
[Activation] 2. ReLU, Softplus, ReLU6, Leaky ReLU, PReLU, RReLU, Maxout
앞선 포스트에서 살펴본 활성화 함수들은 hidden layer 에서는 사용하는 것을 추천하지 않고 output layer 에서 특정 경우에 사용되는 활성화 함수들이었다. 이제부터 hidden layer 에서 굉장히 많이 사용되는 ReLU 계열 활성화 함수에 대해 알아보자.
ReLU
- ReLU 함수는 Sigmoid 함수의 가장 큰 문제였던 gradient vanishing 문제를 해결한 활성화 함수다. 이를 통해 딥러닝의 두번째 겨울을 해결했다.
- XOR 과 같은 복잡한 문제를 해결할 수 없었던 문제로 찾아온 첫번째 겨울은 MLP 와 back propagation 를 통해 해결했다.
- 두번째 겨울은 Sigmoid 의 gradient vanishing 문제로 찾아왔다. 이를 Geoffrey Hinton 교수가 ReLU 활성화 함수를 제안하면서 해결했다.
- 이러한 ReLU 함수는 ImageNet 2012 에서 우승한 AlexNet 이 사용했다.
- 그리고 ReLU 함수는 gradient vanishing 문제 방지를 위해 사용하는 활성화 함수이기 때문에 hidden layer 에서만 사용하는 것이 추천된다.
- gradient vanishing 은 Sigmoid 의 출력값은 항상 양수이기 때문에 layer 를 거칠수록 점점 값이 0 에서 멀어지고, 입력값이 크거나 작을 때 saturation 된 Sigmoid 의 특성상 뒤로 갈수록 gradient 가 전달되지 않았던 문제다.(앞선 포스트 참고)
-
ReLU 는 Rectified(정류된) Linear Unit 의 준말이며,
\[\begin{aligned} \text{ReLU}(x) &= \begin{cases} 0 & \text{if} \; x \leq 0 \\ x & \text{if} \; x > 0 \end{cases} \\ &= \text{max}(0, x) = x\mathbf{1}_{x>0} \end{aligned}\]+, -가 반복되는 신호에서-흐름을 차단한다는 의미다. - 위 식처럼 ReLU 함수는
+신호는 그대로 출력하고,-신호는 0 으로 차단하는 함수다. 즉 양수면 자기 자신을 그대로 반환하고, 음수면 0 을 반환한다. -
이를 그래프로 그려보면 아래와 같다.
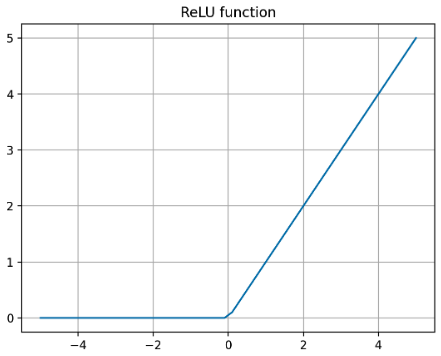
- 이 ReLU 는 Sigmoid, Softmax, Tanh 에 비해 오늘날 가장 많이 사용되는 활성화 함수다. 왜 이러한 ReLU 함수를 hidden layer 에 많이 사용할까?
- 먼저, gradient vanishing 문제가 발생하지 않는다.
- ReLU 함수의 그래프를 보면 알겠지만, Sigmoid 나 Tanh 처럼 특정 양수 값에 수렴하지 않고 출력값의 범위가 넓다.
- 또한
+의 영역에서 자기 자신을 그대로 반환하기 때문에 미분값이 0 으로 수렴하지 않는다.(non-saturated) - 즉 양수 구간이 선형 함수이기 때문에 gradient 가 소실되지 않아 안정적으로 학습이 가능하다.
- 두번째로 구현이 쉽고 기존 활성화 함수에 비해 학습 속도가 매우 빠르다.
- $\text{max}(0, x)$ 로 구현할 수 있어 계산이 가볍다.
- SGD 를 사용한다고 할 때, Sigmoid 나 tanh 에 비해 계산 효율(수렴하는데 까지)이 6배 정도로 훨씬 빠르다.
- ReLU 는 경사하강법 과정에서 편미분 시 기울기가 1 로 일정하므로 가중치 업데이트 속도가 매우 빠르다.
- 이 외에도 생물학적 타당성이 가장 높은 activation function 이다.
- 그러나 이러한 ReLU 함수에도 단점은 존재한다.
non-zero centered
- ReLU 의 출력값은 0 또는 양수이며, ReLU 의 기울기도 0 또는 1이므로, 둘 다 양수이다.
- 이로 인해 Sigmoid 함수와 마찬가지로 가중치 업데이트 시 최적의 가중치를 Zig-Zag 로 찾아가는 현상이 발생한다.
- 즉 ReLU 는 항상 0 이상의 값을 출력하기 때문에 활성화 값의 평균이 0 보다 커 zero centered 하지 않다.
- 이 때문에 가중치 업데이트가 동일한 방향으로만 업데이트가 되어 bias shift 가 일어나고, 최적의 값을 찾아가는 학습의 속도가 느려질 수 있다.
- non-zero centered 에 대한 문제는 앞선 포스트에서 잘 정리했다.
- 이를 해결하기 위해 Batch Normalization 을 사용하거나 zero centered 된 ELU, SeLU 와 같은 활성화 함수를 사용한다.
- 또한 ReLU 의 미분은 0 초과 시 1 이 되고, 0 은 0 으로 끊긴다는 문제가 있다. 즉, ReLU 는 0 에서 미분이 불가능하다. 그러나 0 에서 미분 불가능 하더라도 입력값이 0 에 걸릴 확률이 적어 이를 무시하고 사용한다.
Dying ReLU
- ReLU 함수는 음수 값을 입력 받으면 항상 0 으로 반환한다. 따라서 입력값이 음수인 경우 기울기가 0 이 되어 가중치 업데이트가 안될 수 있다.
