
[CNN] 1. Computer Vision Task
Computer Vision
- Computer Vision(CV) 은 왜 AI 문제일까?
- AI 는 사람의 지능을 컴퓨터 시스템으로 구현하는 것이기 때문에, 시각/소리에 관련된 지각 능력, 이해에 대한 내용도 AI 에 포함된다고 볼 수 있다.
- 이런 지능은 어떻게 기계로 구현할 수 있을까?
- 인공지능의 레퍼런스를 찾아보면 결국 “인간” 이다.
- 인간은 오감을 적극적으로 활용한 지각 능력이 발달했고, 세상과의 상호작용, 관찰로 인과관계를 이해한다.
- 따라서 지능을 구현하기 위한 첫번째는 지각 능력의 획득이다. 그리고 이 지각 능력이 제공하는 것은 “입력과 출력” 이다.
- 인공지능의 입력과 출력 또한 사람이 이해할 수 있어야 한다. 또한 오감에서 더 나아가서 교차 감각, social perception, 촉감, 표정 등에서도 더 많은 것을 얻을 수 있다. 복합적인 감각을 이해함으로써 시스템에게 입력과 출력을 제공할 수 있다.
-
인간은 시각에 압도적으로 의존한다.
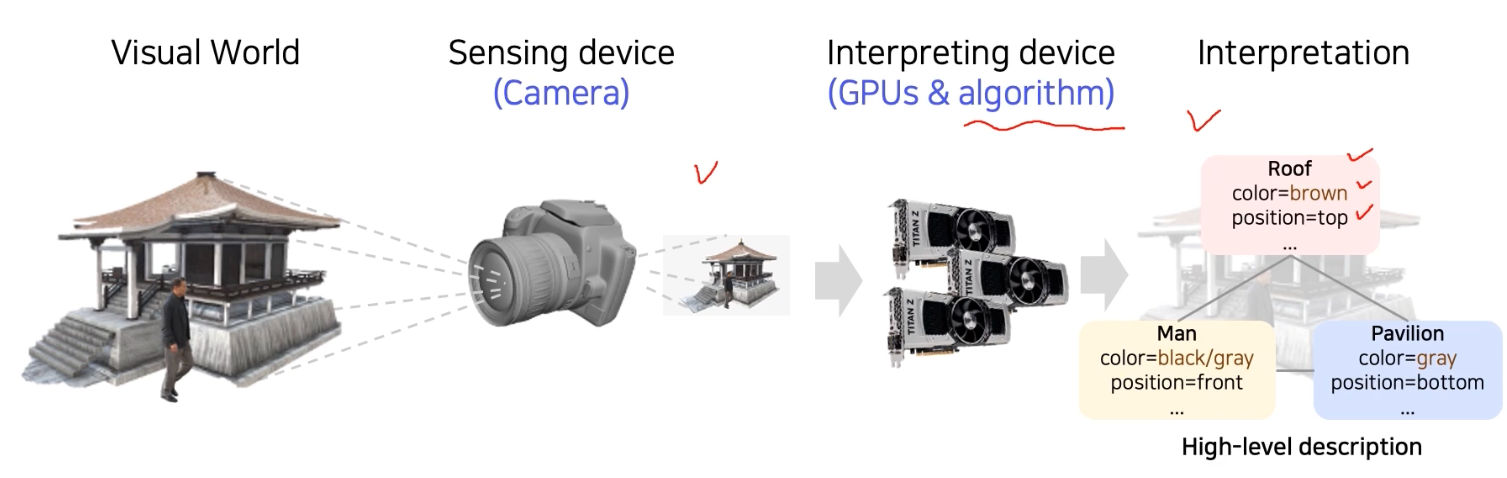
- 마지막 Interpretation 에 보면, 컴퓨터가 이해하기 쉬운 구조로 High-level description 으로 정보가 표현되어 있다.
