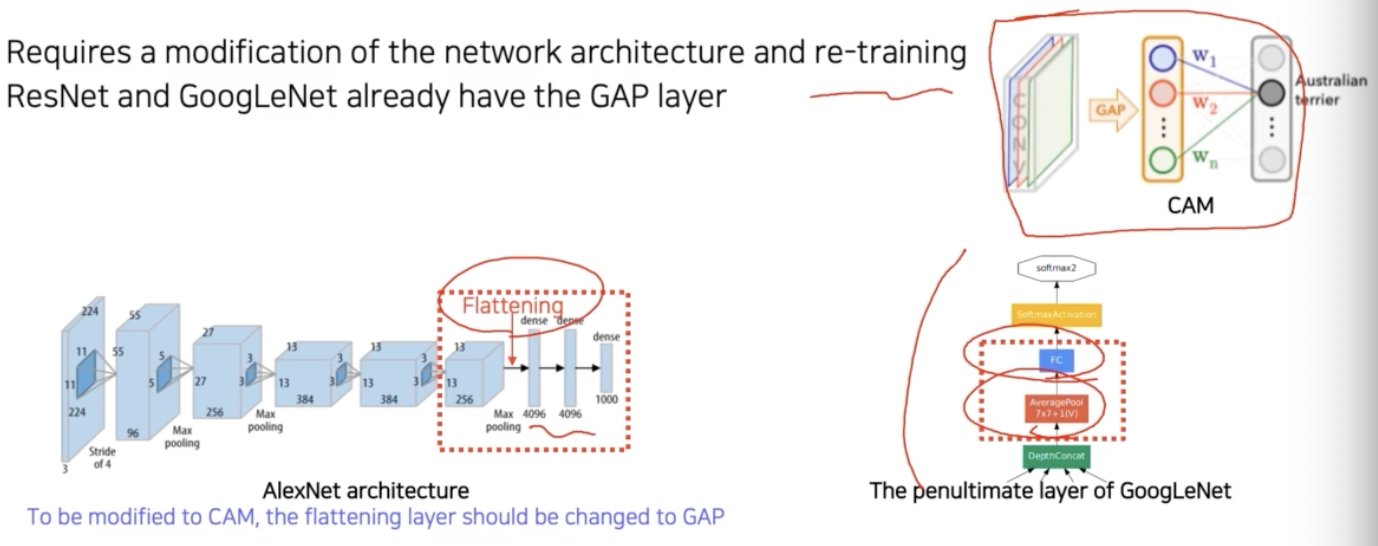
- 다만 CAM 적용이 가능하도록 하는 제약으로는, 마지막 layer 의 구성이 GAP 과 fc layer 로 이루어져야 한다는 것이다(오른쪽 위 그림).
- 또한 아키텍처를 바꾼 상태에서 재학습을 해야하는 것도 단점이다.
- AlexNet 을 보면 마지막 conv layer 이후 flatten 으로 vector 로 만들어준다. 이후 fc layer 도 여러 개가 들어간다(왼쪽 아래).
- 이 부분에 대한 구조를 바꿔주려고 재학습을 해야하는데, 그러면 모델 구조가 바뀌었으니 튜닝된 파라미터들과 안 맞을 수도 있고 성능이 바뀌게 된다. 즉 CAM 을 사용하면 성능이 바뀐다는 것도 단점이 될 수 있다.
- 다행히도 ResNet 이나 GoogLeNet 같은 구조에서는 마지막이 GAP 이 들어가 있고, fc layer 도 하나로 구성되어 있다. 그래서 CAM 을 활용하기 용이한 구조다. 즉 수정하지 않고도 바로 CAM 을 추출하는게 가능하다.
2-3. Grad-CAM
- 모든 아키텍처가 CAM 을 잘 사용할 수 있게끔 설계될 수는 없다.
-
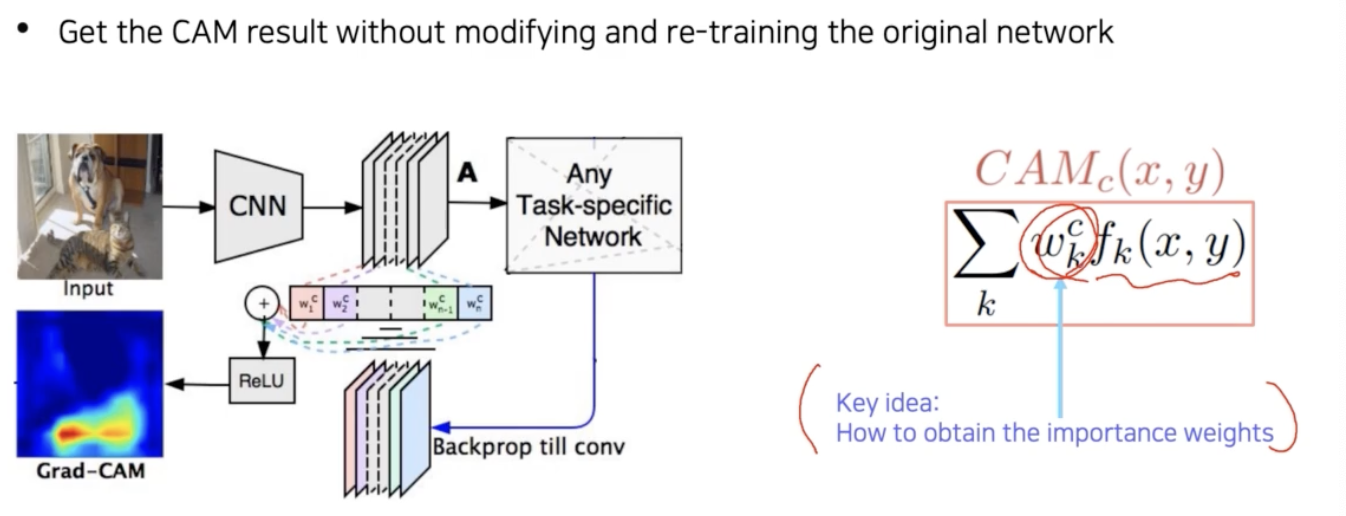
따라서 구조를 변경하지 않고 재학습도 필요 없이, 미리 학습된 네트워크에서 CAM 을 뽑을 수 있는 방법으로 Grad-CAM 이 제안됐다.
