
[Image Classification] 1. AlexNet
- 앞으로 이어질 포스트에서는 AlexNet 을 포함한 CNN 에서 굵직한 영향을 가져온 논문들을 살펴보자.
- ISVRC 에서 해마다 1등했던 모델들이다. 여전히 주의할 것은 각각 네트워크의 parameter 수, 네트워크의 depth 에 유의하자. 모델이 발전할 수록 네트워크의 depth 는 점점 깊어지고, parameter 수는 줄어가며, 성능은 올라간다. 네트워크를 깊게 쌓으면서 어떻게 parameter 수를 줄일 수 있는지를 관심있게 보자.
AlexNet
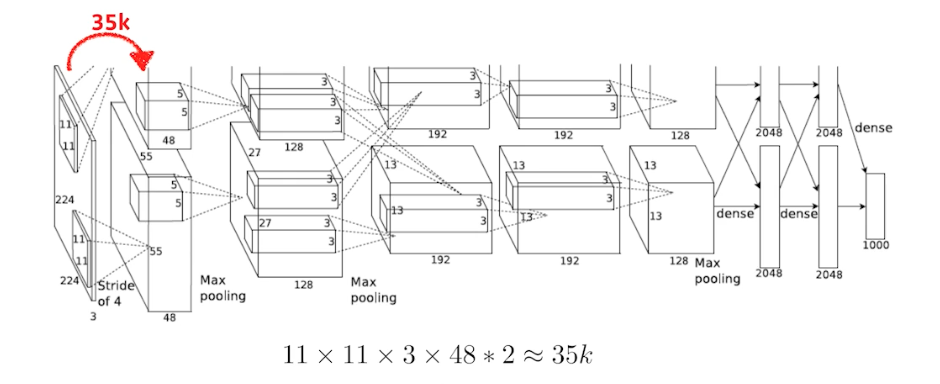
- 이 전에 ReNet(1998) 이라는 논문이 있었는데,
- AlexNet 은 그 당시 GPU 메모리 부족으로 모델을 2갈래로 나눠서 진행함. 그래서 마지막에 2가 곱해지는 것. 즉 첫번째 레이어에서 96 채널의 컨볼루션 피쳐맵을 만들어야 하는데 1개의 GPU 메모리 사이즈에 맞추다 보니 48로 한 것.
- 중요한 것은, 여기서 보는 파라미터 숫자는 컨볼루션 단게에서는 많아야 884k 임. 그런데 뒷단의 fully connected layer 에 들어가면 달라짐.
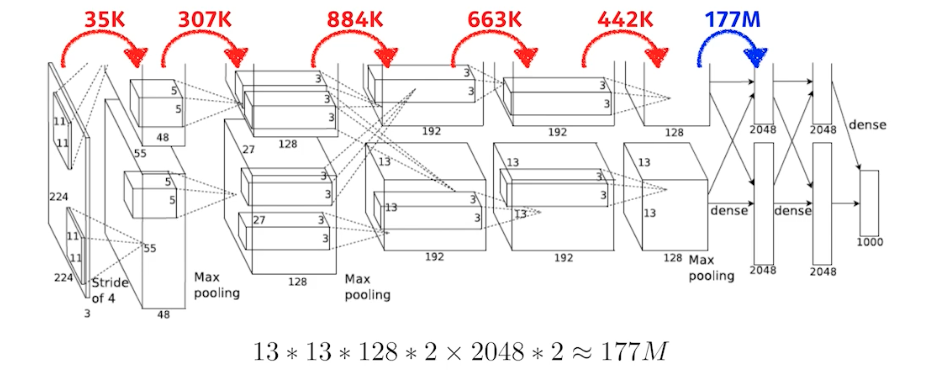
- 여기서 부터는 Dense layer 임. fully connected layer 의 차원은 인풋의 파라미터 개수(뉴런의 개수) 와 아웃풋의 뉴런의 개수를 곱한 것 만큼이다. 값이 엄청 커지는 것.