- 가중치가 업데이트 되는 과정에서 가중치 합이 음수가 되어 0 이 반환되면 기울기에 0 이 곱해져 해당 부분의 뉴런은 죽고 그 이후의 뉴런 모두 죽게 된다. 이처럼 죽은 뉴런(Dead Neuron)을 초래하는 현상이 나타나고, 이를 Dying ReLU 라고 한다.
- 이러한 Dying ReLU 현상은 크게 2 가지 이유로 발생한다.
- wrong initialization
- weight 의 초기화 자체가 잘못된 경우, 예를 들어 input 은 모두 양수더라도 weight 가 모두 음수로 초기화 되면 ReLU 의 output 은 항상 0 일 것이다.
- 이 때문에 초기화 시에 slightly postivie biases 를 주어 살짝 왼쪽으로 이동시키는 방법을 쓰기도 한다.
- Too big learning rate
- 이 경우가 더 흔한 경우인데, learning rate 가 너무 큰 경우 학습이 잘못되어 dying ReLU 가 발생하기 쉽다고 한다.
- 즉 learning rate 가 높은 경우 ReLU 가 데이터의 manifold 를 벗어나게 되는 것이다. 이런 일들은 학습과정에서 흔한 일이고 충분히 발생할 수 있다. 이 때문에 학습이 잘 되다가 죽어버리게 된다.
- 이에 대한 명확한 해결은 존재하지 않는다고 하고, 보통 10 ~ 20% 정도의 dying ReLU 가 발생하지만 학습에 지장이 갈 정도로 문제가 되진 않는다고 한다.
- wrong initialization
- 이를 해결한 Leaky ReLU 는 값이 음수일 때 조금의 음의 기울기를 갖도록 하여 뉴런이 조금이라도 기울기를 갖도록 한다.
ReLU 함수의 곡선 함수 근사
- ReLU 는 양수일 때의 선형 함수와 음수일 때의 선형 함수 두 개가 결합된 형태로 볼 수 있다. 그러나 ReLU 는 선형 함수의 성질 중 가산성($f(x+y) = f(x) + f(y)$)을 만족하지 못하기 때문에 비선형 함수다.
- 이러한 ReLU 가 어떻게 곡선 함수를 근사할 수 있을까?
-
Multi layer 의 activation 으로 ReLU 를 사용하게 되면, 단순히 Linear 한 형태에서 더 나아가 Linear 한 부분들의 결합으로 합성 함수가 만들어지게 된다. 이 Linear 한 부분들의 결합을 최종적으로 보았을 때, Non-linearity 한 성질을 가지게 된다.
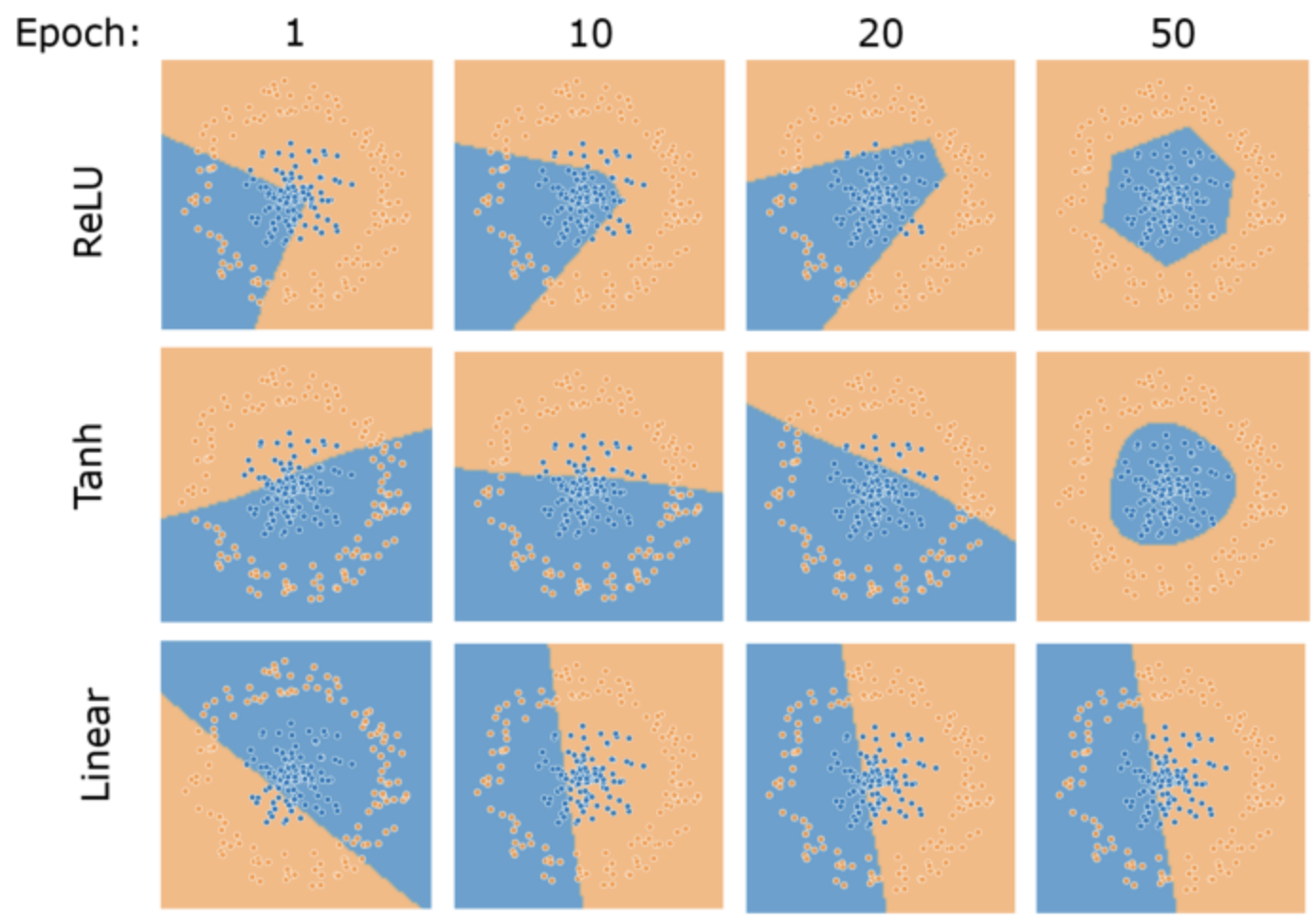
- 즉 ReLU 를 여러 개 결합하면, 위 그림처럼 특정 지점에서 특정 각도만큼 선형 함수를 구부릴 수 있다. 이 성질을 이용하여 곡선 함수 뿐만 아니라 모든 함수에 근사를 할 수 있게 된다.