-
이런 표현들을 이전에는 자료구조라고 불렀지만, 인공지능에서는
“representation”이라는 표현이 자주 사용되고 있다.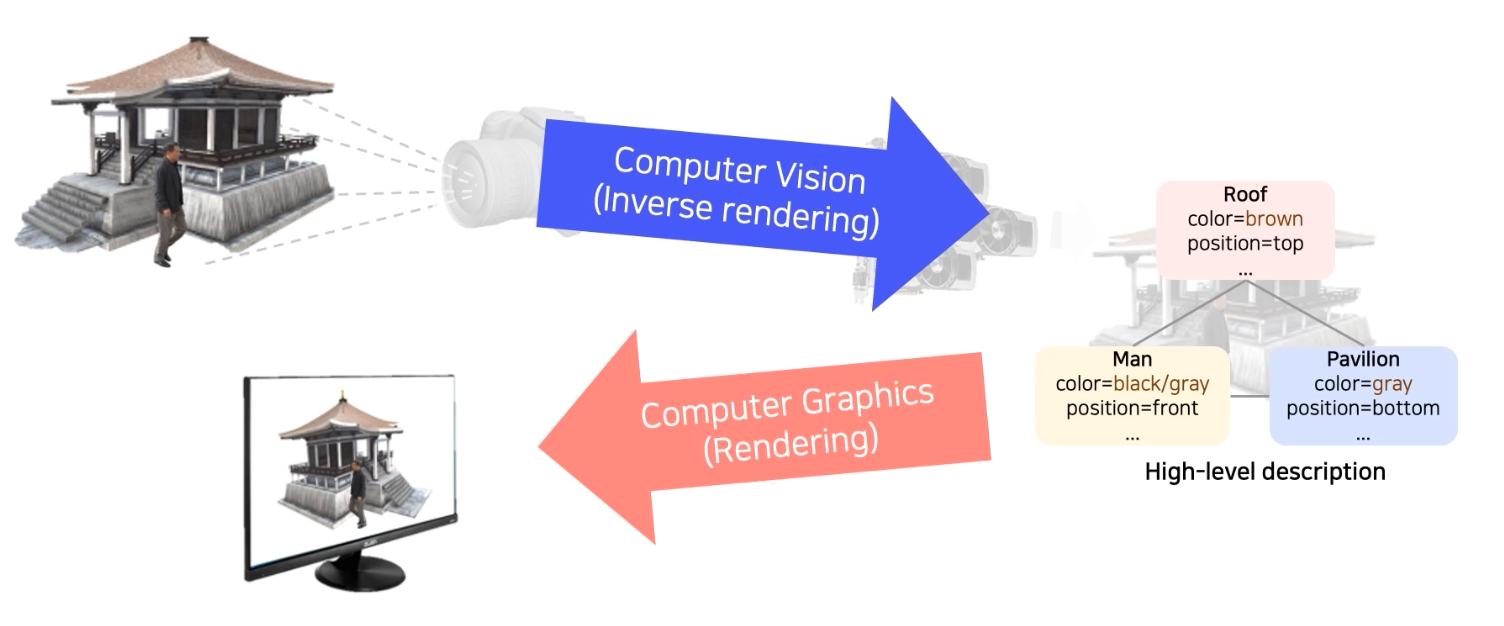
- 이렇게 사람이 시각을 통해 그러는 것처럼, 사물을 보고 high-level description 을 컴퓨터가 이해할 수 있도록 만드는 것이 Computer Vision 이다. 그리고 이를 컴퓨터에 렌더링 하는 분야가 Computer Graphics 다.
- 사람의 생물학적 이해를 바탕으로 어떤 식으로 CV 알고리즘을 구현할지 연구하는 것도 활발하다.
- 사람의 시각에는 그 자체로 불완전성이 있을 수 있다. 인간도 시각기능이 어느정도 bias 되어서 학습되어 있기 때문이다.(똑바로 선 사람만 많이 봐온 것처럼)
CV 알고리즘 구현
-
어떻게 하면 컴퓨터를 활용해서 CV 알고리즘을 구현할 수 있을까?
고전적 머신러닝 방법론
-
데이터를 잘 특징하는 부분 을 feature 라고 부른다. feature 는 노이즈 판단 등의 근거가 된다. 또한 앞으로 다룰 CV 방법론들에서 가장 근간이 된다.