-
CAM 방식은 network 구조를 변경하고 re-training 해야하지만 Grad-CAM 은 이러한 과정이 필요없다.

- 또한 CAM 과 비슷한 성능이 나온다. 고양이로 판별한 경우 어디를 보고 고양이로 판별하는지 명확하게 히트맵을 그려준다.
-
guided backprop 이랑 비교했을 때도 Grad-CAM 이 훨씬 더 해석하기 좋다.
- Grad-CAM 은 꼭 image 인식 task 에 국한될 필요가 없다. 어떤 task 이던지 backbone 이 CNN 이기만 하면 사용할 수 있다.
- 즉 Grad-CAM 은 backbone 이 CNN 이기만 하면, image classification, image captioning, visual question answering 등과 같이 any task head 에서 적용될 수 있다.
- CAM 과 비교를 해보면, 결국의 CAM 은 CNN 의 마지막 feature map 을 weighted sum 으로 합성하는 것인데, CAM 의 수식에서 여기서 결합되는 weight 만 모르기 때문에 이 weight 를 어떻게 구할지만 고민하면 된다.
-
따라서 이 importance weight($w_k^c$)를 어떻게 구할 것인지 그 부분이 Grad-CAM 의 핵심이다.
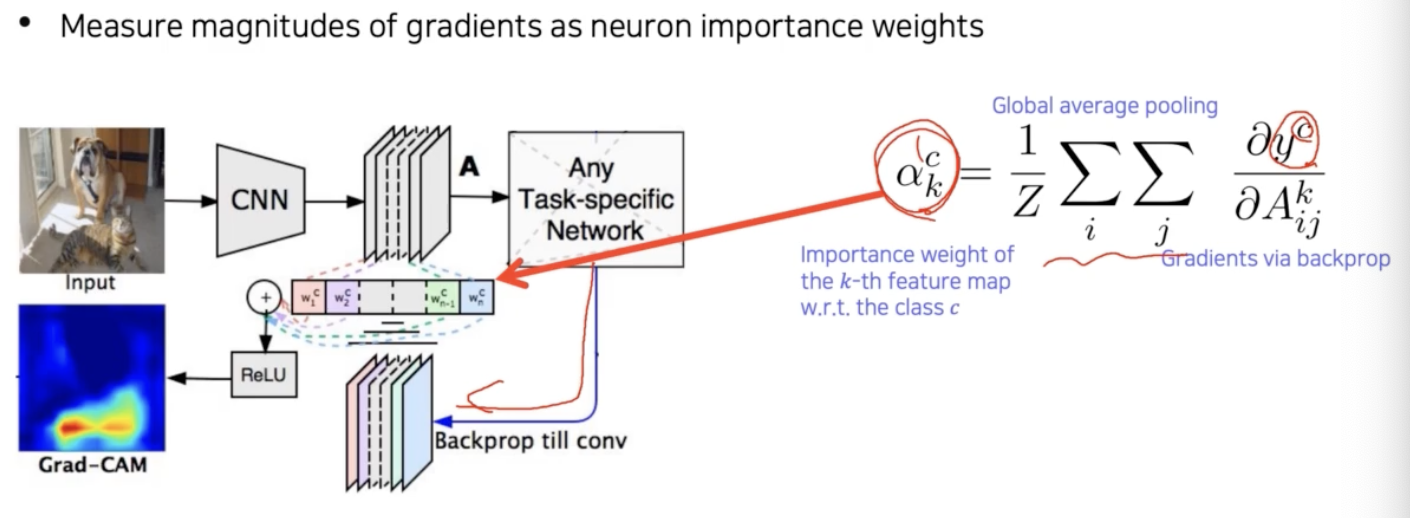
- 이전에 gradient 를 역전파 해서 saliency map 을 유도했던 방법을 응용해서 weight 를 구해보자. Grad-CAM 에서의 weight 는 기존의 weight 와 다르기 때문에 $\alpha_k^c$ 라고 표현한다.
- 이전에 saliency map 을 구하는 방법은 input image 까지 역전파를 했지만, 이번에는 우리가 관심을 가지고 있는 activation map(Mid) 까지만 역전파를 한다.
- 즉 Grad-CAM 은 모델 구조를 변경하지 않는 대신, importance weights 를 확인하기 위해 magnitudes of gradients 를 측정한다.
-
그래서 현재 task 에서 해석하고 싶은 결과, 즉 클래스에 대한 score $y^c$ 를 변화시키는 Loss 로부터 역전파 gradient 를 구하고 GAP($\sum_i \sum_j$)를 공간축(채널)으로 적용한다.
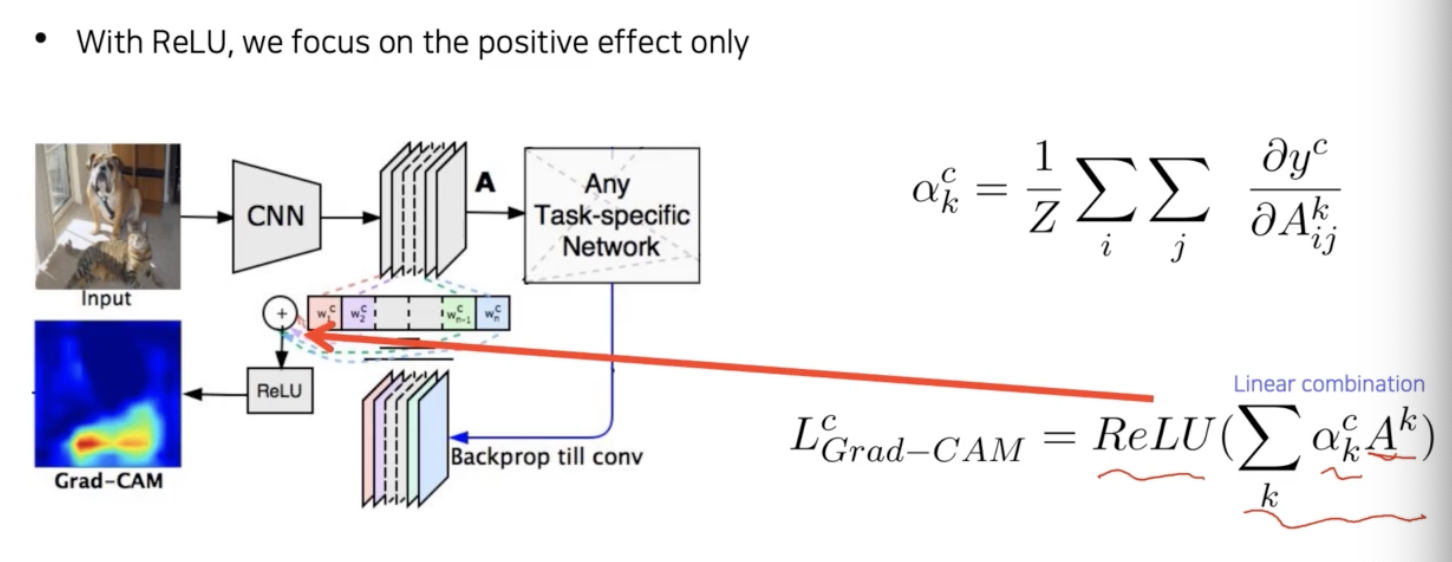
- 그러면 각 채널의 gradient 성분의 크기를 구하게 된다. 그리고 이걸 activation map($A$) 에 결합하기 위한 weight($\alpha_k^c$) 로 사용한다.