- 이를 통해 학습 과정에서 BackPropagation 할 때, non-linearity 한 성질을 가지게 된 모델은 데이터에 적합하도록 fitting 이 된다.
- ReLU 의 장점인 gradient 가 출력층과 멀리 있는 layer 까지 전달된다는 성질로 인하여 데이터에 적합하도록 fitting 이 잘되게 되고 이것으로 곡선 함수에 근사하도록 만들어 지게 되는 것이다.
Softplus
- Softplus 활성화 함수는 일반적으로 사용되는 ReLU(Rectified Linear Unit) 의 단점을 보완하여 사용되는 부드러운 비선형 함수다.
- 즉 softplus 는 ReLU 가 0 에서 미분 불가능하고 양수가 아닌 구간에서는 dying Neuron 현상이 발생하는 한계를 해결하기 위해서 전체가 미분 가능한 부드러운 곡선 함수를 제공하면서 ReLU 를 근사한다.
-
Softplus 는 아래의 식으로 나타낼 수 있다.
\[\text{Softplus}(x) = \frac{1}{\beta}\ast \log(1 + \exp(\beta \ast x))\] -
$\beta$ 가 커질수록 ReLU 와 비슷해진다. 아래 그래프를 보자.
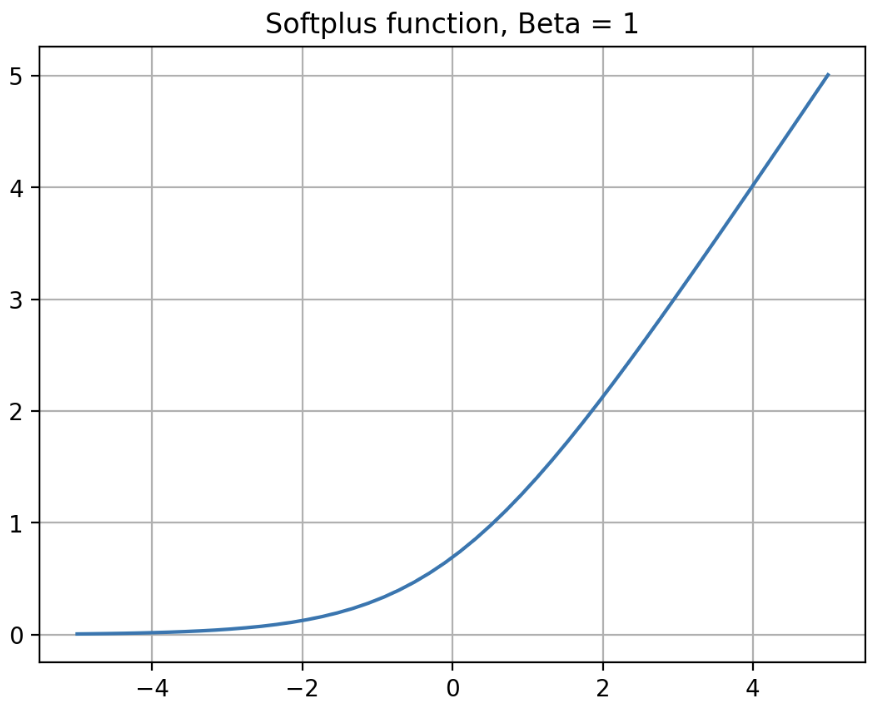
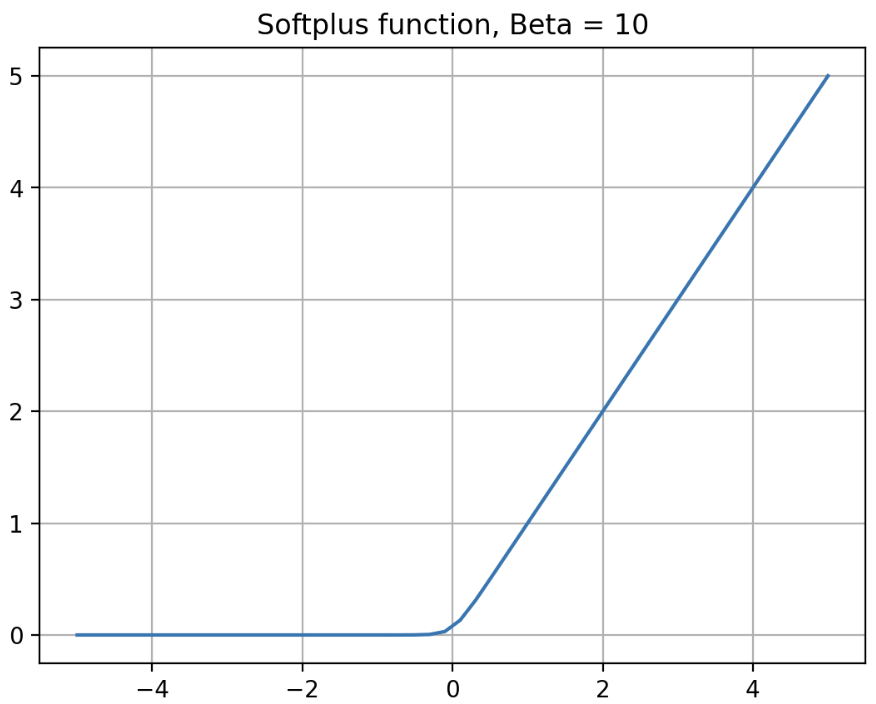
- 이처럼 Softplus 는 어디에서나 미분 가능(smoothness)하면서 neural network 에 non-linearity 를 주도록 설계된 활성화 함수다.