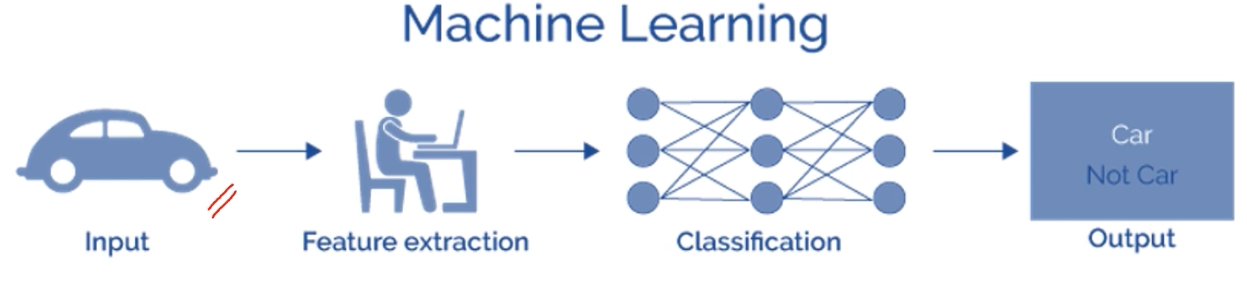
-
고전적 머신러닝 방법론에서는 Feature Extraction 을 전문가들이 많이 담당했다.
딥러닝 방법론
- 딥러닝을 사용하면서 설계방식 패러다임이 바뀐다.
-
전문가가 필요없이, 입력과 출력의 쌍만 넣어주면 알아서 end-to-end 로 학습하고 성능도 매우 좋아졌다.
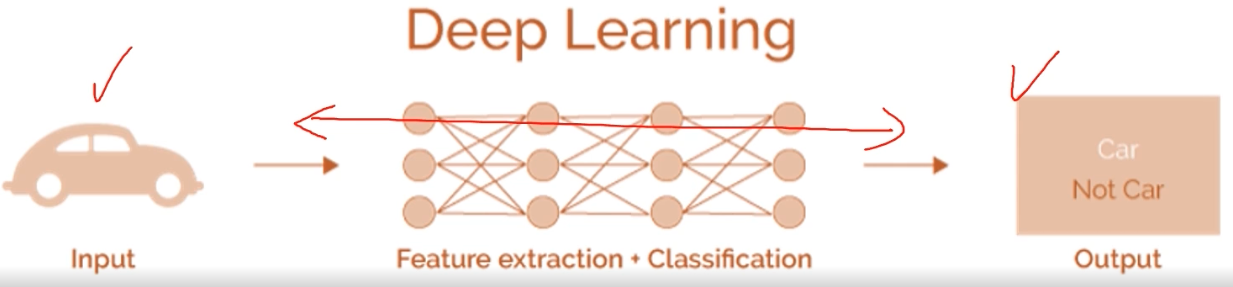
- 사람은 선입견의 동물이다. 따라서 더 중요한 신호를 찾지 못하고 간과할 확률이 높다.
- 그러나 딥러닝에서는 데이터와 학습방법으로 자동적으로 찾는다.
- 즉 사람이 일일이 feature extracion 하는 것과, 딥러닝에서 gradient descent 가 수행하는 것이 대응된다.
- gradient descent 가 특징 추출법과 판별법을 찾는 것이 사람보다 훨씬 낫다!
-
Image Classification
- Image Classification 은 Computer Vision 에서 가장 기본이 되는 task 다.
- 데이터를 가장 잘 특징하는 feature 를 가지고 이 이미지가 어떤 클래스를 가지는지 분류해내는 task다.
k-NN
-
Classifier 는 입력(이미지)에 대해서 그 입력에 해당하는 카테고리 혹은 클래스(출력)를 알려준다. 즉 어떤 물체가 이미지 속에 들어있는지 분류하는 mapping 역할을 수행한다.