- 선형결합을 통해서 activation map 과 weight 를 결합($\sum_k \alpha_k^c A^k$)해주는데, CAM 하고는 다르게 ReLU 를 사용해서 양수값만을 활용한다. 즉 positive effect 에만 집중하는 것이다.
-
이렇게 하면 Grad-CAM 을 얻을 수 있다.
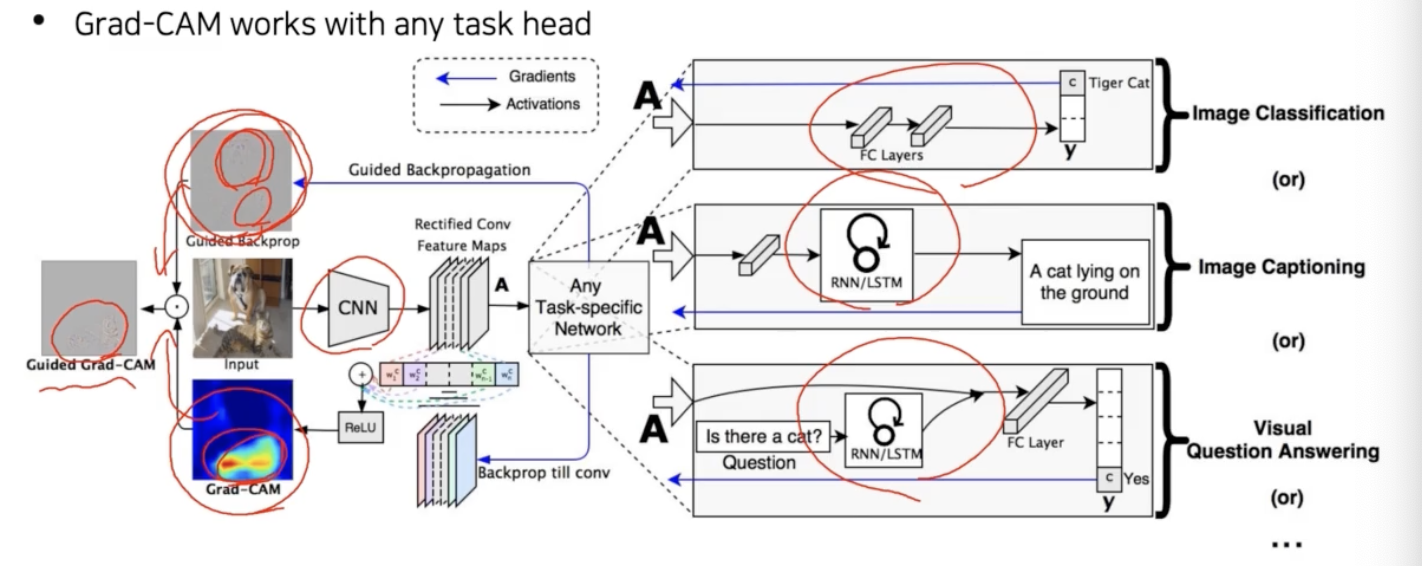
- Grad-CAM 은 CNN backbone 외에는 필요한 특수한 구조나 요구조건이 없었다. 그래서 Grad-CAM 은 뒷단에 classifier 가 붙던, RNN 이 붙던 크게 상관없이 결과를 해석하는데 사용될 수 있는 일반화된 툴이다. head 가 더 복잡해도 상관없다.
- 한발 더 나아가서, guided-backprop 의 saliency map 과 Grad-CAM 의 방법을 결합할 수도 있다. (Guided Grad-CAM)
- Grad-CAM 은 스무스한 특성을 가지고 있고, Guided-backprop 은 샤프하지만 전반적으로 class 에 대한 구분성이 떨어진다. 즉, guided-backprop 에서의 민감하고 high-fequency 의 정보와 Grad-CAM 의 스무스하고 러프하지만 클래스에 민감한 정보가 합쳐져서 고양이에 관련된 texture map 만 알 수 있는 Guided Grad-CAM 을 유도할 수 있다.
-
SCOUTER

- 최근에는 Grad-CAM 을 더 개선시켜서 image 가 어떤 결론(분류 label 등)을 가졌을 때, 왜 그 결론이 났는지 뿐 아니라 왜 다른 것은 아닌지까지 비교 대조해 볼 수 있는 방법으로 확장됐다.
- GAN dissection
- CNN 을 해석하기 위한 시각화 방법을 지금까지 알아봤는데, 이 방법들은 사실 CNN 내부는 바로 해석이 불가능하지만 살짝 만져주면 사람들이 해석가능한 형태의 정보들이 숨어있음을 알게 해주는 방법들이다.
- 이 말은, 우리가 의도하지 않았지만 CNN 이 학습을 하면서 알아서 사람도 공감할만한 지식을 자발적으로 잘 학습했음을 알 수 있다.