- Softplus 를 사용하는 주요 목적은 gradient vanishing 문제가 일어나지 않게 하고, 역전파 과정에서 더 건강한 gradient flow 를 유지하는 데 도움이 된다. 또한 ReLU 와 달리 음수 구간에서 기울기가 0 이 아니기 때문에 Dead Neuron 문제를 피할 수 있다.
- 또한 출력을 항상 양수로 제한하는 데에 사용할 수 있다. 즉 Softplus 는 ReLU 와 달리 음수 구간에서 0 에 매우 가까운 값이지만 완전히 0 은 아니다.
- 그러나 지수 함수가 들어가 있어 ReLU 에 비해 계산 비용이 높고, $x$ 의 절대값이 0 에서 먼 큰 값이라면 saturated gradient 를 얻을 수 있다.
- 그 이유는 Softplus 를 미분하면 Sigmoid 를 얻기 때문이다. 따라서 입력값이 매우 큰 경우 기울기가 0 에 가까워져 학습이 더디게 일어날 수 있다.
ReLU6
- pytorch 의 activation 중애는 ReLU6 라는 함수가 있다.
-
ReLU6 는 기존의 ReLU 에서 상한값을 6 으로 두는 것을 말한다. 아래 식과 같다.
\[\text{ReLU6} = \text{min}(\text{max}(0, x), 6)\] -
그래프로 그리면 아래와 같다.
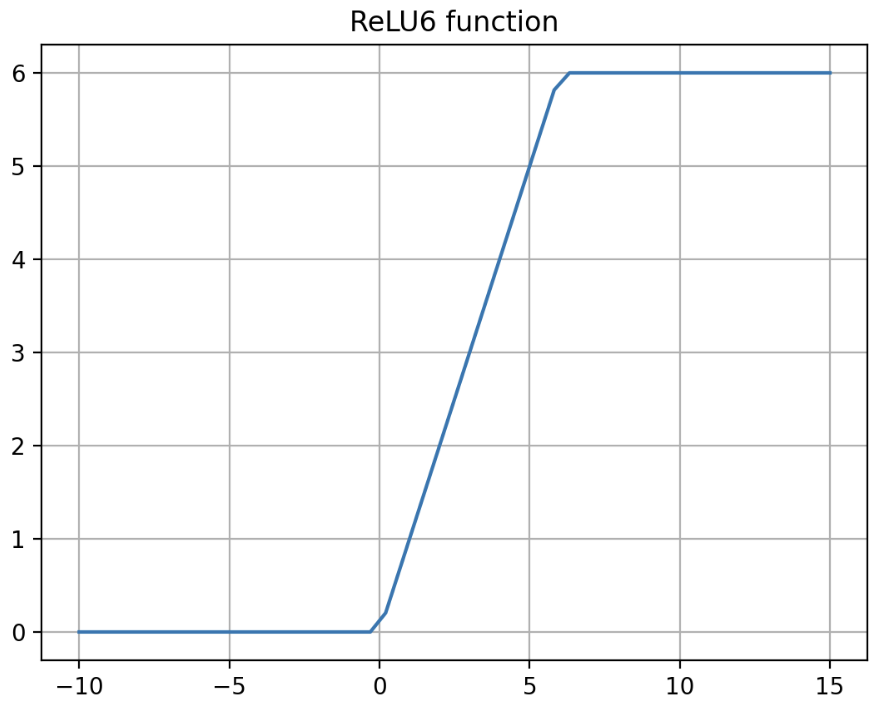
- non-zero centered 와 dying ReLU 말고도 ReLU 의 단점 중 하나는 unbounded problem 이다. 이는 positive input 값이 계속 커지면 무한히 증가하는 것으로 학습의 불안정성을 발생시키게 된다.
-
이에 따라 아래와 같은 BReLU 가 등장했지만 거의 사용되지 않고 있다. 아래 식에서 $A$ 가 6 이 된 것이 ReLU6 다.
\[\text{BReLU} = \text{min}(\text{max}(0, x), A)\] - 왜 upper bound 를 두었을까? 결론적으로 말하면 테스트 결과, 학습 관점에서 성능이 더 좋았고 최적화 관점에서도 더 좋았기 때문이다.
- 딥러닝 모델의 성능 최적화를 할 때 fixed-point 로 변환해야 하는 경우가 있다. 특히 embedded 에서는 중요한 문제다.
- 만약 upper bound 가 없으면 point 를 표현하는 데 수많은 bit 를 사용해야 하지만 6 으로 상한선을 둔다면 최대 3 bit 만 있으면 되기 때문에 상한선을 두는 것은 최적화 관점에서 꽤나 도움이 된다.
- 이처럼 ReLU6 는 하드웨어 상에서 제한된 숫자 범위를 사용하는 환경에서 over-flow 문제를 줄일 수 있기 때문에 모바일 기기나 embedded 시스템에서 사용되는 MobileNet 과 같은 네트워크에서 자주 사용된다.
- 이러한 환경에서는 효율적인 계산이 매우 중요한데, ReLU6 는 숫자 범위가 제한되어 있어 양자화 및 하드웨어 구현이 더 쉬워지기 때문이다.
- 또한 ReLU 에 상한선을 두면 딥러닝 모델이 학습할 때, sparse 한 feature 를 더 일찍 학습할 수 있게 된다고 한다.
- 이에 따라 ReLU 에 상한선을 두고 여러가지 테스트를 통해 확인했을 때, 6 을 상한선으로 둔 것이 성능에 좋았기 때문에 ReLU6 를 사용했다고 한다.
- 그러나 입력값이 6 을 넘으면 기울기가 0 이 되어 더 이상 학습되지 않는 saturation 문제가 발생할 수 있고, 위에서 언급한 것처럼 특정 환경이 아니면 잘 사용되지 않는다.