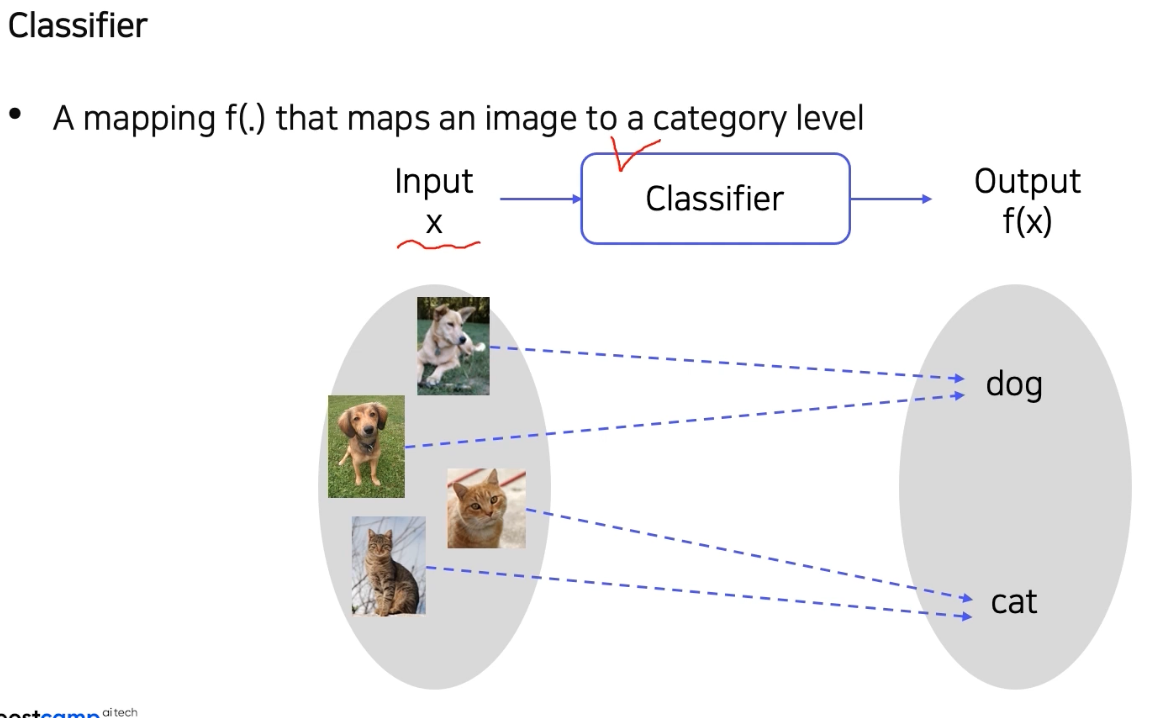
- 이 때 모든 데이터를 다 가지고 있으면 분류는 정말 쉬워진다. 왜냐하면 입력과 비슷한 것을 가지고 있는 데이터 중 찾으면 되기 때문이다. 결국 검색문제(k Nearest Neighbors) 가 된다.
-
k Nearest Neighbors(k-NN) 은 질의 데이터(쿼리 데이터)가 들어오면 근방에 포진하는 k 개의 이웃 데이터를 데이터베이스에서 찾는다. 그 데이터들이 가지고 있던 라벨 정보를 기반으로 해서 판단한다.
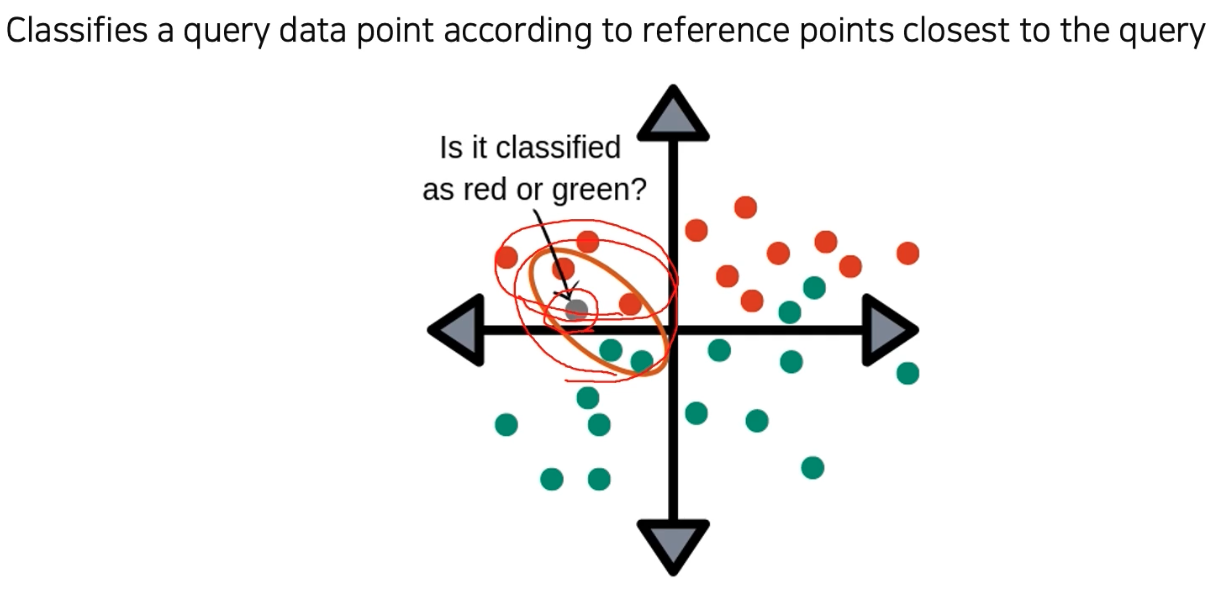
- 이처럼 k-NN 분류 알고리즘을 기반으로 데이터베이스에 모든 데이터가 있으면, 이미지 분류 문제가 검색 문제로 바뀌게 된다.