-
여기서는 해석 방법만 여러가지 설명했지만 이 방법들을 잘 응용하면 GAN dissection 처럼 생성모델도 어떤 hidden node 가 물체의 어떤 부분을 담당하는지, 물체의 어떤 부분을 생성하는데 기여하는지 해석해서 그 부분을 유저가 수정하면서 사용할 수 있게끔 만들 수 있다.

- 즉 위 예시 이미지와 같이 문을 담당하는 채널을 붙이는 것 처럼 사용자가 control 하게끔 만드는 응용에도 사용할 수 있는 것이다.
- 해석할 수 있는 방법을 찾았으면 결과를 해석하고 그치는 것이 아니라, 해석 가능하면 응용도 가능한 것이기 때문에, 한발 더 나아가서 응용 가능성을 찾아서 남들이 하지 못하는 창의적인 것을 해보자!
구현 디테일
- 이제 이 CNN visualization 을 구현하는 방법을 알아보자.
Saliency map (Autograd)
- Saliency map 을 구하기 위해서는 class score 에서부터 역전파로 gradient 를 구해서 input image 의 gradient 를 구하는 것이 목표였다.
-
역전파된 gradient 를 accumulation 한다던지 gradient 자체를 시각화하면서 saliency map 을 얻었다.
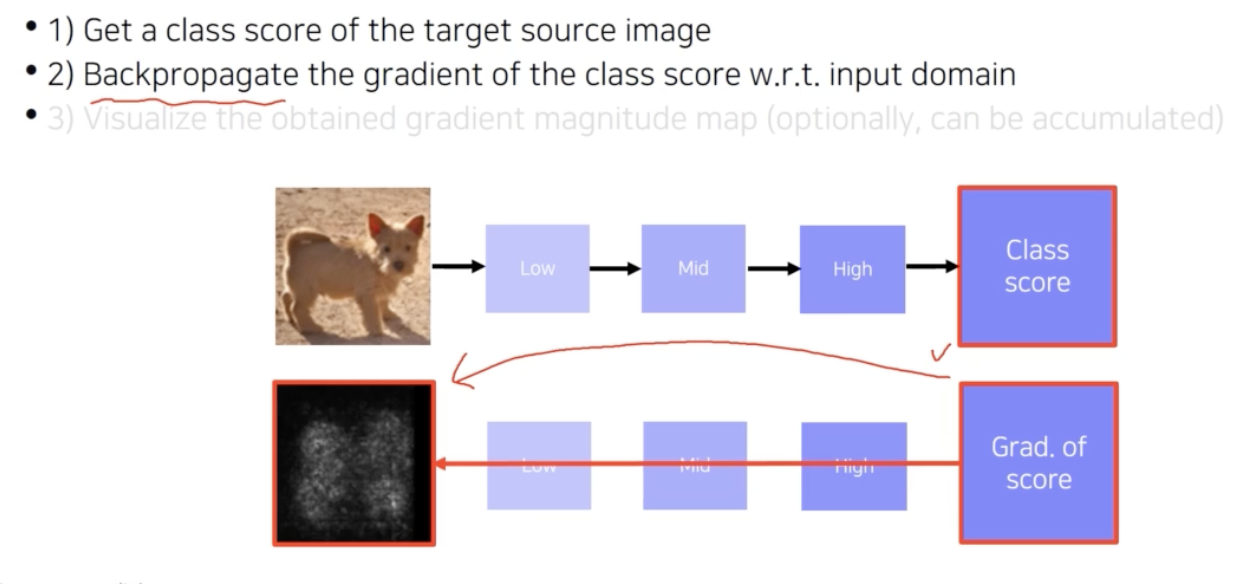
- 그렇다면 gradient 를 구하기 위한 방법을 알아야 한다.
- gradient 는 Autograd 를 활용해서 구한다.
- Autograd 는 automatic differentiation 라고도 부른다. 그리고 대부분의 딥러닝 라이브러리들의 고유한 기능을 의미한다.
-
딥러닝 라이브러리는 기본적으로 행렬 연산을 하는 라이브러리다. 기존의 행렬 연산 라이브러리가 많았는데, 그것과 딥러닝 라이브러리가 가장 크게 다른 점이 바로 Autograd다.
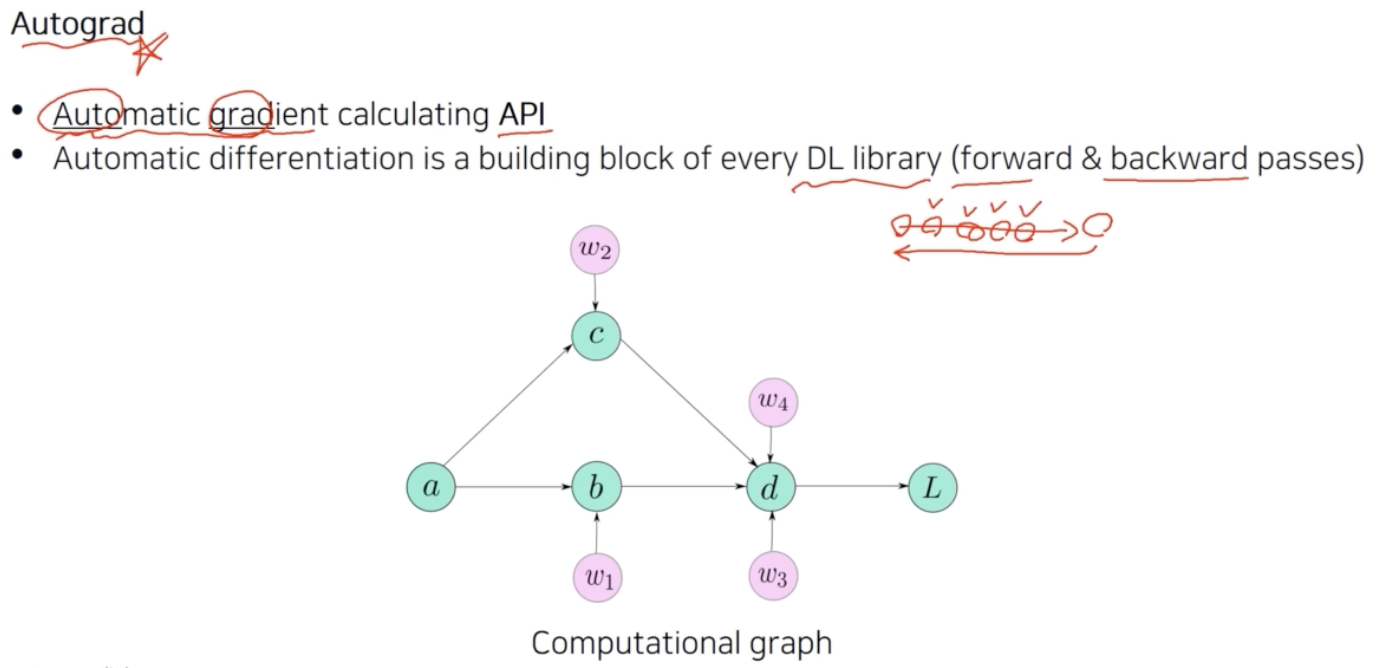
- Autograd 는 forward 와 backward pass 가 가능하게 만들어준다.