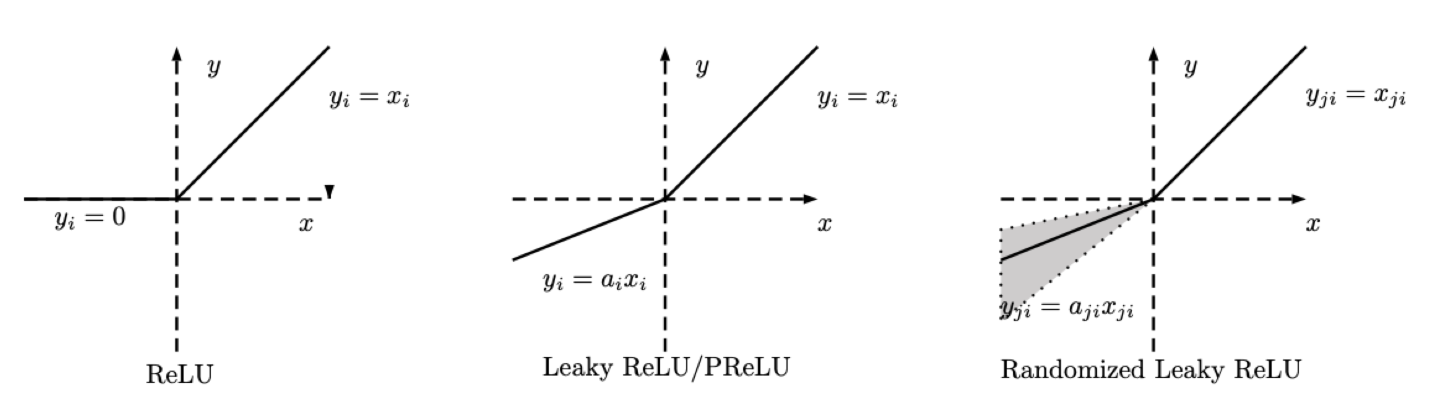
Leaky ReLU
- Leaky ReLU 는 Dying ReLU 문제 해결을 위해서 음수 구간이 0 이 되지 않도록 약간의 기울기를 준다.
-
즉 Leaky ReLU 는 ReLU 와 거의 비슷하지만 가중치 곱의 합이 0 보다 작을 때의 값도 약간 고려하는 것이다.
\[\begin{aligned} \text{Leaky ReLU}(x) &= \begin{cases} 0.01 \ast x & \text{if} \; x \leq 0 \\ x & \text{if} \; x > 0 \end{cases} \\ &= \text{max}(0.01x, x) \end{aligned}\] - 위의 식에서 음수 구간에
0.01대신 다른 매우 작은 값 사용 가능하다. 이처럼 Leakly ReLU 는 음수의 $x$ 값에 대해 미분값이 0 되지 않는다는 점을 제외하면 ReLU 와 같은 특성을 가진다. -
그래프를 보면 아래와 같다. 음수 구간이 0 이 아니라 미세하게 기울기를 가진다.
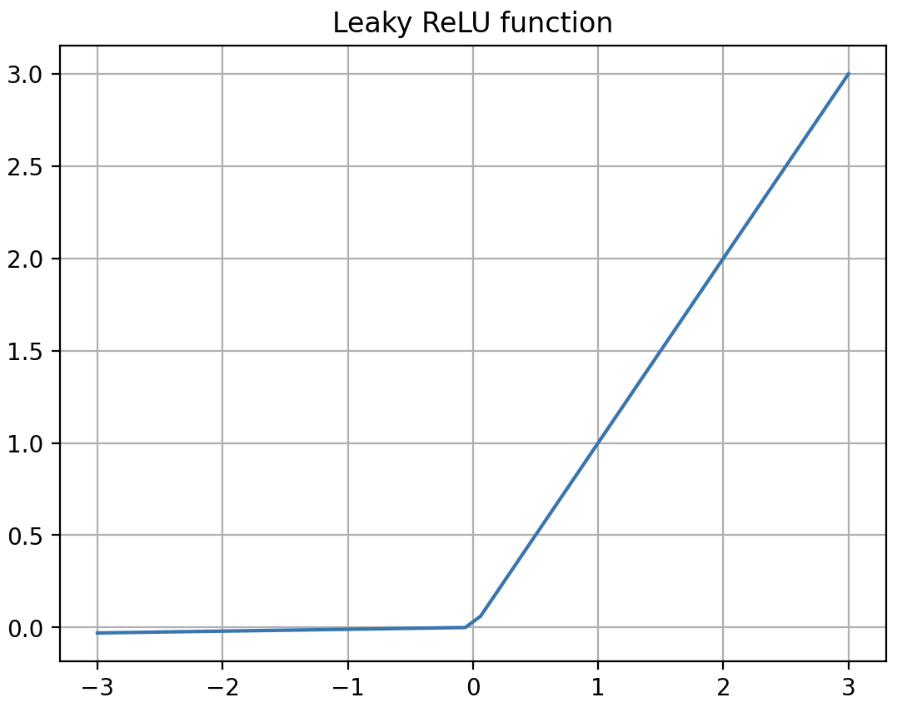
- 이러한 Leaky ReLU 는 아래와 같은 장점을 가진다.
- negative regime 에서 기울기가 0 이 아닌 0.01 을 갖게 된다. 이를 통해 Dying ReLU 현상이 발생하지 않는다.
- saturated 되지 않고 여전히 계산이 효율적이며 빠르다.
- 그러나 음수에서 선형성이 생기게 되고 이로 인해 복잡한 분류에서 사용할 수 없다는 한계가 생긴다. 또한 이 방법은 값의 범위가 $[-\infty, +\infty]$ 로 bounded below 되어있지 않기 때문에 음수곱의 누적으로 feature 가 잘 activation 되지 않을 수도 있다는 단점이 있다.
- 이 외에도 negative regime 에서 곱해주는 0.01 인 하이퍼파라미터가 application 과 network 에 따라서 적합한 값이 다르기 때문에 단점이 된다. 즉 Leaky ReLU 는 기울기가 고정되어 있어서 최적의 성능을 내지 못한다.