- 그러나 세상은 만만치 않다. 검색 시간이 엄청나고, 메모리 용량도 엄청나게 증가한다. 또한 k-NN 을 사용하려면 이미지 간의 유사도를 정의해야 한다. 뭐가 비슷하고 다른지 정의하는 것도 쉬운 문제가 아니다.
- 따라서 데이터가 너무 많으면 시스템 복잡도 때문에 실현할 수 없게 된다.
Neural Network (FCN)
- 이제 딥러닝의 Neural Network 를 보자(NN, single layer).
-
NN 을 보면, 방대한 데이터를 제한된 복잡도의 시스템에 압축해서 녹여 넣는 거라고 볼 수 있다.
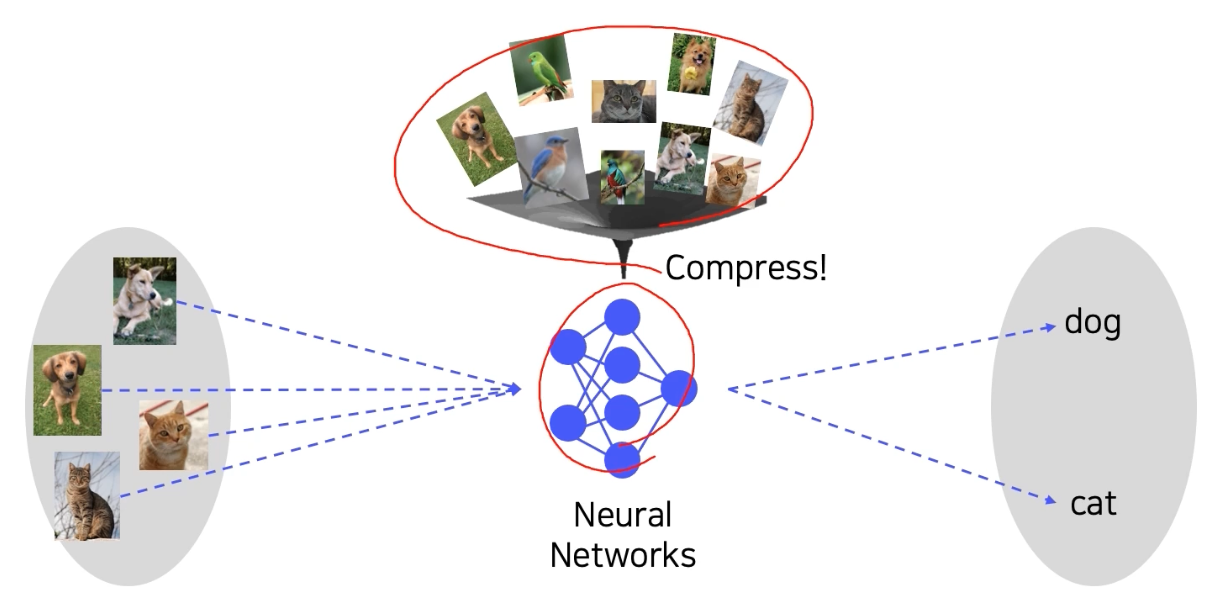
-
이 때 단순한 NN 은 Fully Connected Layer(FCN) 라고도 불린다. 모든 픽셀들을 서로 다른 가중치로 weighted sum(내적)을 하고, non-linear activation func 을 통해서 분류 스코어로 출력한다.