- 우리가 하나의 값을 계산하기 위해서 다양한 프로세스를 거쳐서 계산을 진행하는데, 그러면 많은 변수를 사용하는 것이다. 이 연산을 반대로 gradient 를 계산할 수 있도록 쉽게 만들어주는 것이 Autograd 다.
- 과거에는 forward 를 일일이 손으로 계산하고 backward 를 일일이 구현했다. 그러나 이제는 computational graph(계산그래프) 라는 편리한 데이터 구조를 사용해서 automatic differentiation 을 편하게 그려낼 수 있다.
- 계산그래프 덕분에 딥러닝을 사용하려는 유저의 난이도를 낮춰놨고, 다양한 사람들이 쉽게 딥러닝에 접할 수 있게 됐다.
- 계산그래프는 위 이미지의 $L$ 이 계산되기까지의 history 를 다 가지고 있다. $a$ 에서부터 $L$ 까지 도달하기까지 어떤 연산들을 했는지를 따로 저장한다. 이것을 저장하고 있는 이유는 역전파를 할 때 $a$ 에 대한 gradient 를 구하고 싶다면, $L$ 에서부터 gradient 가 전파되어서 타고 타고 오는 형태로 역전파를 계산할 수 있기 때문이다.
- 이러한 Autograd 에 대해서는 Pytorch 카테고리의 [Deep Learning, Pytorch] Autograd 포스트에 자세히 정리해두었다.
Class activation mapping(CAM)
-
CAM 을 계산할 때는 중간에 gradient 를 저장해야 한다. 이 구현 디테일을 보자.
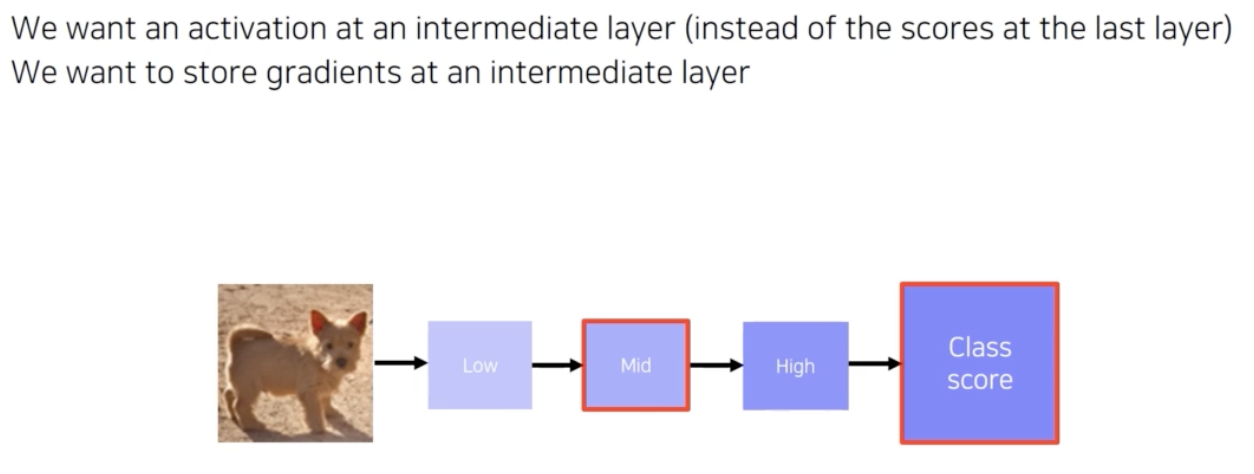
-
중간에서 gradient 를 얻는 방법은 여러가지 있다. torch 의
hooking이 대표적이다.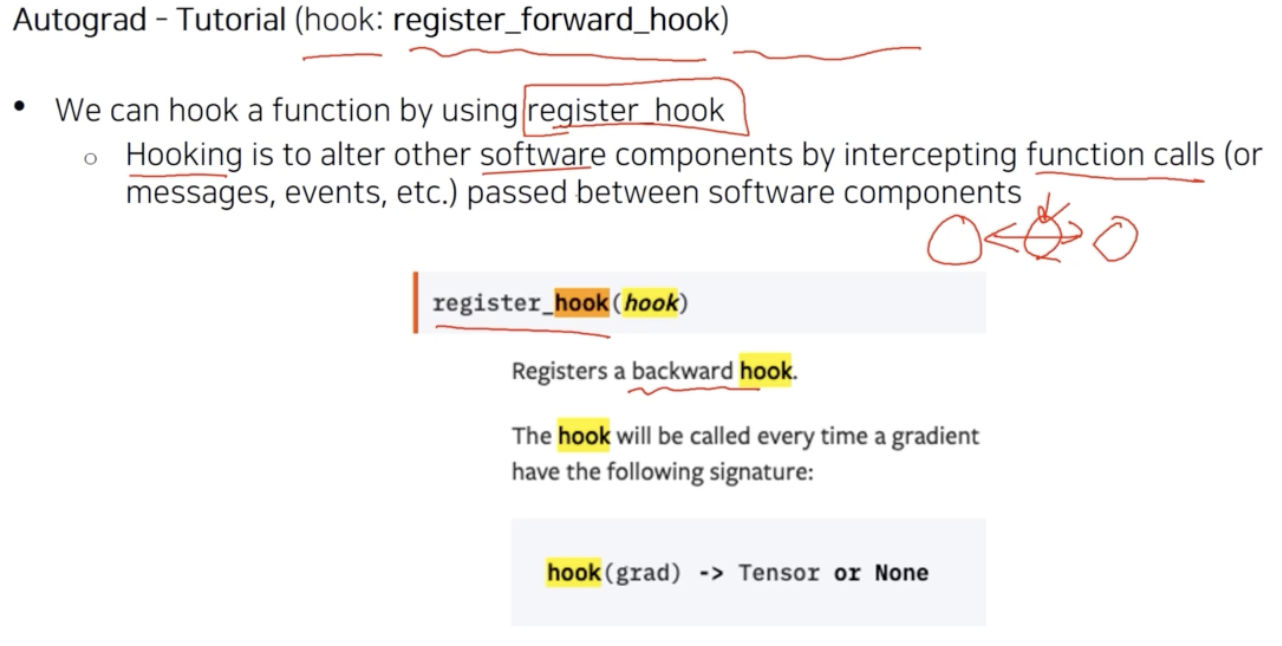
- hook 을 사용할 때는
register_forward_hook함수를 이용한다. - hooking 이라는 용어 자체는 딥러닝 뿐만 아니라 일반적인 컴퓨터 소프트웨어에서 많이 등장한다. hooking 이 의미하는 것은 어떤 func 를 call 했을 때 두 개의 소프트웨어 컴포넌트 사이에 왔다갔다 하는 메시지를 낚아채는 것을 의미한다.