PReLU(Parametric ReLU)
- 이러한 음수 구간의 기울기를 trainable parameter 로 만들어준 것이 PReLU 이며, 뉴런별로 기울기를 학습하므로 성능이 개선된다.
-
즉 negative regime 에 기울기가 있다는 점에서 Leaky ReLU 와 유사하지만 기울기가 $\alpha$ 라는 parameter 로 결정되고, 이 $\alpha$ 는 딱 정해놓는 것이 아니라 back propagation 으로 학습시키는 parameter 로 만든 것이다.
\[\begin{aligned} \text{PReLU}(x) &= \begin{cases} \alpha \ast x & \text{if} \; x \leq 0 \\ x & \text{if} \; x > 0 \end{cases} \\ &= \text{max}(\alpha x, x) \end{aligned}\] -
그래프로 나타내면 아래와 같다. $\alpha = 0.05$ 인 경우다.
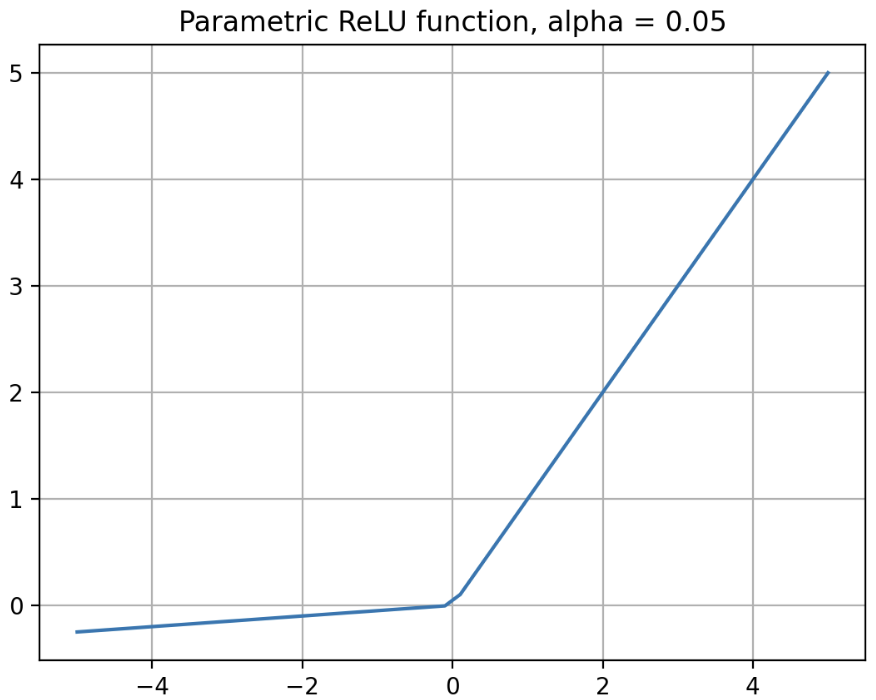
- $\alpha$ 는 학습 가능한 parameter 로서 역전파 시 값이 변경되기 때문에 대규모 이미지 데이터셋에서는 ReLU 보다 성능이 좋을 수 있다.
- 그러나 소규모 데이터셋에서는 학습 시 쉽게 over-fitting 이 발생하여 test 시에 성능을 떨어뜨리는 문제가 존재한다. 이에 따라 자주 사용되지는 않는다.
RReLU(Randomize Leaky ReLU)
- 음수 구간의 기울기가 Random 하게 변동하는 ReLU 도 있다. 이것이 바로 RReLU 다.
- Pytorch 공식문서에 따르면 $\alpha$ 는 Uniform distribution 에서 random 하게 추출되며, evaluation 시에는 $\frac{\text{lower} + \text{upper}}{2}$ 로 고정된다.
- 이는 학습 중 발생한 랜덤성을 평균화하여 더 안정적인 성능을 얻도록 도와준다.
-
그래프로 나타내면 아래와 같다.
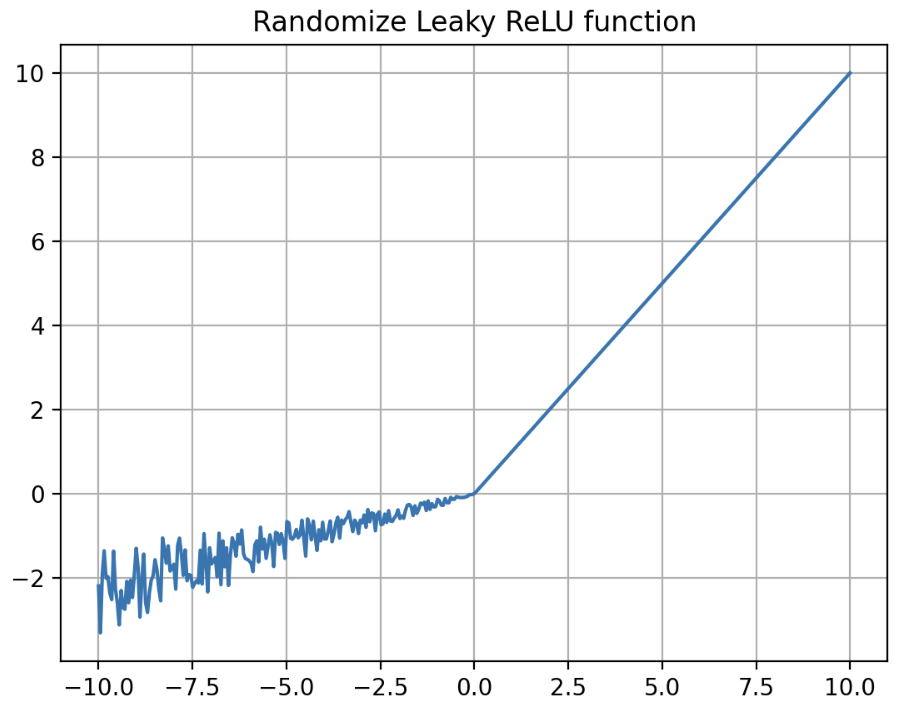
- RReLU 는 학습 중에 기울기인 $\alpha$ 값을 일정 범위에서 무작위로 선택한다. 이는 모델이 학습 데이터에 너무 특정한 패턴으로 적합하지 않도록 유연성을 증가시킨다.