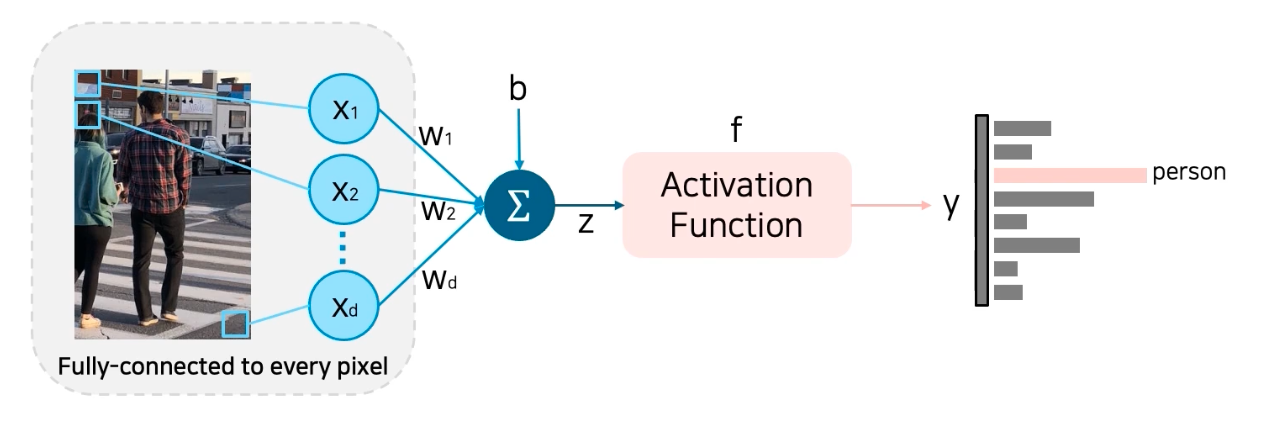
-
문제는 여기에 한계가 있다는 것이다. 문제점을 살펴보기 위해서 각각의 서로 다른 가중치($w$)를 이미지 구조에 맞춰서 reshape 해보자.
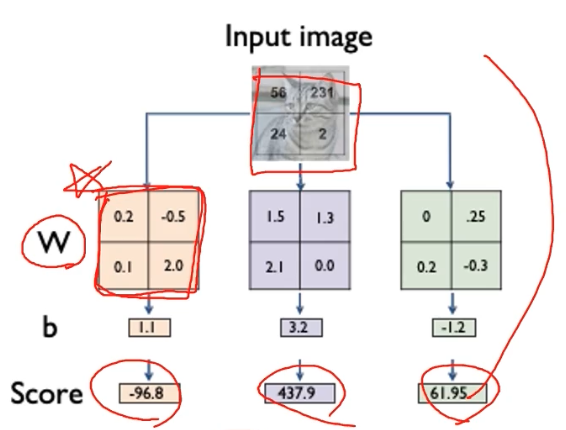
- 그렇게 되면 기존의 layer 는 입력 이미지와 동일한 사이즈의 템플릿이라고 볼 수 있다.
- 이 각각의 템플릿과 내적을 통해서 비교함으로써 클래스의 스코어를 받는다. 따라서 위 그림은 이전 그림과 완전히 동일한 연산을 시점만 바꾼 것이다.
-
이 템플릿들을 이미지처럼 시각화가 가능하다. 이미지처럼 reshape 을 해놨기 때문이다. 그러면 각 클래스마다의 이미지를 볼 수 있다. 아래 예시처럼 흐릿하지만 어떤 정보를 담고 있다.

- 여기서 첫번째 문제는 layer 가 1층으로 단순해서 평균 이미지 같은 것 이외에는 표현이 안된다는 점이다.