- 여기서
register_hook이라고 하면은backward 가 call 될 때 중간에 있는 어떤 정보를 꺼내오는 것이다. 그래서 backward 를 hook 하게 되면 gradient 를 계산할 때 마다 중간의 gradient 를 낚아챌 수 있는 func 이 된다. - hooking 의 사용법을 보자.
-
LeNet 구조
-
hook 이 동작할 때 어떤 것을 수행해야 하는지 signature of hook func 을 정의해야 한다.

- 위 예제는 input 이 들어왔을 때 input 의 타입 등을 출력하라는 hook func 이 작성되어 있다. hook func 이벤트가 발생했을 때, 즉 hook 을 걸어준 곳에서 input 과 output 을 받아서 hook func 결과를 출력한다.
- 그러면 hook 을 어디서 잡을까?
-
hook 을 걸고 싶은 layer 에 register 한다.
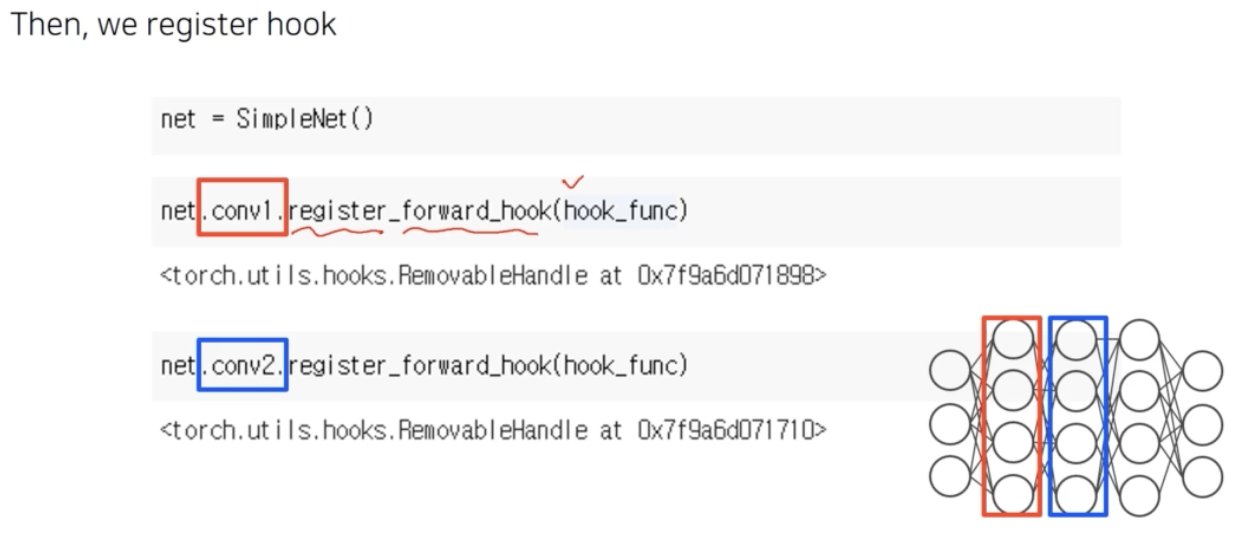
- 위 예제는
register_forward_hook을 통해 feed forward 하면서 activation 이 계산될 때 hooking 이 발생한다. 구체적으로 conv1 layer 가 계산되어 forward 가 될 때 hook func 을 동작시키라고 등록하는 것이다. 그러나 등록만 해주면 아무것도 일어나지 않는다. -
실제로 forward pass 를 실행하면서 activation 이 계산될 때 우리가 등록한 hook_func 이 자동으로 호출된다.