- 빨간색 layer 가 컨볼루션 layer, 파란색 layer 가 Dense layer(MLP) 인데 파라미터 숫자가 컨볼루션에 비해서 dense layer에 넘어가면서 거의 1,000배가 늘어남.
- 왜 이럴까? 네트워크가 인풋에서 아웃풋으로 갈 때 크기가 엄청 변화되는 것도 아닌데, dense layer 가 일반적으로 훨씬 많은 파라미터를 갖게 되는 이유는, 컨볼루션 연산이 각각의 하나의 커널이 모든 위치에 대해서 동일하게 적용되기 때문. 즉, 컨볼루션 연산은 일종의 shared parameter. 같은 커널이 이미지의 오른쪽, 왼쪽, 위, 아래 모두 동일하게 적용됨.
- 뉴럴 네트워크를 성능을 올리기 위해서는 파라미터를 줄이는 것이 중요. 따라서 대부분의 파라미터가 fc layer 에 들어가면 파라미터 수가 엄청 늘어나기 때문에, 네트워크가 발전되는 성향이 뒷단에 있는 fc layer 를 최대한 줄이고 앞단의 convolution layer를 최대한 깊게 쌓는 것이 일반적인 트렌드.
- 여기에 추가로 들어가는 것이 1*1 convolution. 이러한 시도들로 뉴럴 네트워크의 깊이는 깊어지지만 파라미터 숫자는 줄어들고 성능은 올라감.
- 이를 위해 기본이 되는 게 1 x 1 convolution
- 1 x 1 conv는 , 이미지에서 영역을 보지 않음. 한 픽셀만 보는 것. 즉 채널 방향을 줄이는 것.
- 왜 할까? Dimension reduction. 1x1 conv 에서의 dimension 은 채널을 말함.
- 이것의 의미는, 컨볼루션 레이어를 깊게 쌓으면서 동시에 파라미터 숫자를 줄일 수 있게 됨. 즉 뎁스는 늘리고 파라미터 수는 줄임.
- bottleneck architecture 가 바로 이 1x1 conv 을 이용해서 네트워크를 깊게 쌓는데 파라미터 숫자를 줄일 수 있는 것.
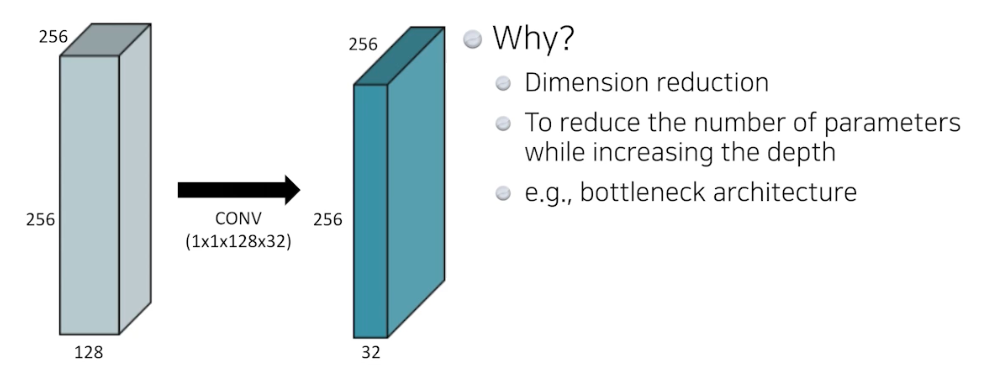
- 실제 이 1x1 conv 테크닉은 굉장히 자주 사용됨. ResNet, DenseNet 등 다 활용됨.
-
나중에 컨볼루션 레이어의 채널 디멘션과 MLP의 히든 디멘션을 정해줄 수 있게 코딩하면 네트워크 튜닝할 때 편해짐.