-
두번째 문제는 적용시점, 즉 test time 에서의 문제다. 학습 시에는 이미지 속 가득찬 하나의 물체에 대해서만 NN 이 열심히 학습해서 그 클래스에 대한 대표적인 패턴을 학습했다고 볼 수 있다.

- 이렇게 학습된 모델을 학습 시에 봐왔던 이미지와 다른 이미지를 넣어주면 결과는 달라진다.
- 이런 패턴에 대해서는 학습동안 본 적이 없기 때문이다. 즉, 조금이라도 템플릿의 위치나 scale 이 안맞으면 다른 결과를 가져온다.
- 이러한 이유로, Convolution Neural Network 가 등장했다. (물론 더 자세한 이유가 있는데, 이는 다음 포스트에서 다뤄보자.)
Convolutional Neural Network
- 한계를 가진 fully connected layer 가 아닌 locally connected layer 를 보자.
- locally connected neural networks 라고도 불린다.
-
하나의 특징을 뽑기 위해서 모든 특징을 고려하는 fc layer 대신에, 하나의 특징을 이미지의 공간적인 특성을 고려해서 국부적인 영역들만 connection 을 고려한 layer 를 locally connected layer라고 한다.
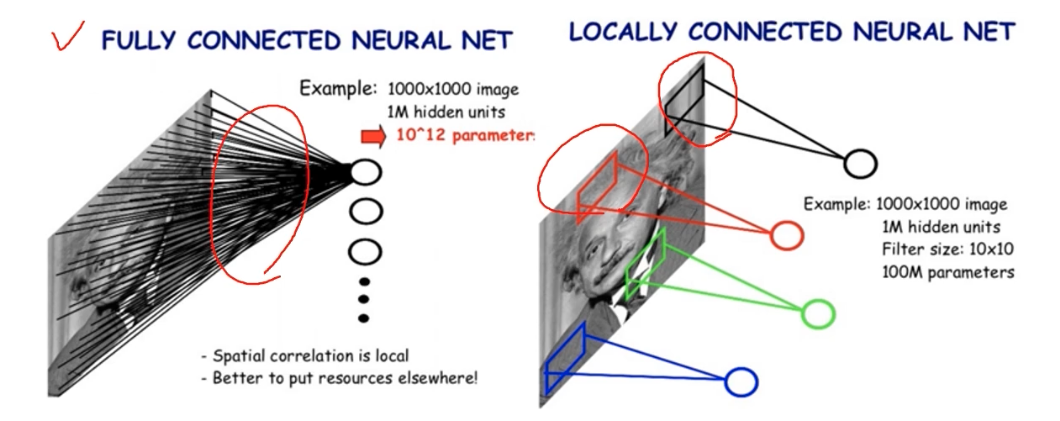
- feature 를 뽑는 측면에서, 필요한 파라미터가 획기적으로 줄어들었다.
- fc layer 는 weight parameter 가 pixel by pixel 로 서로 다른 게 모두 있어야 한다. 그러나 locally connected 는 필요한 것만 있으면 된다.
- 또한 이런 지역적 특징들이 이미지 한 군데서만 발현되기 보다는 이미지 여러 곳에서 비슷한 특징들이 있을 수 있다. 예를 들어 하나의 이미지에 얼굴이 여러 군데 있을 수 있다.
- 그래서 sliding window 처럼 connection 을 다 공유해서 전 영역을 순회하며 feature 를 뽑는 것이 바로 CNN 이다.
- 필터를 옆 영역과 똑같이 적용해서 hidden node 의 activation 들을 feature map 형태로 잔뜩 뽑는 것이다.
- 이렇게 하면 parameter 를 이미지 전체 영역에 대해서 재활용할 수 있기 때문에, 더 적은 parameter 로도 효과적인 특징을 추출할 수 있다. 결국에는 오버피팅도 방지할 수 있는, 이미지에 매우 적합한 네트워크 구조가 된다.
- sliding window 방식으로 필터가 돌아다니면서 특징을 추출한다. 그러면 물체의 위치가 조금 다르더라도 특징은 적절히 잘 뽑힌다.
- 이미지에서 물체가 약간 위치가 바뀌는 문제에 대해서 크게 민감하지 않게 최종적인 결론을 잘 도출할 수 있다는 것이다.