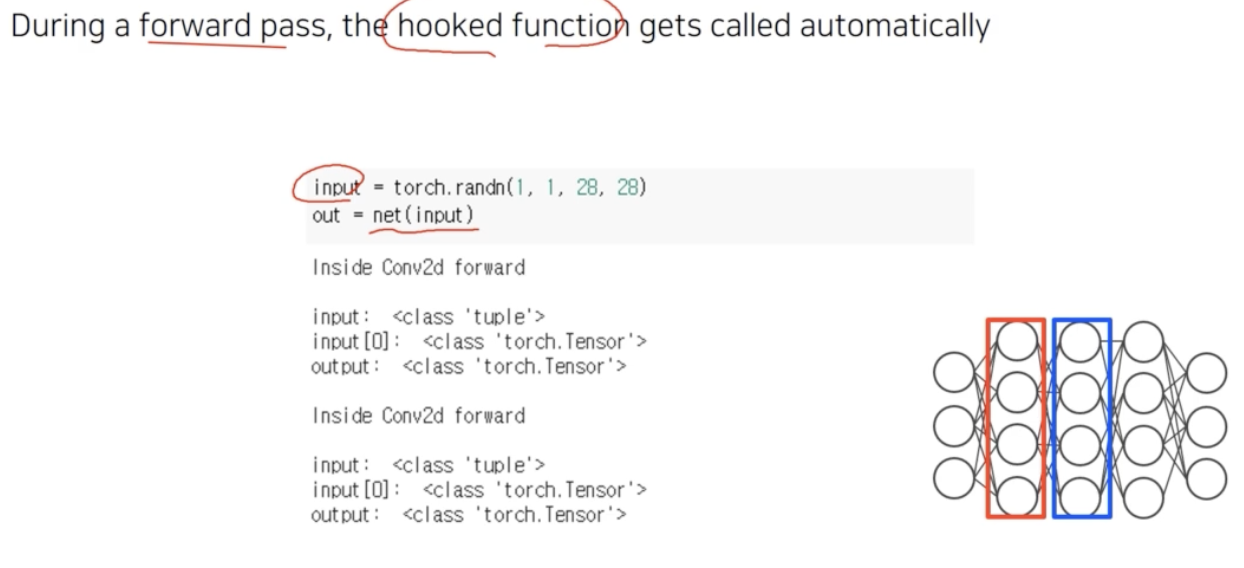
-
register_forward_pre_hook도 있다.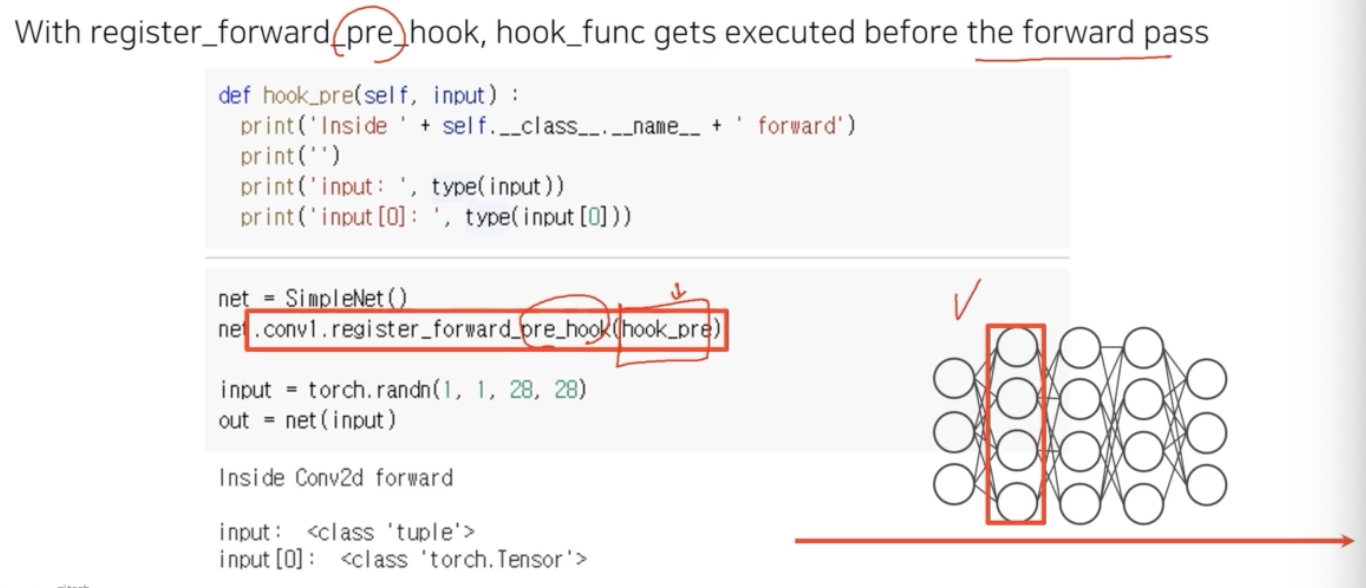
- pre_hook 은 hook 이 발생하는 시점을 forward pass 를 하기 바로 직전에 발생하라는 것이다.
- 그 pre_hook 이 발생하는 그 시점에 호출되어야 할 함수가 argument 로 들어간다.
-
register_backward_hook은 gradient 를 다루는 hook_func(hook_grad) 을 정의해서 넣어줘야 한다.
- conv layer 1 에 backward hook 을 걸어주면, input 을 만들어주고 네트워크로 forward 할 때는 출력이 나오지 않는다. Loss 를 계산하고
Loss.backward()호출을 하면 역전파가 시작되면서, 그 해당 conv layer 1 을 지나가게 될 때 hook_func 이 발생한다. -
hook_grad 를 자세히 살펴보면 아래와 같다. argument 를 잘 기억하자.

- 주의할 점은 argument 인
grad_input, grad_output자체를 변경하면 안된다. gradient 를 좀 바꾸고 싶다면 선택적으로 return 을 할 수 있다. -
어떤 새로운 gradient 를 계산해서 return 해주면, 이 hook 을 통과하면서 역전파 gradient 가 다음으로 넘어갈 때 gradient 가 변형되어 넘어가게 되고 그게 실제로 역전파에 반영된다.