- 즉 매번 다른 기울기 값을 적용하기 때문에, 모델은 고정된 활성화 함수로 학습하는 것이 아니라, 일정한 범위 내에서 다양한 비선형성을 학습하게 된다. 이런 랜덤성은 데이터에 대한 over-fitting 을 완화하는 효과가 있다.
- 이는 Dropout 과 비슷한 개념으로 작용할 수 있다. Dropout 은 뉴런을 무작위로 비활성화하여 네트워크가 특정한 패턴에 의존하지 않도록 하는 반면, RReLU 는 활성화 함수의 비선형성을 다양화하여 학습의 일반화 성능을 향상시킨다.
-
이처럼 RReLU 에서 $\alpha$ 는 학습 중에 주어진 범위 내에서 추출되는 확률 변수이고, PReLU 에서 $\alpha$ 는 학습 가능한 parameter 이며, Leaky ReLU 에서는 $\alpha$ 가 0.01 로 고정된 값이다.
- 특정 모델과 상황에 따라 다르겠지만, ReLU 가 가장 무난하고 가장 많이 사용되고 있다.
- 따라서 learning rate 에 유의하면서 우선적으로 ReLU 를 사용하고, ReLU 를 사용한 이후 Leakly ReLU 등 ReLU 계열의 다른 함수도 사용하여 성능 변화를 관찰하는 것이 좋다.
Maxout
- Maxout 은 지금까지 본 활성화 함수와는 다르게 생겼다. Maxout 은 고정된 활성화 함수를 사용하지 않고, 여러 선형 함수의 출력을 비교하여 그 중 최대값을 선택하는 방식으로 동작한다.
-
활성화 함수를 구간 선형 함수(piece-wise linear function)로 가정하고, 각 뉴런에 최적화된 활성화 함수를 학습을 통해 찾아낸다.
\[\text{Maxout}(x) = \text{max}(w^\top_1 x + b_1, w^\top_2 x + b_2)\] -
위 식처럼 Maxout 은 두 개 이상의 선형 함수들의 출력 중에서 가장 큰 값을 선택하는 방식이다. 아래 그래프를 보자.
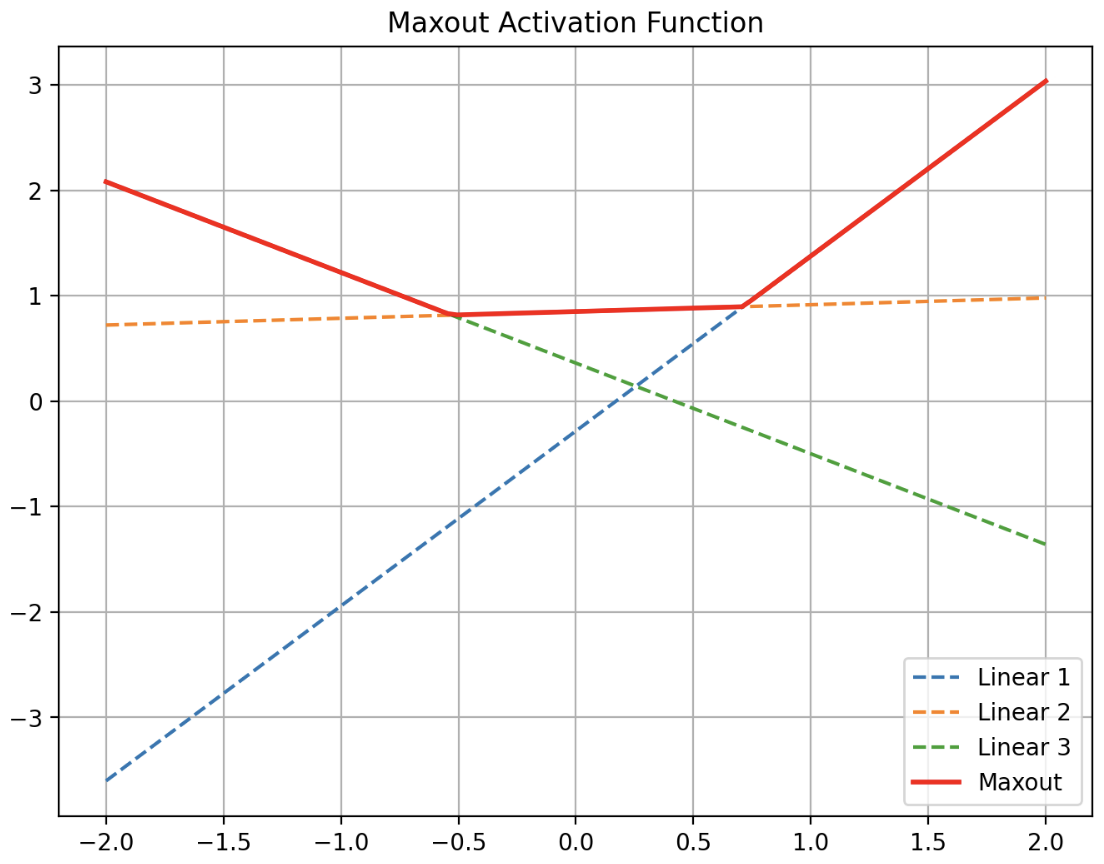
- 이처럼 뉴런 별로 linear function 을 여러 개 학습 시킨 뒤 최댓값을 취한다. 즉 Maxout 은 은 ReLU 의 일반화된 형태라고 볼 수 있으며 성능이 뛰어나다.
- ReLU 는 입력이 음수인 경우에는 역전파 과정에서 gradient 가 0 이 되기 때문에 소실되는 문제가 발생했지만, Maxout 은 입력 중에서 가장 큰 값을 선택하기 때문에, 입력이 음수인 경우에도 항상 gradient 를 전달할 수 있어서 이러한 문제를 완화할 수 있다.