- 이런 이미지에 적합한 특징으로 인해서, CNN 은 다양한 CV task 에서 backbone 네트워크로 잘 사용된다.
-
이미지의 특징을 추출하는 backbone 네트워크 위에 target task 의 head 를 적합하게 디자인해서 사용하는 형태가 기본적인 CV 에서의 알고리즘 디자인 패턴이다.
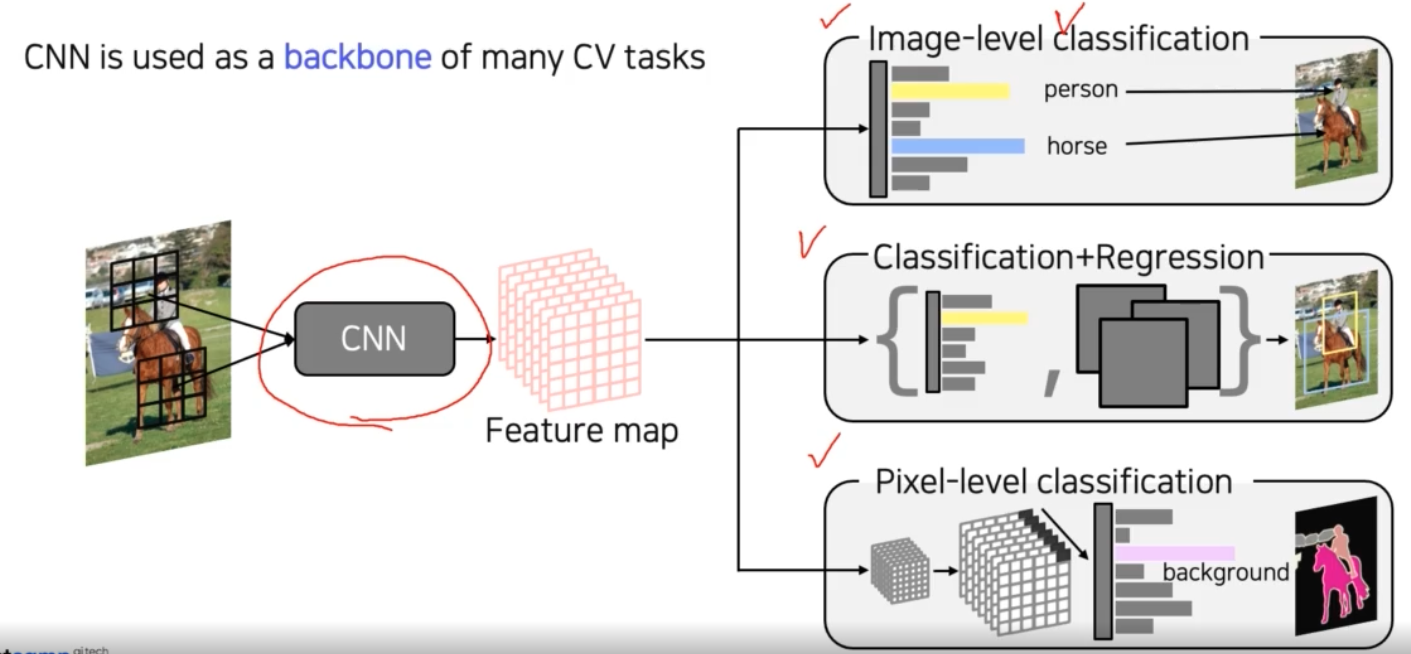
- Image-level classification = Image Recognition
- Classification + Regression = Object detection
- Pixel-level classification = Segmentation
- 이렇게 backbone 네트워크 구조에서 어떻게 head 를 다르게 디자인 할 것인가를 결정할 수 있다.
정리
- CNN 은 FCN 처럼 모든 parameter mapping 을 배우지 않고, locally parameter sharing 을 한다.
- CNN 의 학습 파라미터는 local feature 를 학습할 수 있다.
- CNN 은 FCN 과 비교하였을 때, 위치 변화에 대해 크게 민감하지 않기 때문에 cropping 등의 변화에 비교적 강건하다.
댓글 남기기