- Modern CNNs
- AlexNet, ResNet, GoogLeNet, AlexNet, VGGNet, DenseNet
- ISVRC 에서 해마다 1등했던 모델들. 여전히 주의할 것은 각각 네트워크의 파라미터 숫자, 네트워크의 뎁스를 봐야함. → 네트워크의 뎁스는 점점 깊어지고, 파라미터는 줄어갈 것이고, 성능은 올라감.
- 네트워크를 깊게 쌓으면서 어떻게 파라미터 수를 줄일 수 있는지를 관심있게 보자.
- AlexNet(2012)
- 입력은 같지만 네트워크가 2개로 나뉨. GPU 메모리가 당시 부족했기 때문. GPU 를 최대한 활용하는데 네트워크에 많은 파라미터를 집어넣고 싶어서 이런 전략을 취한 것.
- 인풋 이미지에 11 x 11 커널을 사용함. 파라미터 숫자 관점에서 11x11 은 좋은 선택이 아님. 11x11 필터를 사용하면 receptive field 즉 하나의 커널이 볼 수 있는 이미지 영역은 커지지만 상대적으로 더 많은 파라미터가 필요함.
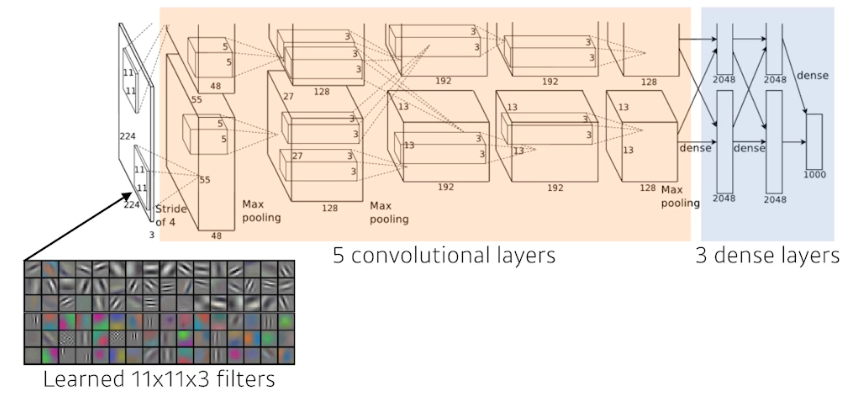
- 8개의 레이어로 되어있음. 당시에는 딥 했음.
- Key ideas.
- ReLU 를 사용. 효과적인 activation func 임. activation func 이 가져야 하는 첫번째 가장 큰 성질은 non-linear. ReLU는 0을 기준으로 linear 한 부분도 있지만 전체 func 은 non-linear 함. 또한 0보다 클 때 기울기도 1이라서 기울기 소실(레이어를 깊게 쌓았을 때)도 잘 없음.
- 선형 모델이 가지는 좋은 성질을 가지고 있음. gradient 가 activation 값이 커도 gradient 를 그대로 가질 수 있음.
- 또한 선형 모델이 가지는 좋은 성능을 가지고 있기 때문에 gradient descent 기법들을 사용해서 학습이 용이함.
- 중요한 것은 기울기 소실 문제를 극복함.
- 이전에 활용하던 시그모이드, 하이퍼볼릭 탄젠트는 0을 기준으로 값이 커지면 slope(gradient) 가 줄어들게 됨. 내가 가진 뉴런의 값이 0에서 많이 벗어나게 되면, activation 을 기준으로 하는 gradient slope 는 0에 가깝게 됨. 그래서 기울기 소실이 생김.
- 2개의 GPU 사용
- local response normalization(LRN), overlapping pooling
- LRN 은 어떤 입력 공간에서 response 가 많이 나오는 몇 개를 죽이는 것. 최종적으로 원하는 것은 sparse 한 activation 이 나오길 원하는 것. 지금은 많이 사용되지 않음.
- Data augmentation
- Dropout
→ 지금 보면 당연한 것들… 2012년도에는 당연하지 않았음. 일반적으로 제일 잘되는 기준을 잡았던 것.
맨 위로 이동 ↑
댓글 남기기