- 즉 Maxout 함수는 ReLU 가 가지는 모든 장점을 가졌으며, dying ReLU 문제도 해결할 수 있다. 즉 Maxout 은 선형이기 때문에 saturated 되지 않으며 gradient 가 죽지 않는다.
- Maxout 은 Dropout 과 잘 어울린다.
- Dropout 은 뉴런을 무작위로 비활성화하는데, Maxout 과 결합되면 각각의 활성화 함수가 다양하게 학습되기 때문에 모델의 일반화 성능이 더 좋아질 수 있다.
- 또한 Maxout 이 뉴런 별로 여러 선형 함수를 학습하는 특성 덕분에, Dropout 을 적용해도 성능 저하가 적고 다양한 활성화 패턴이 학습될 수 있다.
- 또한 Maxout 은 adaptive 한 특성이 있어, 뉴런마다 적합한 활성화 함수를 학습할 수 있다.
- 즉, 모델이 학습 과정에서 각 뉴런의 활성화 함수가 어떤 형태가 되어야 최적의 성능을 발휘할지를 스스로 결정할 수 있다.
- 이처럼 데이터에 맞게 비선형성의 정도를 조정할 수 있기 때문에, 복잡한 패턴을 학습하는 neural network 에서 유용할 수 있다.
- 예를 들어, 음성 인식, 텍스트 데이터 분석 등의 복잡한 문제에서 특정 영역에서는 ReLU, 다른 영역에서는 Sigmoid 와 같은 역할을 수행하는 적응형 활성화 함수가 필요할 때 사용할 수 있다.
- 그러나 Maxout 의 문제점은 parameter 의 수가 증가한다는 것이다.
- Maxout 은 $m$ 개의 선형 함수를 학습해서 $m$ 개의 구간으로 정의되는 구간 선형 함수를 만들기 때문에, 즉 뉴런당 여러 선형 함수의 weight($w$)와 bias($b$) 를 학습해야 하므로 parameter 수가 ReLU 에 비해 훨씬 많다.
- 또한 여러 선형 함수를 계산한 후 최댓값을 선택해야 하므로 계산량이 크게 늘어난다.
- 이에 따라 계산이 복잡하고 비용이 더 많이 소모된다는 단점이 있고, 특히 대규모 neural network 에서 문제가 될 수 있다.
Maxout 함수의 볼록 함수 근사
-
Maxout 은 선형 노드의 개수에 따라 다른 형태의 볼록 함수를 근사한다. 아래 그림과 같이 선형 노드가 2 개이면 ReLU 와 절댓값 함수를 근사할 수 있고, 선형 노드가 5 개면 2 차 함수를 근사할 수 있다.
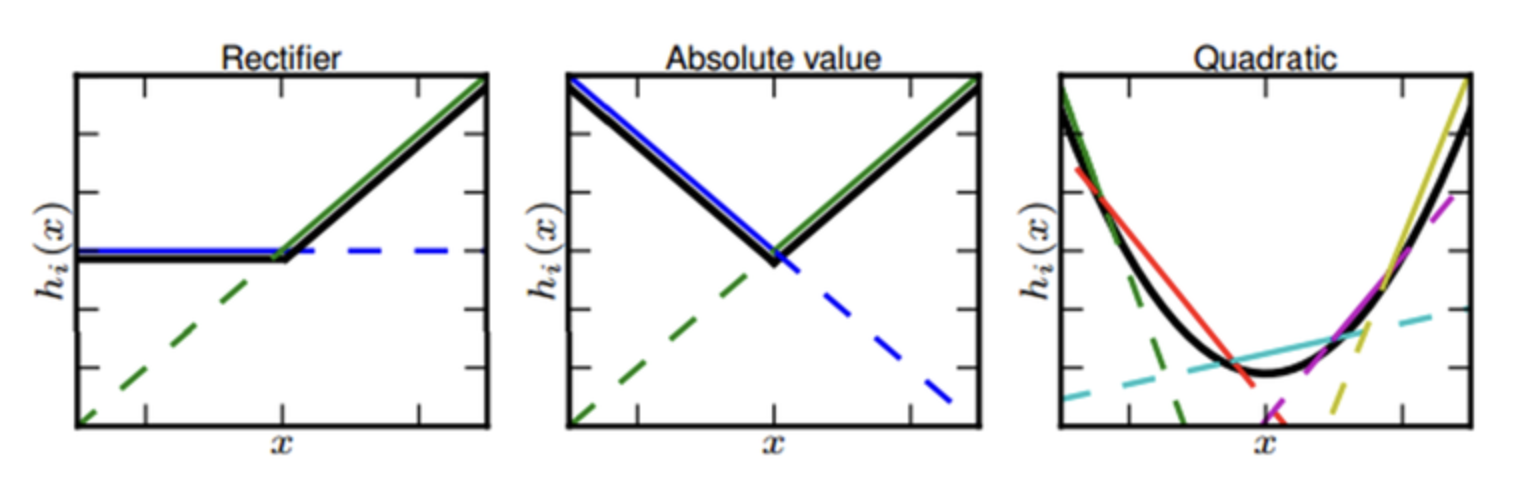 출처 : https://medium.com/@rahuljain13101999/maxout-learning-activation-function-279e274bbf8e
출처 : https://medium.com/@rahuljain13101999/maxout-learning-activation-function-279e274bbf8e - 이처럼 선형 노드가 많아질수록 조금 더 복잡하고 부드러운 곡선 형태의 활성화 함수를 근사하고 학습할 수 있다.
- 그러나 앞서 본 것처럼 parameter 의 수가 선형 노드의 개수에 비례해서 증가하므로 선형 노드를 제한적으로 늘려줘야 한다.
Reference
- https://pgnv.tistory.com/17
- https://gaussian37.github.io/dl-concept-relu6/
- https://deeesp.github.io/deep%20learning/DL-Activation-Functions
댓글 남기기