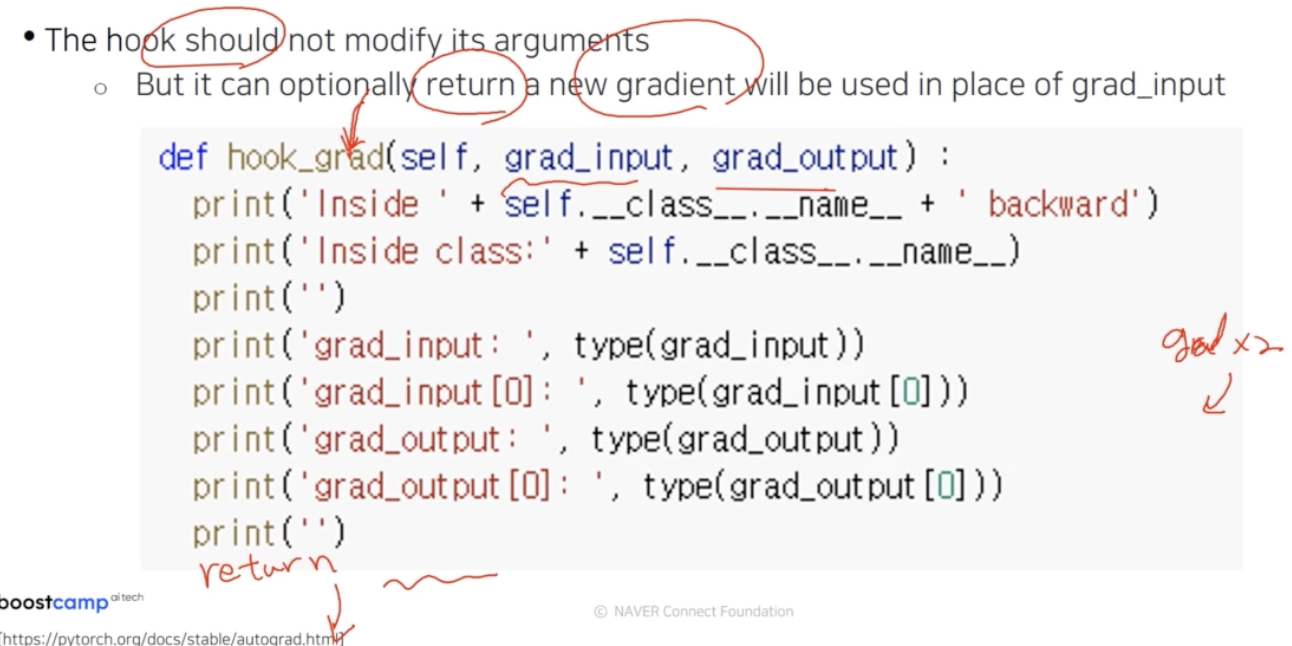
- 즉, gradient 자체에 2배 하도록 hook 에 걸려있으면 그대로 반영된다.
-
한 번 hook 을 등록했다고 계속 call 할 때마다 결과가 프린트되면 곤란하니 register 를 지우는 방법도 있다. register 할 때 return 값을 받는데 이를 handler 라고 부른다.
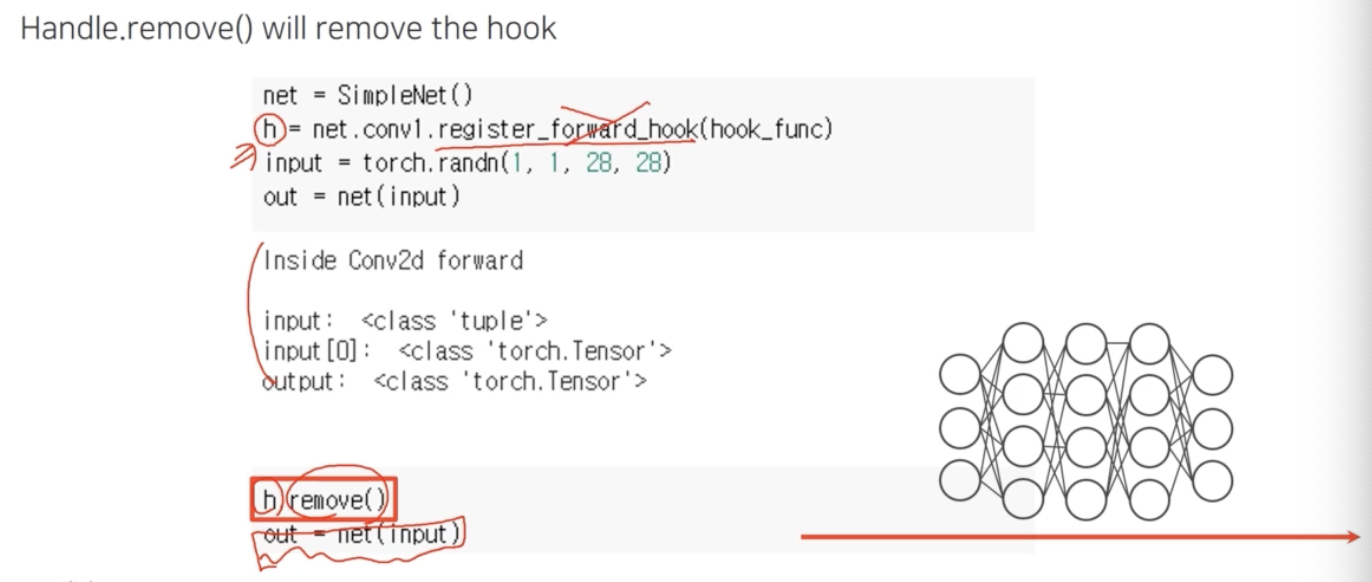 h 가 handler 이다.
h 가 handler 이다. - 이 handle 을 보관하고 있다가 네트워크를 forward 하여 hooking 을 발생시켜 디버깅 하고, hook 이 필요없다면
handle.remove()로 등록된 hook 을 지울 수 있다.
-
- 이를 종합해보면 Grad-CAM 을 구현할 때, 역전파를 얻는 방법에 대해서
register_(forward or backward)_hook을 사용하면 되는 것을 알 수 있다. -
forward hook 에서 중간에 activation 을 가져오는 방법
- 먼저 hook_func 을 정의한다.
- 이 때 feature 는 전역변수(
save_feat)로 저장한다.

- 이 때 feature 는 전역변수(
- 그 다음으로 적절한 위치에 hook 을 등록한다.
- 모델에서 각각의 모듈들을 for loop 을 돌면서 그 모듈의 이름이 우리가 원하는 target_layer_name 과 일치하면 그 모듈에 등록시키게끔 만들 수 있다.

- 그 다음은 input 이 들어왔을 때 forward 를 실행시킨다.
- forward call(
model()) 을 하면, forward pass 를 하면서 타겟으로 지정한 layer 를 지나쳐 갈 때 등록한hook_feat이 실행되고, save_feat 에 output feature 가 저장된다.

- 이 때 save_feat 은 전역변수이기 때문에 계속 누적된다.
- 한번 돌리고 save_feat 을 출력하면 저장된 feature 들을 확인할 수 있다.
- forward call(
- 먼저 hook_func 을 정의한다.
댓글 남기기