
[Image Classification] 4. GoogLeNet
GoogLeNet
- GoogLeNet(2015)
- 1x1 conv 은 dimension reduction 의 효과가 있고 여기서 말하는 dimension 은 channel. 그래서 컨볼루션 피쳐맵이 special dimension(W & H) 이 있는데 그게 아니라 그 이미지 tensor의 depth 방향에 해당하는 channel 을 줄이는 것.
- 이것은 네트워크를 똑같이 딥하게 쌓아도 중간에 1x1 conv 를 잘 활용하면 파라미터 숫자를 줄일 수 있게 됨.
- AlexNet → VGGNet 에서는 11x11, 5x5, 7x7 보다는 input 단의 special receptive field 를 늘리는 차원에서는 3x3 을 여러번 활용하는 것이 좋다는 것을 알게 됨.
- GoogLeNet 에서는 1x1 conv 를 잘 활용해서 전체적인 파라미터 수를 줄일 수 있는지를 볼 수 있음.
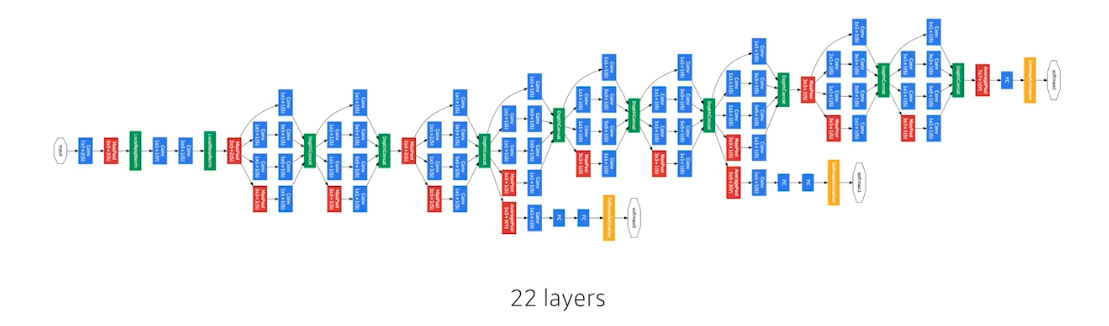
- 비슷하게 보이는 네트워크가 반복됨. 네트워크 모양이 네트워크 안에 있다고 해서 NIN(Network In Network) 구조라고 함.
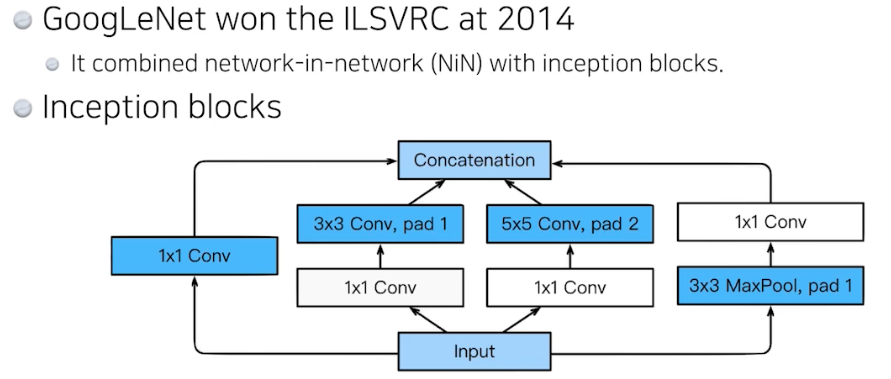
- Inception block? 하나의 입력이 들어왔을 때 퍼졌다가 합쳐짐. 중요한 것은, 각각의 path 를 보면 3x3 conv 를 하기 전에 1x1 Conv 가 들어감. 즉 Convolution filter 전에 1x1 이 들어가는 것. 이게 중요한 역할을 함.
- 왜 중요할까? 하나의 입력에 대해서 여러개의 receptive field 를 갖는 필터를 거치고 이것을 통해서 여러개의 repsonse 들을 concatenation 하는 효과도 있지만, 여기서 1x1 conv 이 중간에 있음으로서 전체 네트워크의 파라미터 수를 줄임.
- 어떻게 파라미터 숫자를 줄이는 것일까? → 그러면 이 1x1 conv 이 왜 중요한지를 알 수 있음.
→ 1x1 conv can be seen as channel-wise dimension reduction ; 채널 방향으로 줄인다!
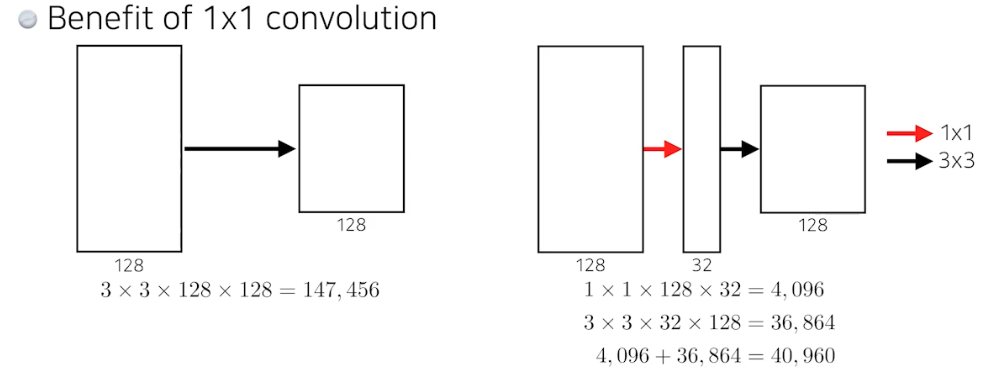
- 앞에서 5x5 보다 3x3이 더 파라미터 수를 줄일 수 있었음. 결과적으로 3x3 이 우리가 줄일 수 있는 최소한인데, 여기서 1x1 을 통해서 더 파라미터 수를 줄이는 것.
- 중간에 1x1 conv 을 통해서 special dimesion 은 그대로 가고 채널 방향으로 정보를 줄인 것. 이렇게 줄이고 얻어지는 ‘어떤 줄어든 채널을 가진 special dimension 의 conv feature map’에 3x3 conv 를 하는 것. 이렇게 만들어진 2layer 의 파라미터 숫자는 더 줄어듦.
- 그래서 입력과 출력만 봤을 때 채널은 똑같음. 또한 receptive field 도 같음. 3x3 를 사용했기 때문. 그런데 파라미터 숫자가 많이 줄어듦. 이런 1x1 conv 을 통해 채널 방향으로 dimension reduction 이 들어가면서 전체적인 파라미터 숫자는 줄어듦. 또한 입력과 출력만 놓고 보면 receptive field 는 똑같고 입력과 출력의 채널 또한 같음.

- GoogLeNet 은 VGGNet 에 비해서 파라미터 수가 엄청 줄어듦. 네트워크는 3단 깊어짐. 이게 바로 뒷단의 dense layer를 줄이고, 11x11 를 줄이고 1x1 conv 로 feature dimension 을 줄이기 때문. → 즉 네트워크는 점점 깊어지고 파라미터 수는 줄어들고 성능은 좋아짐!!
댓글 남기기