
[Image Classification] 3. VGGNet
VGGNet
- VGGNet(2015)
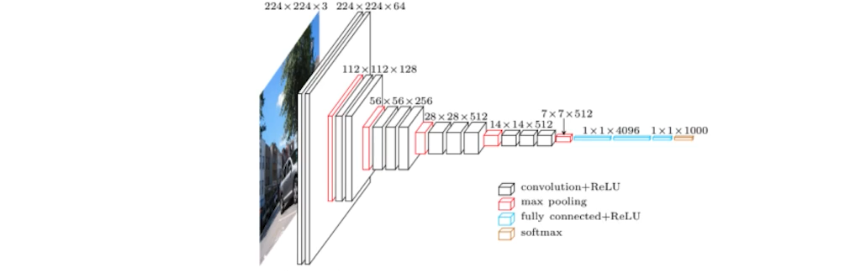
- 3x3 convolution 필터를 사용.
- 1x1 컨볼루션을 fc layer 를 위해 사용함. 그런데 여기서는 파라미터 수를 줄이기 위해 사용된 것은 아님.
- Dropout 을 사용함.
- layer 수에 따라 VGG16, VGG19
- 왜 3x3 convolution?
- 컨볼루션 필터의 크기를 생각해보면, 크기가 커지면서 가지는 이점은 하나의 필터에서 고려되는 인풋의 크기가 커진다는 것. 그것이 Receptive field 를 말함. 하나의 컨볼루션 피쳐맵 값을 얻기 위해서 고려할 수 있는 입력의 spatial dimension 이 바로 receptive field.
- 3x3 conv 를 2번 했을 때, 가장 마지막 단의 하나의 값은, 중간 피쳐맵의 3x3 을 보게 되고, 그 중간 피쳐맵의 하나의 값은 인풋의 3x3 을 보는 것. 사실상 마지막 레이어의 하나의 값은 인풋 레이어의 5x5 의 픽셀값이 합쳐진 값이 됨. 그래서 3x3 이 두 번 이뤄지면 receptive field 는 5x5가 됨.
- 즉, 5x5 하나 사용하는 것과 3x3을 두 개 사용하는 것이 receptive field 측면에서 똑같음. 그러나 총 파라미터 수가 달라짐.
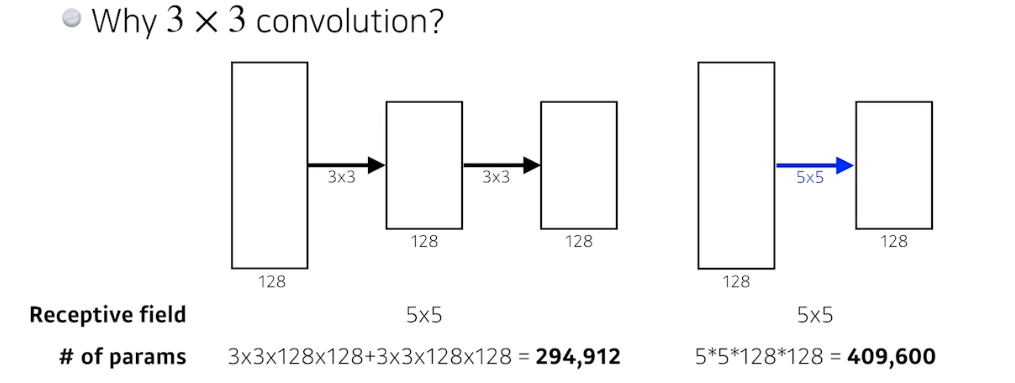
- 왜 이런 일이 일어날까?
→ 레이어를 두 개 쌓고, 그러니까 파라미터가 두 배가 늘어나서 3x3 conv 를 2개 쓴 게 더 많은 수가 있을 것 같지만, 사실상 3x3 은 곱해봤자 9. 2배 해봤자 18. 5x5 는 25.
→ 따라서 같은 receptive field 를 얻는 관점에서는 5x5 1개 보다 3x3을 2개 활용하는게 파라미터 수를 줄일 수 있음.
→ 따라서 뒤에 나오는 대부분의 논문들에서 conv 필터(커널) 의 special dimension 은 7x7 을 벗어나지 않음. 커봤자 5x5 이다. 비슷한 이유로.
맨 위로 이동 ↑
댓글 남기기